基于Resnet-34的树叶分类(李沐深度学习基础竞赛)
目录
一,数据集介绍
1.1 数据集下载
1.2 数据集介绍
二,Resnet-34介绍
三,模型训练
四,模型预测
五,测试结果
5.1 测试集结果
5.2 预测结果
5.3 总结
一,数据集介绍
1.1 数据集下载
本数据集下载至沐神的Kaggle竞赛:
Classify Leaves | KaggleTrain models to predict the plant species![]() https://www.kaggle.com/competitions/classify-leaves/data
https://www.kaggle.com/competitions/classify-leaves/data
1.2 数据集介绍
该数据集包含18000张训练集图片和8000张测试集图片,分别以.csv文件给出来

该数据集一共包含176个类别的树叶种类
二,Resnet-34介绍
ResNet-34 是何恺明等人于 2015 年提出的残差神经网络(ResNet)家族成员,因含 34 层可学习卷积层得名,通过引入残差块(含残差连接)解决深度网络梯度消失 / 爆炸和退化问题,其基础残差块由 2 个 3×3 卷积层构成,输入输出通道一致时直接相加,不一致时通过 1×1 卷积投影调整维度;网络结构包括输入层、5 个阶段的卷积层(含下采样和残差块堆叠)、全局平均池化层和全连接分类层,具有支持更深网络训练、计算效率较高等特点,在 ImageNet 等图像分类任务中表现优异,常作为基准模型或用于特征提取,为后续深层网络发展奠定了基础。
Resnet介绍请看:基于CNN的猫狗识别(自定义Resnet-18模型)-CSDN博客
三,模型训练
# 导入数据处理库
import pandas as pd
# 导入操作系统相关库
import os
# 导入PyTorch核心库
import torch
# 导入PyTorch神经网络模块
import torch.nn as nn
# 导入优化器模块
import torch.optim as optim
# 导入学习率调度器模块
from torch.optim import lr_scheduler
# 导入数据集和数据加载相关模块
from torch.utils.data import Dataset, DataLoader, random_split
# 导入计算机视觉相关工具(如图像变换、预训练模型)
from torchvision import transforms, models
# 导入绘图库
import matplotlib.pyplot as plt
# 导入数值计算库
import numpy as np
# 导入图像处理库
from PIL import Image# --------------------------- 基础配置 ---------------------------
# 设置 matplotlib 显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决 matplotlib 负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 允许PyTorch重复加载动态链接库(解决Windows下的潜在冲突)
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'# --------------------------- 数据预处理 ---------------------------
# 定义训练集数据增强和归一化流程
train_transform = transforms.Compose([transforms.Resize((256, 256)), # 将图像Resize到256x256尺寸transforms.RandomRotation(45), # 随机旋转图像(角度范围±45度)transforms.RandomHorizontalFlip(), # 随机水平翻转图像(概率50%)transforms.RandomVerticalFlip(), # 随机垂直翻转图像(概率50%)transforms.ToTensor(), # 将PIL图像转换为PyTorch张量(数值范围[0,1])transforms.Normalize( # 对图像进行标准化(减去均值,除以标准差)mean=[0.7589, 0.7788, 0.7598], # 图像各通道均值std=[0.2477, 0.2347, 0.2630] # 图像各通道标准差)
])# 定义验证集数据预处理流程(仅调整尺寸、转换张量和标准化,无数据增强)
val_transform = transforms.Compose([transforms.Resize((224, 224)), # 将图像Resize到224x224尺寸(适配ResNet输入要求)transforms.ToTensor(), # 转换为PyTorch张量transforms.Normalize( # 标准化,参数与训练集一致mean=[0.7589, 0.7788, 0.7598],std=[0.2477, 0.2347, 0.2630])
])# --------------------------- 自定义数据集 ---------------------------
# 定义树叶数据集类,继承PyTorch的Dataset类
class LeafDataset(Dataset):def __init__(self, csv_file, root_dir, transform=None):# 读取包含图像路径和标签的CSV文件self.data_frame = pd.read_csv(csv_file)# 图像文件根目录self.root_dir = root_dir# 数据预处理变换(如Resize、归一化等)self.transform = transform# 获取所有唯一的标签类别并排序self.classes = sorted(self.data_frame['label'].unique())# 创建标签到索引的映射字典(用于模型输出转换)self.class_to_idx = {cls: i for i, cls in enumerate(self.classes)}def __len__(self):# 返回数据集样本总数return len(self.data_frame)def __getitem__(self, idx):# 处理输入索引(支持Tensor类型索引)if torch.is_tensor(idx):idx = idx.tolist()# 从DataFrame中获取当前样本的图像名称(第一列)img_name = self.data_frame.iloc[idx, 0]# 移除图像名称中的"images/"前缀(如果存在,确保路径正确拼接)img_name = img_name.replace("images/", "")# 拼接图像的完整路径(根目录 + 图像名称)full_path = os.path.join(self.root_dir, img_name)# 读取图像并转换为RGB格式(处理可能的灰度图像)image = Image.open(full_path).convert('RGB')# 获取当前样本的标签(第二列)label = self.data_frame.iloc[idx, 1]# 将标签转换为索引(通过class_to_idx字典)label_idx = self.class_to_idx[label]# 对图像应用预处理变换(如Resize、归一化等)image = self.transform(image)# 返回处理后的图像张量和标签索引return image, label_idx# --------------------------- 定义ResNet-34模型 ---------------------------
# 创建ResNet-34模型的函数,支持加载预训练权重
def create_resnet_model(pretrained=True):# 根据pretrained参数选择是否加载ImageNet预训练权重weights = models.ResNet34_Weights.IMAGENET1K_V1 if pretrained else None# 实例化ResNet-34模型,传入预训练权重model = models.resnet34(weights=weights)# 获取原模型全连接层的输入特征数in_features = model.fc.in_features# 修改全连接层,适配当前任务的类别数(176类)model.fc = nn.Linear(in_features, 176)# 返回自定义后的模型return model# --------------------------- 训练和验证函数 ---------------------------
# 训练和验证模型的函数
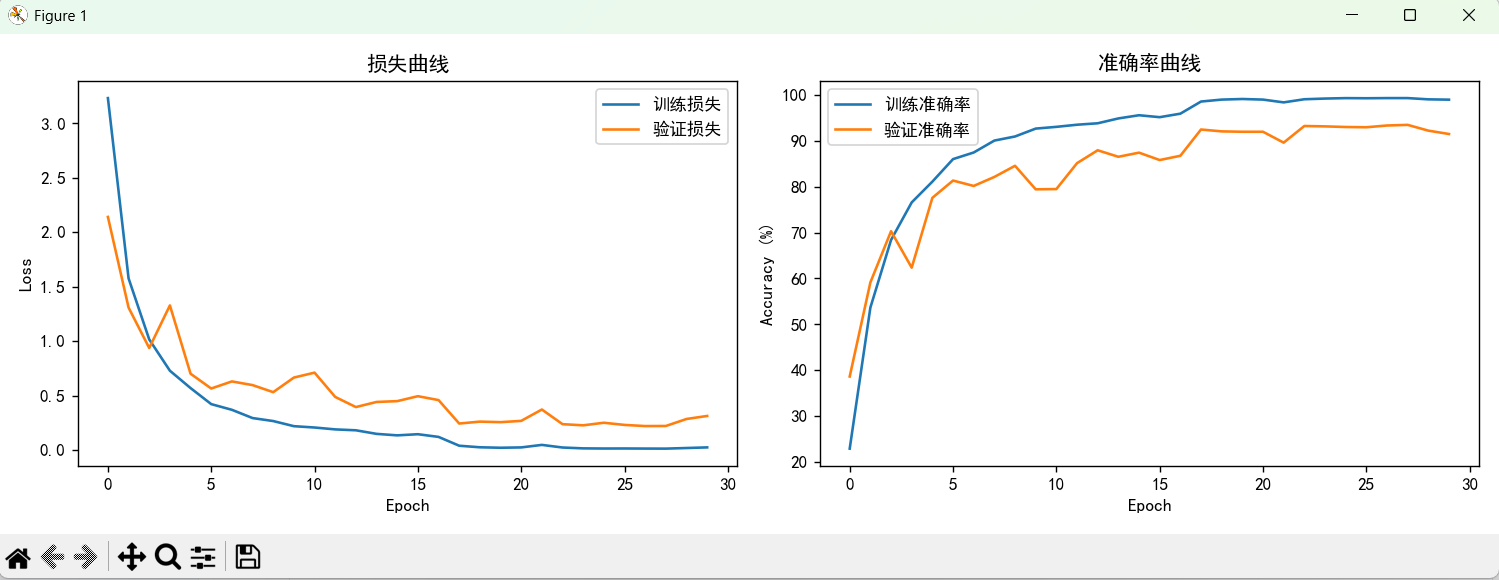
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs, device):# 记录最佳验证准确率best_val_acc = 0.0# 存储训练历史(损失和准确率)的字典history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}for epoch in range(epochs):# --------------------------- 训练阶段 ---------------------------# 设置模型为训练模式(启用Dropout、BatchNorm等训练相关操作)model.train()# 初始化训练损失、正确预测数、样本总数train_loss = 0.0train_correct = 0train_total = 0# 遍历训练数据加载器for inputs, labels in train_loader:# 将输入和标签移动到指定设备(CPU或GPU)inputs, labels = inputs.to(device), labels.to(device)# 清空优化器的梯度缓存optimizer.zero_grad()# 前向传播:模型预测outputs = model(inputs)# 计算损失(交叉熵损失)loss = criterion(outputs, labels)# 反向传播:计算梯度loss.backward()# 优化器更新参数optimizer.step()# 累加训练损失(乘以batch大小,得到总损失)train_loss += loss.item() * inputs.size(0)# 获取预测结果(概率最大的类别索引)_, predicted = outputs.max(1)# 累加样本总数和正确预测数train_total += labels.size(0)train_correct += predicted.eq(labels).sum().item()# 计算平均训练损失和准确率train_loss /= len(train_loader.dataset)train_acc = 100.0 * train_correct / train_total# --------------------------- 验证阶段 ---------------------------# 设置模型为评估模式(禁用Dropout、BatchNorm等训练操作)model.eval()# 初始化验证损失、正确预测数、样本总数val_loss = 0.0val_correct = 0val_total = 0# 禁用梯度计算(节省内存和计算资源)with torch.no_grad():for inputs, labels in val_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)val_loss += loss.item() * inputs.size(0)_, predicted = outputs.max(1)val_total += labels.size(0)val_correct += predicted.eq(labels).sum().item()# 计算平均验证损失和准确率val_loss /= len(val_loader.dataset)val_acc = 100.0 * val_correct / val_total# --------------------------- 学习率调整 ---------------------------# 根据验证损失调整学习率(ReduceLROnPlateau策略)scheduler.step(val_loss)# --------------------------- 保存最佳模型 ---------------------------# 如果当前验证准确率高于历史最佳,保存模型参数if val_acc > best_val_acc:best_val_acc = val_acctorch.save(model.state_dict(), 'ClassifyLeaves_model.pth')print(f'保存最佳模型: 验证准确率 = {val_acc:.2f}%')# --------------------------- 记录训练历史 ---------------------------# 将当前epoch的损失和准确率存入history字典history['train_loss'].append(train_loss)history['train_acc'].append(train_acc)history['val_loss'].append(val_loss)history['val_acc'].append(val_acc)# --------------------------- 打印训练日志 ---------------------------print(f'Epoch {epoch + 1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')print('-' * 50)# 返回训练好的模型和训练历史return model, history# --------------------------- 主程序入口 ---------------------------
if __name__ == '__main__':# --------------------------- 数据加载配置 ---------------------------# 训练数据CSV文件路径(包含图像名称和标签)csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTrain.csv"# 图像文件根目录image_directory = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\images"# 创建完整数据集(包含所有样本,应用训练集预处理)full_dataset = LeafDataset(csv_file, image_directory, transform=train_transform)# 划分训练集和验证集(8:2比例)train_size = int(0.8 * len(full_dataset))val_size = len(full_dataset) - train_sizetrain_subset, val_subset = random_split(full_dataset, [train_size, val_size])# 为验证集单独设置预处理变换(使用val_transform)val_subset.dataset.transform = val_transform# --------------------------- 创建数据加载器 ---------------------------# 训练数据加载器(设置批量大小、是否打乱、线程数等)train_loader = DataLoader(train_subset, # 训练子集batch_size=32, # 批量大小为32shuffle=True, # 训练时打乱数据顺序num_workers=4, # 使用4个线程加载数据pin_memory=torch.cuda.is_available() # 如果有GPU,启用锁页内存加速数据传输)# 验证数据加载器(不打乱数据,其他配置与训练集一致)val_loader = DataLoader(val_subset,batch_size=32,shuffle=False,num_workers=4,pin_memory=torch.cuda.is_available())# 打印数据加载信息print(f"成功加载 {len(full_dataset)} 个样本")print(f"训练集大小: {len(train_subset)}, 验证集大小: {len(val_subset)}")print(f"类别数量: {len(full_dataset.classes)}")# --------------------------- 初始化设备和模型 ---------------------------# 自动检测是否有GPU可用,设置计算设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 创建ResNet-34模型,加载预训练权重,并移动到指定设备model = create_resnet_model(pretrained=True).to(device)# --------------------------- 定义损失函数和优化器 ---------------------------# 交叉熵损失函数(适用于多分类任务)criterion = nn.CrossEntropyLoss()# Adam优化器(学习率0.001)optimizer = optim.Adam(model.parameters(), lr=0.001)# 学习率调度器(根据验证损失降低学习率)scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)# --------------------------- 开始训练 ---------------------------print("开始训练ResNet-34模型...")# 调用训练函数,返回训练好的模型和训练历史model, history = train_model(model=model,train_loader=train_loader,val_loader=val_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,epochs=30, # 训练30个epochdevice=device)# --------------------------- 结果可视化 ---------------------------# 创建绘图窗口plt.figure(figsize=(12, 4))# 绘制损失曲线子图(左)plt.subplot(1, 2, 1)plt.plot(history['train_loss'], label='训练损失')plt.plot(history['val_loss'], label='验证损失')plt.legend() # 显示图例plt.title('损失曲线') # 设置子图标题plt.xlabel('Epoch') # 设置x轴标签plt.ylabel('Loss') # 设置y轴标签# 绘制准确率曲线子图(右)plt.subplot(1, 2, 2)plt.plot(history['train_acc'], label='训练准确率')plt.plot(history['val_acc'], label='验证准确率')plt.legend()plt.title('准确率曲线')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.tight_layout() # 自动调整子图间距plt.show() # 显示图像# 打印最佳验证集准确率print(f"最佳验证集准确率: {max(history['val_acc']):.2f}%") 代码构建了一个基于 ResNet-34 的树叶分类模型训练框架,涵盖数据处理、模型构建、训练优化及结果分析全流程。首先,通过自定义数据集类LeafDataset读取训练数据,分离图像路径与标签并构建类别索引映射,同时对训练集和验证集应用差异化预处理:训练集采用 Resize、随机旋转、翻转等数据增强策略提升泛化能力,验证集仅保留 Resize、标准化以确保数据一致性。模型基于 ResNet-34 架构,加载 ImageNet 预训练权重并修改全连接层适配 176 类分类任务,采用交叉熵损失函数与 Adam 优化器,搭配学习率动态调整策略(ReduceLROnPlateau)以避免过拟合。训练过程中实时记录损失与准确率,自动保存验证准确率最高的模型参数,并通过 Matplotlib 可视化训练历史曲线,直观呈现模型收敛趋势。
四,模型预测
# 导入数据处理库
import pandas as pd
# 导入操作系统相关库
import os
# 导入PyTorch核心库
import torch
# 导入PyTorch神经网络模块
import torch.nn as nn
# 导入数据集和数据加载相关模块
from torch.utils.data import Dataset, DataLoader
# 导入计算机视觉相关工具(如图像变换、预训练模型)
from torchvision import transforms, models
# 导入图像处理库
from PIL import Image# --------------------------- 基础配置 ---------------------------
# 允许PyTorch重复加载动态链接库(解决Windows下的潜在冲突)
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'# --------------------------- 数据预处理 ---------------------------
# 定义测试集数据预处理流程(调整尺寸、转换张量、标准化,无数据增强)
test_transform = transforms.Compose([transforms.Resize((224, 224)), # 将图像Resize到224x224尺寸(适配ResNet输入要求)transforms.ToTensor(), # 将PIL图像转换为PyTorch张量(数值范围[0,1])transforms.Normalize( # 对图像进行标准化(减去均值,除以标准差)mean=[0.7589, 0.7788, 0.7598], # 图像各通道均值(需与训练集一致)std=[0.2477, 0.2347, 0.2630] # 图像各通道标准差(需与训练集一致))
])# --------------------------- 自定义数据集 ---------------------------
# 定义测试数据集类,继承PyTorch的Dataset类
class TestDataset(Dataset):def __init__(self, csv_file, root_dir, transform=None):# 读取测试数据CSV文件(第一列为图像名称,第二列留空)self.data_frame = pd.read_csv(csv_file)# 图像文件根目录self.root_dir = root_dir# 数据预处理变换(如Resize、归一化等)self.transform = transform# 检查图像文件是否存在(自定义方法,用于提前发现缺失文件)self.check_image_files()def __len__(self):# 返回测试数据集样本总数return len(self.data_frame)def __getitem__(self, idx):# 处理输入索引(支持Tensor类型索引)if torch.is_tensor(idx):idx = idx.tolist()# 从DataFrame中获取当前样本的图像名称(第一列)img_name = self.data_frame.iloc[idx, 0]# 移除图像名称中的"images/"前缀(如果存在,确保路径正确拼接)img_name = img_name.replace("images/", "")# 拼接图像的完整路径(根目录 + 图像名称)full_path = os.path.join(self.root_dir, img_name)# 尝试读取图像,若失败则返回空白图像并打印错误信息try:image = Image.open(full_path).convert('RGB') # 转换为RGB格式except Exception as e:print(f"Error loading image {full_path}: {str(e)}")# 返回224x224的白色空白图像作为替代image = Image.new('RGB', (224, 224), color='white')# 对图像应用预处理变换(如Resize、归一化等)if self.transform:image = self.transform(image)# 返回处理后的图像张量和原始图像名称(不含"images/"前缀)return image, img_namedef check_image_files(self):# 检查所有图像文件是否存在,记录缺失的文件名missing_files = []for idx in range(len(self.data_frame)):img_name = self.data_frame.iloc[idx, 0]img_name = img_name.replace("images/", "") # 移除前缀full_path = os.path.join(self.root_dir, img_name) # 完整路径if not os.path.exists(full_path):missing_files.append(img_name) # 记录缺失文件# 打印缺失文件警告(最多显示前10个)if missing_files:print(f"警告: 找不到 {len(missing_files)} 个图像文件")for file in missing_files[:10]:print(f" - {file}")if len(missing_files) > 10:print(f" - ... 和其他 {len(missing_files) - 10} 个文件")# --------------------------- 定义ResNet-34模型 ---------------------------
# 创建ResNet-34模型的函数(支持加载预训练权重或随机初始化)
def create_resnet_model(weights=None):# 实例化ResNet-34模型,传入权重参数(None表示随机初始化)model = models.resnet34(weights=weights)# 获取原模型全连接层的输入特征数in_features = model.fc.in_features# 修改全连接层,适配当前任务的类别数(176类,需与训练时一致)model.fc = nn.Linear(in_features, 176)# 返回自定义后的模型return model# --------------------------- 预测函数 ---------------------------
# 对测试集进行预测的函数
def predict(model, test_loader, device, class_to_idx):# 设置模型为评估模式(禁用Dropout、BatchNorm等训练操作)model.eval()# 初始化预测结果列表和图像名称列表predictions = []image_names = []# 禁用梯度计算(节省内存和计算资源)with torch.no_grad():# 遍历测试数据加载器for inputs, img_names in test_loader:# 将输入数据移动到指定设备(CPU或GPU)inputs = inputs.to(device)# 前向传播:模型预测outputs = model(inputs)# 获取预测结果(概率最大的类别索引)_, predicted = torch.max(outputs, 1)# 将预测索引转换为类别名称(通过反向映射字典)idx_to_class = {v: k for k, v in class_to_idx.items()}predicted_classes = [idx_to_class[idx.item()] for idx in predicted]# 累加预测结果和图像名称predictions.extend(predicted_classes)image_names.extend(img_names)# 返回图像名称列表和预测标签列表return image_names, predictions# --------------------------- 保存结果到CSV ---------------------------
# 将预测结果保存到CSV文件的函数
def save_predictions_to_csv(image_names, predictions, csv_path):# 在图像名称前添加"images/"前缀(符合输出要求)prefixed_image_names = [f"images/{name}" for name in image_names]# 创建DataFrame,结构为:image列(带前缀)、label列(预测标签)result_df = pd.DataFrame({'image': prefixed_image_names,'label': predictions})# 保存为CSV文件,不包含索引列result_df.to_csv(csv_path, index=False)# 打印保存成功信息print(f"预测结果已保存到 {csv_path}")# --------------------------- 主程序入口 ---------------------------
if __name__ == '__main__':# --------------------------- 数据加载配置 ---------------------------# 测试数据CSV文件路径(第一列为图像名称,第二列留空)test_csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTest.csv"# 图像文件根目录image_directory = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\images"# 输出CSV文件路径output_csv = "submission.csv"# 从训练数据中获取类别映射(需与训练时一致)train_csv_file = r"C:\Users\10532\Desktop\Study\Test\Data\classify-leaves\LeavesTrain.csv"train_df = pd.read_csv(train_csv_file) # 读取训练数据CSVclasses = sorted(train_df['label'].unique()) # 获取所有唯一标签并排序class_to_idx = {cls: i for i, cls in enumerate(classes)} # 创建标签到索引的映射# --------------------------- 创建测试数据集和数据加载器 ---------------------------# 实例化测试数据集类,应用测试集预处理变换test_dataset = TestDataset(test_csv_file, image_directory, transform=test_transform)# 创建测试数据加载器(设置批量大小、线程数等)test_loader = DataLoader(test_dataset, # 测试数据集batch_size=32, # 批量大小为32shuffle=False, # 测试时不打乱数据顺序num_workers=4, # 使用4个线程加载数据pin_memory=torch.cuda.is_available() # 如果有GPU,启用锁页内存加速数据传输)# 打印测试数据加载成功信息print(f"成功加载 {len(test_dataset)} 个测试样本")# --------------------------- 初始化设备和模型 ---------------------------# 自动检测是否有GPU可用,设置计算设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 创建ResNet-34模型(不加载预训练权重,使用训练好的参数)model = create_resnet_model(weights=None).to(device)# 加载训练好的模型参数model_path = 'ClassifyLeaves_model.pth'model.load_state_dict(torch.load(model_path, map_location=device)) # map_location确保兼容不同设备print(f"已加载模型: {model_path}")# --------------------------- 进行预测 ---------------------------# 打印提示信息print("开始预测...")# 调用预测函数,获取图像名称和预测标签image_names, predictions = predict(model, test_loader, device, class_to_idx)# --------------------------- 保存预测结果 ---------------------------# 调用保存函数,将结果写入CSV文件save_predictions_to_csv(image_names, predictions, output_csv) 测试代码围绕训练好的 ResNet-34 模型构建推理流程,实现从测试数据加载到预测结果输出的自动化。通过自定义TestDataset类读取测试集 CSV 文件,自动移除图像名称中的固定前缀并拼接完整路径,同时集成文件存在性检查功能(check_image_files),提前捕获缺失文件并输出警告列表,增强鲁棒性。图像加载过程包含异常处理逻辑,若文件读取失败则返回固定尺寸的空白图像,避免单个样本问题导致程序中断。预处理流程与训练阶段的验证集完全一致,确保输入数据格式统一。
模型加载阶段通过create_resnet_model函数实例化 ResNet-34 架构,加载训练保存的参数文件并适配当前设备(CPU/GPU)。预测函数predict采用批量推理模式,禁用梯度计算以提升效率,通过反向映射字典将模型输出的类别索引转换为具体标签名称。结果处理环节为图像名称添加 “images/” 前缀,生成符合要求的 CSV 文件(第一列为带前缀的图像名,第二列为预测标签)
五,测试结果
5.1 测试集结果

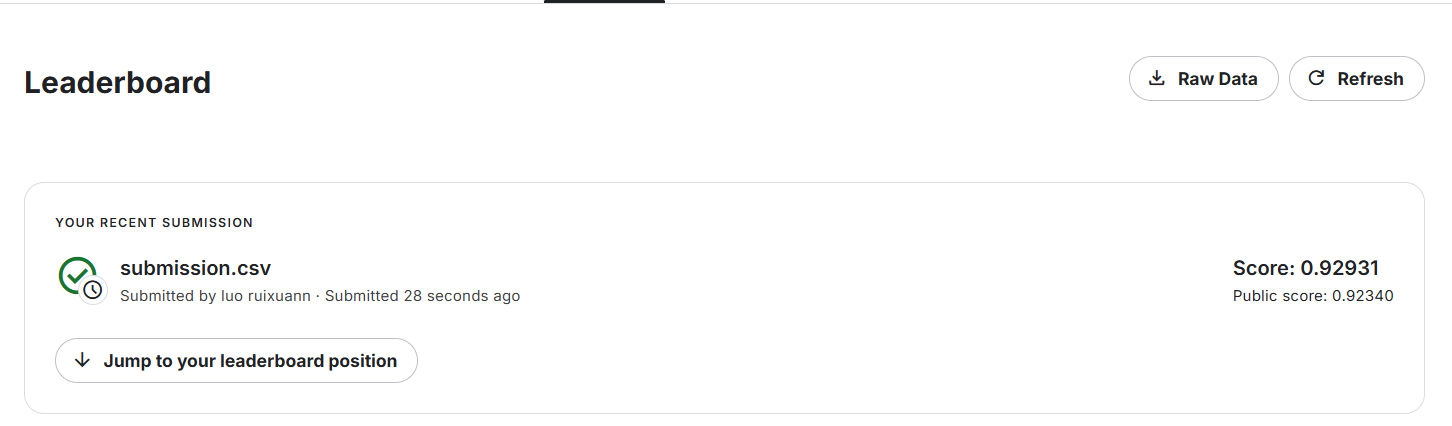
5.2 预测结果
上传至kaggle比赛,准确度大概是92.9%
5.3 总结
本次使用的Resnet-34实测其实和Resnet-18跑出来的结果和准确度是大差不差的,要实现更高的准确度,数据层面,训练集可增加颜色抖动、随机裁剪等增强策略,引入加权采样或 Focal Loss 应对类别不平衡,测试集可添加置信度输出或 Top-K 预测提升结果可靠性;模型训练方面,可集成混合精度训练加速计算,加入早停机制避免过拟合,采用余弦退火等学习率调度策略优化收敛过程,同时补充精确率、召回率等评估指标及混淆矩阵可视化以全面分析性能。
相关文章:
)
基于Resnet-34的树叶分类(李沐深度学习基础竞赛)
目录 一,数据集介绍 1.1 数据集下载 1.2 数据集介绍 二,Resnet-34介绍 三,模型训练 四,模型预测 五,测试结果 5.1 测试集结果 5.2 预测结果 5.3 总结 一,数据集介绍 1.1 数据集下载 本数据集下载…...
什么是阻抗匹配,需要做啥)
PCB设计实践(二十三)什么是阻抗匹配,需要做啥
PCB设计中的阻抗匹配是高速数字电路、射频通信、信号完整性等领域的核心技术,其重要性贯穿从基础理论到复杂系统设计的全流程。本文将从工程实践角度深入探讨阻抗匹配的本质原理、应用场景、设计方法、常见误区及解决方案,全面解析这一影响现代电子设备性…...

网络世界的“变色龙“:动态IP如何重构你的数据旅程?
在深秋的下午调试代码时,我偶然发现服务器日志中出现异常登录记录——IP地址显示为某个境外数据中心。更有趣的是,当我切换到公司VPN后,这个"可疑IP"竟自动消失在了防火墙监控列表中。这个瞬间让我意识到:现代网络架构中…...

Chrome浏览器捕获hover元素样式
–前言– 某些元素,只有hover上去才会看到触发效果,但是鼠标移开就找不到element元素,导致无法调试样式。下属两种方案可参考: 文章目录 一、方式1:通过class伪类触发二、方式2:通过断点调试2.1控制台切换到…...
)
嵌入式自学第二十五天(5.21)
(1)二进制文件读写操作: 例: #include<stdio.h> int main() { FILE *fp fopen("a.out","r"); FILE *fp1 fopen("app","w"); if(NULL fp || NULL fp1) { …...

golang库源码学习——Pond,小而精的工作池库
pond 是一个轻量级的 Goroutine 池库,用于高效管理并发任务。它提供了灵活的配置选项和多种策略,适合处理高并发场景。 GitHub - alitto/pond at v1 一、特点: 1.轻量级 pond 的代码库非常精简,它的V1版本仅有四个业务文件&#…...

Microbiome医口经典思路:退烧药物代谢过程如何进行多组学分析?
乙酰氨基酚(APAP),俗称扑热息痛,是应用最广泛的镇痛和解热药物之一。以往的研究主要集中在分离APAP降解菌株,了解其降解代谢途径。但微生物群与对乙酰氨基酚之间的相互作用、对乙酰氨基酚降解基因的分布特征以及对乙酰…...

微信小程序AI大模型流式输出实践与总结
背景 让Cursor生成小程序中大模型调用内容回复的流式输出时一直有问题,参考整理此文章。 参考原文:https://blog.csdn.net/weixin_47684422/article/details/145859543 一、什么是流式传输? 流式传输(Streaming)指的…...
)
操作系统理解(xv6)
xv6操作系统项目复习笔记 宗旨:只记大框架,不记细节,没有那么多的时间 一、xv6的页表是如何搭建的? xv6这个项目中,虚拟地址用了39位(27位12位(物理内存page偏移地址))…...

2024CCPC辽宁省赛 个人补题 ABCEGJL
Dashboard - 2024 CCPC Liaoning Provincial Contest - Codeforces 过题难度 B A J C L E G 铜奖 4 953 银奖 6 991 金奖 8 1664 B: 模拟题 // Code Start Here string s;cin >> s;reverse(all(s));cout << s << endl;A:很…...

Sentinel原理与SpringBoot整合实战
前言 随着微服务架构的广泛应用,服务和服务之间的稳定性变得越来越重要。在高并发场景下,如何保障服务的稳定性和可用性成为了一个关键问题。阿里巴巴开源的Sentinel作为一个面向分布式服务架构的流量控制组件,提供了从流量控制、熔断降级、…...

Python 训练营打卡 Day 31
文件的规范拆分和写法 把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个好处: 可以让项目文件变得更加规范和清晰可以让项目文件更加容易维护,修改某一个功能的时候&a…...

vue+srpingboot实现多文件导出
项目场景: vuesrpingboot实现多文件导出 解决方案: 直接上干货 <el-button type"warning" icon"el-icon-download" size"mini" class"no-margin" click"exportSelectedFiles" :disabled"se…...

学习 Pinia 状态管理【Plan - May - Week 2】
一、定义 Store Store 由 defineStore() 定义,它的第一个参数要求独一无二的id import { defineStore } from piniaexport const useAlertsStore defineStore(alert, {// 配置 })最好使用以 use 开头且以 Store 结尾 (比如 useUserStore,useCartStore&a…...
 PAM ERROR (Permission denied))
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

数据湖和数据仓库的区别
在当今数据驱动的时代,企业需要处理和存储海量数据。数据湖与数据仓库作为两种主要的数据存储解决方案,各自有其独特的优势与适用场景。本文将客观详细地介绍数据湖与数据仓库的基本概念、核心区别、应用场景以及未来发展趋势,帮助读者更好地…...

OceanBase 开发者大会,拥抱 Data*AI 战略,构建 AI 数据底座
5 月 17 号以“当 SQL 遇见 AI”为主题的 OceanBase 开发者大会在广州举行,因为行程的原因未能现场参会,仍然通过视频直播观看了全部的演讲。总体来说,这届大会既有对未来数据库演进方向的展望,也有 OceanBase 新产品的发布&#…...

鸿蒙HarmonyOS最新的组件间通信的装饰器与状态组件详解
本文系统梳理了鸿蒙(HarmonyOS)ArkUI中组件间通信相关的装饰器及状态组件的使用方法,重点介绍V2新特性,适合开发者查阅与实践。 概述 鸿蒙系统(HarmonyOS)ArkUI提供了丰富的装饰器和状态组件,用…...

OneDrive登录,账号跳转问题
你的OneDrive登录无需密码且自动跳转到其他账号,可能是由于浏览器或系统缓存了登录信息,或存在多个账号的关联。以下是分步解决方案: 方案三对我有效。 强制手动输入密码 访问登录页面时: 在浏览器中打开 OneDrive网页版。 点击…...

9-码蹄集600题基础python篇
题目如上图所示。 这一题,没什么难度。 代码如下: def main():#code here# x,amap(int,input("").split(" "))# sum((1/2)*(a*x(ax)/(4*a)))# print(f"{sum:.2f}")x,amap(int,input().split())print(f"{((1/2)*(a*…...

CAU人工智能class3 优化器
优化算法框架 优化思路 随机梯度下降 随机梯度下降到缺点: SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,每次迭代更新使用的梯度都只与本次迭代的样本有关。 因为每个批次的数据含有抽样误差,每次更新可能并不会 …...
Service)
学习 Android(十一)Service
简介 在 Android 中,Service 是一种无界面的组件,用于在后台执行长期运行或跨进程的任务,如播放音乐、网络下载或与远程服务通信 。Service 可分为“启动型(Started)”和“绑定型(Bound)”两大…...

SpringAI开发SSE传输协议的MCP Server
SpringAI 访问地址:Spring AI Spring AI是一个面向人工智能工程的应用框架,由Spring团队推出,旨在将AI能力集成到Java应用中。Spring AI的核心是解决AI集成的根本挑战,即将企业数据和API与AI模型连接起来。 MCP…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

如何成为更好的自己?
成为更好的自己是一个持续成长的过程,需要结合自我认知、目标规划和行动力。以下是一些具体建议,帮助你逐步提升: 1. 自我觉察:认识自己 反思与复盘:每天花10分钟记录当天的决策、情绪和行为,分析哪些做得…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
)
网站制作公司哪家强?(2025最新版)
在数字化时代,一个优质的网站是企业展示自身实力、拓展业务渠道的重要工具。无论是初创企业还是大型集团,都需要一个功能强大、设计精美的网站来吸引客户、提升品牌形象。但面对市场上众多的网站制作公司,如何选择一家靠谱的合作伙伴呢&#…...
)
23种经典设计模式(GoF设计模式)
目录 🍀 创建型设计模式(5种) 1. 单例模式(Singleton) 2. 工厂方法模式(Factory Method) 3. 抽象工厂模式(Abstract Factory) 4. 建造者模式(Builder&am…...

深入解析Dify:从架构到应用的全面探索
文章目录 引言一、Dify基础架构1.1 架构概述1.2 前端界面1.3 后端服务1.4 数据库设计 二、Dify核心概念2.1 节点(Node)2.2 变量(Variable)2.3 工作流类型 三、代码示例3.1 蓝图注册3.2 节点运行逻辑3.3 工作流运行逻辑 四、应用场…...

电子电路:怎么理解放大电路中集电极电流Ic漂移?
如果放大电路中集电极电阻RC因为温度或老化而阻值变化,Vce Vcc - IcRc - IcRc,这会改变工作点,导致集电极的电流漂移。 IC漂移的定义:集电极电流随时间、温度等变化。影响IC的因素:β、IB、VBE、温度、电源电压、元件…...

【疑难杂症】Mysql 无报错 修改配置文件后服务启动不起来 已解决|设置远程连接
我修改配置后,服务无法启动可以试试用记事本打开后另存为,格式选择ANSI,然后重新启动mysql试试 设置运行远程、 1、配置my.ini文件 在[mysqld]下 添加bind-address0.0.0.0 2、设置root权限 使用MySql命令行执行, CREATE USER…...

Java基础 5.21
1.多态注意事项和细节讨论 多态的前提是:两个对象(类)存在继承关系 多态的向上转型 本质:父类的引用指向了子类的对象语法:父类类型 引用名 new 子类类型();特点:编译类型看左边,运行类型看…...

探索Puter:一个基于Web的轻量级“云操作系统”
在云计算与Web技术高度融合的今天,开发者们不断尝试将传统桌面体验迁移到浏览器中。近期,GitHub上一个名为Puter的开源项目吸引了社区的关注。本文将带你深入解析Puter的设计理念、技术架构与使用场景,探索它如何通过现代Web技术重构用户的“云端桌面”。 一、项目概览 Put…...

Java SpringBoot 项目中 Redis 存储 Session 具体实现步骤
目录 一、添加依赖二、配置 Redis三、配置 RedisTemplate四、创建控制器演示 Session 使用五、启动应用并测试六、总结 Java 在 Spring Boot 项目中使用 Redis 来存储 Session,能够实现 Session 的共享和高可用,特别适用于分布式系统环境。以下是具体的实…...

电商项目-商品微服务-规格参数管理,分类与品牌管理需求分析
本文章介绍:规格参数管理与分类与品牌管理的需求分析和表结构的设计。 一、规格参数管理 规格参数模板是用于管理规格参数的单元。规格是例如颜色、手机运行内存等信息,参数是例如系统:安卓(Android)后置摄像头像素&…...

Java 定时任务中Cron 表达式与固定频率调度的区别及使用场景
Java 定时任务:Cron 表达式与固定频率调度的区别及使用场景 一、核心概念对比 1. Cron 表达式调度 定义:基于日历时间点的调度,通过 秒 分 时 日 月 周 年 的格式定义复杂时间规则。时间基准:绝对时间点(如每天 12:…...
--Java版)
2025年- H39-Lc147 --394.字符串解码(双栈,递归)--Java版
1.题目描述 2.思路 可以用递归也可以用双栈,这边用栈。 首先先创建一个双栈,一个栈存数字(interger),另一个栈存字符(character)。设置数字临时变量num,设置字母临时变量curString在…...

学编程对数学成绩没帮助?
今天听到某机构直播说“学编程对数学成绩没帮助,如果想提高数学成绩那就单独去学数学”,实在忍不住要和各位家长聊聊我的思考,也欢迎各位家长评论。 恰在此时我看见了一道小学6年级的数学题如下,虽然题不难,但立刻让我…...
)
现代计算机图形学Games101入门笔记(十九)
光场 在近处画上图像,VR的效果。 任何时间任何位置看到的图像都不一样,是不是就是一个世界了。 光场就是任何一个位置往任何一个方向去的光的强度 知道光场就能知道这个物体长什么样子。 光线可以用一个点和一个方向确定。 也可以用2个点确定一条光线。 …...

STM32单片机GUI系统1 GUI基本内容
目录 一、GUI简介 1、emWin 2、LVGL (Light and Versatile Graphics Library) 3、TouchGFX 4、Qt for Embedded 5、特性对比总结 二、LVGL移植要求 三、优化LVGL运行效果方法 四、LVGL系统文件 一、GUI简介 在嵌入式系统中,emWin、LVGL、TouchGFX 和 Qt 是…...

Prometheus+Grafana实现对服务的监控
PrometheusGrafana实现对服务的监控 前言:PrometheusGrafana实现监控会更加全面,监控的组件更多 Prometheus官网 https://prometheus.io/docs/prometheus/latest/getting_started/ Grafana官网 https://grafana.com/docs/ 一、安装PrometheusGrafana 这…...

hook原理和篡改猴编写hook脚本
hook原理: hook是常用于js反编译的技术;翻译就是钩子,他的原理就是劫持js的函数然后进行篡改 一段简单的js代码 :这个代码是顺序执行的 function test01(){console.log(test01)test02() } function test02(){console.log(02)tes…...

Sign签证绕过
Sign的简介 Sign是指一种类似于token的东西 他的出现主要是保证数据的完整性,防篡改 就是一般的逻辑是 sign的加密的值和你输入的数据是相连的(比如sign的加密是使用输入的数据的前2位数字配合SHA1 等这样的) 绕过 :碰运气可以…...

【Vue篇】重剑无锋:面经PC项目工程化实战面经全解
目录 引言 一、项目功能演示 1. 目标 2. 项目收获 二、项目创建目录初始化 vue-cli 建项目 三、ESlint代码规范及手动修复 1. JavaScript Standard Style 规范说明 2. 代码规范错误 3. 手动修正 四、通过eslint插件来实现自动修正 五、调整初始化目录结构 1. 删除…...
)
JVM参数详解与实战案例指南(AI)
JVM参数详解与实战案例指南 一、JVM参数概述与分类 JVM参数是控制Java虚拟机运行时行为的关键配置项,合理设置这些参数可以显著提升应用性能。根据功能和稳定性,JVM参数主要分为三类: 标准参数:所有JVM实现都必须支持ÿ…...

C++通过空间配置器实现简易String类
C实现简易String类 在C中,使用空间配置器(allocator)实现自定义string类需要管理内存分配、释放及对象构造/析构。 #include <memory> #include <algorithm> #include <cstring> #include <stdexcept> #include &l…...

MyBatis:简化数据库操作的持久层框架
1、什么是Mybatis? MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由 apachesoftwarefoundation 迁移到了google code,由谷歌托管,并且改名为MyBatis 。 2013年11月迁移到Github。 iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框…...

Spring Boot集成Spring AI与Milvus实现智能问答系统
在Spring Boot中集成Spring AI与Milvus实现智能问答系统 引言 随着人工智能技术的快速发展,越来越多的企业开始探索如何将AI能力集成到现有系统中。本文将介绍如何在Spring Boot项目中集成Spring AI和向量数据库Milvus,构建一个高效的智能问答系统。 …...
:一致性哈希算法)
软件工程(六):一致性哈希算法
哈希算法 定义 哈希算法是一种将任意长度的输入(如字符串、文件等)转换为固定长度输出的算法,这个输出称为“哈希值”或“摘要”。 常见的哈希算法 哈希算法哈希位数特点MD5128位快速,但已不安全SHA-1160位安全性提高…...

Linux内存分页管理详解
Linux内存分页管理详解:原理、实现与实际应用 目录 Linux内存分页管理详解:原理、实现与实际应用 一、引言 二、内存分页机制概述 1. 虚拟地址与物理地址的划分 2. 分页的基本原理 三、虚拟地址到物理地址的转换 1. 地址转换流程 2. 多级页表的遍历 四、多级页表的…...