【KWDB 2025 创作者计划】_KWDB时序数据库特性及跨模查询
一、概述
数据库的类型多种多样,关系型数据库、时序型数据库、非关系型数据库、内存数据库、分布式数据库、图数据库等等,每种类型都有其特定的使用场景和优势,KaiwuDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品,支持同一实例同时建立时序库和关系库并融合处理多模数据,具备时序数据高效处理能力,kwdb支持关系数据库和时序数据库之间跨模检索相关的数据。
什么是时序数据库?
时序数据库(Time Series Database, TSDB)是专门针对时间序列数据(按时间顺序记录的数据点)进行存储和管理的数据库。这类数据通常包含时间戳(Timestamp)和对应的数值,例如传感器读数、服务器监控指标、金融交易记录等。时序数据库的核心特点是高效处理时间范围内的聚合查询、高频数据写入和时间窗口分析。
我们通过与关系型数据库的对比来详细了解时序数据库
关系数据库:采用表格形式存储数据,每个表格由行和列组成,行代表记录,列代表字段。数据之间的关系通过外键和表连接来维护,在复杂查询、多表关联查询和事务处理方面表现出色。然而,在处理大规模时间序列数据时,查询性能可能会下降。适用于需要复杂查询、事务处理和数据一致性的应用场景,如企业资源规划(ERP)、客户关系管理(CRM)等。
时序数据库:专为时间序列数据设计,数据通常按照时间戳排序存储。时序数据库支持高效的时间范围查询、聚合和插值等操作。针对时间序列数据的查询进行了优化,能够高效地处理时间范围查询、数据聚合和降采样等操作。适用于需要实时监控、数据分析和预测的应用场景,如物联网(IoT)、金融交易、能源管理等。
二、KWDB时序数据库特性使用
KWDB 时序数据库支持在创建数据库的时候设置数据库的生命周期和分区时间范围,我们创建数据库到创建表来完整体验时序特性
1、kwdb时序数据库特性使用
1)时序数据库创建
同一数据库实例可以创建一个或多个时序库,时序库只包含时序表,同理时序表也智能创建在时序库。
CREATE TS DATABASE <db_name> [RETENTIONS <keep_duration>] [PARTITION INTERVAL <interval>];
参数说明
| 参数 | 说明 |
|---|---|
db_name | 待创建的数据库的名称。该名称必须唯一,且遵循数据库标识符规则。目前,数据库名称不支持中文字符,最大长度不能超过 63 个字节。 |
keep_duration | 可选参数。指定数据库的生命周期,默认值为 0d,即不会过期删除。支持配置的时间单位包括:秒(S 或 SECOND)、分钟(M 或 MINUTE)、小时(H 或 HOUR)、天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR),例如 RETENTIONS 10 DAY。取值必须是整数值,最大值不得超过 1000 年。 |
interval | 可选参数,指定数据库数据目录分区的时间范围。默认值为 10d,即每 10 天进行一次分区。支持配置的时间单位包括:天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR)。取值必须是整数值,最大值不得超过 1000 年 |
示例
创建一个普通的时序数据库
CREATE TS DATABASE banjin_tsdb;
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb;
CREATE TS DATABASE
Time: 3.406977ms
创建一个带生命周期时序数据库
CREATE TS DATABASE banjin_tsdb_life RETENTIONS 4w; -----生命周期4周
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb_life RETENTIONS 4w;
CREATE TS DATABASE
Time: 4.492758ms
创建一个一个带生命周期并且分区的时序数据库
CREATE TS DATABASE banjin_tsdb_par RETENTIONS 4w PARTITION INTERVAL 1w;-----生命周期为4周与分区间隔为1周
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb_par RETENTIONS 4w PARTITION INTERVAL 1w;
CREATE TS DATABASE
Time: 3.662981ms
2)查询数据库
#查看已创建的数据库
SHOW DATABASES;
#查看数据库的详细信息和创建
SHOW CREATE DATABASE <database_name>;
show create database banjin_tsdb_life;
#查看数据库中的表
SHOW TABLES FROM<database_name>;
##TIME SERIES 为时序库
##RELATIONAL 为关系库
root@192.168.150.135:26257/rdb> SHOW DATABASES;
database_name | engine_type
-------------------+--------------
banjin_tsdb | TIME SERIES
banjin_tsdb_life | TIME SERIES
banjin_tsdb_par | TIME SERIES
defaultdb | RELATIONAL
postgres | RELATIONAL
rdb | RELATIONAL
system | RELATIONAL
tsdb | TIME SERIES
(8 rows)
Time: 2.407129ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_life; ----带生命周期
database_name | create_statement
-------------------+--------------------------------------
banjin_tsdb_life | CREATE TS DATABASE banjin_tsdb_life
| retentions 2419200s
| partition interval 10d
(1 row)
Time: 1.211434ms
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_par; ----带生命周期和分区
database_name | create_statement
------------------+-------------------------------------
banjin_tsdb_par | CREATE TS DATABASE banjin_tsdb_par
| retentions 2419200s
| partition interval 7d ---在此我们可以看到周其实也是转换为d(天)
(1 row)
Time: 1.195576ms
在此我们刚好验证到了:创建数据库时,如果指定 retentions 和 partition interval 参数的取值,则显示指定的取值。如未指定,则显示该参数的默认值。默认情况下,retentions 参数的取值为 0s,partition interval 参数的取值为 10d。
3)数据库的修改
数据库修改支持修改数据库名称、修改数据生命周期或分区时间范围
#修改名称
ALTER DATABASE <old_name> RENAME TO <new_name>;
#修改数据生命周期或分区时间范围
ALTER TS DATABASE <db_name> SET [RETENTIONS = <keep_duration> | PARTITION INTERVAL = <interval> ];
参数介绍:
| 参数 | 说明 |
|---|---|
old_name | 当前数据库的名称。 |
new_name | 拟修改的数据库名称,新数据库名称必须唯一,并且遵循数据库标识符规则。目前,数据库名称不支持中文字符,最大长度不能超过 63 个字节。 |
db_name | 待修改的数据库名称。 |
keep_duration | 数据库的生命周期,默认值为 0d,即不会过期删除。支持配置的时间单位包括:秒(S 或 SECOND)、分钟(M 或 MINUTE)、小时(H 或 HOUR)、天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR),例如 RETENTIONS 10 DAY。取值必须是整数值,最大值不得超过 1000 年。 |
interval | 可选参数,指定数据库数据目录分区的时间范围。默认值为 10d,即每 10 天进行一次分区。支持配置的时间单位包括:天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR)。取值必须是整数值,最大值不得超过 1000 年 |
ALTERroot@192.168.150.135:26257/rdb> ALTER DATABASE banjin_tsdb RENAME TO banjin_tsdb_re; ----修改名称
RENAME DATABASE
Time: 3.381247ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> ALTER TS DATABASE banjin_tsdb_par SET RETENTIONS = 10 day; ---修改生命周期
ALTER TS DATABASE
Time: 2.554524ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> ALTER TS DATABASE banjin_tsdb_par SET PARTITION INTERVAL = 2 day; ---修改分区时间范围
ALTER TS DATABASE
Time: 2.169787ms
root@192.168.150.135:26257/rdb> SHOW DATABASES;
database_name | engine_type
-------------------+--------------
banjin_tsdb_life | TIME SERIES
banjin_tsdb_par | TIME SERIES
banjin_tsdb_re | TIME SERIES
defaultdb | RELATIONAL
postgres | RELATIONAL
rdb | RELATIONAL
system | RELATIONAL
tsdb | TIME SERIES
(8 rows)
Time: 1.461412ms
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_par;
database_name | create_statement
------------------+-------------------------------------
banjin_tsdb_par | CREATE TS DATABASE banjin_tsdb_par
| retentions 864000s
| partition interval 2d
(1 row)
Time: 1.216081ms DATABASE banjin_tsdb RENAME TO banjin_tsdb_re;
4)删除数据库
DROP DATABASE [IF EXISTS] <db_name> [CASCADE];
#删除数据库
DROP DATABASE banjin_tsdb_re;
#在有数据库对象是可以级联删除
DROP DATABASE banjin_tsdb_re CASCADE;
root@192.168.150.135:26257/rdb> DROP DATABASE tsdb;
ERROR: rejected: DROP DATABASE on non-empty database without explicit CASCADE (sql_safe_updates = true)
SQLSTATE: 01000
root@192.168.150.135:26257/rdb> DROP DATABASE tsdb cascade;
DROP DATABASE
Time: 49.574938ms
2、时序表的使用
了解完时序库,接着了解时序表,当然时序表就是同时序库是配套的
1)时序表创建
#语法格式
CREATE TABLE <table_name> (<column_list>)
[TAGS|ATTRIBUTES] (<tag_list>)
PRIMARY [TAGS|ATTRIBUTES] (<primary_tag_list>)
[RETENTIONS <keep_duration>]
[ACTIVETIME <active_duration>]
[PARTITION INTERVAL <interval>]
[DICT ENCODING];CREATE TABLE meter_data (
ts TIMESTAMPTZ(3) NOT NULL, -----第一列,数据类型必须是 TIMESTAMPTZ 或 TIMESTAMP 且非空,用于记录数据采集的时间。
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )-----用于记录采集对象的静态数据。PRIMARY TAGS(meter_id) -----主标签用于区分不同的实体。每张表需要指定至少一个主标签,主标签需要在建表时指定,且后续不允许修改或删除主表签。
retentions 30d -----可选参数,指定表的生命周期。超过设置的生命周期后,系统自动从数据库中清除目标表中数据。默认值为0d,即不会过期删除。
activetime 20d -----可选参数,指定数据的活跃时间。超过设置的时间后,系统自动压缩表数据。
partition interval 10d -----可选参数,指定表数据目录分区的时间范围。默认值为10d。dict encoding;---可选参数,启用字符串的字典编码功能,提升字符串数据的压缩能力,且只能在建表时开启。开启后不支持禁用。
参数详细介绍
| 参数 | 说明 |
|---|---|
table_name | 待创建的时序表的名称,表名的最大长度为 128 字节。在指定数据库中,时序表名称必须唯一,并且遵循数据库标识符规则。 |
column_list | 待创建的数据列列表,支持添加两个以上的列定义,最多可指定 4096 列。列定义包括列名、数据类型和默认值。 列名的最大长度为 128 字节,支持指定 NOT NULL,默认为空值。支持自定义第一列的列名,但数据类型必须是 TIMESTAMPTZ 或 TIMESTAMP 且非空。默认时区为 UTC。 对于非时间类型的数据列,默认值只能是常量。对于时间类型的列(TIMESTAMPTZ 或 TIMESTAMP),默认值可以是常量,也可以是 now() 函数。如果默认值类型与列类型不匹配,设置默认值时,系统报错。支持默认值设置为 NULL。时间戳列支持设置时间精度。目前,KWDB 支持毫秒、微秒和纳秒的时间精度。默认情况下,KWDB 采用毫秒时间精度。 |
tag_list | 标签列表,支持添加一个或多个标签定义,最多可指定 128 个标签。标签定义包含标签名和数据类型,标签名的最大长度为 128 字节,支持指定 NOT NULL,默认为空值。不支持 TIMESTAMP、TIMESTAMPTZ、NVARCHAR 和 GEOMETRY 数据类型。 |
primary_tag_list | 主标签列表,支持添加一个或多个主标签名称,最多可指定 4 个。主标签必须包含在标签列表内且指定为 NOT NULL,不支持浮点类型和除 VARCHAR 之外的变长数据类型。VARCHAR 类型长度默认 64 字节,最大长度为 128 字节。 |
keep_duration | 可选参数,指定表的生命周期。超过设置的生命周期后,系统自动从数据库中清除目标表中数据。默认值为 0d,即不会过期删除。支持配置的时间单位包括:秒(S 或 SECOND)、分钟(M 或 MINUTE)、小时(H 或 HOUR)、天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR)。取值必须是整数值,最大值不得超过 1000 年。说明 - 当用户单独指定或者修改数据库内某一时序表的生命周期或分区时间范围时,该配置只适用于该时序表。 - 生命周期的配置不适用于当前分区。当生命周期的取值小于分区时间范围的取值时,即使表的生命周期已到期,由于数据存储在当前分区中,用户仍然可以查询数据。 - 当时间分区的所有数据超过生命周期时间点( now() - retention time)时,系统尝试删除该分区的数据。如果此时用户正在读写该分区的数据,或者系统正在对该分区进行压缩或统计信息处理等操作,系统无法立即删除该分区的数据。系统会在下一次生命周期调度时再次尝试删除数据(默认情况下,每小时调度一次)。- 生命周期和分区时间范围设置与系统的存储空间密切相关。生命周期越长,分区时间范围越大,系统所需的存储空间也越大。有关存储空间的计算公式,参见预估磁盘使用量。 |
active_duration | 可选参数,指定数据的活跃时间。超过设置的时间后,系统自动压缩表数据。默认值为 1d,表示系统对表数据中 1 天前的分区进行压缩。支持配置的时间单位包括:秒(S 或 SECOND)、分钟(M 或 MINUTE)、小时(H 或 HOUR)、天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR)。默认时间单位为天(D 或 DAY)。取值必须是整数值,最大值不得超过 1000 年。如果设置为 0,表示不压缩表数据。 |
interval | 可选参数,指定表数据目录分区的时间范围。默认值为 10d,即每 10 天进行一次分区。支持配置的时间单位包括:天(D 或 DAY)、周(W 或 WEEK)、月(MON 或 MONTH)、年(Y 或 YEAR)。取值必须是整数值,最大值不得超过 1000 年。 |
DICT ENCODING | 可选参数,启用字符串的字典编码功能,提升字符串数据的压缩能力。表中存储的字符串数据重复率越高,压缩优化效果越明显。该功能只适用于 CHAR 和 VARCHAR 长度小于等于 1023 的字符串,且只能在建表时开启。开启后不支持禁用 |
示例
#创建一个时序表
CREATE TABLE meter_data1 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id);#创建一个生命周期30d和分区时间范围10的时序表
CREATE TABLE meter_data2 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id)
retentions 30d
partition interval 10d;#创建一个活跃时间为20的时序表
CREATE TABLE meter_data3 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id)
activetime 20d
dict encoding;
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data1;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data1 | CREATE TABLE meter_data1 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 864000s
| activetime 1d
| partition interval 2d
(1 row)
Time: 145.235397ms
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data2;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data2 | CREATE TABLE meter_data2 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 30d
| activetime 1d
| partition interval 10d
(1 row)
Time: 125.359513ms
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data3;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data3 | CREATE TABLE meter_data3 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 864000s
| activetime 20d DICT ENCODING
| partition interval 2d
(1 row)
Time: 127.519057ms
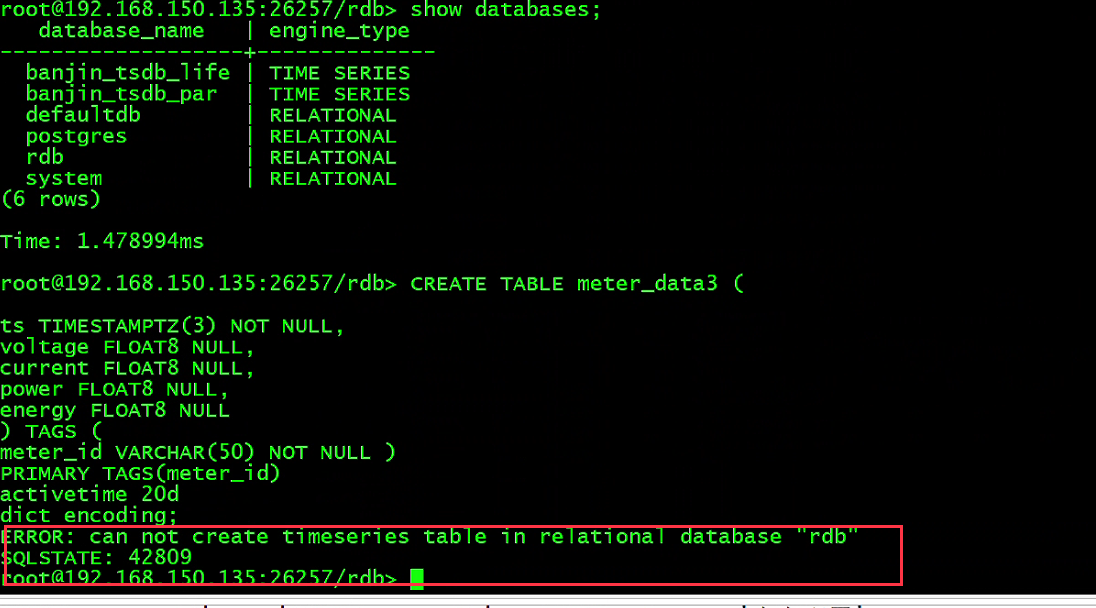
时序表必须创建在时序库里,当在关系库创建时序表时报错如下
2)时序表修改
语法格式:
ALTER TABLE <table_name>
[ADD [COLUMN] [IF NOT EXISTS] <colunm_name> <data_type> [DEFAULT <expr> | NULL ]
|ADD [TAG | ATTRIBUTE] <tag_name> <tag_type>
|ALTER [COLUMN] <colunm_name> [SET DATA] TYPE <new_type> [SET DEFAULT <default_expr> | DROP DEFAULT ]
|ALTER [TAG | ATTRIBUTE] <tag_name> [SET DATA] TYPE <new_type>
|DROP [COLUMN] [IF EXISTS] <colunm_name>
|DROP [TAG | ATTRIBUTE] <tag_name>
|RENAME TO <new_table_name>
|RENAME COLUMN <old_name> TO <new_name>
|RENAME [TAG | ATTRIBUTE] <old_name> TO <new_name>
|SET [RETENTIONS = <keep_duration> | ACTIVETIME = <active_duration> | PARITITION INTERVAL = <interval>]];
一些时序表特有示例
更多修改用例可参考官网:https://www.kaiwudb.com/kaiwudb_docs/#/oss_v2.2.0/db-administration/db-object-mgmt/ts-db/table-mgmt-ts.html
-- 修改表的生命周期。
ALTER TABLE ts_table SET RETENTIONS = 20d;
-- 修改表数据的活跃时间。
ALTER TABLE ts_table SET ACTIVETIME = 20d;
-- 修改表数据目录分区的时间范围。
ALTER TABLE ts_table SET PARTITION INTERVAL = 2d;
-- 新增标签。
ALTER TABLE ts_table ADD TAG color VARCHAR(30);
-- 删除标签。
ALTER TABLE ts_table DROP TAG color;
-- 修改标签名。
ALTER TABLE ts_table RENAME TAG site TO location;
-- 修改标签的宽度。
ALTER TABLE ts_table ALTER color TYPE VARCHAR(50);
3)时序表查询
#查看当前数据库下所有表
SHOW TABLES;
#查看特定数据库下的所有表
SHOW TABLES FROM tablename;
#查看表的详细介绍及创建语句
SHOW CREATE TABLE tablename;
SHOW CREATE TABLE database.tablename;
root@192.168.150.135:26257/banjin_tsdb_par> show tables;
table_name | table_type
--------------+--------------------
meter_data1 | TIME SERIES TABLE
meter_data2 | TIME SERIES TABLE
meter_data3 | TIME SERIES TABLE
(3 rows)
Time: 2.194141ms
root@192.168.150.135:26257/banjin_tsdb_par> show create meter_data2;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data2 | CREATE TABLE meter_data2 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 30d
| activetime 1d
| partition interval 10d
(1 row)
Time: 128.253929ms
三、KWDB的跨模查询
跨模查询是一种用于在不同类型数据库之间检索相关联数据的查询技术。它允许用户在例如关系数据库和时序数据库等不同类型的数据库系统间,查找和获取相关的数据。
可以使用SampleDB来直接体验跨模查询,SampleDB 是一个用于展示示例数据与场景的项目。其核心目标是助力用户快速掌握 KWDB 数据库的使用方法,为用户提供便捷的测试与学习环境,SampleDB数据库模型是一个智能电表项目,包含关系库rdb和时序库tsdb,提供了关系表和时序表的表结构及数据,还提供了很多用例
下载地址:登录 - Gitee.com
官网地址:smart-meter/scenario.md · KWDB/SampleDB - Gitee.com
下载后上传服务器解压
mkdir cd /var/lib/kaiwudb/extern
#上传rdb.tar.gz,tsdb.tar.gz到此目录
cd /var/lib/kaiwudb/extern
tar xvf rdb.tar.gz
tar xvf tsdb.tar.gz
导入关系库 rdb 数据
import database csv data ("nodelocal://1/rdb");
#登录
kwbase sql --certs-dir=/etc/kaiwudb/certs --host=192.168.150.135
#导入
import database csv data ("nodelocal://1/rdb");
root@192.168.150.135:26257/defaultdb> import database csv data ("nodelocal://1/rdb");
job_id | status | fraction_completed | rows | abandon_rows | reject_rows | note
----------------------+-----------+--------------------+------+--------------+-------------+-------
1073655494850838529 | succeeded | 1 | 305 | 0 | 0 | None
(1 row)
Time: 157.913643ms#验证 --切换rdb数据库登录
root@192.168.150.135:26257/defaultdb> use rdb;
SET
Time: 403.717µsroot@192.168.150.135:26257/rdb> show tables;
table_name | table_type
--------------+-------------
alarm_rules | BASE TABLE
area_info | BASE TABLE
meter_info | BASE TABLE
user_info | BASE TABLE
(4 rows)
导入时序库 tsdb 数据
import database csv data ("nodelocal://1/tsdb");
#导入
root@192.168.150.135:26257/rdb> import database csv data ("nodelocal://1/tsdb");
job_id | status | fraction_completed | rows | abandon_rows | reject_rows | note
---------+-----------+--------------------+-------+--------------+-------------+-------
- | succeeded | 1 | 10100 | 0 | 0 | None
(1 row)
Time: 526.048817msroot@192.168.150.135:26257/rdb> \q
#切换tsdb数据库
root@192.168.150.135:26257/defaultdb> use rdb;
SET
Time: 403.717µsroot@192.168.150.135:26257/tsdb> show tables;
table_name | table_type
-------------+--------------------
meter_data | TIME SERIES TABLE
(1 row)
Time: 1.576363ms
场景实例
告警检测查询
SELECT md.meter_id,md.ts,ar.rule_name,md.voltage,md.current,md.power FROM tsdb.meter_data md --时序表 JOIN rdb.alarm_rules ar ON 1=1 --关系表 WHERE (ar.metric = 'voltage' AND ((ar.operator = '>' AND md.voltage < ar.threshold) OR (ar.operator = '<' AND md.voltage > ar.threshold)))OR (ar.metric = 'current' AND md.current > ar.threshold)OR (ar.metric = 'power' AND md.power > ar.threshold) ORDER BY md.ts DESC LIMIT 100;
root@192.168.150.135:26257/banjin_tsdb_par> SELECT
-> md.meter_id,
-> md.ts,
-> ar.rule_name,
-> md.voltage,
-> md.current,
-> md.power
-> FROM tsdb.meter_data md
-> JOIN rdb.alarm_rules ar ON 1=1
-> WHERE (ar.metric = 'voltage'
-> AND ((ar.operator = '>' AND md.voltage < ar.threshold)
-> OR (ar.operator = '<' AND md.voltage > ar.threshold)))
-> OR (ar.metric = 'current' AND md.current > ar.threshold)
-> OR (ar.metric = 'power' AND md.power > ar.threshold)
-> ORDER BY md.ts DESC
-> LIMIT 100;
meter_id | ts | rule_name | voltage | current | power
-----------+-------------------------------+-----------+---------+---------+--------
M2 | 2025-04-08 08:47:24.22+00:00 | 高压告警 | 221 | 5.1 | 1050
M2 | 2025-04-08 08:47:24.22+00:00 | 低压告警 | 221 | 5.1 | 1050
M2 | 2025-04-08 08:42:35.898+00:00 | 高压告警 | 221 | 5.1 | 1050
.........
M26 | 2025-04-08 04:47:24.22+00:00 | 低压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:47:24.22+00:00 | 高压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:42:35.898+00:00 | 低压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:42:35.898+00:00 | 高压告警 | 225 | 6 | 1250
(100 rows)
Time: 107.937794ms
区域用电量top10
SELECT a.area_name,SUM(md.energy) AS total_energy FROM tsdb.meter_data md --时序表 JOIN rdb.meter_info mi ON md.meter_id = mi.meter_id --关系表 JOIN rdb.area_info a ON mi.area_id = a.area_id GROUP BY a.area_name ORDER BY total_energy DESC LIMIT 10;
root@192.168.150.135:26257/tsdb> SELECT
-> a.area_name,
-> SUM(md.energy) AS total_energy
-> FROM tsdb.meter_data md
-> JOIN rdb.meter_info mi ON md.meter_id = mi.meter_id
-> JOIN rdb.area_info a ON mi.area_id = a.area_id
-> GROUP BY a.area_name
-> ORDER BY total_energy DESC
-> LIMIT 10;
area_name | total_energy
------------+---------------
Area 2 | 5.556e+06
Area 1 | 5.55499e+06
Area 100 | 5.55398e+06
Area 99 | 5.55297e+06
Area 98 | 5.55196e+06
Area 97 | 5.55095e+06
Area 96 | 5.54994e+06
Area 95 | 5.54893e+06
Area 94 | 5.54792e+06
Area 93 | 5.54691e+06
(10 rows)
Time: 21.137013ms
KWDB 跨模查询支持的详细项:
KWDB 跨模查询支持以下关联查询:
- 内连接(INNER JOIN)
- 左连接(LEFT JOIN)
- 右连接(RIGHT JOIN)
- 全连接(FULL JOIN)
KWDB 跨模查询支持以下嵌套查询:
- 相关子查询(Correlated Subquery):内部查询依赖于外部查询的结果,每次外部查询的都触发内部查询的执行。
- 非相关子查询(Non-Correlated Subquery):内部查询独立于外部查询,只执行一次内部查询并返回固定的结果。
- 相关投影子查询(Correlated Scalar Subquery): 内部查询依赖于外部查询的结果,并且只返回一个单一的值作为外部查询的结果。
- 非相关投影子查询(Non-Correlated Scalar Subquery):内部查询独立于外部查询,并且只返回一个单一的值作为外部查询的结果。
FROM子查询:将一个完整的 SQL 查询嵌套在另一个查询的FROM子句中,作为临时表格使用。
KWDB 跨模查询支持以下联合查询:
- UNION:合并多个查询结果集,并去除重复行。
- UNION ALL:合并多个查询结果集,但不去除重复行。
- INTERSECT:返回两个查询结果集中都存在的所有行,去除重复行。
- INTERSECT ALL:返回两个查询结果集中都存在的所有行,但不去除重复行。
- EXCEPT:返回第一个查询结果集中不包含在第二个结果集中的行,去除重复行。
- EXCEPT ALL:返回第一个查询结果集中不包含在第二个结果集中的行,不去除重复行。
四、时序特性的注意事项
1、当一个时序数据库指定了生命周期或分区时间范围时,单独指定或者修改数据库内某一时序表的生命周期或分区时间范围时,该配置只适用于该时序表。所以在如果表生命周期或分区时间范围在使用时如果不符合设定,要检查表的生命周期或分区时间范围是否单独设置了
2、生命周期的配置不适用于当前分区(指定表数据目录分区的时间范围的表分区)。当生命周期的取值小于分区时间范围的取值时,即使数据库的生命周期已到期,由于数据存储在当前分区中,用户仍然可以查询数据。当时间分区的所有数据超过生命周期时间点(now() - retention time)时,系统尝试删除该分区的数据。如果此时用户正在读写该分区的数据,或者系统正在对该分区进行压缩或统计信息处理等操作,系统无法立即删除该分区的数据。系统会在下一次生命周期调度时再次尝试删除数据(默认情况下,每小时调度一次)。
3、数据库生命周期和分区时间范围的设置与系统的存储空间密切相关。生命周期越长,分区时间范围越大,系统所需的存储空间也越大。
相关文章:

【KWDB 2025 创作者计划】_KWDB时序数据库特性及跨模查询
一、概述 数据库的类型多种多样,关系型数据库、时序型数据库、非关系型数据库、内存数据库、分布式数据库、图数据库等等,每种类型都有其特定的使用场景和优势,KaiwuDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库…...

树 Part 9
二叉树的建立 了解了二叉树的遍历方法,我们如何在内存中生成一棵二叉链表的二叉树呢?树都没有,哪来遍历。所以我们还得来谈谈关于二叉树建立的问题。 如果要在内存中建立一个如左图这样的树,为了能让每个结点确认是否有左右孩子…...

leetcode每日一题 -- 3362. 零数组变换 III
思路 题意是要找出[最少的区间]使nums数组变为零数组,并且使用的区间可以不连续 我的第一想法是先给区间按照左边界排序(就像区间合并题的准备工作那样)这样的可以使用最大堆,每次将右区间值最大(也就是区间范围最大)的区间应用到差分数组中但是,后续如何处理还是不太会,遂看…...

PARSCALE:大语言模型的第三种扩展范式
----->更多内容,请移步“鲁班秘笈”!!<----- 随着人工智能技术的飞速发展,大语言模型(LLM)已成为推动机器智能向通用人工智能(AGI)迈进的核心驱动力。然而,传统的…...

【 开源:跨平台网络数据传输的万能工具libcurl】
在当今这个互联互通的世界中,数据在各种设备和平台之间自由流动,而 libcurl,就像一把跨平台的万能工具,为开发者提供了处理各种网络数据传输任务所需的强大功能。它不仅是一个库,更是一种通用的解决方案,可…...

2025版 JavaScript性能优化实战指南从入门到精通
JavaScript作为现代Web应用的核心技术,其性能直接影响用户体验。本文将深入探讨JavaScript性能优化的各个方面,提供可落地的实战策略。 一、代码层面的优化 1. 减少DOM操作 DOM操作是JavaScript中最昂贵的操作之一: // 不好的做法&#x…...

RAGFlow知识检索原理解析:混合检索架构与工程实践
一、核心架构设计 RAGFlow构建了四阶段处理流水线,其检索系统采用双路召回+重排序的混合架构: S c o r e f i n a l = α ⋅ B M...

leetcode 148. Sort List
148. Sort List 题目描述 代码: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNod…...

C#学习11——集合
一、集合 是一组对象的容器,提供了高效的存储、检索和操作数据的方式。 C# 集合分为泛型集合(推荐使用)和非泛型集合,主要位于System.Collections和System.Collections.Generic命名空间中。 二、集合有哪些? 1&…...

paddlehub搭建ocr服务
搭建环境: Ubuntu20.041080Ti显卡 由于GPU硬件比较老,是Pascal架构,只能支持到paddle2.4.2版本,更高版本无法支持;同时,因为paddle老版本的依赖发生了变化,有些地方存在冲突,花费了…...

CSS3过渡
一、什么是CSS3过渡 CSS3 过渡(transitions)是一种效果,它允许你平滑地改变CSS属性的值,从一个状态过渡到另一个状态。是一种动画转换的过程,如渐现、渐弱、动画快慢等。过渡效果可以在用户与页面进行交互时触发&#…...

比斯特自动化|移动电源全自动点焊机:高效点焊助力移动电源制造
在移动电源市场蓬勃发展的当下,电池组合的点焊工艺要求愈发严格。移动电源全自动点焊机应运而生,成为提升生产效率与产品质量的关键设备。 工作原理与结构组成 移动电源全自动点焊机通过瞬间放电产生高温,使电池极耳与镍带等材料在极短时间…...

游戏引擎学习第305天:在平台层中使用内存 Arena 的方法与思路
回顾前一天内容,并为今天的开发工作设定方向 我们正在直播制作完整游戏,当前正在实现一个精灵图(sprite graph)的排序系统。排序的代码已经写完,过程并不复杂,虽然还没做太多优化,但总体思路比…...

[Java][Leetcode middle] 6. Z 字形变换
法一,自己想的 使用一个复合结构的 List<ArrayList<String>> 来存储每一行的字母,最后按序输出。 使用flag来判断到底放到哪一行上去。flag按照:0–1–2–1–0–1–2这样变化,实现躺着的Z字形。 public String conve…...

零基础设计模式——第二部分:创建型模式 - 原型模式
第二部分:创建型模式 - 5. 原型模式 (Prototype Pattern) 我们已经探讨了单例、工厂方法、抽象工厂和生成器模式。现在,我们来看创建型模式的最后一个主要成员——原型模式。这种模式关注的是通过复制现有对象来创建新对象,而不是通过传统的…...

完整改进RIME算法,基于修正多项式微分学习算子Rime-ice增长优化器,完整MATLAB代码获取
1 简介 为了有效地利用雾状冰生长的物理现象,最近开发了一种优化算法——雾状优化算法(RIME)。它模拟硬雾状和软雾状过程,构建硬雾状穿刺和软雾状搜索机制。在本研究中,引入了一种增强版本,称为修改的RIME…...
1/3】)
【1——Android端添加隐私协议(unity)1/3】
前言:这篇仅对于unity 发布Android端上架国内应用商店添加隐私协议,隐私协议是很重要的东西,没有这个东西,是不上了应用商店的。 对于仅仅添加隐私协议,我知道有三种方式,第一种和第二种基本一样 1.直接在unity里面新…...
)
笔记本6GB本地可跑的图生视频项目(FramePack)
文章目录 (一)简介(二)本地执行(2.1)下载(2.2)更新(2.3)运行(2.4)生成 (三)注意(3.1)效…...

Android View的事件分发机制
ViewGroup的事件分发逻辑 从Activity传递给Window,再传递给ViewGroup,ViewGroup的dispatchTouchEvent()会被调用,如果onInterceptTouchEvent()返回true 转交自身onTouchEvent()处理,如果返回false继续向子View传递,子View的dispatchTouchEve…...
: f-string的进化)
Python字符串格式化(二): f-string的进化
文章目录 一、Python 3.6:重新发明字符串格式化(2016)1. 语法糖的诞生:表达式直嵌技术2. 性能与可读性的双重提升3. 奠定现代格式化的基础架构 二、Python 3.7:解锁异步编程新场景(2018)1. 异步…...

力扣HOT100之二叉树:124. 二叉树中的最大路径和
这道题是困难题,靠自己想还是挺难想的,还是去看的灵神的题解,感觉还是要多复习一下这道题。这道题的思路和之前做的543. 二叉树的直径很像,可以参考之前的这篇博客。这里我们还是用递归来做,定义一个lambda函数来实现递…...

【C++】位图+布隆过滤器
1.位图 概念 所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的或是否被标记。 1.二进制位表示 : 位图中的每一位(bit)代表一个元素的状态。通常&…...

Google Agent Development Kit与MCP初试
Google Agent Development Kit与MCP初试 一、背景知识二、搭建智能大脑 - Ollama服务器2.1 为什么要先搭建Ollama?2.2 搭建ollama服务器2.2.1 安装2.2.2 试着用curl命令"问"AI一个问题: 三、构建智能体工坊 - ADK环境3.1 创建容器3.2 安装核心…...

云原生+大数据
虚拟化: 虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提…...

基于cornerstone3D的dicom影像浏览器 第二十一章 显示DICOM TAGS
系列文章目录 第一章 下载源码 运行cornerstone3D example 第二章 修改示例crosshairs的图像源 第三章 vitevue3cornerstonejs项目创建 第四章 加载本地文件夹中的dicom文件并归档 第五章 dicom文件生成png,显示检查栏,序列栏 第六章 stack viewport 显…...

【记录】PPT|PPT打开开发工具并支持Quicker VBA运行
文章目录 打开开发者工具支持Quicker VBA运行 打开开发者工具 参考文章,微软文档:显示“开发工具”选项卡,以下直接复制,如侵私删。 适用对象:Microsoft 365 专属 Excel Microsoft 365 专属 Outlook Microsoft 365 专属…...

西门子 S1500 博途软件舞台威亚 3D 控制方案
西门子 S1500 PLC 是工业自动化领域的主流控制器,适合高精度、高可靠性的舞台威亚控制。下面为你提供基于博途 (TIA Portal) 软件的 3D 控制方案设计。 系统架构设计 舞台威亚 3D 控制系统通常包含以下组件: 硬件层: S1500 PLC 主机伺服驱动…...

第三十二天打卡
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier # 加载鸢尾花数据集 iris load_iris() df pd.DataFrame(iris.data, columnsiris.feature_names) …...

同步/异步电路;同步/异步复位
同步/异步电路;同步/异步复位 在 FPGA 设计中,同步电路、异步电路、同步复位和异步复位是基础且关键的概念,它们的特性直接影响电路的可靠性、时序性能和设计复杂度。 一、同步电路(Synchronous Circuit) 定义 同步电…...

spring boot 实现resp视频推流
1、搭建resp服务(docker方式) docker pull aler9/rtsp-simple-serverdocker run -d --restartalways \--name rtsp-server \-p 8554:8554 \aler9/rtsp-simple-server2、maven依赖 <dependency><groupId>org.bytedeco</groupId><a…...

python、R、shell兼容1
一,兼容方式 1,shell中用R、python: (1)python3、R/r(radian)进入 (2)脚本封装:命令行或者封装到sh脚本中 python xxx.py 自定义参数 Rscript xxx.r 自…...

Oracle 11G RAC重启系统异常
vmware安装centos7环境部署Oracle RAC (11.2.0.4) 部署时所有资源情况都是正常的,关机重启虚拟机后集群资源状态异常,请教CSDN大佬 – 部署规划 域名地址备注rac16192.168.31.16rac17192.168.31.17rac16vip192.168.31.26viprac17vip192.168.31.27vip…...

便捷的电脑自动关机辅助工具
软件介绍 本文介绍的软件是一款电脑上实用的倒计时和关机助手。 软件特性 这款关机助手十分贴心,它是一款无需安装的小软件,体积仅60KB,不用担心占用电脑空间,打开即可直接使用。 操作方法 你只需设置好对应的关机时间&#x…...

巧用 FFmpeg 命令行合并多个视频为一个视频文件教程
你是否曾经遇到过需要将多个视频片段合并成一个连续视频的情况?比如,你拍摄了一段旅行的精彩瞬间,想把它们合成一部短片;或者你在制作教学视频时,希望将不同的部分整合在一起。这时候,FFmpeg 就是你的得力助…...

平时使用电脑,如何去维护
在这个数字化的时代,电脑已经成为我们生活和工作中不可或缺的一部分。然而,你是否知道如何正确地维护它,让它始终保持良好的运行状态呢?今天,就让我来为大家揭晓这个谜底。定期清理电脑内部和外部的灰尘是至关重要的。…...
分类、检测与分割在不同网络中的设计体现)
(视觉)分类、检测与分割在不同网络中的设计体现
分类、检测与分割在不同网络中的设计体现 概述 在计算机视觉领域,不同的网络结构在功能和结构上差异显著,同时也共享一些基础设计元素。 卷积神经网络是基石: 卷积层通过特定的卷积核与图像进行卷积运算提取图像中的局部特征,比…...

技术分享 | MySQL大事务导致数据库卡顿
本文为墨天轮数据库管理服务团队第66期技术分享,内容原创,作者为技术顾问孙文龙,如需转载请联系小墨(VX:modb666)并注明来源。 一、现 象 业务侧反馈连接数据库异常,报错 connection is not av…...

C#在 .NET 9.0 中启用二进制序列化:配置、风险与替代方案
在 .NET 9.0 中启用二进制序列化:配置、风险与替代方案 引言一、启用二进制序列化的步骤二、实现序列化与反序列化三、安全风险与缓解措施四、推荐替代方案五、总结 引言 在 .NET 生态中,二进制序列化(Binary Serialization)曾是…...

每日Prompt:像素风格插画
提示词 像素风格插画,日式漫画脸,画面主体为一位站在路边的男孩,人物穿着黑色冲锋衣,手里拿着手机,男孩靠坐在机车旁边,脚边依偎着一只带着小摩托车头盔的小小猫,背景是雨中,身旁停…...

Rust 学习笔记:生命周期
Rust 学习笔记:生命周期 Rust 学习笔记:生命周期使用生命周期防止悬空引用借用检查器函数中的泛型生命周期生命周期注释语法函数签名中的生命周期注解从生命周期的角度思考结构定义中的生命周期注解省略生命周期方法定义中的生命周期注释静态生命周期泛型…...

科学标注法:数据治理的未来之路
在数据治理领域,科学标注法是一种系统化、标准化的数据标注方法论,其核心是通过规范化的流程、技术工具和质量控制机制,将原始数据转化为具有语义和结构特征的可用数据资源。以下从定义、技术特征、应用场景、与传统标注方法的区别以及遵循的标准框架等方面展开详细解析: 一…...

小白刷题 之 如何高效计算二进制数组中最大连续 1 的个数
前言 学习如何快速找出二进制数组中最长的连续 1 序列。 这个问题在数据处理、网络传输和算法面试中经常出现,掌握它不仅能提升编程能力,还能加深对数组操作和循环控制的理解。 🌟 问题背景 想象你是一位网络工程师,正在分析服…...

中科方德鸳鸯火锅平台使用教程:轻松运行Windows应用!
原文链接:中科方德鸳鸯火锅平台使用教程:轻松运行Windows应用! Hello,大家好啊,今天给大家带来一篇中科方德鸳鸯火锅平台使用的文章,欢迎大家分享点赞,点个在看和关注吧!在信创环境…...

完全禁用 Actuator 功能
问题描述: springboot 关闭Actuator无效,原本设置 management:endpoints:enabled-by-default: false # 禁用所有端点屏蔽了/actuator/info和/actuator/health,但/actuator还可以访问。 拉满配置如下,成功屏蔽 # application.y…...
:Netty快速入门及重要组件详解(EventLoop、Channel、ChannelPipeline))
Netty学习专栏(二):Netty快速入门及重要组件详解(EventLoop、Channel、ChannelPipeline)
文章目录 前言一、快速入门:5分钟搭建Echo服务器二、核心组件深度解析2.1 EventLoop:颠覆性的线程模型EventLoop 设计原理核心 API 详解代码实践:完整使用示例 2.2 Channel:统一的网络抽象层Channel 核心架构核心 API 详解代码实践…...

27-FreeRTOS的任务管理
一、FreeRTOS的任务概念 在FreeRTOS中,任务(Task)是操作系统调度的基本单位。每个任务都是一个无限循环的函数,它执行特定的功能。任务可以被看作是一个轻量级的线程,具有自己的堆栈和优先级。下面是如何定义一个任务函…...

upload-labs靶场通关详解:第14关
一、分析源代码 这一关的任务说明已经相当于给出了答案,就是让我们上传一个图片木马,可以理解为图片中包含了一段木马代码。 function getReailFileType($filename){$file fopen($filename, "rb");$bin fread($file, 2); //只读2字节fclose…...

supervisor的进程监控+prometheus+alertmanager实现告警
supervisor服务进程监控实现告警 前提:部署了prometheus(配置了rules文件夹),alertmanager,webhook,python3环境 [roottest supervisor_prometheus]# pwd /opt/supervisor_prometheus [roottest supervisor_prometheus]# ls supervisor_exporter.py supervisor_int…...

HarmonyOS 鸿蒙应用开发基础:父组件调用子组件方法的几种实现方案对比
在ArkUI声明式UI框架中,父组件无法直接调用子组件的方法。本文介绍几种优雅的解决方案,并作出对比分析,分析其适用于不同场景和版本需求。帮助开发者在开发中合理的选择和使用。 方案一:Watch装饰器(V1版本适用&#x…...

Enhancing Relation Extractionvia Supervised Rationale Verifcation and Feedback
Enhancing Relation Extraction via Supervised Rationale Verification and Feedback| Proceedings of the AAAI Conference on Artificial Intelligencehttps://ojs.aaai.org/index.php/AAAI/article/view/34631 1. 概述 关系抽取(RE)任务旨在抽取文本中实体之间的语义关...