(2024,影响 LLaVA 性能的因素,LLM 模型规模,视觉输入配置(网格/token 数),AnyRes,数据量/质量)
LLaVA-NeXT: What Else Influences Visual Instruction Tuning Beyond Data?
![]()
目录
0. 简介
1. 架构
1.1 语言模型
1.2 视觉编码器
2. 视觉表示
2.1 训练时分辨率和 token 数量配置
2.2 LLM 扩展的有效性
2.3 放大原始图像
2.4 推理时分辨率和 token 数量配置
2.5 池化方法
3. 训练策略
3.1 语言-图像对齐
3.2 高质量知识学习
0. 简介
视觉指令调优(Visual instruction tuning)在大型多模态模型(LMM)的发展中起着至关重要的作用,这些模型旨在跟随(follow)人类意图完成各种野外计算机视觉任务。在这一研究领域,研究一贯表明数据驱动方法在取得成功中的有效性,强调高质量指令数据的重要性,正如 LLaVA 系列的进展所示,包括 LLaVA-1.0、LLaVA-1.5 和最新版本 LLaVA-NeXT(分别于 1 月和 5 月发布)。特别是,最大的 LLaVA-NeXT-110B 模型在选定基准测试中表现接近 GPT4-V,这是通过一种高效的训练方案实现的。然而,关于阐明训练方案中额外因素影响的研究较少。这引发了一个问题:除了指令数据本身,视觉指令调优还受到哪些因素的影响?
在本文中,我们呈现了一项全面的消融研究,旨在解决这些被忽视的方面并增强先前的见解:
- 架构:LLaVA 架构由一个预训练的 LLM 和一个预训练的视觉编码器组成。与图像编码器相比,LLM 模型规模的扩展在提升性能方面更为有效。而后者的成功更多与其视觉输入配置(分辨率、token 数量)相关,而非模型规模。
- 视觉表示(Visual Representations):视觉信号的表示与原始像素空间的分辨率以及特征空间中的 token 数量有关。两者的扩展都会提高性能,特别是在需要视觉细节的任务上。为了在性能和成本之间取得平衡,我们观察到分辨率的扩展比 token 数量的扩展更有效,并推荐使用带有池化的 AnyRes 策略。
- 训练策略:与之前仅关注视觉指令调优阶段的 LLaVA 系列不同,我们探索了训练策略在 LLaVA 模型早期生命周期中的影响,具体通过改变训练数据量、质量和可训练模块。我们的发现表明,纳入一个专注于从高质量知识中学习的阶段,比使用低质量的网络规模数据更为重要。具体而言,这涉及使用 LLaVA-NeXT-34B 重新标注的合成高质量数据来训练整个模型。
由于目前没有现有的基准(Benchmark)来评估模型的图像详细描述能力,而我们认为这一能力对于模型的发展至关重要。例如,它可以决定模型是否能够作为数据重新标注(re-captioning)任务的高效详细描述生成器。为了满足这一需求,我们构建了两个任务:
- 图像详细描述任务:我们收集了 100 个英文详细描述实例和 200 个中文详细描述实例,要求模型生成高度详细的描述。我们使用 GPT-4V 来协助评分。
- 视频详细描述任务:为了评估模型的时间序列详细描述能力,我们参考了 VideoChatGPT 评估并选择了 499 个问题。模型生成详细描述,然后使用 GPT-3.5-Turbo 和真实标签进行比较评分。
1. 架构
LLaVA 由两个预训练模块组成:LLM 和视觉编码器。由于这两个模块分别暴露于大量训练数据和利用计算资源的模型生命周期,它们都能够编码丰富的知识。因此,LMM的扩展行为(在模型大小和数据量方面)可能与从零开始训练的 LLM 有所不同 [1,2,3],尤其是在仅考虑 LMM 训练阶段,而不考虑 LLM 和视觉编码器成本的情况下。
对于 LMM,我们在之前的文章中展示了更强大的 LLM 能在实际中带来更好的多模态性能,证明了LLaVA-NeXT-110B的显著改进。在本问中,我们系统地研究了模型大小扩展行为。
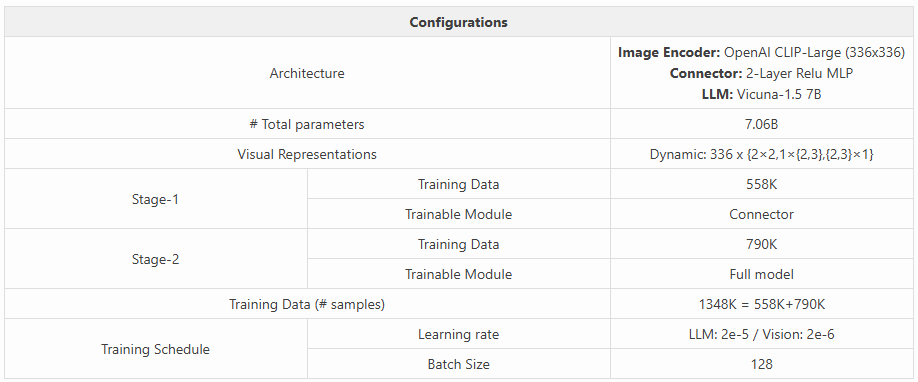
1.1 语言模型
我们报告了一些有趣的观察结果和对 LMM 实践者有用的建议:
更大的语言模型。多模态性能与语言模型性能密切相关,扩展 LLM 直接在所有基准测试中展示了多模态性能的提升。这表明,开发更强大的语言模型能力能够积累更丰富的语言知识,可能由于跨模态的泛化,轻松提高模型的多模态能力。这可能减少对多模态任务的额外训练需求,而高质量数据可能更难获得。
更低的训练损失。更大的语言模型收敛更快,容易达到更低的损失值。这可能是因为更大的模型具有更强的能力来学习更复杂的模式并存储更丰富的语言知识,从而分别导致更快的收敛和更好的泛化。通常,我们观察到训练曲线可以用来监控学习过程:更低的损失值表示在多个任务上有更好的性能。
学习率调整。更大的语言模型需要更小的学习率,以避免训练动态不稳定的问题。我们观察到,训练曲线中的波动通常意味着性能变差,即使损失值已经收敛到相同的水平。降低学习率可以缓解这个问题。我们以(LLM,视觉)的格式,针对 LLM 和视觉编码器尝试了一系列的学习率组合,包括(2e-5,2e-6),(2e-5,1e-6),(1e-5,2e-6),(1e-5,1e-6),(5e-6,1e-6)和(5e-6,5e-7)。我们发现,视觉编码器的学习率应始终比 LLM 解码器的学习率小 10 倍或 5 倍,以稳定训练。尽管我们没有观察到在将 LLM 的学习率从 2e-5 调整到 5e-7 时损失值的显著差异,但最终在评估基准上的表现却有显著差异。
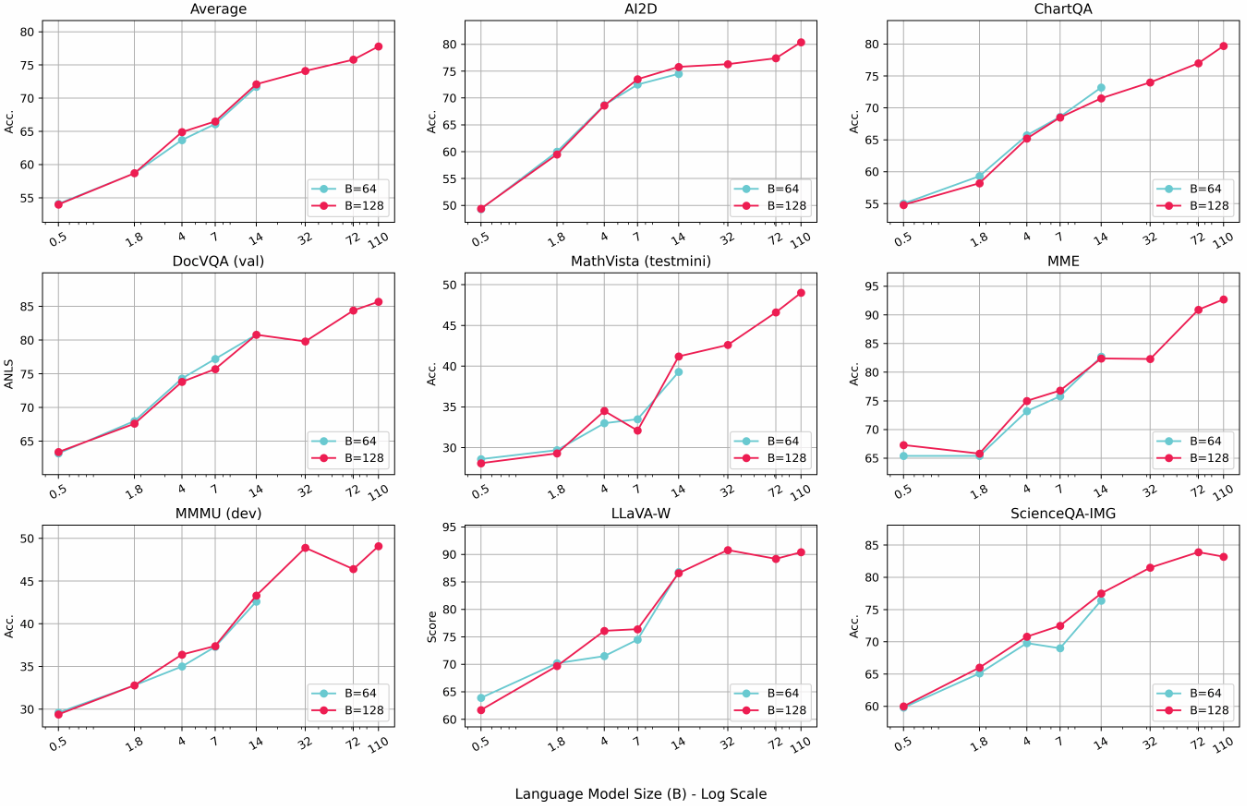
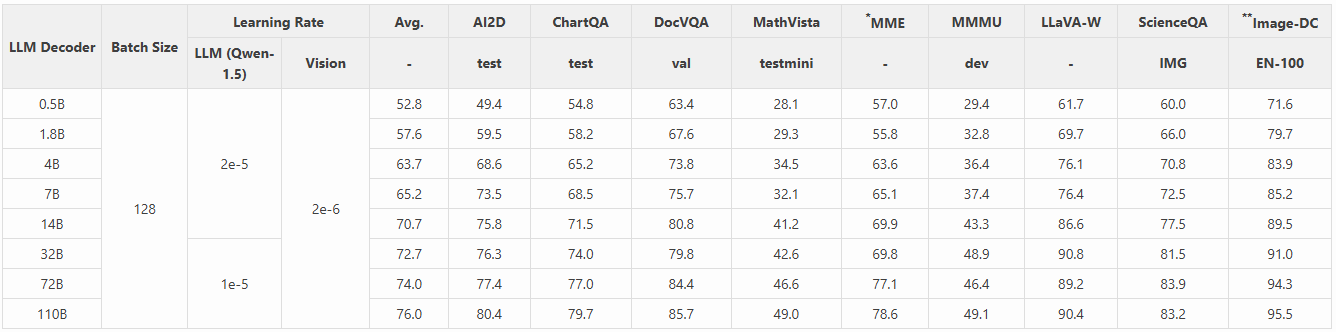
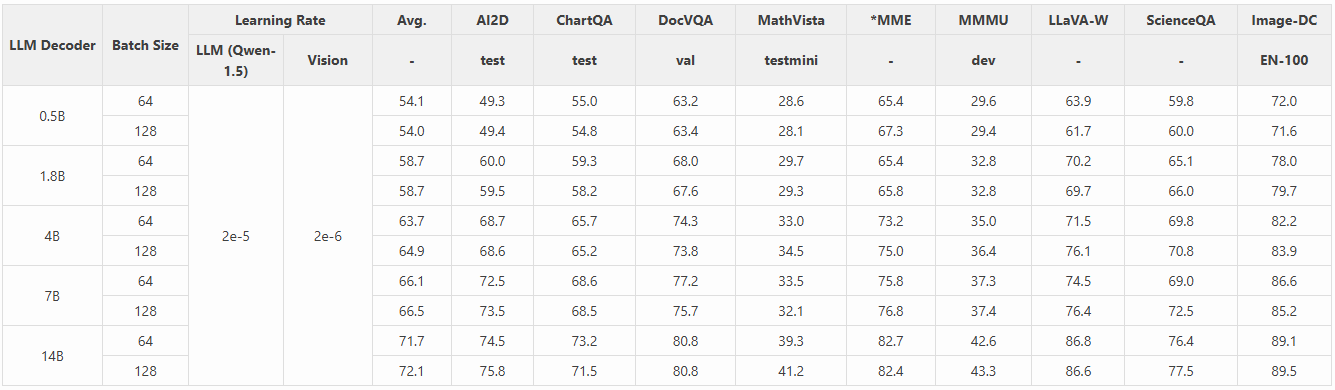
1.2 视觉编码器
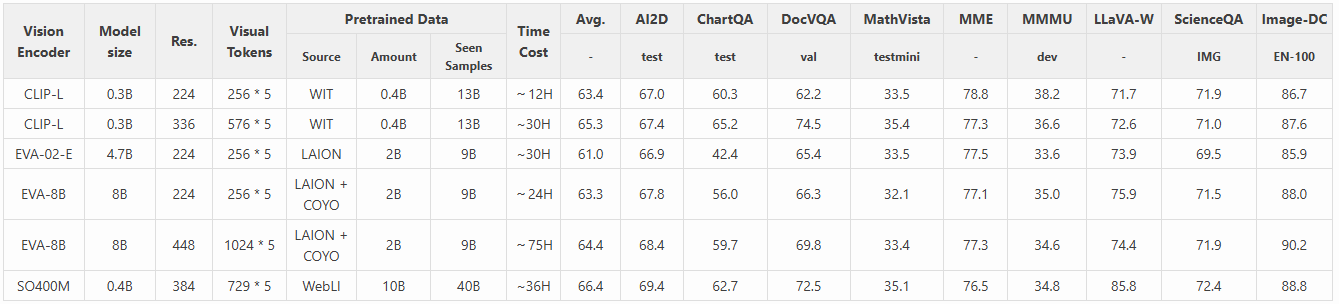
我们在以下实验中考虑使用不同的视觉编码器进行进一步研究。在上表中,我们突出了各种视觉编码器之间的差异。这些差异包括编码器模型大小、分辨率、视觉 token 数量和预训练数据。当将它们集成到 LMM 中时,所需的 LLM 训练时间也有显著差异。
我们得出以下观察结果:
- 对于 LMM 中的视觉编码器,视觉表示(分辨率、token 数量)和预训练数据比模型大小起着更重要的作用。这是因为视觉表示能够编码更多的视觉细节,而预训练数据则使模型能够编码更多的视觉知识。与对比损失的模型大小相比,扩展效果较小。
- 作为成本与性能的折衷,SO400M 显示出最显著的优势。其大规模的预训练数据(WEBLI-10B)、高预训练分辨率(384 x 384)以及它能够表达的视觉 token 数量,很可能是其在集成到 LMM 中时表现优越的原因。
2. 视觉表示
2.1 训练时分辨率和 token 数量配置
视觉表示既与原始像素空间中的分辨率有关,也与特征空间中的 token 数量有关。扩展这两者中的任意一个都能提高性能,但也会引入计算开销。本节旨在研究最佳的(分辨率,token 数量)配置,以实现性能与成本的平衡。
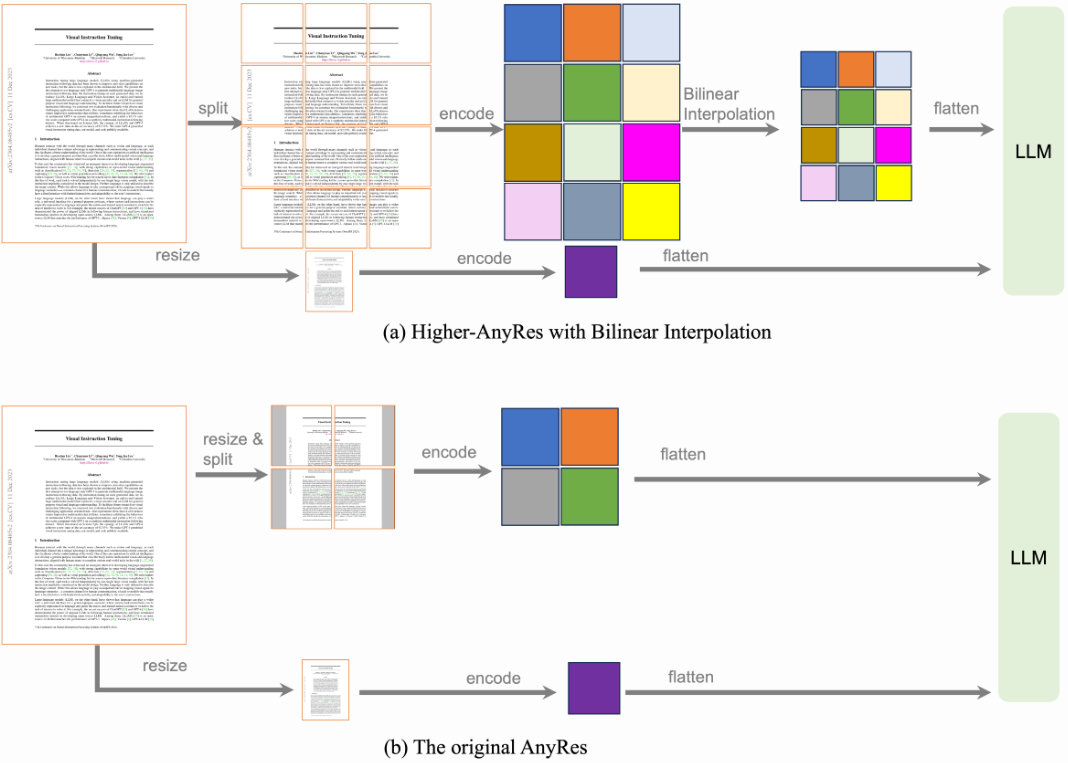
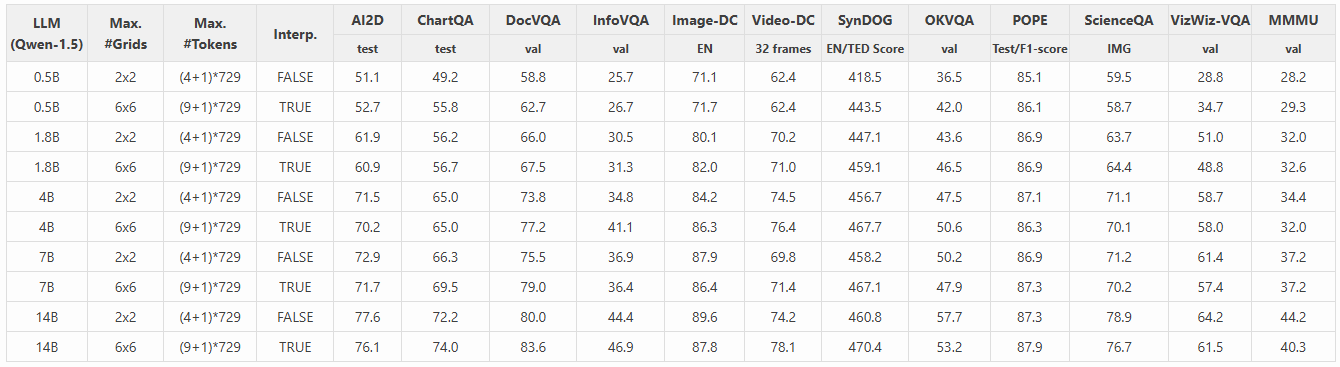
之前的 AnyRes 技术采用网格配置 {2x2, 1x{2,3,4}, {2,3,4}x1},以适应不同分辨率的图像,同时保持数据效率。然而,这种网格配置每张图像最多支持 4 个网格,限制了其在需要更多网格的情况下的能力,例如处理文档数据和长视频。如图(b)所示,对于分辨率高于最大支持分辨率(768x768)的图像,原始 AnyRes 方法将其调整为 768x768。这个调整会导致高分辨率图像的细节丧失。为了解决这个问题,我们探索了更高分辨率的网格配置,如图(a)所示,其中图像被划分为更多的网格。此外,为了保持效率,我们提出了一种阈值双线性插值策略,以防止过多的视觉 token 被输入到 LLM 中。
阈值双线性插值(thresholded bilinear interpolation)。对于具有宽度 a、长度 b 和每个网格的#token T 的网格配置的 AnyRes,总视觉 token 的数量为 L = (a x b +1) x T。在此基础上,我们考虑一个阈值 τ,并在需要时通过双线性插值来减少每个网格的 #token 数量。
![]()
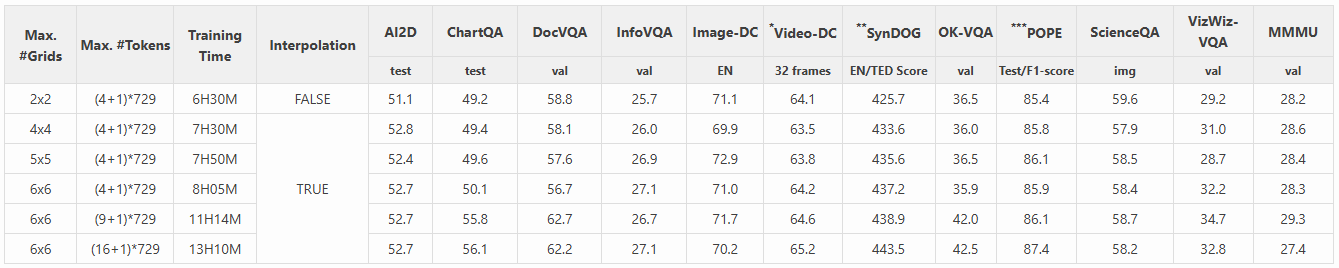
我们将 AnyRes 的最大网格数从 2×2 增加到 6×6,以更好地支持更高的分辨率,并观察到增加网格数量可以提高需要读取图像细节的任务的性能,例如 InfoVQA 和 SynDOG(en)。它还改善了 32 帧的视频详细描述性能。这是因为在训练过程中观察到更长的视觉序列,这种能力可以通过 zero-shot 模态迁移来改善视频任务,基于 LLaVA-Next-Video 中的见解。
与增加最大 #token 的成本相比,增加最大分辨率会导致训练时间的轻微增加。在保持最大网格数为 6×6 的情况下,增加最大 #token 可以显著提高 OCR 能力,例如 ChartQA 和 DocVQA。我们建议优先考虑分辨率,而不是 #token,作为丰富视觉表示的更好权衡。
2.2 LLM 扩展的有效性
我们进一步验证了来自新视觉表示的性能提升随着 LLM 规模的扩展而持续存在。这通过观察 InfoVQA、ChartQA、DocVQA、VDD(32 帧)和 SynDOG 上的一致性改进得到了确认。
2.3 放大原始图像
请注意,在我们更高的 AnyRes 方法中,我们并没有直接增加图像分辨率。相反,我们使用支持更高分辨率的网格配置。我们探讨了增加图像分辨率如何影响性能和训练时间。如以下表格所示,增加图像分辨率显著增加了训练时间,但并没有提高性能。

高效策略。对于需要高效率的应用,我们探索了具有成本效益的策略。在以下实验中,我们将每个网格的特征图池化到 t' = 1/4t。这显著降低了训练成本,尽管对高分辨率数据集(如 InfoVQA、ChartQA 和 DocVQA)的性能有较大影响。然而,在其他数据集上的性能要么保持不变,要么仅略有下降。因此,如果需要在低分辨率数据上实现高效率,可以考虑这一设置。

2.4 推理时分辨率和 token 数量配置
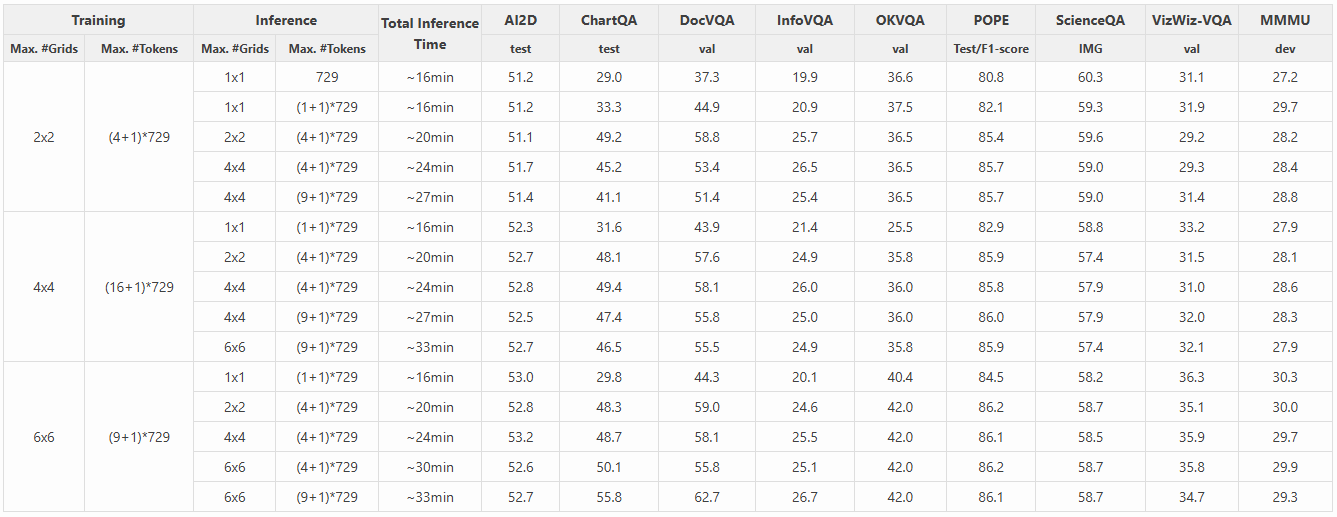
我们研究了在推理过程中调整 AnyRes 网格的最大数量和视觉 token 数量对性能指标和推理时间的影响。研究结果表明,在推理期间增加 AnyRes 网格的数量会显著延长推理时间,但性能没有相应的提升。相反,在推理过程中减少 AnyRes 网格的数量会降低性能,特别是在高分辨率数据集上,但对其他数据集的影响可以忽略不计。
值得注意的是,我们的研究揭示了一个引人注目的发现:当推理的 AnyRes 网格最大数量设置为 1x1 时,采用 AnyRes 策略(即向 LLM 输入 (1+1)*729 个视觉 token)比非 AnyRes 策略(仅使用 729 个视觉 token)表现更优。令人有趣的是,尽管这两种策略的推理时间相似,但 AnyRes 策略表现明显更好。这一发现凸显了在推理过程中采用 AnyRes 策略以提升性能的重要性。
2.5 池化方法
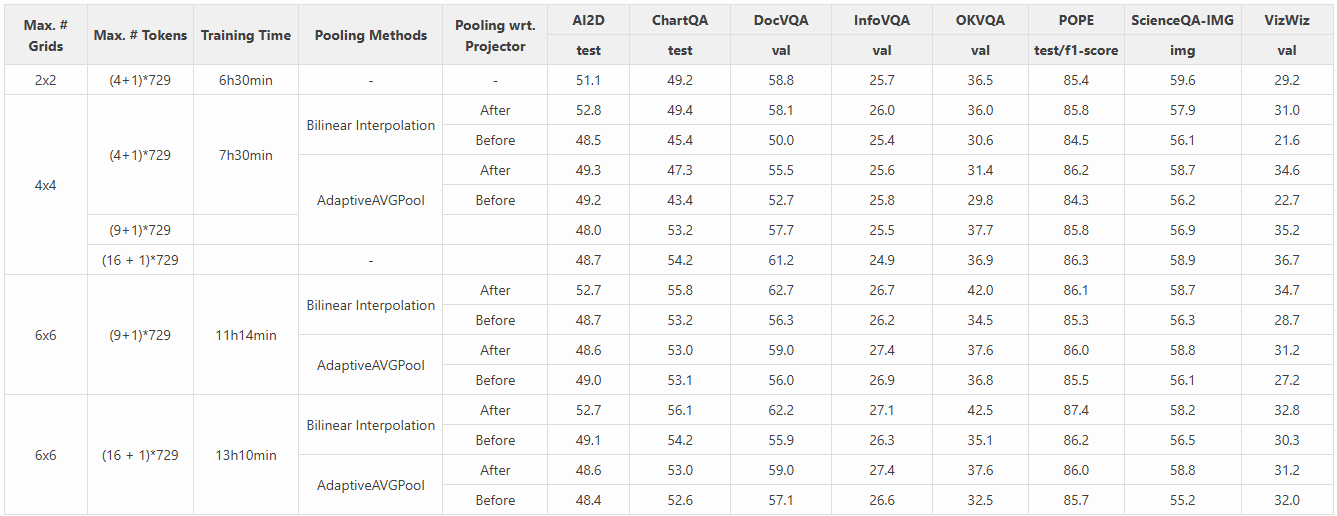
我们基于阈值池化策略比较了自适应平均池化和双线性插值作为池化方法的表现。结果表明,在阈值池化策略下,双线性插值比自适应平均池化表现更佳。我们还比较了在投影器之前和之后进行池化的效果,发现投影器之后的池化表现更好。
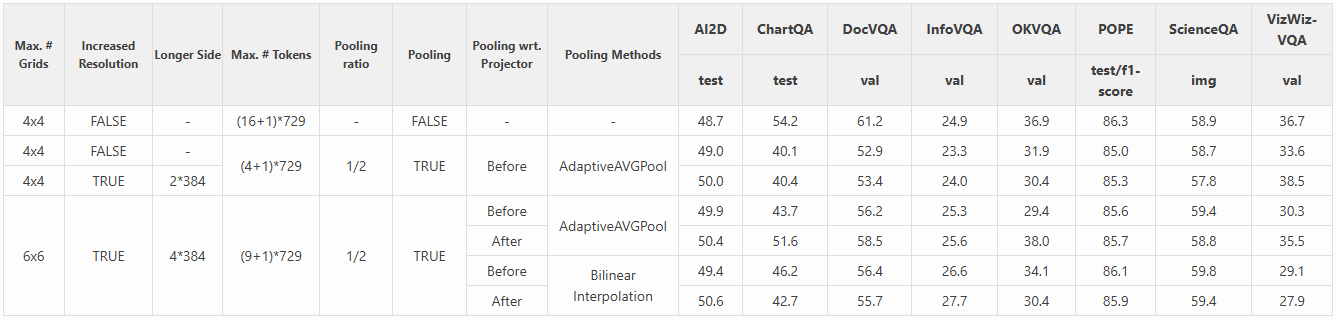
然后,我们在固定池化率(1/2)下比较了两种池化方法。
- 在第一行中,最大网格数为 4 x 4 = 16,没有提升分辨率或进行池化。
- 在第二行中,我们未提升分辨率,而是直接将特征图池化到原始大小的 1/2,性能显著下降。
- 在第三行中,我们提升了分辨率,使较长边至少达到 2 x 384 = 768。相比第二行,结果有所提升。
- 接着,我们将最大网格数增加到 6 x 6 = 36,并将较长边至少提升到 4 x 384 = 1536。在第四到第七行中,我们对更多网格数和更高分辨率重复了这一过程。
结果表明,随着网格数量和分辨率的增加,性能显著提高。
3. 训练策略
为了使 LLM 具备多模态能力,我们确定了三项关键功能,并将其系统性地分为三个不同的学习阶段,以进行消融研究。与大多数现有研究一样,先前的 LLaVA 模型主要针对新场景和性能改进探索第二阶段。然而,前两个功能较少被研究,因此成为本部分的主要研究重点。
- 阶段 1:语言-图像对齐。
- 阶段 1.5:高质量知识学习。
- 阶段 2:视觉指令调优。
3.1 语言-图像对齐
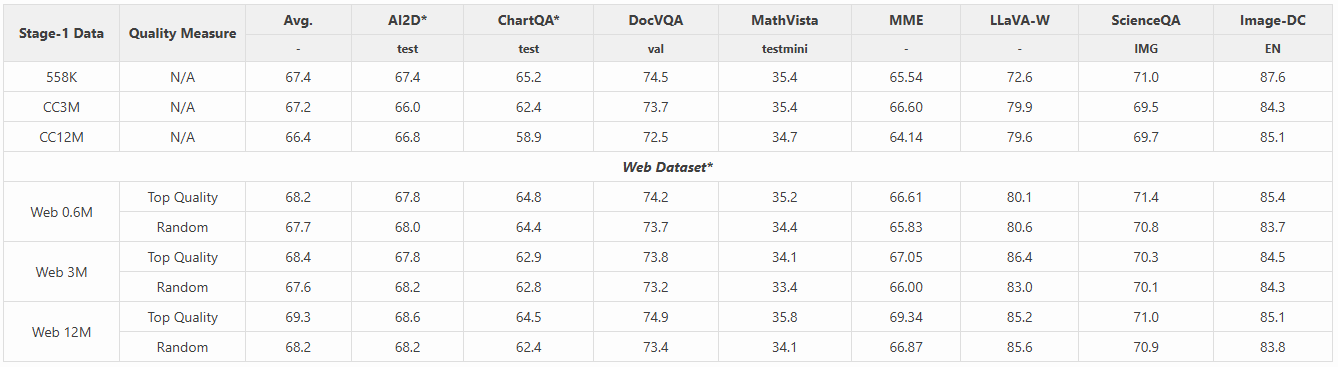
我们考虑了两组数据用于将图像特征对齐到文本嵌入空间:
- 公共数据:包括 BLIP558K、CC3M 和 CC12M。
- 网络数据:为了避免现有公共数据量的限制,我们从互联网收集了类似规模的多模态图像-文本数据。我们通过质量控制措施对这些数据进行筛选,以匹配公共数据的相似规模(0.6M、3M 和 12M)。
训练良好的投影器(projector)直接用于运行包含视觉指令的全模型调优,结果如下所述:
- 仅调优投影器时,公共原始数据的扩展效果较差。
- 使用高质量数据混合效果更好,其次是从同一网络数据集中随机选择的数据混合。
3.2 高质量知识学习
在 LLM 的多模态训练领域,"质量胜于数量" 这一原则尤为重要。这一原则之所以至关重要,是因为预训练的 LLM 和 ViT 已经存储了大量的知识。尽管在 LMM 训练生命周期的最后阶段积累平衡、多样且高质量的指令数据是必不可少的,但一个经常被忽视的方面是,当高质量的新数据可用时,让模型持续接触这些数据以进一步获取知识。我们将这一阶段定义为阶段1.5,专注于高质量知识学习。
训练配置与阶段 2 的设置一致,确保模型能够无缝整合新信息。这种方法承认预训练的 LLM 和 ViT 已经具备大量知识,其目标是通过精心策划的数据进一步优化和增强这些知识。通过优先考虑数据质量,我们可以最大限度地提高计算效率。
为了说明高质量知识的特点,我们选择了以下三大类数据:
-
重新生成的详细描述数据:LLaVA-NeXT-34B 以其在开源 LMM 中强大的详细描述能力而闻名。我们使用该模型为以下数据集的图像生成新的描述:COCO118K、BLIP558K 和 CC3M。
-
文档/OCR数据:我们利用了来自 UReader 数据集的文本阅读子集,总计 100K,这些数据可以通过 PDF 渲染轻松获取。我们将这些文本阅读数据与 SynDOG EN/CN 1M 数据集结合使用。
-
ShareGPT4V中文详细描述数据:我们使用原始的 ShareGPT4V [3] 图像,并利用 Azure API 提供的 GPT-4V 生成详细的中文描述数据,旨在提升模型在中文方面的能力。
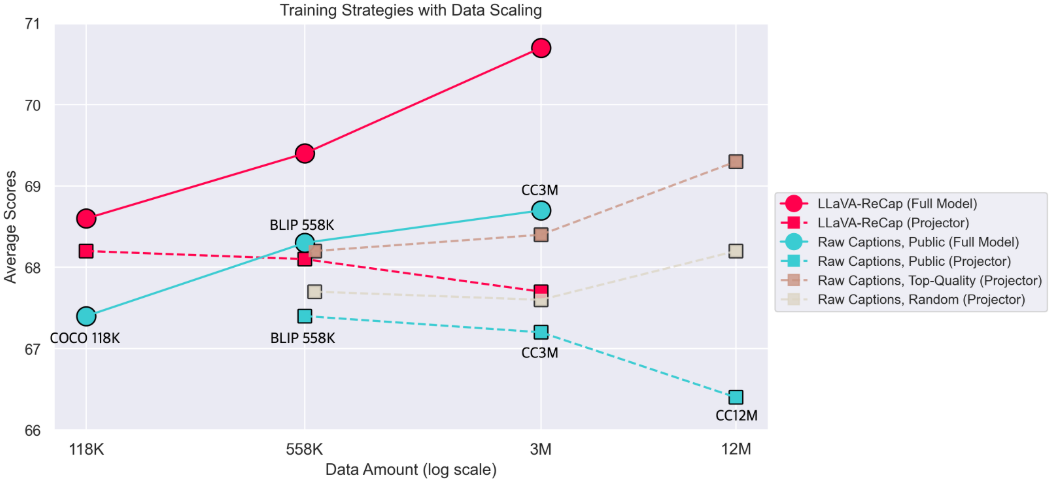
该图显示,在阶段 1.5 训练中使用 LLaVA-ReCap 数据(红色圆圈)能带来最显著的性能提升。使用原始描述数据(例如 COCO18K、BLIP558K 和 CC3M)的表现也较为强劲(蓝色圆圈)。同时,我们还包括第 3.1 节的结果(方形标记),其中仅使用原始描述数据(例如 BLIP558K 到 Web 12M)对投影器进行训练。
【注:根据文本内容,上图图例中第二行和第三行的符号(方,圆)放反了】
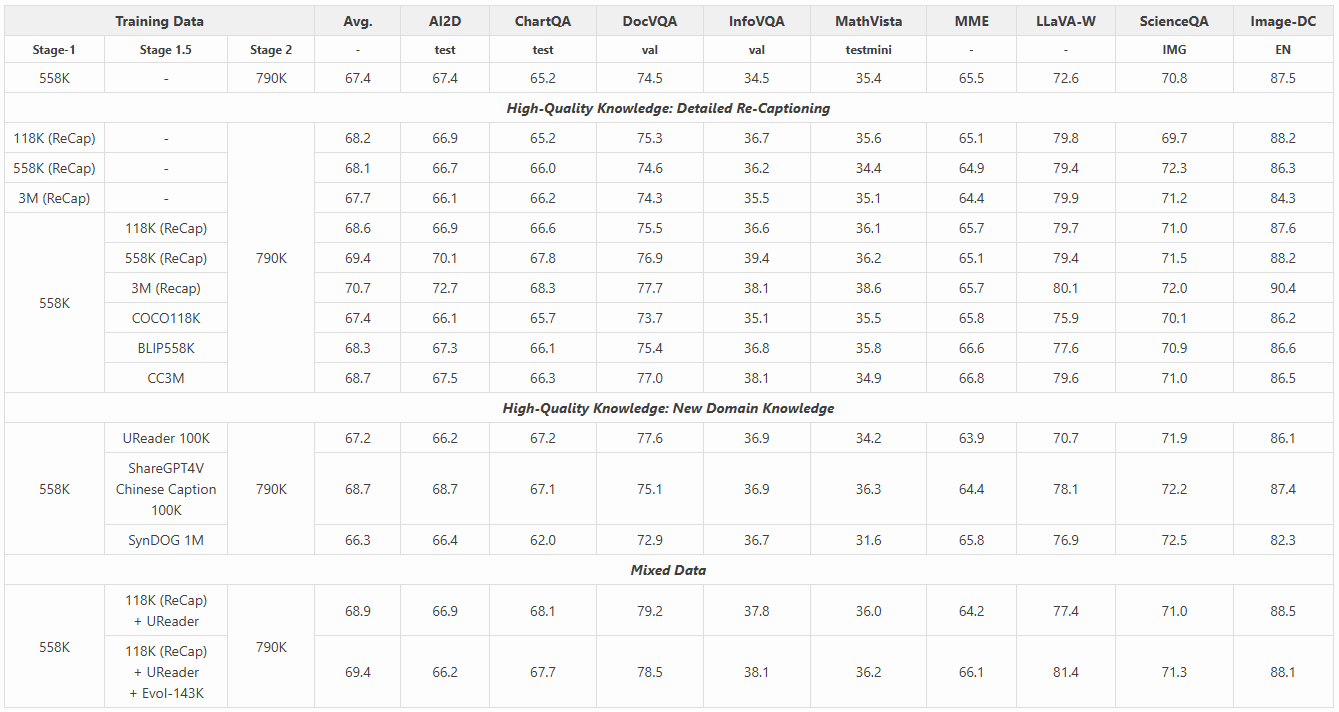
以下是更详细的消融研究,结合下表可以得出以下结论:
使用重生成数据的性能提升:使用重新生成描述数据(ReCap)数据集训练的模型,在需要详细图像描述和文档理解的任务中表现出显著提升趋势。
- 重生成的描述数据(从118K到3M)比原始描述数据表现出更好的扩展性,在多项指标中持续提升模型性能。
- 对于 ReCap 数据,完整模型训练比仅调优投影器更有效,因为需要更大的模型容量来吸收高质量知识。这种方法在 AI2D、DocVQA、ChartQA、InfoVQA 和 ScienceQA 等指标上有显著提升。
新领域知识的引入增强了模型性能:
- 文档/OCR数据:特别是 UReader 100K 和 SynDOG EN/CN 1M,在理解结构化文本数据方面提供了显著的收益。
- ShareGPT4V 中文描述数据:增强了模型理解和处理多语言数据的能力。在多个指标(尤其是 Image-DC 和 CMMU 的中文版本)上的分数显著提高,展示了模型多语言能力的增强。
使用混合数据策略实现平衡改进:
- 结合高质量重生成数据、文档数据和文本数据(例如 Recap-118K、UReader 100K 和 Evol-Instruct),可以构建一个全面的模型,在多样化任务中表现优异。
- 尽管总数据量不足 500K,这种高效的混合数据策略在大多数指标上都实现了平衡的提升。这表明,一个全面且多样的知识库对多模态模型的有效性至关重要。

上表展示了与中文相关任务的结果,包括详细描述任务(Detailed Captions)、CMMU,以及OCRBench(其中一些子集与中文评估相关)。
项目页面:https://llava-vl.github.io/blog/2024-05-25-llava-next-ablations/
相关文章:
,AnyRes,数据量/质量))
(2024,影响 LLaVA 性能的因素,LLM 模型规模,视觉输入配置(网格/token 数),AnyRes,数据量/质量)
LLaVA-NeXT: What Else Influences Visual Instruction Tuning Beyond Data? 目录 0. 简介 1. 架构 1.1 语言模型 1.2 视觉编码器 2. 视觉表示 2.1 训练时分辨率和 token 数量配置 2.2 LLM 扩展的有效性 2.3 放大原始图像 2.4 推理时分辨率和 token 数量配置 2.5 池…...

Vue3 网络请求
文章目录 Vue3 网络请求CORS问题ajaxfetchaxios Vue3 网络请求 CORS问题 同源:指的是当前用户所在的URL与被请求的URL的协议名、域名、端口必须完全相同。一旦有一个或多个不同,就是非同源请求,也就是我们经常说的跨域请求,简称…...

全方位解读消息队列:原理、优势、实例与实践要点
全方位解读消息队列:原理、优势、实例与实践要点 一、消息队列基础认知 在数字化转型浪潮下,分布式系统架构愈发复杂,消息队列成为其中关键一环。不妨把消息队列想象成一个超级“信息驿站”,在古代,各地的信件、物资运…...
)
Java-数据结构-栈与队列(StackQueue)
一、栈(Stack) ① 栈的概念 栈是一种特殊的线性表,它只允许固定一端进行"插入元素"和"删除元素"的操作,这固定的一端被称作"栈顶",对应的另一端就被称做"栈底"。 📚 栈中的元素遵循后…...
Transformer入门教程全解析(一)
一、开篇:走进Transformer的奇妙世界 在当今深度学习领域,Transformer 无疑是一颗璀璨的明星,它如同一股强大的变革力量,席卷了自然语言处理(NLP)乃至更多领域。从机器翻译到文本生成,从问答系…...

拼音读音基础
文章目录 一、音节1、结构2、声母3、韵母 二、声调 拼音读音往往被认为跟应试考试相关,学会正常交流口语以后不再进行关注,其实还是有必要了解细节、查漏补缺。 一、音节 1、结构 音节 声母 韵母;一个音节基本等于一个汉字; 2、…...

Qt 坐标系统和坐标变换
一、概述:1、QPainter在QPaintDevice上绘图的默认坐标系统是,原点(0,0)在左上角,x轴正方向水平向右,y轴正方向竖直向下的坐标系。 2、为了绘图的方便,QPainter提供了一些坐标变换的功能,通过平移、旋转、缩放等坐标变…...

【redis】ubuntu18安装redis7
在Ubuntu 18下安装Redis7可以通过以下两种方法实现:手动编译安装和使用APT进行安装。 Ubuntu 18系统的环境和版本: $ cat /proc/version Linux version 4.15.0-213-generic (builddlcy02-amd64-079) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)…...

Outlook 网页版一直提示:检测到重复的重定向
Outlook 网页版提示“检测到重复的重定向”通常是由于浏览器缓存、Cookie问题或浏览器插件引发的。可以按照以下步骤进行排查和解决: 1. 清除浏览器缓存和 Cookie 在浏览器设置中找到清除浏览数据的选项。勾选“缓存文件”和“Cookies”相关选项,然后清…...

初级前端面试题 - js
前言:众所周知,HTML,CSS,JS是学习前端所必备的。js的基础学好了,框架类的vue,react等都会接受的很快,因此js是前端很总要的一个部分,这篇文章将会结合面试题,对js的知识点进行总结 号外号外,这是…...
添加标量以及格式化输出)
matlab的绘图的标题中(title)添加标量以及格式化输出
有时候我们需要在matlab绘制的图像的标题中添加一些变量,这样在修改某些参数后,标题会跟着一块儿变。可以采用如下的方法: x -10:0.1:10; %x轴的范围 mu 0; %均值 sigma 1; %标准差 y normpdf(x,mu,sigma); %使用normpdf函数生成高斯函数…...
)
51单片机——串口通信(重点)
1、通信 通信的方式可以分为多种,按照数据传送方式可分为串行通信和并行通信; 按照通信的数据同步方式,可分为异步通信和同步通信; 按照数据的传输方向又可分为单工、半双工和全双工通信 1.1 通信速率 衡量通信性能的一个非常…...

mapbox基础,style样式汇总,持续更新
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言二、🍀根属性2.1 so…...

用AI技术提升Flutter开发效率:ScriptEcho的力量
引言 在当今快速发展的技术时代,Flutter作为一种跨平台开发框架,正在越来越多的开发者中崭露头角。它不仅能够为开发者提供一套代码同时部署到iOS和Android平台的解决方案,还能帮助企业节省人力成本和开发时间。然而,对于新手开发…...

Java阶段四04
第4章-第4节 一、知识点 CSRF、token、JWT 二、目标 理解什么是CSRF攻击以及如何防范 理解什么是token 理解什么是JWT 理解session验证和JWT验证的区别 学会使用JWT 三、内容分析 重点 理解什么是CSRF攻击以及如何防范 理解什么是token 理解什么是JWT 理解session验…...

vivado 时钟指南
时钟指南 每个 FPGA 架构都为时钟提供有专用资源。掌握 FPGA 架构中的时钟资源,使您能够规划好自己的时钟,从而实现时钟 资源的最佳利用。大多数设计无需您了解这些细节。但如果您能够控制布局,同时对每个时钟域上的扇出有良好的思 路&a…...
)
git项目提交步骤(简洁版)
1.创建仓库 2.填写 信息 3.点击这个按钮 4.找到要上传的文件,在目录内右键点击 5.依次执行命令 在命令窗口中输入:git init 复制仓库地址: 在命令窗口中输入:git remote add origin 仓库地址 在命令窗口中输入:…...

Jmeter-压测时接口如何按照顺序执行
Jmeter-压测时接口如何按照顺序执行-临界部分控制器 在进行压力测试时,需要按照顺序进行压测,比如按照接口1、接口2、接口3、接口4 进行执行 查询结果是很混乱的,如果请求次数少,可能会按照顺序执行,但是随着次数增加…...

模式识别-Ch5-线性判别函数
Ch5 线性判别函数 文章目录 Ch5 线性判别函数引言:生成模型 vs判别模型生成模型 vs 判别模型判别模型分类 线性判别函数与决策面线性判别函数两类情况下的决策多类问题下决策 多类情形-线性机器线性决策面优缺点 广义线性判别函数例:二次判别函数例1: 1-…...

数据结构二叉树-C语言
数据结构二叉树-C语言 1.树1.1树的概念与结构1.2树的相关术语1.3树的表示1.4树形结构实际运用场景 2.二叉树2.1概念与结构2.2特殊的二叉树2.2.1满二叉树2.2.2完全二叉树 2.3二叉树存储结构2.3.1顺序结构2.3.2链式结构 3.实现顺序结构的二叉树4.实现链式结构二叉树4.1前中后序遍…...

字节小米等后端岗位C++面试题
C 基础 引用和指针之间的区别?堆栈和堆中的内存分配有何区别?存在哪些类型的智能指针?unique_ptr 是如何实现的?我们如何强制在 unique_ptr 中仅存在一个对象所有者?shared_ptr 如何工作?对象之间如何同步…...

IOS HTTPS代理抓包工具使用教程
打开抓包软件 在设备列表中选择要抓包的 设备,然后选择功能区域中的 HTTPS代理抓包。根据弹出的提示按照配置文件和设置手机代理。如果是本机则会自动配置,只需要按照提醒操作即可。 iOS 抓包准备 通过 USB 将 iOS 设备连接到电脑,设备需解…...

renben-openstack-使用操作
管理员操作 (1)上传一个qcow2格式的centos7镜像 (2)管理员------>云主机类型------>创建云主机类型 名称:Centos7 VCPU数量:1 内存: 1024 根磁盘: 10G 其他的默认 点击创建云主机类型即可 界面会显示如下 创建公网络 (1)创建…...
)
HOW - Form 表单确认校验两种模式(以 Modal 场景为例)
目录 一、背景二、具体1. 模式一:点击确认进行校验提示2. 模式二:确认按钮依赖于表单内容实现说明 一、背景 基于react、antd form分别实现如下两种模式: 1、一个 Modal,点击确认进行校验提示2、一个 Modal,确认按钮…...
(二))
MATLAB算法实战应用案例精讲-【数模应用】图像边缘检测(附MATLAB和python代码实现)(二)
目录 前言 算法原理 相关概念 二值图像、灰度图像、彩色图像 邻接性、连通性 图像滤波 频率 滤波器 边缘检测算子:Sobel算子、Scharr算子、Laplacian算子、Canny算子 梯度计算 + 顶帽 + 黑帽 + 拉普拉斯金字塔 相位一致性(Phase Congruency,PC) 几种常见的算法…...

高考日语听力中常考2大类关键词
高考日语听力中,有些关键词的出现频率很高,同学们掌握这些关键词的读音和意思,可以提高听力答题的正确率,如时间类、地点类、天气类关键词……本文档为大家整理了干货,高考日语听力常考关键词,帮助同学们区分和积累常用词汇,记得要持续关注哦! 时间类关键词 1.星期 ∙…...

windows和linux的抓包方式
1.实验准备: 一台windows主机,一台linux主机 wireshark使用: 打开wireshark,这些有波动的就代表可以有流量经过该网卡,选择一张有流量经过的网卡 可以看到很多的流量,然后可以使用过滤器来过滤想要的流量…...

工业 4G 路由器赋能远程医疗,守护生命线
在医疗领域,尤其是偏远地区的医疗救治场景中,工业 4G 路由器正发挥着无可替代的关键作用,宛如一条坚韧的 “生命线”,为守护患者健康持续赋能。 偏远地区医疗资源相对匮乏,常常面临着专业医生短缺、诊疗设备有限等困境…...

《太阳之子》Build16524106官方中文学习版
《太阳之子》官方中文版https://pan.xunlei.com/s/VODabFuJ5gA7rCUACMulT5YGA1?pwdc47e# 集战术狙击、解谜与轻度潜行要素于一身,呈现独一无二的第三人称射击游戏体验。每关你只有一发子弹,但你可以进行在命中时重新瞄准、绕过障碍物、加速击穿护甲等操…...

shell-条件判断
目录 一、条件判断 1.按照文件类型进行判断 2.按照文件权限进行判断 3.两个文件之间进行比较 4.两个整数之间进行比较 5.字符串的判断 6.多重条件判断 二、if条件判断 1.单分支if条件语句 2.双分支if条件语句 (1)判断某文件是否存在 &#x…...

【TI毫米波雷达】DCA1000不使用mmWave Studio的数据采集方法,以及自动化实时数据采集
【TI毫米波雷达】DCA1000不使用mmWave Studio的数据采集方法,以及自动化实时数据采集 mmWave Studio提供的功能完全够用了 不用去纠结用DCA1000低延迟、无GUI传数据 速度最快又保证算力无非就是就是Linux板自己写驱动做串口和UDP 做雷达产品应用也不会采用DCA1000的…...

20250110_ PyTorch中的张量操作
文章目录 前言1、torch.cat 函数2、索引、维度扩展和张量的广播3、切片操作3.1、 encoded_first_node3.2、probs 4、长难代码分析4.1、selected4.1.1、multinomial(1)工作原理: 总结 前言 1、torch.cat 函数 torch.cat 函数将两个张量拼接起来,具体地是…...

【ROS2】☆ launch之Python
☆重点 ROS1和ROS2其中一个很大区别之一就是launch的编写方式。在ROS1中采用xml格式编写launch,而ROS2保留了XML 格式launch,还另外引入了Python和YAML 编写方式。选择哪种编写取决于每位开发人员的爱好,但是ROS2官方推荐使用Python方式编写…...
unity rb.velocity和transform.position
rb.velocity和transform.position是用来控制物体位置的两种方式,前者通常用来控制人物的移动,它们的主要区别和适用场景如下 一,rb.velocity(控制刚体的速度) 它可以直接控制物体的速度,而不是物体的位置…...

景芯SOC设计实战
终身辅导、一对一辅导,手把手教您完成SoC全流程设计,从入门到进阶,带您掌握SoC芯片架构、算法、设计、验证、DFT、后端及低功耗全流程!直播视频不定期升级!让您快速超越同龄人! 景芯团队主打文档服务器实战…...
)
【WRF运行报错】总结WRF运行时报错及解决方案(持续更新)
目录 ./real.exe错误1:ERROR while reading namelist physics./wrf.exe错误1:FATAL CALLED FROM FILE: <stdin> LINE: 2419 Warning: too many input landuse types参考./real.exe 错误1:ERROR while reading namelist physics 执行./real.exe时,报错如下: taski…...

Mysql快速列出来所有列信息
文章目录 需求描述实现思路1、如何查表信息2、如何取字段描述信息3、如何将列信息一行展示4、拼接最终结果 需求描述 如何将MySQL数据库中指定表【tb_order】的所有字段都展示出来,以备注中的中文名为列名。 实现思路 最终展示效果,即拼接出可执行执行…...
3中方式【保姆级教程一,代码直接用】)
spring boot发送邮箱,java实现邮箱发送(邮件带附件)3中方式【保姆级教程一,代码直接用】
文章目录 Java发送邮箱的方式1. 基于 Javax.mail 实现关于附件上传的方法 2. 基于 org.apache.commons.mail 实现常见报错 3. 基于 spring-boot-starter-mail 实现(推荐) 实际开发时需要实现邮件发送,本文章实现如何从零实现邮件发送。也就是…...

数据集-目标检测系列- 电话 测数据集 call_phone >> DataBall
数据集-目标检测系列- 电话 测数据集 call DataBall 助力快速掌握数据集的信息和使用方式,会员享有 百种数据集,持续增加中。 需要更多数据资源和技术解决方案,知识星球: “DataBall - X 数据球(free)” 贵在坚持! …...

Zstandard压缩算法
简介 Zstandard(缩写为zstd)是一种开源的无损数据压缩算法,主要设计目标是提供高比率的压缩和快速的解压缩速度。它由Yann Collet开发,并于2015年首次发布。 特点 高比率的压缩(通常比gzip更好)。快速的解压缩速度(通常比gzip更快)。支持流式解压缩。可以选择不同的压…...

npm i 报错
nodejs中 使用npm install命令时报错 npm err! file C: \user\admin\package.json_package.json 里缺少 description 和 repository 两个n字段。-CSDN博客...
附源码 轮转数组 乘积 矩阵 螺旋矩阵 旋转图像(C++))
【LeetCode】力扣刷题热题100道(26-30题)附源码 轮转数组 乘积 矩阵 螺旋矩阵 旋转图像(C++)
目录 1.轮转数组 2.除自身以外数组的乘积 3.矩阵置零 4.螺旋矩阵 5.旋转图像 1.轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 class Solution { public:void rotate(vector<int>& nums, int k) …...

EFCore HasDefaultValueSql
今天小伙伴在代码中遇到了有关 HasDefaultValue 的疑问,这里整理澄清下... 在使用 Entity Framework Core (EFCore) 配置实体时,HasDefaultValue 方法会为数据库列设置一个默认值。该默认值的行为取决于以下条件: 1. 配置 HasDefaultValue 的…...

【数据结构】栈
目录 1.1 什么是栈 1.2 顺序栈 1.2.1 特性 1.3 链式栈 1.3.1 特性 总结: 1.1 什么是栈 栈是只能在一端进行插入和删除操作的线性表(又称为堆栈),进行插入和删除操作的一端称为栈顶,另一端称为栈底。 特点:栈是先进后出FILO…...

C++初阶—CC++内存管理
第一章:C/C内存分布 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] { 1, 2, 3, 4 };char char2[] "abcd";const char* pChar3 "abcd";int* ptr1 (int*)malloc(si…...

【机器视觉】OpenCV 图像基本变换
文章目录 介绍机器视觉的核心组成部分机器视觉的关键技术和趋势 4. 图像的基本变换4.1 图像的放大与缩小4.2 图像的翻转4.3 图像的旋转4.4 仿射变换之图像平移4.5 仿射变换之获取变换矩阵4.6 透视变换 介绍 机器视觉(Machine Vision)是一门跨学科的领域…...

【数据库】四、数据库管理与维护
文章目录 四、数据库管理与维护1 安全性管理2 事务概述3 并发控制4 备份与恢复管理 四、数据库管理与维护 1 安全性管理 安全性管理是指保护数据库,以避免非法用户进行窃取数据、篡改数据、删除数据和破坏数据库结构等操作 三个级别认证: 服务器级别…...

徐克版射雕唤醒热血武侠魂,共赴新春侠义之约
2025年大年初一,由徐克执导的古装武侠电影《射雕英雄传:侠之大者》将在影院拉开帷幕,在精彩纷呈的春节档电影中,“大IP”“大导演”“大场面”等标签让这部电影自定档起便备受关注,其精良的制作和传统中国武侠风的设定…...
)
设计模式(观察者模式)
设计模式(观察者模式) 第三章 设计模式之观察者模式 观察者模式介绍 观察者模式(Observer Design Pattern) 也被称为发布订阅模式 。模式定义:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候…...

能量函数和能量守恒
在之前的文章1中讨论了与循环坐标相对应的动量守恒定律和动量矩守恒定律,本文将由拉格朗日方程中导出能量函数,进一步讨论能量守恒定律,并给出耗散系统的处理方法,这其中用到的一个关键数学定理是欧拉定理(描述如何将一…...