[Computer Vision]实验七:图像检索
目录
一、实验内容
二、实验过程
2.1 准备数据集
2.2 SIFT特征提取
2.3 学习“视觉词典”(vision vocabulary)
2.4 建立图像索引并保存到数据库中
2.5 用一幅图像查询
三、实验小结
一、实验内容
- 实现基于颜色直方图、bag of word等方法的以图搜图,打印图片特征向量、图片相似度等
- 打印视觉词典大小、可视化部分特征基元、可视化部分图片的频率直方图
二、实验过程
2.1 准备数据集
如图1所示,这里准备的文件夹中含有100张实验图片。
2.2 SIFT特征提取
2.2.1 实验代码
import os
import cv2
import numpy as np
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
#生成特征文件路径
featlist = [os.path.splitext(imlist[i])[0] + '.sift' for i in range(nbr_images)]
#创建sift对象
sift = cv2.SIFT_create()
#提取sift特征并保存
for i in range(nbr_images):try:img = cv2.imread(imlist[i], cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {imlist[i]} could not be read")keypoints, descriptors = sift.detectAndCompute(img, None)locs = np.array([[kp.pt[0], kp.pt[1], kp.size, kp.angle] for kp in keypoints])np.savetxt(featlist[i], np.hstack((locs, descriptors)))print(f"Processed {imlist[i]} to {featlist[i]}")except Exception as e:print(f"Failed to process {imlist[i]}: {e}")
#可视化sift特征
def visualize_sift_features(image_path, feature_path):img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if img is None:raise ValueError(f"Image {image_path} could not be read")features = np.loadtxt(feature_path)locs = features[:, :4]descriptors = features[:, 4:]img_with_keypoints = cv2.drawKeypoints(img, [cv2.KeyPoint(x=loc[0], y=loc[1], _size=loc[2], _angle=loc[3]) for loc in locs], outImage=np.array([]))plt.figure(figsize=(10, 10))plt.imshow(img_with_keypoints, cmap='gray')plt.title('SIFT Features Visualization')plt.axis('off')plt.show()visualize_sift_features(imlist[0], featlist[0])2.2.2 结果展示
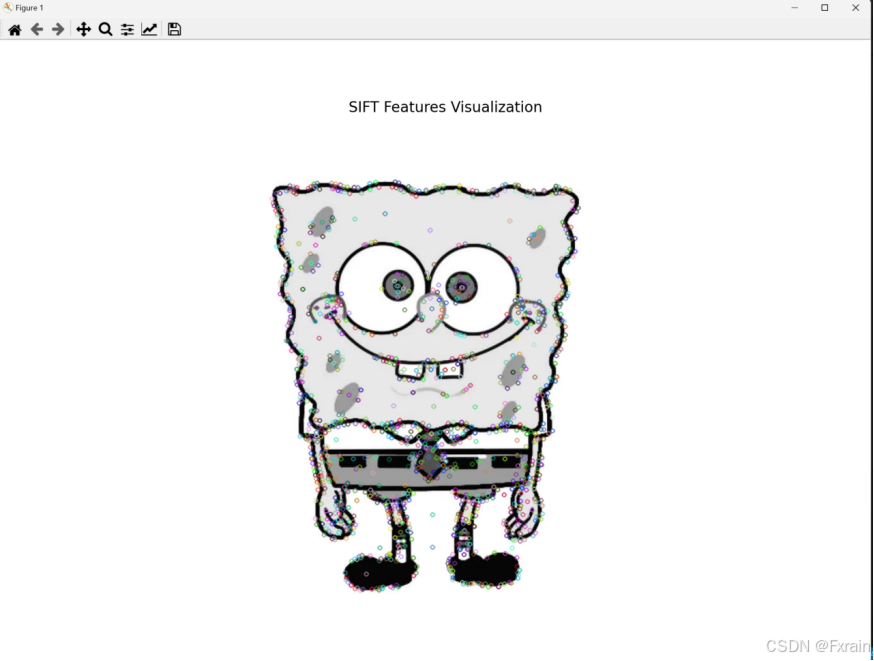
如图2所示,对文件夹中的所有图片使用sift特征描述子,图3展示了对第一个图像的SIFT特征的可视化。
2.3 学习“视觉词典”(vision vocabulary)
2.3.1 实验代码
(1)vocabulary.py文件
from numpy import *
from scipy.cluster.vq import *
from PCV.localdescriptors import sift
#构建视觉词汇表
class Vocabulary(object):#初始化方法def __init__(self,name):self.name = nameself.voc = []self.idf = []self.trainingdata = []self.nbr_words = 0#训练过程def train(self,featurefiles,k=100,subsampling=10):nbr_images = len(featurefiles)descr = []descr.append(sift.read_features_from_file(featurefiles[0])[1])descriptors = descr[0] for i in arange(1,nbr_images):descr.append(sift.read_features_from_file(featurefiles[i])[1])descriptors = vstack((descriptors,descr[i]))#使用K-means聚类生成视觉单词self.voc,distortion = kmeans(descriptors[::subsampling,:],k,1)self.nbr_words = self.voc.shape[0]#生成视觉单词的直方图imwords = zeros((nbr_images,self.nbr_words))for i in range( nbr_images ):imwords[i] = self.project(descr[i])nbr_occurences = sum( (imwords > 0)*1 ,axis=0)#计算每个视觉单词的逆文档频率self.idf = log( (1.0*nbr_images) / (1.0*nbr_occurences+1) )self.trainingdata = featurefiles#投影方法def project(self,descriptors):imhist = zeros((self.nbr_words))words,distance = vq(descriptors,self.voc)for w in words:imhist[w] += 1return imhistdef get_words(self,descriptors):return vq(descriptors,self.voc)[0](2)visual vocabulary.py文件
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlistimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
voc = vocabulary.Vocabulary('bof_test')
voc.train(featlist, 50, 10)with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'wb') as f:pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)2.3.2 结果展示
如图4所示,打印视觉词典的名称和长度

2.4 建立图像索引并保存到数据库中
2.4.1 实验代码
(1)imagesearch.py文件
from numpy import *
import pickle
import sqlite3 as sqlite
from functools import cmp_to_keyclass Indexer(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def db_commit(self):self.con.commit()def get_id(self,imname):cur = self.con.execute("select rowid from imlist where filename='%s'" % imname)res=cur.fetchone()if res==None:cur = self.con.execute("insert into imlist(filename) values ('%s')" % imname)return cur.lastrowidelse:return res[0] def is_indexed(self,imname):im = self.con.execute("select rowid from imlist where filename='%s'" % imname).fetchone()return im != Nonedef add_to_index(self,imname,descr):if self.is_indexed(imname): returnprint ('indexing', imname)imid = self.get_id(imname)imwords = self.voc.project(descr)nbr_words = imwords.shape[0]for i in range(nbr_words):word = imwords[i]self.con.execute("insert into imwords(imid,wordid,vocname) values (?,?,?)", (imid,word,self.voc.name))self.con.execute("insert into imhistograms(imid,histogram,vocname) values (?,?,?)", (imid,pickle.dumps(imwords),self.voc.name))def create_tables(self): self.con.execute('create table imlist(filename)')self.con.execute('create table imwords(imid,wordid,vocname)')self.con.execute('create table imhistograms(imid,histogram,vocname)') self.con.execute('create index im_idx on imlist(filename)')self.con.execute('create index wordid_idx on imwords(wordid)')self.con.execute('create index imid_idx on imwords(imid)')self.con.execute('create index imidhist_idx on imhistograms(imid)')self.db_commit()def cmp_for_py3(a, b):return (a > b) - (a < b)class Searcher(object):def __init__(self,db,voc):self.con = sqlite.connect(db)self.voc = vocdef __del__(self):self.con.close()def get_imhistogram(self, imname):cursor = self.con.execute("select rowid from imlist where filename='%s'" % imname)row = cursor.fetchone()if row is None:raise ValueError(f"No entry found in imlist for filename: {imname}")im_id = row[0]cursor = self.con.execute("select histogram from imhistograms where rowid=%d" % im_id)s = cursor.fetchone()if s is None:raise ValueError(f"No histogram found for rowid: {im_id}")return pickle.loads(s[0])def candidates_from_word(self,imword):im_ids = self.con.execute("select distinct imid from imwords where wordid=%d" % imword).fetchall()return [i[0] for i in im_ids]def candidates_from_histogram(self,imwords):words = imwords.nonzero()[0]candidates = []for word in words:c = self.candidates_from_word(word)candidates+=ctmp = [(w,candidates.count(w)) for w in set(candidates)]tmp.sort(key=cmp_to_key(lambda x,y:cmp_for_py3(x[1],y[1])))tmp.reverse()return [w[0] for w in tmp] def query(self, imname):try:h = self.get_imhistogram(imname)except ValueError as e:print(e)return []candidates = self.candidates_from_histogram(h)matchscores = []for imid in candidates:cand_name = self.con.execute("select filename from imlist where rowid=%d" % imid).fetchone()cand_h = self.get_imhistogram(cand_name)cand_dist = sqrt(sum(self.voc.idf * (h - cand_h) ** 2))matchscores.append((cand_dist, imid))matchscores.sort()return matchscoresdef get_filename(self,imid):s = self.con.execute("select filename from imlist where rowid='%d'" % imid).fetchone()return s[0]def tf_idf_dist(voc,v1,v2):v1 /= sum(v1)v2 /= sum(v2)return sqrt( sum( voc.idf*(v1-v2)**2 ) )def compute_ukbench_score(src,imlist):nbr_images = len(imlist)pos = zeros((nbr_images,4))for i in range(nbr_images):pos[i] = [w[1]-1 for w in src.query(imlist[i])[:4]]score = array([ (pos[i]//4)==(i//4) for i in range(nbr_images)])*1.0return sum(score) / (nbr_images)from PIL import Image
from pylab import *def plot_results(src,res):figure()nbr_results = len(res)for i in range(nbr_results):imname = src.get_filename(res[i])subplot(1,nbr_results,i+1)imshow(array(Image.open(imname)))axis('off')show()(2)quantizeSet.py文件
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
import sqlite3
from PCV.tools.imtools import get_imlist
import cv2
import matplotlib.pyplot as pltimlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f)
indx = imagesearch.Indexer('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)
indx.create_tables()
for i in range(nbr_images)[:100]:locs, descr = sift.read_features_from_file(featlist[i])indx.add_to_index(imlist[i], descr)
indx.db_commit()
con = sqlite3.connect('D:\\Computer vision\\20241217CODES\\testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())
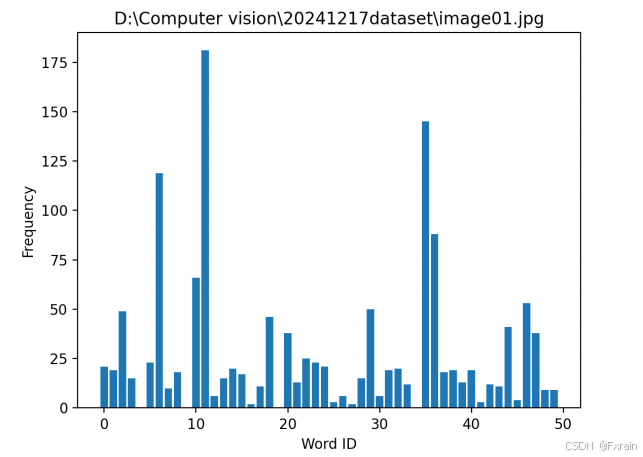
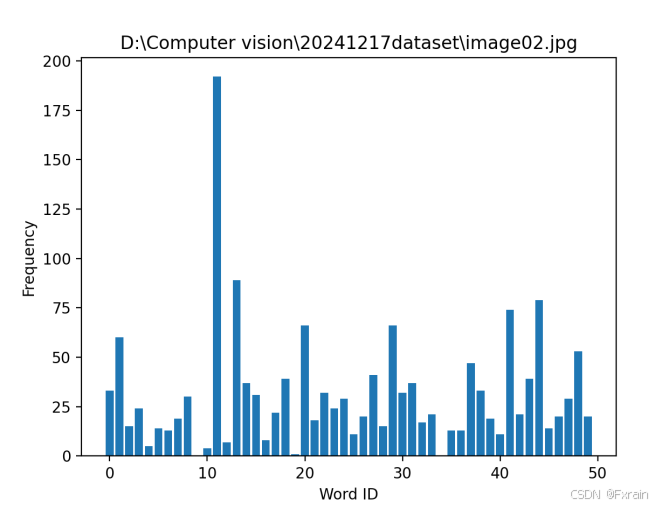
searcher = imagesearch.Searcher('D:\\Computer vision\\20241217CODES\\testImaAdd.db', voc)image_files = imlist[:5]for image_file in image_files:histogram = searcher.get_imhistogram(image_file)plt.figure()plt.title(image_file)plt.bar(range(len(histogram)), histogram)plt.xlabel('Word ID')plt.ylabel('Frequency')plt.show()2.4.2 结果展示
如图5所示,对数据集中的所有图像进行量化,为所有图像创建索引,再遍历所有的图像,将它们的特征投影到词汇上,最终提交到数据库保存下来(如图6)。图7、图8展示了部分图像的频率直方图。

2.5 用一幅图像查询
2.5.1 实验代码
import pickle
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
import numpy as np
import cv2
import warnings
warnings.filterwarnings("ignore")imlist = get_imlist(r'D:\Computer vision\20241217dataset')
nbr_images = len(imlist)
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]with open(r'D:\Computer vision\20241217dataset\vocabulary50.pkl', 'rb') as f:voc = pickle.load(f, encoding='iso-8859-1')src = imagesearch.Searcher(r'D:\Computer vision\20241217CODES\testImaAdd.db', voc)q_ind = 3
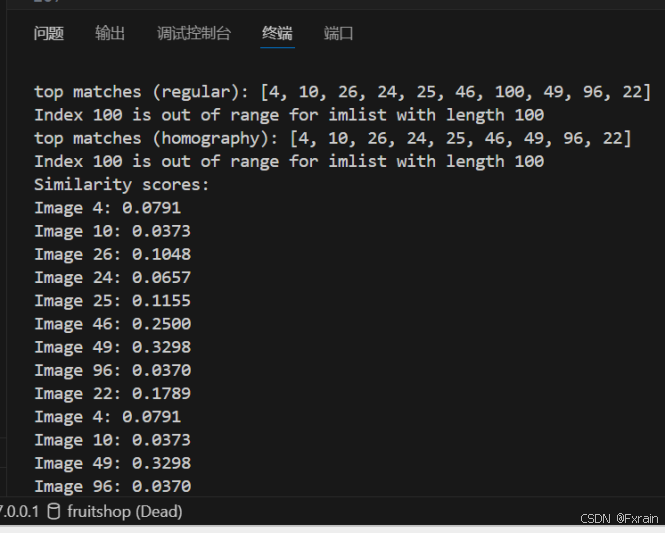
nbr_results = 10res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)img = cv2.imread(imlist[q_ind])
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp, q_descr = sift.detectAndCompute(gray, None)
q_locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])
fp = homography.make_homog(q_locs[:, :2].T)model = homography.RansacModel()
rank = {}bf = cv2.BFMatcher()
for ndx in res_reg[1:]:if ndx >= len(imlist):print(f"Index {ndx} is out of range for imlist with length {len(imlist)}")continueimg = cv2.imread(imlist[ndx])gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)kp, descr = sift.detectAndCompute(gray, None)locs = np.array([[kp[i].pt[0], kp[i].pt[1]] for i in range(len(kp))])matches = bf.knnMatch(q_descr, descr, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)ind = [m.queryIdx for m in good_matches]ind2 = [m.trainIdx for m in good_matches]tp = homography.make_homog(locs[:, :2].T)try:H, inliers = homography.H_from_ransac(fp[:, ind], tp[:, ind2], model, match_theshold=4)except:inliers = []# store inlier countrank[ndx] = len(inliers)sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]] + [s[0] for s in sorted_rank]
print('top matches (homography):', res_geom)def calculate_similarity(query_index, result_indices, imlist):similarities = []for res_index in result_indices:if res_index >= len(imlist):print(f"Index {res_index} is out of range for imlist with length {len(imlist)}")continueimg1 = cv2.imread(imlist[query_index])img2 = cv2.imread(imlist[res_index])gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)sift = cv2.SIFT_create()kp1, des1 = sift.detectAndCompute(gray1, None)kp2, des2 = sift.detectAndCompute(gray2, None)bf = cv2.BFMatcher()matches = bf.knnMatch(des1, des2, k=2)good_matches = []for m, n in matches:if m.distance < 0.75 * n.distance:good_matches.append(m)similarity = len(good_matches) / min(len(kp1), len(kp2))similarities.append((res_index, similarity))return similaritiesquery_index = q_ind
result_indices = res_reg + res_geom
similarities = calculate_similarity(query_index, result_indices, imlist)print("Similarity scores:")
for index, score in similarities:print(f"Image {index}: {score:.4f}")imagesearch.plot_results(src, res_reg)
imagesearch.plot_results(src, res_geom)
imagesearch.plot_results(src, res_reg[:6])
imagesearch.plot_results(src, res_geom[:6]) 2.5.2 结果展示
如图9所示,根据给定的查询图像索引q_ind,执行常规查询,返回前nbr_results个匹配结果,并打印这些结果以及可视化图片。

如图10所示,使用 RANSAC 模型拟合单应性找到与查询图像几何一致的候选图像。

如图11所示,计算查询图像与候选图像之间的相似度分数,并返回一个包含相似度分数的列表。
当生成不同维度视觉词典时,常规排序结果如图12所示。

三、实验小结
图像检索是一项重要的计算机视觉任务,它在根据用户的输入(如图像或关键词),从图像数据库中检索出最相关的图像。Bag of Feature 是一种图像特征提取方法,参考Bag of Words的思路,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。同时从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。
相关文章:

[Computer Vision]实验七:图像检索
目录 一、实验内容 二、实验过程 2.1 准备数据集 2.2 SIFT特征提取 2.3 学习“视觉词典”(vision vocabulary) 2.4 建立图像索引并保存到数据库中 2.5 用一幅图像查询 三、实验小结 一、实验内容 实现基于颜色直方图、bag of word等方法的以图搜…...
思科、华为)
访问控制列表(ACL)思科、华为
访问控制列表(ACL) 一、ACL的基本概念 随着网络的飞速发展,网络安全和网络服务质量QoS(Quality of Service)问题日益突出。 企业重要服务器资源被随意访问,企业机密信息容易泄露,造成安全隐患。…...

linux磁盘满了怎么安全删除文件
df -h 通过df -h /dir 查看被占满的目录,dir替换为你的文件目录 du -sh * 进入被占满的目录,执行 du -sh * ,查看哪些文件占的磁盘大 查看占用磁盘最大的文件 du -sh * | sort -rh | head -n N N通常可以设置为10 有的docker容器文件太…...
)
2025国家护网HVV高频面试题总结来了04(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 一、HVV行动面试题分类 根据面试题的内容,我们将其分为以下几类: 漏洞利用与攻击技术 …...

jenkins使用插件在Build History打印基本信息
1、插件安装 分别是description setter plugin插件和user build vars插件,下面介绍一下这两个插件: description setter plugin:作用是在 Build 栏下方增加一个功能块,用于填写自定义信息,也就是 Build history 中需要显示的文字…...

线程池的工作流程
线程池的工作流程主要包括任务提交、线程分配、任务执行和线程回收等环节,以下是对其详细的描述: 任务提交 当有任务需要执行时,用户通过线程池提供的提交方法,如execute()或submit()方法,将任务(通常是实现…...
《深度学习实战》第4集:Transformer 架构与自然语言处理(NLP)
《深度学习实战》第4集:Transformer 架构与自然语言处理(NLP) 在自然语言处理(NLP)领域,Transformer 架构的出现彻底改变了传统的序列建模方法。它不仅成为现代 NLP 的核心,还推动了诸如 BERT、…...

vue下载插件
1.下载路由组件 npm i vue-router2.创建router文件夹 3.创建router.js文件 import {createRouter, createWebHistory} from "vue-router"let router createRouter({history: createWebHistory(),routes: [{path: "/",component: () > import(".…...

两周学习安排
日常安排 白天 看 MySQL实战45讲,每日一讲 看 图解设计模式 每天1-2道力扣算法题(难度中等以上) 每天复习昨天的单词,记20个单词,写一篇阅读 晚上 写服创项目 每日产出 MySQL实战45讲 读书笔记 设计模式 读书笔…...
)
蓝桥与力扣刷题(蓝桥 k倍区间)
题目:给定一个长度为 N 的数列,A1,A2,⋯AN,如果其中一段连续的子序列 Ai,Ai1,⋯Aj( i≤j ) 之和是 K 的倍数,我们就称这个区间[i,j] 是 K 倍区间。 你能求出数列中总共有多少个 K 倍区间吗? 输入描述 第一行包含两…...
(END))
Spring项目-抽奖系统(实操项目-用户管理接口)(END)
^__^ (oo)\______ (__)\ )\/\ ||----w | || || 一:前言: 活动创建及展示博客链接:Spring项目-抽奖系统(实操项目-用户管理接口)(THREE)-CSDN博客 上一次完成了活动的创建和活动的展示,接下来就是重头戏—…...

5个GitHub热点开源项目!!
1.自托管 Moonlight 游戏串流服务:Sunshine 主语言:C,Star:14.4k,周增长:500 这是一个自托管的 Moonlight 游戏串流服务器端项目,支持所有 Moonlight 客户端。用户可以在自己电脑上搭建一个游戏…...
)
数据结构:二叉搜索树(排序树)
1.二叉搜索树的定义 二叉搜索树要么是空树,要么是满足以下特性的树 (1)左子树不为空,那么左子树左右节点的值都小于根节点的值 (2)右子树不为空,那么右子树左右节点的值都大于根节点的值 &#…...

JavaEE--计算机是如何工作的
一、一台计算机的组成部分 1.CPU(中央处理器) 2.主板(一个大插座) 3.内存(存储数据的主要模板) 4.硬盘(存储数据的主要模板) 内存和硬盘对比: 内存硬盘读写速度快慢存…...
)
Redis 实战篇 ——《黑马点评》(下)
《引言》 (下)篇将记录 Redis 实战篇 最后的一些学习内容,希望大家能够点赞、收藏支持一下 Thanks♪ (・ω・)ノ,谢谢大家。 传送门(上):Redis 实战篇 ——《黑马…...
将一组不同曝光的图像合并成一张高动态范围(HDR)图像的实现类cv::MergeDebevec)
OpenCV计算摄影学(10)将一组不同曝光的图像合并成一张高动态范围(HDR)图像的实现类cv::MergeDebevec
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 resulting HDR 图像被计算为考虑了曝光值和相机响应的各次曝光的加权平均值。 cv::MergeDebevec 是 OpenCV 中用于将一组不同曝光的图像合并成一…...

Linux驱动开发之串口驱动移植
原理图 从上图可以看到RS232的串口接的是UART3,接下来我们需要使能UART3的收发功能。一般串口的驱动程序在内核中都有包含,我们配置使能适配即可。 设备树 复用功能配置 查看6ull如何进行uart3的串口复用配置: 设备树下添加uart3的串口复用…...

c语言中return 数字代表的含义
return 数字的含义:表示函数返回一个整数值,通常用于向调用者(如操作系统或其他程序)传递程序的执行状态或结果。 核心规则: return 0: 含义:表示程序或函数正常结束。 示例: int m…...

Android 端侧运行 LLM 框架 MNN 及其应用
MNN Chat Android App - 基于 MNN 引擎的智能聊天应用 一、MNN 框架简介与工作原理1.1 什么是 MNN?1.2 MNN 的工作原理 二、MNN Chat Android App2.1 MNN Chat 的功能2.2 MNN Chat 的优势2.3 MNN Chat Android App 的使用 三、总结 随着移动端人工智能需求的日益增长…...

jupyter汉化、修改默认路径详细讲解
1、配置镜像路径 修改第三方库的下载路径,比如:[清华镜像pypi](https://mirrors.tuna.tsinghua.edu.cn/help/pypi/),配置镜像地址。 首先执行 pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple 2、安…...
)
java面试笔记(二)
1.流程中如何数据回填 (1)方法1: 在工作流中有一个标识,每一次审批的时候去判断是否审批完成,然后调用反射 (2)方法2: 创建一个流程结束的监听器,监听流程是否结束&a…...

【大语言模型笔记进阶一步】提示语设计学习笔记,跳出框架思维,自己构建提示词
一、大语言模型应用场景 1. 文本生成 文本创作: 诗歌故事,剧本,推文帖子 摘要与改写: 长文本摘要与简化,多语言翻译与本地化 结构化生成: 表格,根据需求生成代码片段,API文档生成…...
 ; 优化吞吐量)
sql调优:优化响应时间(优化sql) ; 优化吞吐量
Sql性能调优的目的 1.优化响应时间>>优化sql 经过调优后,执行查询、更新等操作的时候,数据库的反应速度更快,花费的时间更少。 2.优化吞吐量 即“并发”, 就是“同时处理请求”的能力。 优化sql 尽量将多条SQL语句压缩到一句>…...

debian/control中的包关系
软件包依赖就是软件包关系的一种,一般用 Depends 表示。 每个软件包都可以和其他软件包有各种不同的关系。除 Depends 外,还有 Recommends、Suggests、Pre-Depends、Breaks、Conflicts、Provides 和 Replaces,软件包管理工具(如 …...

python学习第三天
条件判断 条件判断使用if、elif和else关键字。它们用于根据条件执行不同的代码块。 # 条件判断 age 18 if age < 18:print("你还是个孩子!") elif age 18:print("永远十八岁!") else:print("你还年轻!")…...

k8s架构及服务详解
目录 1.1.容器是什么1.2.Namespace1.3.rootfs5.1.Service介绍5.1.1.Serice简介 5.1.1.1什么是Service5.1.1.2.Service的创建5.1.1.3.检测服务5.1.1.4.在运行的容器中远程执行命令 5.2.连接集群外部的服务 5.2.1.介绍服务endpoint5.2.2.手动配置服务的endpoint5.2.3.为外部服务…...

Unity中动态切换光照贴图LightProbe的方法
关键代码:LightmapSettings.lightmaps lightmapDatas; LightmapData中操作三张图:lightmapColor,lightmapDir,以及一张ShadowMap 这里只操作前两张: using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI;public cl…...

基于Matlab的多目标粒子群优化
在复杂系统的设计、决策与优化问题中,常常需要同时兼顾多个相互冲突的目标,多目标粒子群优化(MOPSO)算法应运而生,作为群体智能优化算法家族中的重要成员,它为解决此类棘手难题提供了高效且富有创新性的解决…...

Android Studio 新版本Gradle发布本地Maven仓库示例
发布代码到JitPack示例:https://blog.csdn.net/loutengyuan/article/details/145938967 以下是基于 Android Studio 24.2.2(Gradle 8.10.2 AGP 8.8.0 JDK17) 的本地 Maven 仓库发布示例,包含aar和jar的不同配置: 1.…...
)
Langchain解锁LLM大语言模型的结构化输出能力(多种实现方案)
在 LangChain解锁LLM大语言模型的结构化输出能力:调用 with_structured_output() 方法 这篇博客中,我们了解了格式化LLM输出内容的必要性以及如何通过调用langchain框架中提供的 with_structured_output() 方法对LLM输出进行格式化(三种可选方…...

深入理解Spring @Async:异步编程的利器与实战指南
一、为什么需要异步编程? 在现代高并发系统中,同步阻塞式编程会带来两大核心问题: // 同步处理示例 public void processOrder(Order order) {// 1. 保存订单(耗时50ms)orderRepository.save(order); // 2. 发送短信…...

让Word插上AI的翅膀:如何把DeepSeek装进Word
在日常办公中,微软的Word无疑是我们最常用的文字处理工具。无论是撰写报告、编辑文档,还是整理笔记,Word都能胜任。然而,随着AI技术的飞速发展,尤其是DeepSeek的出现,我们的文字编辑方式正在发生革命性的变…...

清华DeepSeek深度探索与进阶指南
「清华北大-Deepseek使用手册」 链接:https://pan.quark.cn/s/98782f7d61dc 「清华大学Deepseek整理) 1-6版本链接:https://pan.quark.cn/s/72194e32428a AI学术工具公测链接:https://pan.baidu.com/s/104w_uBB2F42Da0qnk78_ew …...

迁移学习策略全景解析:从理论到产业落地的技术跃迁
(2025年最新技术实践指南) 一、迁移学习的范式革命与核心价值 在人工智能进入"大模型时代"的今天,迁移学习已成为突破数据瓶颈、降低训练成本的关键技术。本文基于2025年最新技术进展,系统梳理六大核心策略及其在产业实…...

WireGuard搭建网络,供整个公司使用
一、清理现有配置(如已有失败尝试) # 停止并删除现有 WireGuard 接口 sudo wg-quick down wg0 sudo rm -rf /etc/wireguard/wg0.conf# 验证接口已删除 (执行后应该看不到 wg0) ifconfig二、服务器端完整配置流程 1. 安装 WireGuard sudo apt update &…...

MyAgent:用AI开发AI,开启智能编程的产业革命
在人工智能技术爆发的2025年,MyAgent智能体平台凭借其独特的“AI开发AI”模式,正在重构全球软件开发行业的底层逻辑。这一创新范式不仅将自然语言处理、机器学习、RPA(机器人流程自动化)等技术深度融合,更通过“…...

Cherno C++ P60 为什么不用using namespace std
这篇文章我们讲一下之前写代码的时候的一个习惯,也就是不使用using namespace std。如果我们接触过最早的C教程,那么第一节课都会让我们写如下的代码: #include<iostream>using namespace std;int main() {cout << "Hello …...

el-select的下拉选择框插入el-checkbox
el-check注意这里要使用model-value绑定数据 <el-selectv-model"selectDevice"multiplecollapse-tags:multiple-limit"5"style"width: 200px"popper-class"select-popover-class" ><el-optionv-for"item in deviceList…...

M系列芯片 MacOS 在 Conda 环境中安装 TensorFlow 2 和 Keras 3 完整指南
目录 1. 引言2. 环境准备3. 安装 TensorFlow 和必要依赖4. 结语Reference 1. 引言 Keras 是搞深度学习很可爱的工具,其友好的接口让我总是将其作为搭建模型原型的首选。然而,当我希望在 M 系列芯片的MacBook Pro上使用 Keras时,使用Conda和P…...

GitHub教程
目录 1.是什么?2.安装3.创建库3.增删改查4.远程仓库5.分支6.标签7.使用流程8.总结 1.是什么? Git 是一个命令行工具,但也有许多图形用户界面可用。本地仓库,安装包下载到本地。Git 的一个流行 GUI 是 GitHub,它可以方便地管理存储库、推送…...

《JavaScript解题秘籍:力扣队列与栈的高效解题策略》
232.用栈实现队列 力扣题目链接(opens new window) 使用栈实现队列的下列操作: push(x) -- 将一个元素放入队列的尾部。 pop() -- 从队列首部移除元素。 peek() -- 返回队列首部的元素。 empty() -- 返回队列是否为空。 示例: MyQueue queue new MyQueue(); queue…...

Supra软件更新:AGRV2K CPLD支持无源晶体做时钟输入
Supra软件更新:AGRV2K CPLD支持无源晶体做时钟输入 AGRV2K CPLD支持无源晶体做时钟输入,和AG32一样接入OSC_IN和OSC_OUT管脚。 VE管脚文件设为PIN_HSE,如: clk PIN_HSE ledout[0] PIN_31 ledout[1] PIN_32 ...... 在下载烧录文…...

简易的微信聊天网页版【项目测试报告】
文章目录 一、项目背景二、项目简介登录功能好友列表页面好友会话页面 三、测试工具和环境四、测试计划测试用例部分人工手动测试截图web自动化测试测试用例代码框架配置内容代码文件(Utils.py)登录页面代码文件(WeChatLogin.py)好…...

nio使用
NIO : new Input/Output,,在java1.4中引入的一套新的IO操作API,,,旨在替代传统的IO(即BIO:Blocking IO),,,nio提供了更高效的 文件和网络IO的 操作…...

【蓝桥杯单片机】第十二届省赛
一、真题 二、模块构建 1.编写初始化函数(init.c) void Cls_Peripheral(void); 关闭led led对应的锁存器由Y4C控制关闭蜂鸣器和继电器 由Y5C控制 2.编写LED函数(led.c) void Led_Disp(unsigned char ucLed); 将ucLed取反的值赋给P0 开启锁存器…...

Jenkins与Flutter项目持续集成实战指南
一、环境准备 1. 基础环境要求 Jenkins Server:已安装JDK 11,建议使用Linux服务器(Ubuntu/CentOS)Flutter SDK:全局安装或通过工具动态管理构建代理节点: Android构建:需Android SDK、Gradle、…...

linux常见操作命令
查看目录和文件 ls:列出目录内容。 常用选项: -l:以长格式显示,显示文件的权限、所有者、大小、修改时间等详细信息。-a:显示所有文件和目录,包括隐藏文件(以 . 开头的文件)。-h&…...

6.人工智能与机器学习
一、人工智能基本原理 1. 人工智能(AI)定义与范畴 核心目标:模拟人类智能行为(如推理、学习、决策)分类: 弱人工智能(Narrow AI):专精单一任务(如AlphaGo、…...

GPU架构分类
一、NVIDIA的GPU架构 NVIDIA是全球领先的GPU生产商,其GPU架构在图形渲染、高性能计算和人工智能等领域具有广泛应用。NVIDIA的GPU架构经历了多次迭代,以下是一些重要的架构: 1. Tesla(特斯拉)架构(2006年…...
【设计模式】)
23种设计模式之单例模式(Singleton Pattern)【设计模式】
文章目录 一、简介二、关键点三、实现单例模式的步骤四、C#示例4.1 简单的单例模式4.2 线程安全的单例模式(双重检查锁定)4.3 静态初始化单例模式 五、单例模式优缺点5.1 优点5.2 缺点 六、适用场景七、示例的现实应用 一、简介 单例模式(Si…...