MySQL(InnoDB统计信息)
后面也会持续更新,学到新东西会在其中补充。
建议按顺序食用,欢迎批评或者交流!
缺什么东西欢迎评论!我都会及时修改的!
大部分截图和文章采用该书,谢谢这位大佬的文章,在这里真的很感谢让迷茫的我找到了很好的学习文章。我只是加上了自己的拙见。我只是记录学习没有任何抄袭意思
MySQL 是怎样运行的:从根儿上理解 MySQL - 小孩子4919 - 掘金小册
两种不同的统计数据存储方式
InnoDB提供了两种存储统计数据的方式:
- 永久性的统计数据
这种统计数据存储在磁盘上,也就是服务器重启之后这些统计数据还在。 - 非永久性的统计数据
这种统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了,等到服务器重启之后,在某些适当的场景下才会重新收集这些统计数据。
系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。
在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
mysql> show variables like '%innodb_stats_persistent%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_stats_persistent | ON |
| innodb_stats_persistent_sample_pages | 20 |
+--------------------------------------+-------+
2 rows in set (0.05 sec)
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。
在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
当STATS_PERSISTENT=1时,表明想把该表的统计数据永久的存储到磁盘上。
当STATS_PERSISTENT=0时,表明想把该表的统计数据临时的存储到内存中。
如果在创建表时未指定STATS_PERSISTENT属性,那默认采用系统变量innodb_stats_persistent的值作为该属性的值。
基于磁盘的永久性统计数据
某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
mysql> SHOW TABLES FROM mysql LIKE 'innodb%';
+---------------------------+
| Tables_in_mysql (innodb%) |
+---------------------------+
| innodb_index_stats |
| innodb_table_stats |
+---------------------------+
2 rows in set (0.00 sec)
innodb_table_stats存储了关于表的统计数据,每一条记录对应着一个表的统计数据。innodb_index_stats存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据。
innodb_table_stats
mysql> desc mysql.innodb_table_stats;
+--------------------------+-----------------+------+-----+-------------------+-----------------------------------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+-----------------+------+-----+-------------------+-----------------------------------------------+
| database_name | varchar(64) | NO | PRI | NULL | |
| table_name | varchar(199) | NO | PRI | NULL | |
| last_update | timestamp | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
| n_rows | bigint unsigned | NO | | NULL | |
| clustered_index_size | bigint unsigned | NO | | NULL | |
| sum_of_other_index_sizes | bigint unsigned | NO | | NULL | |
+--------------------------+-----------------+------+-----+-------------------+-----------------------------------------------+
| 字段名 | 描述 |
|---|---|
| database_name | 数据库名 |
| table_name | 表名 |
| last_update | 本条记录最后更新时间 |
| n_rows | 表中记录的条数 |
| clustered_index_size | 表的聚簇索引占用的页面数量 |
| sum_of_other_index_sizes | 表的其他索引占用的页面数量 |
mysql> SELECT * FROM mysql.innodb_table_stats;
+---------------+--------------------+---------------------+---------+----------------------+--------------------------+
| database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes |
+---------------+--------------------+---------------------+---------+----------------------+--------------------------+
| test | single_table | 2025-02-02 10:51:10 | 9913 | 97 | 150 |
+---------------+--------------------+---------------------+---------+----------------------+--------------------------+
34 rows in set (0.00 sec)
n_rows的值是9913,表明single_table表中大约有9913条记录,注意这个数据是估计值。clustered_index_size的值是97,表明single_table表的聚簇索引占用97个页面,这个值是也是一个估计值。sum_of_other_index_sizes的值是150,表明single_table表的其他索引一共占用150个页面,这个值是也是一个估计值。
n_rows统计项的收集
InnoDB统计一个表中有多少行记录的套路是这样的:
- 按照一定算法选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的
n_rows值。
可以看出来这个n_rows值精确与否取决于统计时采样的页面数量,innodb_stats_persistent_sample_pages的系统变量来控制使用永久性的统计数据时,计算统计数据时采样的页面数量。该值设置的越大,统计出的n_rows值越精确,但是统计耗时也就最久;该值设置的越小,统计出的n_rows值越不精确,但是统计耗时特别少。
所以在实际使用是需要我们去权衡利弊,该系统变量的默认值是20。

InnoDB默认是以表为单位来收集和存储统计数据的,我们也可以单独设置某个表的采样页面的数量,设置方式就是在创建或修改表的时候通过指定STATS_SAMPLE_PAGES属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;ALTER TABLE 表名 Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
如果我们在创建表的语句中并没有指定STATS_SAMPLE_PAGES属性的话,将默认使用系统变量innodb_stats_persistent_sample_pages的值作为该属性的值。
clustered_index_size和sum_of_other_index_sizes统计项的收集
这两个统计项的收集过程如下:
- 从数据字典里找到表的各个索引对应的根页面位置。
系统表SYS_INDEXES里存储了各个索引对应的根页面信息。

从根页面的Page Header里找到叶子节点段和非叶子节点段对应的Segment Header。
在每个索引的根页面的Page Header部分都有两个字段:-
PAGE_BTR_SEG_LEAF:表示B+树叶子段的Segment Header信息。 -
PAGE_BTR_SEG_TOP:表示B+树非叶子段的Segment Header信息。
-

- 从叶子节点段和非叶子节点段的
Segment Header中找到这两个段对应的INODE Entry结构。

从对应的INODE Entry结构中可以找到该段对应所有零散的页面地址以及FREE、NOT_FULL、FULL链表的基节点。
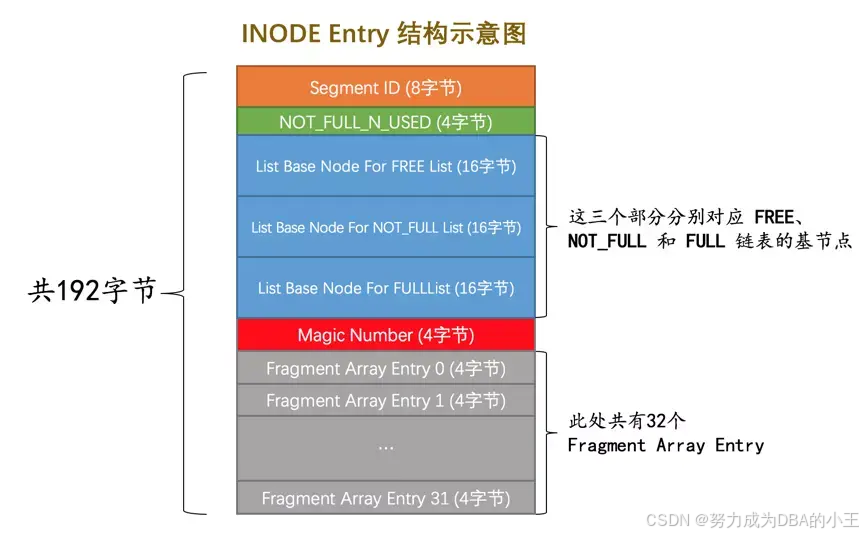
直接统计零散的页面有多少个,然后从那三个链表的List Length字段中读出该段占用的区的大小,每个区占用64个页,所以就可以统计出整个段占用的页面。

- 分别计算聚簇索引的叶子结点段和非叶子节点段占用的页面数,它们的和就是
clustered_index_size的值,按照同样的套路把其余索引占用的页面数都算出来,加起来之后就是sum_of_other_index_sizes的值。
一个段的数据在非常多时(超过32个页面),会以区为单位来申请空间,这里头的问题是以区为单位申请空间中有一些页可能并没有使用,但是在统计
clustered_index_size和sum_of_other_index_sizes时都把它们算进去了,所以说聚簇索引和其他的索引占用的页面数可能比这两个值要小一些。
innodb_index_stats
mysql> desc mysql.innodb_index_stats;
+------------------+---------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+------------------+---------------------+------+-----+-------------------+-----------------------------+
| database_name | varchar(64) | NO | PRI | NULL | |
| table_name | varchar(64) | NO | PRI | NULL | |
| index_name | varchar(64) | NO | PRI | NULL | |
| last_update | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| stat_name | varchar(64) | NO | PRI | NULL | |
| stat_value | bigint(20) unsigned | NO | | NULL | |
| sample_size | bigint(20) unsigned | YES | | NULL | |
| stat_description | varchar(1024) | NO | | NULL | |
+------------------+---------------------+------+-----+-------------------+-----------------------------+
8 rows in set (0.00 sec)
| 字段名 | 描述 |
|---|---|
| database_name | 数据库名 |
| table_name | 表名 |
| index_name | 索引名 |
| last_update | 本条记录最后更新时间 |
| stat_name | 统计项的名称 |
| stat_value | 对应的统计项的值 |
| sample_size | 为生成统计数据而采样的页面数量 |
| stat_description | 对应的统计项的描述 |
注意这个表的主键是(database_name,table_name,index_name,stat_name),其中的stat_name是指统计项的名称,也就是说innodb_index_stats表的每条记录代表着一个索引的一个统计项。
SELECT * FROM mysql.innodb_index_stats WHERE table_name = 'single_table';mysql> SELECT * FROM mysql.innodb_index_stats WHERE table_name = 'single_table';
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| test | single_table | PRIMARY | 2025-02-02 10:51:10 | n_diff_pfx01 | 9913 | 20 | id |
| test | single_table | PRIMARY | 2025-02-02 10:51:10 | n_leaf_pages | 62 | NULL | Number of leaf pages in the index |
| test | single_table | PRIMARY | 2025-02-02 10:51:10 | size | 97 | NULL | Number of pages in the index |
| test | single_table | idx_key1 | 2025-02-02 10:51:10 | n_diff_pfx01 | 10000 | 20 | key1 |
| test | single_table | idx_key1 | 2025-02-02 10:51:10 | n_diff_pfx02 | 10000 | 20 | key1,id |
| test | single_table | idx_key1 | 2025-02-02 10:51:10 | n_leaf_pages | 20 | NULL | Number of leaf pages in the index |
| test | single_table | idx_key1 | 2025-02-02 10:51:10 | size | 21 | NULL | Number of pages in the index |
| test | single_table | idx_key2 | 2025-02-02 10:51:10 | n_diff_pfx01 | 10000 | 10 | key2 |
| test | single_table | idx_key2 | 2025-02-02 10:51:10 | n_leaf_pages | 10 | NULL | Number of leaf pages in the index |
| test | single_table | idx_key2 | 2025-02-02 10:51:10 | size | 11 | NULL | Number of pages in the index |
| test | single_table | idx_key3 | 2025-02-02 10:51:10 | n_diff_pfx01 | 10000 | 20 | key3 |
| test | single_table | idx_key3 | 2025-02-02 10:51:10 | n_diff_pfx02 | 10000 | 20 | key3,id |
| test | single_table | idx_key3 | 2025-02-02 10:51:10 | n_leaf_pages | 20 | NULL | Number of leaf pages in the index |
| test | single_table | idx_key3 | 2025-02-02 10:51:10 | size | 21 | NULL | Number of pages in the index |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | n_diff_pfx01 | 10000 | 37 | key_part1 |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | n_diff_pfx02 | 10000 | 37 | key_part1,key_part2 |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | n_diff_pfx03 | 10000 | 37 | key_part1,key_part2,key_part3 |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | n_diff_pfx04 | 10000 | 37 | key_part1,key_part2,key_part3,id |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | n_leaf_pages | 37 | NULL | Number of leaf pages in the index |
| test | single_table | idx_key_part | 2025-02-02 10:51:10 | size | 97 | NULL | Number of pages in the index |
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
20 rows in set (0.01 sec)
- 先查看
index_name列,这个列说明该记录是哪个索引的统计信息,从结果中我们可以看出来,PRIMARY索引(也就是主键)占了3条记录,idx_key_part索引占了6条记录。

针对index_name列相同的记录,stat_name表示针对该索引的统计项名称,stat_value展示的是该索引在该统计项上的值,stat_description指的是来描述该统计项的含义的。
n_leaf_pages:表示该索引的叶子节点占用多少页面。size:表示该索引共占用多少页面。n_diff_pfxNN:表示对应的索引列不重复的值有多少。其中的NN长得有点儿怪呀。
其实NN可以被替换为01、02、03...这样的数字。比如对于idx_key_part来说:
n_diff_pfx01表示的是统计key_part1这一个列不重复的值有多少。
n_diff_pfx02表示的是统计key_part1、key_part2这两个列组合起来不重复的值有多少。
n_diff_pfx03表示的是统计key_part1、key_part2、key_part3这三个列组合起来不重复的值有多少。
n_diff_pfx04表示的是统计key_part1、key_part2、key_part3、id这四个列组合起来不重复的值有多少。

对于普通的二级索引,并不能保证它的索引列值是唯一的,比如对于
idx_key1来说,key1列就可能有很多值重复的记录。
此时只有在索引列上加上主键值才可以区分两条索引列值都一样的二级索引记录。
对于主键和唯一二级索引则没有这个问题,它们本身就可以保证索引列值的不重复,所以也不需要再统计一遍在索引列后加上主键值的不重复值有多少。
比如上边的idx_key1有n_diff_pfx01、n_diff_pfx02两个统计项,而idx_key2却只有n_diff_pfx01一个统计项

- 在计算某些索引列中包含多少不重复值时,需要对一些叶子节点页面进行采样,
sample_size列就表明了采样的页面数量是多少。
对于有多个列的联合索引来说,采样的页面数量是:
innodb_stats_persistent_sample_pages× 索引列的个数。当需要采样的页面数量大于该索引的叶子节点数量的话,就直接采用全表扫描来统计索引列的不重复值数量了。所以可以在查询结果中看到不同索引对应的size列的值可能是不同的。
定期更新统计数据
- 开启
innodb_stats_auto_recalc。
mysql> show variables like '%innodb_stats_auto_recalc%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_stats_auto_recalc | ON |
+--------------------------+-------+
1 row in set (0.02 sec)
系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON,也就是该功能默认是开启的。每个表都维护了一个变量,该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新innodb_table_stats和innodb_index_stats表。
InnoDB默认是以表为单位来收集和存储统计数据的,也可以单独为某个表设置是否自动重新计算统计数的属性,设置方式就是在创建或修改表的时候通过指定STATS_AUTO_RECALC属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_AUTO_RECALC = (1|0);ALTER TABLE 表名 Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
当STATS_AUTO_RECALC=1时,表明想让该表自动重新计算统计数据,当STATS_AUTO_RECALC=0时,表明不想让该表自动重新计算统计数据。如果在创建表时未指定STATS_AUTO_RECALC属性,那默认采用系统变量innodb_stats_auto_recalc的值作为该属性的值。
- 手动调用
ANALYZE TABLE语句来更新统计信息
如果innodb_stats_auto_recalc系统变量的值为OFF的话
mysql> ANALYZE TABLE single_table;
+-------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-------------------+---------+----------+----------+
| test.single_table | analyze | status | OK |
+-------------------+---------+----------+----------+
1 row in set (0.08 sec)
ANALYZE TABLE语句会立即重新计算统计数据,也就是这个过程是同步的,在表中索引多或者采样页面特别多时这个过程可能会特别慢,请不要没事儿就运行一下ANALYZE TABLE语句,最好在业务不是很繁忙的时候再运行。
手动更新innodb_table_stats和innodb_index_stats表
这个还是别乱改吧!看看就行了影响执行计划的!
其实innodb_table_stats和innodb_index_stats表就相当于一个普通的表一样,我们能对它们做增删改查操作。这也就意味着我们可以手动更新某个表或者索引的统计数据。
- 步骤一:更新
innodb_table_stats表。
//强制告诉InnoDB:“此表当前仅有1行数据”。
//此时磁盘上的实际数据并未改变,仅修改了统计信息。
//如果表中实际有更多数据,这会导致优化器基于错误信息生成低效的执行计划。
UPDATE mysql.innodb_table_stats SET n_rows = 1WHERE table_name = 'single_table';
- 步骤二:让
MySQL查询优化器重新加载更改过的数据。
更新完innodb_table_stats只是单纯的修改了一个表的数据,需要让MySQL查询优化器重新加载我们更改过的数据,运行下边的命令就可以了:
//FLUSH TABLE single_table会清除表的缓存,并触发InnoDB重新加载该表的元数据
FLUSH TABLE single_table;
使用SHOW TABLE STATUS语句查看表的统计数据时就看到Rows行变为了1。


基于内存的非永久性统计数据
把系统变量innodb_stats_persistent的值设置为OFF时,之后创建的表的统计数据默认就都是非永久性的了,或者我们直接在创建表或修改表时设置STATS_PERSISTENT属性的值为0,那么该表的统计数据就是非永久性的了。
与永久性的统计数据不同,非永久性的统计数据采样的页面数量是由innodb_stats_transient_sample_pages控制的,这个系统变量的默认值是8。
mysql> show variables like '%innodb_stats_transient_sample_pages%';
+-------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------+-------+
| innodb_stats_transient_sample_pages | 8 |
+-------------------------------------+-------+
1 row in set (0.00 sec)
innodb_stats_method的使用
索引列不重复的值的数量这个统计数据对于MySQL查询优化器十分重要,因为通过它可以计算出在索引列中平均一个值重复多少行,它的应用场景主要有两个:
- 单表查询中单点区间太多,比方说这样:
SELECT * FROM tbl_name WHERE key IN ('xx1', 'xx2', ..., 'xxn');
当IN里的参数数量过多时,采用index dive的方式直接访问B+树索引去统计每个单点区间对应的记录的数量就太耗费性能了,所以直接依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
- 连接查询时,如果有涉及两个表的等值匹配连接条件,该连接条件对应的被驱动表中的列又拥有索引时,则可以使用
ref访问方法来对被驱动表进行查询,比方说这样:
SELECT * FROM t1 JOIN t2 ON t1.column = t2.key WHERE ...;
在统计索引列不重复的值的数量时,索引列中出现NULL值怎么办,比方说某个索引列的内容是这样:
mysql> create table test(t int);
Query OK, 0 rows affected (0.04 sec)mysql> insert into test values(1),(2),(null),(null);
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0mysql> create index idx_t on test(t);mysql> select * from test;
+------+
| t |
+------+
| 1 |
| 2 |
| NULL |
| NULL |
+------+
4 rows in set (0.00 sec)mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.02 sec)
innodb_stats_method的系统变量,相当于在计算某个索引列不重复值的数量时如何对待NULL值。
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。
如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。nulls_unequal:认为所有NULL值都是不相等的。
如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。nulls_ignored:直接把NULL值忽略掉。
mysql> show variables like '%innodb_stats_method%';
+---------------------+-------------+
| Variable_name | Value |
+---------------------+-------------+
| innodb_stats_method | nulls_equal |
+---------------------+-------------+
1 row in set (0.00 sec)
InnoDB以表为单位来收集统计数据,这些统计数据可以是基于磁盘的永久性统计数据,也可以是基于内存的非永久性统计数据。
innodb_stats_persistent控制着使用永久性统计数据还是非永久性统计数据;innodb_stats_persistent_sample_pages控制着永久性统计数据的采样页面数量;innodb_stats_transient_sample_pages控制着非永久性统计数据的采样页面数量;
innodb_stats_auto_recalc控制着是否自动重新计算统计数据。
可以针对某个具体的表,在创建和修改表时通过指定STATS_PERSISTENT、STATS_AUTO_RECALC、STATS_SAMPLE_PAGES的值来控制相关统计数据属性。
innodb_stats_method决定着在统计某个索引列不重复值的数量时如何对待NULL值。
总结
所有结论都需要反复测试!如果有错误欢迎指正!一起努力!
如果喜欢的话,请点个赞吧就算鼓励我一下。
相关文章:
)
MySQL(InnoDB统计信息)
后面也会持续更新,学到新东西会在其中补充。 建议按顺序食用,欢迎批评或者交流! 缺什么东西欢迎评论!我都会及时修改的! 大部分截图和文章采用该书,谢谢这位大佬的文章,在这里真的很感谢让迷茫的…...

Spring Cloud工程搭建
目录 工程搭建 搭建父子工程 创建父工程 Spring Cloud版本 创建子项目-订单服务 声明项⽬依赖 和 项⽬构建插件 创建子项目-商品服务 声明项⽬依赖 和 项⽬构建插件 工程搭建 因为拆分成了微服务,所以要拆分出多个项目,但是IDEA只能一个窗口有一…...
)
MySQL锁类型(详解)
锁的分类图,如下: 锁操作类型划分 读锁 : 也称为共享锁 、英文用S表示。针对同一份数据,多个事务的读操作可以同时进行而不会互相影响,相互不阻塞的。 写锁 : 也称为排他锁 、英文用X表示。当前写操作没有完成前,它会…...

Kafka SASL/SCRAM介绍
文章目录 Kafka SASL/SCRAM介绍1. SASL/SCRAM 认证机制2. SASL/SCRAM 认证工作原理2.1 SCRAM 认证原理2.1.1 密码存储和加盐2.1.2 SCRAM 认证流程 2.2 SCRAM 认证的关键算法2.3 SCRAM 密码存储2.4 SCRAM 密码管理 3. 配置和使用 Kafka SASL/SCRAM3.1 Kafka 服务器端配置3.2 创建…...

使用VCS进行单步调试的步骤
使用VCS对SystemVerilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;always (posedge clk) beg…...
)
计算机网络 应用层 笔记1(C/S模型,P2P模型,FTP协议)
应用层概述: 功能: 常见协议 应用层与其他层的关系 网络应用模型 C/S模型: 优点 缺点 P2P模型: 优点 缺点 DNS系统: 基本功能 系统架构 域名空间: DNS 服务器 根服务器: 顶级域…...

Node.js下载安装及环境配置
目录 一、下载 1. 查看电脑版本,下载对应的安装包 2. 下载路径下载 | Node.js 中文网 二、安装步骤 1. 双击安装包 2. 点击Next下一步 3. 选择安装路径 4. 这里我选择默认配置,继续Next下一步(大家按需选择) 5. 最后inst…...

LeetCode题练习与总结:任务调度器--621
一、题目描述 给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表,用字母 A 到 Z 表示,以及一个冷却时间 n。每个周期或时间间隔允许完成一项任务。任务可以按任何顺序完成,但有一个限制:两个 相同种类 的任务之间必须有长…...

动手学深度学习-3.2 线性回归的从0开始
以下是代码的逐段解析及其实际作用: 1. 环境设置与库导入 %matplotlib inline import random import torch from d2l import torch as d2l作用: %matplotlib inline:在 Jupyter Notebook 中内嵌显示 matplotlib 图形。random:生成…...

鸿蒙HarmonyOS Next 视频边播放边缓存- OhosVideoCache
OhosVideoCache 是一个专为OpenHarmony开发(HarmonyOS也可以用)的音视频缓存库,旨在帮助开发者轻松实现音视频的边播放边缓存功能。以下是关于 OhosVideoCache 的详细介绍: 1. 核心功能 边播放边缓存:将音视频URL传递给 OhosVideoCache 处理后…...

#systemverilog# Verilog与SystemVerilog发展历程及关系
1. Verilog的发展历史 1984年:Gateway Design Automation公司开发了Verilog,最初作为专有语言,用于逻辑仿真和数字电路设计。 1990年:Cadence收购Gateway,Verilog逐步开放,成为行业标准。 1995年(IEEE 1364-1995):首个IEEE标准,即Verilog-1995,定义基础语法和仿真语…...

【集成Element Plus】
集成Element Plus 安装main.ts中全局引入安装图标库 安装 pnpm add element-plusmain.ts中全局引入 import ElementPlus from element-plus; import element-plus/dist/index.css;app.use(ElementPlus);安装图标库 pnpm install element-plus/icons-vue...
)
基于微信小程序的电子商城购物系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

进阶数据结构——双向循环链表
目录 前言一、定义与结构二、特点与优势三、基本操作四、应用场景五、实现复杂度六、动态图解七、代码模版(c)八、经典例题九、总结结语 前言 这一期我们学习双向循环链表。双向循环链表不同于单链表,双向循环链表是一种特殊的数据结构&…...

Kafka分区策略实现
引言 Kafka 的分区策略决定了生产者发送的消息会被分配到哪个分区中,合理的分区策略有助于实现负载均衡、提高消息处理效率以及满足特定的业务需求。 轮询策略(默认) 轮询策略是 Kafka 默认的分区策略(当消息没有指定键时&…...

【hot100】560和为K的子数组
一、思路 初步思路就是采用双循环以每个节点为头节点,然后向后遍历是否有满足和为K的子数组。 然后我们可以采用另一个新的思路,就是可以采用“前缀和的思路”,具体就是如果hashmap中存在sum-k的值,那就可以说明存在一个何为k的…...

【01】共识机制
BTF共识 拜占庭将军问题 拜占庭将军问题是一个共识问题 起源 Leslie Lamport在论文《The Byzantine Generals Problem》提出拜占庭将军问题。 核心描述 军中可能有叛徒,却要保证进攻一致,由此引申到计算领域,发展成了一种容错理论。随着…...
)
树莓派pico入坑笔记,故障解决:请求 USB 设备描述符失败,故障码(43)
今天心血来潮,拿出吃灰的pico把玩一下,打开thonny,上电,然后...... 上电识别不到端口,windows报错,请求 USB 设备描述符失败,故障码(43) 一开始以为是坏了(磕…...

大语言模型的个性化综述 ——《Personalization of Large Language Models: A Survey》
摘要: 本文深入解读了论文“Personalization of Large Language Models: A Survey”,对大语言模型(LLMs)的个性化领域进行了全面剖析。通过详细阐述个性化的基础概念、分类体系、技术方法、评估指标以及应用实践,揭示了…...

线程互斥同步
前言: 简单回顾一下上文所学,上文我们最重要核心的工作就是介绍了我们线程自己的LWP和tid究竟是个什么,总结一句话,就是tid是用户视角下所认为的概念,因为在Linux系统中,从来没有线程这一说法,…...

高效接口限流:基于自定义注解与RateLimiter的实践
在高并发场景下,接口的流量控制是保证系统稳定性和提升性能的关键之一。通过实现接口限流,我们可以有效避免系统在访问高峰时发生崩溃。本文将详细介绍如何通过自定义注解和切面编程结合RateLimiter来实现接口的限流功能,以应对高并发请求。 …...

嵌入式硬件篇---HAL库内外部时钟主频锁相环分频器
文章目录 前言第一部分:STM32-HAL库HAL库编程优势1.抽象层2.易于上手3.代码可读性4.跨平台性5.维护和升级6.中间件支持 劣势1.性能2.灵活性3.代码大小4.复杂性 直接寄存器操作编程优势1.性能2.灵活性3.代码大小4.学习深度 劣势1.复杂性2.可读性3.可维护性4.跨平台性…...

万字长文深入浅出负载均衡器
前言 本篇博客主要分享Load Balancing(负载均衡),将从以下方面循序渐进地全面展开阐述: 介绍什么是负载均衡介绍常见的负载均衡算法 负载均衡简介 初识负载均衡 负载均衡是系统设计中的一个关键组成部分,它有助于…...

使用递归解决编程题
题目:递归实现组合型枚举 从 1−n 这 n 个整数中随机选取 m 个,每种方案里的数从小到大排列,按字典序输出所有可能的选择方案。 输入 输入两个整数 n,m。(1≤m≤n≤10) 输出 每行一组方案,每组方案中…...

Nginx 中文文档
文章来源:nginx 文档 -- nginx中文文档|nginx中文教程 nginx 文档 介绍 安装 nginx从源构建 nginx新手指南管理员指南控制 nginx连接处理方法设置哈希调试日志记录到 syslog配置文件测量单位命令行参数适用于 Windows 的 nginx支持 QUIC 和 HTTP/3 nginx 如何处理…...
)
2.策略模式(Strategy)
定义 定义一系列算法,把它们一个个封装起来,并且使他们可互相替换(变化)。该模式使算法可独立于使用它的客户程序(稳定)而变化(拓展,子类化)。 动机(Motiva…...

浔川AI翻译v6.0延迟上线说明
浔川社团官方联合会关于浔川AI翻译v6.0版本的说明 尊敬的各位用户: 大家好! 首先,衷心感谢大家一直以来对浔川社团官方联合会以及浔川AI翻译的关注与支持。在此,我们怀着十分遗憾的心情向大家发布一则重要通知:原计划推…...

git基础使用--4---git分支和使用
文章目录 git基础使用--4---git分支和使用1. 按顺序看2. 什么是分支3. 分支的基本操作4. 分支的基本操作4.1 查看分支4.2 创建分支4.3 切换分支4.4 合并冲突 git基础使用–4—git分支和使用 1. 按顺序看 -git基础使用–1–版本控制的基本概念 -git基础使用–2–gti的基本概念…...

[paddle] 矩阵相关的指标
行列式 det 行列式定义参考 d e t ( A ) ∑ i 1 , i 2 , ⋯ , i n ( − 1 ) σ ( i 1 , ⋯ , i n ) a 1 , i 1 a 2 , i 2 , ⋯ , a n , i n det(A) \sum_{i_1,i_2,\cdots,i_n } (-1)^{\sigma(i_1,\cdots,i_n)} a_{1,i_1}a_{2,i_2},\cdots, a_{n,i_n} det(A)i1,i2,⋯,in…...
模块)
CH340G上传程序到ESP8266-01(S)模块
文章目录 概要ESP8266模块外形尺寸模块原理图模块引脚功能 CH340G模块外形及其引脚模块引脚功能USB TO TTL引脚 程序上传接线Arduino IDE 安装ESP8266开发板Arduino IDE 开发板上传失败上传成功 正常工作 概要 使用USB TO TTL(CH340G)将Arduino将程序上传…...

CMake的QML项目中使用资源文件
Qt6.5的QML项目中,我发现QML引用资源文件并不像QtWidgets项目那样直接。 在QtWidgets的项目中,我们一般是创建.qrc资源文件,然后创建前缀/new/prefix,再往该前缀中添加一个图片文件,比如:test.png。…...

FBX SDK的使用:读取Mesh
读取顶点数据 要将一个Mesh渲染出来,必须要有顶点的位置,法线,UV等顶点属性,和三角面的顶点索引数组。在提取这些数据之前,先理解FBX SDK里面的几个概念: Control Point 顶点的位置,就是x,y,z…...

无人机PX4飞控 | PX4源码添加自定义uORB消息并保存到日志
PX4源码添加自定义uORB消息并保存到日志 0 前言 PX4的内部通信机制主要依赖于uORB(Micro Object Request Broker),这是一种跨进程的通信机制,一种轻量级的中间件,用于在PX4飞控系统的各个模块之间进行高效的数据交换…...

在C#中,什么是多态如何实现
在C#中,什么是多态?如何实现? C#中的多态性 多态性是面向对象编程的一个核心概念,他允许对象以多种形式表现.在C#中,多态主要通过虚方法,抽象方法和接口来实现. 多态性的存在使得同一个行为可以有多个不同的表达形式 即同一个接口可以使用不同的实例来执行不同的操作 虚方…...

Vue指令v-text
目录 一、Vue中的v-text指令是什么?二、v-text指令内部支持写表达式。 一、Vue中的v-text指令是什么? v-text指令用于设置标签的文本值(textContent)。 二、v-text指令内部支持写表达式。 注意:v-text指令的默认写法会替换全部内容&#x…...

基于springboot+vue的航空散货调度系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...
在Ubuntu18.04上的编译)
FFmpeg(7.1版本)在Ubuntu18.04上的编译
一、从官网上下载FFmpeg源码 官网地址:Download FFmpeg 点击Download Source Code 下载源码到本地电脑上 二、解压包 tar -xvf ffmpeg-7.1.tar.xz 三、配置configure 1.准备工作 安装编译支持的软件 ① sudo apt-get install nasm //常用的汇编器,用于编译某些需要汇编…...

ZK-ALU-在有限域上实现左移
先看在实数域上实现左移, 再看在有限域上的实现 左移-整数 计算机中的左移计算(<< 操作)通常由处理器的硬件电路直接支持,因此效率非常高。在编程语言中,左移操作可以通过位移运算符(例如 C/C 中的 <<&a…...
:表约束,主键自增,序列[oracle])
建表注意事项(2):表约束,主键自增,序列[oracle]
没有明确写明数据库时,默认基于oracle 约束的分类 用于确保数据的完整性和一致性。约束可以分为 表级约束 和 列级约束,区别在于定义的位置和作用范围 复合主键约束: 主键约束中有2个或以上的字段 复合主键的列顺序会影响索引的使用,需谨慎设计 添加…...

PyTorch生态系统中的连续深度学习:使用Torchdyn实现连续时间神经网络
神经常微分方程(Neural ODEs)是深度学习领域的创新性模型架构,它将神经网络的离散变换扩展为连续时间动力系统。与传统神经网络将层表示为离散变换不同,Neural ODEs将变换过程视为深度(或时间)的连续函数。…...

【PyQt】keyPressEvent键盘按压事件无响应
问题描述 通过load ui 文件加载程序时,keyPressEvent键盘按压事件无响应 原因 主要是由于事件处理的方式和窗口的显示方式不正确所导致的。 解决代码 self:这里的self作为loadUi函数的第二个参数,意味着加载的界面将被设置为当前类实例&…...

redis的分片集群模式
redis的分片集群模式 1 主从哨兵集群的问题和分片集群特点 主从哨兵集群可应对高并发写和高可用性,但是还有2个问题没有解决: (1)海量数据存储 (2)高并发写的问题 使用分片集群可解决,分片集群…...

PHP Composer:高效依赖管理工具详解
PHP Composer:高效依赖管理工具详解 引言 在PHP开发领域,依赖管理是项目构建过程中的重要环节。Composer的出现,极大地简化了PHP项目的依赖管理,使得开发者可以更加高效地构建和维护PHP应用程序。本文将深入探讨PHP Composer的使用方法、功能特点以及它在项目开发中的应用…...

【VUE案例练习】前端vue2+element-ui,后端nodo+express实现‘‘文件上传/删除‘‘功能
近期在做跟毕业设计相关的数据后台管理系统,其中的列表项展示有图片展示,添加/编辑功能有文件上传。 “文件上传/删除”也是我们平时开发会遇到的一个功能,这里分享个人的实现过程,与大家交流谈论~ 一、准备工作 本次案例使用的…...
PyTorchTorchvision安装】)
【B站保姆级视频教程:Jetson配置YOLOv11环境(六)PyTorchTorchvision安装】
Jetson配置YOLOv11环境(6)PyTorch&Torchvision安装 文章目录 1. 安装PyTorch1.1安装依赖项1.2 下载torch wheel 安装包1.3 安装 2. 安装torchvisiion2.1 安装依赖2.2 编译安装torchvision2.2.1 Torchvisiion版本选择2.2.2 下载torchvisiion到Downloa…...

relational DB与NoSQL DB有什么区别?该如何选型?
Relational Database(关系型数据库,简称RDB)与NoSQL Database(非关系型数据库)是两类常见的数据库类型。它们在设计理念、数据存储方式、性能优化、扩展性等方面有许多差异。下面我们将会详细分析它们的区别,以及如何根据应用场景进行选型。 一、数据模型的区别 关系型…...

解决对axios请求返回对象进行json化时报“TypeError Converting circular structure to JSON“错误的问题
发现直接对axios请求返回对象进行json化会报"TypeError: Converting circular structure to JSON"错误,而对返回对象下的data属性进行json化就没问题 如果想对循环引用的对象进行json化,解决方案可参考: TypeError: Converting c…...

优化代码性能:利用CPU缓存原理
在计算机的世界里,有一场如同龟兔赛跑般的速度较量,主角便是 CPU 和内存 。龟兔赛跑的故事大家都耳熟能详,兔子速度飞快,乌龟则慢吞吞的。在计算机中,CPU 就如同那敏捷的兔子,拥有超高的运算速度࿰…...

Rust场景示例:为什么要使用切片类型
通过对比 不用切片 和 使用切片 的场景,说明切片类型在 Rust 中的必要性: 场景:提取字符串中的单词 假设我们需要编写一个函数,从一个句子中提取第一个单词。我们将分别展示 不用切片 和 使用切片 的实现,并对比二者的…...

ubuntu直接运行arm环境qemu-arm-static
qemu-arm-static 嵌入式开发有时会在ARM设备上使用ubuntu文件系统。开发者常常会面临这样一个问题,想预先交叉编译并安装一些应用程序,但是交叉编译的环境配置以及依赖包的安装十分繁琐,并且容易出错。想直接在目标板上进行编译和安装&#x…...