【力扣题目分享】二叉树专题(C++)
目录
1、根据二叉树创建字符串
代码实现:
2、二叉树的层序遍历
代码实现:
变形题:
代码实现:
3、二叉树的最近公共祖先
代码实现:
4、二叉搜索树与双向链表
代码实现:
5、从前序与中序遍历序列构造二叉树
代码实现:
6、从中序与后序遍历序列构造二叉树
代码实现:
7、二叉树的前序遍历(非递归)
代码实现:
8、二叉树的中序遍历(非递归)
代码实现:
9、二叉树的后序遍历(非递归)
代码实现:
学了二叉树但不知道怎么用于做题?本篇将会讲解10道关于二叉树的力扣/牛客题,带大家二叉树进阶
1、根据二叉树创建字符串
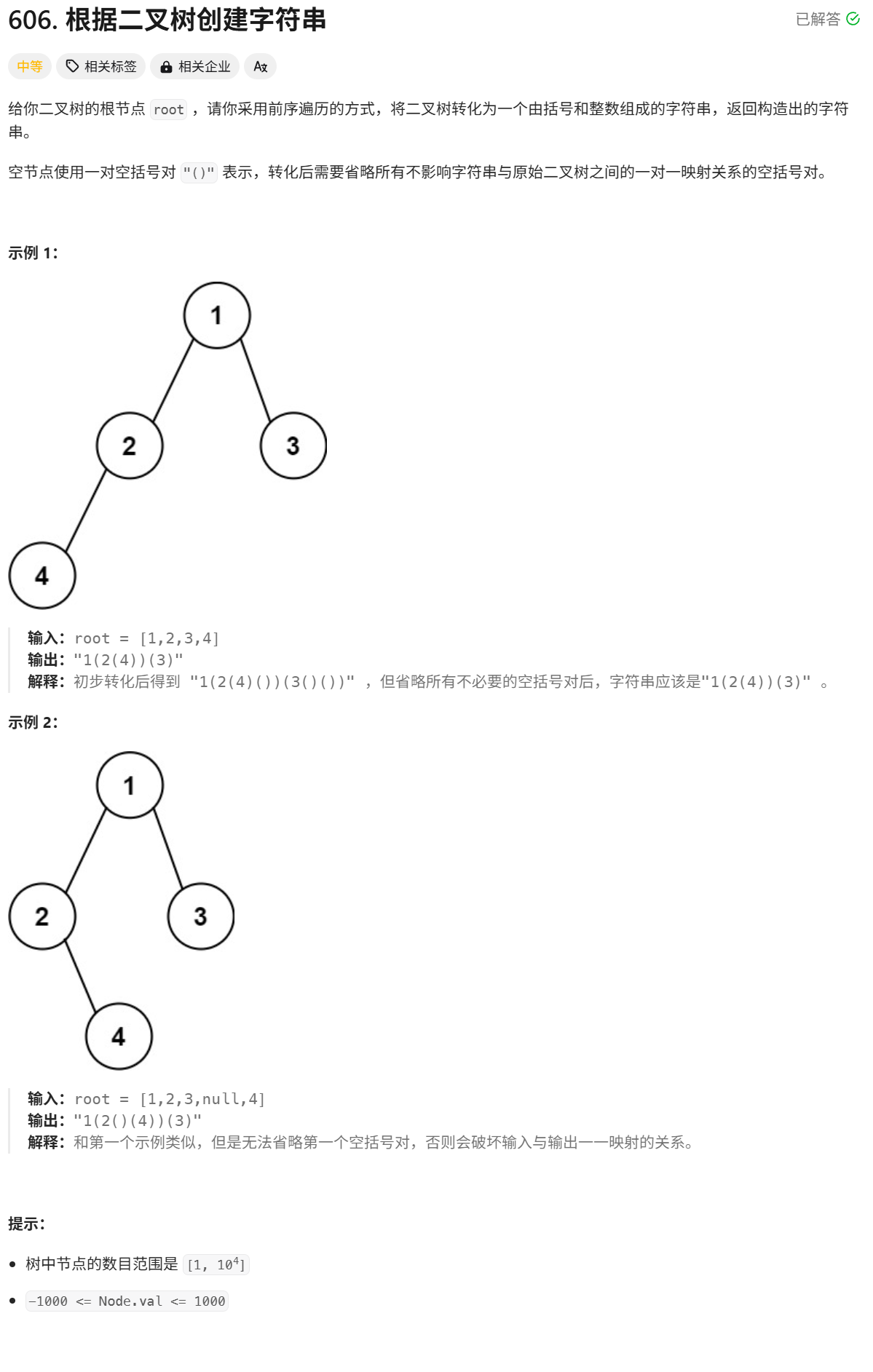
如果只看示例1,很有可能认为只要是空树就不加括号,但只要看了示例二,就知道如果右树存在的前提下,左树即使是空树,也不能省略括号
这道题可以用前序递归遍历来遍历节点,再通过判断当前节点的左右子树是否存在而决定是否加括号和继续递归
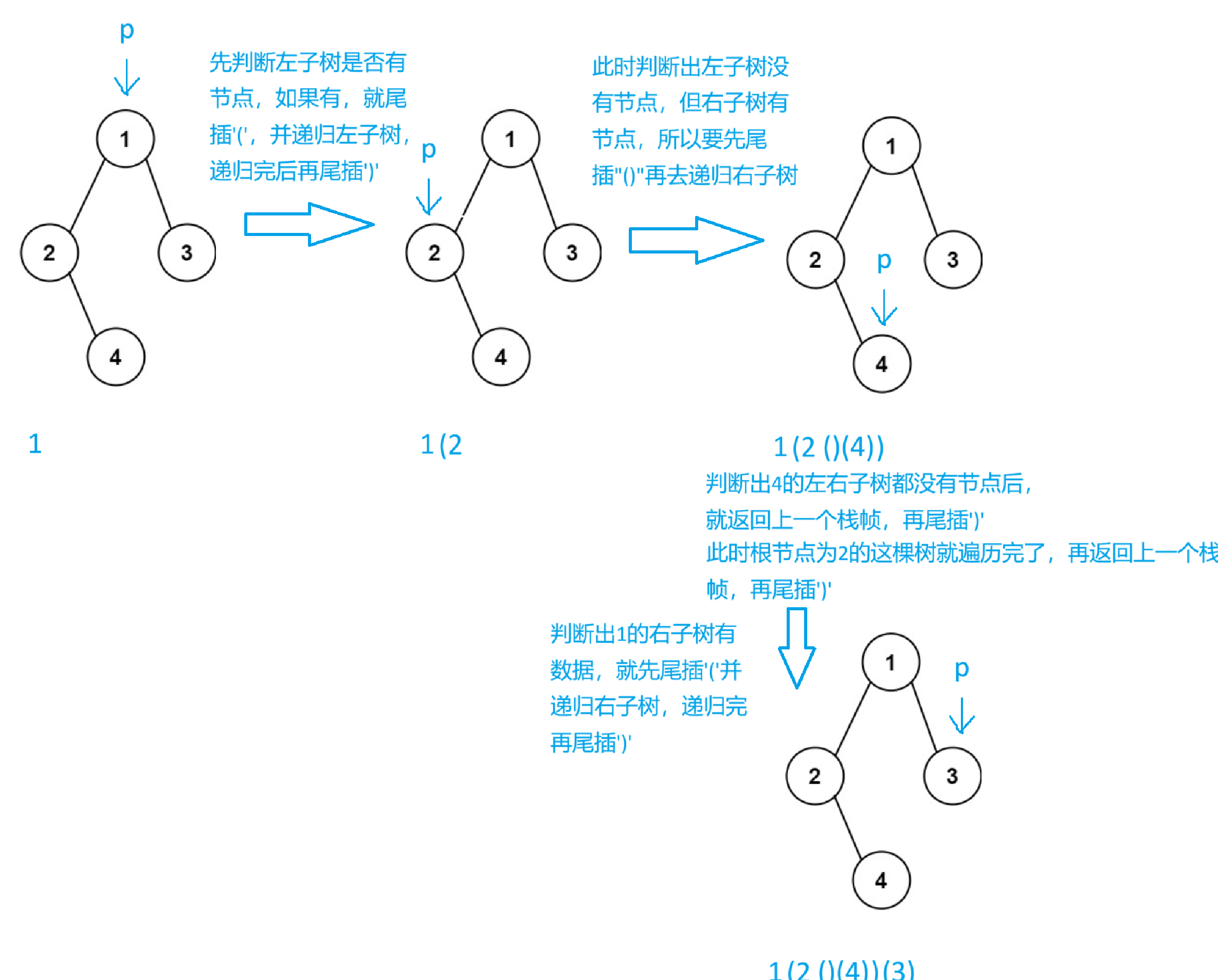
代码实现:
class Solution {
public:string tree2str(TreeNode* root) {string s;//先将根尾插进去s += to_string(root->val);//to_string函数可以把任何类型的数据转为stringif(root->left)//如果左子树存在,就继续递归(加括号){s += '(';s += tree2str(root->left);s += ')';}else if(root->right)//如果左子树不存在,但右子树存在,也加括号s += "()";if(root->right)//如果右子树存在,就继续递归(加括号){s += '(';s += tree2str(root->right);s += ')';}return s;}
};2、二叉树的层序遍历
先来讲讲普通的层序遍历
层序遍历也就是从上到下从左到右来遍历数据,这需要用到队列。将根节点入队后,出该数据时,再将该数据的左右子树入队
void levelOrder(TreeNode* root)
{if(root == nullptr)return;queue<TreeNode*> q;//用队列模拟层序q.push(root);while(!q.empty()){//提出队头数据并输出TreeNode* cur = q.front();q.pop();cout << cur->val << " ";//并将队头的左右子树入队if(cur->left)q.push(cur->left);if(cur->right)q.push(cur->right);}
}但这还不符合题目要求,拿题目中的示例一来举例,现在代码输出的数据是
3 9 20 15 7 看不出来哪个数据是第几层
而题目中要求要返回二维数组,每个二维数组中每个一维数组是一层数据
那么我们只需要知道每一层有几个数据,就可以通过控制循环的次数来分层插入
拿下面这棵树举例,第一层最多就只有1个节点。把根节点的数据入队后,此时队列的数据个数就是第一层的数据个数。提出队头数据并pop掉,将队头的数据的左右树也入队,此时队列的数据个数就是第二层的数据个数
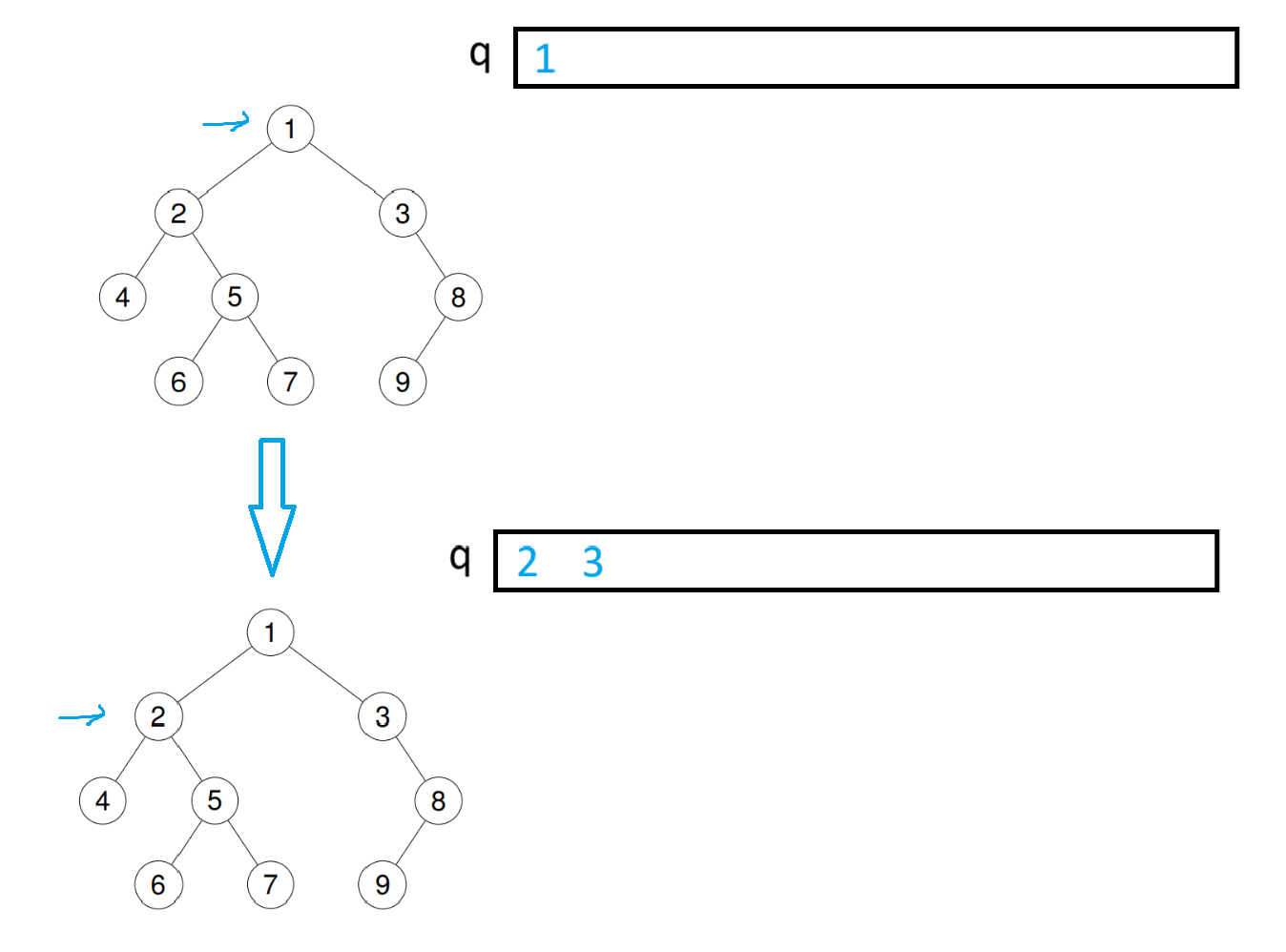
以此类推,到第二层的数据全出队并将左右子树入队后,队中数据个数就是第三层的数据个数
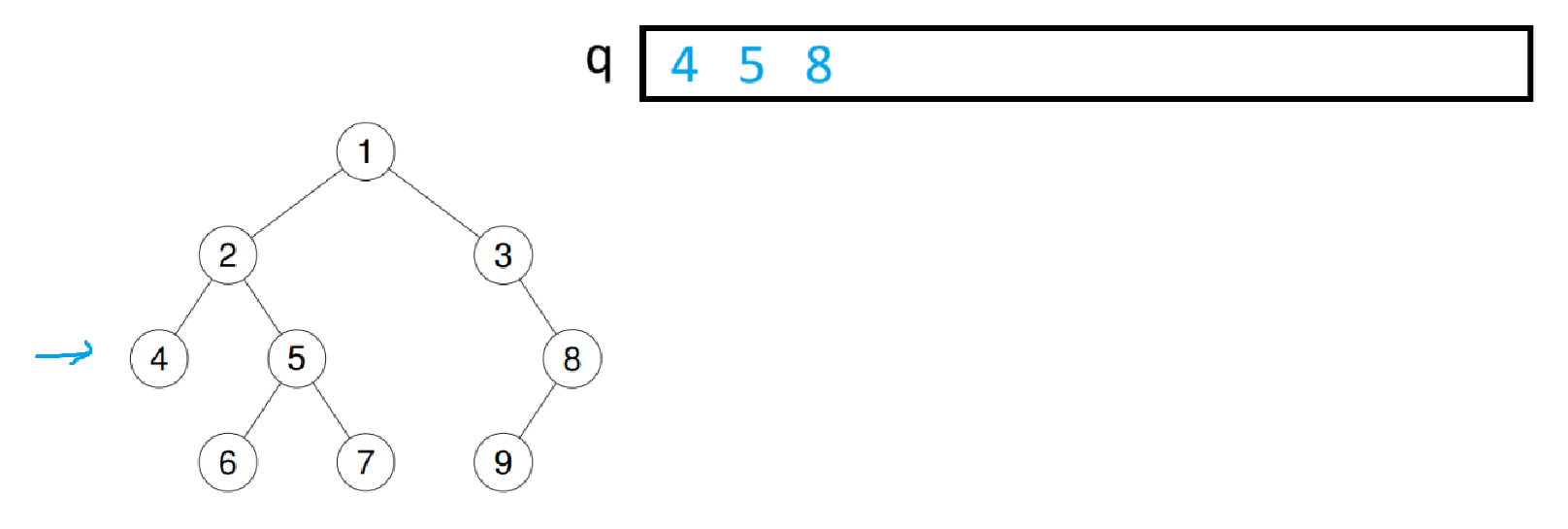
可以通过这个特性分层遍历
代码实现:
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> vv;if(root == nullptr)return vv;queue<TreeNode*> q;//用来模拟层序遍历q.push(root);while(!q.empty()){vector<int> v;//每一层的数据int lengthnum = q.size();//lengthnum是每一层数据的总个数for(int i=0;i<lengthnum;i++)//当本层数据被出完后,队中的数据正好是下一层的数据个数{//取出队头数据,并将队头的左右子树入队TreeNode* cur = q.front();q.pop();v.push_back(cur->val);if(cur->left)q.push(cur->left);if(cur->right)q.push(cur->right);}vv.push_back(v);}return vv;}
};变形题:
该题和上一题唯一的区别就是要倒着层序遍历,这也很简单,可以用算法库(algorithm)中的reverse函数来逆置数组
代码实现:
class Solution {
public:vector<vector<int>> levelOrderBottom(TreeNode* root) {vector<vector<int>> vv;if(root == nullptr)//如果是空树,就直接返回空数组return vv;queue<TreeNode*> q;//用队列存树的节点q.push(root);while(!q.empty()){vector<int> v;int levelnum = q.size();//每次出完上一层的数据,队列中的数据个数正好是当前层的数据个数for(int i=0;i<levelnum;i++)//将当前层的数据出完{TreeNode* cur = q.front();//取出队头数据q.pop();v.push_back(cur->val);//将队头数据入到当前层数组//将左右孩子入队if(cur->left)q.push(cur->left);if(cur->right)q.push(cur->right);}vv.push_back(v);//将当前层数据(一维数组)尾差到二维数组中}reverse(vv.begin(),vv.end());//翻转数组return vv;}
};3、二叉树的最近公共祖先

需要注意的是,节点本身也可以是自己的祖先,所以在示例二,5和4的祖先就是5本身
该题可以将输入划分为四种情况:
- p和q都在左,就递归进入左子树继续判断
- p和q都在右,就递归进入右子树继续判断
- p和q一个在左一个在右,那当前根节点就是最深祖先
- p和q有一个是当前根节点,那当前根节点就是最深祖先
终点其实就只有3,4两种情况,而1,2情况就会继续递归判断是3,4中的哪一种情况
那怎么知道p和q在左还是在右呢?
这里可以写一个Find函数,来递归遍历左右子树,找到p和q,判断出p和q分别在左树还是右树
bool Find(TreeNode* cur,TreeNode* goal)//递归遍历cur判断是否找到goal
{if(cur == nullptr)return false;if(cur == goal)return true;return Find(cur->left,goal) || Find(cur->right,goal);
}下面以分别用示例一和示例二来模拟一下过程
示例一:
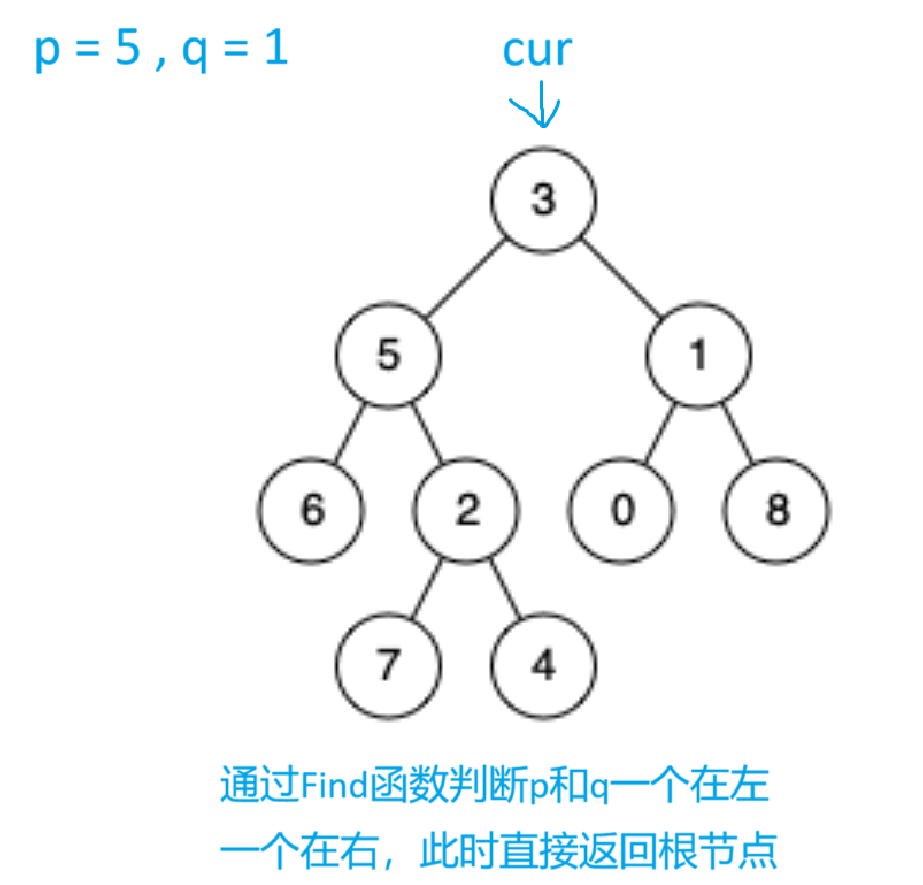
示例二:
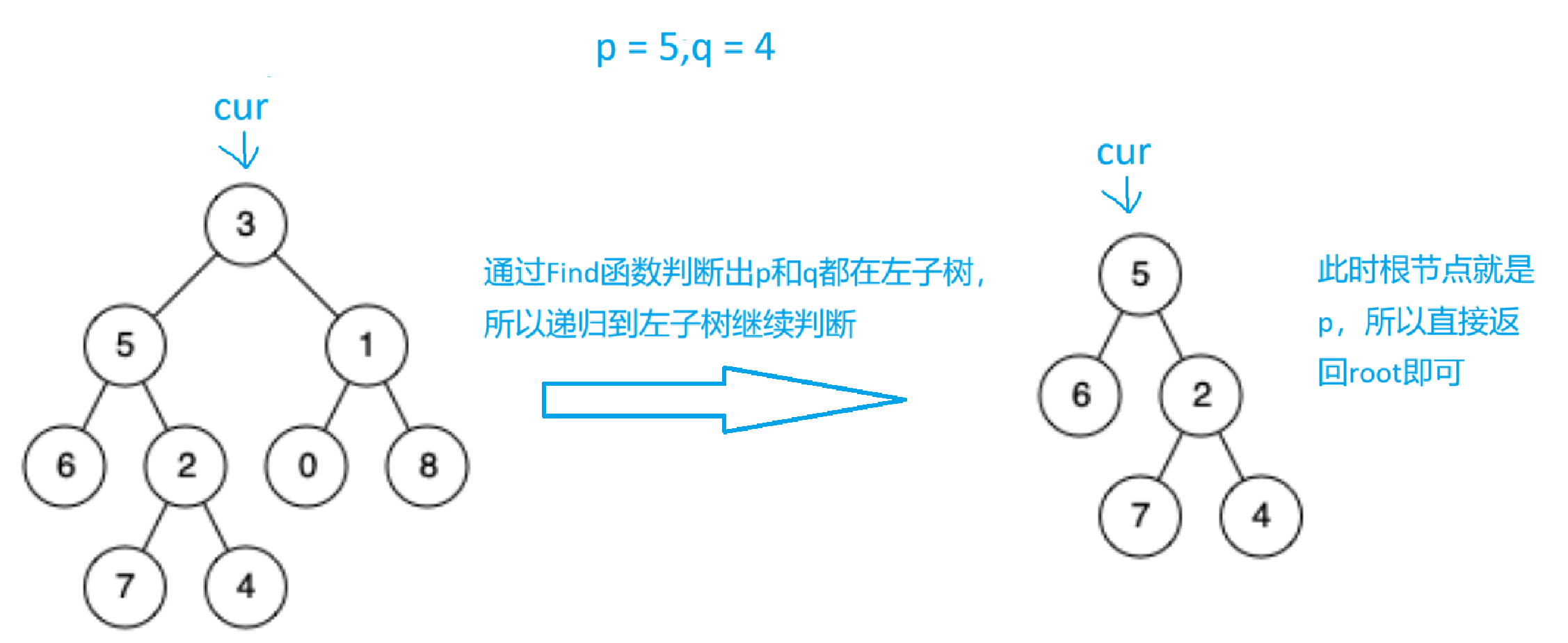
代码实现:
class Solution {
public:TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {if(root == p || root == q)//如果p和q的其中一个就是root,那root就是最近公共祖先return root;//判断p和q在左还是在右bool pInLeft,pInRight,qInLeft,qInRight;pInLeft = Find(root->left,p);pInRight = !pInLeft;qInLeft = Find(root->left,q);qInRight = !qInLeft;if(pInLeft && qInLeft)//如果p和q都在左,就往左树递归return lowestCommonAncestor(root->left,p,q);else if(pInRight && qInRight)//如果p和q都在右,就往右树递归return lowestCommonAncestor(root->right,p,q);return root;//如果能走到这一步,就说明p和q一个在左,一个在右}//每次判断都只会有:p和q都在左、p和q都在右、一个在左一个在右、pq中有一个是根节点,这四种情况,而如果是前两种,就继续递归判断bool Find(TreeNode* cur,TreeNode* goal)//递归遍历cur判断是否找到goal{if(cur == nullptr)return false;if(cur == goal)return true;return Find(cur->left,goal) || Find(cur->right,goal);}
};4、二叉搜索树与双向链表
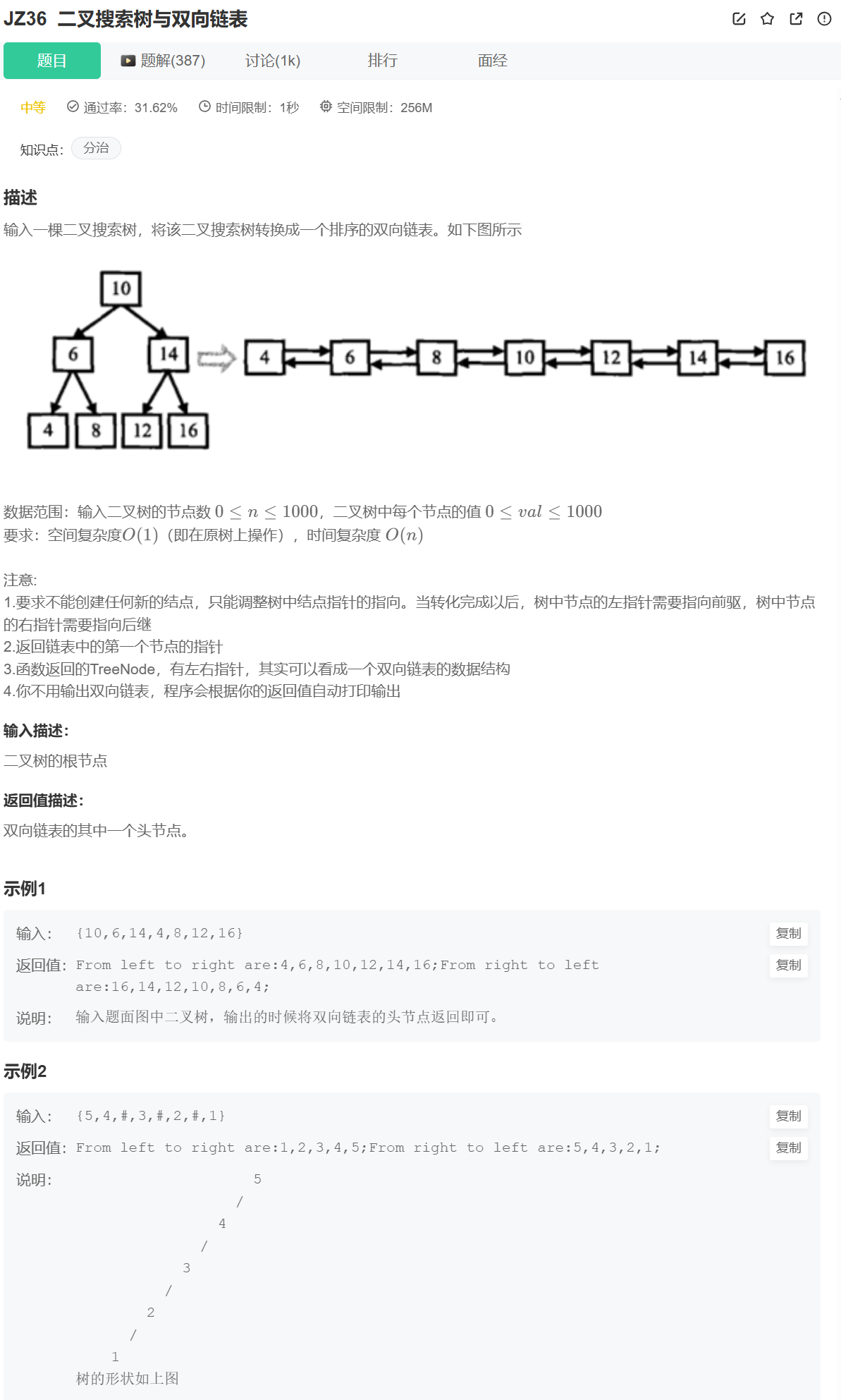
简单点来讲,就是将节点的left视作链表的prev,right视作链表的next,用升序的排列将二叉树链接起来。
众所周知,二叉搜索树的中序遍历(InOrder)就是升序遍历,所以本题就可以用中序遍历的节奏来链接节点
示例一链接完的关系是这样
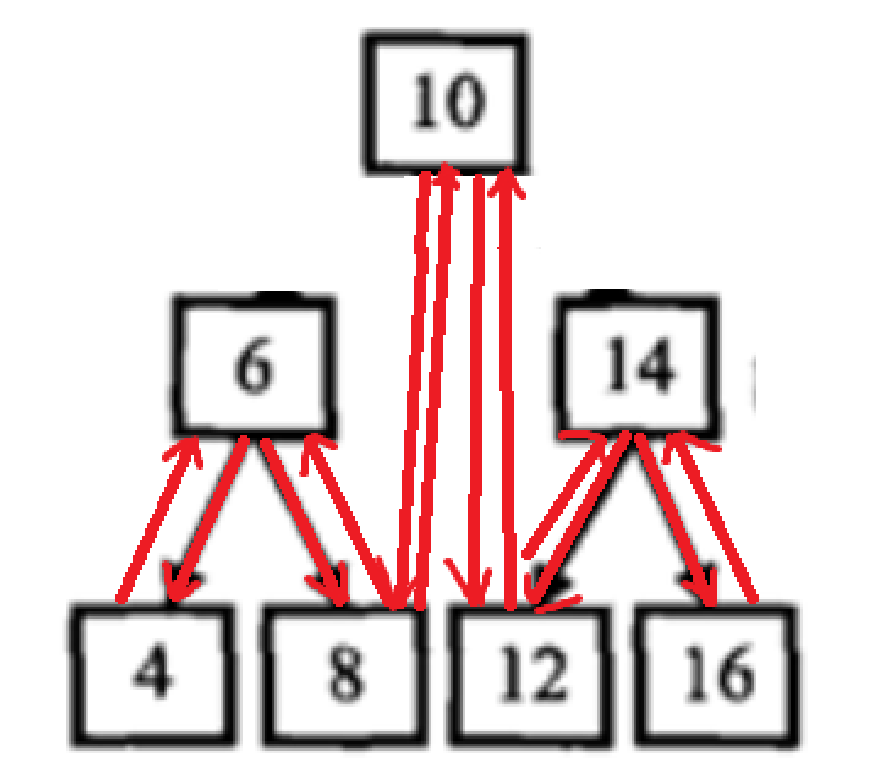
但是在递归途中,访问不到节点的父亲,也不知道哪个孩子是它的前一个
所以这道题需要用到双指针思想:定义一个prev和cur指针,cur指向当前节点,而prev指向上一个节点(上次递归的cur),这样就可以让cur和prev完成双向链接,那cur和next的链接怎么办?在下次递归中,prev就变成了当前的cur,cur就变成了下一个节点,这样每次递归都可以链接当前节点和上一个节点。
下面来模拟一下示例一的过程
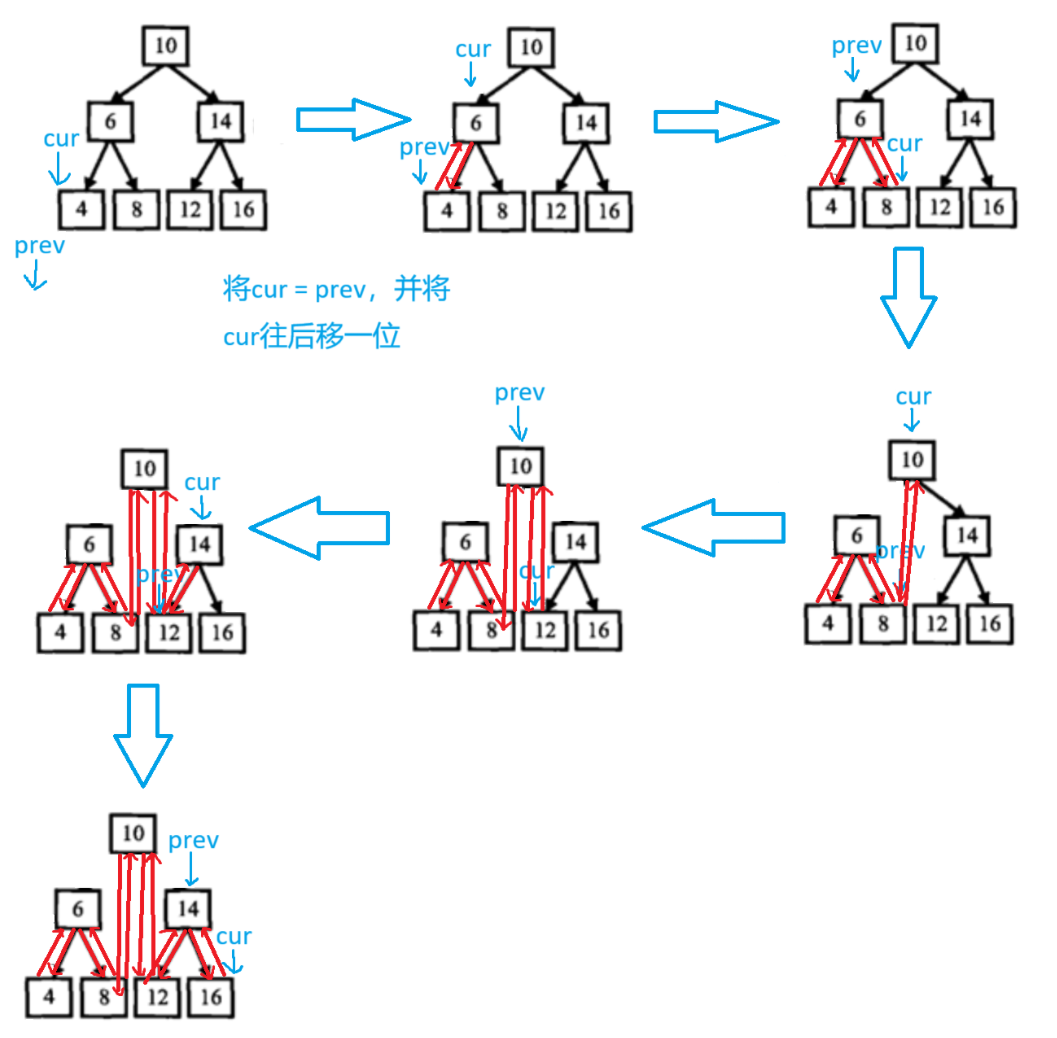
代码实现:
class Solution {
public:TreeNode* Convert(TreeNode* pRootOfTree) {TreeNode *cur = pRootOfTree,*prev = nullptr;InOrderList(cur, prev);//因为二叉搜索树的中序遍历就是有序,所以用中序遍历递归的顺序去链接//链接完后,找到该链表的头,并返回while(cur && cur->left){cur = cur->left;} return cur;}void InOrderList(TreeNode* cur,TreeNode*& prev)//prev必须传引用,这样才能保证当前栈帧中改变的prev能应用到其他栈帧中{if(cur == nullptr)//如果是空,就跳出return;InOrderList(cur->left,prev);//先遍历左子树//此时左子树的根节点就通过34行赋给prev了,如果prev不是引用,下面的操作就不对了cur->left = prev;//将当前节点的左指向上一个节点if(prev)prev->right = cur;//将上一个节点的右指向当前节点//此时就将当前节点和上一个节点的链接完成了,因为找不到下一个节点,所以当前节点和下一个节点的链接只能在下次递归时完成prev = cur;//将当前节点变成上一个节点,这样在下面递归时才能将上当前节点和下一个节点链接InOrderList(cur->right,prev);}
};5、从前序与中序遍历序列构造二叉树
在前序遍历中,节点遍历顺序是根、左、右子树,因此数组的第一个元素就是根。中序遍历的节点遍历顺序是左、根、右子树,那只要先通过前序遍历找到根节点,再通过中序遍历找到根节点所在的位置,判断它有没有左右子树。如果有左子树,那前序遍历的第二个元素就是左子树的根,如果没有左子树,那前序遍历的第二个元素就是右子树的根,再将第二个元素进入递归,如此往复。
但如果直接把整个中序数组传过去也不行,拿示例一中的20来举例
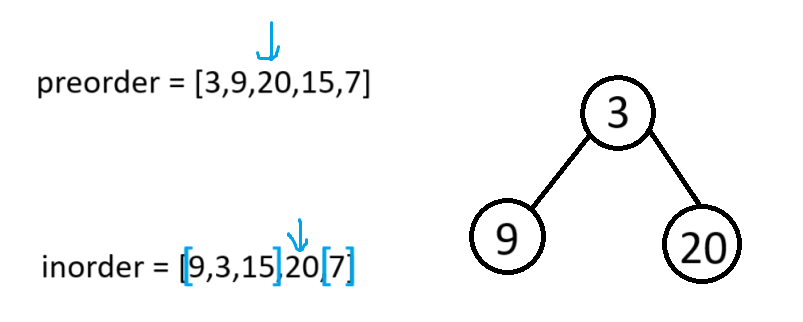
如果这里直接传整个中序数组过去, 那20的左子树就会被认成[9,3,5]所以我们要传一个只包含当前树节点的中序区间
下面来模拟一下示例一的过程
每次递归都要先在inorder中找到preorder[prei]的位置,以判断左右子树有没有数据
第一次递归,把preorder[0]当作根节点,[0,inorder.size()-1]当作当前根节点的中序区间,进去

据inorder的区间可知,当前根节点有左子树,所以prei+1的位置就是左子树的根节点(若没有左子树,那prei+1的位置就是右子树的根节点,那root->left就会置空)所以root->left会以preorder[++prei](也就是9)为根节点,[0,0]为下一个根节点的中序区间,进递归

此时,因为根节点的左右两边就没有数据,因此没有节点给此时的root->left和root->right,就都置空后返回上一个栈帧。

此时根的左子树的递归结束,又因为根的右子树也有节点(若右子树没节点,前序数组就遍历完了,再将root->right置空),所以root->right会以preorder[++prei](也就是20)为根节点,[2,4]为下一个根节点的中序区间,进入递归
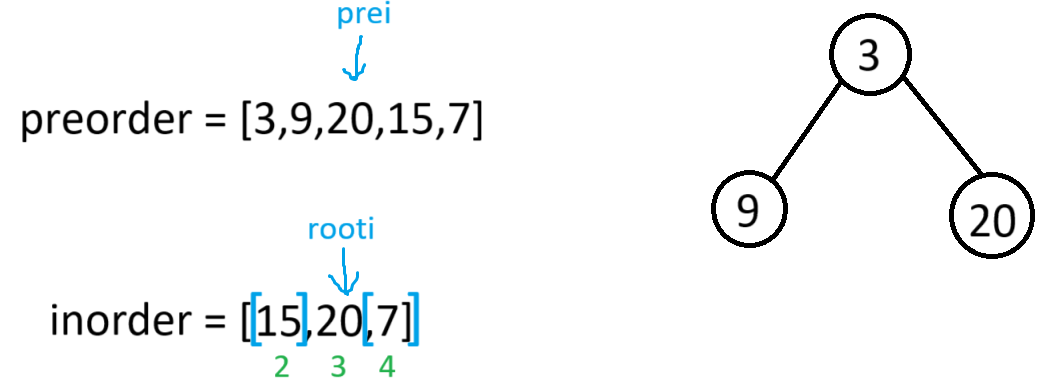
此时因为根节点的左子树有数据(若左子树没数据,prei+1的位置就是右子树的根,左子树就置空了),所以root->left就会以preorder[++prei](也就是15)为根节点,[2,2]为下一个根节点的中序区间,进递归
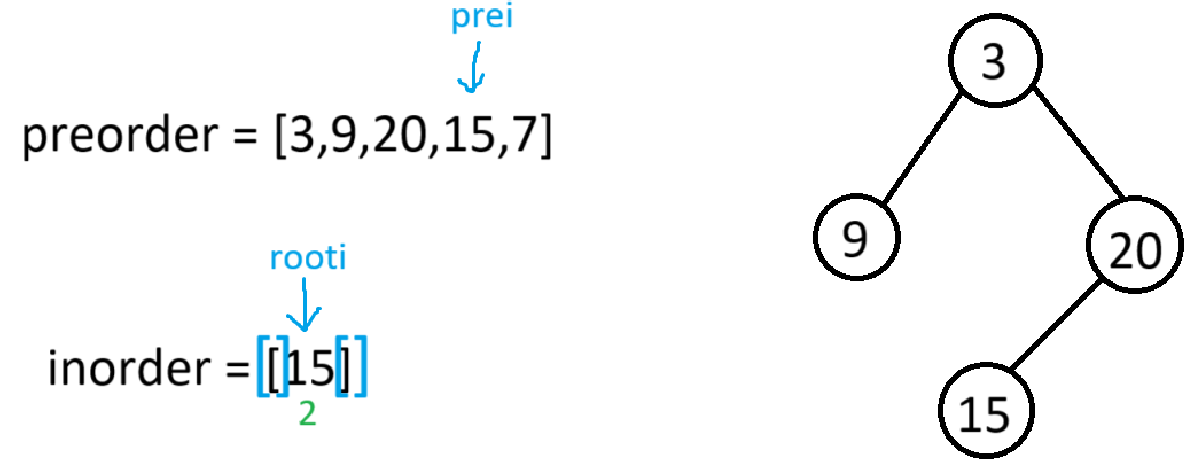
此时因为根节点的左右子树都没有数据,所以root->left和root->right都置空并返回上一个栈帧
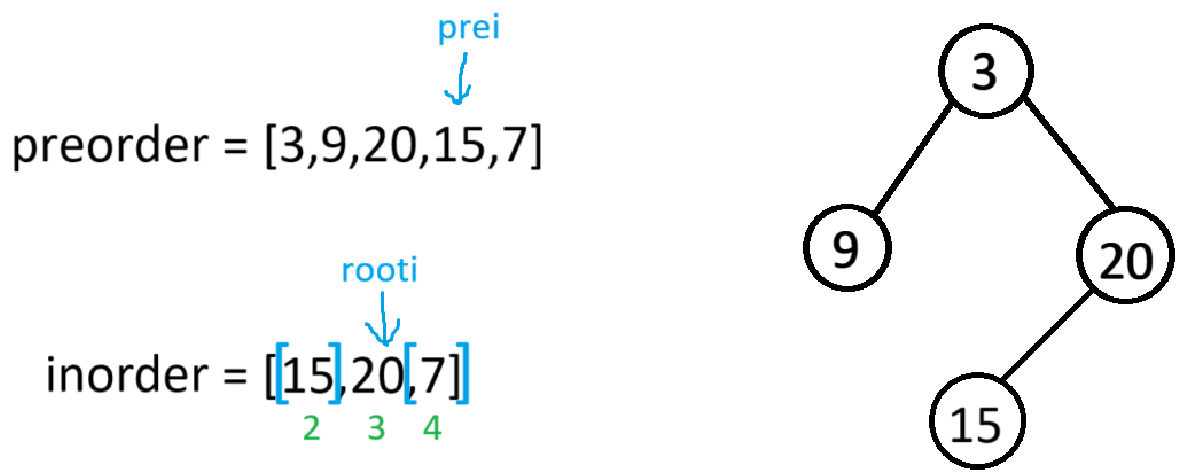
此时根节点的左树递归结束,又因为右树也有数据(若右子树没数据,前序遍历就结束了,二叉树的构建也结束了,把root->right置空),所以root->right就会以preorder[++prei](也就是7)为根节点,[4,4]为下一个根节点的中序区间,进递归
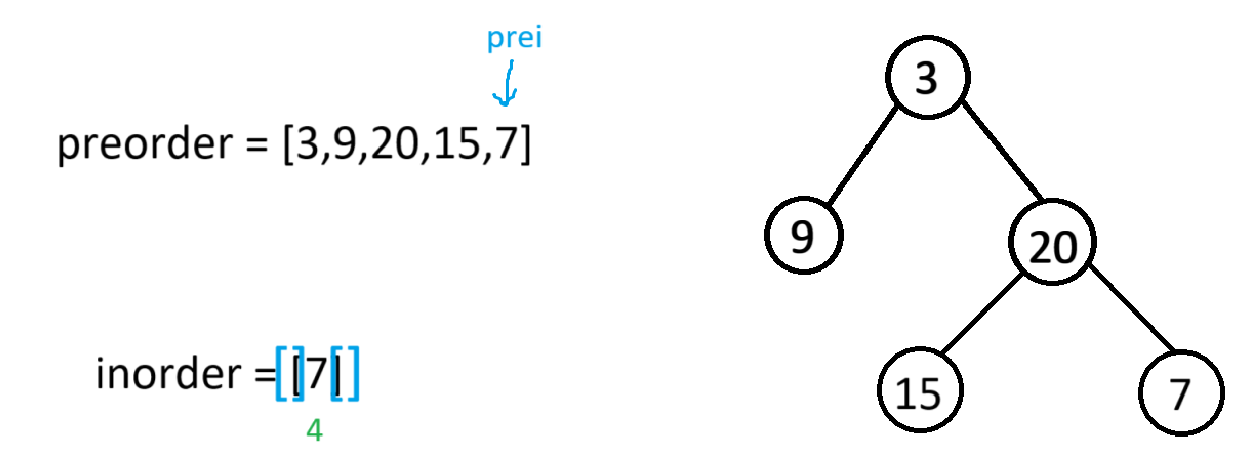
此时,因为7的左右子树都没节点,所以将root->left和root->right置空,并返回上一个栈帧
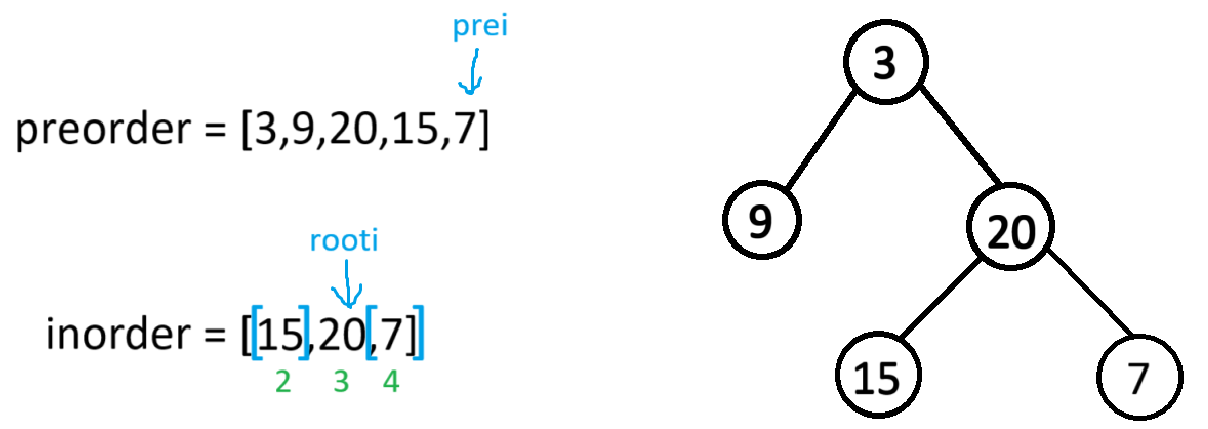
此时root的左右子树也都访问完了,就返回上一个栈帧
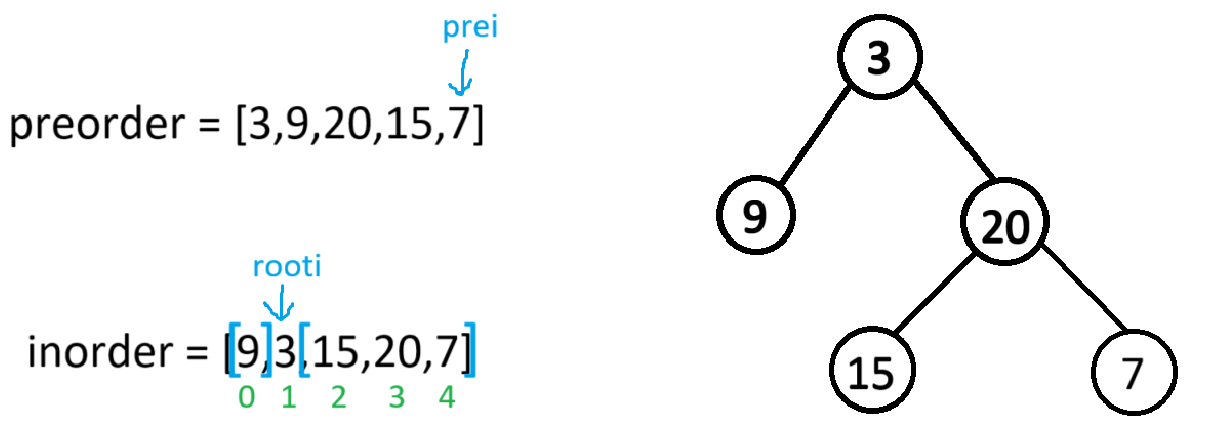
此时root的左右子树也都访问完了,就返回到主函数中了
栈帧模拟图:
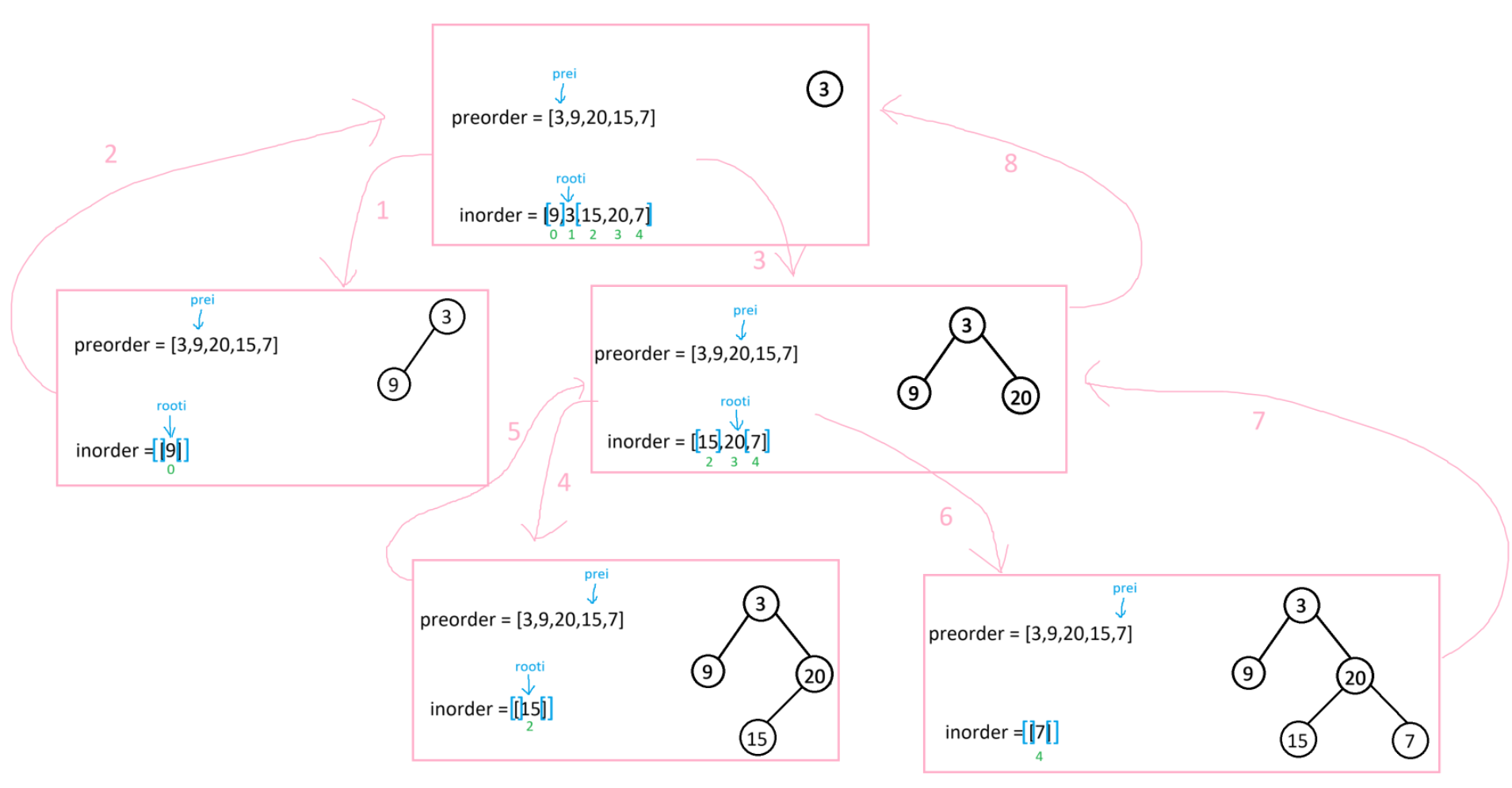
代码实现:
class Solution {
public:TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int prei=0,inbegin=0,inend=inorder.size()-1;return _buildTree(preorder,inorder,prei,inbegin,inend);//用递归去构建}TreeNode* _buildTree(vector<int>& preorder,vector<int>& inorder,int& prei,int inbegin,int inend)//prei必须是引用,才能保证prei每次递归进入都会+1{TreeNode* root = new TreeNode(preorder[prei]);//为当前节点开辟空间//找到根节点在中序区间的位置int rooti = inbegin;while(rooti <= inend){if(preorder[prei] == inorder[rooti])break;rooti++;}//此时中序区间就变成了[inbegin,rooti-1] rooti [rooti+1,inend],左边是rooti的左子树,右边是rooti的右子树if(inbegin <= rooti-1)//如果左子树有节点root->left = _buildTree(preorder,inorder,++prei,inbegin,rooti-1);//将左子树的根节点和中序遍历传过去递归elseroot->left = nullptr;if(rooti+1<=inend)root->right = _buildTree(preorder,inorder,++prei,rooti+1,inend);elseroot->right = nullptr;return root;}
};6、从中序与后序遍历序列构造二叉树

本题也可以用和上一题一样的思路
在前序遍历中,找根节点很容易,第一个节点就是根节点;在后序遍历中,找根节点同样很容易,最后一个节点就是根节点。
先通过后序数组找到根节点,再通过中序数组找到根节点所在位置,判断左右子树有无节点,如果有节点,去递归它的左右子树
不过本题后序数组传参时就不能传根节点的下标了,刚开始下标-1确实是右子树的根,但再-1就是右子树的右子树的根,但我们想要的是左子树的根。因此本题后序数组也需要传子树的后序区间
在后序遍历中,右子树的根也就是当前下标-1,那左子树的根怎么找呢?
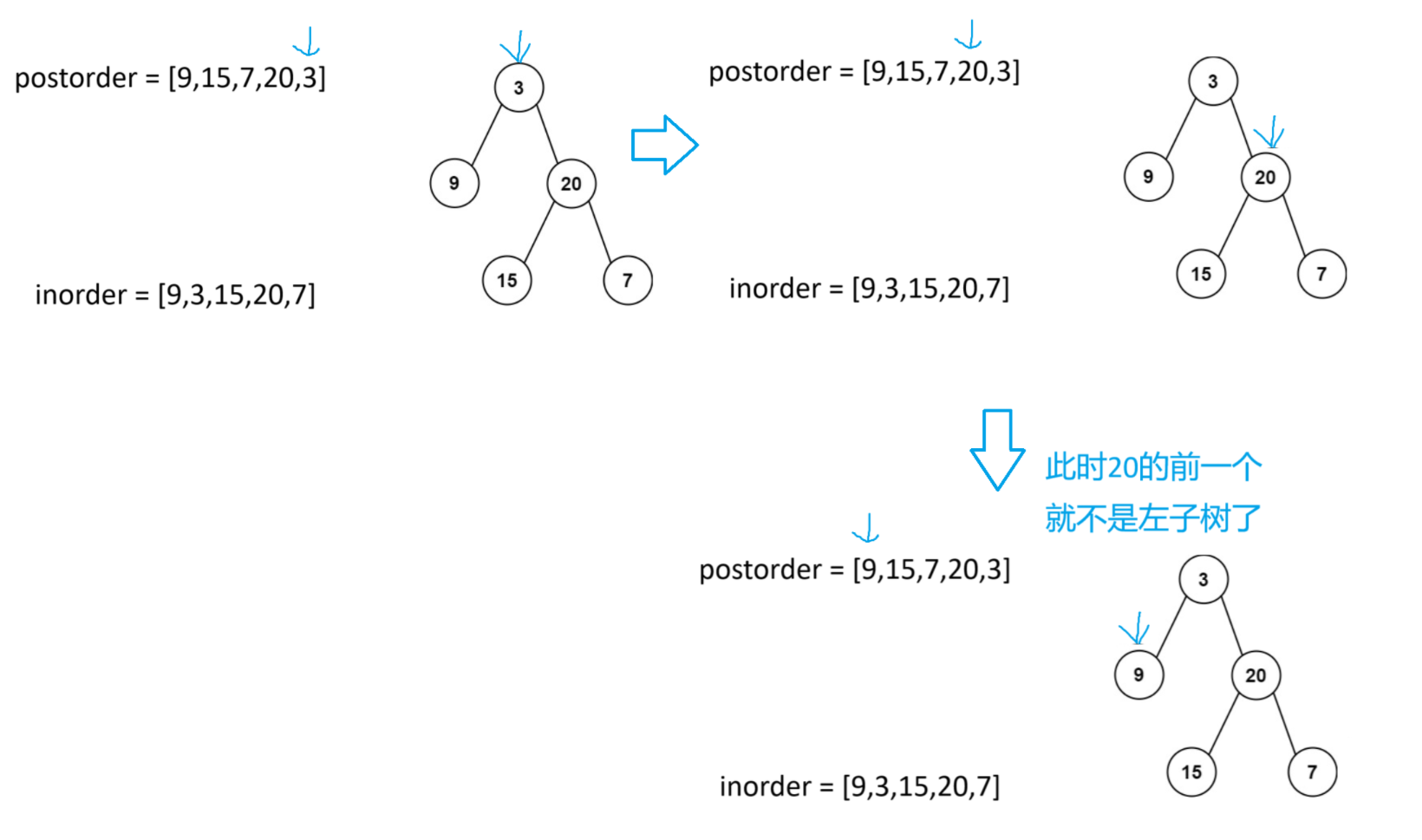
可以先通过中序区间,知道当前根节点的左树有多少个节点
int leftnum = rooti - inbegin;//中序区间中当前根节点所在下标减去中序区间的开始下标此时后序区间就可以被分为
[postbegin,postbegin+leftnum-1][postbegin+leftnum,postend-1] postend
//[后序区间的开始下标,后序区间开始下标+左子树节点个数-1][后序区间开始下标+左子树节点个数,后序区间结束下标-1] 后序区间结束下标再分别递归左子树和右子树
下面模拟一下示例一的过程

每次进入递归都会计算出中序区间左树的节点个数,这样可以算出后序区间的左右子树区间
此时根节点的左子树有数据,所以root->left就会以[0,0]为后序区间,[0,0]为中序区间进入递归
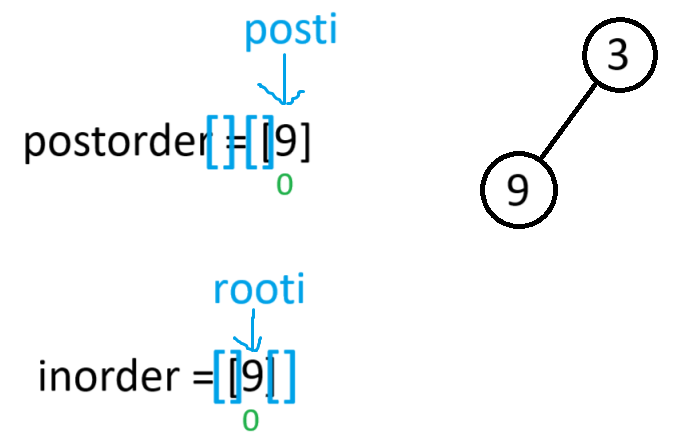
此时根据中序区间可判断出根节点没有左右子树,因此将root->left 和 root->right置空 并返回上一栈帧
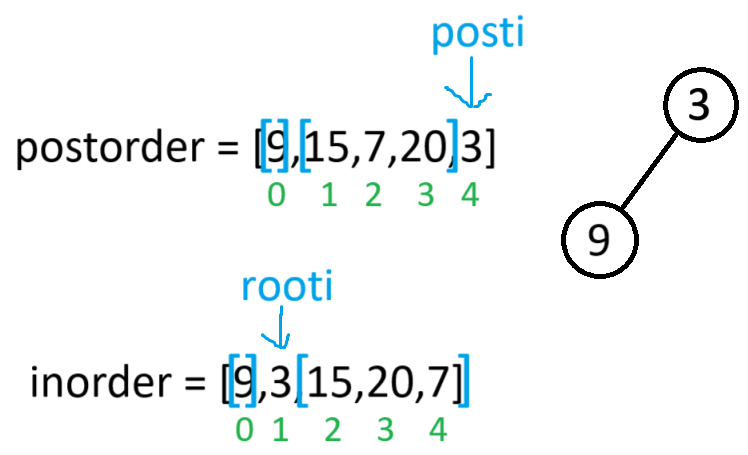
此时当前根节点的左子树构建完毕,又因为右子树也有节点,所以root->right就会以[1,3]为后序区间,[2,4]为中序区间,进递归
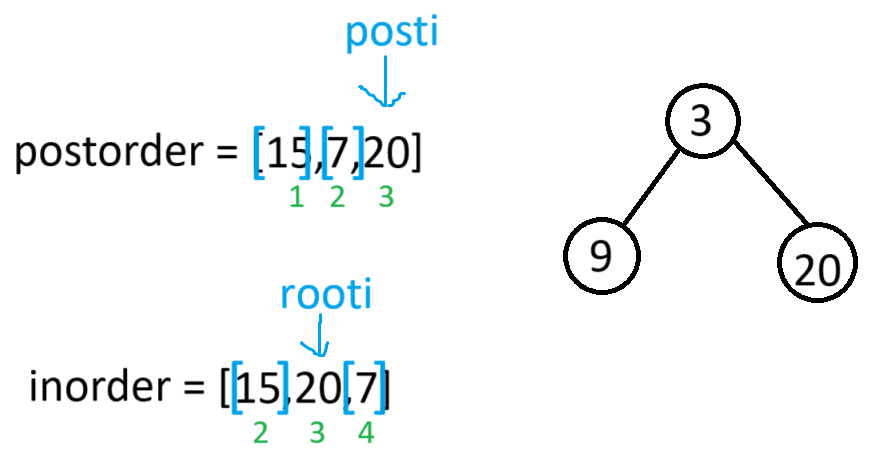
此时根据当前根节点的中序区间可知,左子树有节点,因此root->left就会以[1,1]当作后序区间,[2,2]当作中序区间,进递归
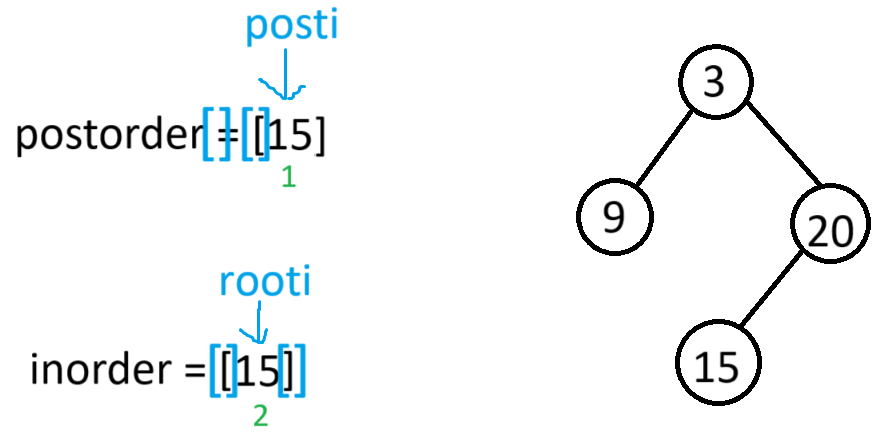
此时根据当前根节点的中序区间可以判断出左右都为空,那么就将root->left和root->right置空后返回上一栈帧
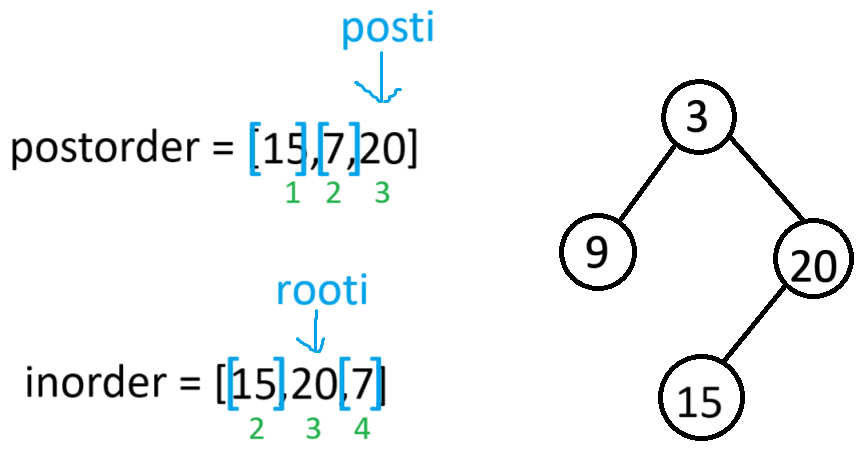
此时当前根节点的左子树构建完,又因为右子树中也有数据,所以root->right就会以[2,2]当作后序区间,[4,4]当作中序区间,进递归
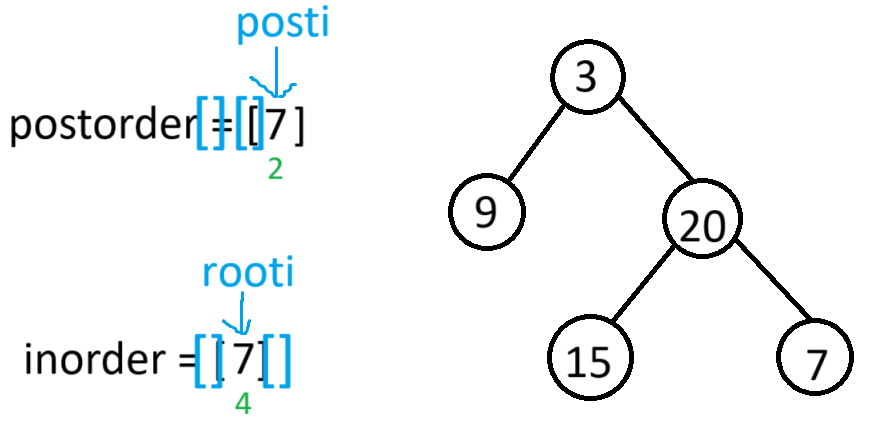
此时根据当前根节点的中序遍历可以判断出左右子树为空,所以将root->left和root->right置空后返回上一栈帧
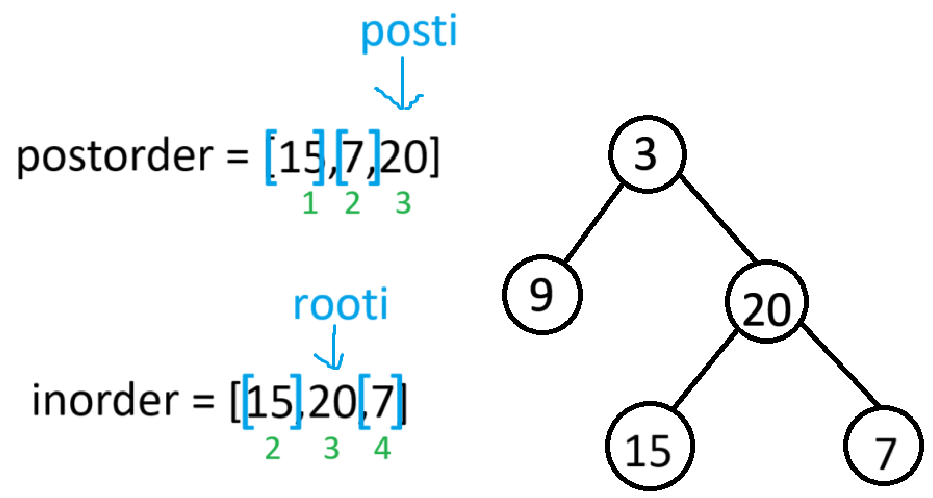
此时当前根节点(20)的左右子树均构建完毕,返回上一栈帧
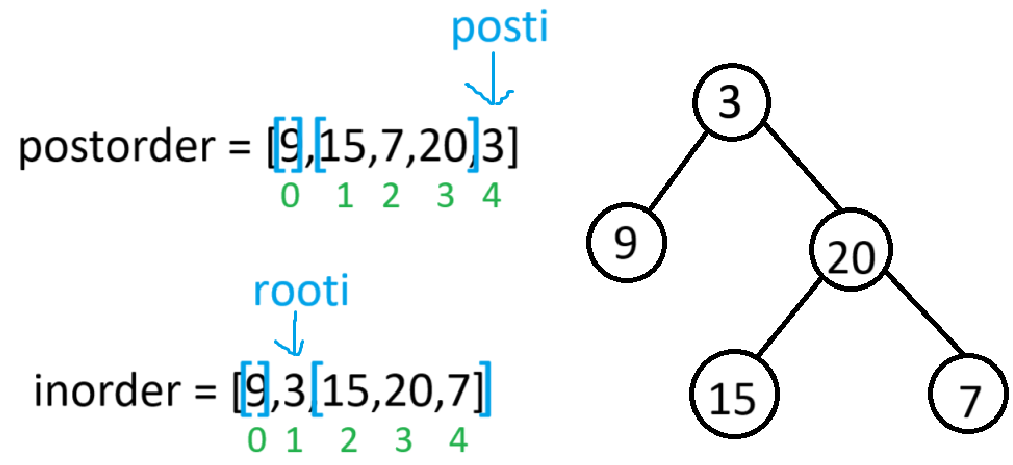
此时当前根节点(3)的左右子树均构建完毕,返回主函数
栈帧模拟图:
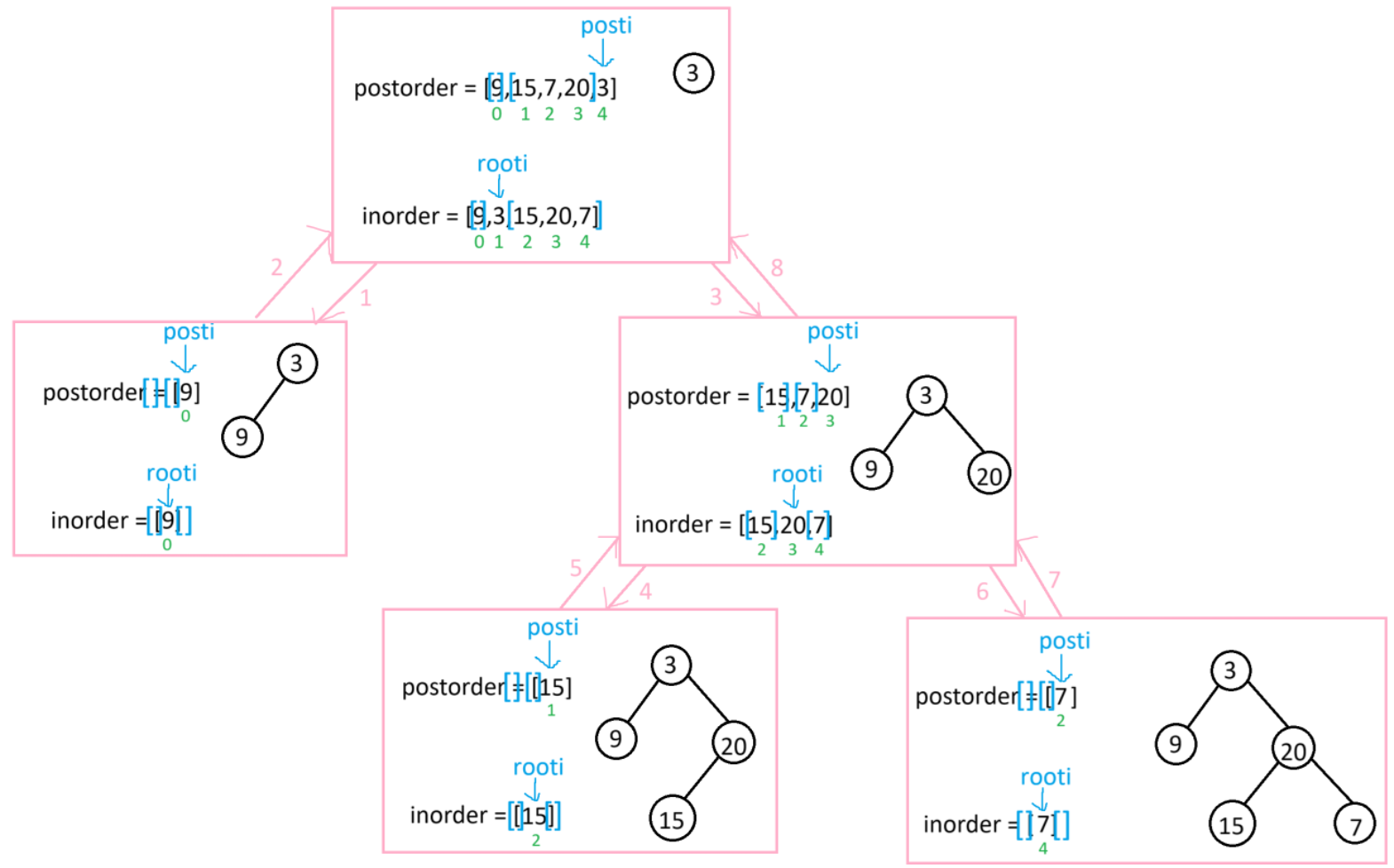
代码实现:
class Solution {
public:TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {int postbegin = 0,postend = postorder.size()-1;//当前根节点的后序区间int inbegin = 0,inend = inorder.size()-1;//当前根节点的中序区间return _buildTree(inorder,postorder,inbegin,inend,postbegin,postend);//通过递归构建}TreeNode* _buildTree(vector<int>& inorder,vector<int>& postorder,int inbegin,int inend,int postbegin,int postend){TreeNode* root = new TreeNode(postorder[postend]);//为当前根节点开辟空间//从中序区间中找到根节点的位置int rooti = inbegin;while(rooti <= inend){if(inorder[rooti] == postorder[postend])break;rooti++;}//此时中序区间就变成了[inbegin,rooti-1] rooti [rooti+1,inend]//判断当前根节点是否有左右树int leftnum = rooti - inbegin;//计算出左树节点的个数,就可以知道右树的节点个数//此时后序就被分成了[postbegin,postbegin+leftnum-1][postbegin+leftnum,postend-1] postend//先递归右子树,因为后序遍历的顺序是左、右、根,右子树在紧跟在根节点的前面if(inbegin <= rooti-1)//如果右子树有节点root->left = _buildTree(inorder,postorder,inbegin,rooti-1,postbegin,postbegin+leftnum-1);elseroot->left = nullptr;//再递归左子树if(rooti+1 <= inend)//如果左子树有节点root->right = _buildTree(inorder,postorder,rooti+1,inend,postbegin+leftnum,postend-1);elseroot->right = nullptr;return root;}
};7、二叉树的前序遍历(非递归)
若要用递归来解这道题,非常简单
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;preorder(v,root);return v;}void preorder(vector<int>& v,TreeNode* root){if(root == nullptr)//判断该节点是否存在return;v.push_back(root->val);//根preorder(v,root->left);//左子树preorder(v,root->right);//右子树}
};本篇的思路重点讲解非递归
前序遍历的特点是先访问根,再访问左子树,最后访问右子树
可以把遍历分为两步:
- 遍历左路节点
- 左路节点的右子树
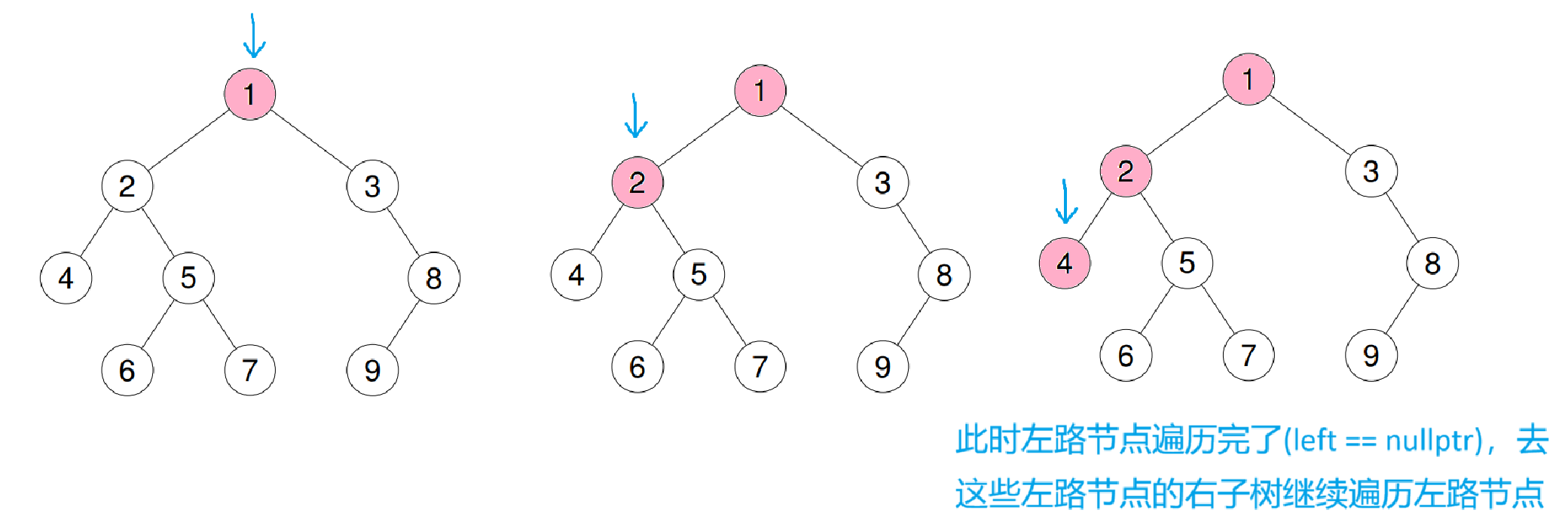
先遍历当前根节点的左路节点,这样就完成了前序的根、左子树操作
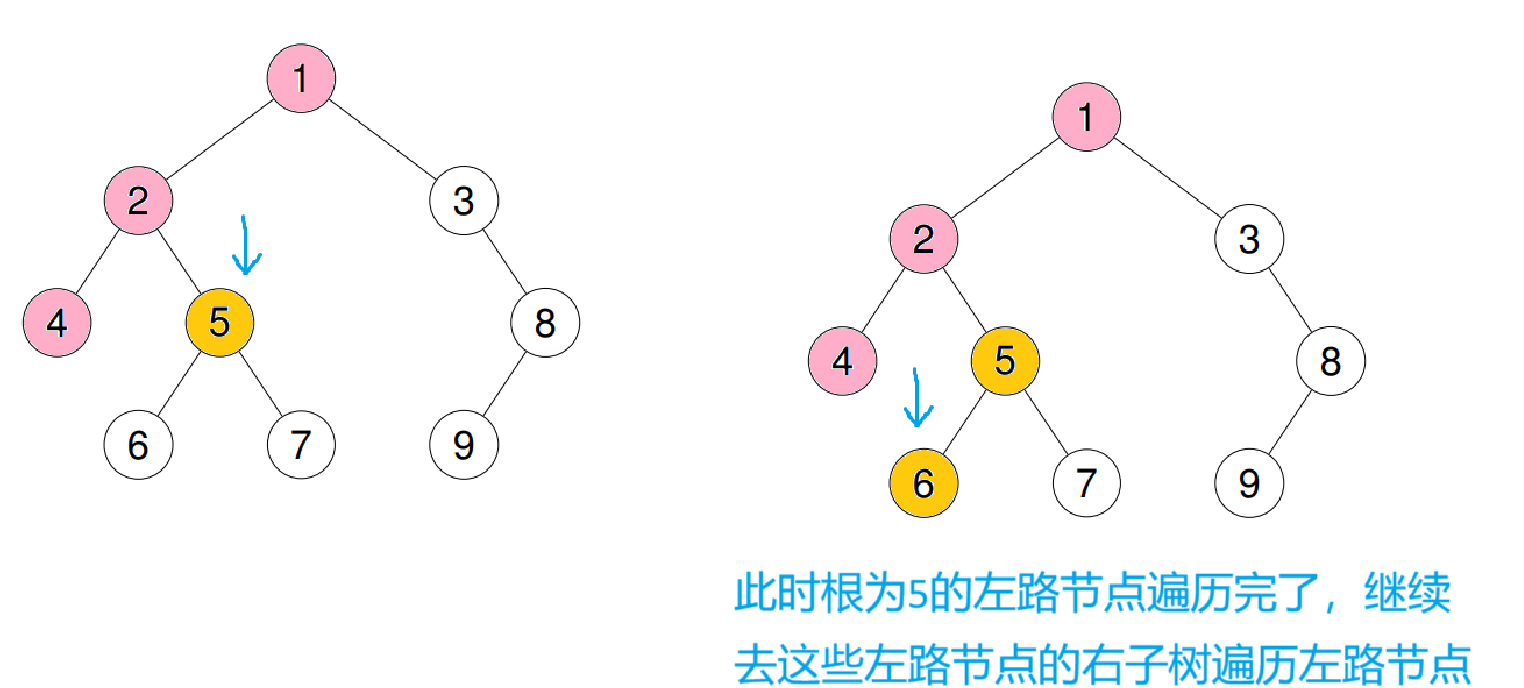
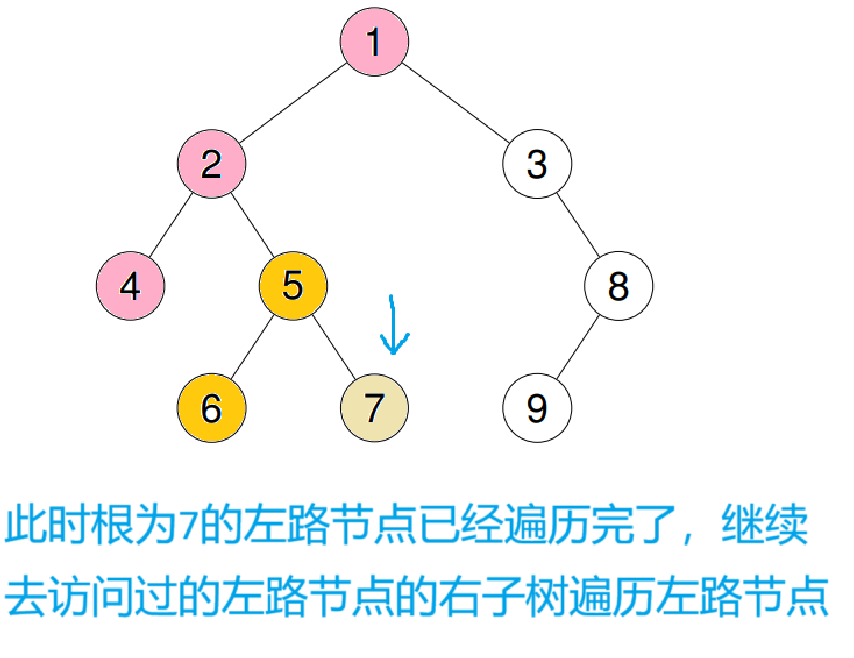
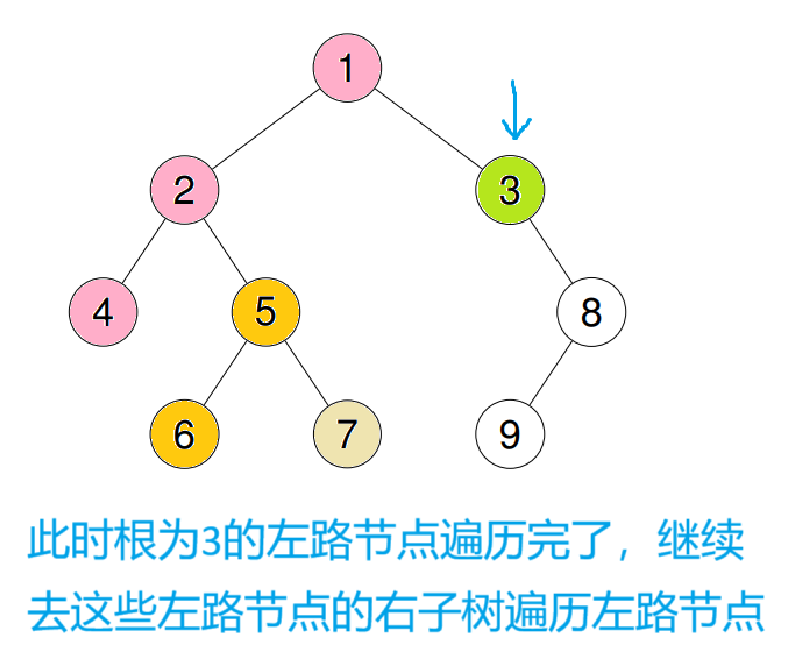
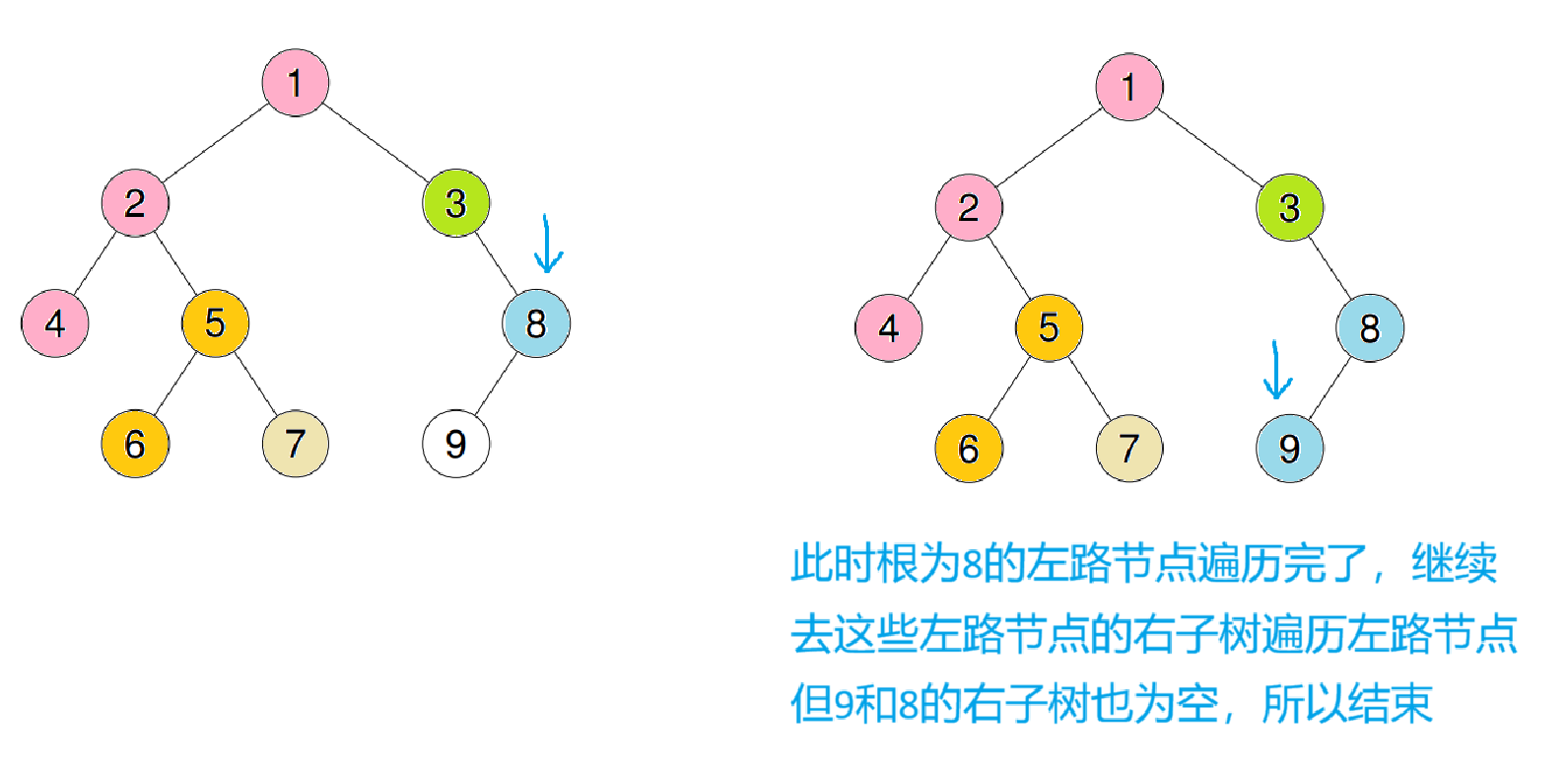
这样就用前序的顺序完成了遍历
那怎么才能知道这些左路节点有没有被访问过呢?
可以用栈模拟栈帧,每次遍历一个左路节点时,就把它本身入栈,它就算一个子树,直到左路节点遍历完(left == nullptr)时,再去提取栈顶的右子树继续遍历左路节点,如此往复
拿示例二来举例,下面模拟一下过程
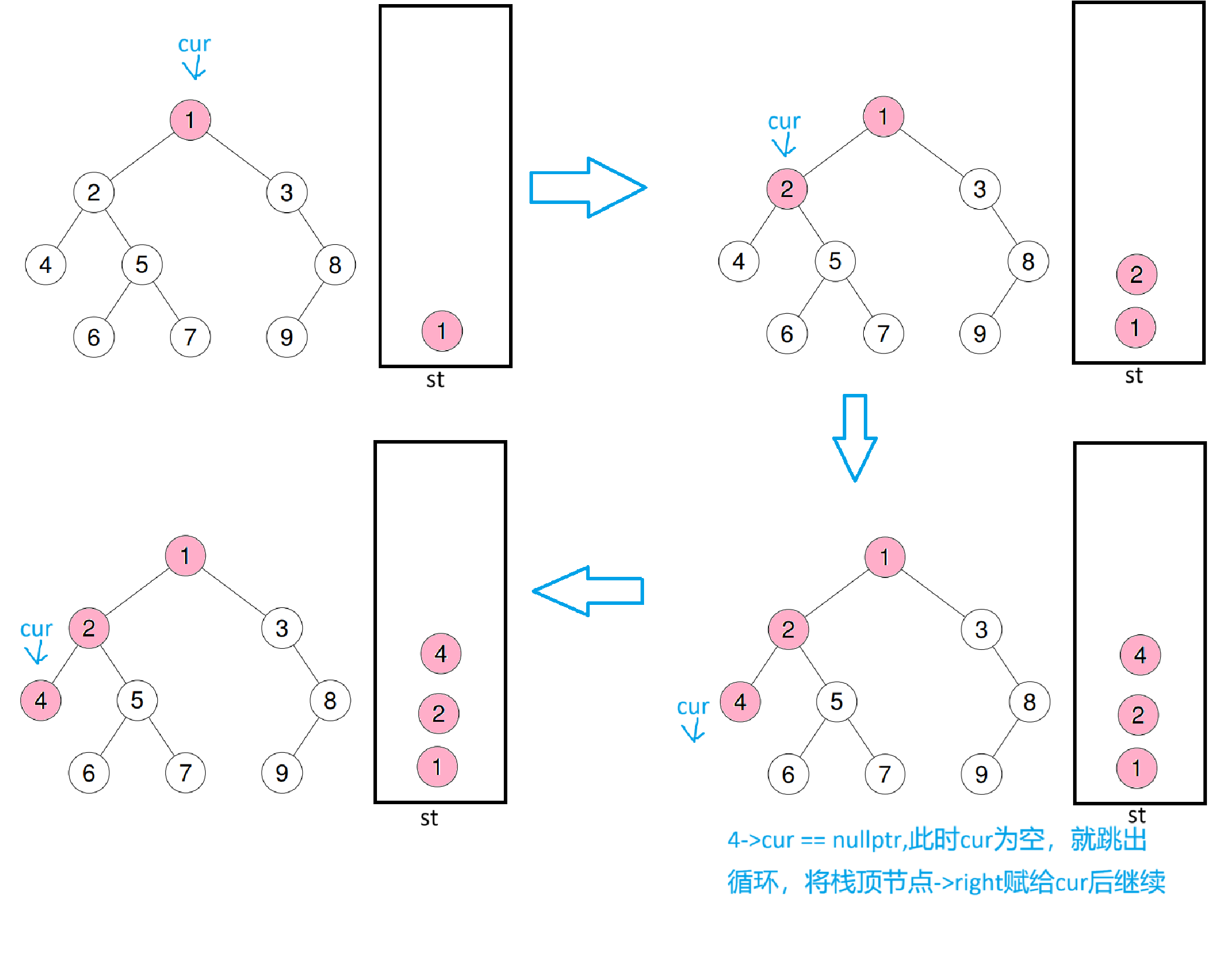
这是第一次进循环,直到cur为空时跳出
cur = st.top()->right后继续进循环(别忘了st.pop()删除栈顶数据)
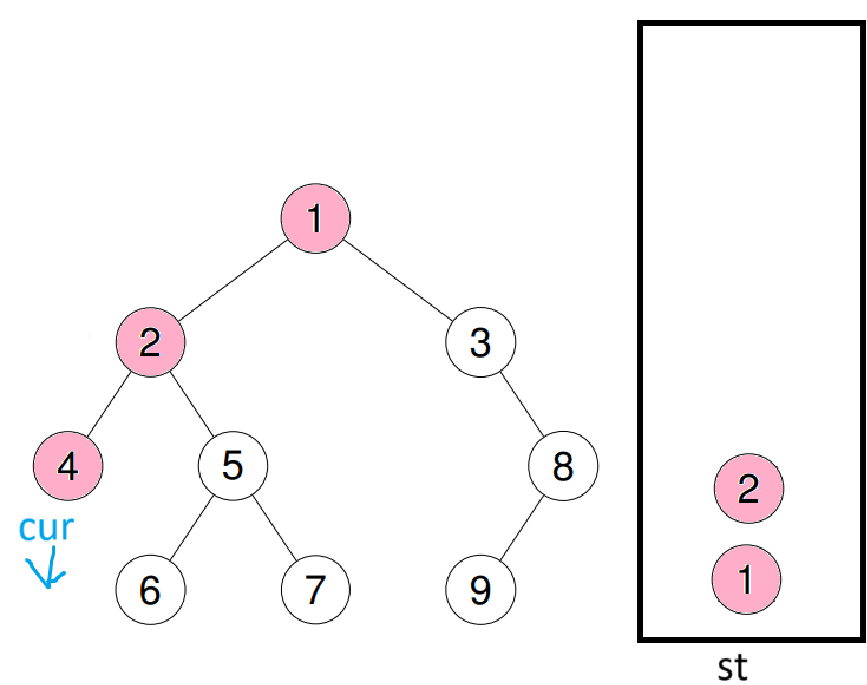
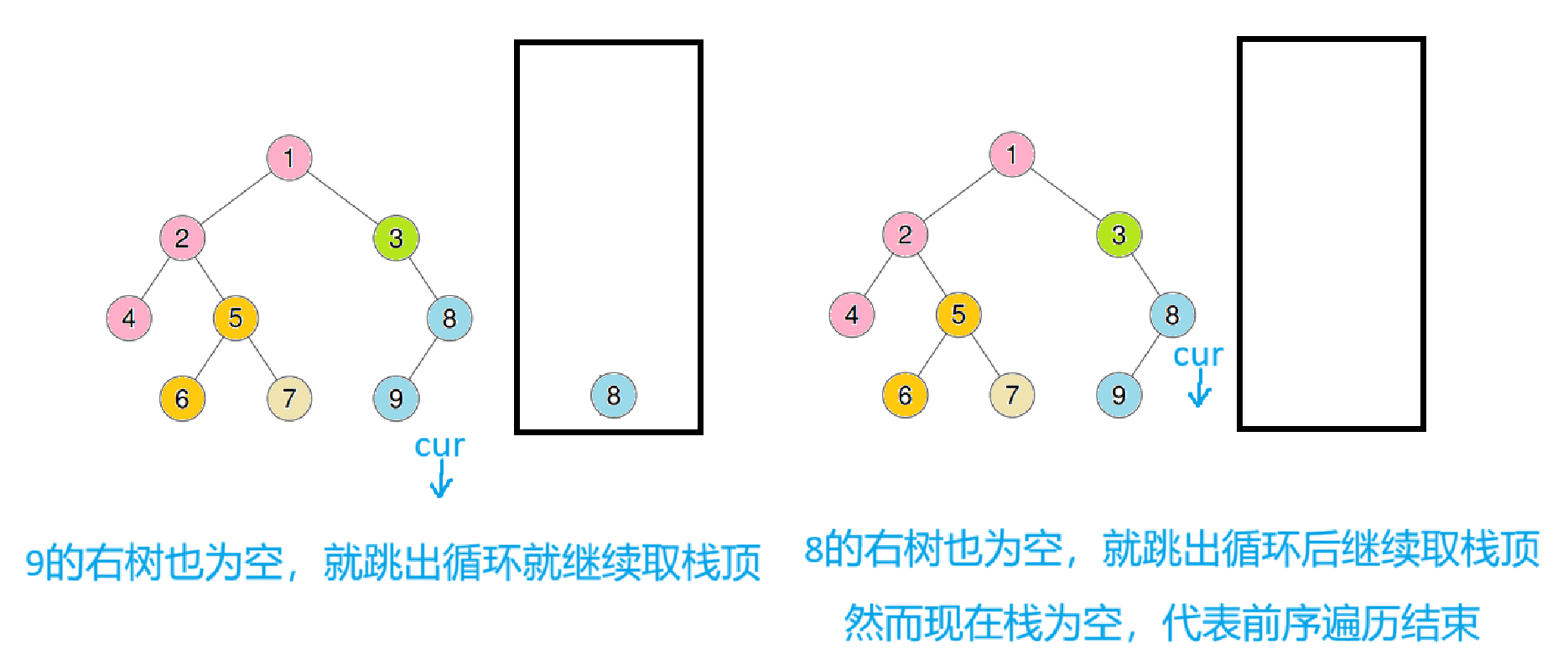
4的右子树也为空,此时跳出循环,继续把栈顶数据右树给cur(cur = st.top->right),进循环
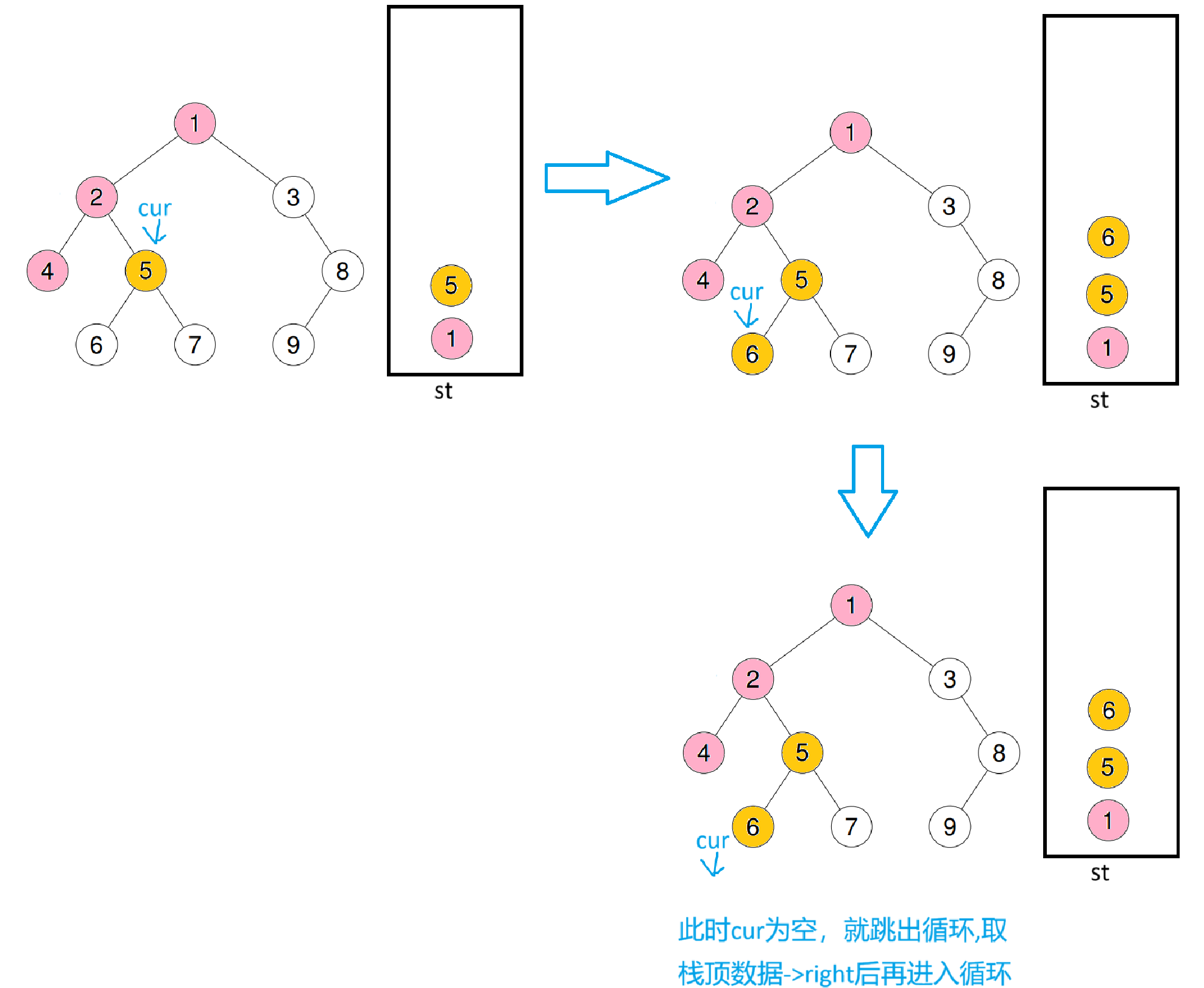
跳出循环后肯定就证明cur为空,所以直接cur = st.top()->right ;st.pop();后再进入循环
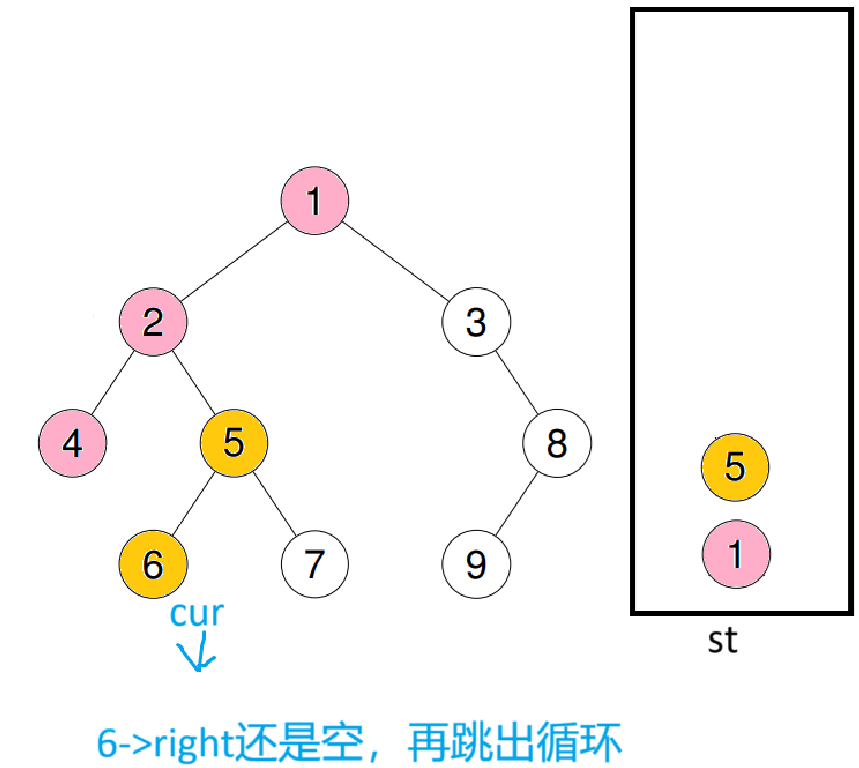
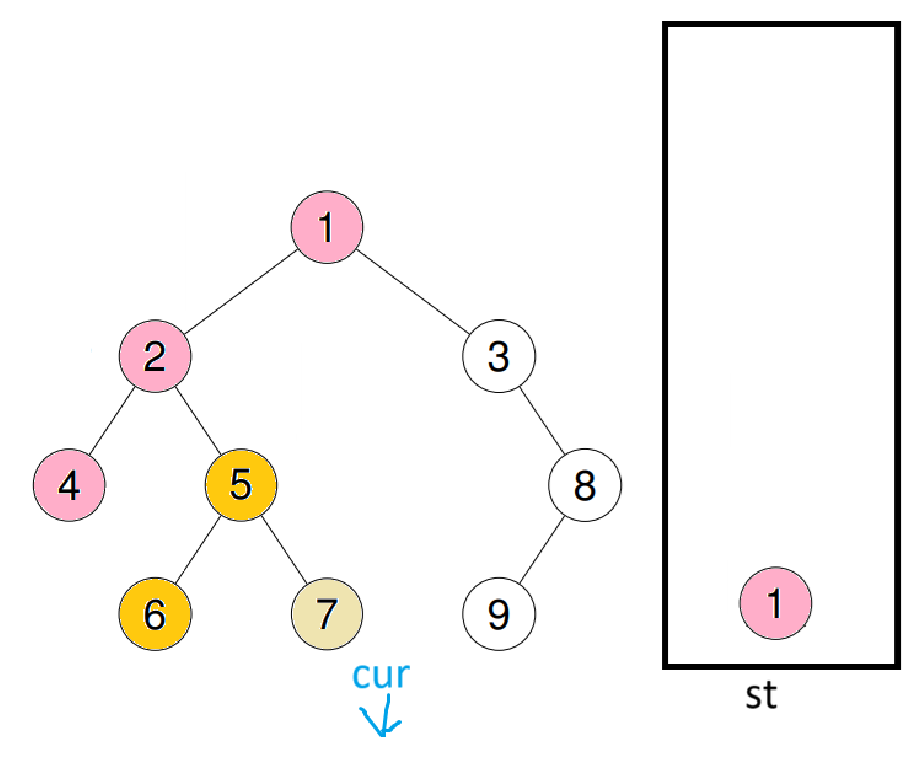
重复之前操作后再入循环
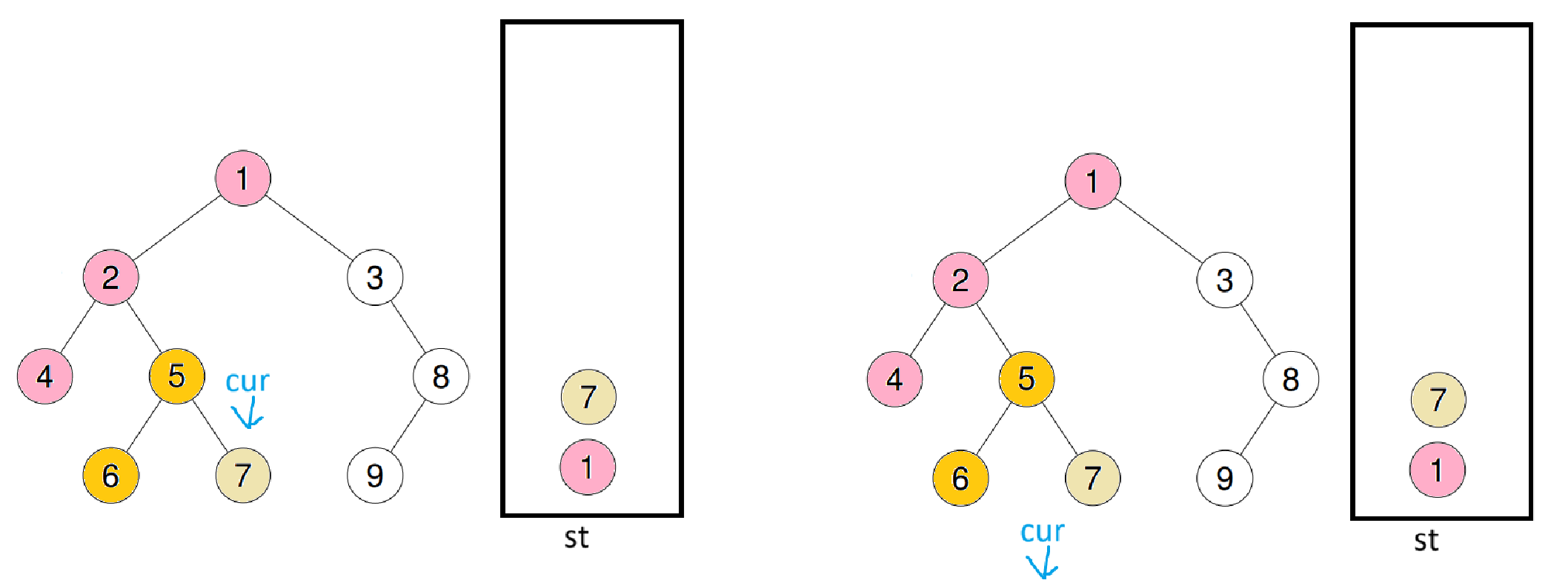
此时cur又会跳出循环,重复之前操作后再进循环
由于7的右子树是空,也不会进循环,继续重复之前操作
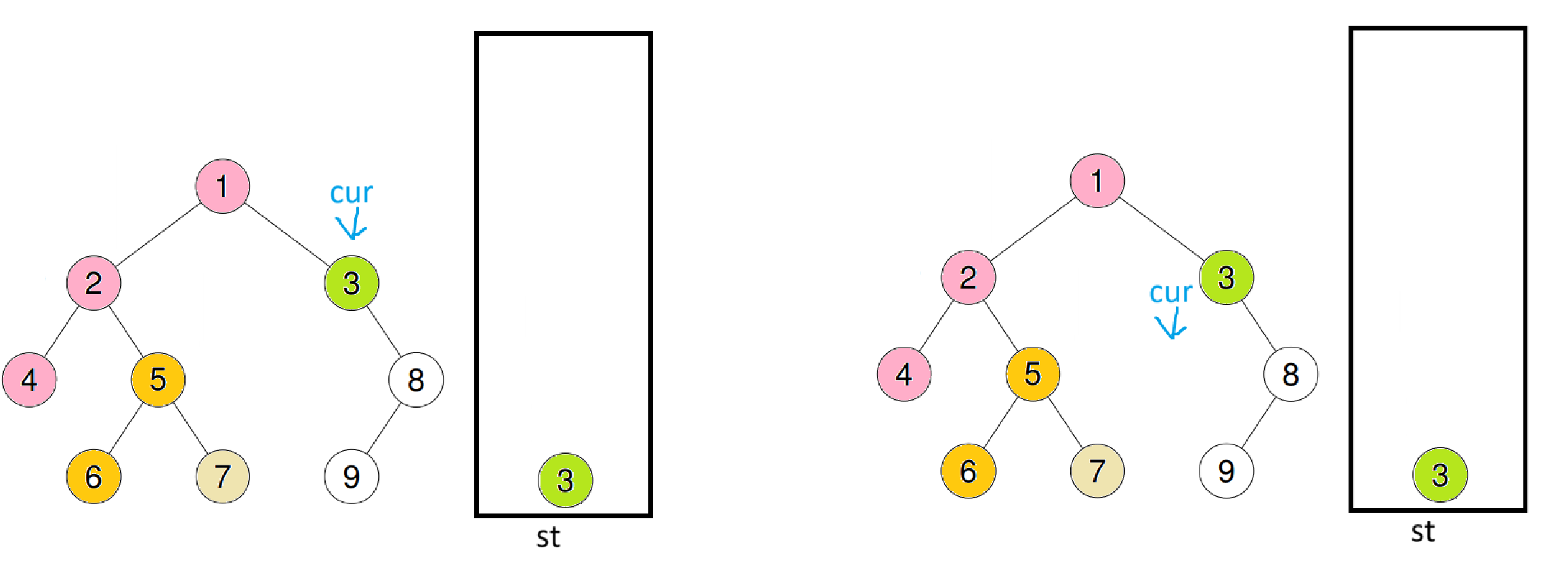
将3压入栈后,又会跳出循环,此时继续重复之前操作后再进入循环
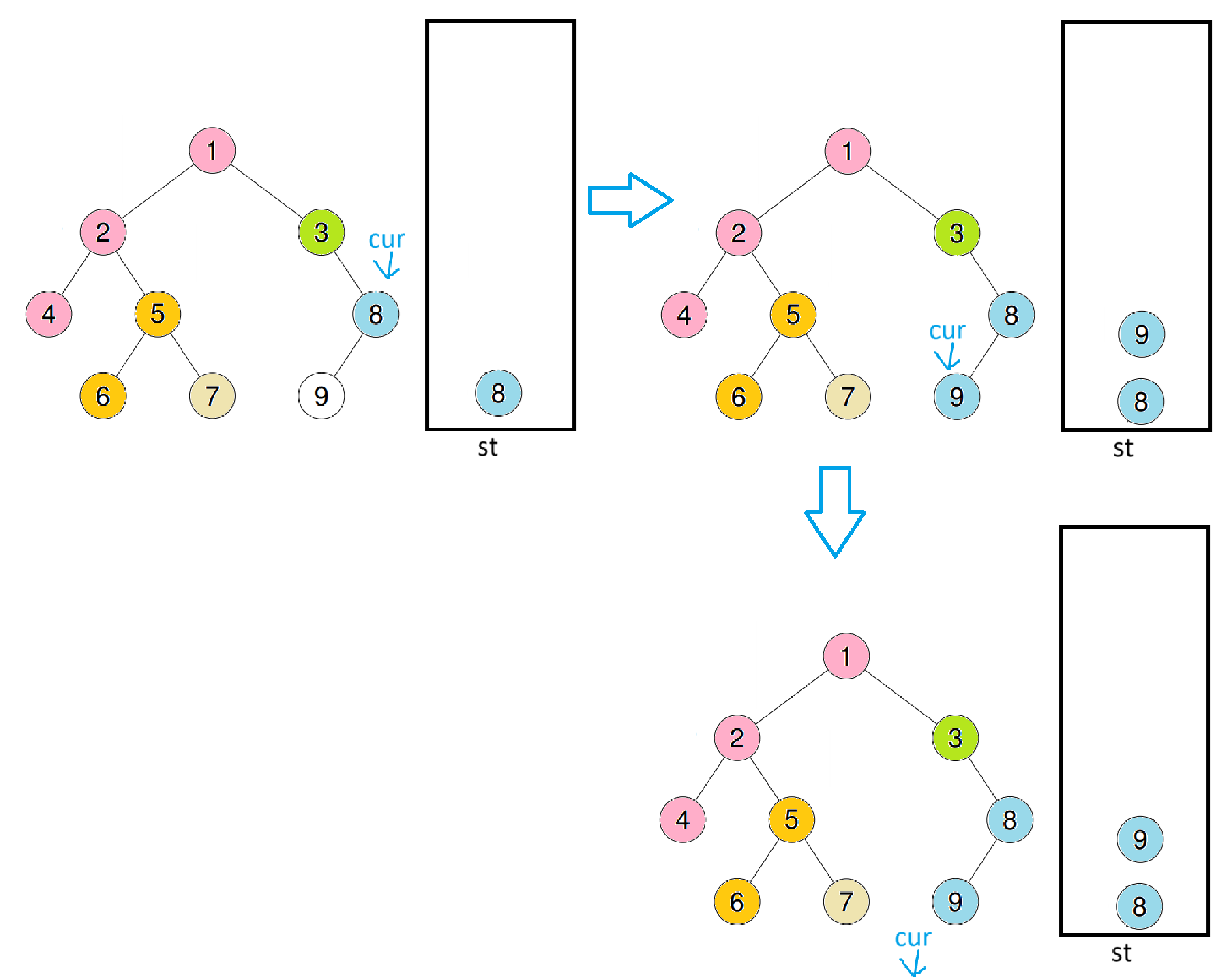
此时cur为空跳出,继续cur = st.top()->right;st.pop();后入循环
代码实现:
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr)return v;stack<TreeNode*> st;//用栈模拟递归栈帧TreeNode* cur = root;while(cur || !st.empty())//第一次进循环时栈为空,所以要加上另外一个条件{while(cur)//1.遍历左路节点访问根并入栈{v.push_back(cur->val);st.push(cur);cur = cur->left;}cur = st.top()->right;//2.取栈顶节点的右子树,继续遍历左路节点访问并入栈st.pop();}return v;}
};8、二叉树的中序遍历(非递归)
本题也可以采用前序遍历非递归的思路,只不过这次遍历左路节点时不能直接把值尾插到数组中,因为中序遍历是顺序是左子树、根、右子树,要在取栈顶数据时把值尾插到数组中
下面还是用刚才的二叉树来模拟一下过程
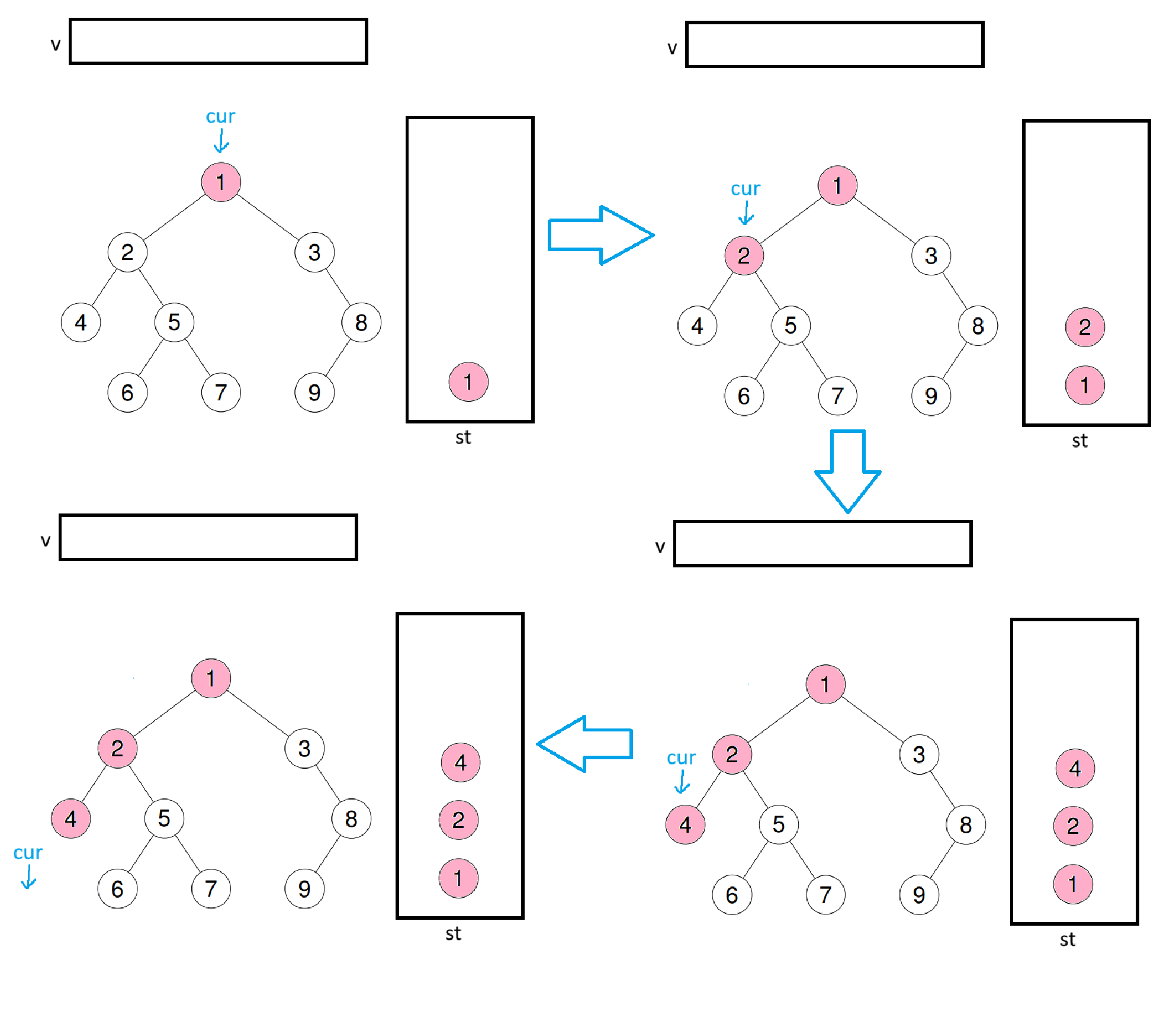
此时cur为空,就跳出循环。但这里就不能直接将cur = st.top()->right了,直接略过节点,就不能把值尾插到数组中了,所以这里要改为
v.push_back(st.top()->val);
cur = st.top()->right;
st.pop();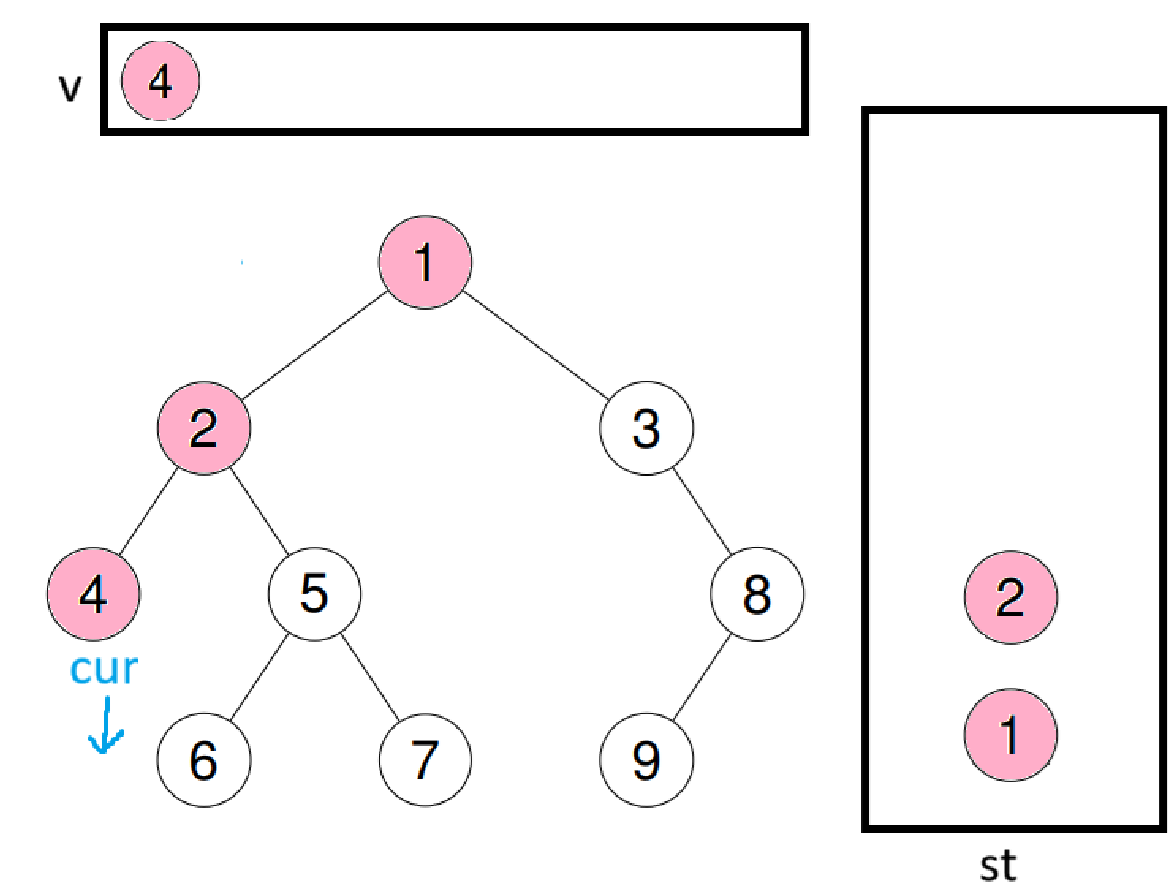
先将栈顶值尾插到数组中,再将栈顶的右子树给cur
此时因为4的子树还是空,所以再跳出循环,将栈顶值尾插到数组中后,再将栈顶右子树给cur
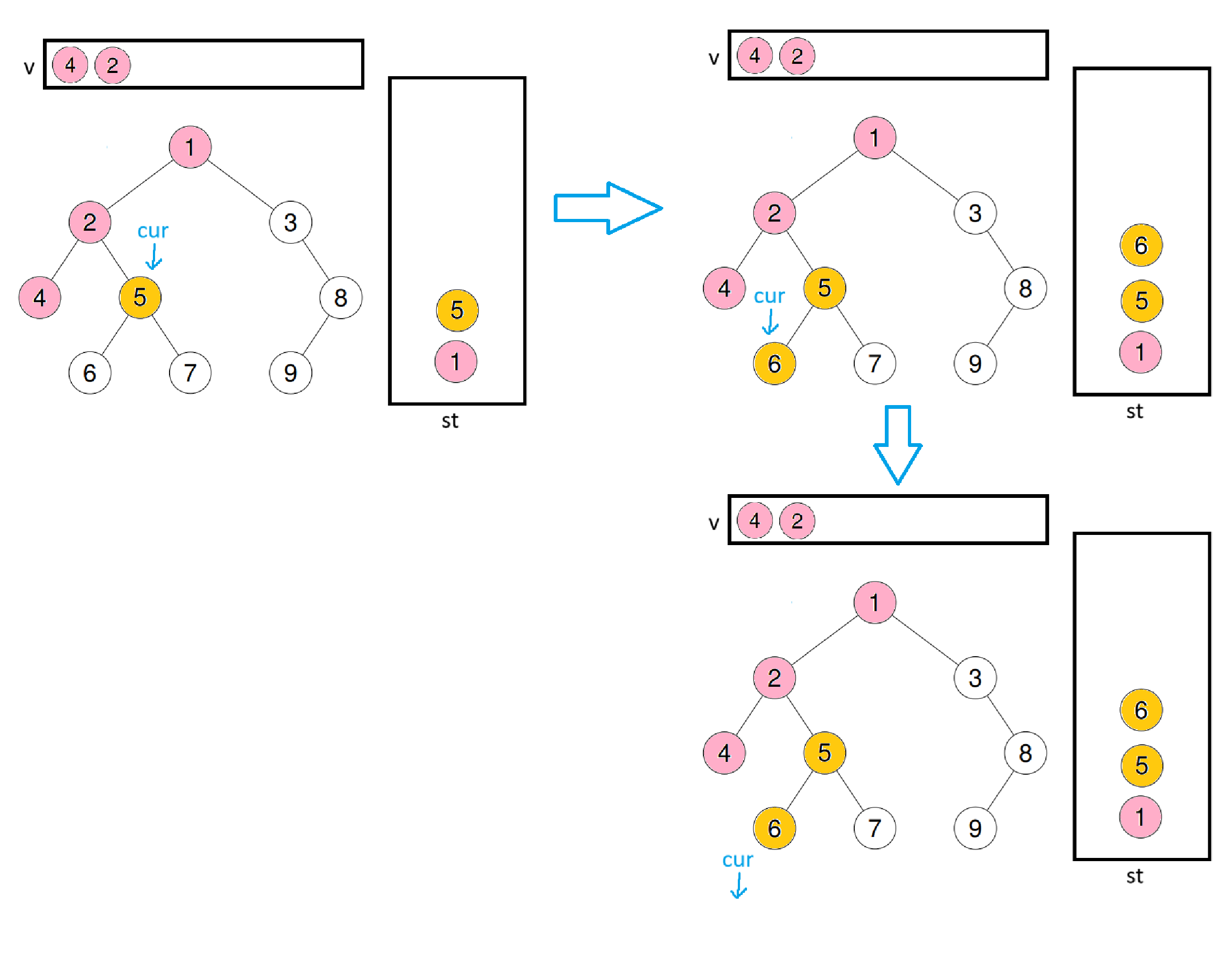
此时再取出栈顶数据尾插到数组中,再将栈顶数据的右子树赋给cur,进入循环
左树剩余过程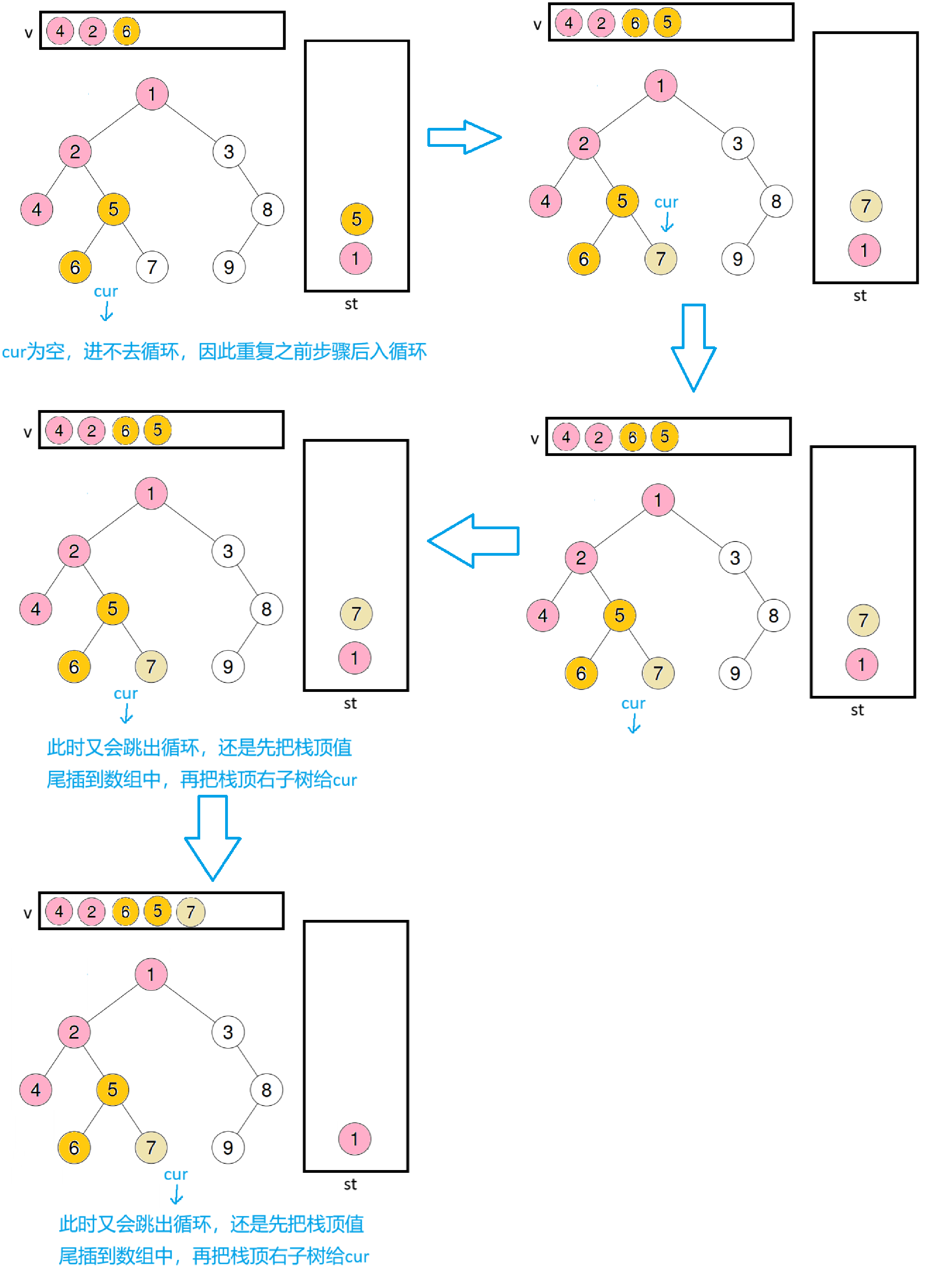
右树剩余过程
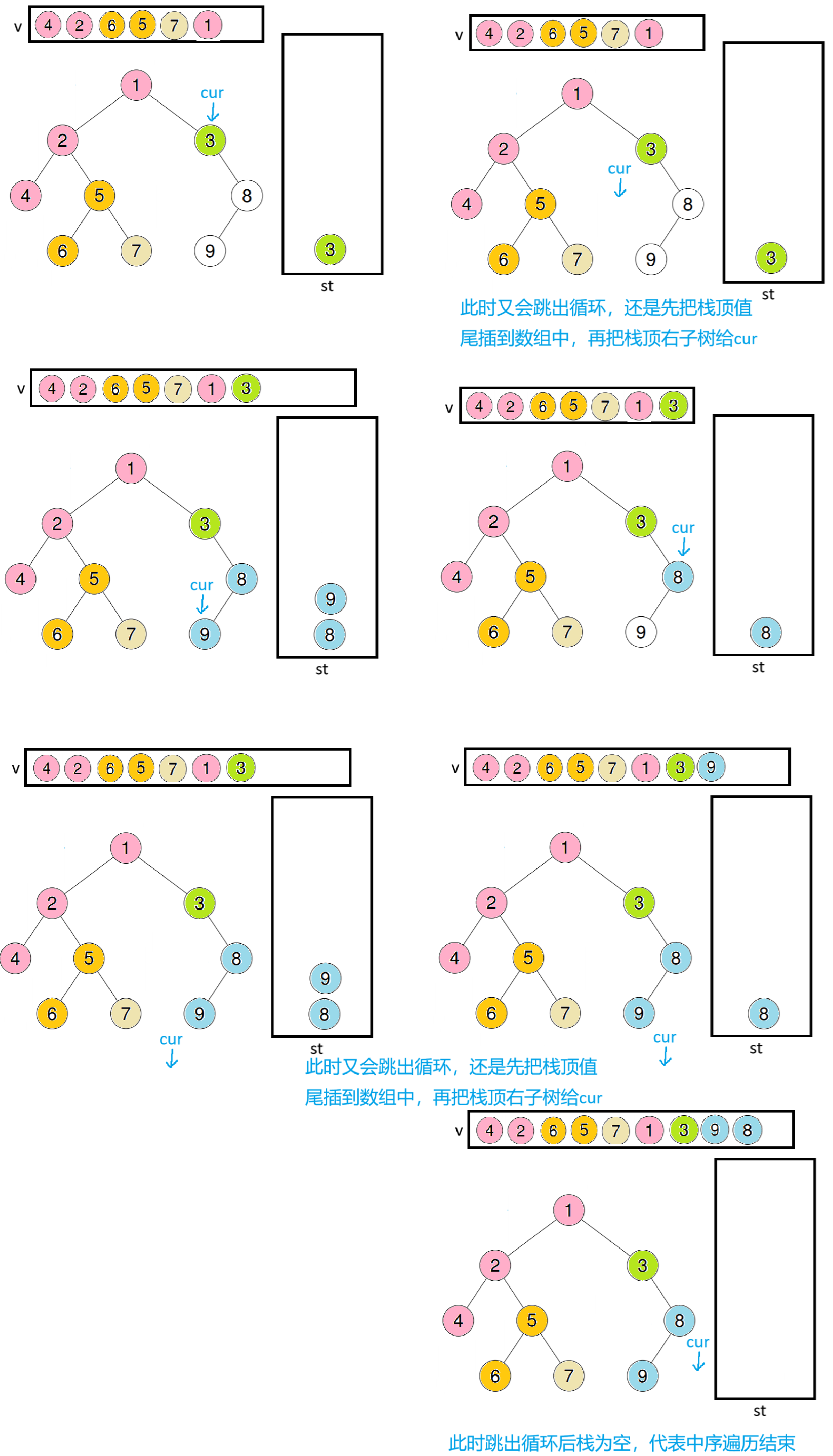
代码实现:
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr)//如果是空树,就返回空数组return v;stack<TreeNode*> st;//用栈模拟递归栈帧TreeNode* cur = root;while(cur || !st.empty())//因为第一次进循环时栈为空,所以多加一个条件{while(cur)//遍历左路节点,但不尾插到数组中{st.push(cur);cur = cur->left;}//取栈顶的右子树之前先将栈顶值尾插到数组中v.push_back(st.top()->val);cur = st.top()->right;st.pop();}return v;}
};9、二叉树的后序遍历(非递归)
后序的非递归也可以用前序和中序的思路
后序遍历的顺序是左、右、根,按照上面的思路:先将左路节点入栈,直到cur->left == nullptr,此时要先遍历右树,再将根尾插进数组
如果遍历完的是左子树,就要再去右树继续入栈;如果遍历完的是右子树,此时就要出栈顶数据并尾插到数组中
要想能够判断刚遍历完的是左树还是右树,就需要除了cur指针外,再有一个指针用来指向上一个尾插进数组的节点,也就是双指针。因为后序遍历的顺序是左、右、根,所以对于一棵树的子树而言,最后一个被尾插进数组的肯定是根节点
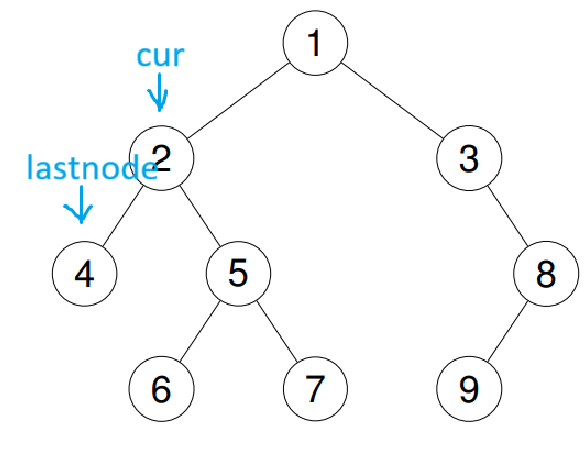
例如,此时取出栈顶是2,只需要判断2的右子树是否为lastnode或空。
若不是,就代表右树还未遍历,就先去遍历cur->right;
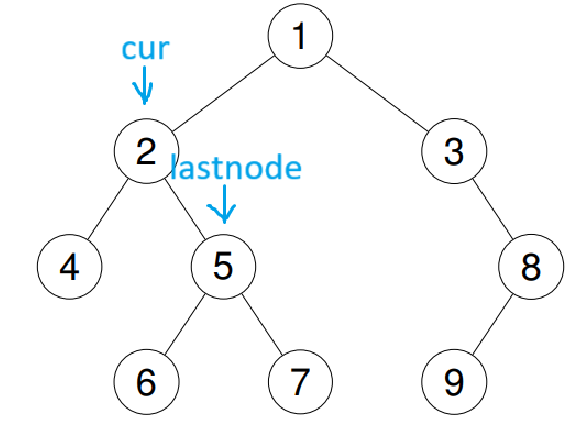
若是右子树,就代表右树已经遍历完,就需要让栈顶出栈并尾插到数组中
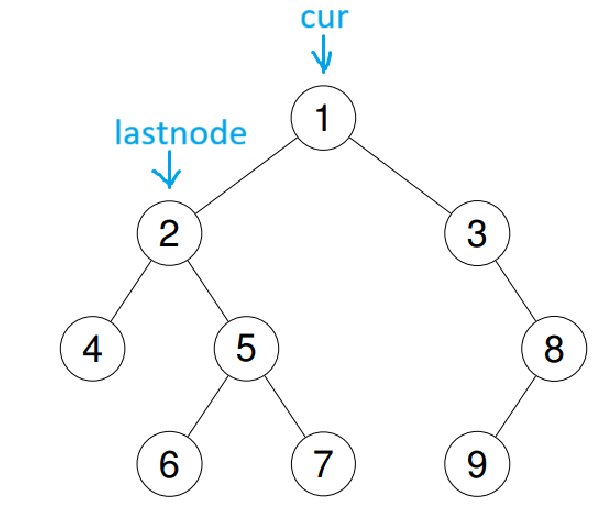
此时lastnode变成了2,cur现在变成了1,根据上面步骤可得此时要先走1的右子树,以此类推
下面以示例二来模拟一下过程
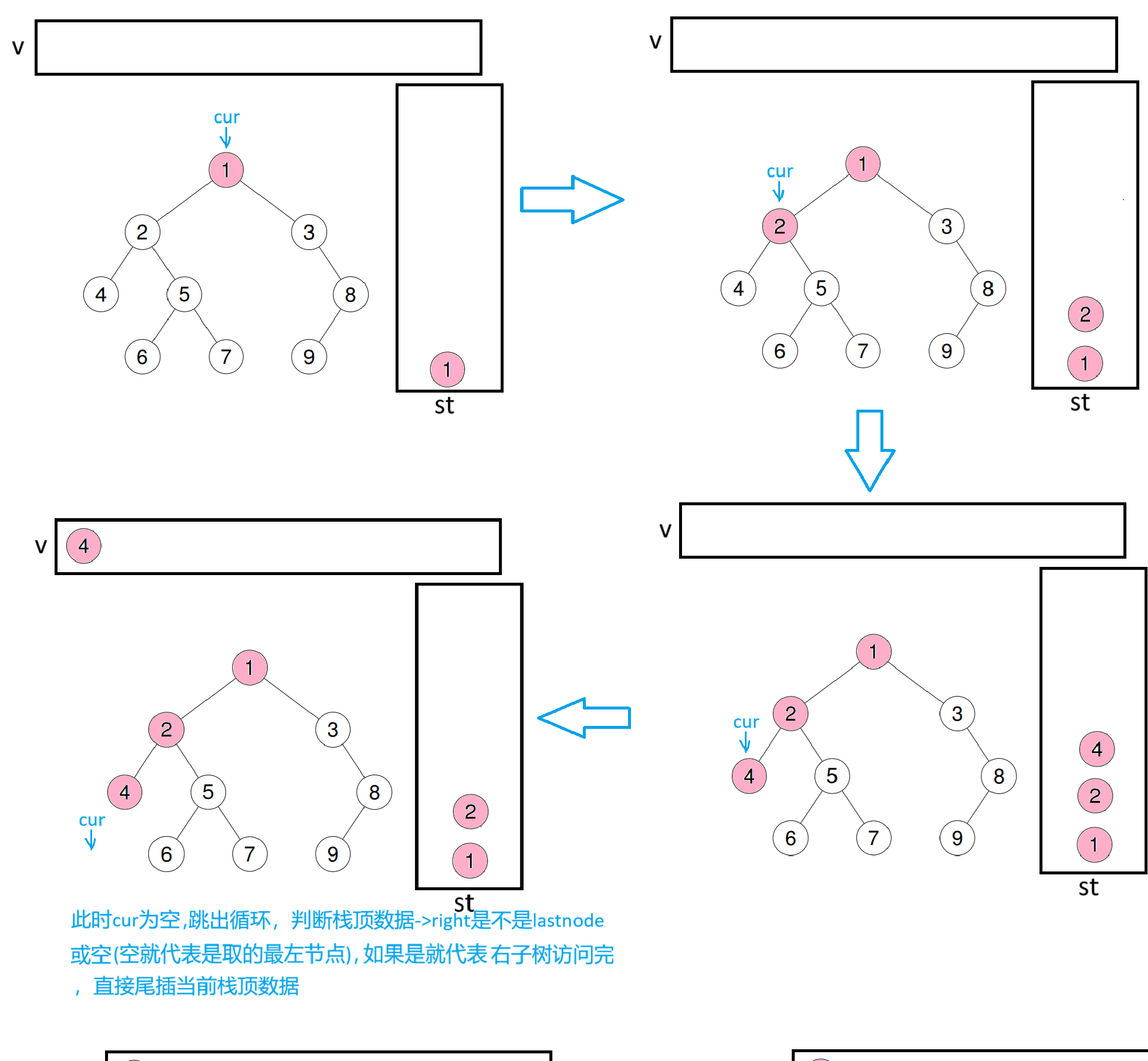
此时因为刚刚尾插了4节点,lastnode会指向4,cur再指向栈顶数据(即2)
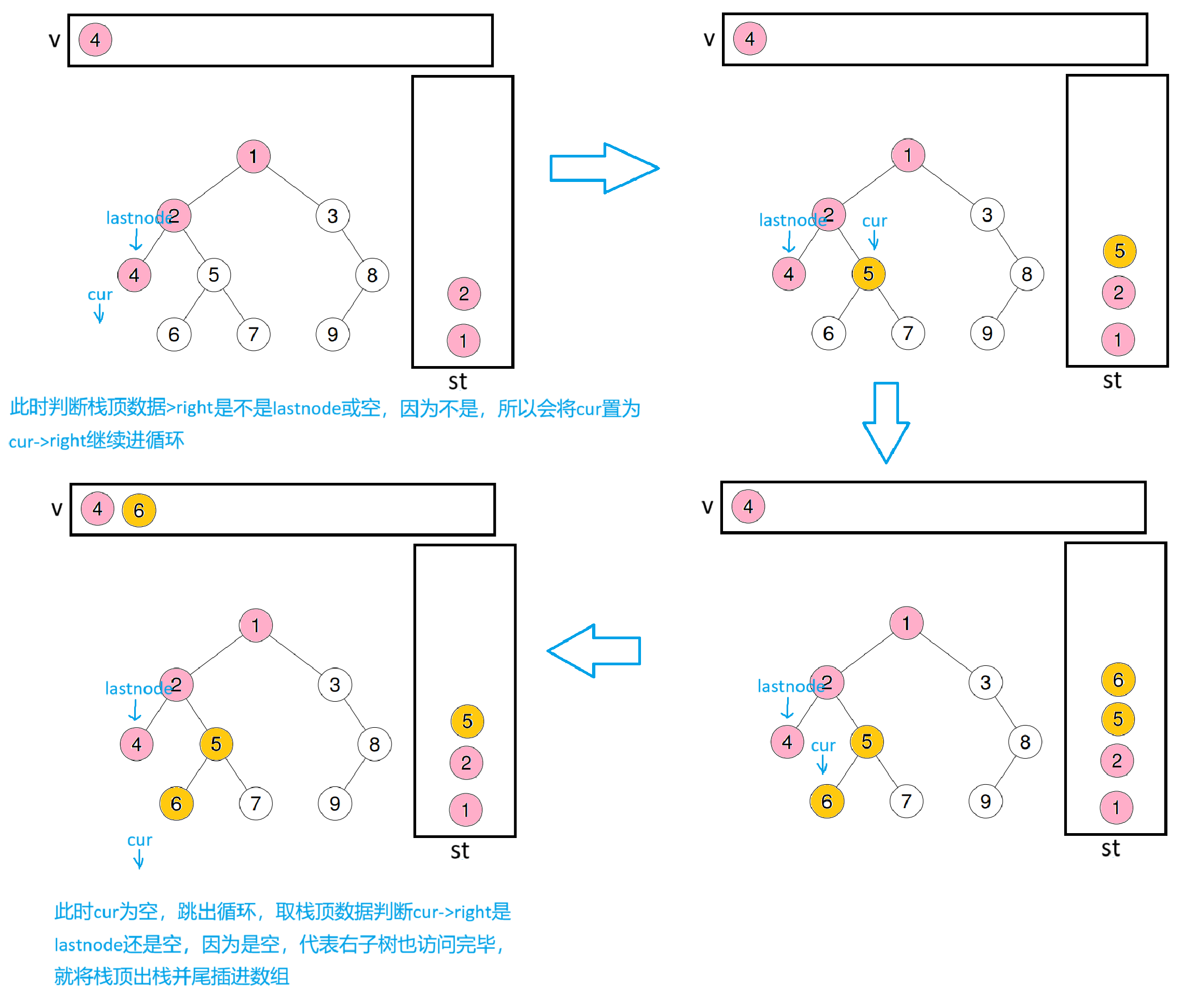
此时lastnode会指向6,会取出栈顶数据(也就是5),判断栈顶->right是不是lastnode或空,因为不是,所以会将cur = st.top()->right继续入循环
此时lastnode会指向7,再取出栈顶数据5,判断栈顶->right是否等于lastnode或空,因为是,代表右子树访问完毕,就出栈并尾插进数组
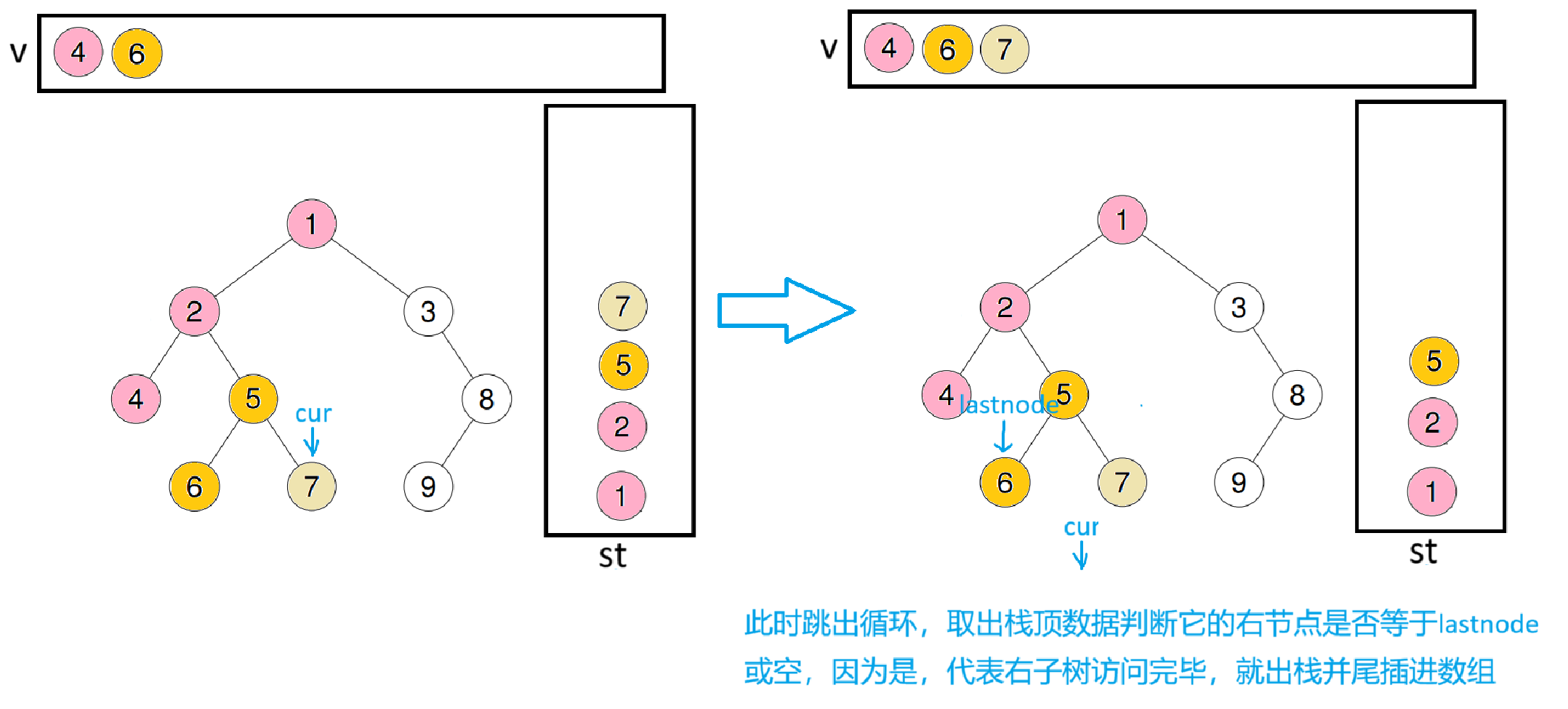
此时lastnode会指向5,再取出栈顶数据2,判断栈顶->right是否为lastnode或空,因为是,所以出栈并尾插进数组
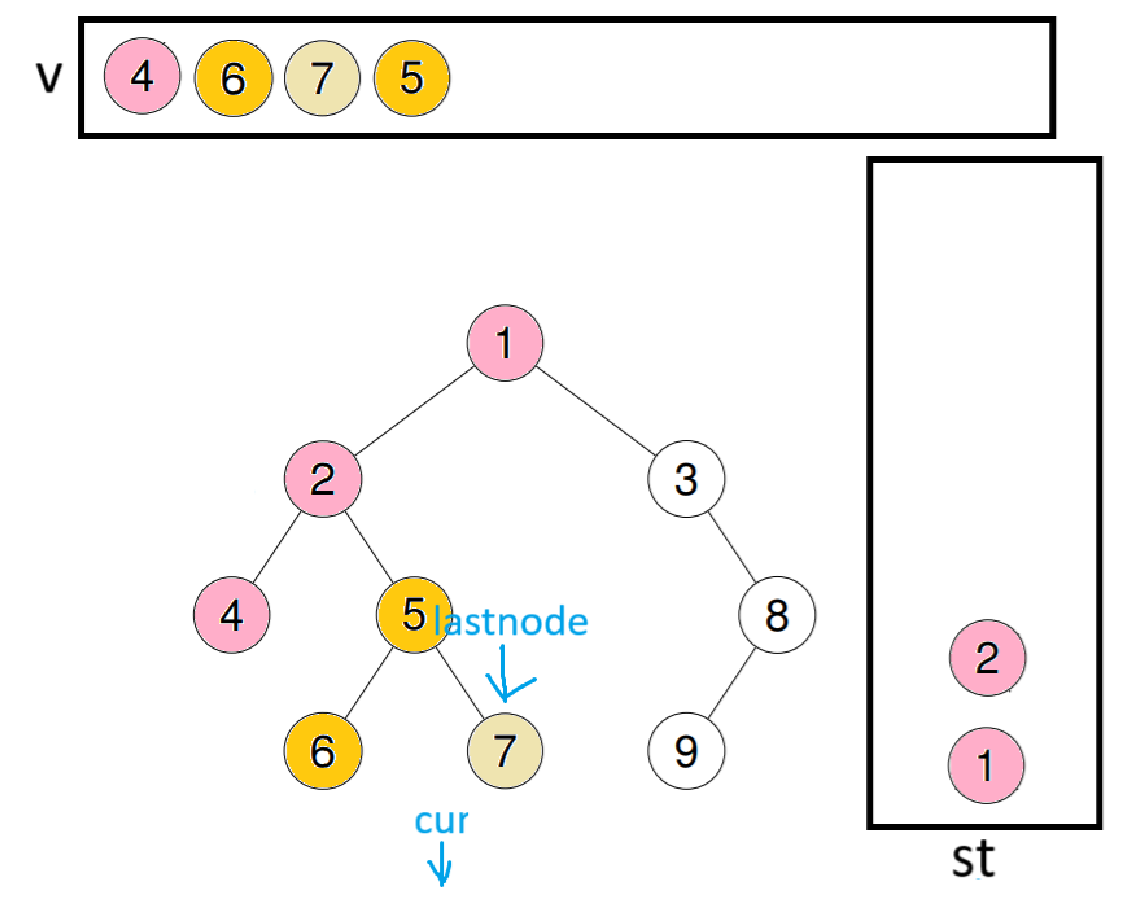
此时lastnode会指向2,取出栈顶数据1,判断栈顶->right是否为lastnode或空,因为不是,所以将cur = st.top()->right继续进循环
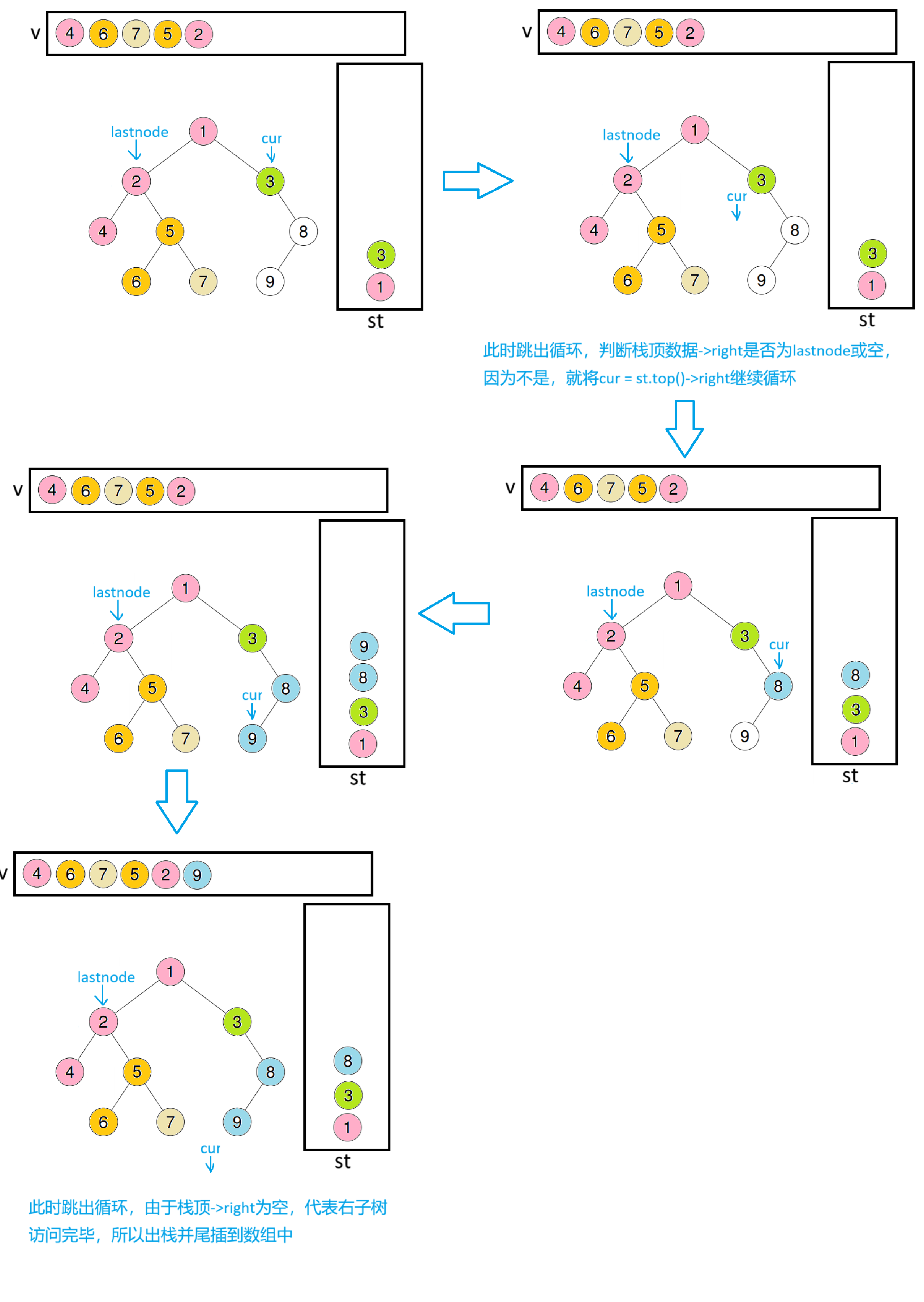
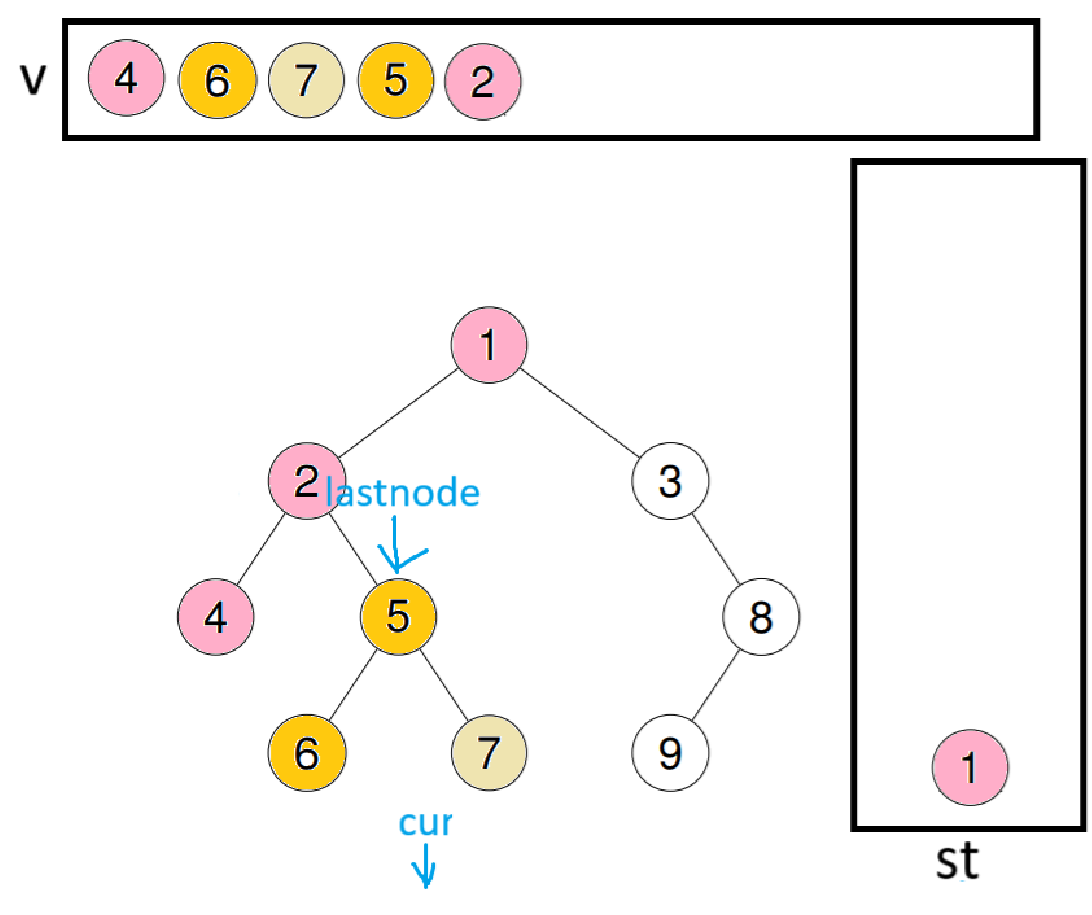
此时last会指向9,取出栈顶数据8,因为8的右子树也是空,所以出栈并尾插进数组
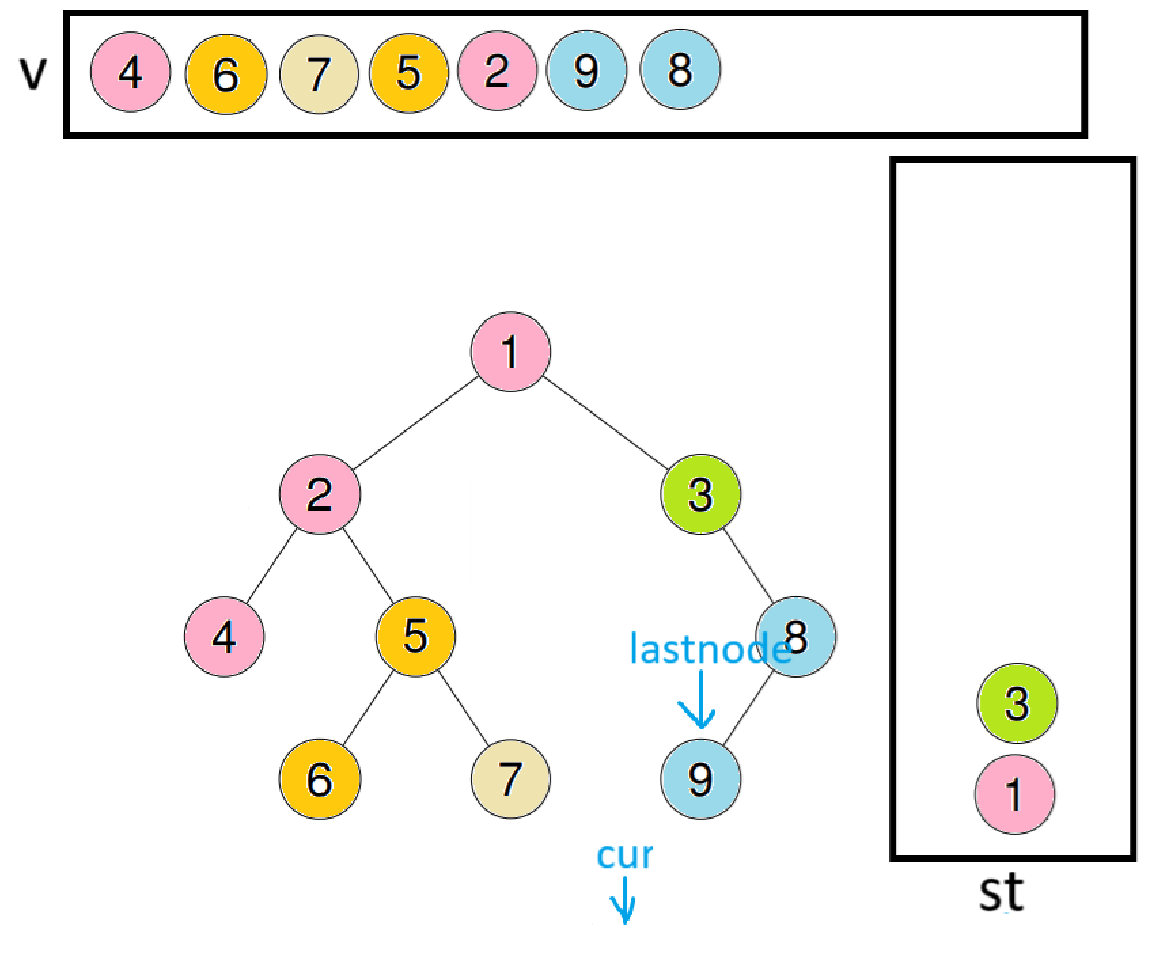
此时lastnode会指向8,取出栈顶数据3,因为3的右节点就是lastnode,代表右子树已访问完毕,所以出栈并尾插进数组
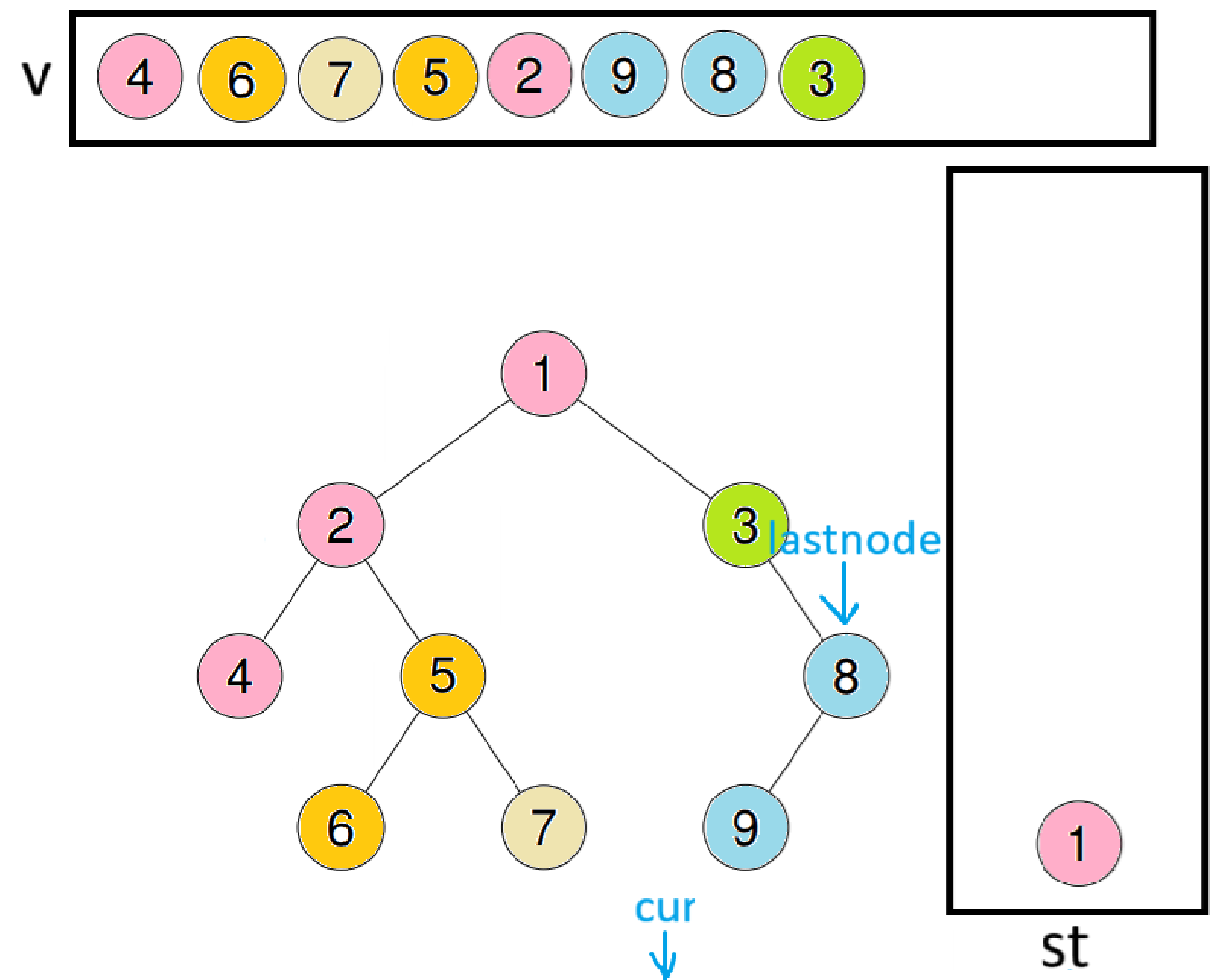
此时lastnode会指向3,再取出栈顶数据1,此时因为1的右节点就是lastnode,代表右子树访问完毕,所以出栈并尾插进数组
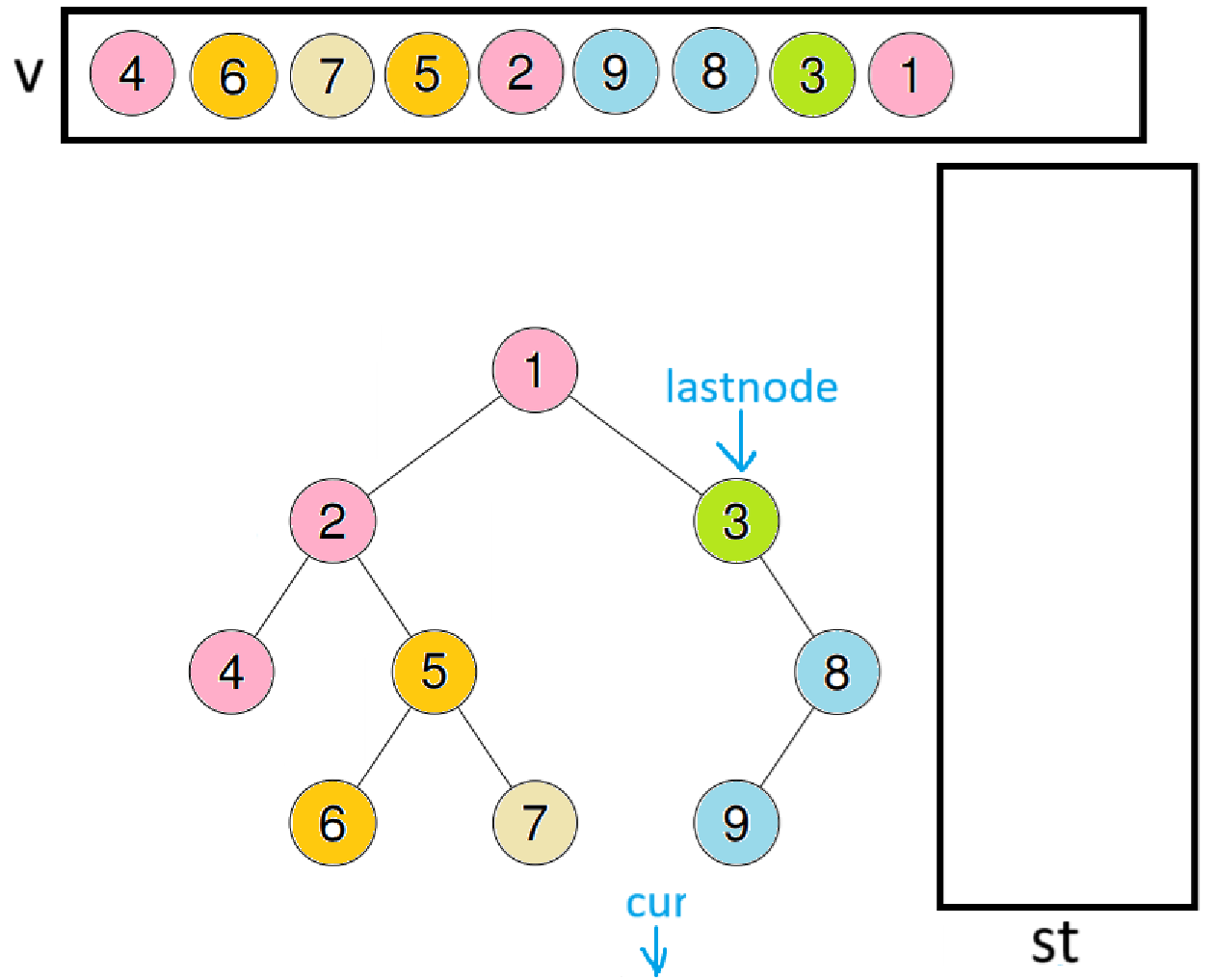
此时因为栈为空,代表遍历完毕。
代码实现:
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;stack<TreeNode*> st;//用栈模拟递归栈帧TreeNode* cur = root;TreeNode* lastnode = nullptr;//定义一个指向上一个尾插节点的指针while(cur || !st.empty()){while(cur)//入栈左路节点{st.push(cur);cur = cur->left;}if(st.top()->right == lastnode || st.top()->right == nullptr)//如果栈顶的右节点等于lastnode或空,就代表右子树访问完毕,可以将当前根节点尾插进数组{ v.push_back(st.top()->val);lastnode = st.top();//更新lastnodest.pop();}else//如果右子树还没被遍历,就先遍历右子树的左路节点{cur = st.top()->right;}}return v;}};相关文章:
)
【力扣题目分享】二叉树专题(C++)
目录 1、根据二叉树创建字符串 代码实现: 2、二叉树的层序遍历 代码实现: 变形题: 代码实现: 3、二叉树的最近公共祖先 代码实现: 4、二叉搜索树与双向链表 代码实现: 5、从前序与中序遍历序列构…...

【烧脑算法】单序列双指针:从暴力枚举到高效优化的思维跃迁
目录 相向双指针 1498. 满足条件的子序列数目 1782. 统计点对的数目 581. 最短无序连续子数组 同向双指针 2122. 还原原数组 编辑 2972. 统计移除递增子数组的数目 II 编辑 思维拓展 1920. 基于排列构建数组 442. 数组中重复的数据 448. 找到所有数组中消失的…...

如何排查服务器 CPU 温度过高的问题并解决?
服务器CPU温度过高是一个常见的问题,可能导致服务器性能下降、系统稳定性问题甚至硬件损坏。有效排查和解决服务器CPU温度过高的问题对于确保服务器正常运行和延长硬件寿命至关重要。本文将介绍如何排查服务器CPU温度过高的问题,并提供解决方法ÿ…...

YOLO篇-3.1.YOLO服务器运行
1.服务器 服务器网站:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL(这个是收费的) 2.数据集上传 进入网站,租用自己的服务器,租用好后点击jupyter。(这里需要先有一个数据集哦) 在根目录下进入datasets创建自己的工程名 在工程文件下…...

数智读书笔记系列034《最优解人生》对编程群体的理念契合
📘 书籍简介 核心观点 《Die with Zero》(中文译为《最优解人生》)由美国对冲基金经理比尔柏金斯(Bill Perkins)撰写,核心理念是“财产归零”。其核心主张是: 金钱是实现体验的工具:金钱本身无意义,其价值在于转化为有意义的体验,如旅行、学习、家庭时光或慈善活动…...

深度学习相比传统机器学习的优势
深度学习相比传统机器学习具有显著优势,主要体现在以下几个方面: 1. 特征工程的自动化 传统机器学习:依赖人工设计特征(Feature Engineering),需要领域专家从原始数据中提取关键特征(如边缘检测…...

深入探究C++11的核心特性
目录 引言 C11简介 统一的列表初始化 1. {} 初始化 2. std::initializer_list 变量类型推导 1. auto 2. decltype 3. nullptr 右值引用和移动语义 1. 左值引用和右值引用 2. 左值引用与右值引用比较 3. 右值引用使用场景和意义 移动赋值与右值引用的深入应用 1. 移…...

nltk-英文句子分词+词干化
一、准备工作 ①安装好nltk模块并在: nltk/nltk_data: NLTK Data 链接中手动下载模型并放入到对应文件夹下。 具体放到哪个文件夹,先执行看报错后的提示即可。 ②准备pos_map.json文件,放置到当前文件夹下。该文件用于词性统一 {"…...
 : Tuning Efforts)
系统性能分析基本概念(3) : Tuning Efforts
系统性能调优(Tuning Efforts)是指通过优化硬件、软件或系统配置来提升性能,减少延迟、提高吞吐量或优化资源利用率。以下是系统性能调优的主要努力方向,涵盖硬件、操作系统、应用程序和网络等多个层面,结合实际应用场…...

部署TOMEXAM
前提:机器上有MySQL,nginx,jdk,tomcat 1.配置MySQL [rootjava-tomcat1 ~]# mysql -u root -pLiuliu!123 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. C…...

Nginx 1.25.4交叉编译问题:编译器路径与aclocal.m4错误解决方案
Nginx 1.25.4交叉编译问题:编译器路径与aclocal.m4错误解决方案 一、问题描述 在对Nginx 1.25.4进行交叉编译时,遇到以下复合问题: 编译器路径失效:尽管在脚本中配置了交叉编译器(如CCaarch64-himix100-linux-gcc&a…...

FPGA通信之VGA
文章目录 基本概念:水平扫描:垂直扫描: 时序如下:端口设计疑问为什么需要输出那么多端口不输出时钟怎么保证电子枪移动速度符合时序VGA转HDMI 仿真电路图代码总结:野火电子yyds 为了做图像处理, 现在我们开…...

[Git] 认识 Git 的三大区域 文件的修改和提交
文章目录 认识 Git 的三大区域:工作区、暂存区、版本库工作区、暂存区、版本库的关系流程图解 (概念) 将文件添加到仓库进行管理:git add 和 git commit场景一:第一次添加文件到仓库查看提交历史:git log(进阶理解&…...

交叉编译DirectFB报错解决方法
configure: error: *** DirectFB compilation requires fluxcomp *** Unless you are compiling from a distributed tarball you need fluxcomp available from git://git.directfb.org/git/directfb/core/flux installed in your PATH. 需要先编译安装flux git clone http…...

AllToAll通信为什么用于EP并行?
1 AllToAll通信原理 首先要明白ALLTOALL通信是做了什么事情。 假设我们有3个进程(A、B、C),每个进程都有三段数据,分别是a1, a2, a3;b1, b2, b3;c1, c2, c3。 进程A想发送:a1到进程A自己&…...

深入掌握Node.js HTTP模块:从开始到放弃
文章目录 一、HTTP模块入门:从零搭建第一个服务器1.1 基础概念解析1.2 手把手创建服务器 二、核心功能深入解析2.1 处理不同请求类型2.2 实现文件下载功能 三、常见问题解决方案3.1 跨域问题处理3.2 防止服务崩溃3.3 调试技巧 四、安全最佳实践4.1 请求头安全设置4.…...

python安装与使用
Python的安装 1.官网下载python安装包 https://www.python.org/ 2.安装python 勾选add python 3.8 to api将python加入变量 选择Customize installation进行自定义安装 一直选next直到下面界面,根据自己需要将python安装到指定位置,然后install 等贷…...

2025最新版Visual Studio Code for Mac安装使用指南
2025最新版Visual Studio Code for Mac安装使用指南 Installation and Application Guide to The Latest Version of Visual Studio Code in 2025 By JacksonML 1. 什么是Visual Studio Code? Visual Studio Code,通常被称为 VS Code,是由…...

VSCode GitHub Copilot 安装与使用完全指南
文章目录 一、安装准备1.1 系统要求1.2 Copilot订阅选择1.3 获取访问权限 二、安装步骤2.1 安装GitHub Copilot基础扩展2.2 安装GitHub Copilot Chat扩展2.3 登录和授权 三、基本使用:代码自动完成3.1 内联代码建议3.2 自定义Copilot配置3.3 使用注释引导Copilot 四…...

Github超19k+ strar的实时协同编辑的开源框架yjs
Yjs 是一个用于实现实时协同编辑的开源框架,具有以下关键特性和应用价值: 核心特性 基于 CRDT 算法 Yjs 采用无冲突复制数据类型(CRDT),确保多用户同时编辑同一文档时无需复杂锁机制或中央协调,最终实现数据…...

【Node.js】工具链与工程化
个人主页:Guiat 归属专栏:node.js 文章目录 1. Node.js 工具链概述1.1 工具链的作用1.2 Node.js 工具链全景 2. 包管理与依赖管理2.1 npm (Node Package Manager)2.2 yarn2.3 pnpm2.4 锁文件与依赖管理2.5 工作空间与 Monorepo 3. 构建工具与打包3.1 Web…...
函数速查表)
OceanBase数据库全面指南(函数篇)函数速查表
文章目录 一、数学函数1.1 基本数学函数1.2 三角函数二、字符串函数2.1 基本字符串函数2.2 高级字符串处理函数三、日期时间函数3.1 基本日期时间函数3.2 日期时间计算函数四、聚合函数4.1 常用聚合函数4.2 分组聚合4.3 高级聚合函数五、条件判断函数5.1 基本条件函数5.2 CASE表…...

Chrome 缓存文件路径
Chrome 缓存文件路径查看方法 启动 Chrome 浏览器, 输入 Chrome://Version Google浏览器版本号以及安装路径 Windows 缓存目录 在 “运行” 中输入 %TEMP% 可打开, 一般路径是: C:\Users\Administrator\AppData\Local\Temp, 其中 Administrator 是用户名。 Windows 目录…...

Ubuntu Desktop 24.04 常用软件安装步骤
文章目录 Ubuntu Desktop 24.04 常用软件安装步骤Snipaste F1快捷截图(超方便 | 我6台电脑每台都用)搜狗输入法快速浏览工具 | 空格键快速预览文件壁纸工具 | varietySSH 工具 | Termius 终端分屏工具 | TmuxCaffeine | 避免息屏小工具 一些设置将启动台…...

Chrome 插件网络请求的全面指南
在 Chrome 插件开发中,网络请求可以在多个上下文中实现,而不仅限于 background.js 和 content.js。以下是完整的网络请求实现方案: 一、主要请求实现位置 1. Background Script (后台脚本) 特点: 生命周期最长适合处理敏感数据…...

SpringBoot Day_03
目录 一、数据校验 二、统一异常处理 1、局部异常处理(少) 2、全局异常处理(多) 三、定时器 四、springboot日志 五、swagger 六、springboot自动装配原理 总结 1、如何实现参数校验功能(掌握) …...

Ubuntu 新建用户
在 Ubuntu 22.04 中创建新用户并赋予 root 权限的步骤如下,综合多篇文档推荐的安全方法: 一、创建新用户 使用 adduser 命令创建用户 sudo adduser your_username系统会提示设置密码及填写用户信息(全名、电话等,可直接回车跳过&a…...

从法律视角看湖北理元理律师事务所的债务优化实践
债务问题解决需要专业法律支持。本文将从实务角度,解析湖北理元理律师事务所在债务优化领域的工作方法,为有需要的读者提供参考。 一、法律框架下的债务重组 利率合法性审查 识别超过法定上限的利息部分 收集相关证据材料 启动协商或诉讼程序 还款…...

# JavaSE核心知识点02面向对象编程
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点02面向对象编程JavaSE核心知…...

从原理到实践:一文详解残差网络
在深度学习的发展历程中,神经网络的深度一直是提升模型性能的关键因素之一。随着网络层数的增加,模型理论上可以学习到更复杂、更抽象的特征表示。然而,在实际训练过程中,研究人员发现,当网络深度达到一定程度后&#…...

把银河装进镜头里!动态星轨素材使用实录
仰望夜空时,神秘的银河与闪烁繁星总令人向往。如今,无需复杂拍摄,借助素材平台就能将绝美星轨融入创作,今天重点安利 制片帮素材! 动态星轨:宇宙的浪漫印记 星轨是地球自转时,星星运动留下的轨…...

C++23中std::span和std::basic_string_view可平凡复制提案解析
文章目录 一、引言二、相关概念解释2.1 平凡复制(Trivially Copyable)2.2 std::span2.3 std::basic_string_view 三、std::span和std::basic_string_view的应用场景3.1 std::span的应用场景3.2 std::basic_string_view的应用场景 四、P2251R1提案对std::…...

【KWDB 2025 创作者计划】_KWDB时序数据库特性及跨模查询
一、概述 数据库的类型多种多样,关系型数据库、时序型数据库、非关系型数据库、内存数据库、分布式数据库、图数据库等等,每种类型都有其特定的使用场景和优势,KaiwuDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库…...

树 Part 9
二叉树的建立 了解了二叉树的遍历方法,我们如何在内存中生成一棵二叉链表的二叉树呢?树都没有,哪来遍历。所以我们还得来谈谈关于二叉树建立的问题。 如果要在内存中建立一个如左图这样的树,为了能让每个结点确认是否有左右孩子…...

leetcode每日一题 -- 3362. 零数组变换 III
思路 题意是要找出[最少的区间]使nums数组变为零数组,并且使用的区间可以不连续 我的第一想法是先给区间按照左边界排序(就像区间合并题的准备工作那样)这样的可以使用最大堆,每次将右区间值最大(也就是区间范围最大)的区间应用到差分数组中但是,后续如何处理还是不太会,遂看…...

PARSCALE:大语言模型的第三种扩展范式
----->更多内容,请移步“鲁班秘笈”!!<----- 随着人工智能技术的飞速发展,大语言模型(LLM)已成为推动机器智能向通用人工智能(AGI)迈进的核心驱动力。然而,传统的…...

【 开源:跨平台网络数据传输的万能工具libcurl】
在当今这个互联互通的世界中,数据在各种设备和平台之间自由流动,而 libcurl,就像一把跨平台的万能工具,为开发者提供了处理各种网络数据传输任务所需的强大功能。它不仅是一个库,更是一种通用的解决方案,可…...

2025版 JavaScript性能优化实战指南从入门到精通
JavaScript作为现代Web应用的核心技术,其性能直接影响用户体验。本文将深入探讨JavaScript性能优化的各个方面,提供可落地的实战策略。 一、代码层面的优化 1. 减少DOM操作 DOM操作是JavaScript中最昂贵的操作之一: // 不好的做法&#x…...

RAGFlow知识检索原理解析:混合检索架构与工程实践
一、核心架构设计 RAGFlow构建了四阶段处理流水线,其检索系统采用双路召回+重排序的混合架构: S c o r e f i n a l = α ⋅ B M...

leetcode 148. Sort List
148. Sort List 题目描述 代码: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNod…...

C#学习11——集合
一、集合 是一组对象的容器,提供了高效的存储、检索和操作数据的方式。 C# 集合分为泛型集合(推荐使用)和非泛型集合,主要位于System.Collections和System.Collections.Generic命名空间中。 二、集合有哪些? 1&…...

paddlehub搭建ocr服务
搭建环境: Ubuntu20.041080Ti显卡 由于GPU硬件比较老,是Pascal架构,只能支持到paddle2.4.2版本,更高版本无法支持;同时,因为paddle老版本的依赖发生了变化,有些地方存在冲突,花费了…...

CSS3过渡
一、什么是CSS3过渡 CSS3 过渡(transitions)是一种效果,它允许你平滑地改变CSS属性的值,从一个状态过渡到另一个状态。是一种动画转换的过程,如渐现、渐弱、动画快慢等。过渡效果可以在用户与页面进行交互时触发&#…...

比斯特自动化|移动电源全自动点焊机:高效点焊助力移动电源制造
在移动电源市场蓬勃发展的当下,电池组合的点焊工艺要求愈发严格。移动电源全自动点焊机应运而生,成为提升生产效率与产品质量的关键设备。 工作原理与结构组成 移动电源全自动点焊机通过瞬间放电产生高温,使电池极耳与镍带等材料在极短时间…...

游戏引擎学习第305天:在平台层中使用内存 Arena 的方法与思路
回顾前一天内容,并为今天的开发工作设定方向 我们正在直播制作完整游戏,当前正在实现一个精灵图(sprite graph)的排序系统。排序的代码已经写完,过程并不复杂,虽然还没做太多优化,但总体思路比…...

[Java][Leetcode middle] 6. Z 字形变换
法一,自己想的 使用一个复合结构的 List<ArrayList<String>> 来存储每一行的字母,最后按序输出。 使用flag来判断到底放到哪一行上去。flag按照:0–1–2–1–0–1–2这样变化,实现躺着的Z字形。 public String conve…...

零基础设计模式——第二部分:创建型模式 - 原型模式
第二部分:创建型模式 - 5. 原型模式 (Prototype Pattern) 我们已经探讨了单例、工厂方法、抽象工厂和生成器模式。现在,我们来看创建型模式的最后一个主要成员——原型模式。这种模式关注的是通过复制现有对象来创建新对象,而不是通过传统的…...

完整改进RIME算法,基于修正多项式微分学习算子Rime-ice增长优化器,完整MATLAB代码获取
1 简介 为了有效地利用雾状冰生长的物理现象,最近开发了一种优化算法——雾状优化算法(RIME)。它模拟硬雾状和软雾状过程,构建硬雾状穿刺和软雾状搜索机制。在本研究中,引入了一种增强版本,称为修改的RIME…...
1/3】)
【1——Android端添加隐私协议(unity)1/3】
前言:这篇仅对于unity 发布Android端上架国内应用商店添加隐私协议,隐私协议是很重要的东西,没有这个东西,是不上了应用商店的。 对于仅仅添加隐私协议,我知道有三种方式,第一种和第二种基本一样 1.直接在unity里面新…...
)
笔记本6GB本地可跑的图生视频项目(FramePack)
文章目录 (一)简介(二)本地执行(2.1)下载(2.2)更新(2.3)运行(2.4)生成 (三)注意(3.1)效…...