第4周_作业题_逐步构建你的深度神经网络
文章目录
- ***逐步构建你的深度神经网络***¶
- 0. 背景¶
- 0.1 要解决的问题¶
- 0.2 作业大纲¶
- 0.3 构建深层神经网络步骤¶
- 1. 导入包¶
- 2. 初始化参数¶
- 2.1 2层神经网络¶
- 2.2 L层神经网络¶
- 3. 前项传播函数¶
- 3.1 前项传播步骤¶
- 3.2 线性前向¶
- 3.3 线性激活部分¶
- 3.4 L层前项传播模型¶
- 3.5 计算成本¶
- 4. 反向传播模块¶
- 4.1 反向传播流程图¶
- 4.2 线性反向¶
- 4.3 线性激活部分¶
- 4.4 L层后项传播模型¶
- 5. 更新参数¶
- 6. 搭建两层神经网络¶
- 6.1 两层神经网络模型¶
- 6.2 加载数据集¶
- 6.3 数据集处理¶
- 6.4 正式训练¶
- 6.5 预测¶
- 6.5.1 预测函数¶
- 6.5.2 预测训练集和测试集¶
- 7. 搭建多层神经网络¶
- 7.1 多层神经网络模型¶
- 7.2 加载数据集¶
- 7.3 数据集处理¶
- 7.4 正式训练¶
- 7.5 预测¶
- 7.5.1 预测函数¶
- 7.5.2 预测训练集和测试集¶
- 8. 分析¶
逐步构建你的深度神经网络¶
0. 背景¶
0.1 要解决的问题¶
案例描述:在此之前你已经训练了一个2层的神经网络(只有一个隐藏层)。本周,你将学会构建一个任意层数的深度神经网络!
- 在此作业中,你将实现构建深度神经网络所需的所有函数。
- 在下一个作业中,你将使用这些函数来构建一个用于图像分类的深度神经网络。
完成此任务后,你将能够:
- 使用ReLU等非线性单位来改善模型
- 建立更深的神经网络(具有1个以上的隐藏层)
- 实现一个易于使用的神经网络类
符号说明:
- 上标 [ l ] [l] [l]表示与 l t h l^{th} lth层相关的数量。
- 示例: a [ L ] a^{[L]} a[L]是 L t h L^{th} Lth层的激活。 W [ L ] W^{[L]} W[L]和$b^{[L]}
是 是 是L^{th}$层参数。
- 上标 ( i ) (i) (i)表示与 i t h i^{th} ith示例相关的数量。
- 示例: x ( i ) x^{(i)} x(i)是第 i t h i^{th} ith的训练数据。
- 下标 i i i表示 i t h i^{th} ith的向量。
- 示例: a [ l ] _ i a^{[l]}\_i a[l]_i表示 l t h l^{th} lth层激活的 i t h i^{th} ith输入。
0.2 作业大纲¶
① 为了构建你的神经网络,你将实现几个“辅助函数”。
② 这些辅助函数将在下一个作业中使用,用来构建一个两层神经网络和一个L层的神经网络。
③ 你将实现的每个函数都有详细的说明,这些说明将指导你完成必要的步骤。
④ 此作业的大纲如下:
- 初始化两层的网络和层的神经网络的参数。
- 实现正向传播模块(在下图中以紫色显示)。
- 完成模型正向传播步骤的LINEAR部分()。
- 提供使用的ACTIVATION函数(relu / Sigmoid)。
- 将前两个步骤合并为新的[LINEAR-> ACTIVATION]前向函数。
- 堆叠[LINEAR-> RELU]正向函数L-1次(第1到L-1层),并在末尾添加[LINEAR-> SIGMOID](最后的层)。这合成了一个新的L_model_forward函数。
- 计算损失。
- 实现反向传播模块(在下图中以红色表示)。
- 完成模型反向传播步骤的LINEAR部分。
- 提供的ACTIVATE函数的梯度(relu_backward / sigmoid_backward)
- 将前两个步骤组合成新的[LINEAR-> ACTIVATION]反向函数。
- 将[LINEAR-> RELU]向后堆叠L-1次,并在新的L_model_backward函数中后向添加[LINEAR-> SIGMOID]
最后更新参数。
注意:对于每个正向函数,都有一个对应的反向函数。 这也是为什么在正向传播模块的每一步都将一些值存储在缓存中的原因。缓存的值可用于计算梯度。 然后,在反向传导模块中,你将使用缓存的值来计算梯度。 此作业将指导说明如何执行这些步骤。
0.3 构建深层神经网络步骤¶
① 我们来说一下步骤:
- 初始化网络参数
- 前向传播
- 2.1 计算一层的中线性求和的部分
- 2.2 计算激活函数的部分(ReLU使用L-1次,Sigmod使用1次)
- 2.3 结合线性求和与激活函数
- 计算误差
- 反向传播
- 4.1 线性部分的反向传播公式
- 4.2 激活函数部分的反向传播公式
- 4.3 结合线性部分与激活函数的反向传播公式
- 更新参数
② 对于每个前向函数,都有一个相应的后向函数。
③ 这就是为什么在我们的前向模块的每一步都会在cache中存储一些值,cache的值对计算梯度很有用,在反向传播模块中,我们将使用cache来计算梯度。
④ 现在我们正式开始分别构建两层神经网络和多层神经网络。
1. 导入包¶
① numpy是Python科学计算的基本包。
② matplotlib是在Python中常用的绘制图形的库。
③ dnn_utils为此笔记本提供了一些必要的函数。
④ testCases提供了一些测试用例来评估函数的正确性
⑤ np.random.seed(1)使所有随机函数调用保持一致。 这将有助于我们评估你的作业,请不要改变seed。
需要的文件连接如下:
下载:https://wwyy.lanzouu.com/ixuBK2ww47ve 密码:29q0
In [2]:
import numpy as np
import h5py
import matplotlib.pyplot as plt
from testCases_v2 import *
from dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward
import lr_utils① 软件包准备好了,我们开始构建初始化参数的函数。
② 为了和我的数据匹配,你需要指定随机种子
In [3]:
np.random.seed(1) 2. 初始化参数¶
2.1 2层神经网络¶
① 对于一个两层的神经网络结构而言,模型结构是线性->ReLU->线性->sigmod函数。
In [4]:
def initialize_parameters(n_x, n_h, n_y):"""此函数是为了初始化两层网络参数而使用的函数。参数:n_x - 输入层节点数量n_h - 隐藏层节点数量n_y - 输出层节点数量返回:parameters - 包含你的参数的python字典:W1 - 权重矩阵,维度为(n_h,n_x)b1 - 偏向量,维度为(n_h,1)W2 - 权重矩阵,维度为(n_y,n_h)b2 - 偏向量,维度为(n_y,1)"""np.random.seed(1)W1 = np.random.randn(n_h, n_x)*0.01b1 = np.zeros((n_h,1))W2 = np.random.randn(n_y, n_h)*0.01b2 = np.zeros((n_y,1)) # 使用断言确保我的数据格式是正确的assert(W1.shape == (n_h, n_x))assert(b1.shape == (n_h, 1))assert(W2.shape == (n_y, n_h))assert(b2.shape == (n_y, 1))parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters In [5]:
# 测试一下 测试initialize_parameters 函数
print("==============测试initialize_parameters==============")
parameters = initialize_parameters(2,2,1)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))==============测试initialize_parameters==============
W1 = [[ 0.01624345 -0.00611756][-0.00528172 -0.01072969]]
b1 = [[0.][0.]]
W2 = [[ 0.00865408 -0.02301539]]
b2 = [[0.]]2.2 L层神经网络¶
① 两层的神经网络测试已经完毕了,那么对于一个L层的神经网络而言呢?初始化会是什么样的?
② 更深的L层神经网络的初始化更加复杂,因为存在更多的权重矩阵和偏差向量。
③ 完成 initialize_parameters_deep 后,应确保各层之间的维度匹配。
④ 回想一下, n [ l ] n^{[l]} n[l]是 l l l层中的神经元数量。
⑤ 因此,如果我们输入的 X X X的大小为 ( 12288 , 209 ) (12288, 209) (12288,209)(以$m=209
$为例),则:
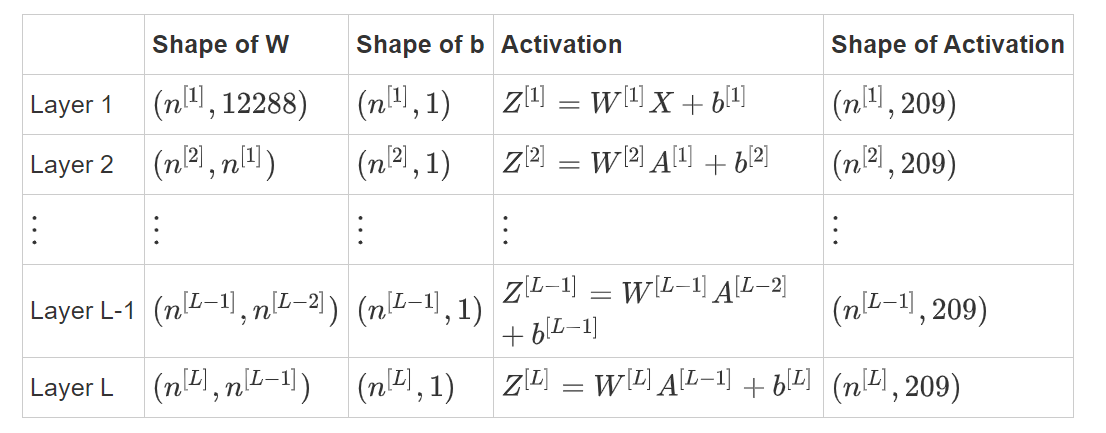
图1
① 矩阵的计算方法还是要说一下的:
KaTeX parse error: \tag works only in display equations
② 如果要计算 W X + b WX + b WX+b 的话,计算方法是这样的:
KaTeX parse error: \tag works only in display equations
③ 在实际中,也不需要你去做这么复杂的运算,下面将展示它是怎样计算的。
④ 这是 L = 1 L=1 L=1(一层神经网络)的实现。以启发你如何实现通用的神经网络(L层神经网络)。
In [ ]:
# 这句不用运行
if L == 1:parameters["W" + str(L)] = np.random.randn(layer_dims[1], layer_dims[0]) * 0.01 parameters["b" + str(L)] = np.zeros((layer_dims[1], 1))In [12]:
def initialize_parameters_deep(layer_dims):"""此函数是为了初始化多层网络参数而使用的函数。参数:layers_dims - 包含我们网络中每个图层的节点数量的列表返回:parameters - 包含参数“W1”,“b1”,...,“WL”,“bL”的字典:W1 - 权重矩阵,维度为(layers_dims [1],layers_dims [1-1])bl - 偏向量,维度为(layers_dims [1],1)"""np.random.seed(3)parameters = {}L = len(layer_dims) # 网络层数for l in range(1, L):parameters['W' + str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])/np.sqrt(layer_dims[l-1])print("w="+str(parameters)) #查看parameters每次的结果parameters['b' + str(l)] = np.zeros((layer_dims[l],1))print("b="+str(parameters))# 确保我要的数据的格式是正确的assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))return parametersIn [13]:
# 测试一下 initialize_parameters_deep 函数
print("==============测试initialize_parameters_deep==============")
layers_dims = [5,4,3]
parameters = initialize_parameters_deep(layers_dims)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))==============测试initialize_parameters_deep==============
w={'W1': array([[ 0.79989897, 0.19521314, 0.04315498, -0.83337927, -0.12405178],[-0.15865304, -0.03700312, -0.28040323, -0.01959608, -0.21341839],[-0.58757818, 0.39561516, 0.39413741, 0.76454432, 0.02237573],[-0.18097724, -0.24389238, -0.69160568, 0.43932807, -0.49241241]])}
b={'W1': array([[ 0.79989897, 0.19521314, 0.04315498, -0.83337927, -0.12405178],[-0.15865304, -0.03700312, -0.28040323, -0.01959608, -0.21341839],[-0.58757818, 0.39561516, 0.39413741, 0.76454432, 0.02237573],[-0.18097724, -0.24389238, -0.69160568, 0.43932807, -0.49241241]]), 'b1': array([[0.],[0.],[0.],[0.]])}
w={'W1': array([[ 0.79989897, 0.19521314, 0.04315498, -0.83337927, -0.12405178],[-0.15865304, -0.03700312, -0.28040323, -0.01959608, -0.21341839],[-0.58757818, 0.39561516, 0.39413741, 0.76454432, 0.02237573],[-0.18097724, -0.24389238, -0.69160568, 0.43932807, -0.49241241]]), 'b1': array([[0.],[0.],[0.],[0.]]), 'W2': array([[-0.59252326, -0.10282495, 0.74307418, 0.11835813],[-0.51189257, -0.3564966 , 0.31262248, -0.08025668],[-0.38441818, -0.11501536, 0.37252813, 0.98805539]])}
b={'W1': array([[ 0.79989897, 0.19521314, 0.04315498, -0.83337927, -0.12405178],[-0.15865304, -0.03700312, -0.28040323, -0.01959608, -0.21341839],[-0.58757818, 0.39561516, 0.39413741, 0.76454432, 0.02237573],[-0.18097724, -0.24389238, -0.69160568, 0.43932807, -0.49241241]]), 'b1': array([[0.],[0.],[0.],[0.]]), 'W2': array([[-0.59252326, -0.10282495, 0.74307418, 0.11835813],[-0.51189257, -0.3564966 , 0.31262248, -0.08025668],[-0.38441818, -0.11501536, 0.37252813, 0.98805539]]), 'b2': array([[0.],[0.],[0.]])}
W1 = [[ 0.79989897 0.19521314 0.04315498 -0.83337927 -0.12405178][-0.15865304 -0.03700312 -0.28040323 -0.01959608 -0.21341839][-0.58757818 0.39561516 0.39413741 0.76454432 0.02237573][-0.18097724 -0.24389238 -0.69160568 0.43932807 -0.49241241]]
b1 = [[0.][0.][0.][0.]]
W2 = [[-0.59252326 -0.10282495 0.74307418 0.11835813][-0.51189257 -0.3564966 0.31262248 -0.08025668][-0.38441818 -0.11501536 0.37252813 0.98805539]]
b2 = [[0.][0.][0.]]3. 前项传播函数¶
3.1 前项传播步骤¶
① 现在,你已经初始化了参数,接下来将执行正向传播模块。 首先实现一些基本函数,用于稍后的模型实现。按以下顺序完成三个函数:
- LINEAR
- LINEAR -> ACTIVATION,其中激活函数采用ReLU或Sigmoid。
- [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID(整个模型)
3.2 线性前向¶
① 线性正向模块(在所有数据中均进行向量化)的计算按照以下公式:
KaTeX parse error: \tag works only in display equations
- 其中 A [ 0 ] = X A^{[0]} = X A[0]=X
② 前向传播中,线性部分计算如下:
In [14]:
def linear_forward(A, W, b):"""实现前向传播的线性部分。参数:A - 来自上一层(或输入数据)的激活,维度为(上一层的节点数量,示例的数量)W - 权重矩阵,numpy数组,维度为(当前图层的节点数量,前一图层的节点数量)b - 偏向量,numpy向量,维度为(当前图层节点数量,1)返回:Z - 激活功能的输入,也称为预激活参数cache - 一个包含“A”,“W”和“b”的字典,存储这些变量以有效地计算后向传递"""Z = np.dot(W,A) + bassert(Z.shape == (W.shape[0], A.shape[1]))cache = (A, W, b)return Z, cacheIn [15]:
#测试一下 linear_forward 函数
print("==============测试linear_forward==============")
A, W, b = linear_forward_test_case()
Z, linear_cache = linear_forward(A, W, b)
print("Z = " + str(Z)) ==============测试linear_forward==============
Z = [[ 3.26295337 -1.23429987]]③ 我们前向传播的单层计算完成了一半啦!我们来开始构建后半部分。
3.3 线性激活部分¶
① 为了更方便,我们将把两个功能(线性和激活)分组为一个功能(LINEAR-> ACTIVATION)。
② 因此,我们将实现一个函数用以执行LINEAR正向步骤和ACTIVATION正向步骤。
③ 实现 LINEAR->ACTIVATION 层的正向传播。 数学表达式为: A [ l ] = g ( Z [ l ] ) = g ( W [ l ] A [ l − 1 ] + b [ l ] ) A^{[l]} = g(Z^{[l]}) = g(W^{[l]}A^{[l-1]} +b^{[l]}) A[l]=g(Z[l])=g(W[l]A[l−1]+b[l]),其中激活"g" 可以是sigmoid()或relu()。
④ 使用 linear_forward()和正确的激活函数。
在此笔记本中,你将使用两个激活函数:
- Sigmoid: σ ( Z ) = σ ( W A + b ) = 1 1 + e − ( W A + b ) \sigma(Z) = \sigma(W A + b) = \frac{1}{ 1 + e^{-(W A + b)}} σ(Z)=σ(WA+b)=1+e−(WA+b)1。
- 我们为你提供了“ Sigmoid”函数。 该函数返回两项值:激活值"a"和包含"Z"的"cache"(这是我们将馈入到相应的反向函数的内容)。
- 你可以按下述方式得到两项值:A, activation_cache = sigmoid(Z)
- ReLU:ReLu的数学公式为 A = R E L U ( Z ) = m a x ( 0 , Z ) A = RELU(Z) = max(0, Z) A=RELU(Z)=max(0,Z)。
- 我们为你提供了relu函数。
- 该函数返回两项值:激活值“A”和包含“Z”的“cache”(这是我们将馈入到相应的反向函数的内容)。
- 你可以按下述方式得到两项值:A, activation_cache = relu(Z)
In [16]:
def linear_activation_forward(A_prev, W, b, activation):'''实现LINEAR-> ACTIVATION 这一层的前向传播参数:A_prev - 来自上一层(或输入层)的激活,维度为(上一层的节点数量,示例数)W - 权重矩阵,numpy数组,维度为(当前层的节点数量,前一层的大小)b - 偏向量,numpy阵列,维度为(当前层的节点数量,1)activation - 选择在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】返回:A - 激活函数的输出,也称为激活后的值cache - 一个包含“linear_cache”和“activation_cache”的字典,我们需要存储它以有效地计算后向传递'''if activation == "sigmoid":Z, linear_cache = linear_forward(A_prev,W,b)A, activation_cache = sigmoid(Z)elif activation == "relu":Z, linear_cache = linear_forward(A_prev,W,b)A, activation_cache = relu(Z)assert (A.shape == (W.shape[0], A_prev.shape[1]))cache = (linear_cache, activation_cache)return A, cacheIn [17]:
#测试一下 linear_activation_forward 函数
print("==============测试linear_activation_forward==============")
A_prev, W, b = linear_activation_forward_test_case()A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "sigmoid")
print("With sigmoid: A = " + str(A))A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "relu")
print("With ReLU: A = " + str(A))==============测试linear_activation_forward==============
With sigmoid: A = [[0.96890023 0.11013289]]
With ReLU: A = [[3.43896131 0. ]]⑤ 在深度学习中,"[LINEAR->ACTIVATION]"计算被视为神经网络中的单个层,而不是两个层。
3.4 L层前项传播模型¶
① 我们把两层模型需要的前向传播函数做完了,那多层网络模型的前向传播是怎样的呢?
② 我们调用上面的那两个函数来实现它,为了在实现L层神经网络时更加方便,我们需要一个函数来复制前一个函数(带有RELU的linear_activation_forward)L-1次,然后用一个带有SIGMOID的linear_activation_forward跟踪它,我们来看一下它的结构是怎样的:
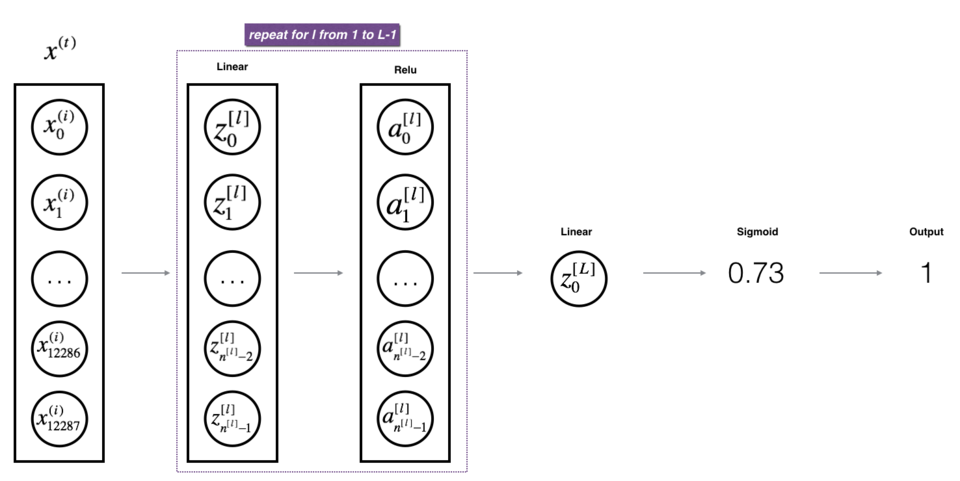
图2 : [LINEAR -> RELU] (L-1) -> LINEAR -> SIGMOID 模型
练习:实现上述模型的正向传播。
说明:在下面的代码中,变量AL表示 A [ L ] = σ ( Z [ L ] ) = σ ( W [ L ] A [ L − 1 ] + b [ L ] ) A^{[L]} = \sigma(Z^{[L]}) = \sigma(W^{[L]} A^{[L-1]} + b^{[L]}) A[L]=σ(Z[L])=σ(W[L]A[L−1]+b[L])(有时也称为Yhat,即 Y ^ \hat{Y} Y^。)
提示:
- 使用你先前编写的函数
- 使用for循环复制[LINEAR-> RELU](L-1)次
- 不要忘记在“cache”列表中更新缓存。 要将新值 c 添加到list中,可以使用list.append©。
In [18]:
def L_model_forward(X, parameters):"""实现[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID计算前向传播,也就是多层网络的前向传播,为后面每一层都执行LINEAR和ACTIVATION参数:X - 数据,numpy数组,维度为(输入节点数量,示例数)parameters - initialize_parameters_deep()的输出返回:AL - 最后的激活值caches - 包含以下内容的缓存列表:linear_relu_forward()的每个cache(有L-1个,索引为从0到L-2)linear_sigmoid_forward()的cache(只有一个,索引为L-1)"""caches = []A = XL = len(parameters) // 2 # 神经网络的层数for l in range(1, L):A_prev = A A, cache = linear_activation_forward(A_prev,parameters['W' + str(l)],parameters['b' + str(l)],activation = "relu")caches.append(cache)AL, cache = linear_activation_forward(A,parameters['W' + str(L)],parameters['b' + str(L)],activation = "sigmoid")caches.append(cache)assert(AL.shape == (1,X.shape[1]))return AL, cachesIn [19]:
# 测试一下 L_model_forward 函数
print("==============测试L_model_forward==============")
X, parameters = L_model_forward_test_case()
AL, caches = L_model_forward(X, parameters)
print("AL = " + str(AL))
print("Length of caches list = " + str(len(caches)))==============测试L_model_forward==============
AL = [[0.17007265 0.2524272 ]]
Length of caches list = 23.5 计算成本¶
① 现在,我们有了一个完整的正向传播模块,它接受输入X并输出包含预测的行向量。 它还将所有中间值记录在"caches"中以计算预测的损失值。
② 我们需要计算成本(误差),以确定它到底有没有在学习,我们使用以下公式计算交叉熵损失 J J J:
KaTeX parse error: \tag works only in display equations
In [20]:
def compute_cost(AL, Y):"""实施等式(5)定义的成本函数。参数:AL - 与标签预测相对应的概率向量,维度为(1,示例数量)Y - 标签向量(例如:如果不是猫,则为0,如果是猫则为1),维度为(1,数量)返回:cost - 交叉熵成本"""m = Y.shape[1]cost = -1 / m * np.sum(Y * np.log(AL) + (1-Y) * np.log(1-AL),axis=1,keepdims=True)cost = np.squeeze(cost) return costIn [21]:
Y, AL = compute_cost_test_case()print("cost = " + str(compute_cost(AL, Y)))cost = 0.41493159961539694③ 我们已经把误差值计算出来了,现在开始进行反向传播。
4. 反向传播模块¶
4.1 反向传播流程图¶
① 反向传播用于计算相对于参数的损失函数的梯度,我们来看看向前和向后传播的流程图:
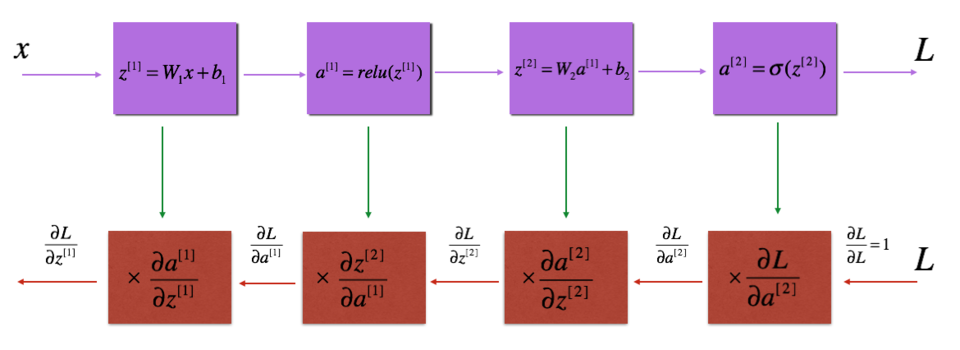
4.2 线性反向¶
① 流程图有了,我们再来看一看对于线性的部分的公式:
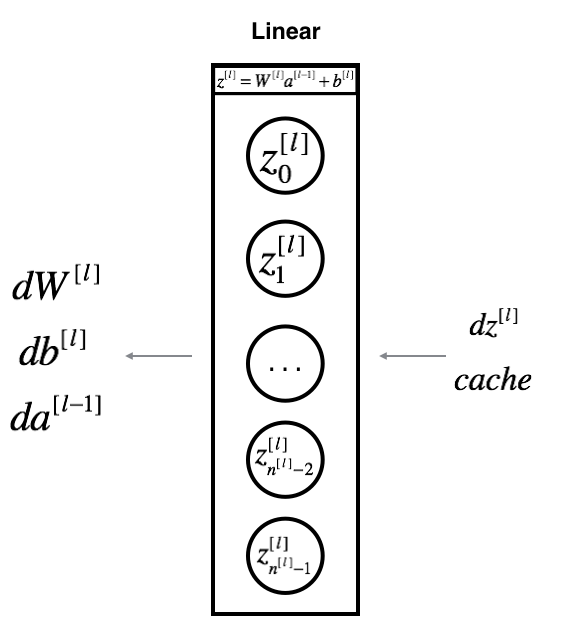
② 使用输入 d Z [ l ] dZ^{[l]} dZ[l]计算三个输出$(dW^{[l]}, db^{[l]}, dA^{[l]})
$,以下是所需的公式:
d W [ l ] = ∂ L ∂ W [ l ] = 1 m d Z [ l ] A [ l − 1 ] T (8) dW^{[l]} = \frac{\partial \mathcal{L} }{\partial W^{[l]}} = \frac{1}{m} dZ^{[l]} A^{[l-1] T} \tag{8} dW[l]=∂W[l]∂L=m1dZ[l]A[l−1]T(8)
d b [ l ] = ∂ L ∂ b [ l ] = 1 m ∑ _ i = 1 m d Z [ l ] ( i ) (9) db^{[l]} = \frac{\partial \mathcal{L} }{\partial b^{[l]}} = \frac{1}{m} \sum\_{i = 1}^{m} dZ^{[l](i)}\tag{9} db[l]=∂b[l]∂L=m1∑_i=1mdZ[l](i)(9)
d A [ l − 1 ] = ∂ L ∂ A [ l − 1 ] = W [ l ] T d Z [ l ] (10) dA^{[l-1]} = \frac{\partial \mathcal{L} }{\partial A^{[l-1]}} = W^{[l] T} dZ^{[l]} \tag{10} dA[l−1]=∂A[l−1]∂L=W[l]TdZ[l](10)
In [22]:
def linear_backward(dZ, cache):"""为单层实现反向传播的线性部分(第L层)参数:dZ - 相对于(当前第l层的)线性输出的成本梯度cache - 来自当前层前向传播的值的元组(A_prev,W,b)返回:dA_prev - 相对于激活(前一层l-1)的成本梯度,与A_prev维度相同dW - 相对于W(当前层l)的成本梯度,与W的维度相同db - 相对于b(当前层l)的成本梯度,与b维度相同"""A_prev, W, b = cachem = A_prev.shape[1]dW = 1 / m * np.dot(dZ ,A_prev.T)db = 1 / m * np.sum(dZ,axis = 1 ,keepdims=True)dA_prev = np.dot(W.T,dZ) assert (dA_prev.shape == A_prev.shape)assert (dW.shape == W.shape)assert (db.shape == b.shape)return dA_prev, dW, dbIn [23]:
#测试一下 linear_backward 函数
print("==============测试linear_backward==============")
dZ, linear_cache = linear_backward_test_case()
dA_prev, dW, db = linear_backward(dZ, linear_cache)
print ("dA_prev = "+ str(dA_prev))
print ("dW = " + str(dW))
print ("db = " + str(db))==============测试linear_backward==============
dA_prev = [[ 0.51822968 -0.19517421][-0.40506361 0.15255393][ 2.37496825 -0.89445391]]
dW = [[-0.10076895 1.40685096 1.64992505]]
db = [[0.50629448]]4.3 线性激活部分¶
① 为了帮助你实现linear_activation_backward,我们提供了两个反向函数:
- sigmoid_backward()
- relu_backward()
② sigmoid_backward():实现sigmoid()函数的反向传播,你可以这样调用它:
d Z = s i g m o i d _ b a c k w a r d ( d A , a c t i v a t i o n _ c a c h e ) dZ = sigmoid\_backward(dA, activation\_cache) dZ=sigmoid_backward(dA,activation_cache)
③ relu_backward():实现relu()函数的反向传播。 你可以这样调用它:
d Z = r e l u _ b a c k w a r d ( d A , a c t i v a t i o n _ c a c h e ) dZ = relu\_backward(dA, activation\_cache) dZ=relu_backward(dA,activation_cache)
④ 如果 g ( . . . ) g(...) g(...)是激活函数,sigmoid_backward()和relu_backward()这样计算:
KaTeX parse error: Undefined control sequence: \* at position 21: …l]} = dA^{[l]} \̲*̲ g'(Z^{[l]}) \t…
⑤ 我们现在正式开始实现后向线性激活:
In [24]:
def linear_activation_backward(dA, cache, activation):"""实现LINEAR-> ACTIVATION层的后向传播。参数:dA - 当前层l的激活后的梯度值cache - 我们存储的用于有效计算反向传播的值的元组(值为linear_cache,activation_cache)activation - 要在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】返回:dA_prev - 相对于激活(前一层l-1)的成本梯度值,与A_prev维度相同dW - 相对于W(当前层l)的成本梯度值,与W的维度相同db - 相对于b(当前层l)的成本梯度值,与b的维度相同"""linear_cache, activation_cache = cacheif activation == "relu":dZ = relu_backward(dA, activation_cache)dA_prev, dW, db = linear_backward(dZ, linear_cache)elif activation == "sigmoid":dZ = sigmoid_backward(dA, activation_cache)dA_prev, dW, db = linear_backward(dZ, linear_cache)return dA_prev, dW, dbIn [25]:
# 测试一下 linear_activation_backward 函数
print("==============测试linear_activation_backward==============")
AL, linear_activation_cache = linear_activation_backward_test_case()dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "sigmoid")
print ("sigmoid:")
print ("dA_prev = "+ str(dA_prev))
print ("dW = " + str(dW))
print ("db = " + str(db) + "\n")dA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = "relu")
print ("relu:")
print ("dA_prev = "+ str(dA_prev))
print ("dW = " + str(dW))
print ("db = " + str(db))==============测试linear_activation_backward==============
sigmoid:
dA_prev = [[ 0.11017994 0.01105339][ 0.09466817 0.00949723][-0.05743092 -0.00576154]]
dW = [[ 0.10266786 0.09778551 -0.01968084]]
db = [[-0.05729622]]relu:
dA_prev = [[ 0.44090989 0. ][ 0.37883606 0. ][-0.2298228 0. ]]
dW = [[ 0.44513824 0.37371418 -0.10478989]]
db = [[-0.20837892]]4.4 L层后项传播模型¶
① 我们已经把两层模型的后向计算完成了,对于多层模型我们也需要这两个函数来完成,我们来看一下流程图:

② 在之前的前向计算中,我们存储了一些包含包含(X,W,b和z)的cache,在每次迭代中,我们将会使用它们来计算梯度值,所以,在L层模型中,我们需要从L层遍历所有的隐藏层,在每一步中,我们需要使用那一层的cache值来进行反向传播。
③ 上面我们提到了 A [ L ] A^{[L]} A[L],它属于输出层 A [ L ] = σ ( Z [ L ] ) A^{[L]} = \sigma(Z^{[L]}) A[L]=σ(Z[L]),所以我们需要计算dAL,我们可以使用下面的代码来计算它:
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
④ 计算完了以后,我们可以使用此激活后的梯度dAL继续向后计算,我们这就开始构建多层模型向后传播函数:
In [26]:
def L_model_backward(AL, Y, caches):"""对[LINEAR-> RELU] *(L-1) - > LINEAR - > SIGMOID组执行反向传播,就是多层网络的向后传播参数:AL - 概率向量,正向传播的输出(L_model_forward())Y - 标签向量(例如:如果不是猫,则为0,如果是猫则为1),维度为(1,数量)caches - 包含以下内容的cache列表:linear_activation_forward("relu")的cache,不包含输出层linear_activation_forward("sigmoid")的cache返回:grads - 具有梯度值的字典grads [“dA”+ str(l)] = ...grads [“dW”+ str(l)] = ...grads [“db”+ str(l)] = ..."""grads = {}L = len(caches) m = AL.shape[1]Y = Y.reshape(AL.shape) # 初始化反向传播dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))current_cache = caches[L-1]grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, activation = "sigmoid")for l in reversed(range(L - 1)):current_cache = caches[l]dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l+2)], current_cache, activation = "relu")grads["dA" + str(l + 1)] = dA_prev_tempgrads["dW" + str(l + 1)] = dW_tempgrads["db" + str(l + 1)] = db_tempreturn gradsIn [27]:
#测试一下 L_model_backward 函数
print("==============测试L_model_backward==============")
AL, Y_assess, caches = L_model_backward_test_case()
grads = L_model_backward(AL, Y_assess, caches)
print ("dW1 = "+ str(grads["dW1"]))
print ("db1 = "+ str(grads["db1"]))
print ("dA1 = "+ str(grads["dA1"]))==============测试L_model_backward==============
dW1 = [[0.41010002 0.07807203 0.13798444 0.10502167][0. 0. 0. 0. ][0.05283652 0.01005865 0.01777766 0.0135308 ]]
db1 = [[-0.22007063][ 0. ][-0.02835349]]
dA1 = [[ 0. 0.52257901][ 0. -0.3269206 ][ 0. -0.32070404][ 0. -0.74079187]]5. 更新参数¶
① 我们把向前向后传播都完成了,现在我们就开始更新参数,当然,我们来看看更新参数的公式吧~
KaTeX parse error: \tag works only in display equations
KaTeX parse error: \tag works only in display equations
其中: α \alpha α是学习率。
② 在计算更新的参数后,将它们存储在参数字典中。
③ 对于 l = 1 , 2 , . . . , L l = 1, 2, ..., L l=1,2,...,L,使用梯度下降更新每个 W [ l ] W^{[l]} W[l]和 b [ l ] b^{[l]} b[l]的参数:
In [28]:
def update_parameters(parameters, grads, learning_rate):"""使用梯度下降更新参数参数:parameters - 包含你的参数的字典grads - 包含梯度值的字典,是L_model_backward的输出返回:parameters - 包含更新参数的字典参数[“W”+ str(l)] = ...参数[“b”+ str(l)] = ..."""# 神经网络的层数L = len(parameters) // 2 # 更新每个参数,使用 for 循环for l in range(L):parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * grads["dW" + str(l + 1)]parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * grads["db" + str(l + 1)]return parametersIn [29]:
# 测试一下 update_parameters 函数
print("==============测试update_parameters==============")
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads, 0.1)print ("W1 = "+ str(parameters["W1"]))
print ("b1 = "+ str(parameters["b1"]))
print ("W2 = "+ str(parameters["W2"]))
print ("b2 = "+ str(parameters["b2"]))==============测试update_parameters==============
W1 = [[-0.59562069 -0.09991781 -2.14584584 1.82662008][-1.76569676 -0.80627147 0.51115557 -1.18258802][-1.0535704 -0.86128581 0.68284052 2.20374577]]
b1 = [[-0.04659241][-1.28888275][ 0.53405496]]
W2 = [[-0.55569196 0.0354055 1.32964895]]
b2 = [[-0.84610769]]④ 至此为止,我们已经实现该神经网络中所有需要的函数。
⑤ 接下来,我们将这些方法组合在一起,构成一个神经网络类,可以方便的使用。
6. 搭建两层神经网络¶
6.1 两层神经网络模型¶
① 一个两层的神经网络模型图如下:
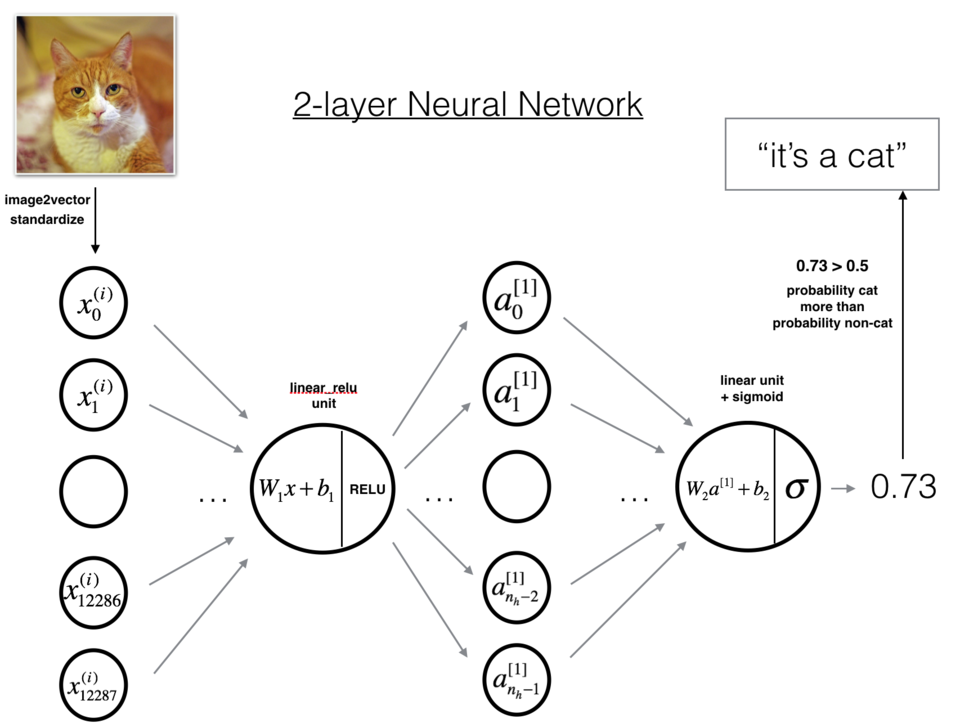
② 该模型可以概括为: INPUT -> LINEAR -> RELU -> LINEAR -> SIGMOID -> OUTPUT
In [30]:
def two_layer_model(X,Y,layers_dims,learning_rate=0.0075,num_iterations=3000,print_cost=False,isPlot=True):"""实现一个两层的神经网络,【LINEAR->RELU】 -> 【LINEAR->SIGMOID】参数:X - 输入的数据,维度为(n_x,例子数)Y - 标签,向量,0为非猫,1为猫,维度为(1,数量)layers_dims - 层数的向量,维度为(n_y,n_h,n_y)learning_rate - 学习率num_iterations - 迭代的次数print_cost - 是否打印成本值,每100次打印一次isPlot - 是否绘制出误差值的图谱返回:parameters - 一个包含W1,b1,W2,b2的字典变量"""np.random.seed(1)grads = {}costs = [](n_x,n_h,n_y) = layers_dims"""初始化参数"""parameters = initialize_parameters(n_x, n_h, n_y)W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]"""开始进行迭代"""for i in range(0,num_iterations):# 前向传播A1, cache1 = linear_activation_forward(X, W1, b1, "relu")A2, cache2 = linear_activation_forward(A1, W2, b2, "sigmoid")# 计算成本cost = compute_cost(A2,Y)# 后向传播## 初始化后向传播dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2))## 向后传播,输入:“dA2,cache2,cache1”。 输出:“dA1,dW2,db2;还有dA0(未使用),dW1,db1”。dA1, dW2, db2 = linear_activation_backward(dA2, cache2, "sigmoid")dA0, dW1, db1 = linear_activation_backward(dA1, cache1, "relu")## 向后传播完成后的数据保存到gradsgrads["dW1"] = dW1grads["db1"] = db1grads["dW2"] = dW2grads["db2"] = db2#更新参数parameters = update_parameters(parameters,grads,learning_rate)W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]# 打印成本值,如果print_cost=False则忽略if i % 100 == 0:# 记录成本costs.append(cost)# 是否打印成本值if print_cost:print("第", i ,"次迭代,成本值为:" ,np.squeeze(cost))# 迭代完成,根据条件绘制图if isPlot:plt.plot(np.squeeze(costs))plt.ylabel('cost')plt.xlabel('iterations (per tens)')plt.title("Learning rate =" + str(learning_rate))plt.show()# 返回 parametersreturn parameters6.2 加载数据集¶
① 我们现在开始加载数据集。
In [31]:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset()6.3 数据集处理¶
① 图像数据集的处理可以参照 课程1_第2周_作业,就连数据集也是一样的。
In [32]:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset()train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).Ttrain_x = train_x_flatten / 255
train_y = train_set_y
test_x = test_x_flatten / 255
test_y = test_set_y6.4 正式训练¶
① 数据集加载完成,开始正式训练:
In [33]:
n_x = 12288
n_h = 7
n_y = 1
layers_dims = (n_x,n_h,n_y)parameters = two_layer_model(train_x, train_set_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True,isPlot=True)第 0 次迭代,成本值为: 0.693049735659989
第 100 次迭代,成本值为: 0.6464320953428849
第 200 次迭代,成本值为: 0.6325140647912677
第 300 次迭代,成本值为: 0.6015024920354665
第 400 次迭代,成本值为: 0.5601966311605747
第 500 次迭代,成本值为: 0.5158304772764729
第 600 次迭代,成本值为: 0.47549013139433255
第 700 次迭代,成本值为: 0.4339163151225749
第 800 次迭代,成本值为: 0.4007977536203887
第 900 次迭代,成本值为: 0.3580705011323798
第 1000 次迭代,成本值为: 0.3394281538366413
第 1100 次迭代,成本值为: 0.3052753636196265
第 1200 次迭代,成本值为: 0.2749137728213016
第 1300 次迭代,成本值为: 0.24681768210614832
第 1400 次迭代,成本值为: 0.19850735037466088
第 1500 次迭代,成本值为: 0.17448318112556688
第 1600 次迭代,成本值为: 0.17080762978096067
第 1700 次迭代,成本值为: 0.11306524562164731
第 1800 次迭代,成本值为: 0.09629426845937152
第 1900 次迭代,成本值为: 0.08342617959726861
第 2000 次迭代,成本值为: 0.07439078704319081
第 2100 次迭代,成本值为: 0.0663074813226793
第 2200 次迭代,成本值为: 0.05919329501038171
第 2300 次迭代,成本值为: 0.05336140348560557
第 2400 次迭代,成本值为: 0.04855478562877016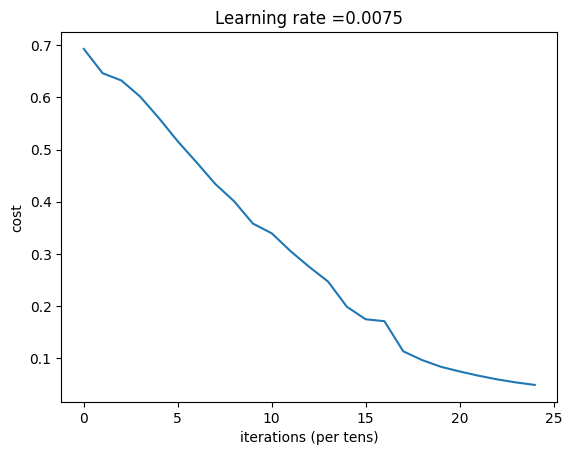
6.5 预测¶
6.5.1 预测函数¶
① 迭代完成之后我们就可以进行预测了,预测函数如下:
In [34]:
def predict(X, y, parameters):"""该函数用于预测L层神经网络的结果,当然也包含两层参数:X - 测试集y - 标签parameters - 训练模型的参数返回:p - 给定数据集X的预测"""m = X.shape[1]n = len(parameters) // 2 # 神经网络的层数p = np.zeros((1,m))# 根据参数前向传播probas, caches = L_model_forward(X, parameters)for i in range(0, probas.shape[1]):if probas[0,i] > 0.5:p[0,i] = 1else:p[0,i] = 0print("准确度为: " + str(float(np.sum((p == y))/m)))return p6.5.2 预测训练集和测试集¶
① 预测函数构建好了我们就开始预测,查看训练集和测试集的准确性:
In [35]:
predictions_train = predict(train_x, train_y, parameters) # 训练集
predictions_test = predict(test_x, test_y, parameters) # 测试集准确度为: 1.0
准确度为: 0.72② 这样看来,我的测试集的准确度要比上一次(课程1_第2周_作业_用神经网络思想实现Logistic回归)高一些,上次的是70%,这次是72%,那如果我使用更多层的神经网络呢?
7. 搭建多层神经网络¶
7.1 多层神经网络模型¶
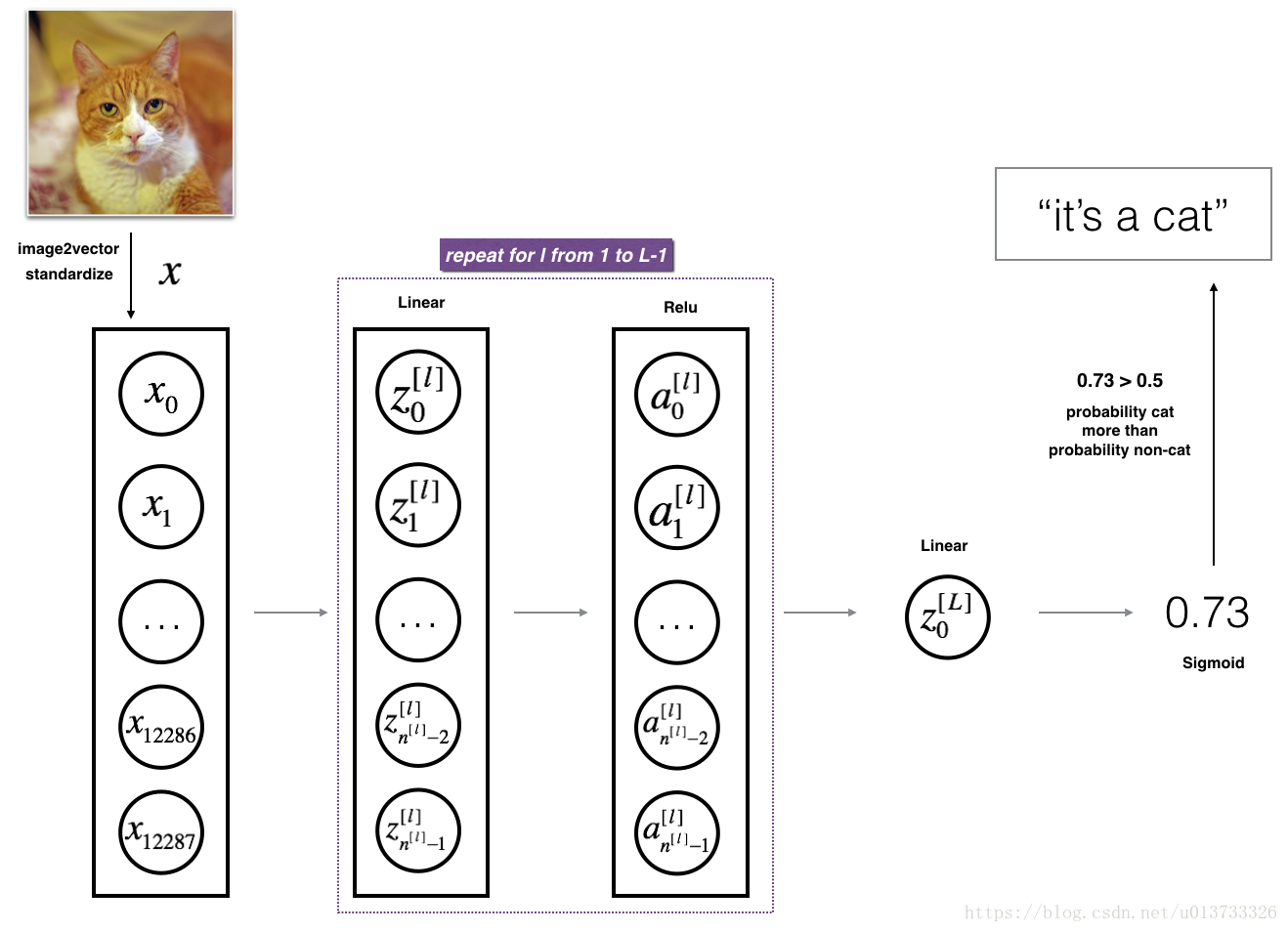
① 我们首先来看看多层的网络的结构吧~
In [36]:
def L_layer_model(X, Y, layers_dims, learning_rate=0.0075, num_iterations=3000, print_cost=False,isPlot=True):"""实现一个L层神经网络:[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID。参数:X - 输入的数据,维度为(n_x,例子数)Y - 标签,向量,0为非猫,1为猫,维度为(1,数量)layers_dims - 层数的向量,维度为(n_y,n_h,···,n_h,n_y)learning_rate - 学习率num_iterations - 迭代的次数print_cost - 是否打印成本值,每100次打印一次isPlot - 是否绘制出误差值的图谱返回:parameters - 模型学习的参数。 然后他们可以用来预测。"""np.random.seed(1)costs = []parameters = initialize_parameters_deep(layers_dims)for i in range(0,num_iterations):AL , caches = L_model_forward(X,parameters)cost = compute_cost(AL,Y)grads = L_model_backward(AL,Y,caches)parameters = update_parameters(parameters,grads,learning_rate)# 打印成本值,如果 print_cost=False 则忽略if i % 100 == 0:# 记录成本costs.append(cost)# 是否打印成本值if print_cost:print("第", i ,"次迭代,成本值为:" ,np.squeeze(cost))# 迭代完成,根据条件绘制图if isPlot:plt.plot(np.squeeze(costs))plt.ylabel('cost')plt.xlabel('iterations (per tens)')plt.title("Learning rate =" + str(learning_rate))plt.show()return parameters7.2 加载数据集¶
① 我们现在开始加载数据集。
In [37]:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset()7.3 数据集处理¶
① 图像数据集的处理可以参照 课程1_第2周_作业,就连数据集也是一样的。
In [38]:
train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).Ttrain_x = train_x_flatten / 255
train_y = train_set_y
test_x = test_x_flatten / 255
test_y = test_set_y7.4 正式训练¶
① 数据集加载完成,开始正式训练:
In [39]:
layers_dims = [12288, 20, 7, 5, 1] # 5-layer model
parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True,isPlot=True)w={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288))}
b={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]])}
w={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]])}
b={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]]), 'b2': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.]])}
w={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]]), 'b2': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W3': array([[-0.11933173, -0.01249723, 0.57965436, -0.3014344 , 0.4033143 ,0.17420813, 0.01226385],[-0.11825862, 0.22104876, 0.35363281, 0.11013422, -0.07328169,0.23315954, 0.42927306],[ 0.33357457, 0.30962251, 0.78787388, 0.18470908, 0.27750815,-0.23189372, 0.87626539],[-0.01545708, 0.61579227, -0.93507207, -0.15141596, 0.05662612,0.24204927, 0.03872557],[ 0.19774909, 0.07395986, 0.11495293, 0.16192564, -0.29223422,-0.0219016 , -0.17339838]])}
b={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]]), 'b2': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W3': array([[-0.11933173, -0.01249723, 0.57965436, -0.3014344 , 0.4033143 ,0.17420813, 0.01226385],[-0.11825862, 0.22104876, 0.35363281, 0.11013422, -0.07328169,0.23315954, 0.42927306],[ 0.33357457, 0.30962251, 0.78787388, 0.18470908, 0.27750815,-0.23189372, 0.87626539],[-0.01545708, 0.61579227, -0.93507207, -0.15141596, 0.05662612,0.24204927, 0.03872557],[ 0.19774909, 0.07395986, 0.11495293, 0.16192564, -0.29223422,-0.0219016 , -0.17339838]]), 'b3': array([[0.],[0.],[0.],[0.],[0.]])}
w={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]]), 'b2': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W3': array([[-0.11933173, -0.01249723, 0.57965436, -0.3014344 , 0.4033143 ,0.17420813, 0.01226385],[-0.11825862, 0.22104876, 0.35363281, 0.11013422, -0.07328169,0.23315954, 0.42927306],[ 0.33357457, 0.30962251, 0.78787388, 0.18470908, 0.27750815,-0.23189372, 0.87626539],[-0.01545708, 0.61579227, -0.93507207, -0.15141596, 0.05662612,0.24204927, 0.03872557],[ 0.19774909, 0.07395986, 0.11495293, 0.16192564, -0.29223422,-0.0219016 , -0.17339838]]), 'b3': array([[0.],[0.],[0.],[0.],[0.]]), 'W4': array([[-0.12437772, 0.0305978 , 0.21866095, 0.33703684, 0.28430918]])}
b={'W1': array([[ 0.01613539, 0.0039378 , 0.00087051, ..., 0.00669395,0.0070159 , -0.01844003],[-0.0183556 , -0.01152091, -0.00762325, ..., -0.01436933,0.01073293, 0.01235069],[ 0.00664245, 0.00938224, -0.00550971, ..., -0.00649494,0.01211102, -0.00175117],...,[ 0.00137742, 0.01057137, -0.01133941, ..., -0.0161836 ,0.00881368, 0.00667983],[ 0.00271738, 0.01370506, 0.00698235, ..., -0.00073793,-0.0043648 , 0.01134661],[ 0.00902553, 0.00473445, -0.00068975, ..., 0.00602823,0.00312704, -0.00558398]], shape=(20, 12288)), 'b1': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W2': array([[-0.09419906, 0.03040597, 0.08590602, 0.0130623 , 0.11941883,0.03455312, -0.0281743 , -0.26183725, 0.2881649 , -0.321709 ,0.10809132, 0.74539339, 0.21400319, 0.32551585, 0.21771165,0.05290571, 0.38721136, 0.01822059, 0.3425938 , -0.600641 ],[ 0.03123257, 0.07044871, 0.03420848, -0.1594023 , -0.05778962,-0.32287613, 0.10639236, -0.02928433, 0.25296891, 0.05918778,-0.09587764, 0.16871618, 0.0908236 , -0.09661074, -0.17290511,0.2187035 , 0.46897212, 0.2811902 , 0.22214372, 0.21663204],[ 0.17090344, -0.02630121, 0.00143437, -0.04716797, -0.05901662,0.36120994, 0.20486008, -0.18441855, 0.22394416, -0.20284717,-0.67142475, 0.29136752, 0.04426756, 0.01464488, 0.16107217,0.01563492, 0.36469118, 0.38616336, 0.04293526, 0.09234398],[ 0.40244948, 0.2785512 , -0.05004821, -0.17193241, 0.40673153,-0.57187785, 0.33869292, -0.09916026, -0.36346142, -0.17299048,0.18093997, 0.15505023, 0.13136035, 0.07647026, -0.26314691,-0.00385993, -0.01818672, 0.14169205, 0.27169692, 0.20816752],[-0.13064258, -0.26750914, 0.17361113, -0.40230209, -0.02814258,-0.23152791, 0.02673417, 0.18124466, -0.25539783, 0.20313216,0.13619753, 0.27752035, 0.01994774, 0.20021301, -0.38174058,-0.05084353, 0.08460939, -0.18651373, -0.56423082, -0.30888195],[-0.14328869, 0.04682534, -0.29795921, -0.0387681 , -0.08100381,0.24728816, -0.1747879 , -0.09175786, 0.09032729, 0.42781254,0.35624356, -0.30336527, 0.18243692, 0.07250816, 0.14918077,0.31537083, 0.46358896, 0.22253074, 0.22088051, 0.23154186],[-0.12416764, -0.49335209, 0.19323838, -0.00858265, -0.19024118,0.07219969, 0.16376104, 0.04090931, -0.11338397, 0.08819734,0.03005855, 0.0033654 , 0.05004124, -0.09120098, -0.41811499,-0.12209824, 0.1175751 , 0.05653372, -0.02466081, -0.07812141]]), 'b2': array([[0.],[0.],[0.],[0.],[0.],[0.],[0.]]), 'W3': array([[-0.11933173, -0.01249723, 0.57965436, -0.3014344 , 0.4033143 ,0.17420813, 0.01226385],[-0.11825862, 0.22104876, 0.35363281, 0.11013422, -0.07328169,0.23315954, 0.42927306],[ 0.33357457, 0.30962251, 0.78787388, 0.18470908, 0.27750815,-0.23189372, 0.87626539],[-0.01545708, 0.61579227, -0.93507207, -0.15141596, 0.05662612,0.24204927, 0.03872557],[ 0.19774909, 0.07395986, 0.11495293, 0.16192564, -0.29223422,-0.0219016 , -0.17339838]]), 'b3': array([[0.],[0.],[0.],[0.],[0.]]), 'W4': array([[-0.12437772, 0.0305978 , 0.21866095, 0.33703684, 0.28430918]]), 'b4': array([[0.]])}
第 0 次迭代,成本值为: 0.7157315134137129
第 100 次迭代,成本值为: 0.6747377593469114
第 200 次迭代,成本值为: 0.6603365433622128
第 300 次迭代,成本值为: 0.6462887802148751
第 400 次迭代,成本值为: 0.6298131216927771
第 500 次迭代,成本值为: 0.606005622926534
第 600 次迭代,成本值为: 0.5690041263975134
第 700 次迭代,成本值为: 0.519796535043806
第 800 次迭代,成本值为: 0.46415716786282296
第 900 次迭代,成本值为: 0.40842030048298916
第 1000 次迭代,成本值为: 0.37315499216069054
第 1100 次迭代,成本值为: 0.3057237457304713
第 1200 次迭代,成本值为: 0.2681015284774086
第 1300 次迭代,成本值为: 0.238724748276725
第 1400 次迭代,成本值为: 0.20632263257914707
第 1500 次迭代,成本值为: 0.17943886927493452
第 1600 次迭代,成本值为: 0.15798735818800563
第 1700 次迭代,成本值为: 0.1424041301227307
第 1800 次迭代,成本值为: 0.1286516599788137
第 1900 次迭代,成本值为: 0.11244314998141401
第 2000 次迭代,成本值为: 0.085056310349417
第 2100 次迭代,成本值为: 0.057583911985884556
第 2200 次迭代,成本值为: 0.044567534546855
第 2300 次迭代,成本值为: 0.03808275166593553
第 2400 次迭代,成本值为: 0.03441074901837627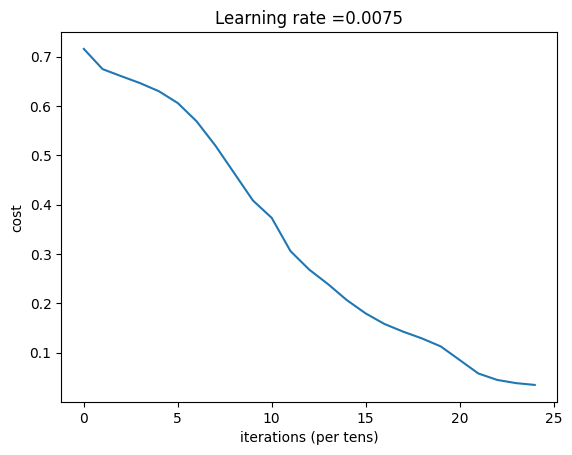
7.5 预测¶
7.5.1 预测函数¶
In [40]:
def predict(X, y, parameters):"""该函数用于预测L层神经网络的结果,当然也包含两层参数:X - 测试集y - 标签parameters - 训练模型的参数返回:p - 给定数据集X的预测"""m = X.shape[1]n = len(parameters) // 2 # 神经网络的层数p = np.zeros((1,m))# 根据参数前向传播probas, caches = L_model_forward(X, parameters)for i in range(0, probas.shape[1]):if probas[0,i] > 0.5:p[0,i] = 1else:p[0,i] = 0print("准确度为: " + str(float(np.sum((p == y))/m)))return p7.5.2 预测训练集和测试集¶
In [41]:
pred_train = predict(train_x, train_y, parameters) #训练集
pred_test = predict(test_x, test_y, parameters) #测试集准确度为: 0.9952153110047847
准确度为: 0.78① 就准确度而言,从70%到72%再到78%,可以看到的是准确度在一点点增加,当然,你也可以手动的去调整layers_dims,准确度可能又会提高一些。
8. 分析¶
① 我们可以看一看有哪些东西在L层模型中被错误地标记了,导致准确率没有提高。
In [42]:
def print_mislabeled_images(classes, X, y, p):"""绘制预测和实际不同的图像。X - 数据集y - 实际的标签p - 预测"""a = p + ymislabeled_indices = np.asarray(np.where(a == 1))plt.rcParams['figure.figsize'] = (40.0, 40.0) # 设置 plot 的默认大小num_images = len(mislabeled_indices[0])for i in range(num_images):index = mislabeled_indices[1][i]plt.subplot(2, num_images, i + 1)plt.imshow(X[:,index].reshape(64,64,3), interpolation='nearest')plt.axis('off')plt.title("Prediction: " + classes[int(p[0,index])].decode("utf-8") + " \n Class: " + classes[y[0,index]].decode("utf-8"))print_mislabeled_images(classes, test_x, test_y, pred_test)
② 分析一下我们就可以得知原因了,模型往往表现欠佳的几种类型的图像包括:
- 猫身体在一个不同的位置
- 猫出现在相似颜色的背景下
- 不同的猫的颜色和品种
- 相机角度
- 图片的亮度
- 比例变化(猫的图像非常大或很小)
相关文章:

第4周_作业题_逐步构建你的深度神经网络
文章目录 ***逐步构建你的深度神经网络***0. 背景0.1 要解决的问题0.2 作业大纲0.3 构建深层神经网络步骤 1. 导入包2. 初始化参数2.1 2层神经网络2.2 L层神经网络 3. 前项传播函数3.1 前项传播步骤3.2 线性前向3.3 线性激活部分3.4 L层前项传播模型3.5 计算成本 4. 反向传播模…...
)
Linux 搭建FTP服务器(vsftpd)
搭建FTP服务器(vsftpd): 文章目录 搭建FTP服务器(vsftpd):配置镜像安装vsftpd配置vsftpd关闭SELinux:配置防火墙启动vsfptd服务并设置开机自启创建FTP用户测试windows中测试Linux测试下载get/mget上传put/mput删除文件delete 搭建SCP服务器(基…...

AWS中国区中API Gateway中403的AccessDeniedException问题
问题 在互联网使用API Gateway的域名访问接口,出现403问题AccessDeniedException。具体如下: 前提 这里API Gateway相关配置都没有问题。而且,vpc内网都能访问被代理的服务。这里api gateway不需要使用自定义域名。 解决 向客服发个工单…...

计量单片机 RN8302:特性、使用与应用
在现代电力监测与能源管理领域,精确的电能计量至关重要。计量单片机 RN8302 作为一款高性能的电能计量芯片,凭借其卓越的特性与功能,在众多应用场景中发挥着关键作用。本文将全面深入地介绍 RN8302 的各项特性、使用方法、注意事项以及广泛的…...

Flutter生物识别认证之Flutter指纹认证Flutter人脸认证
Flutter介绍: Flutter是谷歌开发的开源UI软件开发工具包,用于高效构建跨平台的应用程序,支持iOS、Android、Web、Windows、macOS和Linux。它使用Dart语言编写,提供了丰富的组件和工具,使开发者能够创建高质量、高性能…...
)
了解Android studio 初学者零基础推荐(2)
在kotlin中编写条件语句 if条件语句 fun main() {val trafficLight "gray"if (trafficLight "red") {println("Stop!")} else if (trafficLight "green") {println("go!")} else if (trafficLight "yellow")…...

【Java Web】1.Maven
📘博客主页:程序员葵安 🫶感谢大家点赞👍🏻收藏⭐评论✍🏻 文章目录 一、初始Maven 1.1 什么是Maven 1.2 Maven的作用 二、Maven概述 2.1 Maven模型 2.2 Maven仓库 2.3 创建Maven项目 2.4 POM配置…...

【Spark集成HBase】Spark读写HBase表
Spark读写HBase表 摘要一、实验环境准备1. 技术版本2. Maven 依赖配置 二、实验步骤1. 数据准备2. HBase 表结构设计3. 代码实现3.1 数据写入 HBase(writeDataToHBase 方法)3.2 数据读取与分析(readHBaseData 方法3.3 Spark SQL 分析3.4 完整…...

【Linux】借助gcc源码修改,搜索头文件当前进展
从上图可以看出对于每次的搜索,都是从第一个目录开始搜索,图里也可以看到修改源代码所在的目录,函数,行,昨天的博客感觉对于找到的位置还是不太好。 在使用修改源代码编译的GCC,进行编译内核源代码时&#…...

jmeter登录接口生成一批token并写入csv文件
背景:大部分项目真实的业务接口都是需要token鉴权的,想对一批核心业务接口进行并发压测,必然要先生成一批token给这些接口并发循环调用。 基本的思路是这样的:一批手机号csv文件 -》登录接口循环读取csv文件并生成token -》每次…...

利用 Redis 设计高效分布式锁机制:保障操作原子性
利用 Redis 设计高效分布式锁机制:保障操作原子性 引言 在分布式系统中,多个节点可能会同时操作共享资源,导致数据不一致或竞争条件问题。因此,构建一个高效的 分布式锁机制 是保障数据完整性的重要策略。 Redis 作为一个高性能的内存数据库,因其 单线程特性 和 丰富的数…...

Redis 的速度为什么这么快
这里的速度快,Redis 的速度快是与 MySQL 等数据库相比较的,与直接操作内存数据相比,Redis 还是略有逊色。 Redis 是一个单线程模型,为什么比其他的多线程程序还要快,原因有以几点: 1、访问的对象不同 Re…...

Spring Cloud Gateway高并发限流——基于Redis实现方案解析
本文是一个基于 Spring Cloud Gateway 的分布式限流方案,使用Redis Lua实现高并发场景下的精准流量控制。该方案支持动态配置、多维度限流(API路径/IP/用户),并包含完整的代码实现和性能优化建议。 一、架构设计 #mermaid-svg-vg…...

【VScode】python初学者的有力工具
还记得23年11月,我还在欣喜Spyder像Rstudio一样方便。 但苦于打开软件打开太卡、太耗时(初始化-再加载一些东西),一度耗费了我学习的热情。 就在24年5月份,别人推荐下发现了一个更加轻量级、方便又快速的ID࿰…...

融合蛋白质语言模型和图像修复模型,麻省理工与哈佛联手提出PUPS ,实现单细胞级蛋白质定位
蛋白质亚细胞定位(subcellular localization of a protein)是指蛋白质在细胞结构中具体的定位情况, 这对蛋白质行使其生物学功能至关重要。举个简单例子,如果把细胞想象成一个庞大的企业,其中细胞核、线粒体、细胞膜等…...

火山引擎火山云带宽价格
首先,成本结构方面,火山云可能用的是高质量的带宽资源,比如BGP多线网络,这种网络能保证更好的连通性和稳定性,但成本更高。另外,如果火山云的数据中心节点分布在多个地区,尤其是海外,…...

可信计算是什么?可信逻辑:计算系统安全的形式化分析框架
参考书籍《人工智能安全 (陈左宁 主编;卢锡城 、方滨兴 副主编)》第二章内容; 相关博客:可信执行环境(TEE):保障数据安全的核心技术 文章目录 一、可信计算的逻辑学基础1.1 可信性的逻辑定义与范畴1.2 双体系架构的逻…...

大模型应用开发之Dify进阶版使用教程—react前端+django后端+dify-API制作聊天界面
Dify进阶使用教程 文章目录 Dify进阶使用教程前言一、dify-docker环境搭建及简单使用二、本篇使用API源码部署启动dify后端启动dify前端基于通义模型的智能客服机器人应用与自己项目联动实战1. 使用API进行项目与dify联动1.1 在控制台主页,点击创建访问API1.2 进入API页面,这…...

快速创建 Vue 3 项目
安装 Node.js 和 Vue CL 安装 Node.js:访问 https://nodejs.org/ 下载并安装 LTS 版本。 安装完后,在终端检查版本: node -v npm -v安装 Vue CLI(全局): npm install -g vue/cli创建 Vue 3 项目 vue cr…...

【VLNs篇】05:TGS-在无地图室外环境中使用视觉语言模型进行轨迹生成和选择
栏目内容论文标题TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments (TGS:在无地图室外环境中使用视觉语言模型进行轨迹生成和选择)研究问题在具有非结构化越野特征(如建筑物、草地、路缘&#x…...

【未来展望】云、AI与元宇宙的融合架构
未来展望:云、AI与元宇宙的融合架构 一、技术背景与发展:从独立演进到深度融合二、技术特点:异构协同与场景化适配三、技术细节:架构层解构与核心组件四、未来发展:技术趋势与产业机遇五、结语:硅基与碳基文明的共生演进一、技术背景与发展:从独立演进到深度融合 云计算…...

React+Taro 微信小程序做一个页面,背景图需贴手机屏幕最上边覆盖展示
话不多说 直接上图 第一步 import { getSystemInfoSync } from tarojs/taro;第二步 render() {const cardBanner getImageUrlByGlobal(member-merge-bg.png);const { safeArea, statusBarHeight } getSystemInfoSync();const NAV_BAR_HEIGHT 44;const navBarHeight NAV…...
)
Linux笔记---信号(下)
1. sigaction函数 #include <signal.h>int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact); 功能:sigaction函数用于检查或修改与指定信号相关联的处理动作。它可以用来设置信号处理函数、信号掩码等。 参数 signum&#…...

腾讯云媒体AI解码全球视频出海智能密码
当短剧平台撞上多语种字幕困境,当直播电商遭遇文化审核危机,当经典影视困于格式壁垒——这些内容出海的难题,正被腾讯云媒体AI的智能引擎逐个破解。从东南亚的直播卡顿到中东的宗教符号雷区,从老片的低清画质到元宇宙的渲染瓶颈&a…...

Django的请求和响应+template模板
🌟 如果这篇文章触动了你的心弦,请不要吝啬你的支持! 亲爱的读者, 感谢你花时间阅读这篇分享。希望这里的每一个字都能为你带来启发或是让你会心一笑。如果你觉得这篇文章有价值,或者它解决了你一直以来的一个疑问&a…...

JAVA8怎么使用9的List.of
在 Java 8 中,List.of 方法并不可用,因为这是从 Java 9 开始引入的用于创建不可变列表的便捷方法。要在 Java 8 中达到类似的效果,您需要使用其他方式来创建列表。常规的方法是先创建集合对象然后再添加元素 List<String> list new A…...

无人机避障——深蓝学院浙大Ego-Planner规划部分
ESDF-free: 被这种类型的障碍物死死卡住的情况: 在一定范围内建立ESDF: Ego-Planner框架: 找到{p,v} pair: 【注意】:首先根据在障碍物内航迹上的点Q,以及与它相邻但不在障碍物内的两个点&#…...

Qt 最新版6.9.0使用MQTT连接腾讯云详细教程
Qt 最新版6.9.0使用MQTT连接腾讯云详细教程 一、MQTT介绍二、MQTT库编译1、源码下载2、源码编译 三、库的使用方法四、MQTT连接设备1、包含头文件 2、定义一个mqtt客户端3、实例并连接相关信号与槽4、连接服务器5、订阅topic 一、MQTT介绍 1. 概述 全称: Message Queuing Tel…...

无人机避障——深蓝学院浙大栅格地图以及ESDF地图内容
Occupancy Grid Map & Euclidean Signed Distance Field: 【注意】:目的是为了将有噪声的传感器收集起来,用于实时的建图。 Occupancy Grid Map: 概率栅格: 【注意】:由于传感器带有噪声,在实际中基于…...

Vitis 2021.1安装步骤
1.将压缩文件解压 2.打开解压后的文件夹,双击应用程序 3.安装版本2021.1,不安装2024.2,点击“continue”,然后点击“next” 4.选择“vitis”,然后点击“next” 5.点击“next” 6.选择“I Agree”,点击“next…...

【Harmony】【鸿蒙】List列表View如果刷新内部的自定义View
创建自定义View Component export struct TestView{State leftIcon?:Resource $r(app.media.leftIcon)State leftText?:Resource | string $r(app.string.leftText)State rightText?:Resource | string $r(app.string.rightText)State rightIcon?:Resource $r(app.med…...

我店模式系统开发打造本地生活生态商圈
在当今快节奏的商业环境中,商家们面临着越来越多的挑战,包括市场竞争加剧、消费者需求多样化以及运营效率的提高等。为了应对这些挑战,越来越多的商家开始寻求信息化解决方案,以提升运营效率和客户体验。我的店模式系统平台应运而…...

LeetCode[222]完全二叉树的节点个数
思路: 这个节点个数可以使用递归左儿子个数递归右儿子个数1,这个1是根节点,最后结果为节点个数,但我们没有练习到完全二叉树的性质. 完全二叉树的性质是:我简单说一下,大概就是其他节点都满了,就…...

电机试验平台:实现高效精密测试的关键工具
电机是现代工业中广泛应用的关键设备,其性能直接影响着生产效率和产品质量。为了确保电机的可靠运行和优化设计,电机试验平台成为不可或缺的工具。本文将探讨电机试验平台的概念、功能和应用,以及其在实现高效精密测试中的关键作用。 一、电…...

基于 ZigBee 的 LED 路灯智能控制器的设计
标题:基于 ZigBee 的 LED 路灯智能控制器的设计 内容:1.摘要 本文围绕基于 ZigBee 的 LED 路灯智能控制器展开研究。背景在于传统路灯控制方式存在能耗高、管理不便等问题,为实现路灯的智能化控制和节能目的,采用 ZigBee 无线通信技术来设计 LED 路灯智…...
)
LeetCode Hot100 (哈希)
1. 两数之和 比较简单,建立个map,看看有没有当前对应的相反的值就可以了 class Solution {public int[] twoSum(int[] nums, int target) {TreeMap<Integer, Integer> arrnew TreeMap<Integer, Integer>();int x10;int x20;for(int i0;i<…...
)
【力扣题目分享】二叉树专题(C++)
目录 1、根据二叉树创建字符串 代码实现: 2、二叉树的层序遍历 代码实现: 变形题: 代码实现: 3、二叉树的最近公共祖先 代码实现: 4、二叉搜索树与双向链表 代码实现: 5、从前序与中序遍历序列构…...

【烧脑算法】单序列双指针:从暴力枚举到高效优化的思维跃迁
目录 相向双指针 1498. 满足条件的子序列数目 1782. 统计点对的数目 581. 最短无序连续子数组 同向双指针 2122. 还原原数组 编辑 2972. 统计移除递增子数组的数目 II 编辑 思维拓展 1920. 基于排列构建数组 442. 数组中重复的数据 448. 找到所有数组中消失的…...

如何排查服务器 CPU 温度过高的问题并解决?
服务器CPU温度过高是一个常见的问题,可能导致服务器性能下降、系统稳定性问题甚至硬件损坏。有效排查和解决服务器CPU温度过高的问题对于确保服务器正常运行和延长硬件寿命至关重要。本文将介绍如何排查服务器CPU温度过高的问题,并提供解决方法ÿ…...

YOLO篇-3.1.YOLO服务器运行
1.服务器 服务器网站:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL(这个是收费的) 2.数据集上传 进入网站,租用自己的服务器,租用好后点击jupyter。(这里需要先有一个数据集哦) 在根目录下进入datasets创建自己的工程名 在工程文件下…...

数智读书笔记系列034《最优解人生》对编程群体的理念契合
📘 书籍简介 核心观点 《Die with Zero》(中文译为《最优解人生》)由美国对冲基金经理比尔柏金斯(Bill Perkins)撰写,核心理念是“财产归零”。其核心主张是: 金钱是实现体验的工具:金钱本身无意义,其价值在于转化为有意义的体验,如旅行、学习、家庭时光或慈善活动…...

深度学习相比传统机器学习的优势
深度学习相比传统机器学习具有显著优势,主要体现在以下几个方面: 1. 特征工程的自动化 传统机器学习:依赖人工设计特征(Feature Engineering),需要领域专家从原始数据中提取关键特征(如边缘检测…...

深入探究C++11的核心特性
目录 引言 C11简介 统一的列表初始化 1. {} 初始化 2. std::initializer_list 变量类型推导 1. auto 2. decltype 3. nullptr 右值引用和移动语义 1. 左值引用和右值引用 2. 左值引用与右值引用比较 3. 右值引用使用场景和意义 移动赋值与右值引用的深入应用 1. 移…...

nltk-英文句子分词+词干化
一、准备工作 ①安装好nltk模块并在: nltk/nltk_data: NLTK Data 链接中手动下载模型并放入到对应文件夹下。 具体放到哪个文件夹,先执行看报错后的提示即可。 ②准备pos_map.json文件,放置到当前文件夹下。该文件用于词性统一 {"…...
 : Tuning Efforts)
系统性能分析基本概念(3) : Tuning Efforts
系统性能调优(Tuning Efforts)是指通过优化硬件、软件或系统配置来提升性能,减少延迟、提高吞吐量或优化资源利用率。以下是系统性能调优的主要努力方向,涵盖硬件、操作系统、应用程序和网络等多个层面,结合实际应用场…...

部署TOMEXAM
前提:机器上有MySQL,nginx,jdk,tomcat 1.配置MySQL [rootjava-tomcat1 ~]# mysql -u root -pLiuliu!123 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. C…...

Nginx 1.25.4交叉编译问题:编译器路径与aclocal.m4错误解决方案
Nginx 1.25.4交叉编译问题:编译器路径与aclocal.m4错误解决方案 一、问题描述 在对Nginx 1.25.4进行交叉编译时,遇到以下复合问题: 编译器路径失效:尽管在脚本中配置了交叉编译器(如CCaarch64-himix100-linux-gcc&a…...

FPGA通信之VGA
文章目录 基本概念:水平扫描:垂直扫描: 时序如下:端口设计疑问为什么需要输出那么多端口不输出时钟怎么保证电子枪移动速度符合时序VGA转HDMI 仿真电路图代码总结:野火电子yyds 为了做图像处理, 现在我们开…...

[Git] 认识 Git 的三大区域 文件的修改和提交
文章目录 认识 Git 的三大区域:工作区、暂存区、版本库工作区、暂存区、版本库的关系流程图解 (概念) 将文件添加到仓库进行管理:git add 和 git commit场景一:第一次添加文件到仓库查看提交历史:git log(进阶理解&…...

交叉编译DirectFB报错解决方法
configure: error: *** DirectFB compilation requires fluxcomp *** Unless you are compiling from a distributed tarball you need fluxcomp available from git://git.directfb.org/git/directfb/core/flux installed in your PATH. 需要先编译安装flux git clone http…...