一命通关单调栈

前言
我们只是卑微的后端开发。按理说,我们是不需要学这些比较进阶的算法的,可是,这个世界就是不讲道理。最开始,想法是给leetcode中等题全通关,我又不打ACM我去天天钻研hard干嘛,于是碰见单调栈树状数组的题目就pass。可是不说大厂,现在中厂也会考你hard算法你又不乐意。没办法,笔试全挂颓废了一个多星期之后,还是决定把进阶一点的算法问题更完,也当算法生涯不留遗憾了。
朴素单调栈
光头强追熊二
假如,狗熊岭有一群熊二。先别管为什么会出现这么多熊二,反正熊二太多把光头强整急眼了,光头强拿起枪追着一群熊二跑。
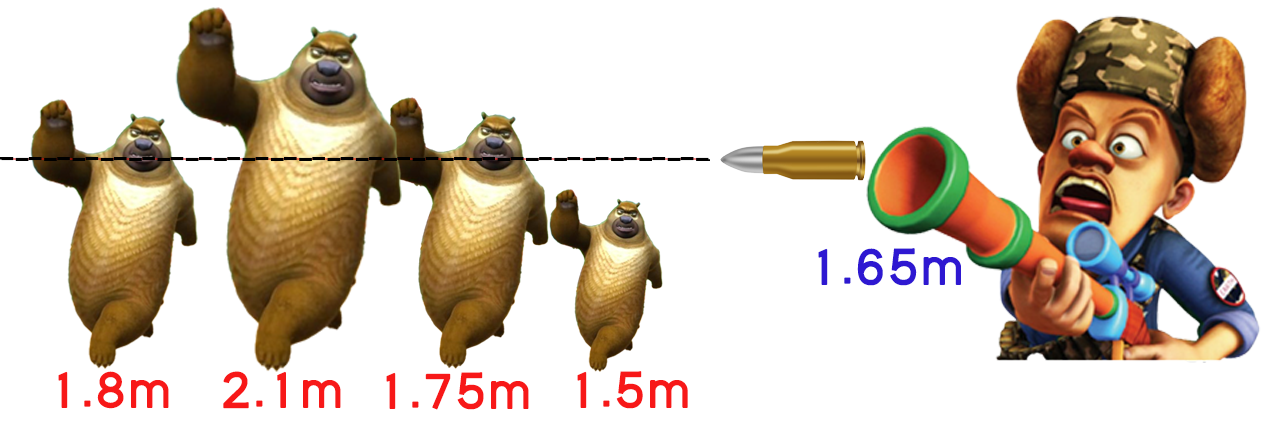
我们用一个数组来表示不同熊二的身高,数组最后一个值为枪管的高度:
vector<double> height = {1.8 , 2.1 , 1.75 , 1.5 , 1.65};假如我只开一枪,不考虑子弹很nb可以穿透,问,这一枪会打到哪一个熊二?
问题分析
-
如果熊二比枪管矮,那么这一枪肯定打不到他,直接排除。
-
如果熊二比枪管高,那么这一枪一定会打到他吗?不一定。因为如果前面有熊二给他挡枪了,那么也是打不到的。
我们要找的熊二,是第一个不会被其他熊挡枪的熊二。不会被其他熊挡枪,意思就是前面一定不会出现比枪管高的熊。所以,我们实际要找的,是枪管左边第一个比枪管高的熊。
转化成程序问题,就是找数组最后一个数(因为最后一个数是枪管高度),左边第一个大于其的数。
问题解决
相信就算是一个初学者,都可以轻易解决这个问题。我们只要从数组最后一个数开始,遍历整个数组,找到第一个大于目标值的数就可以了。
vector<double> height = {1.8 , 2.1 , 1.75 , 1.5 , 1.65};
int size = height.size();int target = -1;//-1代表一个熊也打不到for(int i = size - 1;i >= 0;i--)
{if(height[i]>height[size-1]){target = i;break;}
}光头强追光头强
现在,狗熊岭没有熊二了,可是出现了一堆光头强。每个光头强手上都有枪,假如每个光头强都是便太砂仁饭,
问,如果每个光头强都把枪举到头顶往前开一枪,那么每个光头强会打到谁?
问题分析
和上一个问题一样。因为每个光头强都把枪举过头顶了,所以我们要求的是每个光头强,左边第一个比他高的人。
我们还是用一个数组来表示他们的身高:
vector<double> height = {1.8 , 1.6 , 1.3 , 2.1 , 1.4};也就是求每个元素,左边第一个大于其的元素。
问题解决
拿到这个问题很简单:一个元素我们会求,那所有元素,嵌套一个循环不就好了!
vector<double> height = {1.8 , 2.1 , 1.75 , 1.5 , 1.65};
int size = height.size();vector<int> target(size,-1);//-1代表打不到,其他表示找到元素的下标for(int loop = 0;loop < size;loop++)
{for(int i = loop;i >= 0;i--){if(height[i]>height[loop]){target[loop] = i;break;}}
}可是,这个时间复杂度是典型的O(N^2)

有的兄弟有的。
问题优化
当我们要求某一个位置左侧第一个大于其的元素时,要遍历的是这个元素左侧的所有值:
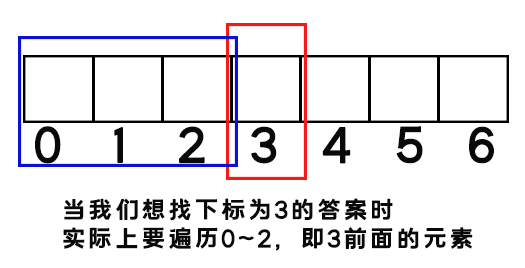
然后,对所有元素,我们是从左往右遍历过来的,即:
-
先求下标为0的答案
-
再求下标为1的答案,遍历0
-
再求下标为2的答案,遍历0~1
-
再求下标为3的答案,遍历0~2
-
...
我们可以发现,我们要遍历的元素,其实是我们已经访问过的。我们可以单开一个数组,来表示每一次需要遍历的元素:
vector<double> height = {1.8 , 2.1 , 1.75 , 1.5 , 1.65};
int size = height.size();vector<int> traverse;//每一个位置需要遍历的元素
vector<int> target(size,-1);//-1代表打不到,其他表示找到元素的下标for(int loop = 0;loop < size;loop++)
{for(int i = traverse.size()-1;i>=0;i--){if(height[traverse[i]]>height[loop]){target[loop] = traverse[i];break;}}//当遍历到这个元素时,后面的所有元素在寻找答案时都会遍历到这个元素,我们就把这个元素的位置插入到数组中traverse.push_back(loop);
}
我们来看看这个traverse数组的特点:
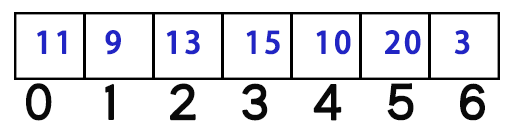
假如我们height数组长这样:
-
循环到0时,左侧没有元素,不管。然后把0插入到traverse数组中
-
循环到1时,遍历traverse数组(0~0),找到了11这个元素比当前位置9大,于是把11的下标0插入到结果数组target中。然后把1插入到traverse数组中
-
循环到2时,遍历traverse数组(0~1),没有找到比当前位置13更大的数,于是不管。然后把2插入到traverse数组中
-
循环到3时,遍历traverse数组(0~2),首先就找到了13,发现当前位置比15小。按理说,我们是应该继续往前找的,可是,我们真的需要往前找吗?我们刚刚已经知道了,13前面都没有比13更大的数了,自然13前面也没有比15更大的数。所以,遍历到13我们就可以终止了,然后得到结论——左边没有比15更大的数。
所以,我们可以得到一个优化方法:
当遍历到左边元素的最大值时,如果还没有找到答案,我们可以立即终止,然后得到结论——左边没有比他更大的元素。而这个最大值,我们可以用一个数字来表示,随时更新:
vector<double> height = {11,9,13,15,10,20,3}; int size = height.size();vector<int> traverse;//每一个位置需要遍历的元素 int leftMax = 0;//左边最大元素的位置vector<int> target(size,-1);//-1代表打不到,其他表示找到元素的下标for(int loop = 0;loop < size;loop++) {for(int i = traverse.size()-1;i>=0;i--){if(height[traverse[i]]>height[loop]){target[loop] = traverse[i];break;}if(i == leftMax)break;}//当遍历到这个元素时,后面的所有元素在寻找答案时都会遍历到这个元素,我们就把这个元素的位置插入到数组中traverse.push_back(loop);//如果当前元素比左边最大元素大,那么更新最大元素if(height[loop] >= height[leftMax])leftMax = loop; }
我们知道了一次循环的终止条件。可是,假如我们循环到了3,要遍历0~2,我们一定要从2开始,判断2,判断1,再判断0吗?我们可不可以,优化一下遍历的顺序呢?
假如我们的height数组变成了这样:
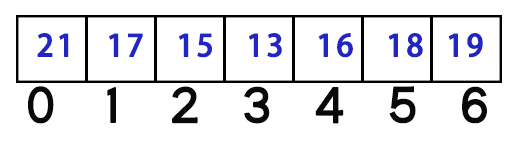
明显的先减后增。而因为左边最大元素在下标0,所以刚刚的优化等于没优化。
-
但是,当我们遍历到下标4即元素16时,我们一直往前找,找到了下标1,于是target[4] = 1;
-
我们遍历到下标5即18时,往前找找到了16,不是想要的答案。正当我们想继续往前一个一个找的时候,16叫住了我们,说道:
"我刚刚已经找过了,2~3都比我小,你不用再找2~3了。"
所以,当我们实际开始找时,找到了16,不是我们要的答案。我们探寻其下标,发现左边第一个比他大的元素是下标1,即2~3都比它小。所以2~3我们就不找了,直接跳到1开始继续往前遍历。
此时,我们又得到了另一个优化算法:
当我们往前遍历到下标i时,会有两种情况:
height[i] > height[loop],i就是我们要找的答案,target[loop] = i,循环终止
height[i] < height[loop],i不是我们要找的答案
而当i不是我们要找的答案时,又会分为两种情况:
target[i] == -1,i前面所有元素都比它小,那肯定也比height[loop]小,故前面没有答案,循环终止
target[i] == j,下标j是i前面第一个比它大的元素。那么j+1~i肯定都不会是答案,我们直接跳到下标j继续遍历
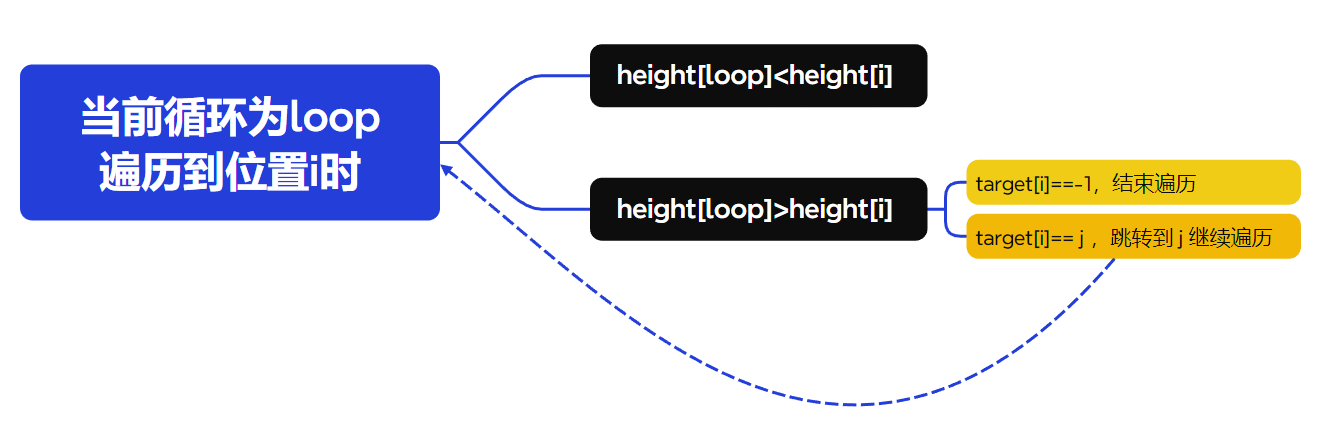
用代码表示:
vector<double> height = {11,9,13,15,10,20,3};
int size = height.size();vector<int> traverse;//每一个位置需要遍历的元素
vector<int> target(size,-1);//-1代表打不到,其他表示找到元素的下标for(int loop = 0;loop < size;loop++)
{for(int i = traverse.size()-1;i>=0;)//就不要i--了,因为他自己会一直往前跳{if(height[traverse[i]]>height[loop]){target[loop] = traverse[i];break;}else{if(target[i]==-1)break;elsei=target[i];}}//当遍历到这个元素时,后面的所有元素在寻找答案时都会遍历到这个元素,我们就把这个元素的位置插入到数组中traverse.push_back(loop);
}代码优化
因为,每当遍历到下标i时,如果是答案,遍历就终止了;如果不是答案,那么一定会跳转到下标j。此时,我们是不是可以认为,j+1~i-1这一段元素,一定永远不会被遍历到,那么他们就可以从traverse数组当中滚蛋?
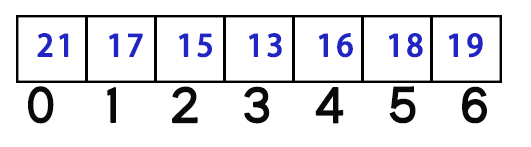
比如这个数组,当遍历到下标4时,要么height[loop]比他小下标4就是答案遍历终止,要么height[loop]比他大会跳转到下标1,下标2~3永远不会被遍历到,那么下标2~3就可以从traverse数组中删除了。此时traverse数组中剩下的,就都是会被遍历到的下标,即[0,1,4],用代码表示:
vector<double> height = {11,9,13,15,10,20,3};
int size = height.size();vector<int> traverse;//每一个位置需要遍历的元素
vector<int> target(size,-1);//-1代表打不到,其他表示找到元素的下标for(int loop = 0;loop < size;loop++)
{for(int i = traverse.size()-1;i>=0;i--){if(height[traverse[i]]>height[loop]){target[loop] = traverse[i];break;}}//如果traverse中,最后一个下标代表的元素比当前元素还小,那么最后一个下标一定不会被遍历到,我们就把他删除掉//一直删除下去,剩下的最后一个元素,就是target[loop]while(!traverse.empty()&&height[traverse.back()]<height[loop]){traverse.pop_back();}//然后把当前元素下标插入进去traverse.push_back(loop);
}这样操作之后,我们会发现,traverse数组会有两个特点:
-
traverse数组中最后一个下标代表的元素一定小于倒数第二个下标代表的元素,即traverse数组下标代表的元素是单调递减的。
-
traverse数组只对最后一个元素进行操作(删除和插入),即traverse数组其实是一个栈。
所以,这样的traverse数组,我们就给他取了一个名字——单调栈。
朴素单调栈
单调栈,解决最直接的问题就是——
找到每一个元素 左边/右边 第一个 大于/小于 其的元素
来看题目:496. 下一个更大元素 I - 力扣(LeetCode)
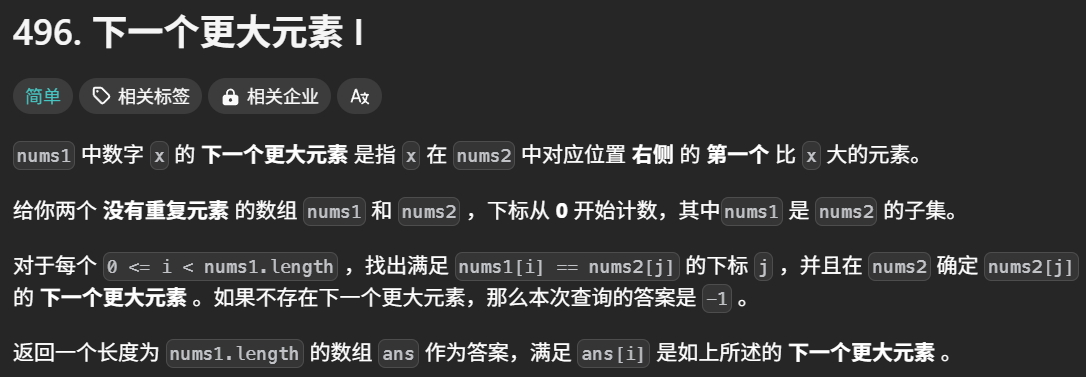
这不就是刚刚说到的问题吗,只不过从找左边,变成了找右边。那解决问题的区别是什么?loop从左往右,变成了loop从右往左。
而刚刚说到,traverse其实就是一个栈,那我们试试用栈来解决。
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {stack<int> traverse;vector<int> target(nums2.size(),-1);for(int loop = nums2.size()-1;loop>=0;loop--){//如果traverse最后一个元素比他小,那么最后一个元素一定不会被遍历到,直接删除//这里,我们只是把遍历和删除放在了一起,因为删除该元素然后再访问最后一个元素,不就是i--吗?while(!traverse.empty()&&nums2[traverse.top()]<nums2[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}}而根据题目的要求,我们只需要再用一个哈希表就能完成了,简略带过:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {stack<int> traverse;vector<int> target(nums2.size(),-1);for(int loop = nums2.size()-1;loop>=0;loop--){while(!traverse.empty()&&nums2[traverse.top()]<nums2[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}unordered_map<int,int> hash;for(int i = 0;i < nums2.size();i++){hash[nums2[i]] = target[i]==-1?-1:nums2[target[i]];}vector<int> ans(nums1.size());for(int i = 0;i<nums1.size();i++){ans[i] = hash[nums1[i]];}return ans;}所以,我们就获得了解题公式:
左边第一个更大的元素
从左往右遍历,维护一个递减单调栈:
vector<int> preGreaterElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(),-1);for(int loop = 0;loop<nums.size();loop++){while(!traverse.empty()&&nums[traverse.top()]<nums[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target; }右边第一个更大的元素
从右往左遍历,维护一个递减单调栈:
vector<int> nextGreaterElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(),-1);for(int loop = nums.size()-1;loop>=0;loop--){while(!traverse.empty()&&nums[traverse.top()]<nums[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target; }左边第一个更小的元素
从左往右遍历,维护一个递增的单调栈
(道理一样,可以自己想想)
vector<int> preLessElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(),-1);for(int loop = 0;loop<nums.size();loop++){while(!traverse.empty()&&nums[traverse.top()]>nums[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target; }右边第一个更小的元素
从右往左遍历,维护一个递增的单调栈
vector<int> nextLessElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(),-1);for(int loop = nums.size()-1;loop>=0;loop--){while(!traverse.empty()&&nums[traverse.top()]>nums[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target; }单调栈变种问题
删除k个元素的最小值
402. 移掉 K 位数字 - 力扣(LeetCode)
删掉k个元素,求剩下的最 大/小 值,其实有有一个相同的解法——单调栈。有人可能会问:

打个比方,1433223,删掉2个数字。我们期望删除的元素,有两个特点:
-
尽量大
-
尽量靠前
也就是,要把靠前的元素,删掉尽量大的。那怎么去定义这个尽量大呢?
假如返回值我们用一个数组来表示。
-
刚开始,1加入数组,然后4加入数组。那这个1该不该删?直觉告诉我们,肯定不该删,因为1很小。4该不该删?不知道,因为我们还不清楚什么是尽量大
-
然后,3加入数组了。那4该不该删?该删!因为4更靠前,而且4更大,这两个条件都满足了,那肯定是我们希望删除的元素。
-
又来一个3加入数组。这个3该不该删?不知道,因为他们是相同的,肯定不满足尽量大这个条件。
-
然后,2加入数组。和4一样,这下3更靠前而且更大,3就应该被删掉。
-
但是,删掉一个3之后,还有第二个3。此时,我们已经删掉两个元素了,再删就多了,所以13223就是我们需要的答案。
而刚刚的流程,用一句话表示:
维护一个递增的单调栈,一直到删除k个元素为止
怎么证明这个方法的正确性呢?
假如一个数字序列abcde...,想删掉一个,我们只考虑第一个位置a,会得到两张情况:
删掉a,序列变成bcde....
不删a,改为从后面随机删一个,序列变成abcde...
那么判断哪个更大,一定要先判断首位的大小。
如果a大,那么abcde...一定大于bcde....
如果a小,那么abcde...一定小于bcde....
如果相等,那么就判断下一位
所以,删不删a,实际上就是先比较a和b哪个更大,如果a>b,那么a一定要被删掉,得到的结果才是更小的。
代码:
string removeKdigits(string num, int k) {vector<char> stk;for (auto& digit: num) {while (stk.size() > 0 && stk.back() > digit && k) {stk.pop_back();k -= 1;}stk.push_back(digit);}for (; k > 0; --k) {stk.pop_back();}string ans = "";bool isLeadingZero = true;for (auto& digit: stk) {if (isLeadingZero && digit == '0') {continue;}isLeadingZero = false;ans += digit;}return ans == "" ? "0" : ans;}思考
如果题目问你,保留k个数字,得到最小结果呢?
实际上就是,删掉n-k个数字,得到最小结果,不多赘述。
扩展阅读
这类题的方法,是从leetcode一个大佬题解中学来的,大家可以相信看看这位大佬的文章:
402. 移掉 K 位数字 - 力扣(LeetCode)402. 移掉 K 位数字 - 给你一个以字符串表示的非负整数 num 和一个整数 k ,移除这个数中的 k 位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字。 示例 1 :输入:num = "1432219", k = 3输出:"1219"解释:移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219 。示例 2 :输入:num = "10200", k = 1输出:"200"解释:移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。示例 3 :输入:num = "10", k = 2输出:"0"解释:从原数字移除所有的数字,剩余为空就是 0 。 提示: * 1 <= k <= num.length <= 105 * num 仅由若干位数字(0 - 9)组成 * 除了 0 本身之外,num 不含任何前导零![]() https://leetcode.cn/problems/remove-k-digits/solutions/290203/yi-zhao-chi-bian-li-kou-si-dao-ti-ma-ma-zai-ye-b-5
https://leetcode.cn/problems/remove-k-digits/solutions/290203/yi-zhao-chi-bian-li-kou-si-dao-ti-ma-ma-zai-ye-b-5
右边最后一个更大的元素
962. 最大宽度坡 - 力扣(LeetCode)
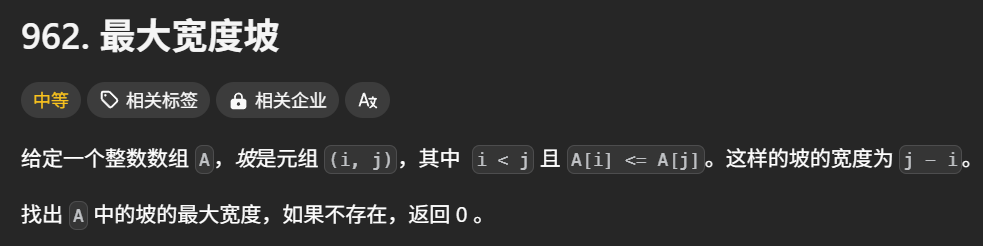
这个题目最优解法并非这个。但是,为了说明共性解,我还是按照最共性的解法去说。
这个题目的问题,实际上就是,找到每个元素右边最后一个更大的元素,然后返回target[i]-i的最大值。
这类题目的解法:
-
对数组中每一个元素,组成pair对
pair<int,int> p={val,pos};vector<pair<int,int>> pairs(nums.size());for(int i = 0;i < nums.size();i++)
{pairs[i] = {nums[i],i};
}2. 将pair对按照val的大小排序
vector<pair<int,int>> pairs(nums.size());sort(pairs.begin(),pairs.end(),[](const pair<int,int>& p1,const pair<int,int>& p2){if(p1.first == p2.first)return p1.second < p2.second;return p1.first < p2.first;
});3. 排序好后,当前下标i右边的所有元素都比他大。而我们要找最远的,即找pos最大的那一个,问题就转变成为了:
找到排序好的数组中,下标为i的元素的右边某个元素j,使得pairs[j].second最大并且pairs[j].second>pairs[i].second
而这就是典型的问题,从右往左遍历,用单个变量记录最大值便可:
int maxPos = -1;vector<int> target(nums.size(),-1);for(int i = pairs.size()-1;i >= 0;i--)
{//没有考虑数组中有重复值if(pairs[i].second<maxPos){target[pairs[i].second] = maxPos;}else{maxPos = pairs[i].second;}
}
//最后得到的target数组,就是每个位置右边最后一个更大元素的下标4. 我们要求的,是target[i]-i的最大值,即遍历target数组找最大值
int ans = 0;
for (int i = 0; i < nums.size(); i++) {ans = max(ans, target[i] - i);
}return ans;结合起来:
int maxWidthRamp(vector<int>& nums) {vector<pair<int, int>> pairs(nums.size());for (int i = 0; i < nums.size(); i++) {pairs[i] = {nums[i], i};}sort(pairs.begin(), pairs.end(),[](const pair<int, int>& p1, const pair<int, int>& p2) {if (p1.first == p2.first)return p1.second < p2.second;return p1.first < p2.first;});int maxPos = -1;vector<int> target(nums.size(), -1);for (int i = pairs.size() - 1; i >= 0; i--) {// 没有考虑数组中有重复值if (pairs[i].second < maxPos) {target[pairs[i].second] = maxPos;} else {maxPos = pairs[i].second;}}int ans = 0;for (int i = 0; i < nums.size(); i++) {ans = max(ans, target[i] - i);}return ans;}右边小于其的最大元素
456. 132 模式 - 力扣(LeetCode)
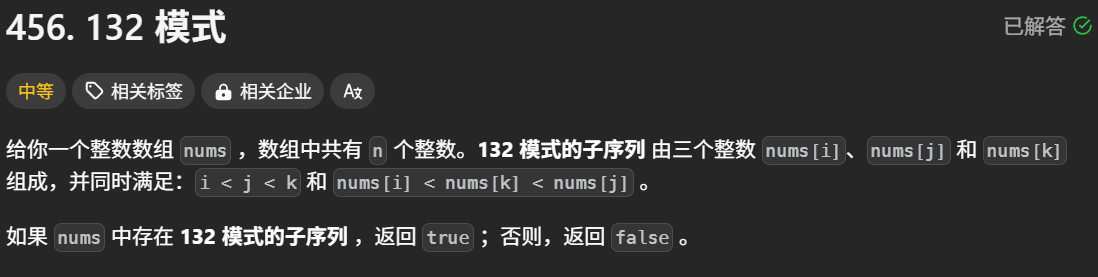
同样,这个题目最优解法并非这个。但是,为了说明共性解,我还是按照最共性的解法去说。
这个题目要寻找的,是每个元素右边小于其的最大元素下标i与左边小于其的最小元素下标j,并让nums[i]<nums[j]
第一个问题简单,只需要遍历的时候用一个变量记录。第二个问题就有些困难,怎么找到右边小于其的最大元素呢?
这类题目的解法,还是依赖排序:
1. 对数组中每一个元素,组成pair对
pair<int,int> p={val,pos};vector<pair<int,int>> pairs(nums.size());for(int i = 0;i < nums.size();i++)
{pairs[i] = {nums[i],i};
}2. 将pair对按照val的大小排序
vector<pair<int,int>> pairs(nums.size());sort(pairs.begin(),pairs.end(),[](const pair<int,int>& p1,const pair<int,int>& p2){if(p1.first == p2.first)return p1.second > p2.second;return p1.first > p2.first;
});3. 排序好后,当前下标i右边的所有元素都比他小。而我们要从中找到找最大的,因为是降序排列,最近的肯定最大。可是最近一定满足条件吗?不一定,因为最近的可能在nums[i]的左边。所以,我们又要最近,又要使得pairs[i].second<pairs[j].second,那么问题就转变成了:
现在只看pairs的second形成一个新的数组pos
vector<int> pos(nums.size());for(int i = 0;i < nums.size();i++) {pos[i] = pairs[i].second; }对pos数组,找到右边第一个更大的元素

那问题就简单了,从右往左遍历,维护一个递减单调栈:
vector<int> nextGreaterElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(),-1);for(int loop = nums.size()-1;loop>=0;loop--){while(!traverse.empty()&&nums[traverse.top()]<nums[loop]){traverse.pop();}if(!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target; }4. 题目要求的,是满足一个就返回true,那我们就从0开始遍历,维护最小值,发现满足条件就返回true就行
int minVal = nums[0];for(int i = 0;i < nums.size();i++)
{if(target[i]!=-1&&nums[target[i]]>minVal)return true;minVal = min(minVal,nums[i]);
}return false;结合起来:
vector<int> nextGreaterElement(vector<int>& nums) {stack<int> traverse;vector<int> target(nums.size(), -1);for (int loop = nums.size() - 1; loop >= 0; loop--) {while (!traverse.empty() && nums[traverse.top()] < nums[loop]) {traverse.pop();}if (!traverse.empty())target[loop] = traverse.top();traverse.push(loop);}return target;}bool find132pattern(vector<int>& nums) {vector<pair<int, int>> pairs(nums.size());for (int i = 0; i < nums.size(); i++) {pairs[i] = {nums[i], i};}sort(pairs.begin(), pairs.end(),[](const pair<int, int>& p1, const pair<int, int>& p2) {if (p1.first == p2.first)return p1.second > p2.second;return p1.first > p2.first;});vector<int> pos(nums.size());for (int i = 0; i < nums.size(); i++) {pos[i] = pairs[i].second;}vector<int> tmp = nextGreaterElement(pos);//这个地方可能有点绕,画图理解一下vector<int> target(nums.size(),-1);for(int i = 0;i<nums.size();i++){if(tmp[i]!=-1)target[pos[i]] = pos[tmp[i]];}int minVal = nums[0];for (int i = 0; i < nums.size(); i++) {if (target[i] != -1 && nums[target[i]] > minVal)return true;minVal = min(minVal, nums[i]);}return false;}习题集
关于习题集这部分,其实没有习题集。leetcode上单调栈也就72题(其中还有一堆会员题),给单调栈的题目一顺做下去就好了,再怎样也逃离不出这几种问题。
单调栈更多是一种优化方法,把O(N^2)的解法优化成O(NlogN)甚至O(N)。所以什么时候想到单调栈?不是刚开始拿到题目就说,哦我要维护一个单调栈;而是在暴力解法的时候发现,啊,我这样超时了,那我要优化一下,哦!这是一个单调栈问题,可以用单调栈优化!

相关文章:

一命通关单调栈
前言 我们只是卑微的后端开发。按理说,我们是不需要学这些比较进阶的算法的,可是,这个世界就是不讲道理。最开始,想法是给leetcode中等题全通关,我又不打ACM我去天天钻研hard干嘛,于是碰见单调栈树状数组的…...

NV009NV010美光闪存颗粒NV011NV012
NV009NV010美光闪存颗粒NV011NV012 美光NV009-NV012闪存颗粒技术解析与行业应用全景 一、核心技术架构与制程突破 美光NV009至NV012系列闪存颗粒基于第九代3D TLC架构,通过垂直堆叠技术突破传统2D平面存储的物理限制。该架构将存储单元分层排列,如同将…...

线程、线程池、异步
目录 什么是线程 什么是线程池 什么是异步 异步与线程关系 JS中的异步 什么是线程 线程 Thread 是计算机执行的最小单位,是 进程 内的一个实体,可以被操作系统独立调用和执行 线程可以理解为进程内的“程序执行流”,一个进程可以包含多…...
)
docker面试题(4)
Docker与Vagrant有何不同 两者的定位完全不同 Vagrant类似于Boot2Docker(一款运行Docker的最小内核),是一套虚拟机的管理环境,Vagrant可 以在多种系统上和虚拟机软件中运行,可以在Windows、Mac等非Linux平台上为Docker…...
单例模式)
双检锁(Double-Checked Locking)单例模式
在项目中使用双检锁(Double-Checked Locking)单例模式来管理 JSON 格式化处理对象(如 ObjectMapper 在 Jackson 库中,或 JsonParser 在 Gson 库中)是一种常见的做法。这种模式确保了对象只被创建一次,同时在…...

建立java项目
java端: 在idea里面新建一个java,maven项目(springboot): 注意:JDK与java都得是一样的 添加基本的依赖项: 也可以在pom.xml中点击这个,从而跳转到添加依赖 建立三层架构: 在相应的java类中添加代码: <1.UserController package com.example.demo.controller;import com…...

Go语言内存共享与扩容机制 -《Go语言实战指南》
切片作为 Go 中的高频数据结构,其内存共享机制和自动扩容策略直接影响程序性能与行为,深入理解这两者,是高效使用切片的关键。 一、切片的内存结构回顾 切片是对底层数组的一个抽象,其本质是一个结构体: type slice …...

如果教材这样讲--单片机IO口Additional Functions和 Alternate Functions的区别
不管是硬件工程师还是嵌入式软件工程师,都应该能够熟练的看懂数据手册,尤其是英文。在设计单片机外围电路时,工程师需要了解单片机的GPIO口的各项功能来满足自己的设计需求,单片机小白们在查看单片机数据手册时,看到Ad…...
》笔记)
《Effective Java(第三版)》笔记
思维导图 1-4章 5-8章 9-12 章 资料 源码:https://github.com/jbloch/effective-java-3e-source-code...
)
实践大模型提示工程(Prompt Engineering)
任务目标 本文将结合实战营中的具体案例,分享在提示词设计、模型调用及复杂任务拆解中的实践心得,希望能为读者打开一扇通往 AI 开发实战的窗口。 书生浦语官方链接 实践一——写一段话介绍书生浦语实战营 在提示工程中,第一点给出清晰的…...

东莞一锂离子电池公司IPO终止,客户与供应商重叠,社保缴纳情况引疑
作者:小熊 来源:IPO魔女 5月17日,深交所发布公告称,东莞市朗泰通科技股份有限公司(简称朗泰通科技)已主动撤回其IPO申请。该公司本次IPO原拟募集资金7.0208亿元,保荐机构为国金证券股份有限公…...

互联网大厂Java求职面试:Spring Cloud微服务架构与AI集成挑战
互联网大厂Java求职面试:Spring Cloud微服务架构与AI集成挑战 引言 在当前快速发展的互联网行业中,Java开发者在面对复杂的分布式系统设计时,需要掌握从微服务架构到AI模型集成的多种技能。本文通过一场模拟面试,深入探讨了基于…...

解决C#泛型类参数无法带参数实例化的问题
概要 本文提供了一个基于C#表达式目录树的方法来解决泛型参数不能调用带参数的构造方法来实例化的问题。 C#泛型的限制 我们看如下的代码,User类需要一个泛型类,泛型类是要以CreditCard为基类。 class User<T> where T :CreditCard, new() {pr…...

微型化GNSS射频前端芯片AT2659S:L1频段多系统支持,SOT23-6封装
AT2659S是一款采用SiGe技术的低噪声放大器(LNA),相比传统CMOS工艺,它在功耗和噪声性能上进行了显著优化。该芯片支持L1频段的多模卫星导航系统,包括北斗二代、GPS、伽利略和Glonass,适用于高灵敏度的GNSS接…...

【图像大模型】深度解析RIFE: 基于中间流估计的实时视频插帧算法
基于深度学习的视频插帧算法RIFE技术解析与实战指南 一、项目背景与技术原理1.1 视频插帧技术概述1.2 RIFE核心创新1.3 算法原理详解1.3.1 网络架构1.3.2 损失函数设计1.3.3 时间自适应训练 二、项目部署与执行指南2.1 环境配置2.2 模型推理2.2.1 快速测试2.2.2 视频处理 2.3 模…...

Docker安装Fluentd采集中间件
Fluentd 简介 :Fluentd 是一个高性能、可扩展的数据收集与聚合工具,能够统一数据收集和消费,实现各种数据源到各种数据接收器的高效传输,广泛应用于日志收集等领域。 功能特点 : 统一日志收集 :支持从各种…...

【攻防实战】MacOS系统上线Cobalt Strike
如果巅峰留不住,那就重走来时路 前言 目前在一些攻防项目中遇到的互联网大厂,很多员工使用的都是MacOS主机。研究过程中发现网上这方面分享比较少,这里记录分享一下。 插件安装 配置cna基础文件,注意路径名不能包含中文或特殊…...
)
基于Resnet-34的树叶分类(李沐深度学习基础竞赛)
目录 一,数据集介绍 1.1 数据集下载 1.2 数据集介绍 二,Resnet-34介绍 三,模型训练 四,模型预测 五,测试结果 5.1 测试集结果 5.2 预测结果 5.3 总结 一,数据集介绍 1.1 数据集下载 本数据集下载…...
什么是阻抗匹配,需要做啥)
PCB设计实践(二十三)什么是阻抗匹配,需要做啥
PCB设计中的阻抗匹配是高速数字电路、射频通信、信号完整性等领域的核心技术,其重要性贯穿从基础理论到复杂系统设计的全流程。本文将从工程实践角度深入探讨阻抗匹配的本质原理、应用场景、设计方法、常见误区及解决方案,全面解析这一影响现代电子设备性…...

网络世界的“变色龙“:动态IP如何重构你的数据旅程?
在深秋的下午调试代码时,我偶然发现服务器日志中出现异常登录记录——IP地址显示为某个境外数据中心。更有趣的是,当我切换到公司VPN后,这个"可疑IP"竟自动消失在了防火墙监控列表中。这个瞬间让我意识到:现代网络架构中…...

Chrome浏览器捕获hover元素样式
–前言– 某些元素,只有hover上去才会看到触发效果,但是鼠标移开就找不到element元素,导致无法调试样式。下属两种方案可参考: 文章目录 一、方式1:通过class伪类触发二、方式2:通过断点调试2.1控制台切换到…...
)
嵌入式自学第二十五天(5.21)
(1)二进制文件读写操作: 例: #include<stdio.h> int main() { FILE *fp fopen("a.out","r"); FILE *fp1 fopen("app","w"); if(NULL fp || NULL fp1) { …...

golang库源码学习——Pond,小而精的工作池库
pond 是一个轻量级的 Goroutine 池库,用于高效管理并发任务。它提供了灵活的配置选项和多种策略,适合处理高并发场景。 GitHub - alitto/pond at v1 一、特点: 1.轻量级 pond 的代码库非常精简,它的V1版本仅有四个业务文件&#…...

Microbiome医口经典思路:退烧药物代谢过程如何进行多组学分析?
乙酰氨基酚(APAP),俗称扑热息痛,是应用最广泛的镇痛和解热药物之一。以往的研究主要集中在分离APAP降解菌株,了解其降解代谢途径。但微生物群与对乙酰氨基酚之间的相互作用、对乙酰氨基酚降解基因的分布特征以及对乙酰…...

微信小程序AI大模型流式输出实践与总结
背景 让Cursor生成小程序中大模型调用内容回复的流式输出时一直有问题,参考整理此文章。 参考原文:https://blog.csdn.net/weixin_47684422/article/details/145859543 一、什么是流式传输? 流式传输(Streaming)指的…...
)
操作系统理解(xv6)
xv6操作系统项目复习笔记 宗旨:只记大框架,不记细节,没有那么多的时间 一、xv6的页表是如何搭建的? xv6这个项目中,虚拟地址用了39位(27位12位(物理内存page偏移地址))…...

2024CCPC辽宁省赛 个人补题 ABCEGJL
Dashboard - 2024 CCPC Liaoning Provincial Contest - Codeforces 过题难度 B A J C L E G 铜奖 4 953 银奖 6 991 金奖 8 1664 B: 模拟题 // Code Start Here string s;cin >> s;reverse(all(s));cout << s << endl;A:很…...

Sentinel原理与SpringBoot整合实战
前言 随着微服务架构的广泛应用,服务和服务之间的稳定性变得越来越重要。在高并发场景下,如何保障服务的稳定性和可用性成为了一个关键问题。阿里巴巴开源的Sentinel作为一个面向分布式服务架构的流量控制组件,提供了从流量控制、熔断降级、…...

Python 训练营打卡 Day 31
文件的规范拆分和写法 把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处: 可以让项目文件变得更加规范和清晰可以让项目文件更加容易维护,修改某一个功能的时候&a…...

vue+srpingboot实现多文件导出
项目场景: vuesrpingboot实现多文件导出 解决方案: 直接上干货 <el-button type"warning" icon"el-icon-download" size"mini" class"no-margin" click"exportSelectedFiles" :disabled"se…...

学习 Pinia 状态管理【Plan - May - Week 2】
一、定义 Store Store 由 defineStore() 定义,它的第一个参数要求独一无二的id import { defineStore } from piniaexport const useAlertsStore defineStore(alert, {// 配置 })最好使用以 use 开头且以 Store 结尾 (比如 useUserStore,useCartStore&a…...
 PAM ERROR (Permission denied))
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

数据湖和数据仓库的区别
在当今数据驱动的时代,企业需要处理和存储海量数据。数据湖与数据仓库作为两种主要的数据存储解决方案,各自有其独特的优势与适用场景。本文将客观详细地介绍数据湖与数据仓库的基本概念、核心区别、应用场景以及未来发展趋势,帮助读者更好地…...

OceanBase 开发者大会,拥抱 Data*AI 战略,构建 AI 数据底座
5 月 17 号以“当 SQL 遇见 AI”为主题的 OceanBase 开发者大会在广州举行,因为行程的原因未能现场参会,仍然通过视频直播观看了全部的演讲。总体来说,这届大会既有对未来数据库演进方向的展望,也有 OceanBase 新产品的发布&#…...

鸿蒙HarmonyOS最新的组件间通信的装饰器与状态组件详解
本文系统梳理了鸿蒙(HarmonyOS)ArkUI中组件间通信相关的装饰器及状态组件的使用方法,重点介绍V2新特性,适合开发者查阅与实践。 概述 鸿蒙系统(HarmonyOS)ArkUI提供了丰富的装饰器和状态组件,用…...

OneDrive登录,账号跳转问题
你的OneDrive登录无需密码且自动跳转到其他账号,可能是由于浏览器或系统缓存了登录信息,或存在多个账号的关联。以下是分步解决方案: 方案三对我有效。 强制手动输入密码 访问登录页面时: 在浏览器中打开 OneDrive网页版。 点击…...

9-码蹄集600题基础python篇
题目如上图所示。 这一题,没什么难度。 代码如下: def main():#code here# x,amap(int,input("").split(" "))# sum((1/2)*(a*x(ax)/(4*a)))# print(f"{sum:.2f}")x,amap(int,input().split())print(f"{((1/2)*(a*…...

CAU人工智能class3 优化器
优化算法框架 优化思路 随机梯度下降 随机梯度下降到缺点: SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,每次迭代更新使用的梯度都只与本次迭代的样本有关。 因为每个批次的数据含有抽样误差,每次更新可能并不会 …...
Service)
学习 Android(十一)Service
简介 在 Android 中,Service 是一种无界面的组件,用于在后台执行长期运行或跨进程的任务,如播放音乐、网络下载或与远程服务通信 。Service 可分为“启动型(Started)”和“绑定型(Bound)”两大…...

SpringAI开发SSE传输协议的MCP Server
SpringAI 访问地址:Spring AI Spring AI是一个面向人工智能工程的应用框架,由Spring团队推出,旨在将AI能力集成到Java应用中。Spring AI的核心是解决AI集成的根本挑战,即将企业数据和API与AI模型连接起来。 MCP…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

如何成为更好的自己?
成为更好的自己是一个持续成长的过程,需要结合自我认知、目标规划和行动力。以下是一些具体建议,帮助你逐步提升: 1. 自我觉察:认识自己 反思与复盘:每天花10分钟记录当天的决策、情绪和行为,分析哪些做得…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
)
网站制作公司哪家强?(2025最新版)
在数字化时代,一个优质的网站是企业展示自身实力、拓展业务渠道的重要工具。无论是初创企业还是大型集团,都需要一个功能强大、设计精美的网站来吸引客户、提升品牌形象。但面对市场上众多的网站制作公司,如何选择一家靠谱的合作伙伴呢&#…...
)
23种经典设计模式(GoF设计模式)
目录 🍀 创建型设计模式(5种) 1. 单例模式(Singleton) 2. 工厂方法模式(Factory Method) 3. 抽象工厂模式(Abstract Factory) 4. 建造者模式(Builder&am…...

深入解析Dify:从架构到应用的全面探索
文章目录 引言一、Dify基础架构1.1 架构概述1.2 前端界面1.3 后端服务1.4 数据库设计 二、Dify核心概念2.1 节点(Node)2.2 变量(Variable)2.3 工作流类型 三、代码示例3.1 蓝图注册3.2 节点运行逻辑3.3 工作流运行逻辑 四、应用场…...

电子电路:怎么理解放大电路中集电极电流Ic漂移?
如果放大电路中集电极电阻RC因为温度或老化而阻值变化,Vce Vcc - IcRc - IcRc,这会改变工作点,导致集电极的电流漂移。 IC漂移的定义:集电极电流随时间、温度等变化。影响IC的因素:β、IB、VBE、温度、电源电压、元件…...

【疑难杂症】Mysql 无报错 修改配置文件后服务启动不起来 已解决|设置远程连接
我修改配置后,服务无法启动可以试试用记事本打开后另存为,格式选择ANSI,然后重新启动mysql试试 设置运行远程、 1、配置my.ini文件 在[mysqld]下 添加bind-address0.0.0.0 2、设置root权限 使用MySql命令行执行, CREATE USER…...

Java基础 5.21
1.多态注意事项和细节讨论 多态的前提是:两个对象(类)存在继承关系 多态的向上转型 本质:父类的引用指向了子类的对象语法:父类类型 引用名 new 子类类型();特点:编译类型看左边,运行类型看…...

探索Puter:一个基于Web的轻量级“云操作系统”
在云计算与Web技术高度融合的今天,开发者们不断尝试将传统桌面体验迁移到浏览器中。近期,GitHub上一个名为Puter的开源项目吸引了社区的关注。本文将带你深入解析Puter的设计理念、技术架构与使用场景,探索它如何通过现代Web技术重构用户的“云端桌面”。 一、项目概览 Put…...