Java集合
写在前面
本人在学习JUC过程中学习到集合和并发时有许多稀碎知识点 需要总结梳理思路与知识点 本文内容会涉及到ArrayList,HashMap以及扩容机制,ConcurrentHashMap,Synchronized,Volatile,ReentrantLock,CAS,AQS以上的底层原理等常见内容 本文内容部分引自Javaguide,小林coding等热门八股 用于个人学习用途 后续会添加内容
Java集合
为什么需要Java集合与Java并发 有什么关联?
对于常见的1+2+3 可以用数组实现该数学问题 但是在实际应用中 数组并不能满足所有的场景 于是出现了数据结构与算法 Java集合与其相互成就 常见Java集合为 List (列表) Set (集合) Map (映射)
同时在高并发场景下一定会有并发安全与线程安全问题 Java集合即能存数据 又能安全操作数据(如ConcurrentHashMap)多好。(Java并发系列单出一page 此处为集合相关八股)
集合常见数据结构
List如何实现?
三种实现方法
Vector 线程安全动态数组 若不需要线程安全 不建议使用 同步毕竟是有开销的Vector内部使用Object[ ]数组存储数据可根据需要自己扩容 扩容原来的1倍 如果数据已满 则copy原数组并重新创建一个数组再copy数据
ArrayList 动态数组实现 非线程安全 性能比Vector要好不少都用Object[ ] 也是根据需要自己扩容
扩容原来的0.5倍
LinkedList是Java提供的双向链表 不需要扩容 因为可以无限加节点 也是非线程安全的
在什么场景下使用List的不同实现?
在需要大量增删改的情况下 链表总是占优的 操作时间复杂度为O(1) 但是遍历时就只能整表遍历
但是在大量查的情况下 用Vector或ArrayList明显占优 查询只要O(1) 但是要修改中间某节点就要移动后续节点 比较繁琐
ArrayList与LinkedList的区别
1.底层实现不同 Array用数组 LinkedLIst用链表
2.在查询和插入时效率不同 用数组时查快插入慢 用链表时插入快查慢
3.两者都不保证线程安全
4.ArrayList支持快速随机访问 LinkedList不支持 需要遍历到指定元素输出
5.内存占用上 ArrayList会在数组末尾留下一定空间 LinkedList则每次保存一个数据就会占很大空间 要保存上个节点到该节点和该节点到下一个节点的两个指针
ArrayList 底层原理
ArrayList 的底层是一个动态数组(Object[] elementData)支持快速随机访问(时间复杂度 O(1)) 核心机制包括:
-
扩容:当数组容量不足时扩容为原来的 1.5 倍 并将旧数据复制到新数组。
-
添加:在末尾添加元素时间复杂度为 O(1) 在指定位置插入需要移动元素 时间复杂度为 O(n)
-
删除:删除元素需要移动后续元素 时间复杂度为 O(n)
-
保证线程安全:ArrayList 是非线程安全的 多线程环境下可用 Collections.synchronizedList 或 CopyOnWriteArrayList
ArrayList扩容机制
1.计算新容量 一般都会扩容为原来的1.5倍再检查是否超过最大容量限制
2.创建新数组 3.copy数据 4.更新引用:把ArrayList内部指向的引用指向到新数组上 5.完成扩容
扩容要扩到原来的1.5倍
因为1.5可以充分利用位运算移位 大大提高运算效率 位运算一定比除2要好很多
grow()方法是扩容机制最核心部分 贴上(代码来自JavaGuide)
/*** 要分配的最大数组大小*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;/*** ArrayList扩容的核心方法。*/
private void grow(int minCapacity) {// oldCapacity为旧容量,newCapacity为新容量int oldCapacity = elementData.length;// 将oldCapacity 右移一位,其效果相当于oldCapacity / 2。// 我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍。int newCapacity = oldCapacity + (oldCapacity >>> 1);// 然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果新容量大于 MAX_ARRAY_SIZE, 进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE// 如果minCapacity大于最大容量,则新容量则为 `Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZEif (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);
}Set
用的不多 提一嘴 Set存储元素不可重复
Set底层实现
用哈希表和红黑树来实现key的无重复 当向Set集合插入元素时 先根据元素Hashcode来判断当前元素存储位置 再用内部的equals方法来判断是否存在已经相同的元素 是则不插入 否则插入 保证元素唯一性
有序Set
有TreeSet(红黑树)和LinkedHashSet(哈希表和双重链表)保证元素自然顺序排序
按照插入顺序排序的set是LinkedHashSet 保证唯一且有序
Map(划重点)
对于在学习过程中 Map是学的最多最杂的 在实际开发中也是应用最广泛的
常见的Map集合:(非线程安全)
HashMap:基于哈希表实现的map 通过key-value(entry)键值对的形式存储值 在jdk1.8中底层实现为数组+链表+红黑树实现 多线程下同时操作数据会不一致 比如扩容时会破坏哈希表结构
LinkedHashMap:继承自HashMap 但是他加上了双向链表保证排序按照插入顺序 同样和hashmap有一致线程安全问题存在
TreeMap:基于红黑树实现的map 可以对键排序 默认情况下升序排序 也可以按照指定比较器排序
常见的Map集合:(线程安全)
HashTable:实现方法与HashMap类似 但在方法上用了synchronized关键字来保证线程安全 这样会导致效率很低 非常僵硬
ConcurrentHashMap
原理:在JDK 1.7之前采用分段锁的方式(segment)实现,把数据分成多个段 每段都有自己独立的锁 在线程对其操作时 只需要获取对应分段的锁 而不是获取整个map的锁 这样做就可以允许多线程访问不同段 而不受到干扰 在JDK 1.8之后就用了volatile+CAS或者synchronized来保证并发安全
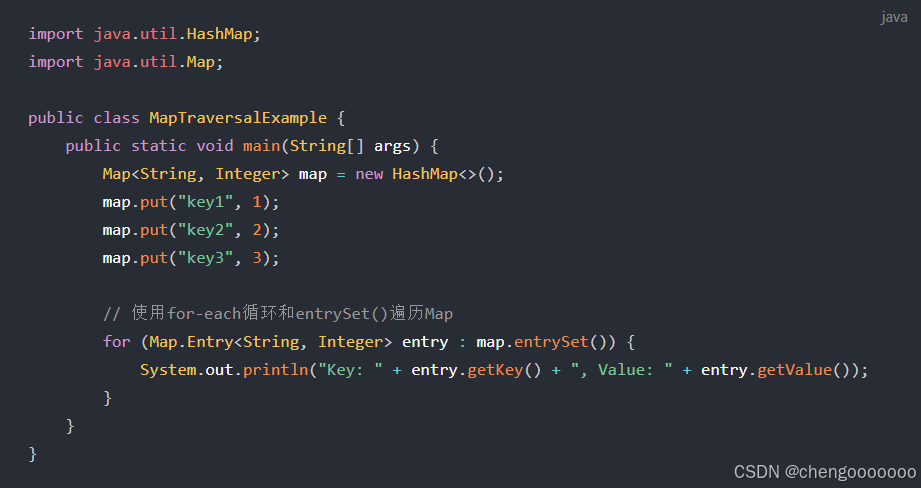
对map快速遍历的方法:
使用for-each和EntrySet方法遍历 输出键值对的键和值
只想输出键用keySet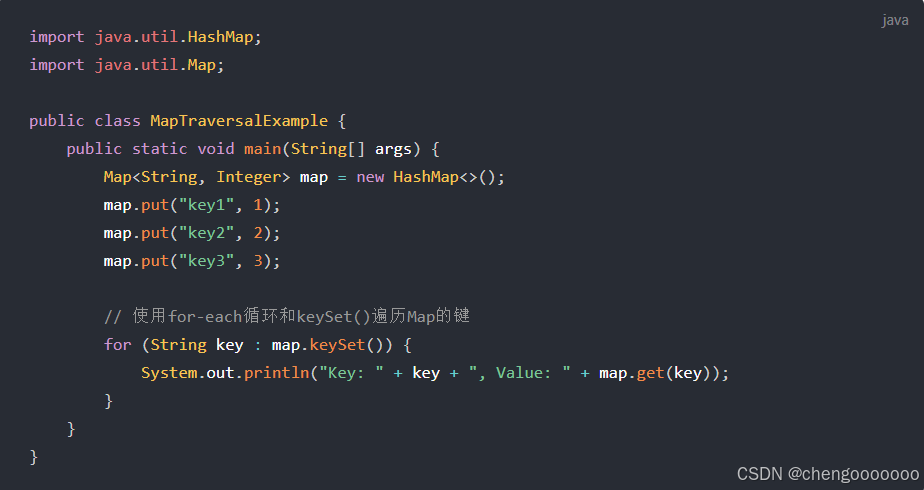
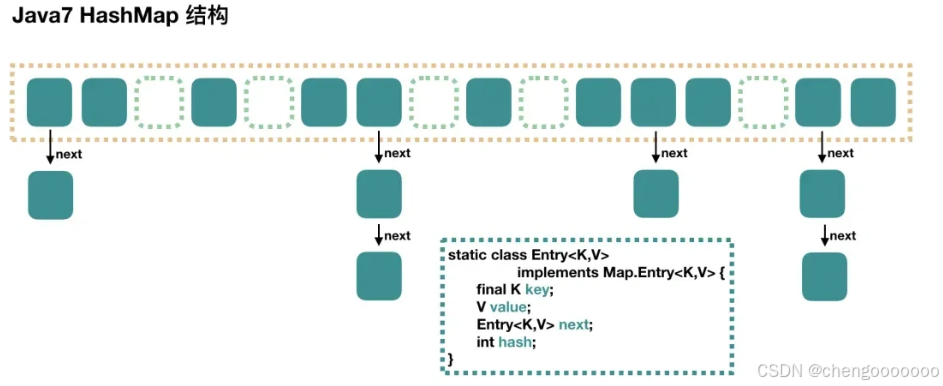
HashMap底层实现原理
JDK1.7之前 HashMap数据结构是数组和链表 HashMap通过哈希算法把元素的键(key)映射到数组中的槽位(Bucket) 若多个键映射到同一个槽位 他们会用链表的形式存储在同槽位上 因为链表的查询时间为O(n) 所以冲突很严重 一旦链表非常长 效率相当低
图解引自小林coding:
所以到了JDK 1.8的时候 当一个链表长度超过8 用红黑树进行存储 查询时为O(logn)的时间复杂度 数量较少时(codes < 6)回退成链表
图解引自小林coding: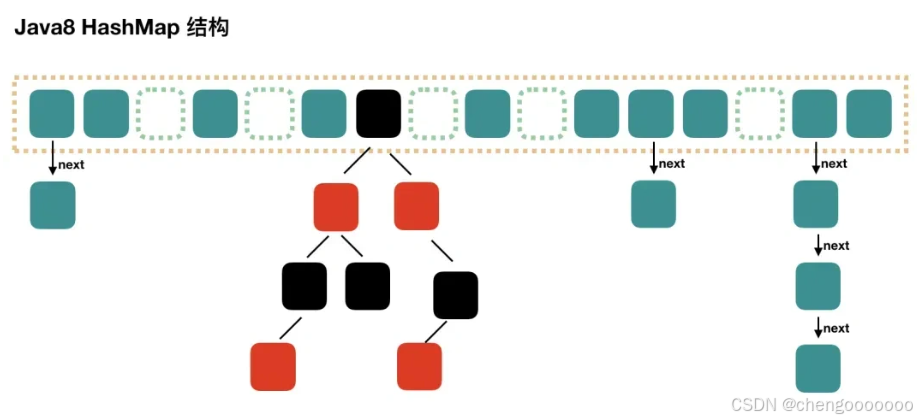
有关红黑树和B+Tree的原理与区别 之后会在mysql时分析
当然有问题存在 如果我存的数据经过hashcode计算后一致 我该怎么存啊 !
存在哈希冲突时的解决方案
链接法 :很简单的第一种方法就是直接采用链表连接 叫做链接法
开放寻址法:或者可以去找找别的地方有没有闲的让我用用 探测一下哪些地方能用 常用的有线性探测 二次探测 双重散列表探测
再哈希法:那我也可以用别的公式再算一遍 在其他槽有空闲位置就到那去 利用其他哈希函数计算hashcode 在表中找到空闲bucket并插入entry
哈希桶扩容:塞得满满当当 就该买家具了 所以可以扩容哈希桶来存储数据 重新分配entry减少哈希冲突
hashmap当然不是线程安全的 有没有替代方案(有没有其他人能处理两个人同时对他说话)
有!
HashMap的线程安全问题
可以用Collections.synchronizedMap同步加锁的方式 也可以用HashTable 但是显而易见 要求同步性能绝对不达标 所以可以用ConcurrentHashMap
ConcurrentHashMap
在JDK 1.7版本中采用分段锁segment+HashEntry的形式存储信息 每段都有自己独立的锁 不同可以获取不同段锁从而独立访问不同段数据 JDK 1.8抛弃了Segment 用volatile+CAS(compare and swap) + synchronized + Node实现 同样也加入了红黑树 避免链表过长导致性能下降
HashMap中 put方法如何执行? 怎么添加Entry?
以JDK 1.8版本为例
1,根据要添加的键的哈希码(hashcode)找到数组中对应的位置
2.检查该位置是否为空 为空 则创建一个Entry把要存入的键值对放进去 并保存在数组的对应位置 把HashMap的修改次数+1(modcount)以便在迭代时发现并发修改
3.若已经存在键值对 检查该位置的第一个键值对的hashcode哈希码和键和添加的键值对是否same如果是 则说明找到相同的key 把新值替换旧值
4.若第一个键值对的哈希码和键不相同 则需要遍历链表或者红黑树来查找是否有相同键
对于链表来说 找到就替代旧值 没找到就把键值对更新在链表头部
对于红黑树 找到就替代 找不到就加入红黑树
5.检查链表长度是否为阈值(默认为8)是且数组长度>=64 则会把链表转化为红黑树 以提高查询效率
6.检查负载因子是否超过阈值(默认0.75)如果键值对的数量(size)与数组长度的比值大于阈值则需要扩容
7.扩容操作 创建一个新的两倍大的数组 把旧数组的重新计算哈希码并分配到新数组的位置 更新hashmap的引用和阈值参数
8.完成添加操作 hashmap还是线程不安全 可以用同步机制或者用ConcurrentHashMap
hashmap中get方法不一定安全!
空指针异常:hashmap可以存null为key 但是用null为键调用get方法会返回空指针异常
线程安全:一个线程调用get 另一个线程update键值对 会导致查到错误结果或者报异常ConcurrentModificationException 。如果需要在多线程环境中使用类似 HashMap 的数据结构,可以考虑使用 ConcurrentHashMap 。
HashMap一般用什么做key? 为什么用String?
String在Java里是不可变的 唯一String确保key的稳定性 若不定可能会导致hashcode和equals方法不一致 进而影响HashMap准确性
为什么 HashMap 使用红黑树而不是平衡二叉树
平衡二叉树是啥?任何节点的左右子树高度差不会小于1 树的节点 虽然平均分配 但是每次修改或者添加节点都会破坏树结构 要保证树结构就要用左旋或者右旋来维持结构
对于红黑树来说 追求“弱平衡” 最长路径不超过最短路径的 2 倍 插入/删除时较少破坏平衡 调整频率低 性能更优 适合频繁插入/删除的场景(如 HashMap 的链表转树)
HashMap 在多线程下的问题
JDK 1.7HashMap头插法扩容可能导致环形链表,造成死循环 JDK 1.8时使用尾插法 避免环形链表问题 都存在多线程put操作扔可能导致数据覆盖或丢失
HashMap扩容机制
hashmap默认负载因子为0.75 超过本身大小的75%就会触发扩容 分为两步
1.对哈希表长度的扩展(两倍)2.把旧哈希表数据放到新哈希表里
图解引自小林coding: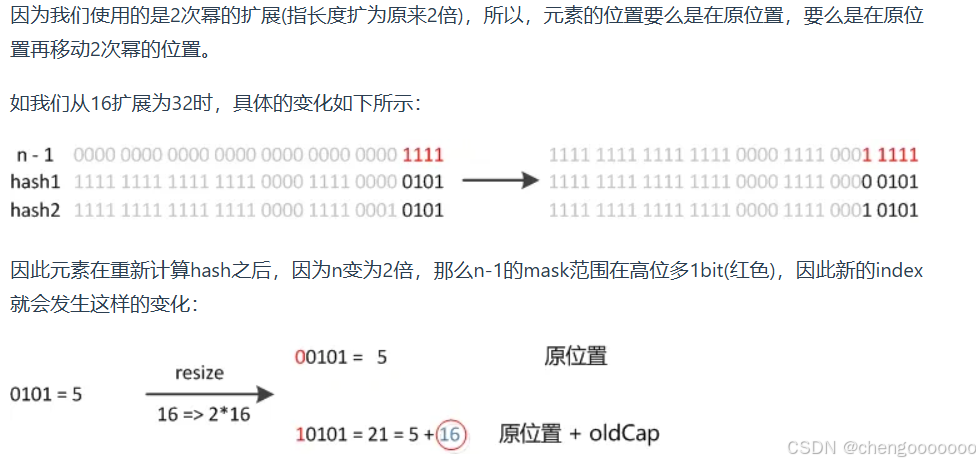
所以在扩充时 不需要重新计算hashcode 只需要看他新的bit是0还是1 是0就不变 是1就是“原索引+oldCap”
图解引自小林coding:
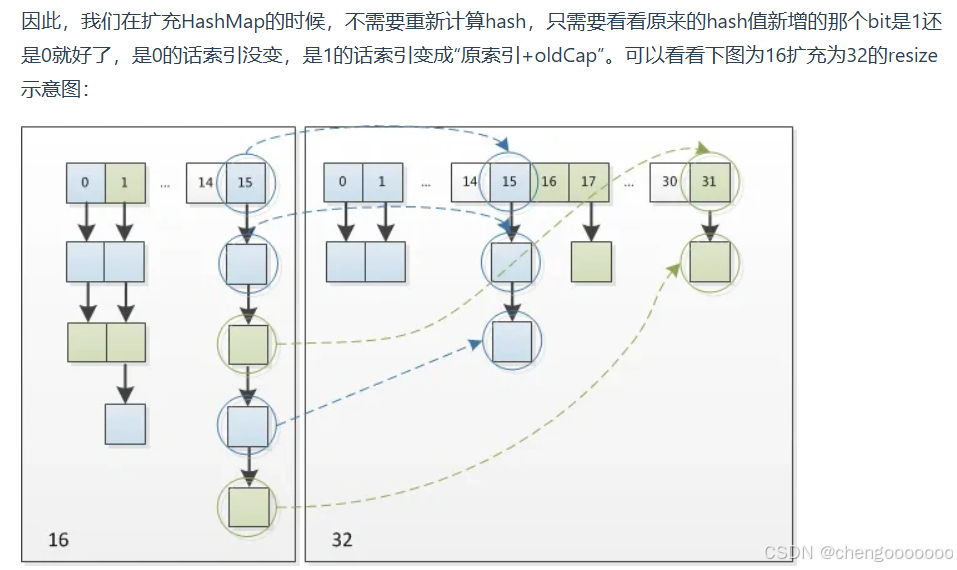
非常好的扩容 省去计算hash值的时间 同时可以通过判断新增的bit是1还是0可以认为是随机的 因此resize的过程 均匀的把之前冲突的节点分散到其他的bucket里了
HashMap 的大小为什么是 2 的 n 次方?
JDK1.7中 HashMap 整个扩容过程就是分别取出数组元素 一般该元素是最后一个放入链表中的元素 然后遍历以该元素为头的单向链表元素 依据每个被遍历元素的hash 值计算其在新数组中的下标然后进行交换 这样的扩容方式会将原来哈希冲突的单向链表尾部变成扩容后单向链表的头部
JDK1.8中 HashMap 对扩容操作做了优化 由于扩容数组的长度是2倍关系 所以对于假设初始tableSize = 4 要扩容到8 来说就是0100 到1000的变化(左移一位就是2倍)在扩容中只用判断原来的hash 值和左移动的一位(newtable的值)按位与操作是0 或1就行 0的话索引不变 1的话索引变成原索引加上扩容前数组
之所以能通过这种“与运算”来重新分配索引 是因为hash 值本来就是随机的 而hash 按位与上newTable得到的0(扩容前的索引位置)和1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的 所以扩容的过程就能把之前哈希冲突的元素再随机分布到不同的索引中去
因为hash值本身是随机的 进行位运算又是基本上相当快的 所以把hash值左移一位时 即把原本数据随机分布 避免哈希冲突 又能迅速扩容 一举两得
HashMap负载因子
负载因子太低会导致产生大量空桶 负载因子过高会导致大量碰撞 降低性能
0.75的负载因子在减少哈希冲突和提高空间利用率之间取得了一个折中,既避免了频繁扩容,也避免了过多的哈希冲突,从而在大多数情况下提供了较好的性能。
ConcurrentHashMap如何实现
JDK1.7 数组加链表 数组又分为大数组(segment)和小数组(hashEntry) Segment是可重入锁(Reentrantlock)扮演锁的角色 HashEntry用于存储键值对数组 每个HashEntry是链表结构元素
JDK 1.8 数组加链表/红黑树 主要通过volatile + CAS 或者 synchronized 来实现线程安全 添加元素时会判断容器是否为空 如果为空会用CAS + volatile 来初始化
如果容器不为空 根据存储元素判断当前位置是否为空 若根据存储元素计算为空 则用CAS 设置改节点 不为空就用synchronized 之后遍历桶数据 并替换新节点到桶里 最后再判断是否需要转为红黑树 就能保证并发安全
总结 ConcurrentHashMap通过对头结点加锁来保证线程安全 锁的粒度相对Segment更小了 发生冲突和加锁的概率降低了 红黑树优化固定链表 可以优化查询时间复杂度
分段锁如何加锁
ConcurrentHashMap把整个数据结构分为多个segment 每个segment类似一个小的hashmap 每个segment都有自己的锁 不同segment之间互不影响 插入 删除 查询操作需要先定位到具体segment然后在改segment上加锁 而不是像传统的HashMap里直接对整个数据结构进行加锁 可以使得不同segment并行操作 提高并发性能
分段锁的基础是 ReentrantLock 是可重入锁
ConcurrentHashMap用的是乐观锁还是悲观锁?
都有用到!首先 添加元素时判断容器是否为空:
如果为空则使用volatile加乐观锁(CAS)来初始化
若不为空就根据元素计算该位置是否为空 为空时 利用乐观锁(CAS)来设置该节点
不为空 就用synchronized(悲观锁)之后遍历桶中数据 替换或者新增节点到桶中 最后判断是否需要转为红黑树 保证并发安全
HashTable底层数据原理
数组加链表 所有方法都用synchronized修饰 保证线程安全 当一个线程访问同步方法 另一个也访问的时候会阻塞或者轮询
HashTable和ConcurrentHashMap有什么区别?如何实现线程安全?
ConcurrentHashMap JDK 1.7之前用分段数组加链表 JDK 1.8之后用数组+链表/红黑树
HashTable采用数组 + 链表 数组是主体 链表是用来解决hash冲突的
实现线程安全方式
jdk8以前 ConcurrentHashMap 用分段锁的方式进行分段分割 每把锁只锁容器里的部分数据 多线程访问不同数据段的数据不会存在锁竞争 jdk8以后 直接采用数组+链表/红黑树 并发控制使用CAS + synchronized实现 更能提高效率
HashTable 所有方法都加锁来保证线程安全 效率很低 当一个线程访问同步方法时 另一个线程同时访问则会陷入阻塞或者轮询状态
什么是哈希函数?常见hashcode方法是什么?
首先 hash函数在计算机科学中 应用于:
-
哈希表(如
HashMap、HashSet):快速定位数据。 -
数据校验(如文件完整性验证)。
-
加密(如密码存储,需结合盐值)。
Java 中的 hashCode() 方法
在 Java 中,hashCode() 是 Object 类的方法,用于返回对象的哈希码。默认实现基于对象的内存地址,但大多数情况下需要根据对象的实际内容重写该方法,以满足以下规则:
-
一致性:如果
a.equals(b)为true,则a.hashCode()必须等于b.hashCode()。 -
非唯一性:允许不同对象有相同的哈希码(哈希冲突),但需尽量降低概率。
基本类型字段的哈希计算
-
int:直接使用值。 -
long:将高32位与低32位异或。long value = 123L; int hash = (int) (value ^ (value >>> 32)); -
double:使用Double.hashCode(value)。 -
boolean:true视为1,false视为0。 -
String:Java 默认实现为多项式哈希。// String 类的哈希计算(简化版) public int hashCode() {int hash = 0;for (char c : chars) {hash = 31 * hash + c;}return hash; }
2. 组合多个字段的哈希值
通过将多个字段的哈希值组合成一个整数,常见方法是使用 素数乘法 和 加法:
@Override
public int hashCode() {int result = 17; // 初始值选一个非零质数result = 31 * result + name.hashCode(); // 31 是常用质数result = 31 * result + age;result = 31 * result + (int) (id ^ (id >>> 32));return result;
}为什么选择 31?
-
31 是奇质数,减少哈希冲突。
-
31 的乘法可优化为
(i << 5) - i,提升性能。
3. 使用工具类简化
Java 7+ 提供了 Objects.hash() 方法,自动组合多个字段:
@Override
public int hashCode() {return Objects.hash(name, age, id);
}HashMap ConcurrentHashMap HashTable的区别?
- HashMap线程不安全 效率比较高 可存储null的key与value null的key只能有一个 null的value可以有多个 默认初始容量为16 每次扩充为原来2倍 创建时若给定初始容量 则扩充为2的幂次方大小 底层结构为数组+链表 插入元素后若链表元素长度大于8 先判断数组长度是否小于64 如果小于 就扩充数组 反之 则链表转换为红黑树 以减少搜索时间
- HashTable 线程安全 效率比较低 内部方法都经过synchronized修饰 不可以有null的key和value 默认初始容量为11 每次扩容都变为原来的2n+1 创建时给定初始容量就用给定大小 底层数据结构为数组+链表
- ConcurrentHashMap 线程安全的哈希表实现 可在多线程环境下并发的进行读写操作 而不需要像传统意义上的hashtable一样对所有读写操作加锁 ConcurreentHashMap基于分段锁和CAS操作 把整个哈希表分成多个段(segment)每个segment都类似于一个小的HashMap 它拥有一个自己的数组和独立的锁 在ConcureentHashMap里 读操作不需要锁 可直接用segment进行读取 而写操作只需要锁定对应的segment 而不是整个哈希表
杂谈
List和Set的读写效率与区别?
1.元素唯一性
list可重复 set不可重复唯一
2.元素顺序
list有序 文件按照插入顺序排序 也可以用下标和索引来排序 ArrayList和LinkedList 都维护插入顺序 set通常是无序的 LinkedHashSet会维护插入顺序 TreeSet根据元素自然顺序或者自定义比较器进行排序
3.实现类 List:
ArrayList基于动态数组 随机访问 LinkedList基于双向链表 适合频繁插入和删除 Vector线程安全的动态数组 Set:HashSet基于Hash表 无序且高效 TreeSet基于红黑树 元素有序 LinkedHashSet基于hash表和链表 维护插入顺序
4.读写效率
List中 ArrayList通过下标访问时间复杂度效率为O(1) 写在尾部为O(1) 插入在头部或者中间位置 假设数组足够长 长度为n 插入在中间需要把后续元素向后移动一个单位 时间复杂度为O(n)
LinkedList通过遍历链表查询访问元素 时间复杂度为O(n) 插入或者删除时间复杂度为O(1)
Set中 HashSet和LinkedHashSet查询效率高O(1) 插入效率高O(1) TreeSet基于红黑树 查询和插入效率都是O(n)
5.使用场景
List适合需要保留元素插入顺序 允许重复元素 高频需要通过索引查询元素 (存储用户操作记录或者日志) Set需要保证元素的唯一性 不需要保留插入元素(除了LinkedHashSet)用于存储唯一用户名 去重操作等等
6.遍历方式
List提供基于索引的方法 get set 支持通过索引遍历 而Set不提供基于索引的方法 只能通过迭代器或者增强for遍历
相关文章:

Java集合
写在前面 本人在学习JUC过程中学习到集合和并发时有许多稀碎知识点 需要总结梳理思路与知识点 本文内容会涉及到ArrayList,HashMap以及扩容机制,ConcurrentHashMap,Synchronized,Volatile,ReentrantLock,…...

el-input 设置类型为number时,输入中文后光标会上移,并且会出现上下箭头
光标上移 设置 el-input 的 typenumber后,只能输入数字,输入中文后会自动清空,但是会出现一个问题:【光标会上移,如下图】 解决方法:修改样式 注意:需要使用样式穿透 :deep( ) /*解决el-in…...

迷你世界脚本自定义UI接口:Customui
自定义UI接口:Customui 彼得兔 更新时间: 2024-11-07 15:12:42 具体函数名及描述如下:(除前两个,其余的目前只能在UI编辑器内部的脚本使用) 序号 函数名 函数描述 1 openUIView(...) 打开一个UI界面(注意…...

解决windows npm无法下载electron包的问题
1.将nsis.zip解压到C:\Users\XXX\AppData\Local\electron-builder\Cache 2.将winCodeSign.zip解压到C:\Users\XXX\AppData\Local\electron-builder\Cache 3.将electron-v20.3.8-win32-ia32.zip复制到C:\Users\XXX\AppData\Local\electron\Cache 4.将electron-v20.3.8-win32-…...
)
Notepad++ 8.6.7 安装与配置全攻略(Windows平台)
一、软件定位与核心优势 Notepad 是开源免费的代码/文本编辑器,支持超过80种编程语言的高亮显示,相比系统自带记事本具有以下优势: 轻量高效:启动速度比同类软件快30%插件扩展:支持NppExec、JSON Viewer等200插件跨文…...

Unity InputField + ScrollRect实现微信聊天输入框功能
1、实现动态高度尺寸的的InputField 通过这两个部件就可以实现inputField的动态改变尺寸。 将inputField放入到scrollview当中作为子类 将scrollview 链接到UIChatInputField脚本中。 2、实现UIChatInputField //聊天输入框(类似wechat) [RequireComp…...
Java-servlet-Web环境搭建(下)详细讲解利用maven和tomcat搭建Java-servlet环境)
Java-servlet(三)Java-servlet-Web环境搭建(下)详细讲解利用maven和tomcat搭建Java-servlet环境
Java-servlet(三)Java-servlet-Web环境搭建(下)利用maven和tomcat搭建Java-servlet环境 前言一、配置maven阿里镜像二、利用IDEA创建maven文件创建maven文件删除src文件创建新的src模版删除example以及org文件 三、在第二个xml文件…...

在 CLion 中使用 Boost.Test 进行 C++ 单元测试
1. 安装 Boost.Test Boost.Test 是 Boost C 库的一部分,因此需要安装完整的 Boost 库。 方法 1:使用包管理器安装(推荐) Windows(vcpkg) 直接使用 CLion 集成的 vcpkg安装 boost-test: 也可…...

极狐GitLab 17.9 正式发布,40+ DevSecOps 重点功能解读【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

文本处理Bert面试内容整理-BERT的预训练任务是什么?
BERT的预训练任务主要有两个,分别是 Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。这两个任务帮助BERT学习从大规模未标注文本中提取深层次的语义和上下文信息。 1. Masked Language Model (MLM)(掩码语言模型)...
【Leetcode 快乐数】)
【蓝桥杯】每天一题,理解逻辑(3/90)【Leetcode 快乐数】
闲话系列:每日一题,秃头有我,Hello!!!!!,我是IF‘Maxue,欢迎大佬们来参观我写的蓝桥杯系列,我好久没有更新博客了,因为up猪我寒假用自己的劳动换了…...
基于C++实现分布式网络通信RPC框架)
“深入浅出”系列之Linux篇:(10)基于C++实现分布式网络通信RPC框架
分布式网络通信rpc框架 项目是分布式网络通信rpc框架, 文中提到单机服务器的缺点: 硬件资源的限制影响并发:受限于硬件资源,聊天服务器承受的用户的并发有限 模块的编译部署难:任何模块小的修改,都导致整…...

Python的那些事第四十一篇:简化数据库交互的利器Django ORM
Django ORM:简化数据库交互的利器 摘要 随着互联网技术的飞速发展,Web开发越来越受到重视。Django作为一款流行的Python Web框架,以其高效、安全、可扩展等特点受到了广大开发者的喜爱。其中,Django ORM(对象关系映射)是Django框架的核心组件之一,它为开发者提供了一种…...

[自动驾驶-传感器融合] 多激光雷达的外参标定
文章目录 引言外参标定原理ICP匹配示例参考文献 引言 多激光雷达系统通常用于自动驾驶或机器人,每个雷达的位置和姿态不同,需要将它们的数据统一到同一个坐标系下。多激光雷达外参标定的核心目标是通过计算不同雷达坐标系之间的刚性变换关系(…...
)
初学STM32之简单认识IO口配置(学习笔记)
在使用51单片机的时候基本上不需要额外的配置IO,不过在使用特定的IO的时候需要额外的设计外围电路,比如PO口它是没有内置上拉电阻的。因此若想P0输出高电平,它就需要外接上拉电平。(当然这不是说它输入不需要上拉电阻,…...
)
【长安大学】苹果手机/平板自动连接认证CHD-WIFI脚本(快捷指令)
背景: 已经用这个脚本的记得设置Wifi时候,关闭“自动登录” 前几天实在忍受不了CHD-WIFI动不动就断开,一天要重新连接,点登陆好几次。试了下在网上搜有没有CHD-WIFI的自动连接WIFI自动认证脚本,那样我就可以解放双手&…...

powermock,mock使用笔记
介于日本的形式主义junit4单体测试,特记笔记,以下纯用手机打出来,因为电脑禁止复制粘贴。 pom文件 powermock-module-junit1.7.4 powermock-api-mokcito 1.7.4 spring-test 8 1,测试类头部打注解 RunWith(PowerMockRunner.class…...

大模型微调实战指南
1. 引言 在人工智能领域,大模型(如GPT、BERT、DeepSeek等)已经展现出了强大的通用能力。然而,要让这些模型在特定任务或领域中发挥最佳性能,微调(Fine-tuning)是必不可少的一步。本文将带你从零…...
)
计算机毕业设计Python+Django+Vue3微博数据舆情分析平台 微博用户画像系统 微博舆情可视化(源码+ 文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

HTML第四节
一.复合选择器 1.后代选择器 注:1.后代选择器会选中后代所有的要选择的标签 2.儿子选择器 3.并集选择器 注:1.注意换行,同时选中多种标签 4.交集选择器 注:1.标签选择器放在最前面,例如放在类选择器的前面 2.两个选择…...

Kubernetes 的正式安装
1.基础的网络结构说明 软件路由器 ikuai 当然同一个仅主机模式 相当于在 同一个我们所谓的广播域内 所以相当于它们的几张网卡 是被连接起来的 为了防止出现问题 我们可以把第二块网卡临时关闭一下 2.准备路由器 ikuai 爱快 iKuai-商业场景网络解决方案提供商 (ikuai8.com)…...

VS2022C#windows窗体应用程序调用DeepSeek API
目录 一、创建DeepSeek API Key 二、创建窗体应用程序 三、设计窗体 1、控件拖放布局 2、主窗体【Form1】设计 3、多行文本框【tbContent】 4、提交按钮【btnSubmit】 5、单行文字框 四、撰写程序 五、完整代码 六、运行效果 七、其它 一、创建DeepSeek API Ke…...
)
7. 机器人记录数据集(具身智能机器人套件)
1. 树莓派启动机器人 conda activate lerobotpython lerobot/scripts/control_robot.py \--robot.typelekiwi \--control.typeremote_robot2. huggingface平台配置 huggingface官网 注册登录申请token(要有写权限)安装客户端 # 安装 pip install -U …...

阿里云操作系统控制台——ECS操作与性能优化
引言:在数字化时代,云服务器作为强大的计算资源承载平台,为企业和开发者提供了灵活且高效的服务。本文将详细介绍如何一步步操作云服务器 ECS,从开通到组件安装,再到内存全景诊断,帮助快速上手,…...

在飞腾E2000Q开发板上,基于RT-Thread操作系统,实现DeepSeek语音交互
目录 一 ,简介 二 ,流程与结果分享 1. Phytium E2000q demo开发板连接 2. RT-Thread Kconfig 配置选择 (1)驱动 (2)软件包 3. 主要代码 (1)录音功能,将录音结果保存…...

navicat导出postgresql的数据库结构、字段名、备注等等
1、执行sql语句 SELECT A.attnum AS "序号",C.relname AS "表名",CAST ( obj_description ( relfilenode, pg_class ) AS VARCHAR ) AS "表名描述",A.attname AS "字段名称",A.attnotnull as "是否不为null",(case when A…...
安装网络插件)
K8s 1.27.1 实战系列(三)安装网络插件
Kubernetes 的网络插件常见的有 Flannel 和 Calico ,这是两种主流的 CNI(容器网络接口)解决方案,它们在设计理念、实现方式、性能特征及适用场景上有显著差异。以下是两者的综合对比分析: 一、Flannel 和 Calico 1. 技术基础与网络实现 Flannel 核心机制:基于 Overlay …...

Python实现鼠标点击获取窗口进程信息
最近遇到挺无解的一个问题:电脑上莫名其妙出现一个白色小方块,点击没有反应,关也关不掉,想知道它和哪个软件有关还是显卡出了问题,也找不到思路,就想着要不获取一下它的进程号看看。 于是写了一个Python脚本…...

文件解析:doc、docx、pdf
1.doc解析 ubuntu/debian系统应先安装工具 apt-get install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr \ flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig pip install textract解析: import te…...

JDBC 完全指南:掌握 Java 数据库交互的核心技术
JDBC 完全指南:掌握 Java 数据库交互的核心技术 一、JDBC 是什么?为什么它如此重要? JDBC(Java Database Connectivity)是 Java 语言中用于连接和操作关系型数据库的标准 API。它允许开发者通过统一的接口访问不同的数…...

【STM32】STM32系列产品以及新手入门的STM32F103
📢 STM32F103xC/D/E 系列是一款高性能、低功耗的 32 位 MCU,适用于工业、汽车、消费电子等领域;基于 ARM Cortex-M3,主频最高 72MHz,支持 512KB Flash、64KB SRAM,适合复杂嵌入式应用,提供丰富的…...

esp32驱动带字库芯片TFT屏幕
前言 学习esp32单片机开发,前段时间在网上买了一块2.0寸TFT屏幕。 长这个样子,这个屏幕带汉字字库的硬件模块。我仔细看了一下这个字库模块上面写的字是25Q32FVSIG 1336 文档 卖家也发来了开发文档,是个doc文档,张这个样子。 开…...
]第5章 列表 元组 字符串)
[Python入门学习记录(小甲鱼)]第5章 列表 元组 字符串
第5章 列表 元组 字符串 5.1 列表 一个类似数组的东西 5.1.1 创建列表 一个中括号[ ] 把数据包起来就是创建了 number [1,2,3,4,5] print(type(number)) #返回 list 类型 for each in number:print(each) #输出 1 2 3 4 5#列表里不要求都是一个数据类型 mix [213,"…...

网络安全等级保护2.0 vs GDPR vs NIST 2.0:全方位对比解析
在网络安全日益重要的今天,各国纷纷出台相关政策法规,以加强信息安全保护。本文将对比我国网络安全等级保护2.0、欧盟的GDPR以及美国的NIST 2.0,分析它们各自的特点及差异。 网络安全等级保护2.0 网络安全等级保护2.0是我国信息安全领域的一…...

由麻省理工学院计算机科学与人工智能实验室等机构创建低成本、高效率的物理驱动数据生成框架,助力接触丰富的机器人操作任务
2025-02-28,由麻省理工学院计算机科学与人工智能实验室(CSAIL)和机器人与人工智能研究所的研究团队创建了一种低成本的数据生成框架,通过结合物理模拟、人类演示和基于模型的规划,高效生成大规模、高质量的接触丰富型机…...

leetcode15 三数之和
1.哈希法 为了避免重复 class Solution { public:vector<vector<int>> threeSum(vector<int>& nums) {set<vector<int>> temple;//使用 set 来存储符合条件的三元组,避免重复vector<vector<int>> out;//存放最终输…...

5c/c++内存管理
1. C/C内存分布 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] { 1, 2, 3, 4 };char char2[] "abcd";const char* pChar3 "abcd";int* ptr1 (int*)malloc(sizeof(int) * 4);i…...
- 数据结构、算法与STL)
蓝桥备赛(11)- 数据结构、算法与STL
一、数据结构 1.1 什么是数据结构? 在计算机科学中,数据结构是一种 数据组织、管理和存储的格式。它是相互之间存在一种 或多种特定关系的数据元素的集合。 ---> 通俗点,数据结构就是数据的组织形式 , 研究数据是用什么方…...

C++ 二叉搜索树代码
C 二叉搜索树代码 #include <iostream> using namespace std;template<typename T> struct TreeNode{T val;TreeNode *left;TreeNode *right;TreeNode():val(0), left(NULL), right(NULL){}TreeNode(T x):val(x), left(NULL), right(NULL){} };template<typena…...

Flask 打包为exe 文件
进入虚拟环境 激活虚拟环境 .venv\Scripts\activatepython build.py 完成标识图片 已经完成打包了,完成,下边是我自己记录的 这时候,我自己数据库文件夹下是没有sql 脚本的,要自己拷贝下这个路径下的文件 E:\开源文件\python-wi…...

JavaWeb-idea配置smart tomcat
一,安装smart tomcat插件 在插件市场搜索smart tomcat 点击安装,我已经安装成功。 二,web项目配置tomcat 点击这里,选择edit 进来之后,选加号 然后选tomcat 在这里,配置完毕后,点apply&…...

DELETE/ UPDATE/ INSERT 语句会自动加锁
在数据库系统中,DELETE、UPDATE 和 INSERT 语句通常会自动加锁,以确保数据的一致性和并发控制。具体的锁类型和效果取决于数据库的实现(如 MySQL、PostgreSQL 等)以及事务的隔离级别。以下是这些操作通常加锁的行为和效果…...

docker本地部署ollama
启动ollama容器 1.使用该命令启动CPU版运行本地AI模型 docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 2.此命令用于启动GPU版本运行AI模型 前提是笔记本已配置NVIDIA的GPU驱动,可在shell中输入nvidia-smi查看详细情况…...

Linux线程机制
Linux 操作系统中的线程机制是基于 POSIX 线程(Pthreads) 标准实现的,通常称为 pthread。Linux 内核通过Native POSIX Thread Library提供了对多线程的支持。 1. 线程的基本概念 线程是进程中的一个执行单元,是 CPU 调度的基本单…...
第八天|二叉树的直径|二叉树的层序遍历|将有序数组转换为二叉搜索树|验证二叉树搜索树|二叉搜索树中第K小的元素)
LeetCode热题100JS(44/100)第八天|二叉树的直径|二叉树的层序遍历|将有序数组转换为二叉搜索树|验证二叉树搜索树|二叉搜索树中第K小的元素
543. 二叉树的直径 题目链接:543. 二叉树的直径 难度:简单 刷题状态:1刷 新知识: 解题过程 思考 示例 1: 输入:root [1,2,3,4,5] 输出:3 解释:3 ,取路径 [4,2,1,3] 或…...

Java与数据库
目录 一.本文焦点: 二.数据库常用数据类型 三.对数据库操作 四.对数据库中的表操作 五.条件表达 六. 表查询操作进阶 1.多表连接查询 1)交叉连接查询 2)内连接(取两表交集) 3)外连接 4)…...

MySQL表中数据基本操作
1.表中数据的插入: 1.insert insert [into] table_name [(column [,column]...)] values (value_list) [,(value_list)] ... 创建一张学生表: 1.1单行指定列插入: insert into student (name,qq) values (‘张三’,’1234455’); values左…...

基于GeoTools的GIS专题图自适应边界及高宽等比例生成实践
目录 前言 一、原来的生成方案问题 1、无法自动读取数据的Bounds 2、专题图高宽比例不协调 二、专题图生成优化 1、直接读取矢量数据的Bounds 2、专题图成果抗锯齿 3、专题成果高宽比例自动调节 三、总结 前言 在当今数字化浪潮中,地理信息系统(…...
)
蓝桥与力扣刷题(蓝桥 数字三角形)
题目: 上图给出了一个数字三角形。从三角形的顶部到底部有很多条不同的路径。对于每条路径,把路径上面的数加起来可以得到一个和,你的任务就是找到最大的和(路径上的每一步只可沿左斜线向下或右斜线向下走)。 输入描述…...
)
6. PromQL的metric name(在node exporter复制下来交给AI解释的)
目录 前言: Go 运行时指标: Go 内存统计指标: CPU 指标: 内存指标: 磁盘指标: 网络指标: 系统指标: 前言: 写这个得目的是为了后续方便查询,因为在pro…...