G1原理—8.如何优化G1中的YGC
大纲
1.5千QPS的数据报表系统发生性能抖动的优化(停顿时间太小导致新生代上不去)
2.由于产生大量大对象导致系统吞吐量降低的优化(大对象太多频繁Mixed GC)
3.YGC其他相关参数优化之TLAB参数优化
4.YGC其他相关参数优化之RSet、PLAB和大对象的处理优化
1.5千QPS的数据报表系统发生性能抖动的优化(停顿时间太小导致新生代上不去)
(1)一些核心参数介绍
(2)一套线上环境的参数设置
(3)停顿时间太小导致新生代不能扩展分区
(4)问题总结
(5)如何解决
(1)一些核心参数介绍
-Xms/InitialHeapSize,初始堆大小 -Xmx/MaxHeapSize,最大堆大小-Xss,每个线程的堆栈大小 -XX:NewRatio,年轻代(包括Eden和两个Survivor区)与年老代的比值,使用G1时一般此参数不设置,由G1来动态的调整,逐渐调整至最优值-XX:SurvivorRatio,Eden区与Survivor区的大小比值,默认是8 -XX:PretenureSizeThreshold,大对象晋升老年代阈值,默认Region的一半 -XX:MaxTenuringThreshold,新生代晋升老年代年龄阈值,默认是15;晋升到老年代对象的年龄,每个对象在坚持过一次YGC后,年龄就增加1,当超过这个参数值时,就进入老年代-XX:MaxGCPauseMillis,垃圾回收的最长时间(最大暂停时间),默认是200ms;设置GC最大的停顿时间,G1会尽量达到此期望值,如果GC时间超长,那么会逐渐减少GC时回收的区域,以此来靠近此阈值;-XX:InitiatingHeapOccupancyPercent,启动Mixed GC并发标记时的老年代以及即将分配的对象的总内存占用堆内存百分比,默认是45 -XX:G1HeapRegionSize,G1堆内存区块大小,(Xms + Xmx ) /2 / 2048, 不大于32M,不小于1M,且为2的幂; -XX:GCTimeRatio,GC时间占运行时间的比例,G1默认为9;GC时间的计算公式为1/(1+9) = 10%-XX:G1HeapWastePercent,触发Mixed GC的可回收空间百分比,默认是5%;在并发标记之后,我们可以知道old gen regions中有多少空间要被回收,在每次YGC之后和再次发生Mixed GC之前,会检查垃圾占比是否达到此参数,只有达到了,下次才会发生Mixed GC-XX:G1MixedGCLiveThresholdPercent,MixGC的Region中存活对象占比,默认是85%;只有小于此参数,才会被选入CSet(新生代会全部被选取)-XX:G1MixedGCCountTarget,一次并发标记之后,最多执行Mixed GC的次数,默认是8-XX:G1NewSizePercent,新生代占堆的最小比例,默认是5%-XX:G1MaxNewSizePercent,新生代占堆的最大比例,默认是60%-XX:G1OldCSetRegionThresholdPercent,Mixed GC每次回收Region的数量,默认是10%;一次Mixed GC中能被选入CSet的最多老年代Region数量比例-XX:ParallelGCThreads,STW期间,并行GC线程数-XX:ConcGCThreads,并发标记阶段,并行执行的线程数,默认是XX:ParallelGCThreads/4 (2)一套线上环境的参数设置
-XX:InitialHeapSize=20G -XX:MaxHeapSize=20G-Xss1M -XX:+UseG1GC-XX:SurvivorRatio=8 -XX:MaxGCPauseMillis=20 -XX:G1HeapRegionSize=4M-XX:MaxTenuringThreshold=15 -XX:InitiatingHeapOccupancyPercent=45
注意-XX:MaxTenuringThreshold最大只能是15,因为在底层这个年龄值是用了一个4位的2进制来存储的。
这一套参数,是一套非常常规的参数。对于一般大内存多核心的机器来说,并发不大一般都没什么性能问题。但也不是说这样的一组参数没有任何问题,可参考如下案例。
(3)停顿时间太小导致新生代不能扩展分区
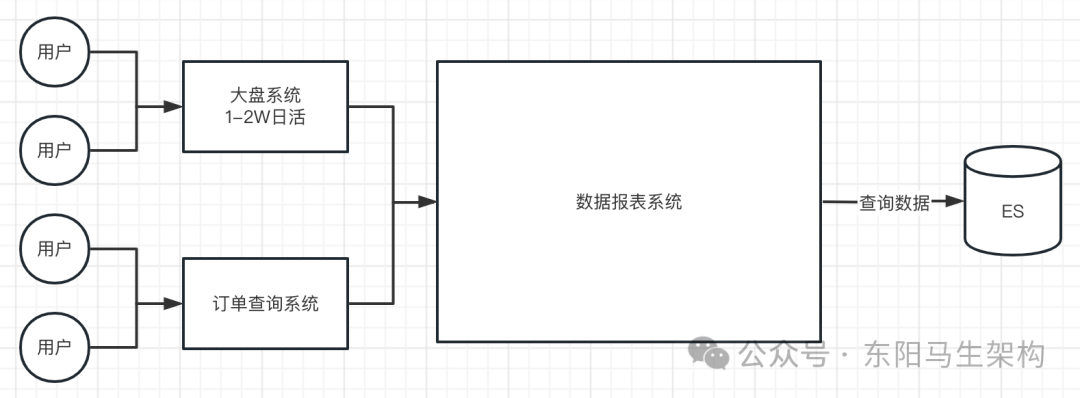
案例的业务背景:一个提供订单数据分析的业务系统。数据报表系统的配置:16核32G,给报表系统的堆内存大小:20G。一般来说,4核8G的机器可以扛1500+QPS。这套系统因为查询数据量大、查询QPS较高,总体的QPS在8K左右。因为报表系统也是集群化部署,单台也就3K-5K之间的QPS,所以整体的性能是完全够用的。
这个系统的职责就是,前置服务是一个订单查询服务 + 一个大盘系统。有大量用户会使用订单查询系统,并根据一些条件来发起一些查询请求。这些查询请求会通过RPC调用这个数据查询服务来查询一套数据报表。但请求相对均衡,对这个系统产生的请求QPS在4K-6K之间(高峰期),大盘系统一般是一些商家在平台的特殊活动时期或交易窗口会开启。总用户量200W,用户量大概在20W左右,日活1W-2W(商家打开大盘)。平常对报表系统的压力,也就是3000QPS的水平,如下图示:
另外数据大盘系统还有一些自动刷新页面,每隔5秒更新一下页面最新的交易数据。这种页面一般都是在交易窗口期,或者是特殊时间段才会开启,类似于秒杀场景的时候做的交易数据监控。

订单数据分析系统的特点:QPS高、查询数据量大、数据会快速成为垃圾数据。这一套数据分析系统,在正常情况下没什么问题,运行的也一直很稳定。
直到有一次特殊的交易窗口,因为这次交易窗口涉及到的商家比较多,活动也比较多,达到了5w日活。打开大盘的人数大大增加,导致产生了8K+的QPS,订单查询的QPS也接近了8000左右。虽然数据报表系统是集群化部署,单台服务分下来的请求量大概在6K+。正常来说,我们服务器的配置已经算不错了,6KQPS还没有达到极限。但不知为什么在数据报表系统运行一段时间后,就会出现一次性能抖动。出现接口查询超时问题,抖动后就会恢复正常,过一段时间又发生抖动。
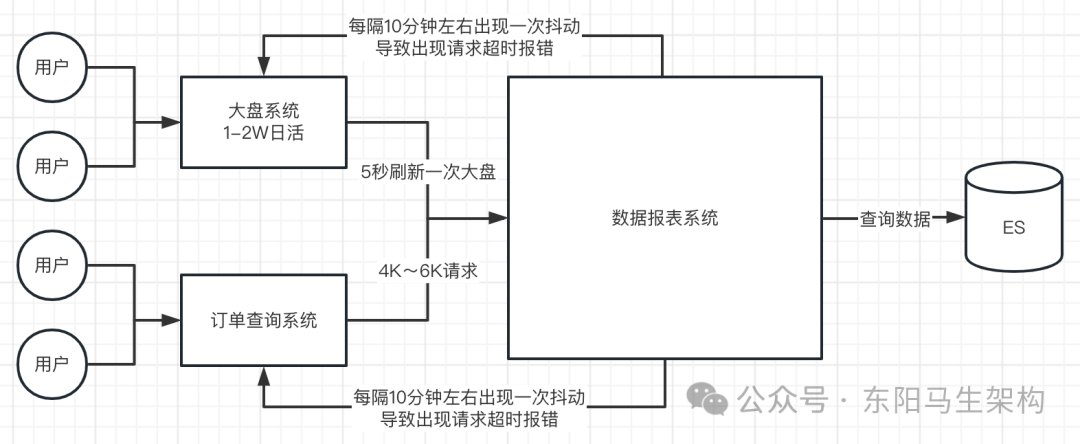
这个现象虽然不会影响系统使用,最多刷新一次就可以了,但用户体验差,于是不得不着手排查原因。
首先登录了服务器,查看了参数配置,具体的参数配置大概就是开头的那一套参数:
-XX:InitialHeapSize=20G -XX:MaxHeapSize=20G-Xss1M -XX:+UseG1GC -XX:SurvivorRatio=8-XX:MaxGCPauseMillis=20 -XX:G1HeapRegionSize=4M-XX:MaxTenuringThreshold=15 -XX:InitiatingHeapOccupancyPercent=45
从参数上来看,暂时没有发现什么问题,接着打开拉下来的GC日志。通过日志发现,虽然给堆内存20G,但Eden区的大小始终是1G~2G。Eden区的总大小在系统运行了很久之后爬到了2G,无法继续往上增加。
而G1本身是一个自动调整新生代区域的回收器,最小内存5% * 20 = 1G。而我们观察的日志中,最大也才给到2G,也就是10%的空间。然后发现很快就会触发一次Mixed GC的过程,几乎每隔几次YGC然后就发生一次Mixed GC。并且每次Mixed GC的分批次垃圾回收的这个过程的次数很多,默认8次。几乎每次Mixed GC混合回收,最终执行的分批次回收都接近8次。每次Mixed GC过程结束后,就会空闲出大量的空间。很显然这个现像是不正常的。
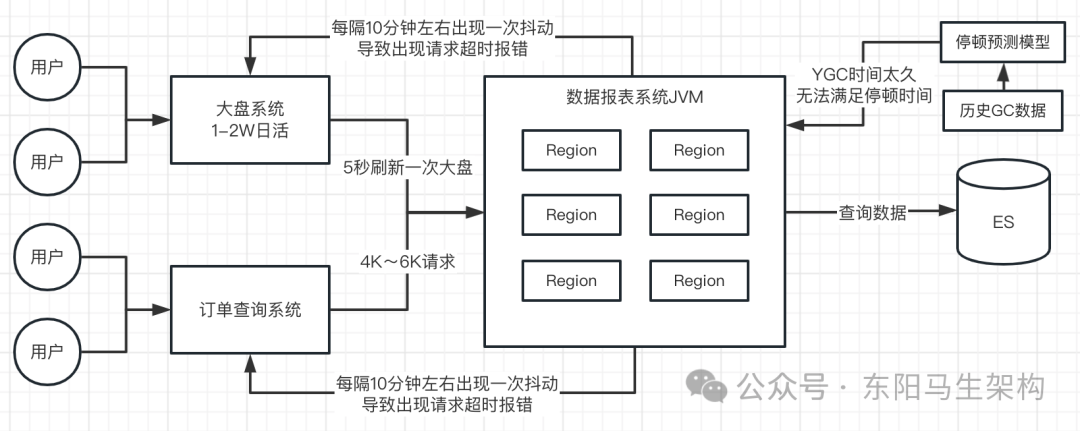
本来以为是参数配置的问题,但是查看参数后,没有发现调整新生代最大空间的这个参数设置。所以一定不是手动配置参数导致的问题,而是G1的自动调整出了问题。除了新生代的5% -60%的比例可自动调整新生代大小外,还有什么因素?
还有一个因素就是停顿预测模型。停顿预测模型 + YGC的时间,是G1动态调整新生代大小的一个依据。预测能够回收的Region的个数是多少—回收能力。根据回收能力,结合YGC的时间 + 停顿时间,就能得到新生代的大小。
假如YGC需要的时间比较久,比如新生代占用了10G内存,每次回收需要的时间大概是在200ms+。此时无法满足停顿时间,只能调小新生代的总大小来尽量满足停顿时间。
所以即使新生代需要扩展,在发生YGC时,结合停顿时间和历史GC数据,就会判定无法满足停顿时间。于是在YGC结束后,会调整Region个数到一个合理范围。这个Region个数不会增大很多,但会达到预测模型中的极限值。然后这个Region个数就会一直在这个附近徘徊。
比如这个案例的情况:从5%上涨到10%时,就一直保持在10%上下浮动。YGC后,新生代Region数量保持在G1认为的一个合理区间。因此新生代的可用内存始终上不去,从而导致QPS高时就会有大量的短周期对象进入老年代,从而导致Mixed GC经常发生。从日志中发现Mixed GC后堆内存会出现空闲情况也可以看出来:其实是有大量对象晋升到老年代,而且这些对象大多数还都是垃圾对象。
(4)问题总结
新生代内存比例始终上不去,导致老年代快速被填满达到45%从而触发Mixed GC,最终导致频繁触发Mixed GC。由于Mixed GC时间较长,包括标记、预清理、选择CSet、最终清理,最终导致系统性能抖动。
(5)如何解决
核心的思路是避免大量短周期存活对象进入老年代,那么应该如何调优呢?
一.调大新生代初始比例是否可行?比如直接把最小值从5%调整到20%;
二.预测模型相关参数?比如设置一个冷门参数,衰减平均差的衰减因子;
三.调整一下停顿时间?调大了会影响响应吗?20ms有必要调大吗?
一.第一个思路—调大新生代比例(不可取)
直接调整新生代的比例,比如初始比例直接调整到20%。然后新生代的Region数量直接就从20%开始了,这样就能解决该问题了。
-XX:InitialHeapSize=20G -XX:MaxHeapSize=20G -Xss1M-XX:+UseG1GC -XX:SurvivorRatio=8-XX:G1NewSizePercent=20 -XX:MaxGCPauseMillis=20-XX:G1HeapRegionSize=4M -XX:MaxTenuringThreshold=15-XX:InitiatingHeapOccupancyPercent=45
这种方式看似还可以,但实际上并不可取,因为这个值只适合在这种特定的时间节点里使用。如果QPS再继续增大,那该怎么办?继续提高这个值到60%吗?到最后需要做的可能就是把新生代的最小值定死在一个比较高的值。也就是到最后做的就是直接定死到60%,最大值和最小值一样。很显然这种方式虽然能暂时解决问题,但无法从根本上解决问题,所以这种方式不可取。
二.第二种思路—调整停顿时间(可取)
由于G1根据停顿时间来预测能回收多少垃圾,以调整新生代Region数量。所以停顿时间的长短,会从根本上影响对新生代的分区。如果停顿时间太短,一定会造成每次回收时,回收不了太多垃圾。而新生代的垃圾回收,只能通过控制新生代的Region数来保证停顿时间。所以可以尝试直接调整这个停顿时间。
-XX:InitialHeapSize=20G -XX:MaxHeapSize=20G-Xss1M -XX:+UseG1GC -XX:SurvivorRatio=8-XX:MaxGCPauseMillis=20 -XX:G1HeapRegionSize=4M-XX:MaxTenuringThreshold=15 -XX:InitiatingHeapOccupancyPercent=45
事实上当时在线上也是这么去做的,因为一开始这个20ms停顿预测时间是考虑到,反正G1能控制停顿时间。所以不希望让接口停顿的时间过长,就简单定了一个特别小的值20ms。
经过重新分析后,最终把停顿时间设定在了300ms。因为报表系统的查询,其实对响应时间的要求没有那么高。并且300ms这个停顿,偶尔发生一次,也不会导致接口的超时。
--XX:InitialHeapSize=20G -XX:MaxHeapSize=20G-Xss1M -XX:+UseG1GC -XX:SurvivorRatio=8-XX:MaxGCPauseMillis=300 -XX:G1HeapRegionSize=4M-XX:MaxTenuringThreshold=15 -XX:InitiatingHeapOccupancyPercent=45
参数调整以后,经过一段时间的运行,以及对GC日志的观察。发现Eden区的数量会随着系统运行不断变大,最终稳定在合理的40%。不管是平时还是高峰期(开启了交易窗口)都没有出现抖动现像了。
(6)总结
系统发生了性能抖动,主要是因为新生代区域过小,导致大量对象进入老年代并快速成为垃圾对象。
优化思路:因为设置的停顿时间不合理导致新生代的大小不合理,从而导致大量对象进入老年代,所以最终的优化手段是调整停顿时间。
由此可见,即使是G1这种非常灵活的回收器,在参数设置上也要慎重。尤其是停顿时间,不一定是停顿时间越小越好。
2.由于产生大量大对象导致系统吞吐量降低的优化(大对象太多频繁Mixed GC)
(1)案例场景介绍
(2)问题原因分析
(3)问题总结
(4)解决思路
(5)总结
(1)案例场景介绍
本次问题发生的场景是在一次需求上线后,该需求是在订单数据分析系统上添加一个功能。这个功能就是简单的数据对比页面,比如价格环比、价格波动、订单量增涨率、增涨环比、平均价格、平均价格环比、中位数、离散分布图等。
有过数据大盘开发经历都知道,这些环比页面和简单数据查询不太一样。
一.数据查询多数还是按照某个周期,或者是某几个条件去查。可通过分页、分日期维度、时间维度来保证每次查询的数据量不会太大。即使是实时监控页面,要展示的数据量也不多,主要的压力来源是QPS。
二.而环比这种操作,需要的是大量历史数据的抽取、计算和对比的。要么就是提前计算好一些数据,然后直接做展示。把最终的结果展示到页面中,这种页面,对内存使用的压力会比较大。
所以在增加这一个页面后,一开始用的人比较少,每天只有几百次请求。随着系统运行,该页面因为能非常全面反映出一段时间的交易情况。于是请求量就开始逐步上升,最终达到高峰期单台服务每秒几百QPS。
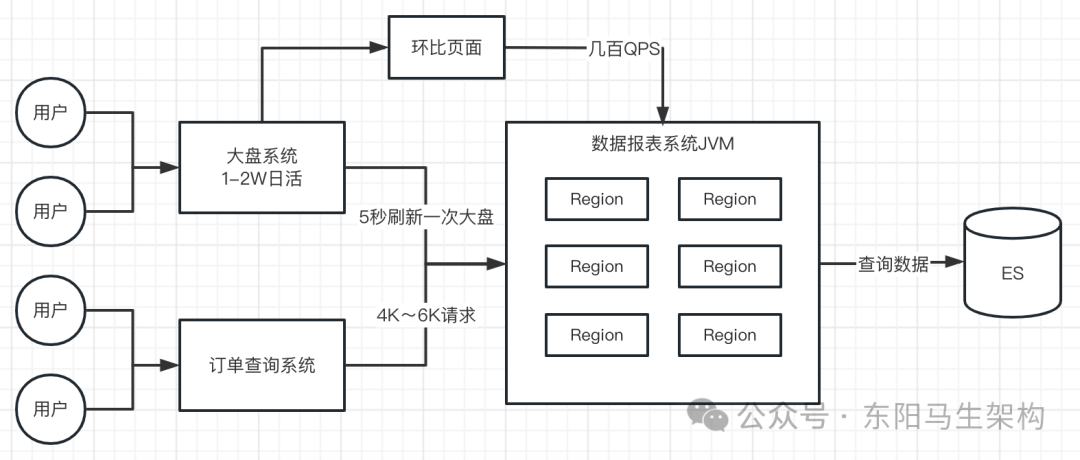
此时,开始有商户反应:有时系统页面刷新要好久才能刷新出来,有时候甚至出现报错,重新刷新才能刷新出数据。这个问题的现象和前面的现象类似。
经过观察GC日志,发现Eden区大小正常,但Mixed GC又开始非常频繁,并且新生代区域的对象增长速度并不快,反而是老年代增长速度非常快。
所以直接导致的结果就是YGC频繁出现Initial Mark,也就是MixedGC的初始标记阶段。然后出现大量的Mixed GC,最终导致系统的整体QPS下降非常多。
QPS下降的直观表现就是:在添加新页面前的单台服务器的QPS可以达到6K。添加了这个页面后,平常问题不大。一到月中和月末就会有大量的商家打开这个环比页面,从而导致QPS骤降至单台3K左右。于是就有用户反馈系统反应慢,偶尔出现超时的现象。
这个现象一开始也尝试修改了一些参数,比如调大停顿时间,包括增大堆内存等。但最终的结果是运行一段时间后,依然会出现上面现象,没有解决问题。
(2)问题原因分析
频繁发生Mixed GC,导致系统QPS下降,并造成大量请求超时,产生问题的原因就是频繁Mixed GC。
那么频繁Mixed GC的原因又是什么呢?除了大量的短周期对象进入老年代外,有没有其他的原因导致大量的对象进入老年代?
在这个案例里面,就存在这样的一个原因。就是在进行报表分析时,由于处理的数据比较多,一次取出来很多数据。导致存储数据的对象直接进行大对象分配,从而导致老年代占比急剧上升。虽然大对象的分配有专门的分区,但它占用的空间是算在老年代空间里的。
正是这个原因才导致了系统经常进入Mixed GC。虽然Mixed GC也会按照满足停顿时间进行,但是频繁发生Mixed GC就导致经常要停顿。导致QPS会被拖的比较慢,因为需要大量是STW去处理GC,并且Mixed GC的回收阶段又会持续很多次(最多8次)。
同时,因为是大对象分配,所以容易出现加锁分配对象的情况,导致这个分配过程的速度也不如对象直接通过TLAB分配的速度快。
当然上面是最终总结出来的结论,当时分析的过程其实还是很曲折的。因为最开始调整停顿时间、堆内存大小等参数没效果。然后又打开了打印Region使用详情的参数,以及开启打印TLAB的日志。最后通过日志发现大量的Region都被标上HUMS类型,才确定这个原因。TLAB日志里会有慢速分配的数据,以及一个线程有多少次慢速分配数据。
开启打印TLAB日志的参数如下:
-XX:+PrintTLAB-XX:+UnlockDiagnosticVMOptions-XX:+G1PrintRegionLivenessInfo
(3)问题总结
由于对象过大,以及出现大量大对象的分配请求,从而拖慢了环比页面。又因大量大对象分配导致Mixed GC频繁触发,导致系统总吞吐量下降。
(4)解决思路
核心思路是:避免大对象分配导致大量短周期的对象进入老年代。
那么应该通过怎样的调整来解决这个问题?大对象的判定规则是什么?能否通过调整TLAB增大TLAB分配对象的次数占总对象分配次数比例?
一.调整Region大小
对象大小达到一个Region大小的一半时,就会进行大对象分配,所以第一个思路就是把Region大小调大。
那么调大的基准是什么呢?调到多大才合适呢?这个就要根据环比页面的功能,看看所分配的对象到底有多大。如果一次性查出10000条数据,就会导致一个List非常大,此时可能就需要进行大对象的分配了。所以要对系统进行分析:List有没有过大、普通的对象有没有过大。
4M的Region是当前的Region大小。经过分析,发现批量查询程序会设置最大查2000条数据,然后分批次查。根据计算,一批数据最大的占用空间为6M,因此可把Region设置成16M。
把Region设置成16M后再进行测试,发现很少出现请求超时了。这样就基本上避免了直接进入大对象分配,解决了频繁Mixed GC的问题。
二.调整TLAB大小
但是还是会有一个并不影响系统使用的小问题。就是压测时发现:刚开始一段时间QPS上不去,会有一个爬升的过程。过了一段时间,QPS才会稳步上升到一个比较高的水准。
考虑到对象分配是优先进行TLAB分配,所以把TLAB的相关内容也打开了。发现TLAB的refill次数非常多,且在开始一段时间的slow分配次数也非常多,很明显这是因为没有进入TLAB分配。
所以经过一段时间的调试,最终把TLAB的初始大小设置到了1M。这样的设置能够直接让系统在启动初期就能达到一个比较高的QPS,即大量的普通查询请求都能直接进入TLAB分配,且允许TLAB自动调整。TLAB的大小一般都是4K或8K,所以要基于实际的系统去调整。
在重新测试后,发现系统到达最高QPS的速度明显快了很多。基本上启动后就可成功达到最高QPS,且能持续很长时间稳定这个QPS。
注意:在调整TLAB时,最好不要指定TLABSize,因为它相当于直接指定TLAB的大小,不允许系统自动调整。如果直接设置了这个值,G1就无法在内存碎片和分配效率直接找平衡点。另外设置了最小值时,不要关闭ResizeTLAB,否则也无法实现自动调整。所以只需要设置一下MinTLABSize=1M即可。
TLAB本身不是G1的专属,是JVM本身就有的一个对象分配的优化。G1只是根据Region分区的这个特点,做了一下自己的适配。
至此这个系统参数基本上就调优完毕了,调优后的参数如下:
-XX:InitialHeapSize=20G -XX:MaxHeapSize=20G-Xss1M -XX:MinTLABSize=1M -XX:+UseG1GC-XX:SurvivorRatio=8 -XX:MaxGCPauseMillis=300-XX:G1HeapRegionSize=16M -XX:MaxTenuringThreshold=15-XX:InitiatingHeapOccupancyPercent=45
(5)总结
一.RegionSize要设置合理,避免出现大量的短周期对象进入大对象分配
二.大量请求不进入TLAB分配会导致QPS下降,所以要调整TLAB大小
由于默认情况下G1会慢慢调整TLAB大小,所以系统一开始可能会出现一段时间的性能爬坡期。因此可以根据系统情况,设置一个稍微大一点的TLAB初始值-XX:MinTLABSize。
3.YGC其他相关参数优化之TLAB参数优化
(1)-XX:+UseTLAB
(2)-XX:+ResizeTLAB
(3)-XX:TLABSize
(4)-XX:MinTLABSize = 64
(5)-XX:TLABWasteTargetPercent = 1
(6)-XX:TLABRefillWasteFraction
(7)-XX:TLABWasteIncreament
(8)-XX:GCLockerRetryAllocationCount
不难发现YGC容易出现性能问题的点,主要就是停顿时间和Region大小。基本上这两个参数设置合理后,很少会出现比较大的性能问题。
此外,在对象分配效率上也有一定的优化空间。比如调大Region大小和调大TLAB,都是为了提升分配对象的效率。
而针对对象分配,最重要的就是TLAB相关的参数,接下来介绍对TLAB相关参数进行优化的一些思路。
注意:TLAB并不是G1的专属,而是JVM本身就有的功能,只不过G1结合Region进行了一些适配。
(1)-XX:+UseTLAB
这个参数表示是否开启TLAB,默认情况下为true,我们一般不是特殊情况不要关闭这个选项。
(2)-XX:+ResizeTLAB
表示是否允许TLAB大小动态调整,G1会动态调整TLAB大小,会基于历史信息(每次分配大小、有多少线程参与对象分配等)进行调整。所以采取动态调整的模式,会让G1的性能更好。
测试发现,在不开启ResizeTLAB的情况下:性能从少量线程到多线程始终都是弱于开启的情况。并且不开启UseTLAB时,性能会非常差。
(3)-XX:TLABSize
这个参数会设置TLAB的值(设置后会固定),并且不能动态调整。如果直接设置这个参数,会导致ResizeTLAB被禁用,可能导致性能下降。
(4)-XX:MinTLABSize = 64
表示设置TLAB的最小值;由于前面案例的那个系统是大数据分析系统,其对象比较大,所以设置了一个比较大的TLAB值。
在实际生产中,这个值需要经过一定的观测才能设置得比较合理。合理的TLAB最小值可让系统更快进入内存碎片与分配效率的平衡期,并且在一定程度上能提升对象分配的效率。
正常来说,设置的值不要太过于奇特,可以设置成4、8、32这样的值。一般来说设置64K作为初始值,就是一个比较合理的值。至于为什么是64K,这个最好结合系统情况去进行分析。
(5)-XX:TLABWasteTargetPercent = 1
这个参数表示TLAB可占用的Eden空间的百分比,默认是1%的Eden空间。增大这个值,可以分配更大的TLAB给线程使用。如果在实际系统运行的过程中线程数量比较多,那么可以调大这个参数。
前面的案例中,因为是16核的机器,系统的压力虽然比较大,由于是大数据系统,线程数量相对来说会少一点,处理时长会长一点。所以调整这个比例的效果,不如调整MinTLABSize。
对于正常QPS压力比较大、线程数较多的系统,可以考虑调大这个参数,这样就可以让每个线程的TLAB不至于太小。
(6)-XX:TLABRefillWasteFraction
指的是TLAB中浪费空间和TLAB块的比例,默认值64,即1/64。可以通过提高TLAB分配的比例来提升对象的分配效率。如果过分追求分配效率,则有可能会导致内存碎片比较大。因为可能会产生大量浪费的内存,这些浪费的内存会被dummy对象填充。
如果要调整此参数,需要观察TLAB日志中的waste中的slow和fast的值。如果这两个值非常大,就说明内存浪费严重,需要适当减少该值。
(7)-XX:TLABWasteIncreament
指的是动态增加浪费空间的字节数,默认值是4。即每次动态增加的时候都增加4字节的浪费空间,一般不需要设置这个值。
(8)-XX:GCLockerRetryAllocationCount
这个参数代表了分配失败的次数阈值。如果超过了这个阈值后,就会直接分配失败,默认值为2。这个值最好不要调整,因为分配2次还是失败的话,基本上说明普通的YGC和Mixed GC已无法清理出足够的空间了。调大该数字可能导致多次无效GC,造成停顿的同时还不能真正解决问题。
4.YGC其他相关参数优化之RSet、PLAB和大对象的处理优化
(1)-XX:ParallelGCThreads
(2)-XX:G1RsetScanBlockSize
(3)-XX:TargetSurvivorRatio
(4)-XX:ParGCArrayScanChunk
(5)-XX:+ResizePLAB
(6)-XX:YoungPLABSize
(7)-XX:OldPLABSize
(8)-XX:ParrallelGCBufferWastePct
(9)G1ReclaimDeadHumongousObjectsAtYoungGC
(10)G1EagerReclaimHumongousObjectsWithStaleRefs
(1)-XX:ParallelGCThreads
STW期间,并行GC线程数,默认值为0,通常来说这个值不需要进行设置。
(2)-XX:G1RsetScanBlockSize
这个值一般是不需要调整的,除非对于个位数毫秒级别的优化有需求,默认值是64。RSet是一个key-value对组成的数据集合,一个Region共享一个RSet。如果引用关系非常复杂,那么RSet会非常大,所以处理时可分批次处理。每次处理一部分,这样就能计算得更快。
不过需要注意的是这个参数和计算机的计算能力是有关的。如果处理器比较强大,计算能力比较强,调大这个参数可以提高效率(相当于减少了取数据的次数)。如果计算能力一般,处理器配置比较差,那么最好不要调整这个参数。因为这个参数如果过大会导致计算速度下降,反而起到反效果。
比如,CPU 1ms能处理128个数据的计算,那么调大了这个值为128。虽然会节省提取数据的时间,但如果CPU 1ms只能处理32个数据的计算,那么肯定还是调小时的整体性能更优。
(3)-XX:TargetSurvivorRatio
这个值参数指的是Survivor区的使用率,默认值是50。达到50%的Survivor区使用率就可能触发对象进入老年代。
即年龄1+年龄2+年龄3 >=50%时,会把年龄3+的对象都升入老年代,这个一般来说也是不需要调整,当然也需要根据具体情况来看。
如果程序中有些对象晋升至老年代的速度过快,可考虑增大该值,减缓对象进入老年代的速度。这其实就是动态年龄判断规则。
这个值还是会对效率有一点点影响,但基本上也是毫秒级别的影响。一般来说这个值会考虑调大,避免对象进入老年代速度过快,并且可以保证Survivor区的内存也能尽可能的被使用。这个参数对性能整体的影响也体现得并不明显。
(4)-XX:ParGCArrayScanChunk
默认值50,指的是如果一个对象数组的大小超过了50,在GC时就不会一次性遍历它,而是每50个元素作为一个chunk去处理。只有最后一次,假如剩余的元素个数是2 * ParGCArrayScanChunk时,才会直接全部处理。
这个参数比较冷门,一般不做调整,但这个参数的调整可起到一些效果。增大该值,处理大数组的效率会略有提升,但是会增加栈溢出的风险。减小该值,可以减小栈溢出风险,但是处理效率会略有下降。
(5)-XX:+ResizePLAB
默认为true,表示在GC结束后,会调整PLAB的大小。PLAB和TLAB类似,只不过TLAB是指对象分配的缓冲。PLAB指在GC过程中,对象复制时的一块缓冲。PLAB和TLAB有同样的效果,PLAB也是用来提升对象分配的效率的,只不过产生的时机不同。
(6)-XX:YoungPLABSize
默认值4096,是新生代PLAB缓存的大小。4096这个数字不是指Byte、K、M这类的单位,而是为了服务于不同JVM而产生的。
在32位JVM中,因为内存单元最少也需要4个字节。一个字节8位,4*8 = 32位,4096 * 4= 16KB。也就是在32位JVM中因为一位要4个字节,所以用4096这个基数乘以4。如果是64位,则需要4096 * 8 = 32KB。
因为该值是GC过程中的复制缓存大小,所以内存充足时可增大该值以提高复制的效率,但有可能增加内存碎片。减小该值可以减少内存碎片,但复制的效率可能会有所下降。
当然也不是绝对,因为在新生代GC中,复制操作是给Survivor区复制。如果PLAB过大,造成内存碎片比较多,会造成Survivor区被快速耗尽。导致复制的效率变低,或者晋升老年代的概率变高。所以这个参数要慎重调大,一般在实际调优中,都需要把这个值调小。
(7)-XX:OldPLABSize
默认值1024,指老年代的PLAB缓存大小。32位JVM中为4KB,64位JVM中为8KB。
注意这个值并不是Mixed GC产生的复制对应的参数,而是从新生代晋升到老年代时PLAB的大小。
所以同样会带来内存碎片的问题。但是一般来说,老年代内存空间比较大,可以容忍更多的内存碎片。所以追求效率的话,可以考虑把这个值调大。
(8)-XX:ParrallelGCBufferWastePct
默认值10,表示从Eden区到Survivor区或者对象晋升至老年代时,如果PLAB剩余的空间小于该比例,且没办法放入一个晋升的新对象,就会丢弃这个PLAB块,同时去申请一个新的PLAB。
所以如果这个值调的比较大,在复制的时候效率会高很多。但是内存浪费会更加严重,类似于TLAB的RefillWaste。
(9)G1ReclaimDeadHumongousObjectsAtYoungGC
这个参数可以控制YGC时是否回收大对象分区,默认是true,表示在YGC时回收大对象。
当然,默认情况下只会去回收失去引用的大对象所在的分区。这个参数在后续更名为XX:+G1EagerReclaimHumongousObjects。如果需要设置的话,开启这个参数即可。
不过有一些研究发现,在YGC时,如果回收大对象可能会引起性能问题,具体的问题地址如下:
https://bugs.openjdk.java.net/browse/JDK-8141637;这个问题其实是:在这个应用里面,虽然每次YGC的耗时并不长,但是每次YGC中,会有20%的耗时是来源于大对象回收的操作。因为它们的系统会创建一些大对象出来,在一些特殊场景,会导致扫描的过程比较长。
如果系统应用出现了大对象回收过程中的耗时占比非常长的情况,可以考虑关闭这个参数。
(10)G1EagerReclaimHumongousObjectsWithStaleRefs
这个参数和上面的参数类似,默认为True。这个参数表示,是否要在YGC时判定那些大对象分区可以回收。如果为true,则表示大对象分区的RSet引用数量小于某阈值时可尝试回收。如果为false,则RSet中的引用数必须是0时,才能回收。
这个参数一般是和上面的参数配和起来使用的,如果上面的那个参数设置为false,是不会在YGC时回收大对象的。
相关文章:

G1原理—8.如何优化G1中的YGC
大纲 1.5千QPS的数据报表系统发生性能抖动的优化(停顿时间太小导致新生代上不去) 2.由于产生大量大对象导致系统吞吐量降低的优化(大对象太多频繁Mixed GC) 3.YGC其他相关参数优化之TLAB参数优化 4.YGC其他相关参数优化之RSet、PLAB和大对象的处理优化 1.5千QPS的数据报表系…...

Hugging Face 的 Trainer类用法
一、使用方法 Hugging Face 的 Trainer 类是一个高级API,用于简化训练、评估和预测的流程。以下是如何使用 Trainer 类的基本步骤: 1. 导入必要的类和函数 首先,您需要导入 Trainer 类以及其他可能需要的类或函数。 from transformers im…...

RabbitMQ前置概念
文章目录 1.AMQP协议是什么?2.rabbitmq端口介绍3.消息队列的作用和使用场景4.rabbitmq工作原理5.整体架构核心概念6.使用7.消费者消息推送限制(work模型)8.fanout交换机9.Direct交换机10.Topic交换机(推荐)11.声明队列…...

IDEA2023版中TODO的使用
介绍:TODO其实本质上还是注释,只不过加上了TODO这几个字符,可以让使用者快速找到。 注意:在类、接口等文件中,注释是使用// 即:// TODO 注释内容 在配置文件中,注释是使用# 即:# TO…...
十二、DMA的基础知识与用法 第二部分)
(STM32笔记)十二、DMA的基础知识与用法 第二部分
我用的是正点的STM32F103来进行学习,板子和教程是野火的指南者。 之后的这个系列笔记开头未标明的话,用的也是这个板子和教程。 DMA的基础知识与用法 二、DMA传输设置1、数据来源与数据去向外设到存储器存储器到外设存储器到存储器 2、每次传输大小3、传…...

windows系统“GameInputRedist.dll”文件丢失或错误导致游戏运行异常如何解决?windows系统DLL文件修复方法
GameInputRedist.dll是存放在windows系统中的一个重要dll文件,缺少它可能会造成部分游戏不能正常运行。当你的电脑弹出提示“无法找到GameInputRedist.dll”或“计算机缺少GameInputRedist.dll”等错误问题,请不用担心,我们将深入解析DLL文件…...

使用分割 Mask 和 K-means 聚类获取天空的颜色
引言 在计算机视觉领域,获取天空的颜色是一个常见任务,广泛应用于天气分析、环境感知和图像增强等场景。本篇博客将介绍如何通过已知的天空区域 Mask 提取天空像素,并使用 K-means 聚类分析天空颜色,最终根据颜色占比查表得到主导…...
)
UML系列之Rational Rose笔记四:时序图(顺序图_序列图)
时序图有很多画法,这基本上能算rose里面要求最乱的一种图了;有些人的需求是BCE模式,这是正常规范点的,有些人就不需要,有些需要用数据库交互,有些不需要;没有一个较为统一的需求;在此…...
)
nginx反向代理http 和 https(案例)
说明:在香港开了一台虚拟机,主要用于将来自国外访问的80和443代理到大陆IDC机房 (1) 定义80和443的upstream 211.155.82.174 是keepalive中VIP对应的公网IP(在国内访问www.playyx.com解析到211.155.82.174) upstream new_server…...

Dify应用-工作流
目录 DIFY 工作流参考 DIFY 工作流 2025-1-15 老规矩感谢参考文章的作者,避免走弯路。 2025-1-15 方便容易上手 在dify的一个桌面上,添加多个节点来完成一个任务。 每个工作流必须有一个开始和结束节点。 节点之间用线连接即可。 每个节点可以有输入和输出 输出类型有,字符串,…...

装备制造业:建立项目“四算”管理:以合同为源头,以项目为手段实现合同的测算、预算、核算与决算的管控体系
尊敬的各位管理层: 大家好!作为装备制造业的 CFO,我今天要向大家汇报的是如何建立项目“四算”管理,即以合同为源头,以项目为手段实现合同的测算、预算、核算与决算的管控体系。在当前市场竞争激烈、成本压力不断增大…...

Centos7将/dev/mapper/centos-home磁盘空间转移到/dev/mapper/centos-root
1、查看存储 df -h文件系统 容量 已用 可用 已用% 挂载点 devtmpfs 126G 0 126G 0% /dev tmpfs 126G 0 126G 0% /dev/shm tmpfs 126G 19M 126G 1% /run tmpfs …...

docker 部署 MantisBT
1. docker 安装MantisBT docker pull vimagick/mantisbt:latest 2.先运行实例,复制配置文件 docker run -p 8084:80 --name mantisbt -d vimagick/mantisbt:latest 3. 复制所需要配置文件到本地路径 docker cp mantisbt:/var/www/html/config/config_inc.php.…...

【Vue - Element 】实现表单输入框的远程搜索功能
需求 表单是一个常见的元素,而在表单中,常常需要用户从大量的数据中选择一个或多个选项。 为了提高用户体验,提供远程搜索功能可以帮助用户快速找到所需的选项,而不是从冗长的下拉列表中手动查找。 以该需求为例,我…...
)
学习华为熵减:激发组织活力(系列之三)
目录 为什么学习华为? 学习华为什么? 一、势:顺势而为,在风口上猪都会飞起来。 二、道:就是认识和利用规律层面,文化和制度创新就是企业经营之道。 三、法:就是一套价值管理的变革方法论。…...

多种vue前端框架介绍
学如逆水行舟,不进则退。 在现今的软件开发领域,Vue.js凭借其高效、灵活和易于上手的特性,成为了前端开发的热门选择。对于需要快速搭建企业级后台管理系统的开发者而言,使用现成的Vue后台管理系统模板无疑是一个明智之举。 本文…...
)
C语言重点回顾(持续更新中~)
个人见解,有异议可以留言~ 第一讲:初识C语言 目录 1.编译和链接 2.main函数 3.库函数 4.关键字 5.字符和字符串 6.转义字符 1.编译和链接 初始的C语言源代码是一个文本文件,要想将一个文本文件变成一个执行文件,需要经过编…...

Navicat Premium 原生支持阿里云 PolarDB 数据库
近日,我司旗下的 Navicat Premium 软件通过了阿里云 PolarDB 数据库产品生态集成认证,这标志着 Navicat 通过原生技术全面实现了对秒级弹性、高性价比、稳定可靠的PolarDB 数据库三大引擎(PolarDB MySQL版、PolarDB PostgreSQL版和 PolarDB f…...

青少年编程与数学 02-006 前端开发框架VUE 25课题、UI数据
青少年编程与数学 02-006 前端开发框架VUE 25课题、UI数据 一、UI数据二、Element Plus处理响应式数据三、Vuetify处理响应式数据 课题摘要:本文探讨了UI数据在用户界面中的重要性和处理方法。UI数据包括展示数据、用户输入、状态数据等,对用户体验和应用交互性有直…...

用css和html制作太极图
目录 css相关参数介绍 边距 边框 伪元素选择器 太极图案例实现、 代码 效果 css相关参数介绍 边距 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>*{margin: 0;padding: 0;}div{width: …...

软件测试入门—功能需求分析:以一个旅游管理系统为例
在软件测试的旅程中,功能需求分析是测试人员构建高质量测试用例的基础,它确保软件的各项功能都能按照预期正常运行。接下来,我们将以一个旅游管理系统为例,详细阐述如何进行功能需求分析,帮助大家更清晰地掌握这一重要…...

深度解析Linux中关于操作系统的知识点
操作系统概述与核心概念 任何计算机系统都包含一个基本的程序集合,成为操作系统OS 操作系统是一款进行软硬件管理的软件 操作系统包括: 内核(进程管理,内存管理,驱动管理) 其他程序(例如数据…...
)
【深度学习】关键技术-激活函数(Activation Functions)
激活函数(Activation Functions) 激活函数是神经网络的重要组成部分,它的作用是将神经元的输入信号映射到输出信号,同时引入非线性特性,使神经网络能够处理复杂问题。以下是常见激活函数的种类、公式、图形特点及其应…...

分布式ID的实现方案
1. 什么是分布式ID 对于低访问量的系统来说,无需对数据库进行分库分表,单库单表完全可以应对,但是随着系统访问量的上升,单表单库的访问压力逐渐增大,这时候就需要采用分库分表的方案,来缓解压力。 …...

电脑有两张网卡,如何实现同时访问外网和内网?
要是想让一台电脑用两张网卡,既能访问外网又能访问内网,那可以通过设置网络路由还有网卡的 IP 地址来达成。 检查一下网卡的连接 得保证电脑的两张网卡分别连到外网和内网的网络设备上,像路由器或者交换机啥的。 给网卡配上不一样的 IP 地…...

Linux 查看内存命令
目录 1. free 2. vmstat 3. top 4. htop 5. /proc/meminfo 1. free free命令是最常用的查看内存使用情况的命令。它显示系统的总内存、已使用内存、空闲内存和交换内存的总量。 free -h -h 选项:以易读的格式(如GB、MB)显示内存大小。…...

无法联网怎么在docker中安装Ribbitmq
如果无法连接互联网,无法在Docker中安装RabbitMQ。但是,您可以使用本地镜像或者手动下载RabbitMQ的Docker镜像并进行安装。 以下是使用本地镜像的步骤: 从可以上网的计算机上拉取RabbitMQ的官方Docker镜像: docker pull rabbitmq:…...

Spring Boot 定时任务搭建及Quartz对比详解
前言: 之前在帮别人搭建定时任务时 被问到为什么不用 Quartz 反而使用 SpringBoot 定时任务 以下是 SpringBoot 定时任务 的使用情况 大家可参考具体情况选择使用 1. 概述: Spring Boot 定时器是基于 Spring Framework 的 Task Scheduling 模块实现的…...

集中式架构vs分布式架构
一、集中式架构 如何准确理解集中式架构 1. 集中式架构的定义 集中式架构是一种将系统的所有计算、存储、数据处理和控制逻辑集中在一个或少数几个节点上运行的架构模式。这些中央节点(服务器或主机)作为系统的核心,负责处理所有用户请求和…...
)
中国数字安全产业年度报告(2024)
数字安全是指,在全球数字化背景下,合理控制个人、组织、国家在各种活动中面临的数字风险,保障数字社会可持续发展的政策法规、管理措施、技术方法等安全手段的总和。 数字安全领域可从三个方面对应新质生产力的三大内涵:一是基于大型语言模型…...

Python Wi-Fi密码测试工具
Python Wi-Fi测试工具 相关资源文件已经打包成EXE文件,可双击直接运行程序,且文章末尾已附上相关源码,以供大家学习交流,博主主页还有更多Python相关程序案例,秉着开源精神的想法,望大家喜欢,点…...

深入探讨DICOM医学影像中的MPPS服务及其具体实现
深入探讨DICOM医学影像中的MPPS服务及其具体实现 1. 引言 在医疗影像的管理和传输过程中,DICOM(数字影像和通信医学)标准发挥着至关重要的作用。除了DICOM影像的存储和传输(如影像存储SCP和影像传输SCP),…...

【Rust自学】12.3. 重构 Pt.1:改善模块化
12.3.0. 写在正文之前 第12章要做一个实例的项目——一个命令行程序。这个程序是一个grep(Global Regular Expression Print),是一个全局正则搜索和输出的工具。它的功能是在指定的文件中搜索出指定的文字。 这个项目分为这么几步: 接收命令行参数读取…...

Cosmos:英伟达发布世界基础模型,为机器人及自动驾驶开发加速!
1. 简介 在2025年消费电子展(CES)上,NVIDIA发布了全新的Cosmos平台,旨在加速物理人工智能(AI)系统的开发,尤其是自主驾驶车辆和机器人。该平台集成了生成式世界基础模型(WFM&#x…...

【Docker】保姆级 docker 容器部署 MySQL 及 Navicat 远程连接
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. docker 容器部署 MySQL1.1 拉取mysql镜像1.2 启动容器1.3 进入容器1.4 使用 root 用户登录 2. Navicat 连…...

Java IDEA中Gutter Icons图标的含义
前些天发现了一个蛮有意思的人工智能学习网站,8个字形容一下"通俗易懂,风趣幽默",感觉非常有意思,忍不住分享一下给大家。 👉点击跳转到教程 前言: 很多人刚开始用IDEA来学习编程,会发现下面这些图标。 但是…...

Broker收到消息之后如何存储
1.前言 此文章是在儒猿课程中的学习笔记,感兴趣的想看原来的课程可以去咨询儒猿课堂《从0开始带你成为RocketMQ高手》,我本人觉得这个作者还是不错,都是从场景来进行分析,感觉还是挺适合我这种小白的。这块主要都是我自己的学习笔…...

RuoYi框架上传图片或文件到阿里云OSS详细教程
为了提供一个更加详细的教程,我们将深入探讨每个步骤,并添加一些额外的细节和最佳实践建议。以下是关于如何在Ruoyi框架中集成阿里云OSS实现文件上传功能的详尽指南。 详细教程 环境准备 注册阿里云账号:访问阿里云官网并创建一个账户。创…...

【论文笔记】SmileSplat:稀疏视角+pose-free+泛化
还是一篇基于dust3r的稀疏视角重建工作,作者联合优化了相机内外参与GS模型,实验结果表明优于noposplat。 abstract 在本文中,提出了一种新颖的可泛化高斯方法 SmileSplat,可以对无约束(未标定相机的)稀疏多…...

python实现收到一封邮件时自动触发执行读取邮件内容及后续操作
要实现收到一封邮件时自动触发执行 getEmailData(),可以结合定时任务或实时事件监控机制来实现。以下是两种常用的方法: 方法 1:轮询方式(定时检测) 使用 schedule 或 time.sleep 循环定期检测收件箱: i…...
)
【Vim Masterclass 笔记12】S06L26 + L27:Vim 文本的搜索、查找及替换同步练习(含点评课)
文章目录 S06L26 Exercise 07 - Search, Find, and Replace1 训练目标2 操作指令2.1. 打开 search-practice.txt 文件2.2. 同一行内的搜索练习2.3. 当前文件内的搜索练习2.4. 单词搜索练习2.5. 全局替换练习 3 退出 Vim S06L27 同步练习点评课 写在前面 Vim 的文本检索、查找与…...

YOLOv11 OBB 任务介绍与数据集构建要求及训练脚本使用指南
YOLO(You Only Look Once)是一个高效且广泛应用于目标检测任务的深度学习框架。在目标检测任务中,传统的边界框(AABB)通过四个参数来定义目标的位置信息:中心坐标、宽度、高度以及目标的旋转角度。然而&…...

Leecode刷题C语言之超过阈值的最小操作数②
执行结果:通过 执行用时和内存消耗如下: // 最小堆的节点结构体 typedef struct {long long* heap;int size;int capacity; } MinHeap;// 初始化最小堆 MinHeap* createMinHeap(int capacity) {MinHeap* minHeap (MinHeap*)malloc(sizeof(MinHeap));minHeap->s…...
)
【Linux】11.Linux基础开发工具使用(4)
文章目录 3. Linux调试器-gdb使用3.1 背景3.2 下载安装3.3 使用gdb查询3.4 开始使用 3. Linux调试器-gdb使用 3.1 背景 程序的发布方式有两种,debug模式和release模式 Linux gcc/g出来的二进制程序,默认是release模式 要使用gdb调试,必须…...

Cesium中的CustomDataSource 详解
Cesium CustomDataSource 详解 在 Cesium 中,CustomDataSource 是一个强大的类,用于处理自定义的地理数据。它提供了一种方法,可以通过程序方式添加、管理和更新动态的地理实体,而无需依赖外部数据格式(如 GeoJSON 或…...

win32汇编环境,窗口程序中组合框的应用举例
;运行效果 ;win32汇编环境,窗口程序中组合框的应用举例 ;比如在窗口程序中生成组合框,增加子项,删除某项,取得指定项内容等 ;直接抄进RadAsm可编译运行。重点部分加备注。 ;以下是ASM文件 ;>>>>>>>>>>>>…...

Wireshark 使用教程:网络分析从入门到精通
一、引言 在网络技术的广阔领域中,网络协议分析是一项至关重要的技能。Wireshark 作为一款开源且功能强大的网络协议分析工具,被广泛应用于网络故障排查、网络安全检测以及网络协议研究等诸多方面。本文将深入且详细地介绍 Wireshark 的使用方法&#x…...
)
菜品管理(day03)
公共字段自动填充 问题分析 业务表中的公共字段: 而针对于这些字段,我们的赋值方式为: 在新增数据时, 将createTime、updateTime 设置为当前时间, createUser、updateUser设置为当前登录用户ID。 在更新数据时, 将updateTime 设置为当前时间…...

Scira - 一个极简的开源 AI 搜索引擎
支持实时搜索 、学术论文分析 、社交媒体洞察 、YouTube 搜索 、航班追踪 、电影搜索,功能倒是挺多。 但是目前只支持 xAI 的 Grok 还不能换模型,不过用的 Vercel SDK 支持下 DeepSeek 应该很容易 https://index.html.zone/ai/scira...

利用源码安装httpd
方法一: 1,下载源码 [rootopenEuler-1 ~]# wget https://archive.apache.org/dist/httpd/httpd-2.4.46.tar.gz [rootopenEuler-1 ~]# ls anaconda-ks.cfg httpd-2.4.46.tar.gz mysql-8.0.36-linux-glibc2.12-x86_64.tar.xz 2,进行压缩 […...