[论文精读]Ward: Provable RAG Dataset Inference via LLM Watermarks
Ward: Provable RAG Dataset Inference via LLM Watermarks
[2410.03537] Ward: Provable RAG Dataset Inference via LLM Watermarks
ICLR 2025
Rebuttal:Ward: 可证明的 RAG 数据集推理通过 LLM 水印 | OpenReview --- Ward: Provable RAG Dataset Inference via LLM Watermarks | OpenReview
论文研究了 RAG 数据集推理(RAG-DI)的问题,即数据所有者希望通过黑盒查询来检测他们的数据集是否包含在 RAG 语料库中。与 RAG MIA 设置的主要区别在于,数据所有者做出的是数据集级别的决策,而不是像 MIA 中那样做出文档级别的决策。
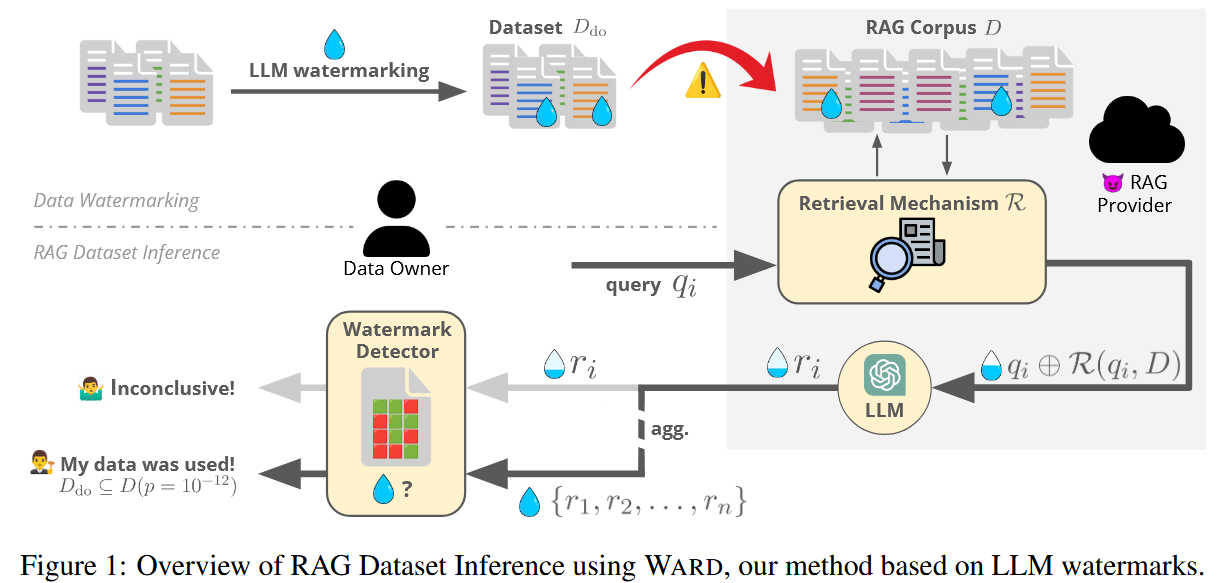
RAG引发了对未经授权使用文档的担忧,文章把这个问题正式称为RAG 数据集推理 (RAG-DI),其中数据所有者旨在通过黑盒查询检测其数据集未经授权包含在 RAG 语料库中(图 1)。在对这个问题的第一次全面研究中,观察到用于 RAG 隐私的相邻工作中使用的现有数据集不适合 RAG-DI。首先,这些数据集中的样本可能已被用于当代 LLM 训练,这使得 RAG 语料库由新数据组成的现实评估变得复杂。其次,这些数据集没有对事实冗余进行建模,这是现实世界 RAG 的一个关键属性,其中多个文档具有相似的内容,要么是由于从各种来源(例如新闻)抓取数据,要么是由于分块。研究 RAG-DI 的另一个挑战源于缺乏适用于现实黑盒设置的基线。
RAG-DI 的基础
在这项工作中,我们采取了多个步骤来弥合这些差距: 首先引入了 FARAD,这是一个专为在现实条件下评估 RAG-DI 而设计的新数据集。FARAD 包含虚构的文章,这些文章在设计上不属于任何 LLM 训练数据,并且可以在事实冗余下进行评估,从而能够准确评估 RAG-DI 方法。其次调整了之前关于 RAG 成员推理攻击 (MIA)对 RAG-DI 问题的工作[Generating is believing: Membership inference attacks against retrieval-augmented generation. ][Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation],并提出了一个简单的基线 FACTS.
后续做了实验评估FARAD,发现它在们没有事实冗余的环境中优于其他baseline,这体现出先前数据集的缺点;当存在数据冗余的时候,所有基线都表现不佳,因此需要能够可靠识别RAG语料库中未经授权使用文档的新检测方法
文章基于LLM水印提出了WARD,它通过印记 LLM 水印来保护数据所有者的数据集【A watermark for large language models. In ICML, 2023.;Robust distortion-free watermarks for language models. TMLR 05/2024, 2024.】。如图 1 所示,给定对检索增强 LLM 的有限数量的黑盒查询 q i,数据所有者可以在响应 r i 中检测到即使是很小的水印痕迹,并首次获得有关其数据集在 RAG 语料库中使用情况的严格统计保证,使他们能够有效地审计 RAG 提供商。由于其跨设置的稳健性,以及它只与检索增强的 LLM 进行自然交互的事实,即使 RAG 提供商试图防止系统意外使用,WARD 也能保持其性能。
主要贡献
• 正式提出了RAG 数据集推理(RAG-DI),其中数据所有者旨在检测在 RAG 系统中未经授权使用其数据集
• 通过以下方式促进对这个问题的研究:(i) 提出一个新的数据集 FARAD,专门用于在现实条件下对 RAG-DI 方法进行基准测试,以及 (ii) 引入一组初始基线方法
• 提出了 LLM 水印作为一种可证明、稳健和可靠地检测 RAG 语料库中未经授权的数据使用的方法,将 WARD 作为一种新的 RAG-DI 方法
• 在各种设置中的实验评估肯定了现有数据集和所有 RAG-DI 基线的基本局限性,并证明了 WARD 的有效性,它始终显示出高准确性, 查询效率和健壮性
LLM水印技术:
参考另一篇文章对开山作《A Watermark for Large Language Models》的分析:大模型水印技术:判断文本是不是LLM生成的 - 知乎
更新的LLM水印方法:THU-BPM/MarkLLM: MarkLLM: An Open-Source Toolkit for LLM Watermarking.(EMNLP 2024 Demo)
RAG数据集推理 RAG-DI
目标实际上和MIA很像。但是MIA是文档级别的检测,这个任务是数据集级别的检测。
RAD-DI问题张的关键实体是数据所有者,目的是从未经授权的RAG语料库应用中保护它们自己的n个文档的数据集D_do。然后RAG语料库使用者的目标是找到是否这些未经授权的内容存在于语料库中,如果存在,就需要对它们进行修改(因为语料库的收集往往是非人工审核的,为了避免纠纷需要对侵权内容进行修改)。最终还是一个二分类问题。
构造适用于RAG-DI任务的数据集
要求:不应该是LLM训练语料的一部分;需要存在事实冗余信息(有重叠主题和信息的文档)。
先前针对RAG隐私的相关工作使用的是EnronEmails(2004年)和Health-careMagic(2021年)两个数据集,因为其中包含PII个人隐私信息,但是发布时间过早,可能被添加到训练语料中了,其次是缺少事实冗余信息。
因此构建了FARAD数据集。
FARAD 由多个组组成。每个组都包含共享一个主题和大量信息的文章,但这些文章是由不同的 (LLM) 作者独立撰写的。使用 RepLiQA作为数据源,其中包含有关虚构实体和事件的文章,通过设计确保这些知识不存在于任何 LLM 训练数据中。RepLiQA数据集不是一下子全部发布完毕的,在创建FARAD的时候使用 split 0 (0号分片)作为撰写本文时唯一可用的 split,但计划将其扩展到未来的 split。
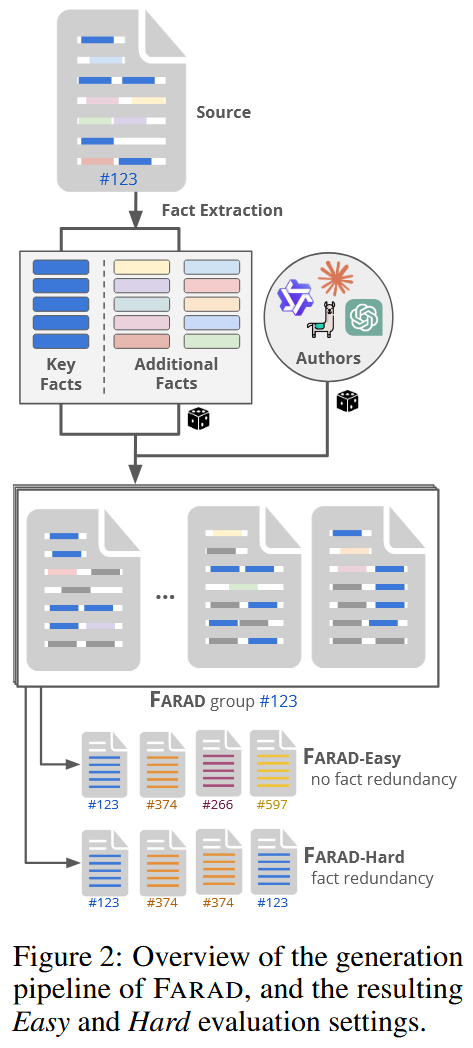
每篇 RepLiQA 文章都是其中一个小组的来源,使用图 2 所示的管道:首先提示 GPT4O 将文章的信息内容提炼成 5 个独立的关键事实,这些事实对理解文章至关重要,以及 10 个独立的附加事实,这些事实存在于文章中,但对其关键信息不是必需的。部分prompt如下:

为了创建一个组,从最先进的 LLM 的集合 A = {GPT4O, CLAUDE3.5-SONNET,LLAMA3.1-405B,QWEN1.5-110B} 中抽取一个作者模型。作者的多样性、抽样事实和(理想的)幻觉内容导致了基于相同核心知识的多样化虚构文章集,这满足了我们之前的要求。虽然此管道可以扩展到更大/更多的组、更多的作者和不同的事实组合,但我们将 FARAD 限制为 3591 个组(3391 个用于测试,200 个用于训练),每个组 4 篇文章,A 中的每位作者一篇。prompt在上面。
在后文的实验中使用 FARAD 创建两个评估设置:简单和困难,如图 2 所示(底部)。简单设置遵循上述传统设置,其中事实是唯一表示的,每个 FARAD 组始终最多使用 1 篇文章。Hard 设置通过始终包含组中的所有 4 篇文章来引入事实冗余。
RAG-DI基线
先把MIA的方案迁移过来,对数据集中的所有文档都使用MIA,得到一组二进制结果,求平均就是数据集级别的评估分数。使用DI的训练数据集实例化几个IN和OUT实例,计算对应的两类评估分数,如果总体数据集的评估分数大于两个评估分数的均值,则认为是成员数据集。
提出了FACTS基线,FACTS 是一种文档级方法。给定一个文档 d,FACTS 提示辅助 LLM 生成一个只能通过阅读 d 来回答的问题,然后,M ⋆ (RAG系统)被提示该问题,如果它认为它无法回答,我们设置 mi(d, M ⋆ ) = 0,否则将其设置为 1。如上所述,我们通过在训练集上拟合阈值,将此类文档级决策聚合为语料库级决策。
LLM水印方案
理想的RAG-DI方案应该满足三个关键要求:
- 单调性:随着对RAG查询的增加,该方法预测的准确性应该不断提高,最好以高速率提高
- 保证该方法应该能够为其决策提供统计保证,既有及其罕见且控制良好的1类错误(把正确的结果误判)因为诬告 RAG 提供者在实践中是非常不可取的,并且会破坏对该方法的信任。
- 稳健性:该方法应在不同的评估设置下保持高准确性,包括 RAG 提供商主动隐藏未经授权的数据使用的尝试。
前文的baseline都在一定程度上违反了这些要求,因此提出了 WARD(RAG-DI 水印),这是一种基于 LLM 水印的主动 RAG-DI 方法,并讨论了为什么它可能满足所有规定的要求。
基本思想
假定数据所有者已通过嵌入 LLM 水印对每个文档 di∈Ddo 进行了保护,方法可以是通过Human-in-the-loop人机回环程序,也可以是(如本工作中的)用带水印的 LM 重新表述每个文档。原则上,任何 LLM 水印都可以应用,但本文将重点放在流行的红绿水印上(相关内容部分的开山文章)。
为了审核 RAG 提供者的语料库,对于每个 di ∈ Ddo,WARD 会生成一个与内容相关的开放式问题 qi,并查询 M⋆。如果 di ∈ D(IN 情况),我们希望检索方法 R 将 di 中的水印内容引入 LLM 上下文。水印对文本转换的鲁棒性足以将信号的痕迹传播到LLM 的最终响应 ri = M⋆(qi)。
增强弱信号
这要求将每个 r i 标记为带水印,即水印检测器 p 值 p < α,将是一个强假设,因为水印信号可能会在整个 RAG 管道中降级。但是,这不是 WARD 有效的必要条件。相反,按照 Sander 等人(Watermarking makes language models radioactive. NeurIPS, 2024.)的说法,在 n 次查询之后,我们计算出一个联合 p 值 R = {r 1 , . . ., r n },直接对应于零假设“数据所有者的数据集 Ddo 不在 RAG 语料库 D 中”。
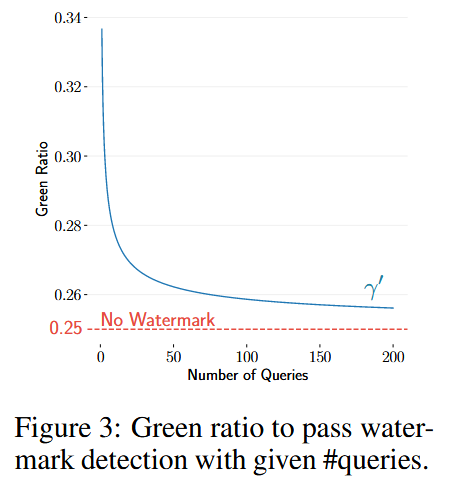
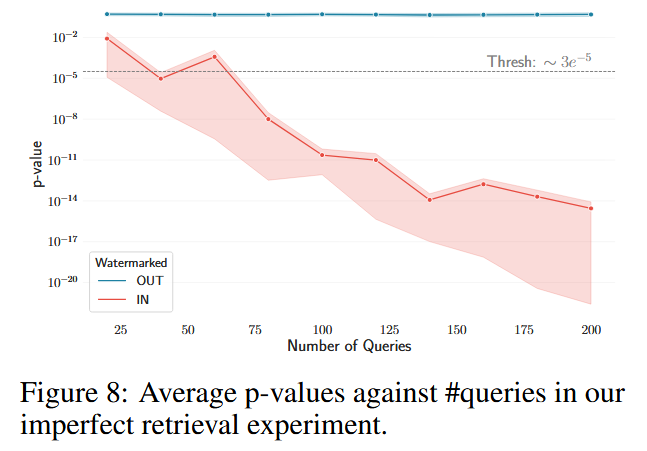
这个联合 p 值可以满足 p < α,即拒绝原假设,即使单个 r i 仅携带微弱的水印信号,也不会单独拒绝它。为了说明这一点,给定一个期望的 p 值的阈值 α,方程 ( 1) 意味着 R 中所需的绿色标记比率至少是![]() 其中 Φ 是标准正态分布 CDF,并且 |R|⊕ 是R 中响应的总长度。此下限会随着 |R|⊕的增加急剧降低:在图 3 中,我们将下限绘制为 n 的函数,假设 ∀i : |r i |= 400 个令牌,α ≈ 3 • 10 -5(z 分数至少为 4),γ = 0.25,和后文的实验设置一致。
其中 Φ 是标准正态分布 CDF,并且 |R|⊕ 是R 中响应的总长度。此下限会随着 |R|⊕的增加急剧降低:在图 3 中,我们将下限绘制为 n 的函数,假设 ∀i : |r i |= 400 个令牌,α ≈ 3 • 10 -5(z 分数至少为 4),γ = 0.25,和后文的实验设置一致。
对于 n ≥ 100,如果通过 RAG 管道传播水印仅将绿色标记的比率增加 1%,则已经可以高置信度检测到它。这使得 WARD 可行,满足 Guarantees 要求,这与任何基线都不同。它还有助于单调性:假设每个 d i 都有一个 γ ′' 的绿色标记比率,通过 M ⋆ 传播的比率减少到 γ ′ ∈ (γ, γ ′′ ),IN 情况的 p 值会随着查询的增加而严格降低。
【图三对于理解这篇文章有很重要的意义,写在下面】
纵轴Green Ratio标识回答中的“绿色词”的比例。这个比例是检测水印信号的关键指标。No Watermark表示没有水印的情况下随机文本的绿色词比例为0.25,对应的就是公式2里面的γ
- 初始阶段(0-50 次查询) :
- 需要较高的 Green Ratio 才能通过检测。
- 这是因为样本量较小,统计显著性较低。
- 中期阶段(50-150 次查询) :
- Green Ratio 快速下降,表明 WARD 方法的效率很高。
- 即使水印信号较弱,也可以通过多次查询积累足够的证据。
- 后期阶段(150-200 次查询) :
- Green Ratio 接近稳定,接近 No Watermark 的基准线。
- 这表明即使在大量查询后,WARD 仍然能够提供可靠的检测结果
单调性的另一个要求是 OUT 情况的 p 值经过良好校准,确保极少见的假阳性。为了确保水印检测器评分的标记之间的独立性,有必要忽略 R 中的重复 h 元语法。虽然这减少了每个查询的有用令牌数量,但后文的实验结果表明,它不会影响 WARD 性能。
红绿方案的关键参数是上下文宽度h。在 LLM 水印的常见应用中,不建议使用低 h,因为它使水印很容易通过重复查询窃取。在 RAG-DI 的上下文中,这并不是一个问题,因为数据所有者永远不会像给 LLM 添加水印时那样公开对水印内容的不受约束的查询访问。因此,由于低 h 有利于水印通过 RAG 的传播,我们使用 h = 2.这有助于 WARD 的高鲁棒性
实用性:使 WARD 健壮的另一个方面是它不显眼,因为它通过合法使用 RAG 系统对看起来自然的文档、查询和响应——这使得 RAG 提供商阻止恶意交互的潜在尝试效果降低。这与 AAG 等基线不同,后者直接揭示了泄露 D 信息的意图。此外,WARD 不需要对 RAG-DI 进行任何训练或适应,因为 LLM 水印自然适用于此任务。
人话描述上面的所有内容
研究背景:大模型私用数据来训练模型有MIA在牵制着,但是一旦引入了RAG,就不好界定训练数据和目标数据之间是否存在一个比较明确的包含关系。先抛开训练数据不谈,未经授权的数据使用(比如爬取并使用他人数据来用作自己的知识库)变得越来越普遍,当前并不存在一种方法来提供统计上的保证来证明数据的不正当使用。
动机是隐私保护,防止偷偷滥用数据,以及考虑到数字水印技术让LLM生成结果可追溯,如果能够迁移过来,对数据加上数字水印是否可以来证明自己数据被偷偷使用了呢?
问题定义:RAG-DI,在一个黑盒环境下(即无法访问模型参数),数据拥有者(Data Owner)想要通过查询接口,判断自己的数据是否被某个 RAG 系统所使用 。
传统MIA的局限性:主要针对的是训练数据的成员推断(判断某条数据是否参与了模型训练)。但在 RAG 场景下,它并不是基于训练数据进行推理,而是基于检索数据,并且文档内容可能重复(fact redundancy),使得传统方法难以区分来源
这一新问题存在的挑战:黑盒环境限制,检测只能对RAG进行查询并获得输出;不同文档可能描述相同或者相似的事实(比如多家媒体报道同一个事件),这就使得如果只依赖于语义相似度或者关键词匹配来判断很容易误判;还缺乏一个数据集,先前的数据集不确定是不是被拿去参与训练了,而且这些数据集中往往不存在数据冗余,导致评估不够真实。
作者也同步定义了三个评估RAG-DI方法好坏的标准:单调性(查询次数越多,检测准确率越高,并且这个提升速度越快越好),统计保证(一类误报错误要极低才能适应真实应用),鲁棒性(即使面对防御手段比如RAG数据集构建者自知理亏,用人家的数据集但是对人家的数据集进行了改写操作,或者是限制了n-gram重叠,此时仍要保证方法的高准确率)
方法的核心思想是基于水印的信号传播:利用LLM水印技术对数据拥有者的文档进行水印化处理,观察这些水印是否会在RAG系统的输出中保留【这个文章急于验证数字水印的潜力以及开辟研究方向,就先只考虑了让私有数据过一遍水印模型来加水印,再投放,因此加水印这里就很简略了】;基于统计实现验证:如果水印再输出中出现的概率显著高于随机水平就说明RAG很有可能使用了这些文档。
具体步骤
(1) 数据准备阶段
- 构建水印文档 :数据拥有者使用带有水印的模型对其文档进行改写(paraphrase),从而在文档中嵌入不可见的水印。
- 构造测试集 :为了评估效果,作者构建了一个名为FARAD的数据集,其中每个文档都有多个由不同LLM生成的版本,并且包含相同的核心事实(key facts)和一些额外的事实(additional facts)。为每个水印文档生成若干个问题,这些问题的答案需要依赖该文档中的信息才能正确回答,目的是确保当 RAG 系统检索到该文档时,会将其内容用于生成答案。
【文章很精明的一点是,他在数据集构造的时候说了,构造的全都是虚假信息,都不是基于真实世界发生的事情,因此谁要是用他这个数据集来参与训练还会吃瘪,影响自己模型的准确性,哪个RAG偷用他的数据集也可能导致他们RAG产生更多幻觉,无懈可击。】
(2) 查询与检测阶段
- 模拟用户查询 :向RAG系统发送一系列问题,这些问题需要从特定文档中提取信息才能回答。(在构造数据集的时候同步构造的问题)
- 收集响应 :记录RAG系统的输出,并检查其中是否包含水印特征。
- 统计分析 :计算水印特征在输出中的出现频率,如果水印特征出现的概率显著高于随机水平,则说明 RAG 系统很可能使用了 Ddo 中的文档。通过 p-value(显著性检验)来量化这种概率,设定阈值 α(如 0.05)作为判断依据
(3) 水印检测机制
- Red-Green水印 :这是目前主流的一种水印技术。在生成过程中,词汇表被划分为“绿色”(鼓励使用的token)和“红色”( discouraged token)。通过调整生成策略,模型倾向于选择绿色token,从而形成可检测的模式。
- 水印传播 :当RAG系统使用水印文档作为输入时,生成的答案会继承这些水印特征,从而可以在输出中检测到。
文章这种检测方式的核心还是因为水印传播,当 RAG 系统使用水印文档作为输入时,它会在生成回答时继承这些水印特征,因为 RAG 系统的生成过程通常是对检索到的内容进行“压缩”或“总结”,而不是完全重新生成。
文章还提到了水印强度控制参数δ和上下文长度h,前者控制水印强度,值越大水印越明显,可能会影响文本的质量(因为绿色列表中的可选词更少了),后者控制水印检测器使用的上下文长度,值越大检测能力越强,但是可能需要更多的样本才能可靠检测。上下文长度 h 是指在使用 Red-Green 水印技术 时,水印检测器在判断一个 token 是否是“绿色词”时所参考的历史 token 数量,如果 h = 2,那么判断当前 token 是否为绿色词时,只看它前面最近的 2 个 token,决定了水印信号的局部上下文依赖性
实验验证
实验设置:
每个 FARAD 组(group)包含 4 篇文章 ,分别由不同的语言模型生成(LLM authors)。这些文章描述相同的“核心事实”,但使用不同的措辞(paraphrase),模拟现实中的事实冗余现象
使用FARAD数据集。在FARAD-EASY情况下,数据集总条目数800,其中测试用的数据条目200(800个里面有200个是故意塞进去的带有水印的文本,需要检测出来)每组只使用一篇文章,确保事实唯一表示(no redundancy)
在FARAD-HARD情况下总条目数3000,每组使用全部 4 篇文章,形成严重的事实冗余,模拟更真实、更具挑战性的场景。
使用的大模型:GPT3.5, Claude3 Haiku, Llama3.1-70B
系统提示词:一个Naive-P,基础rag提示词,没有额外限制

一个Def-p,防御性提示,提示模型不要逐字复制来源内容,并拒绝泄露上下文信息。用于模拟 RAG 提供商试图隐藏未经授权的数据使用的场景。

假定使用一个完美的检索系统,它总能够检索到最相关的文档
完美检索器用来排除检索误差对实验结果的影响,观察WARD在理想条件下的最佳表现。
策略是手动设置返回结果优先级:
如果用户的问题是基于某个特定文档 d∈Ddo 构建的,并且该文档存在于 D 中,则首先将其放入检索结果中;接下来,加入与目标文档属于同一 FARAD 组(即描述相同核心事实的不同版本)的所有文档,这些文档可能来自不同的 LLM 作者(如 A1, A2, A3, A4),它们表达了相同的事实但措辞不同(HARD模式下);最后,从知识库中随机选择其余的文档,直到达到指定的检索数量 k
实验中最多进行 200 次查询,用来测试方法随查询次数增加的表现变化
δ :水印强度(strength),影响绿色词出现的概率范围:2.5 ~ 4.5
h :上下文长度(context size),决定水印检测器使用的上下文窗口大小默认值:h=2
k ∈ {3, 4, 5, 10},以测试检索规模对性能的影响表示,k每次检索返回的文档数量
结果

绿色块表示正确的检测结果(IN状态下正确识别目标模型被使用,OUT状态下正确识别未被使用);红色快表示错误检测结果(IN状态下的漏报,OUT状态下的误报)
在 Hard 设置中,所有基线都无法一致地执行,从而导致误报和假阴性。这可以归因于它们在处理事实冗余方面的缺点:FACTS 直接依赖于事实,而 SIB 和 AAG 依赖于受事实内容影响的语义相似性。值得注意的是,只有 WARD 在所有设置、模型和系统提示中实现了 100% 的准确性,这表明尽管检索到具有部分重叠事实的文档,但水印为数据集推理提供了可靠的信号。这支持了我们关于事实冗余对于实际 RAG-DI 评估的重要性的说法,并强调了水印作为 RAG-DI 方法的潜力
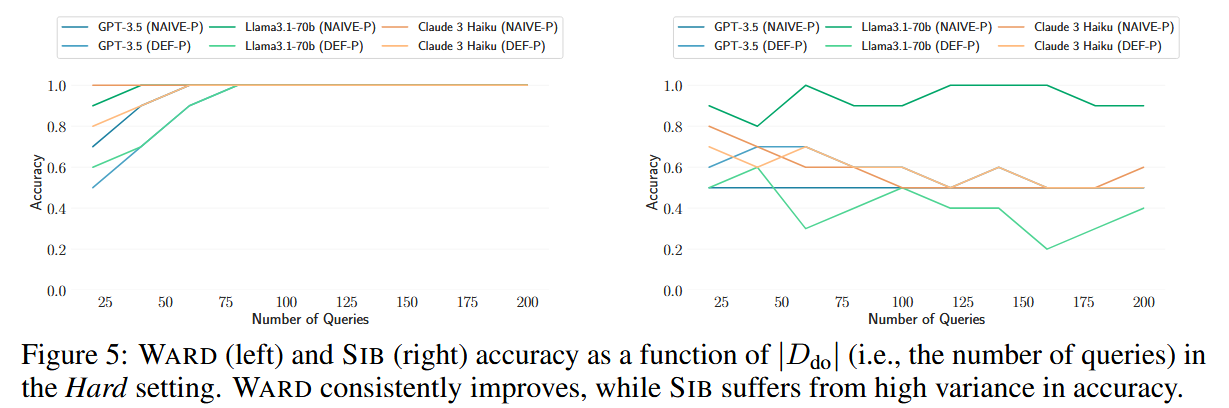
可以看出,baseline不满足定义的单调性

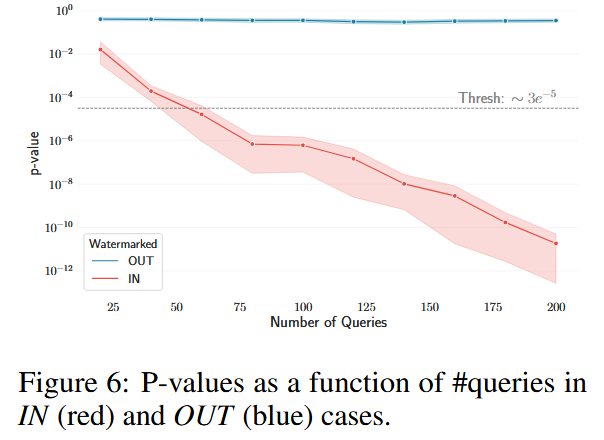
统计保证:
分别测试 IN(文档被使用)和 OUT(文档未被使用)两种情况下的 p-value 变化。
设定显著性阈值 α = 3 × 10⁻⁵。
图6 显示,IN 情况下的 p-value 随查询次数迅速下降至接近 0。
OUT 情况下的 p-value 保持在较高水平(接近随机分布),没有明显下降趋势。
说明WARD 成功提供了严格的统计保证,几乎没有误报(Type I 错误)。这对于法律诉讼、商业合规等场景至关重要。
鲁棒性:实际上图4就是鲁棒性的证明,所有baseline在hard模式下表现不佳。
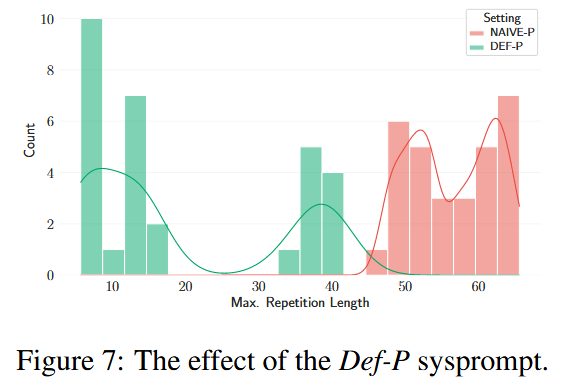
这个是比较两种PROMPT的优劣,是对比输出结果和LLM实际接收到的prompt内容的重复文本数目统计,可以看出Def-p的防护还是可以的,很少出现多词汇泄露。
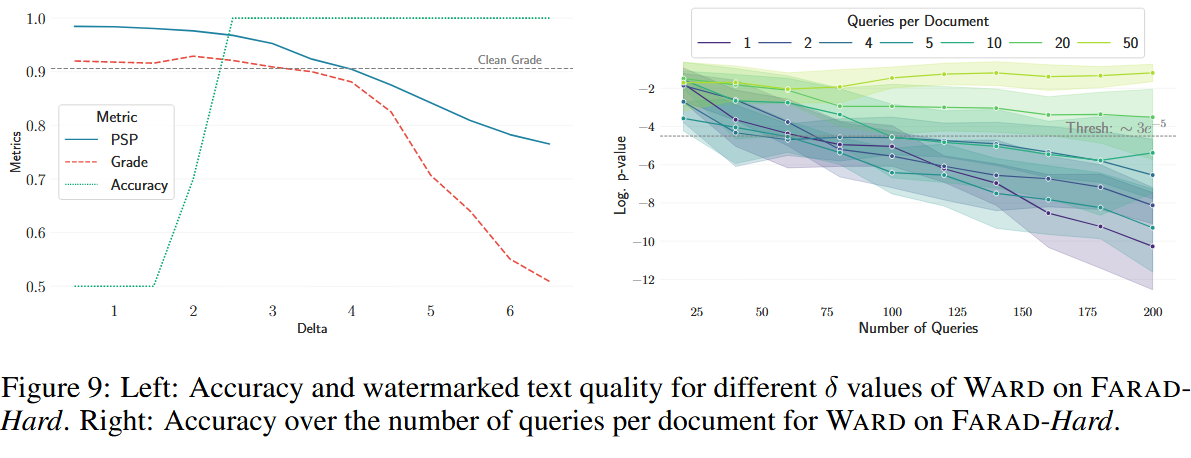
左图是水印强度的探究
p-value值,再IN情况下,随着查询数迅速下降,说明方法有效
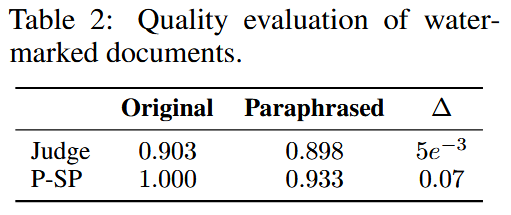
释义前后文本质量变化程度
相关文章:

[论文精读]Ward: Provable RAG Dataset Inference via LLM Watermarks
Ward: Provable RAG Dataset Inference via LLM Watermarks [2410.03537] Ward: Provable RAG Dataset Inference via LLM Watermarks ICLR 2025 Rebuttal:Ward: 可证明的 RAG 数据集推理通过 LLM 水印 | OpenReview --- Ward: Provable RAG Dataset Inference v…...

第23天-Python Flet 开发指南
环境准备 pip install flet 示例1:基础计数器应用 import flet as ftdef main(page: ft.Page):page.title = "计数器"page.vertical_alignment = ft.MainAxisAlignment.CENTERtxt_number = ft.TextField(value="0", text_align=ft.TextAlign.RIGHT, wid…...
——自定义状态)
LangGraph(五)——自定义状态
目录 1. 向状态添加键2. 更新工具中的状态3. 构建状态图4. 提示聊天机器人5. 添加人工协助6. 手动更新状态参考 1. 向状态添加键 通过向状态添加name和birthday键来更新聊天机器人对实体生日的研究: from typing import Annotated from typing_extensions import T…...

fatload使用方式
Fatload是U-Boot中的一个命令,用于从FAT文件系统加载二进制文件到内存中。其基本用法如下: fatload <interface> <dev[:part]> <addr> <filename> <bytes>interface:所使用的接口,如MMC、…...

Pytorch基础操作
面试的时候,PhD看我简历上面写了”熟悉pytorch框架“,然后就猛猛提问了有关于tensor切片的问题…当然是没答上来,因此在这里整理一下pytorch的一些基础编程语法,常看常新 PyTorch基础操作全解 一、张量初始化 PyTorch的核心数据…...

Femap许可证安装与配置指南
在电磁仿真领域,Femap凭借其卓越的性能和广泛的应用场景,已成为许多工程师和科研人员的首选工具。为了确保您能够顺利安装和配置Femap许可证,本文将提供详细的安装和配置指南,帮助您快速完成设置,开启高效的仿真之旅。…...
)
家用和类似用途电器的安全 第1部分:通用要求 与2005版差异(7)
文未有本标准免费下载链接。 ——增加了“对峰值电压大于15kV的,其放电电能应不超过350mJ”的要求(见8.1.4) 1. GB/T4706.1-2024: 8.1.4 如果易触及部件为下述情况,则不认为其是带电的。 ——该部件由安全特低电压供电,且: 对…...

基于Browser Use + Playwright 实现AI Agent操作Web UI自动化
Browser Use是什么 Browser Use是一个开源项目官网:Browser Use - Enable AI to control your browser,专为大语言模型(LLM)设计的只能浏览器工具,能够让AI像人类一样自然的浏览和操作网页,支持多标签页管…...

【题解-洛谷】B4302 [蓝桥杯青少年组省赛 2024] 出现奇数次的数
题目:B4302 [蓝桥杯青少年组省赛 2024] 出现奇数次的数 题目描述 奇数:指不能被 2 2 2 整除的整数。 例如: 3 3...

Redis SETNX:分布式锁与原子性操作的核心
SETNX 是 Redis 中的一个经典命令,全称是 Set if Not eXists(当键不存在时设置值)。它的核心作用是原子性地完成 “检查并设置” 操作,常用于分布式锁、防止重复提交等需要 “独占性” 的场景。 一、基本语法与返回值 命令格式&…...

常见字符串相似度算法详解
目录 引言 一、Levenshtein距离(编辑距离) 1.1 算法原理 1.2 Java实现 1.3 springboot中实现 二、Jaro-Winkler相似度 2.1 算法特点 2.2 Java实现 三、余弦相似度(向量空间模型) 3.1 实现步骤 3.2 Java实现 3.3 简化版…...

红蓝对抗中的网络安全设备操作手册
目录 🔐 关键要点 设备操作与实战应用 📊 1. 防火墙 (Firewall) 蓝队(防御)用法 红队(攻击)用法 🔍 2. 入侵检测/防护系统 (IDS/IPS) 蓝队(防御)用法 红队&#…...

用python实现汉字转拼音工具
用python实现汉字转拼音工具 主要功能特点: 多种拼音风格选择(带声调符号、数字声调、无声调)输出模式:可以选择“普通模式”(仅拼音)或“拼音注音”(每个汉字的拼音显示在上方)可…...

spring中的Interceptor使用说明
一、Interceptor 的核心概念 Interceptor(拦截器) 是 Spring MVC 提供的一种机制,用于在请求处理的不同阶段插入自定义逻辑。其核心作用包括: • 预处理:在控制器方法执行前进行权限校验、日志记录等。 • 后处理&am…...
)
Wi-Fi(无线局域网技术)
Wi-Fi(Wireless Fidelity,无线保真)是通过无线电波传输数据的技术,它使设备能够通过无线连接方式访问网络、共享文件或连接互联网。Wi-Fi已经成为现代家庭、办公室以及公共场所中常见的无线通信方式,支持的设备包括手机…...
)
MySQL Host 被封锁解决方案(全版本适用 + Java 后端优化)
引言 MySQL 中 “Host is blocked because of many connection errors” 是生产环境常见问题,若处理不当会导致服务中断。本文结合 MySQL 官方文档(5.5/8.0)、Java 后端最佳实践及企业级经验,提供从 “快速解封” 到 “根源优化”…...

分类预测 | Matlab实现PSO-RF粒子群算法优化随机森林多特征分类预测
分类预测 | Matlab实现PSO-RF粒子群算法优化随机森林多特征分类预测 目录 分类预测 | Matlab实现PSO-RF粒子群算法优化随机森林多特征分类预测分类效果**功能概述****算法流程** 分类效果 功能概述 数据预处理 读取Excel数据集,划分训练集(前260行&#…...

【苍穹外卖】Day01—Mac前端环境搭建
目录 一、安装Nginx (一)安装Homebrew (二)Homebrew安装Nginx 1. 执行安装命令: 2. 验证安装: (三)启动与停止Nginx 二、配置Nginx 1. 替换nginx.conf 2. 替换html文件夹 三…...

anaconda创建环境出错HTTPS
报错信息 warnings.warn( /home/ti-3/anaconda3/lib/python3.12/site-packages/urllib3/connectionpool.py:1099: InsecureRequestWarning: Unverified HTTPS request is being made to host ‘repo.anaconda.com’. Adding certificate verification is strongly advised. Se…...

Nginx 强制 HTTPS:提升网站安全性的关键一步
在当今互联网时代,网站的安全性至关重要。使用 HTTPS 协议可以有效保护用户数据,防止信息泄露和中间人攻击。本文将详细介绍如何在 Nginx 中设置强制 HTTPS,确保所有 HTTP 请求都被自动重定向到 HTTPS。 一、背景与重要性 HTTPS(…...

青藏高原边界数据总集
关键数据集分类:地表参数数据集空间分辨率:m共享方式:开放获取数据大小:265.87 KB数据时间范围:2016元数据更新时间:2022-04-18 数据集摘要 此边界数据总集包含五种类型的边界: 1、TPBoundary_2500m&#…...

AI赋能R-Meta分析核心技术:从热点挖掘到高级模型
随着人工智能技术的不断进步,Meta分析作为科学研究中的一种重要方法,也在不断地被赋予新的活力。特别是以ChatGPT为代表的AI大语言模型,为Meta分析提供了更为高效和智能的工具。本文将详细介绍AI赋能R-Meta分析的核心技术,并结合实…...

基于R语言地理加权回归、主成份分析、判别分析等空间异质性数据分析实践技术应用
在自然和社会科学领域有大量与地理或空间有关的数据,这一类数据一般具有严重的空间异质性,而通常的统计学方法并不能处理空间异质性,因而对此类型的数据无能为力。以地理加权回归为基础的一系列方法:经典地理加权回归,…...

GPT 等decoder系列常见的下游任务
下面用一句话+四个例子,把上面那张“所有下游任务都要微调”架构图说清楚: 核心思路:不管你要做什么任务,都用同一个 Transformer(这里是 GPT/Decoder-Only 模型)当“特征抽取器”&a…...

java面试每日一背 day1
1.什么是缓存穿透 缓存穿透是指查询一个数据库中根本不存在的数据,导致这个查询请求绕过缓存直接访问数据库的情况。这种情况如果频繁发生,会对数据库造成不必要的压力。 典型特征: (1)查询的数据在数据库和缓存中都…...

Spring Boot AI 之 Chat Client API 使用大全
ChatClient提供了一套流畅的API用于与AI模型交互,同时支持同步和流式两种编程模型。 流畅API包含构建Prompt组成元素的方法,这些Prompt将作为输入传递给AI模型。从API角度来看,Prompt由一系列消息组成,其中包含指导AI模型输出和行为的指令文本。 AI模型主要处理两类消息: …...

初识Linux · 五种IO模型和非阻塞IO
目录 前言: 五种IO模型 什么是IO IO模型 非阻塞IO 前言: 前文我们已经将网络的基本原理介绍完了,都是通过围绕TCP/IP四层协议,将应用层,传输层,网络层,数据链路层全部介绍完毕,…...

牛客网NC15869:长方体边长和计算问题解析
牛客网NC15869:长方体边长和计算问题解析 题目描述 问题分析 设长方体的三条边长为 x, y, z根据题意,三个面的面积分别为: 第一个面面积:a x * y第二个面面积:b x * z第三个面面积:c y * z 解题思路 通过三个面…...

Python60日基础学习打卡D32
我们已经掌握了相当多的机器学习和python基础知识,现在面对一个全新的官方库,看看是否可以借助官方文档的写法了解其如何使用。 我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档。 大多数 Python 库都会有官方文档,里面包含了函数…...

Android本地语音识别引擎深度对比与集成指南:Vosk vs SherpaOnnx
技术选型对比矩阵 对比维度VoskSherpaOnnx核心架构基于Kaldi二次开发ONNX Runtime + K2新一代架构模型格式专用格式(需专用工具转换)ONNX标准格式(跨框架通用)中文识别精度89.2% (TDNN模型)92.7% (Zipformer流式模型)内存占用60-150MB30-80MB迟表现320-500ms180-300ms多线程…...

Flink 核心概念解析:流数据、并行处理与状态
一、流数据(Stream Data) 1. 有界流(Bounded Stream) 定义:有明确起始和结束时间的数据集合,数据量固定,处理逻辑通常是一次性计算所有数据。 典型场景: 历史交易数据统计…...

logits是啥、傅里叶变换
什么是logtis? 在深度学习的上下文中,logits 就是一个向量,下一步通常被投给 softmax/sigmoid 的向量。。 softmax的输出是分类任务的概率,其输入是logits层。 logits层通常产生-infinity到 infinity的值,而softmax层…...

【机器学习基础】机器学习与深度学习概述 算法入门指南
机器学习与深度学习概述 算法入门指南 一、引言:机器学习与深度学习(一)定义与区别(二)发展历程(三)应用场景 二、机器学习基础(一)监督学习(二)无…...

Ajax研究
简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的Web应用…...

小数第n位--快速幂+数学
1.快速幂,a*10的n2次方/b可以实现整数位3位是答案,但是数太大会超限,就要想取余 2.要是取前三位的话,那么肯定就是结果取余1000,对于除法来说,就是分母取余b*1000; 蓝桥账户中心 #include<…...

Python包管理工具uv 国内源配置
macOS 下 .config/uv/uv.toml内 pip源 [[index]] url "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/" default true#uv python install 下载源配置无效,需要在项目里配置 # python-install-mirror "https://mirror.nju.edu.cn/githu…...

RK3588 RKNN ResNet50推理测试
RK3588 RKNN ResNet50推理测试 一、背景二、性能数据三、操作步骤3.1 安装依赖3.2 安装rknn-toolkit,更新librknnrt.so3.3 下载推理图片3.4 生成`onnx`模型转换脚本3.5 生成rknn模型3.6 运行rknn模型一、背景 在嵌入式设备上进行AI推理时,我们面临着算力有限、功耗敏感等挑战…...

RUP的9个核心工作流在电商平台项目中的拆解
以下是对RUP的9个核心工作流在电商平台项目中的每个步骤的极度细化拆解,包含具体操作、角色分工、输入输出和案例细节: 1. 业务建模(Business Modeling) 步骤拆解: 识别业务参与者 操作:与市场部、运营部开会,列出所有业务角色(买家、卖家、物流商、支付网关)。 输…...
)
C++类和对象(2)
类的默认成员函数 类的6个默认成员函数:构造函数、析构函数、拷贝构造函数、赋值运算符重载、取地址& 及 const取地址 操作符重载。 默认成员函数:用户可以实现,但当不显式实现时,编译器会自动生成的成员函数。 构造函数 …...

I.MX6U Mini开发板通过GPIO口测试光敏传感器
原理图 对应的Linux sysfs引脚编号为1,即可导出为gpio1引脚对应规则参考:https://blog.csdn.net/qq_39400113/article/details/127446205 配置引脚参数 #导出编号为1的GPIO引脚(对于I.MX6UL来说,也就是GPIO0_IO1/GPIO_1࿰…...

AI工程师系列——面向copilot编程
前言 笔者已经使用copilot协助开发有一段时间了,但一直没有总结一个协助代码开发的案例,特别是怎么问copilot,按照什么顺序问,哪些方面可以高效的生成需要的代码,这一次,笔者以IP解析需求为例,沉淀一个实践案例,供大家参考 当然,其实也不局限于copilot本身,类似…...

左手腾讯CodeBuddy 、华为通义灵码,右手微软Copilot,旁边还有个Cursor,程序员幸福指数越来越高了
当前AI编程助手的繁荣让开发者拥有了前所未有的高效工具选择。从腾讯的CodeBuddy、阿里的通义灵码,到微软的GitHub Copilot和新兴的Cursor,每个工具都有其独特的优势,让程序员可以根据项目需求和个人偏好灵活搭配使用。以下是它们的核心特点及…...

【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...

力扣-有效三角形的个数
1.题目描述 2.题目链接 611. 有效三角形的个数 - 力扣(LeetCode) 3.题目代码 class Solution {public int triangleNumber(int[] nums) {//先排序Arrays.sort(nums);//若a<b<c,三角形条件可以优化为:ab>cint tempnums.length-1,sum0;while(…...

[Vue]跨组件传值
父子组件传值 详情可以看文章 跨组件传值 Vue 的核⼼是单向数据流。所以在父子组件间传值的时候,数据通常是通过属性从⽗组件向⼦组件,⽽⼦组件通过事件将数据传递回⽗组件。多层嵌套场景⼀般使⽤链式传递的⽅式实现provideinject的⽅式适⽤于需要跨层级…...

Cross-Mix Monitoring for Medical Image Segmentation With Limited Supervision
ζ \zeta ζ is the hyperparameter that controls the mixture rate, u ^ m \hat{u}_m u^m是mixed version 作者未提供代码...

采用线性优化改进评估配电网的灵活性范围
1引言 在本文中,柔性一词被定义为“响应外部信号对发电或消耗的修正”。 文章组织结构如下:第二节介绍了代表典型柔性配电网资源技术局限性的线性模型;在第三节中建立了一个线性优化问题;第四节提出了聚合算法;第五节评…...

用户缓冲区
1. 基本概念 1.1 用户空间与内核空间 用户空间(User Space):用户应用程序运行的内存空间,具有较低的权限,无法直接访问硬件和内核数据结构。内核空间(Kernel Space):操作系统内核运…...

1.4 C++之运算符与表达式
运算符与表达式教程 目标 掌握算术运算符(, -, *, /)和逻辑运算符(&&, ||, !)。理解表达式优先级规则。实现一个简单计算器程序。 一、算术运算符:像数学课上的加减乘除 1. 四种基本运算 加法(…...

目标检测基础知识
如今,使用最新的驾驶辅助技术(如车道检测、盲点、交通信号灯等)驾驶汽车已经很常见。 如果我们退后一步来了解幕后发生的事情,我们的数据科学家很快就会意识到系统不仅对对象进行分类,而且还在场景中(实时…...