Python60日基础学习打卡D32
我们已经掌握了相当多的机器学习和python基础知识,现在面对一个全新的官方库,看看是否可以借助官方文档的写法了解其如何使用。
我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档。
大多数 Python 库都会有官方文档,里面包含了函数的详细说明、用法示例以及版本兼容性信息。
通常查询方式包含以下2种:
- GitHub 仓库:https://github.com/SauceCat/PDPbox
- PyPI 页面:PDPbox · PyPI
- 官方文档:PDPbox — PDPbox 0.2.1+1.g7fae76b.dirty documentation
一般通过github仓库都可以找到对应的官方文档那个。
-在官方文档中搜索函数名,然后查看函数的详细说明和用法示例
# pip install pdpbox scikit-learn pandas plotly
# pip install pdpbox --upgrade # 升级pdpbox下面以鸢尾花三分类项目来演示如何查看官方文档
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier# 加载鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target # 添加目标列(0-2类:山鸢尾、杂色鸢尾、维吉尼亚鸢尾)# 特征与目标变量
features = iris.feature_names # 4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
target = 'target' # 目标列名# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=42
)# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)RandomForestClassifier(random_state=42)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
此时模型已经建模完毕,这是一个经典的三分类项目,之前在基础班的项目三提到过sklearn提供的示例数据集,不了解的同学自行百度了解下该数据。
现在我们开始对这个模型进行解释性分析
先进入官方文档 PDPbox — PDPbox 0.2.1+1.g7fae76b.dirty documentation 
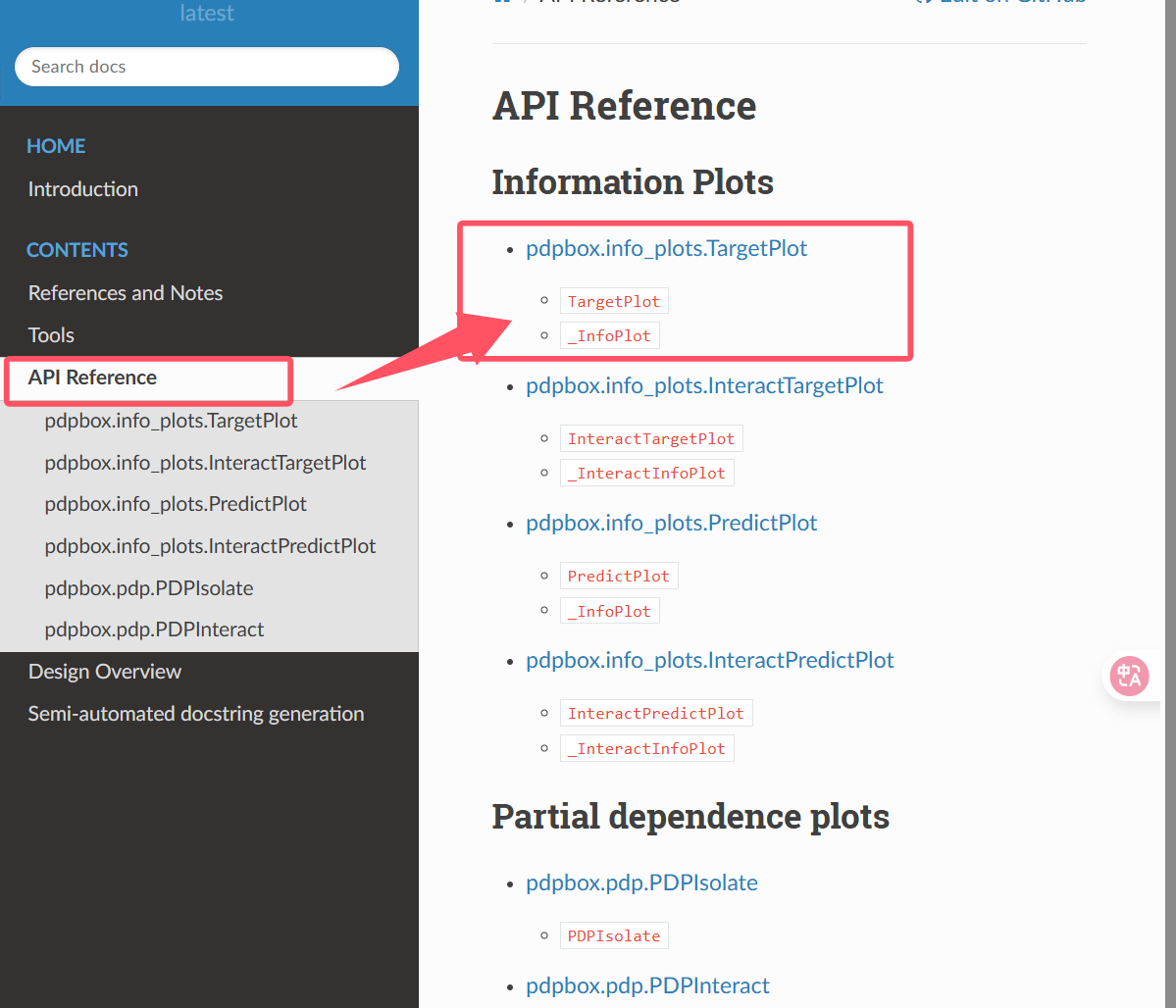
在官方文档中,通常会有一个“API Reference”或“Documentation”部分,列出所有可用的函数、类和方法。
pdpbox这个库比较小,所以非常适合我们学习用法,如果你英语比较差的话,推荐你去应用商店安装一个免费网页翻译插件

插件地址
我们选择第一个图来进行绘制
我的经典如下:
- 库的官方文档是用来知道这个库有什么方法的
- python文件中悬停功能是用来查看这个方法如何用的(也要搭配官方文档的说明)
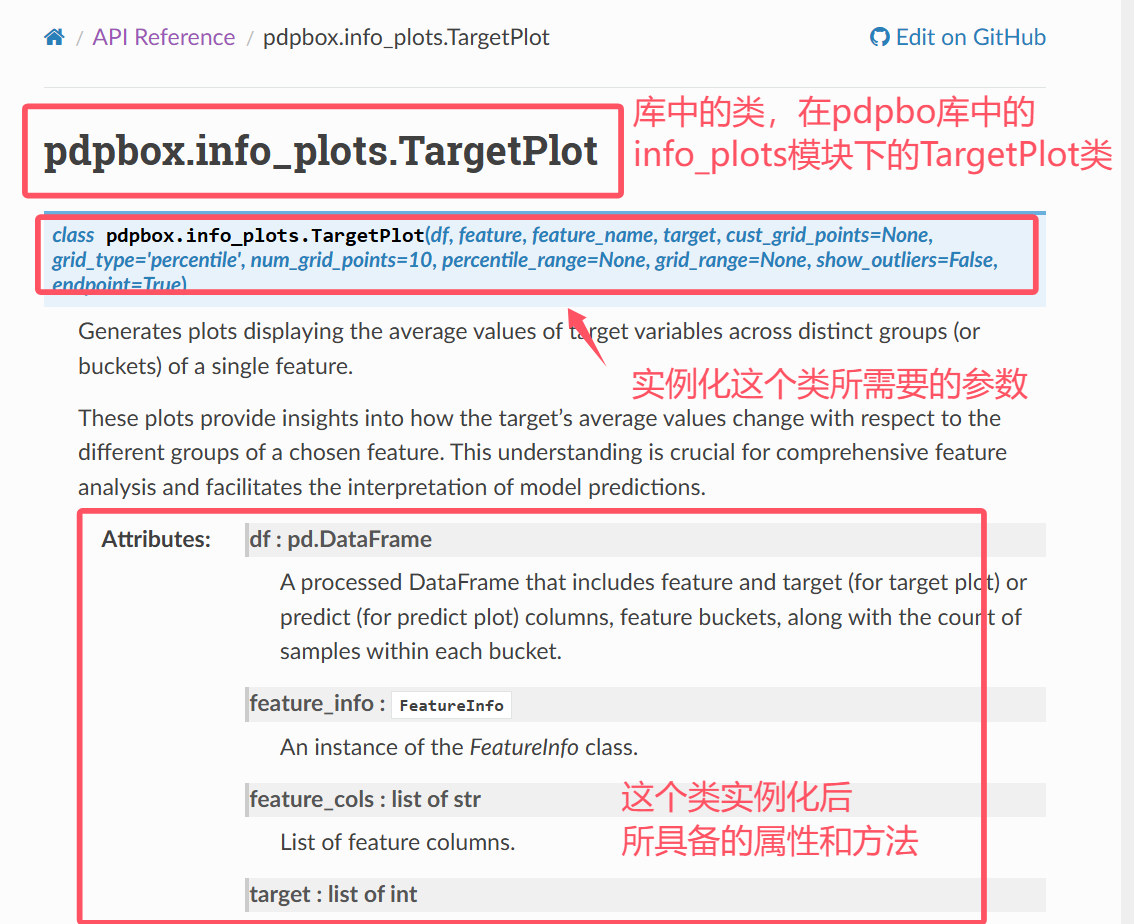
现在我们第一步是实例化这个类,TargetPlot类
- 先导入这个类(三种不同的导入和引用方法)
- 传入实例化参数
# 首先要确保库的版本是最新的,因为我们看的是最新的文档,库的版本可以在github上查看
import pdpbox
print(pdpbox.__version__) # pdpbox版本# 导入这个类
from pdpbox.info_plots import TargetPlot # 导入TargetPlot类可以鼠标悬停在这个类上,来查看定义这个类所需要的参数,以及每个参数的格式
ctrl进入可以查看这个类的详细信息
只能查看到他的初始化方法,但是无法看到他的普通方法。注意到提示我们有plot方法,但是看不到普通方法需要传入的参数
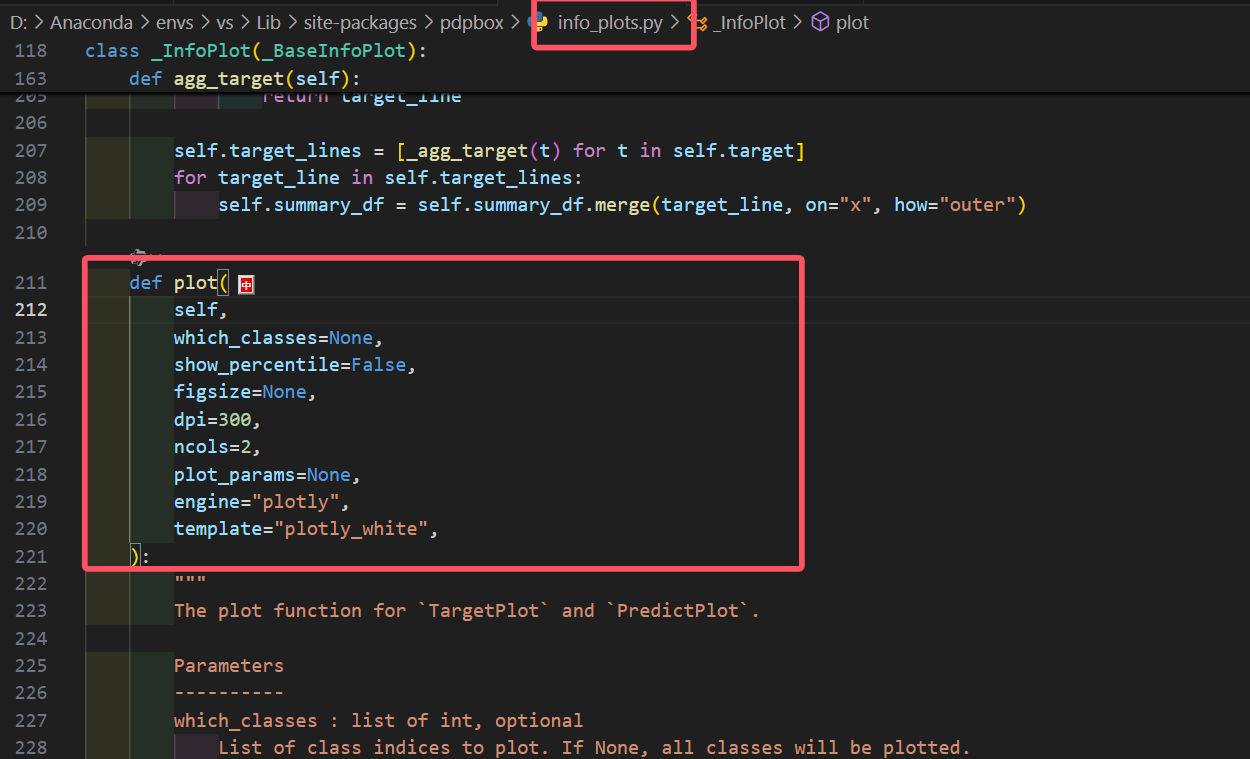
可以发现这个类继承了_InfoPlot类,此时我们再次进入_InfoPlot类里面,可以找到这个继承的plot方法
# 选择待分析的特征(如:petal length (cm))
feature = 'petal length (cm)'
feature_name = feature # 特征显示名称# 选择待分析的特征(如:petal length (cm))
feature = 'petal length (cm)'
feature_name = feature # 特征显示名称# 初始化TargetPlot对象(移除plot_type参数)
target_plot = TargetPlot(df=df, # 原始数据(需包含特征和目标列)feature=feature, # 目标特征列feature_name=feature_name, # 特征名称(用于绘图标签)# target='target', # 多分类目标索引(鸢尾花3个类别)target='target', # 多分类目标索引(鸢尾花3个类别)grid_type='percentile', # 分桶方式:百分位num_grid_points=10 # 划分为10个桶
)d:\Anaconda\envs\vs\lib\site-packages\pdpbox\utils.py:215: SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copyd:\Anaconda\envs\vs\lib\site-packages\pdpbox\utils.py:221: SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value insteadSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
# 调用plot方法绘制图形
target_plot.plot()(Figure({'data': [{'hovertemplate': '%{text}','marker': {'color': '#5BB573', 'opacity': 0.5},'name': 'count','text': array([11., 13., 26., 16., 13., 20., 17., 15., 19.]),'textposition': 'outside','type': 'bar','width': 0.36,'x': array([0, 1, 2, 3, 4, 5, 6, 7, 8], dtype=int64),'xaxis': 'x','y': array([11, 13, 26, 16, 13, 20, 17, 15, 19], dtype=int64),'yaxis': 'y'},{'hovertemplate': '%{text}','line': {'color': '#636EFA'},'marker': {'color': '#636EFA'},'mode': 'lines+markers+text','name': 'Average target','text': [0.0, 0.0, 0.0, 1.0, 1.0, 1.15, 1.765, 2.0, 2.0],'textposition': 'top center','type': 'scatter','x': array([0, 1, 2, 3, 4, 5, 6, 7, 8], dtype=int64),'xaxis': 'x','y': array([0. , 0. , 0. , 1. , 1. , 1.15 ,1.76470588, 2. , 2. ]),'yaxis': 'y2'}],'layout': {'height': 600,'showlegend': False,'template': '...','title': {'text': ('Target plot for feature <b>pet' ... 'ifferent feature values.</sup>'),'x': 0,'xref': 'paper'},'width': 1200,'xaxis': {'anchor': 'y','domain': [0.0, 1.0],'ticktext': [[1.0, 1.4), [1.4, 1.5), [1.5, 2.63), [2.63,4.1), [4.1, 4.5), [4.5, 4.9), [4.9, 5.19),[5.19, 5.7), [5.7, 6.9]],'tickvals': array([0, 1, 2, 3, 4, 5, 6, 7, 8]),'title': {'text': '<b>petal length (cm)</b> (value)'}},'yaxis': {'anchor': 'x', 'domain': [0.0, 0.98], 'range': [0, 31.2], 'title': {'text': 'count'}},'yaxis2': {'anchor': 'x','domain': [0.0, 0.98],'overlaying': 'y','range': [0, 2.4],'showgrid': False,'side': 'right','title': {'text': 'Average target'}}}}),None,x value percentile count target0 0 [1.0, 1.4) [0.0, 11.11) 11 0.0000001 1 [1.4, 1.5) [11.11, 22.22) 13 0.0000002 2 [1.5, 2.63) [22.22, 33.33) 26 0.0000003 3 [2.63, 4.1) [33.33, 44.44) 16 1.0000004 4 [4.1, 4.5) [44.44, 55.56) 13 1.0000005 5 [4.5, 4.9) [55.56, 66.67) 20 1.1500006 6 [4.9, 5.19) [66.67, 77.78) 17 1.7647067 7 [5.19, 5.7) [77.78, 88.89) 15 2.0000008 8 [5.7, 6.9] [88.89, 100.0] 19 2.000000)
# 看起来很奇怪,我们查看下类型
type(target_plot.plot())
Out[ ]:tuplelen(target_plot.plot()) # 查看元组的形状,元组只有len方法,没有shape方法
Out[ ]:3#我们来依次查看这个元组返回的究竟是什么内容?target_plot.plot()[0]target_plot.plot()[1]
# 居然什么也没有返回type(target_plot.plot()[1])
Out[26]:NoneTypetarget_plot.plot()[2]Out[]:
| x | value | percentile | count | target | |
|---|---|---|---|---|---|
| 0 | 0 | [1.0, 1.4) | [0.0, 11.11) | 11 | 0.000000 |
| 1 | 1 | [1.4, 1.5) | [11.11, 22.22) | 13 | 0.000000 |
| 2 | 2 | [1.5, 2.63) | [22.22, 33.33) | 26 | 0.000000 |
| 3 | 3 | [2.63, 4.1) | [33.33, 44.44) | 16 | 1.000000 |
| 4 | 4 | [4.1, 4.5) | [44.44, 55.56) | 13 | 1.000000 |
| 5 | 5 | [4.5, 4.9) | [55.56, 66.67) | 20 | 1.150000 |
| 6 | 6 | [4.9, 5.19) | [66.67, 77.78) | 17 | 1.764706 |
| 7 | 7 | [5.19, 5.7) | [77.78, 88.89) | 15 | 2.000000 |
| 8 | 8 | [5.7, 6.9] | [88.89, 100.0] | 19 | 2.000000 |
这个返回的是目标变量(或预测值)在不同特征区间的统计摘要。这是 PDPbox(Partial Dependence Plot) 库生成的核心分析数据。他已经在图上被可视化出来了
实际上,返回一个三元组 (fig, axes, summary_df),其中 fig 是 Plotly 的 Figure 对象。要查看或修改图形的形状(如宽度、高度、边距等),可以直接操作这个 Figure 对象。
在官方文档介绍中的plot方法最下面,写明了参数和对应的返回值

综上需要注意,我们关注一个类需要关注如下信息
- 传入的参数和对应的格式
- 类对应的方法的返回值
最后,我们用规范的形式来完成
fig, axes, summary_df = target_plot.plot(which_classes=None, # 绘制所有类别(0,1,2)show_percentile=True, # 显示百分位线engine='plotly',template='plotly_white'
)# 手动设置图表尺寸(单位:像素)
fig.update_layout(width=800, # 宽度800像素height=500, # 高度500像素title=dict(text=f'Target Plot: {feature_name}', x=0.5) # 居中标题
)fig.show()其中,fig.update_layout() 是对 Plotly 图表进行 二次修改 的核心方法。很多绘图工具都是调用的底层的绘图包,所以要想绘制出想要的图表,需要先了解底层绘图包的语法。
这里暂且不做阐述,有兴趣自行了解
相关文章:

Python60日基础学习打卡D32
我们已经掌握了相当多的机器学习和python基础知识,现在面对一个全新的官方库,看看是否可以借助官方文档的写法了解其如何使用。 我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档。 大多数 Python 库都会有官方文档,里面包含了函数…...

Android本地语音识别引擎深度对比与集成指南:Vosk vs SherpaOnnx
技术选型对比矩阵 对比维度VoskSherpaOnnx核心架构基于Kaldi二次开发ONNX Runtime + K2新一代架构模型格式专用格式(需专用工具转换)ONNX标准格式(跨框架通用)中文识别精度89.2% (TDNN模型)92.7% (Zipformer流式模型)内存占用60-150MB30-80MB迟表现320-500ms180-300ms多线程…...

Flink 核心概念解析:流数据、并行处理与状态
一、流数据(Stream Data) 1. 有界流(Bounded Stream) 定义:有明确起始和结束时间的数据集合,数据量固定,处理逻辑通常是一次性计算所有数据。 典型场景: 历史交易数据统计…...

logits是啥、傅里叶变换
什么是logtis? 在深度学习的上下文中,logits 就是一个向量,下一步通常被投给 softmax/sigmoid 的向量。。 softmax的输出是分类任务的概率,其输入是logits层。 logits层通常产生-infinity到 infinity的值,而softmax层…...

【机器学习基础】机器学习与深度学习概述 算法入门指南
机器学习与深度学习概述 算法入门指南 一、引言:机器学习与深度学习(一)定义与区别(二)发展历程(三)应用场景 二、机器学习基础(一)监督学习(二)无…...

Ajax研究
简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的Web应用…...

小数第n位--快速幂+数学
1.快速幂,a*10的n2次方/b可以实现整数位3位是答案,但是数太大会超限,就要想取余 2.要是取前三位的话,那么肯定就是结果取余1000,对于除法来说,就是分母取余b*1000; 蓝桥账户中心 #include<…...

Python包管理工具uv 国内源配置
macOS 下 .config/uv/uv.toml内 pip源 [[index]] url "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/" default true#uv python install 下载源配置无效,需要在项目里配置 # python-install-mirror "https://mirror.nju.edu.cn/githu…...

RK3588 RKNN ResNet50推理测试
RK3588 RKNN ResNet50推理测试 一、背景二、性能数据三、操作步骤3.1 安装依赖3.2 安装rknn-toolkit,更新librknnrt.so3.3 下载推理图片3.4 生成`onnx`模型转换脚本3.5 生成rknn模型3.6 运行rknn模型一、背景 在嵌入式设备上进行AI推理时,我们面临着算力有限、功耗敏感等挑战…...

RUP的9个核心工作流在电商平台项目中的拆解
以下是对RUP的9个核心工作流在电商平台项目中的每个步骤的极度细化拆解,包含具体操作、角色分工、输入输出和案例细节: 1. 业务建模(Business Modeling) 步骤拆解: 识别业务参与者 操作:与市场部、运营部开会,列出所有业务角色(买家、卖家、物流商、支付网关)。 输…...
)
C++类和对象(2)
类的默认成员函数 类的6个默认成员函数:构造函数、析构函数、拷贝构造函数、赋值运算符重载、取地址& 及 const取地址 操作符重载。 默认成员函数:用户可以实现,但当不显式实现时,编译器会自动生成的成员函数。 构造函数 …...

I.MX6U Mini开发板通过GPIO口测试光敏传感器
原理图 对应的Linux sysfs引脚编号为1,即可导出为gpio1引脚对应规则参考:https://blog.csdn.net/qq_39400113/article/details/127446205 配置引脚参数 #导出编号为1的GPIO引脚(对于I.MX6UL来说,也就是GPIO0_IO1/GPIO_1࿰…...

AI工程师系列——面向copilot编程
前言 笔者已经使用copilot协助开发有一段时间了,但一直没有总结一个协助代码开发的案例,特别是怎么问copilot,按照什么顺序问,哪些方面可以高效的生成需要的代码,这一次,笔者以IP解析需求为例,沉淀一个实践案例,供大家参考 当然,其实也不局限于copilot本身,类似…...

左手腾讯CodeBuddy 、华为通义灵码,右手微软Copilot,旁边还有个Cursor,程序员幸福指数越来越高了
当前AI编程助手的繁荣让开发者拥有了前所未有的高效工具选择。从腾讯的CodeBuddy、阿里的通义灵码,到微软的GitHub Copilot和新兴的Cursor,每个工具都有其独特的优势,让程序员可以根据项目需求和个人偏好灵活搭配使用。以下是它们的核心特点及…...

【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...

力扣-有效三角形的个数
1.题目描述 2.题目链接 611. 有效三角形的个数 - 力扣(LeetCode) 3.题目代码 class Solution {public int triangleNumber(int[] nums) {//先排序Arrays.sort(nums);//若a<b<c,三角形条件可以优化为:ab>cint tempnums.length-1,sum0;while(…...

[Vue]跨组件传值
父子组件传值 详情可以看文章 跨组件传值 Vue 的核⼼是单向数据流。所以在父子组件间传值的时候,数据通常是通过属性从⽗组件向⼦组件,⽽⼦组件通过事件将数据传递回⽗组件。多层嵌套场景⼀般使⽤链式传递的⽅式实现provideinject的⽅式适⽤于需要跨层级…...

Cross-Mix Monitoring for Medical Image Segmentation With Limited Supervision
ζ \zeta ζ is the hyperparameter that controls the mixture rate, u ^ m \hat{u}_m u^m是mixed version 作者未提供代码...

采用线性优化改进评估配电网的灵活性范围
1引言 在本文中,柔性一词被定义为“响应外部信号对发电或消耗的修正”。 文章组织结构如下:第二节介绍了代表典型柔性配电网资源技术局限性的线性模型;在第三节中建立了一个线性优化问题;第四节提出了聚合算法;第五节评…...

用户缓冲区
1. 基本概念 1.1 用户空间与内核空间 用户空间(User Space):用户应用程序运行的内存空间,具有较低的权限,无法直接访问硬件和内核数据结构。内核空间(Kernel Space):操作系统内核运…...

1.4 C++之运算符与表达式
运算符与表达式教程 目标 掌握算术运算符(, -, *, /)和逻辑运算符(&&, ||, !)。理解表达式优先级规则。实现一个简单计算器程序。 一、算术运算符:像数学课上的加减乘除 1. 四种基本运算 加法(…...

目标检测基础知识
如今,使用最新的驾驶辅助技术(如车道检测、盲点、交通信号灯等)驾驶汽车已经很常见。 如果我们退后一步来了解幕后发生的事情,我们的数据科学家很快就会意识到系统不仅对对象进行分类,而且还在场景中(实时…...

实时监控服务器CPU、内存和磁盘使用率
实时监控服务器CPU、内存和磁盘使用率 监控内存使用率: free -g | awk NR2{printf "%.2f%%\t\t", $3*100/$2 }awk NR2{...} 取第二行(Mem 行)。 $3 为已用内存,$2 为总内存,$3*100/$2 即计算使用率。监控磁…...

前端JavaScript-嵌套事件
点击 如果在多层嵌套中,对每层都设置事件监视器,试试看 <!DOCTYPE html> <html lang"cn"> <body><div id"container"><button>点我!</button></div><pre id"output…...
)
【ULR #1】打击复读 (SAM, DAG链剖分)
好牛的题。 DAG链剖分好牛的 trick。 题意 给定一个字符集大小为 4 4 4,长度为 n n n 的字符串 S S S,同时给定两个长度为 n n n 的数组 { w l i } , { w r i } \{wl_i\}, \{wr_i\} {wli},{wri}。 定义一个字符串 T T T 的左权值为 v l ( T…...

Web3 领域中的一些专业术语
1. Uniswap 是什么: Uniswap 是一个去中心化的交易所,运行在以太坊区块链上,相当于一个“无人管理的货币兑换市场”。它允许用户直接用加密钱包(如 MetaMask)交换不同类型的数字货币(称为代币)…...

Vue组件通信方式及最佳实践
1. Props / 自定义事件 (父子通信) 使用场景 父子组件直接数据传递 代码实现 <!-- Parent.vue --> <template><Child :message"parentMsg" update"handleUpdate" /> </template><script setup> import { ref } from vue…...
)
JUC并发编程(下)
五、共享模型之内存 JMM(java内存模型) 主存:所有线程共享的数据(静态成员变量、成员变量) 工作内存:每个线程私有的数据(局部变量) 简化对底层的控制 可见性 问题 线程t通过r…...

Go语言中new与make的深度解析
在 Go 语言中,new 和 make 是两个用于内存分配的内置函数,但它们的作用和使用场景有显著区别。 理解它们的核心在于: new(T): 为类型 T 分配内存,并将其初始化为零值,然后返回一个指向该内存的指针 (*T)。make(T, ar…...

Xilinx 7Series\UltraScale 在线升级FLASH STARTUPE2和STARTUPE3使用
一、FPGA 在线升级 FPGA 在线升级FLASH时,一般是通过逻辑生成SPI接口操作FLASH,当然也可以通过其他SOC经FPGA操作FLASH,那么FPGA就要实现在启动后对FLASH的控制。 对于7Series FPGA,只有CCLK是专用引脚,SPI接口均为普…...

redisson-spring-boot-starter 版本选择
以下是更详细的 Spring Boot 与 redisson-spring-boot-starter 版本对应关系,按照 Spring Boot 主版本和子版本细分: 1. Spring Boot 3.x 系列 3.2.x 推荐 Redisson 版本:3.23.1(最新稳定版,兼容 Redis 7.x…...

QML定时器Timer和线程任务WorkerScript
定时器 Timer 属性 interval: 事件间隔毫秒repeat: 多次执行,默认只执行一次running: 定时器启动triggeredOnStart: 定时器启动时立刻触发一次事件 信号 triggered(): 定时时间到,触发此信号 方法 restart(): 重启定时器start(): 启动定时器stop(): 停止…...

Jsoup解析商品信息具体怎么写?
使用 Jsoup 解析商品信息是一个常见的任务,尤其是在爬取电商网站的商品详情时。以下是一个详细的步骤和代码示例,展示如何使用 Jsoup 解析商品信息。 一、准备工作 确保你的项目中已经添加了 Jsoup 依赖。如果你使用的是 Maven,可以在 pom.…...

jenkins数据备份
jenkins数据备份一般情况下分为两种, 1.使用crontab进行备份.这种备份方式是技术人员手动填写的备份的时候将workspace目录排除. 2.使用jenkins插件备份. 下载备份插件 ThinBackup,这里已经下载完成,如果没下载的情况下点击 安装好之后重启jenkins(直接点击插件安装位置的闲…...

IP核警告,Bus Interface ‘AD_clk‘: ASSOCIATED_BUSIF bus parameter is missing.
创建IP核生成输出的clk信号无法在GUI(customization GUI)显示clk信号,并且出现如下2个warning: [IP_Flow 19-3153] Bus Interface AD_clk: ASSOCIATED_BUSIF bus parameter is missing. [IP_Flow 19-4751] Bus Interface AD_clk:…...

Nginx配置同一端口不同域名或同一IP不同端口
以下是如何在Nginx中配置同一端口不同域名,以及同一IP不同端口的详细说明: 一、同一端口不同域名(基于名称的虚拟主机) 场景: 通过80端口,让 example.com 和 test.com 指向不同的网站目录(如 /…...

一键启动多个 Chrome 实例并自动清理的 Bash 脚本分享!
目录 一、📦 脚本功能概览 二、📜 脚本代码一览 三、🔍 脚本功能说明 (一)✅ 支持批量启动多个 Chrome 实例 (二)✅ 每个实例使用独立用户数据目录 (三)✅ 启动后自…...

LLaMA-Adapter
一、技术背景与问题 1.1 传统方法的数学局限 二、LLaMA-Adapter 核心技术细节 2.1 Learnable Adaption Prompts 的设计哲学 这种零初始化注意力机制的目的是在训练初期稳定梯度,避免由于随机初始化的适配提示带来的不稳定因素。通过门控因子gl的自适应调整,在训…...

鸿蒙电脑系统和统信UOS都是自主可控的系统吗
鸿蒙电脑系统(HarmonyOS)和统信UOS(Unity Operating System)均被定位为自主可控的操作系统,但两者的技术背景、研发路径和生态成熟度存在差异,需结合具体定义和实际情况分析: 1. 鸿蒙系统&#…...
)
【Unity 如何使用 Mixamo下载免费模型/动画资源】Mixamo 结合在 Unity 中的实现(Animtor动画系统,完整配置以及效果展示)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Mixamo介绍1、网址2、Mixamo功能介绍Mixamo 的核心功能Mixamo 适用场景二、Mixamo下载免费模型三、Mixamo下载免费动画四、导入Unity1.人物模型配置2.动画配置五、场景配置和效果测试1.人物…...

linux文件重命名命令
Linux文件重命名指南 方法一:mv命令(单文件操作) mv 原文件名 新文件名基础用法示例: mv old_file.txt new_name.txt保留扩展名技巧: mv document-v1.doc document-v2.doc方法二:rename命令(…...

JavaScript-DOM-02
自定义属性: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title>…...

跨部门项目管理优化:告别邮件依赖
1. 工具整合 1.1 协作平台集中化 1.1.1 一体化协作工具优势 使用Microsoft Teams、Slack等一体化协作工具替代邮件,集成即时消息、文件共享、任务分配和视频会议功能,减少工具切换成本,提高沟通效率。 1.1.2 具体应用案例 在Teams中创建项目频道,关联任务看板(Planner)…...

ADB常用语句
目录 基本语句 pm 包管理操作 查看文件夹内容 查看文件内容 删除文件 dumpsys查看系统服务状态 logcat保存日志 日志级别 基本语句 查看是否安装成功 adb version查看是否连接成功 adb devices断开连接 adb disconnect进入安卓系统 adb shell 退出安卓系统 exit…...

阿里发布扩散模型Wan VACE,全面支持生图、生视频、图像编辑,适配低显存~
项目背景详述 推出与目的 Wan2.1-VACE 于 2025 年 5 月 14 日发布,作为一个综合模型,旨在统一视频生成和编辑任务。其目标是解决视频处理中的关键挑战,即在时间和空间维度上保持一致性。该模型支持多种任务,包括参考到视频生成&a…...

谷歌开源轻量级多模态文本生成模型:gemma-3n-E4B-it-litert-preview
一、Gemma 3n模型概述 1.1 模型简介 Gemma 3n是Google DeepMind开发的一系列轻量级、最先进的开源模型。这些模型基于与Gemini模型相同的研究和技术构建,适合多种内容理解任务,如问答、摘要和推理等。 1.2 模型特点 Gemma 3n模型专为在资源受限设备上…...

【Linux】了解 消息队列 system V信号量 IPC原理
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、了解消息队列 ✨消息队列函数 🍔ftok() --- 系统调用设置key 🍔 msgget() 🍔msgctl() 🍔msgsnd() ✨消息队列的管理指令 二、了…...

Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡
Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡 今天有朋友问我:“为什么 git clone 下载文件这么快?而我在本地复制粘贴文件时,速度却慢得多?” 这个问题很有意思,因为它涉及…...

高级认知型Agent
目标: 构建一个具备自主规划、多步推理、工具使用、自我反思和环境交互能力的智能代理,使其能够高效、可靠地完成复杂任务。 核心理念: Agent的智能涌现于一个精密的认知循环: 感知 (Perceive) -> 理解与规划 (Think/Plan - 想) -> 信息获取 (Search/Act - 查) -&g…...
详解)
网络爬虫(Web Crawler)详解
网络爬虫(Web Crawler)详解 1. 基本概念与核心目标 定义: 网络爬虫是一种自动化的程序,通过HTTP协议访问网页,提取并存储数据(如文本、链接、图片),并根据策略递归访问新链接。核心目标: 数据采集:抓取特定网站或全网公开数据。索引构建:为搜索引擎提供页面内容(如…...