【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
| 方面 (Aspect) | 内容总结 (Content Summary) |
|---|---|
| 论文标题 | NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models) |
| 核心问题 | 探究大型语言模型 (LLM) 在复杂具身场景(特别是视觉与语言导航 VLN)中的推理能力,以及如何利用其进行零样本顺序动作预测和高级规划。 |
| 提出方案 | 引入 NavGPT,一个纯粹基于 LLM 的指令跟随导航智能体。 |
| NavGPT核心机制 | 1. 输入: 视觉观察的文本描述、导航历史、未来可探索方向的文本描述。 2. 处理: LLM 推理智能体的当前状态。 3. 输出: 做出接近目标的决策(下一个动作)。 |
| 主要创新点 | 1. 纯粹LLM驱动: NavGPT 是一个完全基于现有 LLM(如GPT系列)构建的导航智能体,无需针对VLN任务进行额外的模型训练或微调。 2. 零样本顺序动作预测: NavGPT 能够在VLN任务中执行零样本的顺序动作预测,展示了LLM在未见过的导航场景中的泛化潜力。 3. 显式高级推理与规划: NavGPT 能够显式地执行高级导航规划,其推理过程(“思考”)是透明的,这与许多基于学习的黑箱模型不同。具体规划能力包括: * 指令分解为子目标。 * 整合导航相关的常识知识。 * 从观察场景中识别地标。 * 跟踪导航进度。 * 通过计划调整适应异常情况。 4. 揭示LLM的多方面导航相关能力: 证明LLM不仅能做决策,还能: * 根据观察和路径动作生成高质量的导航指令。 * 根据智能体的导航历史绘制准确的俯视度量轨迹。 |
| 关键能力/发现 | LLM(通过NavGPT)展现出: * 理解复杂导航指令并将其分解的能力。 * 利用常识进行导航决策的能力。 * 识别和利用视觉地标的能力。 * 在导航过程中保持对任务进度的跟踪。 * 在遇到意外情况时调整计划的灵活性。 * 空间感知和历史记忆能力(体现在轨迹绘制和指令生成上)。 |
| 局限性 | 1. 性能差距: 零样本的NavGPT在R2R等VLN任务上的性能仍不及经过专门训练的监督模型。 2. 信息瓶颈: 性能受限于将视觉信号转换为自然语言描述的准确性,以及在总结导航历史时可能发生的信息损失。 |
| 未来方向 | 1. 为LLM适配多模态输入,使其能直接处理视觉信息而非仅文本描述。 2. 将LLM的显式推理能力应用于(或集成到)基于学习的模型中,以提升其性能和可解释性。 |
| 对领域的贡献 | 1. 提出了一个新颖的、纯粹基于LLM的VLN智能体架构 (NavGPT)。 2. 系统地探究并展示了LLM在复杂导航任务中的高级推理和规划能力。 3. 为构建更通用、更具可解释性的具身智能体提供了新的思路和证据。 |
文章目录
- 摘要
- 1 引言
- 2 相关工作
- 3 方法
- 3.1 NavGPT
- 3.2 NavGPT的视觉感知器
- 3.3 在LLM中协同推理和行动
- 3.4 NavGPT提示管理器
- 4 实验
- 4.1 定性结果
- 4.2 与监督方法的比较
- 4.3 视觉组件的效果
- 5 结论
摘要
经过空前规模数据训练的大型语言模型(LLM),如ChatGPT和GPT-4,展现了模型规模扩展带来的显著推理能力。这一趋势凸显了用无限语言数据训练LLM的潜力,推动了通用具身智能体的发展。在这项工作中,我们引入了NavGPT,一个纯粹基于LLM的指令跟随导航智能体,通过在视觉与语言导航(VLN)中执行零样本顺序动作预测,揭示GPT模型在复杂具身场景中的推理能力。在每一步,NavGPT都将视觉观察的文本描述、导航历史和未来可探索方向作为输入,以推断智能体的当前状态,并做出接近目标的决策。通过全面的实验,我们证明NavGPT可以显式地执行高级导航规划,包括将指令分解为子目标、整合与导航任务解决相关的常识知识、从观察到的场景中识别地标、跟踪导航进度以及通过计划调整适应异常情况。此外,我们表明LLM能够根据路径上的观察和动作生成高质量的导航指令,并能根据智能体的导航历史绘制准确的俯视度量轨迹。尽管使用NavGPT进行零样本R2R任务的性能仍不及训练模型,但我们建议为LLM调整多模态输入以用作视觉导航智能体,并应用LLM的显式推理来使基于学习的模型受益。
1 引言
在大型语言模型(LLM)训练取得显著进展的背景下[54, 3, 9, 67, 61, 8, 4, 40],我们注意到一个趋势,即将LLM集成到具身机器人任务中,例如SayCan [1]和PaLM-E [13]。这一趋势源于两个主要考虑:训练数据的规模和模型的规模。首先,处理文本信息的技术发展为学习跨学科和可泛化知识提供了丰富的自然语言训练数据来源。其次,通过访问无限的语言数据,在扩大模型规模时观察到显著的涌现能力[62],从而在解决跨领域问题时显著增强了推理能力。因此,用无限语言数据训练LLM被认为是实现通用具身智能体的可行途径。
这一见解推动了将LLM集成到视觉与语言导航(VLN)[2]中,这是一项旨在实现真实世界指令跟随具身智能体的探索性任务。最新的研究尝试利用GPT模型[40, 3]来辅助导航。例如,使用LLM作为多样化语言输入的解析器[50]——从指令中提取地标以支持视觉匹配和规划,或者利用LLM的常识推理能力[68, 11]来整合对象间相关性的先验知识,以扩展智能体的感知并促进
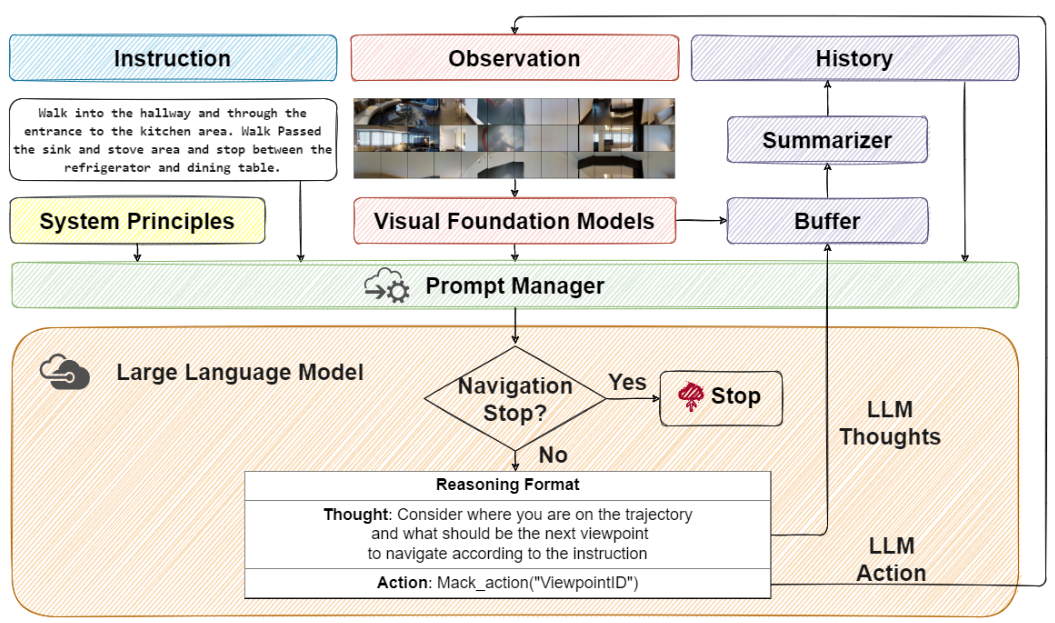
图1:NavGPT的架构。NavGPT协同LLM中的推理和行动,以执行零样本视觉与语言导航,遵循导航系统原则。它与不同的视觉基础模型交互以适应多模态输入,通过历史缓冲区和GPT-3.5摘要器处理历史长度,并通过提示管理器聚合各种信息源。NavGPT解析从LLM生成的结 (LLM思考和LLM行动) 以移动到下一个视点。
决策制定。然而,我们注意到LLM在导航中的推理能力仍未得到充分探索,即LLM能否以文本形式理解交互世界、行动和后果,并利用所有信息来解决导航任务?
有鉴于此,我们引入了NavGPT,一个专为语言引导视觉导航设计的全自动LLM系统,它能够处理多模态输入、无约束的语言引导、与开放世界环境的交互以及通过导航历史跟踪进度。NavGPT通过读取视觉基础模型(VFM)生成的观察描述来感知视觉世界,并以明确的文本形式协同思考(推理)和行动(决策制定)。在极端情况下,我们使用NavGPT执行零样本VLN¹,以清晰地揭示LLM在导航过程中的推理过程。
通过全面的实验,我们发现LLM具备执行复杂导航规划的能力。这包括将指令分解为不同的子目标,吸收与导航任务相关的常识知识,在观察到的环境背景下识别地标,持续监控导航进展,以及通过修改初始计划来应对异常情况。上述现象反映了在理解和解决导航问题方面惊人的推理能力。此外,我们表明LLM有能力在度量地图中绘制导航轨迹,并根据导航历史重新生成导航指令,揭示了LLM对导航任务的历史和空间感知能力。然而,当前开源LLM在VLN中的零样本性能与微调模型相比仍存在显著差距,其中NavGPT的瓶颈在于将视觉信号转换为自然语言以及将观察总结到历史记录中的信息损失。因此,我们建议未来构建通用VLN智能体的方向是具有多模态输入的LLM,或者利用LLM的高级导航规划、历史和空间感知能力的导航系统。
我们的贡献可以总结如下:(1)我们引入了一种新颖的指令跟随LLM智能体用于视觉导航,该智能体带有一个支持系统以与环境交互并跟踪导航历史。(2)我们研究了当前LLM在导航决策推理方面的能力和局限性。(3)我们揭示了LLM在高级规划方面的能力,通过观察LLM的思考,使导航智能体的规划过程变得可访问和可解释。
2 相关工作
视觉与语言导航 语言驱动的视觉导航受到广泛应用的具身导航智能体的需求。先前的研究表明了实现此类目标的模块要素[2, 46, 29, 30, 22, 19, 60, 72, 23, 25],而大量研究揭示了训练策略的关键作用[59, 53]。重要的是,VLN中的主要问题是智能体在未见环境中的泛化能力。数据增强[36, 58, 32, 53, 41, 15, 56]、记忆机制[6, 57, 42]、预训练[39, 21, 20, 65, 44]已被用于缓解数据稀缺性。然而,这些增强和预训练仅限于从固定数量场景中采样的数据,这不足以反映对象可能超出领域且语言指令更加多样化的现实应用场景。在我们的工作中,我们利用LLM的推理和知识存储,以零样本方式执行VLN,作为揭示LLM在野外VLN中潜在用途的初步尝试。许多研究[5, 10, 7, 57]提出了引人注目的方法,强调了拓扑地图在促进长期规划方面的重要性,特别是在回溯到先前位置方面。此外,Dorbala等人[12]使用CLIP[47]通过将指令分块为关键短语并完全依赖CLIP的文本-图像匹配能力来进行零样本VLN导航。然而,上述智能体的规划和决策过程是隐式的且不可访问的。相反,受益于LLM的内在特性,我们能够访问智能体的推理过程,使其可解释和可控。
大型语言模型 随着大规模语言模型训练的巨大成功[54, 3, 9, 67, 61, 8],新一批大型语言模型(LLM)在实现人工智能(AGI)[4, 40]方面取得了进化性的进展。这类新兴的LLM,以日益复杂的架构和训练方法[8, 48]为基础,有潜力通过提供前所未有的自然语言理解和生成能力来革新各个领域。LLM的主要担忧是其知识在训练完成后是有限和受限的。最新的工作研究如何利用LLM与工具交互以扩展其知识作为插件,包括扩展LLM以处理多模态内容[64, 51],教LLM使用正确的API调用访问互联网[49],以及用本地数据库扩展其知识以完成问答任务[43]。另一类工作研究如何提示LLM在分层系统中促进推理和相应行动的对齐[66, 28],超越了思维链(CoT)[63]。这些工作为直接使用LLM构建具身智能体奠定了基础。
LLM在机器人导航中的应用 大型语言模型(LLM)在机器人领域的应用仍处于初级阶段[55, 4]。然而,一些当代研究已经开始探索利用生成模型进行导航。Shah等人[50]尝试使用GPT-3 [3]来识别“地标”或子目标,而Huang等人[27]则专注于将LLM应用于代码生成。Zhou等人[68]使用LLM提取目标与观察中对象之间关系的常识知识,以执行零样本对象导航(ZSON)[16, 38]。尽管最近取得了这些进展,但我们的研究在将视觉场景语义转换为LLM的输入提示,直接基于LLM的常识知识和推理能力执行VLN方面有所不同。与我们最接近的工作是LGX [11],但他们正在进行对象导航,其中智能体不需要遵循指令,并且在他们的方法中,他们使用GLIP [33]模型来决定停止概率,并且没有考虑导航历史、行动和LLM之间推理的记忆。
3 方法
VLN问题表述 我们将VLN问题表述如下:给定一个由一系列词语{W₁,W₂,W₃,…, wn}组成的自然语言指令W,在每一步st,智能体通过模拟器解释当前位置以获得观察Ot。该观察包括N个备选视点,代表智能体在不同方向上的自我中心视角。
每个唯一的视图观察表示为oi (i < N),其关联的角度方向表示为ai (i < N)。因此,观察可以定义为 Ot ≒ [⟨o₁,a₁⟩, ⟨o₂, a₂⟩, …… ,⟨oN, aN⟩]。在整个导航过程中,智能体的动作空间仅限于导航图 G。智能体必须从 M = |Ct+1| 个可导航视点中进行选择,其中 Ct+1 表示候选视点的集合,通过将观察 [⟨o₁f, a₁f⟩, ⟨o₂f, a₂f⟩, …, ⟨oMf, aMf⟩] 与指令 W 对齐。智能体通过从 Of 中选择相对角度 af 来预测后续动作,然后通过与模拟器的交互来执行此动作,从当前状态 st = ⟨vt, Ot, φt⟩ 转换到 st+1 = ⟨vt+1, Ot+1, φt+1⟩,其中 v, θ 和 φ 分别表示当前视点位置、智能体的当前朝向角和俯仰角。智能体还维护状态历史 ht 的记录,并调整状态之间的条件转移概率 St = T(st+1|atf, st, ht),其中函数 T 表示条件转移概率分布。
总之,由Θ参数化的策略,智能体需要学习的,是基于指令W和当前观察Ot,即 π(atf|W, Ot, Of, St; Θ)。在本研究中,NavGPT以零样本方式执行VLN任务,其中Θ不是从VLN数据集中学习的,而是从LLM训练所用的语言语料库中学习的。
3.1 NavGPT
NavGPT是一个与环境、语言引导和导航历史交互以执行动作预测的系统。令 H<t+1 = [⟨O₁, R₁, A₁⟩, ⟨O₂, R₂, A₂⟩, …, ⟨Ot, Rt, At⟩] 为前t步的观察O、LLM推理R和动作A三元组的导航历史。为了获得导航决策At+1,NavGPT需要借助提示管理器M,协同来自VFM F的视觉感知、语言指令W、历史H和导航系统原则P,定义如下:
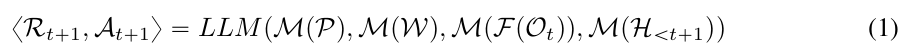
导航系统原则P。 导航系统原则将LLM的行为表述为VLN智能体。它清晰地定义了VLN任务以及NavGPT在每个导航步骤中的基本推理格式和规则。例如,NavGPT应该通过识别唯一的视点ID在环境预定义图的静态视点(位置)之间移动。NavGPT不应捏造不存在的ID。详细信息在3.4节中讨论。
视觉基础模型F。 NavGPT作为LLM智能体,需要VFM的视觉感知和表达能力,以将当前环境的视觉观察转换为自然语言描述。这里的VFM扮演翻译者的角色,使用它们自己的语言(例如自然语言、对象的边界框和对象的深度)来翻译视觉观察。通过提示管理过程,视觉感知结果将被重新格式化并转换为纯自然语言,供LLM理解,具体在3.2节中讨论。
导航历史H<t+1。 导航历史对于NavGPT评估指令完成进度、更新当前状态并做出后续决策至关重要。历史由先前观察O<t+1和动作A<t+1的摘要描述以及来自LLM的推理思路R<t+1组成,具体在3.3节中讨论。
提示管理器M。 将LLM用作VLN智能体的关键是将上述所有内容转换为LLM可以理解的自然语言。这个过程由提示管理器完成,它收集来自不同组件的结果并将它们解析为单个提示,供LLM做出导航决策,具体在3.4节中讨论。
3.2 NavGPT的视觉感知器
在本节中,我们介绍NavGPT的视觉感知过程。我们将视觉信号视为一种外语,并使用不同的视觉基础模型处理视觉输入,将其转换为自然语言,如图2所示。
对于站在环境中任何视点的智能体,观察由来自不同方向的自我中心视图组成。总视图数量由每个视图图像的视场角和每个视图的相对角度定义。在我们的工作中,我们将每个视图的视场角设置为45°,并且每个视图的航向角θ从0°到360°旋转45°,总共8个方向。此外,我们
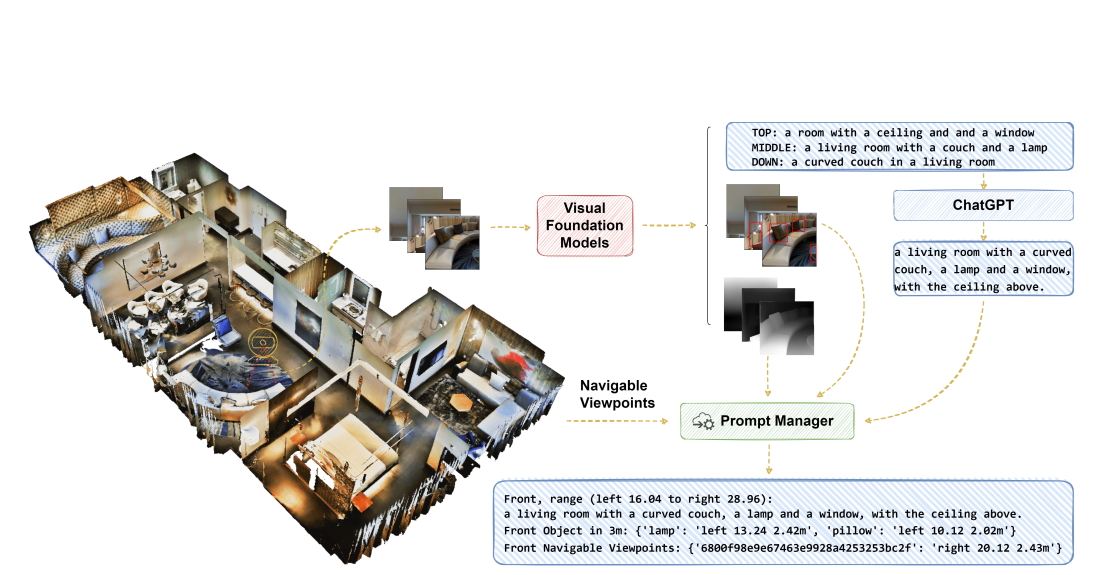
图2:从视觉输入形成自然语言描述的过程。我们使用8个方向来表示一个视点,并展示了形成其中一个方向描述的过程。
将每个视图的俯仰角φ从水平面上方30°转到下方30°,总共3个级别。因此,我们为每个视点获得3 × 8 = 24个自我中心视图。
为了将视觉观察转换为自然语言,我们首先利用BLIP-2 [31]模型作为翻译器。凭借LLM强大的文本生成能力,BLIP-2可以实现令人惊叹的零样本图像到文本生成质量。通过仔细设置视觉观察的粒度(视场角和每个观察中的总视图数量),我们提示BLIP-2为每个视图生成一个不错的语言描述,详细描绘对象的形状和颜色以及它们所在的场景,同时避免对较小视场角(FoV)视图进行无用的描述,因为这些视图只能提供部分观察,即使对人类来说也很难识别。详情请参见附录。
请注意,对于航向方向,旋转间隔等于视场角,因此每个方向之间没有重叠。对于俯仰角,顶部、中部和底部视图之间有15°的重叠。在NavGPT中,我们主要关注导航过程中智能体的航向角,因此,我们提示GPT-3.5将每个方向的顶部、中部和底部视图的场景总结为一个描述句子。
除了来自BLIP-2的场景自然语言描述外,我们还挖掘了其他视觉模型提取的较低级别特征。这些视觉模型充当辅助翻译器,将视觉输入转换为它们自己的“语言”,例如对象的类别和相应的边界框。检测结果将由提示管理器聚合成LLM的提示。在这项工作中,我们利用Fast-RCNN [18]来提取每个自我中心视图中对象的边界框。定位对象后,我们计算每个对象与智能体之间的相对航向角。我们还提取由Matterport3D模拟器[2]提供的对象中心像素的深度信息。根据深度、对象的相对方向和类别,我们通过保留当前视点3米内的对象来过滤检测结果。来自VFM的结果将由提示管理器处理成当前视点的自然语言观察。
3.3 在LLM中协同推理和行动
在VLN任务中,智能体需要学习策略π(at|W, Ot, Of, St; Θ),这很困难,因为行动与观察之间的隐式联系以及领域密集型计算。为了明确访问和增强智能体在导航过程中对当前状态的理解,我们遵循ReAct论文[66]将智能体的行动空间扩展到Ā = A ∪ R,其中R ∈ L是整个语言空间L中的内容,表示智能体的思考或推理轨迹。
智能体的推理轨迹R不会触发与外部环境的任何交互,因此当智能体在每个导航步骤输出推理时,不会返回任何观察。我们通过提示NavGPT在每个步骤输出推理轨迹后做出导航决策,从而协同其行动和思考。引入推理轨迹旨在从两个方面引导LLM:
首先,在选择行动之前提示LLM进行思考,使LLM能够在新观察下执行复杂的推理,以规划和创建策略来遵循指令。例如,如图3所示,NavGPT可以通过分析当前观察和指令来生成长期导航计划,执行更高级别的规划,例如分解指令和规划到达子目标,这在以前的工作中从未明确出现过。
其次,在导航历史H<t中包含推理轨迹R可以增强NavGPT解决问题的能力。通过将推理轨迹注入导航历史,NavGPT继承了先前推理轨迹的成果,以高级别的规划持续地通过多个步骤达到子目标,并且可以跟踪导航进度,具备异常处理能力,例如调整计划。
3.4 NavGPT提示管理器
利用导航系统原则P、来自VFM的翻译结果以及导航历史H<t,提示管理器解析并将它们重新格式化为LLM的提示。提示的详细信息在附录中呈现。
具体来说,对于导航系统原则P,NavGPT提示管理器将创建一个提示,向LLM传达规则,声明VLN任务定义,定义NavGPT的模拟环境,并以给定的推理格式限制LLM的行为。
对于来自VFM F的感知结果,提示管理器收集每个方向的结果,并以NavGPT的当前方向为前方,按顺时针排列8个方向的描述,将它们连接成提示,如图2所示。
对于导航历史H<t+1,观察、推理和行动三元组⟨Oi, Ri, Ai⟩存储在历史缓冲区中,如图1所示。直接提取缓冲区中的所有三元组将为LLM创建一个过长的提示。为了处理历史长度,提示管理器利用GPT-3.5总结轨迹中视点的观察,将总结的观察插入到观察、推理和行动三元组的提示中。
4 实验
实现细节。 我们在R2R-VLN数据集[2]上基于GPT-4 [40]和GPT-3.5评估NavGPT。R2R数据集由7189条轨迹组成,每条轨迹对应三个细粒度指令。数据集分为训练集、验证集(已见场景)、验证集(未见场景)和测试集(未见场景)四个部分,分别包含61、56、11和18个室内场景。我们在所有实验中应用了11个未见验证环境中的783条轨迹,并与先前的监督方法进行比较。我们使用BLIP-2 ViT-G FlanT5XL [31]作为图像翻译器,使用Faster-RCNN [18]作为对象检测器。对象的深度信息通过获取边界框中心像素的深度从Matterport3D模拟器[2]中提取。
评估指标。 NavGPT的评估利用R2R数据集的标准化指标。这些指标包括轨迹长度(TL),表示智能体行进的平均距离;导航错误(NE),表示智能体最终位置与目标位置之间的平均距离;成功率(SR),表示智能体在3米误差范围内成功到达目标位置的导航事件比例;Oracle成功率(OSR),智能体在其轨迹上距离目标最近点停止时的成功率;以及路径长度加权成功率(SPL),这是一个更细致的度量,通过根据最佳路径长度与智能体预测路径长度的比率调整成功率来平衡导航精度和效率。
4.1 定性结果
我们详细研究了NavGPT推理轨迹的定性结果。我们揭示了GPT-4在具身导航任务下潜在的高级规划能力。
GPT-4在语言引导导航中的推理能力 如图3所示,使用GPT-4,NavGPT可以在导航过程中执行各种类型的推理和高级规划。对于简短指令,NavGPT可以通过步骤跟踪导航进度,以完成指令中描述的单个动作,类似于自我监控VLN智能体[37, 70]。对于长

图3:NavGPT的定性结果。NavGPT可以显式地执行顺序动作预测的高级规划,包括将指令分解为子目标、整合常识知识、从观察到的场景中识别地标、跟踪导航进度、通过计划调整处理异常。
指令,NavGPT可以将其分解为子目标,类似于先前关于细化R2R数据的工作[24, 22, 71],并通过有效识别观察中的地标来规划到达目的地,类似于利用对象信息在VLN中执行跨模态匹配的工作[17, 45, 44]。当导航到具有意外观察的视点时,NavGPT可以计划探索环境并使用常识知识来辅助决策,类似于包含外部知识的VLN方法[35, 17, 34]。
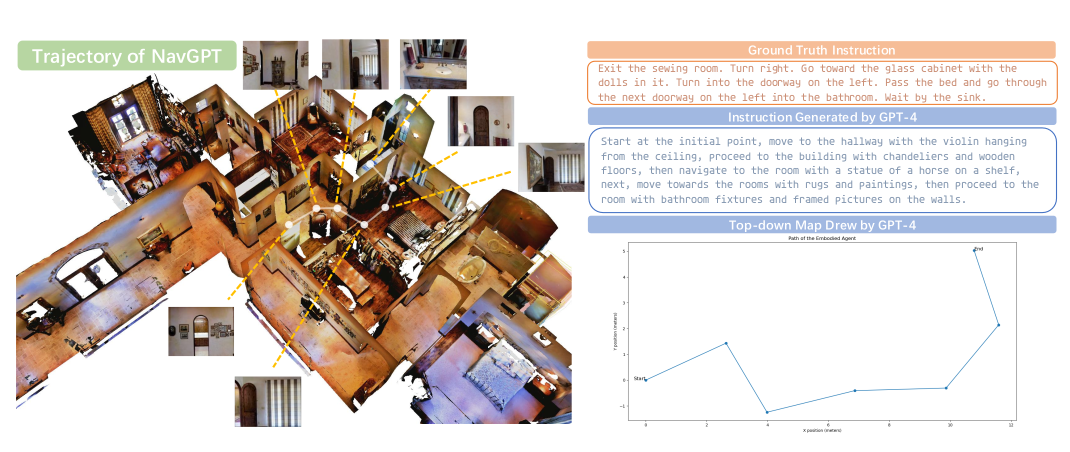
图4:我们评估GPT-4在一个案例中的表现,其中NavGPT成功遵循了地面真实路径,仅使用历史动作A<t+1和观察O<t+1来生成指令(不包含推理轨迹R<t+1以避免信息泄露),并使用整个导航历史H<t+1来绘制俯视轨迹。
LLM在导航过程中的历史和空间相对关系感知 我们通过使用GPT-4描绘导航历史中的轨迹并利用pyplot构建已访问视点的地图,来检验NavGPT对历史和空间关系的感知能力。该过程仅涉及提取动作At+1、观察Ot+1和整个导航历史Ht+1。提示的具体细节在附录中呈现。
如图4所示,我们观察到GPT-4可以有效地从冗余的观察描述中提取地标,并生成带有动作的导航历史描述。这可能是为VLN生成新轨迹指令的一种潜在方式。此外,结果表明GPT-4可以全面理解导航历史,因此可以执行必要的进度跟踪。此外,如图4所示,GPT-4可以成功捕捉视点之间的相对位置关系,并绘制已访问视点的轨迹俯视图。通过提供智能体所采取动作的语言描述,包括视点之间的转弯角度和相对距离,GPT-4展示了对空间关系的惊人感知能力。这种令人印象深刻的推理能力支持NavGPT执行图3所示的高级规划,突显了LLM在具身导航任务中具有的巨大潜力。
4.2 与监督方法的比较
我们将使用NavGPT与GPT-4进行零样本顺序导航任务的结果与先前在R2R数据集上训练的模型进行了比较。如表1所示,可以辨别出显著的差异。我们认为,限制LLM在解决VLN问题中性能的因素主要可归因于两个方面:视觉场景的基于语言的描述精度以及对象的跟踪能力。
表1:与先前方法在R2R验证未见分割上的比较。
| 训练方案 | 方法 | TL | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|---|
| 仅训练 | Seq2Seq [2] | 8.39 | 7.81 | 28 | 21 | - |
| Speaker Follower [14] | - | 6.62 | 45 | 35 | - | |
| EnvDrop [53] | 10.70 | 5.22 | - | 52 | 48 | |
| 预训练 + 微调 | PREVALENT [21] | 10.19 | 4.71 | - | 58 | 53 |
| VLNBERT [26] | 12.01 | 3.93 | 69 | 63 | 57 | |
| HAMT [6] | 11.46 | 2.29 | 73 | 66 | 61 | |
| DuET [7] | 13.94 | 3.31 | 81 | 72 | 60 | |
| 无训练 | DuET (Init. LXMERT [52]) | 22.03 | 9.74 | - | 7 | 1 |
| NavGPT (Ours) | 11.45 | 6.46 | 42 | 34 | 29 |
NavGPT的功能严重依赖于VFM生成的字幕质量。如果指令中描述的目标对象在观察描述中缺失,NavGPT将被迫探索环境。理想情况是所有目标对象都根据指令可见。然而,语言描述固有的粒度不可避免地会导致信息丢失。此外,NavGPT必须管理导航历史的长度以防止随着步骤的累积,描述变得过于冗长。为此,实现了一个摘要器,尽管这会以进一步的信息损失为代价。这削弱了NavGPT的跟踪能力,阻碍了在轨迹变长时形成对整个环境的无缝感知。
4.3 视觉组件的效果
我们进行了额外的实验来研究NavGPT中视觉组件的有效性,我们使用GPT-3.5构建了一个基线,因为它更易于访问且成本更低。为了评估在各种环境中的零样本能力,我们构建了一个新的验证分割,从原始训练集和验证未见集中采样。训练集和验证未见集的场景分别为61和11个,总共72个场景。我们从72个环境中随机选择了1条轨迹,每条轨迹关联3条指令。总共,我们采样了216个样本进行消融研究。
视觉观察描述中粒度的影响。 图像的视场角(FoV)严重影响BLIP-2的字幕能力,过大的FoV会导致泛化的房间描述,而极小的FoV由于内容有限会阻碍对象识别。如表2所示,我们研究了
表2:视觉观察描述中粒度的影响。
| 粒度 | # | TL | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|---|
| FoV@60, 12个视图 | 1 | 12.38 | 9.07 | 14.35 | 10.19 | 6.52 |
| FoV@30, 36个视图 | 2 | 12.67 | 8.92 | 15.28 | 13.89 | 9.12 |
| FoV@45, 24个视图 | 3 | 12.18 | 8.02 | 26.39 | 16.67 | 13.00 |
从一个视点出发的3种视觉表示粒度。具体来说,变体#1使用60 FoV的图像,顺时针旋转航向角30度以从一个视点获得12个视图,而变体#2和#3使用30、45 FoV的图像,从上到下转动俯仰角30度,并顺时针转动航向角30、45度以分别形成36个视图、24个视图。从结果来看,我们发现使用FoV 45和24个视图为一个视点生成最适合BLIP-2模型进行导航的自然语言描述。使用这种粒度下的描述分别比变体#1和#2高出6.48%和2.78%。
语义场景理解和深度估计的影响。 除了环境的自然语言描述的粒度外,NavGPT还与其他视觉基础模型(如对象检测器和深度估计器)协作,以增强对当前环境的感知。我们研究了
表3:语义场景理解和深度估计的影响。
| 智能体观察 | # | TL | NE↓ | OSR↑ | SR↑ | SPL↑ |
|---|---|---|---|---|---|---|
| 基线 | 1 | 16.11 | 9.83 | 15.28 | 11.11 | 6.92 |
| 基线 + 对象 | 2 | 11.07 | 8.88 | 23.34 | 15.97 | 11.71 |
| 基线 + 对象 + 距离 | 3 | 12.18 | 8.02 | 26.39 | 16.67 | 13.00 |
添加对象信息和智能体与检测到的对象之间相对距离的有效性。我们构建了一个基于BLIP-2字幕结果并由GPT-3.5驱动的基线方法。如表3所示,通过添加对象信息,SR比基线增加了4.86%,因为额外的对象信息强调了场景中的显著对象。此外,我们观察到一个现象,即智能体未能到达目的地是因为它们不知道自己离目的地有多近。一旦目标视点在视线范围内可见,它们往往会立即停止。因此,通过添加深度信息,智能体对当前位置有了更好的理解,并进一步将SR提高了0.7%,SPL提高了1.29。
5 结论
在这项工作中,我们探索了在具身导航任务中利用LLM的潜力。我们提出了NavGPT,一个专为语言引导导航设计的自主LLM系统,具备处理多模态输入和无限制语言引导、与开放世界环境互动以及维护导航历史的能力。受限于视觉场景语言描述的质量和对象的跟踪能力,NavGPT在VLN上的零样本性能仍无法与训练方法相媲美。然而,GPT-4的推理轨迹阐明了LLM在具身导航规划中的潜在潜力。LLM与下游专业模型的交互或多模态LLM在导航中的发展,预示着多功能VLN智能体的未来。
相关文章:

【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...

力扣-有效三角形的个数
1.题目描述 2.题目链接 611. 有效三角形的个数 - 力扣(LeetCode) 3.题目代码 class Solution {public int triangleNumber(int[] nums) {//先排序Arrays.sort(nums);//若a<b<c,三角形条件可以优化为:ab>cint tempnums.length-1,sum0;while(…...

[Vue]跨组件传值
父子组件传值 详情可以看文章 跨组件传值 Vue 的核⼼是单向数据流。所以在父子组件间传值的时候,数据通常是通过属性从⽗组件向⼦组件,⽽⼦组件通过事件将数据传递回⽗组件。多层嵌套场景⼀般使⽤链式传递的⽅式实现provideinject的⽅式适⽤于需要跨层级…...

Cross-Mix Monitoring for Medical Image Segmentation With Limited Supervision
ζ \zeta ζ is the hyperparameter that controls the mixture rate, u ^ m \hat{u}_m u^m是mixed version 作者未提供代码...

采用线性优化改进评估配电网的灵活性范围
1引言 在本文中,柔性一词被定义为“响应外部信号对发电或消耗的修正”。 文章组织结构如下:第二节介绍了代表典型柔性配电网资源技术局限性的线性模型;在第三节中建立了一个线性优化问题;第四节提出了聚合算法;第五节评…...

用户缓冲区
1. 基本概念 1.1 用户空间与内核空间 用户空间(User Space):用户应用程序运行的内存空间,具有较低的权限,无法直接访问硬件和内核数据结构。内核空间(Kernel Space):操作系统内核运…...

1.4 C++之运算符与表达式
运算符与表达式教程 目标 掌握算术运算符(, -, *, /)和逻辑运算符(&&, ||, !)。理解表达式优先级规则。实现一个简单计算器程序。 一、算术运算符:像数学课上的加减乘除 1. 四种基本运算 加法(…...

目标检测基础知识
如今,使用最新的驾驶辅助技术(如车道检测、盲点、交通信号灯等)驾驶汽车已经很常见。 如果我们退后一步来了解幕后发生的事情,我们的数据科学家很快就会意识到系统不仅对对象进行分类,而且还在场景中(实时…...

实时监控服务器CPU、内存和磁盘使用率
实时监控服务器CPU、内存和磁盘使用率 监控内存使用率: free -g | awk NR2{printf "%.2f%%\t\t", $3*100/$2 }awk NR2{...} 取第二行(Mem 行)。 $3 为已用内存,$2 为总内存,$3*100/$2 即计算使用率。监控磁…...

前端JavaScript-嵌套事件
点击 如果在多层嵌套中,对每层都设置事件监视器,试试看 <!DOCTYPE html> <html lang"cn"> <body><div id"container"><button>点我!</button></div><pre id"output…...
)
【ULR #1】打击复读 (SAM, DAG链剖分)
好牛的题。 DAG链剖分好牛的 trick。 题意 给定一个字符集大小为 4 4 4,长度为 n n n 的字符串 S S S,同时给定两个长度为 n n n 的数组 { w l i } , { w r i } \{wl_i\}, \{wr_i\} {wli},{wri}。 定义一个字符串 T T T 的左权值为 v l ( T…...

Web3 领域中的一些专业术语
1. Uniswap 是什么: Uniswap 是一个去中心化的交易所,运行在以太坊区块链上,相当于一个“无人管理的货币兑换市场”。它允许用户直接用加密钱包(如 MetaMask)交换不同类型的数字货币(称为代币)…...

Vue组件通信方式及最佳实践
1. Props / 自定义事件 (父子通信) 使用场景 父子组件直接数据传递 代码实现 <!-- Parent.vue --> <template><Child :message"parentMsg" update"handleUpdate" /> </template><script setup> import { ref } from vue…...
)
JUC并发编程(下)
五、共享模型之内存 JMM(java内存模型) 主存:所有线程共享的数据(静态成员变量、成员变量) 工作内存:每个线程私有的数据(局部变量) 简化对底层的控制 可见性 问题 线程t通过r…...

Go语言中new与make的深度解析
在 Go 语言中,new 和 make 是两个用于内存分配的内置函数,但它们的作用和使用场景有显著区别。 理解它们的核心在于: new(T): 为类型 T 分配内存,并将其初始化为零值,然后返回一个指向该内存的指针 (*T)。make(T, ar…...

Xilinx 7Series\UltraScale 在线升级FLASH STARTUPE2和STARTUPE3使用
一、FPGA 在线升级 FPGA 在线升级FLASH时,一般是通过逻辑生成SPI接口操作FLASH,当然也可以通过其他SOC经FPGA操作FLASH,那么FPGA就要实现在启动后对FLASH的控制。 对于7Series FPGA,只有CCLK是专用引脚,SPI接口均为普…...

redisson-spring-boot-starter 版本选择
以下是更详细的 Spring Boot 与 redisson-spring-boot-starter 版本对应关系,按照 Spring Boot 主版本和子版本细分: 1. Spring Boot 3.x 系列 3.2.x 推荐 Redisson 版本:3.23.1(最新稳定版,兼容 Redis 7.x…...

QML定时器Timer和线程任务WorkerScript
定时器 Timer 属性 interval: 事件间隔毫秒repeat: 多次执行,默认只执行一次running: 定时器启动triggeredOnStart: 定时器启动时立刻触发一次事件 信号 triggered(): 定时时间到,触发此信号 方法 restart(): 重启定时器start(): 启动定时器stop(): 停止…...

Jsoup解析商品信息具体怎么写?
使用 Jsoup 解析商品信息是一个常见的任务,尤其是在爬取电商网站的商品详情时。以下是一个详细的步骤和代码示例,展示如何使用 Jsoup 解析商品信息。 一、准备工作 确保你的项目中已经添加了 Jsoup 依赖。如果你使用的是 Maven,可以在 pom.…...

jenkins数据备份
jenkins数据备份一般情况下分为两种, 1.使用crontab进行备份.这种备份方式是技术人员手动填写的备份的时候将workspace目录排除. 2.使用jenkins插件备份. 下载备份插件 ThinBackup,这里已经下载完成,如果没下载的情况下点击 安装好之后重启jenkins(直接点击插件安装位置的闲…...

IP核警告,Bus Interface ‘AD_clk‘: ASSOCIATED_BUSIF bus parameter is missing.
创建IP核生成输出的clk信号无法在GUI(customization GUI)显示clk信号,并且出现如下2个warning: [IP_Flow 19-3153] Bus Interface AD_clk: ASSOCIATED_BUSIF bus parameter is missing. [IP_Flow 19-4751] Bus Interface AD_clk:…...

Nginx配置同一端口不同域名或同一IP不同端口
以下是如何在Nginx中配置同一端口不同域名,以及同一IP不同端口的详细说明: 一、同一端口不同域名(基于名称的虚拟主机) 场景: 通过80端口,让 example.com 和 test.com 指向不同的网站目录(如 /…...

一键启动多个 Chrome 实例并自动清理的 Bash 脚本分享!
目录 一、📦 脚本功能概览 二、📜 脚本代码一览 三、🔍 脚本功能说明 (一)✅ 支持批量启动多个 Chrome 实例 (二)✅ 每个实例使用独立用户数据目录 (三)✅ 启动后自…...

LLaMA-Adapter
一、技术背景与问题 1.1 传统方法的数学局限 二、LLaMA-Adapter 核心技术细节 2.1 Learnable Adaption Prompts 的设计哲学 这种零初始化注意力机制的目的是在训练初期稳定梯度,避免由于随机初始化的适配提示带来的不稳定因素。通过门控因子gl的自适应调整,在训…...

鸿蒙电脑系统和统信UOS都是自主可控的系统吗
鸿蒙电脑系统(HarmonyOS)和统信UOS(Unity Operating System)均被定位为自主可控的操作系统,但两者的技术背景、研发路径和生态成熟度存在差异,需结合具体定义和实际情况分析: 1. 鸿蒙系统&#…...
)
【Unity 如何使用 Mixamo下载免费模型/动画资源】Mixamo 结合在 Unity 中的实现(Animtor动画系统,完整配置以及效果展示)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Mixamo介绍1、网址2、Mixamo功能介绍Mixamo 的核心功能Mixamo 适用场景二、Mixamo下载免费模型三、Mixamo下载免费动画四、导入Unity1.人物模型配置2.动画配置五、场景配置和效果测试1.人物…...

linux文件重命名命令
Linux文件重命名指南 方法一:mv命令(单文件操作) mv 原文件名 新文件名基础用法示例: mv old_file.txt new_name.txt保留扩展名技巧: mv document-v1.doc document-v2.doc方法二:rename命令(…...

JavaScript-DOM-02
自定义属性: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title>…...

跨部门项目管理优化:告别邮件依赖
1. 工具整合 1.1 协作平台集中化 1.1.1 一体化协作工具优势 使用Microsoft Teams、Slack等一体化协作工具替代邮件,集成即时消息、文件共享、任务分配和视频会议功能,减少工具切换成本,提高沟通效率。 1.1.2 具体应用案例 在Teams中创建项目频道,关联任务看板(Planner)…...

ADB常用语句
目录 基本语句 pm 包管理操作 查看文件夹内容 查看文件内容 删除文件 dumpsys查看系统服务状态 logcat保存日志 日志级别 基本语句 查看是否安装成功 adb version查看是否连接成功 adb devices断开连接 adb disconnect进入安卓系统 adb shell 退出安卓系统 exit…...

阿里发布扩散模型Wan VACE,全面支持生图、生视频、图像编辑,适配低显存~
项目背景详述 推出与目的 Wan2.1-VACE 于 2025 年 5 月 14 日发布,作为一个综合模型,旨在统一视频生成和编辑任务。其目标是解决视频处理中的关键挑战,即在时间和空间维度上保持一致性。该模型支持多种任务,包括参考到视频生成&a…...

谷歌开源轻量级多模态文本生成模型:gemma-3n-E4B-it-litert-preview
一、Gemma 3n模型概述 1.1 模型简介 Gemma 3n是Google DeepMind开发的一系列轻量级、最先进的开源模型。这些模型基于与Gemini模型相同的研究和技术构建,适合多种内容理解任务,如问答、摘要和推理等。 1.2 模型特点 Gemma 3n模型专为在资源受限设备上…...

【Linux】了解 消息队列 system V信号量 IPC原理
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、了解消息队列 ✨消息队列函数 🍔ftok() --- 系统调用设置key 🍔 msgget() 🍔msgctl() 🍔msgsnd() ✨消息队列的管理指令 二、了…...

Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡
Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡 今天有朋友问我:“为什么 git clone 下载文件这么快?而我在本地复制粘贴文件时,速度却慢得多?” 这个问题很有意思,因为它涉及…...

高级认知型Agent
目标: 构建一个具备自主规划、多步推理、工具使用、自我反思和环境交互能力的智能代理,使其能够高效、可靠地完成复杂任务。 核心理念: Agent的智能涌现于一个精密的认知循环: 感知 (Perceive) -> 理解与规划 (Think/Plan - 想) -> 信息获取 (Search/Act - 查) -&g…...
详解)
网络爬虫(Web Crawler)详解
网络爬虫(Web Crawler)详解 1. 基本概念与核心目标 定义: 网络爬虫是一种自动化的程序,通过HTTP协议访问网页,提取并存储数据(如文本、链接、图片),并根据策略递归访问新链接。核心目标: 数据采集:抓取特定网站或全网公开数据。索引构建:为搜索引擎提供页面内容(如…...

SQL 数值计算全解析:ABS、CEIL、FLOOR与ROUND函数深度精讲
一、问题拆解:数值计算需求分析 1.1 业务需求转换 题目:在numbers表中计算每个数值的绝对值、向上取整、向下取整和四舍五入值。 关键分析点: 需要对同一字段进行四种不同的数学运算每种运算对应一个特定的SQL数学函数需保持原始数据完整…...

智能导览系统多语言解说与AI问答功能:从deepseek到景区知识图谱的构建
本文面向 文旅行业技术决策者、GIS 开发者、AI 算法工程师,旨在解决不够智能化导致游客体验不足的核心痛点,提供从技术选型到落地部署的全链路解决方案。 如需获取智慧景区导览系统解决方案请前往文章最下方获取,如有项目合作及技术交流欢迎私…...

10.18 LangChain ToolMessage实战:多轮交互与状态管理全解析
使用 ToolMessage 管理工具调用输出 关键词:LangChain ToolMessage, 工具调用管理, 多轮交互控制, 状态持久化, 输出解析 1. ToolMessage 的定位与价值 在 LangChain v0.3 的 Agent 工作流中,ToolMessage 是专门用于管理工具调用输出的消息类型,主要解决以下核心问题: #m…...
)
linux基础操作11------(运行级别)
一.前言 这个是linux最后一章节内容,主要还是介绍一下,这个就和安全有关系了,内容还是很多的,但是呢,大家还是做个了解就好了。 二.权限掩码 运行级别 0 关机 运行级别 1 单用户 ,这个类似于windows安全…...

Python Ray 扩展指南
Python Ray 扩展指南 Ray 是一个开源的分布式计算框架,专为扩展 Python 应用程序而设计,尤其在人工智能和机器学习领域表现出色。它提供了简单的 API,使开发者能够轻松编写并行和分布式代码,而无需关注底层复杂性。以下是关于 Py…...

笑林广记读书笔记三
《锯箭杆》 一人往观武场,飞箭误中其臂。请外科医治疗,医遂用小锯截其外露箭杆,即索谢礼。 问:“内截箭头如何?” 医曰:“此是内科的事,你去找他们。” 白话翻译: 有…...

npm、pnpm、yarn 各自优劣深度剖析
在前端开发领域,包管理工具是开发者的得力助手,它们负责处理项目中的依赖安装、更新与管理。npm、pnpm、yarn 是目前最主流的三款包管理工具,它们在功能上有诸多相似之处,但在实际使用中又各有优劣。本文将结合包管理工具常见问题…...

Ulisses Braga-Neto《模式识别和机器学习基础》
模式识别和机器学习基础 [专著] Fundamentals of pattern recognition and machine learning / (美)乌利塞斯布拉加-内托(Ulisses Braga-Neto)著 ; 潘巍[等]译 推荐这本书,作者有自己的见解,而且提供代码。问题是难度高,对于初学…...

python查询elasticsearch 获取指定字段的值的list
from elasticsearch import Elasticsearch from datetime import datetime, timedelta# 1.connect to Elasticsearch------------------------------------------------------------------------------------------------------ # prod连接到 Elasticsearch es_of_prod Elasti…...

百度Q1财报:总营收325亿元超预期 智能云同比增速达42%
发布 | 大力财经 5月21日晚,百度发布2025年第一季度财报,显示一季度总营收达325亿元,百度核心营收255亿元,同比增长7%,均超市场预期。一季度,百度核心净利润同比增48%至76.3亿元,智能云持续强劲…...

BurpSuite Montoya API 详解
文章目录 前言1. API 结构1.1 概述1.2 API文件源码解析 2. BurpExtension 接口3. MontoyaApi接口4. package burp.api.montoya.proxy4.1 Proxy 接口4.2 ProxyRequestHandler接口4.3 Demo 5. BurpSuite burpSuite()6. Extension extension()7. Http http()参考 前言 我们已经学…...

oracle使用SPM控制执行计划
一 SPM介绍 Oracle在11G中推出了SPM(SQL Plan management),SPM是一种主动的稳定执行计划的手段,能够保证只有被验证过的执行计划才会被启用,当由于种种原因(比如统计信息的变更)而导致目标SQL产生了新的执…...

YCKC【二分查找专题】题解
数的范围题解点击跳转题目链接:数的范围 比较经典的二分查找例题,不做过多赘述。注意看二分的对象以及最终想求什么:想求尽可能大 ,那么就是最大值类型的二分;想求尽可能小,就是最小值类型的二分。注意二分…...

【Java高阶面经:微服务篇】8.高可用全链路治理:第三方接口不稳定的全场景解决方案
一、第三方接口治理的核心挑战与架构设计 1.1 不稳定接口的典型特征 维度表现影响范围响应时间P99超过2秒,波动幅度大(如100ms~5s)导致前端超时,用户体验恶化错误率随机返回5xx/429,日均故障3次以上核心业务流程中断,交易失败率上升协议不一致多版本API共存,字段定义不…...