UE_C++ —— Container TArray
目录
一,TArray
二,Creating and Filling an Array
三,Iteration
四,Sorting
五,Queries
六,Removal
七,Operators
八,Heap
九,Slack
十,Raw Memory
十一,Miscellaneous
UE中最简单的容器类是 TArray,负责同类型其他对象(称为"元素")序列的所有权和组织;由于 TArray 是一个序列,其元素的排序定义明确,其函数用于确定性地操纵此类对象及其顺序;
一,TArray
TArray 是UE中最常用的容器类,其速度快、内存消耗小、安全性高;TArray 类型由两大属性定义:元素类型和可选分配器;
元素类型是存储在数组中的对象类型,TArray 被称为同质容器;换言之,其所有元素均完全为相同类型;单个 TArray 中不能存储不同类型的元素;
分配器常被省略,默认为最常用的分配器;其定义对象在内存中的排列方式,以及数组如何进行扩展,以容纳更多的元素;若默认行为不符合要求,可选取多种不同的分配器,或自行编写;
Tarray 为值类型,意味其与其他内置类型(如 int32 或 浮点)的处理方式相同;它不是为扩展而设计的,不建议使用new和delete创建或销毁TArray实例;元素也为数值类型,为容器所拥有;TArray 被销毁时其中的元素也将被销毁;若在另一TArray中创建TArray变量,其元素将复制到新变量中,且不会共享状态;
二,Creating and Filling an Array
创建用于存储整数序列的空数组,其元素类型是可根据普通C++值规则进行复制和销毁的数值类型,如 int32、FString、TSharedPtr 等;由于无指定分配器,因此 TArray 将采用基于堆的默认分配器;此时尚未分配内存;
//创建用于存储整数序列的空数组
TArray<int32> IntArray;有多种填充
Tarray的方法:
//填充 Tarray 的方法:使用 Init 函数,将大量元素副本填入数组;
IntArray.Init(10, 5);
// IntArray == [10,10,10,10,10]//填充 Tarray 的方法:使用 Add 和 Emplace 函数用于在数组末尾添加对象;
TArray<FString> StrArr;
StrArr.Add(TEXT("Hello"));
StrArr.Emplace(TEXT("World"));
// StrArr == ["Hello","World"] 新元素添加到数组时,分配器将根据需要分配内存;当数组大小超出时,默认分配器将添加足够的内存,以存储多个新元素;Add 和 Emplace 函数的多数效果相同,细微区别在于:
Add(或Push)将元素类型的实例复制(或移动)到数组中;Emplace使用给定参数构建元素类型的新实例;
因此在 TArray<FString> 中,Add 将用字符串文字创建临时 FString,然后将该临时 FString 的内容移至容器内的新 FString 中,而 Emplace 将用字符串文字直接新建 FString;最终结果相同,但 Emplace 可避免创建临时文件;对于 FString 等非浅显数值类型而言,临时文件通常不理想;
总之,Emplace 优于 Add,因此其可避免在调用点创建无需临时变量,并将此类变量复制或移动到容器中;根据经验,可将 Add 用于浅显类型,将 Emplace 用于其他类型;Emplace 的效率始终高于 Add,但 Add 的可读性可能更好;
//Append 可一次性添加多个元素,从其他TArray或指向常规C数组的指针及该数组的大小
FString Arr[] = { TEXT("of"), TEXT("Tomorrow") };
StrArr.Append(Arr, ARRAY_COUNT(Arr));
// StrArr == ["Hello","World","of","Tomorrow"]//AddUnique 仅添加新元素(不存在相等的元素),使用 operator== 检查;
StrArr.AddUnique(TEXT("!"));
// StrArr == ["Hello","World","of","Tomorrow","!"]StrArr.AddUnique(TEXT("!"));
// StrArr is unchanged as "!" is already an element//与 Add、Emplace 和 Append 相同,Insert 将在给定索引处添加单个元素或元素数组的副本;
StrArr.Insert(TEXT("Brave"), 1);
// StrArr == ["Hello","Brave","World","of","Tomorrow","!"]//SetNum 函数可直接设置数组元素的数量
//如新数量大于当前数量,则使用元素类型的默认构造函数新建元素;
StrArr.SetNum(8);
// StrArr == ["Hello","Brave","World","of","Tomorrow","!","",""]//新数量小于当前数量,SetNum 将移除元素;
StrArr.SetNum(6);
// StrArr == ["Hello","Brave","World","of","Tomorrow","!"]
三,Iteration
有多种方法可迭代数组的元素,建议使用C++的范围(ranged-for)功能;
FString JoinedStr;
for (auto& Str : StrArr)
{JoinedStr += Str;JoinedStr += TEXT(" ");
}
// JoinedStr == "Hello Brave World of Tomorrow ! "同时也可使用基于索引的常规迭代;
for (int32 Index = 0; Index != StrArr.Num(); ++Index)
{JoinedStr += StrArr[Index];JoinedStr += TEXT(" ");
} 还可通过数组迭代器类型控制迭代,函数 CreateIterator 和 CreateConstIterator 可分别用于元素的读写和只读访问;
for (auto It = StrArr.CreateConstIterator(); It; ++It)
{JoinedStr += *It;JoinedStr += TEXT(" ");
}四,Sorting
调用 Sort 函数即可对数组进行排序;数值按元素类型的 operator< 排序,在FString中,此为忽略大小写的比较;
StrArr.Sort();
// StrArr == ["!","Brave","Hello","of","Tomorrow","World"]StrArr.Sort([](const FString& A, const FString& B) {return A.Len() < B.Len();});
// StrArr == ["!","of","Hello","Brave","World","Tomorrow"] 字符串按长度排序,长度相同的字符串"Hello"、"Brave"和"World"的相对排序发生了变化;是因为 Sort 不稳定,等值元素的相对排序无法保证;Sort 作为quicksort实现;
HeapSort 函数,是否使用binary predicate,均可执行堆排序;使用HeapSort函数与否,取决于特定数据与Sort函数相比时的排序效率;与 Sort 一样,HeapSort 也不稳定;
StrArr.HeapSort([](const FString& A, const FString& B) {return A.Len() < B.Len();});
// StrArr == ["!","of","Hello","Brave","World","Tomorrow"] StableSort 用于在排序后保证等值元素的相对顺序,StableSort 作为归并排序实现;
StrArr.StableSort([](const FString& A, const FString& B) {return A.Len() < B.Len();});
// StrArr == ["!","of","Brave","Hello","World","Tomorrow"]五,Queries
使用 Num 函数可查询数组保存的元素数量;
int32 Count = StrArr.Num();
// Count == 6 如需直接访问数组内存,可使用 GetData 函数将指针返回到数组中的元素;仅在数组存在且未执行更改数组的操作时,此指针方有效;仅 StrPtr 的首个 Num 索引才可被解引用;如容器为常量,则返回的指针也为常量;
FString* StrPtr = StrArr.GetData();
// StrPtr[0] == "!"
// StrPtr[1] == "of"
// ...
// StrPtr[5] == "Tomorrow"
// StrPtr[6] - undefined behavior对容器元素大小进行询问;
uint32 ElementSize = StrArr.GetTypeSize();
// ElementSize == sizeof(FString) 使用 operator[]获取元素,从0开始索引;传递小于0或大于等于Num()的无效索引将导致运行时错误,使用 IsValidIndex 函数询问容器,可确定特定索引是否有效;operator[]将返回引用,因此还可用于改变数组中的元素;
FString Elem1 = StrArr[1];
// Elem1 == "of"bool bValidM1 = StrArr.IsValidIndex(-1);
bool bValid0 = StrArr.IsValidIndex(0);
bool bValid5 = StrArr.IsValidIndex(5);
bool bValid6 = StrArr.IsValidIndex(6);
// bValidM1 == false
// bValid0 == true
// bValid5 == true
// bValid6 == falseStrArr[3] = StrArr[3].ToUpper();
// StrArr == ["!","of","Brave","HELLO","World","Tomorrow"] 与GetData函数相同:如数组为常量,operator[] 将返回常量引用;还可使用 Last 函数从数组末端反向索引,索引默认为零;Top 函数是 Last 的同义词,唯一区别是其不接受索引;
FString ElemEnd = StrArr.Last();
FString ElemEnd0 = StrArr.Last(0);
FString ElemEnd1 = StrArr.Last(1);
FString ElemTop = StrArr.Top();
// ElemEnd == "Tomorrow"
// ElemEnd0 == "Tomorrow"
// ElemEnd1 == "World"
// ElemTop == "Tomorrow"可询问数组是否包含特定元素;
bool bHello = StrArr.Contains(TEXT("Hello"));
bool bGoodbye = StrArr.Contains(TEXT("Goodbye"));
// bHello == true
// bGoodbye == false
询问数组是否包含与特定谓词匹配的元素;
bool bLen5 = StrArr.ContainsByPredicate([](const FString& Str) {return Str.Len() == 5;});
bool bLen6 = StrArr.ContainsByPredicate([](const FString& Str) {return Str.Len() == 6;});
// bLen5 == true
// bLen6 == false 使用 Find 函数族可查找元素,可使用Find确定元素是否存在并返回其索引,找到的为首个元素索引,如存在重复元素而希望找到最末元素的索引,则使用 FindLast 函数;
int32 Index;
if (StrArr.Find(TEXT("Hello"), Index)) //Index为首个元素的索引
{// Index == 3
}int32 IndexLast;
if (StrArr.FindLast(TEXT("Hello"), IndexLast))
{// IndexLast == 3, because there aren't any duplicates
} Find 和 FindLast 也可直接返回元素索引;如不将索引作为显式参数传递,这两个函数便会执行此操作;此将比上述函数更简洁,使用的函数则取决于特定需求或风格;如未找到元素,将返回特殊 INDEX_NONE 值;
int32 Index2 = StrArr.Find(TEXT("Hello"));
int32 IndexLast2 = StrArr.FindLast(TEXT("Hello"));
int32 IndexNone = StrArr.Find(TEXT("None"));
// Index2 == 3
// IndexLast2 == 3
// IndexNone == INDEX_NONE IndexOfByKey 的工作方式类似,但元素可与任意对象比较;开始搜索前,使用 Find 函数会将参数实际转换为元素类型(此本例中为 FString);使用 IndexOfByKey,可直接对"键"比较,因此即使键类型无法直接转换为元素类型,也可进行搜索;
IndexOfByKey 适用于存在 operator==(ElementType, KeyType) 的键类型;IndexOfByKey 将返回找到的首个元素的索引;如未找到元素,则返回 INDEX_NONE;
int32 Index = StrArr.IndexOfByKey(TEXT("Hello"));
// Index == 3 IndexOfByPredicate 函数用于查找与特定谓词匹配的首个元素的索引;如未找到,同样返回特殊 INDEX_NONE 值;
int32 Index = StrArr.IndexOfByPredicate([](const FString& Str) {return Str.Contains(TEXT("r"));});
// Index == 2 可将指针返回指向找到的元素,而不返回索引;FindByKey 与 IndexOfByKey 相似,将元素和任意对象进行对比,但返回指向所找到元素的指针;如未找到元素,则返回nullptr;
auto* OfPtr = StrArr.FindByKey(TEXT("of")));
auto* ThePtr = StrArr.FindByKey(TEXT("the")));
// OfPtr == &StrArr[1]
// ThePtr == nullptr
FindByPredicate 的使用方式和 IndexOfByPredicate 相似,不同点是返回指针而非索引;
auto* Len5Ptr = StrArr.FindByPredicate([](const FString& Str) {return Str.Len() == 5;});
auto* Len6Ptr = StrArr.FindByPredicate([](const FString& Str) {return Str.Len() == 6;});
// Len5Ptr == &StrArr[2]
// Len6Ptr == nullptr 使用 FilterByPredicate 函数可获取与特定谓词匹配的元素数组;
auto Filter = StrArray.FilterByPredicate([](const FString& Str) {return !Str.IsEmpty() && Str[0] < TEXT('M');});六,Removal
Remove 函数族用于移除数组中的元素,将根据元素类型的 operator== 函数移除所有与提供元素等值的元素;
TArray<int32> ValArr;
int32 Temp[] = { 10, 20, 30, 5, 10, 15, 20, 25, 30 };
ValArr.Append(Temp, ARRAY_COUNT(Temp)); // ValArr == [10,20,30,5,10,15,20,25,30]
ValArr.Remove(20); // ValArr == [10,30,5,10,15,25,30] RemoveSingle 用于擦除数组中的首个匹配元素;在数组中可能存在重复,而只希望擦除一个时,或作为优化,数组只能包含一个匹配元素时;
ValArr.RemoveSingle(30);
// ValArr == [10,5,10,15,25,30] RemoveAt 函数用于按从零开始的索引移除元素;可使用 IsValidIndex 确定数组中的元素是否使用计划提供的索引,将无效索引传递给此函数会导致运行时错误;
ValArr.RemoveAt(2); // Removes the element at index 2
// ValArr == [10,5,15,25,30]
ValArr.RemoveAt(99); // This will cause a runtime error as there is no element at index 99 RemoveAll 也可用于函数移除与谓词匹配的元素;
ValArr.RemoveAll([](int32 Val) {return Val % 3 == 0;});
// ValArr == [10,5,25]注,在所有这些情况中,由于数组中不能出现空位,因此移除元素时其后的元素将被下移到更低索引中;
移动过程存在开销,如不需剩余元素排序,可使用 RemoveSwap、RemoveAtSwap 和 RemoveAllSwap 函数减少此开销;此类函数的工作方式与其非交换变种相似,不同之处在于其不保证剩余元素的排序,因此可更快地完成任务;
TArray<int32> ValArr2;
for (int32 i = 0; i != 10; ++i)
ValArr2.Add(i % 5);
// ValArr2 == [0,1,2,3,4,0,1,2,3,4]ValArr2.RemoveSwap(2);
// ValArr2 == [0,1,4,3,4,0,1,3]ValArr2.RemoveAtSwap(1);
// ValArr2 == [0,3,4,3,4,0,1]ValArr2.RemoveAllSwap([](int32 Val) {return Val % 3 == 0;});
// ValArr2 == [1,4,4] 使用 Empty 函数移除数组中所有元素;
ValArr2.Empty();
// ValArr2 == []七,Operators
数组是常规值类型,可使用标准复制构造函数或赋值运算符进行复制;由于数组严格拥有其元素,复制数组的操作是深拷贝,因此新数组将拥有其自身的元素副本;
TArray<int32> ValArr3;
ValArr3.Add(1);
ValArr3.Add(2);
ValArr3.Add(3);auto ValArr4 = ValArr3;
// ValArr4 == [1,2,3];
ValArr4[0] = 5;
// ValArr3 == [1,2,3];
// ValArr4 == [5,2,3]; 作为 Append 函数的替代,可使用 operator+= 对数组进行串联;
ValArr4 += ValArr3;
// ValArr4 == [5,2,3,1,2,3] TArray 还支持移动语义,使用 MoveTemp 函数可调用这些语义;移动后,源数组必定为空;
ValArr3 = MoveTemp(ValArr4);
// ValArr3 == [5,2,3,1,2,3]
// ValArr4 == [] 使用 operator== 和 operator!= 对数组进行比较;元素的排序很重要:只有元素的顺序和数量相同时,两个数组才被视为相同;元素通过其自身的 operator== 进行比较;
TArray<FString> FlavorArr1;
FlavorArr1.Emplace(TEXT("Chocolate"));
FlavorArr1.Emplace(TEXT("Vanilla"));
// FlavorArr1 == ["Chocolate","Vanilla"]auto FlavorArr2 = Str1Array;
// FlavorArr2 == ["Chocolate","Vanilla"]bool bComparison1 = FlavorArr1 == FlavorArr2;
// bComparison1 == truefor (auto& Str : FlavorArr2)
{Str = Str.ToUpper();
}
// FlavorArr2 == ["CHOCOLATE","VANILLA"]bool bComparison2 = FlavorArr1 == FlavorArr2;
// bComparison2 == true, because FString comparison ignores caseExchange(FlavorArr2[0], FlavorArr2[1]);
// FlavorArr2 == ["VANILLA","CHOCOLATE"]bool bComparison3 = FlavorArr1 == FlavorArr2;
// bComparison3 == false, because the order has changed八,Heap
TArray 拥有支持二叉堆数据结构的函数;堆是一种二叉树,使用数组实现时,树的根节点位于元素0,索引N处节点的左右子节点的指数分别为2N+1和2N+2;子节点彼此间不存在特定排序;
调用
Heapify函数可将现有数组转换为堆;此会重载为是否接受谓词,无谓词的版本将使用元素类型的 operator< 确定排序;
TArray<int32> HeapArr;
for (int32 Val = 10; Val != 0; --Val)
{HeapArr.Add(Val);
}
// HeapArr == [10,9,8,7,6,5,4,3,2,1]
HeapArr.Heapify();
// HeapArr == [1,2,4,3,6,5,8,10,7,9]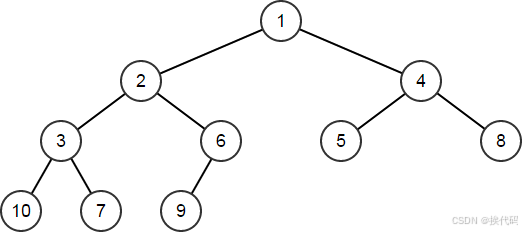
树中的节点按堆化数组中元素的排序从左至右、从上至下读取;注:数组在转换为堆后无需排序;排序数组也是有效堆,但堆结构的定义较为宽松,同一组元素可存在多个有效堆;
通过HeapPush函数可将新元素添加到堆,会对堆进行维护
HeapArr.HeapPush(4);
// HeapArr == [1,2,4,3,4,5,8,10,7,9,6]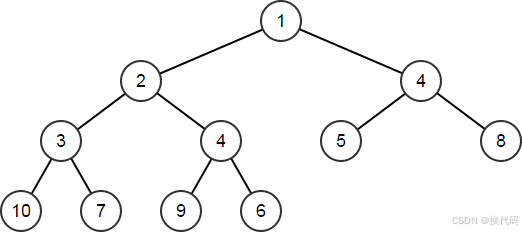
HeapPop和HeapPopDiscard函数用于移除堆顶节点;区别在于前者引用元素的类型来返回顶部元素的副本,而后者只是简单地移除顶部节点,不进行任何形式的返回;两个函数得出的数组变更一致,对堆进行维护;
int32 TopNode;
HeapArr.HeapPop(TopNode);
// TopNode == 1
// HeapArr == [2,3,4,6,4,5,8,10,7,9]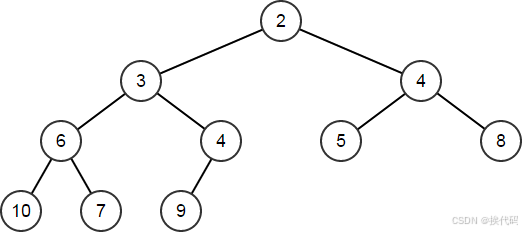
HeapRemoveAt将删除数组中给定索引处的元素,然后对堆进行维护;
HeapArr.HeapRemoveAt(1);
// HeapArr == [2,4,4,6,9,5,8,10,7]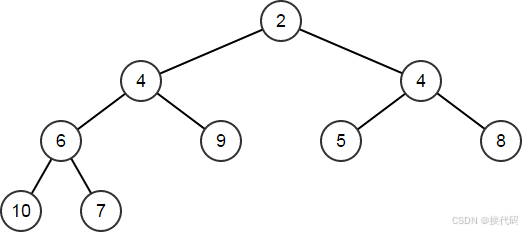
注,仅在已是有效堆时(如在 Heapify 调用、其他堆操作或手动将数组操作到堆中之后),才应调用 HeapPush、HeapPop、HeapPopDiscard 和 HeapRemoveAt;
可使用
HeapTop检查堆的顶部节点,无需变更数组;
int32 Top = HeapArr.HeapTop();
// Top == 2九,Slack
由于数组的大小是可变的,因此使用的内存量会不同;为避免每次添加元素时重新分配内存,分配器提供的内存通常会超过必要内存,使之后调用 Add 时不会因重新分配内存而降低性能;同样,删除元素通常不会释放内存;因此数组拥有Slack元素,也就是当前未使用的有效预分配元素储存槽;数组中存储的元素量与数组使用分配内存可存储的元素数量间的差值即为数组中的Slack量;
由于默认构建的数组不分配内存,Slack初始为零;使用 GetSlack 函数可找出数组中的Slack量;通过 Max 函数可获取容器重新分配前数组可保存的最大元素数量;GetSlack 等同 Max 和 Num 间的差值;
TArray<int32> SlackArray;
// SlackArray.GetSlack() == 0
// SlackArray.Num() == 0
// SlackArray.Max() == 0SlackArray.Add(1);
// SlackArray.GetSlack() == 3
// SlackArray.Num() == 1
// SlackArray.Max() == 4SlackArray.Add(2);
SlackArray.Add(3);
SlackArray.Add(4);
SlackArray.Add(5);
// SlackArray.GetSlack() == 17
// SlackArray.Num() == 5
// SlackArray.Max() == 22分配器会确定重新分配后容器中的Slack量,用户Slack不是常量;
虽然无需管理Slack,但可管理Slack对数组进行优化,以满足需求;如需要向数组添加大约100个新元素,则可在添加前确保拥有可至少存储100个新元素的Slack,以便添加新元素时无需分配内存;
SlackArray.Empty();
// SlackArray.GetSlack() == 0
// SlackArray.Num() == 0
// SlackArray.Max() == 0
SlackArray.Empty(3);
// SlackArray.GetSlack() == 3
// SlackArray.Num() == 0
// SlackArray.Max() == 3
SlackArray.Add(1);
SlackArray.Add(2);
SlackArray.Add(3);
// SlackArray.GetSlack() == 0
// SlackArray.Num() == 3
// SlackArray.Max() == 3 Reset 函数与Empty函数类似,不同之处是若当前内存分配已提供请求的Slack,该函数将不释放内存;但若请求的Slack较大,其将分配更多内存;
SlackArray.Reset(0);
// SlackArray.GetSlack() == 3
// SlackArray.Num() == 0
// SlackArray.Max() == 3
SlackArray.Reset(10);
// SlackArray.GetSlack() == 10
// SlackArray.Num() == 0
// SlackArray.Max() == 10 使用 Shrink 函数可移除所有Slack;此将把内存分配调整为保存当前元素所需的最小内存;Shrink 不会对数组中的元素产生影响;
SlackArray.Add(5);
SlackArray.Add(10);
SlackArray.Add(15);
SlackArray.Add(20);
// SlackArray.GetSlack() == 6
// SlackArray.Num() == 4
// SlackArray.Max() == 10
SlackArray.Shrink();
// SlackArray.GetSlack() == 0
// SlackArray.Num() == 4
// SlackArray.Max() == 4十,Raw Memory
本质上,TArray 只是分配内存的包装器;直接修改分配的字节和自行创建元素即可将其用作包装器,此操作十分实用;Tarray 将尽量利用其拥有的信息进行执行,但有时需降低等级;
注,利用以下函数可在较低级别快速访问 TArray 及其数据,但若利用不当,可能会导致容器无效和未知行为;在调用此类函数后(但在调用其他常规函数前),可决定是否将容器返回有效状态;
AddUninitialized 和 InsertUninitialized 函数可将未初始化的空间添加到数组;两者工作方式分别与 Add 和 Insert 函数相同,只是不调用元素类型的构造函数;若要避免调用构造函数,建议使用此类函数;
int32 SrcInts[] = { 2, 3, 5, 7 };
TArray<int32> UninitInts;
UninitInts.AddUninitialized(4);
FMemory::Memcpy(UninitInts.GetData(), SrcInts, 4 * sizeof(int32));
// UninitInts == [2,3,5,7]//也可使用此功能保留计划自行构建对象所需内存
TArray<FString> UninitStrs;
UninitStrs.Emplace(TEXT("A"));
UninitStrs.Emplace(TEXT("D"));
UninitStrs.InsertUninitialized(1, 2);
new ((void*)(UninitStrs.GetData() + 1)) FString(TEXT("B"));
new ((void*)(UninitStrs.GetData() + 2)) FString(TEXT("C"));
// UninitStrs == ["A","B","C","D"]
AddZeroed 和 InsertZeroed 的工作方式相似,不同点是会将添加/插入的空间字节清零;
struct S
{S(int32 InInt, void* InPtr, float InFlt):Int(InInt), Ptr(InPtr), Flt(InFlt){}int32 Int;void* Ptr;float Flt;
};
TArray<S> SArr;
SArr.AddZeroed();
// SArr == [{ Int:0, Ptr: nullptr, Flt:0.0f }] SetNumUninitialized 和 SetNumZeroed 函数的工作方式与 SetNum 类似,不同之处在于新数量大于当前数量时,将保留新元素的空间为未初始化或按位归零。与 AddUninitialized 和 InsertUninitialized 函数相同,必要时需将新元素正确构建到新空间中;
SArr.SetNumUninitialized(3);new ((void*)(SArr.GetData() + 1)) S(5, (void*)0x12345678, 3.14);new ((void*)(SArr.GetData() + 2)) S(2, (void*)0x87654321, 2.72);// SArr == [// { Int:0, Ptr: nullptr, Flt:0.0f },// { Int:5, Ptr:0x12345678, Flt:3.14f },// { Int:2, Ptr:0x87654321, Flt:2.72f }// ]SArr.SetNumZeroed(5);// SArr == [// { Int:0, Ptr: nullptr, Flt:0.0f },// { Int:5, Ptr:0x12345678, Flt:3.14f },// { Int:2, Ptr:0x87654321, Flt:2.72f },// { Int:0, Ptr: nullptr, Flt:0.0f },// { Int:0, Ptr: nullptr, Flt:0.0f }// ]注,应谨慎使用"Uninitialized"和"Zeroed"函数族。如函数类型包含要构建的成员或未处于有效按位清零状态的成员,可导致数组元素无效和未知行为。此类函数适用于固定的数组类型,例如FMatrix和FVector;
十一,Miscellaneous
BulkSerialize 函数是序列化函数,可用作替代 operator<<,将数组作为原始字节块进行序列化,而非执行逐元素序列化;如使用内置类型或纯数据结构体等浅显元素,可改善性能;
CountBytes 和 GetAllocatedSize 函数用于估算数组当前内存占用量;CountBytes 接受 FArchive,可直接调用 GetAllocatedSize;此类函数常用于统计报告;
Swap 和 SwapMemory 函数均接受两个索引并交换此类索引上的元素值;这两个函数相同,不同点是 Swap 会对索引执行额外的错误检查,并断言索引是否超出范围;
相关文章:

UE_C++ —— Container TArray
目录 一,TArray 二,Creating and Filling an Array 三,Iteration 四,Sorting 五,Queries 六,Removal 七,Operators 八,Heap 九,Slack 十,Raw Memor…...

第435场周赛:奇偶频次间的最大差值 Ⅰ、K 次修改后的最大曼哈顿距离、使数组包含目标值倍数的最少增量、奇偶频次间的最大差值 Ⅱ
Q1、奇偶频次间的最大差值 Ⅰ 1、题目描述 给你一个由小写英文字母组成的字符串 s 。请你找出字符串中两个字符的出现频次之间的 最大 差值,这两个字符需要满足: 一个字符在字符串中出现 偶数次 。另一个字符在字符串中出现 奇数次 。 返回 最大 差值…...

模拟解决哈希表冲突
目录 解决哈希表冲突原理: 模拟解决哈希表冲突代码: 负载因子: 动态扩容: 总结: HashMap和HashSet的总结: 解决哈希表冲突原理: 黑色代表一个数组,当 出现哈希冲突时࿰…...

UIView 与 CALayer 的联系和区别
今天说一下UIView 与 CALayer 一、UIView 和 CALayer 的关系 在 iOS 开发中,UIView 是用户界面的基础,它负责处理用户交互和绘制内容,而 CALayer 是 UIView 内部用于显示内容的核心图层(Layer)。每个 UIView 内部都有…...

Android 10.0 移除wifi功能及相关菜单
介绍 客户的机器没有wifi功能,所以需要删除wifi相关的菜单,主要有设置-网络和互联网-WLAN,长按桌面设置弹出的WALN快捷方式,长按桌面-微件-设置-WLAN。 修改 Android10 上直接将config_show_wifi_settings改为false,这样wifi菜单的入口就隐…...

电力与能源杂志电力与能源杂志社电力与能源编辑部2024年第6期目录
研究与探索 含电动汽车虚拟电厂的优化调度策略综述 黄灿;曹晓满;邬楠; 643-645663 含换电站的虚拟电厂优化调度策略综述 张杰;曹晓满;邬楠;杨小龙; 646-649667 考虑虚拟负荷研判的V2G储能充电桩设计研究 徐颖;张伟阳;陈豪; 650-654 基于状态估计的电能质量监测…...

简站主题:简洁、实用、SEO友好、安全性高和后期易于维护的wordpress主题
简站主题以其简洁的设计风格、实用的功能、优化的SEO性能和高安全性而受到广泛好评。 简洁:简站主题采用扁平化设计风格,界面简洁明了,提供多种布局和颜色方案,适合各种类型的网站,如个人博客和企业网站。 实用&…...
03章——缓存双写一致性之更新策略探讨)
Redis(高阶篇)03章——缓存双写一致性之更新策略探讨
一、反馈回来的面试题 一图你只要用缓存,就可能会涉及到redis缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性的问题双写一致性,你先动缓存redis还是数据库mysql哪一个&#x…...

【Git】说说Git中开发测试的使用Git分支Git标签的使用场景
一、环境介绍 dev环境:开发环境,外部用户无法访问,开发人员使用,版本变动很大。test环境:测试环境,外部用户无法访问,专门给测试人员使用的,版本相对稳定。pre环境:灰度环…...
 实现实时数据推送教程)
Spring Boot中使用Server-Sent Events (SSE) 实现实时数据推送教程
一、简介 Server-Sent Events (SSE) 是HTML5引入的一种轻量级的服务器向浏览器客户端单向推送实时数据的技术。在Spring Boot框架中,我们可以很容易地集成并利用SSE来实现实时通信。 二、依赖添加 在Spring Boot项目中,无需额外引入特定的依赖&#x…...
)
【Golang学习之旅】Go 语言微服务架构实践(gRPC、Kafka、Docker、K8s)
文章目录 1. 前言:为什么选择Go语言构建微服务架构1.1 微服务架构的兴趣与挑战1.2 为什么选择Go语言构建微服务架构 2. Go语言简介2.1 Go 语言的特点与应用2.2 Go 语言的生态系统 3. 微服务架构中的 gRPC 实践3.1 什么是 gRPC?3.2 gRPC 在 Go 语言中的实…...
及其实现)
数据结构:栈(Stack)及其实现
栈(Stack)是计算机科学中常用的一种数据结构,它遵循先进后出(Last In, First Out,LIFO)的原则。也就是说,栈中的元素只能从栈顶进行访问,最后放入栈中的元素最先被取出。栈在很多应用…...

DeepSeek在linux下的安装部署与应用测试
结合上一篇文章,本篇文章主要讲述在Redhat linux环境下如何部署和使用DeepSeek大模型,主要包括ollama的安装配置、大模型的加载和应用测试。关于Open WebUI在docker的安装部署,Open WebUI官网也提供了完整的docker部署说明,大家可…...
)
Next.js【详解】获取数据(访问接口)
Next.js 中分为 服务端组件 和 客户端组件,内置的获取数据各不相同 服务端组件 方式1 – 使用 fetch export default async function Page() {const data await fetch(https://api.vercel.app/blog)const posts await data.json()return (<ul>{posts.map((…...

pnpm, eslint, vue-router4, element-plus, pinia
利用 pnpm 创建 vue3 项目 pnpm 包管理器 - 创建项目 Eslint 配置代码风格(Eslint用于规范纠错,prettier用于美观) 在 设置 中配置保存时自动修复 提交前做代码检查 husky是一个 git hooks工具(git的钩子工具,可以在特定实际执行特…...

将jar安装到Maven本地仓库中
将jar安装到Maven本地仓库中 1. 使用 mvn install:install-file 命令模版示例 2.项目中添加依赖 将一个 .jar 文件安装到 Maven 本地仓库中是一个常见的操作,尤其是在你想要在本地测试一个尚未发布到中央仓库的库时。以下是如何将 .jar 文件安装到 Maven 本地仓库的…...

Spring 和 Spring MVC 的关系是什么?
Spring和Spring MVC的关系就像是“大家庭和家里的小书房”一样。 Spring是一个大家庭,提供了各种各样的功能和服务,比如管理Bean的生命周期、事务管理、安全性等,它是企业级应用开发的全方位解决方案。这个大家庭里有很多房间,每个…...
)
Ollama ModelFile(模型文件)
1. 什么是 Modelfile? Modelfile 是 Ollama 的配置文件,用于定义和自定义模型的行为。通过它,你可以: 基于现有模型(如 llama2、mistral)创建自定义版本 调整生成参数(如温度、重复惩罚&#…...

基于python深度学习遥感影像地物分类与目标识别、分割实践技术应用
我国高分辨率对地观测系统重大专项已全面启动,高空间、高光谱、高时间分辨率和宽地面覆盖于一体的全球天空地一体化立体对地观测网逐步形成,将成为保障国家安全的基础性和战略性资源。未来10年全球每天获取的观测数据将超过10PB,遥感大数据时…...
洛斯里克城志愿者问题详解)
(蓝桥杯——10. 小郑做志愿者)洛斯里克城志愿者问题详解
题目背景 小郑是一名大学生,她决定通过做志愿者来增加自己的综合分。她的任务是帮助游客解决交通困难的问题。洛斯里克城是一个六朝古都,拥有 N 个区域和古老的地铁系统。地铁线路覆盖了树形结构上的某些路径,游客会询问两个区域是否可以通过某条地铁线路直达,以及有多少条…...

基于 Ollama 工具的 LLM 大语言模型如何部署,以 DeepSeek 14B 本地部署为例
简简单单 Online zuozuo :本心、输入输出、结果 文章目录 基于 Ollama 工具的 LLM 大语言模型如何部署,以 DeepSeek 14B 本地部署为例前言下载 Ollama实际部署所需的硬件要求设置 LLM 使用 GPU ,发挥 100% GPU 性能Ollama 大模型管理命令大模型的实际运行资源消耗基于 Ollam…...

大模型工具大比拼:SGLang、Ollama、VLLM、LLaMA.cpp 如何选择?
简介:在人工智能飞速发展的今天,大模型已经成为推动技术革新的核心力量。无论是智能客服、内容创作,还是科研辅助、代码生成,大模型的身影无处不在。然而,面对市场上琳琅满目的工具,如何挑选最适合自己的那…...

【05】密码学与隐私保护
5-1 零知识证明 零知识证明介绍 零知识证明的概念 设P(Prover)表示掌握某些信息,并希望证实这一事实的实体,V(Verifier)是验证这一事实的实体。 零知识证明是指P试图使V相信某一个论断是正确的,但却不向…...
)
Flink SQL与Doris实时数仓Join实战教程(理论+实例保姆级教程)
目录 第一章:Regular Joins 深度解析 1.1 核心原理与适用场景 1.2 电商订单 - 商品实时关联案例 1.2.1 数据流设计 1.2.2 Doris 表设计优化 1.2.3 性能调优要点 第二章:Interval Joins 实战应用 2.1 时间区间关联原理 2.2 优惠券使用有效性验证 2.2.1 业务场景说明 …...
)
DeepSeek 助力 Vue 开发:打造丝滑的范围选择器(Range Picker)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...
)
68页PDF | 数据安全总体解决方案:从数据管理方法论到落地实践的全方位指南(附下载)
一、前言 这份报告旨在应对数字化转型过程中数据安全面临的挑战,并提供全面的管理与技术体系建设框架。报告首先分析了数字化社会的发展背景,强调了数据安全在国家安全层面的重要性,并指出数据安全风险的来源和防护措施。接着,报…...

【Github每日推荐】-- 2024 年项目汇总
1、AI 技术 项目简述OmniParser一款基于纯视觉的 GUI 智能体,能够准确识别界面上可交互图标以及理解截图中各元素语义,实现自动化界面交互场景,如自动化测试、自动化操作等。ChatTTS一款专门为对话场景设计的语音生成模型,主要用…...

【Spring详解一】Spring整体架构和环境搭建
一、Spring整体架构和环境搭建 1.1 Spring的整体架构 Spring框架是一个分层架构,包含一系列功能要素,被分为大约20个模块 Spring核心容器:包含Core、Bean、Context、Expression Language模块 Core :其他组件的基本核心ÿ…...
深入理解 @Autowired 注解:使用场景与实战示例)
Spring Boot(8)深入理解 @Autowired 注解:使用场景与实战示例
搞个引言 在 Spring 框架的开发中,依赖注入(Dependency Injection,简称 DI)是它的一个核心特性,它能够让代码更加模块化、可测试,并且易于维护。而 Autowired 注解作为 Spring 实现依赖注入的关键工具&…...

Machine Learning:Optimization
文章目录 局部最小值与鞍点 (Local Minimum & Saddle Point)临界点及其种类判断临界值种类 批量与动量(Batch & Momentum)批量大小对梯度下降的影响动量法 自适应学习率AdaGradRMSPropAdam 学习率调度优化总结 局部最小值与鞍点 (Local Minimum & Saddle Point) 我…...
;与wp_footer();的区别的关系)
wordpress get_footer();与wp_footer();的区别的关系
在WordPress中,get_footer() 和 wp_footer() 是两个不同的函数,它们在主题开发中扮演着不同的角色,但都与页面的“页脚”部分有关。以下是它们的区别和关系: 1. get_footer() get_footer() 是一个用于加载页脚模板的函数。它的主…...

Windows Docker运行Implicit-SVSDF-Planner
Windows Docker运行GitHub - ZJU-FAST-Lab/Implicit-SVSDF-Planner: [SIGGRAPH 2024 & TOG] 1. 设置环境 我将项目git clone在D:/Github目录中。 下载ubuntu20.04 noetic镜像 docker pull osrf/ros:noetic-desktop-full-focal 启动容器,挂载主机的D:/Github文…...

设计模式14:职责链模式
系列总链接:《大话设计模式》学习记录_net 大话设计-CSDN博客 1.概述 职责链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许将请求沿着处理者链传递,直到有一个处理者能够处理该请求。这种模式通过…...

Golang GORM系列:GORM并发与连接池
GORM 是一个流行的 Go 语言 ORM(对象关系映射)库,用于简化数据库操作。它支持连接池和并发访问功能,这些功能对于高性能、高并发的应用场景非常重要。本文结合示例详细介绍gorm的并发处理能力,以及如何是哟个连接池提升…...

linux笔记:shell中的while、if、for语句
在Udig软件的启动脚本中使用了while循环、if语句、for循环,其他内容基本都是变量的定义,所以尝试弄懂脚本中这三部分内容,了解脚本执行过程。 (1)while循环 while do循环内容如下所示,在循环中还用了expr…...

【Java】逻辑运算符详解:、|| 与、 | 的区别及应用
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: Java 文章目录 💯前言💯一、基本概念与运算符介绍💯二、短路与与非短路与:&& 与 & 的区别1. &&:短路与(AND)2. …...

Java 设计模式之解释器模式
文章目录 Java 设计模式之解释器模式概述UML代码实现 Java 设计模式之解释器模式 概述 解释器模式(interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。如果一种特定…...

关于前后端分离跨域问题——使用DeepSeek分析查错
我前端使用ant design vue pro框架,后端使用kratos框架开发。因为之前也解决过跨域问题,正常是在后端的http请求中加入中间件,设置跨域需要通过的字段即可,代码如下所示: func NewHTTPServer(c *conf.Server, s *conf…...

Linux下ioctl的应用
文章目录 1、ioctl简介2、示例程序编写2.1、应用程序编写2.2、驱动程序编写 3、ioctl命令的构成4、测试 1、ioctl简介 ioctl(input/output control)是Linux中的一个系统调用,主要用于设备驱动程序与用户空间应用程序之间进行设备特定的输入/…...

Windows 环境下 Grafana 安装指南
目录 下载 Grafana 安装 Grafana 方法 1:使用 .msi 安装程序(推荐) 方法 2:使用 .zip 压缩包 启动 Grafana 访问 Grafana 配置 Grafana(可选) 卸载 Grafana(如果需要) 下载 G…...

【操作系统】操作系统概述
操作系统概述 1.1 操作系统的概念1.1.1 操作系统定义——什么是OS?1.1.2 操作系统作用——OS有什么用?1.1.3 操作系统地位——计算机系统中,OS处于什么地位?1.1.4 为什么学操作系统? 1.2 操作系统的历史1.2.1 操作系统…...

基于SSM+uniapp的鲜花销售小程序+LW示例参考
1.项目介绍 系统角色:管理员、商户功能模块:用户管理、商户管理、鲜花分类管理、鲜花管理、订单管理、收藏管理、购物车、充值、下单等技术选型:SSM,Vue(后端管理web),uniapp等测试环境&#x…...

第3章 .NETCore核心基础组件:3.1 .NET Core依赖注入
3.1.1 什么是控制反转、依赖注入 杨老师在书中进行了一系列的文字阐述,总结一下就是:软件设计模式中有一种叫做【控制反转】的设计模式,而依赖注入是实现这种设计模式的一个很重要的方式。也就是说学习依赖注入,是学习怎样实现控…...

排序与算法:插入排序
执行效果 插入排序的执行效果是这样的: 呃……看不懂吗?没关系,接着往下看介绍 算法介绍 插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,…...

uniapp 打包安卓 集成高德地图
接入高德地图 let vm this;uni.chooseLocation({success: function (res) {// console.log(位置名称: res.name);// console.log(详细地址: res.address);// console.log(纬度: res.latitude);// console.log(经度: res.long…...

python爬虫系列课程2:如何下载Xpath Helper
python爬虫系列课程2:如何下载Xpath Helper 一、访问极简插件官网二、点击搜索按钮三、输入xpath并点击搜索四、点击推荐下载五、将下载下来的文件解压缩六、打开扩展程序界面七、将xpath.crx文件拖入扩展程序界面一、访问极简插件官网 极简插件官网地址:https://chrome.zzz…...

win10系统上的虚拟机安装麒麟V10系统提示找不到操作系统
目录预览 一、问题描述二、原因分析三、解决方案四、参考链接 一、问题描述 win10系统上的虚拟机安装麒麟V10系统提示找不到操作系统,报错:Operating System not found 二、原因分析 国产系统,需要注意的点: 需要看你的系统类…...
+Vue+毕业论文+指导搭建视频)
基于微信小程序的宿舍报修管理系统设计与实现,SpringBoot(15500字)+Vue+毕业论文+指导搭建视频
运行环境 jdkmysqlIntelliJ IDEAmaven3微信开发者工具 项目技术SpringBoothtmlcssjsjqueryvue2uni-app 宿舍报修小程序是一个集中管理宿舍维修请求的在线平台,为学生、维修人员和管理员提供了一个便捷、高效的交互界面。以下是关于这些功能的简单介绍: …...

分布式同步锁:原理、实现与应用
分布式同步锁:原理、实现与应用 引言1. 分布式同步锁的基本概念1.1 什么是分布式同步锁?1.2 分布式锁的特性 2. 分布式锁的实现方式2.1 基于数据库的分布式锁实现原理优缺点示例 2.2 基于 Redis 的分布式锁实现原理优缺点示例Redlock 算法 2.3 基于 ZooK…...

Chrome多开终极形态解锁!「窗口管理工具+IP隔离插件
Web3项目多开,继ads指纹浏览器钱包被盗后,更多人采用原生chrome浏览器,当然对于新手,指纹浏览器每月成本也是一笔不小开支,今天逛Github发现了这样一个解决方案,作者开发了窗口管理工具IP隔离插件ÿ…...