【C++】stack和queue
目录
1. stack的介绍和使用
1.1 stack的介绍
1.2 stack的使用
2. queue的介绍和使用
2.1 queue的介绍
2.2 queue的使用
3. 容器适配器
3.1 什么是适配器
3.2 STL标准库中stack和queue的底层结构
3.3 deque的简单介绍(了解)
3.3.1 deque的原理介绍
3.3.2 deque优势与缺陷
3.4 为什么选择deque作为stack和queue的底层默认容器
3.5 STL标准库中对于stack和queue的模拟实现
3.5.1 stack的模拟实现
3.5.2 queue的模拟实现
4.priority_queue的介绍和使用
4.1 priority_queue的介绍
4.2 priority_queue的使用
【注意】1. 默认情况下,priority_queue是大堆。
4.2.1仿函数的介绍
4.2.1需要写仿函数的情形
4.3 在OJ中的使用
4.4 priority_queue的模拟实现
注:本文的学习是基于对于数据结构栈与队列、堆有一定基础上的,未学习相关知识的读者可以移步学习数据结构部分相关内容。
栈和队列
堆
1. stack的介绍和使用
1.1 stack的介绍
stack的文档介绍
C++中的stack模拟了数据结构栈的特性,具有先进后出的特性,数据进出都只从一边进出。(在前面string与vector学习的基础上,我们对于STL相关接口已经非常熟悉,因此,本文不在详细介绍相关接口。
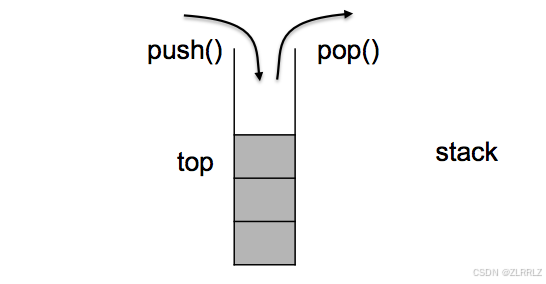
1.2 stack的使用
| 函数说明 | 接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将stack中尾部的元素弹出 |
2. queue的介绍和使用
2.1 queue的介绍
queue的文档介绍
翻译:
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元
素,另一端提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供
一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少
支持以下操作:
empty:检测队列是否为空
size:返回队列中有效元素的个数
front:返回队头元素的引用
back:返回队尾元素的引用
push_back:在队列尾部入队列
pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器
类,则使用标准容器deque。
C++中queue同样模拟了数据结构中队列,具有先进先出的特性,数据从一边进,从另一边出。
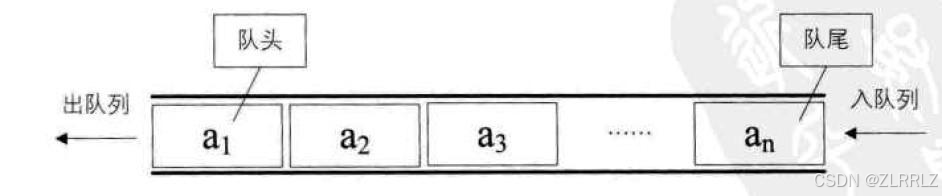
2.2 queue的使用
| 函数声明 | 接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空,是返回true,否则返回false |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 在队尾将元素val入队列 |
| pop() | 将队头元素出队列 |
3. 容器适配器
3.1 什么是适配器
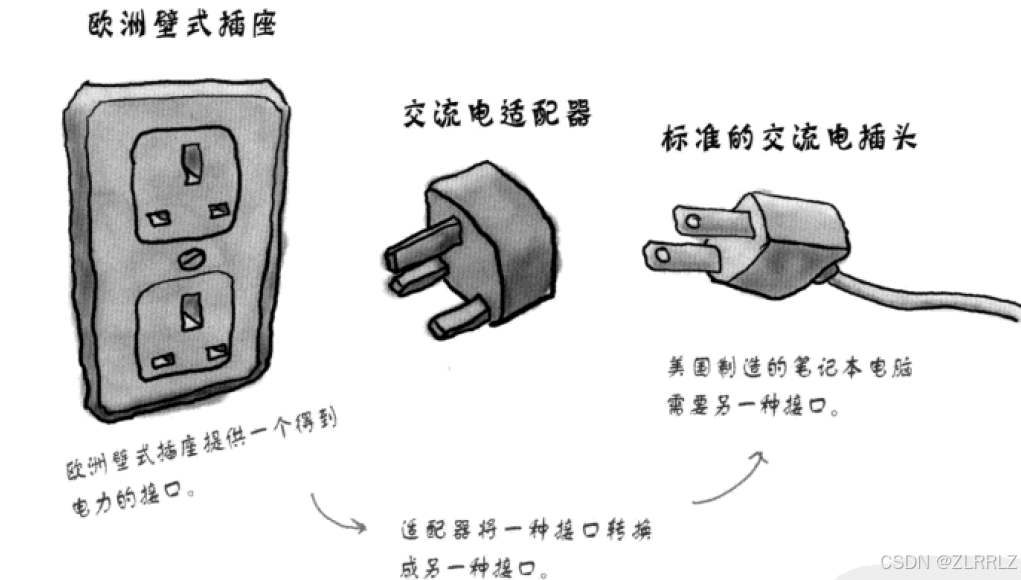
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结,我们之前所使用的迭代器iterator就是一种设计模式,不过设计模式相对在Java中运用更多,C++中较少。),该种模式是将一个类的接口转换成客户希望的另外一个接口。就像我们日常的插座,我们给手机充电不可能直接使用220V的交流电压,我们都是通过插座将交流电转换为我们所需要的电流。
因此STL中很多接口就是在其他已实现的接口的基础上封装而来,这样的代码复用就可以节省大量的资源。
同时对应的接口实现内部细节我们不需要再考虑具体的类型,因为是在已实现的接口基础上实现的,对应的类对象会自己调用自己对应类型的接口,这也体现了泛型编程的思想
3.2 STL标准库中stack和queue的底层结构
C++中的底层结构无非是数组或者链式结构,观察stack与queue的特征,我们发现这两者最突出的特点无非是先进先出与先进后出,其他与vector与list并无区别。
那么在vector与list(数组与链式结构)封装的非常完善的条件下,我们还有必要在数组与链表的结构基础上再封装stack与queue吗?显然不再需要了。
那么这里我们就运用到我们上面提到过的适配器的思想,我们再将vector与list封装一下,将接口转变成我们期待的符合先进先出与先进后出的形式就可以了。
所以虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,但是查阅文档我们又发现STL中stack和queue默认使用deque?为什么STL底层使用的不是vector与list,deque又是什么呢?



3.3 deque的简单介绍(了解)
3.3.1 deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,
双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
注:deque与队列没有明确的联系,不需要满足先进先出的特点。
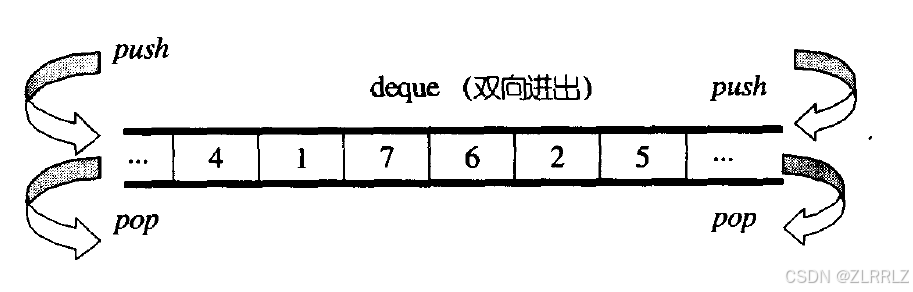
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,本质上就是数组与链表的"缝合怪",deque类似于一个动态的二维数组,其底层结构如下图所示:
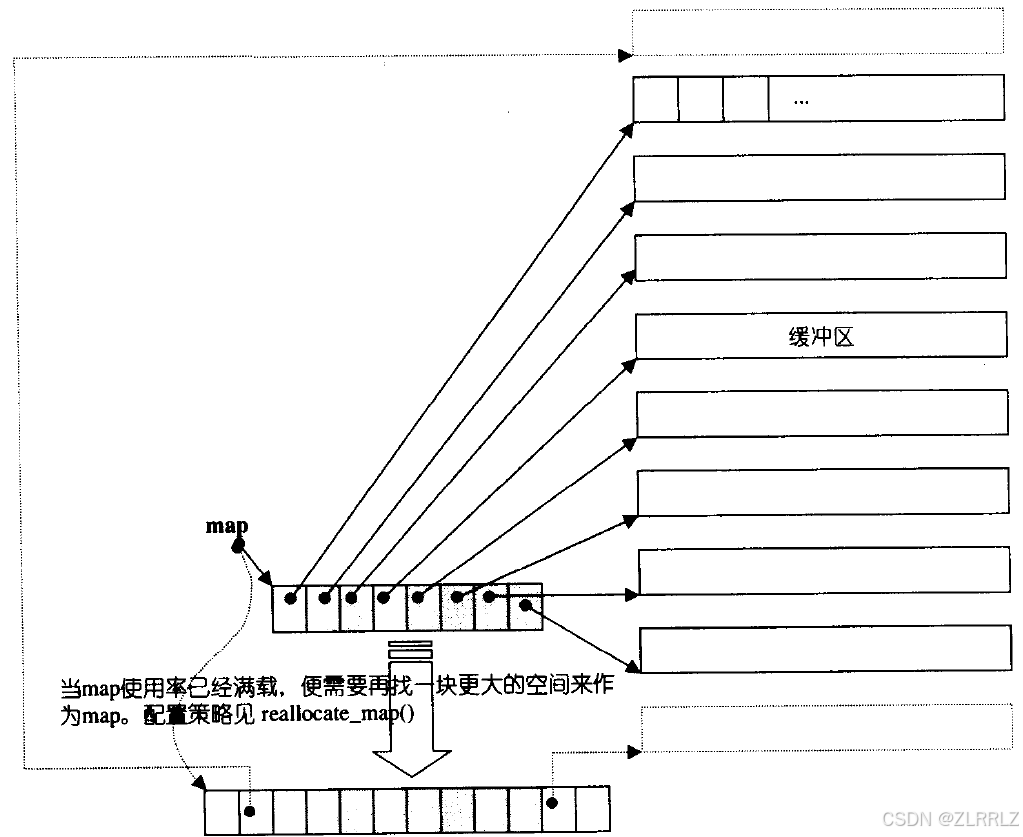
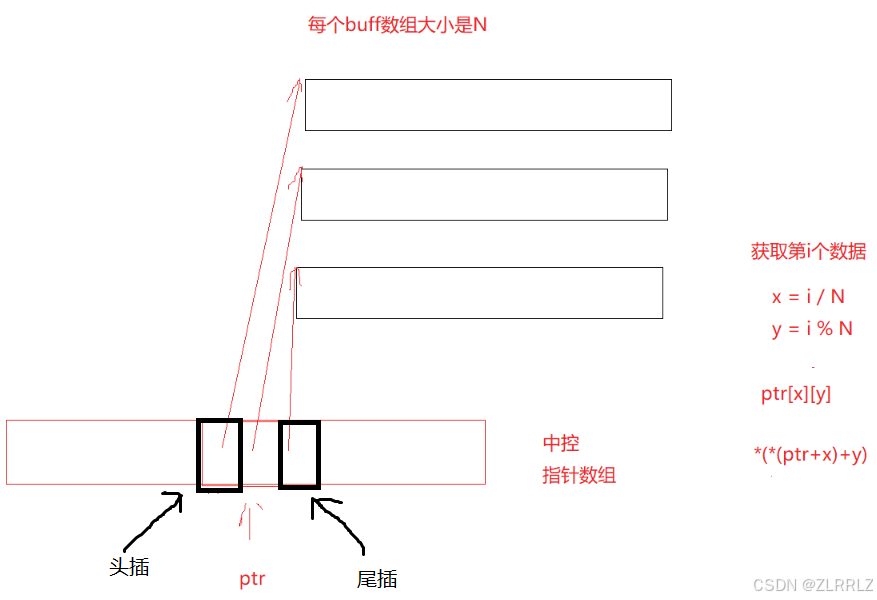
deque有一块大的中控指针数组,数组中的每一块指针又管理着一块buff数组空间用来存储数据,每一块buff数组长度相等,deque中控数组以中间分界,当我们对deque进行尾插时,会先开辟一块buff空间,然后将这块空间的地址向中控数组中间往右插入;如果头插,则将地址中间向左插入。如果删除数据,我们释放对应buff空间,再删除中控数组中对应指针。当中控数组中的空间装满,我们就开辟一块更大的中控数组,然后将原来中控数组中的指针拷贝过来,这个过程当中,我们对buff不做任何处理。
deque也支持[]访问,[]的重载底层是通过除法来完成的,buff数组的长度一直,我们先/N可以确定是哪一块buff数组,然后再%N,我们确定的是数组中哪一个数。
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象的责任,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
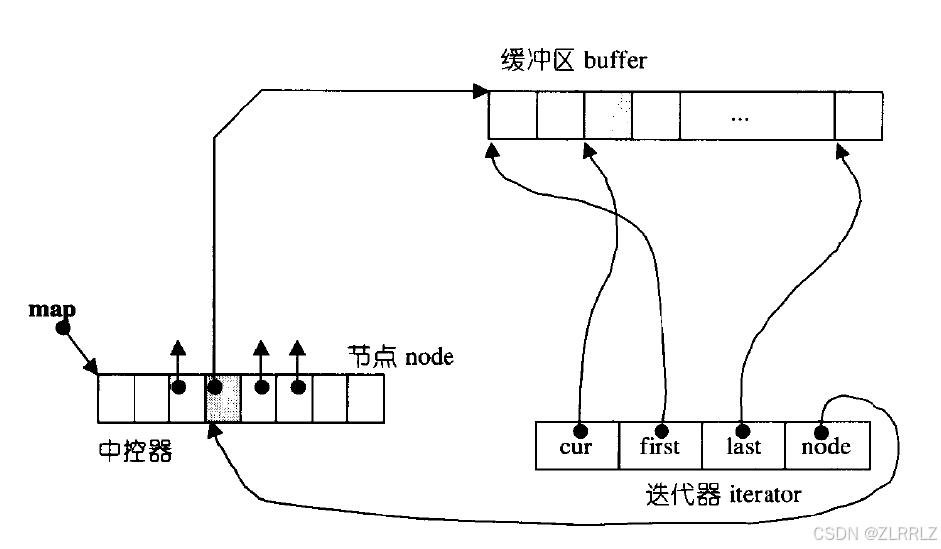

deque迭代器内部封装了四个指针,node指向buff对应在中控数组中的指针,first指向数组的开始位置,last指向数组的尾,cur用来遍历访问buff数组。
那deque是如何借助其迭代器维护其假想连续的结构呢?
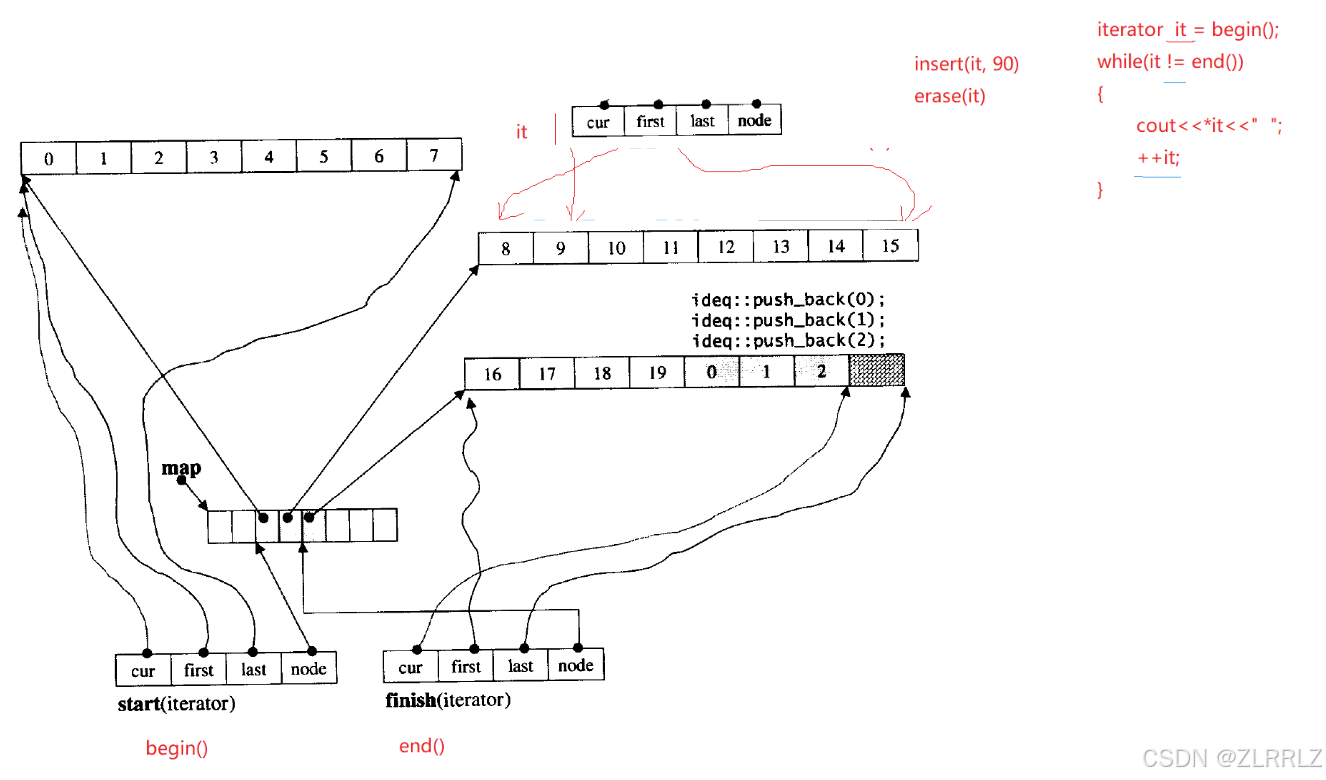

deque类本身封装了四个对象,start迭代器中的node指针用来指向中控器内的第一个数组指针,start内的first指向对应buff数组的内第一个数据,last指向数组尾,first内的node指针指向中控器内的最后一个数组指针,内部其他指针行为与start相同,start与first共同管理中控器中数据。map指针用来指向中控数组,map_size用来记录中控器数据个数。

迭代器++会先通过cur==last判断当前buff数组是否遍历完了,如果遍历完,通过node移动迭代器到下一数组(更新迭代器内指针的指向)。
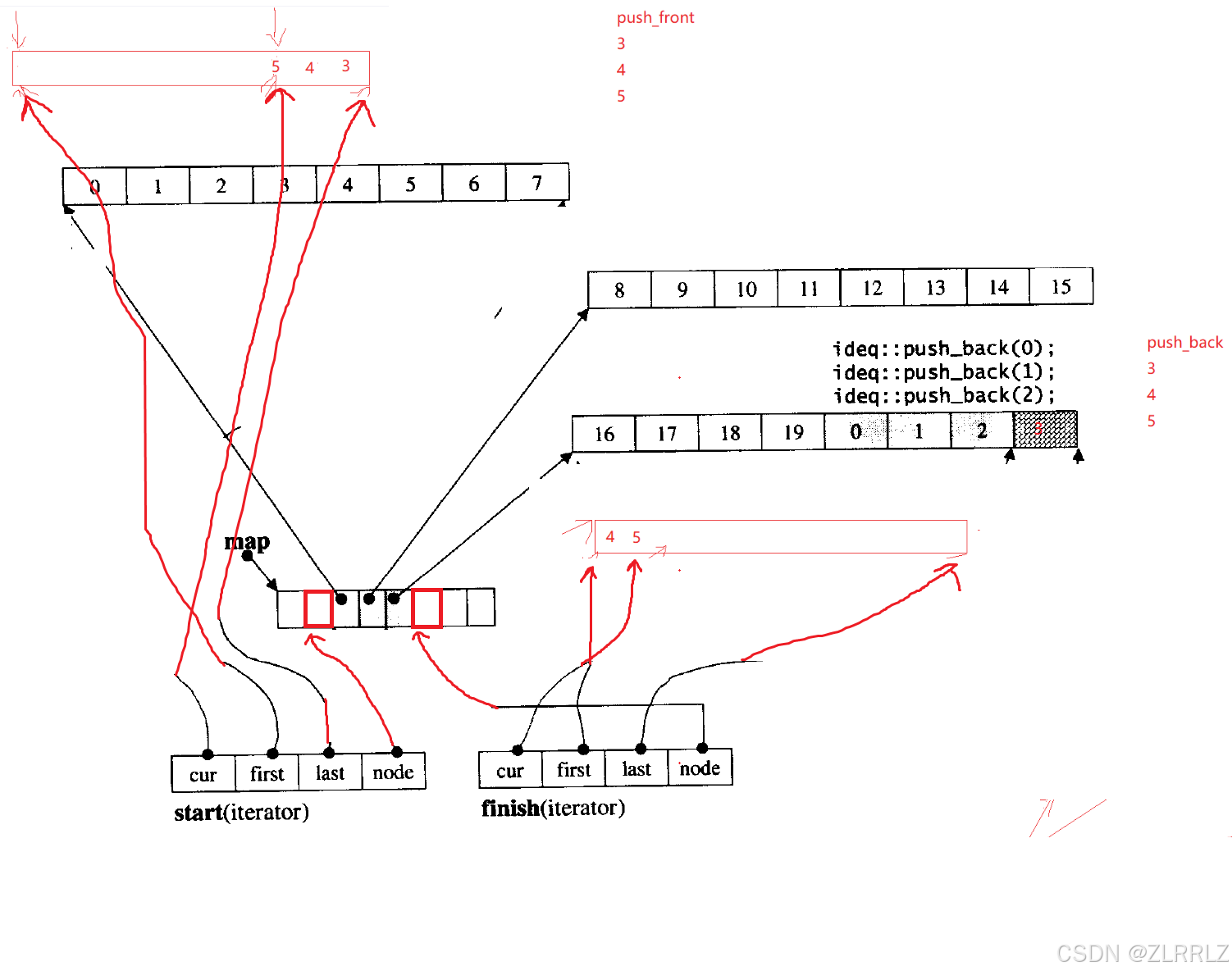
deque的尾插,首先会找到finish指向的buff数组,如果空间足够,我们直接在数组后面插入数据,那如果数组空间不够呢?通常我们会想到重新开辟一块更大的数组再将原数组中数据拷贝到新数组中,但是我们这里一定要注意deque的buff数组长度控制相同(原因下文解释),因此,这里我们直接开辟一块新buff数组,然后我们将finish(iterator)的node指向新开辟的数组,将剩余数据插入到新数组中。
deque的头插,先查看左边数组是否有空间,如果没有就开辟新数组,同样改变start(iterator)内node指向,需要注意的是头插时候的数据是从数组的尾向头增长的,first指向数组开始,last指向数组尾,cur也是从数组尾向前移动的。

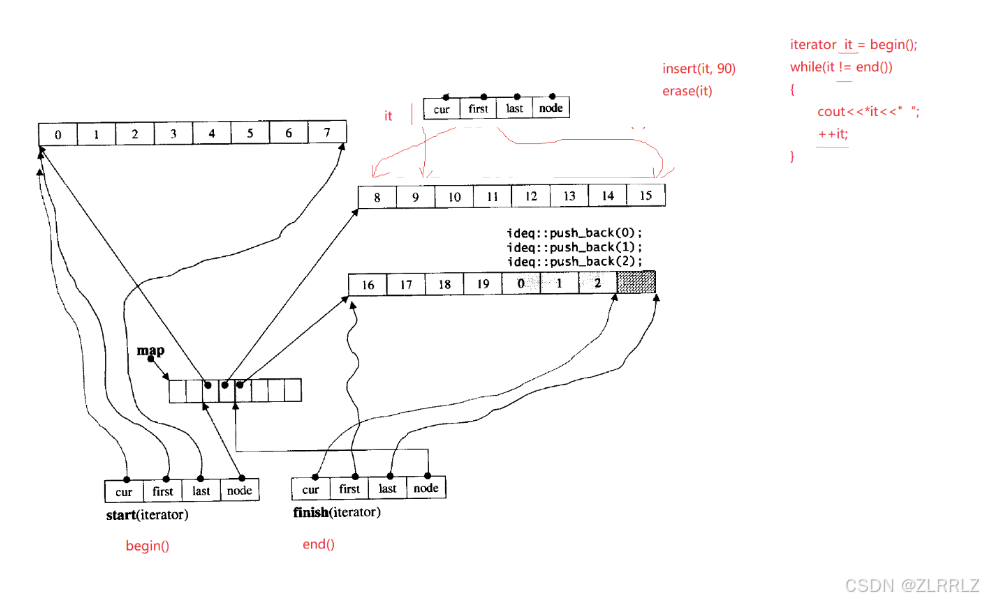
对于deque的中间插入,我们先找到对应buff数组,然在buff中间位置插入数据,然后这里问题就出现了,如果数据是满的,我们插入数据,是改变buff数组长度,还是重新开辟新数组,然后将插入位置之后的所有数据(包括该buff之后的其他buff的所有数据)?如果我们选择前一种,那么我们只需要改变对应一个buff数组,但是会导致不同buff长度不一致,那么对于像++、+=这样依赖除法实现的功能,我们再想实现,就需要知道前一个buff的长度,原来总的数据个数等等,这样以来,这些接口性能会大幅下降;我们保证buff长度不变,那么就需要挪动大量的数据,这样中间插入接口的性能就非常低了。最终我们发现sgi版本中选择牺牲中间插入接口的性能。

3.3.2 deque优势与缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩
容时,也不需要搬移大量的元素,因此其效率是比vector高的,并且deque的下标随机访问也还不错,相比vector稍逊一筹(vector下标直接移动,deque需要通过复杂除法计算)。
与list比较,listd底层是多块细碎的空间,deque底层空间较长,没那么碎片化,空间利用率比较高,不需要存储额外字段。
但是,deque有致命缺陷:1.不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其
是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,2.此外对于需要频繁中间插入的情况,deque需要移动依次按序移动多个连续buff空间内数据,效率非常低下
因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
3.4 为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性
结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据
结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如
list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进
行操作。且不需要考虑频繁的中间插入情况。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的
元素增长时,deque不仅效率高,而且内存使用率高。
3.5 STL标准库中对于stack和queue的模拟实现
3.5.1 stack的模拟实现
#include<deque> namespace zlr { template<class T, class Container = deque<T>> class stack { public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top() const{return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;//自定义对象调用自己的析构和构造函数,我们不需要写 };}
3.5.2 queue的模拟实现
#include<deque>
#include <list>
namespace zlr
{
template<class T, class Container = deque<T>>
class queue
{
public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front() const{return _con.front();}const T& back() const{return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;
};
}4.priority_queue的介绍和使用
4.1 priority_queue的介绍
priority_queue文档介绍
翻译:
1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素
中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶
部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue
提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的
顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过
随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
5. 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue
类实例化指定容器类,则使用vector。
6. 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用
算法函数make_heap、push_heap和pop_heap来自动完成此操作。
优先级队列本质上就是我们熟知的堆排序和堆,跟队列没有什么关系(设计者这样命名是出于应用层的考虑),它的底层也不是堆(STL中只有堆排序Heap)
4.2 priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆排序算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用
priority_queue。注意:默认情况下priority_queue是大堆。
| 函数声明 | 接口说明 |
|---|---|
| priority_queue()/priority_queue(first,last) | 构造一个空的优先级队列 |
| empty( ) | 检测优先级队列是否为空,是返回true,否则返回false |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
【注意】
1. 默认情况下,priority_queue是大堆。
#include <vector>
#include <queue>
#include <functional> // greater算法的头文件
void TestPriorityQueue()
{// 默认情况下,创建的是大堆,其底层按照小于号比较vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };priority_queue<int> q1;for (auto& e : v)q1.push(e);cout << q1.top() << endl;// 如果要创建小堆,将第三个模板参数换成greater比较方式priority_queue<int, vector<int>, greater<int>> q2(v.begin(), v.end());cout << q2.top() << endl;
}4.2.1仿函数的介绍
之前学习类的时候,我们了解到如果类中没有成员变量,类的对象大小是1,这样的类叫做空类,
这里的仿函数就是这样的空类。
//仿函数:本质是一个类,这个类重载operator(),他的对象可以像函数一样使用
template<class T>
class Less//仿函数
{
public:bool operator()(const T& x, const T& y){return x < y;}
};template<class T>
class Greater//仿函数
{
public:bool operator()(const T& x, const T& y){return x > y;}
};//< 升序//> 降序
template<class Compare>
void BubbleSort(int* a, int n, Compare com)
{for (int j = 0; j < n; j++){// 单趟int flag = 0;for (int i = 1; i < n - j; i++){//if (a[i] < a[i - 1])if (com(a[i], a[i - 1]))//通过仿函数,这里的比较逻辑{ //我们就可以通过传比较器(仿函数)控制swap(a[i - 1], a[i]);flag = 1;}}if (flag == 0){break;}}
}int main()
{Less<int> LessFunc;Greater<int> GreaterFunc;// 函数对象cout << LessFunc(1, 2) << endl;//仿函数的类可以像函数一样使用cout << LessFunc.operator()(1, 2) << endl;int a[] = { 9,1,2,5,7,4,6,3 };BubbleSort(a, 8, LessFunc);//传入比较器(仿函数)控制内部的比较逻辑BubbleSort(a, 8, GreaterFunc);BubbleSort(a, 8, Less<int>());//上面的使用方法太麻烦,这里可以使用匿名对象BubbleSort(a, 8, Greater<int>());return 0;
}仿函数的作用就是作为比较器,让使用者根据需要传入对应的比较器(仿函数),自主选择比较逻辑
4.2.1需要写仿函数的情形
1.如果在priority_queue中放自定义类型的数据,本身的自定义类型不支持自定义类型,用户需要在自定义类型中提供> 或者< 的重载(仿函数)。
2.库中提供的仿函数的比较逻辑不是我们想要的,如下图日期类的比较,库中的比较逻辑比的是地址,不是我们想要的数值大小的比较,这时候我们也需要手动写一下仿函数
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};
void TestPriorityQueue()
{// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q1;q1.push(Date(2018, 10, 29));q1.push(Date(2018, 10, 28));q1.push(Date(2018, 10, 30));cout << q1.top() << endl;// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q2;q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));cout << q2.top() << endl;
}class Date
{friend ostream& operator<<(ostream& _cout, const Date& d);
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}
private:int _year;int _month;int _day;
};ostream& operator<<(ostream& _cout, const Date& d)
{_cout << d._year << "-" << d._month << "-" << d._day;return _cout;
}class DateLess
{
public:bool operator()(Date* p1, Date* p2){return *p1 < *p2;}
};// 1、类类型不支持比较大小// 2、支持比较大小,但是比较的逻辑不是你想要的// 需要自己实现仿函数priority_queue<Date*, vector<Date*>, DateLess> q2;priority_queue<Date*> q2;q2.push(new Date(2018, 10, 29));q2.push(new Date(2018, 10, 28));q2.push(new Date(2018, 10, 30));cout << *q2.top() << endl;q2.pop();cout << *q2.top() << endl;q2.pop();cout << *q2.top() << endl;q2.pop();priority_queue<int*> q3;q3.push(new int(2));q3.push(new int(1));q3.push(new int(3));cout << *q3.top() << endl;q3.pop();cout << *q3.top() << endl;q3.pop();cout << *q3.top() << endl;q3.pop();4.3 在OJ中的使用
数组中第K个大的元素
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {// 将数组中的元素先放入优先级队列中priority_queue<int> p(nums.begin(), nums.end());// 将优先级队列中前k-1个元素删除掉for (int i = 0; i < k - 1; ++i){p.pop();}return p.top();}
};根据堆堆顶数最大或最小的特性,我们容易从一堆数中找到前最大或最小的几个数。
4.4 priority_queue的模拟实现
通过对priority_queue的底层结构就是vector的接口分装加上堆排序相关的向上和向下调整算法(相关内容不了解的读者可以不先去了解堆排序,由于内容一致,笔者这里就不再赘叙了,堆相关内容),因此此处只需对对进行通用的封装即可。
(因为建堆算法与堆排序都会涉及大量中间数值的移动,deque中间移动效率非常低下,因此底层使用vector)
优先级队列的模拟实现
namespace zlr
{// 默认是大堆template<class T, class Container = vector<T>, class Compare = Less<T>>class priority_queue{public:void AdjustUp(int child)//向上调整算法{Compare com;int parent = (child - 1) / 2;while (child > 0){//if (_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void push(const T& x){_con.push_back(x);AdjustUp(_con.size() - 1);}void AdjustDown(int parent)//向下调整算法{// 先假设左孩子小size_t child = parent * 2 + 1;Compare com;while (child < _con.size()) // child >= n说明孩子不存在,调整到叶子了{// 找出小的那个孩子//if (child + 1 < _con.size() && _con[child] < _con[child + 1])if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){++child;}//if (_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(0);}const T& top(){return _con[0];}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}
相关文章:

【C++】stack和queue
目录 1. stack的介绍和使用 1.1 stack的介绍 1.2 stack的使用 2. queue的介绍和使用 2.1 queue的介绍 2.2 queue的使用 3. 容器适配器 3.1 什么是适配器 3.2 STL标准库中stack和queue的底层结构 3.3 deque的简单介绍(了解) 3.3.1 deque的原理介绍 3.3.2 deque优势与…...

向量的内积和外积 为什么这样定义
向量的内积和外积 为什么这样定义 flyfish 定义、公理与证明的区别 定义: 定义是人为规定的,用于描述概念的含义。例如,内积和外积是根据实际需求定义的,目的是描述几何和代数性质。定义不需要证明。 公理: 公理是数…...

简述循环神经网络RNN
1.why RNN CNN:处理图像之间没有时间/先后关系 RNN:对于录像,图像之间也许有时间/先后顺序,此时使用CNN效果不会很好,同理和人类的语言相关的方面时间顺序就更为重要了 2.RNN和CNN之间的关联 RNN和CNN本质上其实一…...
】进程通信(IPC))
【Electron学习笔记(四)】进程通信(IPC)
进程通信(IPC) 进程通信(IPC)前言正文1、渲染进程→主进程(单向)2、渲染进程⇌主进程(双向)3、主进程→渲染进程 进程通信(IPC) 前言 在Electron框架中&…...

APP自动化测试框架的开发
基于appium的APP自动化测试框架的开发流程概览 1. 环境搭建 安装Appium Server 下载与安装:可以从Appium官方网站(Redirecting)下载安装包。对于Windows系统,下载.exe文件后双击安装;对于Mac系统,下载.dmg…...

【深度学习】各种卷积—卷积、反卷积、空洞卷积、可分离卷积、分组卷积
在全连接神经网络中,每个神经元都和上一层的所有神经元彼此连接,这会导致网络的参数量非常大,难以实现复杂数据的处理。为了改善这种情况,卷积神经网络应运而生。 一、卷积 在信号处理中,卷积被定义为一个函数经过翻转…...

pytorch 融合 fuse 学习笔记
目录 fuse_lora 作用是什么 fuse_modules源码解读 fuse_lora 作用是什么 在深度学习模型微调场景下(与 LoRA 相关) 参数融合功能 在使用 LoRA(Low - Rank Adaptation)对预训练模型进行微调后,fuse_lora函数的主要作…...

41 基于单片机的小车行走加温湿度检测系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 基于51单片机,采样DHT11温湿度传感器检测温湿度,滑动变阻器连接数码转换器模拟电量采集传感器, 电机采样L298N驱动,各项参数通过LCD1602显示&#x…...

GitLab: You cannot create a branch with a SHA-1 or SHA-256 branch name
最近在迁移git库,把代码从gerrit迁移到gitlab,有几个库报错如下: GitLab: You cannot create a branch with a SHA-1 or SHA-256 branch name ! [remote rejected] refs/users/73/373/edit-95276/1 -> refs/users/73/373/edit-95276/1 (p…...
YOLOv9改进,YOLOv9引入TransNeXt中的ConvolutionalGLU模块,CVPR2024,二次创新RepNCSPELAN4结构
摘要 由于残差连接中的深度退化效应,许多依赖堆叠层进行信息交换的高效视觉Transformer模型往往无法形成足够的信息混合,导致视觉感知不自然。为了解决这个问题,作者提出了一种聚合注意力(Aggregated Attention),这是一种基于仿生设计的token混合器,模拟了生物的中央凹…...
)
TorchMoji使用教程/环境配置(2024)
TorchMoji使用教程/环境配置(2024) TorchMoji简介 这是一个基于pytorch库,用于将文本分类成不同的多种emoji表情的库,适用于文本的情感分析 配置流程 从Anaconda官网根据提示安装conda git拉取TorchMoji git clone https://gi…...

uniapp运行时,同步资源失败,未得到同步资源的授权,请停止运行后重新运行,并注意手机上的授权提示。
遇到自定义基座调试时安装无效或无反应?本文教你用 ADB 工具快速解决:打开 USB 调试,连接设备,找到应用包名,一键卸载问题包,清理干净后重新运行调试基座,轻松搞定! 问题场景&#…...

uniapp中父组件调用子组件方法
实现过程(setup语法糖形式下) 在子组件完成方法逻辑,并封装。在子组件中使用defineExpose暴露子组件的该方法。在父组件完成子组件ref的绑定。通过ref调用子组件暴露的方法。 子组件示例 <template> </template><script se…...

腾讯云 AI 代码助手:单元测试应用实践
引言 在软件开发这一充满创造性的领域中,开发人员不仅要构建功能强大的软件,还要确保这些软件的稳定性和可靠性。然而,开发过程中并非所有任务都能激发创造力,有些甚至是重复且乏味的。其中,编写单元测试无疑是最令人…...

ArcGIS栅格影像裁剪工具
1、前言 在最近的栅格转矢量处理过程中,发现二值化栅格规模太大,3601*3601,并且其中的面元太过细碎,通过arcgis直接栅格转面有将近几十万的要素,拿这样的栅格数据直接运行代码,发现速度很慢还难以执行出来结…...

VueWordCloud标签云初实现
文章目录 VueWordCloud学习总结安装初使用在组件中注册该组件简单使用项目中实现最终实现效果 VueWordCloud学习总结 本次小组官网的项目中自己要负责标签模块,想要实现一个标签云的效果,搜索了很多,发现vue有一个VueWordCloud库,…...
)
AI数据分析工具(二)
豆包-免费 优点 强大的数据处理能力: 豆包能够与Excel无缝集成,支持多种数据类型的导入,包括文本、数字、日期等,使得数据整理和分析变得更加便捷。豆包提供了丰富的数据处理功能,如数据去重、填充缺失值、转换格式等…...
)
sizeof和strlen区分,(好多例子)
sizeof算字节大小 带\0 strlen算字符串长度 \0之前...

求100之内的素数-多语言
目录 C 语言实现 方法 1: 使用 for 循环 方法 2: 使用埃拉托斯特尼筛法 方法 3: 使用自定义判断素数 Python 实现 方法 1: 使用自定义函数判断素数 方法 2: 使用埃拉托斯特尼筛法(Sieve of Eratosthenes) 方法 3: 使用递归方法 Java 实现 方法…...

0.shell 脚本执行方式
1.脚本格式要求 🥑脚本以 #!/bin/bash 开头 🥦 脚本要有可执行权限 2.执行脚本的两种方式 🥬 方式1:赋予x执行权限 🥒 方式2: sh执行 ...

Web实时通信@microsoft/signalr
概要说明 signalr 是微软对 websocket技术的封装; build() 与后端signalR服务建立链接;使用 on 方法监听后端定义的函数;ps:由后端发起,后端向前端发送数据使用 invoke 主动触发后端的函数;ps:由前端发起&a…...

智截违规,稳保安全 | 聚铭视频专网违规外联治理系统新品正式发布
“千里之堤,毁于蚁穴”。 违规外联作为网络安全的一大隐患, 加强防护已刻不容缓。 这一次, 我们带着全新的解决方案来了 ——聚铭视频专网违规外联治理系统, 重磅登场!...

博弈论算法详解与Python实现
目录 博弈论算法详解与Python实现第一部分:博弈论简介与算法概述1.1 博弈论概述1.2 博弈论算法概述第二部分:纳什均衡算法2.1 纳什均衡的定义2.2 纳什均衡算法的实现2.2.1 算法思路2.2.2 Python实现2.2.3 设计模式分析第三部分:囚徒困境问题的博弈论算法3.1 囚徒困境的定义3…...

Python学习笔记之IP监控及告警
一、需求说明 作为一名运维工程师,监控系统必不可少。不过我们的监控系统往往都是部署在内网的,如果互联网出口故障,监控系统即使发现了问题,也会告警不出来,这个时候我们就需要补充监控措施,增加从外到内的…...

2024/11/30 RocketMQ本机安装与SpringBoot整合
目录 一、RocketMQ简介 1.1、核心概念 1.2、应用场景 1.3、架构设计 2、RocketMQ Server安装 3、RocketMQ可视化控制台安装与使用 4、SpringBoot整合RocketMQ实现消息发送和接收 4.1、添加maven依赖 4.2、yaml配置 4.3、生产者 4.4、消费者 4.5、接口 4.6、接口测试 一、R…...

解决“磁盘已插上,但Windows系统无法识别“问题
电脑上有2块硬盘,一块是500GB的固态硬盘,另一块是1000GB的机械硬盘,按下开机键,发现500G的固态硬盘识别了,但1000GB的机械硬盘却无法识别。后面为了描述方便,将"500GB的固态硬盘"称为X盘…...

解决vue3,动态添加路由,刷新页面出现白屏或者404
解决vue3,动态添加路由,刷新页面出现白屏或者404 1.解决出现刷新页面,出现404的情况 1.问题的出现 在做毕设的时候,在权限路由得到时候,我问通过router**.**addRoute(item)的方式,在路由守卫动态添加路由…...
(18/ 30))
大数据新视界 -- 大数据大厂之 Hive 数据质量监控:实时监测异常数据(下)(18/ 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

可视化建模以及UML期末复习篇----相关软件安装
作为一个过来人,我的建议是别过来。 一、可视化建模 <1>定义: 官方:一种使用图形符号来表示系统结构和行为的建模技术。 我:其实说白了就是把工作流程用图形画出来。懂不? <2>作用: 提高理解和分析复杂系统的能力。促…...

Flask项目入门—request以及Response
导入 request(请求)以及Response(响应)通过flask导入,如下: from flask import Blueprint, request, render_template, \jsonify, make_response, Response, redirect, url_for, abort requestÿ…...

【VUE3】【Naive UI】<n-button> 标签
【VUE3】【Naive UI】<n-button> 标签 **type**- 定义按钮的类型,这会影响按钮的颜色和样式。**size**- 设置按钮的大小。**disabled**- 布尔值,控制按钮是否处于禁用状态。**loading**- 布尔值,表示按钮是否处于加载状…...

接口测试工具:reqable
背景 在众多接口测试工具中挑选出一个比较好用的接口测试工具。使用过很多工具,如Postman、Apifox、ApiPost等,基本上是同类产品,一般主要使用到的功能就是API接口和cURL,其他的功能目前还暂未使用到。 对比 性能方面ÿ…...
--perception:radar_tracks_msgs_converter)
autoware.universe源码略读(3.20)--perception:radar_tracks_msgs_converter
autoware.universe源码略读3.20--perception:radar_tracks_msgs_converter Overviewradar_tracks_msgs_converter_node Overview 这里看起来是非常简单的一个模块,作用就是把radar_msgs/msg/RadarTracks类型的消息数据转换到autoware_auto_perception_msgs/msg/Tra…...

【论文阅读】Multi-level Semantic Feature Augmentation for One-shot Learning
用于单样本学习的多层语义特征增强 引用:Chen, Zitian, et al. “Multi-level semantic feature augmentation for one-shot learning.” IEEE Transactions on Image Processing 28.9 (2019): 4594-4605. 论文地址:下载地址 论文代码:https:…...

说说Elasticsearch查询语句如何提升权重?
大家好,我是锋哥。今天分享关于【说说Elasticsearch查询语句如何提升权重?】面试题。希望对大家有帮助; 说说Elasticsearch查询语句如何提升权重? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Elasticsearch 中&…...

jeecgbootvue2重新整理数组数据或者添加合并数组并遍历背景图片或者背景颜色
想要实现处理后端返回数据并处理,添加已有静态数据并遍历快捷菜单背景图 遍历数组并使用代码 需要注意: 1、静态数组的图片url需要的格式为 require(../../assets/b.png) 2、设置遍历背景图的代码必须是: :style"{ background-image: url( item…...

Vue-常用指令-02
目录 Vue常用指令 实操 v-bind、v-model v-bind v-model 总结 v-on 总结 编辑 v-if、v-show v-if v-show 总结 v-for 总结 综合案例 编辑 Vue常用指令 Vue指令:在HTML文件或者HTML标签中涉及的带有v-..的指令都是Vue的指令。不同指令不同含义不同作用。v-…...
)
ESLint 配置文件全解析:格式、层叠与扩展(3)
配置文件系统处于一个更新期,存在两套配置文件系统,旧的配置文件系统适用于 v9.0.0 之前的版本,而新的配置文件系统适用于 v9.0.0之后的版本,但是目前还处于 v8.x.x 的大版本。 配置文件格式 在 ESLint 中,支持如下格…...

曲面单值化定理
曲面单值化定理(Uniformization Theorem)是复分析、几何和拓扑学中的一个重要结果。它为紧致黎曼曲面提供了标准化的几何结构,是研究复几何和代数几何的基础。以下是对曲面单值化定理的详细介绍以及其应用场景。 曲面单值化定理的陈述 基本版…...

数据预处理方法—数据增强、数据平衡
1.数据增强 1.1 原理 通过对数据进行变换增加数据的多样性,提高模型泛化能力,常用于图像和文本处理任务。 1.2 核心公式 例如:图像旋转: 其中,R()是旋转矩阵,是旋转角度。 1.3 Python案例 下面是一个…...

从扩散模型开始的生成模型范式演变--SDE
SDE是在分数生成模型的基础上,将加噪过程扩展时连续、无限状态,使得扩散模型的正向、逆向过程通过SDE表示。在前文讲解DDPM后,本文主要讲解SDE扩散模型原理。本文内容主要来自B站Up主deep_thoughts分享视频Score Diffusion Model分数扩散模型…...

基于Java Springboot 协同过滤算法音乐推荐系统
一、作品包含 源码数据库设计文档万字全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue2、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA 数据库&#x…...

【NLP高频面题 - LLM架构篇】旋转位置编码RoPE相对正弦位置编码有哪些优势?
【NLP高频面题 - LLM架构篇】旋转位置编码RoPE相对正弦位置编码有哪些优势? 重要性:⭐⭐⭐ 💯 NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练…...

win10中使用ffmpeg的filter滤镜
1 给视频加文字水印 1.1 添加播放时间 ffmpeg -i input.mp4 -vf "drawtextfontfileC\\:/Windows/fonts/consola.ttf:fontsize30:fontcolorwhite:timecode00\:00\:00\:00:rate25:textTCR\::boxcolor0x000000AA:box1:x20:y20" -y output.mp4 在视频的x20:y20位置添加t…...

shell编程7,bash解释器的 for循环+while循环
声明! 学习视频来自B站up主 泷羽sec 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&#…...

Flutter 1.2:flutter配置gradle环境
1、在android的模块中进行gradle环境配置 ①在 gradle-wrapper.properties文件中将url配置为阿里云镜像,因为gradle的服务器在国外,国内下载非常慢,也可在官网进行下载 gradle版本下载 gradle版本匹配 阿里云镜像gradle下载 可以通过复制链…...

LVS 负载均衡面试题及参考答案
目录 什么是 LVS 负载均衡?它的主要作用是什么? 为什么要使用 LVS 进行负载均衡? LVS 有哪些组成部分? 简述 LVS 的架构。 LVS 中有哪两种典型的架构?请简要说明它们的特点。 LVS 的工作原理是怎样的?简述 LVS 的工作原理。 解释 LVS 中的虚拟服务器(VS)概念。 …...
常用命令和注意事项)
GaussDB(类似PostgreSQL)常用命令和注意事项
文章目录 前言GaussDB(类似PostgreSQL)常用命令和注意事项1. 连接到GaussDB数据库2. 查看当前数据库中的所有Schema3. 进入指定的Schema4. 查看Schema下的表、序列、视图5. 查看Schema下所有的表6. 查看表结构7. 开始事务8. 查询表字段注释9. 注意事项&a…...

c语言编程1.17蓝桥杯历届试题-回文数字
题目描述 观察数字:12321,123321 都有一个共同的特征,无论从左到右读还是从右向左读,都是相同的。这样的数字叫做:回文数字。 本题要求你找到一些5位或6位的十进制数字。满足如下要求: 该数字的各个数位之…...

MVC core 传值session
MVC Entity Framework MVC Core session 》》 需要添加 Session 服务 和 Session中间件 builder.Services.AddSession(); app.UseSession(); 》》》控制器中 public IActionResult Privacy(){HttpContext.Session.SetString("key", "123");return View(…...