逻辑回归:Sigmoid函数在分类问题中的应用
欢迎来到我的主页:【Echo-Nie】
本篇文章收录于专栏【机器学习】

1 什么是Sigmoid函数?
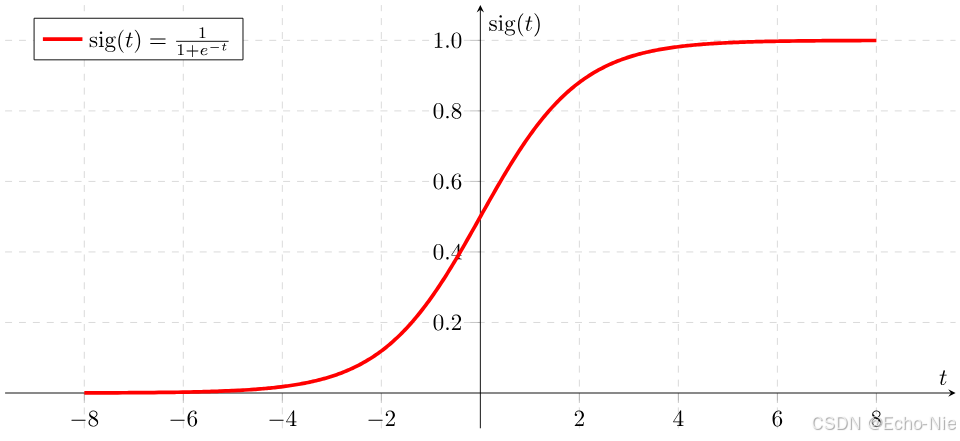
Sigmoid函数(Logistic函数)是机器学习中最经典的激活函数之一,是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,常被用作神经网络的激活函数,将变量映射到0,1之间。其数学表达如下:
σ ( x ) = 1 1 + e − x = e x e x + 1 \sigma(x) = \frac{1}{1 + e^{-x}} = \frac{e^x}{e^x + 1} σ(x)=1+e−x1=ex+1ex
函数图像呈现典型的 “S” 形曲线,具有以下特征:
- 定义域: ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)
- 值域: ( 0 , 1 ) (0, 1) (0,1)
- 对称性:关于点(0, 0.5)中心对称
- 可导性:处处可导
2 数学性质详解
2.1 导数计算
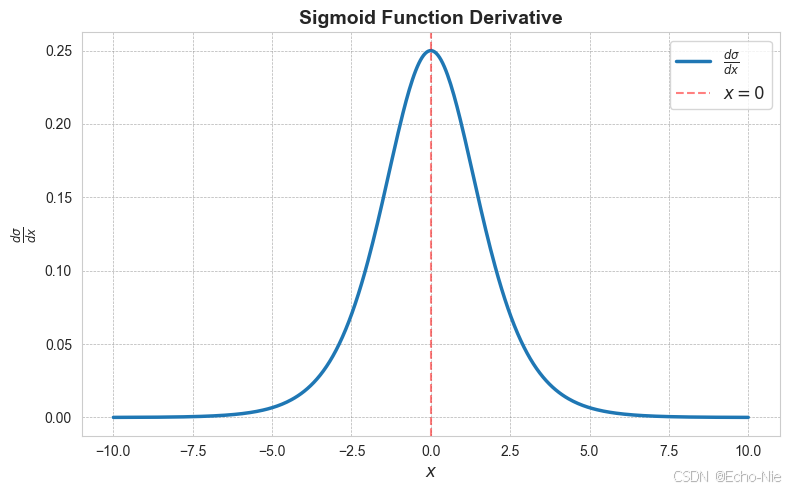
Sigmoid的导数可用其自身表示,这在反向传播中非常关键:
d σ d x = σ ( x ) ( 1 − σ ( x ) ) \frac{d\sigma}{dx} = \sigma(x)(1 - \sigma(x)) dxdσ=σ(x)(1−σ(x))
数学推导:
d d x σ ( x ) = d d x ( 1 1 + e − x ) = e − x ( 1 + e − x ) 2 = 1 1 + e − x ⋅ e − x 1 + e − x = σ ( x ) ( 1 − σ ( x ) ) \begin{aligned} \frac{d}{dx}\sigma(x) &= \frac{d}{dx}\left( \frac{1}{1 + e^{-x}} \right) \\ &= \frac{e^{-x}}{(1 + e^{-x})^2} \\ &= \frac{1}{1 + e^{-x}} \cdot \frac{e^{-x}}{1 + e^{-x}} \\ &= \sigma(x)(1 - \sigma(x)) \end{aligned} dxdσ(x)=dxd(1+e−x1)=(1+e−x)2e−x=1+e−x1⋅1+e−xe−x=σ(x)(1−σ(x))
2.2 重要性质
| 特性 | 说明 |
|---|---|
| 非线性 | 使神经网络可以学习非线性模式 |
| 饱和性 | 当输入绝对值较大时梯度趋近于零 |
| 概率解释 | 输出值可直接解释为概率 |
| 平滑性 | 函数各阶导数均存在,有利于数值计算 |
3 Python实现
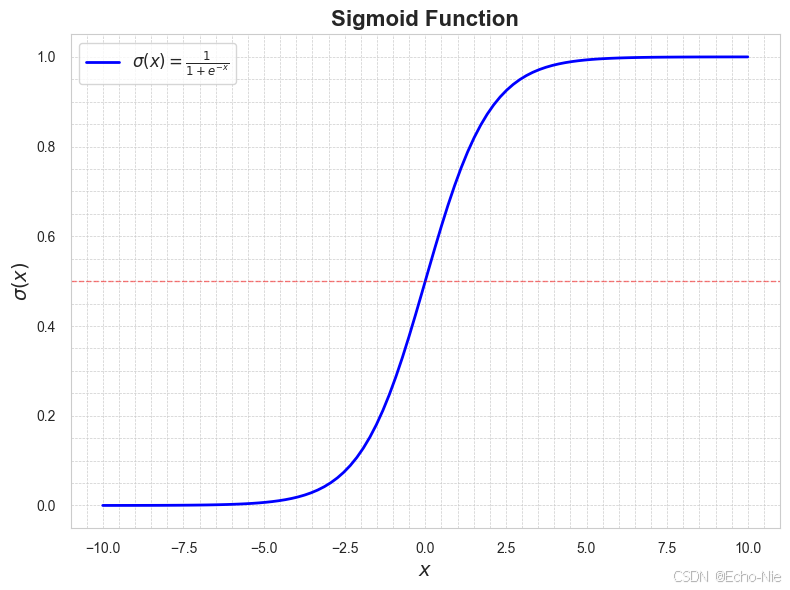
3.1 函数可视化
import numpy as np
import matplotlib.pyplot as plt# 定义Sigmoid函数
def sigmoid(x):return 1 / (1 + np.exp(-x))# 生成x值范围
x = np.linspace(-10, 10, 100)
y = sigmoid(x)plt.figure(figsize=(8, 6))
# 绘制Sigmoid曲线
plt.plot(x, y, label=r'$\sigma(x) = \frac{1}{1 + e^{-x}}$', color='blue', linewidth=2)
plt.title("Sigmoid Function", fontsize=16, fontweight='bold')
plt.xlabel(r"$x$", fontsize=14)
plt.ylabel(r"$\sigma(x)$", fontsize=14)
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.minorticks_on()
plt.tick_params(which='both', width=2)
plt.tick_params(which='major', length=7)
plt.tick_params(which='minor', length=4, color='gray') # 添加水平参考线(y=0.5)
plt.axhline(0.5, color='red', linestyle='--', alpha=0.5, linewidth=1)plt.legend(fontsize=12)
plt.tight_layout()
# 显示图形
plt.show()
3.2 导数可视化
import numpy as np
import matplotlib.pyplot as plt# Sigmoid函数
def sigmoid(x):return 1 / (1 + np.exp(-x))# Sigmoid导数
def sigmoid_derivative(x):s = sigmoid(x)return s * (1 - s)# 生成数据点
x = np.linspace(-10, 10, 400) # 生成-10到10之间的400个点
dy = sigmoid_derivative(x) # 计算导数# 绘制Sigmoid导数图
plt.figure(figsize=(8, 5))
plt.plot(x, dy, label=r"$\frac{d\sigma}{dx}$", linewidth=2.5)
plt.title("Sigmoid Function Derivative", fontsize=14, fontweight='bold')
plt.xlabel("$x$", fontsize=12)
plt.ylabel("$\\frac{d\sigma}{dx}$", fontsize=12)
plt.axvline(0, color='red', linestyle='--', alpha=0.5, label="$x=0$")
plt.grid(color='gray', linestyle='--', linewidth=0.5, alpha=0.6)
plt.legend(loc='best', fontsize=12)
plt.tight_layout()
plt.show()
4 应用场景
4.1 逻辑回归做二分类
在逻辑回归中,Sigmoid将线性组合 z = w T x + b z = w^Tx + b z=wTx+b 转换为概率:
P ( y = 1 ∣ x ) = σ ( z ) = 1 1 + e − ( w T x + b ) P(y=1|x) = \sigma(z) = \frac{1}{1 + e^{-(w^Tx + b)}} P(y=1∣x)=σ(z)=1+e−(wTx+b)1
决策边界:当 σ ( z ) ≥ 0.5 \sigma(z) \geq 0.5 σ(z)≥0.5时预测为类别1,等价于 z ≥ 0 z \geq 0 z≥0
from sklearn.linear_model import LogisticRegression
X = [[1.2], [2.4], [3.1], [4.8], [5.0]]
y = [0, 0, 1, 1, 1]
model = LogisticRegression()
model.fit(X, y)
# 预测概率
print(model.predict_proba([[3.0]]))
4.2 神经网络激活函数
虽然现代深度学习更多使用ReLU,但在以下场景仍有用:
- 输出层需要概率输出的分类任务
- LSTM等特殊网络结构的门控机制
- 强化学习的动作选择概率
4.2.1 概率输出的分类任务
在二分类问题中,Sigmoid函数常用于输出层,将线性组合的结果转换为一个介于0到1之间的值,表示样本属于正类的概率。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 生成二分类数据集
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 转换为 PyTorch 张量
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1)# 定义模型
class SimpleNN(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(10, 5)self.act = nn.Sigmoid()self.fc2 = nn.Linear(5, 1)def forward(self, x):x = self.act(self.fc1(x))return self.fc2(x)# 初始化模型和优化器
model = SimpleNN()
criterion = nn.BCEWithLogitsLoss() # 二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.01)# 训练模型
epochs = 100
for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")# 评估模型
model.eval()
with torch.no_grad():y_pred = torch.sigmoid(model(X_test)).round().numpy()
accuracy = accuracy_score(y_test.numpy(), y_pred)
print(f"Test Accuracy: {accuracy:.4f}")
Epoch [10/100], Loss: 0.6665
Epoch [20/100], Loss: 0.6172
Epoch [30/100], Loss: 0.5569
Epoch [40/100], Loss: 0.4926
Epoch [50/100], Loss: 0.4361
Epoch [60/100], Loss: 0.3928
Epoch [70/100], Loss: 0.3627
Epoch [80/100], Loss: 0.3431
Epoch [90/100], Loss: 0.3307
Epoch [100/100], Loss: 0.3229
Test Accuracy: 0.8400
4.2.2 LSTM 网络中的门控机制
import torch
import torch.nn as nnclass SimpleLSTM(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h0 = torch.zeros(1, x.size(0), self.lstm.hidden_size)c0 = torch.zeros(1, x.size(0), self.lstm.hidden_size)out, (hn, cn) = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出return torch.sigmoid(out) # 输出概率# 随机数据测试模型
input_size = 10
hidden_size = 5
output_size = 1model = SimpleLSTM(input_size, hidden_size, output_size)
x = torch.randn(32, 5, input_size) # 32 是 batch_size,5 是序列长度
output = model(x)
print("LSTM output:", output)
LSTM output: tensor([[0.5431],[0.4636],[0.4578],[0.5197],[0.5001],[0.5229],[0.4976],[0.4924],[0.5234],[0.5413],[0.4881],[0.4861],[0.5162],[0.5169],[0.4688],[0.5114],[0.5059],[0.5013],[0.5215],[0.4460],[0.5219],[0.5306],[0.5099],[0.4722],[0.4930],[0.5114],[0.5249],[0.4784],[0.4850],[0.4994],[0.4955],[0.4910]], grad_fn=<SigmoidBackward0>)
4.2.3 强化学习的动作选择概率
举例:预测用户是否会点击某个广告,0 or 1
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report# 生成模拟数据集
# 特征:用户年龄、浏览历史、广告类型、设备类型
# 标签:是否点击广告(0:未点击,1:点击)
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 预测测试集
y_pred = model.predict(X_test)
print("预测结果:", y_pred)# 模型评估
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))
预测结果: [1 1 0 0 0 1 0 0 0 0 0 1 1 0 1 1 0 0 0 0 1 0 0 1 1 1 1 0 0 1 1 0 1 1 1 1 00 0 1 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 1 1 0 0 0 1 0 0 1 1 1 1 00 0 1 0 0 1 0 0 1 0 0 0 0 1 1 0 0 1 0 1 1 1 0 1 1 1 0 0 0 1 1 0 0 1 0 0 01 1 0 0 0 1 0 0 1 1 1 1 1 0 1 1 0 1 1 0 1 0 1 0 0 1 1 0 0 0 1 1 1 1 0 1 01 0 0 1 0 0 1 1 0 1 1 0 1 0 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 0 1 0 1 0 1 0 11 1 0 0 1 0 0 1 0 0 0 1 1 1 1 0 1 1 1 0 0 0 1 1 0 0 1 0 1 0 0 1 0 1 0 0 00 1 1 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 1 0 1 1 1 0 0 0 0 1 1 1 0 0 0 0 0 1 11 1 0 1 1 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1 0 1 1 0 1 1 1 1 1 0 1 0 0 01 0 1 0]
准确率: 0.8666666666666667
分类报告:precision recall f1-score support0 0.85 0.90 0.87 1531 0.88 0.84 0.86 147accuracy 0.87 300macro avg 0.87 0.87 0.87 300
weighted avg 0.87 0.87 0.87 300
4.3 数据标准化
将任意范围的特征值压缩到(0,1)区间:
def normalize(values):scaled = (values - np.min(values)) / (np.max(values) - np.min(values))return sigmoid(scaled * 10 - 5) # 加强非线性缩放original = np.array([10, 20, 30, 40, 50])
print(normalize(original))
5 sklearn代码实战
5.1 基于sklearn的逻辑回归实例
使用 sklearn.datasets 中的 make_classification 数据集,这是一个用于生成二分类或多分类问题的合成数据集。通过该数据集,可以灵活地控制特征数量、类别分布等参数。
数据加载与预处理
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split# 生成二分类数据集
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, random_state=42)# 划分训练集和测试集,8:2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
from sklearn.linear_model import LogisticRegression
# 逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
模型评估
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 预测测试集
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(conf_matrix)
class_report = classification_report(y_test, y_pred)
print("分类报告:")
print(class_report)
模型准确率: 0.90
混淆矩阵:
[[97 7][13 83]]
分类报告:precision recall f1-score support0 0.88 0.93 0.91 1041 0.92 0.86 0.89 96accuracy 0.90 200
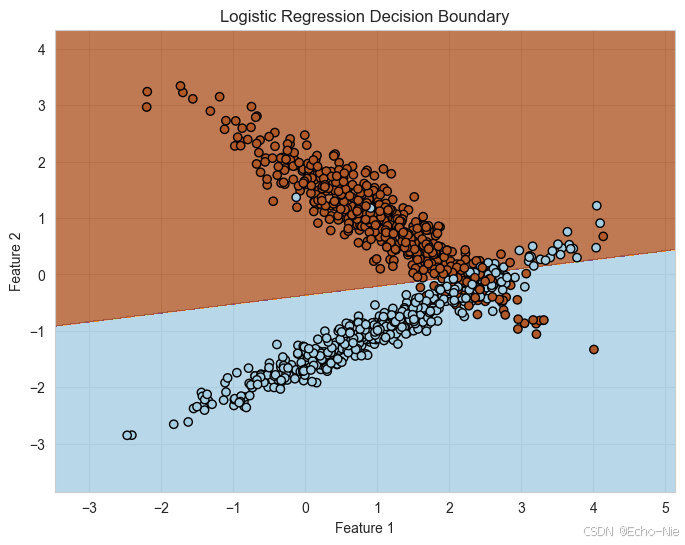
可视化决策边界
import numpy as np
import matplotlib.pyplot as pltx_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),np.arange(y_min, y_max, 0.01))# 预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界和数据点
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', cmap=plt.cm.Paired)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Logistic Regression Decision Boundary")
plt.show()
5.2 sklearn乳腺癌数据集
使用 sklearn.datasets 中的 load_breast_cancer 数据集,这是一个用于乳腺癌诊断的二分类数据集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, auc, accuracy_score, classification_report# 加载乳腺癌数据集
data = load_breast_cancer()
X, y = data.data, data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 创建逻辑回归模型
model = LogisticRegression(max_iter=300, solver='lbfgs')
model.fit(X_train_scaled, y_train)# 预测测试集的概率
y_scores = model.predict_proba(X_test_scaled)[:, 1]
y_pred = model.predict(X_test_scaled)print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))# 计算ROC
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
roc_auc = auc(fpr, tpr)# ROC曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkblue', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=14)
plt.ylabel('True Positive Rate', fontsize=14)
plt.title('Receiver Operating Characteristic (ROC) Curve', fontsize=16)
plt.legend(loc='lower right', fontsize=12)
plt.grid(color='lightgray', linestyle='--', linewidth=0.5)
plt.gca().spines['top'].set_color('none')
plt.gca().spines['right'].set_color('none')
plt.gca().spines['bottom'].set_linewidth(1.2)
plt.gca().spines['left'].set_linewidth(1.2)
plt.gca().tick_params(axis='both', which='major', labelsize=12)
plt.tight_layout()
plt.show()
准确率: 0.9736842105263158
分类报告:precision recall f1-score support0 0.98 0.95 0.96 431 0.97 0.99 0.98 71accuracy 0.97 114macro avg 0.97 0.97 0.97 114
weighted avg 0.97 0.97 0.97 114


相关文章:

逻辑回归:Sigmoid函数在分类问题中的应用
欢迎来到我的主页:【Echo-Nie】 本篇文章收录于专栏【机器学习】 1 什么是Sigmoid函数? Sigmoid函数(Logistic函数)是机器学习中最经典的激活函数之一,是一个在生物学中常见的S型函数,也称为S型生长曲线。…...
上安装 Java 8)
使用 SDKMAN! 在 Mac(包括 ARM 架构的 M1/M2 芯片)上安装 Java 8
文章目录 1. 安装 SDKMAN!2. 查找可用的 Java 8 版本3. 安装 Java 84. 验证安装5. 切换 Java 版本(可选)6. 解决 ARM 架构兼容性问题总结 可以使用 SDKMAN! 在 Mac(包括 ARM 架构的 M1/M2 芯片)上安装 Java 8。SDKMAN! 是一个强大…...

AUTOSAR汽车电子嵌入式编程精讲300篇-基于FPGA的CAN FD汽车总线数据交互系统设计
目录 前言 汽车总线以及发展趋势 汽车总线技术 汽车总线发展趋势 CAN FD总线国内外研究现状 2 系统方案及CAN FD协议分析 2.1系统控制方案设计 2.2 CAN FD总线帧结构分析 2.2.1数据帧分析 2.2.2远程帧分析 2.2.3过载帧分析 2.2.4错误帧分析 2.2.5帧间隔分析 2.3位…...

滴水逆向_程序实现弹窗修改OEP
作业: 几个很重要的注意事项。 1 我们模拟的是内核如何将一个文件硬盘中拉伸到内存中,但是我们做的仅仅是 模拟拉伸过程。也就是说其中的属性字段是无差别的拷贝的。 但是加载exe的时候 ,imagebase 是随机分配的。 我们打开内存中的exe&…...

HTTP报文格式
HTTP请求报文格式 1. 结构: [请求行] [请求头] [空行] [请求体] (可选)请求行:方法 URI HTTP版本 常见方法:GET(获取资源)、POST(提交数据)、PUT(替…...

pytest.fixture
pytest.fixture 是 pytest 测试框架中的一个非常强大的功能,它允许你在测试函数运行前后执行一些设置或清理代码。以下是关于 pytest.fixture 的详细介绍: 一、定义与用途 pytest.fixture 是一个装饰器,用于标记一个函数为 fixture。Fixture 函数中的代码可以在测试函数运…...

位运算算法篇:进入位运算的世界
位运算算法篇:进入位运算的世界 本篇文章是我们位运算算法篇的第一章,那么在我们是算法世界中,有那么多重要以及有趣的算法,比如深度优先搜索算法以及BFS以及动态规划算法等等,那么我们位运算在这些算法面前相比&#…...
)
Heterogeneous Graph Attention Network(HAN)
HAN WWW19 分类:异构图神经网络 元路径 (图片地址:异构图注意力网络(3) HAN_哔哩哔哩_bilibili) 如图所示,假如异构图如上所示。那么,按照MAM和MDM就可以生成不同的子图。这样,就可以生成MAM与MDM的一阶邻居…...

重学SpringBoot3-Spring WebFlux之SSE服务器发送事件
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞??收藏评论 Spring WebFlux之SSE服务器发送事件 1. 什么是 SSE?2. Spring Boot 3 响应式编程与 SSE 为什么选择响应式编程实现 SSE? 3. 实现 SSE 的基本步骤 3.1 创建 Spr…...
)
Java中实现定时锁屏的功能(可以指定时间执行)
Java中实现定时锁屏的功能(可以指定时间执行) 要在Java中实现定时锁屏的功能,可以使用java.util.Timer或java.util.concurrent.ScheduledExecutorService来调度任务,并通过调用操作系统的命令来执行锁屏。下面我将给出一个基本的…...

工作案例 - python绘制excell表中RSRP列的CDF图
什么是CDF图 CDF(Cumulative Distribution Function)就是累积分布函数,是概率密度函数的积分。CDF函数是一个在0到1之间的函数,描述了随机变量小于或等于一个特定值的概率。在可视化方面,CDF图表明了一个随机变量X小于…...

推理大模型DeepSeek迅速觉醒
随着人工智能技术的快速发展,DeepSeek作为一种创新的技术工具,正在重塑行业格局。本文将深入分析如何把握这一波由DeepSeek带来的流量红利,揭示其在市场洞察、技术创新和用户需求中的潜在机会,并提供实用策略帮助个人或企业快速融…...

Ubuntu22.04部署deepseek大模型
Ollama 官方版 Ollama 官方版: https://ollama.com/ 若你的显卡是在Linux上面 可以使用如下命令安装 curl -fsSL https://ollama.com/install.sh | shollama命令查看 rootheyu-virtual-machine:~# ollama -h Large language model runnerUsage:ollama [flags]ollama [comman…...

redis的数据结构介绍(string
redis是键值数据库,key一般是string类型,value的类型很多 string,hash,list,set,sortedset,geo,bitmap,hyperlog redis常用通用命令: keys: …...

QUIC 与 UDP 关系
QUIC协议是建立在UDP之上的,这意味着QUIC的数据包实际上是通过UDP传输的。QUIC的设计使其能够利用UDP的特性,同时在其上实现更复杂的功能。以下是QUIC如何体现出其基于UDP的特性,以及QUIC头部字段的详细介绍。 QUIC与UDP的关系 UDP封装:QUIC数据包被封装在UDP数据包中进行…...

webview_flutter的使用
目录 步骤示例代码 步骤 1.配置依赖。根目录下运行如下命令: flutter pub add webview_flutter 2.所需页面导入: import ‘package:webview_flutter/webview_flutter.dart’; 3.初始化WebViewController overridevoid initState() {super.initState();…...

Centos执行yum命令报错
错误描述 错误:为仓库 ‘appstream’ 下载元数据失败 : Cannot prepare internal mirrorlist: Curl error (6): Couldn’t resolve host name for http://mirrorlist.centos.org/?release8&archx86_64&repoAppStream&infrastock [Could not resolve h…...
)
aio-pika 快速上手(Python 异步 RabbitMQ 客户端)
目录 简介官方文档如何使用 简介 aio-pika 是一个 Python 异步 RabbitMQ 客户端。5.0.0 以前 aio-pika 基于 pika 进行封装,5.0.0 及以后使用 aiormq 进行封装。 https://github.com/mosquito/aio-pikahttps://pypi.org/project/aio-pika/ pip install aio-pika官…...
)
AI安全最佳实践:AI应用开发安全评估矩阵(上)
生成式AI开发安全范围矩阵简介 生成式AI目前可以说是当下最热门的技术,吸引各大全球企业的关注,并在全球各行各业中带来浪潮般的编个。随时AI能力的飞跃,大语言模型LLM参数达到千亿级别,它和Transformer神经网络共同驱动了我们工…...
)
疯狂前端面试题(二)
一、Webpack的理解 Webpack 是一个现代 JavaScript 应用程序的静态模块打包工具。Webpack 能够将各种资源(JavaScript、CSS、图片、字体等)视为模块,并通过依赖关系图将这些模块打包成一个或多个最终的输出文件(通常是一个或几个…...

深入探究 C++17 std::is_invocable
文章目录 一、引言二、std::is_invocable 概述代码示例输出结果 三、std::is_invocable 的工作原理简化实现示例 四、std::is_invocable 的相关变体1. std::is_invocable_r2. std::is_nothrow_invocable 和 std::is_nothrow_invocable_r 五、使用场景1. 模板元编程2. 泛型算法 …...

【R语言】卡方检验
一、定义 卡方检验是用来检验样本观测次数与理论或总体次数之间差异性的推断性统计方法,其原理是比较观测值与理论值之间的差异。两者之间的差异越小,检验的结果越不容易达到显著水平;反之,检验结果越可能达到显著水平。 二、用…...
)
DeepSeek LLM 论文解读:相信长期主义开源理念可扩展大语言模型(DeepSeek 吹响通用人工智能的号角)
论文链接:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism(相信长期主义开源理念可扩展大语言模型) 目录 摘要一、数据处理(一)数据清洗与丰富(二)分词器与词汇设置 二、模…...

指针基础知识2
1. 指针运算 1.1 指针 - 整数 以数组举例:因为数组在内存中是连续存放的,只要知道第⼀个元素的地址,顺藤摸瓜就能找到后面的所有元素。这时就会用到指针加减整数。 1.2指针-指针 指针 - 指针可以得到两个指针之间的数据个数。但是…...

nginx的4层和7层配置证书
4层证书代理 # 定义上游服务器组 stream {upstream tcp-25510 {hash $remote_addr consistent;server ip:5510;}# 配置监听 25510 端口的服务器块server {listen 25510 ssl; # 监听 25510 端口并启用 SSL# 指定 SSL 证书和私钥ssl_certificate /etc/nginx/key/bundle.crt;ssl…...
)
【大数据技术】搭建完全分布式高可用大数据集群(Flume)
搭建完全分布式高可用大数据集群(Flume) apache-flume-1.11.0-bin.tar.gz注:请在阅读本篇文章前,将以上资源下载下来。 写在前面 本文主要介绍搭建完全分布式高可用集群 Flume 的详细步骤。 注意: 统一约定将软件安装包存放于虚拟机的/software目录下,软件安装至/opt目…...

C++ 顺序表
顺序表的操作有以下: 1 顺序表的元素插入 给定一个索引和元素,这个位置往后的元素位置都要往后移动一次,元素插入的步骤有以下几步 (1)判断插入的位置是否合法,如果不合法则抛出异常 (2&…...
)
Python----Python高级(网络编程:网络基础:发展历程,IP地址,MAC地址,域名,端口,子网掩码,网关,URL,DHCP,交换机)
一、网络 早期的计算机程序都是在本机上运行的,数据存储和处理都在同一台机器上完成。随着技术的发展,人 们开始有了让计算机之间相互通信的需求。例如安装在个人计算机上的计算器或记事本应用,其运行环 境仅限于个人计算机内部。这种设置虽然…...

Spring Boot 的问题:“由于无须配置,报错时很难定位”,该怎么解决?
Spring Boot 的 "由于无须配置,报错时很难定位" 主要指的是: 传统 Spring 框架 需要大量 XML 或 Java 配置,开发者对应用的组件、Bean 加载情况有清晰的控制,出错时可以从配置入手排查。Spring Boot 采用自动配置&…...
)
基于javaweb的SpringBoot小区智慧园区管理系统(源码+文档+部署讲解)
🎬 秋野酱:《个人主页》 🔥 个人专栏:《Java专栏》《Python专栏》 ⛺️心若有所向往,何惧道阻且长 文章目录 运行环境开发工具适用功能说明 运行环境 Java≥8、MySQL≥5.7、Node.js≥14 开发工具 后端:eclipse/idea/myeclipse…...

一文解释nn、nn.Module与nn.functional的用法与区别
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀零基础入门PyTorch框架_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 …...

vscode安装ESP-IDF
引言 ESP-IDF(Espressif IoT Development Framework)是乐鑫官方为其 ESP32、ESP32-S 系列等芯片提供的物联网开发框架。结合 Visual Studio Code(VSCode)这一强大的开源代码编辑器,能极大提升开发效率。本教程将详细介…...

springboot配置https
注意: 此配置只能本地环境或测试环境使用,生产环境使用https,应该配置nginx!请参考:使用certbot给nginx配置https-CSDN博客 1. 生成证书 使用JDK的keytool命令生成证书 注意:JDK版本需要和项目的JDK版本一…...

数据库的关系代数
关系就是表 属性(Attribute)是关系中的列.例如,关系 “学生” 中可能有属性 “学号”、“姓名”、“班级”。 元组(Tuple)是关系中的一行数据 1. 基本运算符 选择(Selection) 符号:σ 作用:从关…...

【服务器知识】如何在linux系统上搭建一个nfs
文章目录 NFS网络系统搭建**1. 准备工作****2. 服务器端配置****(1) 安装 NFS 服务****(2) 创建共享目录****(3) 配置共享规则****(4) 生效配置并启动服务****(5) 防火墙配置** **3. 客户端配置****(1) 安装 NFS 客户端工具****(2) 创建本地挂载点****(3) 挂载 NFS 共享目录***…...

【学习总结|DAY037】Linux 项目部署
引言 在当今的软件开发领域,Linux 以其安全、稳定、免费且开源的特性,成为项目部署的首选操作系统。无论是 Java 项目,还是各类开发、测试、生产环境中的软件安装,Linux 都占据着重要地位。本文将结合我今天所学内容,…...

【算法】动态规划专题⑧ —— 分组背包问题 python
目录 前置知识进入正题实战演练总结 前置知识 【算法】动态规划专题⑤ —— 0-1背包问题 滚动数组优化 python 进入正题 分组背包问题的详细解析 1. 问题定义 在 分组背包问题 中,物品被划分为若干组,每组内的物品 互斥(只能选择其中一个或…...

数据结构:算法复杂度
前言 数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。没有一种单一的数据结构对所有用途都有用,所以我们要学各式各样的数据结构,如:线性表、树…...

Mac本地体验LM studio
博主很懒,不爱打字! 1、LM studio官网:LM Studio - Discover, download, and run local LLMs 2、下载DMG文件,安装 3、使用vscode工具,commandshiftH【全局替换功能】,选择目录/Applications/LM\ Studio…...
(8000 字终极指南)】)
【EPSG 坐标系系统完全解析(一)(8000 字终极指南)】
EPSG 坐标系系统完全解析(8000 字终极指南) 一、EPSG 的起源与定义(1200 字) 1.1 石油工业催生的标准 行业需求:20 世纪 80 年代石油勘探需要统一坐标参考成立过程: 1985 年欧洲石油公司成立 EPSG 工作组…...

【C++高并发服务器WebServer】-13:多线程服务器开发
本文目录 一、多线程服务器开发二、TCP状态转换三、端口复用 一、多线程服务器开发 服务端代码如下。 #include <stdio.h> #include <arpa/inet.h> #include <unistd.h> #include <stdlib.h> #include <string.h> #include <pthread.h>s…...

【CubeMX-HAL库】STM32F407—无刷电机学习笔记
目录 简介: 学习资料: 跳转目录: 一、工程创建 二、板载LED 三、用户按键 四、蜂鸣器 1.完整IO控制代码 五、TFT彩屏驱动 六、ADC多通道 1.通道确认 2.CubeMX配置 ①开启对应的ADC通道 ②选择规则组通道 ③开启DMA ④开启ADC…...

mysql8 sql语法错误,错误信息是怎么通过网络发送给客户端的,C++源码展示
在 MySQL 8 中,错误信息通过网络发送给客户端的过程涉及多个步骤,主要包括错误信息的生成、格式化、以及通过网络协议(如 TCP/IP)将错误信息发送给客户端。以下是详细的流程和相关代码分析: 1. 错误信息的生成 当 My…...

人工智能D* Lite 算法-动态障碍物处理、多步预测和启发式函数优化
在智能驾驶领域,D* Lite 算法是一种高效的动态路径规划算法,适用于处理环境变化时的路径重规划问题。以下将为你展示 D* Lite 算法的高级用法,包含动态障碍物处理、多步预测和启发式函数优化等方面的代码实现。 代码实现 import heapq impo…...
)
【学术投稿】第五届计算机网络安全与软件工程(CNSSE 2025)
重要信息 官网:www.cnsse.org 时间:2025年2月21-23日 地点:中国-青岛 简介 第五届计算机网络安全与软件工程(CNSSE 2025)将于2025年2月21-23日在中国-青岛举行。CNSSE 2025专注于计算机网络安全、软件工程、信号处…...
)
spring学习(spring 配置文件详解)
一 了解如何创建基本的spring 配置文件 步骤 1 导入 spring-context 依赖 <!-- https://mvnrepository.com/artifact/org.springframework/spring-context --><dependency><groupId>org.springframework</groupId><artifactId>spring-context&l…...

创建一个javaWeb Project
文章目录 前言一、eclipse创建web工程二、web.xmlservlet.xml< mvc:annotation-driven/ > Spring MVC 驱动< context:component - scan >:扫描< bean > ... < /bean >< import > config/beans.xml beans.xmlmybatis.xml 前言 javaWe…...

大模型推理——MLA实现方案
1.整体流程 先上一张图来整体理解下MLA的计算过程 2.实现代码 import math import torch import torch.nn as nn# rms归一化 class RMSNorm(nn.Module):""""""def __init__(self, hidden_size, eps1e-6):super().__init__()self.weight nn.Pa…...

洛谷网站: P3029 [USACO11NOV] Cow Lineup S 题解
题目传送门: P3029 [USACO11NOV] Cow Lineup S - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 前言: 这道题的核心问题是在一条直线上分布着不同品种的牛,要找出一个连续区间,使得这个区间内包含所有不同品种的牛,…...

DeepSeek-R1 云环境搭建部署流程
DeepSeek横空出世,在国际AI圈备受关注,作为个人开发者,AI的应用可以有效地提高个人开发效率。除此之外,DeepSeek的思考过程、思考能力是开放的,这对我们对结果调优有很好的帮助效果。 DeepSeek是一个基于人工智能技术…...