第R4周:LSTM-火灾温度预测(pytorch版)
>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客**
>- **🍖 原作者:[K同学啊]**
往期文章可查阅: 深度学习总结
任务说明:数据集中提供了火灾温度(Tem1)、一氧化碳浓度(CO 1)、烟雾浓度(Soot 1)随着时间变化数据,我们需要根据这些数据对未来某一时刻的火灾温度做出预测
🍺要求:
1、了解LSTM是什么,并使用其构建一个完整的程序。
2、R2达到0.83
🍻拔高:
使用第1~8个时刻的数据 预测第9~10个时刻的温度数据。
🏡 我的环境:
- 语言环境:Python3.8
- 编译器:Jupyter Notebook
- 深度学习环境:Pytorch
-
- torch==2.3.1+cu118
-
- torchvision==0.18.1+cu118
本文完全根据 xxx 中的内容转换为pytorch,所以前述性的内容不在一一重复,仅就pytorch的内容进行叙述。
一、前期工作
导入下面需要用到的库
import torch.nn.functional as F
import numpy as np
import pandas as pd
import torch
from torch import nn运行过程中发现自己的pytorch环境中没有pandas,又重新添加,但是网速实在不给力,添加清华源地址后速度很快。各位同学在安装库的过程中应尽可能使用各种源地址,我常用的就是清华源地址,以下列出一些常用地址:
名称 地址
阿里 https://mirrors.aliyun.com/pypi/simple
豆瓣 http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple
华中理工大学 http://pypi.hustunique.com/simple
山东理工大学 http://pypi.sdutlinux.org/simple
网易 https://mirrors.163.com/pypi/simple/
腾讯 https://mirrors.cloud.tencent.com/pypi/simple
1. 导入数据
data=pd.read_csv("D:\THE MNIST DATABASE\RNN\R4\woodpine2.csv")
data运行结果:
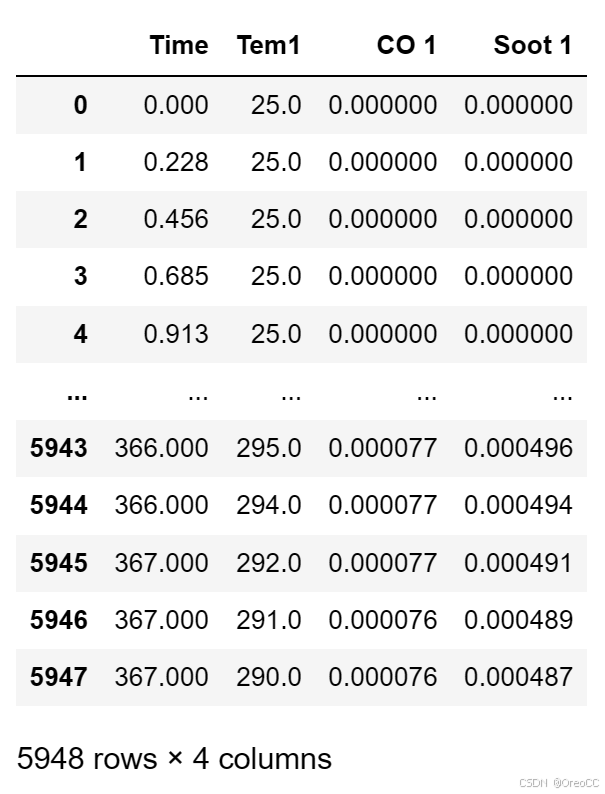
2. 数据集可视化
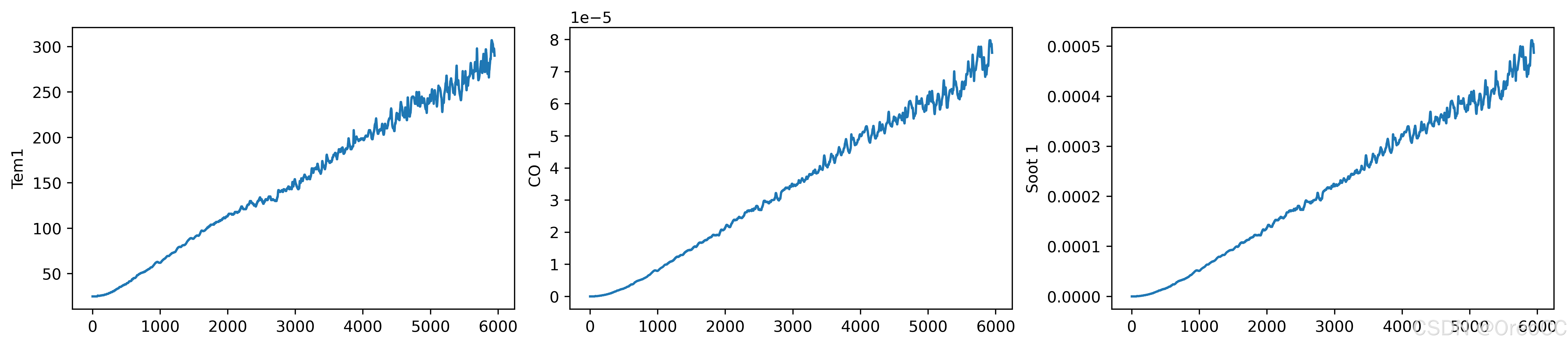
import matplotlib.pyplot as plt
import seaborn as snsplt.rcParams['savefig.dpi']=500 #图片像素
plt.rcParams['figure.dpi']=500 #分辨率fig,ax=plt.subplots(1,3,constrained_layout=True,figsize=(14,3))sns.lineplot(data=data["Tem1"],ax=ax[0])
sns.lineplot(data=data["CO 1"],ax=ax[1])
sns.lineplot(data=data["Soot 1"],ax=ax[2])
plt.show()运行结果:
dataFrame=data.iloc[:,1:]
dataFrame使用 .iloc 方法按位置选择数据。: 表示选择所有行,1: 表示从第二列开始选择所有列(Python中的索引从0开始)。
这段代码的作用是去掉数据框 data 的第一列,创建一个新的数据框 dataFrame。
运行结果:
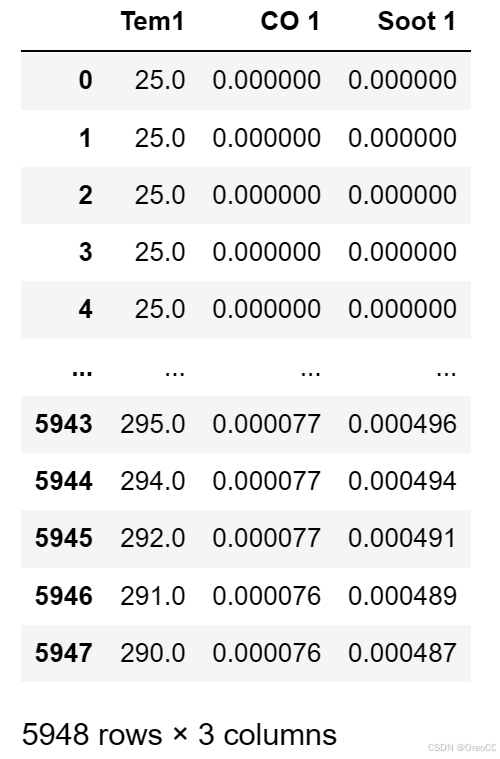
二、构建数据集
1. 数据集预处理
from sklearn.preprocessing import MinMaxScalerdataFrame=data.iloc[:,1:].copy()
sc=MinMaxScaler(feature_range=(0,1)) #将数据归一化,范围是0到1for i in ['CO 1','Soot 1','Tem1']:dataFrame[i]=sc.fit_transform(dataFrame[i].values.reshape(-1,1))dataFrame.shape(1) 导入`MinMaxScaler`,这是一个用于将数据按最小最大值进行缩放的类。`MinMaxScaler`将数据缩放到给定的范围内(默认为0到1)。
(2)`data.iloc[:, 1:]`表示从`data`数据框中提取除第一列之外的所有列(假设第一列可能是索引或无关列)。然后,用`.copy()`方法创建一个新的数据框`dataFrame`,以免修改原始数据。
(3)初始化`MinMaxScaler`,指定特征缩放的范围为0到1。这个缩放器会将数据的最小值映射为0,最大值映射为1,中间的数值按比例缩放。
(4)**逐列缩放数据**:
for i in ['CO 1','Soot 1','Tem1']:
dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1,1))
这段代码对`dataFrame`中的三列数据——'CO 1'、'Soot 1'、'Tem1'——进行归一化处理。具体过程:
- `dataFrame[i].values`提取出第`i`列的数据,以NumPy数组的形式表示。
- `reshape(-1,1)`将数组从一维变为二维(这是因为`MinMaxScaler`需要二维数组作为输入,数据通常按行进行操作)。
- `sc.fit_transform()`会根据每一列的数据计算最小值和最大值,并将这些数据缩放到0到1之间。
- 缩放后的数据会替换原数据框`dataFrame`中的对应列。
(5)输出数据框形状:
print("dataFrame",dataFrame.shape)然后将时间序列数据转换为模型训练所需的输入(X)和输出(y),以便能够在机器学习模型(例如神经网络)中进行训练。
运行结果:
(5948, 3)2. 设置x,y
width_x=8
width_y=1# 取前8个时间段的Tem1、CO 1、Soot 1为x,第9个时间段的Tem1为y
x=[]
y=[]in_start=0for _,_ in data.iterrows():in_end=in_start+width_xout_end=in_end+width_yif out_end<len(dataFrame):x_=np.array(dataFrame.iloc[in_start:in_end,])y_=np.array(dataFrame.iloc[in_end:out_end,0])x.append(x_)y.append(y_)in_start+=1x=np.array(x)
y=np.array(y).reshape(-1,1,1)x.shape,y.shape运行结果:
((5939, 8, 3), (5939, 1, 1))检查数据集中是否有空值
print(np.any(np.isnan(x)))
print(np.any(np.isnan(y)))运行结果:
False
False3. 划分数据集
x_train=torch.tensor(np.array(x[:5000]),dtype=torch.float32)
y_train=torch.tensor(np.array(y[:5000]),dtype=torch.float32)x_test=torch.tensor(np.array(x[5000:]),dtype=torch.float32)
y_test=torch.tensor(np.array(y[5000:]),dtype=torch.float32)
x_train.shape,y_train.shape运行结果:
(torch.Size([5000, 8, 3]), torch.Size([5000, 1, 1]))加载数据
from torch.utils.data import TensorDataset,DataLoadertrain_dl=DataLoader(TensorDataset(x_train,y_train),batch_size=64,shuffle=False)
test_dl=DataLoader(TensorDataset(x_test,y_test),batch_size=64,shuffle=False)三、模型训练
1. 构建模型
class model_lstm(nn.Module):def __init__(self):super(model_lstm,self).__init__()self.lstm0=nn.LSTM(input_size=3,hidden_size=320,num_layers=1,batch_first=True)self.lstm1=nn.LSTM(input_size=320,hidden_size=320,num_layers=1,batch_first=True)self.fc0=nn.Linear(320,1)def forward(self,x):out,hidden1=self.lstm0(x)out,_=self.lstm1(out,hidden1)out=self.fc0(out)return out[:,-1:,:] #取2个预测值,否则经过lstm会得到8*2个预测model=model_lstm()
model运行结果:
model_lstm((lstm0): LSTM(3, 320, batch_first=True)(lstm1): LSTM(320, 320, batch_first=True)(fc0): Linear(in_features=320, out_features=1, bias=True)
)1.1 LSTM层:
1.1.1 self.lstm0 = nn.LSTM(input_size=3, hidden_size=320, num_layers=1, batch_first=True):
① 这是模型的第一个LSTM层,接受的输入特征维度为3,隐藏层的特征维度为320,LSTM层的层数为1。
② batch_first=True 指定输入数据的维度顺序为 (batch_size, seq_len, input_size),也就是以batch为第一维度。
1.1.2 self.lstm1 = nn.LSTM(input_size=320, hidden_size=320, num_layers=1, batch_first=True):
第二个LSTM层,接受前一个LSTM层的输出(大小为320),继续处理。
1.2 全连接层:
self.fc0 = nn.Linear(320, 1):
全连接层,将第二个LSTM层的输出从320维的特征映射到1维,用于输出最终预测结果。
1.3 前向传播 (forward method):
1.3.1 第一个LSTM层:
out, hidden1 = self.lstm0(x):将输入x传入第一个LSTM层。out是LSTM层的输出,hidden1是LSTM的隐藏状态(包括h_n和c_n)。
1.3.2第二个LSTM层:
out, _ = self.lstm1(out, hidden1):将第一个LSTM层的输出和其隐藏状态传递给第二个LSTM层,继续处理。
1.3.3 全连接层:
out = self.fc0(out):将第二个LSTM层的输出传递给全连接层,将输出维度从320变成1,得到每个时间步的预测值。
1.3.4 只保留最后一个时间步的输出:
return out[:, -1:, :]:LSTM模型通常会输出整个序列的预测,但在这段代码中,只取最后一个时间步的预测作为最终输出,这种方法常用于预测下一个时间步的值。
观察模型的输出数据集格式:
model(torch.rand(30,8,3)).shape运行结果:
torch.Size([30, 1, 1])2. 定义训练函数
import copy
def train(train_dl,model,loss_fn,opt,lr_scheduler=None):size=len(train_dl.dataset)num_batches=len(train_dl)train_loss=0 #初始化训练损失和正确率for x,y in train_dl:x,y=x.to(device),y.to(device)#计算预测误差pred=model(x) #网络输出loss=loss_fn(pred,y) #计算网络输出和真实值之间的差距#反向传播opt.zero_grad() #grad属性归零loss.backward() #反向传播opt.step() #每一步自动更新#记录losstrain_loss+=loss.item()if lr_scheduler is not None:lr_scheduler.step()print("learning rate={:.5f}".format(opt.param_groups[0]['lr']),end=" ")train_loss/=num_batchesreturn train_loss学习率进行动态调整,有效改善了模型的收敛性能。学习率从初始值逐渐衰减,避免了在训练中期因学习率过大导致的训练不稳定。
3. 定义测试函数
def test(dataloader,model,loss_fn):size=len(dataloader.dataset) #测试集的大小num_batches=len(dataloader) #批次数目test_loss=0#当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for x,y in dataloader:x,y=x.to(device),y.to(device)#计算lossy_pred=model(x)loss=loss_fn(y_pred,y)test_loss+=loss.item()test_loss/=num_batchesreturn test_loss4. 正式训练模型
# 设置GPU训练
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device运行结果:
device(type='cuda')#训练模型
model=model_lstm()
model=model.to(device)
loss_fn=nn.MSELoss() #创建损失函数
learn_rate=1e-1 #学习率
opt=torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)
epochs=50
train_loss=[]
test_loss=[]
lr_scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs,last_epoch=-1)for epoch in range(epochs):model.train()epoch_train_loss=train(train_dl,model,loss_fn,opt,lr_scheduler)model.eval()epoch_test_loss=test(test_dl,model,loss_fn)train_loss.append(epoch_train_loss)test_loss.append(epoch_test_loss)template=('Epoch:{:2d},Train_loss:{:.5f},Test_loss:{:.5f}')print(template.format(epoch+1,epoch_train_loss,epoch_test_loss))print("="*20,'Done',"="*20)运行结果:
learning rate=0.09990 Epoch: 1,Train_loss:0.00117,Test_loss:0.01199
learning rate=0.09961 Epoch: 2,Train_loss:0.01358,Test_loss:0.01160
learning rate=0.09911 Epoch: 3,Train_loss:0.01326,Test_loss:0.01119
learning rate=0.09843 Epoch: 4,Train_loss:0.01290,Test_loss:0.01076
learning rate=0.09755 Epoch: 5,Train_loss:0.01248,Test_loss:0.01028
learning rate=0.09649 Epoch: 6,Train_loss:0.01199,Test_loss:0.00975
learning rate=0.09524 Epoch: 7,Train_loss:0.01142,Test_loss:0.00916
learning rate=0.09382 Epoch: 8,Train_loss:0.01075,Test_loss:0.00851
learning rate=0.09222 Epoch: 9,Train_loss:0.00998,Test_loss:0.00779
learning rate=0.09045 Epoch:10,Train_loss:0.00911,Test_loss:0.00703
learning rate=0.08853 Epoch:11,Train_loss:0.00815,Test_loss:0.00623
learning rate=0.08645 Epoch:12,Train_loss:0.00713,Test_loss:0.00543
learning rate=0.08423 Epoch:13,Train_loss:0.00607,Test_loss:0.00464
learning rate=0.08187 Epoch:14,Train_loss:0.00503,Test_loss:0.00390
learning rate=0.07939 Epoch:15,Train_loss:0.00405,Test_loss:0.00322
learning rate=0.07679 Epoch:16,Train_loss:0.00317,Test_loss:0.00264
learning rate=0.07409 Epoch:17,Train_loss:0.00242,Test_loss:0.00215
learning rate=0.07129 Epoch:18,Train_loss:0.00180,Test_loss:0.00176
learning rate=0.06841 Epoch:19,Train_loss:0.00132,Test_loss:0.00146
learning rate=0.06545 Epoch:20,Train_loss:0.00096,Test_loss:0.00122
learning rate=0.06243 Epoch:21,Train_loss:0.00070,Test_loss:0.00105
learning rate=0.05937 Epoch:22,Train_loss:0.00051,Test_loss:0.00092
learning rate=0.05627 Epoch:23,Train_loss:0.00038,Test_loss:0.00083
learning rate=0.05314 Epoch:24,Train_loss:0.00029,Test_loss:0.00076
learning rate=0.05000 Epoch:25,Train_loss:0.00023,Test_loss:0.00071
learning rate=0.04686 Epoch:26,Train_loss:0.00019,Test_loss:0.00067
learning rate=0.04373 Epoch:27,Train_loss:0.00016,Test_loss:0.00064
learning rate=0.04063 Epoch:28,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.03757 Epoch:29,Train_loss:0.00013,Test_loss:0.00060
learning rate=0.03455 Epoch:30,Train_loss:0.00012,Test_loss:0.00058
learning rate=0.03159 Epoch:31,Train_loss:0.00012,Test_loss:0.00057
learning rate=0.02871 Epoch:32,Train_loss:0.00011,Test_loss:0.00057
learning rate=0.02591 Epoch:33,Train_loss:0.00011,Test_loss:0.00056
learning rate=0.02321 Epoch:34,Train_loss:0.00011,Test_loss:0.00056
learning rate=0.02061 Epoch:35,Train_loss:0.00011,Test_loss:0.00056
learning rate=0.01813 Epoch:36,Train_loss:0.00011,Test_loss:0.00056
learning rate=0.01577 Epoch:37,Train_loss:0.00012,Test_loss:0.00056
learning rate=0.01355 Epoch:38,Train_loss:0.00012,Test_loss:0.00057
learning rate=0.01147 Epoch:39,Train_loss:0.00012,Test_loss:0.00057
learning rate=0.00955 Epoch:40,Train_loss:0.00013,Test_loss:0.00058
learning rate=0.00778 Epoch:41,Train_loss:0.00013,Test_loss:0.00059
learning rate=0.00618 Epoch:42,Train_loss:0.00013,Test_loss:0.00060
learning rate=0.00476 Epoch:43,Train_loss:0.00014,Test_loss:0.00061
learning rate=0.00351 Epoch:44,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00245 Epoch:45,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00157 Epoch:46,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00089 Epoch:47,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00039 Epoch:48,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00010 Epoch:49,Train_loss:0.00014,Test_loss:0.00062
learning rate=0.00000 Epoch:50,Train_loss:0.00014,Test_loss:0.00062
==================== Done ====================四、模型评估
1. LOSS图
import matplotlib.pyplot as pltplt.figure(figsize=(5,3),dpi=300)plt.plot(train_loss,label='LSTM Training Loss')
plt.plot(test_loss,label='LSTM Validation Loss')plt.title('Training and Validation Loss')
plt.legend()
plt.show()运行结果:
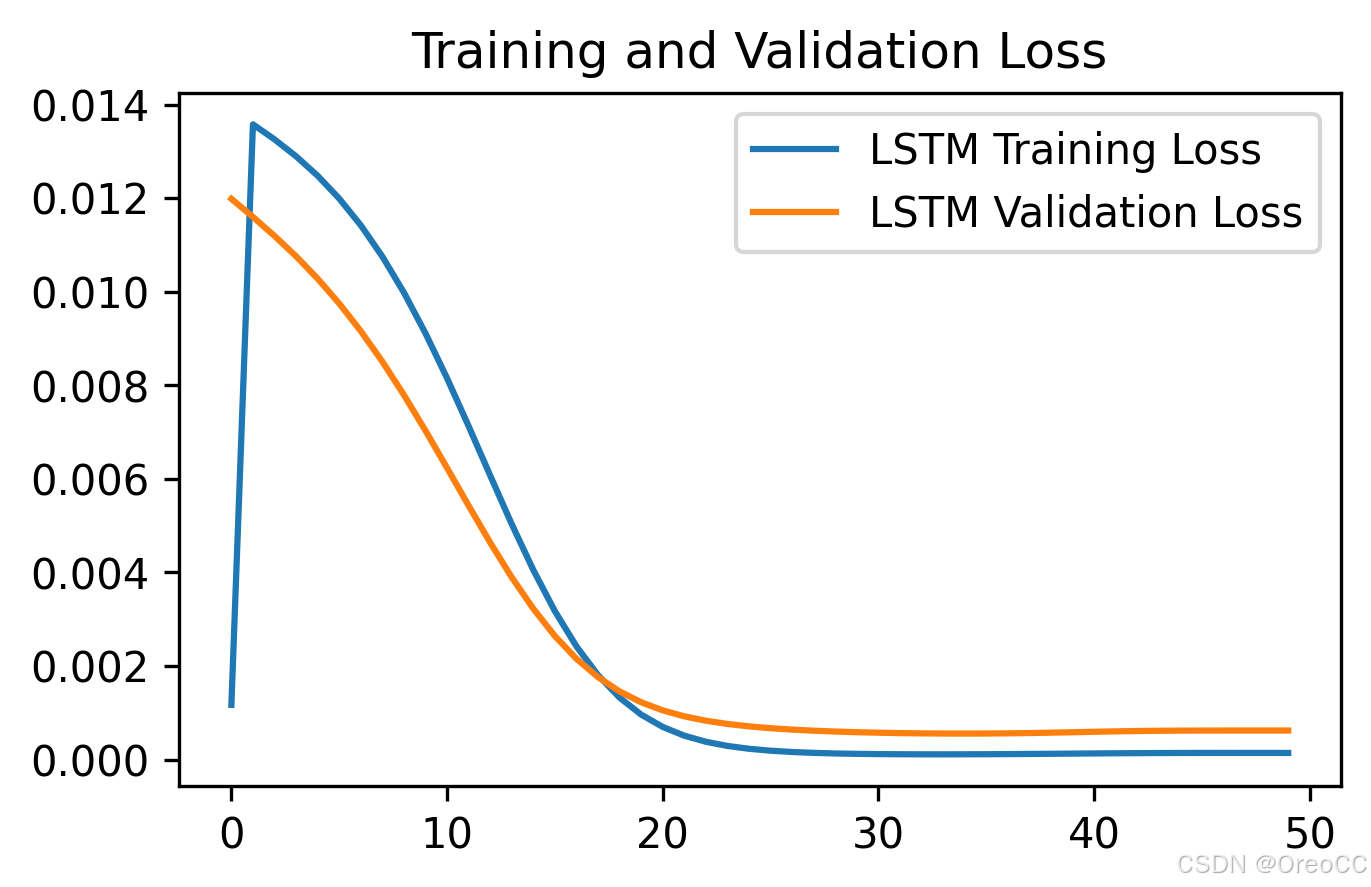
2. 调用模型进行预测
x_test = x_test.to(device)
predicted_y_lstm=sc.inverse_transform(model(x_test).detach().cpu().numpy().reshape(-1,1))
y_test_1=sc.inverse_transform(y_test.reshape(-1,1))
y_test_one=[i[0] for i in y_test_1]
predicted_y_lstm_one=[i[0] for i in predicted_y_lstm]plt.figure(figsize=(5,3),dpi=500)
#画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000],color='red',label='real_temp')
plt.plot(predicted_y_lstm_one[:2000],color='blue',label='prediction')plt.title('Title')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()运行结果:
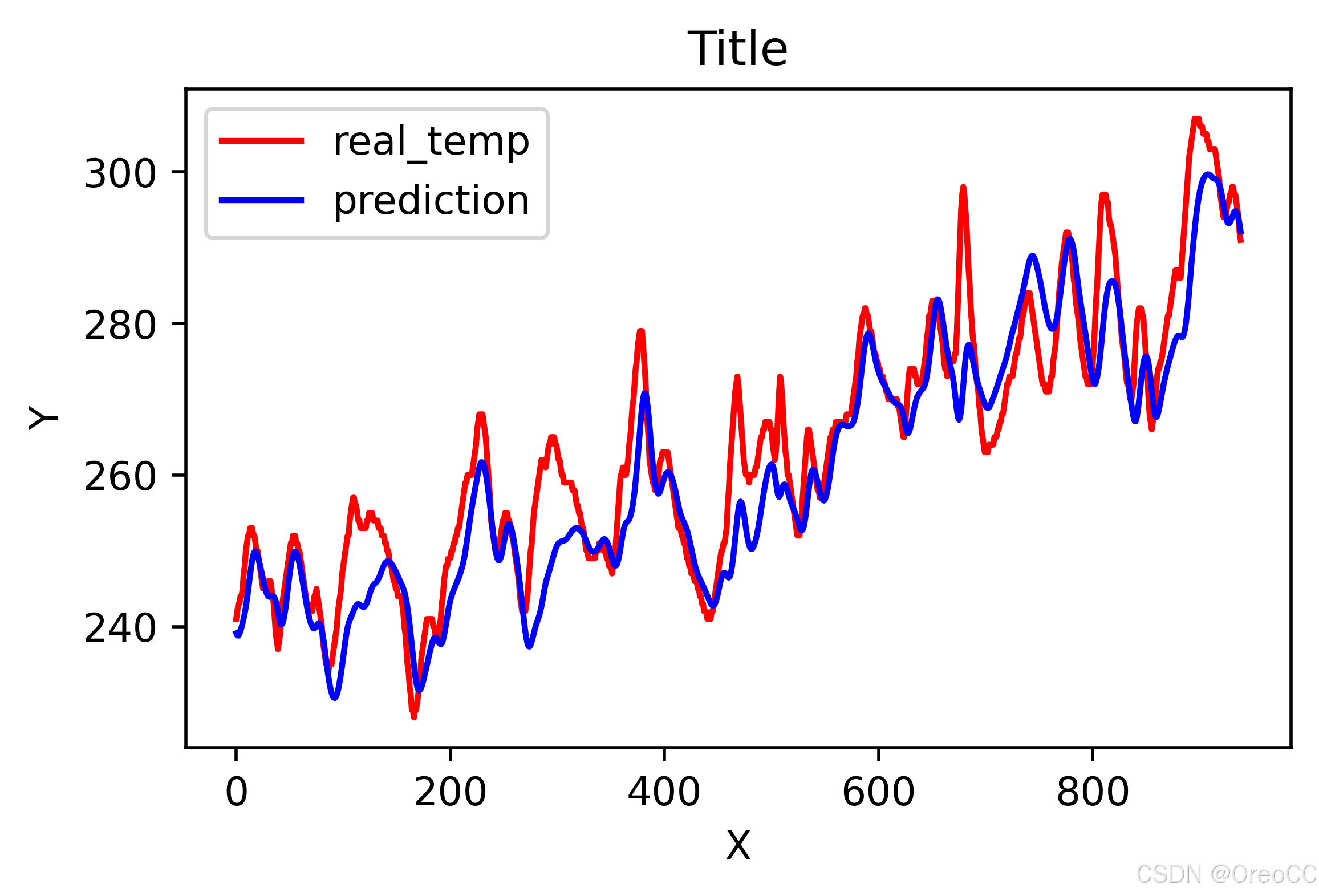
3. R2值评估
from sklearn import metrics
"""
RMSE : 均方根误差 ----> 对均方误差开方
R2 : 决定系数,可以简单理解为反映模型拟合优度的重要的统计量
"""
RMSE_lstm=metrics.mean_squared_error(predicted_y_lstm_one,y_test_1)**0.5
R2_lstm=metrics.r2_score(predicted_y_lstm_one,y_test_1)print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)运行结果:
均方根误差: 7.06313
R2: 0.82236五、心得体会
深入体会了pytorch在时间序列的预测应用。模型总体与RNN模型较为相似,但与RNN相比,可以进行长记忆模式。
相关文章:
)
第R4周:LSTM-火灾温度预测(pytorch版)
>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客** >- **🍖 原作者:[K同学啊]** 往期文章可查阅: 深度学习总结 任务说明:数据集中提供了火灾温度(Tem1)、一氧化碳浓度…...

基于SpringBoot和uniapp开发的医护上门系统上门护理小程序
项目分析 一、市场需求分析 人口老龄化趋势:随着全球及中国人口老龄化的加剧,老年人口数量显著增加,对医疗护理服务的需求也随之增长。老年人由于身体机能下降,更需要便捷、高效的医护服务,而医护上门服务恰好满足了这…...

js批量输入地址获取经纬度
使用js调用高德地图的接口批量输入地址获取经纬度。 以下的请求接口的key请换成你的key。 创建key:我的应用 | 高德控制台 ,服务平台选择《Web服务》。 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-…...

Python自动化测试实践中pytest用到的功能dependency和parametrize
Python自动化测试中pytest用到的功能 1、pytest之@pytest.mark.dependency装饰器设置测试用例之间的依赖关系 1.1说明: 1、这是一个pytest第三方插件,主要解决用例之间的依赖关系。如果依赖的上下文测试用例失败后续的用例会被标识为跳过执行,相当于执行了 pytest.mark.s…...

json-bigint处理前端精度丢失问题
问题描述:前后端调试过程中,有时候会遇到精度丢失的问题,比如后端给过来的id超过16位,就会出现精度丢失的情况,前端拿到的id与后端给过来的不一致。 解决方案: 1、安装 npm i json-bigint 2、在axios中配置…...
神经网络10-Temporal Fusion Transformer (TFT)
Temporal Fusion Transformer (TFT) 是一种专为时序数据建模而设计的深度学习模型,它结合了Transformer架构和其他技术,旨在有效地处理和预测时序数据中的复杂模式。TFT 于 2020 年由 Google Research 提出,旨在解决传统模型在时序预测中的一…...

django基于django的民族服饰数据分析系统的设计与实现
摘 要 随着网络科技的发展,利用大数据分析对民族服饰进行管理已势在必行;该平台将帮助企业更好地理解服饰市场的趋势,优化服装款式,提高服装的质量。 本文讲述了基于python语言开发,后台数据库选择MySQL进行数据的存储…...

html数据类型
数据类型是字面含义,表示各种数据的类型。在任何语言中都存在数据类型,因为数据是各式各样。 1.数值类型 number let a 1; let num 1.1; // 整数小数都是数字值 // 数字肯定有个范围 正无穷大和负无穷大 // Infinity 正无穷大 // -Infinity 负…...

Springboot启动异常 错误: 找不到或无法加载主类 xxx.Application异常
Springboot启动异常 错误: 找不到或无法加载主类 xxx.Application异常 报错提示 Connected to the target VM, address: 127.0.0.1:57210, transport: socket 错误:找不到或无法加载主类 global.hh.manage.HHMicroCloudProviderApplication Disconnected from the target VM, …...

哋它亢SEO技术分析:如何提升网站在搜索引擎中的可见性
文章目录 哋它亢SEO技术分析:如何提升网站在搜索引擎中的可见性网站的基本情况SEO优化分析与建议1. 元数据优化2. 关键词优化3. URL结构4. 图像优化5. 移动端优化6. 网站速度7. 结构化数据(Schema Markup)8. 内链与外链9. 社交分享 哋它亢SEO…...

web——upload-labs——第十一关——黑名单验证,双写绕过
还是查看源码, $file_name str_ireplace($deny_ext,"", $file_name); 该语句的作用是:从 $file_name 中去除所有出现在 $deny_ext 数组中的元素,替换为空字符串(即删除这些元素)。str_ireplace() 在处理时…...
)
ElasticSearch7.x入门教程之中文分词器 IK(二)
文章目录 前言一、内置分词器二、中文IK分词器(第三方)三、本地自定义四、远程词库总结 前言 ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。 查询分析则主要分为两个步骤: 1、词条化:分词器将输入…...

体积全息及平面全息图的衍射效率
一、体积全息 当记录材料的厚度是条纹间距的若干倍时,则在记录材料体积内将记录下干涉全息图的三维空间分布,就形成了体积全息。 按物光和参考光入射方向和再现方式的不同体积全息可以分为两种。 一种是物光和参考光在记录介质的同一侧入射,得…...

【常用组件整理】
xgplayer 字节开发的前端视频播放器 xgplayer是一个由字节跳动开发的强大的前端视频播放器,具有稳定性高、文档清晰、支持弹幕和移动端优化 等特点。相较于VideoJs,xgplayer的文档更简洁,自定义插件更为便捷。xgplayer还提供了丰富的插件来扩…...

用指针函数寻找数组中的最大值与次大值
#include <stdio.h>// 函数用于找出数组中的最大值和次大值 void LargestTow(int a[], int n, int *pfirst, int *psecond) {*pfirst a[0];*psecond a[1];if (*psecond > *pfirst) {// 如果初始的次大值大于最大值,交换它们int temp *pfirst;*pfirst *…...

原生微信小程序在顶部胶囊左侧水平设置自定义导航兼容各种手机模型
无论是在什么手机机型下,自定义的导航都和右侧的胶囊水平一条线上。如图下 以上图iphone12,13PRo 以上图是没有带黑色扇帘的机型 以下是调试器看的wxml的代码展示 注意:红色阔里的是自定义导航(或者其他的logo啊,返回之…...

Android Gradle自定义任务在打包任务执行完成后执行cmd命令
背景 在每次打包之后需要做某事,例如每次打包后我都会安装某个目录下的一个apk。这个apk是通过一堆shell命令过滤得到一个apk的地址,然后把执行的几个shell命令何必成一个alias指令,在打包后只需要执行alias指令实现功能。当然也可以直接写在…...
)
http自动发送请求工具(自动化测试http请求)
点击下载《http自动发送请求工具(自动化测试http请求)》 前言 在现代软件开发过程中,HTTP 请求的自动化测试是确保应用程序稳定性和可靠性的关键环节。为了满足这一需求,我开发了一款功能强大且易于使用的自动化 HTTP 请求发送工具。该工具基于 C# 开发…...

解决Docker环境变量的配置的通用方法
我们部署的很多服务都是以Docker容器的形式存在的。 在运行Docker容器前,除了设置网络、数据卷之外,还需要设置各种各样的环境变量。 有时候,由于容器版本的问题,一些文档没有及时更新,可能同时存在多个新旧版本的环…...

SpringBoot3整合Hutool-captcha实现图形验证码
文章目录 验证码需求分析:项目创建import方式的使用说明exclude方式定义接口:接口定义定义 CaptchaController前端代码在整合技术框架的时候,想找一个图形验证码相关的框架,看到很多验证码不在更新了或者是在中央仓库下载不下来,还需要多引入依赖。后面看到了Hutool **图形…...

Spring Boot核心概念:日志管理
日志记录是软件开发的重要组成部分,它帮助开发人员了解应用程序运行时的状态,以及在故障排查和性能监控时提供关键信息。Spring Boot通过提供默认的日志配置,简化了日志管理。 Spring Boot默认日志框架 Spring Boot默认使用Logback作为日志…...

selenium grid 远程webdriver添加上网代理
################## selenium grid config start ####################### # UI自动化测试策略 Grid/Local UIAutomation_TestStrategy Grid selenium_grid_url http://172.16.99.131:4444/wd/hub # Windows XP / linux grid_platformName linux # windows capabilities win…...
debug运行生成的项目,不能手动点击运行)
Flutter踩坑记录(一)debug运行生成的项目,不能手动点击运行
问题 IOS14设备,切后台划掉,二次启动崩溃。 原因 IOS14以上 flutter 不支持debugger模式下的二次启动 。 要二次启动需要以release方式编译工程安装至手机。 操作步骤 清理项目:在命令行中运行flutter clean来清理之前的构建文件。重新构…...

Spring Boot 项目 myblog 整理
myblog 项目是一个典型的 Spring Boot 项目,主要包括用户注册、登录、文章管理(创建、查询、更新、删除)等功能。 1. 项目结构与依赖设置 项目初始化与依赖 使用 Spring Initializr 创建项目。引入必要的依赖包: Spring Boot W…...

【前端知识】nodejs项目配置package.json深入解读
package.json详细解读 文件解读一、文件结构二、字段详解三、使用场景四、注意事项 组件版本匹配规则 文件解读 package.json 文件是 Node.js 项目中的一个核心配置文件,它位于项目的根目录下,并包含项目的基本信息、依赖关系、脚本、版本等内容。以下是…...

51c嵌入式~IO合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/11697814 一、STM32串口通信基本原理 通信接口背景知识 设备之间通信的方式 一般情况下,设备之间的通信方式可以分成并行通信和串行通信两种。并行与串行通信的区别如下表所示。 串行通信的分类 1、按照数据传…...

在应用启动时,使用 UniApp 提供的 API 检查和请求权限。
在使用 UniApp 开发 App 时,如果你需要在应用启动时提示用户获取本地媒体权限,可以按照以下步骤操作: 1. 明确需要的权限 要访问本地媒体(如相机、麦克风或文件存储),需要申请以下权限: Andr…...
)
前端知识点---伪数组是什么 , 伪数组如何转换为真数组(Javascript)
伪数组是什么 , 伪数组如何转换为真数组(Javascript) 在 JavaScript 中,伪数组对象是具有类似数组特性的对象,但并不是数组(即不继承 Array.prototype)。这些对象通常有一个 length 属性以及以数字索引为键的属性,但不…...

嵌入式 UI 开发的开源项目推荐
嵌入式开发 UI 难吗?你的痛点我懂!作为嵌入式开发者,你是否也有以下困扰?设备资源太少,功能和美观只能二选一?调试效率低,每次调整都要反复烧录和测试?开发周期太长,让你…...

《智能指针频繁创建销毁:程序性能的“隐形杀手”》
在 C编程的世界里,智能指针无疑是管理内存资源的得力助手。它们为我们自动处理内存的分配与释放,极大地减少了因手动管理内存而可能引发的诸如内存泄漏、悬空指针等棘手问题。然而,就像任何工具都有其两面性一样,智能指针在带来便…...
)>)
28.<Spring博客系统⑤(部署的整个过程(CentOS))>
引入依赖 Spring-boot-maven-plugin 用maven进行打包的时候必须用到这个插件。看看自己pom.xml中有没有这个插件 并且看看配置正确不正常。 注:我们这个项目打的jar包在30MB左右。 <plugin><groupId>org.springframework.boot</groupId><artif…...

mongodb多表查询,五个表查询
需求是这样的,而数据是从mysql导入进来的,由于mysql不支持数组类型的数据,所以有很多关联表。药剂里找药物,需要药剂与药物的关联表,然后再找药物表。从药物表里再找药物与成分关联表,最后再找成分表。 这里…...
 与客户端渲染 (CSR))
服务器端渲染 (SSR) 与客户端渲染 (CSR)
嘿程序员!我们都知道,新时代的 Javascript 已经彻底改变了现代网站的结构和用户体验。如今,网站的构建更像是一个应用程序,伪装成一个能够发送电子邮件、通知、聊天、购物、支付等的网站。今天的网站是如此先进、互动,…...

【已解决】“EndNote could not connect to the online sync service”问题的解决
本人不止一次在使用EndNote软件时遇到过“EndNote could not connect to the online sync service”这个问题。 过去遇到这个问题都是用这个方法来解决: 这个方法虽然能解决,但工程量太大,每次做完得歇半天身体才能缓过来。 后来再遇到该问…...

HTML5拖拽API学习 托拽排序和可托拽课程表
文章目录 前言拖拽API核心概念拖拽式使用流程例子注意事项综合例子🌰 可拖拽课程表拖拽排序 前言 前端拖拽功能让网页元素可以通过鼠标或触摸操作移动。HTML5 提供了标准的拖拽API,简化了拖放操作的实现。以下是拖拽API的基本使用指南: 拖拽…...

sed使用扩展正则表达式时, -i 要写在 -r 或 -E 的后面
sed使用扩展正则表达式时, -i 要写在 -r 或 -E 的后面 前言 -r 等效 -E , 启用扩展正则表达式 -E是新叫法,更统一,能增强可移植性 , 但老系统,比如 CentOS-7 的 sed 只能用 -r ### Ubuntu24.04-E, -r, --regexp-extendeduse extended regular expressions in the script(fo…...

CSS中Flex布局应用实践总结
① 两端对齐 比如 要求ul下的li每行四个,中间间隔但是需要两段对齐,如下图所示: 这是除了基本的flex布局外,还需要用到:nth-of-type伪类来控制每行第一个与第四个的padding。 .hl_list{width: 100%;display: flex;align-items…...

【前端】CSS修改div滚动条样式
示例 分别是滚动条默认样式和修改后的样式 代码 <div class"video-list"><div class"list-item" onclick"videoinfo(100)"><img src"/index/images/coverimg/方和谦.png"><div class"txt">国医大…...

鸿蒙多线程开发——线程间数据通信对象02
1、前 言 本文的讨论是接续鸿蒙多线程开发——线程间数据通信对象01的讨论。在上一篇文章中,我们讨论了常规的JS对象(普通JSON对象、Object、Map、Array等)、ArrayBuffer。其中讨论了ArrayBuffer的复制传输和转移传输方式。 下面,我们将讨论SharedArra…...

Kotlin的data class
在 Kotlin 中,data class 是一种专门用来存储数据的类。与普通类相比,data class 提供了简化数据存储的语法,并且自动生成了一些常用的方法,例如 toString()、equals()、hashCode() 和 copy()。 1. 定义 data class data class …...

Proxy 在 JavaScript的用法
Proxy 是 JavaScript 提供的一个构造函数,用于创建一个“代理对象”。这个代理对象可以拦截目标对象的基本操作,例如读取属性、赋值、删除、调用函数等。通过它,我们可以修改或扩展对象的默认行为。 Proxy 的基本语法 const proxy = new Proxy(target, handler);target:被…...

vue3的attr透传属性详解和使用法方式。以及在css样式的伪元素中实现
在 Vue 3 和 TypeScript 中,属性透传(attr pass-through)是指将组件的属性传递到其根元素或某个子元素中。这个概念在开发可复用的组件时非常有用,尤其是当你希望将父组件的属性动态地传递给子组件的某个 DOM 元素时。 在 Vue 3 …...

《人工智能深度学习的基本路线图》
《人工智能深度学习的基本路线图》 基础准备阶段 数学基础: 线性代数:深度学习中大量涉及矩阵运算、向量空间等概念,线性代数是理解和处理这些的基础。例如,神经网络中的权重矩阵、输入向量的运算等都依赖于线性代数知识。学习内容…...

Matlab 答题卡方案
在现代教育事业的飞速发展中,考试已经成为现代教育事业中最公平的方式方法,而且也是衡量教与学的唯一方法。通过考试成绩的好与坏,老师和家长可以分析出学生掌握的知识多少和学习情况。从而老师可以了解到自己教学中的不足来改进教学的方式方…...

[Unity]TileMap开发,TileMap地图缝隙问题
环境: windows11 unity 2021.3.14f1c1 tilemap使用的图是美术已经拼接到一起的整图,块与块之间没有留缝隙 问题: TileMap地图直接在Unity中使用时,格子边缘会出现缝隙,移动或缩放地图时较明显。 解决方案&#x…...

pnpm : 无法加载文件 D:\Tool\environment\NodeAndNvm\node\pnpm.ps1,因为在此系统上禁止运行脚本。
问题 在终端(cmd)输入 pnpm -v,报错如下 pnpm : 无法加载文件 D:\Tool\environment\NodeAndNvm\node\pnpm.ps1,因为在此系统上禁止运行脚本。解决 1. 在终端输入get-ExecutionPolicy(查看执行策略/权限) 输出如下: # (受限的) Restricte…...
和压缩列表(ZipList))
redis的map底层数据结构 分别什么时候使用哈希表(Hash Table)和压缩列表(ZipList)
在Redis中,Hash数据类型的底层数据结构可以是压缩列表(ZipList)或者哈希表(HashTable)。这两种结构的使用取决于特定的条件: 1. **使用ZipList的条件**: - 当Hash中的数据项(即f…...
)
通达OA前台submenu.php存在SQL注入漏洞(CVE-2024-10600)
通达OA前台submenu.php存在SQL注入漏洞(CVE-2024-10600) pda/appcenter/submenu.php 未包含inc/auth.inc.php且 $appid 参数未用’包裹导致前台SQL注入 影响范围 v2017-v11.6 fofa app"TDXK-通达OA" && icon_hash"-759108386"poc http://url…...

Flutter:photo_view图片预览功能
导入SDK photo_view: ^0.15.0单张图片预览,支持放大缩小 import package:flutter/material.dart; import package:photo_view/photo_view.dart;... ...class _MyHomePageState extends State<MyHomePage>{overrideWidget build(BuildContext context) {return…...

C++结构型设计模式之使用抽象工厂来创建和配置桥接模式的例子
下面是一个使用抽象工厂模式来创建和配置桥接模式的示例,场景是创建不同操作系统的窗口(Window)及其对应的实现(WindowImpl)。我们将通过抽象工厂来创建不同操作系统下的窗口和实现。 代码示例 #include <iostrea…...