【机器学习基础】机器学习与深度学习概述 算法入门指南

机器学习与深度学习概述 算法入门指南
- 一、引言:机器学习与深度学习
- (一)定义与区别
- (二)发展历程
- (三)应用场景
- 二、机器学习基础
- (一)监督学习
- (二)无监督学习
- (三)特征工程
- 三、深度学习入门
- (一)神经网络基础
- (二)常用的深度学习框架
- (三)深度学习中的优化算法
- 四、深度学习进阶
- (一)卷积神经网络(CNN)
- (二)循环神经网络(RNN)及其变体
- (三)生成对抗网络(GAN)
- 五、模型部署与优化
- (一)模型部署流程
- (二)模型优化技巧
- 六、未来展望与挑战
- (一)技术发展趋势
- (二)面临的挑战
- 七、附录
一、引言:机器学习与深度学习
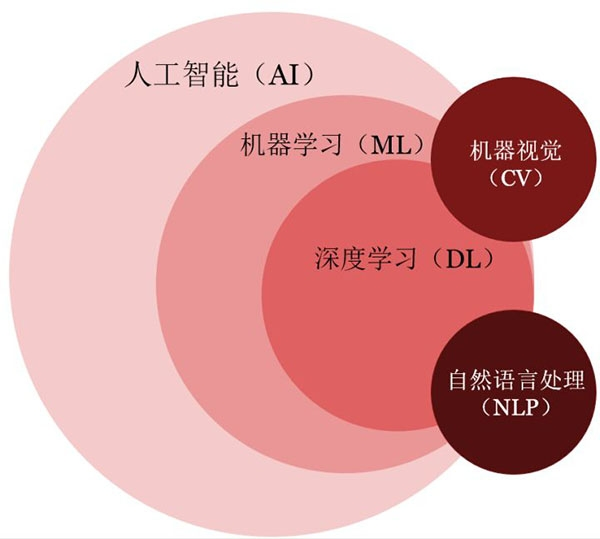
(一)定义与区别
- 机器学习
- 定义:机器学习是人工智能的一个分支,通过算法让计算机从数据中自动学习规律,从而对新的数据进行预测或决策。
- 核心思想:强调“数据驱动”,通过特征工程提取数据中的有用信息。
- 应用场景:垃圾邮件分类、股票价格预测、客户画像等。
- 深度学习
- 定义:深度学习是机器学习的一个子领域,以神经网络为核心,通过多层结构自动学习数据的特征表示。
- 核心思想:自动提取特征,减少人工干预,能够处理复杂的非线性关系。
- 应用场景:图像识别(人脸识别、自动驾驶)、语音识别(智能语音助手)、自然语言处理(机器翻译、文本生成)等。
- 两者关系
- 联系:深度学习是机器学习的一个重要分支,继承了机器学习的基本思想,但在特征提取和模型复杂度上有显著提升。
- 区别:机器学习依赖人工特征工程,而深度学习通过多层神经网络自动学习特征。
(二)发展历程
- 机器学习
- 早期发展:20世纪中叶,线性回归、逻辑回归等算法被提出,奠定了统计学基础。
- 中期发展:20世纪末,决策树、支持向量机(SVM)等算法被广泛研究和应用。
- 现代应用:随着数据量的增加和计算能力的提升,机器学习在工业界和学术界得到广泛应用。
- 深度学习
- 起源:20世纪40年代,人工神经网络的概念被提出。
- 突破:2012年,Hinton团队在ImageNet竞赛中使用深度卷积神经网络(CNN)取得突破性成绩,标志着深度学习的崛起。
- 发展:近年来,深度学习在图像识别、语音识别、自然语言处理等领域取得了显著成果。
(三)应用场景
- 机器学习
- 垃圾邮件分类:通过特征提取(如关键词频率)和分类算法(如朴素贝叶斯)判断邮件是否为垃圾邮件。
- 股票价格预测:利用历史价格数据和回归算法(如线性回归)预测未来的股票价格。
- 客户画像:通过聚类算法(如K均值)对客户进行分群,为精准营销提供支持。
- 深度学习
- 图像识别:使用卷积神经网络(CNN)识别图像中的物体,如人脸识别、自动驾驶中的交通标志识别。
- 语音识别:通过循环神经网络(RNN)及其变体(如LSTM、GRU)将语音信号转换为文字。
- 自然语言处理:使用Transformer架构实现机器翻译、文本生成等任务。
二、机器学习基础
(一)监督学习
- 算法原理与实例
- 线性回归
- 原理:通过最小化预测值与真实值之间的平方误差,找到最佳的线性关系。
- 数学公式:
y = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n y = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \dots + \theta_n x_n y=θ0+θ1x1+θ2x2+⋯+θnxn - 实例:房价预测,根据房屋面积、房间数量等特征预测房价。
- 逻辑回归
- 原理:通过Sigmoid函数将线性回归的输出映射到(0,1)区间,用于二分类问题。
- 数学公式:
P ( y = 1 ∣ x ) = 1 1 + e − ( θ 0 + θ 1 x 1 + ⋯ + θ n x n ) P(y=1|x) = \frac{1}{1 + e^{-(\theta_0 + \theta_1 x_1 + \dots + \theta_n x_n)}} P(y=1∣x)=1+e−(θ0+θ1x1+⋯+θnxn)1 - 实例:医学诊断,判断患者是否患有某种疾病。
- 决策树
- 原理:通过特征选择(如信息增益、增益率)构建树形结构,将数据划分为不同的类别。
- 实例:客户购买行为预测,根据客户的年龄、收入等特征判断其是否购买某产品。
- 支持向量机(SVM)
- 原理:在高维空间中寻找最优分割超平面,最大化不同类别之间的间隔。
- 数学公式:
maximize 2 ∥ w ∥ subject to y i ( w ⋅ x i + b ) ≥ 1 \text{maximize} \ \frac{2}{\|w\|} \quad \text{subject to} \ y_i(w \cdot x_i + b) \geq 1 maximize ∥w∥2subject to yi(w⋅xi+b)≥1 - 实例:图像分类,将图像分为不同的类别。
- 线性回归
- 模型评估方法
- 交叉验证
- 原理:将数据集划分为k个子集,每次使用一个子集作为测试集,其余作为训练集,重复k次。
- 实例:通过10折交叉验证评估模型的性能。
- 混淆矩阵
- 定义:用于评估分类模型的性能,包括真正例(TP)、假正例(FP)、真负例(TN)、假负例(FN)。
- 指标:准确率(Accuracy)、召回率(Recall)、F1值等。
- 实例:通过混淆矩阵评估医学诊断模型的性能。
- 交叉验证
(二)无监督学习
- 算法原理与实例
- K均值聚类
- 原理:通过迭代优化,将数据划分为k个簇,每个簇内的数据点相似度高,簇间相似度低。
- 实例:客户分群,根据客户的消费行为、年龄等特征将客户划分为不同群体。
- 主成分分析(PCA)
- 原理:通过降维技术,将高维数据投影到低维空间,同时保留数据的主要特征。
- 实例:高维数据可视化,将多维数据降维到2D或3D进行可视化。
- K均值聚类
- 聚类效果评估
- 轮廓系数
- 定义:衡量聚类效果的指标,值越接近1,聚类效果越好。
- 实例:通过轮廓系数选择合适的聚类簇数。
- 轮廓系数
(三)特征工程
- 特征选择
- 过滤法
- 原理:基于统计学方法(如卡方检验)筛选与目标变量相关性高的特征。
- 实例:在文本分类中,通过卡方检验筛选关键词。
- 包裹法
- 原理:通过模型性能(如交叉验证准确率)选择特征。
- 实例:递归特征消除法(RFE)用于选择对模型性能贡献最大的特征。
- 过滤法
- 特征构造
- 多项式特征
- 原理:通过原始特征构造新的特征,如 ( x_1^2, x_1 x_2 ) 等,提升模型性能。
- 实例:在房价预测中,构造房屋面积的平方特征。
- 交互特征
- 原理:结合不同特征生成新的特征,如用户年龄与消费频次的交互特征。
- 实例:在客户购买行为预测中,构造年龄与收入的交互特征。
- 多项式特征
- 特征归一化与标准化
- 归一化
- 原理:将特征值缩放到[0,1]区间,公式为
x ′ = x − min ( x ) max ( x ) − min ( x ) x' = \frac{x - \min(x)}{\max(x) - \min(x)} x′=max(x)−min(x)x−min(x) - 实例:在距离计算中,避免不同量纲特征对结果的影响。
- 原理:将特征值缩放到[0,1]区间,公式为
- 标准化
- 原理:将特征值转换为均值为0,标准差为1的分布,公式为
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ - 实例:在机器学习模型中,避免不同量纲特征对模型的影响。
- 原理:将特征值转换为均值为0,标准差为1的分布,公式为
- 归一化
三、深度学习入门
(一)神经网络基础
- 神经元模型
- 生物神经元与人工神经元
- 类比:生物神经元通过突触传递信号,人工神经元通过权重和激活函数模拟这一过程。
- 结构:输入(特征)、权重、偏置、激活函数、输出。
- 激活函数
- Sigmoid函数:将输出映射到(0,1)区间,公式为
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1 - ReLU函数:将负值置为0,正值保持不变,公式为
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x) - 实例:在神经网络中,选择合适的激活函数可以加速训练并避免梯度消失问题。
- Sigmoid函数:将输出映射到(0,1)区间,公式为
- 生物神经元与人工神经元
- 神经网络结构
- 单层感知机
- 原理:只能解决线性可分问题,通过线性组合和激活函数输出结果。
- 局限性:无法处理非线性问题。
- 多层感知机(MLP)
- 原理:通过隐藏层解决非线性问题,隐藏层的神经元可以提取数据的复杂特征。
- 实例:手写数字识别,通过多层感知机提取数字的特征并进行分类。
- 单层感知机
- 前向传播与反向传播
- 前向传播
- 过程:从输入层到输出层逐层计算,最终得到预测值。
- 实例:在神经网络中,输入特征通过每一层的计算得到最终输出。
- 反向传播
- 原理:通过链式法则计算梯度,更新网络的权重,以最小化损失函数。
- 实例:在训练过程中,通过反向传播调整权重,使模型的预测值接近真实值。
- 前向传播
(二)常用的深度学习框架
- TensorFlow
- 特点
- 计算图:通过构建静态计算图优化计算效率。
- 硬件加速:支持GPU、TPU等硬件加速。
- 特点
- PyTorch
- 特点
- 动态图:通过动态图便于调试和开发。
- 灵活性:支持自定义操作和灵活的张量操作。
- 特点
(三)深度学习中的优化算法
- 梯度下降法
- 批量梯度下降
- 原理:每次更新使用全部数据,计算梯度,更新公式为
θ = θ − α ∇ θ J ( θ ) \theta = \theta - \alpha \nabla_\theta J(\theta) θ=θ−α∇θJ(θ) - 优点:收敛稳定。
- 缺点:计算量大,速度慢。
- 原理:每次更新使用全部数据,计算梯度,更新公式为
- 随机梯度下降
- 原理:每次只用一个样本更新,更新公式为
θ = θ − α ∇ θ J ( θ ; x ( i ) ; y ( i ) ) \theta = \theta - \alpha \nabla_\theta J(\theta; x^{(i)}; y^{(i)}) θ=θ−α∇θJ(θ;x(i);y(i)) - 优点:计算速度快。
- 缺点:收敛过程有波动。
- 原理:每次只用一个样本更新,更新公式为
- 小批量梯度下降
- 原理:每次使用小批量数据更新,综合了批量和随机梯度下降的优点。
- 实例:在深度学习中,通常使用小批量梯度下降进行训练。
- 批量梯度下降
- 动量优化算法
- 原理:在梯度下降中引入动量项,公式为
v = γ v − α ∇ θ J ( θ ) θ = θ + v \begin{aligned} v &= \gamma v - \alpha \nabla_\theta J(\theta) \\ \theta &= \theta + v \end{aligned} vθ=γv−α∇θJ(θ)=θ+v- 作用:加快收敛速度,避免局部最优。
- 实例:在训练深度神经网络时,动量优化算法可以加速收敛。
- 原理:在梯度下降中引入动量项,公式为
- Adam优化算法
- 原理:结合了动量和自适应学习率的优点,公式为
m = β 1 m + ( 1 − β 1 ) ∇ θ J ( θ ) v = β 2 v + ( 1 − β 2 ) ( ∇ θ J ( θ ) ) 2 θ = θ − α m v + ϵ \begin{aligned} m &= \beta_1 m + (1 - \beta_1) \nabla_\theta J(\theta) \\ v &= \beta_2 v + (1 - \beta_2) (\nabla_\theta J(\theta))^2 \\ \theta &= \theta - \alpha \frac{m}{\sqrt{v} + \epsilon} \end{aligned} mvθ=β1m+(1−β1)∇θJ(θ)=β2v+(1−β2)(∇θJ(θ))2=θ−αv+ϵm - 优点:自适应调整学习率,适合处理稀疏梯度。
- 实例:在深度学习中,Adam优化算法是常用的优化算法之一。
- 原理:结合了动量和自适应学习率的优点,公式为
四、深度学习进阶
(一)卷积神经网络(CNN)
- 卷积层
- 卷积操作
- 原理:通过滤波器在输入数据上滑动,提取局部特征。
- 实例:在图像处理中,使用卷积操作提取边缘特征。
- 滤波器参数
- 大小:如3×3、5×5等,影响特征提取的范围。
- 数量:决定输出特征图的维度。
- 步长:决定滤波器移动的步长,步长越大,输出特征图越小。
- 卷积操作
- 池化层
- 最大池化
- 原理:在局部区域内取最大值,减少特征图的尺寸。
- 实例:在图像分类中,通过最大池化保留重要特征。
- 平均池化
- 原理:在局部区域内取平均值,平滑特征。
- 实例:在图像处理中,通过平均池化减少噪声。
- 最大池化
- 全连接层
- 作用:将卷积层和池化层提取的特征进行整合,用于分类或回归任务。
- 实例:在图像分类任务中,全连接层将特征图展平后进行分类。
- 经典CNN架构
- LeNet
- 结构:简单的卷积神经网络,用于手写数字识别。
- 特点:包含卷积层、池化层和全连接层。
- AlexNet
- 结构:在ImageNet竞赛中取得突破性成果,包含多个卷积层和全连接层。
- 特点:使用ReLU激活函数,引入Dropout防止过拟合。
- VGGNet
- 结构:使用多个3×3卷积层堆叠,结构简单但参数量大。
- 特点:适用于图像分类任务。
- ResNet
- 结构:引入残差连接,解决了深层网络训练困难的问题。
- 特点:可以构建非常深的网络,如ResNet-50、ResNet-101等。
- LeNet
(二)循环神经网络(RNN)及其变体
- RNN基本原理
- 结构
- 时间步:RNN通过时间步处理序列数据,每个时间步的输出依赖于前一时间步的输出。
- 公式:
h t = f ( W h h h t − 1 + W x h x t + b h ) h_t = f(W_{hh} h_{t-1} + W_{xh} x_t + b_h) ht=f(Whhht−1+Wxhxt+bh)
- 实例
- 文本生成:根据前一个字符生成下一个字符。
- 问题:梯度消失和梯度爆炸问题,导致无法处理长序列。
- 结构
- 长短期记忆网络(LSTM)
-
结构
- 输入门:控制新信息进入细胞状态。
- 遗忘门:控制旧信息从细胞状态中移除。
- 输出门:控制细胞状态输出到隐藏状态。
- 公式:
i t = σ ( W x i x t + W h i h t − 1 + b i ) f t = σ ( W x f x t + W h f h t − 1 + b f ) o t = σ ( W x o x t + W h o h t − 1 + b o ) c ~ t = tanh ( W x c x t + W h c h t − 1 + b c ) c t = f t c t − 1 + i t c ~ t h t = o t tanh ( c t ) \begin{aligned} i_t &= \sigma(W_{xi} x_t + W_{hi} h_{t-1} + b_i) \\ f_t &= \sigma(W_{xf} x_t + W_{hf} h_{t-1} + b_f) \\ o_t &= \sigma(W_{xo} x_t + W_{ho} h_{t-1} + b_o) \\ \tilde{c}_t &= \tanh(W_{xc} x_t + W_{hc} h_{t-1} + b_c) \\ c_t &= f_t c_{t-1} + i_t \tilde{c}_t \\ h_t &= o_t \tanh(c_t) \end{aligned} itftotc~tctht=σ(Wxixt+Whiht−1+bi)=σ(Wxfxt+Whfht−1+bf)=σ(Wxoxt+Whoht−1+bo)=tanh(Wxcxt+Whcht−1+bc)=ftct−1+itc~t=ottanh(ct)
-
实例
- 机器翻译:通过编码器 - 解码器架构将源语言翻译为目标语言。
- 优势:解决了RNN中的梯度消失问题,能够处理长序列。
-
- 门控循环单元(GRU)
- 结构
- 更新门:控制旧信息的保留和新信息的更新。
- 重置门:控制旧信息对新信息的影响。
- 公式:
z t = σ ( W x z x t + W h z h t − 1 + b z ) r t = σ ( W x r x t + W h r h t − 1 + b r ) h ~ t = tanh ( W x h x t + W h h ( r t h t − 1 ) + b h ) h t = ( 1 − z t ) h t − 1 + z t h ~ t \begin{aligned} z_t &= \sigma(W_{xz} x_t + W_{hz} h_{t-1} + b_z) \\ r_t &= \sigma(W_{xr} x_t + W_{hr} h_{t-1} + b_r) \\ \tilde{h}_t &= \tanh(W_{xh} x_t + W_{hh} (r_t h_{t-1}) + b_h) \\ h_t &= (1 - z_t) h_{t-1} + z_t \tilde{h}_t \end{aligned} ztrth~tht=σ(Wxzxt+Whzht−1+bz)=σ(Wxrxt+Whrht−1+br)=tanh(Wxhxt+Whh(rtht−1)+bh)=(1−zt)ht−1+zth~t
- 实例
- 语音识别:将语音信号转换为文字。
- 优势:结构比LSTM简单,训练速度更快。
- 结构
- 应用案例
- 机器翻译
- 编码器 - 解码器架构:编码器将源语言序列编码为固定长度的向量,解码器将其解码为目标语言序列。
- 实例:将英文翻译为中文。
- 语音识别
- 过程:将语音信号转换为特征向量,通过RNN及其变体进行建模,输出文字。
- 实例:智能语音助手(如Siri、小爱同学)。
- 机器翻译
(三)生成对抗网络(GAN)
- 生成器与判别器
- 生成器
- 作用:生成虚假数据,使其尽可能接近真实数据。
- 结构:通常是一个神经网络,输入噪声向量,输出生成的数据。
- 实例:生成图像、文本等。
- 判别器
- 作用:判断输入数据是真实数据还是虚假数据。
- 结构:通常是一个神经网络,输出一个概率值,表示输入数据为真实数据的概率。
- 实例:判断图像是否为真实图像。
- 生成器
- 训练过程
- 交替训练
- 过程:生成器和判别器交替更新,生成器试图欺骗判别器,判别器试图正确区分真实和虚假数据。
- 公式:
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
- 实例
- 图像生成:通过GAN生成艺术图像、虚拟人物等。
- 数据增强:在小样本数据集上通过生成数据提升模型性能。
- 交替训练
- 应用领域
- 图像生成
- 实例:生成艺术图像、虚拟人物等。
- 数据增强
- 实例:在医学图像领域,通过生成数据扩充数据集。
- 图像生成
五、模型部署与优化
(一)模型部署流程
- 模型保存与加载
- 保存模型
- TensorFlow:使用
model.save()保存模型为H5文件或SavedModel格式。 - PyTorch:使用
torch.save()保存模型的权重。
- TensorFlow:使用
- 加载模型
- TensorFlow:使用
tf.keras.models.load_model()加载模型。 - PyTorch:使用
torch.load()加载模型权重。
- TensorFlow:使用
- 保存模型
- 模型转换
- ONNX格式
- 定义:ONNX(Open Neural Network Exchange)是一种开放的模型格式,支持多种深度学习框架之间的模型转换。
- 实例:将TensorFlow模型转换为ONNX格式,然后在PyTorch中加载。
- ONNX格式
- 部署平台
- 服务器端部署
- API接口:使用Flask或FastAPI等框架搭建API接口,将模型部署到服务器上。
- 实例:通过API接口接收用户请求,返回模型预测结果。
- 移动端部署
- 模型压缩:通过剪枝、量化等技术减小模型大小。
- 实例:将模型部署到移动设备上,如iOS或Android应用。
- 服务器端部署
(二)模型优化技巧
- 模型剪枝
- 原理:去除不重要的权重或神经元,减少模型大小和计算量。
- 实例:通过剪枝将模型的参数量减少一半,同时保持性能。
- 模型量化
- 原理:将模型参数从浮点数转换为低精度表示(如INT8),加速模型推理速度。
- 实例:将模型量化后部署到边缘设备上,提升推理速度。
- 知识蒸馏
- 原理:将复杂模型的知识迁移到轻量级模型,提升轻量级模型的性能。
- 实例:通过知识蒸馏将ResNet-50的知识迁移到MobileNet,提升MobileNet的性能。
六、未来展望与挑战
(一)技术发展趋势
- 自动机器学习(AutoML)
- 定义:通过自动化流程选择模型、调整超参数,降低算法工程师的工作负担。
- 实例:使用AutoML工具(如Google AutoML)自动选择最佳模型和超参数。
- 强化学习与深度学习的结合
- 定义:强化学习通过与环境交互获得奖励,深度学习用于建模和优化。
- 实例:在机器人控制中,通过强化学习和深度学习实现自主决策。
- 联邦学习
- 定义:在数据隐私保护的前提下,通过分布式训练实现模型优化。
- 实例:在医疗领域,通过联邦学习在不同医院之间共享模型,保护患者隐私。
(二)面临的挑战
- 数据隐私与安全
- 问题:在大规模数据收集和使用过程中,如何保护用户隐私,防止数据泄露。
- 解决方案:使用加密技术、差分隐私等方法保护数据隐私。
- 模型可解释性
- 问题:深度学习模型通常被视为“黑盒”,难以解释其决策过程。
- 解决方案:开发可解释性工具(如LIME、SHAP)帮助理解模型的决策依据。
- 算力需求
- 问题:随着模型规模的增大,对计算资源的需求越来越高。
- 解决方案:使用更高效的硬件(如GPU、TPU)、优化算法(如分布式训练)。
七、附录
- 数学基础
- 线性代数
- 向量与矩阵运算:加法、乘法、转置等。
- 特征值与特征向量:在PCA和SVD中的应用。
- 概率论
- 概率分布:高斯分布、伯努利分布等。
- 贝叶斯定理:在朴素贝叶斯分类器中的应用。
- 优化理论
- 梯度下降法:原理和应用。
- 拉格朗日乘数法:在约束优化中的应用。
- 线性代数
- 编程基础
- Python基础
- 数据结构:列表、字典、集合等。
- 函数与类:定义和使用。
- NumPy库
- 数组操作:创建、索引、切片等。
- 矩阵运算:加法、乘法、转置等。
- Pandas库
- 数据处理:读取、清洗、筛选数据。
- 数据可视化:使用Matplotlib和Seaborn绘制图表。
- Python基础
- 实验与实践
- 实验设计
- 数据集选择:常见的机器学习和深度学习数据集。
- 实验流程:数据预处理、模型训练、模型评估。
- 实践项目
- 机器学习项目:垃圾邮件分类、房价预测等。
- 深度学习项目:手写数字识别、图像分类、文本生成等。
- 实验设计
相关文章:

【机器学习基础】机器学习与深度学习概述 算法入门指南
机器学习与深度学习概述 算法入门指南 一、引言:机器学习与深度学习(一)定义与区别(二)发展历程(三)应用场景 二、机器学习基础(一)监督学习(二)无…...

Ajax研究
简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的Web应用…...

小数第n位--快速幂+数学
1.快速幂,a*10的n2次方/b可以实现整数位3位是答案,但是数太大会超限,就要想取余 2.要是取前三位的话,那么肯定就是结果取余1000,对于除法来说,就是分母取余b*1000; 蓝桥账户中心 #include<…...

Python包管理工具uv 国内源配置
macOS 下 .config/uv/uv.toml内 pip源 [[index]] url "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/" default true#uv python install 下载源配置无效,需要在项目里配置 # python-install-mirror "https://mirror.nju.edu.cn/githu…...

RK3588 RKNN ResNet50推理测试
RK3588 RKNN ResNet50推理测试 一、背景二、性能数据三、操作步骤3.1 安装依赖3.2 安装rknn-toolkit,更新librknnrt.so3.3 下载推理图片3.4 生成`onnx`模型转换脚本3.5 生成rknn模型3.6 运行rknn模型一、背景 在嵌入式设备上进行AI推理时,我们面临着算力有限、功耗敏感等挑战…...

RUP的9个核心工作流在电商平台项目中的拆解
以下是对RUP的9个核心工作流在电商平台项目中的每个步骤的极度细化拆解,包含具体操作、角色分工、输入输出和案例细节: 1. 业务建模(Business Modeling) 步骤拆解: 识别业务参与者 操作:与市场部、运营部开会,列出所有业务角色(买家、卖家、物流商、支付网关)。 输…...
)
C++类和对象(2)
类的默认成员函数 类的6个默认成员函数:构造函数、析构函数、拷贝构造函数、赋值运算符重载、取地址& 及 const取地址 操作符重载。 默认成员函数:用户可以实现,但当不显式实现时,编译器会自动生成的成员函数。 构造函数 …...

I.MX6U Mini开发板通过GPIO口测试光敏传感器
原理图 对应的Linux sysfs引脚编号为1,即可导出为gpio1引脚对应规则参考:https://blog.csdn.net/qq_39400113/article/details/127446205 配置引脚参数 #导出编号为1的GPIO引脚(对于I.MX6UL来说,也就是GPIO0_IO1/GPIO_1࿰…...

AI工程师系列——面向copilot编程
前言 笔者已经使用copilot协助开发有一段时间了,但一直没有总结一个协助代码开发的案例,特别是怎么问copilot,按照什么顺序问,哪些方面可以高效的生成需要的代码,这一次,笔者以IP解析需求为例,沉淀一个实践案例,供大家参考 当然,其实也不局限于copilot本身,类似…...

左手腾讯CodeBuddy 、华为通义灵码,右手微软Copilot,旁边还有个Cursor,程序员幸福指数越来越高了
当前AI编程助手的繁荣让开发者拥有了前所未有的高效工具选择。从腾讯的CodeBuddy、阿里的通义灵码,到微软的GitHub Copilot和新兴的Cursor,每个工具都有其独特的优势,让程序员可以根据项目需求和个人偏好灵活搭配使用。以下是它们的核心特点及…...

【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...

力扣-有效三角形的个数
1.题目描述 2.题目链接 611. 有效三角形的个数 - 力扣(LeetCode) 3.题目代码 class Solution {public int triangleNumber(int[] nums) {//先排序Arrays.sort(nums);//若a<b<c,三角形条件可以优化为:ab>cint tempnums.length-1,sum0;while(…...

[Vue]跨组件传值
父子组件传值 详情可以看文章 跨组件传值 Vue 的核⼼是单向数据流。所以在父子组件间传值的时候,数据通常是通过属性从⽗组件向⼦组件,⽽⼦组件通过事件将数据传递回⽗组件。多层嵌套场景⼀般使⽤链式传递的⽅式实现provideinject的⽅式适⽤于需要跨层级…...

Cross-Mix Monitoring for Medical Image Segmentation With Limited Supervision
ζ \zeta ζ is the hyperparameter that controls the mixture rate, u ^ m \hat{u}_m u^m是mixed version 作者未提供代码...

采用线性优化改进评估配电网的灵活性范围
1引言 在本文中,柔性一词被定义为“响应外部信号对发电或消耗的修正”。 文章组织结构如下:第二节介绍了代表典型柔性配电网资源技术局限性的线性模型;在第三节中建立了一个线性优化问题;第四节提出了聚合算法;第五节评…...

用户缓冲区
1. 基本概念 1.1 用户空间与内核空间 用户空间(User Space):用户应用程序运行的内存空间,具有较低的权限,无法直接访问硬件和内核数据结构。内核空间(Kernel Space):操作系统内核运…...

1.4 C++之运算符与表达式
运算符与表达式教程 目标 掌握算术运算符(, -, *, /)和逻辑运算符(&&, ||, !)。理解表达式优先级规则。实现一个简单计算器程序。 一、算术运算符:像数学课上的加减乘除 1. 四种基本运算 加法(…...

目标检测基础知识
如今,使用最新的驾驶辅助技术(如车道检测、盲点、交通信号灯等)驾驶汽车已经很常见。 如果我们退后一步来了解幕后发生的事情,我们的数据科学家很快就会意识到系统不仅对对象进行分类,而且还在场景中(实时…...

实时监控服务器CPU、内存和磁盘使用率
实时监控服务器CPU、内存和磁盘使用率 监控内存使用率: free -g | awk NR2{printf "%.2f%%\t\t", $3*100/$2 }awk NR2{...} 取第二行(Mem 行)。 $3 为已用内存,$2 为总内存,$3*100/$2 即计算使用率。监控磁…...

前端JavaScript-嵌套事件
点击 如果在多层嵌套中,对每层都设置事件监视器,试试看 <!DOCTYPE html> <html lang"cn"> <body><div id"container"><button>点我!</button></div><pre id"output…...
)
【ULR #1】打击复读 (SAM, DAG链剖分)
好牛的题。 DAG链剖分好牛的 trick。 题意 给定一个字符集大小为 4 4 4,长度为 n n n 的字符串 S S S,同时给定两个长度为 n n n 的数组 { w l i } , { w r i } \{wl_i\}, \{wr_i\} {wli},{wri}。 定义一个字符串 T T T 的左权值为 v l ( T…...

Web3 领域中的一些专业术语
1. Uniswap 是什么: Uniswap 是一个去中心化的交易所,运行在以太坊区块链上,相当于一个“无人管理的货币兑换市场”。它允许用户直接用加密钱包(如 MetaMask)交换不同类型的数字货币(称为代币)…...

Vue组件通信方式及最佳实践
1. Props / 自定义事件 (父子通信) 使用场景 父子组件直接数据传递 代码实现 <!-- Parent.vue --> <template><Child :message"parentMsg" update"handleUpdate" /> </template><script setup> import { ref } from vue…...
)
JUC并发编程(下)
五、共享模型之内存 JMM(java内存模型) 主存:所有线程共享的数据(静态成员变量、成员变量) 工作内存:每个线程私有的数据(局部变量) 简化对底层的控制 可见性 问题 线程t通过r…...

Go语言中new与make的深度解析
在 Go 语言中,new 和 make 是两个用于内存分配的内置函数,但它们的作用和使用场景有显著区别。 理解它们的核心在于: new(T): 为类型 T 分配内存,并将其初始化为零值,然后返回一个指向该内存的指针 (*T)。make(T, ar…...

Xilinx 7Series\UltraScale 在线升级FLASH STARTUPE2和STARTUPE3使用
一、FPGA 在线升级 FPGA 在线升级FLASH时,一般是通过逻辑生成SPI接口操作FLASH,当然也可以通过其他SOC经FPGA操作FLASH,那么FPGA就要实现在启动后对FLASH的控制。 对于7Series FPGA,只有CCLK是专用引脚,SPI接口均为普…...

redisson-spring-boot-starter 版本选择
以下是更详细的 Spring Boot 与 redisson-spring-boot-starter 版本对应关系,按照 Spring Boot 主版本和子版本细分: 1. Spring Boot 3.x 系列 3.2.x 推荐 Redisson 版本:3.23.1(最新稳定版,兼容 Redis 7.x…...

QML定时器Timer和线程任务WorkerScript
定时器 Timer 属性 interval: 事件间隔毫秒repeat: 多次执行,默认只执行一次running: 定时器启动triggeredOnStart: 定时器启动时立刻触发一次事件 信号 triggered(): 定时时间到,触发此信号 方法 restart(): 重启定时器start(): 启动定时器stop(): 停止…...

Jsoup解析商品信息具体怎么写?
使用 Jsoup 解析商品信息是一个常见的任务,尤其是在爬取电商网站的商品详情时。以下是一个详细的步骤和代码示例,展示如何使用 Jsoup 解析商品信息。 一、准备工作 确保你的项目中已经添加了 Jsoup 依赖。如果你使用的是 Maven,可以在 pom.…...

jenkins数据备份
jenkins数据备份一般情况下分为两种, 1.使用crontab进行备份.这种备份方式是技术人员手动填写的备份的时候将workspace目录排除. 2.使用jenkins插件备份. 下载备份插件 ThinBackup,这里已经下载完成,如果没下载的情况下点击 安装好之后重启jenkins(直接点击插件安装位置的闲…...

IP核警告,Bus Interface ‘AD_clk‘: ASSOCIATED_BUSIF bus parameter is missing.
创建IP核生成输出的clk信号无法在GUI(customization GUI)显示clk信号,并且出现如下2个warning: [IP_Flow 19-3153] Bus Interface AD_clk: ASSOCIATED_BUSIF bus parameter is missing. [IP_Flow 19-4751] Bus Interface AD_clk:…...

Nginx配置同一端口不同域名或同一IP不同端口
以下是如何在Nginx中配置同一端口不同域名,以及同一IP不同端口的详细说明: 一、同一端口不同域名(基于名称的虚拟主机) 场景: 通过80端口,让 example.com 和 test.com 指向不同的网站目录(如 /…...

一键启动多个 Chrome 实例并自动清理的 Bash 脚本分享!
目录 一、📦 脚本功能概览 二、📜 脚本代码一览 三、🔍 脚本功能说明 (一)✅ 支持批量启动多个 Chrome 实例 (二)✅ 每个实例使用独立用户数据目录 (三)✅ 启动后自…...

LLaMA-Adapter
一、技术背景与问题 1.1 传统方法的数学局限 二、LLaMA-Adapter 核心技术细节 2.1 Learnable Adaption Prompts 的设计哲学 这种零初始化注意力机制的目的是在训练初期稳定梯度,避免由于随机初始化的适配提示带来的不稳定因素。通过门控因子gl的自适应调整,在训…...

鸿蒙电脑系统和统信UOS都是自主可控的系统吗
鸿蒙电脑系统(HarmonyOS)和统信UOS(Unity Operating System)均被定位为自主可控的操作系统,但两者的技术背景、研发路径和生态成熟度存在差异,需结合具体定义和实际情况分析: 1. 鸿蒙系统&#…...
)
【Unity 如何使用 Mixamo下载免费模型/动画资源】Mixamo 结合在 Unity 中的实现(Animtor动画系统,完整配置以及效果展示)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Mixamo介绍1、网址2、Mixamo功能介绍Mixamo 的核心功能Mixamo 适用场景二、Mixamo下载免费模型三、Mixamo下载免费动画四、导入Unity1.人物模型配置2.动画配置五、场景配置和效果测试1.人物…...

linux文件重命名命令
Linux文件重命名指南 方法一:mv命令(单文件操作) mv 原文件名 新文件名基础用法示例: mv old_file.txt new_name.txt保留扩展名技巧: mv document-v1.doc document-v2.doc方法二:rename命令(…...

JavaScript-DOM-02
自定义属性: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title>…...

跨部门项目管理优化:告别邮件依赖
1. 工具整合 1.1 协作平台集中化 1.1.1 一体化协作工具优势 使用Microsoft Teams、Slack等一体化协作工具替代邮件,集成即时消息、文件共享、任务分配和视频会议功能,减少工具切换成本,提高沟通效率。 1.1.2 具体应用案例 在Teams中创建项目频道,关联任务看板(Planner)…...

ADB常用语句
目录 基本语句 pm 包管理操作 查看文件夹内容 查看文件内容 删除文件 dumpsys查看系统服务状态 logcat保存日志 日志级别 基本语句 查看是否安装成功 adb version查看是否连接成功 adb devices断开连接 adb disconnect进入安卓系统 adb shell 退出安卓系统 exit…...

阿里发布扩散模型Wan VACE,全面支持生图、生视频、图像编辑,适配低显存~
项目背景详述 推出与目的 Wan2.1-VACE 于 2025 年 5 月 14 日发布,作为一个综合模型,旨在统一视频生成和编辑任务。其目标是解决视频处理中的关键挑战,即在时间和空间维度上保持一致性。该模型支持多种任务,包括参考到视频生成&a…...

谷歌开源轻量级多模态文本生成模型:gemma-3n-E4B-it-litert-preview
一、Gemma 3n模型概述 1.1 模型简介 Gemma 3n是Google DeepMind开发的一系列轻量级、最先进的开源模型。这些模型基于与Gemini模型相同的研究和技术构建,适合多种内容理解任务,如问答、摘要和推理等。 1.2 模型特点 Gemma 3n模型专为在资源受限设备上…...

【Linux】了解 消息队列 system V信号量 IPC原理
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、了解消息队列 ✨消息队列函数 🍔ftok() --- 系统调用设置key 🍔 msgget() 🍔msgctl() 🍔msgsnd() ✨消息队列的管理指令 二、了…...

Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡
Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡 今天有朋友问我:“为什么 git clone 下载文件这么快?而我在本地复制粘贴文件时,速度却慢得多?” 这个问题很有意思,因为它涉及…...

高级认知型Agent
目标: 构建一个具备自主规划、多步推理、工具使用、自我反思和环境交互能力的智能代理,使其能够高效、可靠地完成复杂任务。 核心理念: Agent的智能涌现于一个精密的认知循环: 感知 (Perceive) -> 理解与规划 (Think/Plan - 想) -> 信息获取 (Search/Act - 查) -&g…...
详解)
网络爬虫(Web Crawler)详解
网络爬虫(Web Crawler)详解 1. 基本概念与核心目标 定义: 网络爬虫是一种自动化的程序,通过HTTP协议访问网页,提取并存储数据(如文本、链接、图片),并根据策略递归访问新链接。核心目标: 数据采集:抓取特定网站或全网公开数据。索引构建:为搜索引擎提供页面内容(如…...

SQL 数值计算全解析:ABS、CEIL、FLOOR与ROUND函数深度精讲
一、问题拆解:数值计算需求分析 1.1 业务需求转换 题目:在numbers表中计算每个数值的绝对值、向上取整、向下取整和四舍五入值。 关键分析点: 需要对同一字段进行四种不同的数学运算每种运算对应一个特定的SQL数学函数需保持原始数据完整…...

智能导览系统多语言解说与AI问答功能:从deepseek到景区知识图谱的构建
本文面向 文旅行业技术决策者、GIS 开发者、AI 算法工程师,旨在解决不够智能化导致游客体验不足的核心痛点,提供从技术选型到落地部署的全链路解决方案。 如需获取智慧景区导览系统解决方案请前往文章最下方获取,如有项目合作及技术交流欢迎私…...

10.18 LangChain ToolMessage实战:多轮交互与状态管理全解析
使用 ToolMessage 管理工具调用输出 关键词:LangChain ToolMessage, 工具调用管理, 多轮交互控制, 状态持久化, 输出解析 1. ToolMessage 的定位与价值 在 LangChain v0.3 的 Agent 工作流中,ToolMessage 是专门用于管理工具调用输出的消息类型,主要解决以下核心问题: #m…...
)
linux基础操作11------(运行级别)
一.前言 这个是linux最后一章节内容,主要还是介绍一下,这个就和安全有关系了,内容还是很多的,但是呢,大家还是做个了解就好了。 二.权限掩码 运行级别 0 关机 运行级别 1 单用户 ,这个类似于windows安全…...