Hadoop生态圈框架部署(八)- Hadoop高可用(HA)集群部署
文章目录
- 前言
- 一、部署规划
- 二、Hadoop HA集群部署(手动部署)
- 1. 下载hadoop
- 2. 上传安装包
- 2. 解压hadoop安装包
- 3. 配置hadoop配置文件
- 3.1 虚拟机hadoop1修改hadoop配置文件
- 3.1.1 修改 hadoop-env.sh 配置文件
- 3.3.2 修改 core-site.xml 配置文件
- 3.3.3 修改 hdfs-site.xml 配置文件
- 3.3.4 修改 mapred-site.xml 配置文件
- 3.3.5 修改 yarn-site.xml 配置文件
- 3.3.6 修改 workers 配置文件
- 3.2 虚拟机hadoop2安装并配置hadoop
- 3.3 虚拟机hadoop3安装并配置hadoop
- 4. 配置hadoop环境变量
- 4.1 配置虚拟机hadoop1的hadoop环境变量
- 4.2 配置虚拟机hadoop2的hadoop环境变量
- 4.3 配置虚拟机hadoop3的hadoop环境变量
- 三、启动过程
- 1. 启动zookeeper
- 2. 启动JournalNode
- 3. 格式化HDFS(Hadoop分布式文件系统)
- 4. FSImage文件同步
- 5. 格式化ZKFC
- 6. hadoop集群启动和停止
- 6.1 启动 hadoop HA 集群
- 6.2 停止 hadoop HA 集群
- 四、测试NameNode和ResourceManager的主备切换
- 1. 启动 hadoop HA 集群
- 2. 通过服务ID查看NameNode和ResourceManager的状态
- 2.1 查看NameNode的状态
- 2.2 查看ResourceManager的状态
- 3. 测试主备切换
- 3.1 查看NameNode的状态
- 3.2 查看ResourceManager的状态
- 注意
前言
在当今大数据时代,Hadoop作为一种强大的分布式计算框架,广泛应用于海量数据的存储与处理。为了确保系统的高可用性和可靠性,Hadoop引入了高可用性(HA)架构,通过部署多个NameNode和ResourceManager,实现故障转移和负载均衡。本篇文章将详细介绍如何在虚拟机环境中手动部署Hadoop高可用集群,包括环境准备、配置文件修改、服务启动与测试等步骤。通过本指南,读者将能够掌握Hadoop HA集群的搭建过程,为后续的大数据应用打下坚实的基础。
一、部署规划
| 虚拟机 | Name Node | Data Node | Resource Manager | Node Manager | Journal Node | QuorumPeer Main | ZKFC |
|---|---|---|---|---|---|---|---|
| hadoop1 | √ | √ | √ | √ | √ | √ | √ |
| hadoop2 | √ | √ | √ | √ | √ | √ | √ |
| hadoop3 | √ | √ | √ | √ |
二、Hadoop HA集群部署(手动部署)
1. 下载hadoop
点击下载hadoop3.3.0安装包:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
2. 上传安装包
通过拖移的方式将下载的hadoop安装包hadoop-3.3.0.tar.gz上传至虚拟机hadoop1的/export/software目录。

2. 解压hadoop安装包
在虚拟机hadoop1创建Hadoop HA的安装目录。
mkdir -p /export/servers/hadoop-HA

在虚拟机hadoop1上传完成后将hadoop安装包通过解压方式安装至/export/servers/hadoop-HA目录。
tar -zxvf /export/software/hadoop-3.3.0.tar.gz -C /export/servers/hadoop-HA/
解压完成如下图所示。

3. 配置hadoop配置文件
3.1 虚拟机hadoop1修改hadoop配置文件
3.1.1 修改 hadoop-env.sh 配置文件
在虚拟机hadoop1修改hadoop运行时环境变量配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh,使用echo命令向hadoop-env.sh文件追加如下内容。
echo >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export JAVA_HOME=/export/servers/jdk1.8.0_421' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_NAMENODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_DATANODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_SECONDARYNAMENODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export YARN_RESOURCEMANAGER_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export YARN_NODEMANAGER_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_JOURNALNODE_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
echo 'export HDFS_ZKFC_USER=root' >> /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh

查看文件内容是否添加成功。
cat /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hadoop-env.sh

3.3.2 修改 core-site.xml 配置文件
在虚拟机hadoop1修改hadoop核心配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml,使用echo命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/core-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定HDFS的通信地址 --><property><name>fs.defaultFS</name><value>hdfs://ns1</value></property><!-- 指定Hadoop临时数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop-HA/hadoop/</value></property><!-- 配置ZooKeeper集群的地址列表,用于Hadoop高可用性(HA) --><property><name>ha.zookeeper.quorum</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property><!-- 设置访问Hadoop Web界面时使用的静态用户名 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 允许root用户代理任何主机上的请求,指定了哪些主机可以作为代理用户来提交作业 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 允许root用户代理任何组的用户 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>
EOF

3.3.3 修改 hdfs-site.xml 配置文件
在虚拟机hadoop1修改hdfs的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/hdfs-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 设置HDFS的副本数 --><property><name>dfs.replication</name><value>3</value></property><!-- NameNode的元数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>/export/data/hadoop/namenode</value></property><!-- DataNode的数据存储目录 --><property><name>dfs.datanode.data.dir</name><value>/export/data/hadoop/datanode</value></property><!-- 设置命名服务的名称,在 HDFS 中,nameservices 是一个逻辑名称,用于标识一组 NameNode 实例。它允许客户端和其他 HDFS 组件通过一个统一的名称来访问多个 NameNode,从而实现高可用性。 --><property><name>dfs.nameservices</name><value>ns1</value></property><!-- 配置高可用性NameNode --><property><name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value></property><!-- NameNode nn1 的 RPC 地址 --><property><name>dfs.namenode.rpc-address.ns1.nn1</name><value>hadoop1:9000</value></property><!-- NameNode nn1 的 HTTP 地址 --><property><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop1:9870</value></property><!-- NameNode nn2 的 RPC 地址 --><property><name>dfs.namenode.rpc-address.ns1.nn2</name><value>hadoop2:9000</value></property><!-- NameNode nn2 的 HTTP 地址 --><property><name>dfs.namenode.http-address.ns1.nn2</name><value>hadoop2:9870</value></property><!-- 共享edits日志的目录,在 HA 配置中,多个 NameNode 需要访问同一组edits日志,以确保它们之间的数据一致性。 --><!-- qjournal 是一种用于存储edits日志的机制。它允许多个 NameNode 通过一个共享的、可靠的日志系统来记录对文件系统的修改。qjournal 由多个 JournalNode 组成,这些 JournalNode 负责接收和存储来自 NameNode 的编辑日志。 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1</value></property><!-- JournalNode的edits日志存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>/export/data/journaldata</value></property><!-- 启用自动故障转移 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置客户端故障转移代理提供者 --><property><name>dfs.client.failover.proxy.provider.ns1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 禁用权限检查 --><property><name>dfs.permissions.enable</name><value>false</value></property><!-- 配置高可用性隔离方法 --><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><!-- SSH围栏使用的私钥文件 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- SSH连接超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property>
</configuration>
EOF




3.3.4 修改 mapred-site.xml 配置文件
在虚拟机hadoop1修改mapreduce的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/mapred-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定MapReduce框架使用的资源管理器名称,这里设置为YARN --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 设置MapReduce JobHistory服务的地址,用于存储已完成作业的历史信息 --><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value></property><!-- 设置MapReduce JobHistory Web应用程序的地址,可以通过浏览器访问来查看作业历史记录 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value></property><!-- 为MapReduce Application Master设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><!-- 为Map任务设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property><!-- 为Reduce任务设置环境变量,指定HADOOP_MAPRED_HOME路径 --><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=\${HADOOP_HOME}</value></property>
</configuration>
EOF

3.3.5 修改 yarn-site.xml 配置文件
在虚拟机hadoop1修改yarn的配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/yarn-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 启用YARN ResourceManager的高可用性(HA) --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 设置YARN集群的唯一标识符,自定义YARN高可用集群的标识符 --><property><name>yarn.resourcemanager.cluster-id</name><value>jyarn</value></property><!-- 列出所有ResourceManager实例的ID,指定YARN高可用集群中每个ResourceManager的唯一标识符 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 指定第一个ResourceManager实例(rm1)的主机名 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop1</value></property><!-- 指定第二个ResourceManager实例(rm2)的主机名 --><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop2</value></property><!-- 指定ZooKeeper服务器地址,用于存储ResourceManager的状态信息 --><property><name>yarn.resourcemanager.zk-address</name><value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value></property><!-- 配置NodeManager上的辅助服务,这里设置为MapReduce shuffle服务 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 启用日志聚合功能,将容器日志收集到HDFS中 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志保留时间(秒),这里是1天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><!-- 启用ResourceManager的恢复功能 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定ResourceManager状态存储的实现类,这里使用ZooKeeper作为存储 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><!-- 指定第一个ResourceManager实例(rm1)Web应用程序的地址 --><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop1:8188</value></property><!-- 指定第一个ResourceManager实例(rm1)调度器的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>hadoop1:8130</value></property><!-- 指定第二个ResourceManager实例(rm2)Web应用程序的地址 --><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop2:8188</value></property><!-- 指定第二个ResourceManager实例(rm2)调度器的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>hadoop2:8130</value></property>
</configuration>
EOF


3.3.6 修改 workers 配置文件
在虚拟机hadoop1修改hadoop的从节点服务器配置文件/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers,使用cat命令把配置内容重定向并写入到 /export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers 文件。
cat >/export/servers/hadoop-HA/hadoop-3.3.0/etc/hadoop/workers <<EOF
hadoop1
hadoop2
hadoop3
EOF

3.2 虚拟机hadoop2安装并配置hadoop
在虚拟机hadoop1远程登录到hadoop2创建hadoop高可用的安装目录,使用scp命令把虚拟机hadoop1的hadoop的安装目录复制到虚拟机hadoop2的相同目录下,就相当于在hadoop2安装并配置了hadoop。
ssh hadoop2 'mkdir -p /export/servers/hadoop-HA exit'
scp -r /export/servers/hadoop-HA/hadoop-3.3.0 hadoop2:/export/servers/hadoop-HA

3.3 虚拟机hadoop3安装并配置hadoop
在虚拟机hadoop1远程登录到hadoop3创建hadoop高可用的安装目录,使用scp命令把虚拟机hadoop1的hadoop的安装目录复制到虚拟机hadoop3的相同目录下,就相当于在hadoop3安装并配置了hadoop。
ssh hadoop3 'mkdir -p /export/servers/hadoop-HA exit'
scp -r /export/servers/hadoop-HA/hadoop-3.3.0 hadoop3:/export/servers/hadoop-HA

4. 配置hadoop环境变量
4.1 配置虚拟机hadoop1的hadoop环境变量
在虚拟机hadoop1使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

4.2 配置虚拟机hadoop2的hadoop环境变量
在虚拟机hadoop2使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

4.3 配置虚拟机hadoop3的hadoop环境变量
在虚拟机hadoop3使用echo命令向环境变量配置文件/etc/profile追加环境变量内容,使用source命令加载环境变量配置文件,然后使用echo命令打印环境变量,查看环境变量是否生效。
echo >> /etc/profile
echo 'export HADOOP_HOME=/export/servers/hadoop-HA/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo $HADOOP_HOME

三、启动过程
1. 启动zookeeper
由于 Hadoop 的高可用性依赖于 ZooKeeper 来实现 HDFS 和 YARN 的高可用性,因此在启动 Hadoop 之前,必须确保 ZooKeeper 正常运行。
依次在虚拟机 hadoop1、hadoop2 和 hadoop3 启动 ZooKeeper,并检查其状态是否正常。
zkServer.sh start

zkServer.sh status

2. 启动JournalNode
在格式化 Hadoop 高可用集群的 HDFS 文件系统时,系统会向 Quorum Journal Manager 写入 EditLog。在首次启动之前,需要在虚拟机 Hadoop1、Hadoop2 和 Hadoop3 上分别执行以下命令以启动 JournalNode。
hdfs --daemon start journalnode



3. 格式化HDFS(Hadoop分布式文件系统)
在虚拟机hadoop1执行如下命令格式化Hadoop分布式文件系统HDFS。
hdfs namenode -format
格式化成功如下图所示,会提示我们存储目录 /export/data/hadoop/namenode 已经成功格式化。

4. FSImage文件同步
为了确保HDFS初次启动时两个NameNode节点上的FSImage文件保持一致,在虚拟机hadoop1上完成HDFS格式化后(此操作仅初始化虚拟机hadoop1的NameNode并生成FSImage文件),需要将生成的FSImage文件从hadoop1复制到hadoop2对应的目录中。
在虚拟机hadoop1执行如下命令把hadoop1生成的FSImage文件复制到hadoop2对应的目录。
ssh hadoop2 'mkdir -p /export/data/hadoop'
scp -r /export/data/hadoop/namenode hadoop2:/export/data/hadoop

5. 格式化ZKFC
ZKFC(ZooKeeper Failover Controller)是Hadoop高可用性(HA)架构中的一个关键组件,主要用于NameNode的故障转移管理。在HDFS HA配置中,通常会部署两个NameNode节点来提供服务冗余,其中一个处于Active状态负责处理客户端请求,另一个则处于Standby状态作为备份。ZKFC的作用就是在主NameNode发生故障时自动切换到备用NameNode,从而保证系统的连续性和数据的一致性。
在虚拟机hadoop1执行如下命令格式化ZKFC。
hdfs zkfc -formatZK

6. hadoop集群启动和停止
6.1 启动 hadoop HA 集群
在虚拟机hadoop1执行如下命令同时启动 hdfs 高可用集群和 yarn 高可用集群。
start-all.sh

hadoop 高可用集群启动之后使用如下命名分别在虚拟机hadoop1、虚拟机hadoop2和虚拟机hadoop3执行如下命令查看对应进程是否正常。
jps正常如下图所示。

访问 HDFS(NameNode)的 Web UI 页面
在启动 hadoop 高可用集群后,在浏览器输入http://192.168.121.160:9870进行访问,如下图,可以看到处于active(活跃)状态的NameNode。
在浏览器输入
http://192.168.121.161:9870进行访问,如下图,可以看到处于standby(备用)状态的NameNode。
检查DataNode是否正常,正常如下图所示。



访问 YARN 的 Web UI 页面
在启动hadoop集群后,在浏览器输入http://192.168.121.161:8188进行访问,如下图,可以看到处于active(活跃)状态的ResourceManager。
在浏览器输入http://192.168.121.160:8188进行访问,如下图,可以看到处于standby(备用)状态的ResourceManager。


6.2 停止 hadoop HA 集群
如果需要停止 hadoop HA 集群运行,在虚拟机hadoop1执行如下命令同时停止 hdfs 高可用集群和 yarn高可用集群。
stop-all.sh

四、测试NameNode和ResourceManager的主备切换
1. 启动 hadoop HA 集群
在虚拟机hadoop1执行如下命令同时启动 hdfs 高可用集群和 yarn 高可用集群。
start-all.sh

2. 通过服务ID查看NameNode和ResourceManager的状态
下图所示是设置的NameNode服务的ID。

2.1 查看NameNode的状态
hadoop配置中设置的nn1在hadoop1,nn2在hadoop2。
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

可以看出hadoop1上的NameNode是active状态。
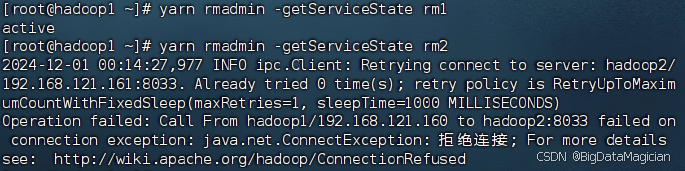
2.2 查看ResourceManager的状态
hadoop配置中设置的rm1在hadoop1,rm2在hadoop2。
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2

可以看出hadoop2上的ResourceManager是active状态。
3. 测试主备切换
根据上面得到的处于active状态的NameNode和ResourceManager的虚拟机,分别在对应的虚拟机停止处于active状态的服务,测试主备切换。
在虚拟机hadoop1执行如下命令停止虚拟机hadoop1的NameNode。
hdfs --daemon stop namenode
在虚拟机hadoop2执行如下命令停止虚拟机hadoop2的ResourceManager。
yarn --daemon stop resourcemanager
再次通过服务ID查看NameNode和ResourceManager的状态。
3.1 查看NameNode的状态
hadoop配置中设置的nn1在hadoop1,nn2在hadoop2。
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

可以看出hadoop1上的NameNode已经由active状态变为不正常,hadoop2上的NameNode已经由standby转为active。
3.2 查看ResourceManager的状态
hadoop配置中设置的rm1在hadoop1,rm2在hadoop2。
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
可以看出hadoop2上的ResourceManager已经由active状态变为不正常,hadoop1上的ResourceManager已经由standby转为active。
注意
若启动过程中出现问题,需要重新执行启动过程,需要删除生成的对应目录或文件。
rm -rf /export/data/hadoop-HA
rm -rf /export/data/hadoop
rm -rf /export/data/journaldata
zkCli.sh
deleteall /hadoop-ha
deleteall /rmstore
deleteall /yarn-leader-election
quit
相关文章:
- Hadoop高可用(HA)集群部署)
Hadoop生态圈框架部署(八)- Hadoop高可用(HA)集群部署
文章目录 前言一、部署规划二、Hadoop HA集群部署(手动部署)1. 下载hadoop2. 上传安装包2. 解压hadoop安装包3. 配置hadoop配置文件3.1 虚拟机hadoop1修改hadoop配置文件3.1.1 修改 hadoop-env.sh 配置文件3.3.2 修改 core-site.xml 配置文件3.3.3 修改 …...

抗干扰设计的检查细则
抗干扰设计是确保电子系统或设备在复杂电磁环境中稳定运行的重要环节,涉及多个方面的设计和实施。以下是对抗干扰设计的检查细则的详细归纳: 一、电源线与地线设计 电源线设计:选择合适的电源,尽量加宽电源线,保证电源…...

[Redis#12] 常用类型接口学习 | string | list
目录 0.准备 1.string get | set set_with_timeout_test.cpp set_nx_xx_test.cpp mset_test.cpp mget_test.cpp getrange_setrange_test.cpp incr_decr_test.cpp 2.list lpush_lrange_test.cpp rpush_test.cpp lpop_rpop_test.cpp blpop_test.cpp llen_test.cpp…...

React的ts文件中通过createElement拼接一段内容出来
比如接口返回一个值 const values [23.00, 40.00/kg];想做到如下效果, 如果单纯的用render渲染会很简单, 但是在ts文件中处理,所以采用了createElement拼接 代码如下: format: (values: string[]) > {if (!values || !val…...

【Git系列】Git 提交历史分析:深入理解`git log`命令
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

深度学习笔记——生成对抗网络GAN
本文详细介绍早期生成式AI的代表性模型:生成对抗网络GAN。 文章目录 一、基本结构生成器判别器 二、损失函数判别器生成器交替优化目标函数 三、GAN 的训练过程训练流程概述训练流程步骤1. 初始化参数和超参数2. 定义损失函数3. 训练过程的迭代判别器训练步骤生成器…...

《地球科学与环境学报》
《地球科学与环境学报》报道范围涵盖基础地质、矿产地质、水资源与环境、工程地质、地球物理、地球信息科学等领域,刊载国内外未公开发表的有创新性或意义重大的研究论文和综述文章。 来稿必须包括以下项目:题名(尽可能不要超过20字&…...

k8s 1.28 聚合层部署信息记录
–requestheader-client-ca-file –requestheader-allowed-namesfront-proxy-client –requestheader-extra-headers-prefixX-Remote-Extra- –requestheader-group-headersX-Remote-Group –requestheader-username-headersX-Remote-User –proxy-client-cert-file –proxy-cl…...

组件化设计的意义
鸿蒙操作系统(HarmonyOS)是华为公司开发的一款面向未来、面向全场景的分布式操作系统。它不仅能够支持多种智能终端设备,还能够实现跨设备之间的协同工作。为了满足不同设备的资源能力和业务需求,鸿蒙操作系统采用了组件化的设计方…...
赛项样题)
2025 年河北省职业院校大数据应用与 服务(中职组)赛项样题
— 1 — 2025 年河北省职业院校大数据应用与 服务(中职组)赛项样题 一、背景描述 近年来,随着旅游业的快速发展和社交媒体的普及,一 些目的地因其独特的魅力或者事件而迅速走红,吸引了大量 游客涌入,使得当…...

宏集eXware物联网网关在水务管理系统上的应用
一、前言 水务管理系统涵盖了对城市水网、供水、排水、污水处理等多个环节的监控与管理。随着物联网(IoT)技术的快速发展,物联网网关逐渐成为水务管理系统中的关键组成部分。 宏集物联网网关以其高效的数据采集、传输和管理功能,…...

【看海的算法日记✨优选篇✨】第三回:二分之妙,寻径中道
🎬 个人主页:谁在夜里看海. 📖 个人专栏:《C系列》《Linux系列》《算法系列》 ⛰️ 一念既出,万山无阻 目录 📖一、算法思想 细节问题 📚左右临界 📚中点选择 📚…...

yolov5 解决:export GIT_PYTHON_REFRESH=quiet
当我们在第一次运行YOLOv5中的train.py程序时:可能会出现以下报错: This initial warning can be silenced or aggravated in the future by setting the $GIT_PYTHON_REFRESH environment variable. Use one of the following values: - quiet|q|silen…...

MongoDB聚合操作
1.聚合操作 聚合操作处理数据记录并返回计算结果。聚合操作组值来自多个文档,可以对分组数据执行各种操作以返回单个结果。聚合操作包含三类:单一作用聚合、聚合管道、MapReduce。 单一作用聚合:提供了对常见聚合过程的简单访问,…...

Apple雷电5到底有多快?
在科技日新月异的今天,苹果公司始终走在技术创新的前沿。2023年9月12日,随着英特尔发布雷电5(Thunderbolt 5)规范,苹果迅速跟进,将其应用于自家的产品中。雷电5接口以其卓越的性能,彻底颠覆了我…...

项目快过:知识蒸馏 | 目标检测 |FGD | Focal and Global Knowledge Distillation for Detectors
公开时间:2022年3月9号 项目地址:https://github.com/yzd-v/FGD 论文地址:https://arxiv.org/pdf/2111.11837 知识蒸馏已成功地应用于图像分类。然而,目标检测要复杂得多,大多数知识蒸馏方法都失败了。本文指出&#…...

Spring Boot日志总结
文章目录 1.我们的日志2.日志的作用3.使用日志对象打印日志4.日志框架介绍5.深入理解门面模式(外观模式)6.日志格式的说明7.日志级别7.1日志级别分类7.2配置文件添加日志级别 8.日志持久化9.日志文件的拆分9.1官方文档9.2IDEA演示文件分割 10.日志格式的配置11.更简单的日志输入…...

PostgreSQL最常用数据类型-重点说明自增主键处理
简介 PostgreSQL提供了非常丰富的数据类型,我们平常使用最多的基本就3类: 数字类型字符类型时间类型 这篇文章重点介绍这3中类型,因为对于高并发项目还是推荐:尽量使用简单类型,把运算和逻辑放在应用中,…...

androidstudio 最新继承 proto kts 方式
在Android Studio中,如果你使用的是Kotlin DSL(.kts文件)来配置你的Gradle项目,并且你想集成Protocol Buffers(Proto),你需要稍微调整你的配置方式。以下是如何在Kotlin DSL中配置Proto集成的步…...

【STM32学习】TB6612FNG驱动芯片的学习,驱动电路的学习
目录 1、TB6612电机驱动芯片 1.1如下是芯片的引脚图: 1.2如下图是电机的控制逻辑: 1.3MOS管运转逻辑 1.3典型应用电路 2、H桥驱动电路 2.1、单极模式 2.2、双极模式 2.3、高低端MOS管导通条件 2.4、H桥电路设计 2.5、自举电路 3、电气特性 3…...

【AI战略思考13】克服懒惰,保持专注,提升效率,不再焦虑
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 引言 我发现自己最近非常懒惰,浪费了很多时间,也容易分心,不够专注,效率低下,且每天都有点焦虑,因此制定了下面的要求和作息时间表。 目…...

基于Vue3+Element Plus 实现多表单校验
使用场景 表单校验在日常的开发需求中是一种很常见的需求,通常在提交表单发起请求前校验用户输入是否符合规则,通常只需formRef.value.validate()即可校验,但是,例如一些多步骤表单、动态表单、以及不同的用户角色可能看到不同的表…...

“岗位复合化、技能层次化” 高职大数据技术专业人才培养实践
在全球数字化浪潮的推动下,大数据技术已经成为引领社会进步和经济发展的核心动力。随着《关于深化现代职业教育体系建设改革的意见》等系列指导问文件的发布,我国高职大数据技术专业的教育正迎来全新机遇与挑战。这些政策不仅明确了职业教育改革的方向&a…...

Day2 生信新手笔记: Linux基础
一、基础知识 1.1 服务器 super computer 或 server 1.2 组学数据分析 组学数据:如基因组学、转录组学、蛋白质组学等; 上游分析:主要涉及原始数据的获取和初步处理,计算量大,消耗的资源较多,在服务器完…...

AI开发-数据可视化库-Seaborn
1 需求 概述 Seaborn 是一个基于 Python 的数据可视化库,它建立在 Matplotlib 之上。其主要目的是使数据可视化更加美观、方便和高效。它提供了高层次的接口和各种美观的默认主题,能够帮助用户快速创建出具有吸引力的统计图表,用于数据分析和…...

如何把Qt exe文件发送给其他人使用
如何把Qt exe文件发送给其他人使用 1、先把 Debug改成Release2、重新构建项目3、运行项目4、找到release文件夹5、新建文件夹,存放exe文件6、打开qt控制台串口7、下载各种文件8、压缩,发送压缩包给别人 1、先把 Debug改成Release 2、重新构建项目 3、运行…...

力扣103.二叉树的锯齿形层序遍历
题目描述 题目链接103. 二叉树的锯齿形层序遍历 给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。 示例 1ÿ…...

MOH: MULTI-HEAD ATTENTION AS MIXTURE-OFHEAD ATTENTION
当前的问题 多头注意力使用多个头部可以提高模型的精度。然而,并不是所有的注意力头都具有同样的重要性。一些研究表明,许多注意力头可以被修剪而不影响准确性。 此外,在多头注意中,每个注意头并行操作,最终输出是所…...

Linux的文件系统
这里写目录标题 一.文件系统的基本组成索引节点目录项文件数据的存储扇区三个存储区域 二.虚拟文件系统文件系统分类进程文件表读写过程 三.文件的存储连续空间存放方式缺点 非连续空间存放方式链表方式隐式链表缺点显示链接 索引数据库缺陷索引的方式优点:多级索引…...

力扣78题详解:C语言实现子集问题
力扣78题详解:C语言实现子集问题 题目描述 给定一个不含重复元素的整数数组 nums,返回其所有可能的子集(幂集)。 说明:解集不能包含重复的子集,顺序无关。 示例 输入:nums [1,2,3] 输出&am…...

按行数据拆分到工作表-Excel易用宝
有这样一份工作表,现在要对工作表按指定行数进行拆分,如果你还在选择数据区域复制粘贴到每个工作表中,那这样的效率也太低了。 按指定行数拆分工作表,就用易用宝。 单击Excel易用宝,合并与拆分,拆分工作表…...

.net core 创建linux服务,并实现服务的自我更新
目录 创建服务创建另一个服务,用于执行更新操作给你的用户配置一些systemctl命令权限 创建服务 /etc/systemd/system下新建服务配置文件:yourapp.service,内容如下: [Unit] Descriptionyourapp Afternetwork.target[Service] Ty…...

无人机的起降装置:探索起飞和降落的秘密 !
一、起降系统的运行方式 起飞方式 垂直起飞:小型无人机通常采用垂直起飞方式,利用螺旋桨产生的升力直接从地面升起。这种方式适用于空间有限或需要快速起飞的场景。 跑道起飞:大型无人机或需要较长起飞距离的无人机,可能会采用…...

Apache Airflow 快速入门教程
Apache Airflow已经成为Python生态系统中管道编排的事实上的库。与类似的解决方案相反,由于它的简单性和可扩展性,它已经获得了普及。在本文中,我将尝试概述它的主要概念,并让您清楚地了解何时以及如何使用它。 Airflow应用场景 …...

数学题转excel;数学题库;数学试卷转excel;大风车excel
一、数学试卷转excel 有些需要刷题的朋友,需要将题库数学题转为excel格式,便于管理 前端时间帮一位朋友实现了数学题转excel,包括选择题、填空题、分析题 示例: 二、问题 数学题是最难以处理的试题,理由如下 1、有…...
)
【C++】类和对象(下)
目录 前言 一、再探构造函数 二、类型转换 三、static 成员 四、友元 五、内部类 六、匿名对象 七、对象拷贝时的编译器优化 总结 前言 本文主要内容:构造函数的再探--初始化列表、内置类型与自定义类型之间的转换、类的static成员、友元、内部类、匿名对…...

vue多页面应用集成时权限处理问题
在多页面应用(MPA)中,权限管理通常会涉及到每个页面的访问控制、身份验证、以及权限校验。以下是几种常见的权限处理方式: 1. 前端路由权限控制 原理:虽然是多页面应用,通常每个页面会独立加载和渲染&…...

输出保留3位小数的浮点数
输出保留3位小数的浮点数 C语言代码C代码Java代码Python代码 💐The Begin💐点点关注,收藏不迷路💐 读入一个单精度浮点数,保留3位小数输出这个浮点数。 输入 只有一行,一个单精度浮点数。 输出 也只有一…...

openssl的运用
一、概述 Opssl是一个用于TLS/SSL协议的工具包,也是一个通用密码库。 包含了国密sm2 sm3 sm4,包含了对称加密,非对称加密,单项散列,伪随机、签名,密码交换,证书等一些算法库。 为了深层次的学习…...
)
C++STL之vector(超详细)
CSTL之vector 1.vector基本介绍2.vector重要接口2.1.构造函数2.2.迭代器2.3.空间2.3.1.resize2.3.2.capacity 2.4.增删查找 3.迭代器失效4.迭代器分类 🌟🌟hello,各位读者大大们你们好呀🌟🌟 🚀Ὠ…...

RabbitMQ消息可靠性保证机制5--消息幂等性处理
RabbitMQ层面有实现“去重机制”来保证“恰好一次”吗?答案是没并没有,而且现在主流的消息中间件都没有实现。 一般解决重复消息的办法是:在消费端让我们消费消息操作具有幂等性。 幂等性问题并不是消息系统独有,而是࿰…...

24/12/1 算法笔记<强化学习> 创建Maze交互
我们今天制作一个栅格的游戏。 我们直接上代码教学。 1.载入库和查找相应的函数版本 import numpy as np import time import sysif sys.version_info.major 2:import Tkinter as tk else:import tkinter as tk 2.设置长宽和单元格大小 UNIT 40 MAZE_H 4 MAZE_W 4 3.初始…...

c++:模版 template
一、模版 1.格式: template <typname T> 2.实现 2.1自动推导 模板只对紧跟在后面的第一行代码有效,如果后面还想定义模板函数需要重新定义模板 #include <iostream> #include <string>template <typename T> void Print(T v…...

javascript切换类、删除类、修改类以及增加类
在JavaScript中,操作DOM元素的类(class)是一个常见的操作。以下是一些基本的方法来切换类、删除类、修改类以及增加内联样式: 切换类(Toggle Class) 切换类意味着如果类存在则移除它,如果不存…...
--区块链的交易模型part1)
区块链学习笔记(2)--区块链的交易模型part1
模型基础 区块链的tx分为两种模型,分别是比特币为代表的UTXO(Unspent Transaction Output)模型,和以太坊为代表的Account模型。前者适用于货币记账,后者适用于链上应用。 UTXO模型 类似于现金的交易模型 一个tx包含…...

反射知识总结
狂神说 反射的功能: 类加载内存分析 类加载的时候,class对象就形成了。 类无论有多少对象,class对象只有一个。 获取类对象三种方式 反射,就是通过api获取一个类的类对象: 有三种方式: 方法一…...

selenium部署分布式 UI 自动化测试环境-Docker
一、根据selenium/hub官网的配置信息,进行配置。 How to run this image The Hub and Nodes will be created in the same network and they will recognize each other by their container name. A Docker network needs to be created as a first step.Create …...

算法刷题Day5: BM52 数组中只出现一次的两个数字
描述: 一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。 要求:空间复杂度 O(1),时间复杂度O(n)。 题目传送门 is here 思路: 方法一:最简单的思路就…...

使用docker-compose部署搜索引擎ElasticSearch6.8.10
背景 Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建。它被广泛用于实时数据搜索、日志分析、全文检索等应用场景。 Elasticsearch 支持高效的全文搜索,并提供了强大的聚合功能,可以处理大规模的数据集并进行快速…...
)
多线程篇-5--线程分类(线程类型,springboot中常见线程类型,异步任务线程)
常见的线程类型包括用户线程(User Threads)、守护线程(Daemon Threads)、主线程(Main Thread)、工作线程(Worker Threads)和线程池中的线程。 一、用户线程(User Thread…...