golang库源码学习——Pond,小而精的工作池库
pond 是一个轻量级的 Goroutine 池库,用于高效管理并发任务。它提供了灵活的配置选项和多种策略,适合处理高并发场景。
GitHub - alitto/pond at v1
一、特点:
1.轻量级
pond 的代码库非常精简,它的V1版本仅有四个业务文件!因此它的体积小,加载速度快。
2.零依赖
只依赖于 Go 的标准库(如 sync、time 等),这个是它最大的特点,其实看代码就能看出来,基本上就是用的chan的封装,但是在这个基础上增加了动态设置的功能
3.稳定性高
因为依赖少,pond 不会因为第三方库的更新或兼容性问题而受到影响,稳定性更高。在复杂的项目环境中,零依赖的库更容易维护和调试
4.易于集成
pond基本可以无缝集成到任何 Go 项目中,无需担心依赖冲突或版本问题
二、场景:
1.嵌入式系统
在资源受限的嵌入式系统中,零依赖的库可以显著减少内存占用和二进制文件大小。
pond 的轻量级特性使其非常适合在嵌入式设备中管理并发任务。
2. 复杂框架
比如业界的负责RPC、HTTP框架,可以减少对原始框架的侵害
3. 微服务架构
在微服务架构中,每个服务通常需要独立部署和运行。零依赖的库可以避免引入不必要的依赖,减少部署复杂度。
pond 可以用于处理微服务中的高并发任务,如请求处理、数据同步等。
4. 高性能计算
在高性能计算场景中,零依赖的库可以减少额外的开销,提升计算效率。
pond 的 Goroutine 池机制可以高效管理并发任务,适合用于并行计算、数据处理等场景。
5. 库开发
如果你正在开发一个 Go 库,并且希望尽量减少对外部依赖的引入,pond 是一个理想的选择。
零依赖的特性可以确保你的库更加通用和易于集成。
三、功能:
1.动态设置 Goroutine 池的大小和工作线程:
package mainimport ("fmt""github.com/alitto/pond"
)func main() {// Create a buffered (non-blocking) pool that can scale up to 100 workers// and has a buffer capacity of 1000 taskspool := pond.New(100, 1000)// Submit 1000 tasksfor i := 0; i < 1000; i++ {n := ipool.Submit(func() {fmt.Printf("Running task #%d\n", n)})}// Stop the pool and wait for all submitted tasks to completepool.StopAndWait()
}这里例子里面设置了一个1000协程的任务池,并有100个工作线程来处理
我们看下pond的源代码:
func New(maxWorkers, maxCapacity int, options ...Option) *WorkerPool {// Instantiate the poolpool := &WorkerPool{maxWorkers: maxWorkers,maxCapacity: maxCapacity,idleTimeout: defaultIdleTimeout,strategy: Eager(),panicHandler: defaultPanicHandler,}// Apply all optionsfor _, opt := range options {opt(pool)}// Make sure options are consistentif pool.maxWorkers <= 0 {pool.maxWorkers = 1}if pool.minWorkers > pool.maxWorkers {pool.minWorkers = pool.maxWorkers}if pool.maxCapacity < 0 {pool.maxCapacity = 0}if pool.idleTimeout < 0 {pool.idleTimeout = defaultIdleTimeout}// Initialize base context (if not already set)if pool.context == nil {Context(context.Background())(pool)}// Create tasks channelpool.tasks = make(chan func(), pool.maxCapacity)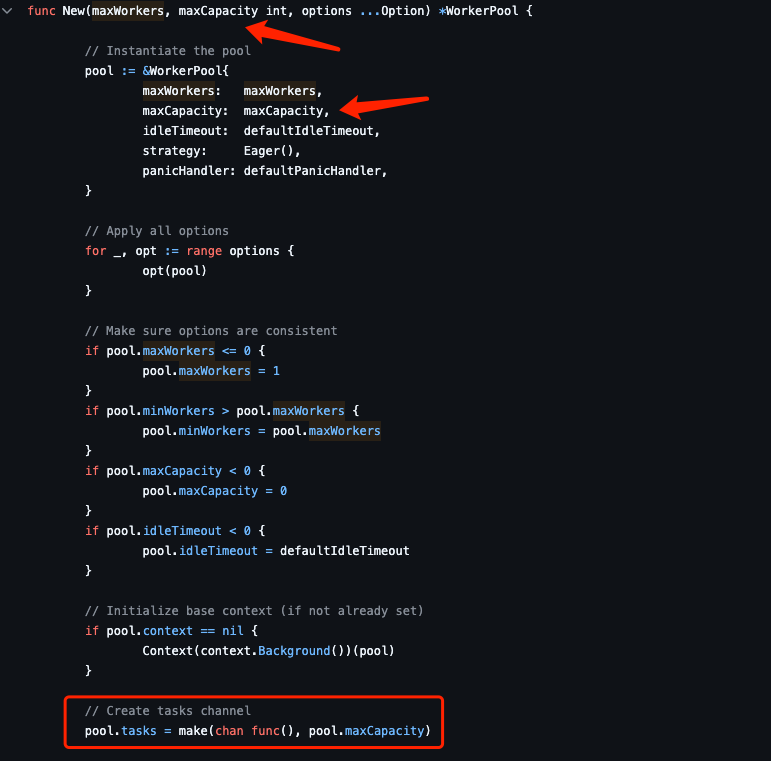
本质上就是创建了一个长度为1000的chan
而启动并执行工作线程的前提这里主要做一个“正在工作的线程”数目的比较,如果
runningWorkerCount大于等于设置的线程,或者还有空闲工作线程,则不再生成新的工作线程
func (p *WorkerPool) incrementWorkerCount() bool {p.mutex.Lock()defer p.mutex.Unlock()runningWorkerCount := p.RunningWorkers()// Reached max workers, do not create a new oneif runningWorkerCount >= p.maxWorkers {return false}// Idle workers available, do not create a new oneif runningWorkerCount >= p.minWorkers && runningWorkerCount > 0 && p.IdleWorkers() > 0 {return false}// Execute the resizing strategy to determine if we should create more workersif resize := p.strategy.Resize(runningWorkerCount, p.minWorkers, p.maxWorkers); !resize {return false}// Increment worker countatomic.AddInt32(&p.workerCount, 1)// Increment wait groupp.workersWaitGroup.Add(1)return true
}
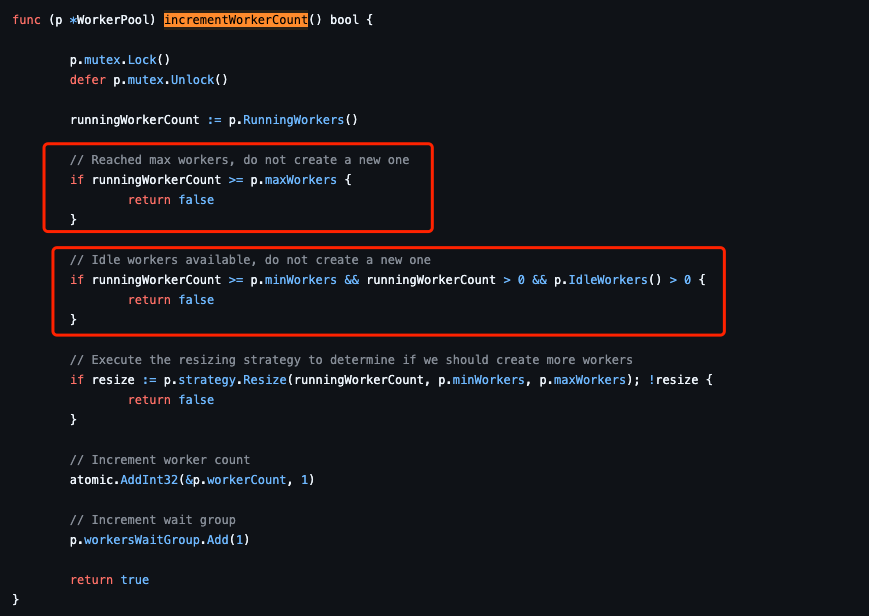
当然这里还有一个策略问题后面会讲到
2.动态设置 Goroutine 池的大小和工作线程及最小的工作协程数:
package mainimport ("fmt""github.com/alitto/pond"
)func main() {// Create an unbuffered (blocking) pool with a fixed // number of workerspool := pond.New(10, 0, pond.MinWorkers(10))// Submit 1000 tasksfor i := 0; i < 1000; i++ {n := ipool.Submit(func() {fmt.Printf("Running task #%d\n", n)})}// Stop the pool and wait for all submitted tasks to completepool.StopAndWait()
}这样设置确保池中始终至少有 10 个 Goroutine,即使没有任务需要处理。当任务到来时,这些 Goroutine 可以立即处理任务,而不需要等待新的,这种设置适合的场景为:
1. 高并发场景:
如果你的应用需要处理大量并发任务,设置 MinWorkers 可以确保有足够的 Goroutine 来处理任务,避免任务堆积。
2. 低延迟场景:
如果你的应用对响应速度要求较高,设置 MinWorkers 可以减少任务处理的时间,提高整体性能。
3. 资源敏感场景:
如果你的应用需要严格控制资源使用,设置 MinWorkers 可以确保 Goroutine 的数量不会低于某个阈值,从而避免资源不足的问题
其中,这里有一个很好的设计模式,设计模式:函数式选项模式(Functional Options Pattern)
看下源码:
func New(maxWorkers, maxCapacity int, options ...Option) *WorkerPool {// Instantiate the poolpool := &WorkerPool{maxWorkers: maxWorkers,maxCapacity: maxCapacity,idleTimeout: defaultIdleTimeout,strategy: Eager(),panicHandler: defaultPanicHandler,}// Apply all optionsfor _, opt := range options {opt(pool)}...
}
func MinWorkers(minWorkers int) Option {return func(pool *WorkerPool) {pool.minWorkers = minWorkers}
}可以看出来New方法这里传参都是函数式的,并通过opt进行执行
这样就是典型的函数式选项模式(Functional Options Pattern)
这种模式的核心思想是:
·通过传递函数来配置对象,而不是直接传递参数
·每个函数负责设置对象的一个特定属性
为什么使用函数式选项模式?
可扩展性
如果直接在 New 函数中传递参数,当需要新增配置选项时,必须修改 New 函数的签名,这会导致破坏性变更(Breaking Change)。
使用函数式选项模式,可以通过新增函数来扩展配置选项,而无需修改 New 函数的签名。
灵活性
函数式选项模式允许用户只设置需要的选项,而忽略其他选项。
例如,pond.New 可以接受任意数量的配置函数,用户可以根据需求选择性地传递这些函数。
可读性
通过函数式选项模式,代码的可读性更高。每个配置函数都有一个明确的名称,可以直观地表达其作用。
例如,pond.MinWorkers(10) 比直接传递一个 10 更容易理解。
默认值
函数式选项模式可以方便地为配置选项提供默认值。如果用户没有传递某个配置函数,则使用默认值。
3.动态设置 Goroutine 池的大小和工作线程及任务组和上下文:
单独创建组:
package mainimport ("fmt""github.com/alitto/pond"
)func main() {// Create a poolpool := pond.New(10, 1000)defer pool.StopAndWait()// Create a task groupgroup := pool.Group()// Submit a group of tasksfor i := 0; i < 20; i++ {n := igroup.Submit(func() {fmt.Printf("Running group task #%d\n", n)})}// Wait for all tasks in the group to completegroup.Wait()
}创建组及设置组内上下文:
package mainimport ("context""fmt""net/http""github.com/alitto/pond"
)func main() {// Create a worker poolpool := pond.New(10, 1000)defer pool.StopAndWait()// Create a task group associated to a contextgroup, ctx := pool.GroupContext(context.Background())var urls = []string{"https://www.golang.org/","https://www.google.com/","https://www.github.com/",}// Submit tasks to fetch each URLfor _, url := range urls {url := urlgroup.Submit(func() error {req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)resp, err := http.DefaultClient.Do(req)if err == nil {resp.Body.Close()}return err})}// Wait for all HTTP requests to complete.err := group.Wait()if err != nil {fmt.Printf("Failed to fetch URLs: %v", err)} else {fmt.Println("Successfully fetched all URLs")}
}此功能为共同任务的子任务提供同步、错误传播和上下文取消功能。类似于 golang.org/x/sync/errgroup 软件包中的 errgroup.Group,并发性受 Worker 池约束。
这里主要是便于业务管理
1. 一些灵活的设置:
比如这是工作线程的自动销毁,为闲时降低工作负载
// This will create a pool that will remove workers 100ms after they become idle
pool := pond.New(10, 1000, pond.IdleTimeout(100 * time.Millisecond))比如做一些panic的收集
// Custom panic handler function
panicHandler := func(p interface{}) {fmt.Printf("Task panicked: %v", p)
}// This will create a pool that will handle panics using a custom panic handler
pool := pond.New(10, 1000, pond.PanicHandler(panicHandler)))2. 工作线程策略:
这里是一个比较有意思的地方
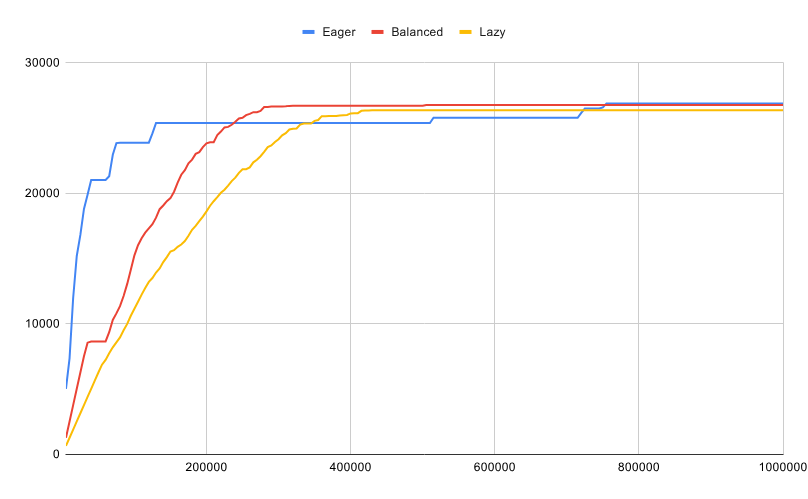
池大小调整策略:预设了三种常见场景的策略:进取型、均衡型和懒惰型
进取型:以提高资源使用率为代价最大化响应速度,在某些情况下可能会降低吞吐量。该策略适用于在大部分时间内以小部分容量运行,偶尔会收到突发任务的工人池。这是默认策略。
均衡型:试图在响应速度和吞吐量之间找到平衡。它适用于一般用途的工作池,或那些大部分时间都以接近 50%的容量运行的工作池。
懒惰型:以牺牲响应速度为代价最大化吞吐量。这种策略适用于大部分时间都将以接近最大容量运行的工人池。
默认是Eager
下图说明了随着提交任务数量的增加,不同池大小调整策略的行为。每条线代表池中工作进程的数量(池规模),X 轴代表已提交任务的数量(累计)。
我们看看源码实现:
var maxProcs = runtime.GOMAXPROCS(0)// Preset pool resizing strategies
var (// Eager maximizes responsiveness at the expense of higher resource usage,// which can reduce throughput under certain conditions.// This strategy is meant for worker pools that will operate at a small percentage of their capacity// most of the time and may occasionally receive bursts of tasks. It's the default strategy.Eager = func() ResizingStrategy { return RatedResizer(1) }// Balanced tries to find a balance between responsiveness and throughput.// It's suitable for general purpose worker pools or those// that will operate close to 50% of their capacity most of the time.Balanced = func() ResizingStrategy { return RatedResizer(maxProcs / 2) }// Lazy maximizes throughput at the expense of responsiveness.// This strategy is meant for worker pools that will operate close to their max. capacity most of the time.Lazy = func() ResizingStrategy { return RatedResizer(maxProcs) }
)// ratedResizer implements a rated resizing strategy
type ratedResizer struct {rate uint64hits uint64
}// RatedResizer creates a resizing strategy which can be configured
// to create workers at a specific rate when the pool has no idle workers.
// rate: determines the number of tasks to receive before creating an extra worker.
// A value of 3 can be interpreted as: "Create a new worker every 3 tasks".
func RatedResizer(rate int) ResizingStrategy {if rate < 1 {rate = 1}return &ratedResizer{rate: uint64(rate),}
}func (r *ratedResizer) Resize(runningWorkers, minWorkers, maxWorkers int) bool {if r.rate == 1 || runningWorkers == 0 {return true}r.hits++return r.hits%r.rate == 1
}可以看到三种策略的本质实现是:基于当前可以运行的CPU核数来判断的
1.进取型默认为一,即主要需要工作线程,就增加
2.均衡型为CPU核数的一半,即如果在一个16核的机器上,每增加8个任务,增加一个工作线程
3.懒惰型为CPU核数,即如果在一个16核的机器上,每增加16个任务,增加一个工作线程
这里就是为什么进取型适合前端页面API的类型,有时猛的过来一堆任务需要完成,但很多时候并不会有线程过来
3. 异步工作:
那提交任务是同步还是异步的?
答案是可以同步、也可以异步
分别是TrySubmit和Submit
func (p *WorkerPool) TrySubmit(task func()) bool {return p.submit(task, false)
}func (p *WorkerPool) submit(task func(), mustSubmit bool) (submitted bool) {if task == nil {return}if p.Stopped() {// Pool is stopped and caller must submit the taskif mustSubmit {panic(ErrSubmitOnStoppedPool)}return}// Increment submitted and waiting task counters as soon as we receive a taskatomic.AddUint64(&p.submittedTaskCount, 1)atomic.AddUint64(&p.waitingTaskCount, 1)p.tasksWaitGroup.Add(1)defer func() {if !submitted {// Task was not sumitted to the pool, decrement submitted and waiting task countersatomic.AddUint64(&p.submittedTaskCount, ^uint64(0))atomic.AddUint64(&p.waitingTaskCount, ^uint64(0))p.tasksWaitGroup.Done()}}()// Start a worker as long as we haven't reached the limitif submitted = p.maybeStartWorker(task); submitted {return}if !mustSubmit {// Attempt to dispatch to an idle worker without blockingselect {case p.tasks <- task:submitted = truereturndefault:// Channel is full and can't wait for an idle worker, so need to exitreturn}}// Submit the task to the tasks channel and wait for it to be picked up by a workerp.tasks <- tasksubmitted = truereturn
}通过源码可以知道:
异步和同步的区别在于,提交任务后,是否要等提交成功再返回
刚才说到pond本质上是一个chan,长度固定没,如果任务满了,再提交任务,chan会堵塞
所以如果是异步提交就不会堵塞
这里保证的服务不会卡在这里
在很多程序中推荐使用TrySubmit
可观测
能看的数据:
pool.RunningWorkers() int: Current number of running workers
pool.IdleWorkers() int: Current number of idle workers
pool.MinWorkers() int: Minimum number of worker goroutines
pool.MaxWorkers() int: Maxmimum number of worker goroutines
pool.MaxCapacity() int: Maximum number of tasks that can be waiting in the queue at any given time (queue capacity)
pool.SubmittedTasks() uint64: Total number of tasks submitted since the pool was created
pool.WaitingTasks() uint64: Current number of tasks in the queue that are waiting to be executed
pool.SuccessfulTasks() uint64: Total number of tasks that have successfully completed their exection since the pool was created
pool.FailedTasks() uint64: Total number of tasks that completed with panic since the pool was created
pool.CompletedTasks() uint64: Total number of tasks that have completed their exection either successfully or with panic since the pool was created
所以虽然代码量很少,但依然有做指标监控,使用的时候可以做日志上报
相关文章:

golang库源码学习——Pond,小而精的工作池库
pond 是一个轻量级的 Goroutine 池库,用于高效管理并发任务。它提供了灵活的配置选项和多种策略,适合处理高并发场景。 GitHub - alitto/pond at v1 一、特点: 1.轻量级 pond 的代码库非常精简,它的V1版本仅有四个业务文件&#…...

Microbiome医口经典思路:退烧药物代谢过程如何进行多组学分析?
乙酰氨基酚(APAP),俗称扑热息痛,是应用最广泛的镇痛和解热药物之一。以往的研究主要集中在分离APAP降解菌株,了解其降解代谢途径。但微生物群与对乙酰氨基酚之间的相互作用、对乙酰氨基酚降解基因的分布特征以及对乙酰…...

微信小程序AI大模型流式输出实践与总结
背景 让Cursor生成小程序中大模型调用内容回复的流式输出时一直有问题,参考整理此文章。 参考原文:https://blog.csdn.net/weixin_47684422/article/details/145859543 一、什么是流式传输? 流式传输(Streaming)指的…...
)
操作系统理解(xv6)
xv6操作系统项目复习笔记 宗旨:只记大框架,不记细节,没有那么多的时间 一、xv6的页表是如何搭建的? xv6这个项目中,虚拟地址用了39位(27位12位(物理内存page偏移地址))…...

2024CCPC辽宁省赛 个人补题 ABCEGJL
Dashboard - 2024 CCPC Liaoning Provincial Contest - Codeforces 过题难度 B A J C L E G 铜奖 4 953 银奖 6 991 金奖 8 1664 B: 模拟题 // Code Start Here string s;cin >> s;reverse(all(s));cout << s << endl;A:很…...

Sentinel原理与SpringBoot整合实战
前言 随着微服务架构的广泛应用,服务和服务之间的稳定性变得越来越重要。在高并发场景下,如何保障服务的稳定性和可用性成为了一个关键问题。阿里巴巴开源的Sentinel作为一个面向分布式服务架构的流量控制组件,提供了从流量控制、熔断降级、…...

Python 训练营打卡 Day 31
文件的规范拆分和写法 把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处: 可以让项目文件变得更加规范和清晰可以让项目文件更加容易维护,修改某一个功能的时候&a…...

vue+srpingboot实现多文件导出
项目场景: vuesrpingboot实现多文件导出 解决方案: 直接上干货 <el-button type"warning" icon"el-icon-download" size"mini" class"no-margin" click"exportSelectedFiles" :disabled"se…...

学习 Pinia 状态管理【Plan - May - Week 2】
一、定义 Store Store 由 defineStore() 定义,它的第一个参数要求独一无二的id import { defineStore } from piniaexport const useAlertsStore defineStore(alert, {// 配置 })最好使用以 use 开头且以 Store 结尾 (比如 useUserStore,useCartStore&a…...
 PAM ERROR (Permission denied))
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

数据湖和数据仓库的区别
在当今数据驱动的时代,企业需要处理和存储海量数据。数据湖与数据仓库作为两种主要的数据存储解决方案,各自有其独特的优势与适用场景。本文将客观详细地介绍数据湖与数据仓库的基本概念、核心区别、应用场景以及未来发展趋势,帮助读者更好地…...

OceanBase 开发者大会,拥抱 Data*AI 战略,构建 AI 数据底座
5 月 17 号以“当 SQL 遇见 AI”为主题的 OceanBase 开发者大会在广州举行,因为行程的原因未能现场参会,仍然通过视频直播观看了全部的演讲。总体来说,这届大会既有对未来数据库演进方向的展望,也有 OceanBase 新产品的发布&#…...

鸿蒙HarmonyOS最新的组件间通信的装饰器与状态组件详解
本文系统梳理了鸿蒙(HarmonyOS)ArkUI中组件间通信相关的装饰器及状态组件的使用方法,重点介绍V2新特性,适合开发者查阅与实践。 概述 鸿蒙系统(HarmonyOS)ArkUI提供了丰富的装饰器和状态组件,用…...

OneDrive登录,账号跳转问题
你的OneDrive登录无需密码且自动跳转到其他账号,可能是由于浏览器或系统缓存了登录信息,或存在多个账号的关联。以下是分步解决方案: 方案三对我有效。 强制手动输入密码 访问登录页面时: 在浏览器中打开 OneDrive网页版。 点击…...

9-码蹄集600题基础python篇
题目如上图所示。 这一题,没什么难度。 代码如下: def main():#code here# x,amap(int,input("").split(" "))# sum((1/2)*(a*x(ax)/(4*a)))# print(f"{sum:.2f}")x,amap(int,input().split())print(f"{((1/2)*(a*…...

CAU人工智能class3 优化器
优化算法框架 优化思路 随机梯度下降 随机梯度下降到缺点: SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,每次迭代更新使用的梯度都只与本次迭代的样本有关。 因为每个批次的数据含有抽样误差,每次更新可能并不会 …...
Service)
学习 Android(十一)Service
简介 在 Android 中,Service 是一种无界面的组件,用于在后台执行长期运行或跨进程的任务,如播放音乐、网络下载或与远程服务通信 。Service 可分为“启动型(Started)”和“绑定型(Bound)”两大…...

SpringAI开发SSE传输协议的MCP Server
SpringAI 访问地址:Spring AI Spring AI是一个面向人工智能工程的应用框架,由Spring团队推出,旨在将AI能力集成到Java应用中。Spring AI的核心是解决AI集成的根本挑战,即将企业数据和API与AI模型连接起来。 MCP…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

如何成为更好的自己?
成为更好的自己是一个持续成长的过程,需要结合自我认知、目标规划和行动力。以下是一些具体建议,帮助你逐步提升: 1. 自我觉察:认识自己 反思与复盘:每天花10分钟记录当天的决策、情绪和行为,分析哪些做得…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
)
网站制作公司哪家强?(2025最新版)
在数字化时代,一个优质的网站是企业展示自身实力、拓展业务渠道的重要工具。无论是初创企业还是大型集团,都需要一个功能强大、设计精美的网站来吸引客户、提升品牌形象。但面对市场上众多的网站制作公司,如何选择一家靠谱的合作伙伴呢&#…...
)
23种经典设计模式(GoF设计模式)
目录 🍀 创建型设计模式(5种) 1. 单例模式(Singleton) 2. 工厂方法模式(Factory Method) 3. 抽象工厂模式(Abstract Factory) 4. 建造者模式(Builder&am…...

深入解析Dify:从架构到应用的全面探索
文章目录 引言一、Dify基础架构1.1 架构概述1.2 前端界面1.3 后端服务1.4 数据库设计 二、Dify核心概念2.1 节点(Node)2.2 变量(Variable)2.3 工作流类型 三、代码示例3.1 蓝图注册3.2 节点运行逻辑3.3 工作流运行逻辑 四、应用场…...

电子电路:怎么理解放大电路中集电极电流Ic漂移?
如果放大电路中集电极电阻RC因为温度或老化而阻值变化,Vce Vcc - IcRc - IcRc,这会改变工作点,导致集电极的电流漂移。 IC漂移的定义:集电极电流随时间、温度等变化。影响IC的因素:β、IB、VBE、温度、电源电压、元件…...

【疑难杂症】Mysql 无报错 修改配置文件后服务启动不起来 已解决|设置远程连接
我修改配置后,服务无法启动可以试试用记事本打开后另存为,格式选择ANSI,然后重新启动mysql试试 设置运行远程、 1、配置my.ini文件 在[mysqld]下 添加bind-address0.0.0.0 2、设置root权限 使用MySql命令行执行, CREATE USER…...

Java基础 5.21
1.多态注意事项和细节讨论 多态的前提是:两个对象(类)存在继承关系 多态的向上转型 本质:父类的引用指向了子类的对象语法:父类类型 引用名 new 子类类型();特点:编译类型看左边,运行类型看…...

探索Puter:一个基于Web的轻量级“云操作系统”
在云计算与Web技术高度融合的今天,开发者们不断尝试将传统桌面体验迁移到浏览器中。近期,GitHub上一个名为Puter的开源项目吸引了社区的关注。本文将带你深入解析Puter的设计理念、技术架构与使用场景,探索它如何通过现代Web技术重构用户的“云端桌面”。 一、项目概览 Put…...

Java SpringBoot 项目中 Redis 存储 Session 具体实现步骤
目录 一、添加依赖二、配置 Redis三、配置 RedisTemplate四、创建控制器演示 Session 使用五、启动应用并测试六、总结 Java 在 Spring Boot 项目中使用 Redis 来存储 Session,能够实现 Session 的共享和高可用,特别适用于分布式系统环境。以下是具体的实…...

电商项目-商品微服务-规格参数管理,分类与品牌管理需求分析
本文章介绍:规格参数管理与分类与品牌管理的需求分析和表结构的设计。 一、规格参数管理 规格参数模板是用于管理规格参数的单元。规格是例如颜色、手机运行内存等信息,参数是例如系统:安卓(Android)后置摄像头像素&…...

Java 定时任务中Cron 表达式与固定频率调度的区别及使用场景
Java 定时任务:Cron 表达式与固定频率调度的区别及使用场景 一、核心概念对比 1. Cron 表达式调度 定义:基于日历时间点的调度,通过 秒 分 时 日 月 周 年 的格式定义复杂时间规则。时间基准:绝对时间点(如每天 12:…...
--Java版)
2025年- H39-Lc147 --394.字符串解码(双栈,递归)--Java版
1.题目描述 2.思路 可以用递归也可以用双栈,这边用栈。 首先先创建一个双栈,一个栈存数字(interger),另一个栈存字符(character)。设置数字临时变量num,设置字母临时变量curString在…...

学编程对数学成绩没帮助?
今天听到某机构直播说“学编程对数学成绩没帮助,如果想提高数学成绩那就单独去学数学”,实在忍不住要和各位家长聊聊我的思考,也欢迎各位家长评论。 恰在此时我看见了一道小学6年级的数学题如下,虽然题不难,但立刻让我…...
)
现代计算机图形学Games101入门笔记(十九)
光场 在近处画上图像,VR的效果。 任何时间任何位置看到的图像都不一样,是不是就是一个世界了。 光场就是任何一个位置往任何一个方向去的光的强度 知道光场就能知道这个物体长什么样子。 光线可以用一个点和一个方向确定。 也可以用2个点确定一条光线。 …...

STM32单片机GUI系统1 GUI基本内容
目录 一、GUI简介 1、emWin 2、LVGL (Light and Versatile Graphics Library) 3、TouchGFX 4、Qt for Embedded 5、特性对比总结 二、LVGL移植要求 三、优化LVGL运行效果方法 四、LVGL系统文件 一、GUI简介 在嵌入式系统中,emWin、LVGL、TouchGFX 和 Qt 是…...

Prometheus+Grafana实现对服务的监控
PrometheusGrafana实现对服务的监控 前言:PrometheusGrafana实现监控会更加全面,监控的组件更多 Prometheus官网 https://prometheus.io/docs/prometheus/latest/getting_started/ Grafana官网 https://grafana.com/docs/ 一、安装PrometheusGrafana 这…...

hook原理和篡改猴编写hook脚本
hook原理: hook是常用于js反编译的技术;翻译就是钩子,他的原理就是劫持js的函数然后进行篡改 一段简单的js代码 :这个代码是顺序执行的 function test01(){console.log(test01)test02() } function test02(){console.log(02)tes…...

Sign签证绕过
Sign的简介 Sign是指一种类似于token的东西 他的出现主要是保证数据的完整性,防篡改 就是一般的逻辑是 sign的加密的值和你输入的数据是相连的(比如sign的加密是使用输入的数据的前2位数字配合SHA1 等这样的) 绕过 :碰运气可以…...

【Vue篇】重剑无锋:面经PC项目工程化实战面经全解
目录 引言 一、项目功能演示 1. 目标 2. 项目收获 二、项目创建目录初始化 vue-cli 建项目 三、ESlint代码规范及手动修复 1. JavaScript Standard Style 规范说明 2. 代码规范错误 3. 手动修正 四、通过eslint插件来实现自动修正 五、调整初始化目录结构 1. 删除…...
)
JVM参数详解与实战案例指南(AI)
JVM参数详解与实战案例指南 一、JVM参数概述与分类 JVM参数是控制Java虚拟机运行时行为的关键配置项,合理设置这些参数可以显著提升应用性能。根据功能和稳定性,JVM参数主要分为三类: 标准参数:所有JVM实现都必须支持ÿ…...

C++通过空间配置器实现简易String类
C实现简易String类 在C中,使用空间配置器(allocator)实现自定义string类需要管理内存分配、释放及对象构造/析构。 #include <memory> #include <algorithm> #include <cstring> #include <stdexcept> #include &l…...

MyBatis:简化数据库操作的持久层框架
1、什么是Mybatis? MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由 apachesoftwarefoundation 迁移到了google code,由谷歌托管,并且改名为MyBatis 。 2013年11月迁移到Github。 iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框…...

Spring Boot集成Spring AI与Milvus实现智能问答系统
在Spring Boot中集成Spring AI与Milvus实现智能问答系统 引言 随着人工智能技术的快速发展,越来越多的企业开始探索如何将AI能力集成到现有系统中。本文将介绍如何在Spring Boot项目中集成Spring AI和向量数据库Milvus,构建一个高效的智能问答系统。 …...
:一致性哈希算法)
软件工程(六):一致性哈希算法
哈希算法 定义 哈希算法是一种将任意长度的输入(如字符串、文件等)转换为固定长度输出的算法,这个输出称为“哈希值”或“摘要”。 常见的哈希算法 哈希算法哈希位数特点MD5128位快速,但已不安全SHA-1160位安全性提高…...

Linux内存分页管理详解
Linux内存分页管理详解:原理、实现与实际应用 目录 Linux内存分页管理详解:原理、实现与实际应用 一、引言 二、内存分页机制概述 1. 虚拟地址与物理地址的划分 2. 分页的基本原理 三、虚拟地址到物理地址的转换 1. 地址转换流程 2. 多级页表的遍历 四、多级页表的…...

work-platform阅读
Redis存储的是字节数据,所以任何对象想要存进redis,都要转化成字节。对象转化为字节流的过程,叫序列化,反之,叫反序列化 Redis 序列化详解及高性能实践-CSDN博客https://blog.csdn.net/zhangkunls/article/details/14…...

在 Excel xll 自动注册操作 中使用东方仙盟软件————仙盟创梦IDE
windows 命令 "C:\Program Files\Microsoft Office\root\Office16\EXCEL.EXE" /X "C:\Path\To\仙盟.xll" excel 注册 Application.RegisterXLL "XLMAPI.XLL" 重点代码解析 excel 命令模式 [ExcelCommand(Description "使用参数")] …...

微调后的模型保存与加载
在Hugging Face Transformers库中,微调后的模型保存与加载方式因微调方法(如常规微调或参数高效微调)而异。 一、常规微调模型的保存与加载 1、 保存完整模型 使用 save_pretrained() 方法可将整个模型(包含权重、配置、分词器…...

PostgreSQL 日常维护
目录 一、基本使用 1、登录数据库 2、数据库操作 (1)列出库 (2)创建库 (3)删除库 (4)切换库 (5)查看库大小 3、数据表操作 (1ÿ…...

Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT=0x90的一个例子
Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT0x90的一个例子 1: kd> dx -id 0,0,899a2278 -r1 ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) : 0xc431a400 [Type: _FILE_RECORD_SEGMENT_HEADER …...