Python 训练营打卡 Day 31
文件的规范拆分和写法
把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处:
- 可以让项目文件变得更加规范和清晰
- 可以让项目文件更加容易维护,修改某一个功能的时候,只需要修改一个文件,而不需要修改多个文件。
- 文件变得更容易复用,部分通用的文件可以单独拿出来,进行其他项目的复用。
一、文件的组织
1. 项目核心代码组织
- src/(source的缩写):存放项目的核心源代码。按照机器学习项目阶段进一步细分:
- src/data/:放置与数据相关的代码。
src/data/load_data.py:负责从各类数据源(如文件系统、数据库、API 等)读取原始数据。src/data/preprocess.py:进行数据清洗(处理缺失值、异常值)、数据转换(标准化、归一化、编码等)操作。src/data/feature_engineering.py:根据业务和数据特点,创建新特征或对现有特征进行选择、优化。
- src/models/:关于模型的代码。
src/models/model.py:定义模型架构,比如神经网络结构、机器学习算法模型设定等。src/models/train.py:设置模型超参数,并执行训练过程,保存训练好的模型。src/models/evaluate.py:使用合适的评估指标(如准确率、召回率、均方误差等),在测试集上评估模型性能,生成评估报告。src/models/predict.py或src/models/inference.py:利用训练好的模型对新数据进行预测。
- src/utils/:存放通用辅助函数代码,可进一步细分:
src/utils/io_utils.py:包含文件读写相关帮助函数,比如读取特定格式文件、保存数据到文件等。src/utils/logging_utils.py:实现日志记录功能,方便记录项目运行过程中的信息,便于调试和监控。src/utils/math_utils.py:特定的数值计算函数,像自定义的矩阵运算、统计计算等。src/utils/plotting_utils.py:绘图工具函数,用于生成数据可视化图表(如绘制损失函数变化曲线、特征分布直方图等 )。
- src/data/:放置与数据相关的代码。
2. 配置文件管理
- config/ 目录:集中存放项目的配置文件,方便管理和切换不同环境(开发、测试、生产)的配置。
config/config.py或config/settings.py:以 Python 代码形式定义配置参数。config/config.yaml或config/config.json:采用 YAML 或 JSON 格式,清晰列出文件路径、模型超参数、随机种子、API 密钥等可配置参数。.env文件:通常放在项目根目录,用于存储敏感信息(如数据库密码、API 密钥等),在代码中通过环境变量的方式读取,一般会被.gitignore忽略,防止敏感信息泄露。
3. 实验与探索代码
-
notebooks/ 或 experiments/ 目录:用于初期的数据探索、快速实验、模型原型验证。
notebooks/initial_eda.ipynb:在项目初期,使用 Jupyter Notebook 进行数据探索与可视化,了解数据特性,分析数据分布、相关性等。experiments/model_experimentation.py:编写脚本对不同模型架构、超参数组合进行快速实验,对比实验结果,寻找最优模型设置。
这部分往往是最开始的探索阶段,后面跑通了后拆分成了完整的项目,留作纪念用。
4. 项目产出物管理
- data/ 目录:存放项目相关数据。
data/raw/:放置从外部获取的未经处理的原始数据,保持数据原始状态。data/processed/:存放经过预处理(清洗、转换、特征工程等操作)后的数据,供模型训练和评估使用。data/interim/:(可选)保存中间处理结果,比如数据清洗过程中生成的临时文件、特征工程中间步骤产生的数据等。
- models/ 目录:专门存放训练好的模型文件,根据模型保存格式不同,可能是
.pkl(Python pickle 格式,常用于保存 sklearn 模型 )、.h5(常用于保存 Keras 模型 )、.joblib等。 - reports/ 或 output/ 目录:存储项目运行产生的各类报告和输出文件。
reports/evaluation_report.txt:记录模型评估的详细结果,包括各项评估指标数值、模型性能分析等。reports/visualizations/:存放数据可视化图片,如损失函数收敛图、预测结果对比图等。output/logs/:保存项目运行日志文件,记录项目从开始到结束过程中的关键信息,如训练开始时间、训练过程中的损失值变化、预测时间等。
总结一下通用的拆分起步思路:
-
首先,按照机器学习的主要工作流程(数据处理、训练、评估等)将代码分离到不同的
.py文件中。 这是最基本也是最有价值的一步。 -
然后,创建一个
utils.py来存放通用的辅助函数。 -
考虑将所有配置参数集中到一个
config.py文件中。 -
为你的数据和模型产出物创建专门的顶层目录,如
data/和models/,将它们与你的源代码(通常放在src/目录)分开。
当遵循这些通用的拆分思路和原则时,项目结构自然会变得清晰。
二、以心脏病数据集为例进行拆分
import pandas as pd
import numpy as np
import sys
import os
from typing import Tuple, Dict
from sklearn.preprocessing import MinMaxScaler, StandardScaler
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import time
import joblib # 用于保存模型
from typing import Tuple # 用于类型注解
# 加载数据
def load_data(file_path: str): #传入路径为字符串路径"""加载数据文件Args:file_path: 数据文件路径Returns:加载的数据框"""return pd.read_csv(file_path)def encode_categorical_features(data):"""对分类特征进行编码Args:data: 原始数据框Returns:编码后的数据框和编码映射字典"""# 有序特征使用字典映射进行标签编码ordinal_mappings = {'cp': {0: 0, 1: 1, 2: 2, 3: 3},'restecg': {0: 0, 1: 1, 2: 2},'slope': {0: 0, 1: 1, 2: 2},'ca': {0: 0, 1: 1, 2: 2, 3: 3, 4: 4},}data_encoded = data.copy()for feature, mapping in ordinal_mappings.items():data_encoded[feature] = data[feature].map(mapping)# 独热编码(仅对thal特征)thal_mapping = {1: 0, 2: 1, 3: 2}data_encoded['thal'] = data['thal'].map(thal_mapping)data_encoded = pd.get_dummies(data_encoded, columns=['thal'], prefix='thal', dtype=int)# 存储映射关系mappings = {'ordinal_mappings': ordinal_mappings,'thal_mapping': thal_mapping}return data_encoded, mappingsdef handle_missing_values(data: pd.DataFrame) -> pd.DataFrame:"""处理缺失值Args:data: 包含缺失值的数据框Returns:处理后的数据框"""data_clean = data.copy()discrete_features = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal', 'target']continuous_features = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']# 离散特征用众数补全for feature in discrete_features:if feature in data.columns and data[feature].isnull().any():mode_value = data[feature].mode()[0]data_clean[feature].fillna(mode_value, inplace=True)# 连续特征用中位数补全for feature in continuous_features:if feature in data.columns and data[feature].isnull().any():median_value = data[feature].median()data_clean[feature].fillna(median_value, inplace=True)return data_cleandef scale_features(data):"""特征缩放处理Args:data: 需要缩放的数据框Returns:缩放后的数据框"""data_scaled = data.copy()norm_features = ['oldpeak'] # 归一化特征std_features = ['age', 'trestbps', 'chol', 'thalach'] # 标准化特征# 归一化处理if 'oldpeak' in data.columns:minmax_scaler = MinMaxScaler()data_scaled[norm_features] = minmax_scaler.fit_transform(data[norm_features])# 标准化处理std_scaler = StandardScaler()data_scaled[std_features] = std_scaler.fit_transform(data[std_features])return data_scaledif __name__ == "__main__":# 测试代码data = load_data("heart.csv")data_encoded, mappings = encode_categorical_features(data)data_clean = handle_missing_values(data_encoded)data_scaled = scale_features(data_clean)print("预处理已完成")# 训练模型
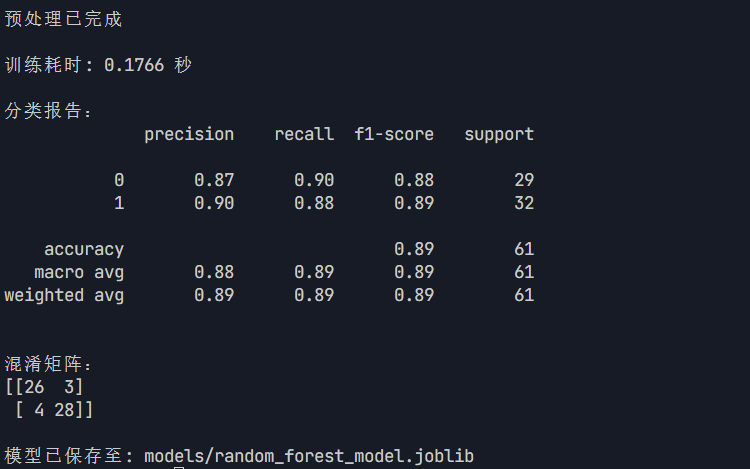
def prepare_data():"""准备训练数据Returns:训练集和测试集的特征和标签"""# 加载和预处理数据data = load_data("heart.csv")data_encoded, _ = encode_categorical_features(data)data_clean = handle_missing_values(data_encoded)# 分离标签与特征X = data_clean.drop(['target'], axis=1)y = data_clean['target']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)return X_train, X_test, y_train, y_testdef train_model(X_train, y_train, model_params=None):"""训练随机森林模型Args:X_train: 训练特征y_train: 训练标签model_params: 模型参数字典Returns:训练好的模型"""if model_params is None:model_params = {'random_state': 42}model = RandomForestClassifier(**model_params)model.fit(X_train, y_train)return modeldef evaluate_model(model, X_test, y_test):"""评估模型性能Args:model: 训练好的模型X_test: 测试特征y_test: 测试标签"""y_pred = model.predict(X_test)print("\n分类报告:")print(classification_report(y_test, y_pred))print("\n混淆矩阵:")print(confusion_matrix(y_test, y_pred))def save_model(model, model_path: str):"""保存模型Args:model: 训练好的模型model_path: 模型保存路径"""os.makedirs(os.path.dirname(model_path), exist_ok=True)joblib.dump(model, model_path)print(f"\n模型已保存至: {model_path}")if __name__ == "__main__":# 准备数据X_train, X_test, y_train, y_test = prepare_data()# 记录开始时间start_time = time.time()# 训练模型model = train_model(X_train, y_train)# 记录结束时间end_time = time.time()print(f"\n训练耗时: {end_time - start_time:.4f} 秒")# 评估模型evaluate_model(model, X_test, y_test)# 保存模型save_model(model, "models/random_forest_model.joblib") 生成结果为:
相关文章:

Python 训练营打卡 Day 31
文件的规范拆分和写法 把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处: 可以让项目文件变得更加规范和清晰可以让项目文件更加容易维护,修改某一个功能的时候&a…...

vue+srpingboot实现多文件导出
项目场景: vuesrpingboot实现多文件导出 解决方案: 直接上干货 <el-button type"warning" icon"el-icon-download" size"mini" class"no-margin" click"exportSelectedFiles" :disabled"se…...

学习 Pinia 状态管理【Plan - May - Week 2】
一、定义 Store Store 由 defineStore() 定义,它的第一个参数要求独一无二的id import { defineStore } from piniaexport const useAlertsStore defineStore(alert, {// 配置 })最好使用以 use 开头且以 Store 结尾 (比如 useUserStore,useCartStore&a…...
 PAM ERROR (Permission denied))
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

数据湖和数据仓库的区别
在当今数据驱动的时代,企业需要处理和存储海量数据。数据湖与数据仓库作为两种主要的数据存储解决方案,各自有其独特的优势与适用场景。本文将客观详细地介绍数据湖与数据仓库的基本概念、核心区别、应用场景以及未来发展趋势,帮助读者更好地…...

OceanBase 开发者大会,拥抱 Data*AI 战略,构建 AI 数据底座
5 月 17 号以“当 SQL 遇见 AI”为主题的 OceanBase 开发者大会在广州举行,因为行程的原因未能现场参会,仍然通过视频直播观看了全部的演讲。总体来说,这届大会既有对未来数据库演进方向的展望,也有 OceanBase 新产品的发布&#…...

鸿蒙HarmonyOS最新的组件间通信的装饰器与状态组件详解
本文系统梳理了鸿蒙(HarmonyOS)ArkUI中组件间通信相关的装饰器及状态组件的使用方法,重点介绍V2新特性,适合开发者查阅与实践。 概述 鸿蒙系统(HarmonyOS)ArkUI提供了丰富的装饰器和状态组件,用…...

OneDrive登录,账号跳转问题
你的OneDrive登录无需密码且自动跳转到其他账号,可能是由于浏览器或系统缓存了登录信息,或存在多个账号的关联。以下是分步解决方案: 方案三对我有效。 强制手动输入密码 访问登录页面时: 在浏览器中打开 OneDrive网页版。 点击…...

9-码蹄集600题基础python篇
题目如上图所示。 这一题,没什么难度。 代码如下: def main():#code here# x,amap(int,input("").split(" "))# sum((1/2)*(a*x(ax)/(4*a)))# print(f"{sum:.2f}")x,amap(int,input().split())print(f"{((1/2)*(a*…...

CAU人工智能class3 优化器
优化算法框架 优化思路 随机梯度下降 随机梯度下降到缺点: SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,每次迭代更新使用的梯度都只与本次迭代的样本有关。 因为每个批次的数据含有抽样误差,每次更新可能并不会 …...
Service)
学习 Android(十一)Service
简介 在 Android 中,Service 是一种无界面的组件,用于在后台执行长期运行或跨进程的任务,如播放音乐、网络下载或与远程服务通信 。Service 可分为“启动型(Started)”和“绑定型(Bound)”两大…...

SpringAI开发SSE传输协议的MCP Server
SpringAI 访问地址:Spring AI Spring AI是一个面向人工智能工程的应用框架,由Spring团队推出,旨在将AI能力集成到Java应用中。Spring AI的核心是解决AI集成的根本挑战,即将企业数据和API与AI模型连接起来。 MCP…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

如何成为更好的自己?
成为更好的自己是一个持续成长的过程,需要结合自我认知、目标规划和行动力。以下是一些具体建议,帮助你逐步提升: 1. 自我觉察:认识自己 反思与复盘:每天花10分钟记录当天的决策、情绪和行为,分析哪些做得…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
)
网站制作公司哪家强?(2025最新版)
在数字化时代,一个优质的网站是企业展示自身实力、拓展业务渠道的重要工具。无论是初创企业还是大型集团,都需要一个功能强大、设计精美的网站来吸引客户、提升品牌形象。但面对市场上众多的网站制作公司,如何选择一家靠谱的合作伙伴呢&#…...
)
23种经典设计模式(GoF设计模式)
目录 🍀 创建型设计模式(5种) 1. 单例模式(Singleton) 2. 工厂方法模式(Factory Method) 3. 抽象工厂模式(Abstract Factory) 4. 建造者模式(Builder&am…...

深入解析Dify:从架构到应用的全面探索
文章目录 引言一、Dify基础架构1.1 架构概述1.2 前端界面1.3 后端服务1.4 数据库设计 二、Dify核心概念2.1 节点(Node)2.2 变量(Variable)2.3 工作流类型 三、代码示例3.1 蓝图注册3.2 节点运行逻辑3.3 工作流运行逻辑 四、应用场…...

电子电路:怎么理解放大电路中集电极电流Ic漂移?
如果放大电路中集电极电阻RC因为温度或老化而阻值变化,Vce Vcc - IcRc - IcRc,这会改变工作点,导致集电极的电流漂移。 IC漂移的定义:集电极电流随时间、温度等变化。影响IC的因素:β、IB、VBE、温度、电源电压、元件…...

【疑难杂症】Mysql 无报错 修改配置文件后服务启动不起来 已解决|设置远程连接
我修改配置后,服务无法启动可以试试用记事本打开后另存为,格式选择ANSI,然后重新启动mysql试试 设置运行远程、 1、配置my.ini文件 在[mysqld]下 添加bind-address0.0.0.0 2、设置root权限 使用MySql命令行执行, CREATE USER…...

Java基础 5.21
1.多态注意事项和细节讨论 多态的前提是:两个对象(类)存在继承关系 多态的向上转型 本质:父类的引用指向了子类的对象语法:父类类型 引用名 new 子类类型();特点:编译类型看左边,运行类型看…...

探索Puter:一个基于Web的轻量级“云操作系统”
在云计算与Web技术高度融合的今天,开发者们不断尝试将传统桌面体验迁移到浏览器中。近期,GitHub上一个名为Puter的开源项目吸引了社区的关注。本文将带你深入解析Puter的设计理念、技术架构与使用场景,探索它如何通过现代Web技术重构用户的“云端桌面”。 一、项目概览 Put…...

Java SpringBoot 项目中 Redis 存储 Session 具体实现步骤
目录 一、添加依赖二、配置 Redis三、配置 RedisTemplate四、创建控制器演示 Session 使用五、启动应用并测试六、总结 Java 在 Spring Boot 项目中使用 Redis 来存储 Session,能够实现 Session 的共享和高可用,特别适用于分布式系统环境。以下是具体的实…...

电商项目-商品微服务-规格参数管理,分类与品牌管理需求分析
本文章介绍:规格参数管理与分类与品牌管理的需求分析和表结构的设计。 一、规格参数管理 规格参数模板是用于管理规格参数的单元。规格是例如颜色、手机运行内存等信息,参数是例如系统:安卓(Android)后置摄像头像素&…...

Java 定时任务中Cron 表达式与固定频率调度的区别及使用场景
Java 定时任务:Cron 表达式与固定频率调度的区别及使用场景 一、核心概念对比 1. Cron 表达式调度 定义:基于日历时间点的调度,通过 秒 分 时 日 月 周 年 的格式定义复杂时间规则。时间基准:绝对时间点(如每天 12:…...
--Java版)
2025年- H39-Lc147 --394.字符串解码(双栈,递归)--Java版
1.题目描述 2.思路 可以用递归也可以用双栈,这边用栈。 首先先创建一个双栈,一个栈存数字(interger),另一个栈存字符(character)。设置数字临时变量num,设置字母临时变量curString在…...

学编程对数学成绩没帮助?
今天听到某机构直播说“学编程对数学成绩没帮助,如果想提高数学成绩那就单独去学数学”,实在忍不住要和各位家长聊聊我的思考,也欢迎各位家长评论。 恰在此时我看见了一道小学6年级的数学题如下,虽然题不难,但立刻让我…...
)
现代计算机图形学Games101入门笔记(十九)
光场 在近处画上图像,VR的效果。 任何时间任何位置看到的图像都不一样,是不是就是一个世界了。 光场就是任何一个位置往任何一个方向去的光的强度 知道光场就能知道这个物体长什么样子。 光线可以用一个点和一个方向确定。 也可以用2个点确定一条光线。 …...

STM32单片机GUI系统1 GUI基本内容
目录 一、GUI简介 1、emWin 2、LVGL (Light and Versatile Graphics Library) 3、TouchGFX 4、Qt for Embedded 5、特性对比总结 二、LVGL移植要求 三、优化LVGL运行效果方法 四、LVGL系统文件 一、GUI简介 在嵌入式系统中,emWin、LVGL、TouchGFX 和 Qt 是…...

Prometheus+Grafana实现对服务的监控
PrometheusGrafana实现对服务的监控 前言:PrometheusGrafana实现监控会更加全面,监控的组件更多 Prometheus官网 https://prometheus.io/docs/prometheus/latest/getting_started/ Grafana官网 https://grafana.com/docs/ 一、安装PrometheusGrafana 这…...

hook原理和篡改猴编写hook脚本
hook原理: hook是常用于js反编译的技术;翻译就是钩子,他的原理就是劫持js的函数然后进行篡改 一段简单的js代码 :这个代码是顺序执行的 function test01(){console.log(test01)test02() } function test02(){console.log(02)tes…...

Sign签证绕过
Sign的简介 Sign是指一种类似于token的东西 他的出现主要是保证数据的完整性,防篡改 就是一般的逻辑是 sign的加密的值和你输入的数据是相连的(比如sign的加密是使用输入的数据的前2位数字配合SHA1 等这样的) 绕过 :碰运气可以…...

【Vue篇】重剑无锋:面经PC项目工程化实战面经全解
目录 引言 一、项目功能演示 1. 目标 2. 项目收获 二、项目创建目录初始化 vue-cli 建项目 三、ESlint代码规范及手动修复 1. JavaScript Standard Style 规范说明 2. 代码规范错误 3. 手动修正 四、通过eslint插件来实现自动修正 五、调整初始化目录结构 1. 删除…...
)
JVM参数详解与实战案例指南(AI)
JVM参数详解与实战案例指南 一、JVM参数概述与分类 JVM参数是控制Java虚拟机运行时行为的关键配置项,合理设置这些参数可以显著提升应用性能。根据功能和稳定性,JVM参数主要分为三类: 标准参数:所有JVM实现都必须支持ÿ…...

C++通过空间配置器实现简易String类
C实现简易String类 在C中,使用空间配置器(allocator)实现自定义string类需要管理内存分配、释放及对象构造/析构。 #include <memory> #include <algorithm> #include <cstring> #include <stdexcept> #include &l…...

MyBatis:简化数据库操作的持久层框架
1、什么是Mybatis? MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由 apachesoftwarefoundation 迁移到了google code,由谷歌托管,并且改名为MyBatis 。 2013年11月迁移到Github。 iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框…...

Spring Boot集成Spring AI与Milvus实现智能问答系统
在Spring Boot中集成Spring AI与Milvus实现智能问答系统 引言 随着人工智能技术的快速发展,越来越多的企业开始探索如何将AI能力集成到现有系统中。本文将介绍如何在Spring Boot项目中集成Spring AI和向量数据库Milvus,构建一个高效的智能问答系统。 …...
:一致性哈希算法)
软件工程(六):一致性哈希算法
哈希算法 定义 哈希算法是一种将任意长度的输入(如字符串、文件等)转换为固定长度输出的算法,这个输出称为“哈希值”或“摘要”。 常见的哈希算法 哈希算法哈希位数特点MD5128位快速,但已不安全SHA-1160位安全性提高…...

Linux内存分页管理详解
Linux内存分页管理详解:原理、实现与实际应用 目录 Linux内存分页管理详解:原理、实现与实际应用 一、引言 二、内存分页机制概述 1. 虚拟地址与物理地址的划分 2. 分页的基本原理 三、虚拟地址到物理地址的转换 1. 地址转换流程 2. 多级页表的遍历 四、多级页表的…...

work-platform阅读
Redis存储的是字节数据,所以任何对象想要存进redis,都要转化成字节。对象转化为字节流的过程,叫序列化,反之,叫反序列化 Redis 序列化详解及高性能实践-CSDN博客https://blog.csdn.net/zhangkunls/article/details/14…...

在 Excel xll 自动注册操作 中使用东方仙盟软件————仙盟创梦IDE
windows 命令 "C:\Program Files\Microsoft Office\root\Office16\EXCEL.EXE" /X "C:\Path\To\仙盟.xll" excel 注册 Application.RegisterXLL "XLMAPI.XLL" 重点代码解析 excel 命令模式 [ExcelCommand(Description "使用参数")] …...

微调后的模型保存与加载
在Hugging Face Transformers库中,微调后的模型保存与加载方式因微调方法(如常规微调或参数高效微调)而异。 一、常规微调模型的保存与加载 1、 保存完整模型 使用 save_pretrained() 方法可将整个模型(包含权重、配置、分词器…...

PostgreSQL 日常维护
目录 一、基本使用 1、登录数据库 2、数据库操作 (1)列出库 (2)创建库 (3)删除库 (4)切换库 (5)查看库大小 3、数据表操作 (1ÿ…...

Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT=0x90的一个例子
Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT0x90的一个例子 1: kd> dx -id 0,0,899a2278 -r1 ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) : 0xc431a400 [Type: _FILE_RECORD_SEGMENT_HEADER …...

leetcode hot100刷题日记——7.最大子数组和
class Solution { public:int maxSubArray(vector<int>& nums) {//方法一:动态规划//dp[i]表示以i下标结尾的数组的最大子数组和//那么在i0时,dp[0]nums[0]//之后要考虑的就是我们要不要把下一个数加进来,如果下一个数加进来会使结…...

LlamaIndex
1、大语言模型开发框架的价值是什么? SDK:Software Development Kit,它是一组软件工具和资源的集合,旨在帮助开发者创建、测试、部署和维护应用程序或软件。 所有开发框架(SDK)的核心价值,都是降低开发、维护成本。 大语言模型开发框架的价值,是让开发者可以更方便地…...
的关键技术)
下一代电子电气架构(EEA)的关键技术
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

CSDN gitcode代码推送
当我使用用户名密码时一直无法推送,报下面这个错误 找了半天才知道, 他这个git不能用账号密码推送代码,idea弹出来的用户名,就是你头像旁边这个,没有符号 密码需要你创建一个令牌 这个令牌才是你要填写的密码&#x…...

中级统计师-统计学基础知识-第五章 相关分析
第一节 相关关系 1. 函数关系 vs 相关关系 函数关系 定义:变量间存在严格确定性的对应关系(如 y f ( x ) y f(x) yf(x))例子:本金 x x x 与利息收入 y x 0.027 x y x 0.027x yx0.027x特点:一一对应ÿ…...
函数createBoxMaxFilter())
OpenCV CUDA模块图像过滤------用于创建一个最大值盒式滤波器(Max Box Filter)函数createBoxMaxFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 createBoxMaxFilter()函数创建的是一个 最大值滤波器(Maximum Filter),它对图像中每个像素邻域内的像素值取最…...