MySQL数据库入门到大蛇尚硅谷宋红康老师笔记 高级篇 part 6
从6到12章将会是重中之重,请一定好好看
第06章_索引的数据结构
1.为什么使用索引
索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教课书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。MySQL中也是一样的道理,进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据,如果不符合则需要全表扫描,即需要一条一条地查找记录,直到找到与条件符合的记录。
假如给数据使用二叉搜索树这样的数据结构进行存储,如下图所示,时间复杂度达到O(log2n) 比我们的O(N)更好一些 .(这个容易倾斜,所以有了AVG,因为AVG需要频繁调整树形,所以才有了红黑树)
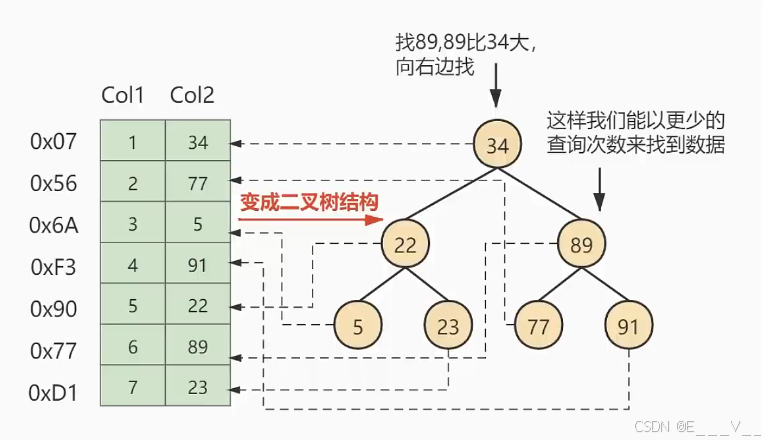 这就是我们为什么要建索引,目的就是为了减少磁盘I/0的次数,加快查询速率。
这就是我们为什么要建索引,目的就是为了减少磁盘I/0的次数,加快查询速率。
2.索引及其优缺点
2.1索引概述
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。你可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法。
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎不一定支持所有索引类型。同时,存储引擎可以定义每个表的最大索引数和最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。有些存储引擎支持更多的索引数和更大的索引长度。
2.2优点
(1)类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本,这也是创建索引最主要的原因。
(2)通过创建唯一索引,可以保证数据库表中每一行数据的唯一性(唯一约束)。
(3)在实现数据的参考完整性方面,可以加速表和表之间的连接。换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询速度。
(4) 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间,降低了CPU的消耗。
2.3缺点
增加索引也有许多不利的方面,主要表现在如下几个方面:
(1)创建索引和维护索引要耗费时间,并且随着数据量的增加,所耗费的时间也会增加。
(2)索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,存储在磁盘上,如果有大量的索引,索引文件就可能比数据文件更快达到最大文件尺寸。
(3)虽然索引大大提高了查询速度,同时却会降低更新表的速度。当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
因此,选择使用索引时,需要综合考虑索引的优点和缺点。
提示:
索引可以提高查询的速度,但是会影响插入记录的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
3.InnoDB中索引的推演
3.1索引之前的查找
先来看一个精确匹配的例子:
SELECT [列名列表] FROM 表名 WHERE 列名=XXX;假设目前表中的记录比较少,所有的记录都可以被存放到一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况:
1. 以主键为搜索条件
由于她有顺序 , 可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
2. 以其他列作为搜索条件
因为在数据页中并没有对非主键列建立所谓的页目录,所以我们无法通过二分法快速定位相应的槽。这种情况下只能从最小记录开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。
2.在很多页中查找
大部分情况下我们表中存放的记录都是非常多的,需要好多的数据页来存储这些记录。在很多页中查找记录的话 , 可以分为两个步骤:
1.定位到记录所在的页。
2. 从所在的页内中查找相应的记录。
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能从第一个页沿着双向链表一直往下找,在每一个页中根据我们上面的查找方式去查找指定的记录。因为要遍历所有的数据页,所以这种方式显然是超级耗时的。如果一个表有一亿条记录呢?此时索引应运而生。
3.2设计索引
建一个表:
mysql> CREATE TABLE index_demo(-> C1 INT,-> C2 INT,-> C3 CHAR(1).-> PRIMARY KEY(c1)-> ) ROW_FORMAT=Compact;这个新建的index_demo表中有2个INT类型的列,1个CHAR(1)类型的列,而且我们规定了c1列为主键,这个表使用Compact行格式来实际存储记录的。这里我们简化了index_demo表的行格式示意图:
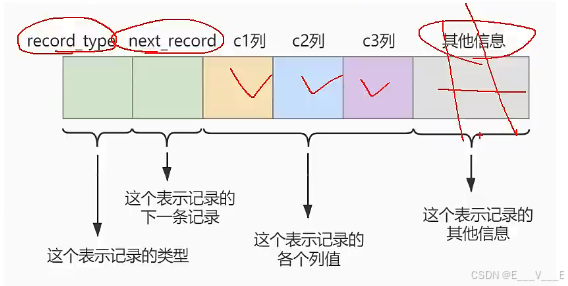
我们只在示意图里展示记录的这几个部分:
- record_type:记录头信息的一项属性,表示记录的类型,0表示普通记录、2表示最小记录、3表示最大记录、1暂时还没用过,下面讲。
- next_record:记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量,我们用箭头来表明下一条记录是谁。
- 各个列的值:这里只记录在index_demo表中的三个列,分别是c1、c2和c3。
- 其他信息:除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。
将记录格式示意图的其他信息项暂时去掉并把它竖起来的效果就是这样:
没有自增主键的话会有一个隐藏的,默认自增的id
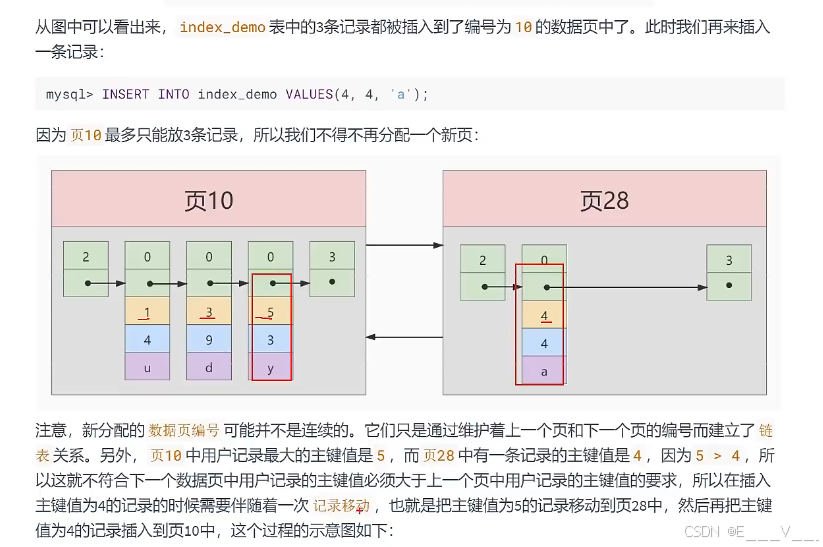
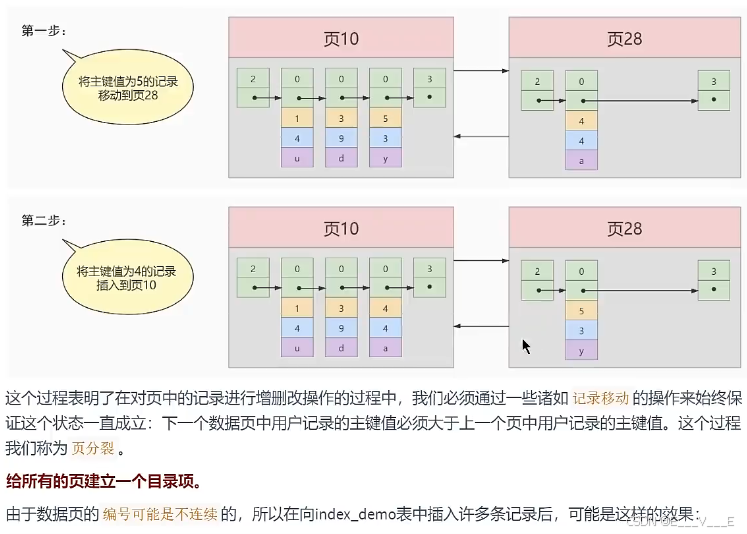
到需要查找的记录在哪些数据页中该咋办?我们可以为快速定位记录所在的数据贞而建立一个目录,建这个目录必须完成下边这些事:
下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。
假设:每个数据页最多能存放3条记录(实际上一个数据页非常大,可以存放下好多记录)。有了这个假设之后我们向index_demo表插入3条记录:
mysql>INSERT INTO index_demo VALUES(1,4,'u'),(3,9,'d'),(5,3,'y');
Query 0K, 3 rows affected (0.01 sec)
Records:3 Duplicates:0 Warnings:0那么这些记录已经按照主键值的大小串联成一个单向链表了,如图所示:这些看看就好,因为这是最简单的大概原理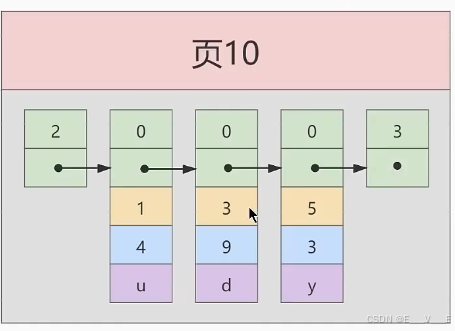

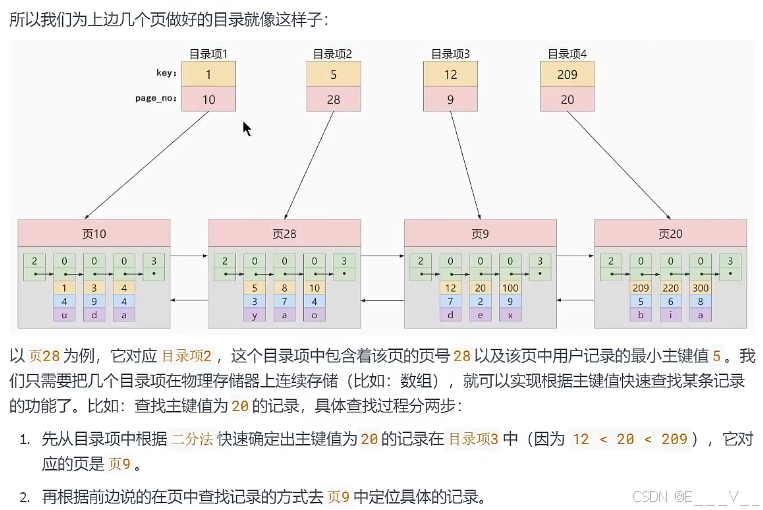 实际上 查找时只看主键 , 比如我们要找C1的20 ,因此先看目录,定位到目录项3中,然后递增的很容易到二分 , 因此就能找到 20
实际上 查找时只看主键 , 比如我们要找C1的20 ,因此先看目录,定位到目录项3中,然后递增的很容易到二分 , 因此就能找到 20
2 .InnoDB中的索引方案
①迭代1次:目录项纪录的页

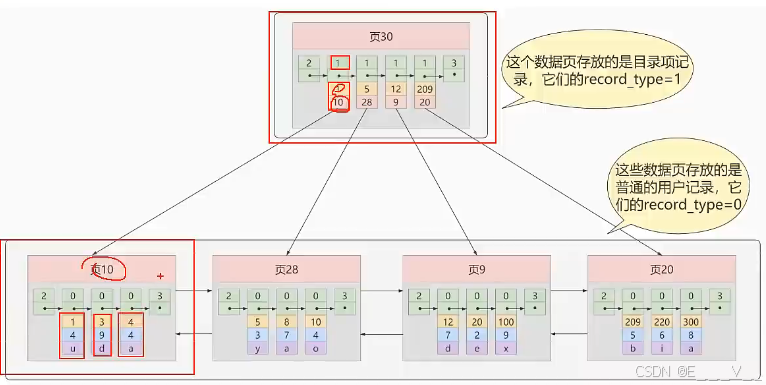
从图中可以看出来,我们新分配了一个编号为30的页来专门存储目录项记录。这里再次强调目录项记录和普通的用户记录的不同点:
- 目录项记录的record_type值是1,而普通用户记录的record_type值是o。
- 目录项记录只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有InnoDB自己添加的隐藏列。
- 了解:记录头信息里还有一个叫min_rec_mask的属性,只有在存储目录项记录的页中的主键值最小的目录项记录的min_rec_mask值为1,其他别的记录的min_rec_mask值都是0。
这时磁盘io的次数只有两次 , 把总目录项的数据页加载到内存中是一次 , 判断完后把目标数据页加载过去就是第二次 .
相同点:两者用的是一样的数据页,都会为主键值生成PageDirectory(页目录),从而在按照主键值进行查找时可以使用二分法来加快查询速度。
现在以查找主键为20的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
1.先到存储目录项记录的页,也就是页30中通过二分法快速定位到对应目录项,因为12<20<209,所以定位到对应的记录所在的页就是页9。
2.再到存储用户记录的页9中根据二分法快速定位到主键值为20的用户记录。
②迭代2次:多个目录项纪录的页
虽然说目录项记录中只存储主键值和对应的页号,比用户记录需要的存储空间小多了,但是不论怎么说一个页只有16KB大小,能存放的目录项记录也是有限的,那如果表中的数据太多,以至于一个数据页不足以存放所有的目录项记录,如何处理呢?
这里我们假设一个存储目录项记录的页最多只能存放4条目录项记录,所以如果此时我们再向上图中插入一条主键值为320的用户记录的话,那就需要分配一个新的存储目录项记录的页:
我们仍然查找C1 : 20 ,首先在两个数据页中查找 ,再找到目标页,一共3次IO.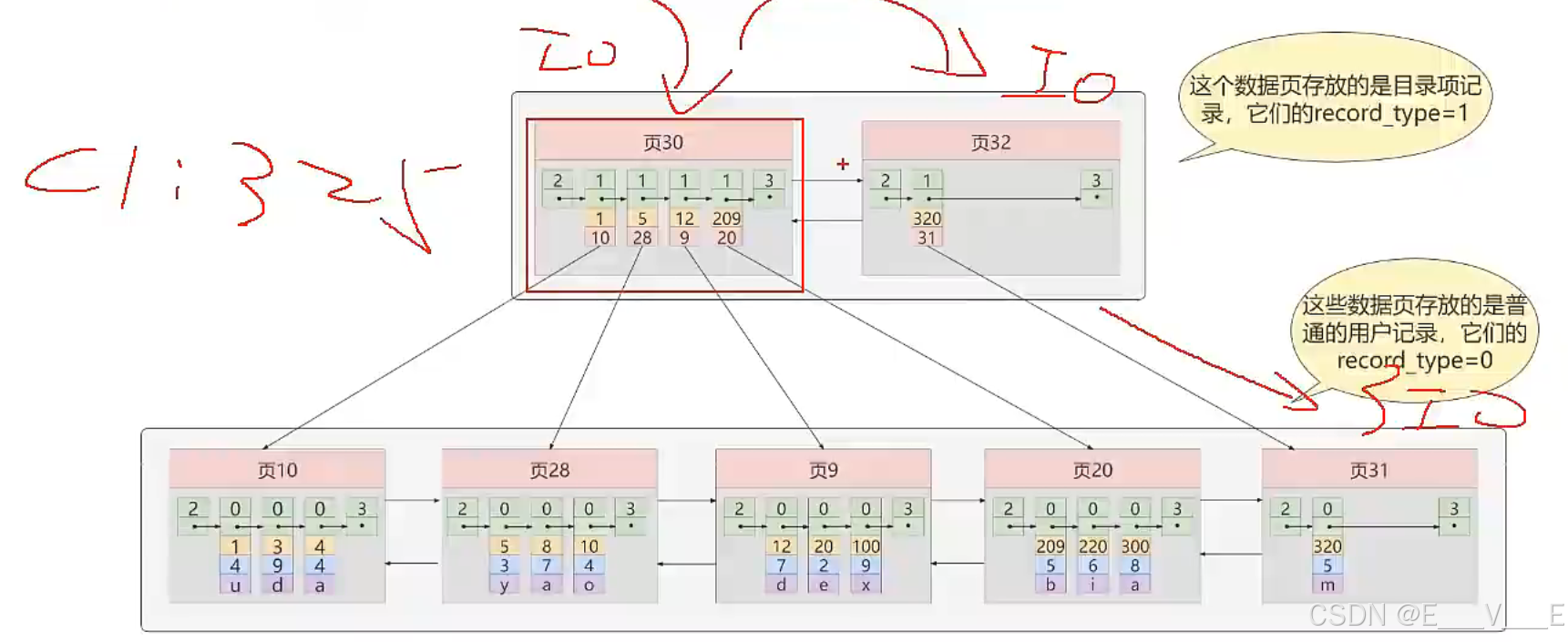
③迭代3次:目录项记录页的目录页
问题来了,在这个查询步骤的第1步中我们需要定位存储目录项记录的页,但是这些页是不连续的,如果我们表中的数据非常多则会产生很多存储目录项记录的页,那我们怎么根据主键值快速定位一个存储目录项记录的页呢?那就为这些存储目录项记录的页再生成一个更高级的目录,就像是一个多级目录一样,大目录里嵌套小目录,小目录里才是实际的数据,所以现在各个页的示意图就是这样子:(可以无限套娃一般不超4层,但是迭代三次就可以储存很多数据了,就没必要继续套娃了)
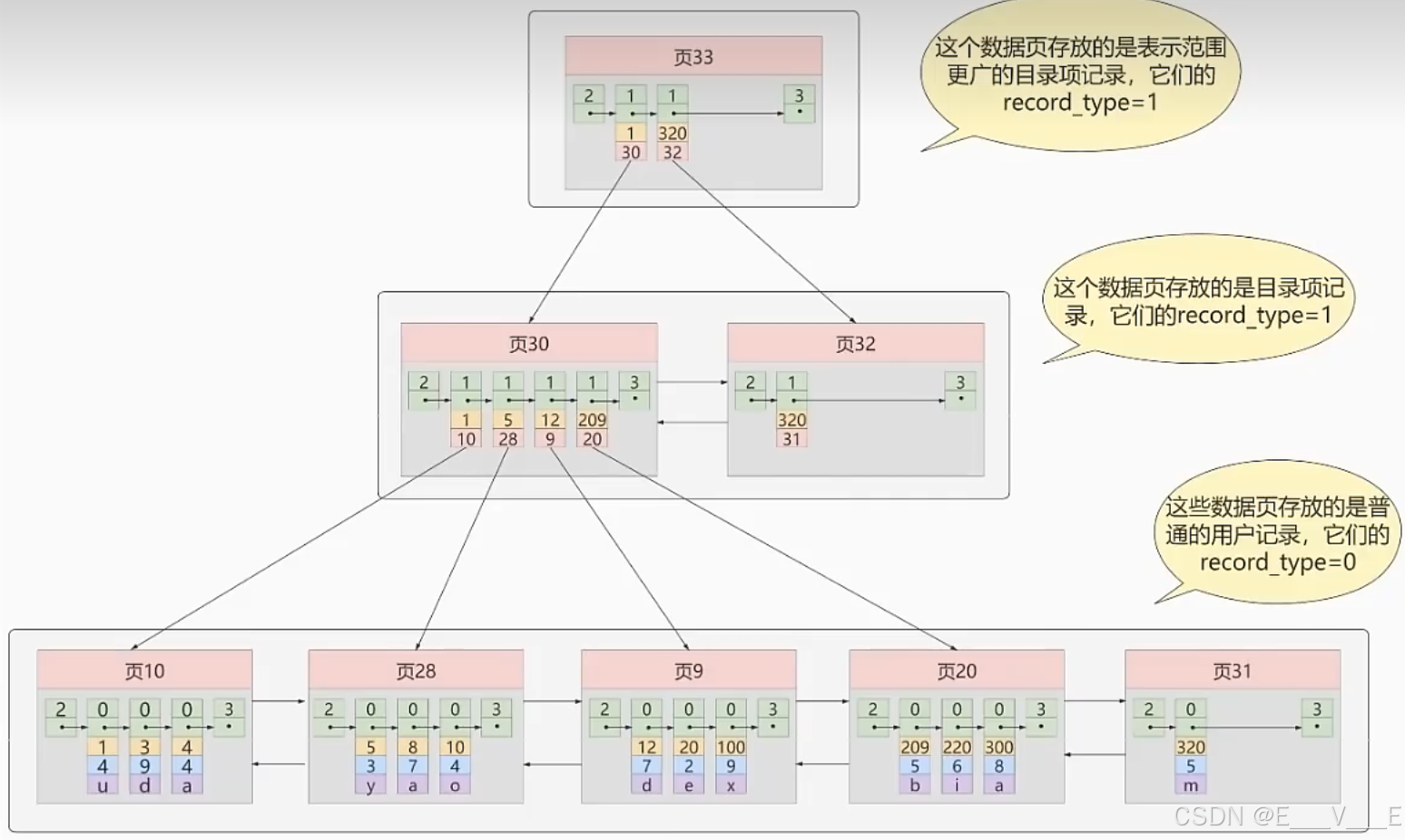
如图,我们生成了一个存储更高级目录项的页33,这个页中的两条记录分别代表页30和页32,如果用户记录的主键值在[1,320)之间,则到页30中查找更详细的目录项记录,如果主键值不小于320的话,就到页32中查找更详细的目录项记录。
随着表中记录的增加,这个目录的层级会继续增加,如果简化一下,那么我们可以用下边这个图来描述它:B+树(这个树的层次越低,总的IO次数越少)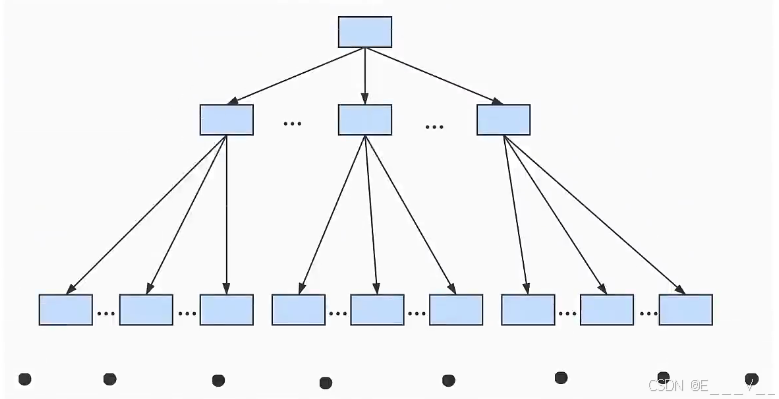
一个B+树的节点其实可以分成好多层,规定最下边的那层,也就是存放我们用户记录的那层为第0层,之后依次往上加。之前我们做了一个非常极端的假设:存放用户记录的页最多存放3条记录,存放目录项记录的页最多存放4条记录。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录,那么:
·如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放100条记录。
·如果B+树有2层,最多能存放1000x100=10,0000条记录。
·如果B+树有3层,最多能存放1000x1000×100=1,0000,0000条记录。
·如果B+树有4层,最多能存放1000x1000x1000x100=1000,0000,0000条记录。相当多的记录!!!
你的表里能存放100000000000条记录吗?所以一般情况下,我们用到的B+树都不会超过4层,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的PageDirectory(页目录),所以在页面内也可以通过二分法实现快速定位记录。
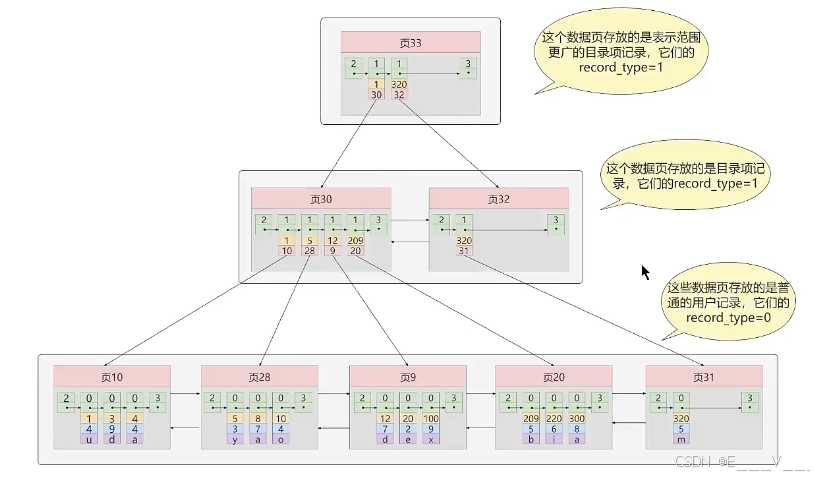
3.3常见索引概念
索引按照物理实现方式,索引可以分为2种:聚簇(聚集)和非聚簇(非聚集)索引。我们也把非聚集索引称为二级索引或者辅助索引。
1.聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。
术语“聚簇“表示数据行和相邻的键值聚簇的存储在一起。
我们回到B+树中,这个最下面的第0层,实打实的每一条数据,基于主键升序排列,双向链表构成了所有的第0层 ; 上升到目录项和目录页的第一层 , 自然而然也是升序的关系,就这样一步一步往上升和拓展.
1.使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。
各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
2.B+树的叶子节点存储的是完整的用户记录。
所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的B+树称为聚簇索引,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。这种聚簇索引并不需要我们在MySQL语句中显式的使用INDEX语句去创建,InnoDB存储引擎会自动的为我们创建聚簇索引。
优点:
·数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
·聚簇索引对于主键的排序查找和范围查找速度非常快
·按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以节省了大量的io操作。
缺点:
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新
二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
限制:
·对于MySQL数据库目前只有InnoDB数据引擎支持聚簇索引,而MyISAM并不支持聚簇索引。
·由于数据物理存储排序方式只能有一种,所以每个MySQL的表只能有一个聚簇索引。一般情况下就是该表的主键。
·如果没有定义主键,Innodb会选择非空的唯一索引代替。如果没有这样的索引,Innodb会隐式的定义一个主键来作为聚簇索引。
·为了充分利用聚簇索引的聚簇的特性,所以innodb表的主键列尽量选用有序的顺序id,而不建议用无序的id,比如UUID、MD5、HASH、字符串列作为主键无法保证数据的顺序增长。
2.二级索引(辅助索引、非聚簇索引)
上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该怎么办呢?肯定不能是从头到尾沿着链表依次遍历记录一遍。
答案:我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。比方说我们用c2列的大小作为数据页、页中记录的排序规则,再建一棵B+树,效果如下图所示:
叶子节点 存储的不再是完整数据 ,只是记录了一下C2记录的值 ,和这条记录的C1记录的值.
构建了一个这种B+树 , 后面的目录思路和以前一样了
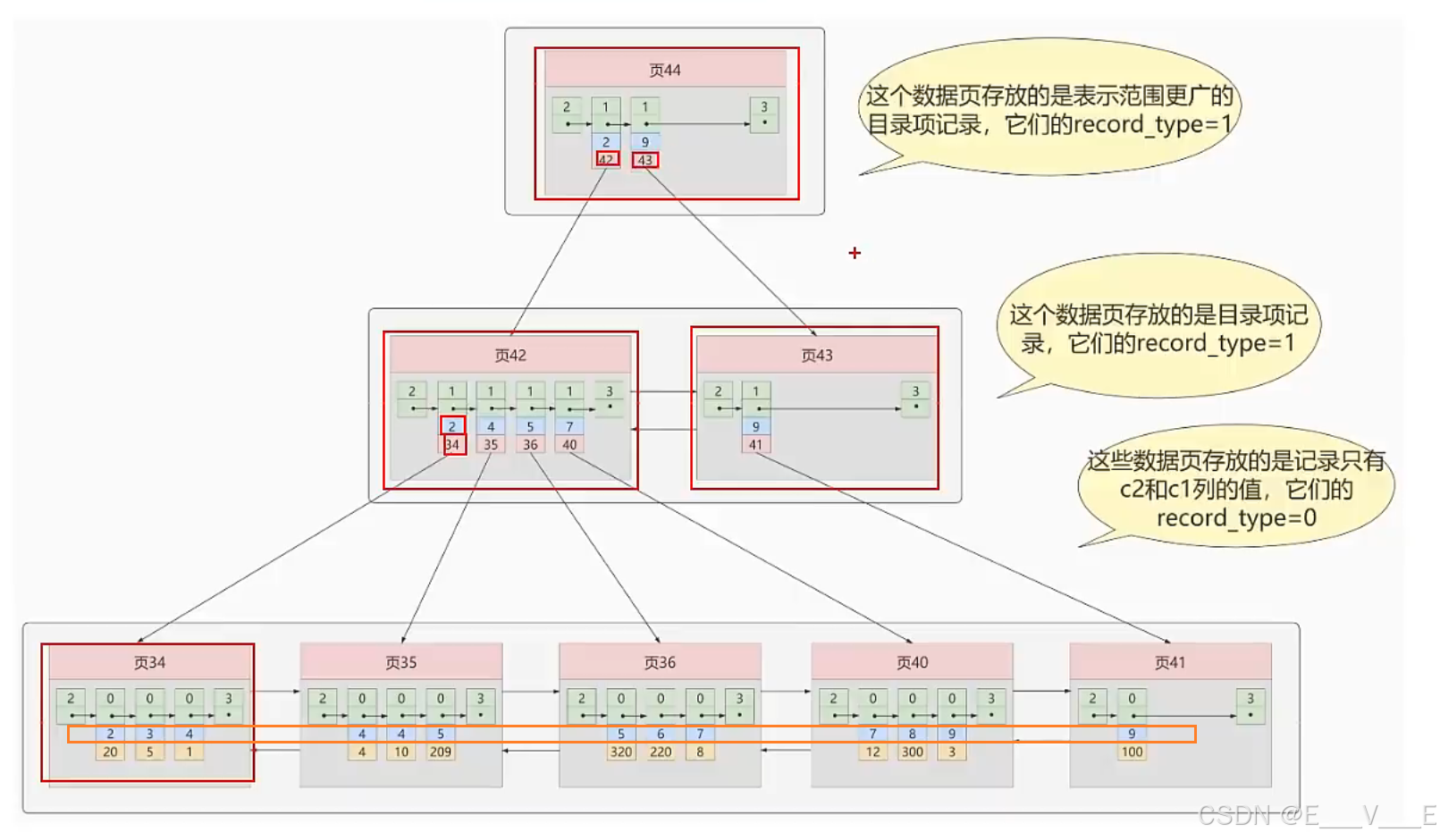
现在我们要找C2:4 ,首先我们过来到左边这个页里边儿呢,去找发现是2和9于是就在左边找,然后在这里边儿找到找的时候呢,还是用这2在这儿呢,就找到一条记录,然后在这里边儿呢,我们找到了两条儿记录 , 是2和4 , 4就是目标语句。那假设呢,我们现在呢,是这样的一个sql语句,叫做select*from 我们这个表,然后where C2=4,那么我们要找的是*呢,是不是就C1C2C3这三个4的二值都要列出来。但是呢,我们这个B+树当中是不是只有C1和C2没有C3呀?那怎么办呢?那怎么办呢? 通过C2 4呢,我是不是找到C11呀,然后呢,拿着这1呢,我们是不是接下来了再去找咱们那个上边儿的那个找到聚簇索引 . 那个C1C2,然后呢C3是多少? 同样的道理呢,你再找我们这个C1是4,C1是10的啊,这个数据再回到咱们上边儿。那也就是说呢,我们找这个C24的这个数据呢,必须要是再回到我们聚簇索引里边儿。也叫做回表



因为聚簇索引的字段一改所有非聚簇索引也要改,而一个非聚簇索引的字段改了只有它自己和聚簇索引需要改。这里说的是修改c3不会影响c2的索引,修改c3当然会影响c3的索引了,但是和c2有什么关系。
小结:聚簇索引与非聚簇索引的原理不同,在使用上也有一些区别:
1.聚簇索引的叶子节点存储的就是我们的数据记录,非聚簇索引的叶子节点存储的是数据位置。非聚簇索引|不会影响数据表的物理存储顺序。
2.一个表只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引,也就是多个索引目录提供数据检索。
3.使用聚簇索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚簇索引低。
3.联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照c2和c3列的大小进行排序,这个包含两层含义:
·先把各个记录和页按照c2列进行排序。
·在记录的c2列相同的情况下,采用c3列进行排序
为c2和c3列建立的索引的示意图如下:
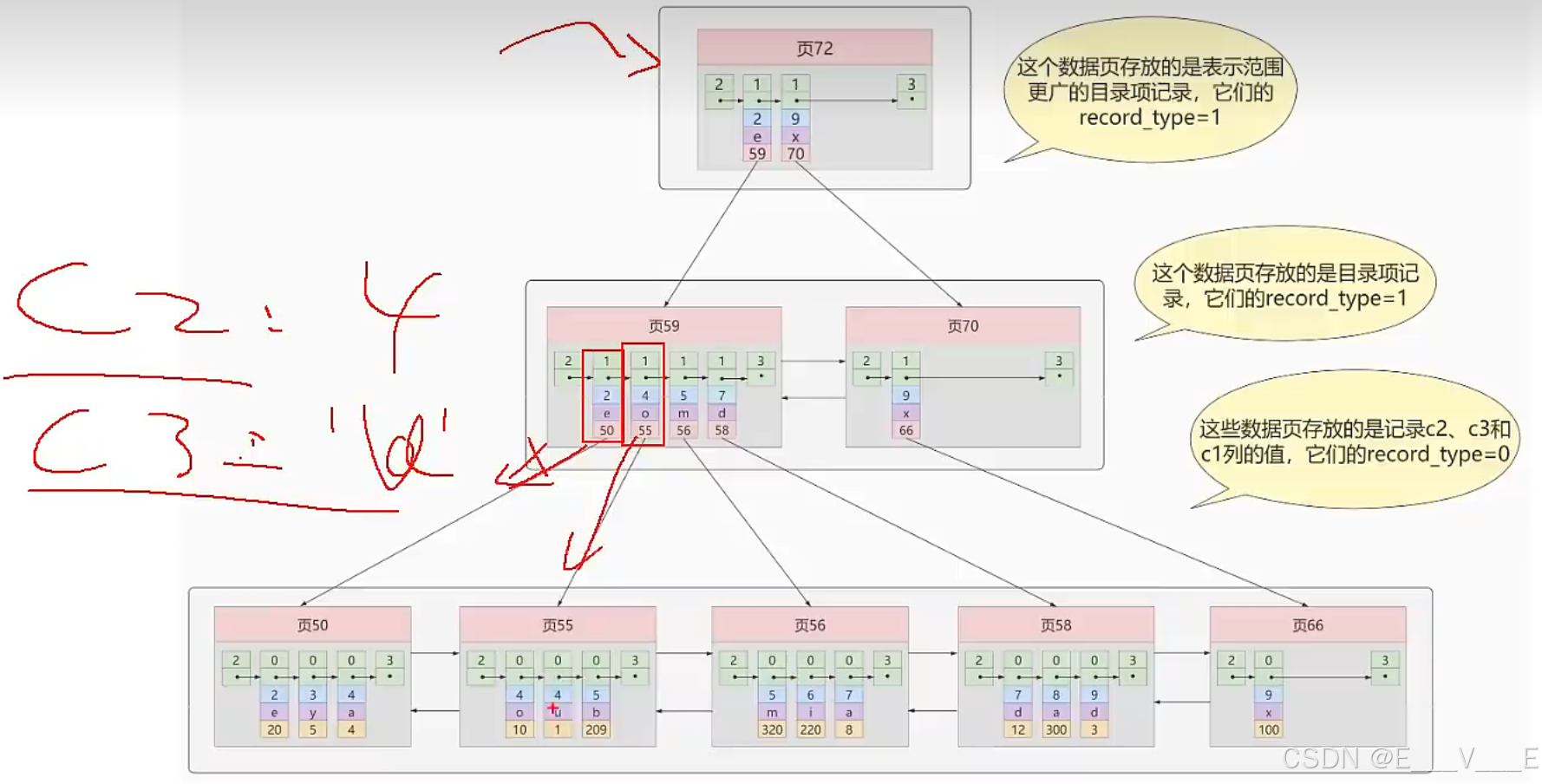
如图所示,我们需要注意以下几点:
·每条目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。
·B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
注意一点,以c2和c3列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引l。它的意思与分别
为c2和c3列分别建立索引的表述是不同的,不同点如下:
·建立联合索引只会建立如上图一样的1棵B+树。
·为c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。
3.4InnoDB的B+树索引的注意事项
1.根页面位置万年不动
我们前边介绍B+树索引的时候,为了大家理解上的方便,先把存储用户记录的叶子节点都画出来,然后接着画存储目录项记录的内节点,实际上B+树的形成过程是这样的:
- 每当为某个表创建一个B+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录。
- 随后向表中插入用户记录时,先把用户记录存储到这个根节点中。
- 当根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。
这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。
2.内节点中目录项记录的唯一性(非聚簇索引)
我们知道B+树索引的内节点中目录项记录的内容是索引列+页号的搭配,但是这个搭配对于二级索引来说有点儿不严谨。还拿index_demo表为例,假设这个表中的数据是这样的:
| C1 | C2 | C3 |
| 1 | 1 | 'u' |
| 3 | 1 | 'd' |
| 5 | 1 | 'y' |
| 7 | 1 | 'a' |
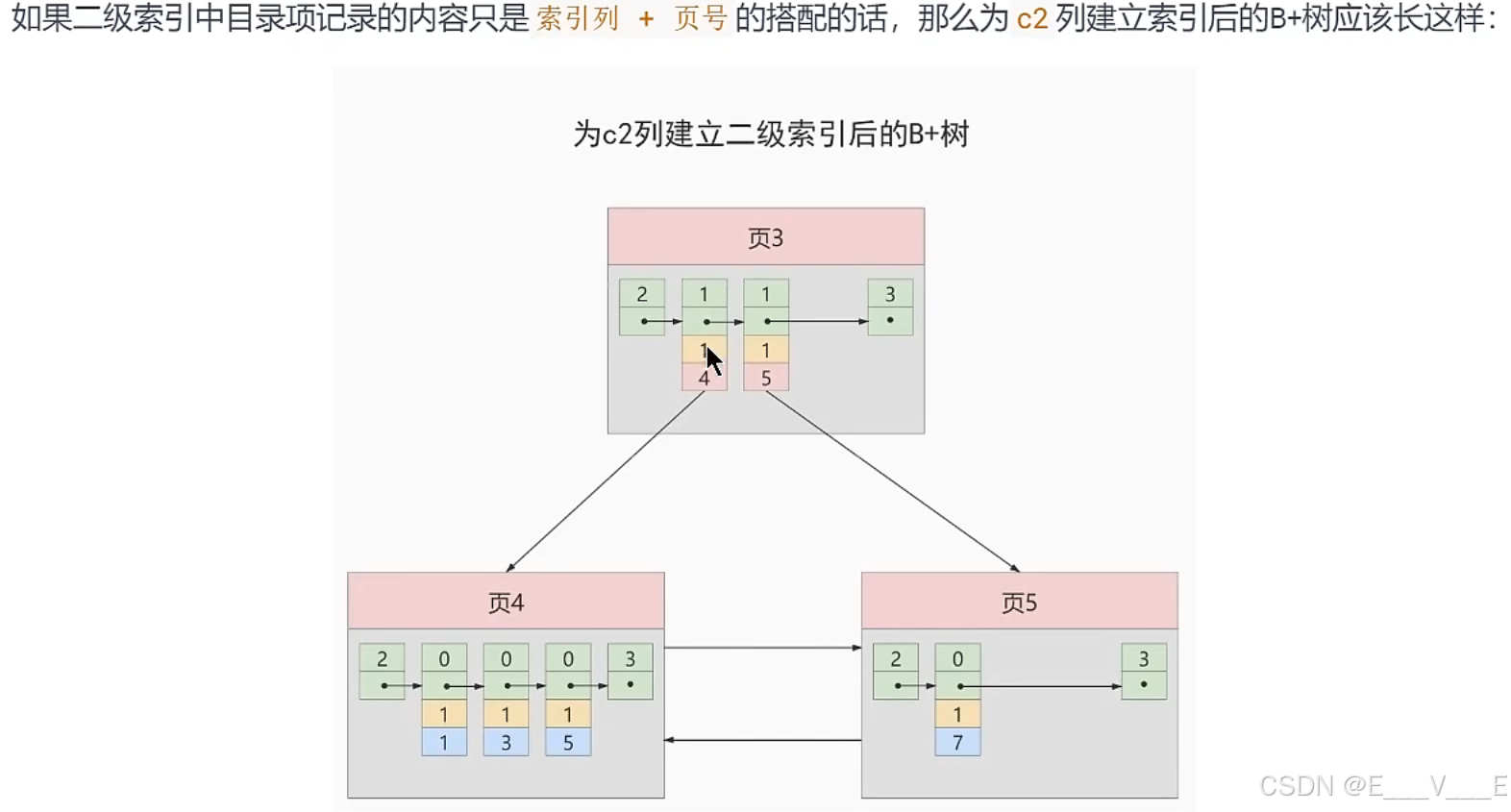
如果我们想新插入一行记录,其中 c1、c2、c3 的值分别是:9、1、'c',那么在修改这个为 c2 列建立的二级索引对应的 B+ 树时便碰到了 3 个大问题:由于页 3 中存储的目录项记录是由 c2 列 + 页号的值构成的,页 3 中的两条目录项记录对应的 c2 列的值都是 1,而我们新插入的这条记录的 c2 列的值也是 1,那我们这条新插入的记录到底应该放到页 4 中,还是应该放到页 5 中啊?答案是:对不起,懵了。
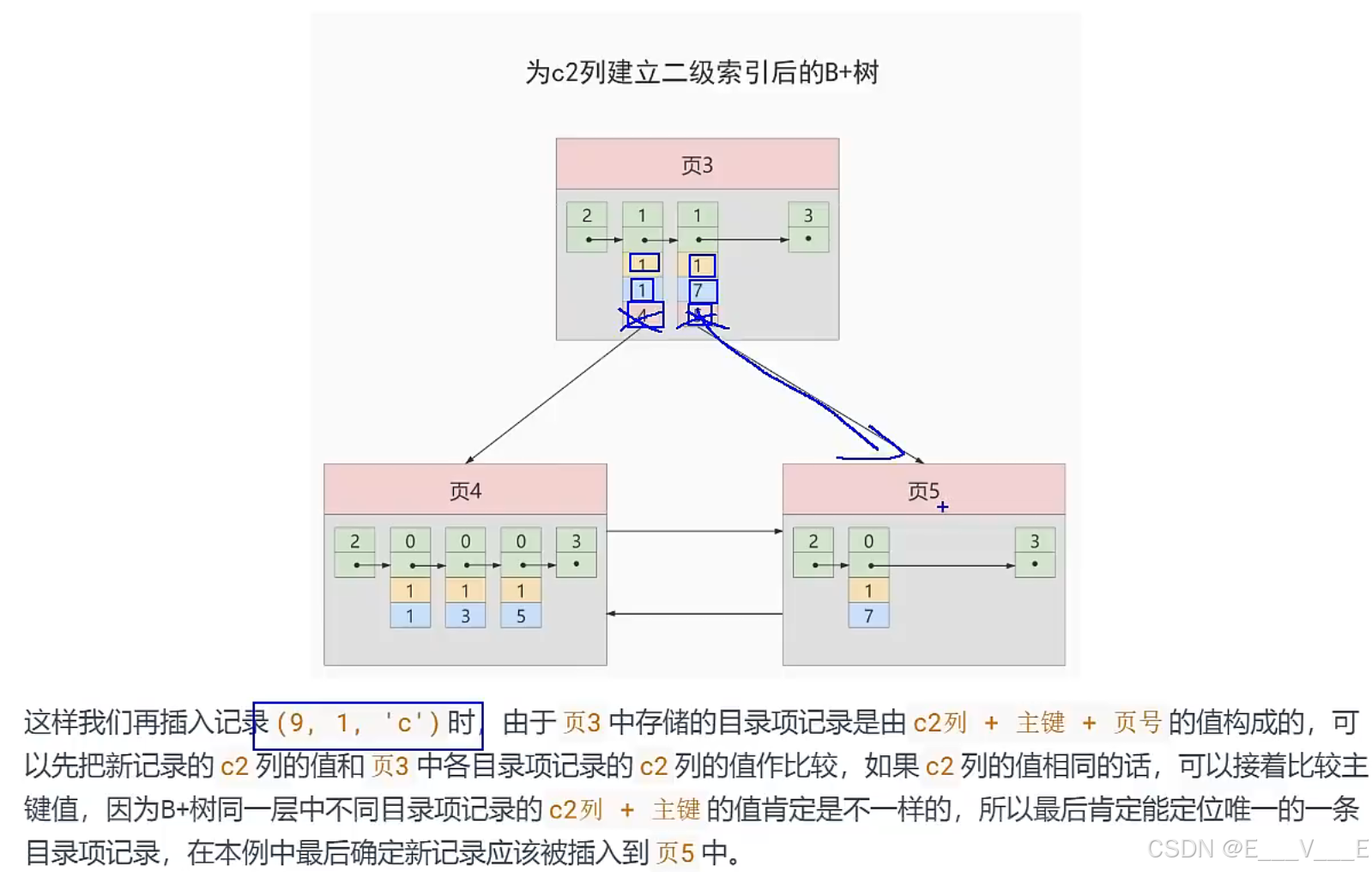
为了让新插入记录能找到自己在那个页里,我们需要保证在 B+ 树的同一层内节点的目录项记录除页号这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的:
- 索引列的值
- 主键值
- 页号
也就是我们把主键值也添加到二级索引内节点中的目录项记录了,这样就能保证 B+ 树每一层节点中各条目录项记录除页号这个字段外是唯一的,所以我们为 c2 列建立二级索引后的示意图实际上应该是这样子的:
3.一个页面最少存储2条记录
一个B+树只需要很少的层级就可以轻松存储数亿条记录,查询速度相当不错!这是因为B+树本质上就是一个大的多层级目录,每经过一个目录时都会过滤掉许多无效的子目录,直到最后访问到存储真实数据的目录。那如果一个大的目录中只存放一个子目录是个啥效果呢?那就是目录层级非常非常非常多,而且最后的那个存放真实数据的目录中只能存放一条记录。费了半天劲只能存放一条真实的用户记录?所以InnoDB的一个数据页至少可以存放两条记录。
4.MyISAM中的索引方案
| 索引/存储引擎 | MylSAM | InnqDB | Memory |
| B-Tree索引 | 支持 | 支持 | 支持 |
即使多个存储引擎支持同一种类型的索引l,但是他们的实现原理也是不同的。Innodb和MyISAM默认的索引是Btree索引;而Memory默认的索引是Hash索引。
MylSAM引擎使用B+Tree作为索引结构,叶子节点的data域存放的是数据记录的地址。
4.2MyISAM索引I的原理
下图是MyISAM索引的原理图。
我们知道InnoDB中索引即数据,也就是聚簇索引的那棵B+树的叶子节点中已经把所有完整的用户记录都包含了,而MyISAM的索引引方案虽然也使用树形结构,但是却将索引和数据分开存储:
- 将表中的记录按照记录的插入顺序单独存储在一个文件中,称之为数据文件。这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少记录就成了。由于在插入数据的时候并没有刻意按照主键大小排序,所以我们并不能在这些数据上使用二分法进行查找。
- 使用MyISAM存储引擎的表会把索引信息另外存储到一个称为索引文件的另一个文件中。MyISAM会单独为表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是主键值+数据记录地址的组合。(可以看作myisam是没有聚簇索引,只有二级索引)
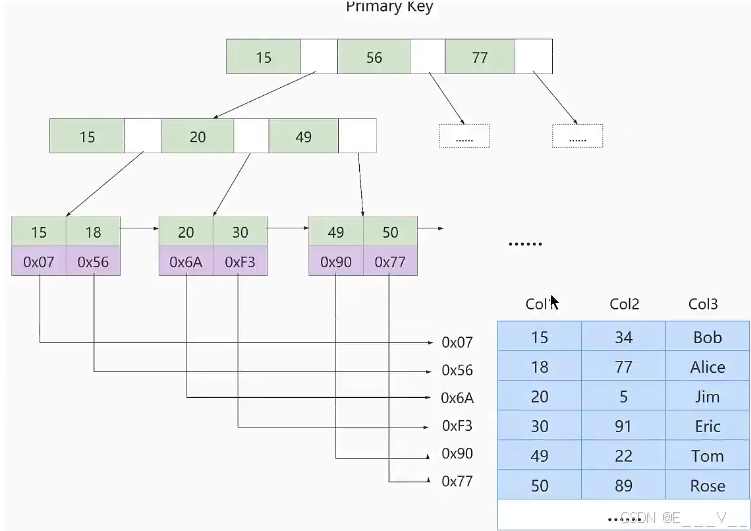
这里设表一共有三列,假设我们以col1为主键,上图是一个MyISAM表的主索引(Primarykey)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址**。在MyISAM中,主键索引和二级索引(Secondarykey)在结构上没有任何区别,只是主键索引要求key是唯一的,而二级索引的key可以重复。如果我们在Col2上建立一个二级索引,则此索引的结构如下图所示:
4.3MyISAM与InnoDB对比
MyISAM的索引方式都是“非聚簇"的,与InnoDB包含1个聚簇索引是不同的。小结两种引擎中索引的区别:
- ①在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引。
- ②InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
- ③ InnoDB的非聚簇索引ldata域存储相应记录主键的值,而MyISAM索引引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域。
- ④MyISAM的回表操作是十分快速的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。
- ⑤InnoDB要求表必须有主键(MyISAM可以没有)。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
小结:
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助。比如:
举例1:知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有二级索引都引用主键索引,过长的主键索引会令二级索引变得过大。
举例2:用非单调的字段作为主键在lnnoDB中不是个好主意,因为lnnoDB数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时,数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
5.索引的代价
索引是个好东西,可不能乱建,它在空间和时间上都会有消耗:
空间上的代价
建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,一棵很大的B+树由许多数据页组成,就是很大的一片存储空间。
时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收等操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,会给性能拖后腿。
6.MySQL数据结构选择的合理性
磁盘的IO操作次数对索引的使用效率至关重要。
查找都是索引操作,一般来说索引非常大,尤其是关系型数据库,当数据量比较大的时候,索引的大小有可能几个G甚至更多,为了减少索引在内存的占用,数据库索引是存储在外部磁盘上的。当我们利用索引查询的时候,不可能把整个索引全部加载到内存,只能逐一加载,那么MySQL衡量查询效率的标准就是磁盘IO次数。
6.1全表遍历
这个没什么
6.2Hash结构
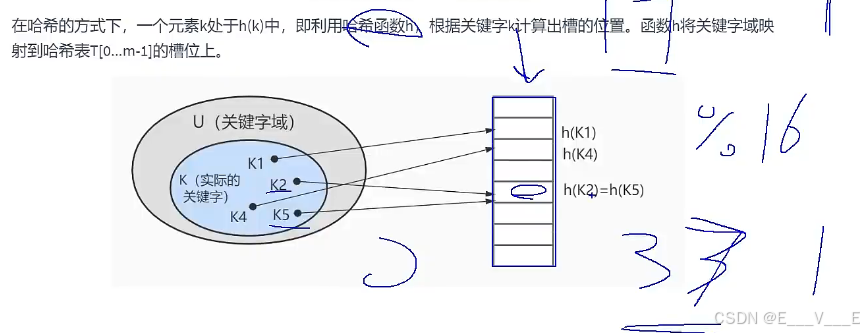
Hash本身是一个函数,又被称为散列函数,它可以帮助我们大幅提升检索数据的效率。
Hash算法是通过某种确定性的算法(比如MD5、SHA1、SHA2、SHA3)将输入转变为输出。相同的输入永远可以得到相同的输出,假设输入内容有微小偏差,在输出中通常会有不同的结果。
举例:如果你想要验证两个文件是否相同,那么你不需要把两份文件直接拿来比对,只需要让对方把Hash函数计算得到的结果告诉你即可,然后在本地同样对文件进行Hash函数的运算,最后通过比较这两个Hash函数的结果是否相同,就可以知道这两个文件是否相同。
加速查找速度的数据结构,常见的有两类:
(1)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O (log2N);
(2)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);从效率来说Hash比B+树更快。
但是如果17和37共同%16怎么办?那么我们链接一下,类似java中的hashmap思想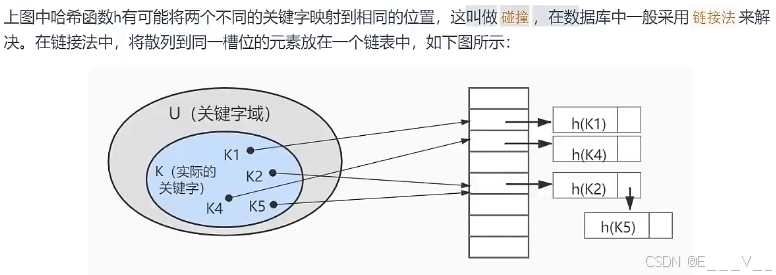
// 算法复杂度为 O(n2)
@Test
public void test1(){int[] arr = new int[100000];for(int i = 0; i < arr.length; i++){arr[i] = i + 1;}long start = System.currentTimeMillis();for(int j = 1; j <= 100000; j++){int temp = j;for(int i = 0; i < arr.length; i++){if(temp == arr[i]){break;}}}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 823
}// 算法复杂度为 O(1)
@Test
public void test2(){HashSet<Integer> set = new HashSet<>(100000);for(int i = 0; i < 100000; i++){set.add(i + 1);}long start = System.currentTimeMillis();for(int j = 1; j <= 100000; j++){int temp = j;boolean contains = set.contains(temp);}long end = System.currentTimeMillis();System.out.println("time: " + (end - start)); //time: 5
}Hash结构效率高,那为什么索引结构要设计成树型呢?
原因1:Hash索引l仅能满足(=)(<>)和IN查询。如果进行范围查询,哈希型的索引l,时间复杂度会退化为O(n):而树型的“有序"特性,依然能够保持O(log2N)的高效率。
原因2:Hash索引还有一个缺陷,数据的存储是没有顺序的,在ORDERBY的情况下,使用Hash索引还需要对数据重新排序。
原因3:对于联合索引的情况,Hash值是将联合索引键合并后一起来计算的,无法对单独的一个键或者几个索引键进行查询。
原因4:对于等值查询来说,通常Hash索引的效率更高,不过也存在一种情况,就是索引列的重复值如果很多,效率就会降低。这是因为遇到Hash冲突时,需要遍历桶中的行指针来进行比较,找到查询的关键字,非常耗时。所以,Hash索引通常不会用到重复值多的列上,比如列为性别、年龄的情况等。
HASH索引 仅在memory中 支持
Hash索引存在着很多限制,相比之下在数据库中B+树索引的使用面会更广,不过也有一些场景采用Hash索引效率更高,比如在键值型(Key-Value)数据库中,Redis存储的核心就是Hash表。
另外,InnoDB本身不支持Hash索引,但是提供自适应Hash索引(AdaptiveHashIndex)。什么情况下才会使用自适应Hash索引呢?如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到Hash表中。这样下次查询的时候,就可以直接找到这个页面的所在位置。这样让B+树也具备了Hash索引的优点。
采用自适应Hash索引目的是方便根据SQL的查询条件加速定位到叶子节点,特别是当B+树比较深的时候,通过自适应Hash索引可以明显提高数据的检索效率。
我们可以通过innodb_adaptive_hash_index变量来查看是否开启了自适应Hash,比如:
mysql> show variables like '%adaptive_hash_index';6.3 二叉搜索树
左子节点<本节点;右子节点>=本节点,比我大的向右,比我小的向左
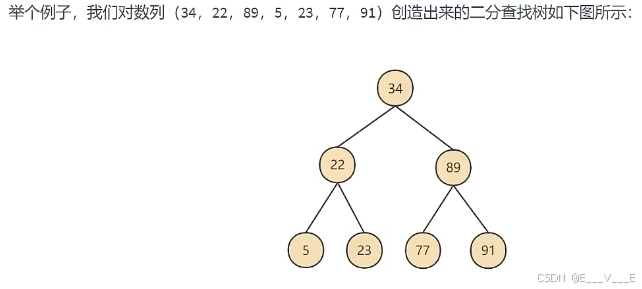
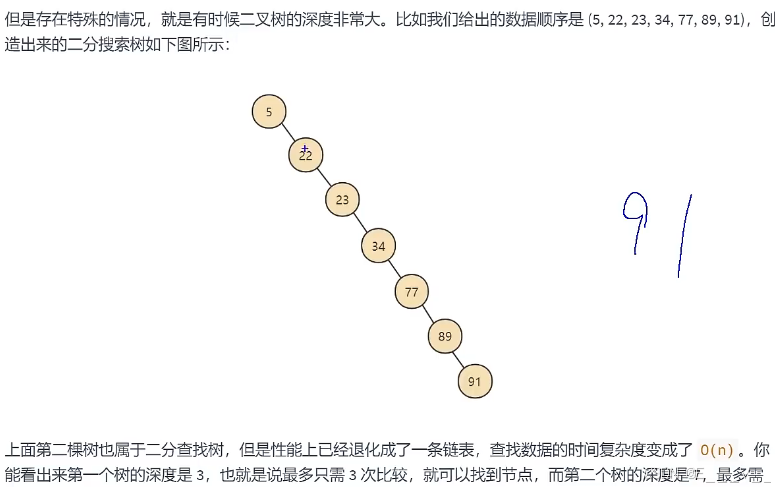 7次比较才能找到节点
7次比较才能找到节点
6.4 AVL树
为了解决上面二叉查找树退化成链表的问题,人们提出了平衡二叉搜索树(BalancedBinaryTree),又称为AVL树(有别于AVL算法),它在二叉搜索树的基础上增加了约束,具有以下性质:
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
这里说一下,常见的平衡二叉树有很多种,包括了平衡二叉搜索树、红黑树、数堆、伸展树。平衡二叉搜索树是最早提出来的自平衡二叉搜索树,当我们提到平衡二叉树时一般指的就是平衡二叉搜索树。事实上,第一棵树就属于平衡二叉搜索树,搜索时间复杂度就是O( log2n)。
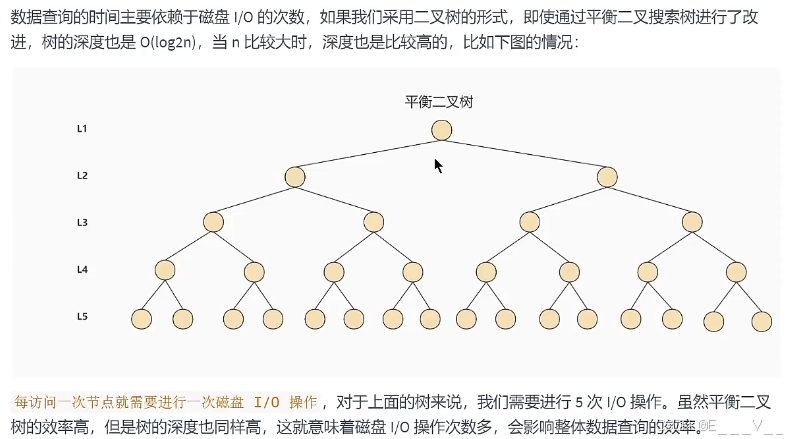
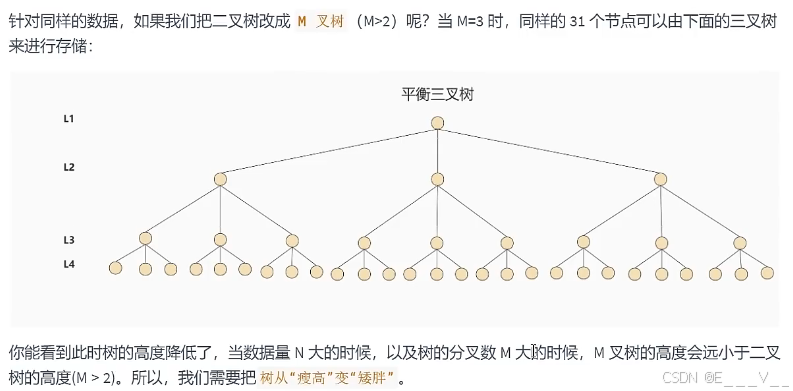
6.5 B-Tree
B树的英文是BalanceTree,也就是多路平衡查找树。简写为B-Tree(注意横杠表示这两个单词连起来的意思,不是减号)。它的高度远小于平衡二叉树的高度。
B树的结构如下图所示: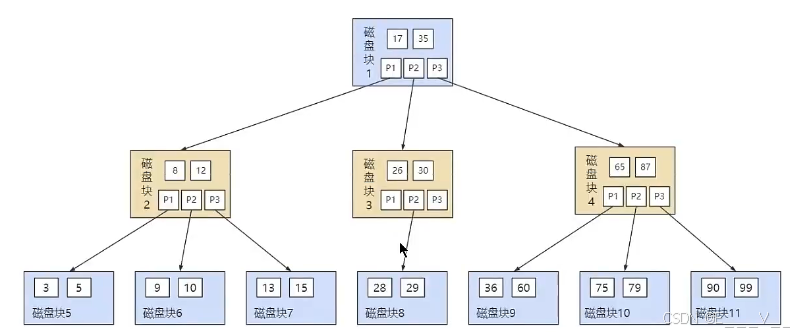
- B树在插入和删除节点的时候如果导致树不平衡,就通过自动调整节点的位置来保持树的自平衡。
- 关键字集合分布在整棵树中,即叶子节点和非叶子节点都存放数据。搜索有可能在非叶子节点结束
- 其搜素性能等价于在关键字全集内做一次二分查找。

6.6 B+Tree
B+树也是一种多路搜索树,基于B树做出了改进,主流的DBMS都支持B+树的索引方式,比如MySQL。相比于B-Tree,B+Tree适合文件索引系统。
B+树和B树的差异在于以下几点:
- 1.有k个孩子的节点就有k个关键字。也就是孩子数量=关键字数,而 B 树中,孩子数量=关键字数+1。
- 2.非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- 3.非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而B 树中,非叶子节点既保存索引,也保存数据记录。
- 4.所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
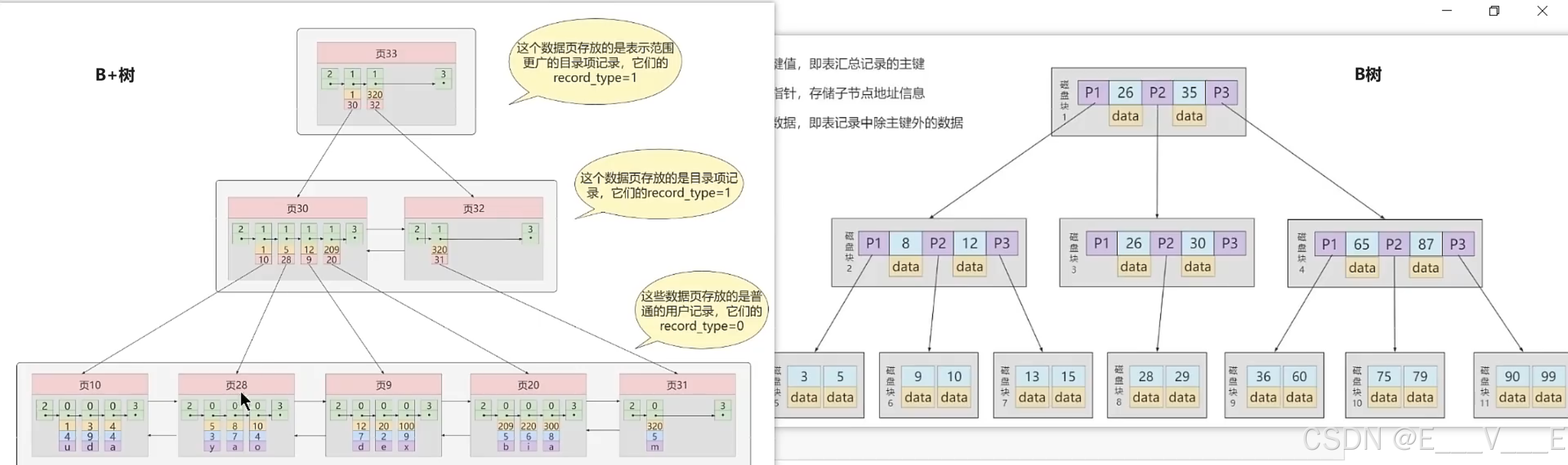
 比如,我们想要查找关键字16,B+树会自顶向下逐层进行查找:
比如,我们想要查找关键字16,B+树会自顶向下逐层进行查找:
1. 与根节点的关键字(1,18,35)进行比较,16在1和18之间,得到指针P1(指向磁盘块2)
2. 找到磁盘块2,关键字为(1,8,14),因为16大于14,所以得到指针P3(指向磁盘块7)
3. 找到磁盘块7,关键字为(14,16,17),然后我们找到了关键字16,所以可以找到关键字16所对应的数据。
整个过程一共进行了3次io操作,看起来B+树和B树的查询过程差不多,但是B+树和B树有个根本的差异在于,B+树的中间节点并不直接存储数据。这样的好处都有什么呢?
首先,B+树查询效率更稳定。因为B+树每次只有访问到叶子节点才能找到对应的数据,而在B树中,非叶子节点也会存储数据,这样就会造成查询效率不稳定的情况,有时候访问到了非叶子节点就可以找到关键字,而有时需要访问到叶子节点才能找到关键字。其次,B+树的查询效率更高。这是因为通常B+树比B树更矮胖(阶数更大,深度更低),查询所需要的磁盘I/O也会更少。同样的磁盘页大小,B+树可以存储更多的节点关键字。
不仅是对单个关键字的查询上,在查询范围上,B+树的效率也比B树高。这是因为所有关键字都出现在B+树的叶子节点中,叶子节点之间会有指针,数据又是递增的,这使得我们范围查找可以通过指针连接查找。而在B树中则需要通过中序遍历才能完成查询范围的查找,效率要低很多。
B树和B+树都可以作为索引I的数据结构,在MySQL中采用的是B+树。
但B树和B+树各有自己的应用场景,不能说B+树完全比B树好,反之亦然。
思考题:为了减少IO,索引树会一次性加载吗?
1、数据库索引是存储在磁盘上的,如果数据量很大,必然导致索引的大小也会很大,超过几个G。
2、当我们利用索引查询时候,是不可能将全部几个G的索引都加载进内存的,我们能做的只能是:逐一加载每一个磁盘页,因为磁盘页对应着索引树的节点。
思考题:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储
16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为10^3。也就是说一个深度为3的B+Tree索引|可以维护10^3*10^3*10^3=10亿条记录。(这里假定一个数据页也存储10^3条行记录数据了)
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1-3次磁盘IO操作。
比较理想的情况下,b+树里面的页里面的数据其实至少有三个(主键,页指针,链表的next指针)因此老师这个数算出来是偏大的,而且占最大头的那一部分子叶的数据行被忽略了所以要多加一层才更加的合理;填充不满的原因在于一个Datapage是16kB,有可能刚好塞不下最后一条数据
思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
1、B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说io读写次数也就降低了。
2、B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
思考题:Hash 索引与 B+ 树索引的区别
我们之前讲到过B+树索引的结构,Hash索引引结构和B+树的不同,因此在索引使用上也会有差别。
1、Hash索引不能进行范围查询,而B+树可以。这是因为Hash索引指向的数据是无序的,而B+树的叶子节点是个有序的链表。
2、Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。对于联合索引来说,Hash索引|在计算Hash值的时候是将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值。因此如果用到联合索引的一个或者几个索引时,联合索引|无法被利用。
3、Hash索引不支持ORDER BY排序,因为Hash索引指向的数据是无序的,因此无法起到排序优化的作用,而B+树索引数据是有序的,可以起到对该字段ORDERBY排序优化的作用。同理,我们也无法用Hash索引进行模糊查询,而B+树使用LIKE进行模糊查询的时候,LIKE后面后模糊查询(比如%结尾)的话就可以起到优化作用。
4、InnoDB不支持哈希索引
思考题:Hash 索引与 B+ 树索引是在建索引的时候手动指定的吗?
你能看到,针对InnoDB和MyISAM存储引擎,都会默认采用B+树索引l,无法使用Hash索引l。InnoDB提供的自适应Hash是不需要手动指定的。如果是Memory/Heap和NDB存储引擎,是可以进行选择Hash索引 的。
6.7 R树
R树就很好的解决了这种高维空间搜索问题。
相关文章:

MySQL数据库入门到大蛇尚硅谷宋红康老师笔记 高级篇 part 6
从6到12章将会是重中之重,请一定好好看 第06章_索引的数据结构 1.为什么使用索引 索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教课书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。MySQL中也是一…...

C++动态与静态转换区别详解
文章目录 前言一、 类型检查的时机二、安全性三、适用场景四、代码示例对比总结 前言 在 C 中,dynamic_cast 和 static_cast 是两种不同的类型转换操作符,主要区别体现在类型检查的时机、安全性和适用场景上。以下是它们的核心区别: 一、 类…...

面向AI 的前端发展及初识大模型
AI带来的开发范式迁移 随着AI的涌现,对前端的发展也有着非常大的影响,总结过去前端的发展路径,目前应该属于又一次的大规模的开发范式迁移阶段。上一个阶段是从jquery到React/Vue/Angular迁移(jquery之前的就不讨论了)…...

Java入门的基础学习
Java的基础语法知识 一 初始Java二 Java数据类型和变量1.字面常量2.数据类型基本数据类型引用数据类型 3.变量整型变量浮点型变量字符型变量布尔型变量 4.类型转化和提升类型转化类型提升 三 运算符1.算数运算符2.关系操作符3.逻辑运算符:&&,||&…...

万字详解 MySQL MGR 高可用集群搭建
文章目录 1、MGR 前置介绍 1.1、什么是 MGR1.2、MGR 优点1.3、MGR 缺点1.4、MGR 适用场景 2、MySQL MGR 搭建流程 2.1、环境准备2.2、搭建流程 2.2.1、配置系统环境2.2.2、安装 MySQL2.2.3、配置启动 MySQL2.2.4、修改密码、设置主从同步2.2.5、安装 MGR 插件 3、MySQL MGR 故…...
)
脚本无法获取响应主体(原因:CORS Missing Allow Credentials)
背景: 前端的端口号8080,后端8000。需在前端向后端传一个参数,让后端访问数据库去检测此参数是否出现过。涉及跨域请求,一直有这个bug是404文件找不到。 在修改过程当中不小心删除了一段代码,出现了这个bug࿰…...

GD32F450 使用
GB32F450使用 1. 相关知识2. 烧写程序3. SPI3.1 spi基础3.2 spi代码 4. 串口4.1 串口引脚4.2 串口通信代码 问题记录1. 修改晶振频率 注意:GD32F450 总共有三种封装形式,本文所述的相关代码和知识,均为 GD32F450IX 系列。 1. 相关知识 参数配…...

神经网络代码入门解析
神经网络代码入门解析 import torch import matplotlib.pyplot as pltimport randomdef create_data(w, b, data_num): # 数据生成x torch.normal(0, 1, (data_num, len(w)))y torch.matmul(x, w) b # 矩阵相乘再加bnoise torch.normal(0, 0.01, y.shape) # 为y添加噪声…...
)
Android 数据库查询对比(APN案例)
功能背景 APN 数据通常存储在数据库中,由TelephonyProvider提供。当用户进入APN设置界面时,Activity会启动,AOSP源码通过ContentResolver查询APN数据。关键分析点在于这个查询操作是否在主线程执行,因为主线程上的耗时操作会导致…...

神卓 S500 异地组网设备实现监控视频异地组网的详细步骤
一、设备与环境准备 硬件清单 主设备:神卓 S500 异地组网路由器 1子设备:神卓 S500 或兼容设备 N(需通过官网认证)监控设备:支持 RTSP/ONVIF 协议的 NVR、摄像头网络要求:各网点需稳定联网(推荐…...
)
golang安装(1.23.6)
1.切换到安装目录 cd /usr/local 2.下载安装包 wget https://go.dev/dl/go1.23.6.linux-amd64.tar.gz 3.解压安装包 sudo tar -C /usr/local -xzf go1.23.6.linux-amd64.tar.gz 4.配置环境变量 vi /etc/profile export PATH$…...

leetcode35.搜索插入位置
题目: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target 5 输出…...

LeetCode第57题_插入区间
LeetCode 第57题:插入区间 题目描述 给你一个 无重叠的 ,按照区间起始端点排序的区间列表。在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。 难度 中…...

人工智能之数学基础:线性代数中矩阵的运算
本文重点 矩阵的运算在解决线性方程组、描述线性变换等方面发挥着至关重要的作用。通过对矩阵进行各种运算,可以简化问题、揭示问题的本质特征。在实际应用中,我们可以利用矩阵运算来处理图像变换、数据分析、电路网络等问题。深入理解和掌握矩阵的运算,对于学习线性代数以…...

SQL Server 创建用户并授权
创建用户前需要有一个数据库,创建数据库命令如下: CREATE DATABASE [数据库名称]; CREATE DATABASE database1;一、创建登录用户 方式1:SQL命令 命令格式:CREATE LOGIN [用户名] WITH PASSWORD ‘密码’; 例如,创…...

MySQL双主搭建-5.7.35
文章目录 上传并安装MySQL 5.7.35双主复制的配置实例一:172.25.0.19:实例二:172.25.0.20: 配置复制用户在实例 1 (172.25.0.19)上执行:在实例 2 (172.25.0.20)上执行&…...
)
RNN实现精神分裂症患者诊断(pytorch)
RNN理论知识 RNN(Recurrent Neural Network,循环神经网络) 是一种 专门用于处理序列数据(如时间序列、文本、语音、视频等)的神经网络。与普通的前馈神经网络(如 MLP、CNN)不同,RNN…...

Python中字符串的常用操作
一、r原样输出 在 Python 中,字符串前加 r(即 r"string" 或 rstring)表示创建一个原始字符串(raw string)。下面详细介绍原始字符串的特点、使用场景及与普通字符串的对比。 特点 忽略转义字符࿱…...
)
uniapp 本地数据库多端适配实例(根据运行环境自动选择适配器)
项目有个需求,需要生成app和小程序,app支持离线数据库,如果当前没有网络提醒用户开启离线模式,所以就随便搞了下,具体的思路就是: 一个接口和多个实现类(类似后端的模板设计模式)&am…...

Spring Cloud Gateway 整合Spring Security
做了一个Spring Cloud项目,网关采用 Spring Cloud Gateway,想要用 Spring Security 进行权限校验,由于 Spring Cloud Gateway 采用 webflux ,所以平时用的 mvc 配置是无效的,本文实现了 webflu 下的登陆校验。 1. Sec…...

【异地访问本地DeepSeek】Flask+内网穿透,轻松实现本地DeepSeek的远程访问
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言依赖Flask构建本地网页访问LM Studio 开启网址访问DeepSeek 调用模板Flask 访问本…...

Windows对比MacOS
Windows对比MacOS 文章目录 Windows对比MacOS1-环境变量1-Windows添加环境变量示例步骤 1:打开环境变量设置窗口步骤 2:添加系统环境变量 2-Mac 系统添加环境变量示例步骤 1:打开终端步骤 2:编辑环境变量配置文件步骤 3࿱…...

React实现无缝滚动轮播图
实现效果: 由于是演示代码,我是直接写在了App.tsx里面在 文件位置如下: App.tsx代码如下: import { useState, useEffect, useCallback, useRef } from "react"; import { ImageContainer } from "./view/ImageC…...

Ubuntu20.04确认cuda和cudnn已经安装成功
当我们通过官网安装cuda和cudnn时,终端执行完命令后我们仍不能确定是否已经安装成功。接下来教大家用几句命令测试。 cuda 检测版本号 nvcc -V如果输出如下,则安装成功。 可以看到版本号是11.2 cudnn检测版本号 有两种命令:如果你的cudn…...
)
sqlilab 46 关(布尔、时间盲注)
sqlilabs 46关(布尔、时间盲注) 46关有变化了,需要我们输入sort,那我们就从sort1开始 递增测试: 发现测试到sort4就出现报错: 我们查看源码: 从图中可看出:用户输入的sort值被用于查…...

AI时代保护自己的隐私
人工智能最重要的就是数据,让我们面对现实,大多数人都不知道他们每天要向人工智能提供多少数据。你输入的每条聊天记录,你发出的每条语音命令,人工智能生成的每张图片、电子邮件和文本。我建设了一个网站(haptool.com),…...
与监督微调(SFT)的区别和联系)
模型优化之强化学习(RL)与监督微调(SFT)的区别和联系
强化学习(RL)与监督微调(SFT)是机器学习中两种重要的模型优化方法,它们在目标、数据依赖、应用场景及实现方式上既有联系又有区别。 想了解有关deepseek本地训练的内容可以看我的文章: 本地基于GGUF部署的…...

Buildroot 添加自定义模块-内置文件到文件系统
目录 概述实现步骤1. 创建包目录和文件结构2. 配置 Config.in3. 定义 cp_bin_files.mk4. 添加源文件install.shmy.conf 5. 配置与编译 概述 Buildroot 是一个高度可定制和模块化的嵌入式 Linux 构建系统,适用于从简单到复杂的各种嵌入式项目. buildroot的源码中bui…...

蓝牙接近开关模块感应开锁手机靠近解锁支持HID低功耗
ANS-BT101M是安朔科技推出的蓝牙接近开关模块,低功耗ble5.1,采用UART通信接口,实现手机自动无感连接,无需APP,人靠近车门自动开锁,支持苹果、安卓、鸿蒙系统,也可以通过手机手动开锁或上锁&…...
)
计算机毕业设计SpringBoot+Vue.js基于工程教育认证的计算机课程管理平台(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

企业知识库搭建:14款开源与免费系统选择
本文介绍了以下14 款知识库管理系统:1.Worktile;2.PingCode;3.石墨文档; 4. 语雀; 5. 有道云笔记; 6. Bitrix24; 7. Logseq等。 在如今的数字化时代,企业和团队面临着越来越多的信息…...
)
蓝桥杯(握手问题)
小蓝组织了一场算法交流会议,总共有 50 人参加了本次会议。在会议上,大家进行了握手交流。按照惯例他们每个人都要与除自己以外的其他所有人进行一次握手 (且仅有一次)。 但有 7个人,这 7 人彼此之间没有进行握手 (但这 7 人与除这 7 人以外…...

如何使用 Jenkins 实现 CI/CD 流水线:从零开始搭建自动化部署流程
如何使用 Jenkins 实现 CI/CD 流水线:从零开始搭建自动化部署流程 在软件开发过程中,持续集成(CI)和持续交付(CD)已经成为现代开发和运维的标准实践。随着代码的迭代越来越频繁,传统的手动部署方式不仅低效,而且容易出错。为了提高开发效率和代码质量,Jenkins作为一款…...

c++字符编码/乱码问题
基本概念 c11版本引入了char16_t和char32_t两个类型,他们的特点分别如下: char16_t 16位的unicode字符类型用于表示UTF-16编码大小:2字节字面量前缀:u char32_t 32位unicode字符类型用于表示UTF-32编码大小:4字节…...

侯捷 C++ 课程学习笔记:深入理解类与继承
文章目录 每日一句正能量一、课程背景二、学习内容:类与继承(一)类的基本概念1. 类的定义与实例化2. 构造函数与析构函数 (二)继承1. 单继承与多继承2. 虚函数与多态 三、学习心得四、总结 每日一句正能量 有种承担&am…...

初始化列表
一:声明,定义,赋值的区别 ①:声明 这里,int _year; int _month;int _day; 是成员变量的声明,它们告诉编译器: 类 Date中有三个成员变量_year和 _month和_day。 它们的类型分别都是 int 此…...

7.1 - 定时器之中断控制LED实验
文章目录 1 实验任务2 系统框图3 软件设计 1 实验任务 本实验任务是通过CPU私有定时器的中断,每 200ms 控制一次PS LED灯的亮灭。 2 系统框图 3 软件设计 注意事项: 定时器中断在收到中断后,只需清除中断状态,无需禁用中断、启…...

Pytest之fixture的常见用法
文章目录 1.前言2.使用fixture执行前置操作3.使用conftest共享fixture4.使用yield执行后置操作 1.前言 在pytest中,fixture是一个非常强大和灵活的功能,用于为测试函数提供固定的测试数据、测试环境或执行一些前置和后置操作等, 与setup和te…...

【分库分表】基于mysql+shardingSphere的分库分表技术
目录 1.什么是分库分表 2.分片方法 3.测试数据 4.shardingSphere 4.1.介绍 4.2.sharding jdbc 4.3.sharding proxy 4.4.两者之间的对比 5.留个尾巴 1.什么是分库分表 分库分表是一种场景解决方案,它的出现是为了解决一些场景问题的,哪些场景喃…...

合并两个有序链表:递归与迭代的实现分析
合并两个有序链表:递归与迭代的实现分析 在算法与数据结构的世界里,链表作为一种基本的数据结构,经常被用来解决各种问题。特别是对于有序链表的合并,既是经典面试题,也是提高编程能力的重要练习之一。合并两个有序链…...

HTML AI 编程助手
HTML AI 编程助手 引言 随着人工智能技术的飞速发展,编程领域也迎来了新的变革。HTML,作为网页制作的基础语言,与AI技术的结合,为开发者带来了前所未有的便利。本文将探讨HTML AI编程助手的功能、应用场景以及如何利用它提高编程…...

备战蓝桥杯Day11 DFS
DFS 1.要点 (1)朴素dfs 下面保存现场和恢复现场就是回溯法的思想,用dfs实现,而本质是用递归实现,代码框架: ans; //答案,常用全局变量表示 int mark[N]; //记录状态i是否被处理过 …...

Oracle 认证为有哪几个技术方向
Oracle 认证技术方向,分别是数据库管理、开发、云平台,每个方向都有不同的学习等级 数据库运维方向 Oracle Certified Professional(OCP):19c OCA内容已和OCP合并 OCP 19c属于oracle认证专家,要求考生掌握深…...

25物理学研究生复试面试问题汇总 物理学专业知识问题很全! 物理学复试全流程攻略 物理学考研复试调剂真题汇总
正在为物理考研复试专业面试发愁的你,是不是不知道从哪开始准备? 学姐告诉你,其实物理考研复试并没有你想象的那么难!只要掌握正确的备考方法,稳扎稳打,你也可以轻松拿下高分!今天给大家准备了…...

网络安全技术与应用
文章详细介绍了网络安全及相关技术,分析了其中的一类应用安全问题——PC机的安全问题,给出了解决这类问题的安全技术——PC防火墙技术。 1 网络安全及相关技术 自20世纪…...

APISIX Dashboard上的配置操作
文章目录 登录配置路由配置消费者创建后端服务项目配置上游再创建一个路由测试 登录 http://192.168.10.101:9000/user/login?redirect%2Fdashboard 根据docker 容器里的指定端口: 配置路由 通过apisix 的API管理接口来创建(此路由,直接…...

深度剖析数据分析职业成长阶梯
一、数据分析岗位剖析 目前,数据分析领域主要有以下几类岗位:业务数据分析师、商业数据分析师、数据运营、数据产品经理、数据工程师、数据科学家等,按照工作侧重点不同,本文将上述岗位分为偏业务和偏技术两大类,并对…...

HarmonyOS学习第11天:布局秘籍RelativeLayout进阶之路
布局基础:RelativeLayout 初印象 在 HarmonyOS 的界面开发中,布局是构建用户界面的关键环节,它决定了各个组件在屏幕上的位置和排列方式。而 RelativeLayout(相对布局)则是其中一种功能强大且灵活的布局方式࿰…...

问题修复-后端返给前端的时间展示错误
问题现象: 后端给前端返回的时间展示有问题。 需要按照yyyy-MM-dd HH:mm:ss 的形式展示 两种办法: 第一种 在实体类的属性上添加JsonFormat注解 第二种(建议使用) 扩展mvc框架中的消息转换器 代码: 因为配置类继…...

怎么排查页面响应慢的问题
一、排查流程图 -----------------| 全局监控报警触发 |-----------------|▼-----------------| 定位异常服务节点 |-----------------|------------------▼ ▼ ----------------- ----------------- | 基础设施层排查 | | 应用层代码排查 | | (网…...