『Linux』 第十一章 线程同步与互斥
1. 线程互斥
1.1 进程线程间的互斥相关背景概念
- 临界资源:多线程执行流共享的资源就叫做临界资源
- 临界区:每个线程内部,访问临界资源的代码,就叫做临界区
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
- 原子性(后面讨论如何实现):不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成。
1.2 互斥量mutex
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况下,变量归属单个线程,其他线程无法获得这种变量。(即便获得了,也无法析构销毁)
但有时候,很多变量都需要在线程间共享的,这样的变量称之为共享变量,可以通过数据的共享,完成线程之间的交互。
多个线程并发的操作共享变量,会带来一些问题。
下面,我们来写一个操作共享变量会有问题的售票系统代码

执行结果:

变量tickets,是共享数据,在多线程并发读写时,并没有按照我们的预期减到0,而是直接干到了负数。
我们进一步分析下,为什么可能无法得到期望结果?
- if语句判断条件为真以后,代码可以并发的切换到其他线程
- usleep 这个模拟漫长业务的过程,在这个漫长的业务过程中,可能会有很多线程会进入代码段
- --ticket 操作本身就不是一个原子操作!!!
我们将这种状况称之为数据在无保护的情况下,被多线程访问,造成了数据不一致问题。
思考一个问题:对一个全局变量进行多线程并发 --/++ 操作是否是安全的? 答案是不安全的。
为什么不安全? 我们一起来探索一下。
上面说到过ticket--/--ticket这种操作,实际上是会有三步操作。
- 第一步先将内存中ticket值读入CPU的寄存器中。
- 第二步,在CPU内部进行--操作。
- 第三步,将计算结果写回内存。
刚刚这三步分别对应着三条汇编指令
- load:将共享变量ticket从内存加载到寄存器中
- update:更新寄存器里面的值,执行-1操作
- store:将新值,从寄存器写回到共享变量ticket的内存地址
取出ticket--部分的汇编代码
objdump -d a.out > test.objdump
152 40064b: 8b 05 e3 04 20 00 mov 0x2004e3(%rip),%eax #600b34 <ticket>
153 400651: 83 e8 01 sub $0x1,%eax
154 400654: 89 05 da 04 20 00 mov %eax,0x2004da(%rip) #600b34 <ticket>接下来我们来模拟一下,这个状况的发生过程
假设有一个线程叫thread-1,他要进行ticket--操作,刚刚执行完第一步,刚刚将数据读到CPU里,很不巧,发生线程切换了。
线程切换,是需要保存上下文的(线程的上下文是指线程在CPU中的状态和数据)。于是,thread-1 就把寄存器中的1000保存到自己的PCB中,

切换线程,切换到thread-2。thread-2很幸运,一直没有被打断,它一直执行tick--,减到了10。但这个时候,被切换了。

又切换到了trhead-1。调度thread-1,首先要做的就是恢复thread-1的上下文。也就是将1000恢复到寄存器中,然后,接着执行第二步,--操作得到999。第三步,将999写回内存中。我们就发现,票数好不容易减到了10,怎么又变回了999,这种情况,就导致了数据不一致。

而我们的代码中,不仅有--操作,还有判断操作(ticket>0)。判断操作,是逻辑运算,也是一种运算,实际上,这玩意,它也不是原子操作。
假设thicket减到了1,thread-1,进行if判断满足条件,进入if。这时候,又来了thread-2,thread-3,进行ticket>0判断。tickets为1,它们两个也满足条件,也进入了if。thread-1将tickets减到0,thread-2,trhead-3,再继续往下减,就出现了,我们看到的负数。
针对多线程并发访问无保护数据,导致的苏剧不一致问题,我们该怎么解决呢?
我们只需要做到三点:
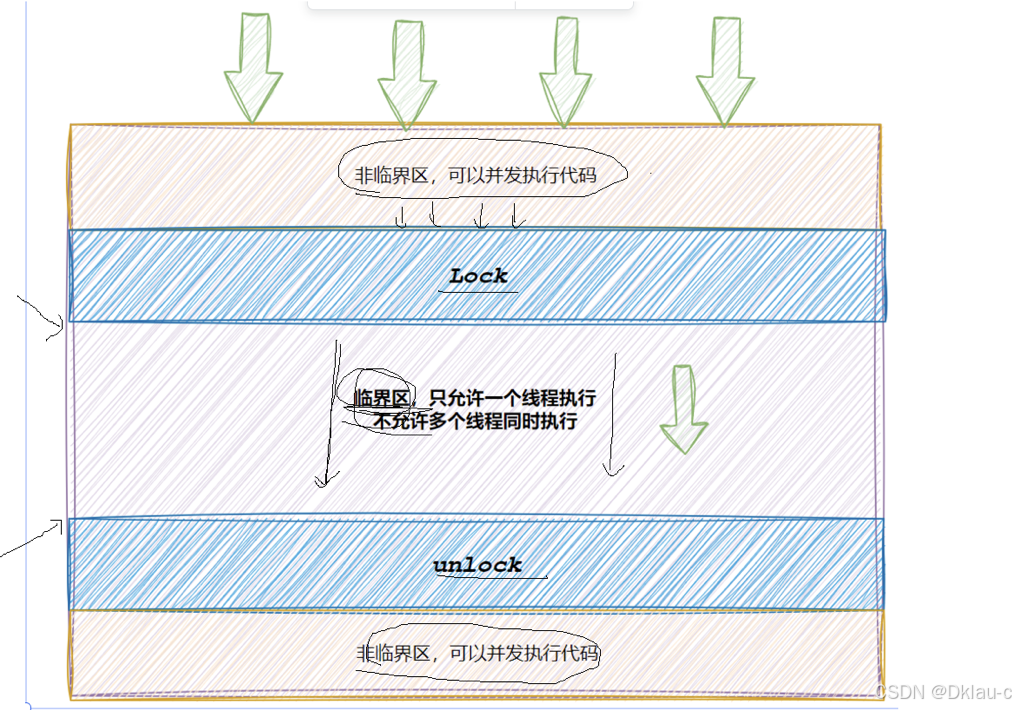
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
要做到这三点,本质上就是需要一把锁。 Linux上提供的这把锁叫互斥量。


1.3 互斥量的各个接口
既然我们要解决多线程并发访问,导致的数据不一致问题,需要使用锁,那么我们再细化下,如何使用锁来解决上面的问题
解决方案:
- 所有对资源的保护,都是对临界区代码的保护,因为资源是通过代码访问的!
- 加锁,一定不能大块代码进行加锁,要保证细粒度。
- 加锁就是找到临界区,对临界区进行加锁
了解了上面的几点之后,我们来学习下如何使用锁,也就是学习互斥量的各个接口
1.3.1 初始化互斥量
初始化互斥量共有两种方式
- 第一种,动态分配
定义一个局部的锁,使用pthread_mutex_init初始化;用完之后,在使用pthread_mutex_destrory进行销毁。
- 第二种,静态分配
定义一个全局的锁,使用宏PTHREAD_MUTEX_INITALIZER 进行初始化,不需要使用函数pthread_mutex_destrory销毁锁。

pthread_mutex_init 参数:
mutex:要初始化的互斥量地址。 attr: 所得的属性,直接设置为nullptr即可
1.3.2销毁互斥量

销毁互斥量需要注意:
- 使用PTHREAD_MUTEX_INITALIZER 初始化的互斥量(即全局互斥量)不需要销毁。
- 不要销毁一个已经加锁的互斥量
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁。
返回值: 成功返回0,失败返回错误码。
1.3.3 互斥量的加解锁

返回值:成功返回0,失败返回错误码。
调用用pthread_lock时,可能会遇到以下情况:
- 互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功
- 发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_lock调用回陷入阻塞(执行流被挂起),等待互斥量解锁。
pthread_trylock 和pthread_lock一样,都是申请锁,不同的是,pthread_trylock是非阻塞性的,即: 在使用pthread_trylock 申请锁失败的时,不会陷入阻塞,而是会直接返回false,
pthread_unlock 顾名思义,就是解锁。
1.4 锁的使用
已经了解了锁的各个接口,接下来,我们就开始使用它吧,我们在上面介绍接口的时候提到过,锁的初始化有两种方式。
1.4.1 局部锁的使用
我们先来演示下第一种方法:
我们需要让所有线程都申请到同一把锁。那怎么才能让所有线程看到的是同一把锁呢?我们可以在主线程创建一个局部锁,然后再传给其他线程。
接下来,我们直接在外面之前写的抢票模拟器上作修改。


锁外面已经定义好了,怎么去加锁,解锁呢?使用pthread_mutex_lock和pthread_mutex_unlock函数。

具体使用如下:

加锁成功之后,我们把tickets共享资源称之为临界资源。而访问临界资源的那一小块大妈,我们称之为临界区。
以下四点是我们需要知道的:
- 加锁的本质是用时间来换取安全。
- 加锁的表现是线程对于临界区代码串行执行。
- 加锁的原则是尽量要保证临界区代码,越少越好。
- 加锁的目的是让临界区代码变为原子的。
为什么要保证临界区越小越好呢?锁是不是越多越好呢?
线程执行临界区的代码,只能串行跑。线程默认是并发访问的,加锁多了,临界区增多,串行就增多 了,会降低线程的并发度,进而降低效率。
现在,我们来编译运行一下,我们的程序:

通过运行效果,我们可以看到虽然抢票没有抢到负数的现象了,但抢票的线程好像只有thread-2 这是为什么呢?
1.4.2 饥饿问题
这里引入一个超级自习室的例子讲解,我们每次进入超级自习室之前,可以拿走自习室门前挂着的钥匙,进入自习室之后,可以用这个锁,把自习室的门锁住,避免别人来打扰。
由于来自习的人很多,但自习室很少。自习室外就站了很多人。你写了很久的作业,想走了,你刚把锁挂到门上,就后悔了,又拿着锁回到了自习室。可你学了一会,又想走了,刚挂上锁,看到外面的人,又拿着锁回到了自习室,你就这样,拿锁换锁来回了好几次。别人依旧拿不到锁,这是什么原因呢? 因为你离锁最近,竞争力最强。

刚刚这个例子的竞争环境,我们可以理解为纯互斥环境。如果锁分配不合理,就容易导致其他人拿不到锁,进入不了自习室。结合我们的线程,我们可以把人理解为线程,自习室就是临界资源,因为锁的分配不均,就会容易导致其他线程拿不到锁。我们就把这个问题,称之为饥饿问题。
这时我们再回头看看程序的运行结果,就理解了为什么一直是thread-2在抢票。因为thread-2刚刚把锁放下,就又拿了起来。
只有一个线程抢票,这是不是说明我们的代码有问题?其实并不是,我们的代码没有问题,只是逻辑上有问题。
我们只需要让刚放下锁的线程,休眠几秒,让他不能立即抢锁,就可以了。

编译运行,我们就可以看到三个线程交替着抢票

线程对于锁的访问一定是并发的,但不同的线程对于锁的竞争能力可能不同。如果一个线程的竞争能力,比较强,就可能造成饥饿问题。
那针对饥饿问题,我们该怎么解决呢?
我们接着我们的故事。
自习室的观察员,观察了一下,发现这样下去可不行,不能光让那小子学下去,于是,定下来两个规矩:
- 等的人,必须排队。
- 出来的人,自习完毕,归还钥匙,不能立即重新申请,必须排到队伍的尾部!!
依照新规矩,自习室,外排起了长队,依次申请锁。我们把按照一定的顺序获取资源,称之为同步!

同步的意义:
互斥保证安全性,安全不一定合理或者高效!!
同步主要在保证安全的前提下,让系统变得更加合理和高效!!
每个线程在进入临界区访问临界资源的时候,它的第一件事都必须是先申请同一把锁。那么大家都要申请锁,那锁不也是共享资源吗?
锁本身是共享资源。所以,申请锁和释放锁本身就是被设计成了原子性操作(如何做到?)
思考一个问题:在临界区中,线程可以被切换吗?
答案是可以的。为啥?
线程调度是OS层面上的,我们的锁只是在软件上,对线程进行了限制,线程发生切换之后,由于我们还没有解锁,所以切换之后的线程也只会被阻塞住,所以即便发生了切换无所谓,
我们还可以那刚刚自习室的例子来理解,你自习,自习着突然想上厕所,可以去吗?当然可以了。去厕所的这段时间,别人能不能进自习室? 不能,为啥? 因为你去厕所的这段时间,锁一直都在你身上,别人进不去。
我们站在等待人的视角看,对于我们而言,锁只有释放和申请两种状态。其他线程就相当于等待人,也就是其他线程只能看到两种状态,申请与释放,而申请锁和释放锁,分别对应着,任务未开始做与任务已完成。如果一件事,只有未完成和已完成两种状态,要么不做,要做就是做完。不存在正在做这一状态,我们就称这件事为原子的
这样一来,通过加锁,我们就可以保证,我们当前在访问临界区的这段时间,对于其他线程来讲是原子的,这也就是加锁的目的。

我们回顾一下之前的问题,我们就会发现一个问题
我们一开始的问题是,为什么加锁? -> 因为并发问题。 -> 为什么会有并发问题? -> 因为我们想使用多线程访问全局变量。 -> 为什么用多线程? -> 提高并发度,但不想像创建进程那么复杂,而是通过线程的方式简单创建一个流来执行。
从一开始的加锁问题,延伸到多线程问题。我们会发现每解决一个问题,又会诞生出新的问题。也就是说任何的解决方案,都会伴随着新的问题产生。至于是否继续解决新的问题,取决于问题是否影响着我们。
1.4.3 全局锁的使用
我们来演示第二种使用锁的方式:
这种方式是定义一个全局的锁,使用宏来初始化。它既不需要pthread_mutex_destroy销毁锁,也不需要使用pthread_mutex_init进行初始化。

编译运行,效果是一样的

锁的使用,我们了解完了,那它究竟做了什么呢?
1.5 锁的原理
我们知道ticket--不是原子的,会变成三条汇编语句。那什么是原子呢? 我们可以简单理解为一条汇编语句就是原子的。
为了实现互斥锁操作,CPU中会有一条指令swap或exchange,它的作用就是把寄存器和内存单元的数据相互交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。现在我们可以看一下lock和unlock的伪代码:

加解锁的本质就是调用函数,那我们应该如何去理解加锁和解锁这两个函数呢?
早期的通用寄存器,简称ax,只有16位。后来扩展成了32位,就叫eax(Extended Accumulator Register) 。 怎么扩展? 在拼一个16位的寄存器。较低的16位,用al表示,ah则表示较高的16位。

这里方便理解,我们就简单的认为al就是eax。锁其实就是一个mutex变量,它的值最开始为1。
假设线程1调用了,lock函数。第一步 movb $0, %al, 作用是将寄存器al的内容置为0,第二步 xchgb %al, mutex , 的作用就是将寄存器al的内容和内存中的mutex进行交换。交换完成后,寄存器al中的内容为1.mutex的内容为0。

这个时候很不巧,线程1被切换走了,它会吧上下文拿走,也就是把1拿走。
线程2来了,他先执行第一步 movb $0, %al,将al寄存器的内容置0。再执行第二步 xchgb %al, mutex,进行交换。交换之后,al的内容还是0。再往后走,线程2就被挂起来了。
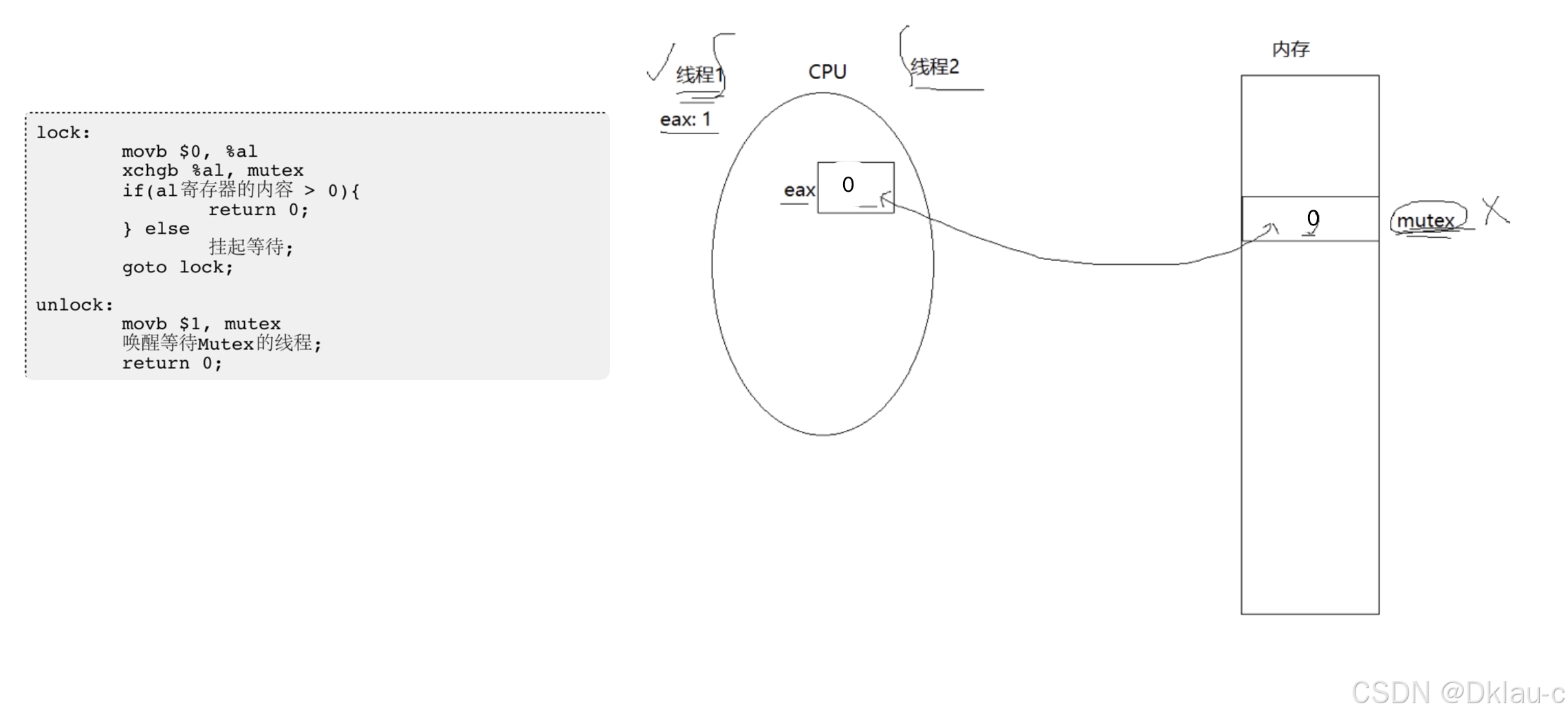
线程1回来了,它会先把自己的上下文,加载到寄存器。加载之后,al的内容为1,再往后执行,就返回0。不会被挂起,去执行临界区的代码了。
交换数据的本质是,把内存中的数据,交换到CPU的寄存器中,而把数据交换到寄存器中,实际上,是把数据交换到线程的硬件上下文中,线程的上下文是私有的。如此一来,我们就把一个共享的锁,让线程以汇编的方式,交换到自己的上下文中,这个线程就持有了锁了。
加锁的本质:将共享的锁转变为线程私有
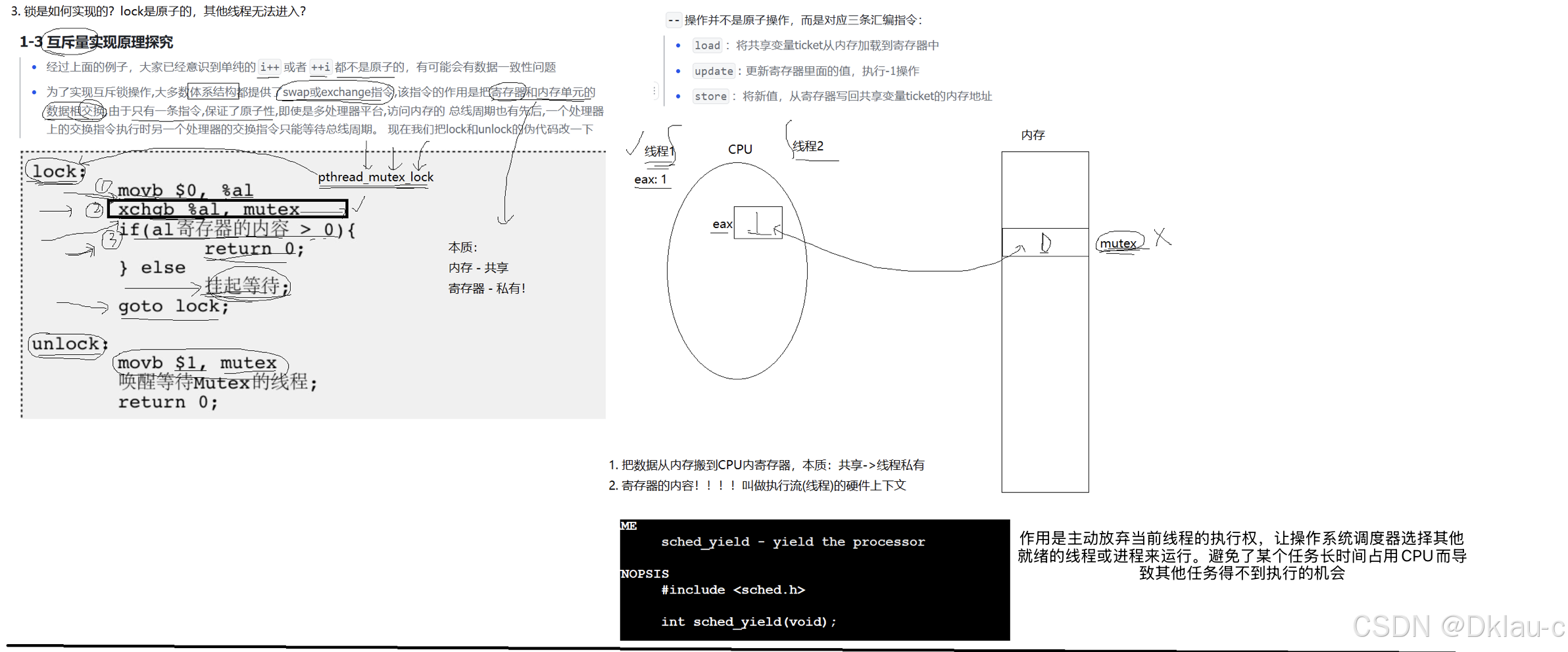
加锁过程,我们理解了,那解锁怎么理解?
解锁其实就是把mutex的内容置1.

为什么解锁,不是在回来的时候调用xchgb把寄存器中的1置换到mutex中呢?
谁说锁一定要自己来解,这样设计是为了方便别人也可以来帮助解锁。
1.6 锁的封装
我们可以原生库中的锁进行封装,做一个我们自己的锁。


我们的在刚刚的抢票程序中,使用下我们自己的锁

编译运行:

RAII编程范式风格:
RALL即资源获取即初始化,是C++中常见编程范式。他将资源生命周期绑定到对象生命周期,通过对象构造函数获取资源,析构函数释放资源,具有资源安全释放、简化代码、异常安全等优点,常用于内存管理、文件操作、线程同步等场景。
我们上面封装的锁采用的就是RAII风格。RAII风格的互斥锁,C++11也有,比如:
- std::mutex mtx;
- std::lock_guard<std::mutex> guard(mtx);
我们之后也可以直接使用C++封装的互斥锁。
2. 线程同步
我们在上一节中的发现在纯互斥(只用互斥、不用同步)的情况下,会因为各个线程的竞争力不同,进而导致线程的饥饿问题。故而为了解决饥饿问题,我们需要引入同步。
同步,是在保证数据安全的前提下,让多线程能够按照某种特定的顺序来访问临界资源,从而有效避免饥饿问题。
与同步相对立的就是竞态问题。
竞态问题:因为时序问题,而导致程序异常,我们称之为竞态问题。在多线程场景下,这种问题也不难理解。
同步, 如果用我们的超级自习室例子来说,就是刚从自习室出来的人,不能马上又进入自习室,而是排到队伍的后面去
思考一个问题:大家为什么不直接排队访问临界资源?
我们需要明确我们为什么排队? 是因为访问临界资源失败了,才去排的队。
如果多线程分配资源,本身就是均衡的,竞争锁的能力都差不多,那用纯互斥也是没问题的。
那如何做到同步呢?
Linux中的解决方案是使用条件变量。也就是说,我们的超级自习室,实现同步,就需要用到条件变量。
2.1 条件变量
- 当一个线程互斥地访问某个变量时,它可能发现在其他线程改变状态之前,它什么也做不了。
- 例如当一个线程访问队列时,发现队列为空,那它只能等待,直到其他线程将一个节点条件到队列中。这种情况就需要用到条件变量。
我们在返回到我们之前的故事中,我们再加入一个规则,那就是每次从超级自习室中出来的人,除了要把钥匙放回到原位,之外,还需要敲一下门口的铃铛,以此来通知排队的人,自习室没人了。
这样排队的人也就知道了拿钥匙进去自习。
在我们的计算机中,没有铃铛和排队。我们用一种通知机制来充当铃铛,用等待队列来充当排队。通知机制和等待队列,这就是条件变量。换个角度理解就是,条件变量必须提供一种通知机制和等待用的队列。
需要注意的是: 同步的前提是安全,如何做到安全? 那就是加锁,也就是说,条件变量必须依赖于锁的使用。
说到这,你可能还是不太了解条件变量。系统中有那么多临界资源,条件变量的管理,我们也可以创建条件变量,那么这么多条件变量,需不需要被管理起来,那么怎么管理?
先描述,在组织。说白了,条件变量即是一个结构体 pthread_cond_t。

2.2 条件变量函数
2.2.1 初始化和销毁

参数 :
cond:要初始化的条件变量。 atter:nullptr
看到这两个接口,有没有感觉很眼熟? 这和创建锁的接口是类似的。创建局部条件变量,需要调用init初始化,和destroy销毁。创建全局条件变量使用宏初始化即可,不需要调用init初始化和destroy销毁
2.2.2 等待条件满足
当条件不满足的时候,我们使用pthread_cond_wait函数,让进程进行排队。一般程序员在系统设计接口时,会尽量少的减少耦合度,但pthread_cond_wait 竟然把条件变量和锁放到了一起。这说明条件变量和锁的关系密切。

pthread_cond_wait的功能为,调用该函数会自动原子地释放指定的互斥锁(为什么传锁的原因),并使当前线程阻塞,进入等待状态,直到其他线程通过 pthread_cond_signal 或pthread_cond_broadcast函数唤醒。当线程唤醒后,pthread_cond_wait函数会再次获取互斥锁,然后返回。
注意:pthread_cond_wait 只是暂时释放锁,等资源就绪了还是会归还的,所以后面还是要解锁的,所以pthread_cond_wait 必须写在pthread_mutex_lock 和pthread_mutex_unlock之间的,这一点我们后面还会做更深的解释。
2.2.3 唤醒等待

我们可以使用pthread_cond_broadcast函数和pthread_cond_signal函数来通知唤醒处于排队队列的线程。broadcast是唤醒所有的线程,signal是唤醒队列最前面的一个线程。

2.2.4 简单案例
思路:依次创建四个线程,让它们访问临界资源count,每访问一次,count++一次,线程的返回值我们并不关心,让每个线程分离。主线程,每隔1秒唤醒一个线程。
具体实现如下:
注意: 第31行,有一个细节。我们传给线程值的时候,为什么传的(void*)i 而不是&i呢?因为如果使用&i,那么线程中操作的i就是主线程for循环中的i, 注意这里i的地址是主线程的局部地址,出了循环也就是销毁了,而传给其他线程使用是非常危险的,并且,这里i传的是地址,i的修改也会改变其他线程中的i,也就无法确定i真正的值是多少,你是第几个线程,所以,我们在创建线程,传参尽量进行值传参。

编译运行,我们就可以看到:

各个线程依次轮流进行操作,这更加说明了cond内部有队列
接下来,我们改为唤醒所有线程


2.3 为什么 pthread_cond_wait 需要互斥量?
条件等待是线程间同步的一种手段,如果只有一个线程,条件不满足,一直等下去都不会满足,所以必须要有一个线程通过某些操作,改变共享变量,使原先不满足的条件变得满足,并且友好的通知等待在条件变量上的线程。
条件不会无缘无故的突然变得满足了,必然会牵扯到共享数据的变化。所以一定要用互斥锁来保护。没有互斥锁就无法安全的获取和修改共享数据。

如图,如果我们拿着锁进入了等待,那么其他的进程再也拿不到锁了,也就发送不了signal信号,至此就形成了死锁。
按照上面的说法,我们设计出如下代码:先上锁,发现条件不满足,解锁,然后等待在条件变量上不就行了,如下代码:
// 错误的设计
pthread_mutex_lock(&mutex);
while (condition_is_false) {pthread_mutex_unlock(&mutex);//解锁之后,等待之前,条件可能已经满⾜,信号已经发出,但是该信号可能被错过pthread_cond_wait(&cond);pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);上面代码还会出现如下问题:
由于解锁和等待并不是原子操作的。调用解锁之后,pthread_cond_wait之前,如果已经有其他线程获取到互斥量,并条件满足,发送了信号,那么pthread_cond_wait将会错过这个信号,可能会导致线程永远阻塞在这个pthread_cond_wait。所以解锁和等待必须是一个原子操作。
可如果要让解锁和等待变为原子操作,就又需要加锁,可一加锁就又会出现上面那样的问题,那怎么办?
其实在 int pthread_cond_wait(pthread_cond_t* cond,pthread_mutex_t* mutex)内部,挤就已经帮我们解决了,在进入该函数后,会去看条件变量是否等于0,如果等于0,就把互斥量变为1(解锁),直到cond_signal返回,把条件变量改为1,把互斥量恢复成原样。
注:这里是pthread_cond_wait内部帮我们短暂释放锁了,正常情况下,我们一定要注意进程带锁沉睡的情况。
2.4 条件变量使用规范
- 等待条件代码
pthread_mutex_lock(&mutex);
while(条件为假) // 防止伪沉睡pthreead_cond_wait(cond,mutex);
修改条件
pthread_mutex_unlock(&mutex);伪唤醒: 线程可能会因为OS的线程调度策略或底层硬件中断导致线程意外唤醒。进程也可能收到一些无关的信号,这些信号也可能导致在条件变量上的线程被唤醒- 给条件发送信号代码
pthread_mutex_lock(&mmutex)
设置条件为真
pthread_cond_signal(cond);
pthread_mutex_unlock(&mutex);
2.5 条件变量的封装
基于上⾯的基本认识,我们已经知道条件变量如何使⽤,虽然细节需要后⾯再来进⾏解释,但这⾥可以做⼀下基本的封装,以备后⽤。
Cond.hpp:

2.6 生产者消费者模型(consumer producter)
我们以大家熟知的超市为例说明
供货商向超市提供商品,消费者从超市购买商品。那为什么消费者不直接向供货商购买呢?如果供货商一个一个商品提供给消费者,就需要一个一个的生产,这样会极大降低生产效率。况且,生产是需要时间的。如果让你买一个电器,说让你等几天过来拿,你愿意吗?
超市就相当于一个大号的缓冲区。一次向供货商购买一批商品,供货商一次生产一批商品。消费者需要的时候直接到超市里购买,马上就能使用。这种的效率明显更高。同时也即绝了需求和生产不在同一时间点的问题,对生产和消费者的行为,进行了一定程度的解耦合。

在计算机中,没有超市,生产者和消费者。我们用线程来充当生产者和消费者,用特定结构的内存空间来充当超市。生产者和消费者之间流通的商品,实际上就是一个一个的数据。线程之间进行数据交互,不就是我们之前讲的通信吗?但通信是我们上一章的话题,不是我们这次的重点,我们的重点在于如何安全高效的通信。
生产者和消费者都会访问超市,也就是说会有很多线程访问特定结构的内存空间。那么,这里的特定的内存空间是什么资源?
是共享资源。多线程访问共享资源会有什么问题? 会有并发问题!
要解决并发问题,我们还需要明确消费者和消费者,生产者和生产者,以及生产者和消费者之间的关系是互斥,还是同步,还是既互斥也同步。
接下来,我们引入一个故事来介绍它们之间的故事:
今天,超市货架,只剩下最后一包泡面了,a消费者先拿了,b消费者就不能拿了。所以,消费者之间的关系是互斥关系。超市没货了。找供货商a拿了货,供货商b不知道,就一直打电话问超市,需不需要进货超市经理接电话烦了,于是就说,我们已经进了货了,要不你隔5天再来电给我。供货商b说,可以。所以,供货商之间是互斥关系。
供货商的货刚到,超市的工作人员就给货架补货。工作人员,刚往货架上放,就来了一个消费者来拿货物。那最后,消费者有没有拿到货物呢?不确定。如果要保证消费者拿到户舞,是不是得先等工作人员将货物放到货架上。也就是需要按照一定的顺序。所以,消费者和生产者之间的关系是互斥与同步关系。
那么我们怎么记住生产消费者模型呢?
321原则,3种关系,2种角色(生产者,消费者),1个交易场所(特定结构的内存空间)。

2.6.1 为什么要使用生产者消费者模型
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦合的。
有的人说生产消费者模型高效,怎么理解?
仓库是公共资源,每次只能够有一个线程访问它,这不是串行吗? 高效体现在哪里?
它的高效体现在在整个进程中,有的线程在获取数据,有的线程在处理加工数据。 只有生产数据到队列的线程和未拿到数据的线程需要竞争锁。换句话说就是:访问临界资源的线程串行,访问非临界资源的线程并行。
2.6.2 生产者消费者模型优点
- 解耦合(两者关联性不高)
- 支持并发(即多线程场景)。
- 支持忙闲不均(即一边忙,一边闲的情况)。
2.7 基于BlockingQueue的生产者消费者模型
2.7.1 BlockQueue
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说,线程在对阻塞队列进程操作时会被阻塞)
不同的线程,看到同一份BlockQueue

2.7.2 C++ queue模拟阻塞队列的生产消费模型
为了方便理解,我们先以单生产者,单消费者,采用原始接口来讲解,
后续改为多生产者,多消费者(这里代码其实不变)+ 我们封装的接口来实现
version 1 
测试代码

注意: 这里采用模板,是想告诉我们,队列中不仅仅可以放置内置类型,比如int,对象也是可以作为任务来参与生产消费的过程的。
例如:
#pragma once
#include <iostream>
#include <string>
#include <functional>// 生产者可以生产(构造)一个任务Task对象,然后让消费者进行执行
// 任务类型1
class Task
{
public:Task() {}Task(int a, int b) : _a(a), _b(b), _result(0){}void Excute(){_result = _a + _b;}std::string ResultToString(){return std::to_string(_a) + "+" + std::to_string(_b) + "=" +std::to_string(_result);}std::string DebugToString(){return std::to_string(_a) + "+" + std::to_string(_b) + "=?";}private:int _a;int _b;int _result;
};
// 同样的,生产者也可以生产将要执行的函数,让消费者进行执行
// 实际上这也就是我们后面要实现的线程池的原理
// 任务类型2
using Task = std::function<void()>;编译运行:

versino2:
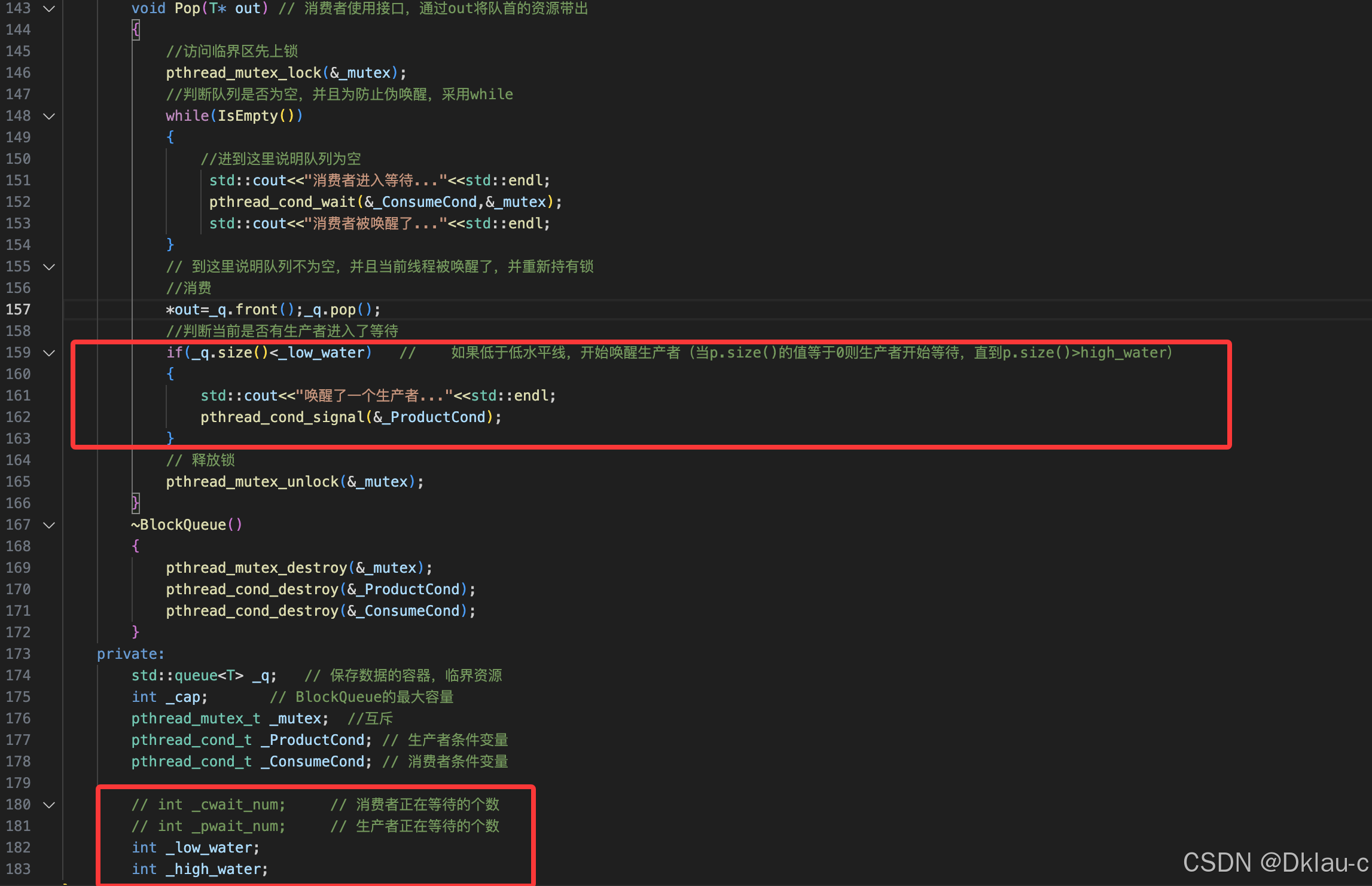
如果你不想生产一个,消费一个。可以增加一个水位线高于水位线hight_water,就让消费者赶紧消费。低于水位线low_water,就让生产者赶紧生产。处于两者之间,则让它们自由竞争。

具体实现如下:

我们把多余的打印提示去掉之后,方便观察,编译运行,我们就能够看到一批任务被执行和生产:

需要注意的是,这里其实是有bug的,因为我们采用的是单线程生产和单线程消费,所以如果我们要生产的值在生产消费一波之后,再生产的值达不到高位,那么唯一的生产线程不会被唤醒,这时我们的程序就会彻底阻塞住。
就像这样:

这里我们为了解决这种情况的产生,我们制定要求场上一定要有一个消费者在消费,当所有消费者都陷入沉睡了,即便没有达到高水位,依旧唤醒一个消费者。
我们选择在构造的时候,选择传入消费者的个数,以方便我们维护场上消费者的个数。

version3:
在这个版本中,我们将在第一版上,将所使用的原始锁和信号量,更改为我们自己封装的锁和信号量。

task-version
接下来,我们实现一个任务类,并且通过这个生产消费者模型来实现,执行,

 编译运行:
编译运行:


多线程:


2.8 信号量
刚刚我们生产消费模型中,使用的共享资源_q,只有一份。它被当成一个整体使用。一份共享资源能被分成多份吗,我们可不可以把它分成三份来使用? 如果线程访问的是三份不同的资源,我们是不是就可以让三个线程,同时进来访问共享资源?你说能同时访问,就能吗,凭什么? 凭信号量。

举一个简单的例子,一场电影,对应一个放映厅,这个放映厅就相当于一个共享资源,但是我们可以让很多的人(线程)进来。为什么?因为一个放映厅里有很多的位置,相当于把放映厅这个共享资源分了很多份。这么多的人(线程)进来,不会混乱吗? 当然会。所以,我们需要保证进来的人是和位置的数量是对应上的,并且可以保证每个人坐到的是自己的位置,这就是电影票(信号量)的作用
信号量,我们之前的文章介绍过,本质上就是一把计数器,起到记录的作用。那计数器的本质是什么呢? 计数器的本质就是用来描述资源数目的,把判断资源是否就绪放在了临界区之外。为什么说把资源就绪放在了临界区之外呢?因为申请信号量时,系统间接做了判断当前临界区资源是否空闲。一旦申请成功,就肯定有一份资源给你。用电影院来举例,就是你一旦买了票,那那个位置就一定是你的了,不管你去还是不去。
而且我们刚刚到代码是先加锁,再进行资源的判断。也就是判断资源是否就绪是放在临界区内的。在个别情况下,如果信号量只有1的话,是可以当作锁来使用的。
2.8.1 POSIX 信号量
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源的目的。但POSIX可以用于线程间同步。
初始化信号量

参数:
- sem 表示信号量,这里需要传入一个地址
- pshared: 0 表示线程间共享,非0表示进程间共享。
- value:信号量初始值。
注:POSIX 接口返回值都是0表示成功,-1表示失败,并设置错误码。
销毁信号量

等待信号量

我们主要适用 sem_wait 这个接口,功能相当于P操作,会将信号量的值-1.
发布信号量

功能:发布信号量,表示资源使用完毕,可以归还资源了,相当于V操作,将信号量值+1。
信号量的封装

2.8.2 基于环形队列的生产消费者模型
环形队列,底层我们可以用一个数组实现。用模运算来模拟环形特性
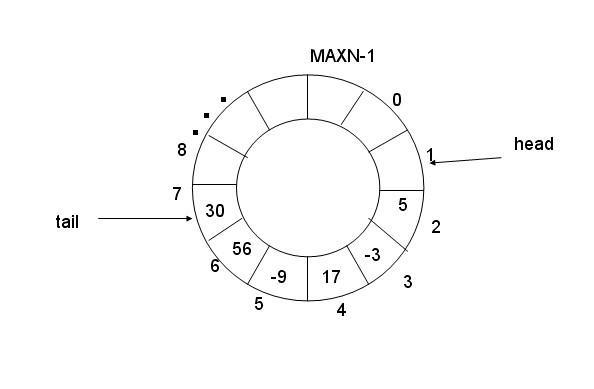
假设我们的数组大小为20,那么当队列为空或者满的时候,tail和head都指向同一个位置,我们没法区分,队列为空还是为满。

针对这个为空为满的问题,我们有三种方案,第一种是增加计数器,第二种是通过一个标记位来判断队列为满为空。另外也可以预留一个空位置,作为满的状态,即 当tail和head指向同一个位置时队列为空;当head的下一个位置是tail的时候,队列为满。
使用环形队列,单生产单消费。我们都知道怎么实现,每生产一个产品,就入队,放入到head 的位置,再让head指向下一个位置,每消费一个产品,就出去一个tail位置的数据,再让tailt指向下一个位置。那如何使用环形队列来实现同时生产消费呢?

要实现同时生产和消费,需要遵循3个原则。
- 指向同一个位置,只能一个人访问。
- 我只有先生产了,你才能消费,所以消费者不能超过生产者。
- 生产满了,我只有先消费了,你才能生产,所以生产者不能超过消费者,也就是套一个圈
我们举个例子,a是消费者,b是生产者。此时a无法进行消费,因为没有生产,b在盘子上放苹果,沿着顺时针方向,依次把所有的盘子都放满苹果,刚好回到一开始的时候,和a指向同一个地方,此时,b还不能接着放苹果,因为,没有盘子放了,得等消费者消费了才能,接着放。盘子都满了,a和b在同一个位置,只能是a先消费了,b才能生产,不能同时访问。
那么a和b什么时候会指向同一个位置呢? 队列为空为满,也就是说当不为空不为满的时候,我们一定会指向不同的位置,此时我们可以同时进行生产和消费。
P(生产者)关注什么资源? 还有多少剩余空间。C(消费者) 关注什么资源? 还有多少剩余数据。我们可以用两个信号量分别表示,空间资源(SpaceSem)和数据资源(DataSem)。空间资源的初始值为N,数组资源的初始值为0。
生产者进行生产,先P操作,信号量SpaceSem--,再进行生产,生产结束,V操作,DataSem++。消费者进行消费,先P操作,DataSem--,在进行消费,消费结束,V操作,SpaceSem++。 这样交叉操作,就完成了生产者和消费者之间的同步操作了。
如果只是单生产者单消费者这样就已经足够了,但如果是多生产者和多消费者的话,就需要靠路生产者和生产者,消费者和消费者之间的关系了。
显然生产者和生产者之间是不能同时访问同一个位置的,同理消费者也是,所以我们就要在加入互斥的思想。
在生产者之间加一把锁,在消费者之间也加一把锁即可。
这里借助信号量,已经实现了生产者和消费者之间的互斥了,当它们两个指向同一个地方的时候,只有可能是空或满,而为空的时候消费者是不能取的,为满的时候生产者是不能取的,所以这里天然就已经互斥了。
接下来,我们来使用信号量,来封装实现下这个过程吧
原始接口封装的:
注:这里信号量应该在加锁之前,这里我们因为信号量的缘故,生产者和消费者之间没有用锁。
一是信号量本身就是原子操作的,不需要保护,二是 临界区承载的代码应当尽可能的小。三是放在锁之前可以实现锁和申请信号量的并行。
如果这里没有使用信号量,采用条件变量wait,signal的方式实现同步,生产者和消费者使用同一把锁,这时如果先拿到锁,在等待的话,就有可能陷入死锁。
使用我们封装接口的版本:

看着是不是简洁,方便多了。
测试代码

运行结果:

3. 线程池
下面,我们结合我们之前所做的所有封装,进行一个线程池的设计。在写之前,我们要做如下准备
- 准备线程的封装
- 准备锁和条件变量的封装。
- 引入日志,对线程进行封装。
这里我们前两步都已经做了,所以我们直接开始日志的设计
3.1 日志与策略模式
3.1.1 什么是设计模式
现在大家都知道IT行业这么火,涌入的人很多,俗话说林子大了啥鸟都哟,大佬和菜鸡们两级分化的越来越严重,为了让菜鸟们不太拖大佬的后腿,于是大佬们针对一些经典的常见的场景,给出了一些对应的解决方案,这个就是设计模式
其实就是将很多场景下常见的代码和编写方式,总结成了一套模版,这套模版的编码方式就是设计模式
3.1.2 日志认识
计算机中的日志是记录系统和软件运行中发生事件的文件,主要作用是监控运行状态、记录一场信息,帮助快速定位问题并支持程序员进行问题修复。它是系统维护、故障排查和安全管理的重要工具。
日志格式以下几个指标是必须得有的
- 时间戳
- 日志等级
- 日志内容
以下几个指标是可选的
- 文件名行号
- 进程,线程相关id信息等。
日志有现成的解决方案,如:spdlog、glog、Boost.log、Log4cxx等等,我们依旧采用自定义日志的方式。
这里我们采用设计模式-策略模式来进行日志的设计。
策略模式是一种行为设计模式,其核心思想是将一系列相关的算法/接口封装成独立的策略类,这些策略类都实现了相同的接口,使得它们可以在运行时可以根据要求相互替换策略。这样做的好处是:算法的定义和实现分离,算法的变化是黑盒的不会影响到使用算法的客户端代码,提高了代码的可维护性和可扩展性。
具体策略模式的实现,详细看代码的实现。
我们想要的日志格式:
[可读性很好的时间] [⽇志等级] [进程pid] [打印对应⽇志的⽂件名][⾏号] - 消息内容,⽀持可
变参数
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [16] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [17] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [18] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [20] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [21] - hello world
[2024-08-04 12:27:03] [WARNING] [202938] [main.cc] [23] - hello world
3.1.3 日志的实现
Log.cpp
#include <iostream>
#include <string>
#include <memory>
#include <time.h>
#include <unistd.h>
#include <sys/types.h>
#include <sstream>
#include <fstream>
#include <filesystem> // C++17编译器才支持#include "Mutex.hpp"namespace LogMoudle
{// [可读性很好的时间] [⽇志等级] [进程pid] [打印对应⽇志的⽂件名][⾏号] - 消息内容,⽀持可变参数// [2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [16] - hello world// 1. 构成 日志存放的位置const char *default_logpath = "./log/";const char *default_logfile = "log.txt";enum class LogLevel{Normal = 0,Debug,Warning,Error,Fatal,};std::string LevelToString(LogLevel &level){switch (level){case LogLevel::Normal:return "Normal";case LogLevel::Debug:return "Debug";case LogLevel::Warning:return "Warning";case LogLevel::Error:return "Error";case LogLevel::Fatal:return "Fatal";default:return "None";}}std::string GetCurrent(){time_t time_stamp = ::time(nullptr);struct tm curr; // tm 是系统自带的关于日期时间的结构体localtime_r(&time_stamp, &curr); // 获取当前日期时间char buffer[1024];snprintf(buffer, sizeof(buffer), "%4d-%02d-%02d %02d:%02d:%02d",curr.tm_year + 1900, curr.tm_mon + 1, curr.tm_mday,curr.tm_hour, curr.tm_min, curr.tm_sec);return buffer;}// 日志策略class LogStrategy{// 将析构函数设为虚函数,不会因为派生类而造成内存泄漏public:virtual ~LogStrategy() = default;virtual void SyncLog(const std::string &str) = 0;};// 具体日志策略实现// 控制台策略class LogConsoleStrategy : public LogStrategy{public:void SyncLog(const std::string &str) override{MutexMoudle::LockGuard lock(_mutex);std::cout << str << std::endl;}~LogConsoleStrategy(){}private:MutexMoudle::Mutex _mutex; // 显示器也是一个共享资源};// 文件级(磁盘级)策略class FileLogStrategy : public LogStrategy{public:FileLogStrategy(const std::string& logpath=default_logpath,const std::string& logfile=default_logfile ):_logpath(logpath),_logfile(logfile){if(!std::filesystem::exists(_logpath)){try{std::filesystem::create_directory(_logpath); }catch(const std::filesystem::filesystem_error& e){std::cerr<<e.what()<<std::endl;}}}void SyncLog(const std::string &str) override{MutexMoudle::LockGuard lock (_mutex);const std::string log=_logpath+_logfile;std::ofstream out(log,std::ios::app);if(!out.is_open()) return; out<<str<<'\n';out.close();}~FileLogStrategy(){}private:std::string _logpath;std::string _logfile;MutexMoudle::Mutex _mutex; // 文件也是公共资源,也需要保护互斥};// 具体的日志实现// 日志类: 构建日志字符串, 根据策略,进行刷新class Logger{public:Logger(){// 默认采用屏幕刷新_Strategy = std::make_shared<LogConsoleStrategy>();}void EnableLogConsoleStrategy(){_Strategy = std::make_shared<LogConsoleStrategy>();}void EnableFileLogStrategy(){_Strategy = std::make_shared<FileLogStrategy>();}~Logger() {}class LogMessage{// 采用RAII风格,一个对象表示一条完整的日志语句,销毁时刷新public:LogMessage(LogLevel level, const std::string& filename, int line, Logger &logger): _time(GetCurrent()),_level(level),_pid(getpid()),_filename(filename),_line(line),_logger(logger){std::stringstream ss;ss << "[" << _time << "]" << "[" << LevelToString(_level) << "]" << "[" << _pid << "]" << "[" << _filename << "]"<< "[" << _line << "] ";_loginfo = ss.str();}// 加上模版,适用于任何类型template <class T>LogMessage &operator<<( const T &info){std::stringstream ss;ss << info;_loginfo += ss.str();return *this;}~LogMessage(){_logger._Strategy->SyncLog(_loginfo);}private:std::string _time;LogLevel _level;pid_t _pid;std::string _filename;int _line;std::string _loginfo; // 最后输出的日志语句Logger &_logger; // 负责最后析构时使用策略};// 临时变量/匿名变量的底层实际就是调用拷贝构造,形成一个临时变量// 故意写拷贝构造,让其形成临时变量,后续在被<<的时候,可以持续引用。// 直到语句结束,才会自动析构临时LogMessage,至此也完成了日志的显示和刷新。// 同时形成的临时变量,内部也有独立的日志数据。LogMessage operator()(LogLevel level, const char *filename, int line){return LogMessage(level, filename, line, *this);}private:std::shared_ptr<LogStrategy> _Strategy; // 日志所采用的策略};Logger logger;
#define LOG(level) logger(level,__FILE__,__LINE__)
#define ENABLE_CONSOLE_LOG logger.EnableLogConsoleStrategy()
#define ENABLE_FILE_LOG logger.EnableFileLogStrategy()
}测试样例:

3.2 线程池设计
线程池:
一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护者多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
说白了,就是提前创建一批线程,等业务来的时候,直接让线程去执行就可以了。
线程池的应用场景:
- 需要大量的线程来完成任务,且完成任务的时间比较短。比如WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,但在短时间内产生大量线程可能使内存到达极限,出现错误。
线程池的种类
- 创建固定数量线程池,循环从任务队列中获取任务对象,获取到任务对象后,执行任务对象中的任务接口。
- 浮动线程池,即线程个数不固定,其他同上。
此处。我们选择实现固定线程个数的线程池。

通过上面这个图,我们发现,这个图和生产消费者模型很像,没错,线程池就是采用的生产消费者模型实现的,线程就是消费者,我们就是生产者,我们只管往里面放任务,线程只管执行任务,双方解耦合。
下面我们来实现
这里我们直接使用的我们封装的接口来实现
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <functional>
#include <memory>#include "Log.hpp"
#include "Mutex.hpp"
#include "Cond.hpp"
#include "Thread.hpp"namespace ThreadPoolMouble
{using namespace LogMoudle;using namespace MutexMoudle;using namespace CondMoudle;using namespace ThreadMouble;using thread_t = std::shared_ptr<Thread>; // 对象必须在堆上构建const int Default_nums = 5;// T 为任务类型, 函数指针,任务类template <class T>class ThreadPool{void HandleTask(std::string name){LOG(LogLevel::NORMAL)<<"线程"<<name<<"创建成功...";while(1){T t;{// 1. 取等任务LockGuard lock (_mutex);while (_taskq.empty() && _running){_wait_num++;_cond.Wait(_mutex);_wait_num--;}// 到这要么有任务了,要么进程池不运行了。if (_taskq.empty() && !_running)break;t = _taskq.front();_taskq.pop();}// 2. 执行任务t(name); // 规定所有任务处理必须都重载了()方法。}LOG(LogLevel::NORMAL)<<"线程"<<name<<"退出...";}public:ThreadPool( int num = Default_nums): _num(num), _wait_num(0), _running(false){for (int i = 0; i < _num; i++){_threads.push_back(std::make_shared<Thread>(std::bind(&ThreadPool::HandleTask , this, std::placeholders::_1)));LOG(LogLevel::NORMAL) << "构造线程 " << _threads.back()->Name() << "成功...";}}void Equeue(T&& in) //对临时变量的引用,避免了值拷贝的消耗{LockGuard lock (_mutex);{if(_running){_taskq.push(std::move(in));LOG(LogLevel::NORMAL)<<"新任务已入队...";if(_wait_num>0) _cond.Notify();}}}void Start(){if (_running)return;_running = true; // 这里需不需要加锁? 不需要,因为此时线程还没有启动,还有进程池主线程在for (int i = 0; i < _num; i++){_threads[i]->Start();LOG(LogLevel::NORMAL) << "线程" << _threads[i]->Name() << "启动了...";}}void Wait(){for (int i = 0; i < _num; i++){if (_threads[i]->GetJoin()){_threads[i]->Join();LOG(LogLevel::NORMAL) << "线程" << _threads[i]->Name() << "已回收...";}}}void Stop(){LockGuard lock (_mutex);if (_running){_running=false; // 防止再有新的任务入列if(_wait_num>0)_cond.NotifyAll(); // 线程回收需要线程执行完毕 && 历史上的任务执行完了}}~ThreadPool(){}private:std::vector<thread_t> _threads; // 线程池int _num; // 线程池中的数量int _wait_num; // 线程池中等待的线程数量std::queue<T> _taskq; // 任务队列bool _running; // 是否正在运行Mutex _mutex; // 线程之间互斥,线程与线程池之间也是互斥的Cond _cond;};}测试代码:
Task.hpp
#pragma once
#include <iostream>
#include <string>
#include <functional>#include "Log.hpp"using namespace LogMoudle;using task_t = std::function<void(std::string)>;class task
{void operator()(std::string name){LOG(LogLevel::NORMAL)<<"我是一个测试类 "<<name;}
};void Push(std::string name)
{LOG(LogLevel::NORMAL)<<"我是一个测试函数 "<<name;
}
#include <iostream>
#include <memory>#include "ThreadPool.hpp"
#include "Task.hpp"using namespace std;
using namespace ThreadPoolMouble;int main()
{ENABLE_CONSOLE_LOG;unique_ptr<ThreadPool<task_t>> tp=make_unique<ThreadPool<task_t>>();tp->Start();int cnt = 10;char c;while (true){std::cin >> c;tp->Equeue(Push);cnt--;if(cnt==0) break;sleep(1);}tp->Stop();sleep(3);tp->Wait();return 0;
}运行结果:

3.3 线程安全的单例模式
3.3.1 什么是单例模式
我们在日志那里提到过设计模式,单例模式是一种软件设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问这个实例。
3.3.2 单例模式的特点
某些类,只应该具有一个对象(实例),就称之为单例。
我们后面编写的各种服务器,我们都期望它是单例模式。服务器启动一个就够了,不需要创建多个。
它有懒汉模式和饿汉模式两种理念。
这两种理念的区别在于创建对象的时间。懒汉模式,是在需要它的时候,才会创建对象。饿汉模式,是程序加载之后,就创建了。你可以这么理解,吃完饭,立刻洗碗,这种就是饿汉模式,因为下一顿吃的时候可以立刻拿着碗就能吃饭;吃完饭,先把碗放在,然后下一顿饭用到这个碗了再洗碗,就是懒汉模式。
懒汉模式最核心的思想是“延时加载”,从而能够优化服务器的启动速度。
在操作系统中,有很多地方都有着这种延时加载的思想,比如页表,中断,父子进程之间的资源。
思考一个问题:全局变量,是不是编译完成后,一加载就有了? 是的
我们可以做个实验证明下:
我们定义一个Init类,并在主函数中创建Init对象。

编译运行,为程序运行了之后,才创建的Init对象。

我们这次创建一个全局的Init对象。

编译运行,程序一加载,Init对象就被创建了。所以,全局变量,是在程序加载完成,就有了。

3.3.3 饿汉方式实现单例模式
我们在上面测试过,全局变量就是在程序加载好时,就已经创建的,所以我们就可以直接使用static 来实现我们的模式。

只要通过Singleton 这个包装类来使用T对象,则一个进程中就只有一个T对象的实例。
3.3.4 懒汉模式实现单例模式

但是这个代码,存在一个严重的问题,线程不安全。
在第一个调用GetInstance的时候,如果两个线程同时调用,那么可能会创建出两份T对象的实例。
但是后续再调用,就没有问题了,因为返回的都是同一份。
那怎么办呢? 加锁!
3.3.5 懒汉模式实现单例模式(线程安全版本)

注意事项:
- 加锁解锁的位置
- 双重if判断,避免不必要的锁竞争,提高了性能。
- volatile关键字防止过度优化。
3.4 单例式线程池
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <functional>
#include <memory>#include "Log.hpp"
#include "Mutex.hpp"
#include "Cond.hpp"
#include "Thread.hpp"namespace SingleThreadPoolMouble
{using namespace LogMoudle;using namespace MutexMoudle;using namespace CondMoudle;using namespace ThreadMouble;using thread_t = std::shared_ptr<Thread>; // 对象必须在堆上构建const int Default_nums = 5;// T 为任务类型, 函数指针,任务类template <class T>class ThreadPool{void HandleTask(std::string name){LOG(LogLevel::NORMAL) << "线程" << name << "创建成功...";while (1){T t;{// 1. 取等任务LockGuard lock(_mutex);while (_taskq.empty() && _running){_wait_num++;_cond.Wait(_mutex);_wait_num--;}// 到这要么有任务了,要么进程池不运行了。if (_taskq.empty() && !_running)break;t = _taskq.front();_taskq.pop();}// 2. 执行任务t(name); // 规定所有任务处理必须都重载了()方法。}LOG(LogLevel::NORMAL) << "线程" << name << "退出...";}ThreadPool(int num = Default_nums): _num(num), _wait_num(0), _running(false){for (int i = 0; i < _num; i++){_threads.push_back(std::make_shared<Thread>(std::bind(&ThreadPool::HandleTask, this, std::placeholders::_1)));LOG(LogLevel::NORMAL) << "构造线程 " << _threads.back()->Name() << "成功...";}}ThreadPool(const ThreadPool<T> &) = delete;ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;public:static ThreadPool* GetInstance(){if(instance==nullptr){LockGuard lock(mutex);if(instance==nullptr){LOG(LogLevel::NORMAL)<<"线程单例化完成...";instance=new ThreadPool<T>();}}return instance;}void Equeue(T &&in) // 对临时变量的引用,避免了值拷贝的消耗{LockGuard lock(_mutex);{if (_running){_taskq.push(std::move(in));LOG(LogLevel::NORMAL) << "新任务已入队...";if (_wait_num > 0)_cond.Notify();}}}void Start(){if (_running)return;_running = true; // 这里需不需要加锁? 不需要,因为此时线程还没有启动,还有进程池主线程在for (int i = 0; i < _num; i++){_threads[i]->Start();LOG(LogLevel::NORMAL) << "线程" << _threads[i]->Name() << "启动了...";}}void Wait(){for (int i = 0; i < _num; i++){if (_threads[i]->GetJoin()){_threads[i]->Join();LOG(LogLevel::NORMAL) << "线程" << _threads[i]->Name() << "已回收...";}}}void Stop(){LockGuard lock(_mutex);if (_running){_running = false; // 防止再有新的任务入列if (_wait_num > 0)_cond.NotifyAll(); // 线程回收需要线程执行完毕 && 历史上的任务执行完了}}~ThreadPool(){}private:std::vector<thread_t> _threads; // 线程池int _num; // 线程池中的数量int _wait_num; // 线程池中等待的线程数量std::queue<T> _taskq; // 任务队列bool _running; // 是否正在运行Mutex _mutex; // 线程之间互斥,线程与线程池之间也是互斥的Cond _cond;static ThreadPool<T>* instance;static Mutex mutex; // 用于保护单例的锁};// 静态类变量,类内声明,类外初始化template<class T>ThreadPool<T>* ThreadPool<T>::instance=nullptr;template<class T>Mutex ThreadPool<T>::mutex;}
测试用例

4. 线程安全和重入问题
概念:
线程安全:就是多个线程在访问共享资源时,能够正确地执行,不会相互干扰或破坏彼此的执行结果。一般而言,多个线程并发同一段只有局部变量的代码时,不会出现不同的结果(线程具有独立的栈)。但是对全局变量或者静态变量进行操作,并且没有锁保护的情况下,就容易出现该问题。
重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
学到这里,其实我们已经能够理解重入其实可以分为两种情况。
- 多线程重入函数
- 信号导致一个执行流重复进入函数
4.1 线程安全与重入的各个情况
常见的线程不安全的情况:
- 不保护共享变量的函数
- 函数状态随着被调用,状态发生变化的桉树
- 返回指向静态变量的函数
- 调用线程不安全函数的函数
常见的线程安全的情况:
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的
- 类或者接口对于线程来说都是原子操作
- 多个线程之间的切换不会导致该接口的执行结果存在二义性。
常见的不可重入的情况
- 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆堆
- 调用标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构。
- 可重入函数体内使用了静态的数据结构。
常见可重入的情况:
- 不使用全局变量或静态变量
- 不使用malloc或者new开辟出来的空间
- 不调用不可重入函数
- 不返回静态或全局数据,所有数据都由函数的调用者提供。
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
结论:
不要被上面绕口令式的话唬住了,你只要自己观察,其实对应概念说的都是一回事。
可重入与线程安全联系
- 函数是可重入的,那就是线程安全的(其实知道这一句话就够了)
- 函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题
- 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的。
可重入与线程安全的区别
- 可重入函数是线程安全函数的一种
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果将对临界资源的访问加上锁,则这个函数是线程安全的,但是如果这个重入函数若锁还没释放则会产生死锁,因此是不可重入的。
注意:
- 如果不考虑信号导致一个执行流重复进入函数这种重入情况,线程安全和重入在安全角度不做区分。
- 但是线程安全侧重说明线程访问公共资源的安全情况,表现的是并发线程的特点
- 可重入描述的是一个函数是否能被重复进入,表示的是函数的特点
5. 常见锁概念
5.1 死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所占用不会释放的资源而陷入的一种云久等待状态。
为了方便表述,假设现在线程A,线程B必须同时持有锁1和锁2,才能继续后续资源的访问。

申请一把锁是原子的,但是申请两把锁就不一定了
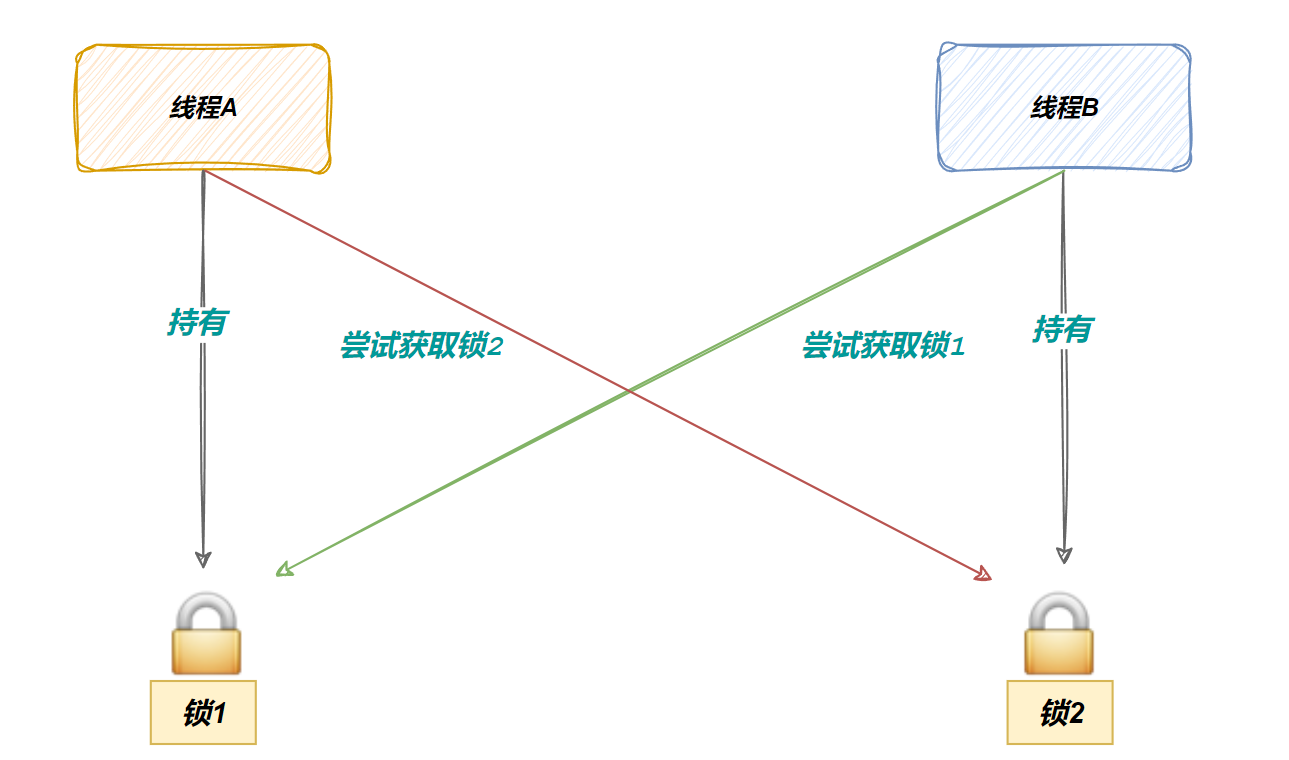
造成的结果就是

5.2 死锁的四个必要条件
- 互斥条件:一个资源每次只能被一个执行流使用
- 好理解,不做解释
- 请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放

- 不剥夺条件:一个执行流已获得的资源,在未使用完之前,不能强行剥夺

- 循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系

5.3 避免死锁
破坏死锁的四个必要条件
破坏循环等待条件问题:资源一次性分配(多个锁一次全部分配),使用超时机制(等待一段时间,自动释放锁),加锁顺序一致(不同进程的加锁位置一致)

不一次申请

一次申请

避免锁未释放的场景
5.4 避免死锁的算法
在多线程编程中,避免死锁通常可以采用资源有序分配法、银行家算法等。
资源有序分配法
- 原理:为系统中的资源分配一个唯一的序号,规定每个进程必须按照资源序号递增的顺序请求资源。当进程请求一组资源时,它必须先请求序号最小的资源,然后依次请求其他资源。这样可以确保不会出现循环等待资源的情况,从而避免死锁。
- 示例:假设有三个资源 R1、R2、R3,分别分配序号为 1、2、3。进程 P1 需要使用 R1 和 R3,那么它必须先请求 R1,再请求 R3。进程 P2 需要使用 R2 和 R3,它也必须先请求 R2,再请求 R3。由于所有进程都按照资源序号递增的顺序请求资源,不会出现循环等待,从而避免了死锁。
- 优点:实现相对简单,不需要复杂的资源分配和回收算法。
- 缺点:资源序号一旦确定,很难动态调整,可能导致资源分配不够灵活,降低资源利用率。
银行家算法
- 原理:该算法基于系统资源分配的安全性检查。系统中存在多个进程和多种资源,银行家算法通过跟踪每个进程对资源的最大需求、已分配资源和系统剩余资源,来判断系统是否处于安全状态。如果系统处于安全状态,意味着可以找到一种进程执行顺序,使得每个进程都能在有限时间内获得所需资源并完成执行;如果系统处于不安全状态,则可能发生死锁。
- 示例:假设系统中有三个进程 P1、P2、P3,三种资源 R1、R2、R3。进程 P1 对资源的最大需求为 (3, 2, 2),已分配资源为 (1, 1, 0);进程 P2 对资源的最大需求为 (6, 1, 3),已分配资源为 (5, 1, 1);进程 P3 对资源的最大需求为 (3, 1, 4),已分配资源为 (2, 1, 1)。系统剩余资源为 (1, 0, 1)。通过银行家算法的安全性检查,可以判断出系统当前处于安全状态,因为可以找到一个安全序列,如 < P1, P3, P2>,使得每个进程都能获得足够资源完成执行。
- 优点:能准确判断系统是否处于安全状态,有效避免死锁的发生,资源分配相对灵活。
- 缺点:需要记录每个进程的资源需求和分配情况,算法实现复杂,系统开销较大。
死锁检测算法用于检测系统中是否存在死锁,并在存在死锁时找出处于死锁状态的进程和资源。常见的死锁检测算法有资源分配图化简法和基于向量时钟的死锁检测算法。
资源分配图化简法
- 原理:系统可以用资源分配图来描述进程对资源的请求和分配关系。资源分配图由节点和边组成,节点分为进程节点和资源节点,边表示进程对资源的请求或资源对进程的分配。通过不断简化资源分配图,若最终能将图化简为没有任何边的状态,则系统不存在死锁;若无法化简,且图中存在环路,则系统存在死锁,环路上的进程就是处于死锁状态的进程。
- 化简步骤
- 寻找一个既不阻塞又非孤立的进程节点。如果一个进程的所有资源请求都能得到满足,那么它就是不阻塞的;如果一个进程节点没有任何边与之相连,那么它就是孤立的。
- 移除该进程节点及其所有的请求边和分配边,将其释放的资源分配给其他阻塞的进程,使它们有可能变为不阻塞的进程。
- 重复上述步骤,直到无法再找到可化简的进程节点。
- 示例:假设有三个进程 P1、P2、P3,两种资源 R1、R2。P1 持有 R1 并请求 R2,P2 持有 R2 并请求 R1,P3 请求 R1。资源分配图中会形成一个环路 P1 - R2 - P2 - R1 - P1,通过资源分配图化简法,会发现无法将图化简为无环状态,从而判断系统存在死锁,P1 和 P2 处于死锁状态。
- 优点:直观形象,易于理解和实现,能够清晰地展示进程和资源之间的关系。
- 缺点:当系统规模较大时,资源分配图的化简过程可能会非常复杂,计算量较大。
基于向量时钟的死锁检测算法
- 原理:向量时钟是一种用于记录分布式系统中事件发生顺序的机制。在多线程环境中,每个线程维护一个向量时钟,用于记录自己对不同资源的访问顺序。通过比较线程之间的向量时钟,可以判断是否存在循环等待关系,从而检测死锁。
- 实现方式
- 每个线程在访问资源时,更新自己的向量时钟,并将其与资源相关联。
- 当一个线程请求资源时,它会将自己的向量时钟与目标资源上记录的向量时钟进行比较。如果发现存在循环等待的情况,即自己的向量时钟显示某个资源的访问顺序在另一个线程之后,而另一个线程又在等待自己释放其他资源,那么就可能存在死锁。
- 示例:在线程 T1 中,向量时钟初始化为 [0, 0, 0],当它访问资源 R1 后,向量时钟更新为 [1, 0, 0]。线程 T2 的向量时钟初始为 [0, 0, 0],访问资源 R2 后变为 [0, 1, 0]。如果 T1 请求 R2,T2 请求 R1,通过比较向量时钟可以发现 T1 的向量时钟显示它在 T2 之后访问了 R2,而 T2 的向量时钟显示它在 T1 之后访问了 R1,这就形成了循环等待,可能存在死锁。
- 优点:适用于分布式系统和多线程环境,能够有效地检测出复杂的死锁情况。
- 缺点:需要维护向量时钟,增加了系统的开销和复杂性。同时,对于大规模系统,向量时钟的比较和分析也可能会带来较大的计算量。
银行家算法的变种用于死锁检测
- 原理:银行家算法原本是用于避免死锁的,但也能稍作修改用于死锁检测。该算法会跟踪每个进程对资源的最大需求、已分配资源和系统剩余资源。在检测死锁时,它会模拟资源分配过程,尝试找出一个安全序列,即能让所有进程依次完成执行的资源分配顺序。若找不到这样的安全序列,就说明系统存在死锁。
- 示例:假设有进程 P1、P2、P3,资源类型为 R1、R2、R3。P1 最大需求 (7, 5, 3),已分配 (0, 1, 0);P2 最大需求 (3, 2, 2),已分配 (2, 0, 0);P3 最大需求 (9, 0, 2),已分配 (3, 0, 2)。系统剩余资源 (3, 3, 2)。算法会尝试分配资源,若发现无法让所有进程都完成执行,就判定存在死锁。
- 优点:能准确判断系统是否处于死锁状态,且逻辑相对清晰,因为它和资源分配的实际情况紧密相关。
- 缺点:需要维护每个进程的资源需求和分配信息,随着进程和资源数量增加,计算复杂度会显著上升。
等待图算法
- 原理:等待图是资源分配图的简化版本,它只关注进程之间的等待关系。图中的节点是进程,有向边表示一个进程等待另一个进程释放资源。通过检测等待图中是否存在环来判断是否存在死锁,若存在环,环上的进程就处于死锁状态。
- 示例:若进程 P1 等待 P2 释放资源,P2 等待 P3 释放资源,P3 又等待 P1 释放资源,那么在等待图中就会形成一个环 P1 -> P2 -> P3 -> P1,表明这三个进程处于死锁状态。
- 优点:相较于资源分配图,等待图更简洁,减少了不必要的信息,检测死锁的效率可能更高。
- 缺点:构建等待图需要准确获取进程间的等待关系,在复杂系统中获取这些信息可能存在一定难度。
时间戳算法
- 原理:为每个进程分配一个时间戳,当进程请求资源时,会记录请求的时间戳。若一个进程等待另一个进程释放资源的时间超过了预设的阈值,就认为可能存在死锁。该算法通过时间维度来判断是否出现死锁情况。
- 示例:设定时间阈值为 10 秒,进程 P1 请求资源 R1 时记录时间戳 t1,若在 t1 + 10 秒后 P1 仍在等待 R1,且 R1 被进程 P2 持有,就可能存在死锁。
- 优点:实现相对简单,不需要复杂的图结构和资源分配信息,只需要记录时间戳和时间阈值。
- 缺点:时间阈值的设定比较困难,若阈值设置过大,可能无法及时检测到死锁;若设置过小,可能会误判死锁情况。
6. STL,智能指针和线程安全
6.1 STL中的容器是否是线程安全的?
不是.
原因是,STL的设计初衷是将性能挖掘到极致,而一旦涉及到加锁保证线程安全,会对线程造成巨大的影响
而且对于不同的容器,加锁方式的不同,性能可能也不同(例如hash表的锁表和锁桶),
因此STL默认不线程安全,如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全。
6.2 智能指针是否是线程安全的?
对于unique_ptr,由于只是在当前代码块范围内生效,因此不涉及线程安全问题。
对于shared_ptr,多个对象需要共用一个引用计数变量,所以会存在线程安全问题,但是标准库实现的时候考虑到了这个问题,基于原子操作(CAS)的方式保证shared_ptr能够高效,原子的操作引用计数。
7.其他常见的各种锁(不做具体介绍,具体看后续其他文章)
- 悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
- 乐观锁:每次取数据时候,总是乐观地认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
- CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失效,失效则重试,一般是一个自旋的过程,即不断重试。
- 自旋锁,读写锁,后续看其他板块文章。
至此,Linux系统篇正式完结,总共11个章节,都是2万字以上的详细讲解,每一个的更新周期都很长,更新不易,还望支持,下个月正式开始Linux网络篇!!!
相关文章:

『Linux』 第十一章 线程同步与互斥
1. 线程互斥 1.1 进程线程间的互斥相关背景概念 临界资源:多线程执行流共享的资源就叫做临界资源临界区:每个线程内部,访问临界资源的代码,就叫做临界区互斥:任何时刻,互斥保证有且只有一个执行流进入临界…...

【数据结构】队列
目录 一、队列1、概念与结构2、队列的实现3、队列的初始化4、打印队列数据5、入队6、销毁队列7、队列判空8、出队9、取队头、队尾数据10、队列中有效元素个数 二、源码 个人主页,点击这里~ 数据结构专栏,点击这里~ 一、队列 1、概念与结构 概念&#x…...

【导航定位】GNSS数据协议-RINEX OBS
RINEX协议 RINEX(Receiver INdependent EXchange format,与接收机无关的交换格式)是一种在GPS测量应用中普遍采用的标准数据格式,该格式采用文本文件形式(ASCII码)存储数据数据记录格式与接收机的制造厂商和具体型号无关。目前RINEX版本已经发布到了4.x…...

Qt中的事件循环
Qt的事件循环是其核心机制之一,它是一种消息处理机制,负责处理各种事件(如用户输入、定时器、网络请求等)的分发和处理。Qt中的事件循环是一个持续运行的循环,负责接收事件并将它们分发给相应的对象进行处理。当没有事件需要处理时࿰…...

Android并发编程:线程池与协程的核心区别与最佳实践指南
1. 基本概念对比 特性 线程池 (ThreadPool) 协程 (Coroutine) 本质 Java线程管理机制 Kotlin轻量级并发框架 最小执行单元 线程(Thread) 协程(Coroutine) 创建开销 较高(需分配系统线程资源) 极低(用户态调度) 并发模型 基于线程的抢占式调度 基于协程的协作式调度 2. 核心差异…...
神经网络的基本原理轮廓)
吴恩达深度学习复盘(2)神经网络的基本原理轮廓
笔者注 这两节课主要介绍了神经网络的大的轮廓。而神经网络基本上是在模拟人类大脑的工作模式,有些仿生学的意味。为了便于理解,搜集了一些脑神经的资料,这部分是课程中没有讲到的。 首先要了解一下大脑神经元之间结构。 细胞体࿱…...

【redis】集群 数据分片算法:哈希求余、一致性哈希、哈希槽分区算法
文章目录 什么是集群数据分片算法哈希求余分片搬运 一致性哈希扩容 哈希槽分区算法扩容相关问题 什么是集群 广义的集群,只要你是多个机器,构成了分布式系统,都可以称为是一个“集群” 前面的“主从结构”和“哨兵模式”可以称为是“广义的…...
——2.2机器数的定点表示和浮点表示)
计算机组成原理笔记(六)——2.2机器数的定点表示和浮点表示
计算机在进行算术运算时,需要指出小数点的位置,根据小数点的位置是否固定,在计算机中有两种数据格式:定点表示和浮点表示。 2.2.1定点表示法 一、基本概念 定点表示法是一种小数点的位置固定不变的数据表示方式,用于表示整数或…...

将树莓派5当做Ollama服务器,C#调用generate的API的示例
其实完全没这个必要,性能用脚后跟想都会很差。但基于上一篇文章的成果,来都来了就先简单试试吧。 先来看看这个拼夕夕上五百多块钱能达到的效果: 只要对速度没要求,那感觉就还行。 Ollama默认只在本地回环(127.0.0…...
)
MYSQL数据库(一)
一.数据库的操作 1.显示数据库 show databases; 2.创建数据库 create database 数据库名; 3.使用数据库 use 数据库名; 4.删除数据库 drop database 数据库名; drop database if exists 数据库名; 二.表的操作 1.显示所有表 show tables; 2.查看表结构 des…...

Python Cookbook-4.15 字典的一键多值
任务 需要一个字典,能够将每个键映射到多个值上。 解决方案 正常情况下,字典是一对一映射的,但要实现一对多映射也不难,换句话说,即一个键对应多个值。你有两个可选方案,但具体要看你怎么看待键的多个对…...

IDEA 终端 vs CMD:为什么 java -version 显示的 JDK 版本不一致?
前言:离谱的 JDK 版本问题 今天遇到了一个让人抓狂的现象:在 Windows 的 CMD 里输入 java -version 和在 IntelliJ IDEA 终端输入 java -version,居然显示了不同的 JDK 版本! 本以为是环境变量、缓存或者 IDEA 设置的问题&#x…...

Flask登录页面后点击按钮在远程CentOS上自动执行一条命令
templates文件夹和app.py在同一目录下。 templates文件夹下包括2个文件:index.html login.html app.py代码如下: import os import time from flask import Flask, render_template, request, redirect, session, make_response import mysql.con…...

深度解析:文件夹变白色文件的数据恢复之道
在数字化时代,数据的重要性不言而喻。然而,当我们在使用计算机时,偶尔会遇到一些棘手的问题,其中“文件夹变白色文件”便是一个令人困惑且亟待解决的难题。这一现象不仅影响了文件的正常访问,更可能隐藏着数据丢失的风…...

【Matlab】-- 基于MATLAB的飞蛾扑火算法与反向传播算法的混凝土强度预测
文章目录 文章目录 01 内容概要02 MFO-BP模型03 部分代码04 运行结果05 参考文献06 代码下载 01 内容概要 本资料介绍了一种基于飞蛾扑火算法(Moth Flame Optimization, MFO)与反向传播算法(Backpropagation, BP)的混凝土强度预…...

【Python实例学习笔记】图像相似度计算--哈希算法
【Python实例学习笔记】图像相似度计算--哈希算法 一、哈希算法的实现步骤:二、对每一步都进行注解的代码 一、哈希算法的实现步骤: 1、缩小尺寸: 将图像缩小到8*8的尺寸,总共64个像素。这一步的作用是去除图像的细节,…...

2025DevSecOps标杆案例|智能制造国际领导厂商敏捷安全工具链实践
某智能制造国际领导厂商是涵盖智能家居、楼宇科技,工业技术、机器人与自动化和数字化创新业务五大业务板块为一体的全球化科技集团,连续入选《财富》世界500强,每年为全球超过4亿用户、各领域的重要客户与战略合作伙伴提供产品和服务。 数智化…...

【YOLOv11】目标检测任务-实操过程
目录 一、torch环境安装1.1 创建虚拟环境1.2 启动虚拟环境1.3 安装pytorch1.4 验证cuda是否可用 二、yolo模型推理2.1 下载yolo模型2.2 创建模型推理文件2.3 推理结果保存路径 三、labelimg数据标注3.1 安装labelimg3.2 解决浮点数报错3.3 labelimg UI界面介绍3.4 数据标注案例…...

第十七章:Python数据可视化工工具-Pyecharts库
一、Pyecharts简介 资源绑定附上完整资源供读者参考学习! Pyecharts是一个基于百度开源可视化库ECharts的Python数据可视化工具,支持生成交互式的HTML格式图表。相较于Matplotlib等静态图表库,Pyecharts具有以下优势: 丰富的图表…...

解决【vite-plugin-top-level-await】 插件导致的 Bindings Not Found 错误
解决【vite-plugin-top-level-await】 插件导致的 Bindings Not Found 错误 环境设置 操作系统: macOS硬件平台: M1 Pro前端框架: Vue 3Node.js 版本: 20 在使用 Vue 项目时,我们尝试集成 vite-plugin-top-level-await 插件以支持顶层 await 语法。然而ÿ…...

《八大排序算法》
相关概念 排序:使一串记录,按照其中某个或某些关键字的大小,递增或递减的排列起来。稳定性:它描述了在排序过程中,相等元素的相对顺序是否保持不变。假设在待排序的序列中,有两个元素a和b,它们…...
)
六十天前端强化训练之第三十七天之Docker 容器化部署实战指南(大师级详解)
欢迎来到编程星辰海的博客讲解 看完可以给一个免费的三连吗,谢谢大佬! 目录 一、Docker 核心知识体系 1.1 容器革命:改变开发方式的技术 1.2 Docker 三剑客 1.3 Docker 生命周期管理 1.4 关键命令详解 二、前端容器化实战案例ÿ…...

RabbitMQ--延迟队列事务消息分发
目录 1.延迟队列 1.1应用场景 1.2利用TTL死信队列模拟延迟队列存在的问题 1.3延迟队列插件 1.4常见面试题 2.事务 2.1配置事务管理器 3.消息分发 3.1概念 3.2应用场景 3.2.1限流 3.2.2负载均衡 1.延迟队列 延迟队列(Delayed Queue),即消息被发送以后, 并…...

列表,元组,字典,集合,之间的嵌套关系
在 Python 中,列表、元组、字典和集合的嵌套关系需要遵循各自的特性(如可变性、可哈希性)。以下是它们之间的嵌套规则、示例和典型应用场景的详细梳理: 1. 列表(List)的嵌套 特性: 可变、有序…...

【行驶证识别】批量咕嘎OCR识别行驶证照片复印件图片里的文字信息保存表格或改名字,基于QT和腾讯云api_ocr的实现方式
项目背景 在许多业务场景中,如物流管理、车辆租赁、保险理赔等,常常需要处理大量的行驶证照片复印件。手动录入行驶证上的文字信息,像车主姓名、车辆型号、车牌号码等,不仅效率低下,还容易出现人为错误。借助 OCR(光学字符识别)技术,能够自动识别行驶证图片中的文字信…...

鸿蒙HarmonyOS NEXT设备升级应用数据迁移流程
数据迁移是什么 什么是数据迁移,对用户来讲就是本地数据的迁移,终端设备从HarmonyOS 3.1 Release API 9及之前版本(单框架)迁移到HarmonyOS NEXT(双框架)后保证本地数据不丢失。例如,我在某APP…...

MCP从零开始
MCP简介 MCP,全称是Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于去年11月正式提出。MCP解决的最大痛点就是Agent开发中调用外部工具的技术门槛过高的问题。 能调用外部工具,是大模型进化为智能体Agent的关…...
介绍,实现场景中物体或设备标注标签信息)
Three.js 快速入门教程【十九】CSS2DRenderer(CSS2D渲染器)介绍,实现场景中物体或设备标注标签信息
系列文章目录 Three.js 快速入门教程【一】开启你的 3D Web 开发之旅 Three.js 快速入门教程【二】透视投影相机 Three.js 快速入门教程【三】渲染器 Three.js 快速入门教程【四】三维坐标系 Three.js 快速入门教程【五】动画渲染循环 Three.js 快速入门教程【六】相机控件 Or…...

横扫SQL面试——连续性登录问题
横扫SQL面试 📌 连续性登录问题 在互联网公司的SQL面试中,连续性问题堪称“必考之王”。💻🔍 用户连续登录7天送优惠券🌟,服务器连续报警3次触发熔断⚠️,图书馆连续3天人流破百开启限流⚡” …...

爱因斯坦求和 torch
目录 向量点积 矩阵乘法 矩阵转置 向量转换相机坐标系 在 Python 的科学计算库(如 NumPy)中,einsum 是一个强大的函数,它可以简洁地表示各种张量运算。下面是几个不同类型的使用示例: 向量点积 向量点积是两个向量…...

Spring Initializr搭建spring boot项目
介绍 Spring Initializr 是一个用于快速生成 Spring Boot 项目结构的工具。它为开发者提供了一种便捷的方式,可以从预先定义的模板中创建一个新的 Spring Boot 应用程序,从而节省了从头开始设置项目的大量时间。 使用 Spring Initializr,你…...

【实战】渗透测试下的文件操作
目录 Linux查找文件 Windows查找文件 查找可写目录 windows Linux 创建 Windows Linux 压缩 解压 远程解压文件 Linux查找文件 >find / -name index.php 查找木马文件 >find . -name *.php | xargs grep -n eval( >find . -name *.php | xargs grep -n ass…...

MATLAB 控制系统设计与仿真 - 30
用极点配置设计伺服系统 方法2-反馈修正 如果我们想只用前馈校正输入,从而达到伺服控制的效果,我们需要很精确的知道系统的参数模型,否则系统输出仍然具有较大的静态误差。 但是如果我们在误差比较器和系统的前馈通道之间插入一个积分器&a…...

P1091 [NOIP 2004 提高组] 合唱队形
题目链接: 思路: 题目意思,找出最少的同学出列,保证学生 1-t 上升, t-n 下降。我们只要求出每个点的最长上升子序列和最长不上升子序列,然后总人数-最长上升子序列和最长不上升子序列1,就是最少…...

小林coding-12道Spring面试题
1.说一下你对 Spring 的理解?spring的核心思想说说你的理解? 2.Spring IoC和AOP 介绍一下?Spring的aop介绍一下?IOC和AOP是通过什么机制来实现的?怎么理解SpringIoc?依赖倒置,依赖注入,控制反转分别是什么?依赖注…...

通过Spring Boot集成WebSocket进行消息通信
文章目录 通过Spring Boot集成WebSocket进行消息通信1. 创建 Spring Boot 项目2. 添加 WebSocket 依赖3. 配置 WebSocket4. 创建 WebSocket 处理器5. 创建控制器(可选)6. 前端页面测试7. 运行项目注意事项 通过Spring Boot集成WebSocket进行消息通信 1.…...

ComfyUI发展全景:从AI绘画新星到多功能创意平台的崛起
在人工智能技术迅猛发展的浪潮中,ComfyUI作为基于Stable Diffusion的开源工具,已经从最初的AI绘画辅助软件成长为支持多模态创作的强大平台。本文将全面梳理ComfyUI的发展历程、技术特点、应用场景及其在AIGC生态中的独特地位,同时展望这一工…...

11-项目涉及设备的问题
我们部门在开发一些项目时,确实需要借用设备,但每次开发新需求时都要从硬件部门借设备,开发完成后又要归还。这种频繁的借还流程不仅增加了沟通成本,还导致项目负责人和开发人员对设备的功能和应用场景缺乏直观的了解。有时甚至连…...

将 Markdown 表格结构转换为Excel 文件
在数据管理和文档编写过程中,我们经常使用 Markdown 来记录表格数据。然而,Markdown 格式的表格在实际应用中不如 Excel 方便,特别是需要进一步处理数据时。因此,我们开发了一个使用 wxPython 的 GUI 工具,将 Markdown…...

C++学习之Linux文件编译、调试及库制作
目录 1.rwx对于文件和目录的区别 2.gcc编译过程 3.数据段合并和地址回填说明 4.gcc编译其他参数 5.函数库简介 6.静态库的使用 7.动态库的简介 8.动态库制作基本流程 9.启动APP错误解决方案12 10.启动APP错误解决方案34 11.makefile一组规则 12.makefile的两个函数 …...

neo4j中导入csv格式的三元组数据
csv数据格式: head_entity,relation,tail_entity 02.02类以外的脂肪乳化制品,包括混合的和(或)调味的脂肪乳化制品,允许添加,β-胡萝卜素 02.02类以外的脂肪乳化制品,包括混合的和(或)调味的脂…...

高项第十六章——项目采购管理
什么是采购管理?项目采购管理包括从项目团队外部采购或获取所需产品、服务或成果的各个过程。 项目采购管理包括编制和管理协议所需的管理和控制过程。 16_1 管理基础 什么是协议?协议是用于明确项目初步意向的任何文件或沟通结果,协议的范…...
:TCP 协议)
架构师面试(二十二):TCP 协议
问题 今天我们聊一个非常常见的面试题目,不管前端还是后端,也不管做的是上层业务还是底层框架,更不管技术方向是运维还是架构,都可以思考和参与一下哈! TCP协议无处不在,我们知道 TCP 是基于连接的端到端…...

五.ubuntu20.04 - ffmpeg推拉流以及Nginx、SRS本地部署
一.本地部署nginx 1.编译ffmpeg,参考这位博主的,编译选项有的enable找不到的不需要的可以直接删除,但是像sdl(包含ffplay)、h264、h265这些需要提前下载好,里面都有下载指令。 Ubuntu20.04 编译安装 FFmp…...

JS 手撕题高频考点
前端面试中,JS 手撕题是高频考点,主要考察 编程能力、算法思维、JS 核心知识。以下是最常见的手撕题分类 代码示例: 目录 📌 1. 手写函数柯里化📌 2. 手写 debounce(防抖)📌 3. 手写…...

Hyperlane框架临时上下文数据管理:提升Web开发效率的利器
Hyperlane框架临时上下文数据管理:提升Web开发效率的利器 在现代Web开发中,临时上下文数据管理是实现高效请求处理的关键。Hyperlane框架通过创新的临时上下文存储机制,为开发者提供了一套简洁、安全的解决方案,让数据在请求生命…...

QT操作PDF文件
Qt 早期本身不提供原生的 PDF 操作功能。从 Qt 5.15 开始,Qt 提供了 PDF 模块,可以显示和提取 PDF 内容。Qt中有如下几种方式实现 PDF 文件的生成、读取和操作。 1、使用 QPrinter 生成 PDF 2、使用 Qt PDF 模块 (Qt 5.15+) 3、使用第三方库(比如:Poppler) 一、使用 Q…...

【算法手记8】NC95 数组中的最长连续子序列 字母收集
🦄个人主页:修修修也 🎏所属专栏:刷题 ⚙️操作环境:牛客网 目录 一.NC95 数组中的最长连续子序列 题目详情: 题目思路: 解题代码: 二.字母收集 题目详情: 题目思路: 解题代码: 结语 一.NC95 数组中的最长连续子序列 牛客网题目链接(点击即可跳转):NC95 …...

AI渗透测试:网络安全的“黑魔法”还是“白魔法”?
引言:AI渗透测试,安全圈的“新魔法师” 想象一下,你是个网络安全新手,手里攥着一堆工具,正准备硬着头皮上阵。这时,AI蹦出来,拍着胸脯说:“别慌,我3秒扫完漏洞࿰…...

使用perf工具分析Linux系统的性能瓶颈
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring 使用perf工具分析Linux系统的性能瓶颈 在现代计算系统中,性能瓶颈是一个经常遇到…...