《八大排序算法》
相关概念
- 排序:使一串记录,按照其中某个或某些关键字的大小,递增或递减的排列起来。
- 稳定性:它描述了在排序过程中,相等元素的相对顺序是否保持不变。假设在待排序的序列中,有两个元素a和b,它们的值相等,并且在排序前a在b前面。如果在排序后,a仍然在b前面,那么就称该排序算法是稳定的;反之,如果排序后a跑到了b后面,那么这个排序算法就是不稳定的。
- 内部排序:当排序的数据量非常小时,待排序的数据全部存放在计算机的内存中,并且排序操作也在内存里完成。
- 外部排序:当待排序的数据量非常大,无法全部存入内存时,就需要借助外部存储设备(如硬盘、磁带等)来辅助完成排序。外部排序通常将数据分成多个较小的部分,先把这些部分依次读入内存进行内部排序,生成有序的子文件,再把这些有序子文件合并成一个最终的有序文件。
任何排序都可以分为单趟排序和多趟排序。将排序拆解开来,更方便理解。
插入排序
直接插入排序
直接插入排序的思想是:将插入的元素按大小逐一插入到已经排序好的有序序列中,直到所有的元素都插入完成,得到一个新的有序序列。
// 打印
void PrintArr(int* a, int n)
{assert(a);for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}单趟排序的思路:假设一个序列已经排序好了,现在要插入一个元素,怎么插入呢?看下面的过程。

// 单趟
// 要比较的最后一个元素的下标
int end;
// 要插入的新元素,先保存起来
int temp = a[end+1];
while(end >= 0)
{// 如果比要比较的元素小,则将这个元素后移if(tmp < a[end]){a[end+1] = a[end];// 继续跟前一个元素比较end--;}else{break;}
}
// 走到这,1.tmp比要比较的元素大 2.比较完了,tmp比第一个元素还小,end为-1
a[end+1] = tmp;多趟排序的思路:那么,我们就可以将乱序序列的第一个元素看做是一个已经排序好的序列,将它的后一个元素插入到这个排序好的序列中,这两个元素就是新的排序好的序列,再将后一个元素插入到这个已经排序好的序列,依次类比。直到最后一个元素插入到已经排序好的序列中,这整个乱序序列就变成有序序列了。
void InsertSort(int* a, int n)
{assert(a);//多趟排序for (int i = 0; i < n - 1; i++) // 注意:i结束条件为最后一个元素的前一个元素下标{// 单趟// 要比较的最后一个元素的下标int end = i;// 要插入的新元素,先保存起来int tmp = a[end + 1];// 把end+1的元素插入到[0,end]while (end >= 0){// 如果比最后一个元素小,则将最后一个元素后移if (tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}// 走到这,1.tmp比要比较的元素大 2.比较完了,比第一个元素还小,end为-1a[end + 1] = tmp;}
}我们来测试一下。
void TestInsertSort()
{int a[] = {2, 1, 4, 3, 6, 7, 0, 5, 10, 8, 9};PrintArr(a, sizeof(a) / sizeof(a[0]));InsertSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestInsertSort();return 0;
}
特性总结
- 元素集合越接近有序,直接插入排序算法的时间效率越高。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
希尔排序
也叫缩小增量排序。对直接插入排序的优化。直接插入排序在序列有序或接近有序的情况下效率可以达到O(N),而在逆序或接近逆序的情况下效率就是O(N^2),所以效率时好时坏。
希尔排序是如何对直接插入排序进行优化的呢?
- 预排序。先将数组接近有序。
- 直接插入排序。数组接近有序,再直接插入排序。
预排序:将间距为gap的值分为一组,分别对每个组进行插入排序。

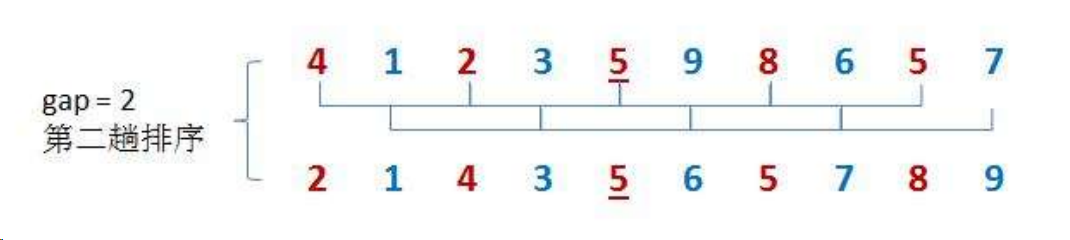

我们先实现一组的直接插入排序。
int gap;
int end;
int tmp = a[end+gap];while(end >= 0)
{if(tmp < a[end]){a[end+gap] = a[end];end -= gap;}else{break;}
}
a[end+gap] = tmp;其实,就相当于是插入排序,只不过插入排序gap为1。
多组是怎么排序的呢?一组一组排吗?不是的,多组并排,非常巧妙。
int gap;
for (int i = 0; i < n - gap; i++) // i < n-gap很巧妙
{int end = i;int tmp = end + gap;while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;
}gap越大,前面大的数据可以越快到后面,后面小的数,可以越快到前面,但是gap越大,越不接近有序。gap=1时,就是直接插入排序。
那gap设置为几呢?希尔是这样设计的:gap=n;gap = n / gap + 1;只要gap大于1就是预排序,gap等于1为直接插入排序。
void ShellSort(int* a, int n)
{assert(a);int gap = n;// gap大于1预排序 ==1直接插入排序while (gap > 1){//预排序:把间距为gap的值分为一组 进行插入排序。+1保证最后是直接插入排序gap = gap / 3 + 1;//多组并排for (int i = 0; i < n - gap; i++){int end = i;int tmp = end + gap;while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}// 测试用的打印PrintArr(a, n);}
}我们来测试一下。
void TestInsertSort()
{int a[] = {2, 1, 4, 3, 6, 7, 0, 5, 10, 8, 9};PrintArr(a, sizeof(a) / sizeof(a[0]));InsertSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}void TestShellSort()
{int a[] = { 19,30,11,20,1,2,5,7,4,8,6,26,3,29 };PrintArr(a, sizeof(a) / sizeof(a[0]));ShellSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}
下面我们来测试一下直接插入排序和希尔排序的效率。
void TestOp()
{const int N = 100000;srand(time(0));int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; i++){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();printf("InsertSort time: %d milliseconds\n", end1 - begin1);printf("ShellSort time: %d milliseconds\n", end2 - begin2);free(a1);free(a2);
}int main()
{TestOp();return 0;
}
特性总结
- 希尔排序是对直接插入排序的优化。
- 当gap>1时都是预排序,目的是让序列接近有序。当gap==1时,数组已经接近有序了,直接插入排序,可以达到优化效果。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法有很多。大概为O(N^1.25)~O(1.6 * N^1.25)。
- 稳定性:不稳定。
选择排序
直接选择排序
每一次都从待排序序列中找出最小元素与最大元素,放在序列的起始位置和末尾位置,直到最后所有元素排完。
void SelectSort(int* a, int n)
{assert(a);int begin = 0;int end = n-1;while (begin < end){int mini = begin; // 最小元素的下标int maxi = begin; // 最小元素的下标for (int i = begin + 1; i <= end; i++){//在[begin,end]找最小值和最大值的下标if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}Swap(&a[begin], &a[mini]);// 如果begin和maxi的位置重叠,最大值已经被换走了,所以maxi的值需要修正if (begin == maxi){maxi = mini;}Swap(&a[end], &a[maxi]);begin++;end--;}
}来测试一下。
void TestSelectSort()
{int a[] = { 9,1,2,5,7,4,8,6,3,5 };PrintArr(a, sizeof(a) / sizeof(a[0]));SelectSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestSelectSort();return 0;
}

特性总结
- 效率不高。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
堆排序
利用堆来进行选择排序,排升序,建大堆;排降序,建小堆。关于堆排序可以看下面这篇文章。
《二叉树:二叉树的顺序结构->堆》
// 大堆向下调整算法
// 注意:调整的树的左右子树必须为大堆
void AdjustDown(int* a, int n, int root)
{// 父亲int parent = root;// 1.选出左右孩子较大的孩子跟父亲比较// 默认较大的孩子为左孩子int child = parent * 2 + 1;// 终止条件孩子到叶子结点最后跟父亲比一次while (child < n){// 2.如果右孩子大于左孩子,则较大的孩子为右孩子 if (child + 1 < n && a[child + 1] > a[child]){child++;}// 3.如果孩子大于父亲,则跟父亲交换if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{assert(a);//建堆 排升序 建大堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end >= 1){// 交换堆顶与最后一个元素Swap(&a[0], &a[end]);// 向下调整AdjustDown(a, end, 0);end--;}
}来测试一下。
void TestHeapSort()
{int a[] = { 9,1,2,5,7,4,8,6,3,5 };PrintArr(a, sizeof(a) / sizeof(a[0]));HeapSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestHeapSort();return 0;
}
特性总结
- 使用堆来选数,效率高。
- 时间复杂度:O(NlogN)。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
交换排序
根据序列中两个键值的比较结果来对换这两个记录在序列中的位置。特点是:键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
冒泡排序
void BubbleSort(int* a, int n)
{assert(a);int i = 0;// 整体for (int j = 0; j < n; j++){// 单趟// 判断是否有序,如果有序,不用比较了,直接退出int flag = 0;for (i = 0; i < n-1-j; i++){if (a[i] > a[i + 1]){// 交换Swap(&a[i], &a[i + 1]);flag = 1;}}if (flag == 0){break;}}
}来测试一下。
void TestBubbleSort()
{//int a[] = { 0,5,7,6,8,9,3,2,4,1 };//int a[] = { 0,9,1,2,3,4,5,6,7,8 };int a[] = { 9,8,7,6,5,4,3,2,1,0 };PrintArr(a, sizeof(a) / sizeof(a[0]));BubbleSort(a, sizeof(a) / sizeof(a[0]));PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestSelectSort();return 0;
}
特性总结
- 非常容易理解。
- 时间复杂度:O(N^2)。
- 空间复杂度:O(1)。
- 稳定性:稳定。
快速排序
是一种二叉树结构的交换排序方法。取待排序元素序列中的某元素key作为基准值,按照该key,将排序集合分为两个子序列,左子序列中所有元素都小于key,右子序列所有元素都大于key。然后左子序列和右子序列分别重复该过程,直到所有的元素都到相应的位置上。
通常取key为最右边的值,或最左边的值。
左右指针法


这样,比key小的值,都换到前面了,比key大的值都换到后面了,而key在正确位置。
来看单趟排序是怎么排的。
// 单趟
int PartSort(int* a, int begin, int end)
{// key下标// 选最后一个值作为keyint keyIndex = end;while (begin < end){// 让左边先走// 左边找比key大的while (begin < end && a[begin] <= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5{begin++;}// 右边再走// 右边找比key小的while (begin < end && a[end] >= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5{end--;}// 交换// 左边的大值就交换到后边了,右边的小值就交换到前面了Swap(&a[begin], &a[end]);}// 走到这,代表相遇了,相遇的位置的值和key交换// 交换完之后,不管左边和右边是否是有序的,总之,key的位置到了正确的位置// 如果选最后一个值作为key,让左边先走可以保证相遇的位置的值是比key大的Swap(&a[begin], &a[keyIndex]);// 返回相遇位置return begin;
}多趟排序,将左子序列和右子序列递归重复该过程即可完成整个排序。
// 多趟
void QuickSort(int* a, int left, int right)
{// 递归结束条件if (left >= right)return;// 此时相遇位置的值已经是正确的位置int div = PartSort(a, left, right);PrintArr(a + left, right - left + 1);// 用于打印测试的printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);// 递归的思想,让该位置的左边和右边按照同样的思想进行排序QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}来测试一下。
void TestQuickSort()
{int a[] = { 6,1,2,7,9,3,4,8,10,5 };// 如果序列本来就有序// int a[] = { 1,2,3,4,5,6,7,8,9};PrintArr(a, sizeof(a) / sizeof(a[0]));QuickSort(a, 0,sizeof(a) / sizeof(a[0])-1);PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestQuickSort();return 0;
}
可以看到递归的整个过程。
再来测试一下。
void TestQuickSort()
{// int a[] = { 6,1,2,7,9,3,4,8,10,5 };// 如果序列本来就有序int a[] = { 1,2,3,4,5,6,7,8,9};PrintArr(a, sizeof(a) / sizeof(a[0]));QuickSort(a, 0,sizeof(a) / sizeof(a[0])-1);PrintArr(a, sizeof(a) / sizeof(a[0]));
}int main()
{TestQuickSort();return 0;
}
快速排序的最好情况:如果每次递归取key值都能取到中位数,排序的效率是最高的,因为每次都能平均将左子序列和右子序列划分开。时间复杂度为O(NlogN)。

快速排序的最坏情况:每次递归取key值都是最大值或最小值,排序的效率是最差的,也就是序列在有序或接近有序的情况下,每次划分都会产生一个空的子序列和一个长度仅比原序列少 1 的子序列。时间复杂度为O(N^2)。

那么,实际中,我们无法保证取到的key是中位数,但是,是不是可以考虑不要取到最大的或最小的。
三位数取中
三位数取中,能避免取到最大值和最小值。如果在最坏的情况有序的情况下,取序列中间的元素作为key值,与最后的元素交换,还是最右边的值作为key值,此时就变成了最好的情况。如果是在其他,也能避免取到最大值和最小值。也就是说三位数取中,让最坏的情况不再出现,时间复杂度综合为O(NlogN)。
// 三位数选中
int GetMidIndex(int* a,int begin,int end)
{int midIndex = (begin + end) / 2;if (a[begin] > a[midIndex]){// begin > mid mid > endif (a[midIndex] > a[end]){return midIndex;}// begin > mid mid<end else{if (a[begin] < a[end]){return begin;}else{return midIndex;}}}// begin <midelse{if (a[midIndex] < a[end]){return midIndex;}// begin<mid mid>endelse{if (a[begin] < a[end]){return end;}else{return begin;}}}
}// 单趟
int PartSort1(int* a, int begin, int end)
{// 三位数选中 避免最坏情况int midIndex = GetMidIndex(a, begin, end);Swap(&a[midIndex], &a[end]);// key下标// 选最后一个值作为keyint keyIndex = end;while (begin < end){// 让左边先走// 左边找比key大的while (begin < end && a[begin] <= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5{begin++;}// 右边再走// 右边找比key小的while (begin < end && a[end] >= a[keyIndex]) // 注意:为>=,不然会造成死循环,例如 3 5 4 7 1 2 8 5 7 5{end--;}// 交换// 左边的大值就交换到后边了,右边的小值就交换到前面了Swap(&a[begin], &a[end]);}// 走到这,代表相遇了,相遇的位置的值和key交换// 交换完之后,不管左边和右边是否是有序的,总之,key的位置到了正确的位置// 如果选最后一个值作为key,让左边先走可以保证相遇的位置的值是比key大的Swap(&a[begin], &a[keyIndex]);// 返回相遇位置return begin;
}// 多趟
void QuickSort(int* a, int left, int right)
{// 递归结束条件if (left >= right)return;// 此时相遇位置的值已经是正确的位置int div = PartSort1(a, left, right);// PrintArr(a + left, right - left + 1);// 用于打印测试的// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);// 递归的思想,让该位置的左边和右边按照同样的思想进行排序QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}挖坑法
取最右边(也可以左边的)的值作为key。该位置为坑,左边找比key大的元素,填入到坑里,该元素的位置成为新的坑;右边找比坑小的元素,填入到新坑里,该元素位置成为新的坑,直到相遇,将key填入到新坑。此时key的左边就是比key小的,右边就是比key大的。再将该key左边的序列和右边的序列迭代重复此操作即可。


// 单趟
int PartSort2(int* a, int begin, int end)
{assert(a);// 三位数选中 避免最坏情况int midIndex = GetMidIndex(a, begin, end);Swap(&a[midIndex], &a[end]);// 最后一个元素为坑// 坑的意思就是这的值被拿走了,可以覆盖新的值int key = a[end];while (begin < end){// begin找大的放进坑 begin成为新坑while (begin < end && a[begin] <= key){begin++;}a[end] = a[begin];// end找小的放进新坑 end成为新坑while (begin < end && a[end] >= key){end--;}a[begin] = a[end];}//把最后一个元素放到相遇位置a[begin] = key;return begin;
}
// 多趟
void QuickSort(int* a, int left, int right)
{// 递归结束条件if (left >= right)return;// 此时相遇位置的值已经是正确的位置// 左右指针法// int div = PartSort1(a, left, right);// 挖坑法int div = PartSort2(a, left, right);// PrintArr(a + left, right - left + 1);// 用于打印测试的// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);// 递归的思想,让该位置的左边和右边按照同样的思想进行排序QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}前后指针法

// 单趟
int PartSort3(int* a, int begin, int end)
{assert(a);//三位数选中 避免最坏情况int midIndex = GetMidIndex(a, begin, end);Swap(&a[midIndex], &a[end]);int keyIndex = end;int prev = begin - 1;int cur = begin;while (cur < end){if (a[cur] < a[keyIndex] && ++prev != a[cur]) // ++prev如果和cur相等 自己跟自己交换不用交换{//交换Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[++prev], &a[keyIndex]);return prev;
}
// 多趟
void QuickSort(int* a, int left, int right)
{// 递归结束条件if (left >= right)return;// 此时相遇位置的值已经是正确的位置// 左右指针法// int div = PartSort1(a, left, right);// 挖坑法// int div = PartSort2(a, left, right);// 前后指针法int div = PartSort3(a, left, right);// PrintArr(a + left, right - left + 1);// 用于打印测试的// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);// 递归的思想,让该位置的左边和右边按照同样的思想进行排序QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}快速排序就像一颗二叉树一样,选出一个key分出左区间和右区间,左区间的值都比key小,右区间的值都比key大,再再左区间中找出一个key分出左区间和右区间,在右区间中找出一个key分出左区间和右区间......
快速排序还有可以优化的地方,当不断的递归划分区间,区间已经数据很少时,不用再递归方式划分区间排序了,使用插入排序去排序,减少整体的递归次数。
// 多趟
void QuickSort(int* a, int left, int right)
{// 递归结束条件if (left >= right)return;// 此时相遇位置的值已经是正确的位置// 左右指针法// int div = PartSort1(a, left, right);// 挖坑法// int div = PartSort2(a, left, right);// 前后指针法int div = PartSort3(a, left, right);// PrintArr(a + left, right - left + 1);// 用于打印测试的// printf("[%d, %d]%d[%d, %d]\n", left, div - 1, div, div + 1, right);// 区间大于十个元素用快速排序if ((right - left + 1) > 10){int div = PartSort3(a, left, right);// 递归的思想,让该位置的左边和右边按照同样的思想进行排序QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);}// 小于十个元素用插入排序else{InsertSort(a + left, right - left + 1);}
}特性总结
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序。
- 时间复杂度:O(NlogN)。
- 空间复杂度:O(1),使用栈模拟则为O(logN)。
- 稳定性:不稳定。
相关文章:

《八大排序算法》
相关概念 排序:使一串记录,按照其中某个或某些关键字的大小,递增或递减的排列起来。稳定性:它描述了在排序过程中,相等元素的相对顺序是否保持不变。假设在待排序的序列中,有两个元素a和b,它们…...
)
六十天前端强化训练之第三十七天之Docker 容器化部署实战指南(大师级详解)
欢迎来到编程星辰海的博客讲解 看完可以给一个免费的三连吗,谢谢大佬! 目录 一、Docker 核心知识体系 1.1 容器革命:改变开发方式的技术 1.2 Docker 三剑客 1.3 Docker 生命周期管理 1.4 关键命令详解 二、前端容器化实战案例ÿ…...

RabbitMQ--延迟队列事务消息分发
目录 1.延迟队列 1.1应用场景 1.2利用TTL死信队列模拟延迟队列存在的问题 1.3延迟队列插件 1.4常见面试题 2.事务 2.1配置事务管理器 3.消息分发 3.1概念 3.2应用场景 3.2.1限流 3.2.2负载均衡 1.延迟队列 延迟队列(Delayed Queue),即消息被发送以后, 并…...

列表,元组,字典,集合,之间的嵌套关系
在 Python 中,列表、元组、字典和集合的嵌套关系需要遵循各自的特性(如可变性、可哈希性)。以下是它们之间的嵌套规则、示例和典型应用场景的详细梳理: 1. 列表(List)的嵌套 特性: 可变、有序…...

【行驶证识别】批量咕嘎OCR识别行驶证照片复印件图片里的文字信息保存表格或改名字,基于QT和腾讯云api_ocr的实现方式
项目背景 在许多业务场景中,如物流管理、车辆租赁、保险理赔等,常常需要处理大量的行驶证照片复印件。手动录入行驶证上的文字信息,像车主姓名、车辆型号、车牌号码等,不仅效率低下,还容易出现人为错误。借助 OCR(光学字符识别)技术,能够自动识别行驶证图片中的文字信…...

鸿蒙HarmonyOS NEXT设备升级应用数据迁移流程
数据迁移是什么 什么是数据迁移,对用户来讲就是本地数据的迁移,终端设备从HarmonyOS 3.1 Release API 9及之前版本(单框架)迁移到HarmonyOS NEXT(双框架)后保证本地数据不丢失。例如,我在某APP…...

MCP从零开始
MCP简介 MCP,全称是Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于去年11月正式提出。MCP解决的最大痛点就是Agent开发中调用外部工具的技术门槛过高的问题。 能调用外部工具,是大模型进化为智能体Agent的关…...
介绍,实现场景中物体或设备标注标签信息)
Three.js 快速入门教程【十九】CSS2DRenderer(CSS2D渲染器)介绍,实现场景中物体或设备标注标签信息
系列文章目录 Three.js 快速入门教程【一】开启你的 3D Web 开发之旅 Three.js 快速入门教程【二】透视投影相机 Three.js 快速入门教程【三】渲染器 Three.js 快速入门教程【四】三维坐标系 Three.js 快速入门教程【五】动画渲染循环 Three.js 快速入门教程【六】相机控件 Or…...

横扫SQL面试——连续性登录问题
横扫SQL面试 📌 连续性登录问题 在互联网公司的SQL面试中,连续性问题堪称“必考之王”。💻🔍 用户连续登录7天送优惠券🌟,服务器连续报警3次触发熔断⚠️,图书馆连续3天人流破百开启限流⚡” …...

爱因斯坦求和 torch
目录 向量点积 矩阵乘法 矩阵转置 向量转换相机坐标系 在 Python 的科学计算库(如 NumPy)中,einsum 是一个强大的函数,它可以简洁地表示各种张量运算。下面是几个不同类型的使用示例: 向量点积 向量点积是两个向量…...

Spring Initializr搭建spring boot项目
介绍 Spring Initializr 是一个用于快速生成 Spring Boot 项目结构的工具。它为开发者提供了一种便捷的方式,可以从预先定义的模板中创建一个新的 Spring Boot 应用程序,从而节省了从头开始设置项目的大量时间。 使用 Spring Initializr,你…...

【实战】渗透测试下的文件操作
目录 Linux查找文件 Windows查找文件 查找可写目录 windows Linux 创建 Windows Linux 压缩 解压 远程解压文件 Linux查找文件 >find / -name index.php 查找木马文件 >find . -name *.php | xargs grep -n eval( >find . -name *.php | xargs grep -n ass…...

MATLAB 控制系统设计与仿真 - 30
用极点配置设计伺服系统 方法2-反馈修正 如果我们想只用前馈校正输入,从而达到伺服控制的效果,我们需要很精确的知道系统的参数模型,否则系统输出仍然具有较大的静态误差。 但是如果我们在误差比较器和系统的前馈通道之间插入一个积分器&a…...

P1091 [NOIP 2004 提高组] 合唱队形
题目链接: 思路: 题目意思,找出最少的同学出列,保证学生 1-t 上升, t-n 下降。我们只要求出每个点的最长上升子序列和最长不上升子序列,然后总人数-最长上升子序列和最长不上升子序列1,就是最少…...

小林coding-12道Spring面试题
1.说一下你对 Spring 的理解?spring的核心思想说说你的理解? 2.Spring IoC和AOP 介绍一下?Spring的aop介绍一下?IOC和AOP是通过什么机制来实现的?怎么理解SpringIoc?依赖倒置,依赖注入,控制反转分别是什么?依赖注…...

通过Spring Boot集成WebSocket进行消息通信
文章目录 通过Spring Boot集成WebSocket进行消息通信1. 创建 Spring Boot 项目2. 添加 WebSocket 依赖3. 配置 WebSocket4. 创建 WebSocket 处理器5. 创建控制器(可选)6. 前端页面测试7. 运行项目注意事项 通过Spring Boot集成WebSocket进行消息通信 1.…...

ComfyUI发展全景:从AI绘画新星到多功能创意平台的崛起
在人工智能技术迅猛发展的浪潮中,ComfyUI作为基于Stable Diffusion的开源工具,已经从最初的AI绘画辅助软件成长为支持多模态创作的强大平台。本文将全面梳理ComfyUI的发展历程、技术特点、应用场景及其在AIGC生态中的独特地位,同时展望这一工…...

11-项目涉及设备的问题
我们部门在开发一些项目时,确实需要借用设备,但每次开发新需求时都要从硬件部门借设备,开发完成后又要归还。这种频繁的借还流程不仅增加了沟通成本,还导致项目负责人和开发人员对设备的功能和应用场景缺乏直观的了解。有时甚至连…...

将 Markdown 表格结构转换为Excel 文件
在数据管理和文档编写过程中,我们经常使用 Markdown 来记录表格数据。然而,Markdown 格式的表格在实际应用中不如 Excel 方便,特别是需要进一步处理数据时。因此,我们开发了一个使用 wxPython 的 GUI 工具,将 Markdown…...

C++学习之Linux文件编译、调试及库制作
目录 1.rwx对于文件和目录的区别 2.gcc编译过程 3.数据段合并和地址回填说明 4.gcc编译其他参数 5.函数库简介 6.静态库的使用 7.动态库的简介 8.动态库制作基本流程 9.启动APP错误解决方案12 10.启动APP错误解决方案34 11.makefile一组规则 12.makefile的两个函数 …...

neo4j中导入csv格式的三元组数据
csv数据格式: head_entity,relation,tail_entity 02.02类以外的脂肪乳化制品,包括混合的和(或)调味的脂肪乳化制品,允许添加,β-胡萝卜素 02.02类以外的脂肪乳化制品,包括混合的和(或)调味的脂…...

高项第十六章——项目采购管理
什么是采购管理?项目采购管理包括从项目团队外部采购或获取所需产品、服务或成果的各个过程。 项目采购管理包括编制和管理协议所需的管理和控制过程。 16_1 管理基础 什么是协议?协议是用于明确项目初步意向的任何文件或沟通结果,协议的范…...
:TCP 协议)
架构师面试(二十二):TCP 协议
问题 今天我们聊一个非常常见的面试题目,不管前端还是后端,也不管做的是上层业务还是底层框架,更不管技术方向是运维还是架构,都可以思考和参与一下哈! TCP协议无处不在,我们知道 TCP 是基于连接的端到端…...

五.ubuntu20.04 - ffmpeg推拉流以及Nginx、SRS本地部署
一.本地部署nginx 1.编译ffmpeg,参考这位博主的,编译选项有的enable找不到的不需要的可以直接删除,但是像sdl(包含ffplay)、h264、h265这些需要提前下载好,里面都有下载指令。 Ubuntu20.04 编译安装 FFmp…...

JS 手撕题高频考点
前端面试中,JS 手撕题是高频考点,主要考察 编程能力、算法思维、JS 核心知识。以下是最常见的手撕题分类 代码示例: 目录 📌 1. 手写函数柯里化📌 2. 手写 debounce(防抖)📌 3. 手写…...

Hyperlane框架临时上下文数据管理:提升Web开发效率的利器
Hyperlane框架临时上下文数据管理:提升Web开发效率的利器 在现代Web开发中,临时上下文数据管理是实现高效请求处理的关键。Hyperlane框架通过创新的临时上下文存储机制,为开发者提供了一套简洁、安全的解决方案,让数据在请求生命…...

QT操作PDF文件
Qt 早期本身不提供原生的 PDF 操作功能。从 Qt 5.15 开始,Qt 提供了 PDF 模块,可以显示和提取 PDF 内容。Qt中有如下几种方式实现 PDF 文件的生成、读取和操作。 1、使用 QPrinter 生成 PDF 2、使用 Qt PDF 模块 (Qt 5.15+) 3、使用第三方库(比如:Poppler) 一、使用 Q…...

【算法手记8】NC95 数组中的最长连续子序列 字母收集
🦄个人主页:修修修也 🎏所属专栏:刷题 ⚙️操作环境:牛客网 目录 一.NC95 数组中的最长连续子序列 题目详情: 题目思路: 解题代码: 二.字母收集 题目详情: 题目思路: 解题代码: 结语 一.NC95 数组中的最长连续子序列 牛客网题目链接(点击即可跳转):NC95 …...

AI渗透测试:网络安全的“黑魔法”还是“白魔法”?
引言:AI渗透测试,安全圈的“新魔法师” 想象一下,你是个网络安全新手,手里攥着一堆工具,正准备硬着头皮上阵。这时,AI蹦出来,拍着胸脯说:“别慌,我3秒扫完漏洞࿰…...

使用perf工具分析Linux系统的性能瓶颈
想获取更多高质量的Java技术文章?欢迎访问Java技术小馆官网,持续更新优质内容,助力技术成长 Java技术小馆官网https://www.yuque.com/jtostring 使用perf工具分析Linux系统的性能瓶颈 在现代计算系统中,性能瓶颈是一个经常遇到…...

知识就是力量——HELLO GAME WORD!
你好!游戏世界! 简介环境配置前期准备好文章介绍创建头像小功能组件安装本地中文字库HSV颜色空间音频生成空白的音频 游戏UI开发加载动画注册登录界面UI界面第一版第二版 第一个游戏(贪吃蛇)第二个游戏(俄罗斯方块&…...
_20)
LeetCode算法题(Go语言实现)_20
题目 给你两个下标从 0 开始的整数数组 nums1 和 nums2 ,请你返回一个长度为 2 的列表 answer ,其中: answer[0] 是 nums1 中所有 不 存在于 nums2 中的 不同 整数组成的列表。 answer[1] 是 nums2 中所有 不 存在于 nums1 中的 不同 整数组成…...

ES拼音分词自动补全实现
#测试拼音分词 POST /_analyze { "text":"如家酒店真不错", "analyzer": "pinyin" } #这里把拼音的首字母放到这里,也说明了这句话没有被分词,而是作为一个整体出现的 #还把每一个字都形成了一个拼音&#…...

Spring Boot 日志 配置 SLF4J 和 Logback
文章目录 一、前言二、案例一:初识日志三、案例二:使用Lombok输出日志四、案例三:配置Logback 一、前言 在开发 Java 应用时,日志记录是不可或缺的一部分。日志可以记录应用的运行状态、错误信息和调试信息,帮助开发者…...
)
构建大语言模型应用:数据准备(第二部分)
本专栏通过检索增强生成(RAG)应用的视角来学习大语言模型(LLM)。 本系列文章 简介数据准备(本文)句子转换器向量数据库搜索与检索大语言模型开源检索增强生成评估大语言模型服务高级检索增强生成 RAG 如上…...

mac m 芯片 动态切换 jdk 版本jdk8.jdk11.jdk17
下载 jdk 版本. 默认安装路径在. /Library/Java/JavaVirtualMachines配置环境变量 # 动态获取所有 JDK 路径 export JAVA_8_HOME$(/usr/libexec/java_home -v 1.8) export JAVA_11_HOME$(/usr/libexec/java_home -v 11) export JAVA_17_HOME$(/usr/libexec/java_home -v 17)#…...

如何通过python将视频转换为字符视频
请欣赏另类的老鼠舞 字符老鼠舞 与原版对比 对比 实现过程 1. 安装库 pip install numpy pip install Pillow pip install opencv-python pip install moviepy 2. 读取视频帧并转换为灰度图 import cv2def make_video(input_video_path, output_video_path):video_cap cv2…...
组)
如何高效备考蓝桥杯(c/c++)组
以下是针对蓝桥杯C/C组的高效备考策略,结合你的当前基础(C语法简单算法题),分阶段提升竞赛能力,重点突破高频考点: 一、蓝桥杯C/C组核心考点梳理 根据历年真题,重点考察以下内容(按…...

两数之和-力扣
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回答案。 示例 1…...

react撤销和恢复
创建一个历史记录栈past,和一个撤销过的栈future,,在每次操作store的时候,将当前的store的数据,存入历史记录栈past中,, 如果是撤销操作,,就从这个历史栈中取最后面那个数…...

华为机试—密码验证合格程序
题目 你需要书写一个程序验证给定的密码是否合格。 合格的密码要求: 长度超过 8 位必须包含大写字母、小写字母、数字、特殊字符中的至少三种不能分割出两个独立的、长度大于 2 的连续子串,使得这两个子串完全相同;更具体地,如果…...

分布式ID生成器:雪花算法原理与应用解析
在互联网分布式系统中,生成全局唯一的ID是一个核心问题。传统的数据库自增ID、UUID虽然各有优缺点,但在高并发、分库分表场景下往往无法满足需求。美团Leaf分布式ID生成器便是为了解决这些问题而诞生的,其核心实现便是基于Snowflakeÿ…...

搭建Flutter开发环境 - MacOs
一、配置Flutter SDK 1.1 到官网下载Flutter SDK 打开Flutter中文社区网址,往下滚动,找到下载并安装Flutter,选择适合自己电脑的安装包进行下载。下载完毕后,解压放到你想要放置的目录下,我放到了 User/账户/develop…...
】Dart访问控制)
【Flutter学习(1)】Dart访问控制
疑问代码片段: class _MyHomePageState extends State<MyHomePage> {int _counter 0;void _incrementCounter() {setState(() {_counter;});} }对Flutter初始文件里下划线的疑问 为什么这里的类和申明的计数器都要在前面加一个下划线? 在 Dart 中…...

Day50 单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。 class Solution {public boolean wordPattern(String p…...

HTTP和HTTPS区别
一:工作原理 HTTP 超文本传输协议。 一种应用层协议,用于在客户端(如浏览器)和服务器之间传输超文本数据(如HTML、图片)。 明文传输,无加密。 HTTPS 安全的超文本传输协议。 是HTTP的加密…...

拥抱AI变革机遇,联易融自研供应链金融垂直领域大模型“蜂联 AI”
2025年3月25日,中国领先的供应链金融科技解决方案服务商联易融科技集团(09959.HK,以下简称“联易融”)发布2024年业绩公告。2024年公司总收入及收益达10.3亿元,同比增长19%;受益于产品结构优化与运营效率改…...

常用数据库
模式的定义于删除 1.定义模式 CREATE SCHEMA [ <模式名> ] AUTHORIZATION < 用户名 >;要创建模式,调用该命令的用户必须拥有数据库管理员权限,或者获得了DBA授权 eg:为用户WANG定义一个模式S-C-SC CREATE SCHEMA "S-C-SC" AUT…...

Hive UDF开发实战:构建高性能JSON生成器
目录 一、背景与需求场景 二、开发环境准备 2.1 基础工具栈 2.2 Maven依赖配置 三、核心代码实现...
——利用Multisim软件实现3线-8线译码器)
数字电子技术基础(三十六)——利用Multisim软件实现3线-8线译码器
目录 1 手动方式实现3线-8线译码器 2 使用字选择器实现3线-8线译码器 现在尝试利用Multisim软件来实现3线-8线译码器。本实验目的是验证74LS138的基本功能,简单来说就是“N中选1”。 实验设计: (1)使能信号:时&am…...