JUC并发编程(下)
五、共享模型之内存
JMM(java内存模型)
主存:所有线程共享的数据(静态成员变量、成员变量)
工作内存:每个线程私有的数据(局部变量)
简化对底层的控制

可见性
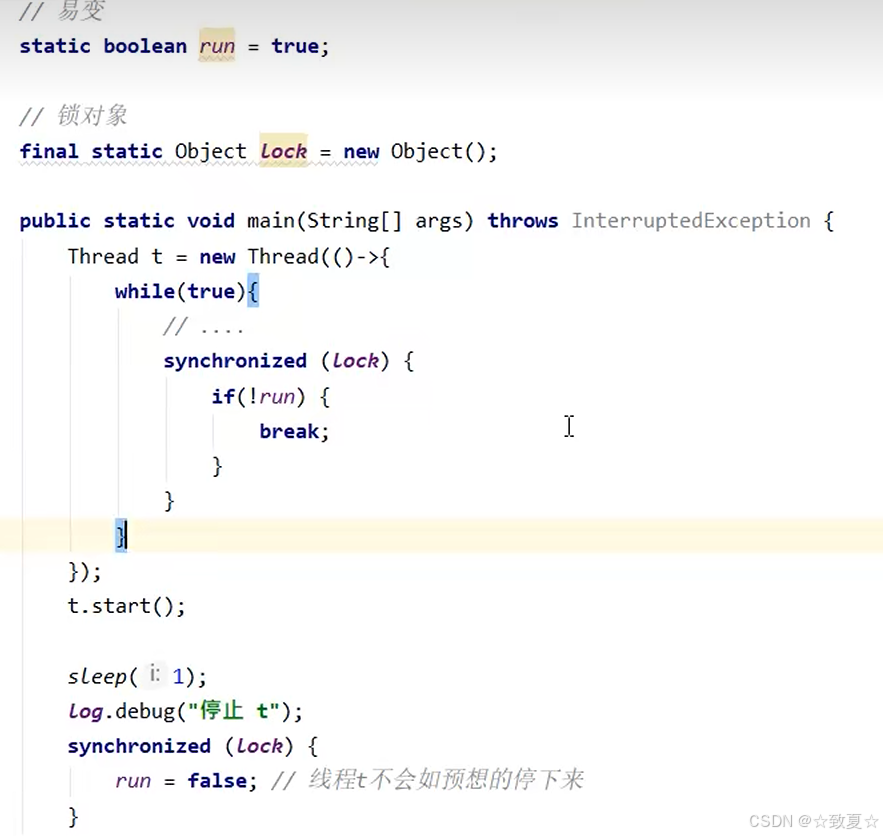
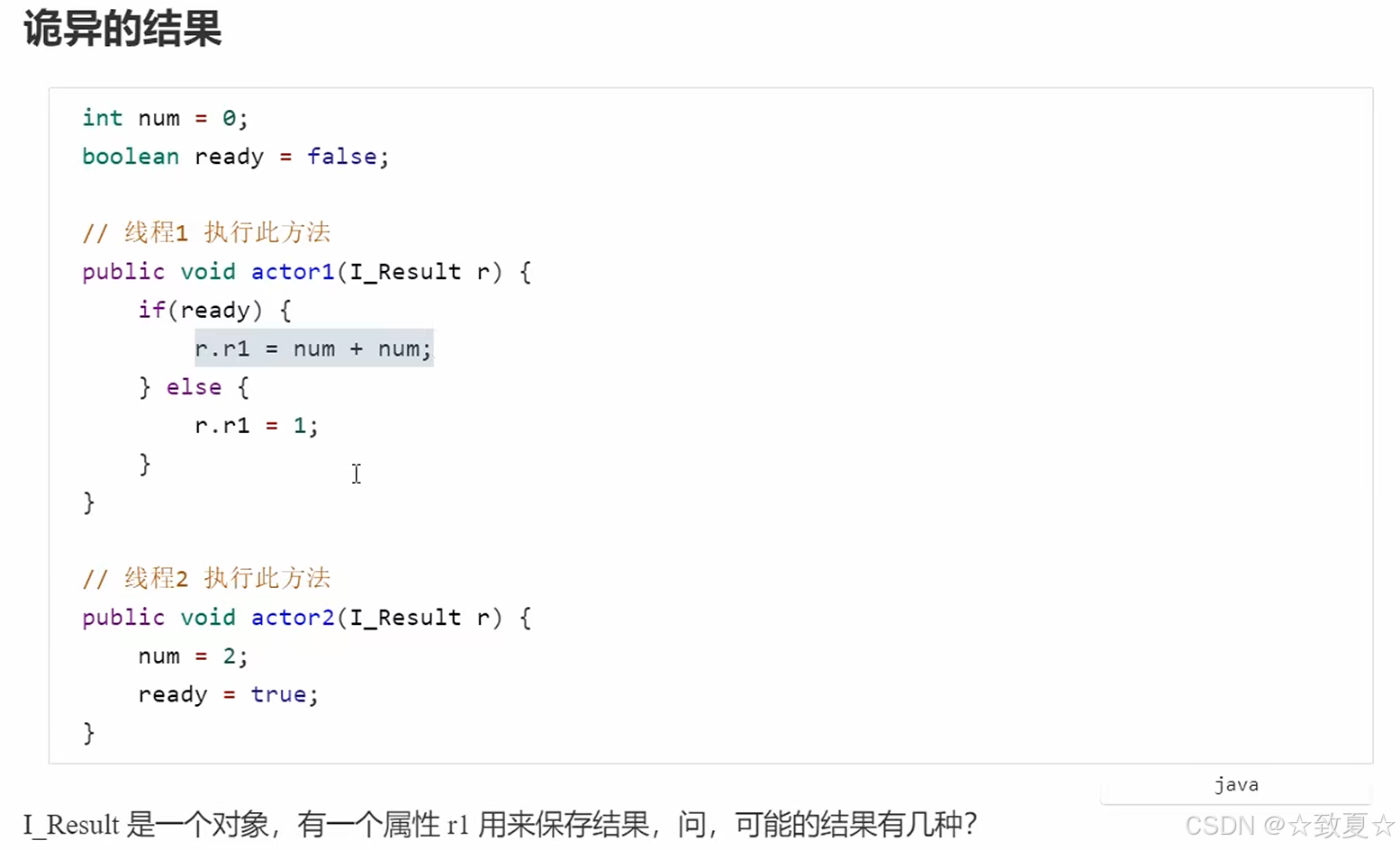
问题
线程t通过run变量的值决定是否循环,main线程修改了run变量的之后无法让t线程停下来
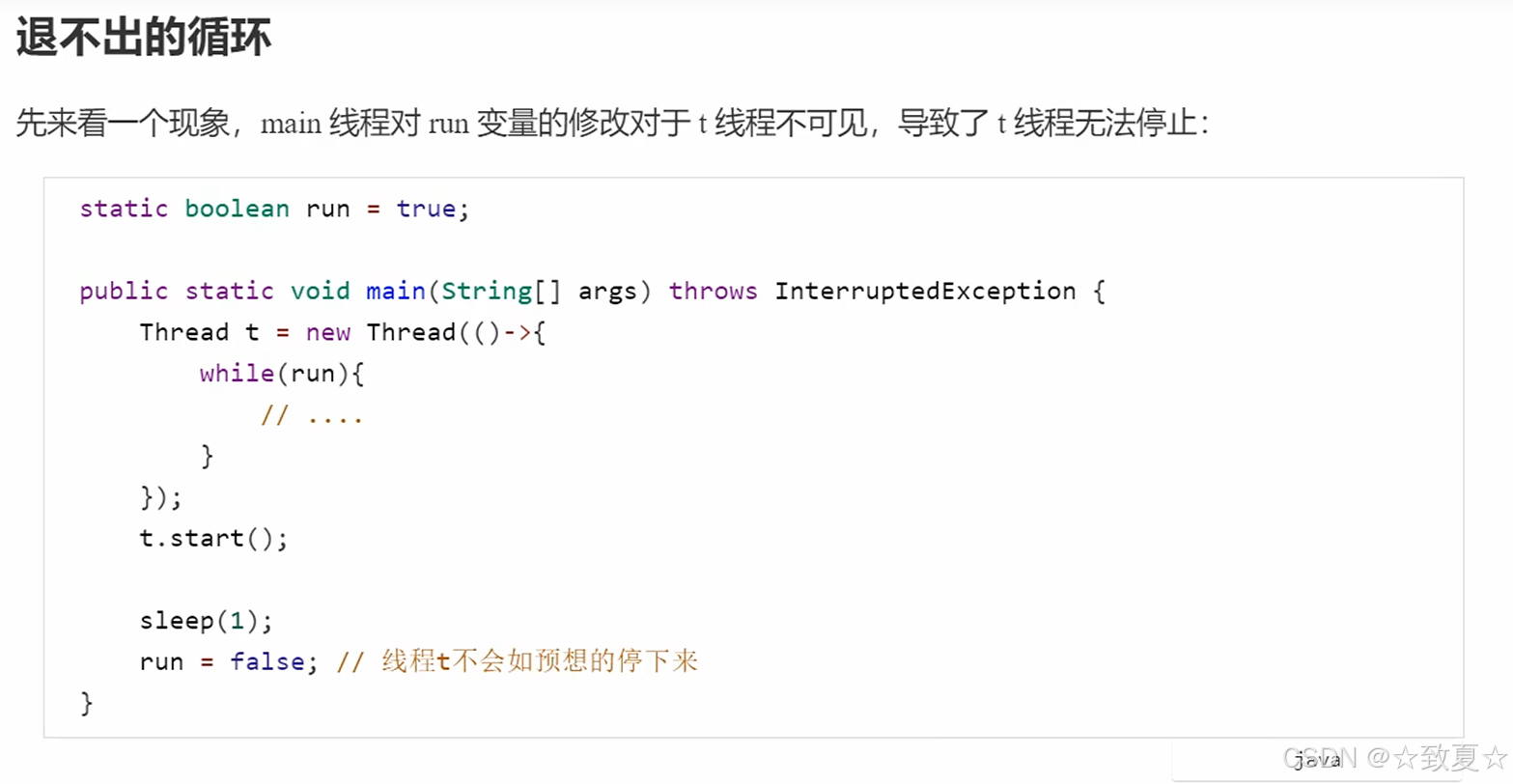
分析
一个线程对主存的修改对另一个线程不可见。
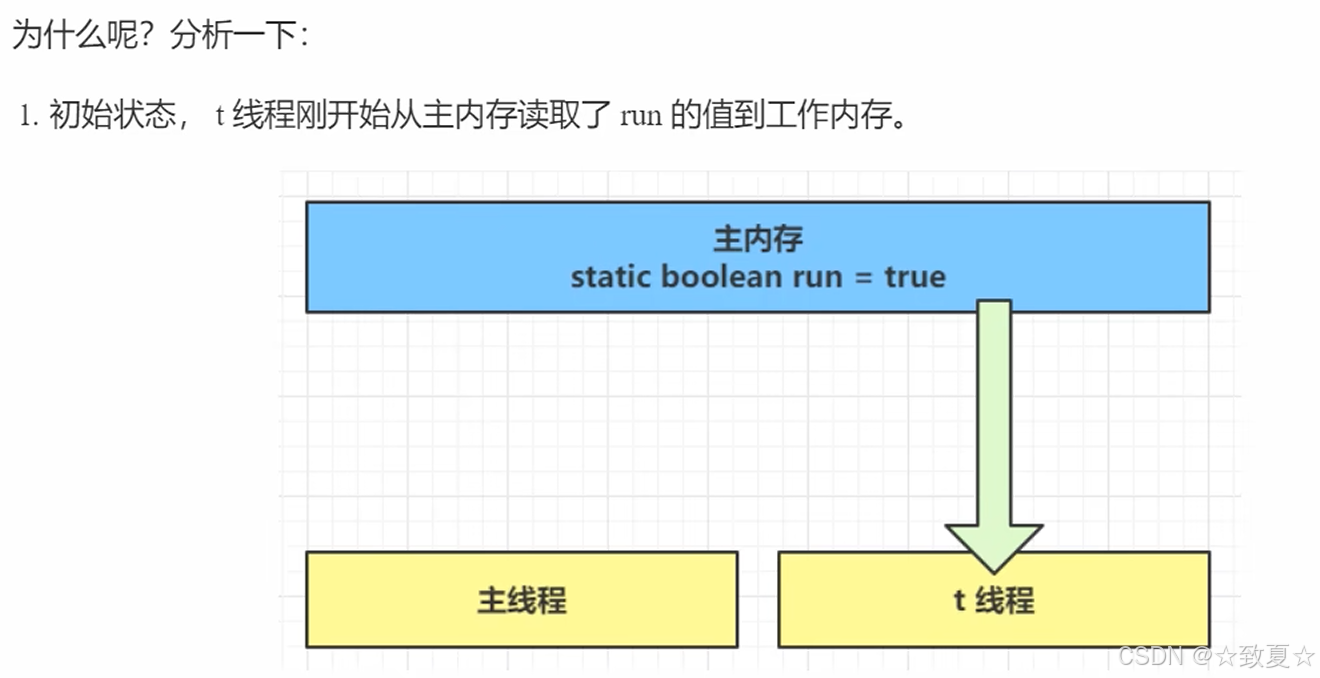
可以把主内存看成物理内存,工作内存看成缓存
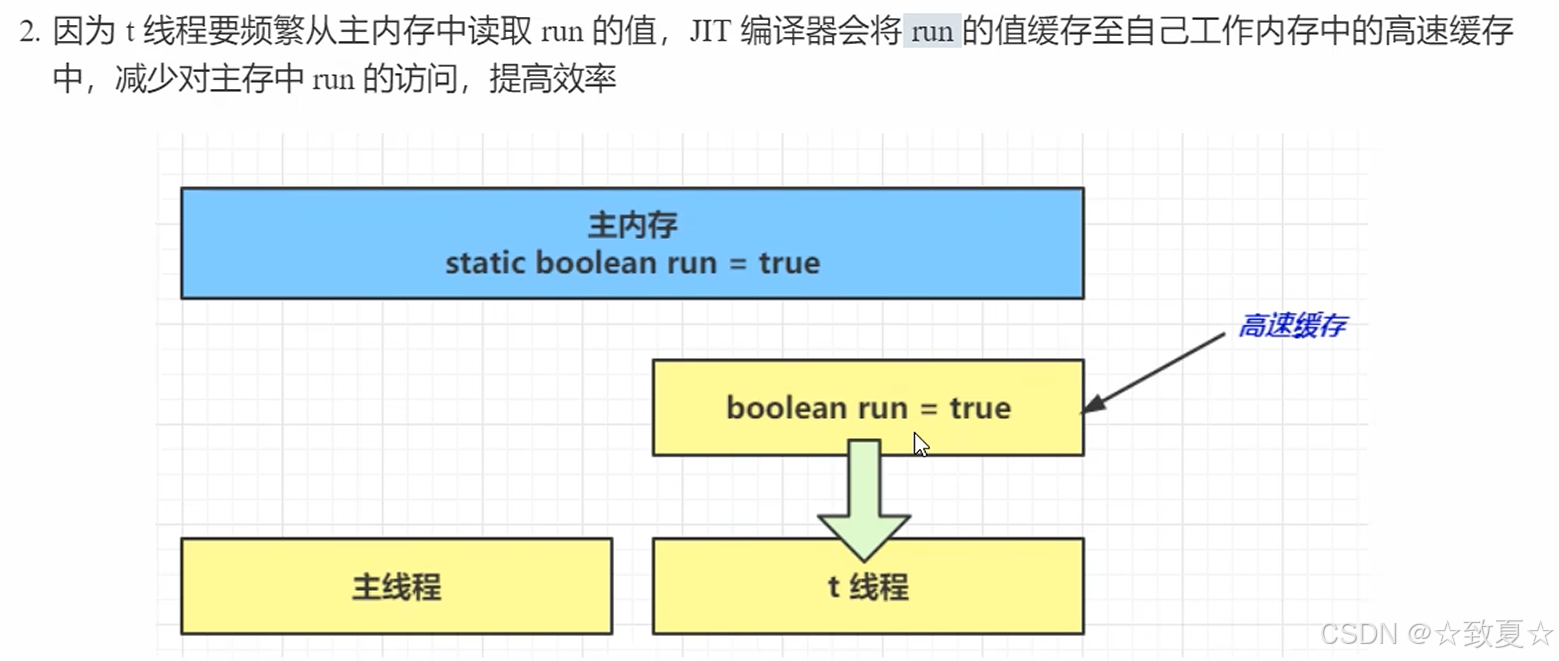
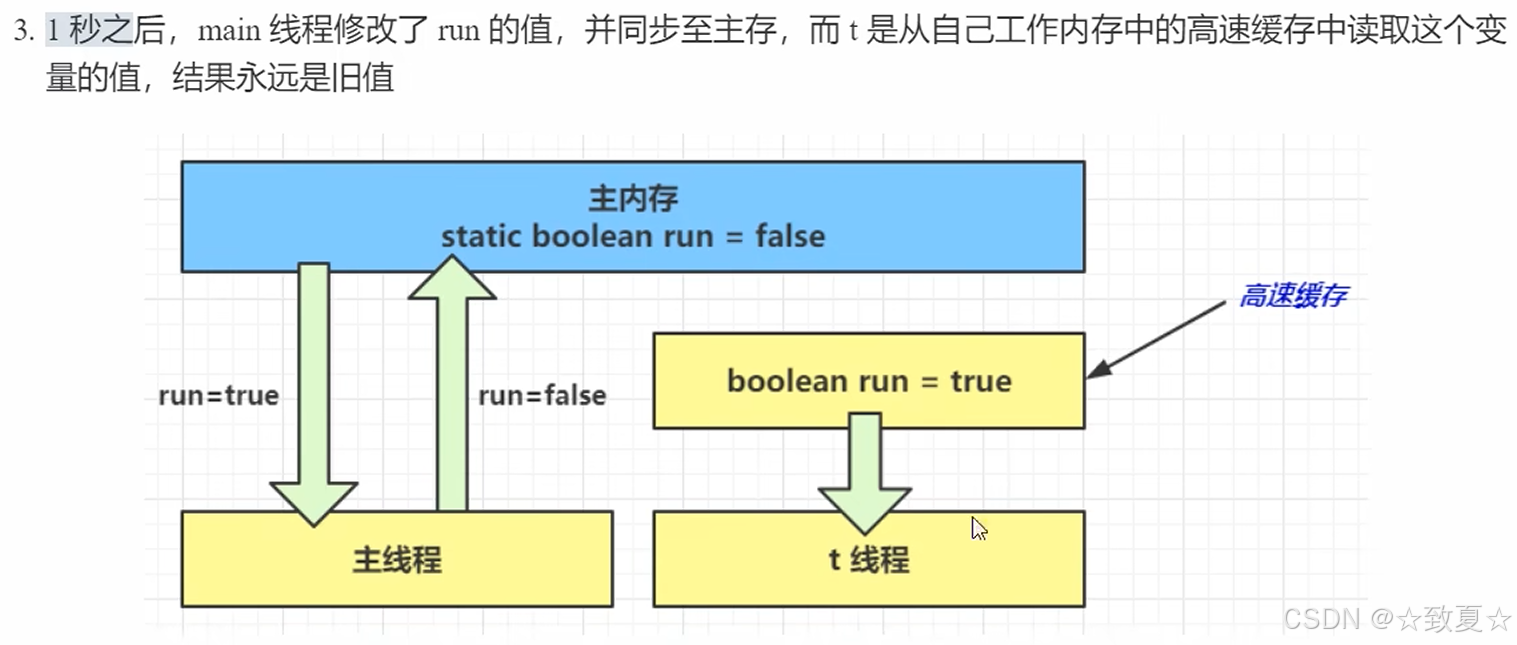
解决方法

使用volatile,效率有所损失,但保证共享变量在多个线程间的可见性
也可以使用syschronized保证可见性
可见性 VS 原子性

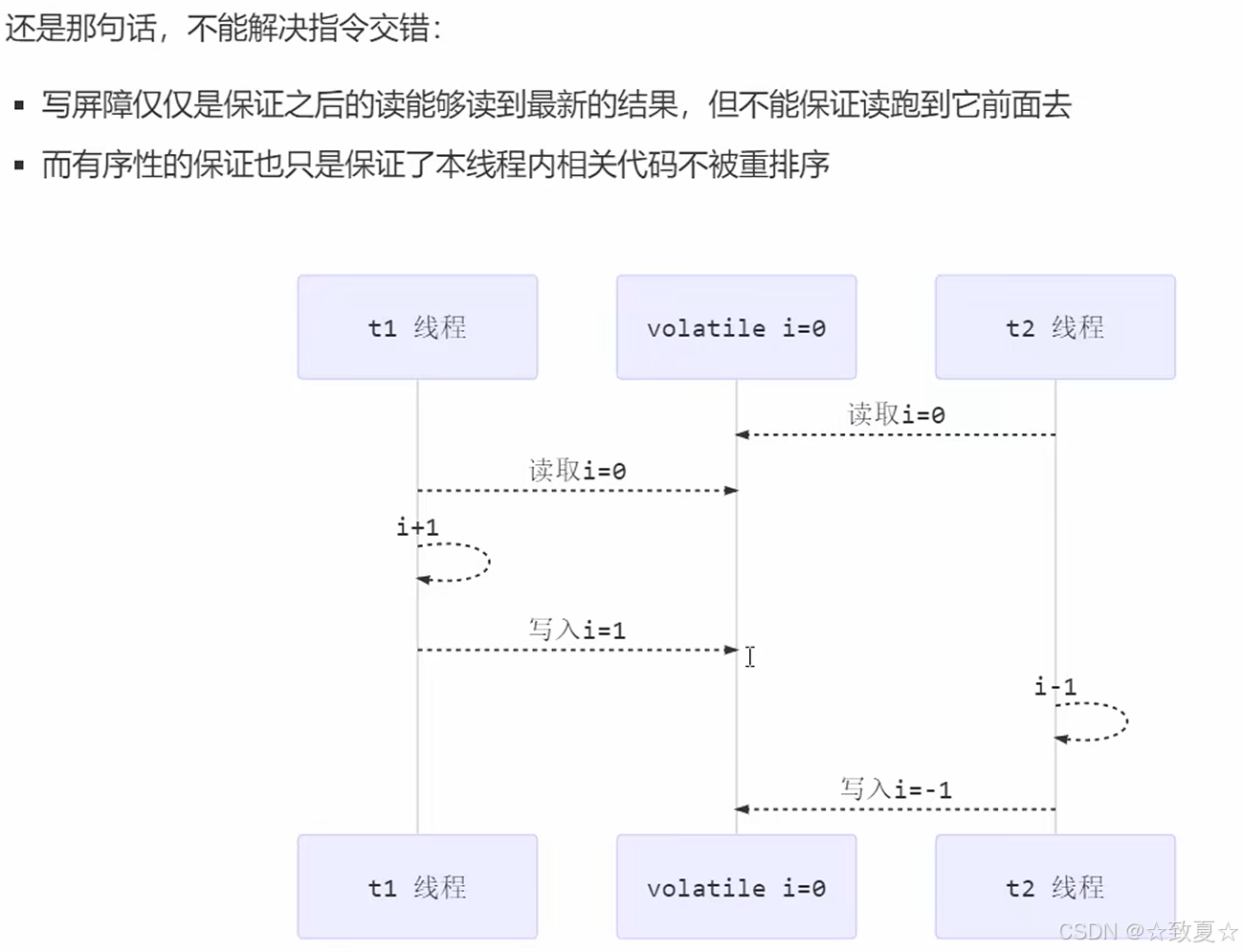
指令交错是原子性问题,volatile只能保证线程读取最新值,并不能解决原子性问题。

两阶段终止模式--volatile改进

改进前代码使用打断标记来控制退出循环
在捕捉错误很容易遗漏重新设置打断标记,如果没有正确设置打断标记,导致没办法进入if块,没法退出循环
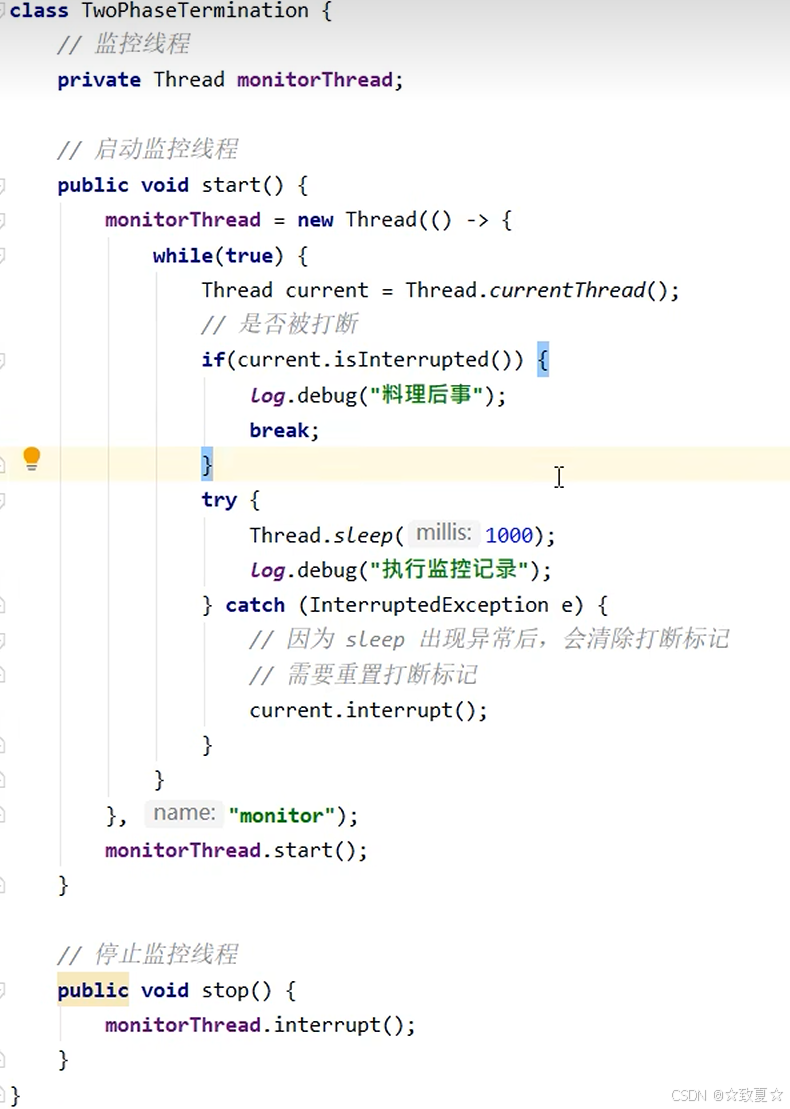
volatile改进后使用布尔变量来控制退出循环

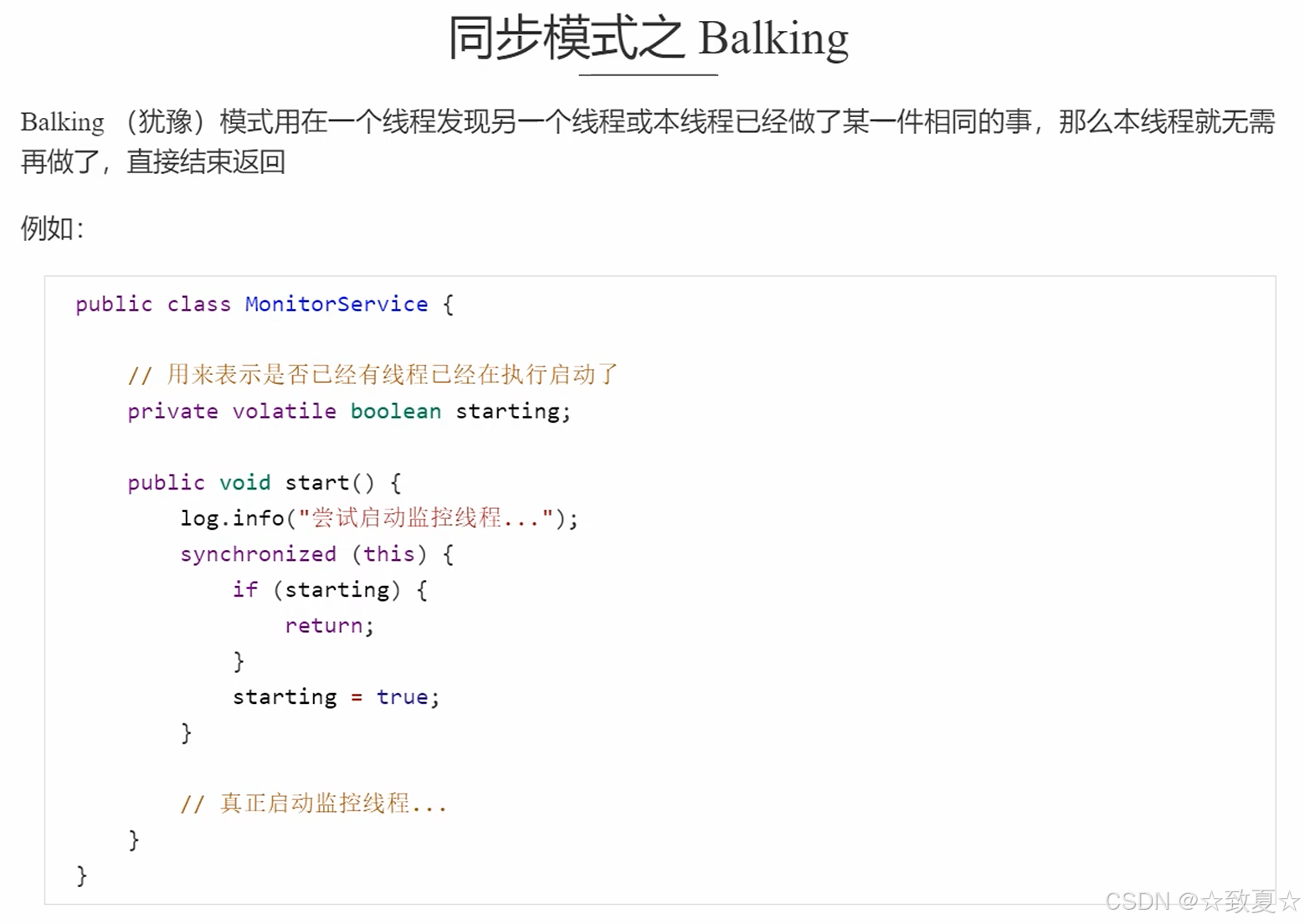
同步模式之Balking(犹豫模式)
让某个方法只执行一次,再次执行直接返回。
例如,上述的启动监控线程,只需要一个即可
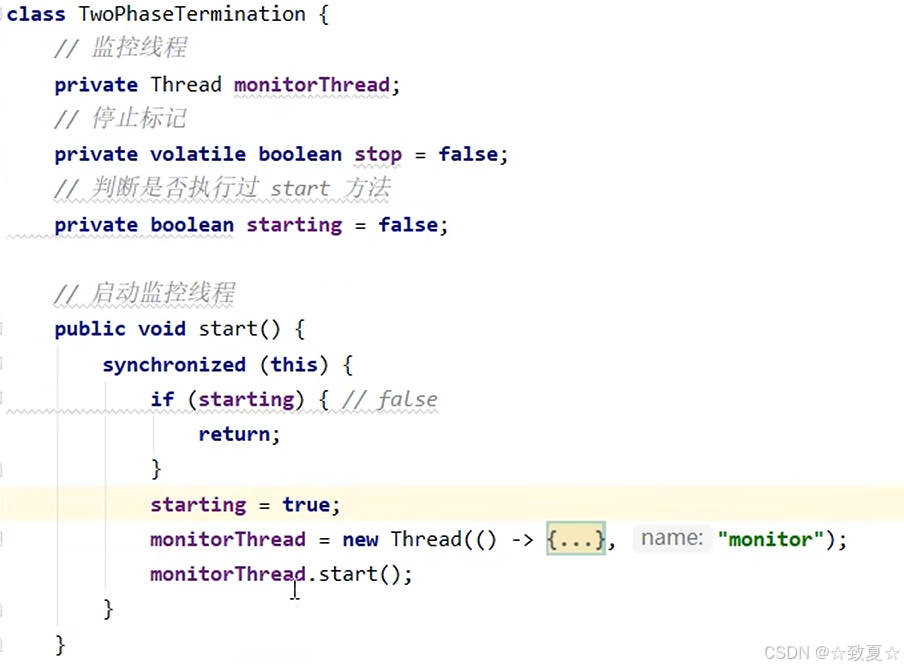
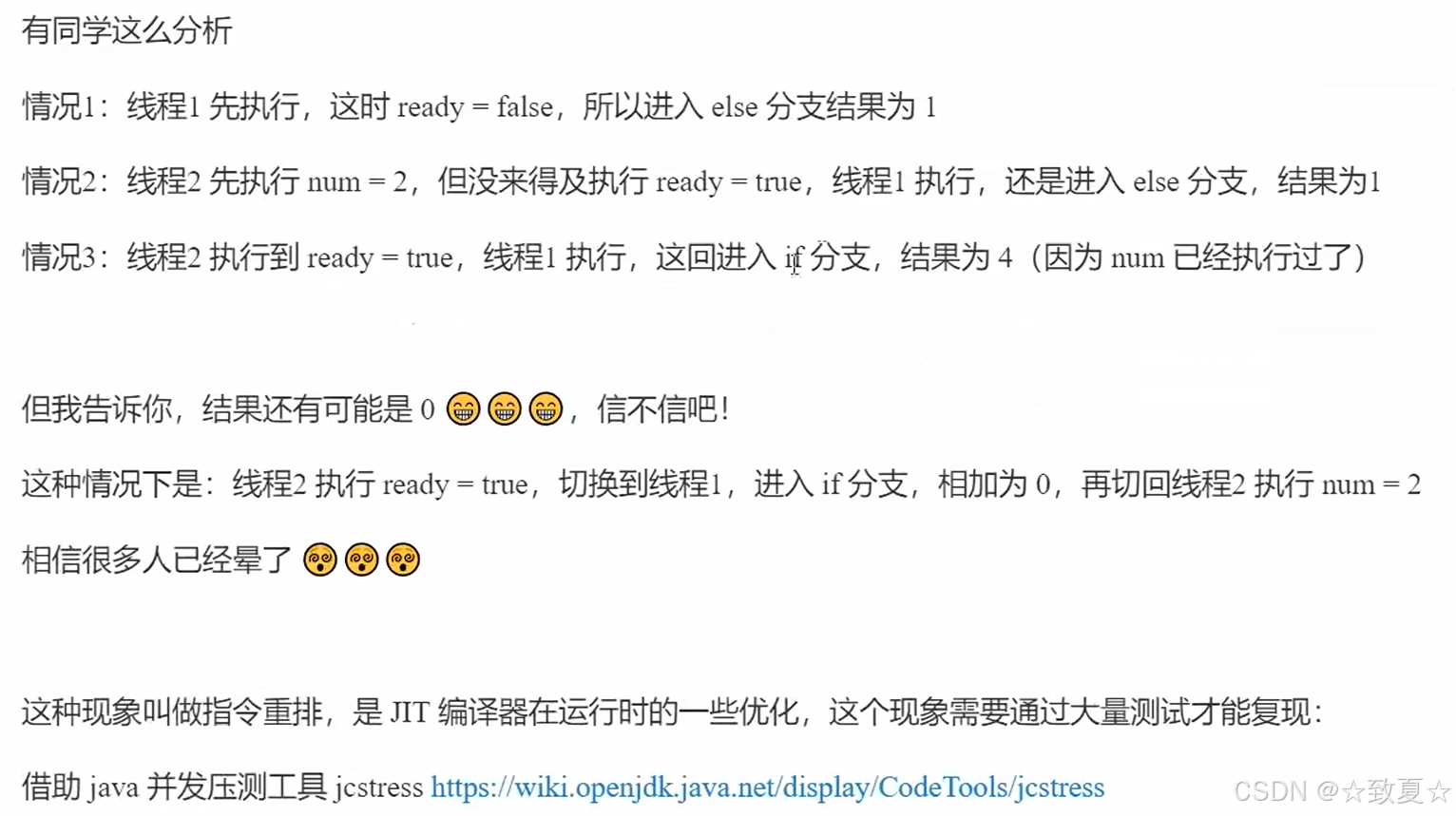
犹豫模式应用场景
1.防止多线程方法启动多次
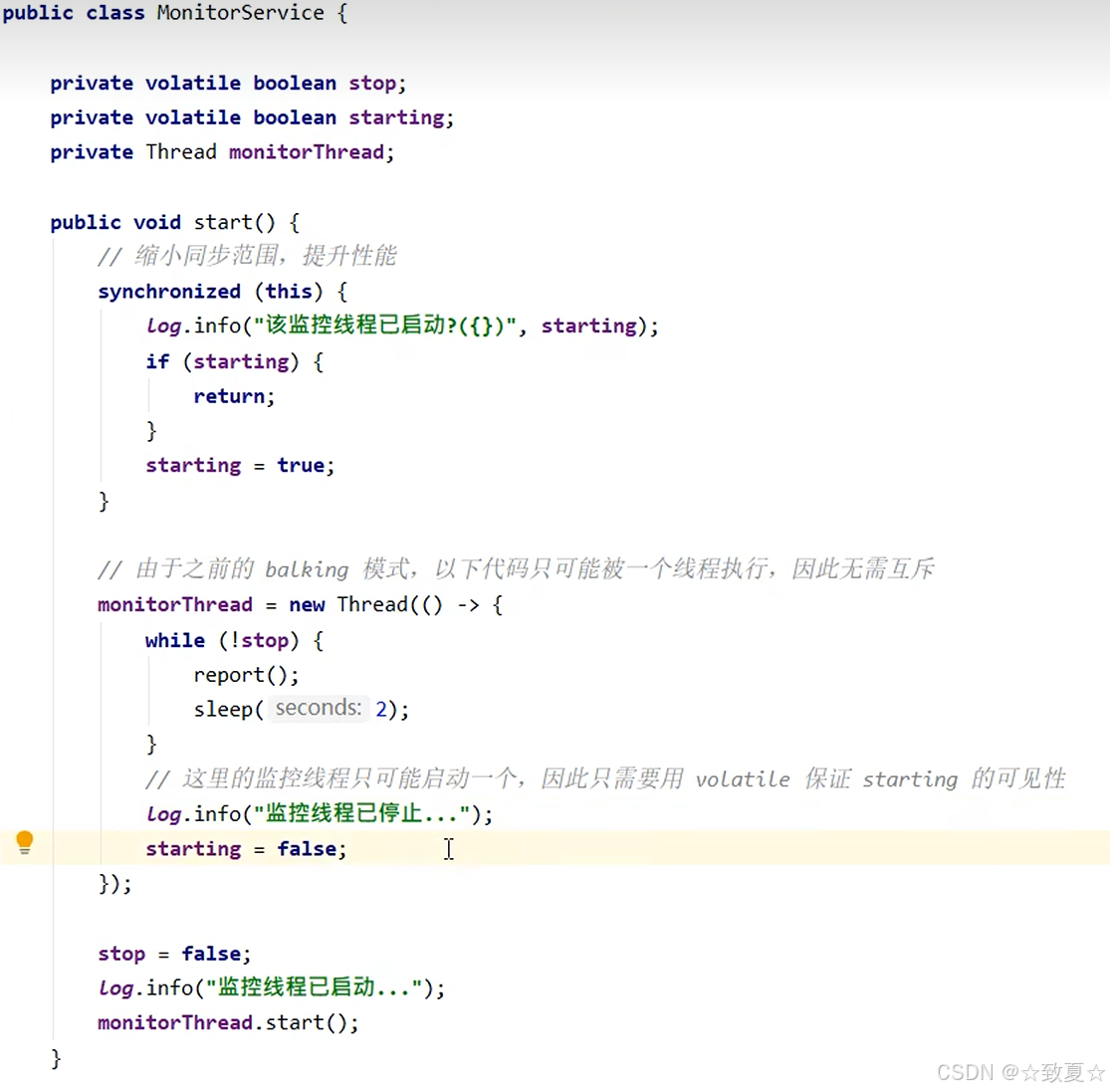
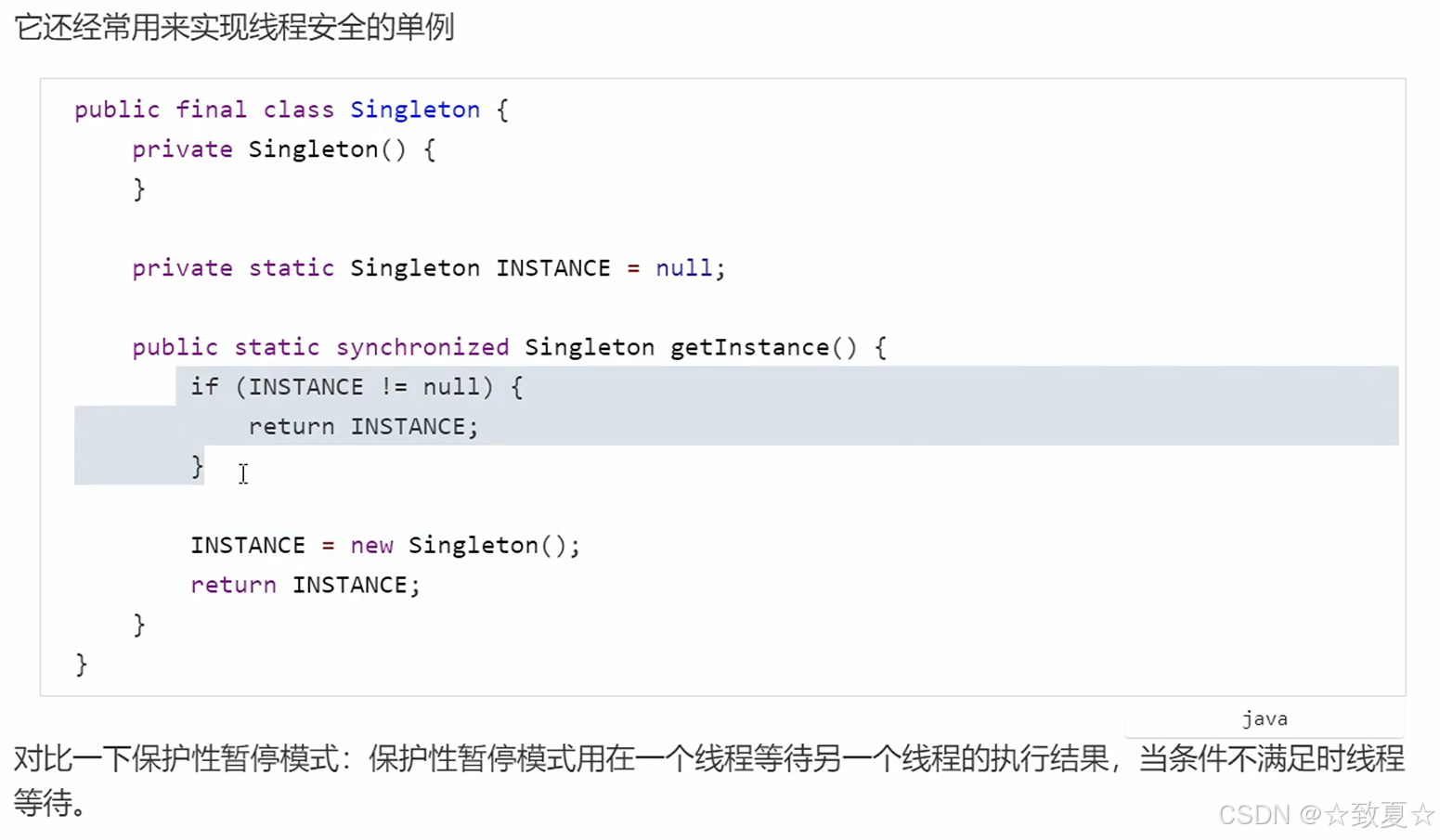
 2.实现线程安全的单例(懒加载)
2.实现线程安全的单例(懒加载)
有序性
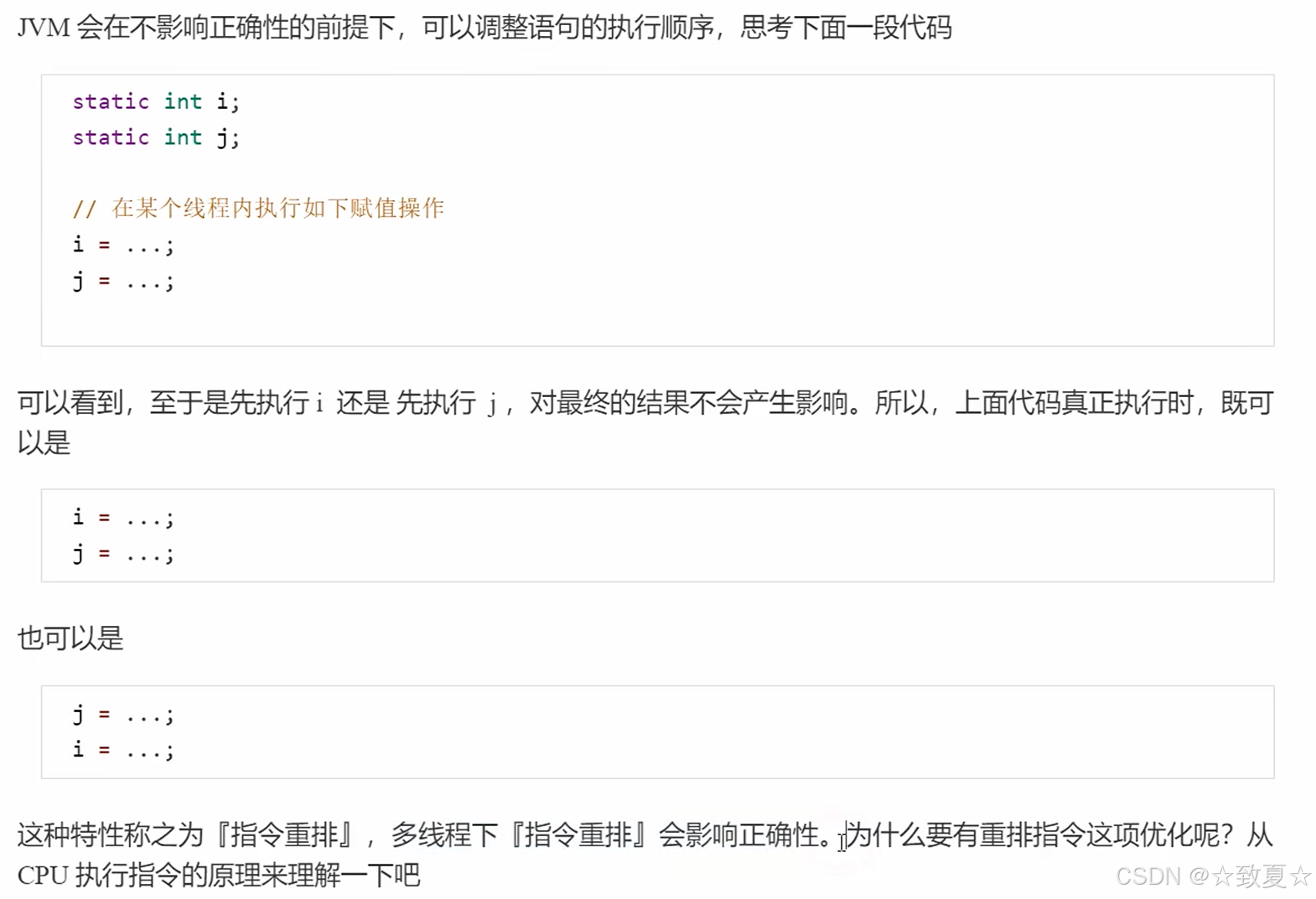
指令重排
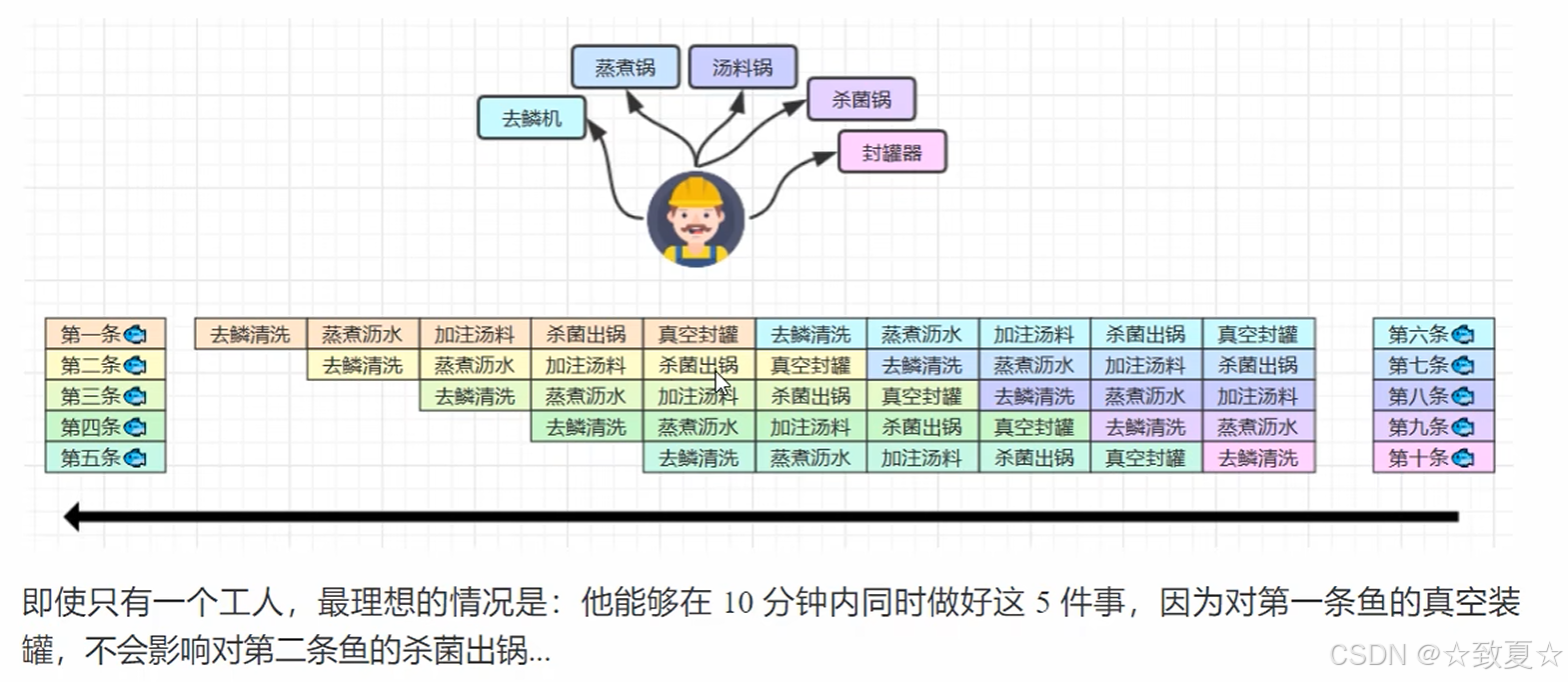
指令重排的故事
做鱼罐头需要5个步骤
在每个步骤不互相影响的情况下,实现5个步骤同时执行
处理一条鱼的总时间没变,但可以在同一时刻对多条鱼的不同步骤进行执行
增加了指令执行的并行度(吞吐量),划分步骤带来了效率上的提升

指令重排的原理图解

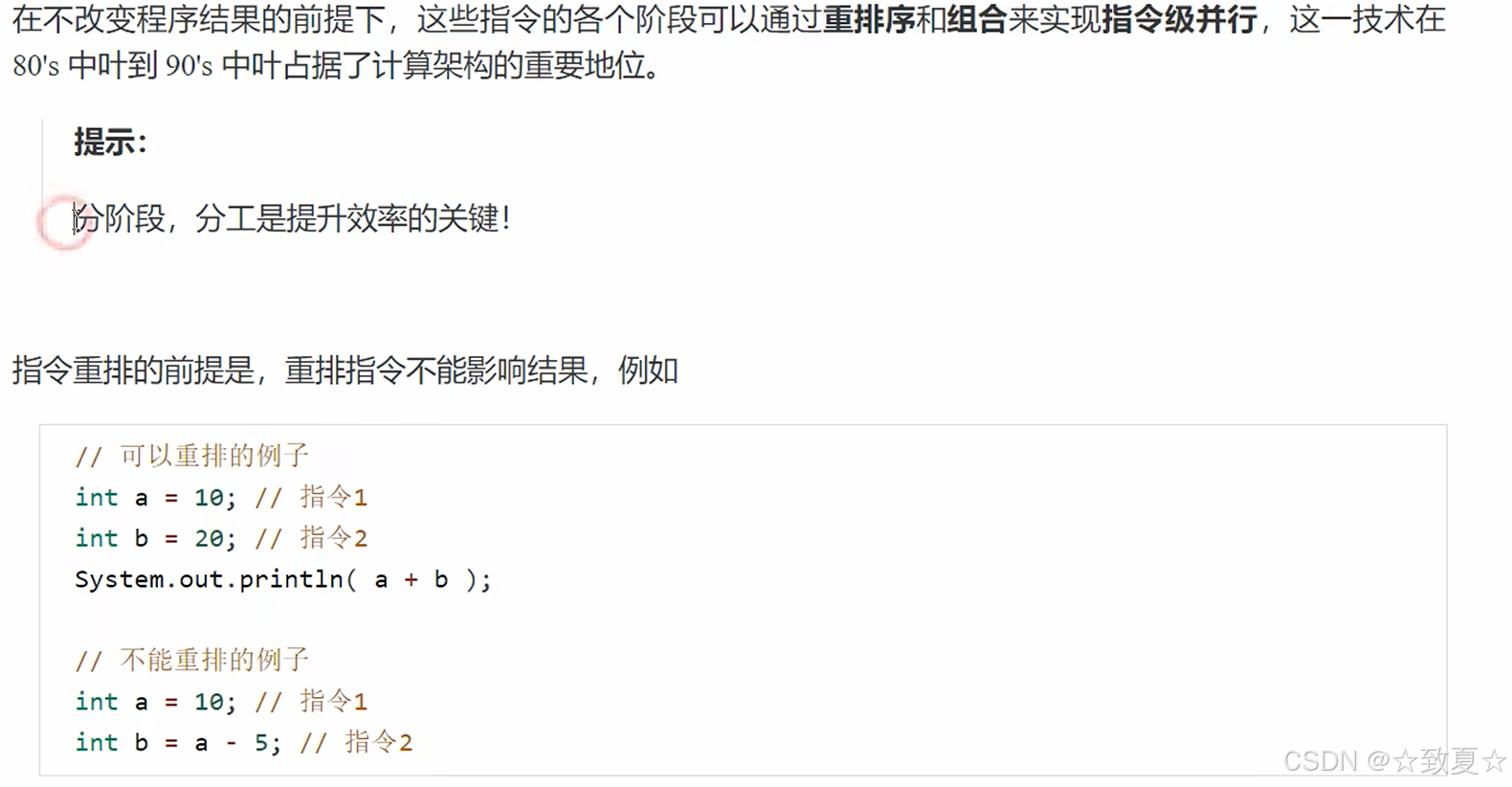

原本指令的执行顺序是串行(一个接一个),为了执行每个指令的不同部分,指令的执行次序可能会被调整。
指令重排问题
并发压测工具jcstress的使用(指令重排验证)

idea打开Terminal粘贴运行命令

运行成功后生成一个ordering项目
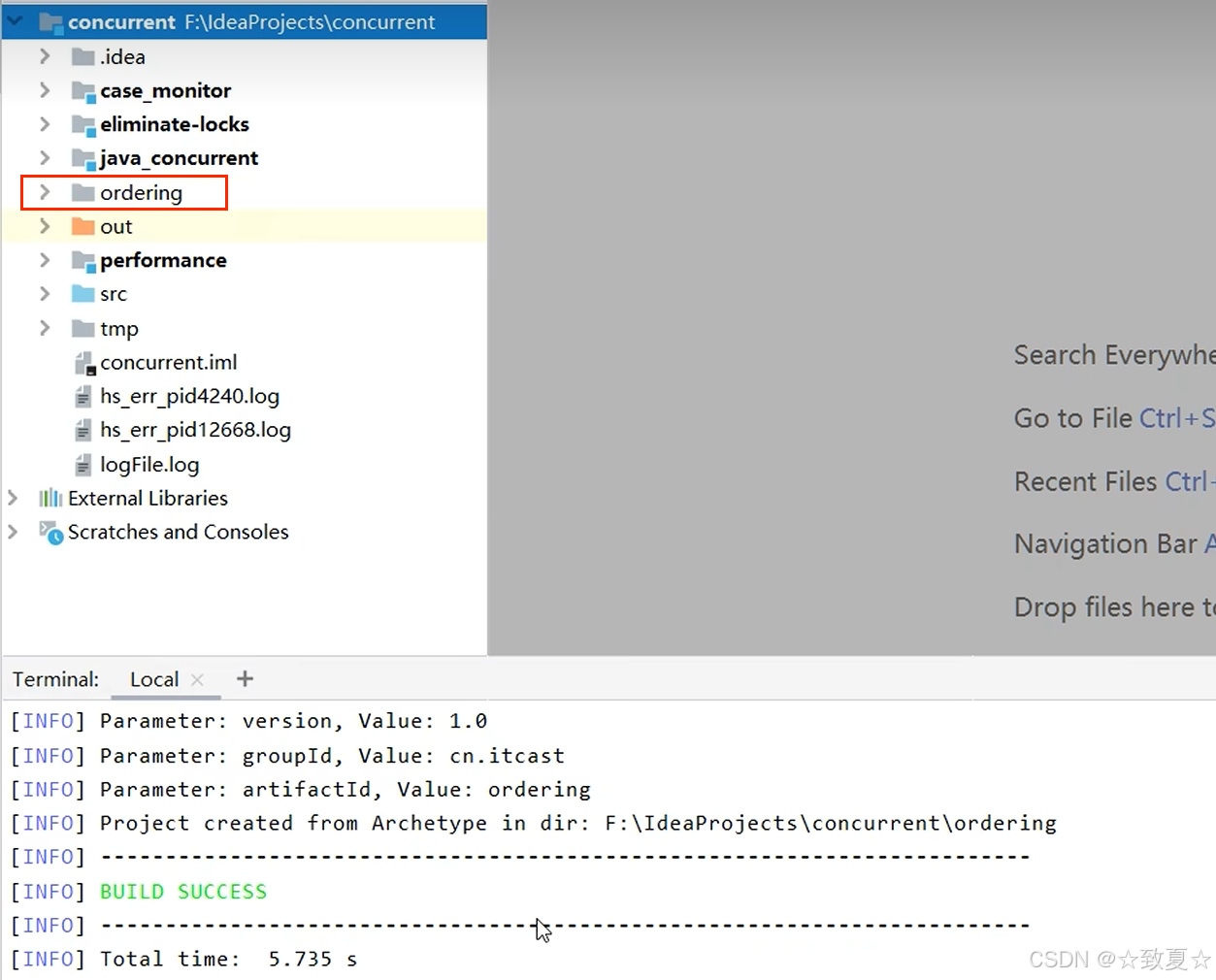
导入生成的pom项目
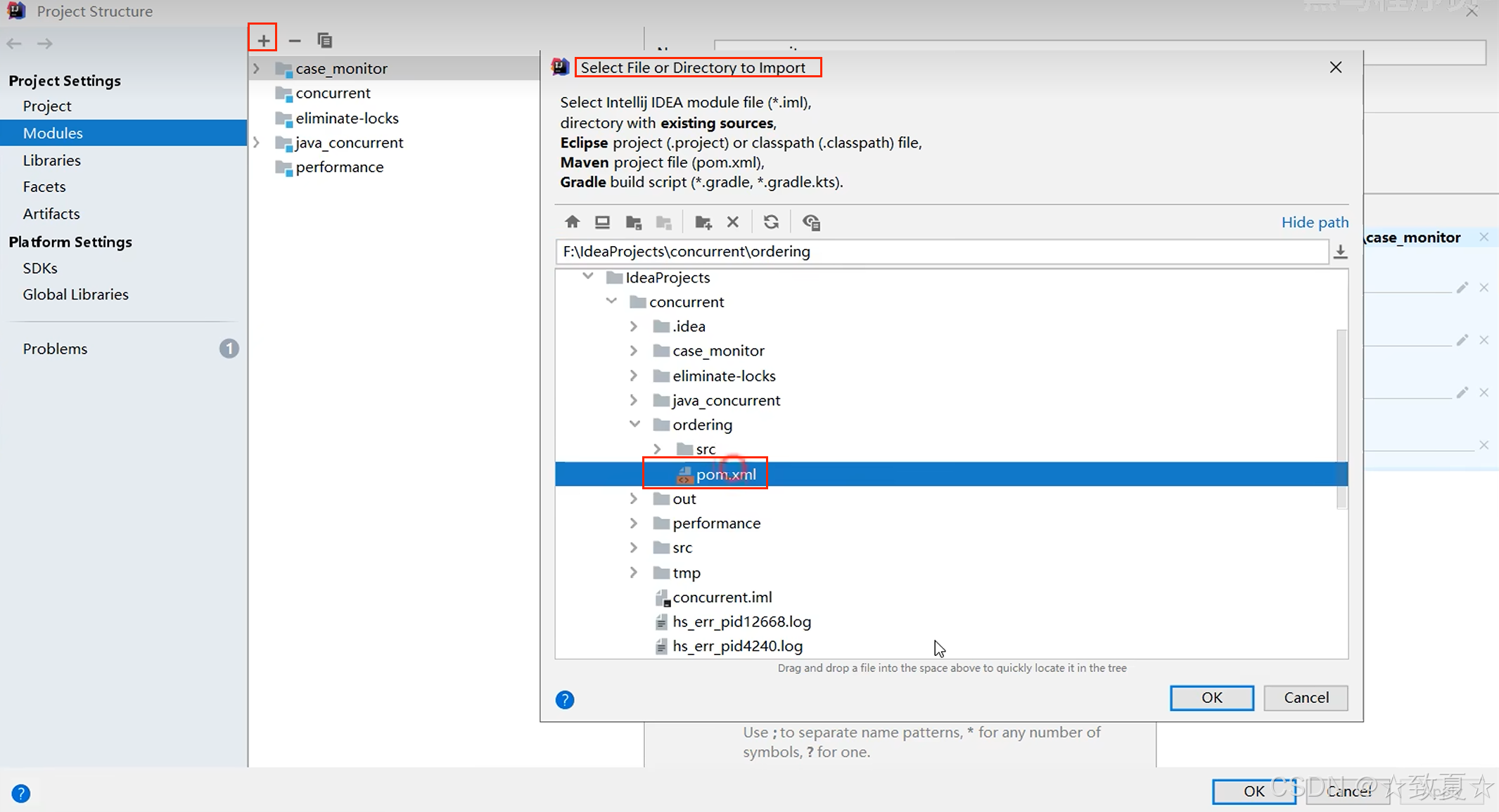
生成的测试文件编写好测试代码后,通过maven打包运行
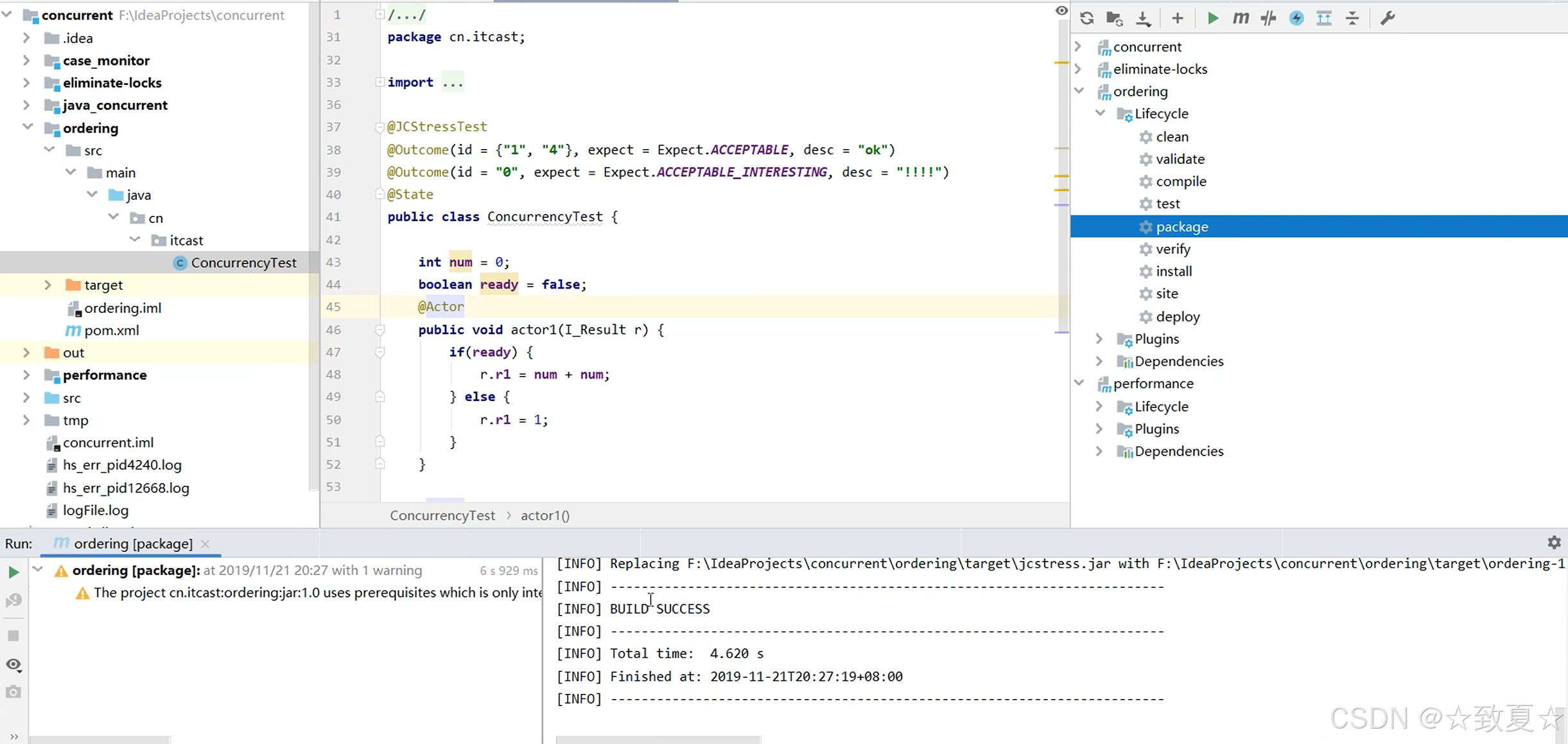
打包好后进入target目录
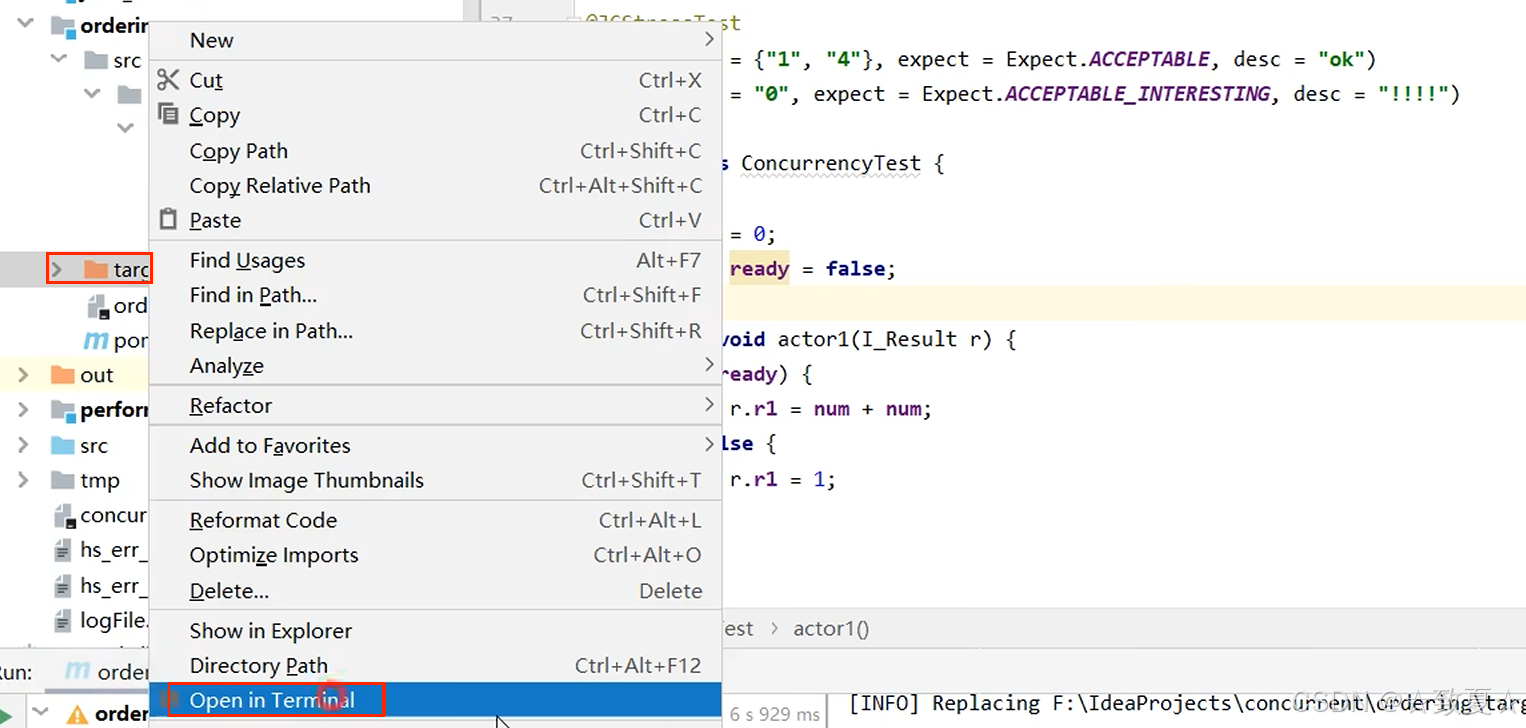
通过 dir 命令查看生成的文件并运行jar包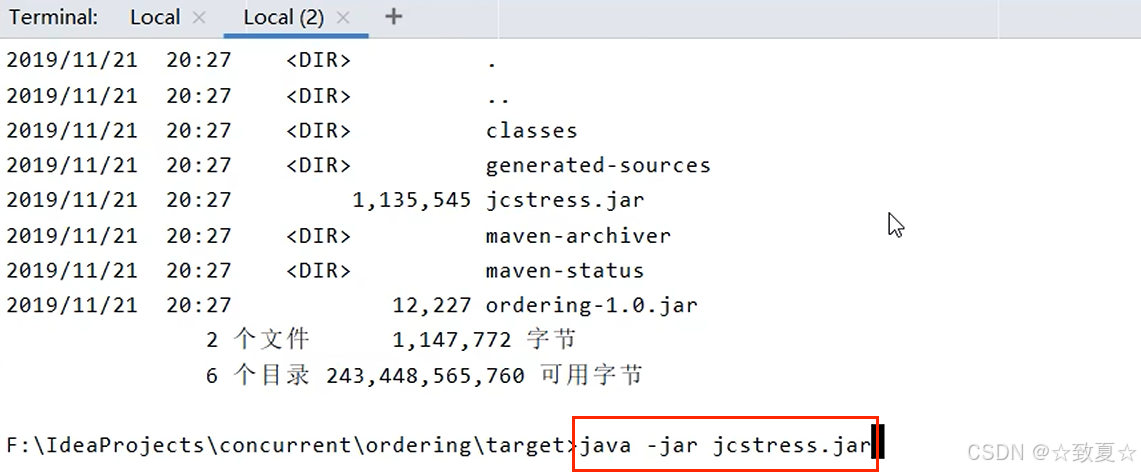
测试结果
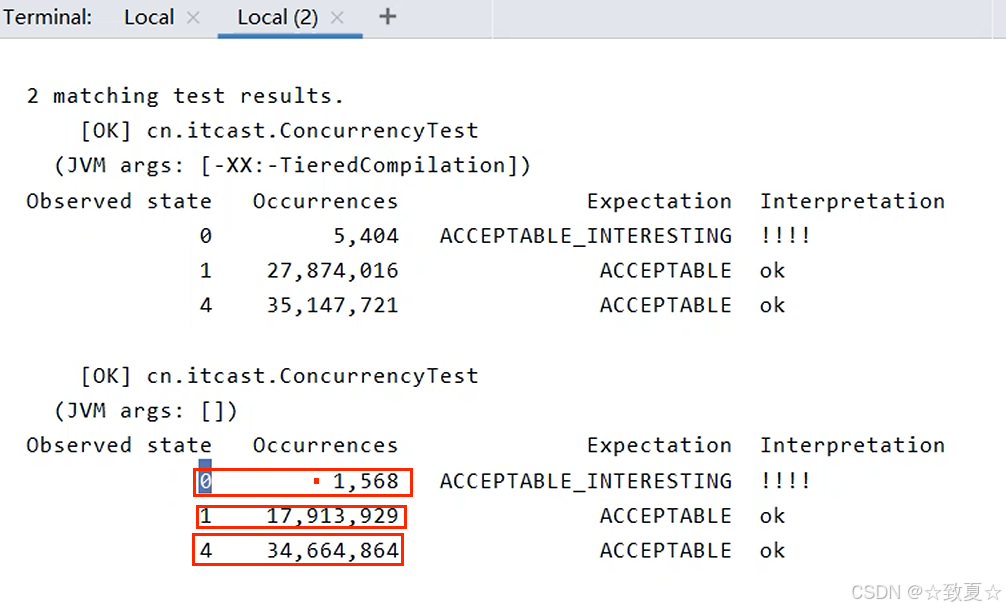
指令重排的禁用
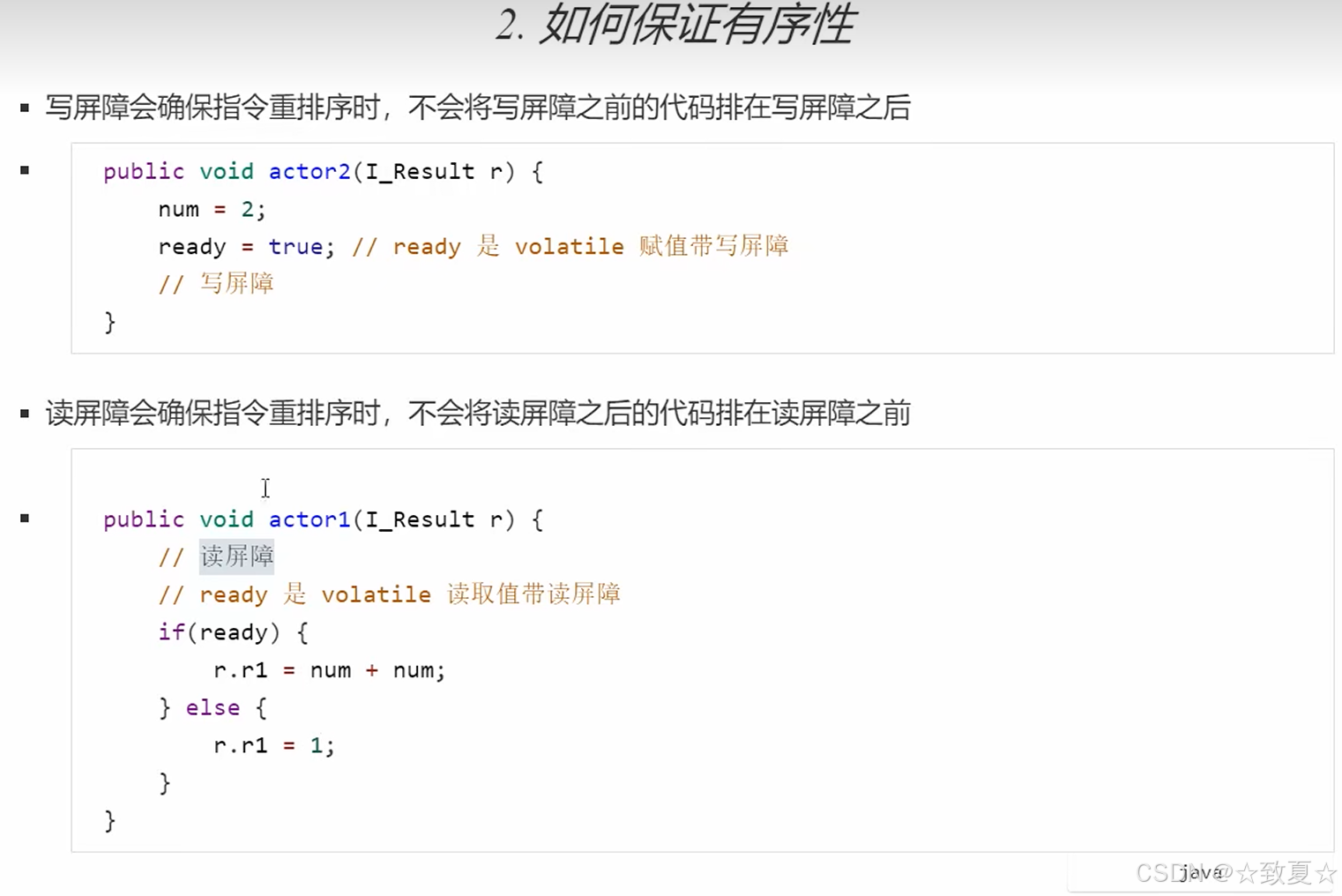
加volatile,能够防止之前的代码被重排(相当于加了写屏障),所以不用两个都加,只在最后一个加即可
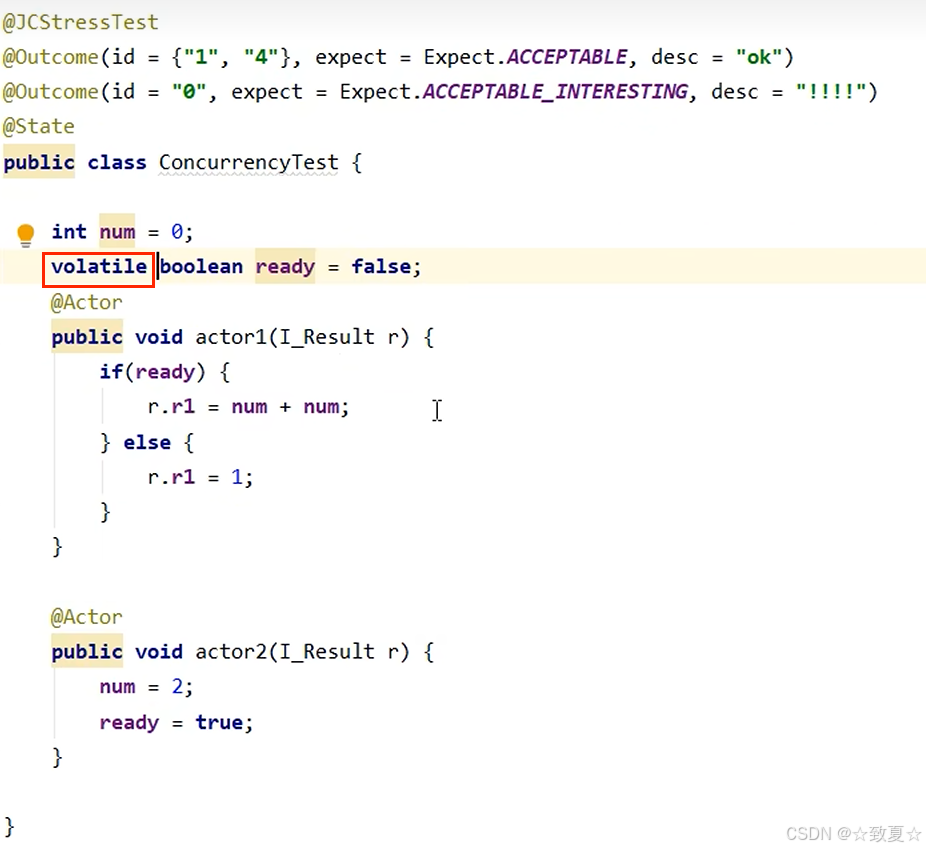
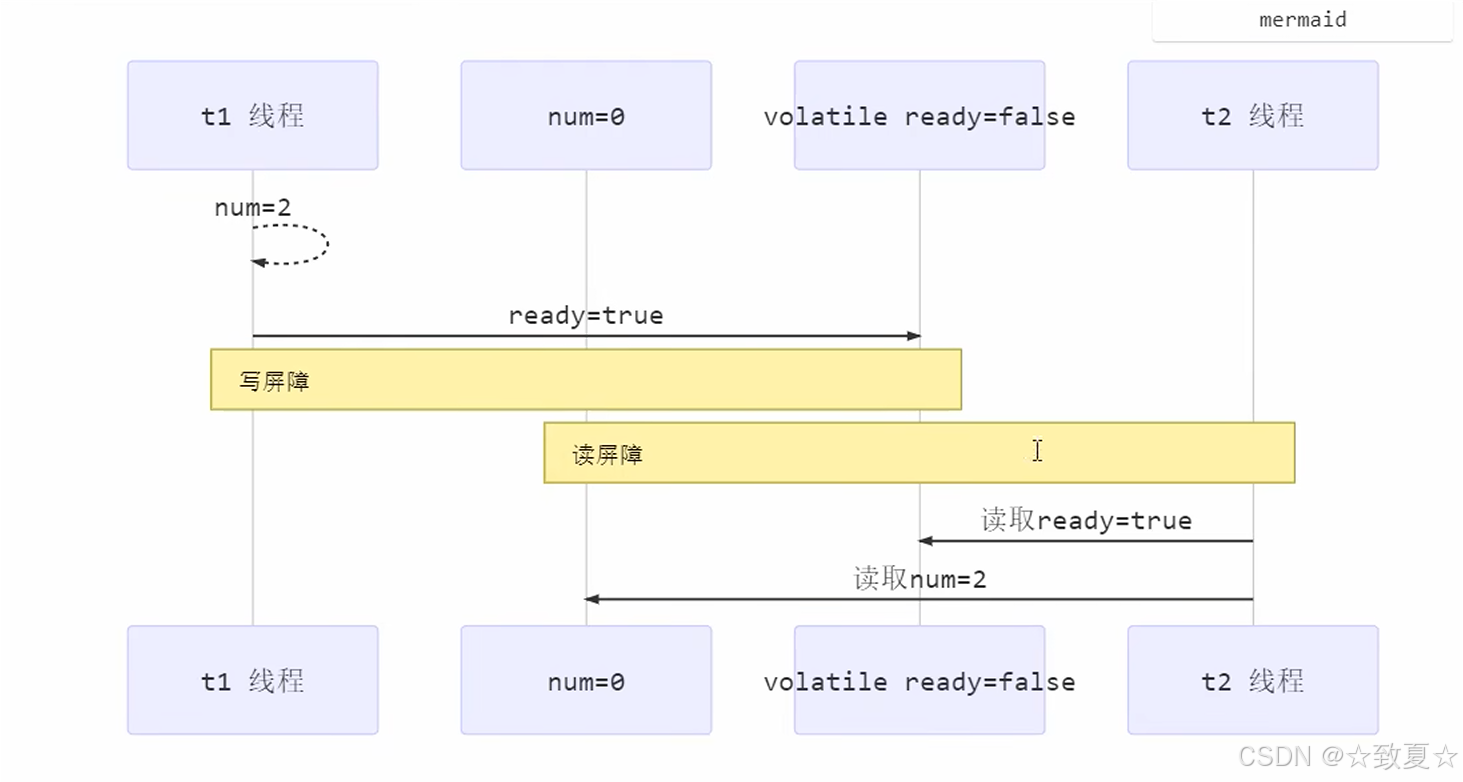
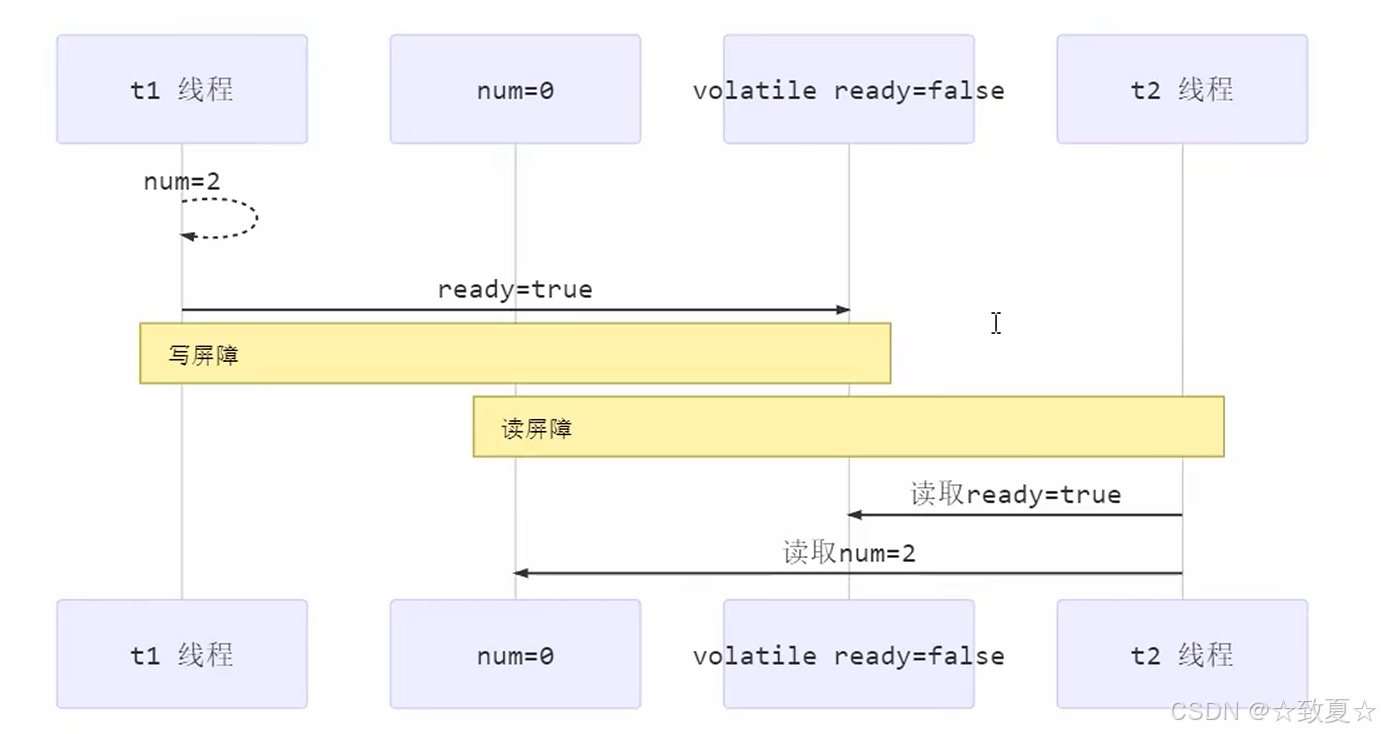
volatile原理

保证可见性
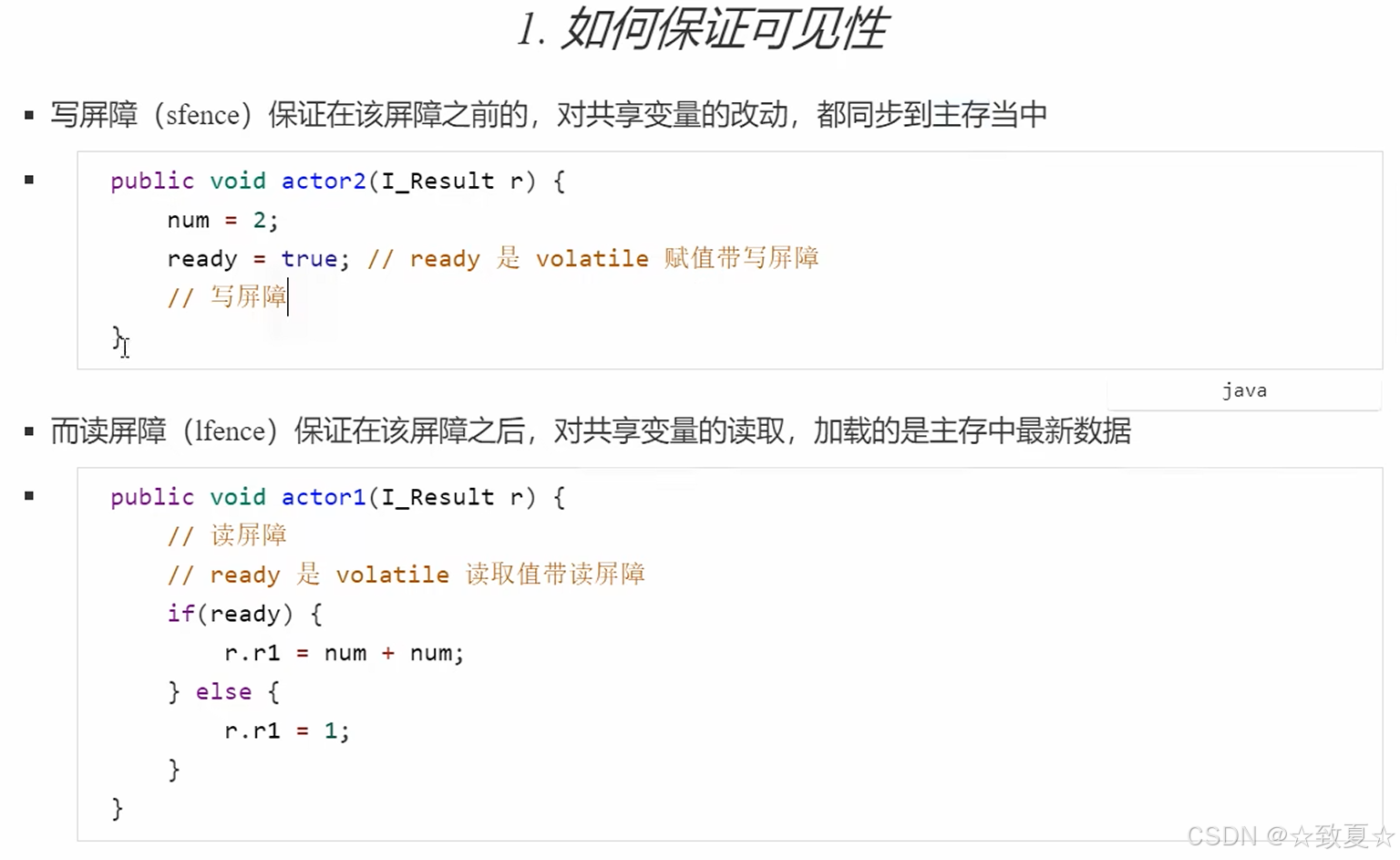
写屏障加入在volatile变量赋值操作之后
写屏障之前共享变量的改动都同步到主存
读屏障加在volatile变量读取之前
读屏障之后共享变量的读取都从主存加载,而不是工作内存
保证有序性
volatile保证可见性、有序性,不能保证原子性
syschronized可以三种都保证
dcl简介
首先分析之前的线程安全单例代码
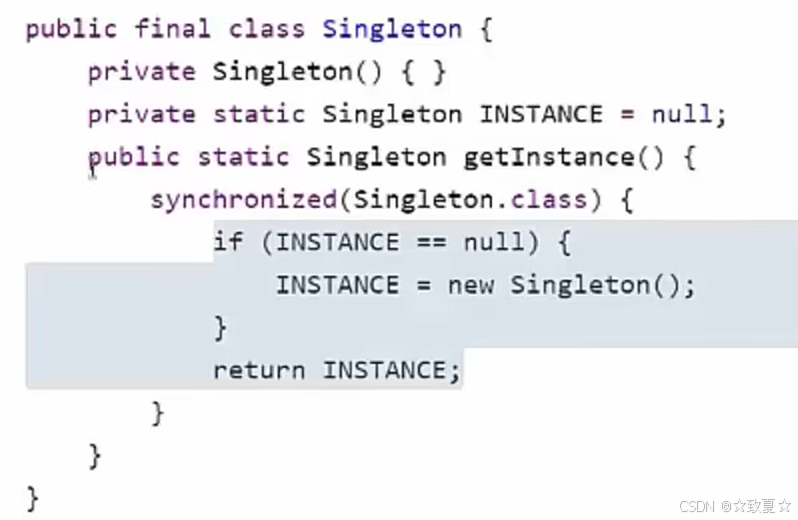
上述代码的问题是synchronized范围太大,导致每次调用getInstance()都会经过线程安全保护,影响性能,其实只需在第一次创建单例是进行线程安全保护即可,于是有了下图的双重校验的优化代码
dcl问题分析

new指令获取一个Singleton引用
dup是复制一份引用
复制的引用用来调用构造方法 指令invokespecial
new指令的引用用来赋值给静态变量INSTANCE 指令putstatic
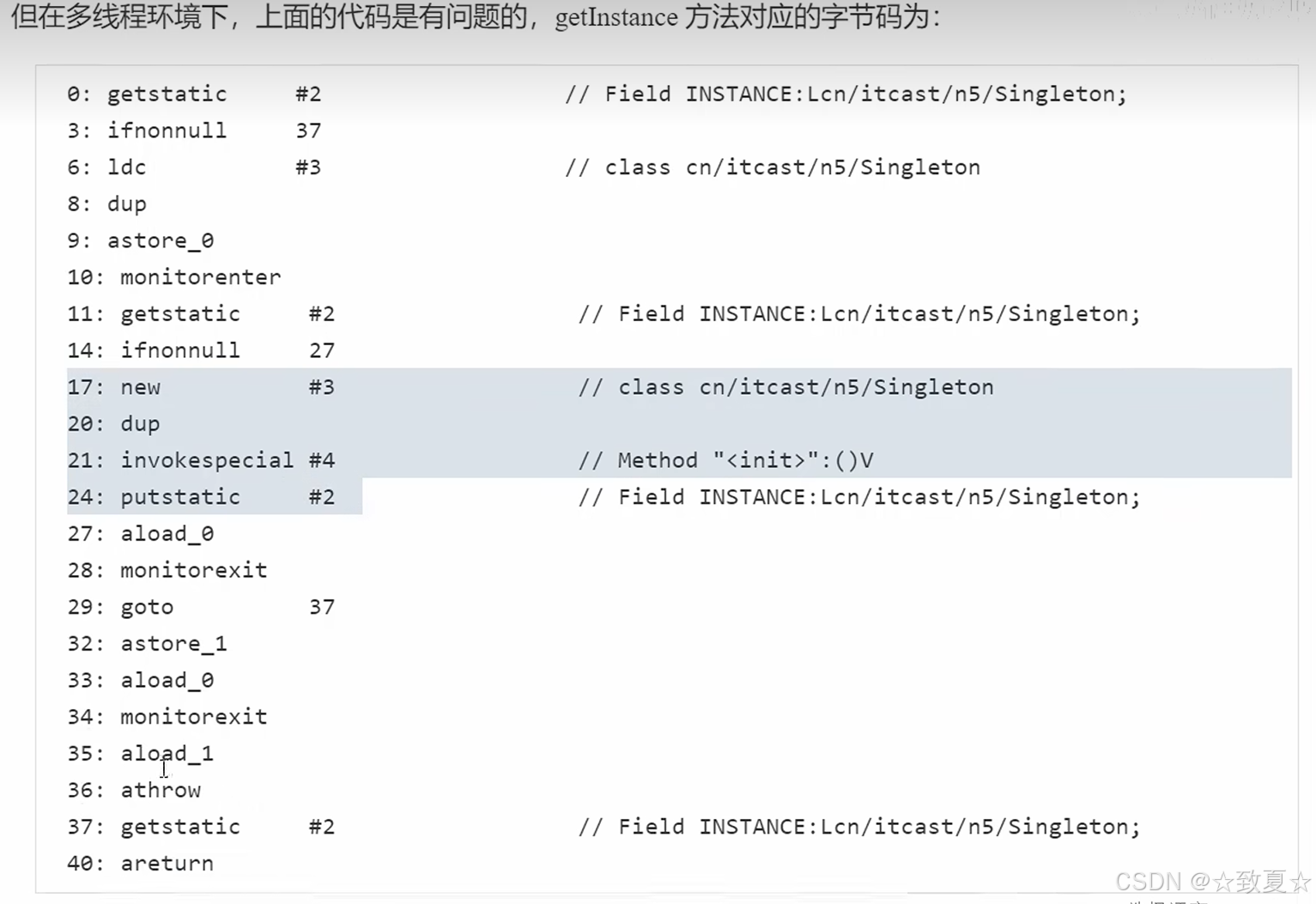
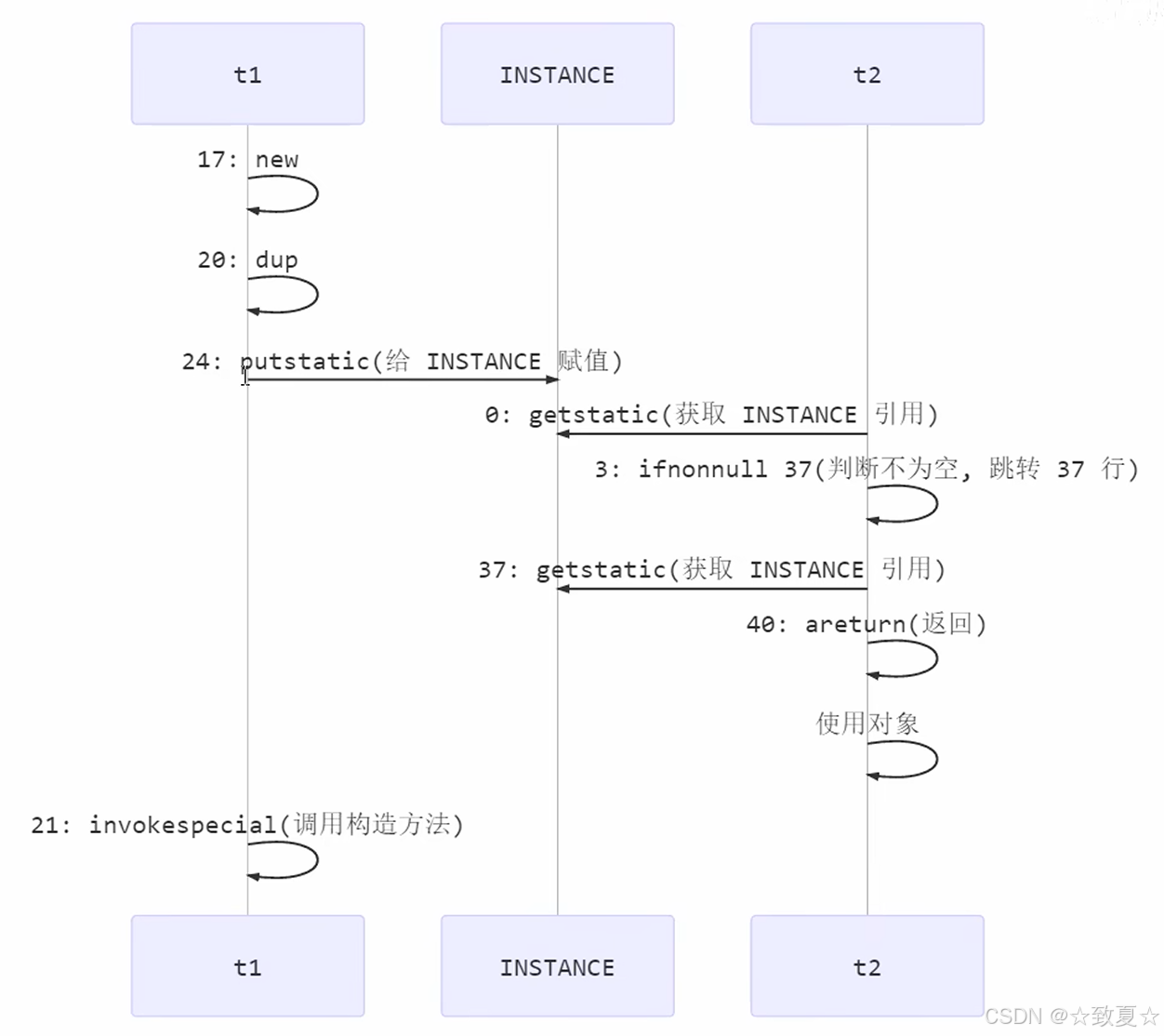
synchronized代码块中的指令仍可以被重排序,synchronized不能阻止重排序,volatile可以阻止
如果共享变量完全被synchronized保护管理,是不会有原子性、有序性、可见性问题的,上述代码的INSTANCE没有被完全保护,导致其他线程可以访问。


dcl问题解决


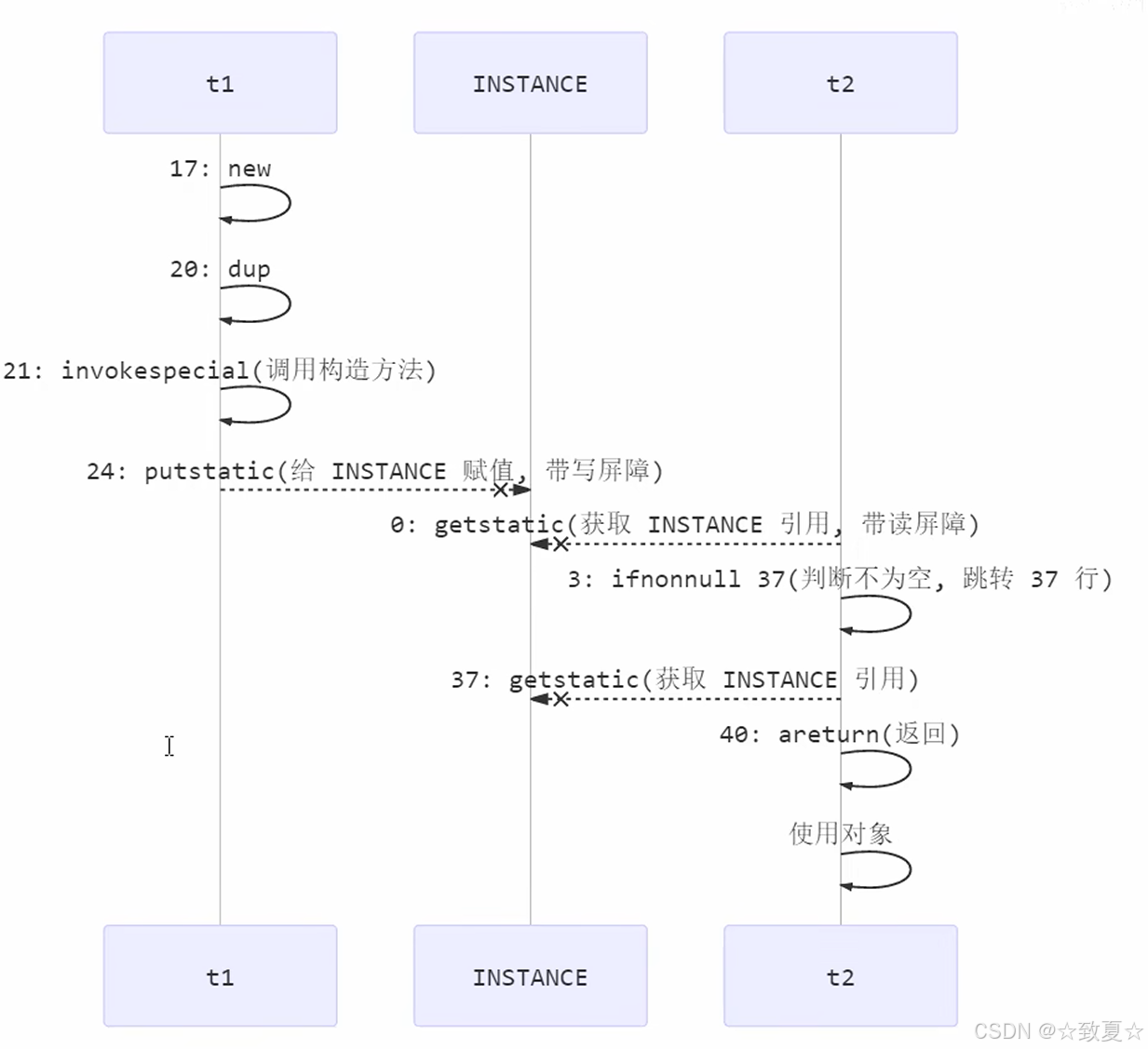
volatile保证的可见性、有序性在jdk1.5之后才生效
happens-before规则





六、共享模型之无锁
乐观锁无锁并发
保护共享资源-加锁实现
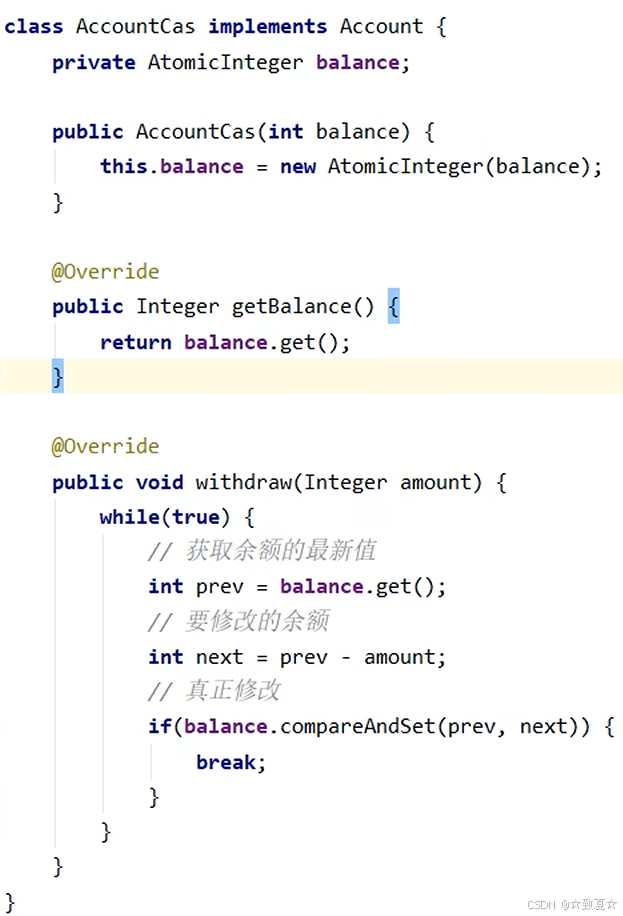
定义一个接口Account,有获取存款方法,取款方法和一个创建1000个线程消费的静态方法
实现类实现接口;调用静态方法。
保证共享资源的线程安全
public class Test28 {public static void main(String[] args) throws InterruptedException {Account account = new AccountUnsafe(10000);Account.demo(account);}
}class AccountUnsafe implements Account {private Integer balance;public AccountUnsafe(Integer balance) {this.balance = balance;}@Overridepublic Integer getBalance() {synchronized (this) {return balance;}}@Overridepublic void withdraw(Integer amount) {synchronized (this) {balance -= amount;}}
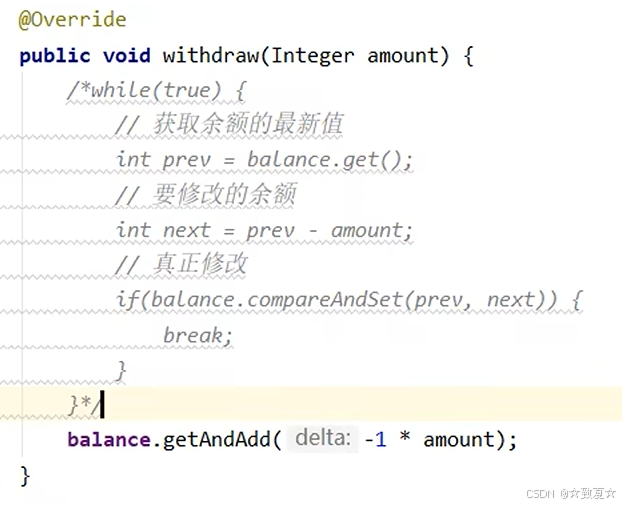
}interface Account {// 获取余额Integer getBalance();// 取款void withdraw(Integer amount);/*** 创建1000个线程,每个线程取10元,模拟取款1000次后,余额是否为0** @param account*/static void demo(Account account) {List<Thread> ts = new ArrayList<>();for (int i = 0; i < 1000; i++) {ts.add(new Thread(() -> {account.withdraw(10);}));}long start = System.nanoTime();// 启动所有线程ts.forEach(Thread::start);// 等待所有线程执行结束ts.forEach(t -> {try {t.join();} catch (InterruptedException e) {e.printStackTrace();}});long end = System.nanoTime();System.out.println(account.getBalance() + " cost " + (end - start) / 1000_000 + " ms");}}保护共享资源-无锁实现
局部变量prev, next存储在线程的工作内存中,不会同步到主存中
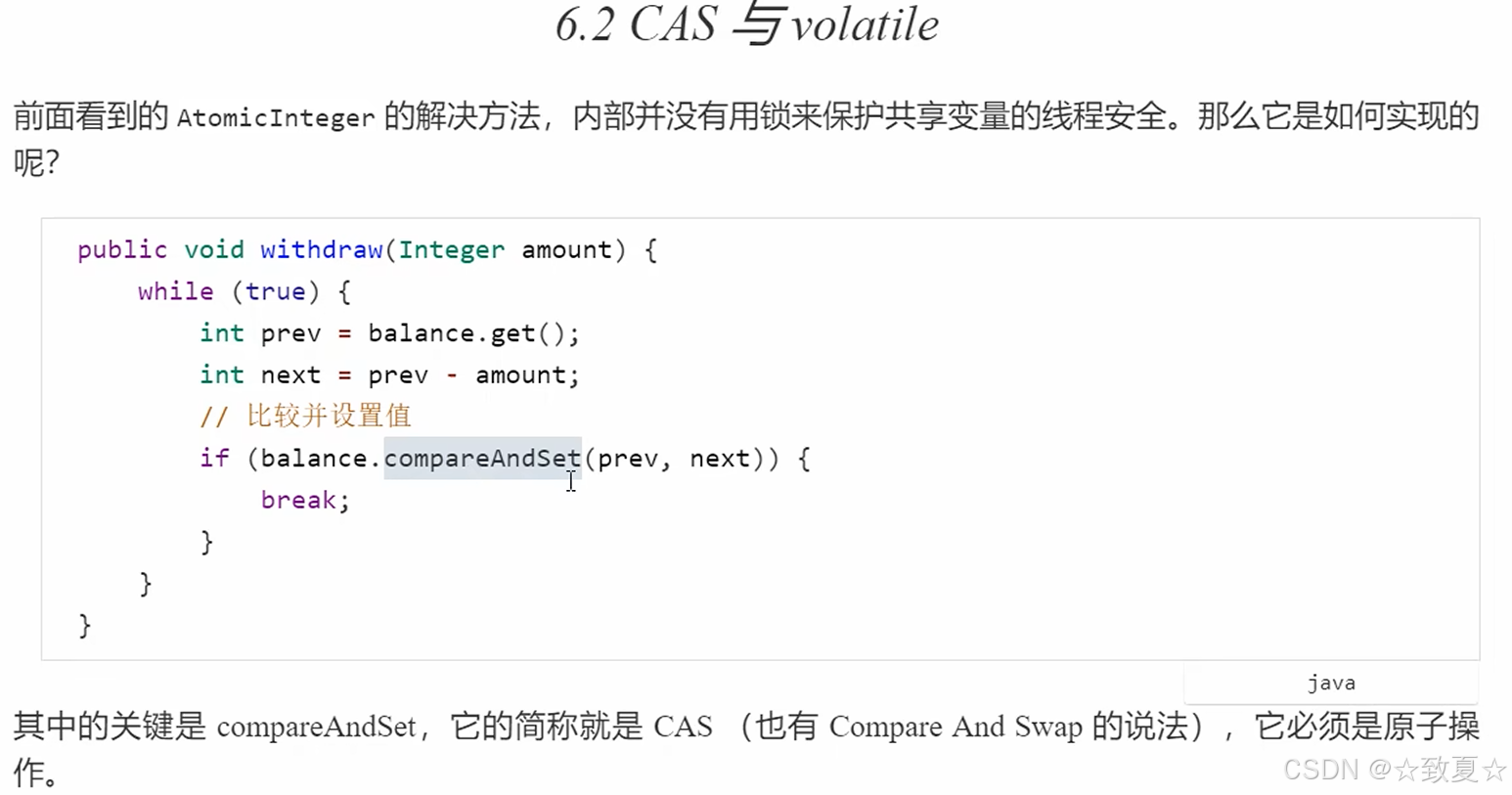
CAS与volatile
cas保证了一些复合操作是原子性的,比如i++,i--(这两个复合操作不是原子性的)等,可以用getAndIncrement,getAndDecrement代替。
cas工作方式
cas主要是不断尝试修改,如果在执行compareAndSet时,要修改的balance变量,已经被其他线程修改,那么此次修改会失败,再次获取新的balance的值尝试修改。
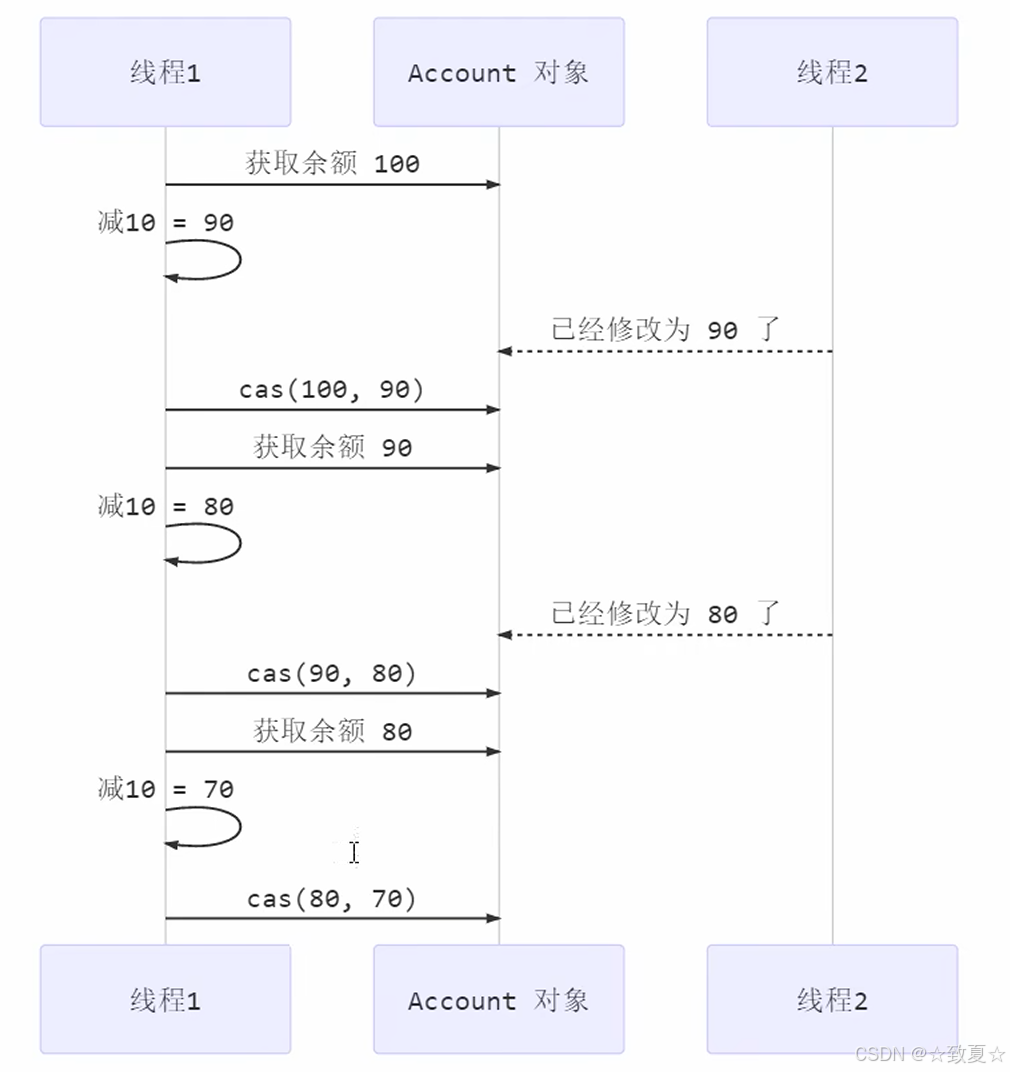

cas执行流程分析
1.在cas执行前打断点
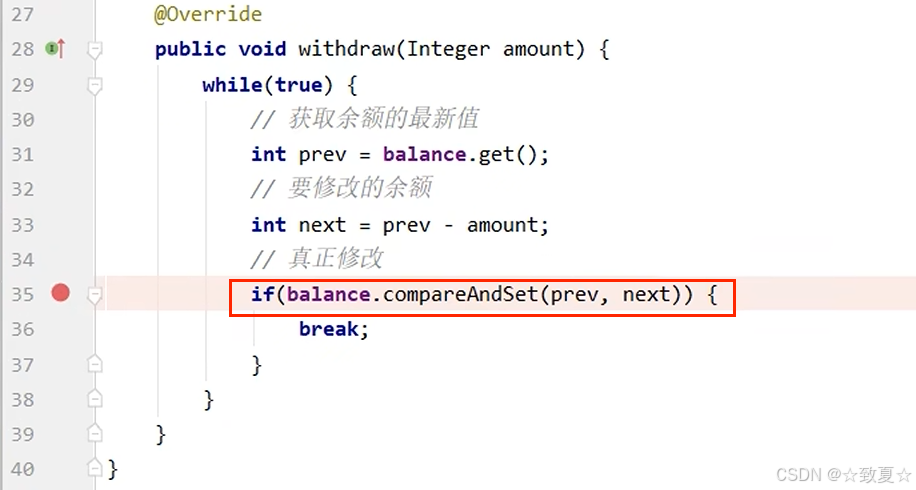
2.开启debug后,模拟其他线程已对balance修改
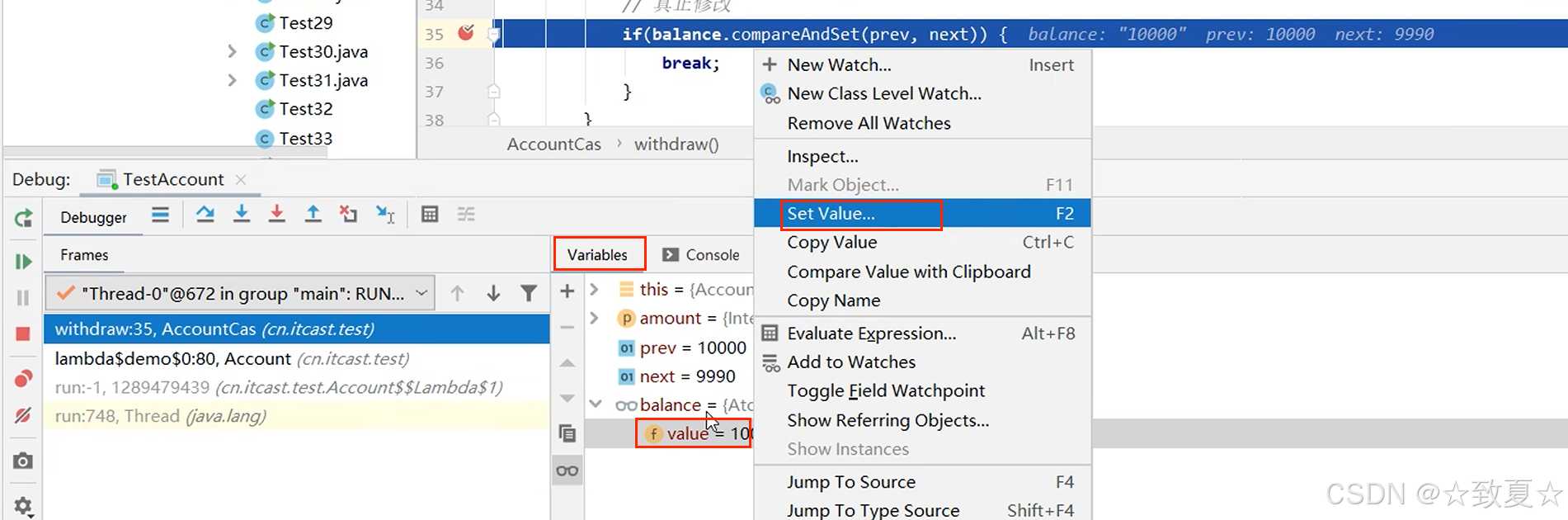
3.执行cas方法,获取balance最新值,发现和prev值不同,比较后返回为false,继续返回循环,尝试修改,直至balance最新值和prev值相等。
cas与volatile的关系
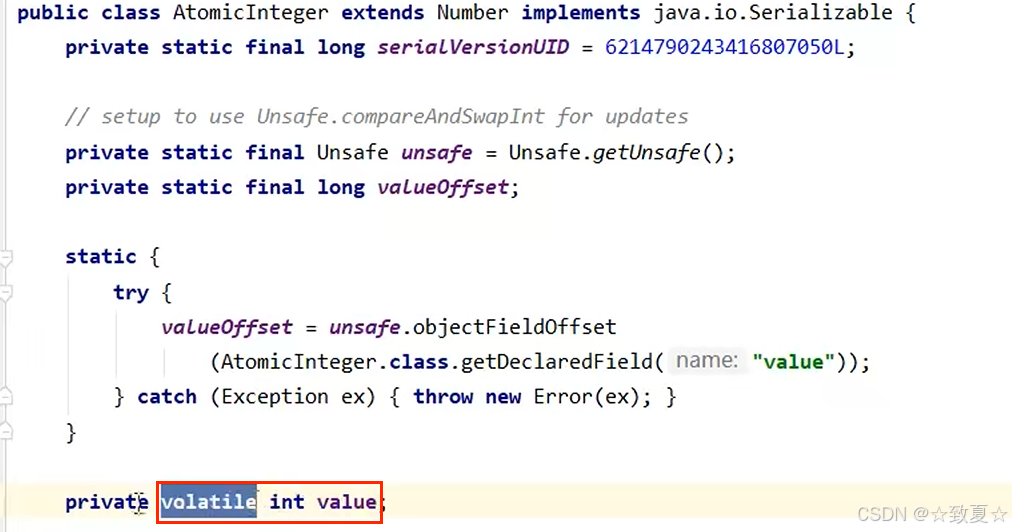
分析源代码可知,值是保存在AtomicInteger的属性value中,且被volatile修饰。
如果不被volatile修饰,cas就获取不到最新的共享变量值,此时比较结果就不确定了。

cas效率分析(为什么无锁效率高)
加锁会导致未获取锁的线程阻塞,进而发生上下文切换,在切换频繁情况下非常消耗性能。
而无锁需要保证线程数不能超过cpu数,因为无锁需要保证线程一直运行,超过的线程分不到时间片无法运行也会发生上下文切换,从运行状态进入可运行状态。

cas特点

原子整数

原子整数--加减实现
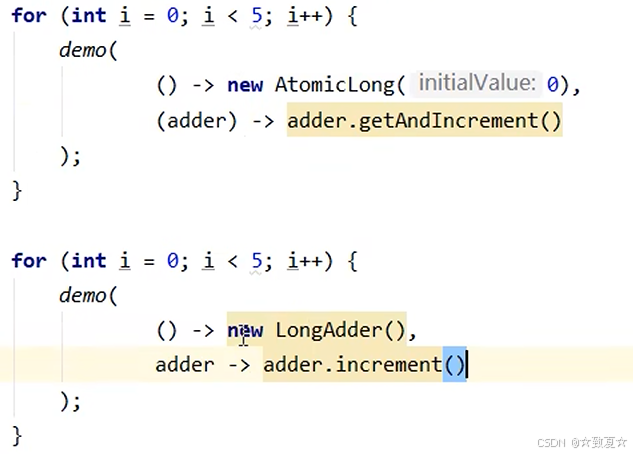
使用示例
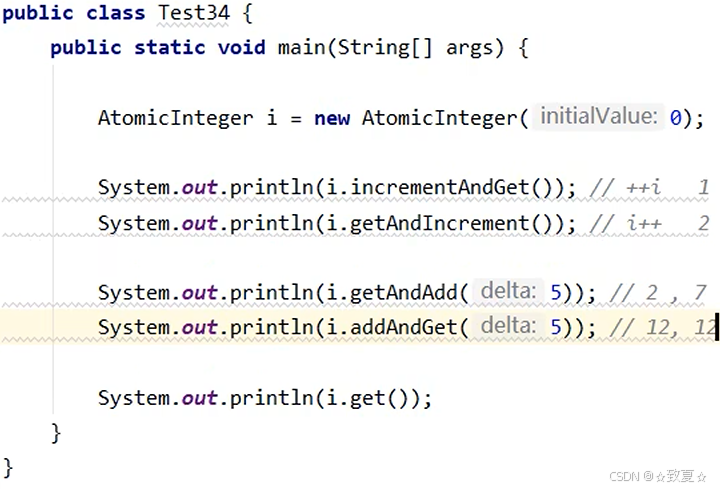
之前的代码compareAndSet需要和while共同保证原子性,比较繁琐
如下图,可以用原子整数保证复合操作的原子性,一行代码可以取代整个注释的多行代码
原子整数--乘除实现
使用updateAndGet更加灵活。
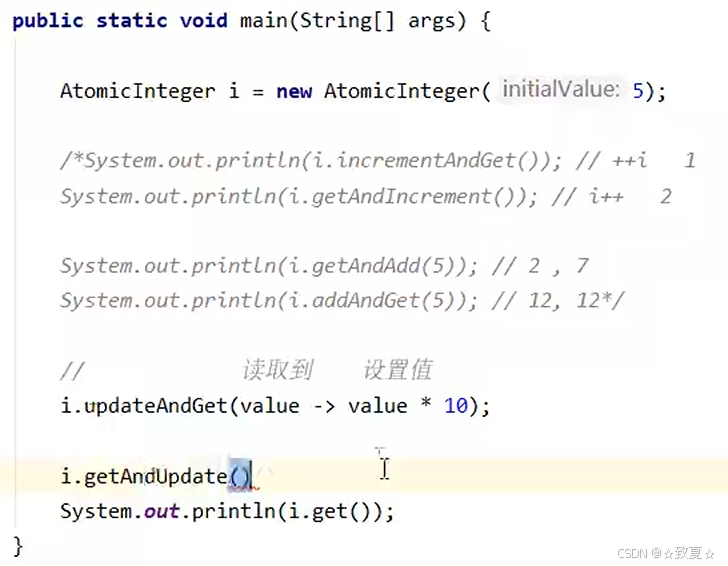
自己尝试实现内部逻辑
首先在内部逻辑里实现乘10运算,考虑到代码通用性,需要优化代码

优化后代码
中间的具体计算交给接口的实现方法完成
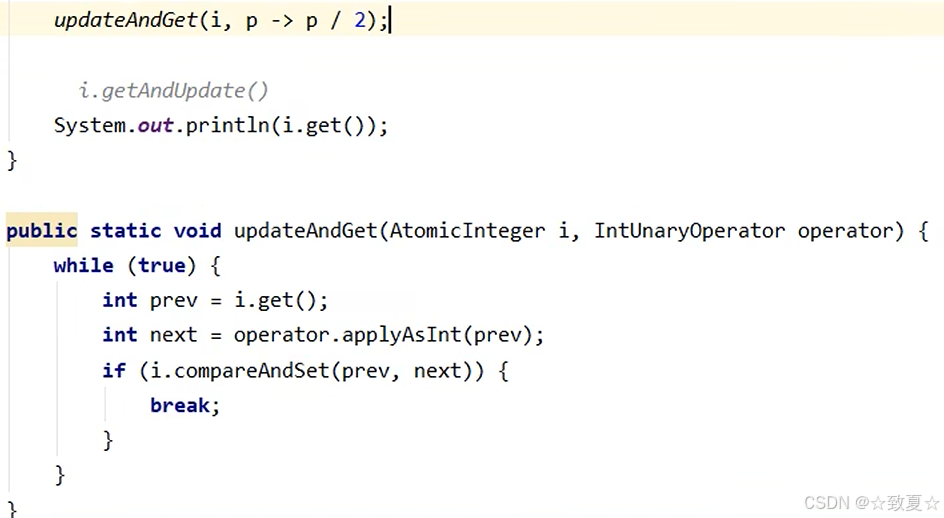
给一个返回值
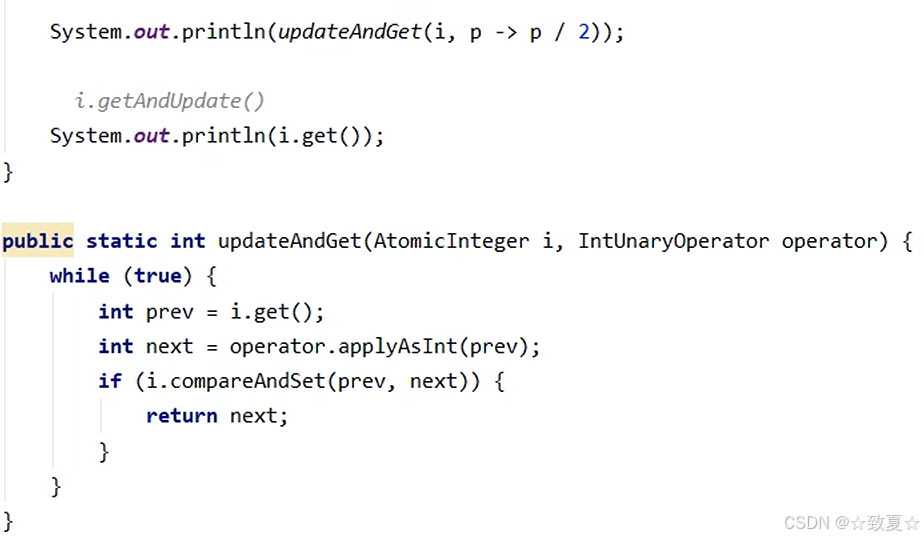
IntUnaryOperator接口源码
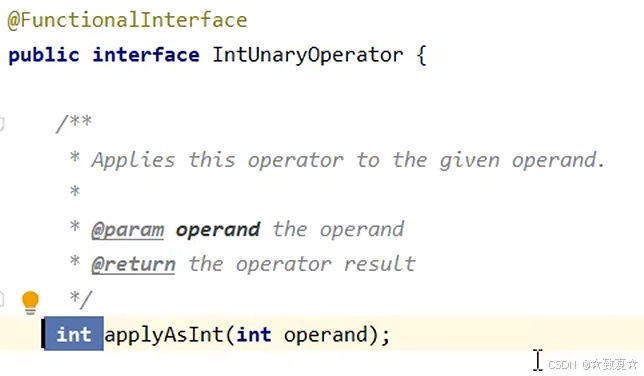
不用lambda表达式 p -> p / 2 演变前的匿名内部类实现
updateAndGet(i, new IntUnaryOperator() {@Overridepublic int applyAsInt(int operand) {return operand / 2;}
});
updateAndGet源码比较
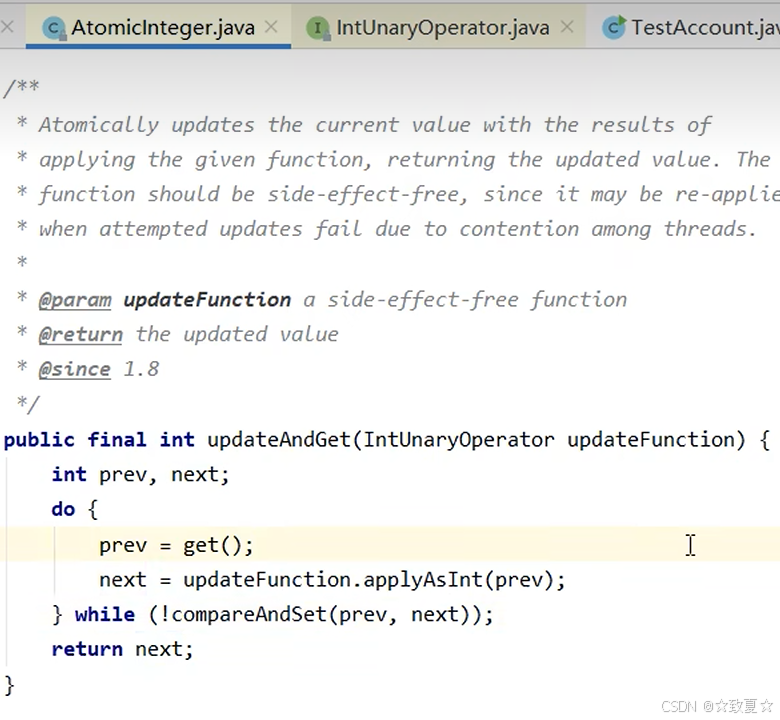
原子引用
需要保护的共享数据类型不一定是基本类型,也可能是引用类型,此时需要原子引用
 原子引用的使用
原子引用的使用
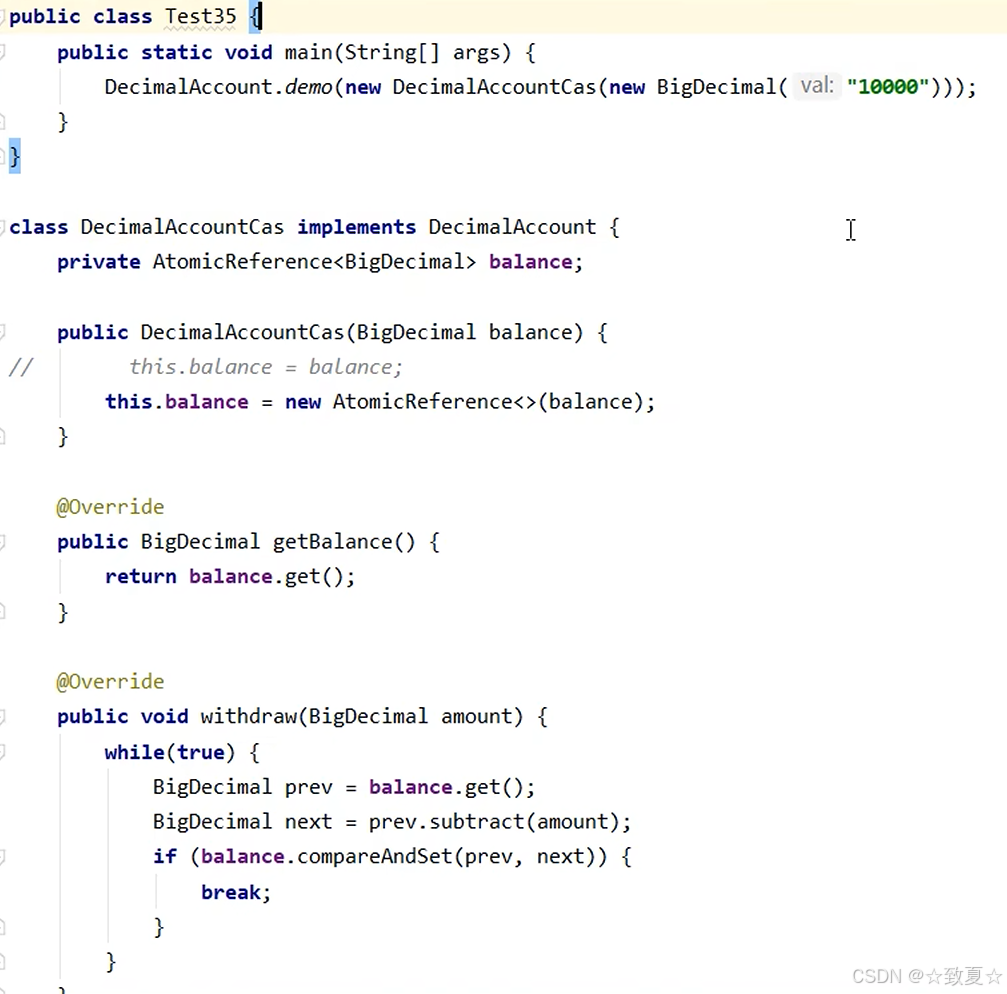
ABA问题
主线程无法感知共享变量是否被修改过,对于一些需要判断共享变量是否修改的需求无法满足
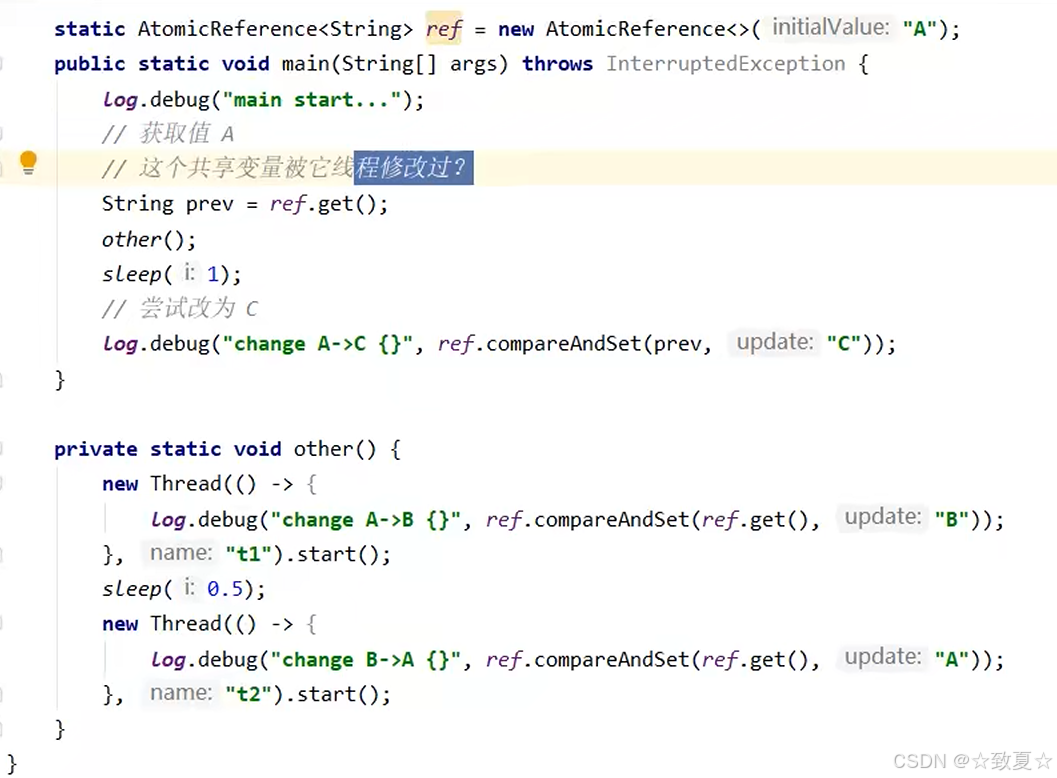
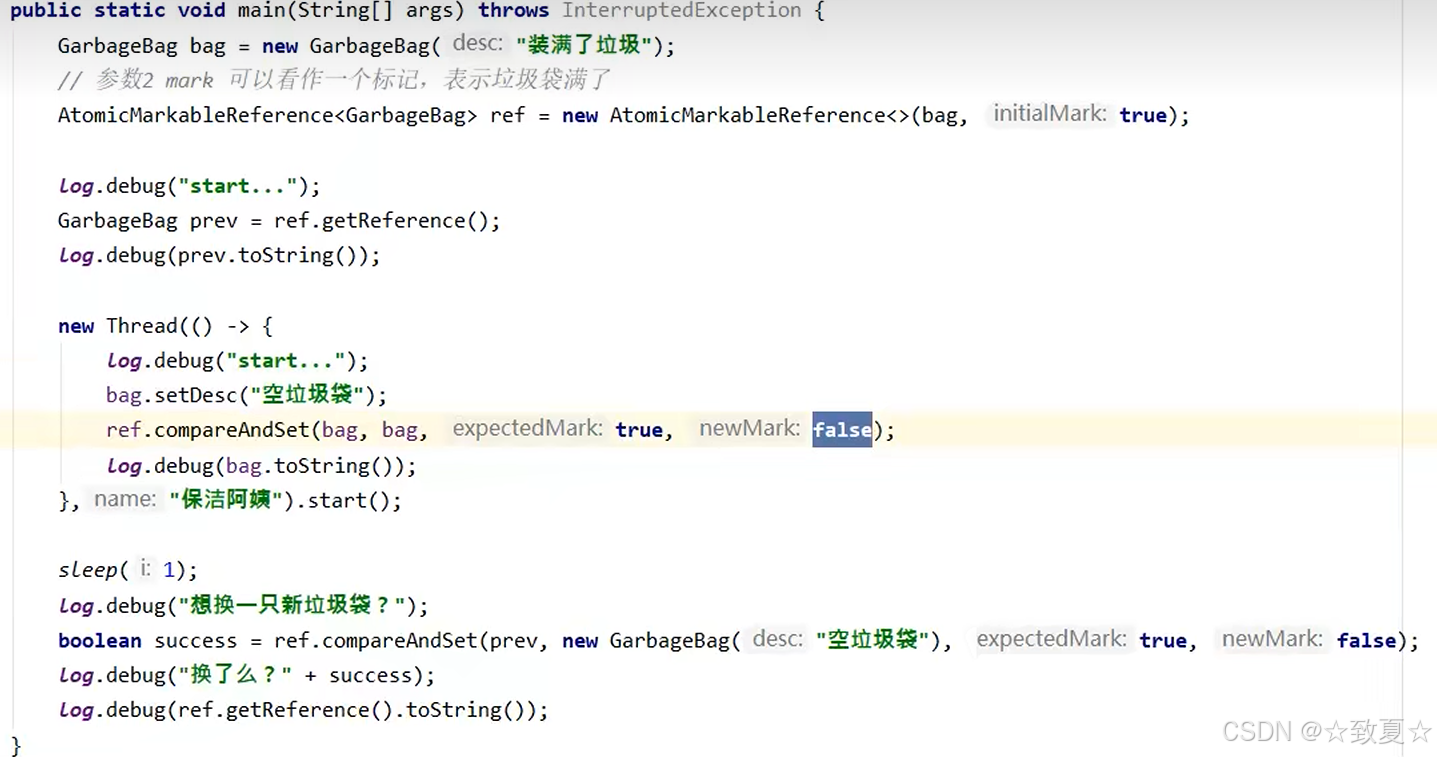
AtomicStampedReference的使用
主线程仅能判断出共享变量的值与最初值A是否相同,不能感知到这种从A改为B又改回A的情况,如果主线程希望:
只要有其它线程【动过了】共享变量,那么自己的cas就算失败,这时,仅比较值是不够的,需要再加一个版本号
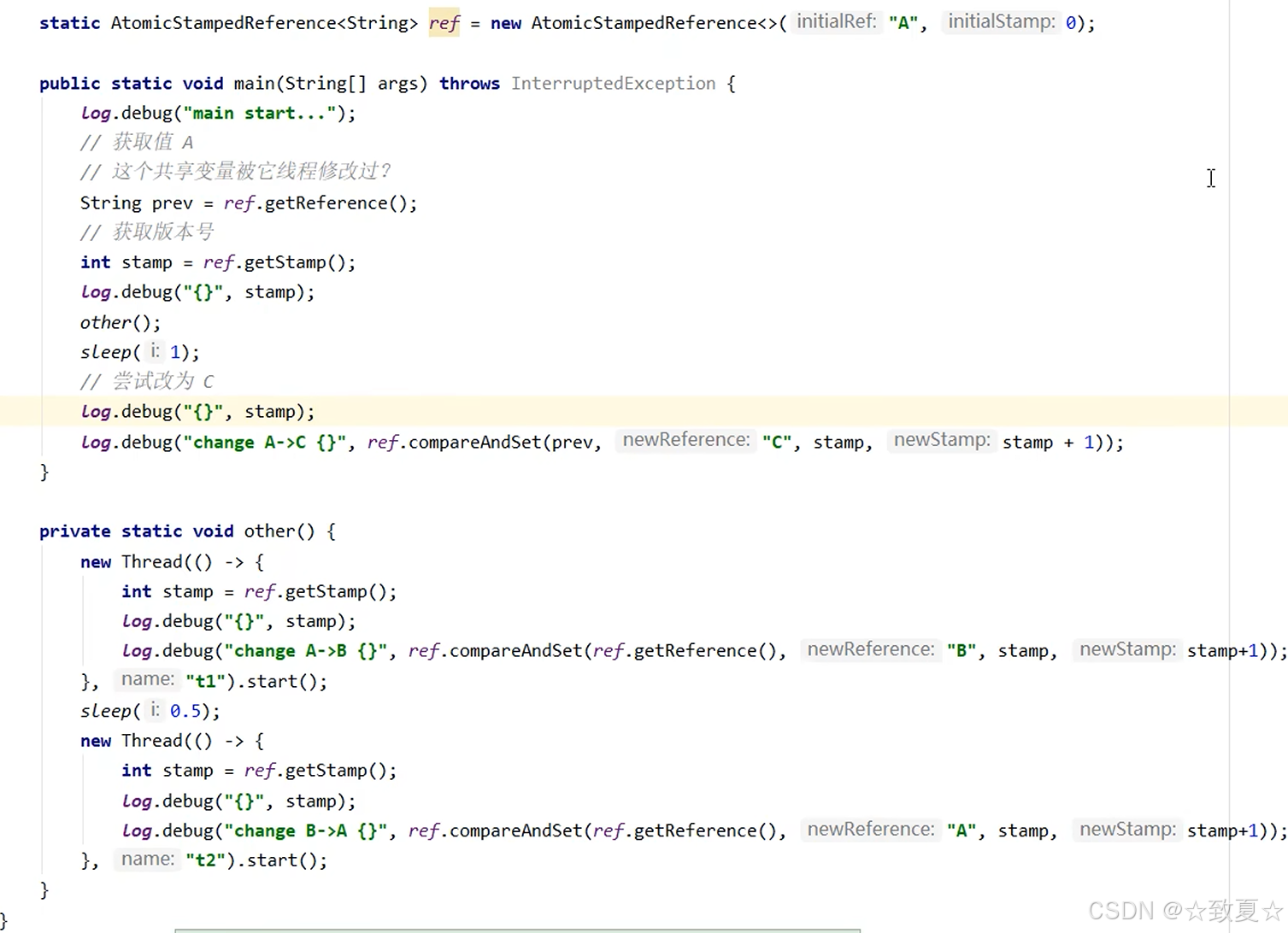

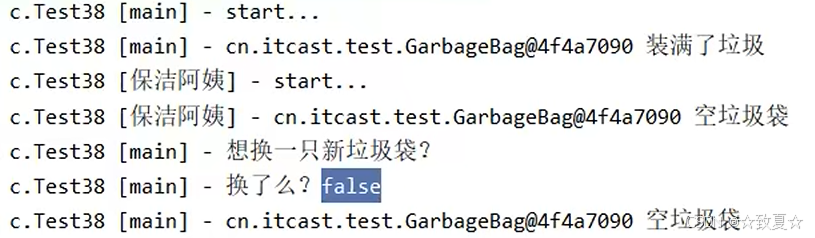
AtomicMarkableReference的使用
原子数组
保护数组里元素的安全性

函数式接口

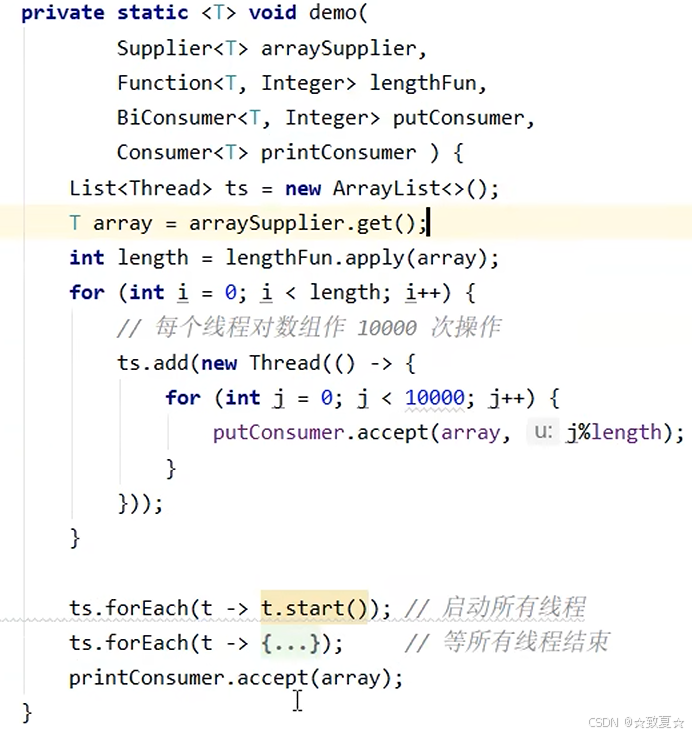
原子数组的使用
demo代码
使用普通数组
多线程下使用普通数组,数组元素没有线程安全性

数组元素结果不是10000,说明有线程安全问题
![]()
使用原子数组

![]()
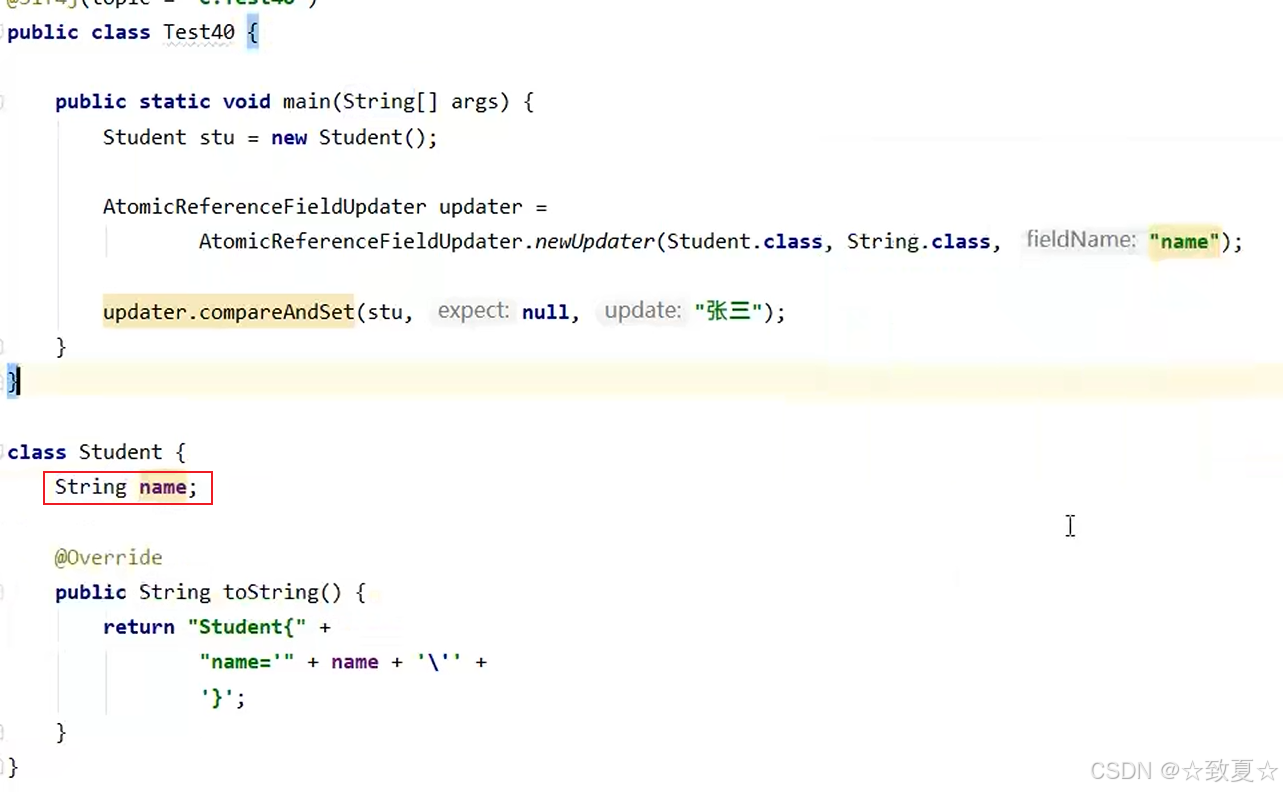
字段更新器
保护多线程访问同一对象的属性(成员变量)的线程安全性

字段更新器的使用
字段没有用volatile修饰会报错,因为使用cas必须保证共享变量的可见性
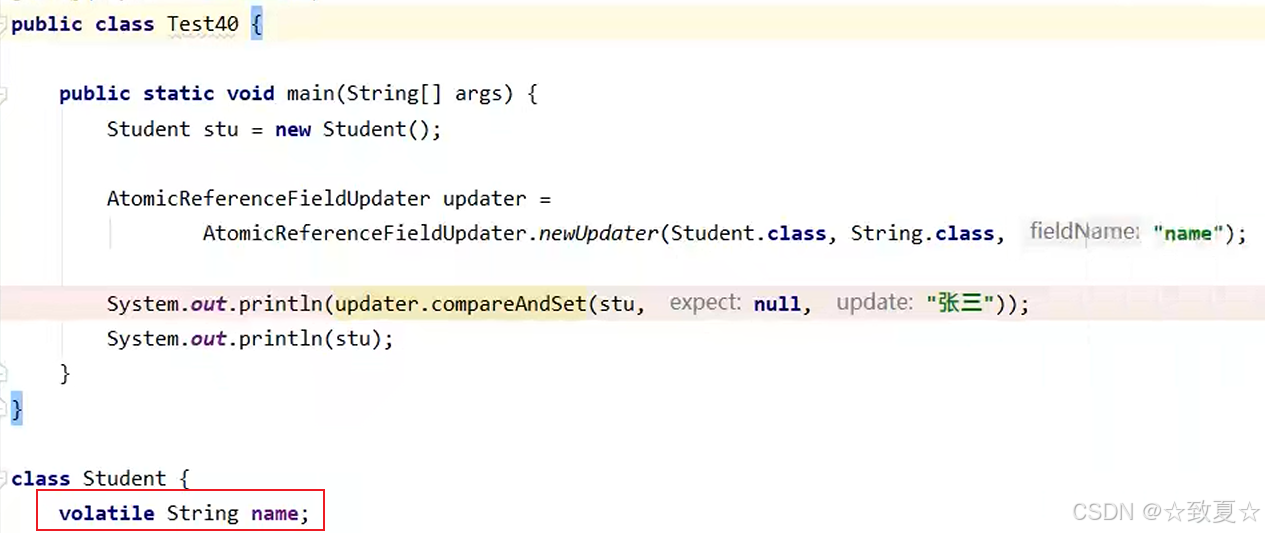
 正确修改后并打印
正确修改后并打印

原子累加器
原子累加器比较AtomicInteger,性能上得到提升
使用原子整数进行累加
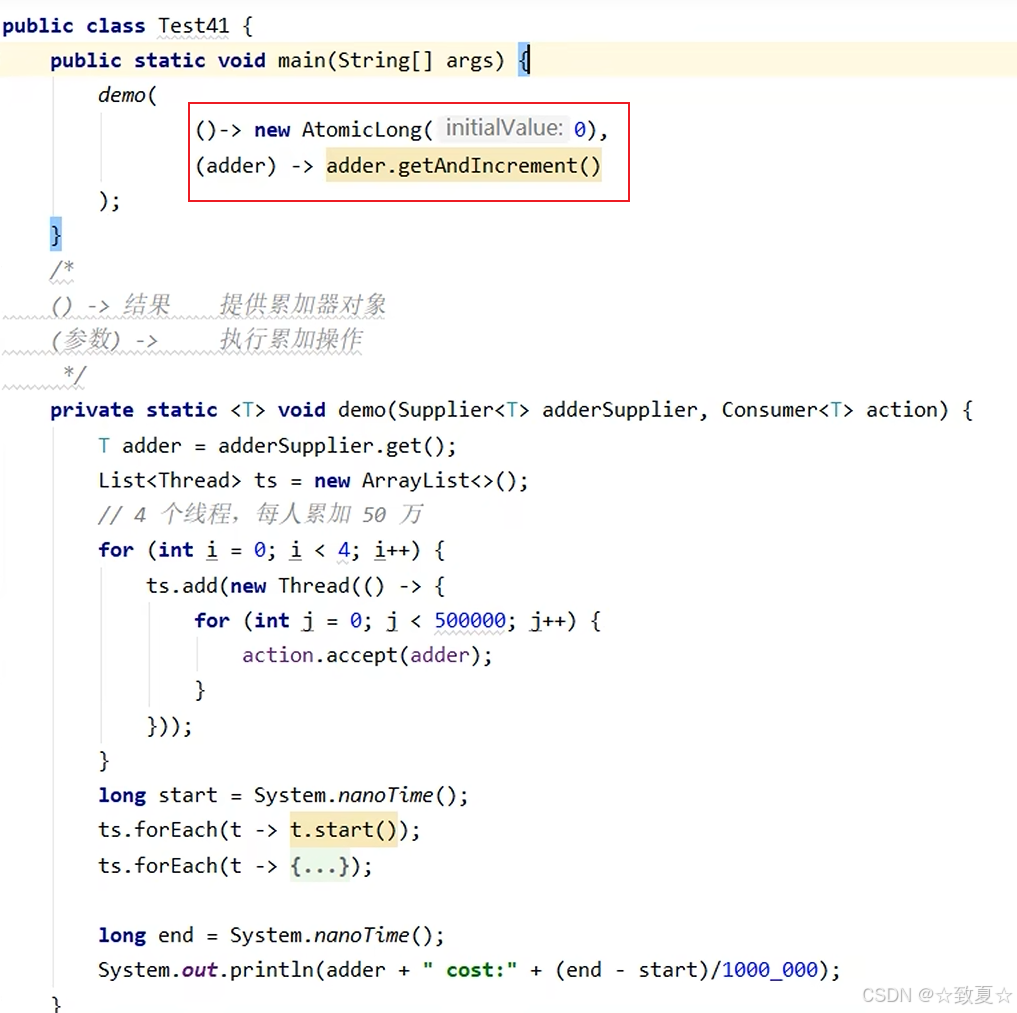
使用原子累加器

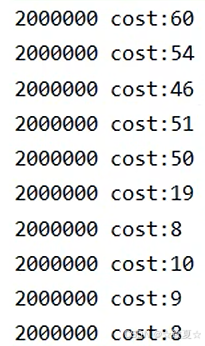
执行一次结果,可以明显看出耗时减少,快了一倍
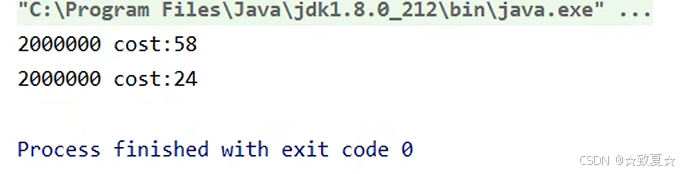
但第一次运行一般不准确,在程序反复执行后,JVM才能做出优化。可以多执行几次求平均效果
这里运行5次查看效果,性能几乎提升了5倍
性能提升原因--设置多个累加单元,避免竞争

LongAdder原理

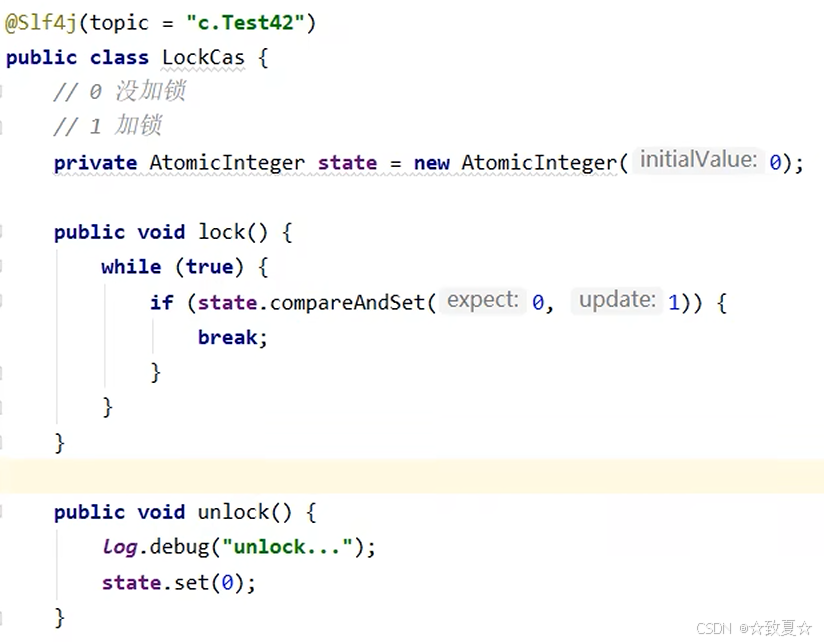
cas锁
代码示例
不建议自己用于生产实践,因为涉及底层优化且会造成线程空转,只作了解
被阻塞的线程会一直自旋(循环重试),直到获取锁的线程释放锁
测试代码
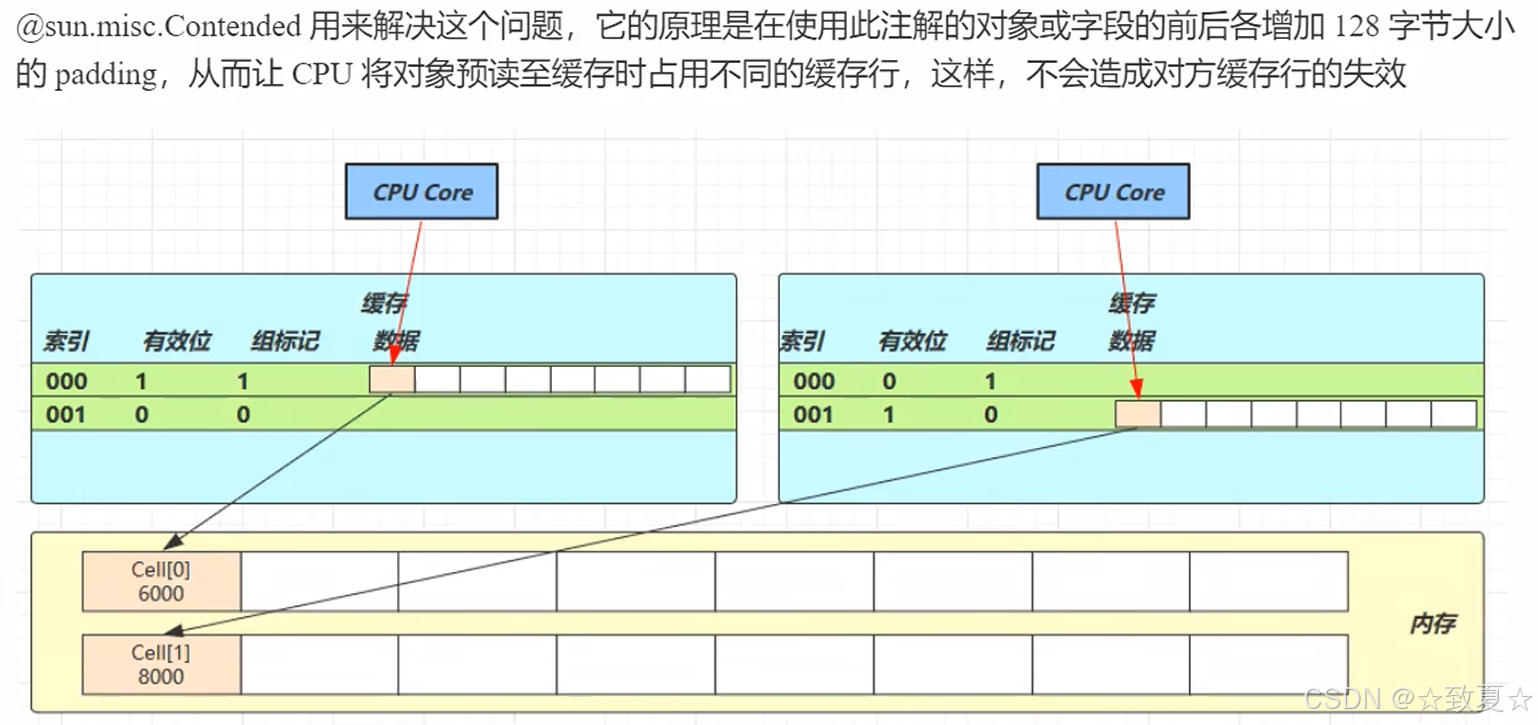
伪共享
一个缓存行加载多个cell称作伪共享

cpu内存结构
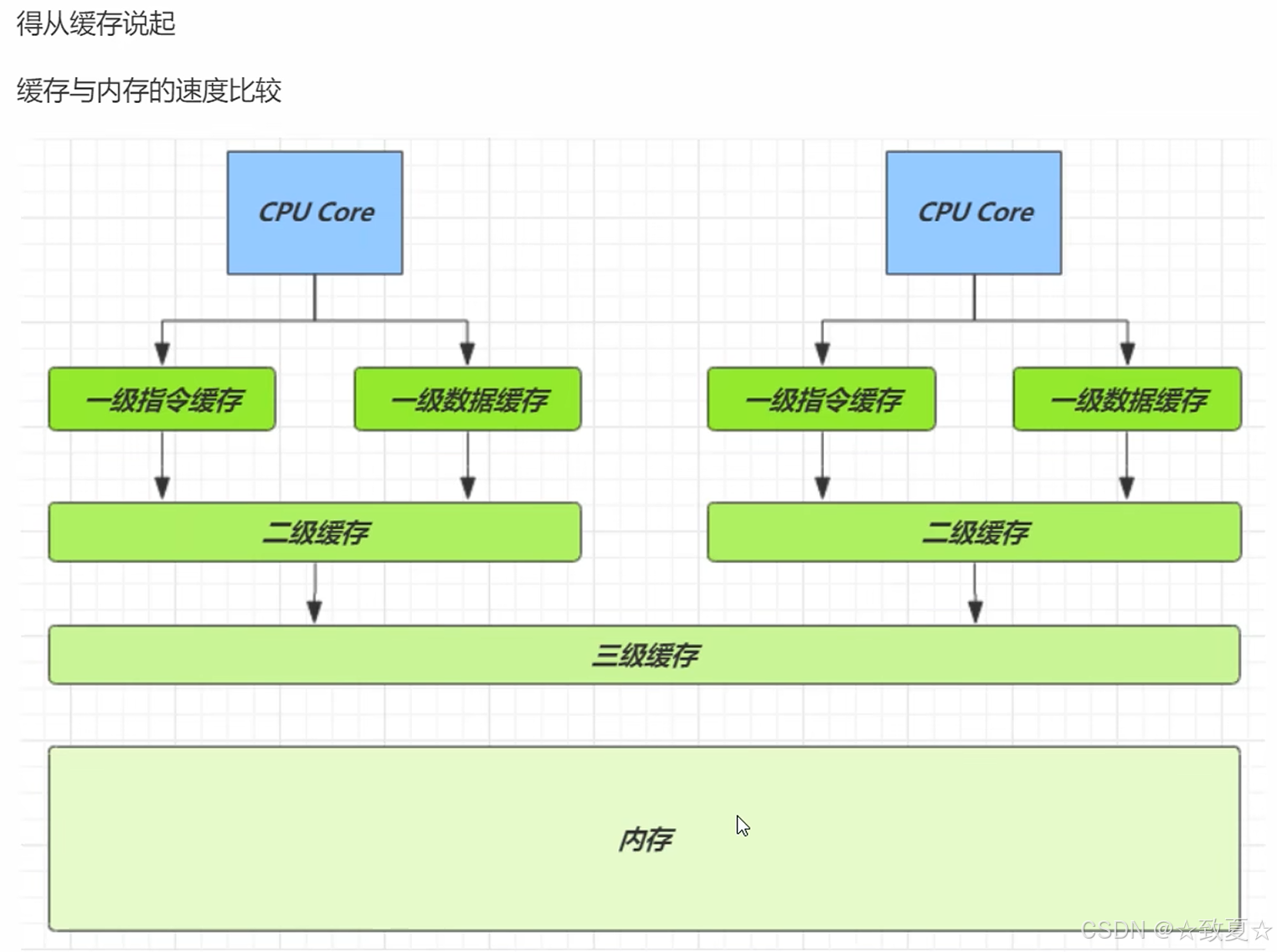
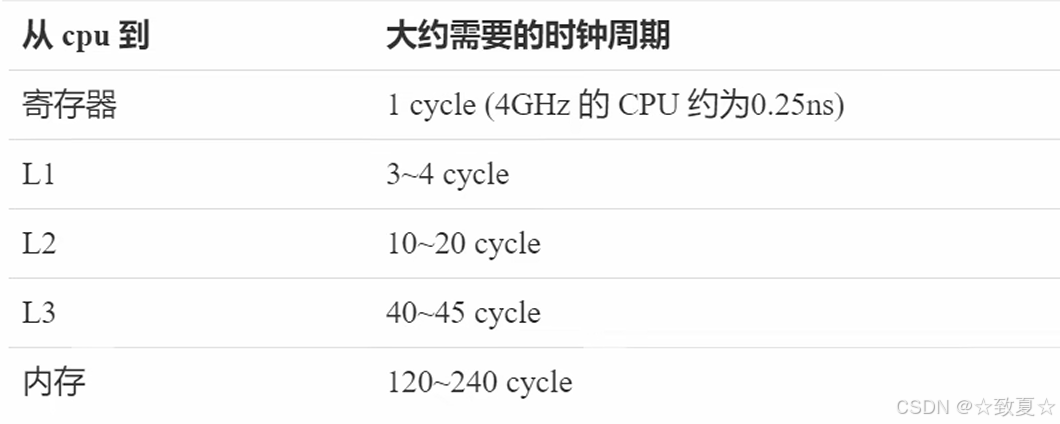
为什么cpu不直接从内存读取数据?
如下图可知,cpu到内存读取数据耗时比到缓存中多的多
缓存优点:读取效率高
缓存缺点:产生数据副本

失效以缓存行为单位,缓存行为64个字节,cell为24个字节,又因数组是连续的,所以一个缓存行可以放2个cell。
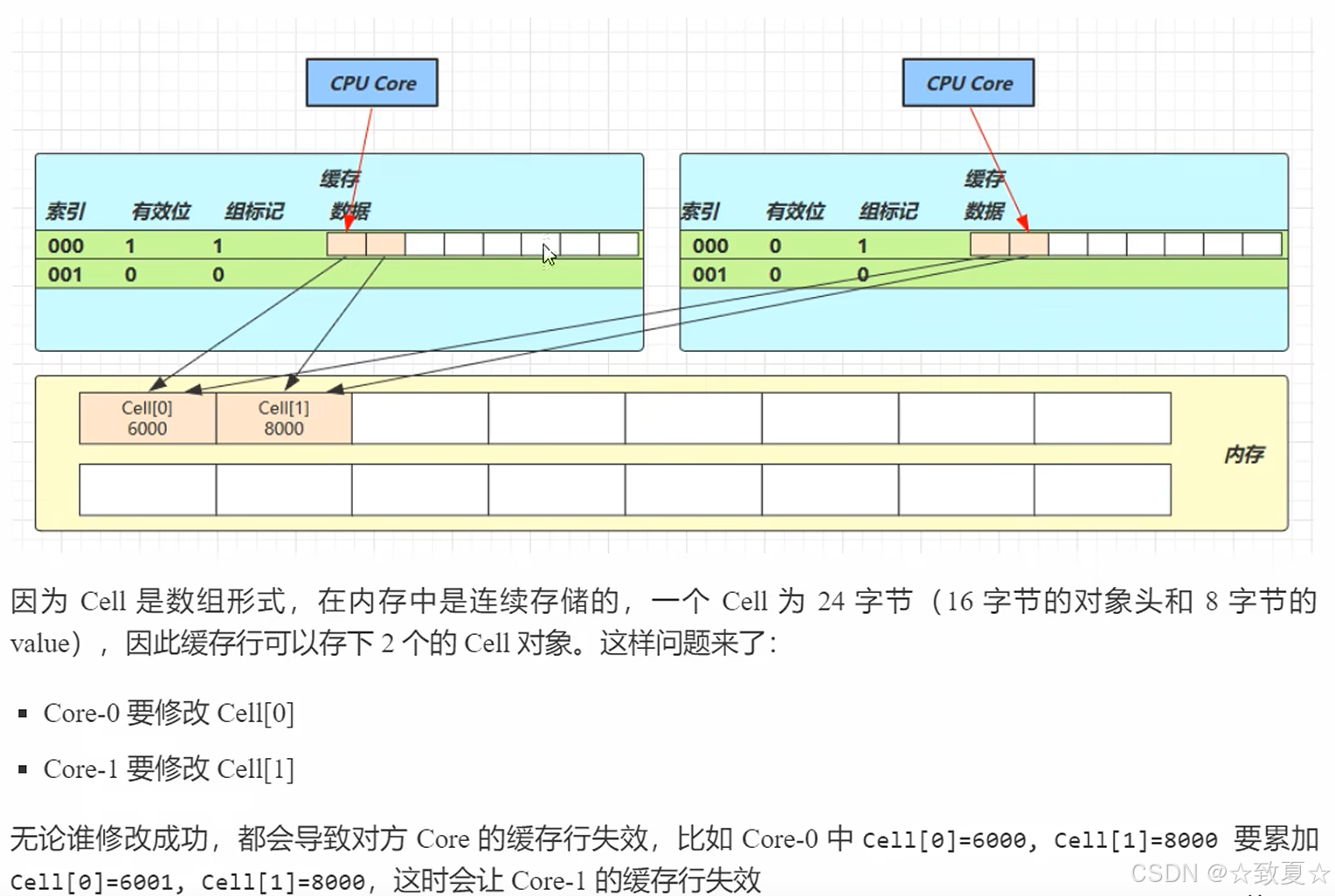
要避免两个cell共享一个缓存行导致cell修改带来的缓存行失效问题
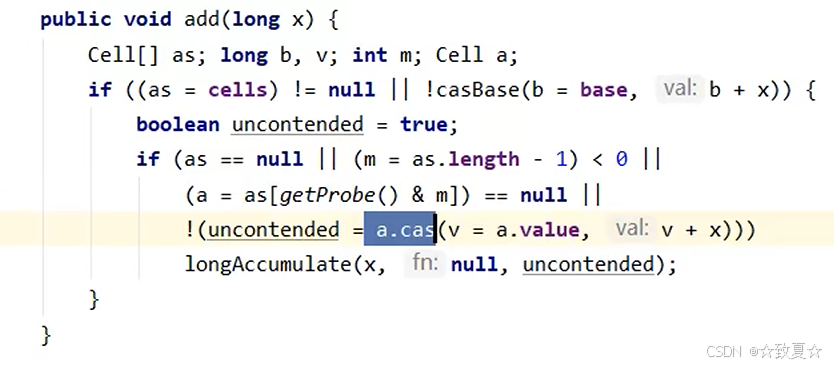
LongAdder源码--add

cells数组是懒加载的,如果没有竞争为null,有竞争才会尝试创建。
先判断cells是否为null,如果为空进入if的第二个条件,对基础域base进行累加
如果基础域累加成功则不会进入if块,add方法直接成功,基础域累加失败则进入if块执行longAccumulate方法
如果cells不为null且cells数组不为空(这两个条件保证cells数组可用),判断当前线程是否创建cell;如果cell创建了则使用cell进行累加,累加成功 -> add方法直接成功;
cell累加失败/未创建 -> 进入if块执行longAccumulate方法.
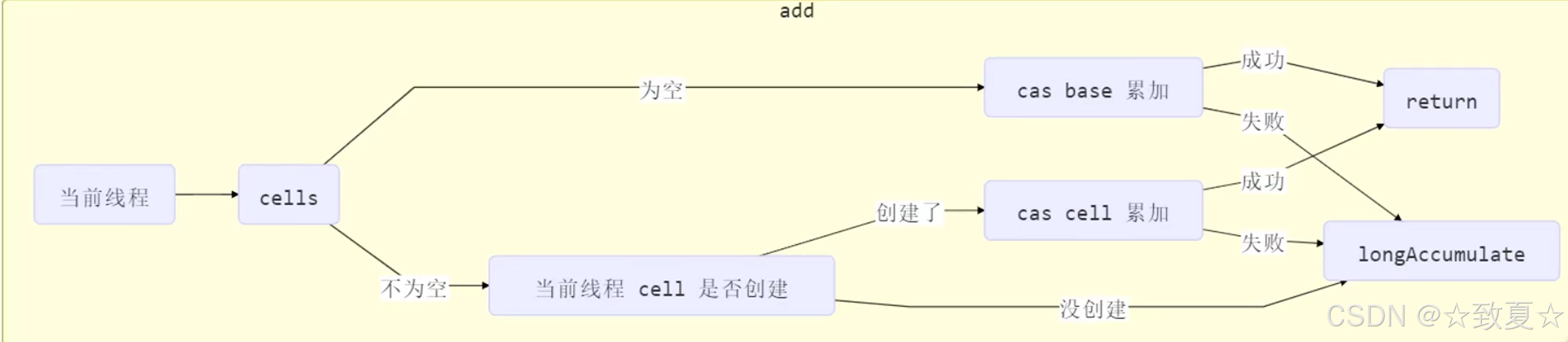
LongAdder源码--longAccumulate
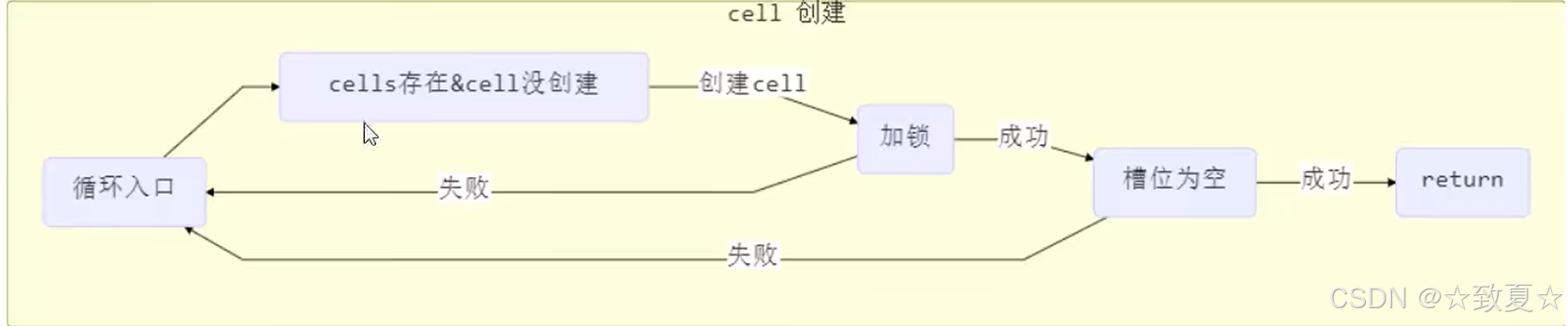
1.首先分析cells数组未创建的情况。
满足条件:cellsBusy == 0(未加锁)、cells == as(cells未新建,如果不等说明有其他线程创建)
casCellsBusy()(执行加锁方法成功)
如果条件全部满足,执行如下流程:
创建 大小为2的Cell数组,创建Cell随机放入Cell数组的其中一个位置,将该Cell数组赋给cells,初始化完成init设为true,将锁打开cellsBusy设为0,结束循环。

如果有条件不满足,则执行casBase方法,对base累加,累加成功则直接返回,失败则再次进入循环重试。
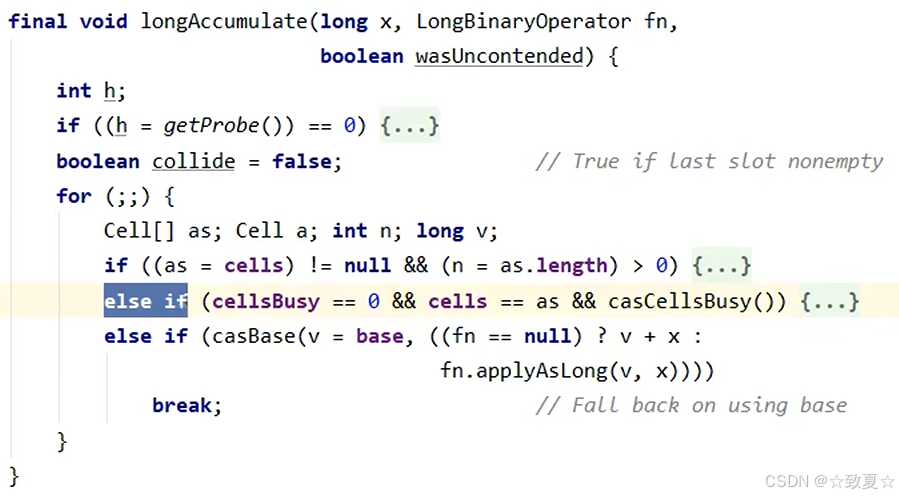

2.其次分析cells数组已创建,线程对应的累加单元cell未创建情况。
从上个代码可知,在创建cells数组时,只给当前线程创建了一个累加单元cell,对于其他线程是没有创建的。累加单元在用到时才会创建。
分析源代码可知,首先if判断cells数组是否可用;接着判断线程cell是否未创建(数组索引位置为null);确定线程cell未创建后,尝试加锁并新建cell放入cells数组,如果成功则直接返回,如果失败则再次进入循环重试。
as[(n - 1) & h] == null
- 使用上述索引访问数组中的元素。
- 判断这个位置上的元素是否为 null。
- 通常用于判断某个槽(bucket)是否被占用,例如在哈希冲突处理中。
为什么用位运算?
位运算比取模运算快很多。
当 n 是 2 的幂时,(n - 1) & h 等价于 h % n(取模)。
这种技巧常用于 HashMap、ConcurrentHashMap、ThreadLocal 等 Java 集合类源码中。

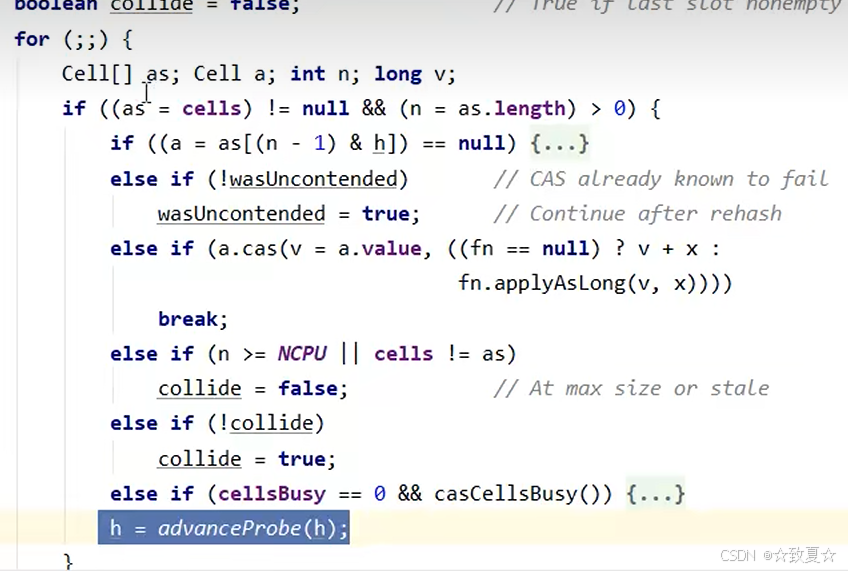
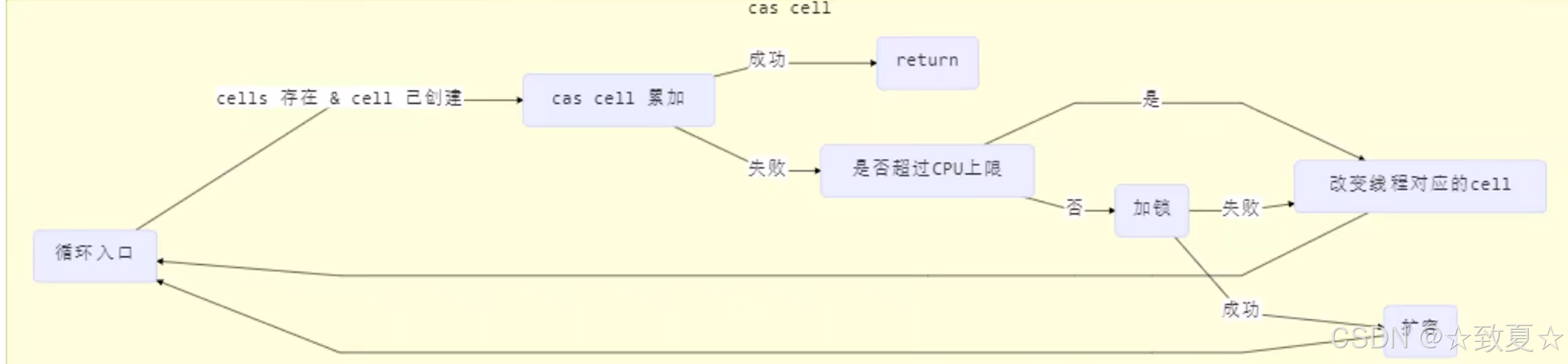
3.最后分析cells数组存在,累加单元已创建情况
线程的累加单元存在时,直接调用cas方法进行累加,如果累加成功直接返回,如果失败则进行判断是否超过CPU上限,是则改变线程对应的cell(累加失败表示有竞争,改变成没有竞争的累加单元让累加成功),否则尝试加锁扩容
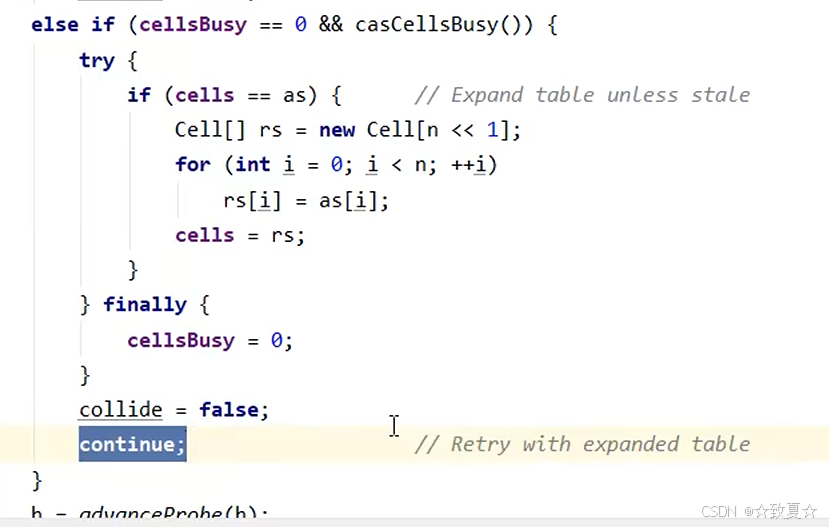
Cell数组扩容流程
进入扩容流程后,Cell数组扩容一倍,将原Cell数组元素赋值到新Cell数组中,并让cells指向新数组,最后解锁并跳过此次循环,再次进入循环后,为线程创建新的cell对象,放入cells的空槽位再完成累加。
 LongAdder源码--sum
LongAdder源码--sum

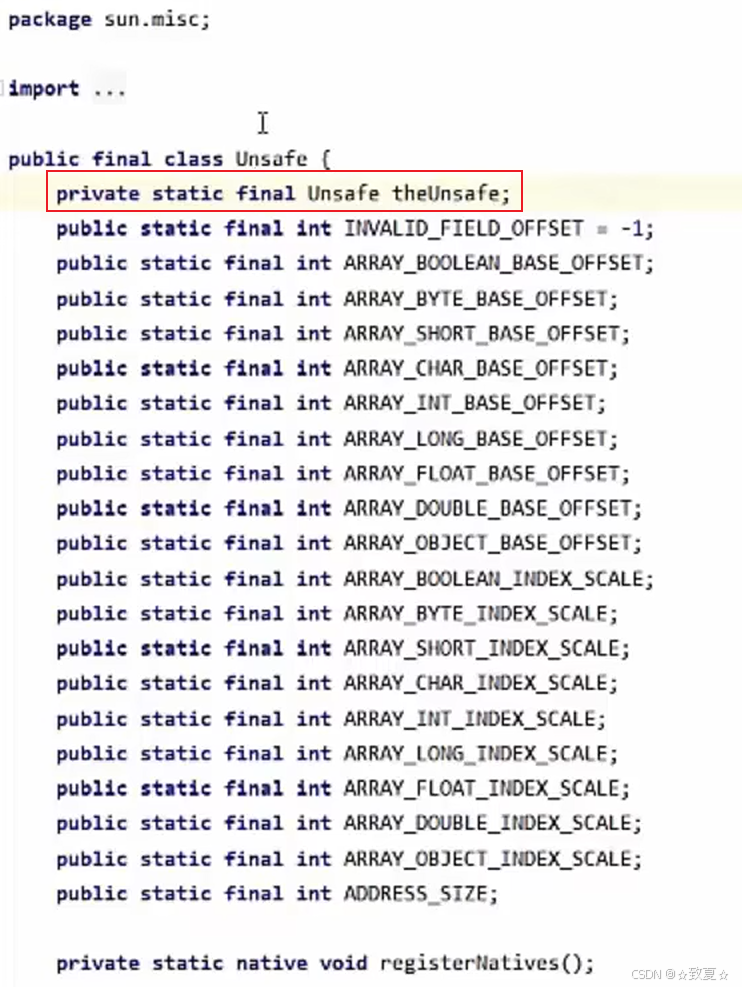
Unsafe
unsafe对象--获取

通过源码可知,Unsafe有一个单例对象,且被 private 修饰,不能直接获得,需要通过反射获取。
Unsafe用来操作内存、线程,如果误用会导致不安全发生。
public class TestUnsafe {public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {//用Declared获取私有成员变量theUnsafe的域对象Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");//允许访问私有成员变量theUnsafe.setAccessible(true);//由于theUnsafe是static的,所以不需要传入实例化对象获取Unsafe unsafe = (Unsafe) theUnsafe.get(null);System.out.println(unsafe);}
}unsafe对象--cas操作
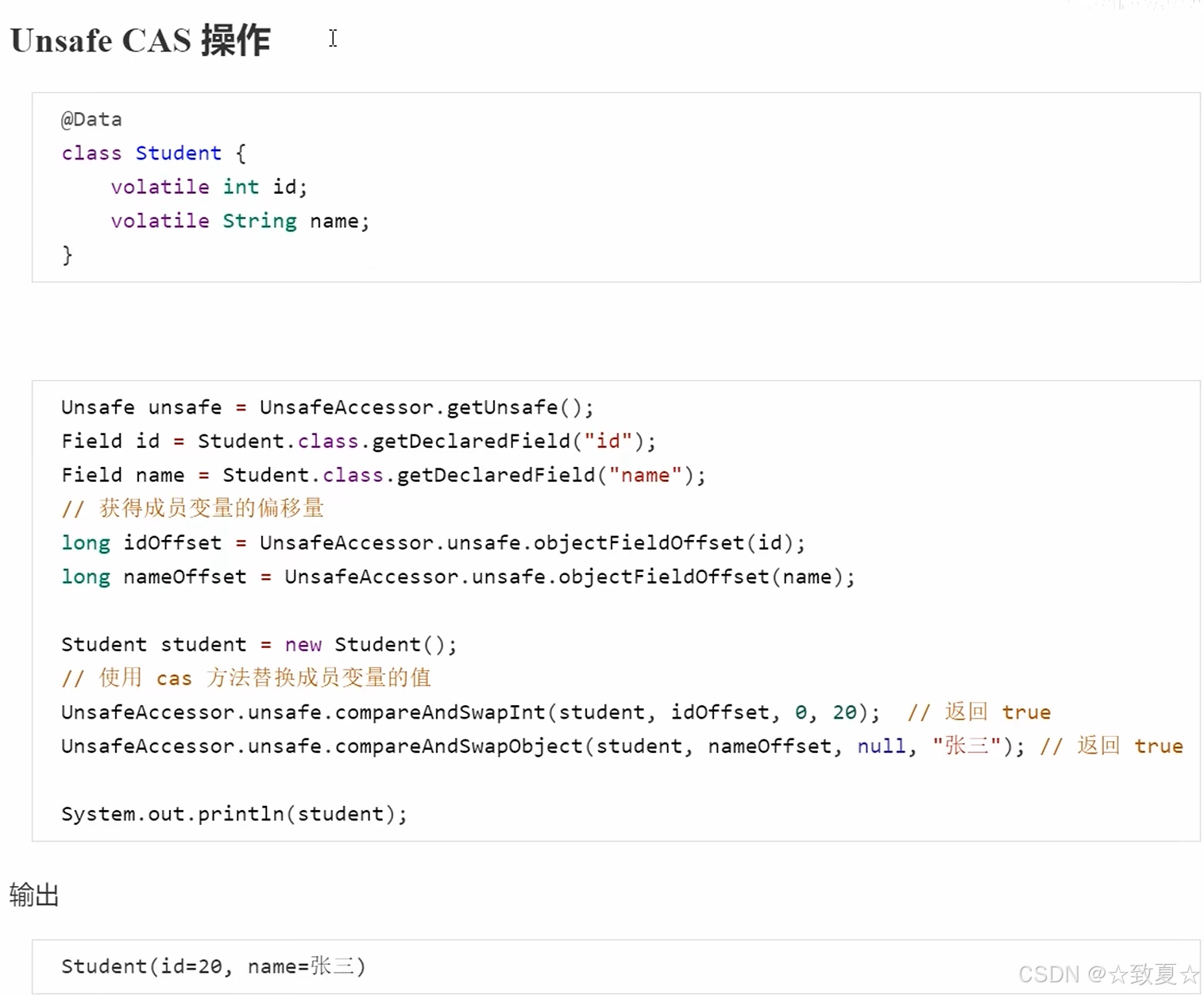
unsafe对象--模拟实现原子整数
Account类沿用了之前的类,TestUnsafe修改之前的代码变成工具类。
@Slf4j(topic = "c.Test29")
public class Test29 {public static void main(String[] args) throws InterruptedException {Account accout = new MyAutiomicInteger(10000);Account.demo(accout);}
}class MyAutiomicInteger implements Account {private volatile int value;private static final long valueOffset;private static final Unsafe UNSAFE;public MyAutiomicInteger(int initValue) {value = initValue;}static {try {UNSAFE = TestUnsafe.getUnsafe();valueOffset = UNSAFE.objectFieldOffset(MyAutiomicInteger.class.getDeclaredField("value"));} catch (NoSuchFieldException e) {throw new RuntimeException(e);}}private void decrement(int amount) {while (true) {int prev = value;int next = prev - amount;if (UNSAFE.compareAndSetInt(this, valueOffset, prev, next)) {break;}}}@Overridepublic Integer getBalance() {return value;}@Overridepublic void withdraw(Integer amount) {decrement(amount);}
}七、共享模型之不可变

不可变对象--使用
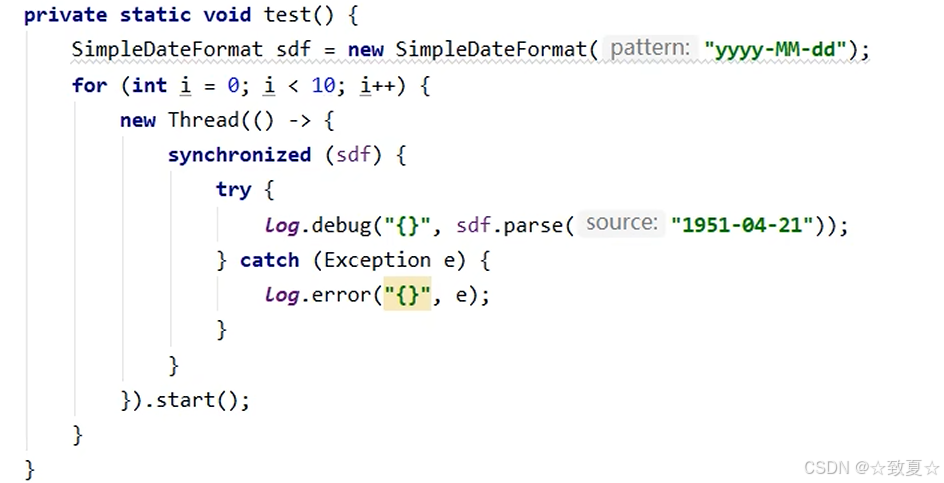
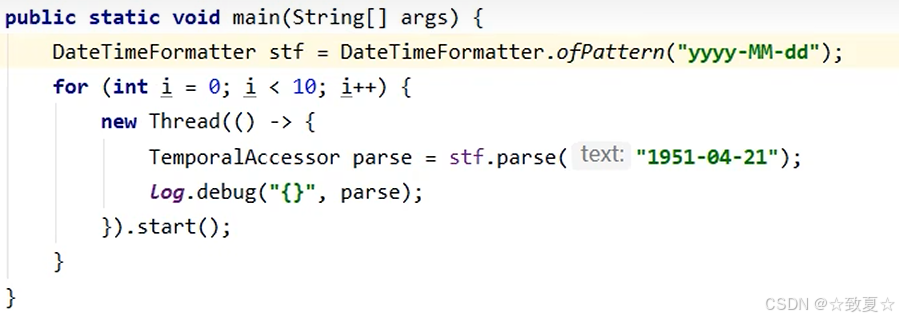
日期转换问题
多线程下运行会报错

加锁解决,会降低性能
使用线程安全的DateTimeFormatter(不可变对象)
不可变对象--设计
jdk8之前用成员变量char数组保存字符串字符,加了final表示只能在调用构造方法时被赋值,后面就不可改变value的引用。
hash用来缓存字符串生成的哈希码,首次调用hashcode生成,之后把hash值缓存在成员变量hash里,避免以后hash值的计算。

final修饰数组只能保证引用不能改变,不能保证数组内容不发生改变
使用保护性拷贝

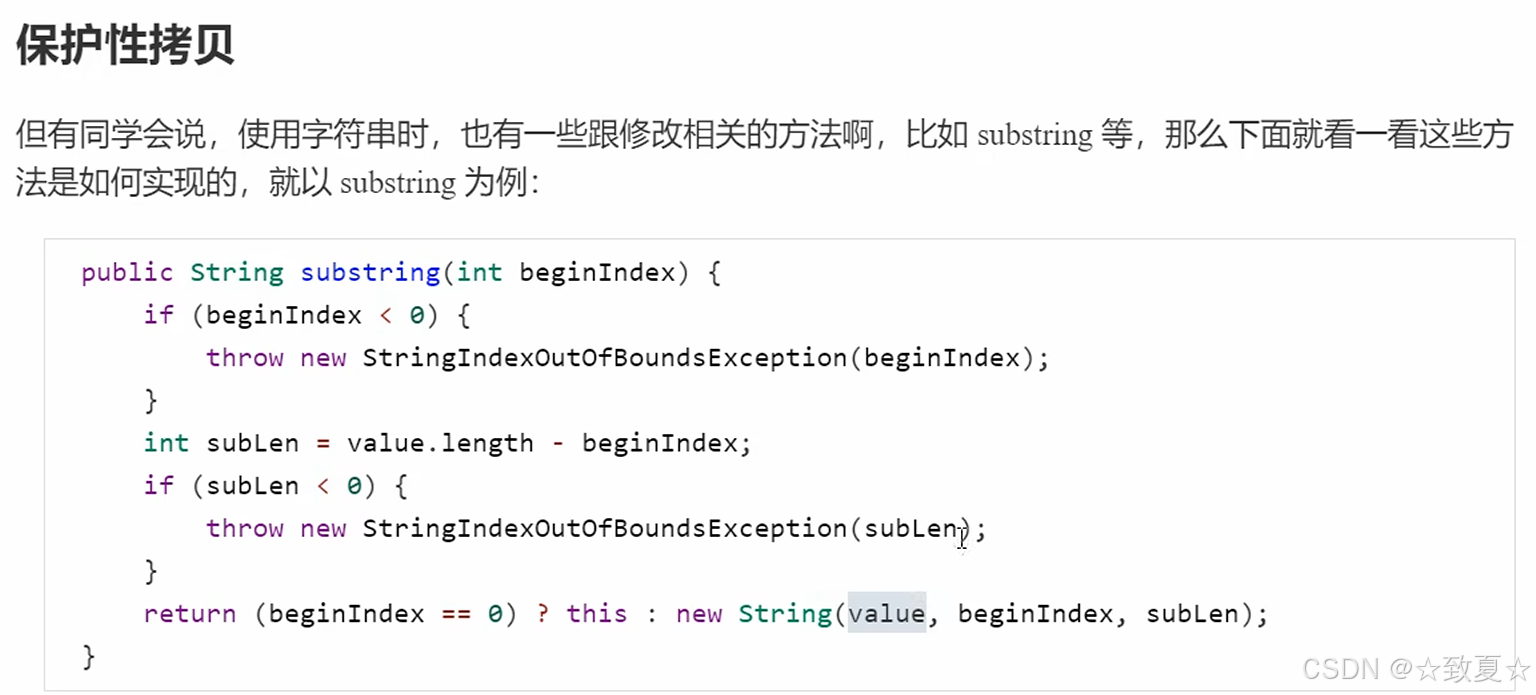
先判断下标可用性(是否小于0,是否超过长度),确定可用后,如果下标不是0,则创建一个新的String对象
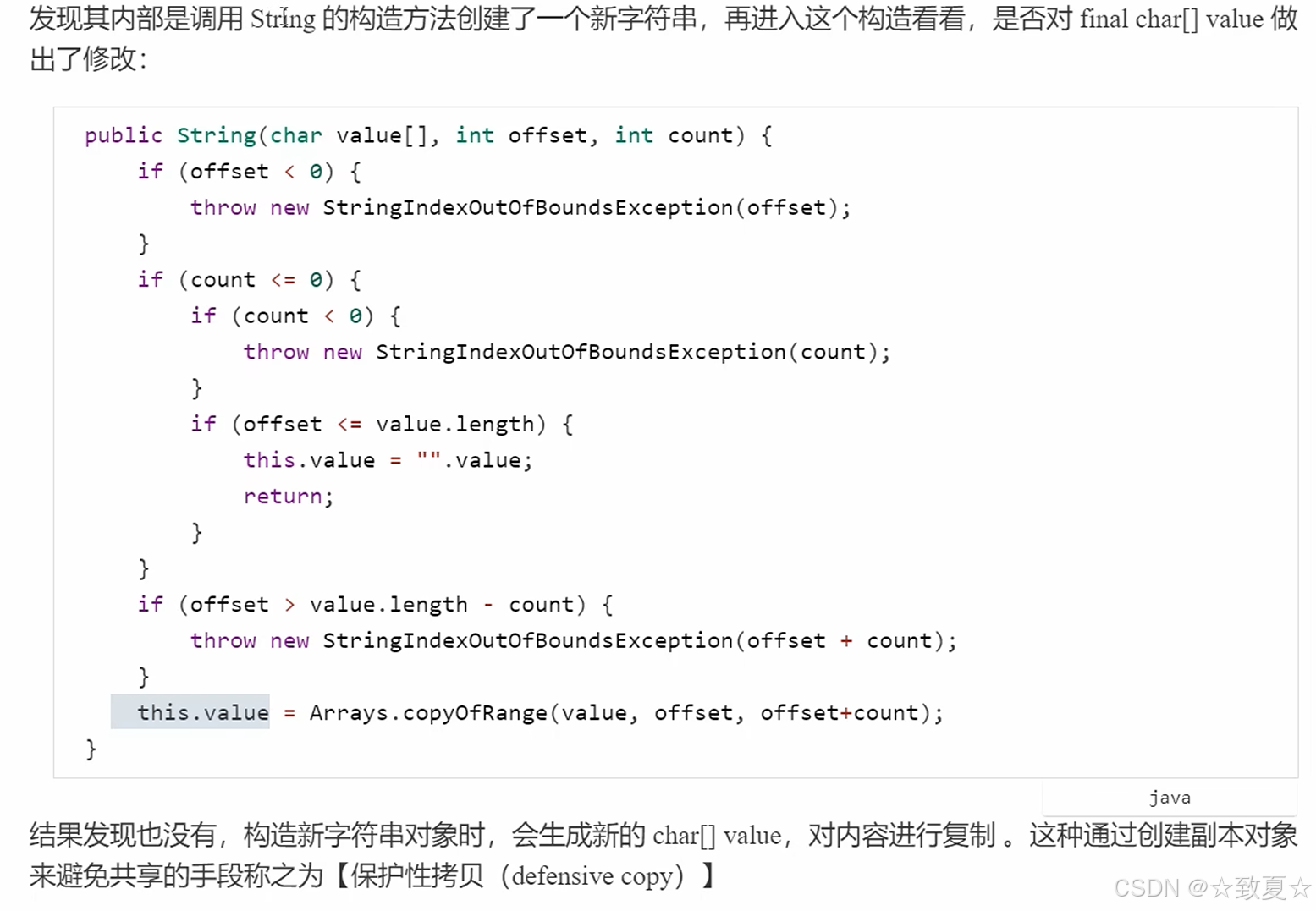
保护性拷贝缺点:为了避免共享,保护线程安全,有修改出现时,就会创建新的对象,而对象创建频繁导致对象个数较多。
解决方法:不可变类关联设计模式-享元模式
享元模式
简介

体现


BigDecimal类型是线程安全的,之前金额转账的例子还是用AtomicReference来保证BigDecimal共享变量是为什么?
从BigDecimal源码可以看出采取了保护性拷贝机制来保证线程安全,线程安全类使用单个方法是原子性的且是线程安全的,但无法保证复合操作的原子性。
如图,需要先获取金额,再做转账减少金额,存在两个方法组合操作,此时使用BigDecimal无法保证线程安全。
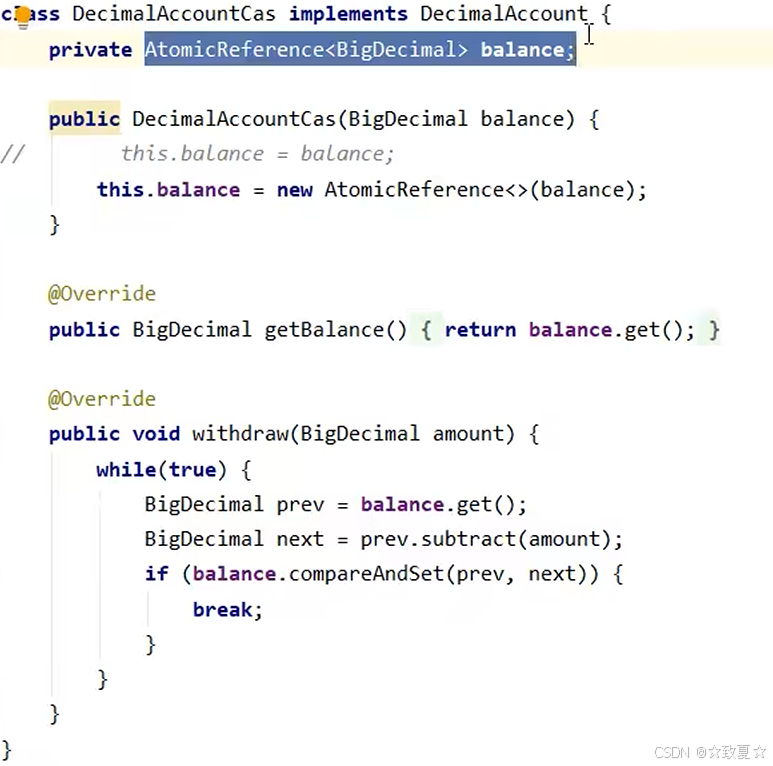
DIY
自定义连接池-分析
用享元模式和多线程知识保护数据库连接池的线程安全,每个web请求都对应一个线程,都要从连接池获取连接,归还连接,要保证这些方法的线程安全

自定义连接池-实现和测试
连接池有大小,支持扩容和收缩
class MyConnection implements Connection {…}
MyConnection类实现Connection即可,下列代码中没有体现
代码实现
@Slf4j(topic = "c.Test30")
public class Test30 {public static void main(String[] args) throws InterruptedException {Pool pool = new Pool(2);for (int i = 0; i < 5; i++) {new Thread(() -> {log.debug("开始获取连接...");Connection connection = pool.getConnection();// 模拟使用连接耗时try {Thread.sleep(new Random().nextInt(1000));} catch (InterruptedException e) {e.printStackTrace();}pool.releaseConnection(connection);log.debug("释放连接完毕");}).start();}}
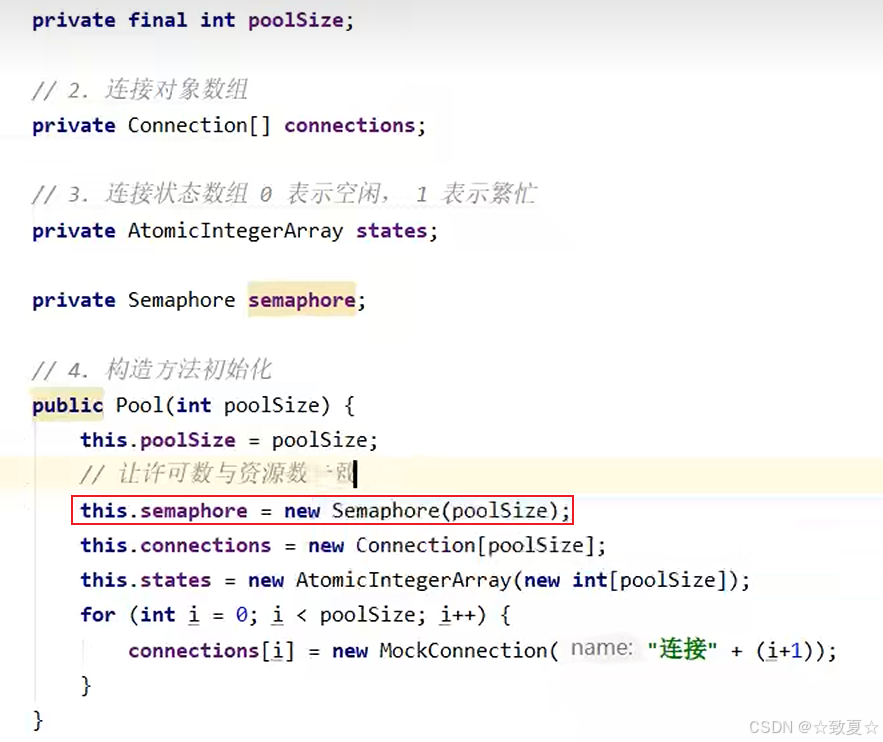
}@Slf4j(topic = "c.Pool")
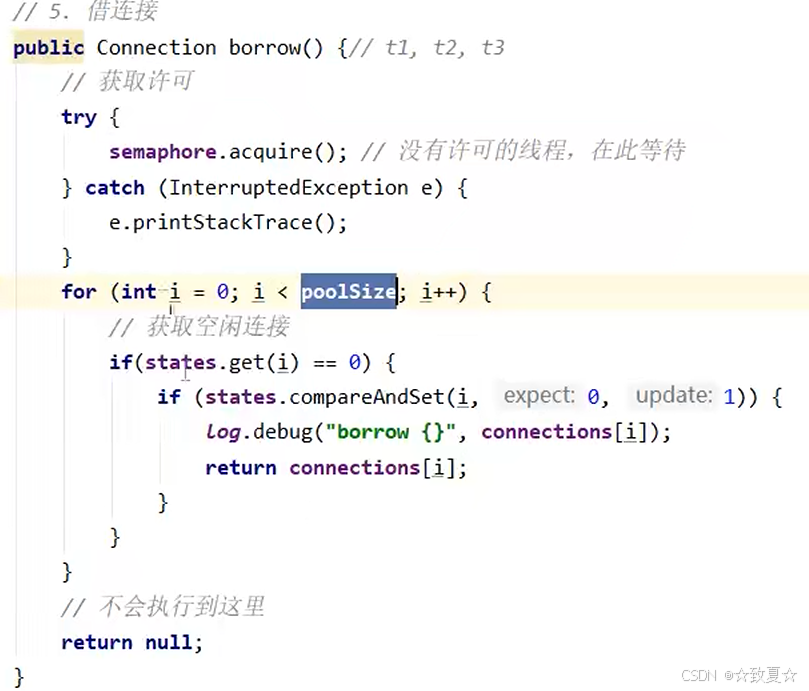
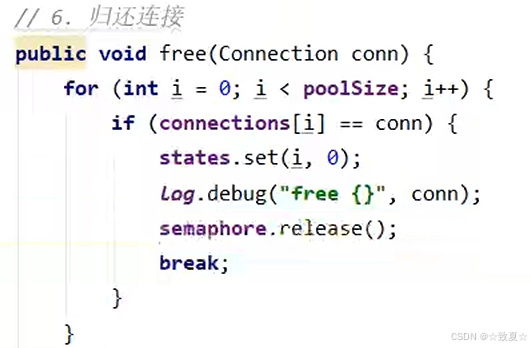
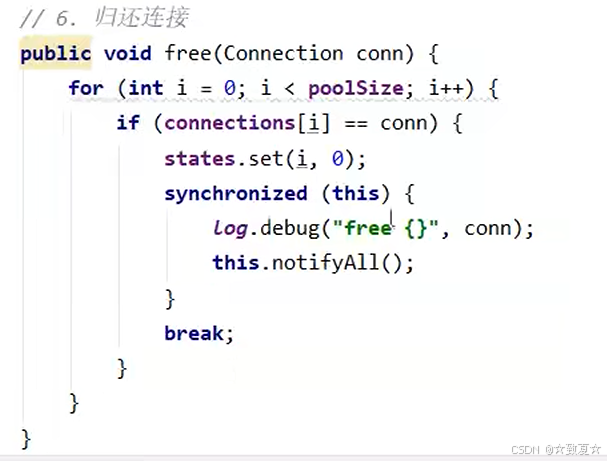
class Pool {// 连接池的大小private final int size;// 连接数组private Connection[] connections;// 状态数组,0表示空闲,1表示繁忙private AtomicIntegerArray states;public Pool(int size) {this.size = size;connections = new Connection[size];states = new AtomicIntegerArray(new int[size]);for (int i = 0; i < size; i++) {connections[i] = new MyConnection();}}// 获取连接public Connection getConnection() {while (true) {for (int i = 0; i < size; i++) {if (states.get(i) == 0) {if (states.compareAndSet(i, 0, 1)) {log.debug("获取连接{}成功", i + 1);return connections[i];}}}synchronized (this) {try {this.wait();log.debug("暂时没有可用连接,请等待...");} catch (InterruptedException e) {throw new RuntimeException(e);}}}}// 归还连接public void releaseConnection(Connection connection) {for (int i = 0; i < size; i++) {if (connections[i] == connection) {states.set(i, 0);log.debug("归还连接{}成功", i + 1);synchronized (this) {this.notifyAll();}break;}}}
}
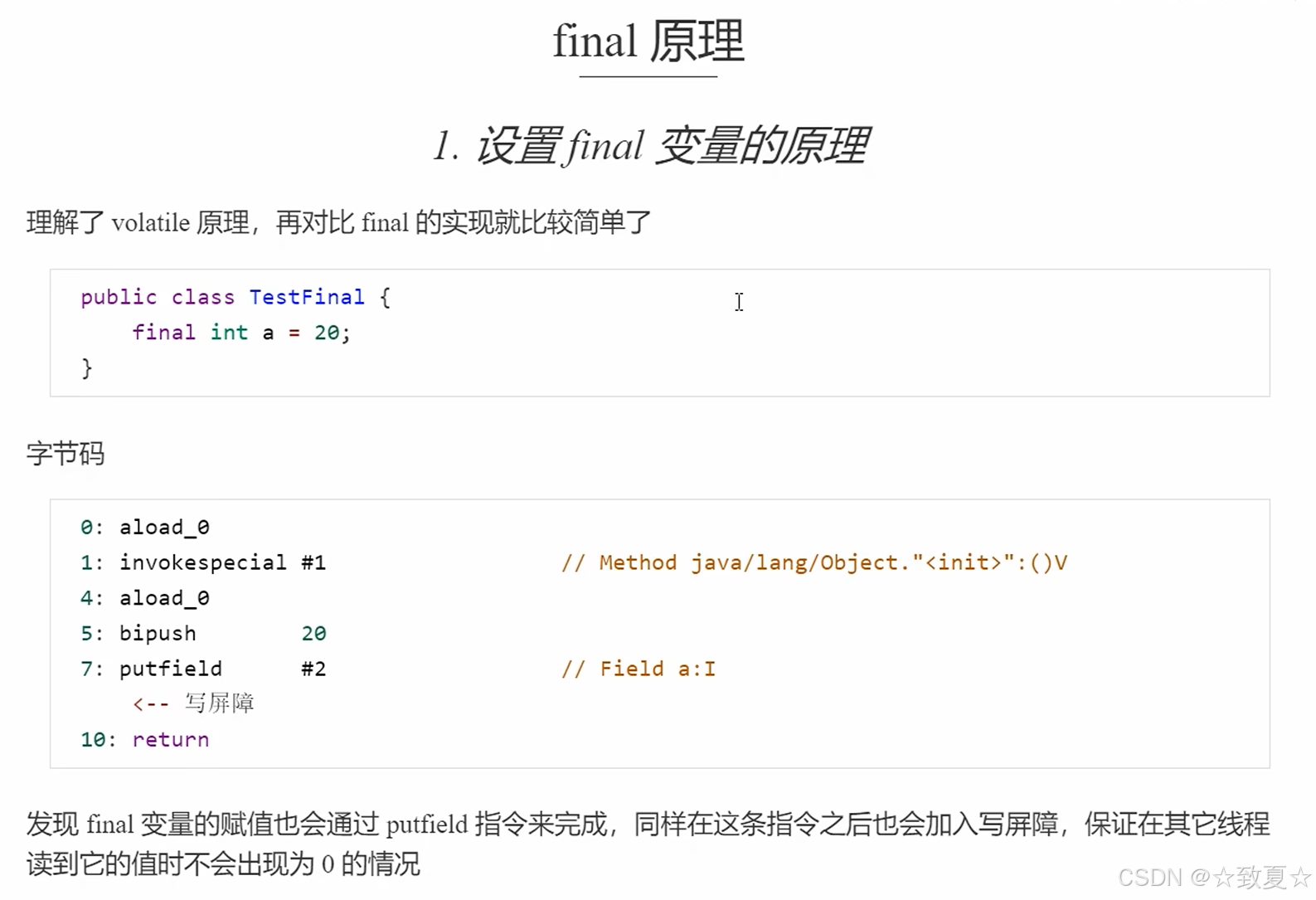
final原理
设置final变量原理
成员变量被final修饰,那么它在被赋值之后会加入写屏障
写屏障解决两个问题:
1.保证写屏障之前指令不会被排到写屏障后面去
2.保证写屏障之前的所有修改操作同步到主存
final保证其他线程只能看到一个值(可见性)
获取final变量原理
final优化会将较小的数值复制一份放入方法栈中,数值较大放入常量池,不加final放入堆中
final修饰的值,在其他类获取时,数值比较小会直接复制一份该值到使用类的栈内存中,没有共享操作
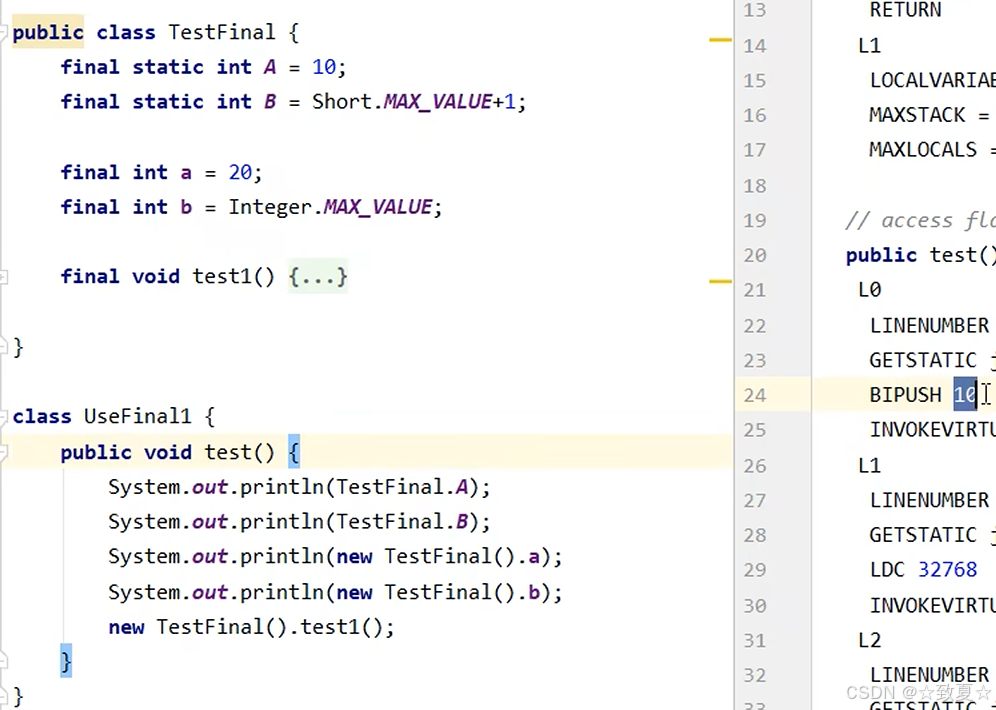
如果数值超过了短整型的最大值,会读取常量池里的内容
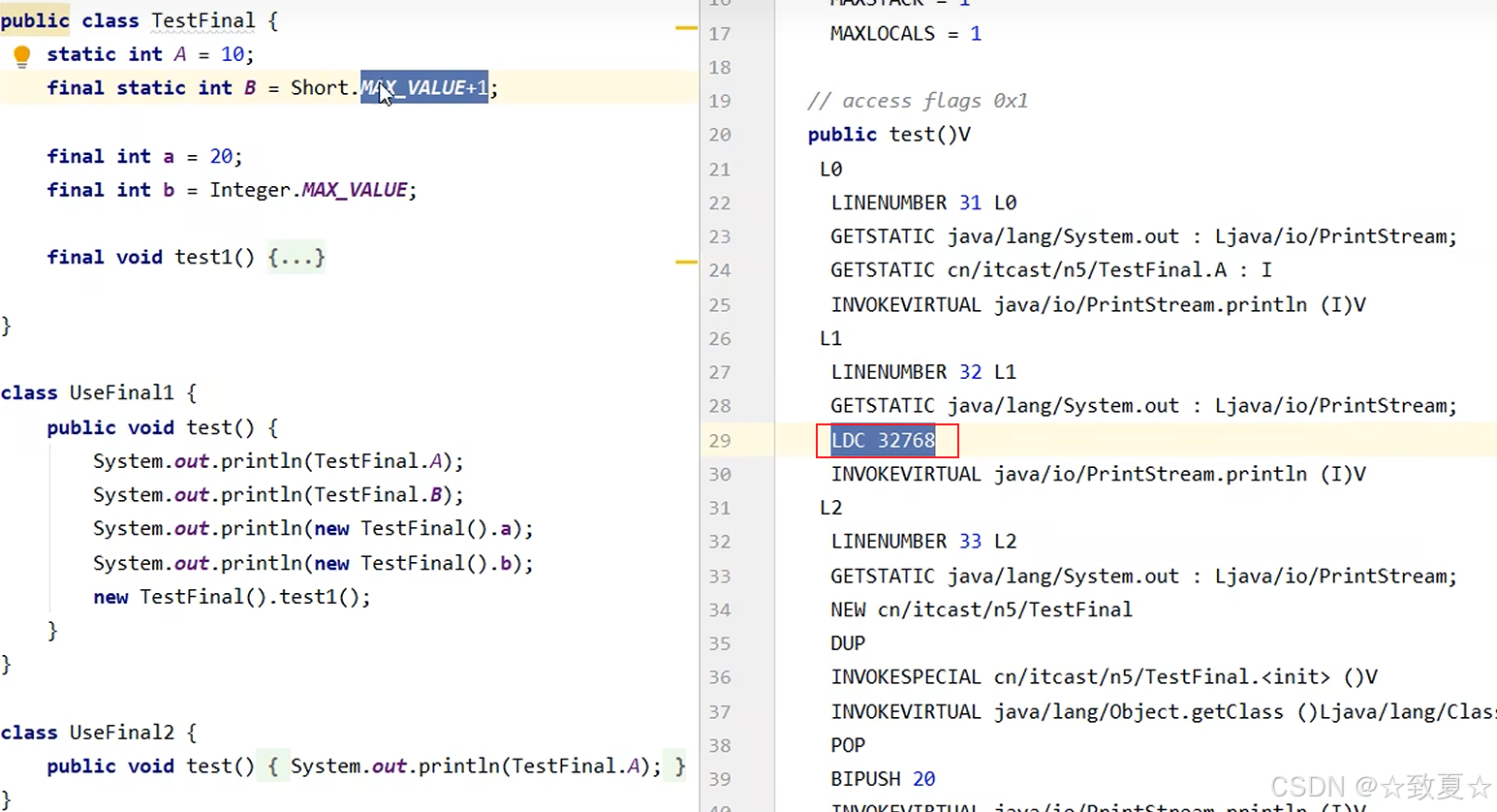
不加final修饰,从字节码可以看出使用了GETSTATIC来获取变量A的值,走共享内存(算在堆中),读取效率比走栈内存,常量池要低
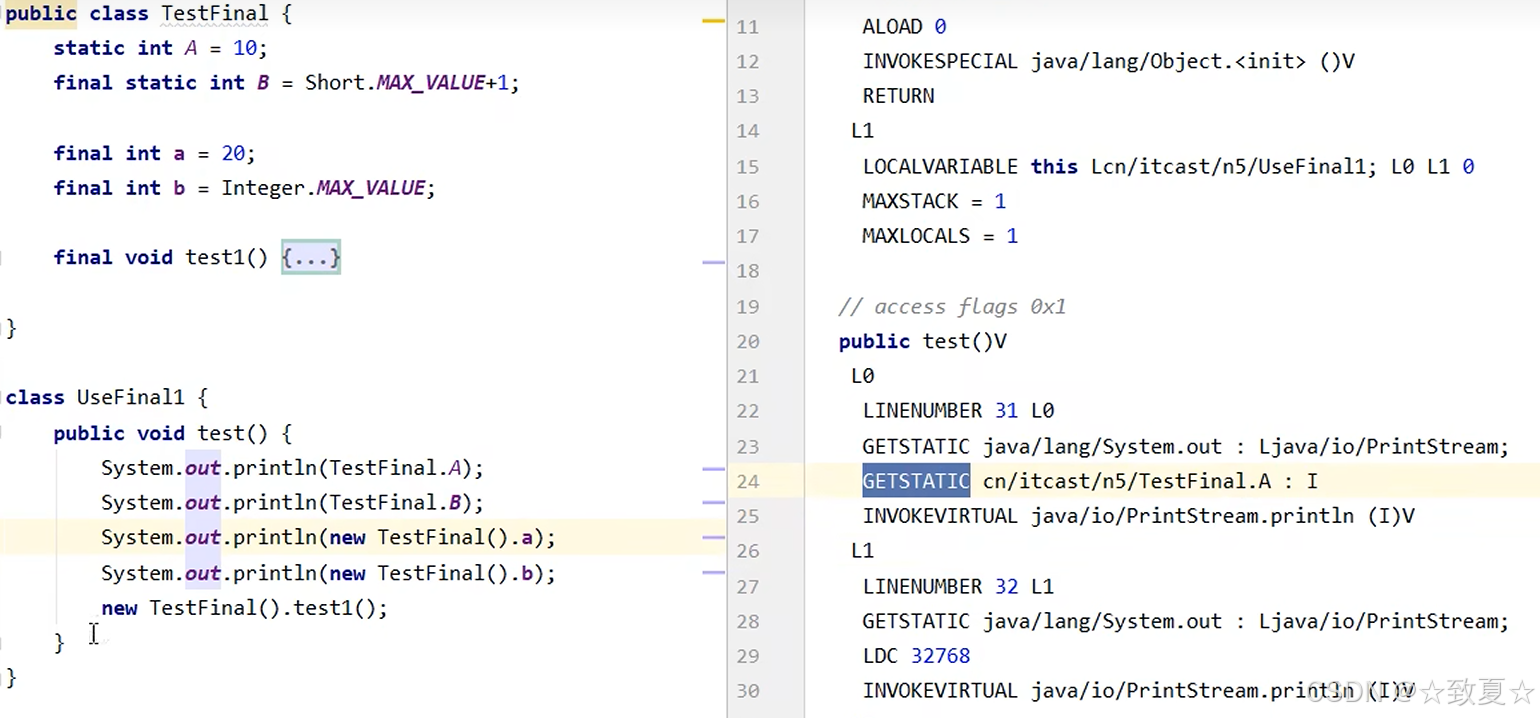
无状态

八、并发工具
自定义线程池
线程池产生背景
线程是系统资源,每产生一个线程需要分配内存(栈内存)。高并发情况下来了很多任务,如果为每个任务都创建新线程,占用的内存很大;且线程很多,cpu数一定的情况下,一定有一部分线程被阻塞发生线程上下文切换问题,切换越频繁,对系统性能影响越大。基于以上两种原因,为了充分使用已有线程,线程池出现了。
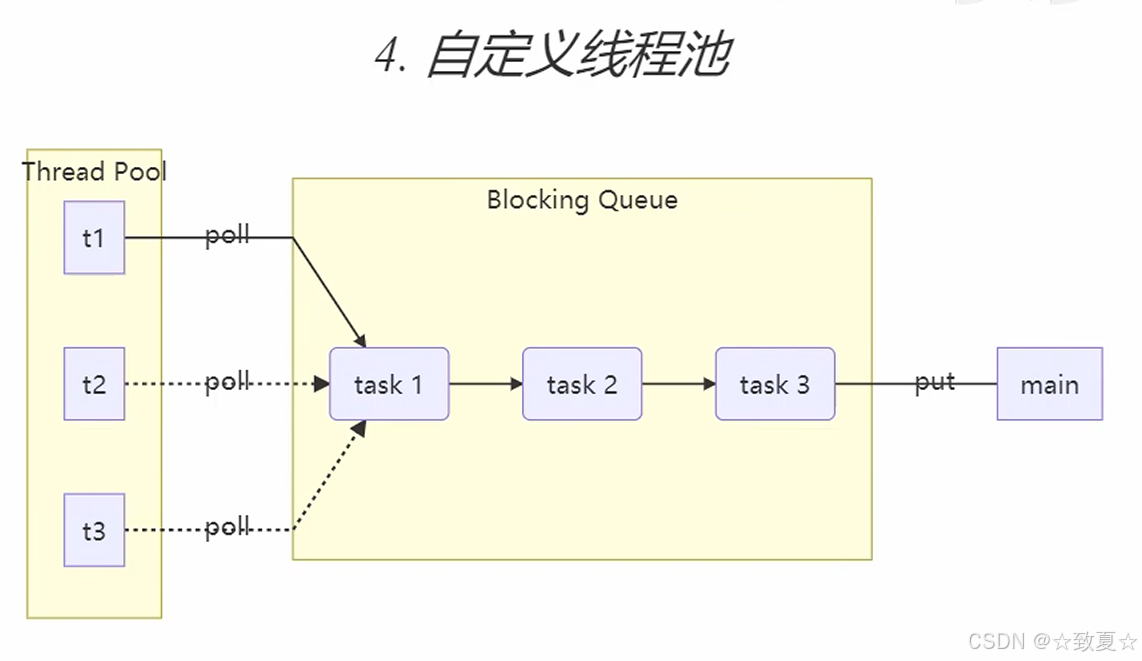
自定义线程池实现
任务阻塞队列定义属性

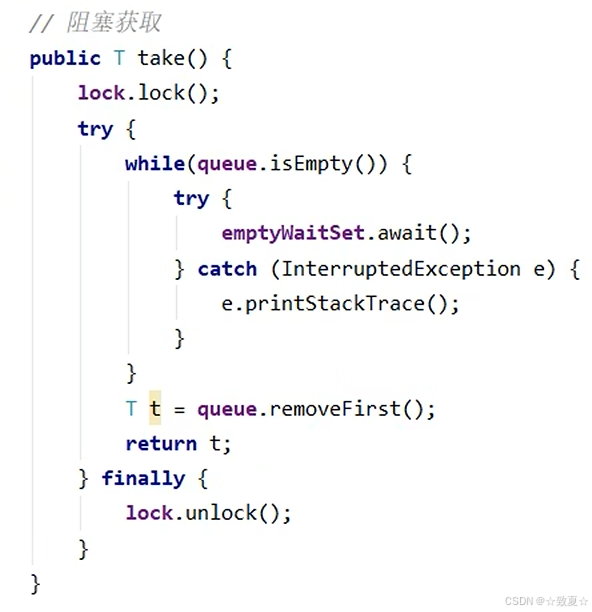
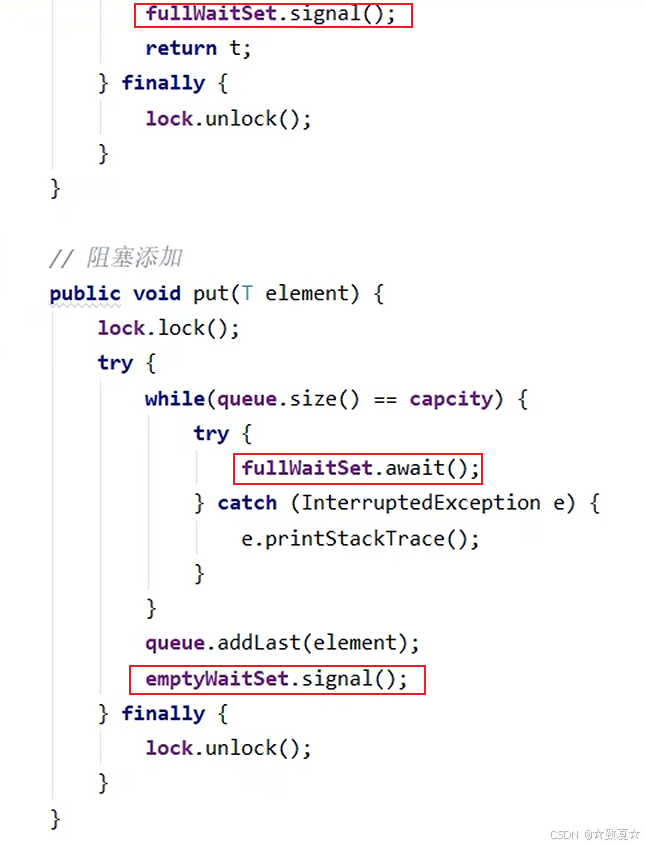
阻塞获取&阻塞添加&获取大小

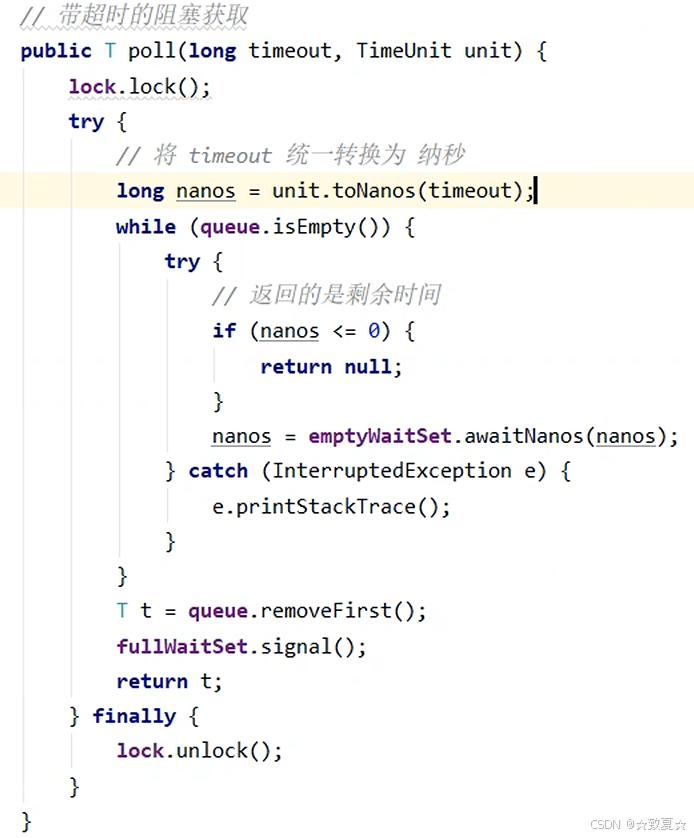
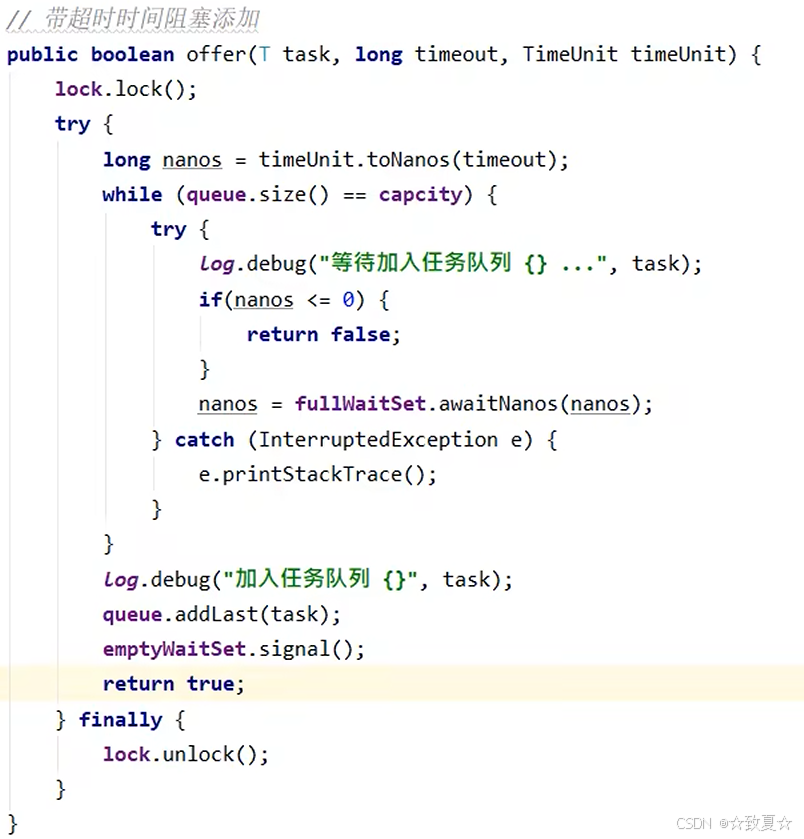
超时阻塞获取
线程池定义属性
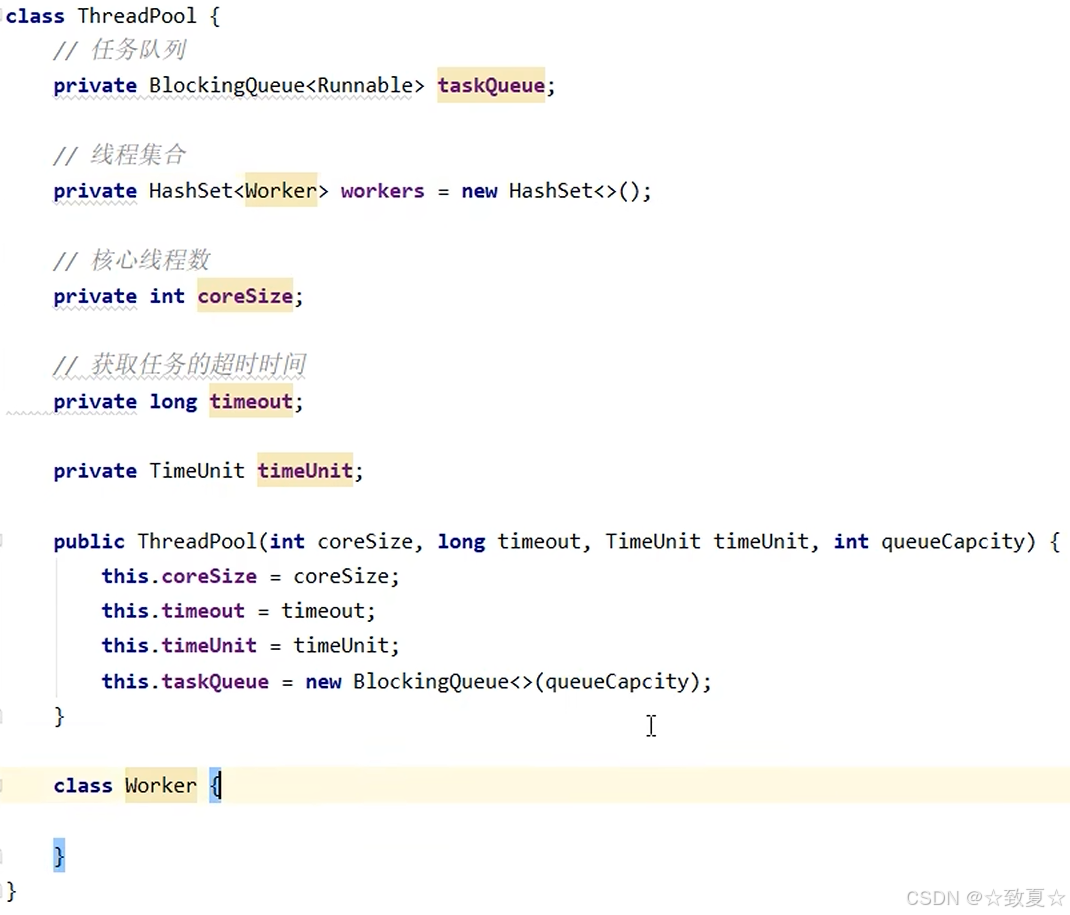
任务提交和Worker实现

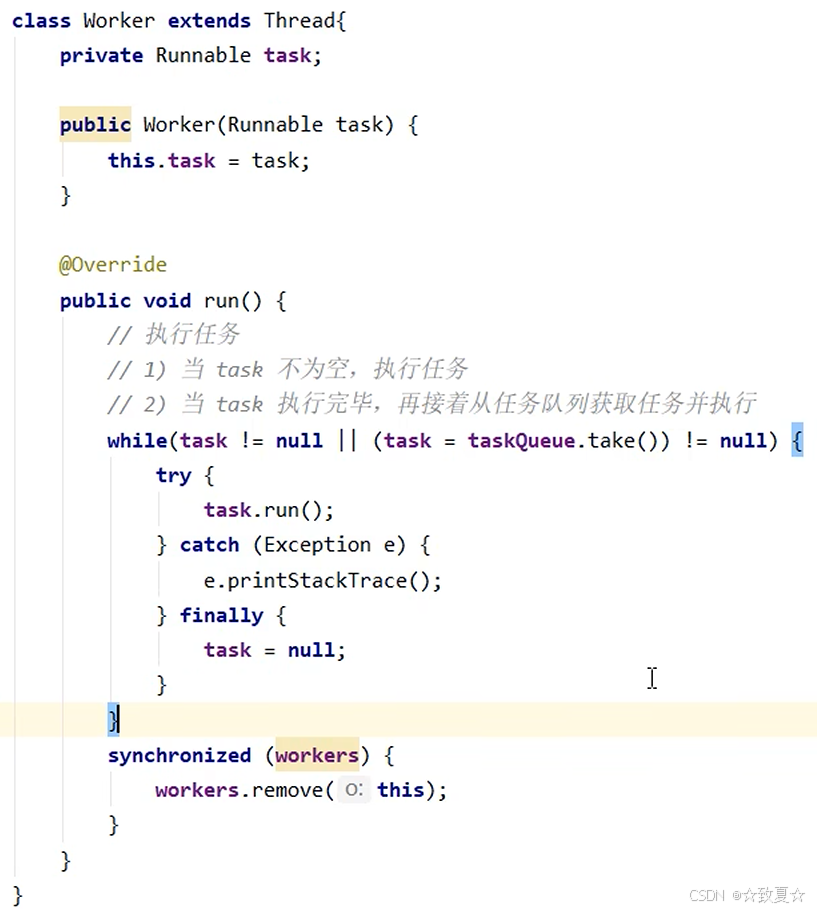
模拟超时等待
上面的Worker实现中,如果队列没有任务,还会一直等待新任务,这是一种策略。还可设置等待时间,如果超过时间还没有任务,就退出循环,结束等待。
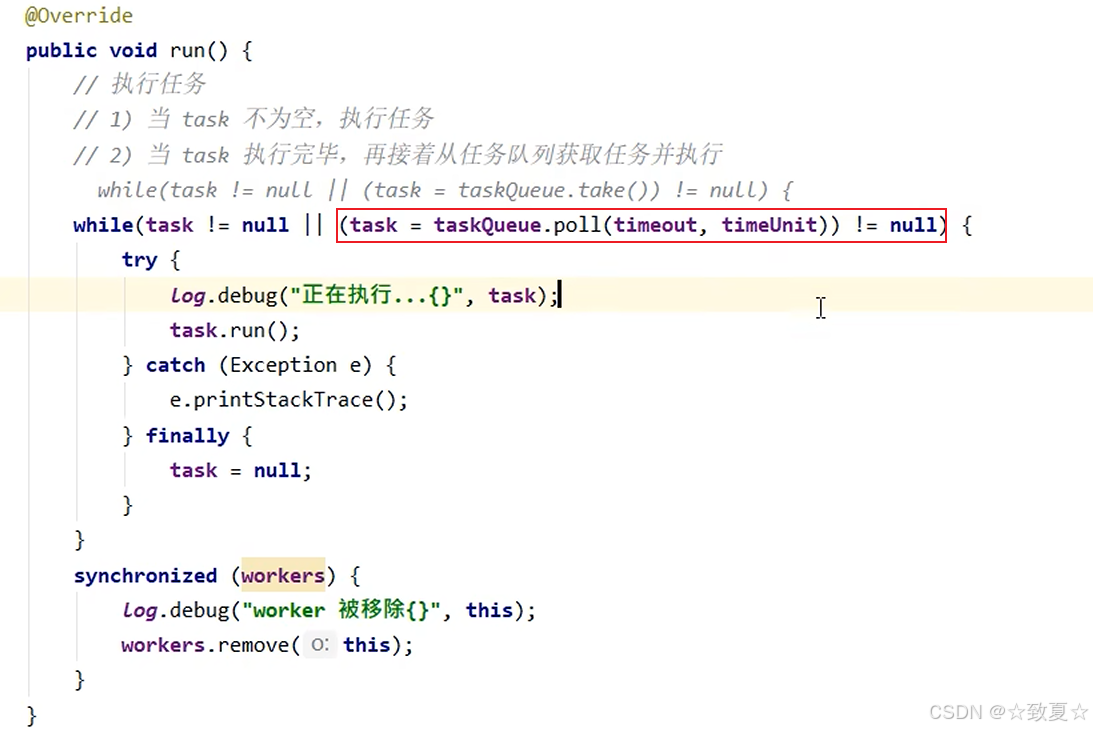
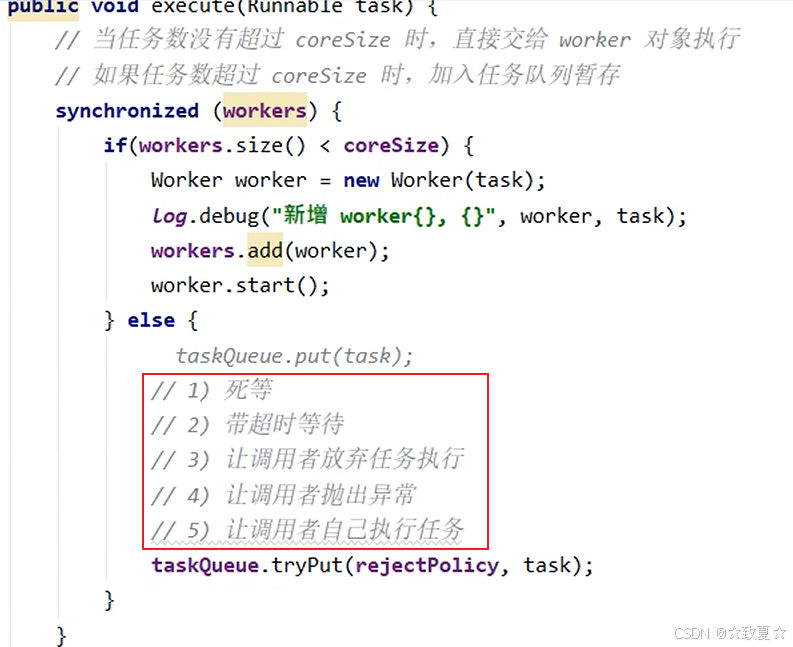
模拟核心线程在忙,任务队列也满的情况
分析可知,此时对主线程很不友好,当队列满时,主线程需要一直等待。需要给主线程一个选择,是继续等还是抛出异常,给主线程制定一个拒绝策略。
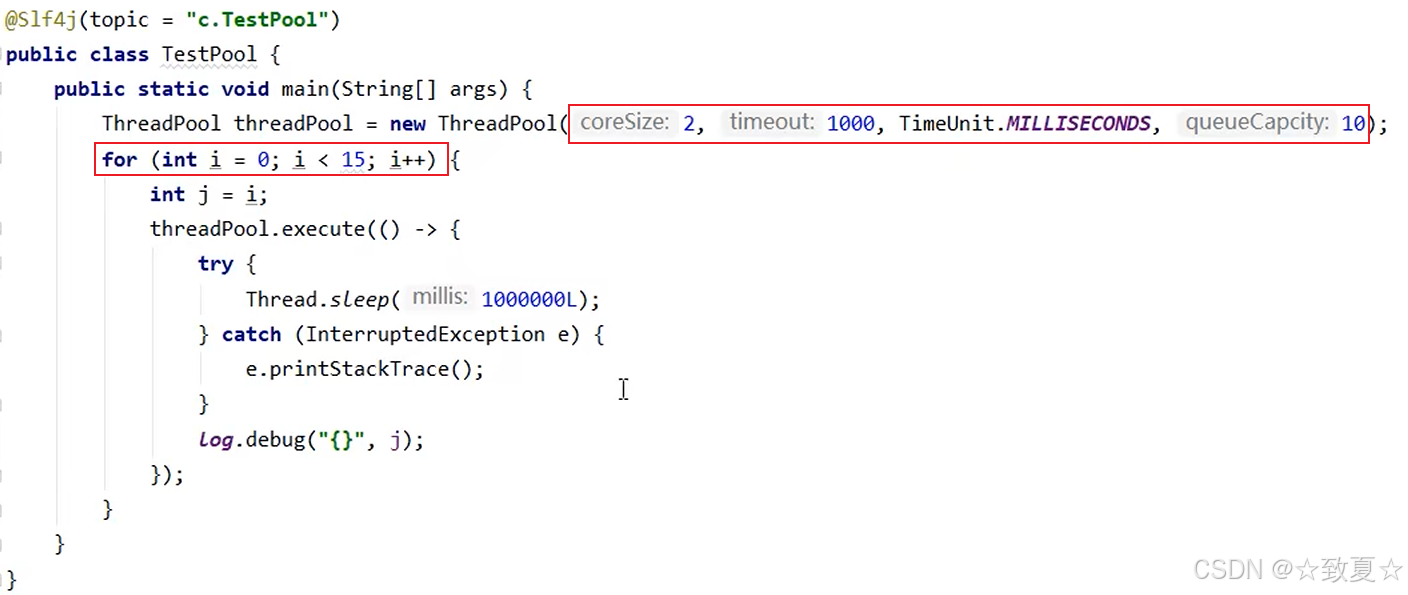
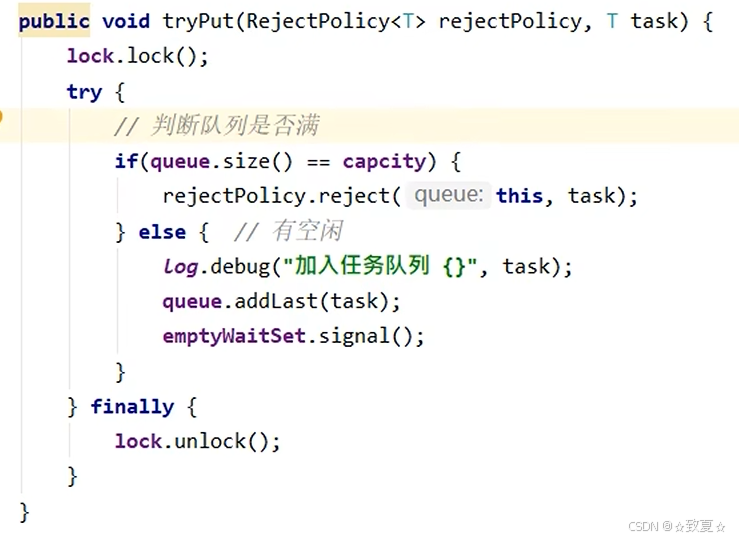
offer增强-超时阻塞添加
拒绝策略
如果将拒绝策略写死在代码里,会出现很多if-else,可以把使用拒绝策略的权力下放给调用者,让调用者自己决定用哪个。用到设计模式-策略模式。拒绝策略实现代码由调用者传过来。

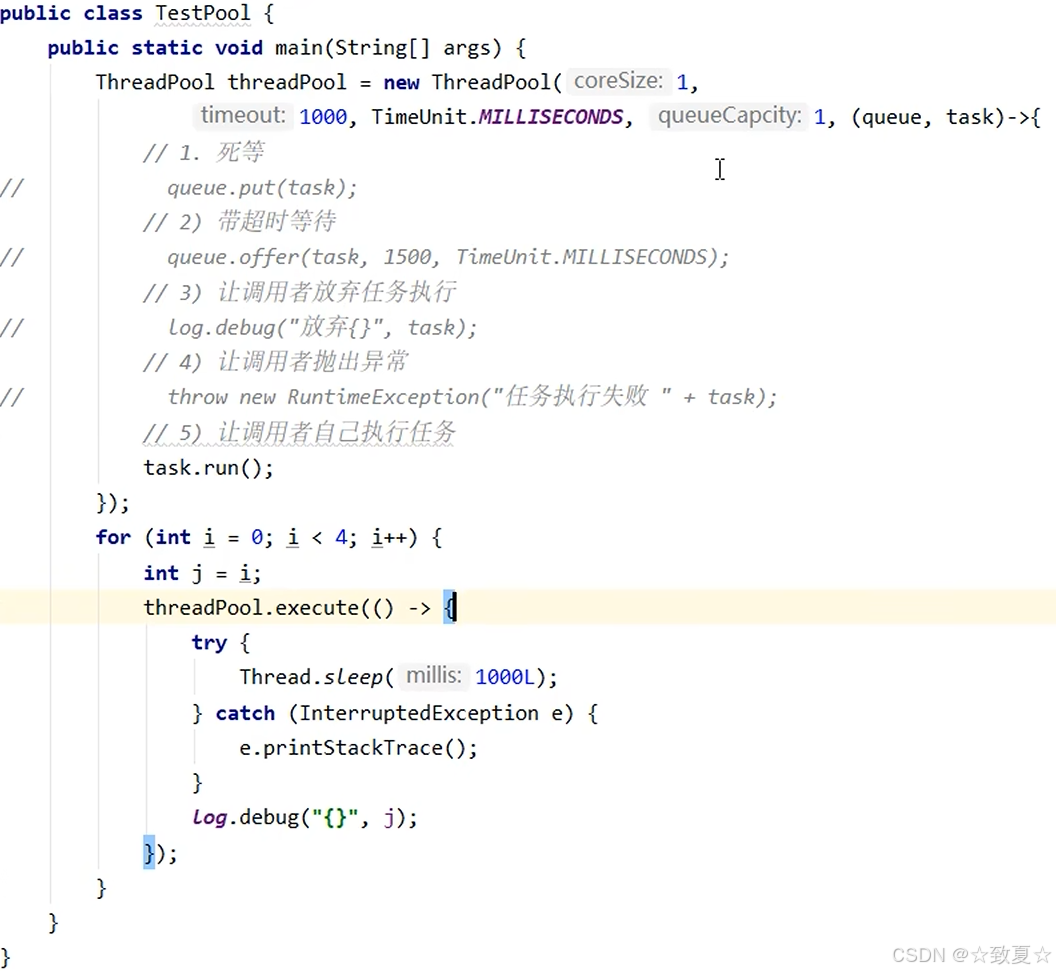
拒绝策略使用演示
JDK线程池
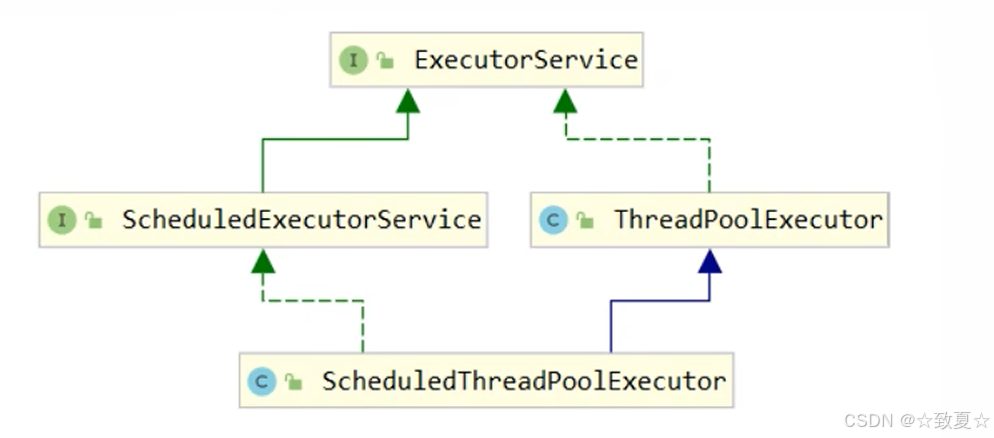
ThreadPoolExecutor
线程池状态
高3位表示状态,RUNNING高3位的第一位是1,代表负数,所以最小。
用一个int整数保存两种信息(线程池状态和线程数量)是为了减少cas操作。

构造方法

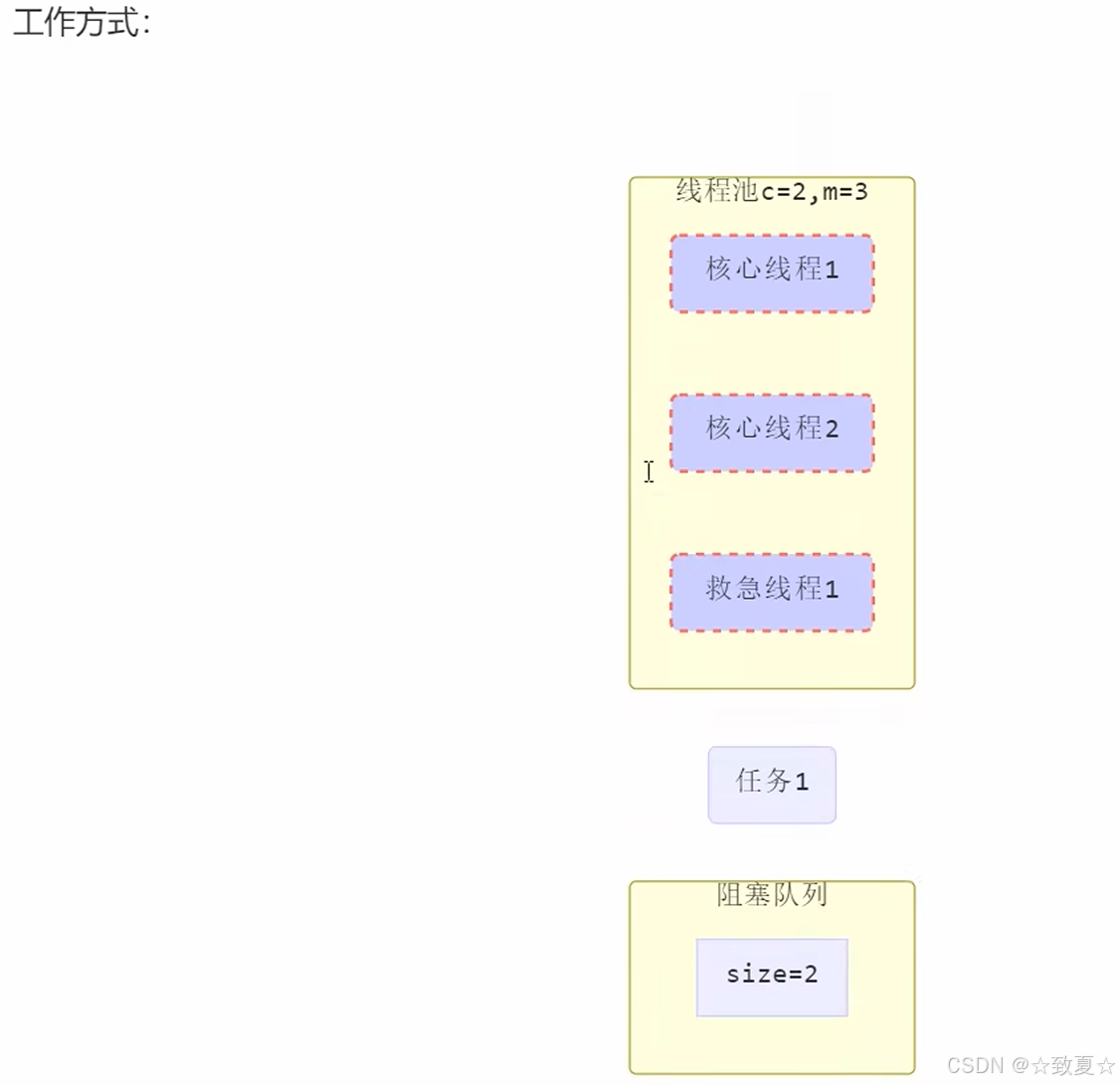
最大线程数 = 核心线程数 + 救急线程数
当任务来时,核心线程满,任务进入阻塞队列;阻塞队列满,创建救急线程执行;救急线程满,执行拒绝策略。
救急线程创建后有生存时间,当救急任务执行完时,救急线程会被销毁。
而核心线程的任务执行完后,核心线程依然存在。
线程池注意事项&拒绝策略实现

 工厂方法-固定线程池
工厂方法-固定线程池

使用该工厂方法有默认工厂,也可以自己定义工厂方法。
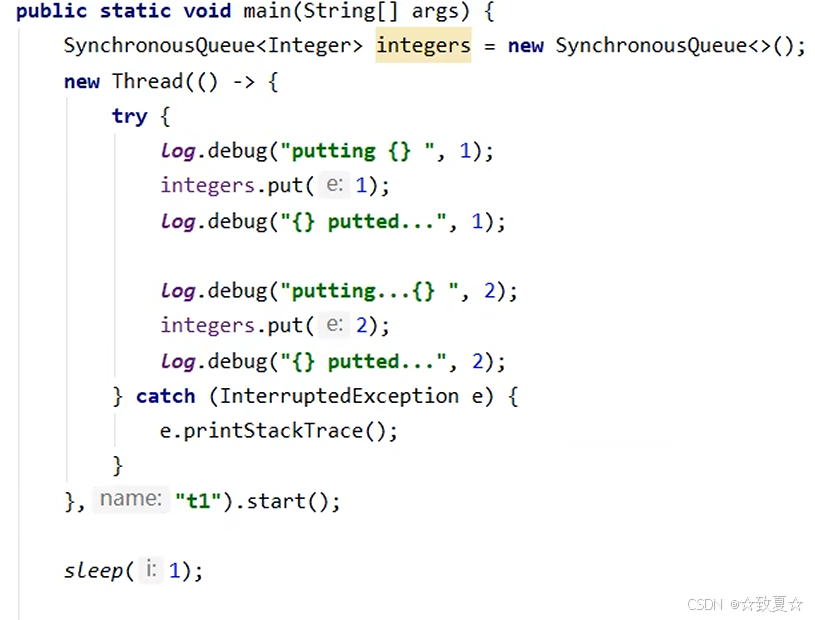
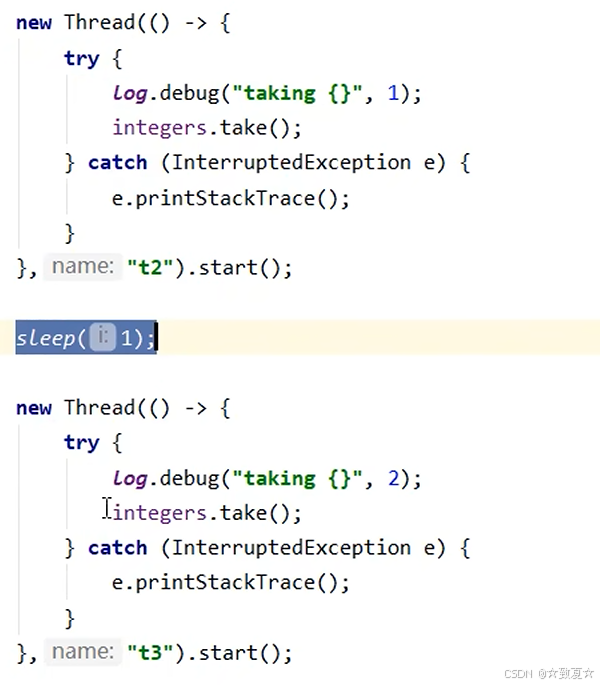
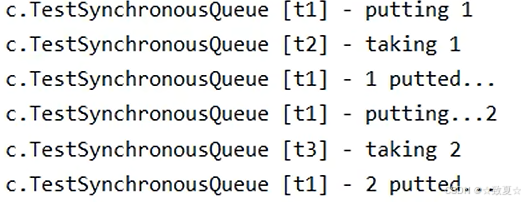
工厂方法-带缓冲线程池
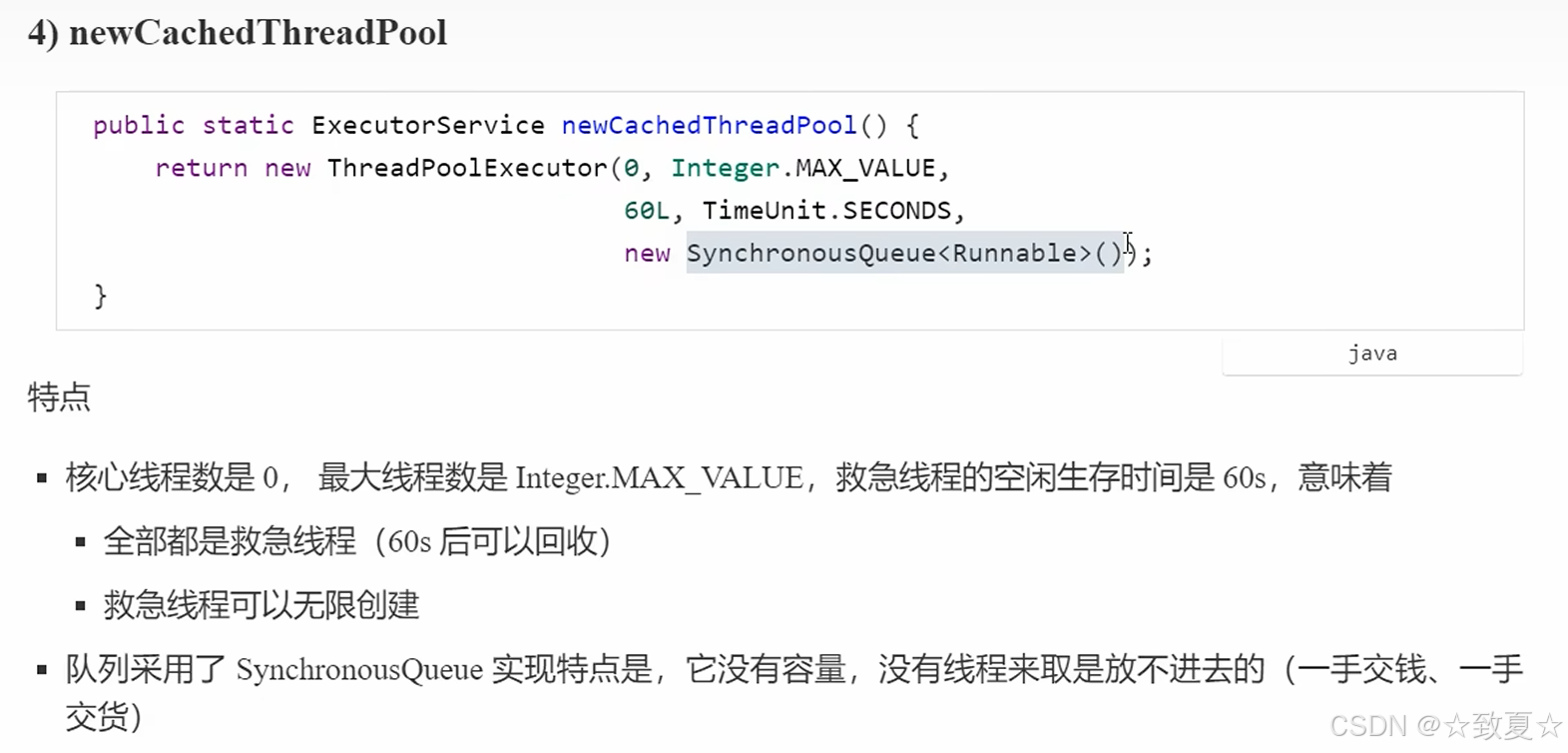
当有线程来存放数据调用put方法时,如果没有其他线程来取,则put会一直阻塞,直到有其他线程来取take,put方法才会执行完。

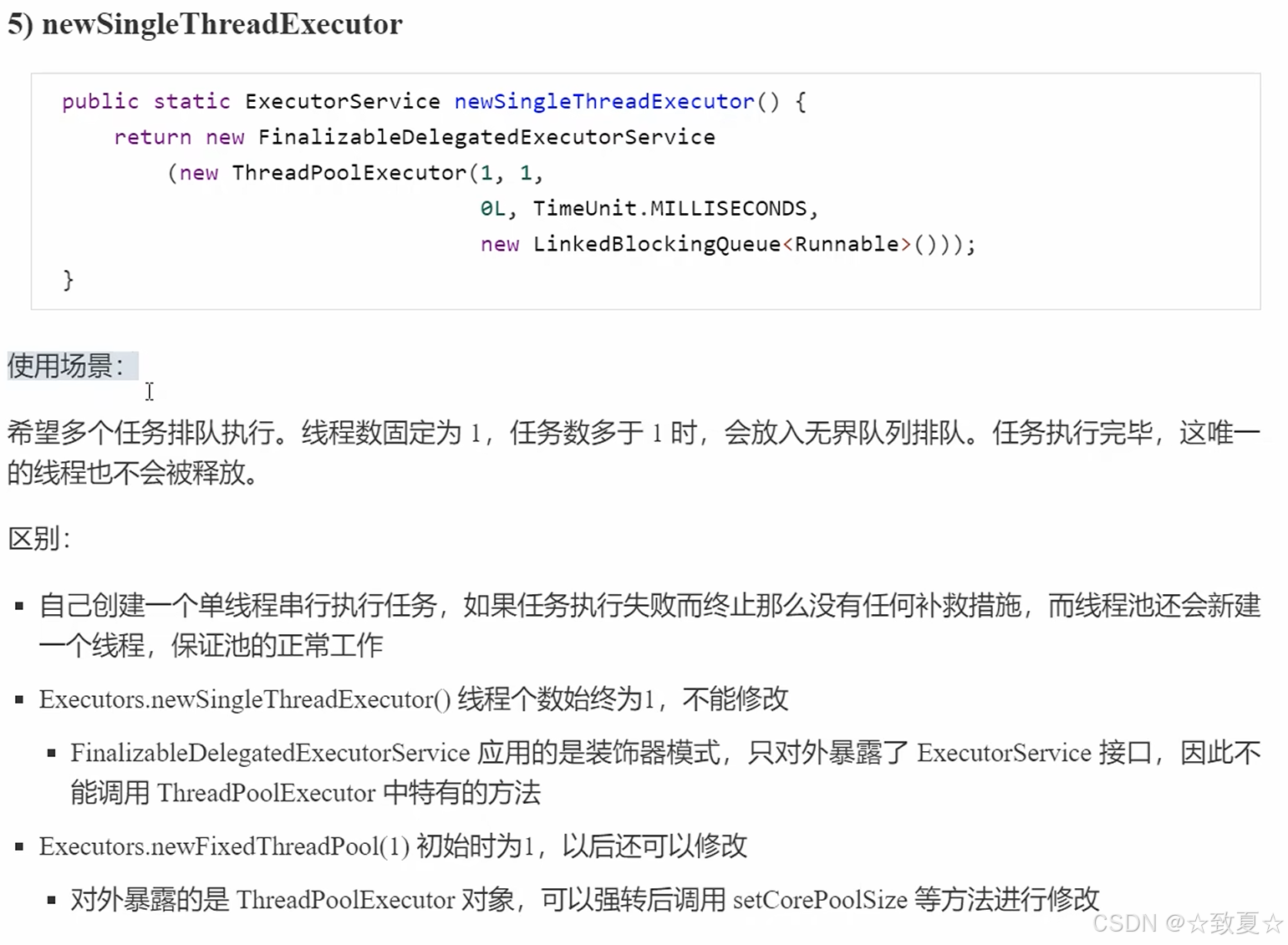
工厂方法-单线程线程池
单线程线程池最终返回的对象对外只暴露了ExecutorService接口,保证了单线程的线程池不会被修改破坏。
线程池提交任务方法

sumbit

使用示例
Future内部也是基于保护性暂停的。
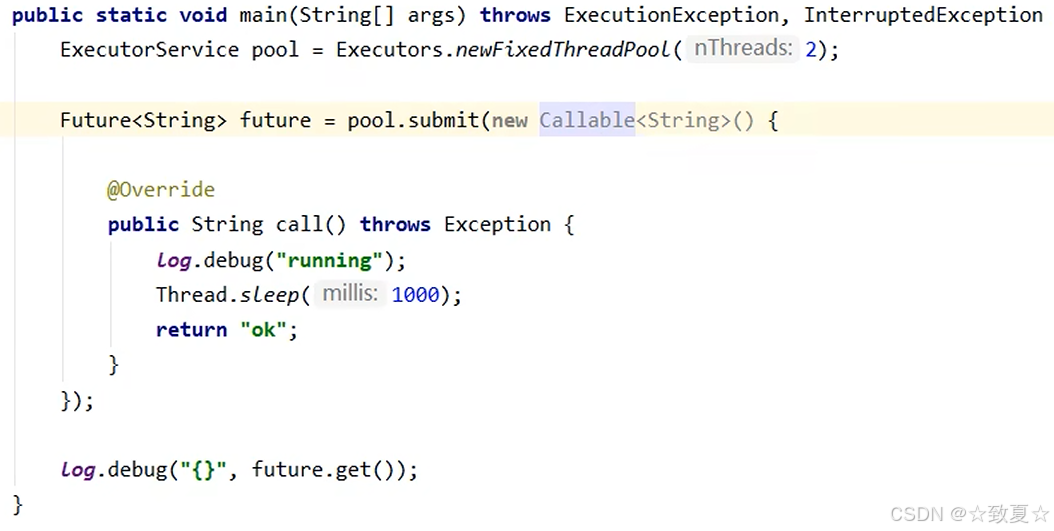

invokeAll

使用示例
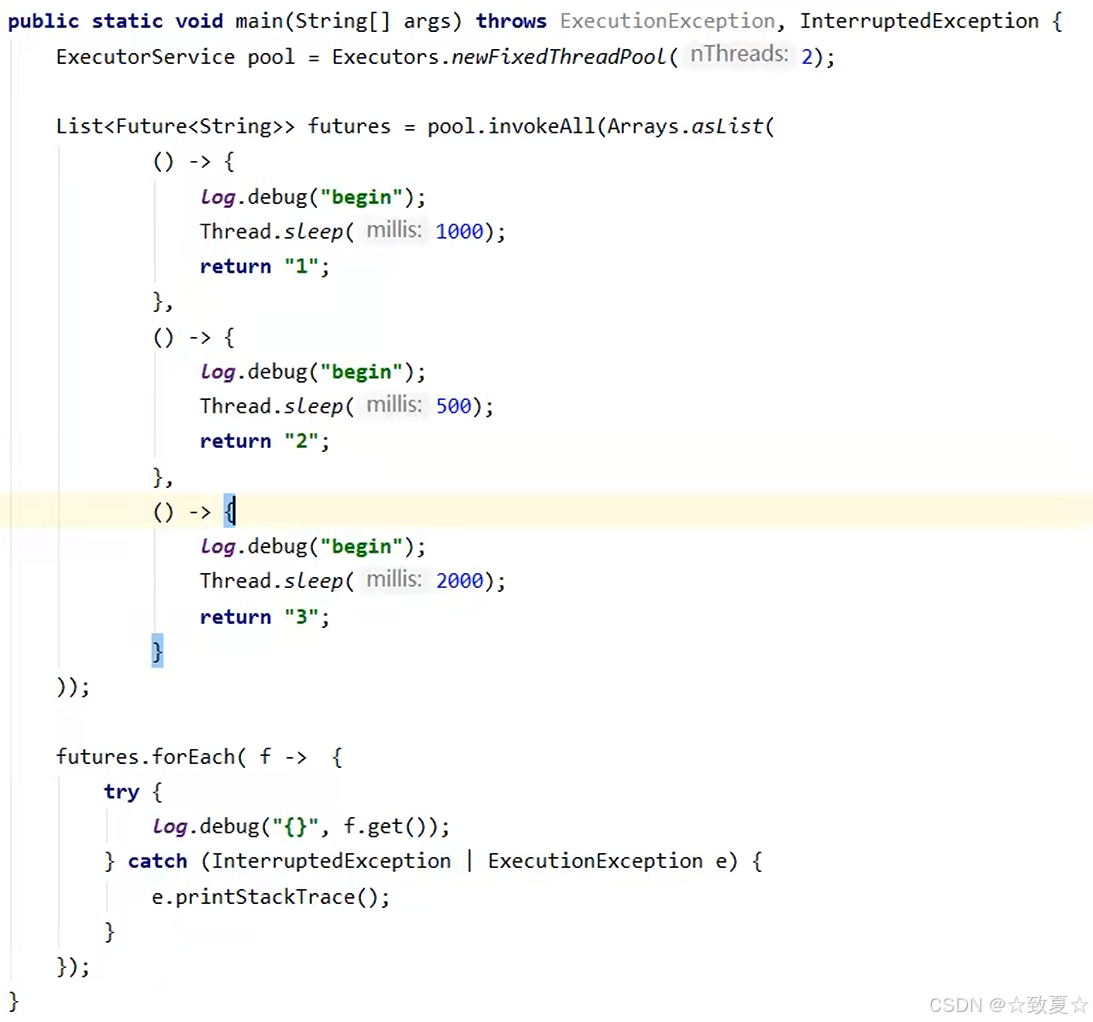
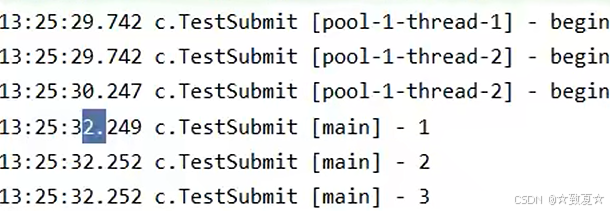
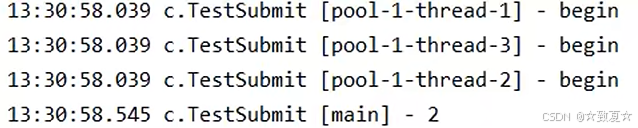
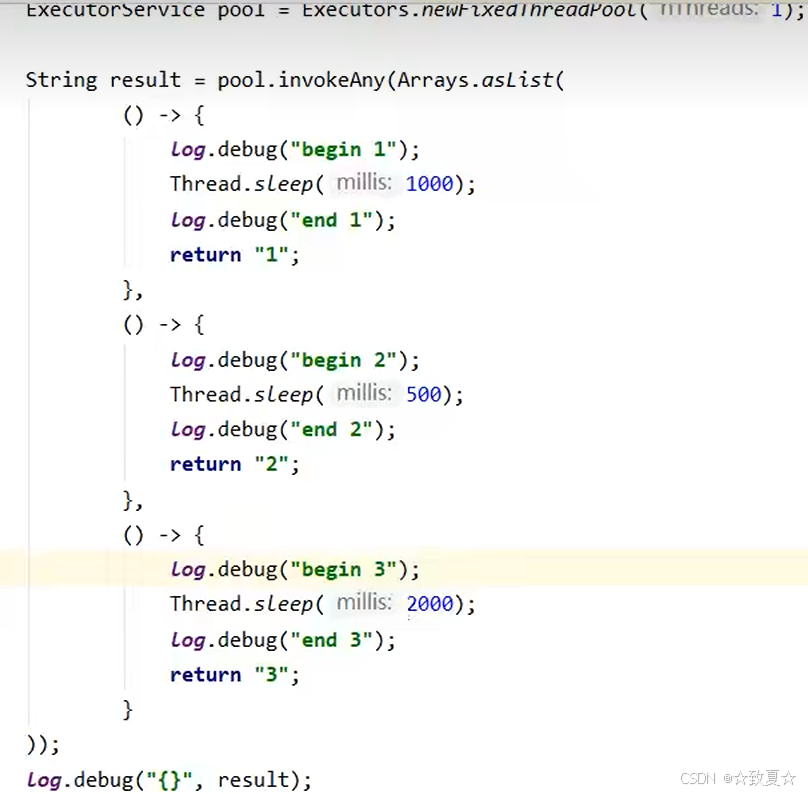
invokeAny

使用示例
3个线程同时运行,拿到最先返回线程结果,其他线程没运行完就会结束
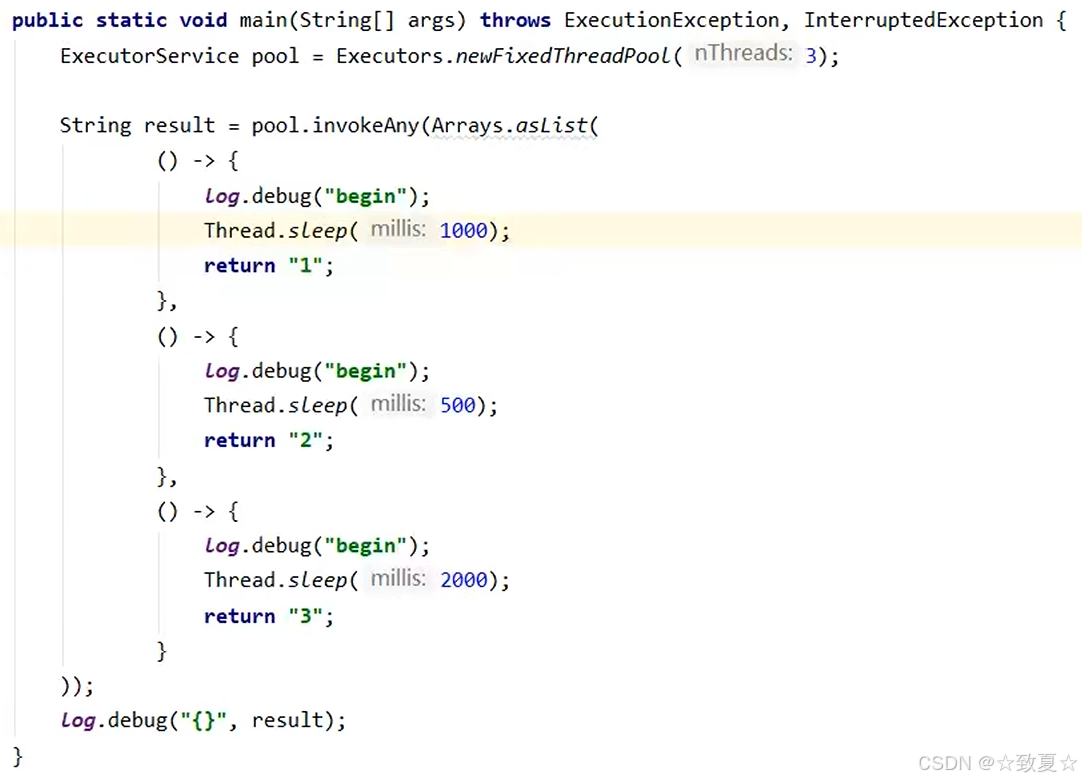
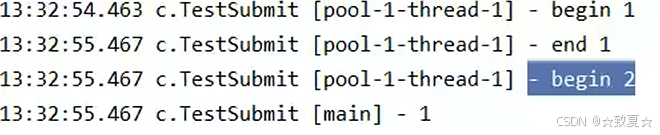
只有一个线程,拿到第一个结果后就会返回
线程池关闭方法
shutdown
使用示例
使用shutdown不会影响正在执行的任务和已提交到队列的任务,在执行shutdown之后提交任务会报错,且主线程调用之后不会阻塞,可以执行后续代码。
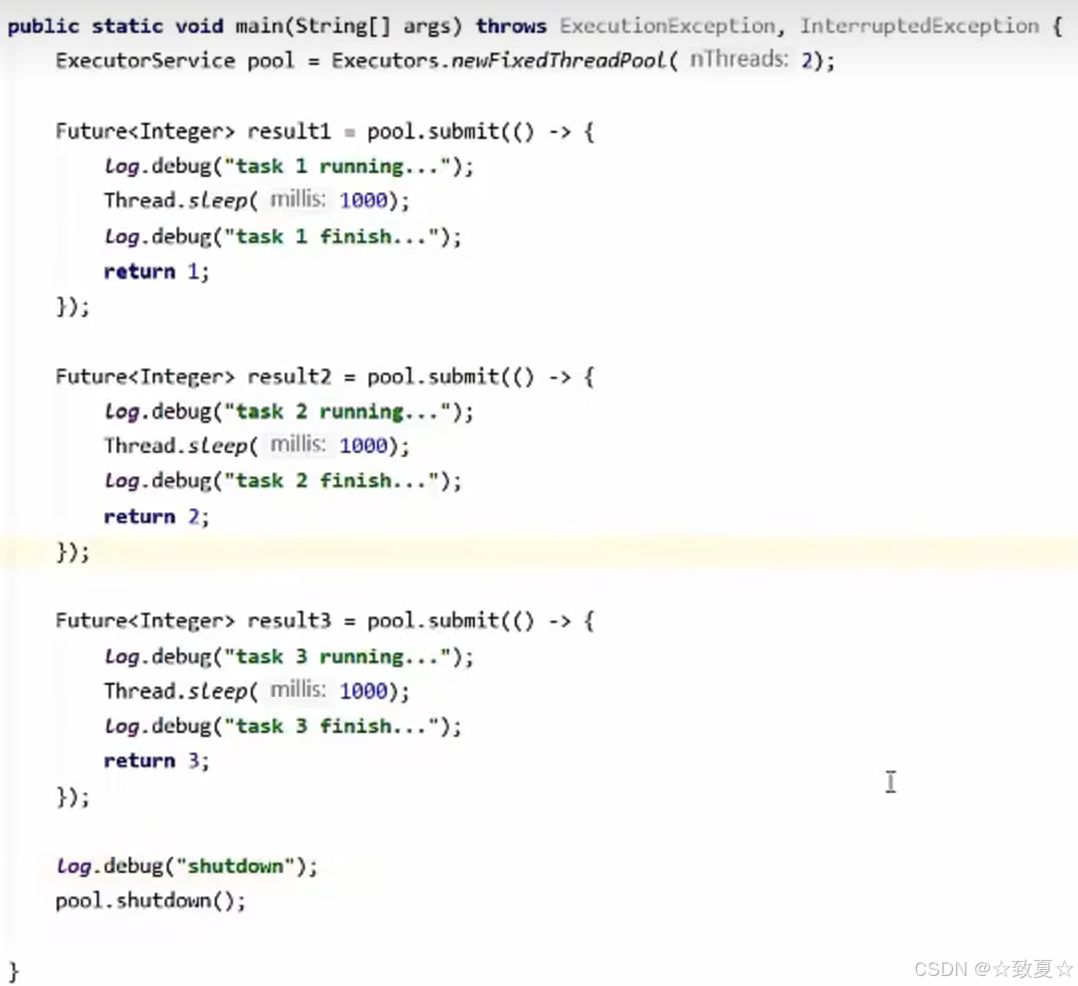

shutdownNow
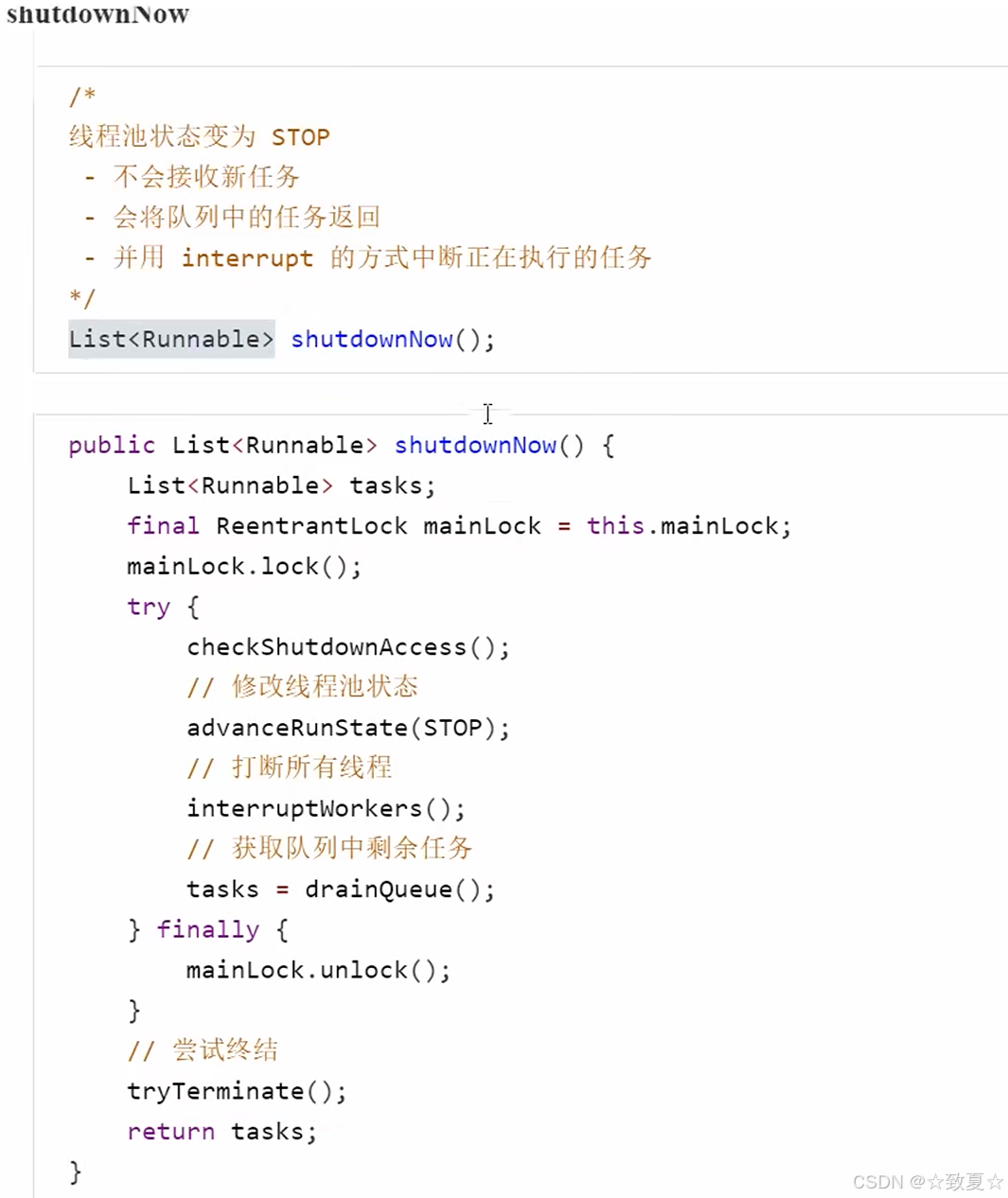
使用示例
上述代码修改shutdown -> shutdownNow即可

正在运行的线程被打断,不会运行后续代码(不执行的原因是sleep被打断抛出异常)。任务队列里未执行的任务被封装成FutureTask对象返回给Runnable集合。

其他方法

异步模式之工作线程
定义

饥饿

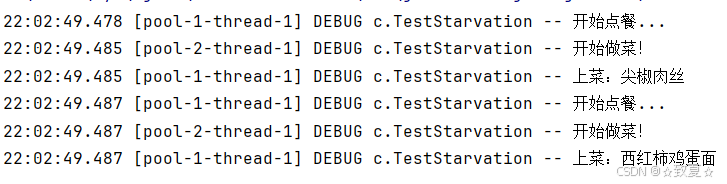
代码示例
线程池只有2个线程资源,全部用来点餐后,等待做菜结果,而此时已经没有线程资源处理做菜了,陷入了死等。
使用 jconsole 检测死锁,发现此时是没有死锁的。
所以只是现象类似,饥饿与死锁是有区别的,死锁是两个线程各自已经有了一把锁,且想要获取对方的锁。
@Slf4j(topic = "c.TestStarvation")
public class TestStarvation {static List<String> MENU = Arrays.asList("鱼香肉丝", "牛排", "西红柿鸡蛋面", "小炒肉", "尖椒肉丝");static Random RANDOM = new Random();static String cooking() {return MENU.get(RANDOM.nextInt(MENU.size()));}public static void main(String[] args) throws InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(2);executorService.execute(() -> {log.debug("开始点餐...");Future<String> f = executorService.submit(() -> {log.debug("开始做菜!");return cooking();});try {log.debug("上菜:{}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});executorService.execute(() -> {log.debug("开始点餐...");Future<String> f = executorService.submit(() -> {log.debug("开始做菜!");return cooking();});try {log.debug("上菜:{}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});}
}

饥饿现象解决
从上述代码可以看出是线程数不够导致的,因此我们想到了增加线程数解决问题,可是线程池中线程是固定,如果一遇到点餐多的问题,就增加线程,无法从根本解决问题,所以我们可以给任务分类分给不同线程池。
如下代码,只是给线程池分工,线程数不变,成功解决了问题。
public class TestStarvation {static List<String> MENU = Arrays.asList("鱼香肉丝", "牛排", "西红柿鸡蛋面", "小炒肉", "尖椒肉丝");static Random RANDOM = new Random();static String cooking() {return MENU.get(RANDOM.nextInt(MENU.size()));}public static void main(String[] args) throws InterruptedException {ExecutorService waitPool = Executors.newFixedThreadPool(1);ExecutorService cookPool = Executors.newFixedThreadPool(1);waitPool.execute(() -> {log.debug("开始点餐...");Future<String> f = cookPool.submit(() -> {log.debug("开始做菜!");return cooking();});try {log.debug("上菜:{}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});waitPool.execute(() -> {log.debug("开始点餐...");Future<String> f = cookPool.submit(() -> {log.debug("开始做菜!");return cooking();});try {log.debug("上菜:{}", f.get());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}});}
}
池大小-创建多少线程池合适
线程池过小容易导致饥饿,且如果8核cpu只用一个线程,不能充分利用cpu资源
线程池过大容易导致频繁的线程上下文切换,8核cpu800个线程显然不行,且创建线程过多会导致内存溢出。

cpu计算时间占比可以用一些分析和监控工具估算出来。

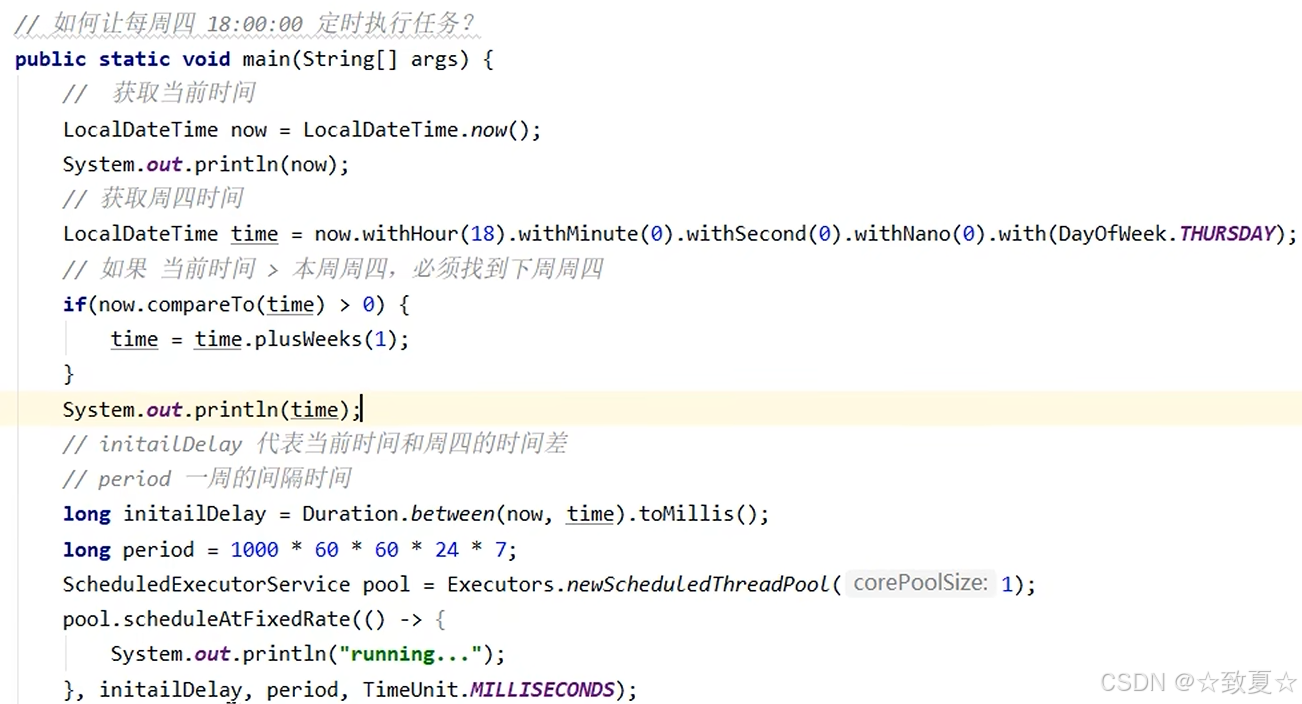
任务调度线程池
任务延时/定时执行或反复执行
Timer的缺点
Timer的所有任务都是由一个线程调度,导致所有任务串行执行,上一个任务执行会影响到下一个任务的执行。上一个任务异常会导致后续任务无法执行。

ScheduledThreadPoolExecutor-延时执行
任务并行执行;线程池中线程数为1时串行执行,上一个任务的执行时间会影响下一个任务,但报错不会影响下一个任务,并且报错信息不会在控制台输出
@Slf4j(topic = "c.TestScheduled")
public class TestScheduled {public static void main(String[] args) throws InterruptedException {ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);pool.schedule(() -> {log.debug("task1");try {sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}}, 1, TimeUnit.SECONDS);pool.schedule(() -> {log.debug("task2");}, 1, TimeUnit.SECONDS);}
}ScheduledThreadPoolExecutor-定时执行
以一定的时间间隔定时执行任务,如果任务执行时间超过设置的时间间隔,下个任务会紧挨着执行,不会出现两个任务重叠执行。

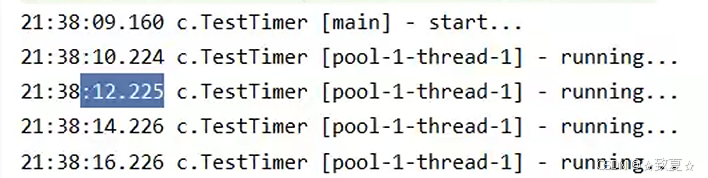
设置的时间间隔以上次任务执行结束后开始。
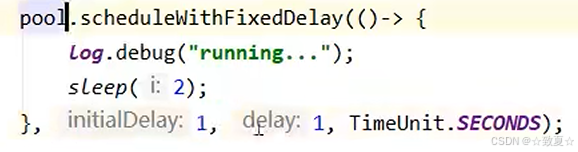
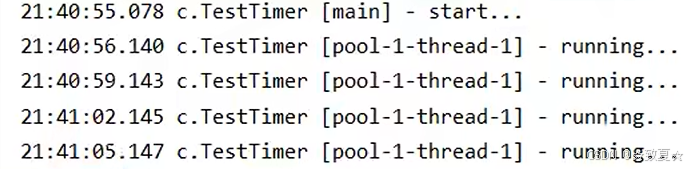
正确处理线程池异常
1.由任务自己捕捉处理
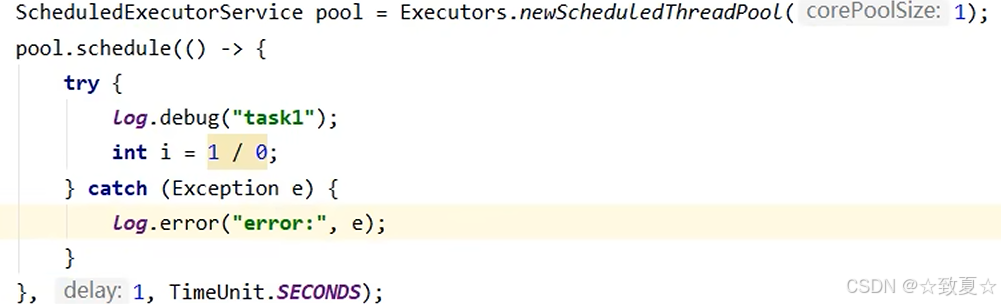

2.使用Future
普通线程池里的线程执行任务也不会在控制台报错,可以通过submit的Future返回值获取,错误信息会被封装到Future的对象里。
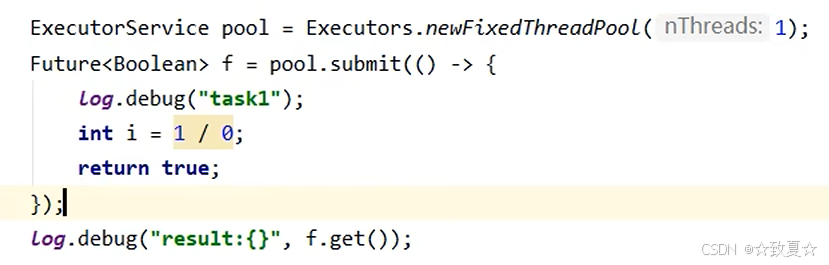

线程池应用-定时任务
使用示例
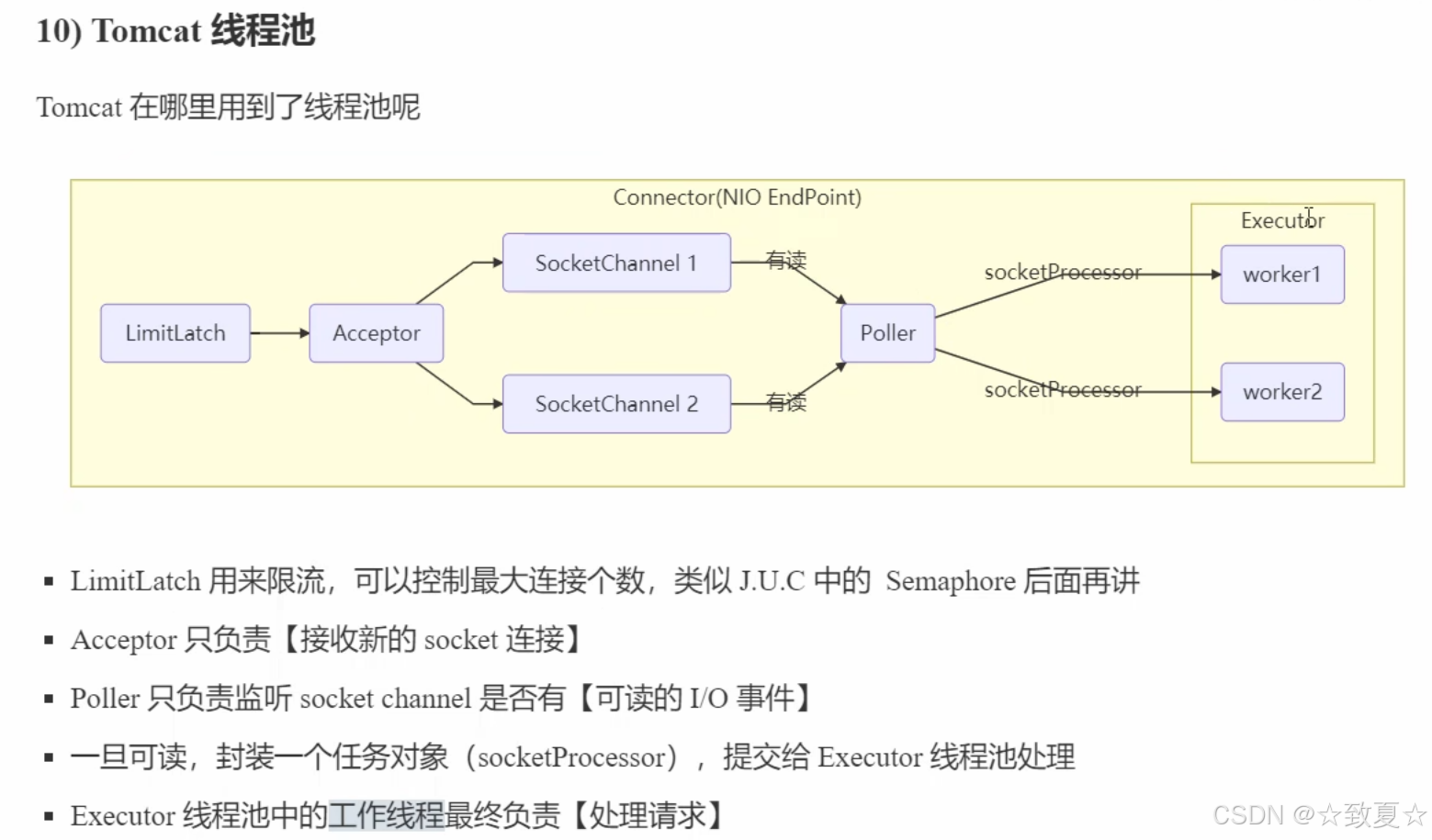
Tomcat线程池
Tomcat线程合理的分工保证了高并发,确保每个线程处理的任务是不一样的。



Tomcat线程池配置

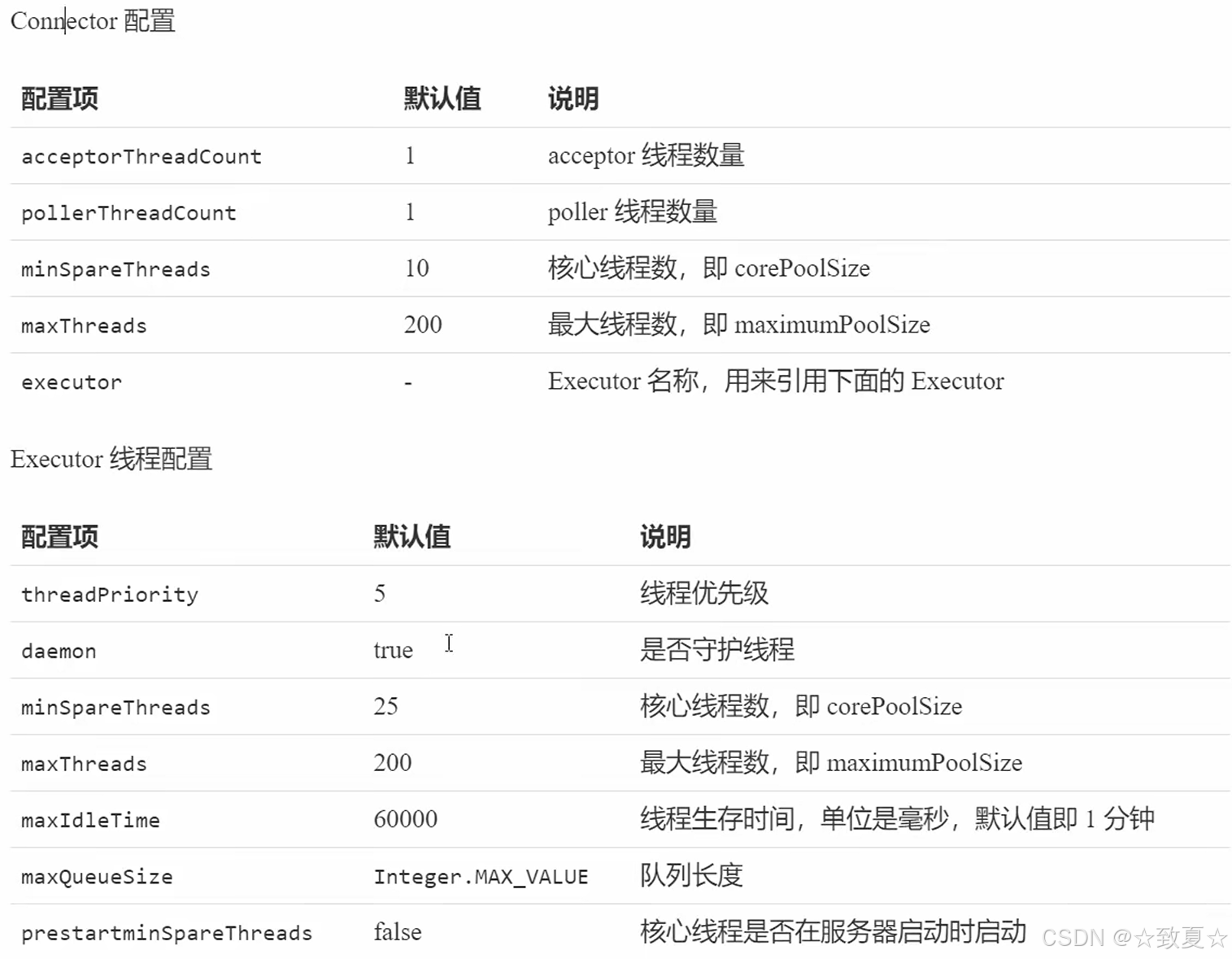
Connector配置如果和Executor配置有重复的,后者的优先级比前者高。

普通线程池是等队列满了再创建救急线程。
Tomcat线程池会对所有提交的任务计数,任务执行完计数减一,新增任务计数加一。
当任务计数 < 核心线程数,直接将任务加入队列;
当核心线程数 ≤ 任务计数 < 最大线程数,创建救急线程;
当任务计数 > 最大线程数,直接加入队列。
Fork/Join
概念
拆分/合并思想

使用示例
如何打印1+2+…+n的值?
首先拆分成1+2+...+(n-1)和n两个值的和
而1+2+...+(n-1)的值又可以拆分成1+2+...+(n-2)和(n-1)两个值的和;依次拆分后合并结果就能得到最终结果。
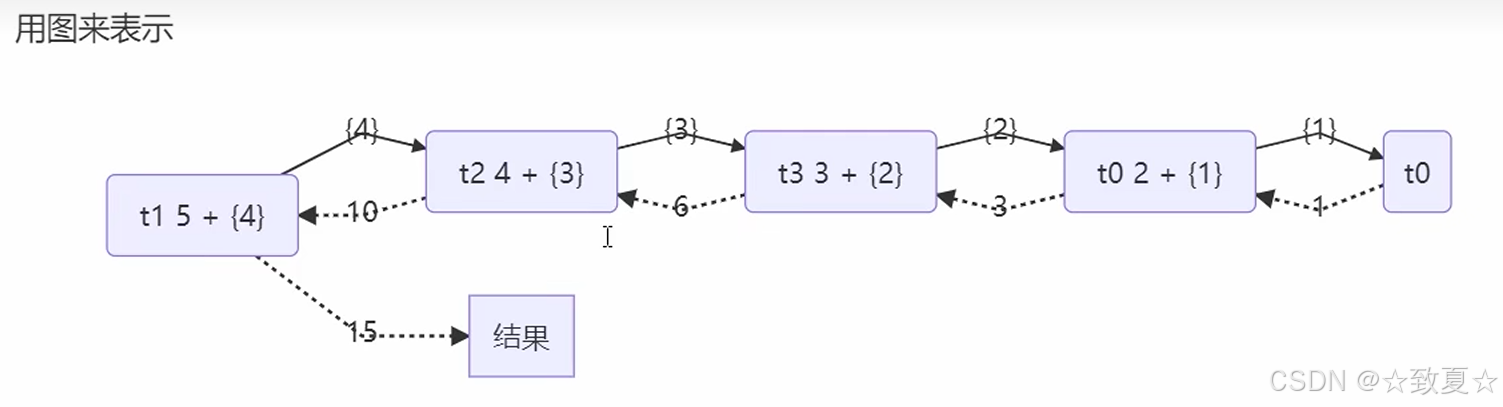
@Slf4j(topic = "c.Test32")
public class Test32 {public static void main(String[] args) throws InterruptedException {ForkJoinPool forkJoinPool = new ForkJoinPool(4);System.out.println(forkJoinPool.invoke(new MyTask(5)));}
}@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {private int n;public MyTask(int n) {this.n = n;}@Overridepublic String toString() {return "{" + n + "}";}@Overrideprotected Integer compute() {// 终止条件if (n == 1) {log.debug("join(){}", n);return 1;}MyTask t1 = new MyTask(n - 1);t1.fork();// 让一个线程去执行log.debug("fork(){} + {}", n, t1);int result = n + t1.join();log.debug("join(){} + {} = {}", n, t1, result);return result;// 等待线程执行完,获取结果}
}
优化
上述的拆分不好,只用了一个线程,上一个结果必须等待拆分后传回来的值才能计算结果,并行度不高。
优化拆分手段
将从计算1+2+...+n的结果拆分为计算1+2+...+(1+n)/2和[(1+n)/2+1]+...+n两个公式的值
这样两个公式调用2个线程各自计算值,不用等待,最后把结果汇总即可,提高了并行度。
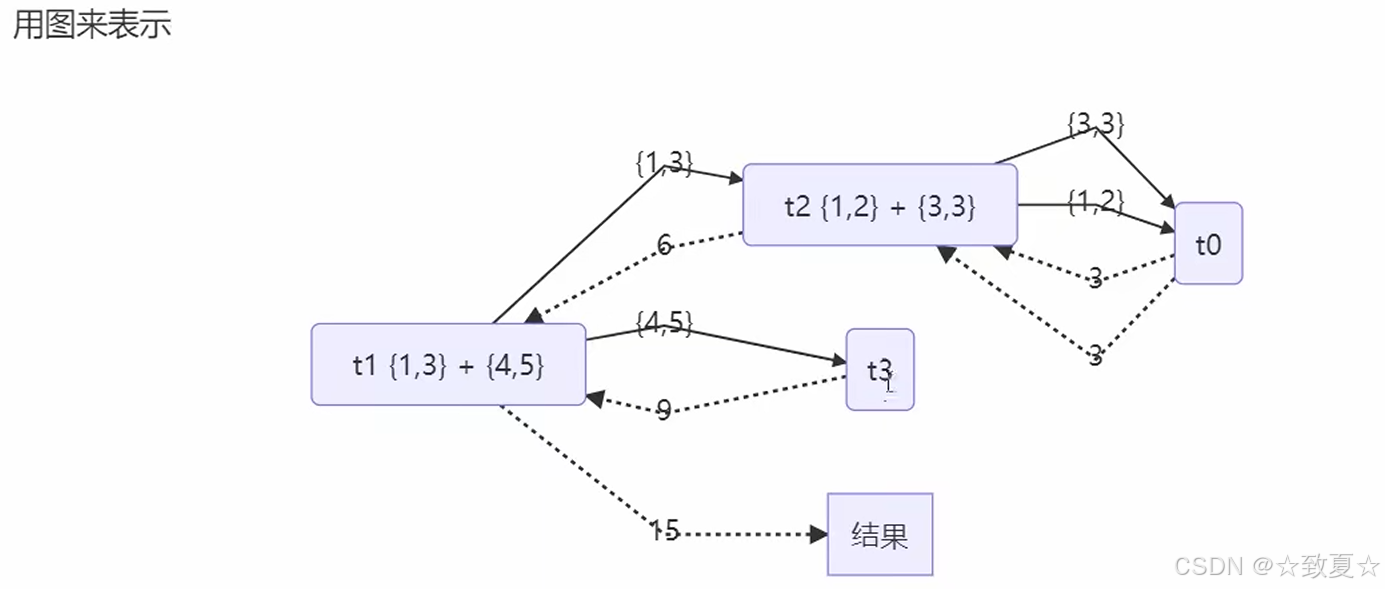
public class Test33 {public static void main(String[] args) throws InterruptedException {ForkJoinPool forkJoinPool = new ForkJoinPool(4);System.out.println(forkJoinPool.invoke(new MyTask2(1, 5)));}
}class MyTask2 extends RecursiveTask<Integer> {private int begin;private int end;public MyTask2(int begin, int end) {this.begin = begin;this.end = end;}@Overrideprotected Integer compute() {if (begin == end) {return begin;}if (end - begin == 1) {return begin + end;}/**1+2+3+4+5 -> (1+2+3) + (4+5)* -> (1+2) + 3 + (4+5)*/int mid = (begin + end) / 2;MyTask2 t1 = new MyTask2(begin, mid);t1.fork();MyTask2 t2 = new MyTask2(mid + 1, end);t2.fork();return t1.join() + t2.join();}
}
AQS原理
概述

FIFO先进先出的等待队列,与Monitor的EntryList(基于C++实现)不同,它是JAVA实现的

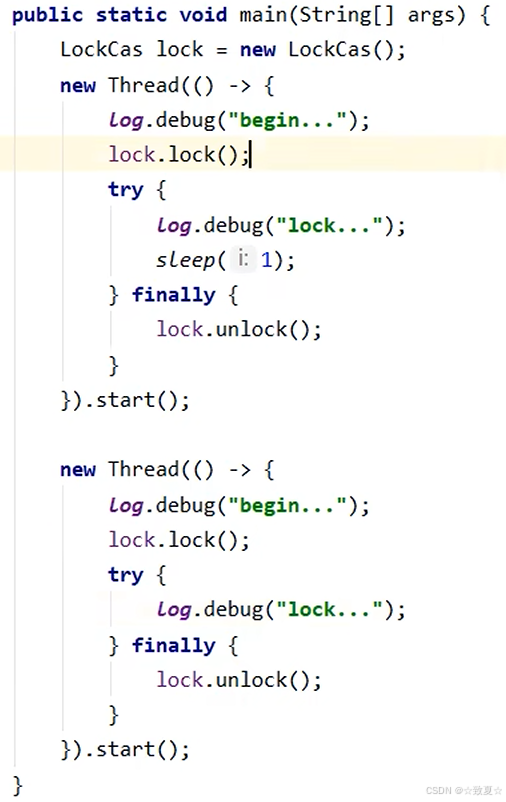
自定义锁-不可重入锁
在main方法中测试了不重入锁,线程在第一次lock后进入阻塞(WAITTING),所以此锁不支持可重入。

@Slf4j(topic = "c.TestAqs")
public class TestAqs {public static void main(String[] args) throws InterruptedException {MyLock lock = new MyLock();new Thread(() -> {lock.lock();log.debug("lock...");lock.lock();log.debug("lock...");try {log.debug("lock...");sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);} finally {log.debug("unlock...");lock.unlock();}}, "t1").start();new Thread(() -> {lock.lock();try {log.debug("lock...");} finally {log.debug("unlock...");lock.unlock();}}, "t2").start();}
}class MyLock implements Lock {// 独占锁 同步器类class MySync extends AbstractQueuedSynchronizer {@Overrideprotected boolean tryAcquire(int arg) {//加锁,并设置owner为当前线程if (compareAndSetState(0, 1)) {setExclusiveOwnerThread(Thread.currentThread());return true;}return false;}@Overrideprotected boolean tryRelease(int arg) {setExclusiveOwnerThread(null);setState(0);return true;}@Overrideprotected boolean isHeldExclusively() {return getState() == 1;}public Condition newCondition() {return new ConditionObject();}}private MySync sync = new MySync();// 加锁 不成功会进入等待队列@Overridepublic void lock() {sync.acquire(1);}@Overridepublic void lockInterruptibly() throws InterruptedException {sync.acquireInterruptibly(1);}@Overridepublic boolean tryLock() {return sync.tryAcquire(1);}@Overridepublic boolean tryLock(long time, TimeUnit unit) throws InterruptedException {return sync.tryAcquireNanos(1, unit.toNanos(time));}@Overridepublic void unlock() {//release方法不仅会释放锁(调用tryRelease),还会唤醒等待队列中的线程(unpark)sync.release(1);}@Overridepublic Condition newCondition() {return sync.newCondition();}
}ReentrantLock原理
ReentrantLock实现了Lock接口
内部同步器Sync继承AQS,而非公平锁和公平锁继承了抽象类Sync

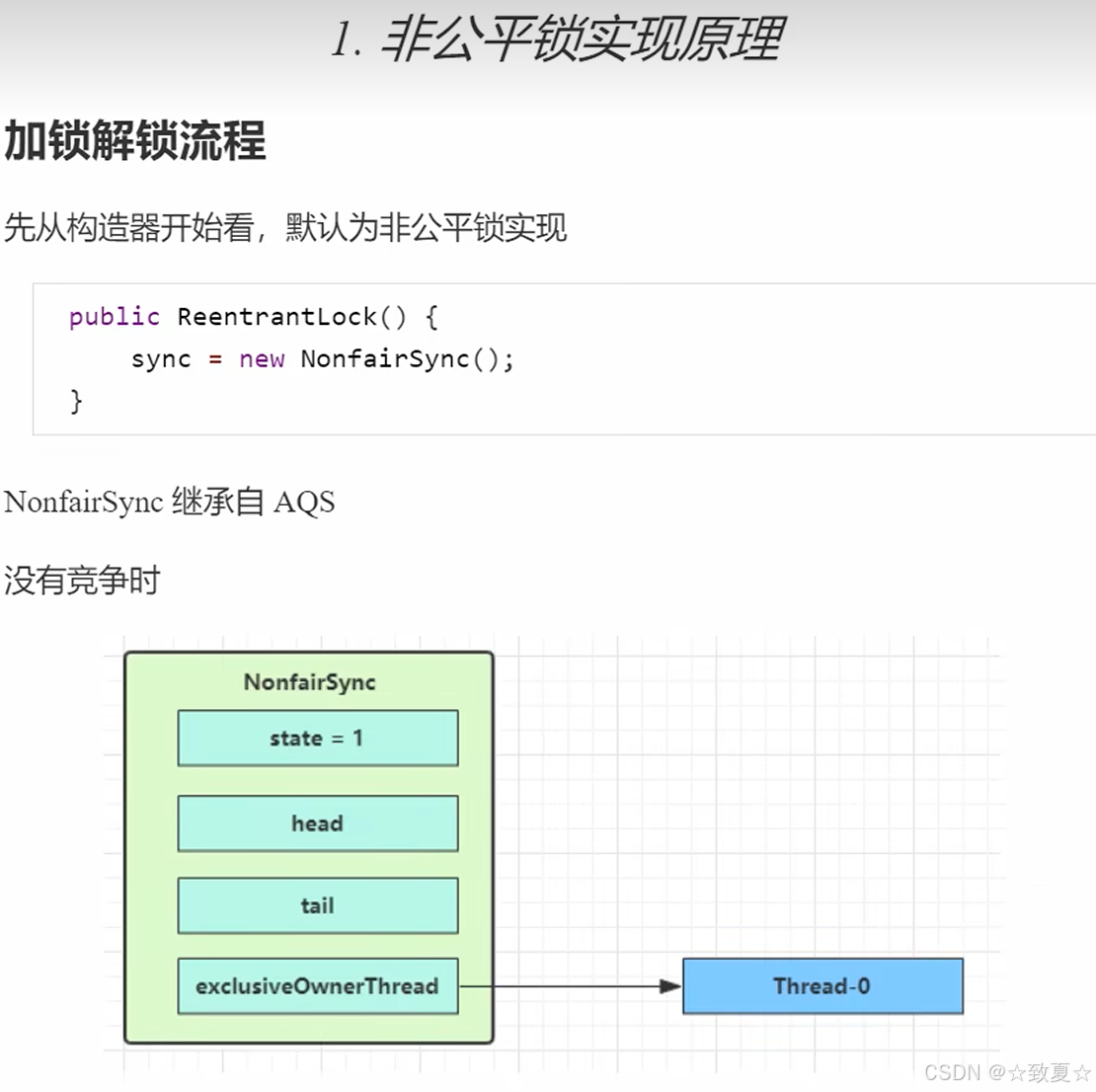
非公平锁实现原理
加锁成功流程
加锁失败流程
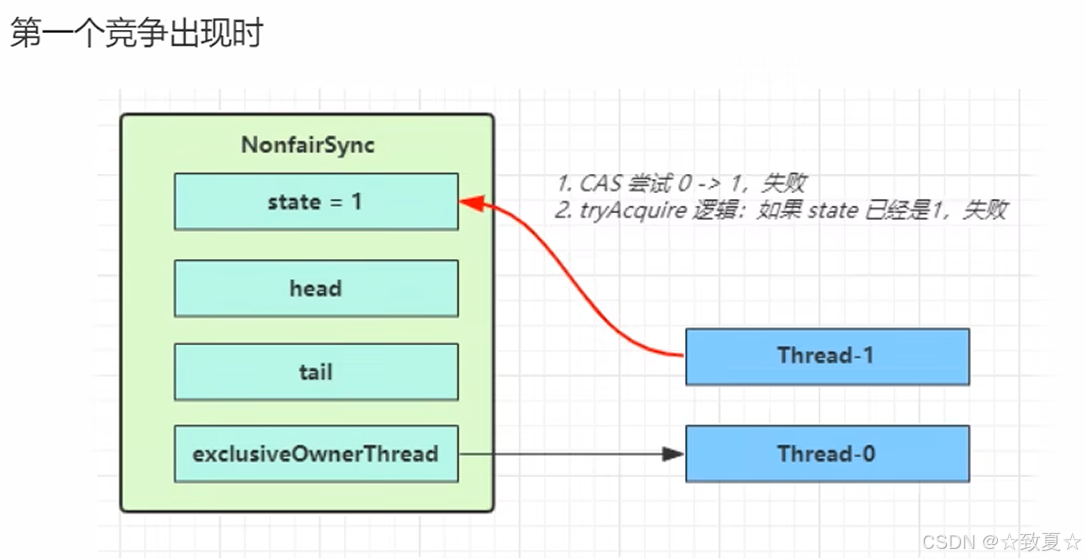
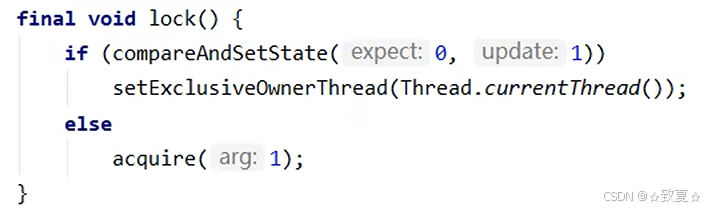
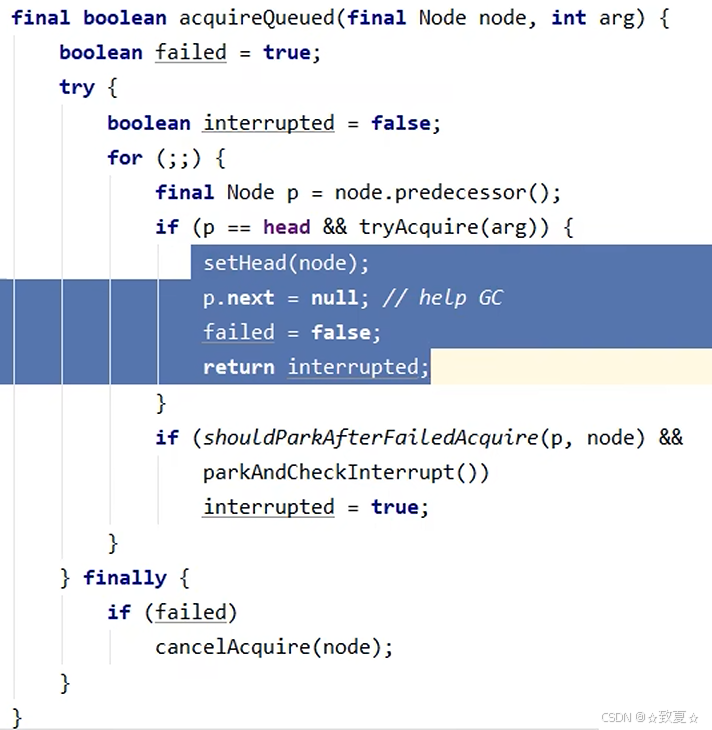
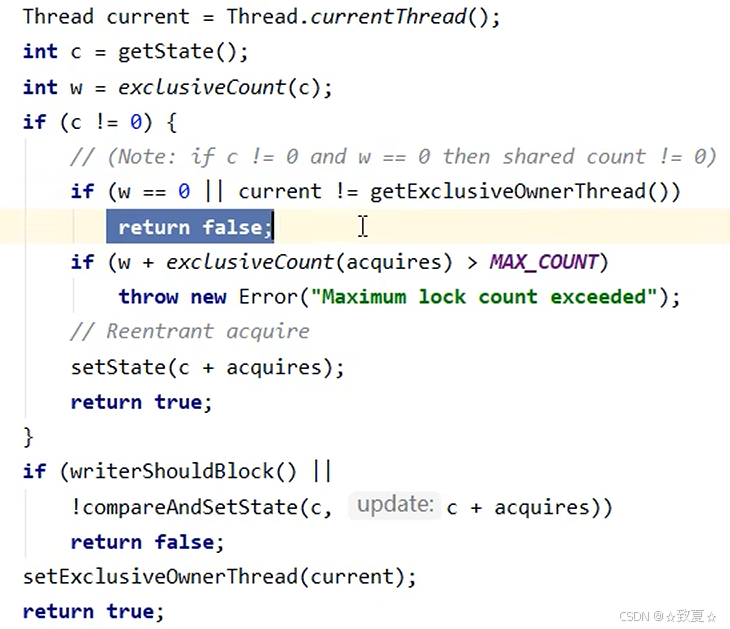
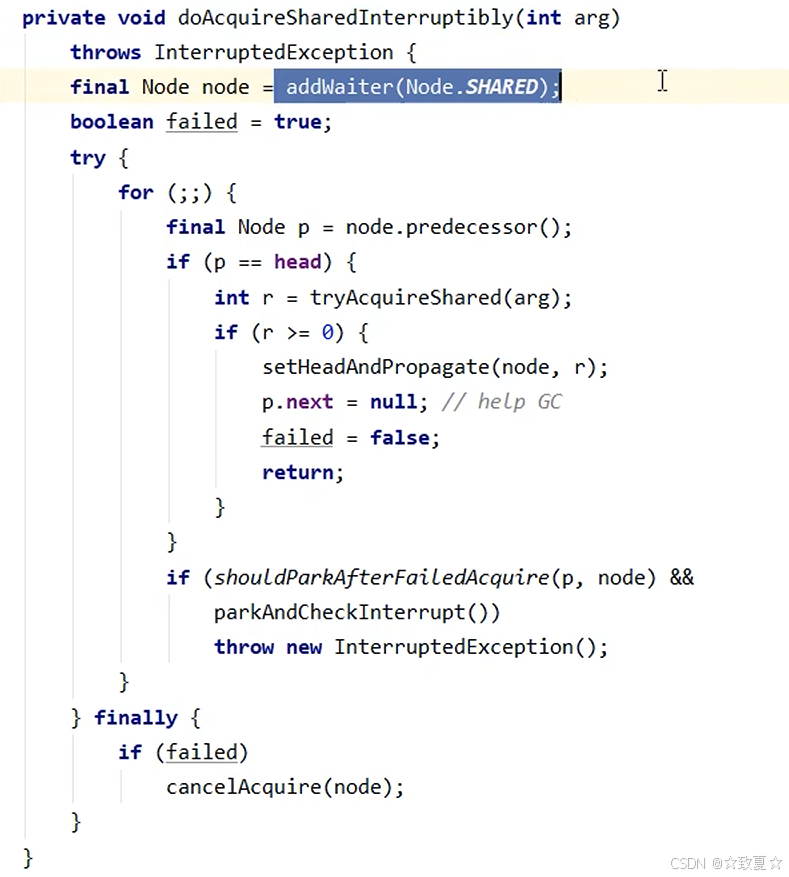
线程加锁失败后,执行acquire方法,执行acquire会再次尝试加锁一次,因为此时锁可能被释放,如果成功则不会执行方法体;如果失败开始执行下一个条件,addWaiter添加节点,执行acquireQueued方法。

队列是一个双向链表,首次创建节点会创建2个Node。
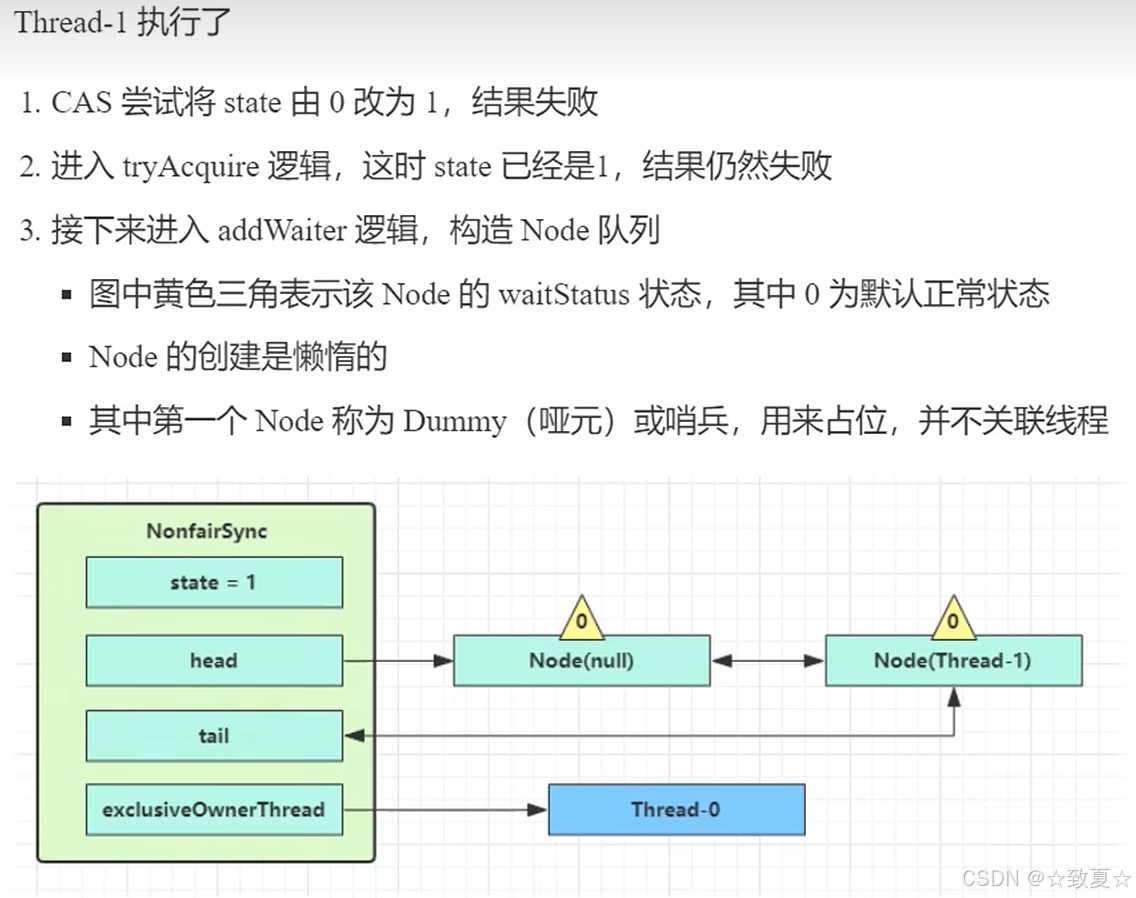

进入acquireQueued后,判断当前节点的前驱节点是不是头节点,如果是,则可以再次尝试获取锁,如果失败则执行shouldParkAfterFailedAcquire方法,将节点的waitStatus设为-1,为唤醒后一节点做准备,然后再次进入循环尝试获取锁,此次如果还是失败,则会执行parkAndCheckInterrupt方法阻塞当前线程(共计4次尝试获取锁失败才会被阻塞)
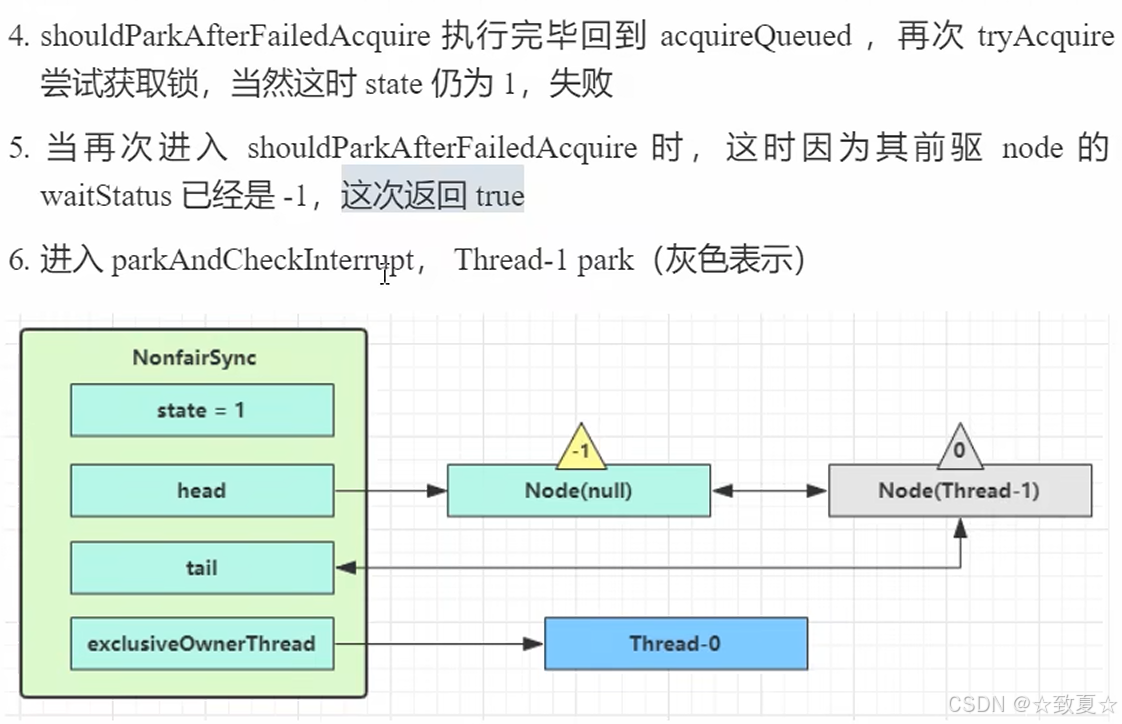
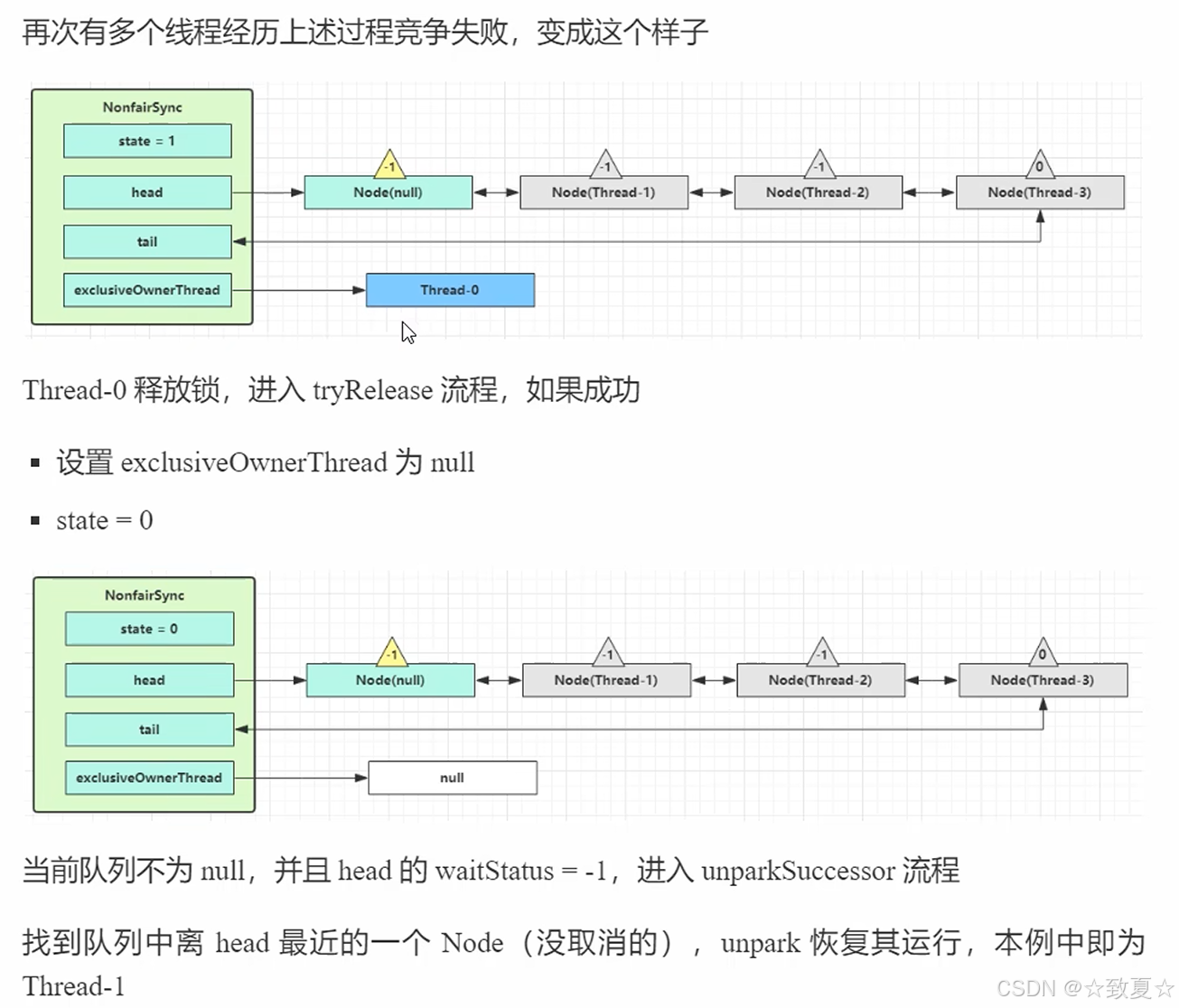
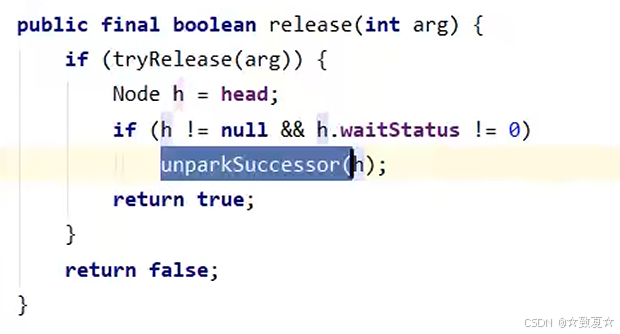
解锁竞争成功流程-释放锁
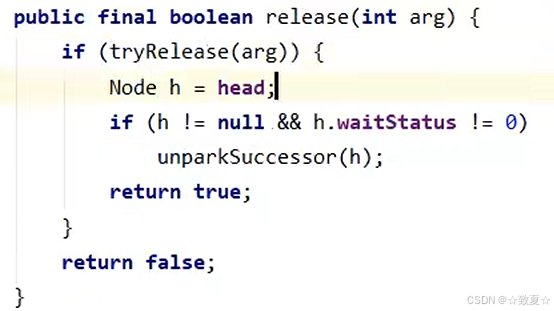
锁释放时执行unlock方法

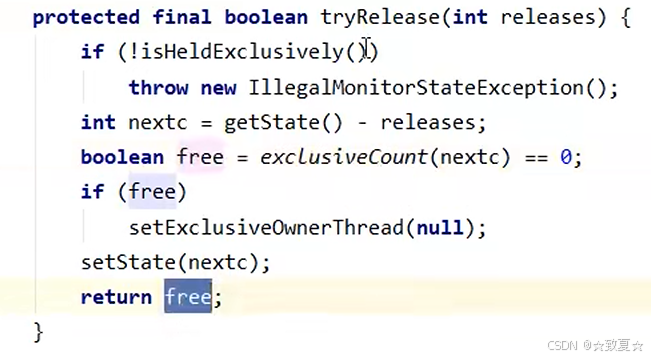
接着进入release方法执行tryRelease方法,将锁的owner置为null,state置为0;然后判断头节点是否为null(避免空指针异常)。
注:图中Node(null)代表首次创建节点时头节点里的线程是null,源码里h != null代表头节点对象还未创建。
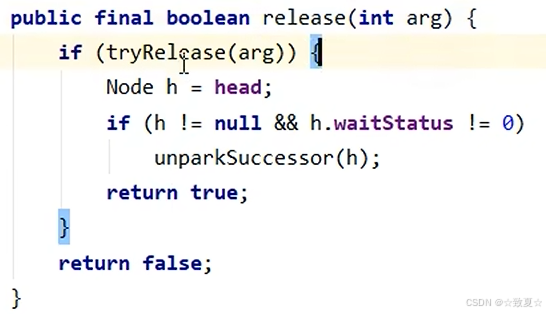
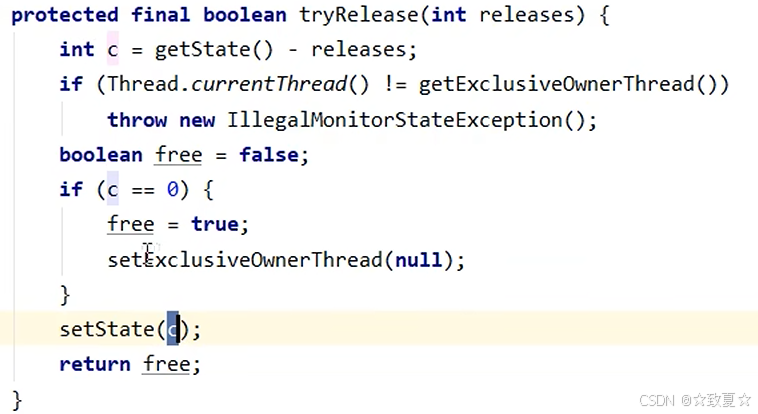
if条件成立后执行unparkSuccessor方法,唤醒后继节点。

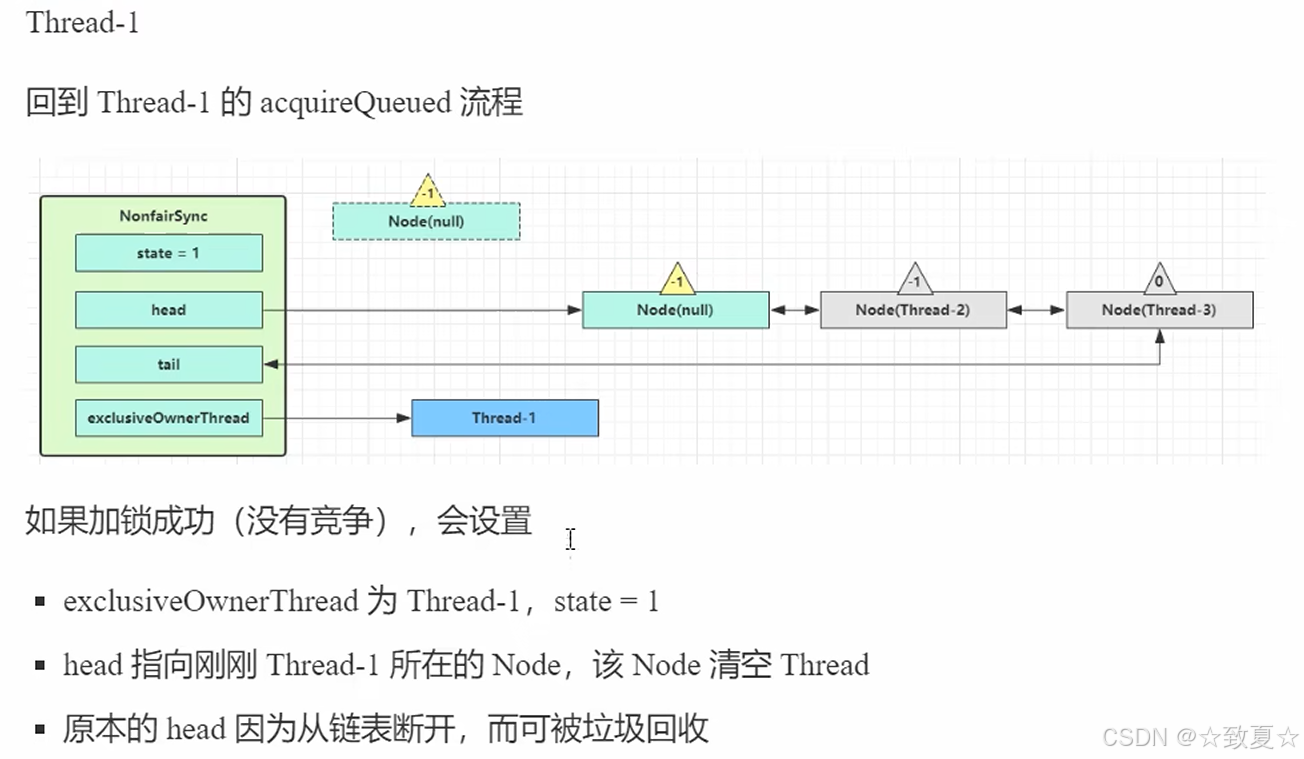
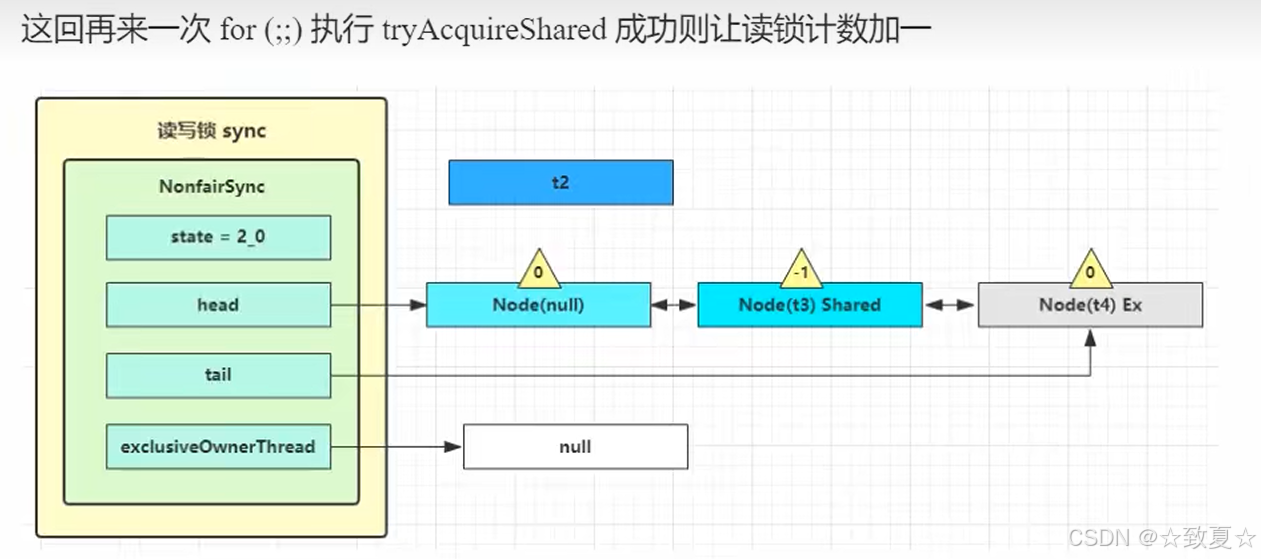
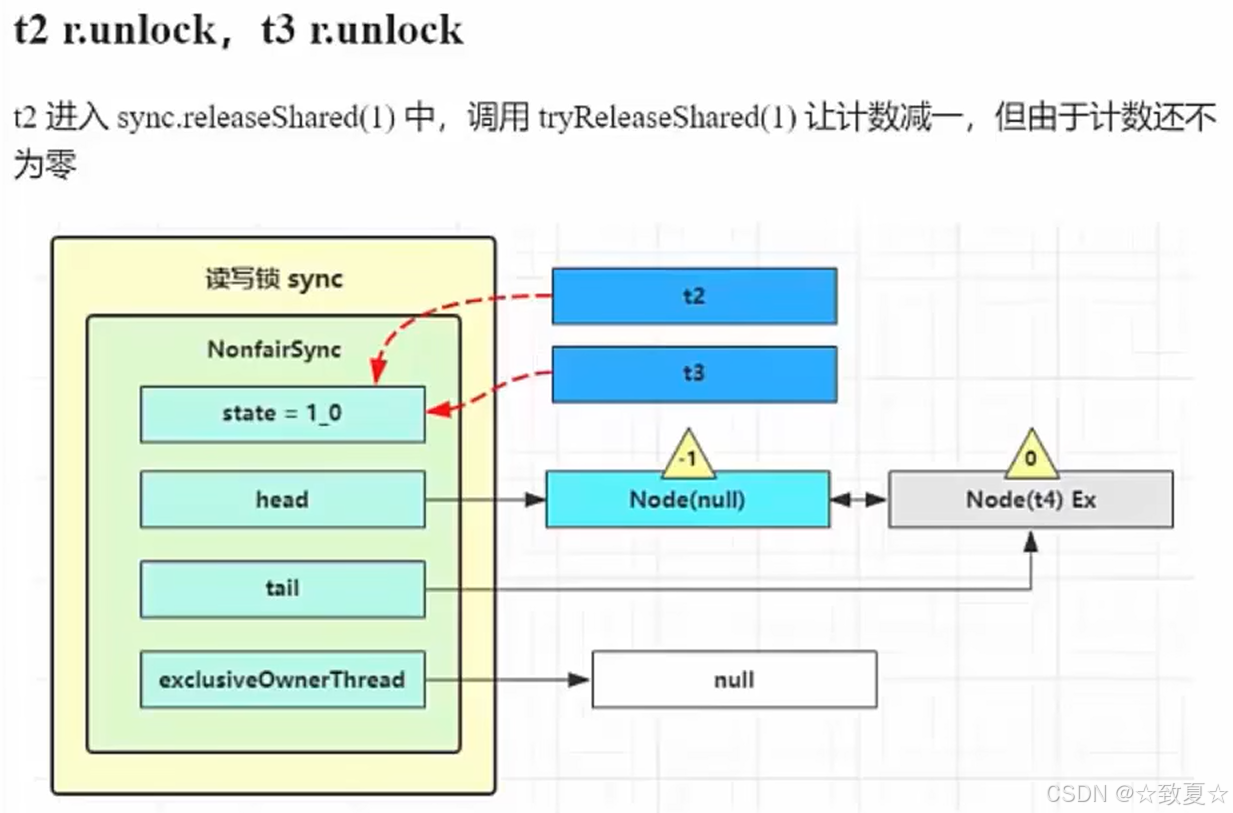
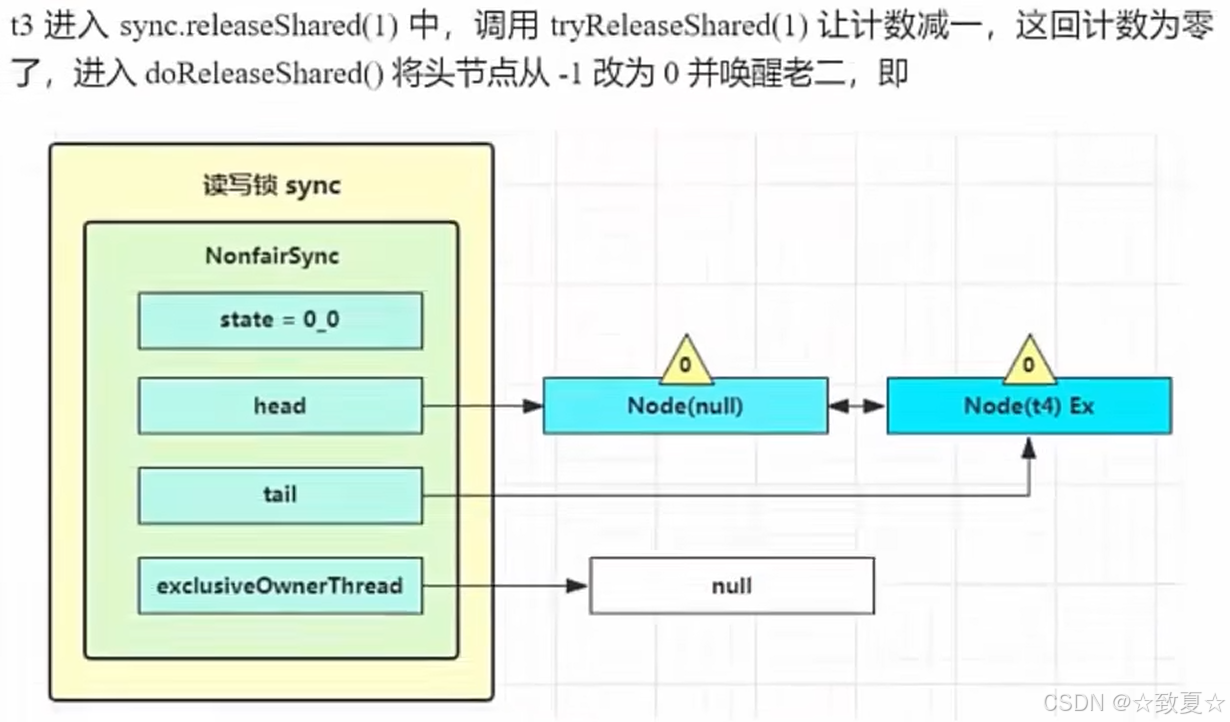
解锁竞争失败流程
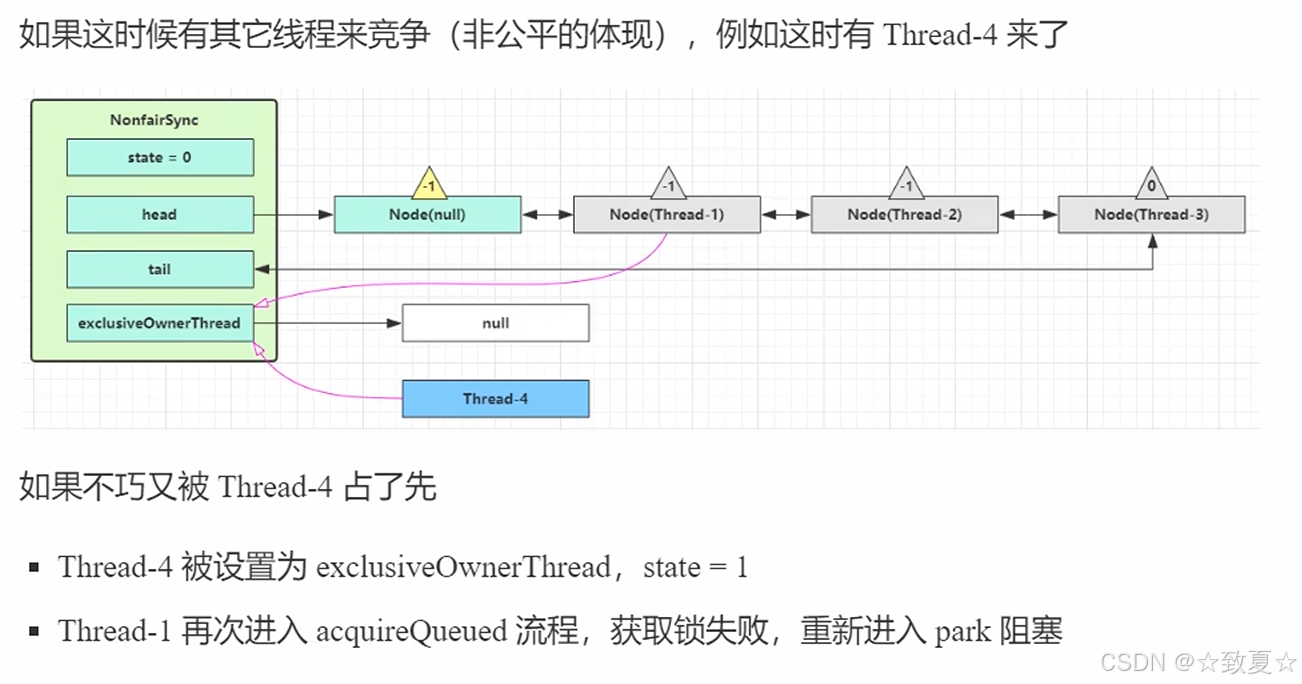

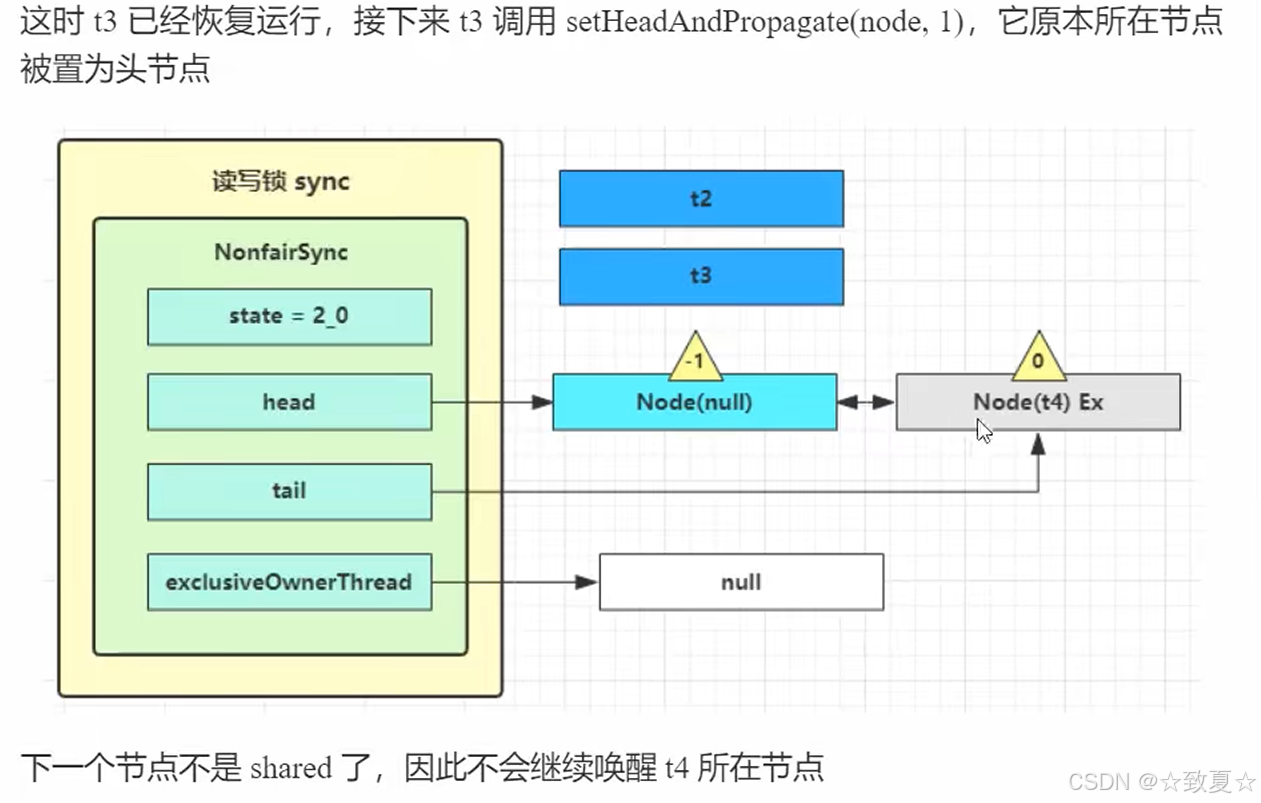
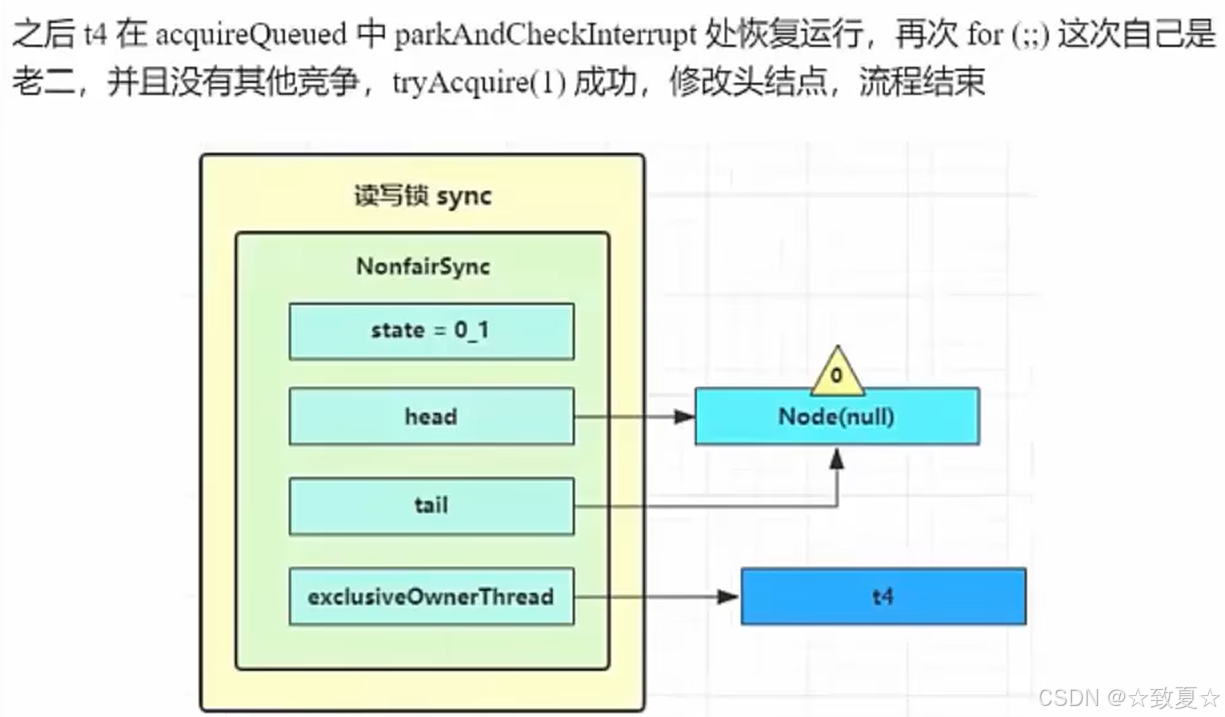
当线程被唤醒后,流程来线程被阻塞的地方,接着向下执行,来到循环尝试获取锁(这里还存在锁竞争,新创建的线程是可能会尝试获取锁的,这也是不公平锁的体现),成功后会将当前Node设为头节点且关联线程设为null(在setHead方法里设置的),将原来头节点指向null(等待GC回收)
获取锁并成为头节点的Node里的线程为什么要置为null?
在 AQS 中,只要一个线程成功获取锁并成为 head,就表示它已经“完成排队任务”,即使它仍在执行业务逻辑,AQS 也可以将其 thread 设为 null,因为它不再需要被唤醒或参与队列流转。
此时虽然业务代码还没执行完,但 AQS 认为它已经“完成排队任务”。因此:
AQS 可以安全地清空 thread 字段(帮助 GC);
不影响线程继续执行自己的逻辑。
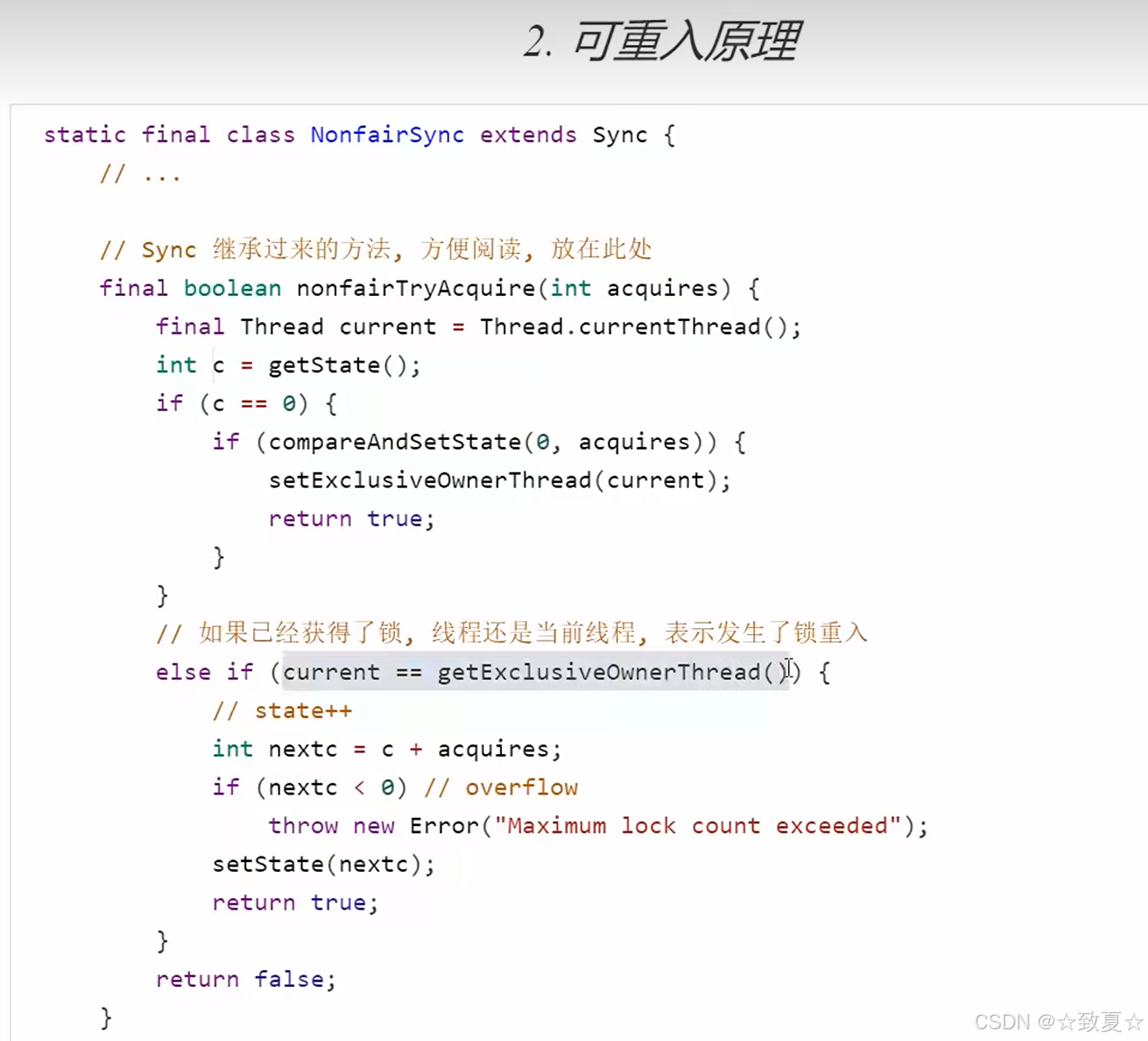
可重入原理
锁重入时,当前线程已经获取锁,state = 1,此时state会+1,每重入一次,都会加一,当释放锁调用tryRelease方法,state会-1,直到state为零时才会解锁成功。

可打断原理
不可打断模式
当线程被打断时,parkAndCheckInterrupt方法会继续执行返回true,然后进入循环尝试获取锁,直到获取到锁后,当前线程才能被打断;如果未获取到锁,由于调用Thread.interrupted()清除了打断标记,线程再次遇到park还是会被阻塞。




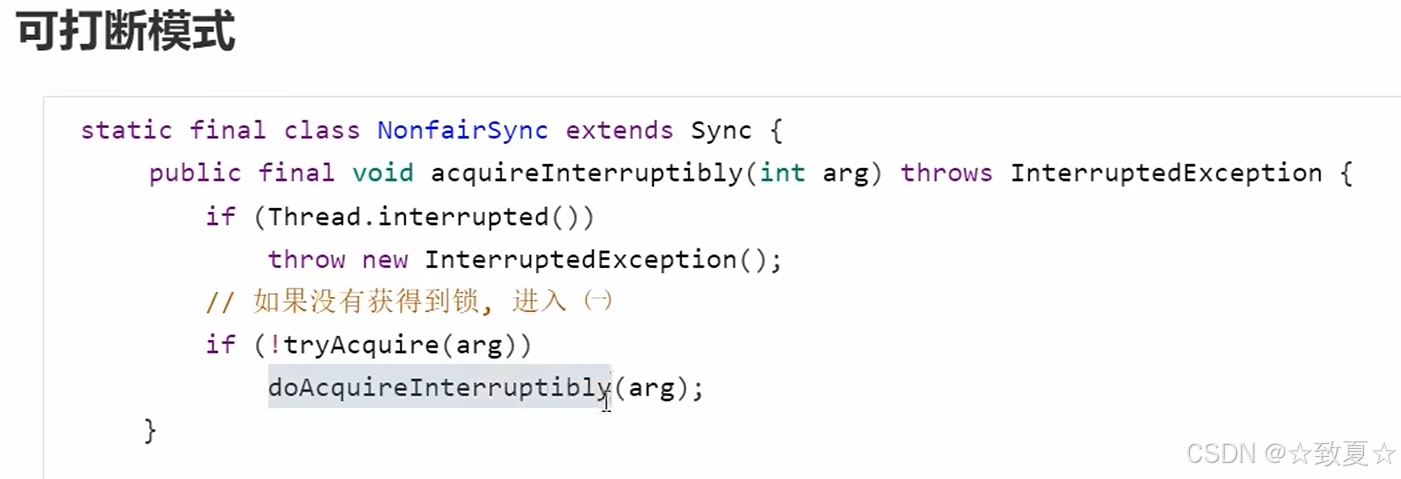
可打断模式
线程被打断唤醒后,抛出异常退出锁竞争的循环,停止等待锁。

公平锁原理
先看一下非公平锁实现,线程在尝试获取锁时,在确定state为0后,直接用cas获得,不考虑AQS队列

公平锁实现
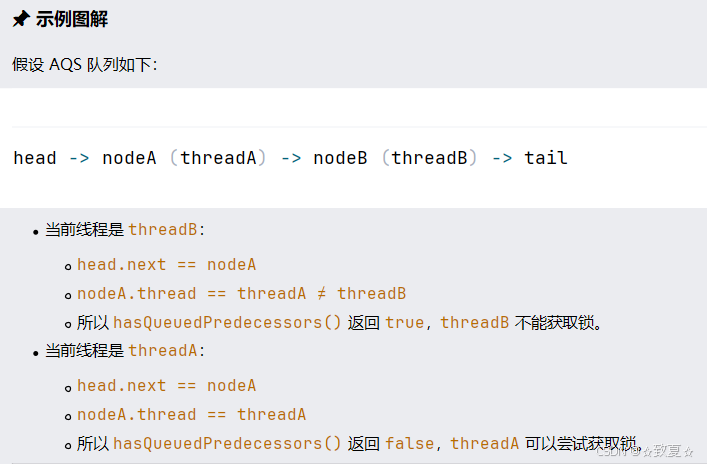
如果队列未初始化,即没有头节点,此时头尾节点h和t都为null,h != t 条件为false,hasQueuedPredecessors()直接返回false,公平锁创建的线程可以获取锁
如果队列只有头节点,此时h == t,h != t 条件为false,hasQueuedPredecessors()直接返回false,公平锁创建的线程可以获取锁;
如果队列不仅有头节点,还有第二节点,那么h != t条件为true,
(s = h.next) == null可能true(获取到中间态,原头节点指向null时)hasQueuedPredecessors()返回true公平锁创建的线程无法获取锁;
(s = h.next) == null也可能为false ,表明有Node老二,再判断Node老二里的线程是不是当前线程
如果是当前线程值为false,hasQueuedPredecessors()直接返回false,公平锁创建的线程可以获取锁;
如果不是当前线程值为true,hasQueuedPredecessors()返回true公平锁创建的线程无法获取锁;


条件变量实现原理
await流程

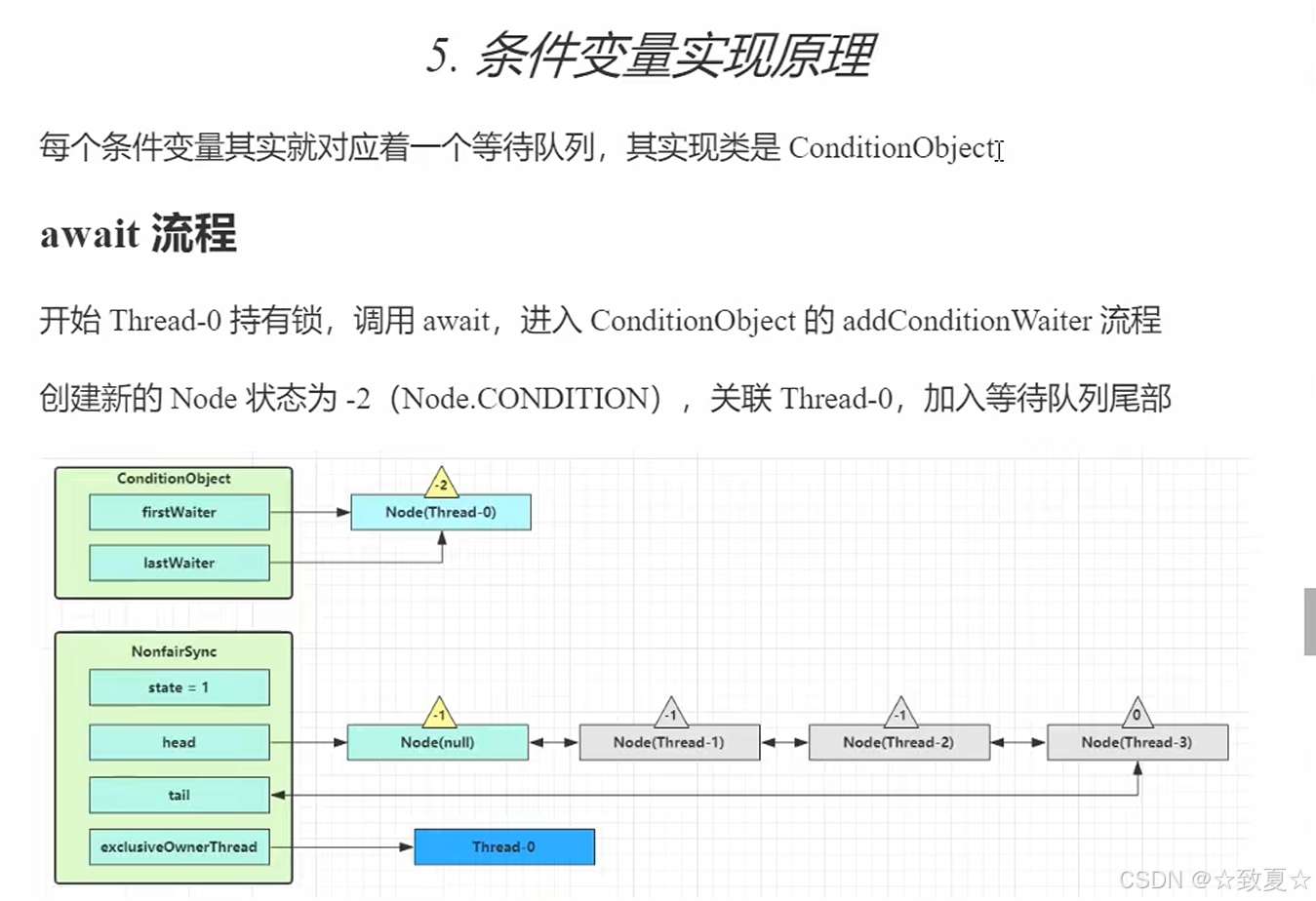
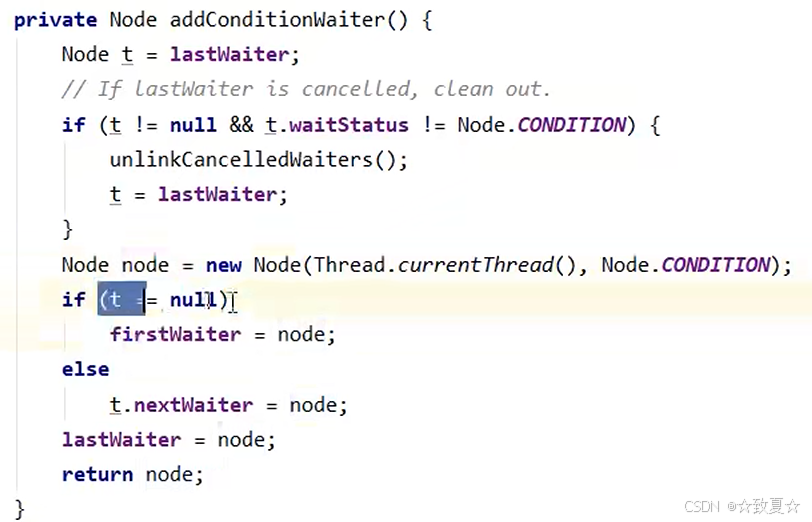
持有锁的线程加入到ConditionObject的等待队列尾部,状态设为-2
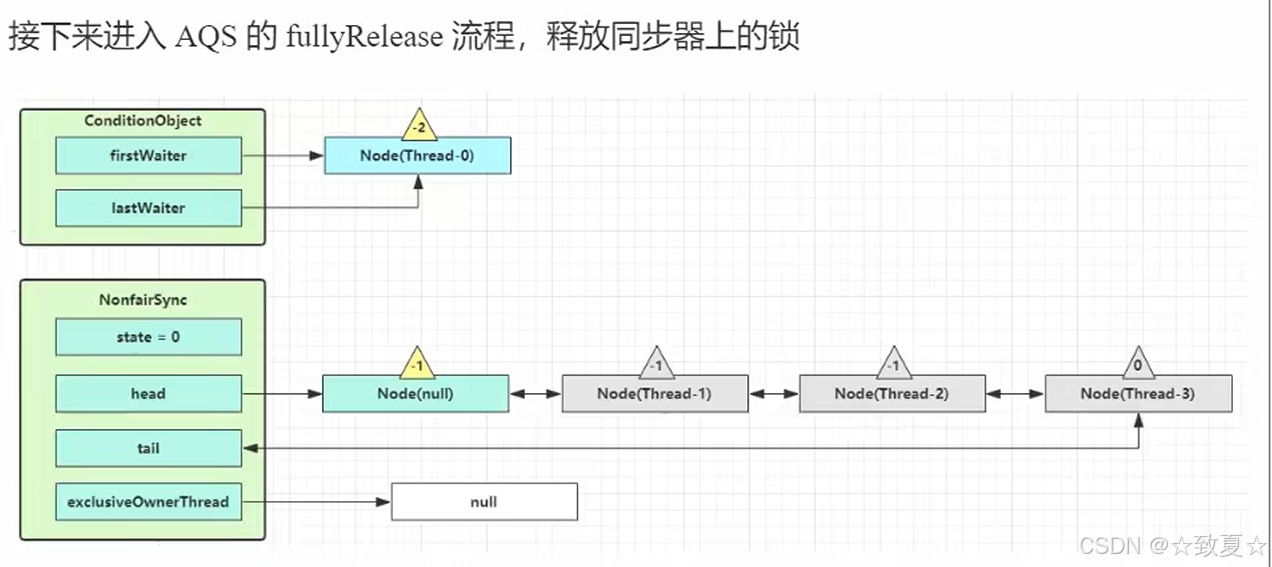
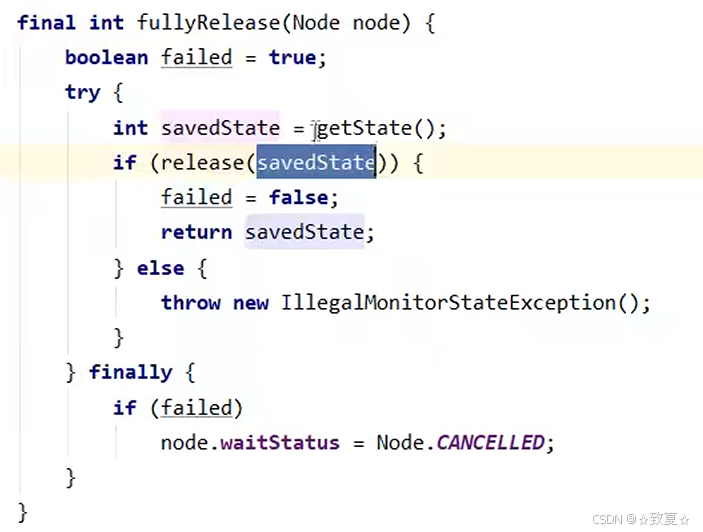
普通release只能将state的值-1,而重入锁可能导致state值大于1,调用fullyRelease加state全部释放
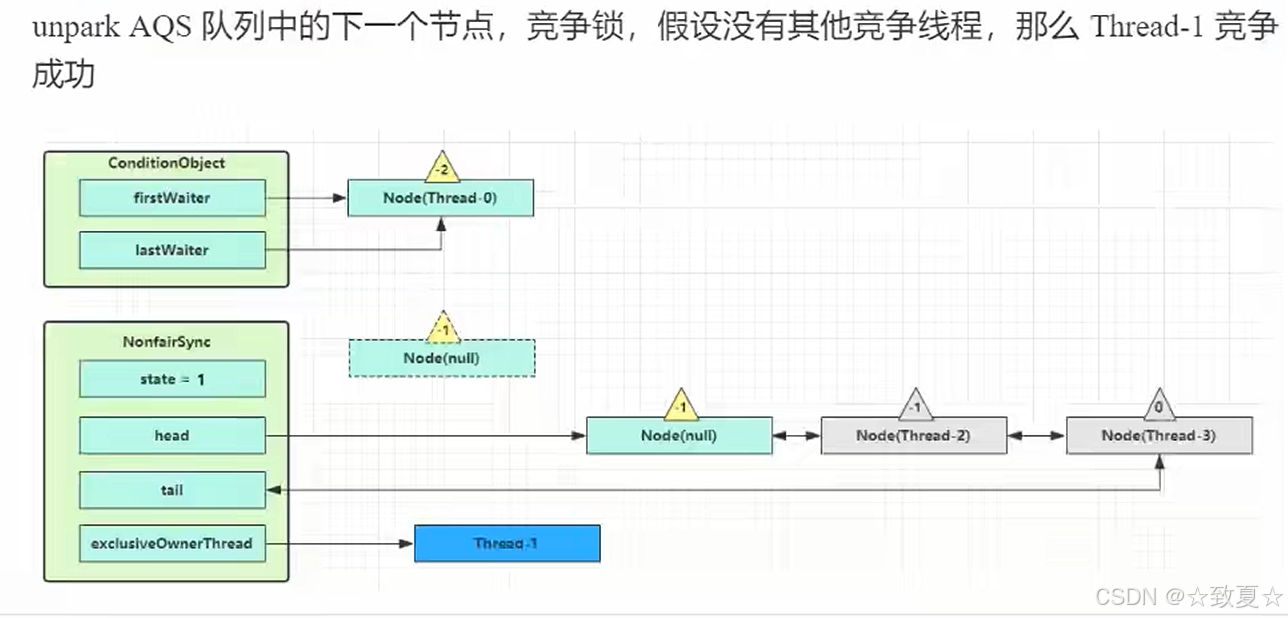
释放锁后,会唤醒AQS队列的下一个节点
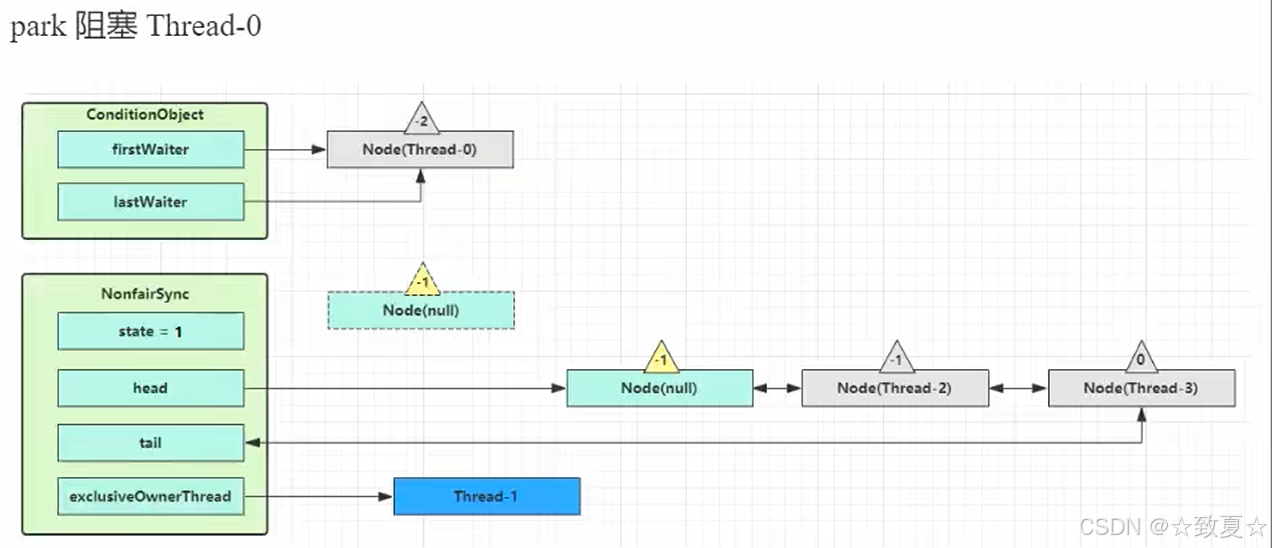
进入wait队列后,线程被park,等待被唤醒
signal流程
持有锁的线程可以唤醒处于wait队列的线程
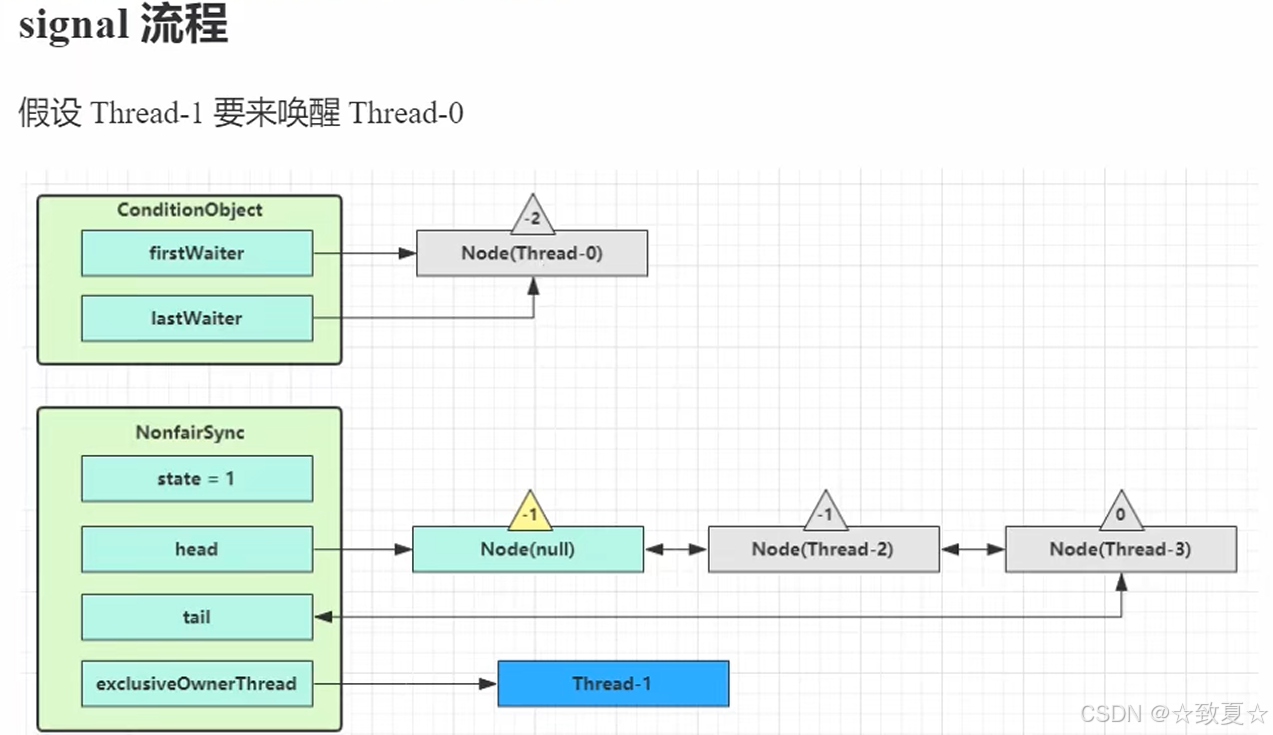
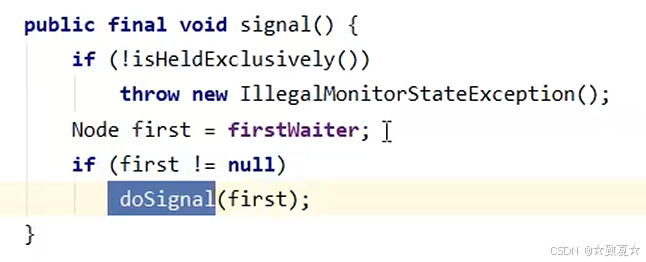

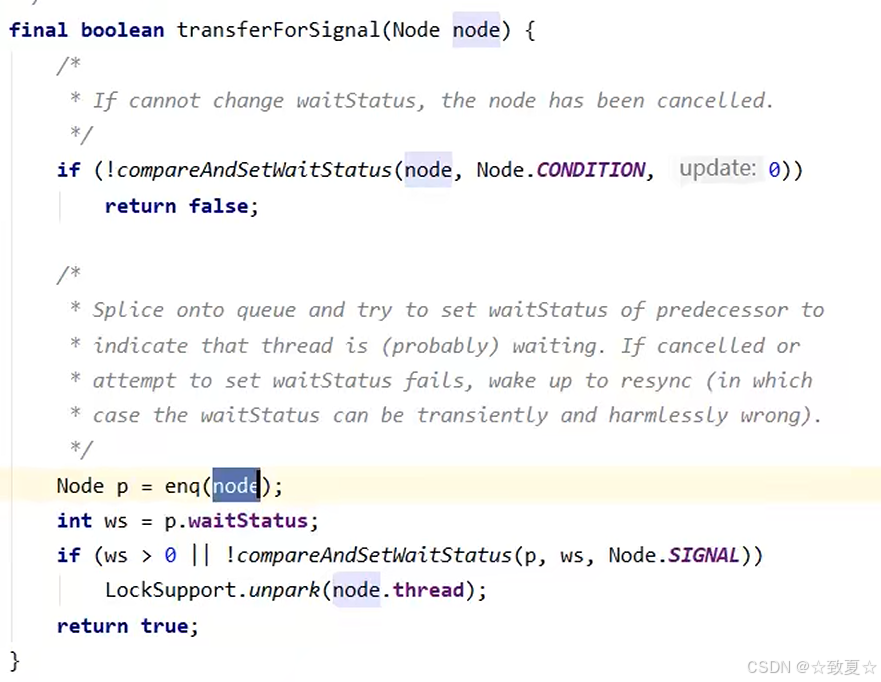
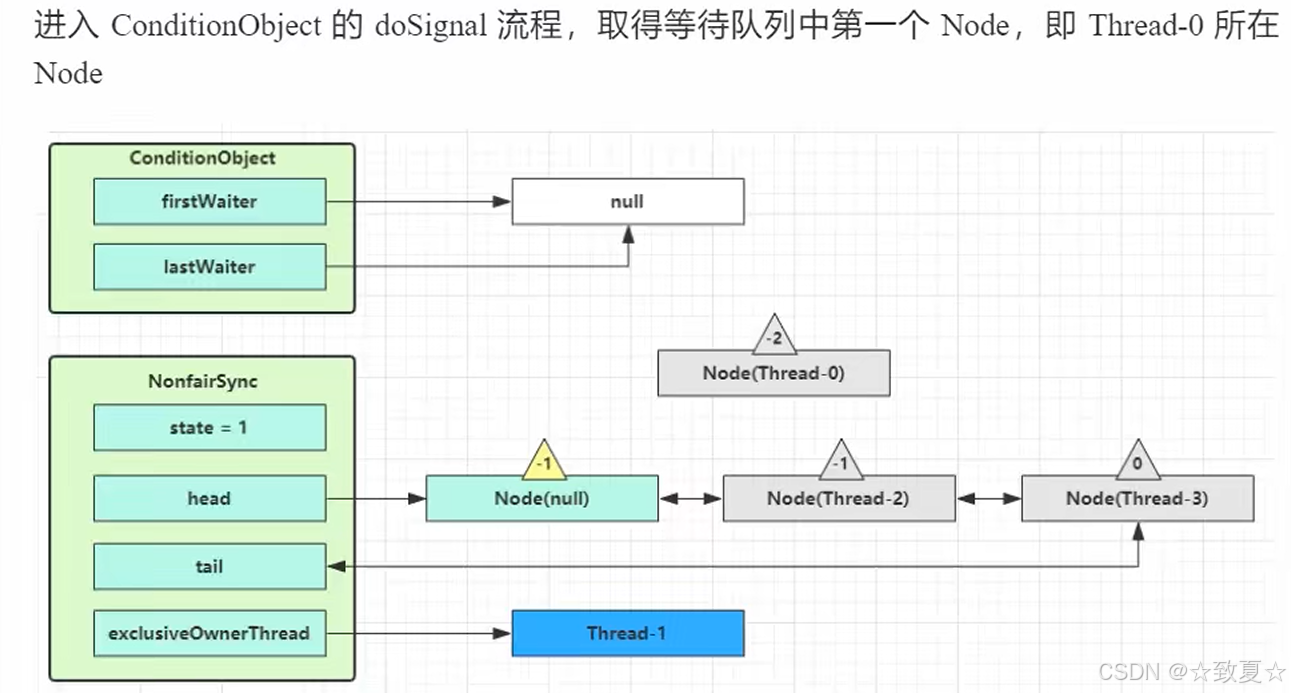
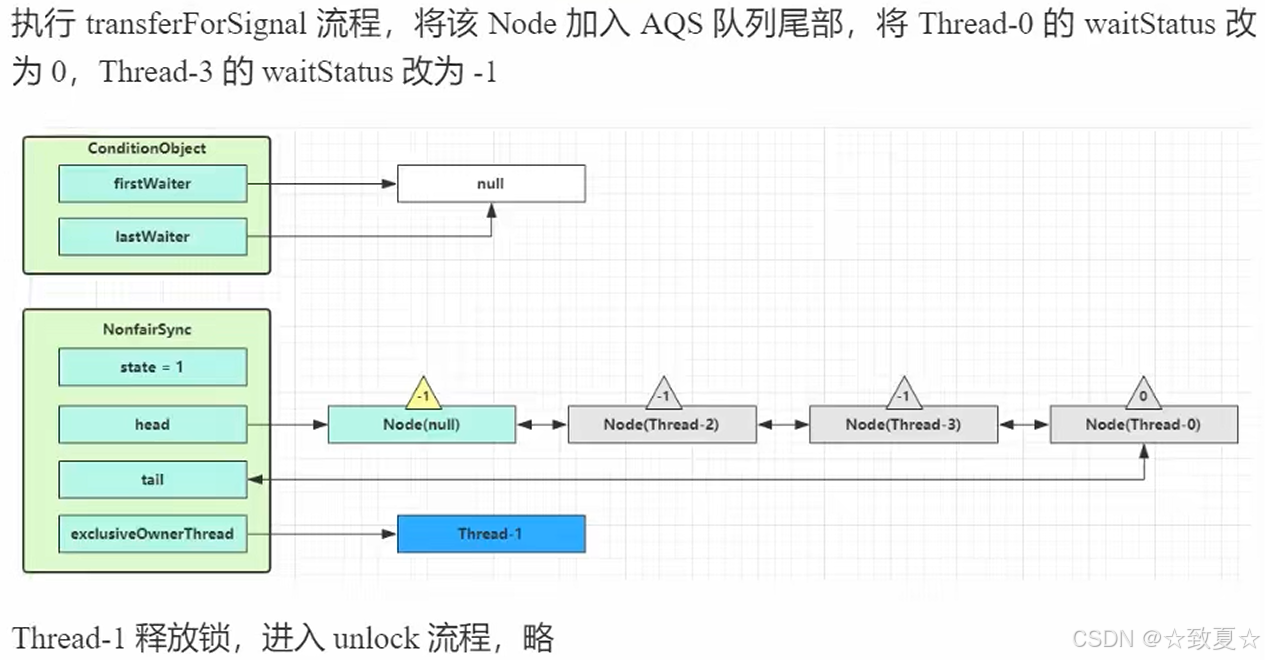
首先判断调用signal的线程是不是持有锁线程,未持锁会抛出异常;确定持锁后,唤醒wait队列首个线程并转移到AQS队列尾部,状态改为0,前驱节点状态改为-1
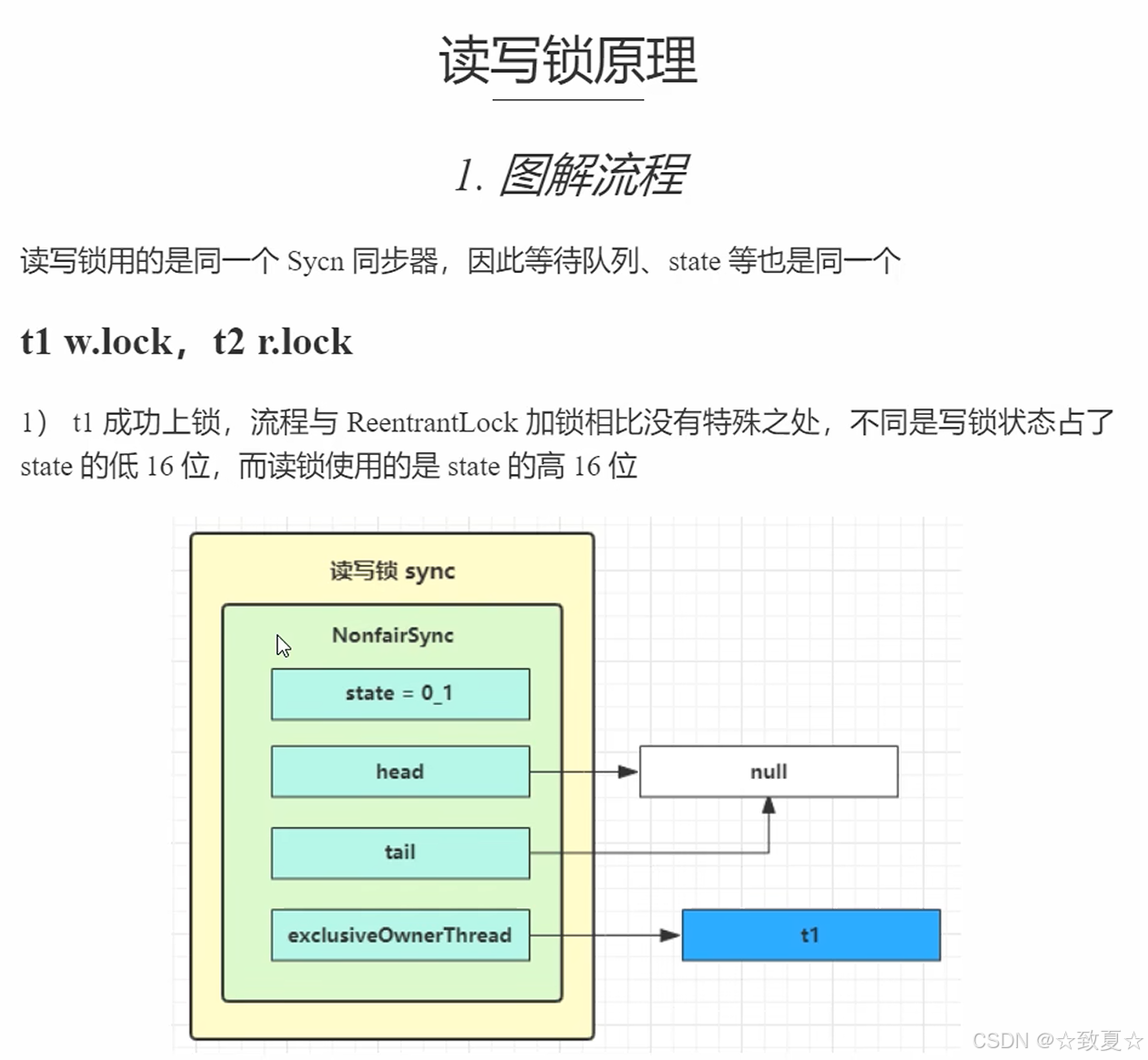
读写锁
ReentrantReadWriteLock的使用
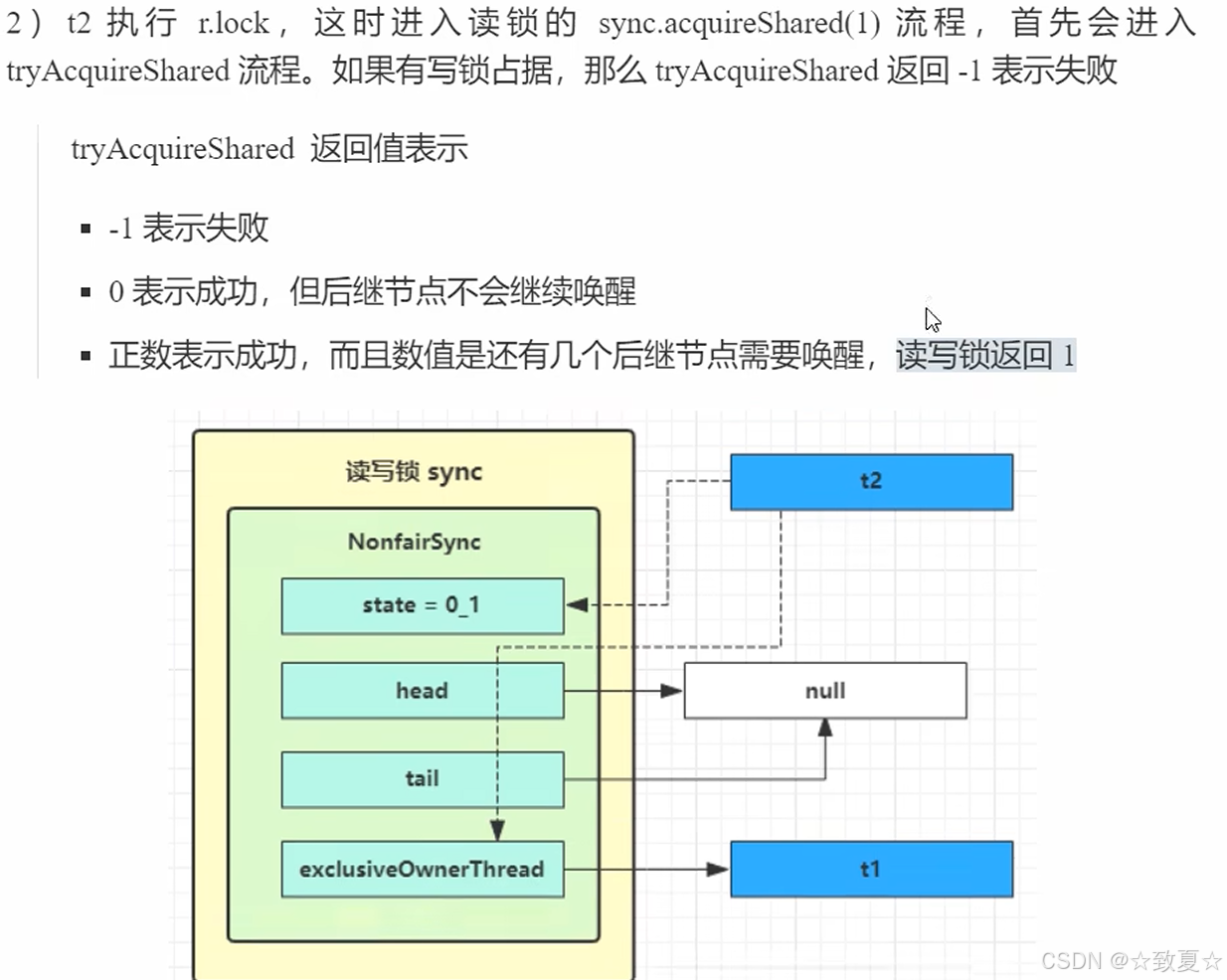
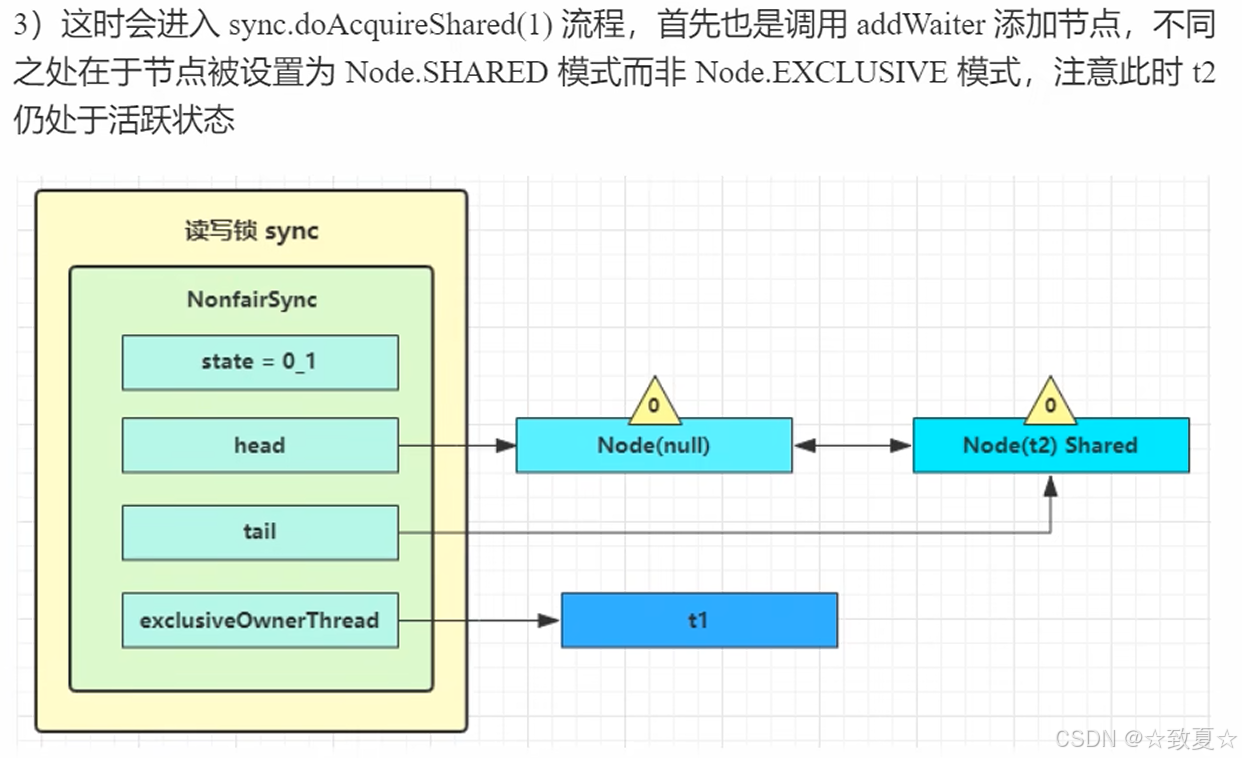
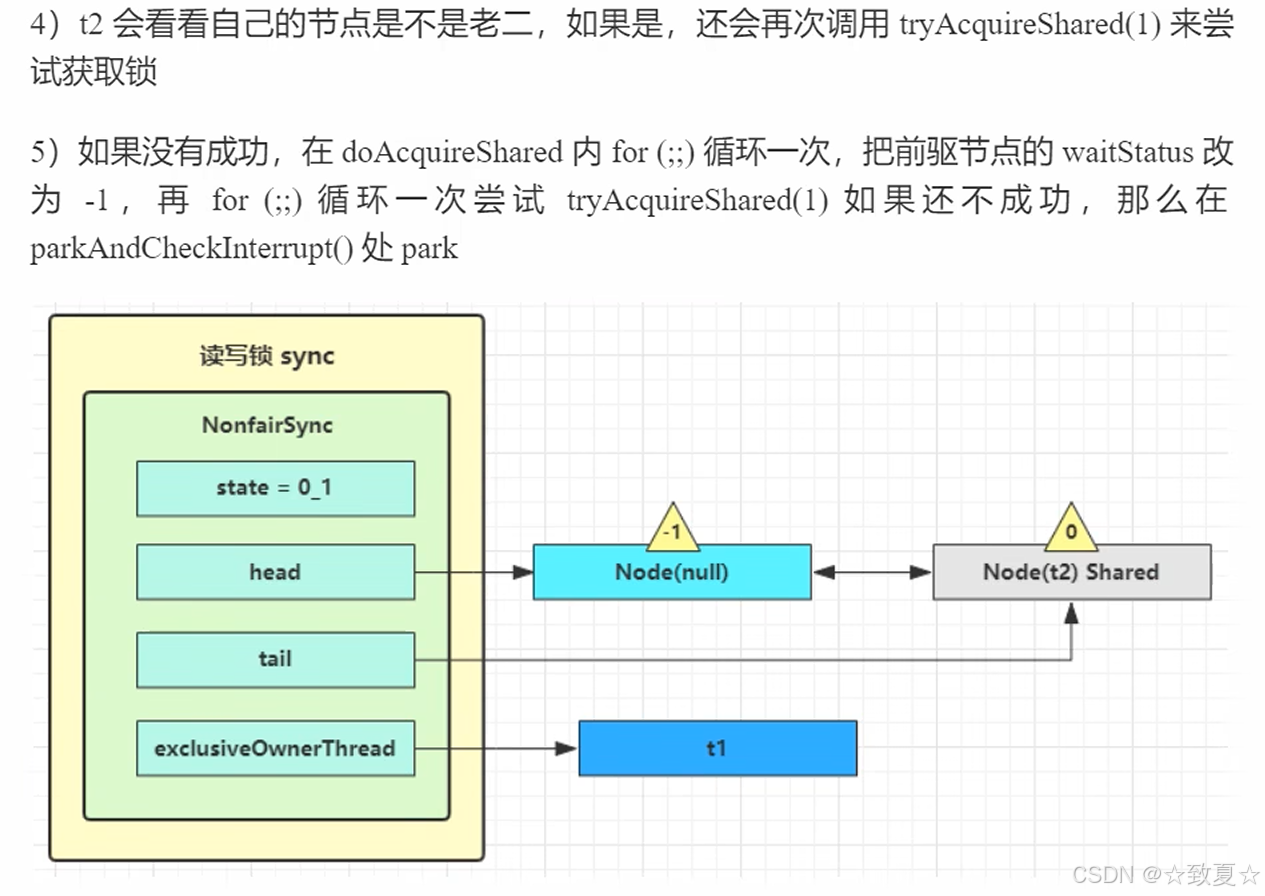
读-读并发
读-写互斥
写-写互斥

测试读读时并发,读写时互斥,写写时互斥
@Slf4j(topic = "c.Test34")
public class Test34 {public static void main(String[] args) throws InterruptedException {DataContainer dataContainer = new DataContainer();new Thread(() -> {dataContainer.read();}, "t1").start();new Thread(() -> {dataContainer.read();}, "t2").start();}
}
@Slf4j(topic = "c.DataContainer")
class DataContainer {ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();ReentrantReadWriteLock.ReadLock r = rwLock.readLock();ReentrantReadWriteLock.WriteLock w = rwLock.writeLock();public void read() {log.debug("获取读锁");r.lock();try {log.debug("读取");} finally {r.unlock();log.debug("释放读锁");}}public void write() {log.debug("获取写锁");w.lock();try {log.debug("写入");} finally {w.unlock();log.debug("释放写锁");}}
}读读并发
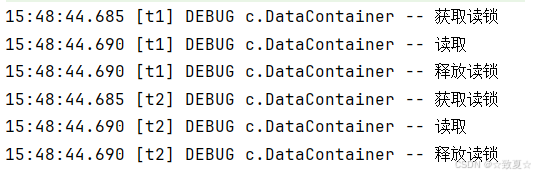
读写互斥,让读写锁中间都休息一秒,可见只有一方释放锁,另一方才能获取锁执行。
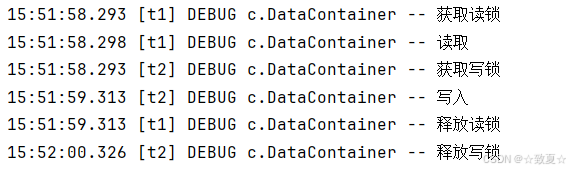
写写锁互斥,同理
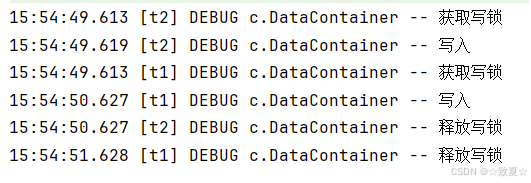
ReentrantReadWriteLock的注意事项
锁重入的升级与降级

这里cacheValid使用了双重检验机制


ReentrantReadWriteLock应用之缓存
如果在数据库里查询很少变化的数据,每次查询都是相同的结果。为了提升查询速度,减少磁盘IO次数,可以采用缓存。对比直接访问数据库,使用缓存有以下优点。
如果缓存中数据被修改,此时清空缓存,再次查询数据时,从数据库查询后保存到缓存。
提升访问速度:缓存通常基于内存实现,相比磁盘 I/O 更快,能显著减少数据访问的延迟。
减轻数据库压力:通过缓存热点数据,可以减少对数据库的直接访问请求,降低数据库负载。
提高系统吞吐量:缓存使得应用能够更快响应请求,从而提升整体系统的并发处理能力。
支持高可用性:在数据库暂时不可用时,若缓存中仍有有效数据,可提供一定程度的服务降级支持。
降低网络开销:本地缓存(如 Caffeine)或靠近应用部署的分布式缓存(如 Redis 集群),可减少远程数据库访问带来的网络延迟。
测试示例
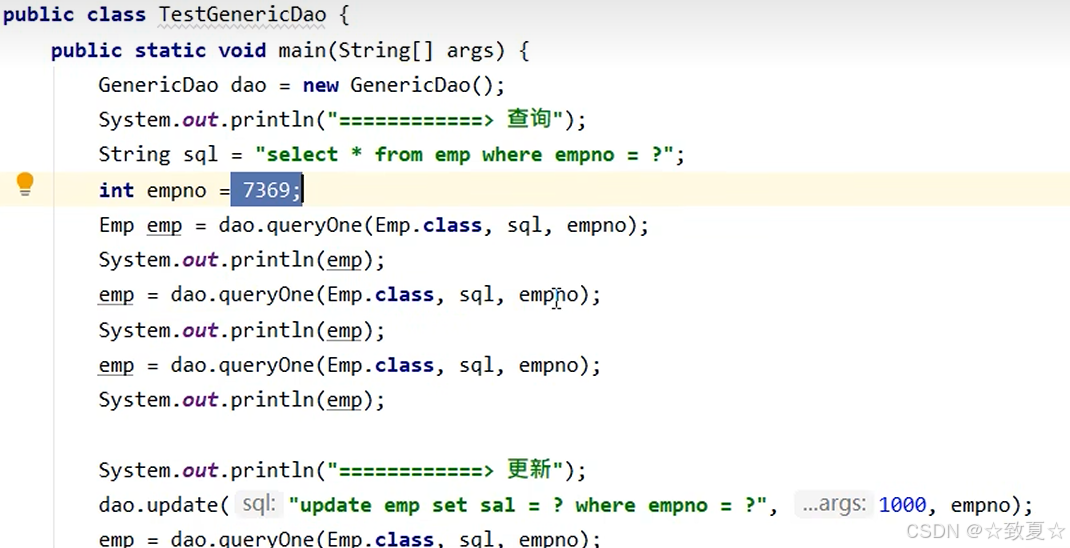
使用缓存前,每次都要从数据库查询
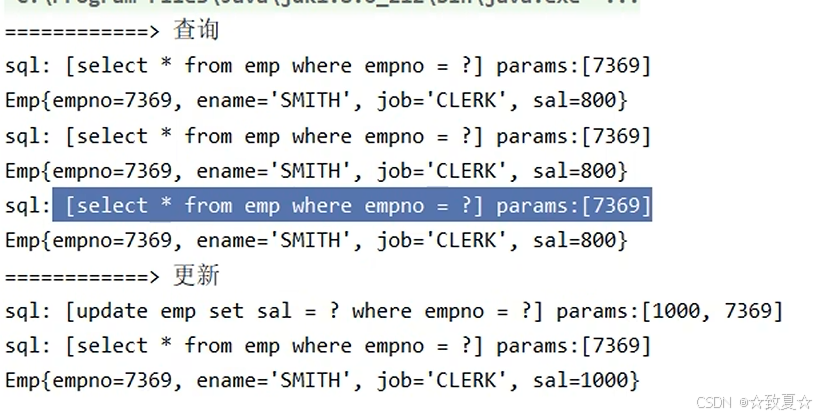
使用缓存后
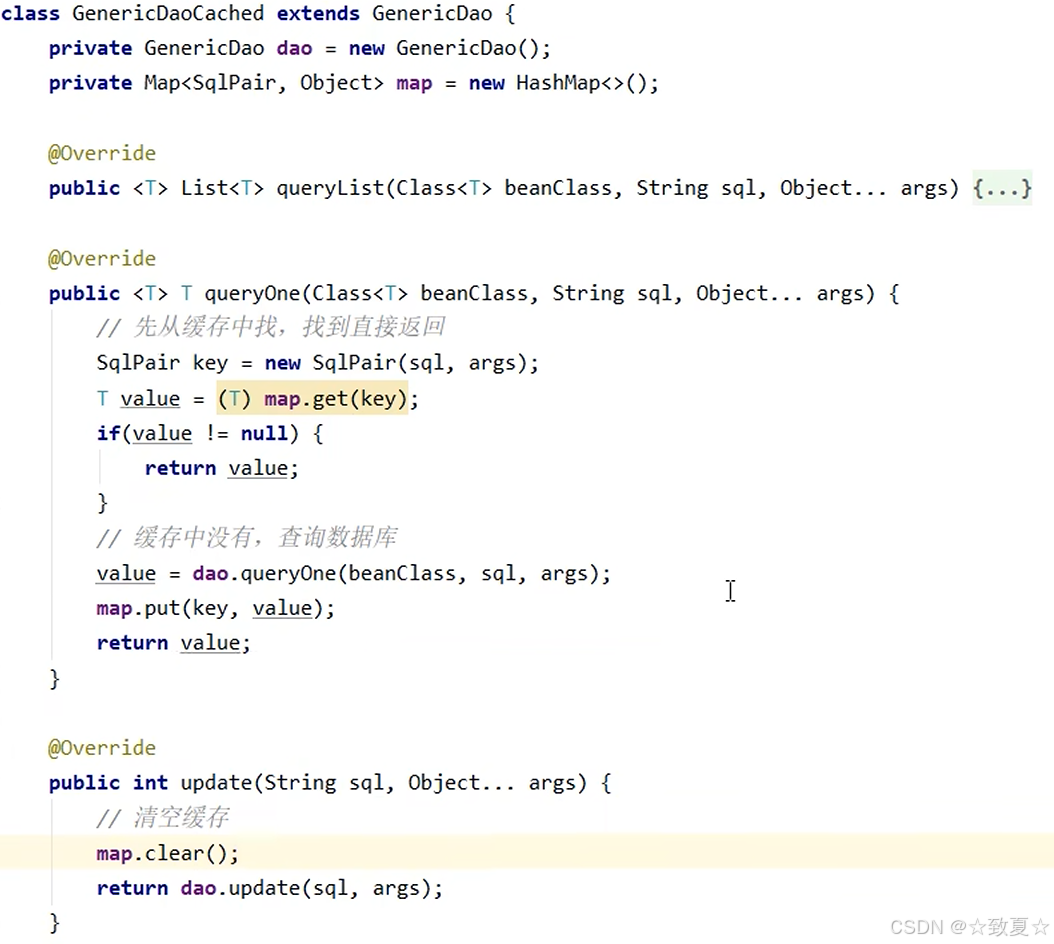
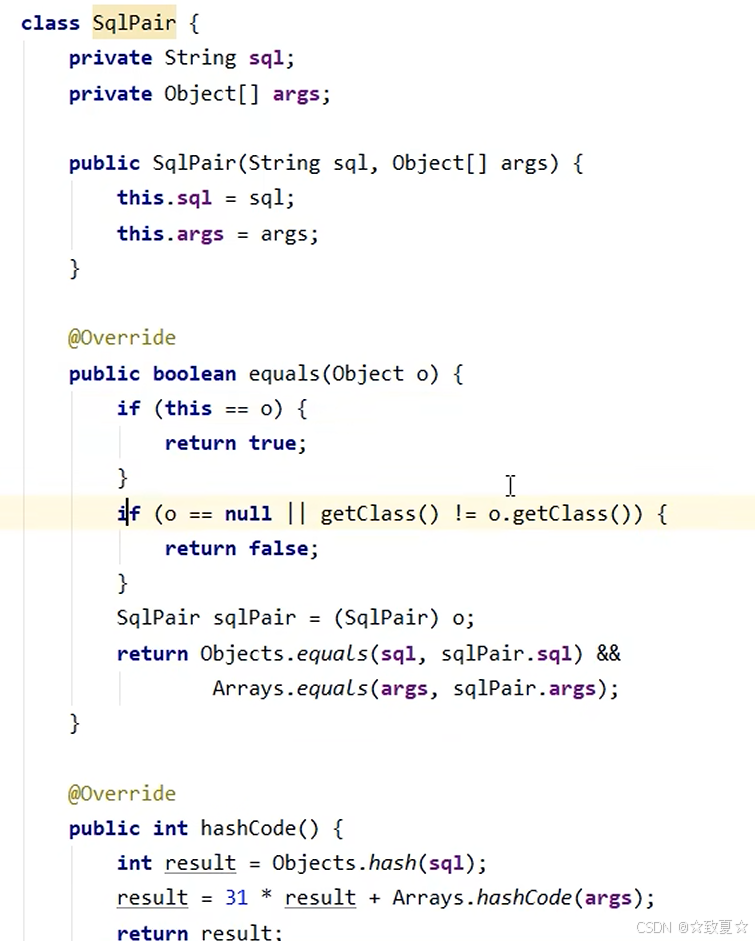
先从缓存中获取数据,提升查询速度

缓存问题-可能存在的多线程并发问题
1.缓存使用的Map是HashMap,存在线程安全问题
2.如果首次查询的数据被多线程访问,缓存中都查不到,都会从数据库查询
3.缓存更新策略。在缓存更新时,如下图
如果线程A先清缓存,还未执行数据更新到数据库,此时有其他线程B插入查询要更新的数据会查到还未更新的旧值,并将结果保存到缓存,然后轮到线程A执行数据更新操作,之后的线程查询会一直查到缓存中的旧值,造成很长一段时间的数据不一致情况。

同理,按照下图流程,如果先更新数据库,再清空缓存,中间会出现短暂的数据不一致情况。
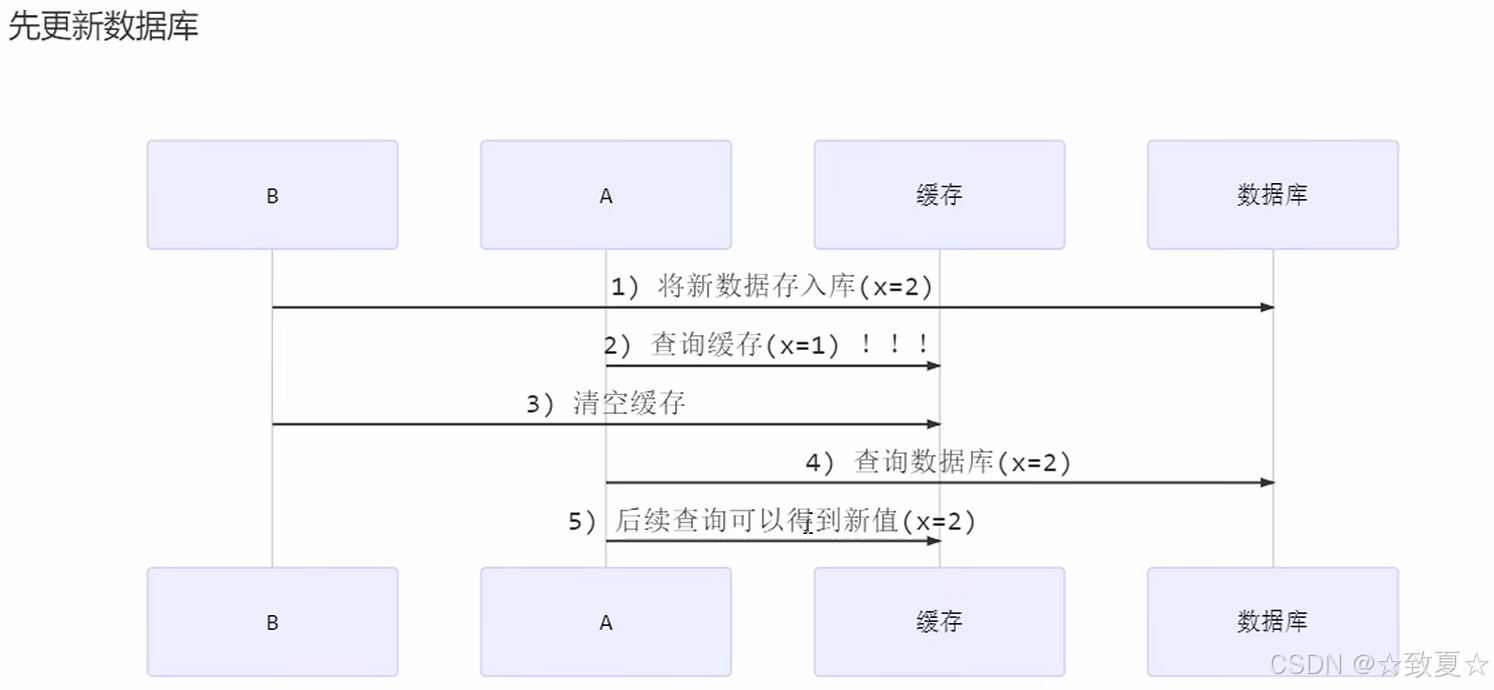
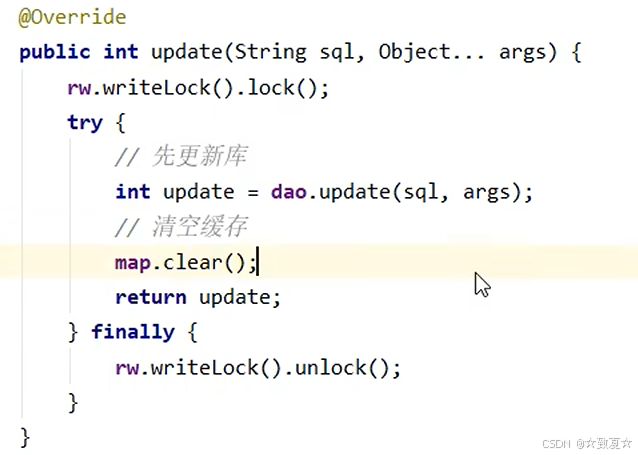
缓存优化-读写锁实现
1.map的操作都放到了锁里,线程安全得到保障
2.双重检验保证首次访问不会出现多线程访问数据库的情况
3.缓存更新加了写锁保证了原子性
读写锁不支持读锁到写锁的升级,必须把读锁释放掉再获得写锁
读锁是共享锁,写锁为独占锁。读锁提高了并发性,写锁保证了数据一致性。在读多写少的情景下对比只用独占锁,使用读写锁显著提高性能。

使用读写锁保证了有多个线程能够读取缓存数据,当在缓存查不到时,写锁保证了只有一个线程访问数据库并将查到的数据放入缓存,此时释放写锁,多线程进入对缓存数据的双重校验,这次一定能查到数据直接返回,从而减少了对数据库的访问压力
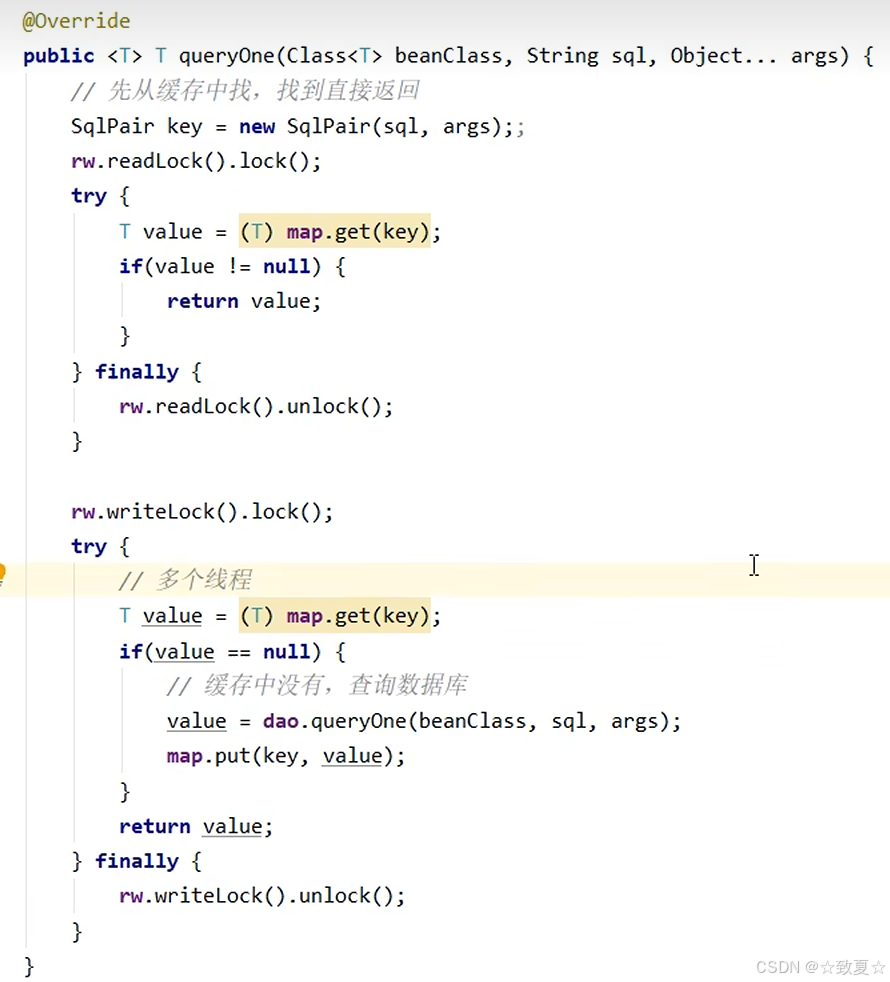
使用写锁保证更新操作的原子性,是整个更新操作是一个整体。
缓存实现补充

读写锁原理
w.lock

如果没加读锁和写锁,state = 0.此时线程可以尝试加锁,成功则把owner设为当前线程;
如果state != 0,表示已经加了读锁/写锁,w == 0表示加的读锁,直接返回false,w 不等于0表示加的写锁,如果此时的owner不是当前线程,直接返回false,如果是当前线程则判断w+1是否超过最大范围65535,将state设为c+1后返回true,表明加写锁成功。
r.lock
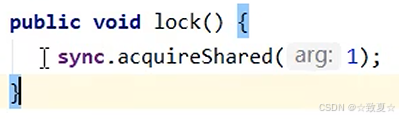
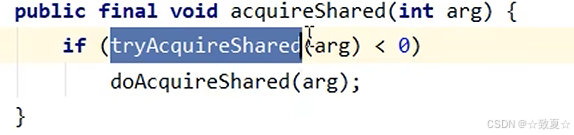
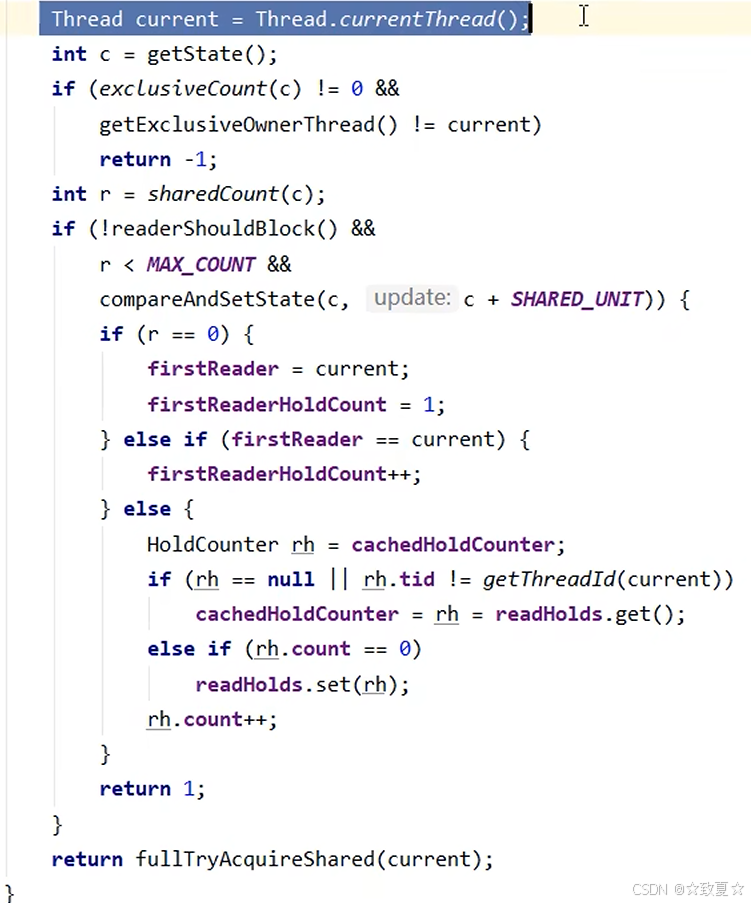

后续线程加读写锁图解
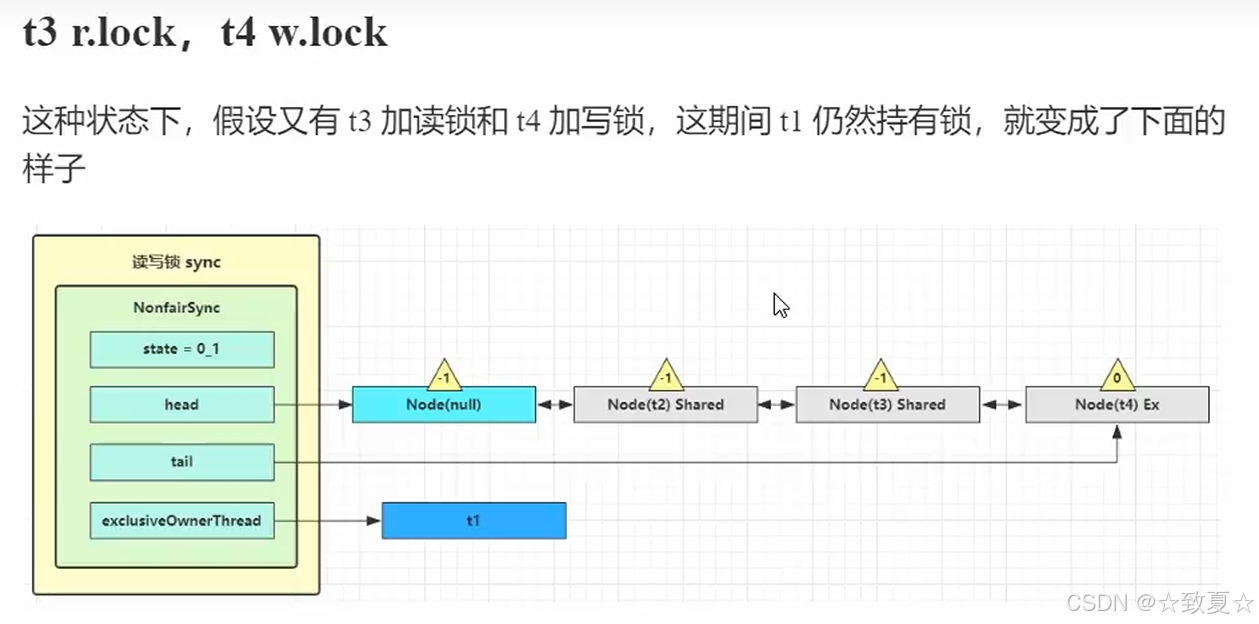
w.unlock
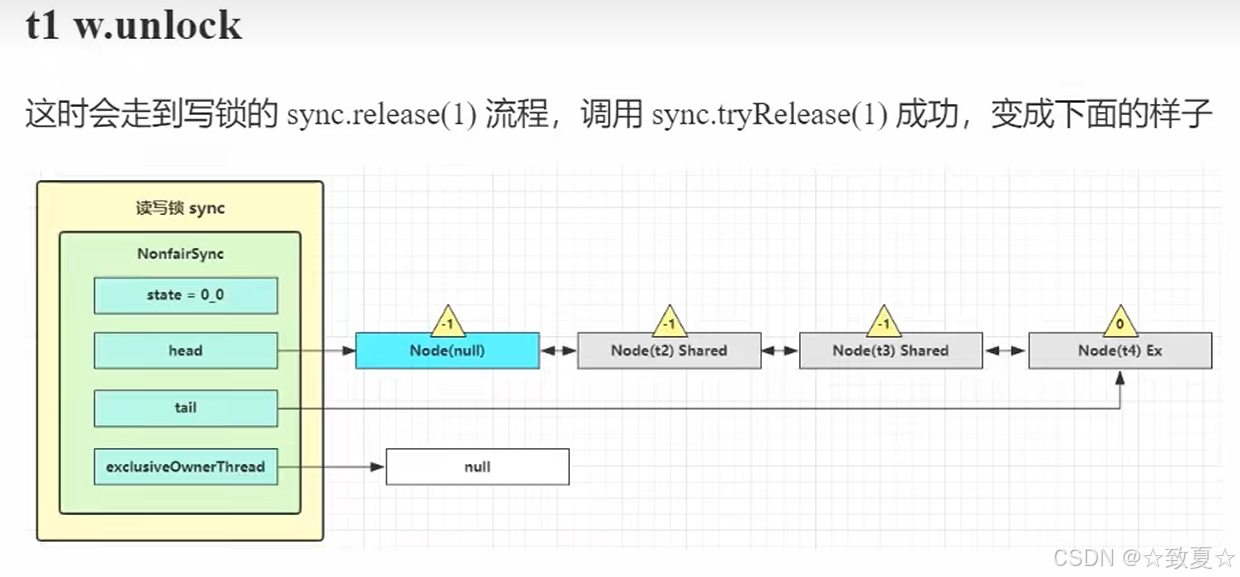
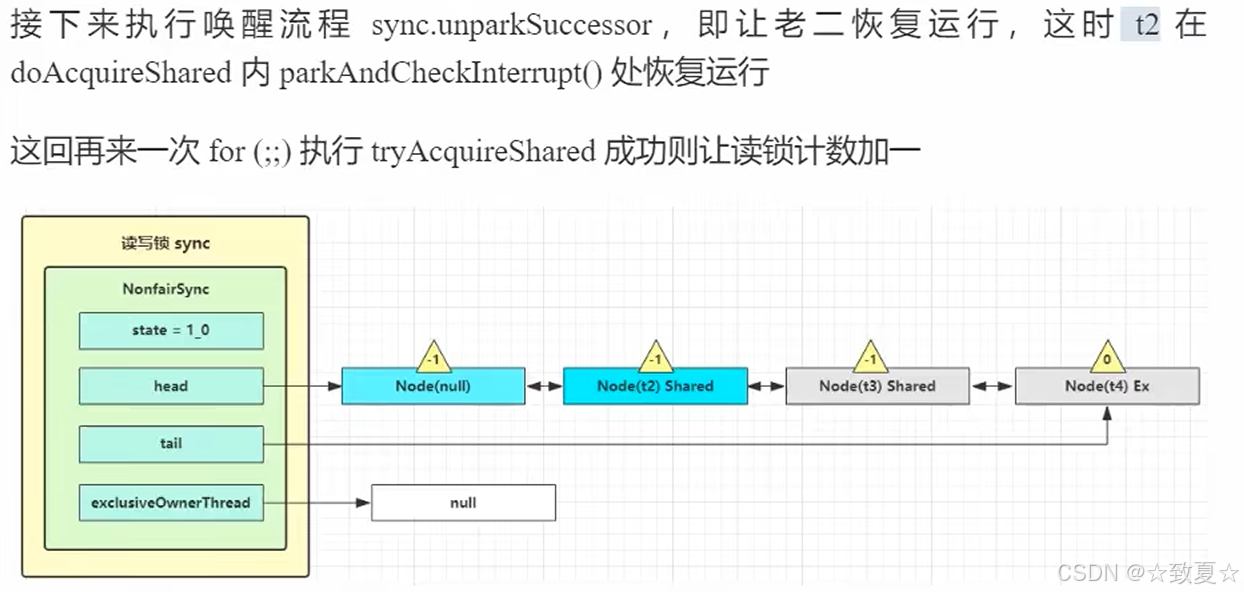
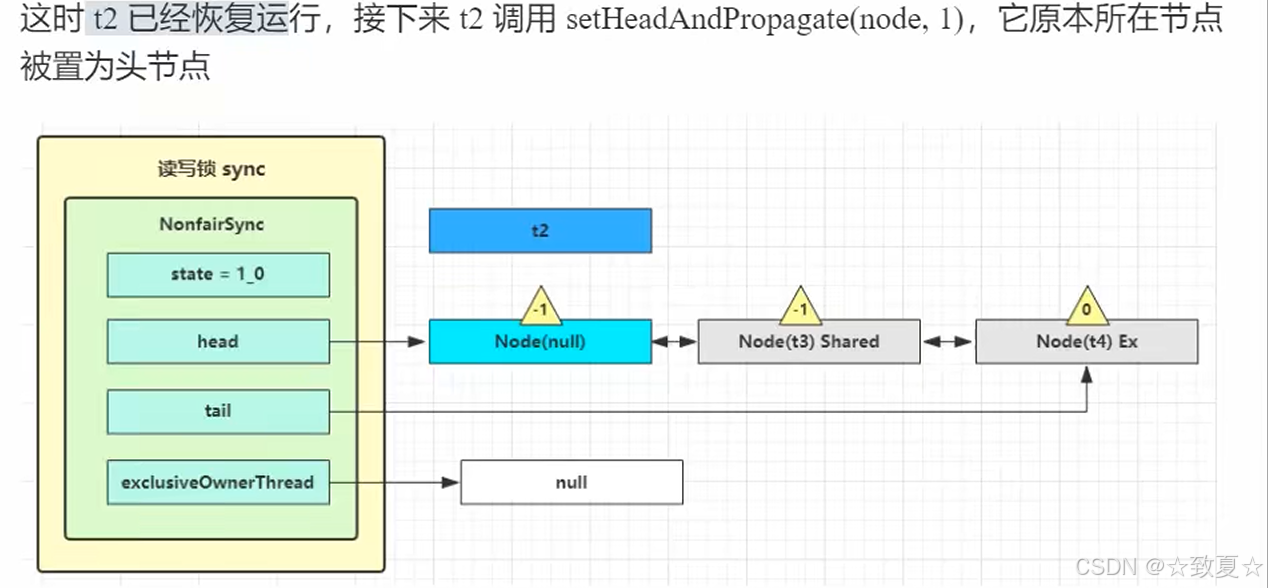
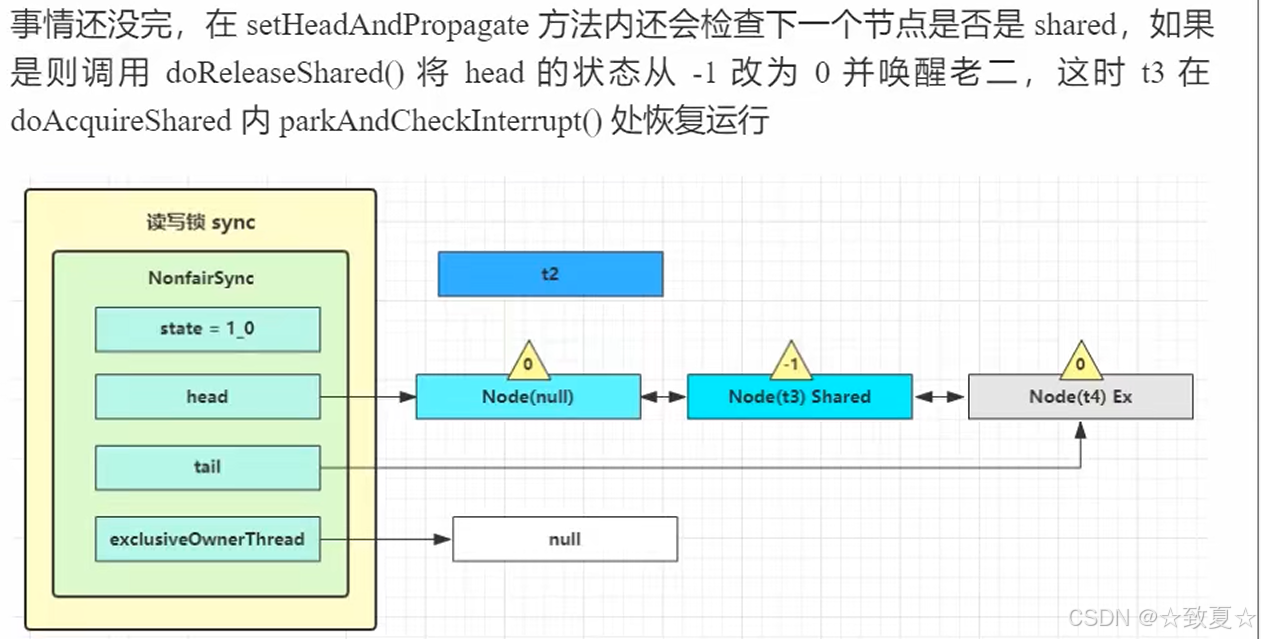

r.unlock


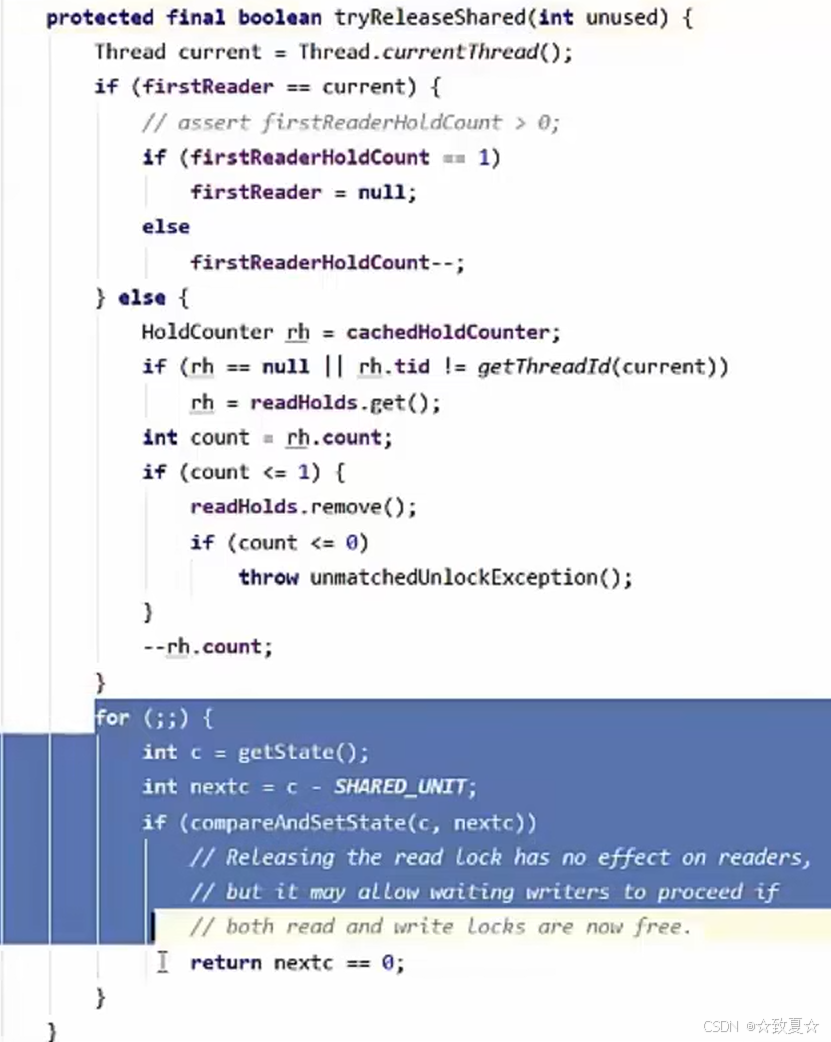
stampedLock-作用
用戳校验结果来决定要不要加锁。

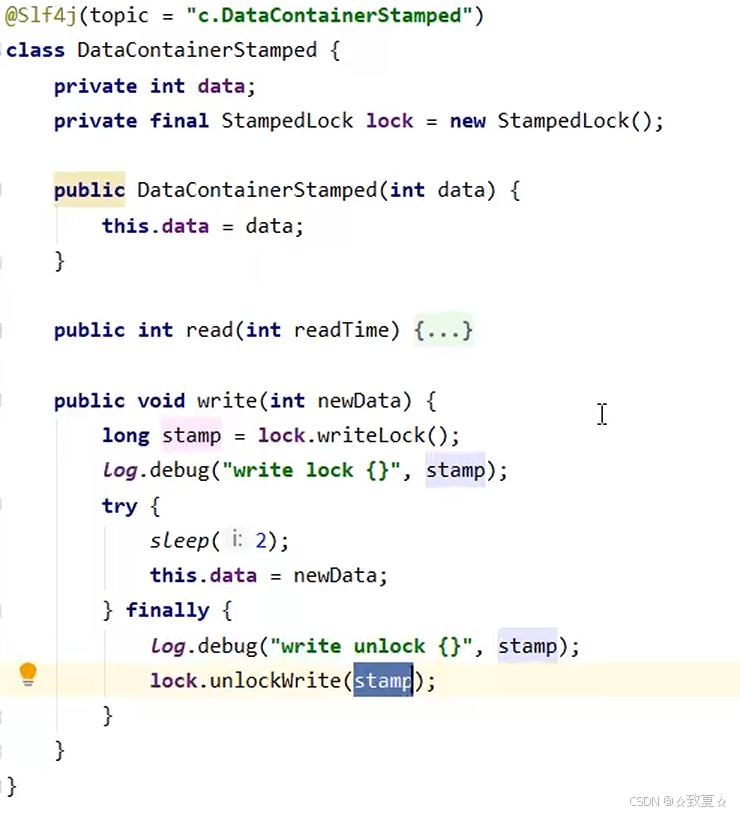
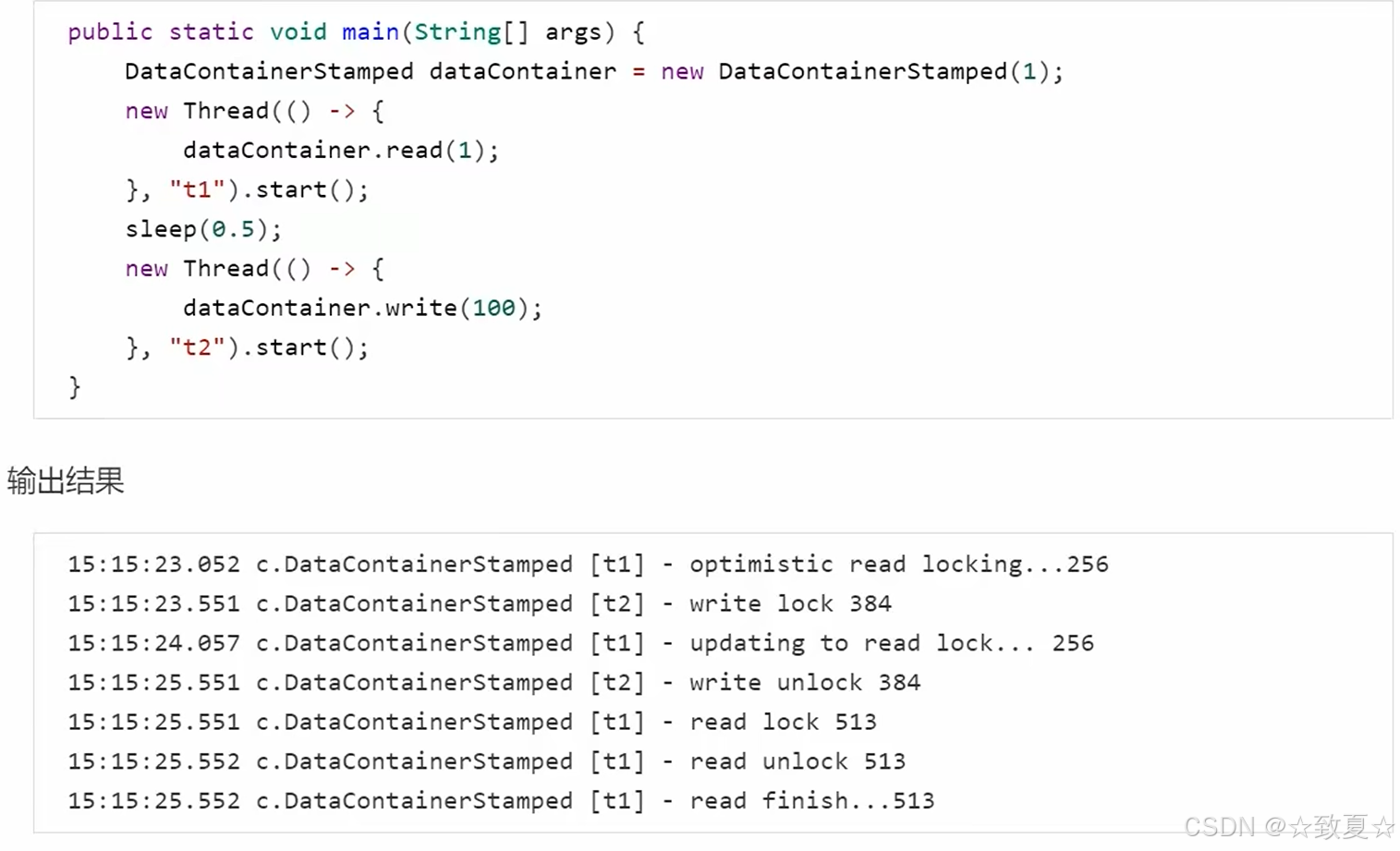
stampedLock-演示
加写锁
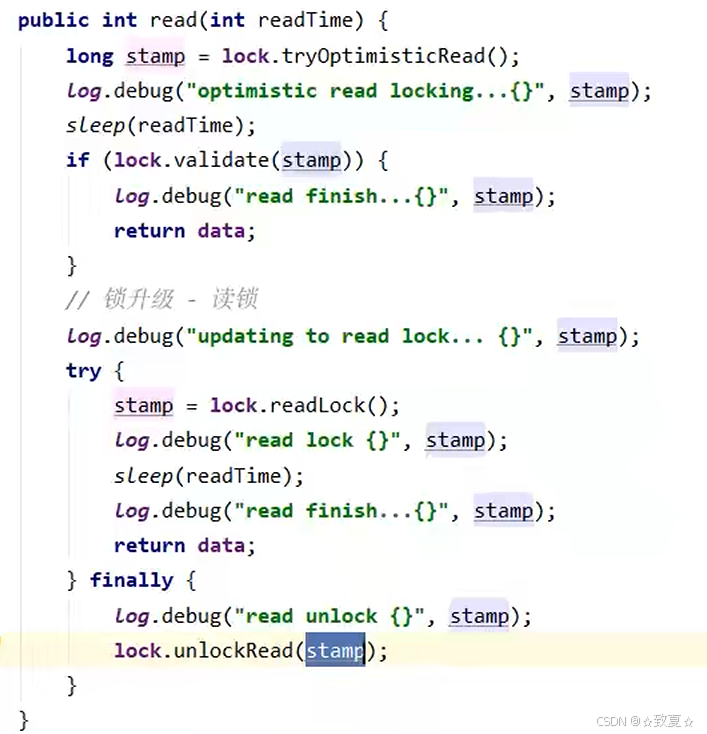
加乐观读锁(戳改变会使乐观读锁升级成读锁,升级的读锁也支持多线程)
如果没有写线程,戳值不会改变
测试乐观读锁的并发
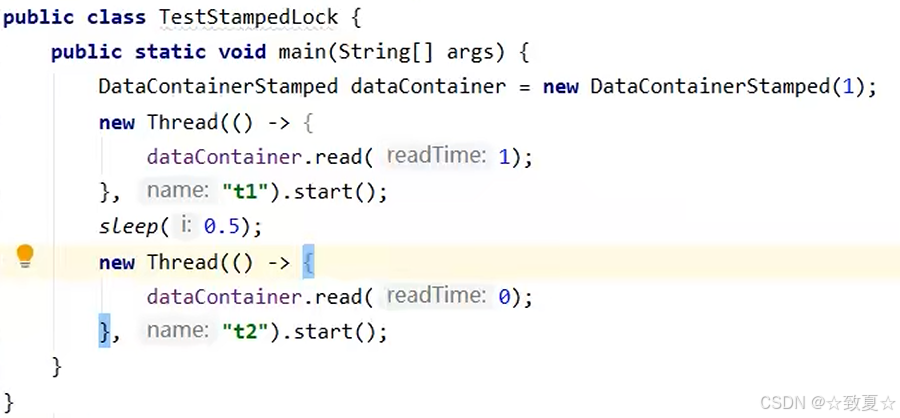

测试乐观读锁的升级->读锁
从测试结果可以看出,stamp戳值在有写线程加入后被改变。乐观读锁在读取后进行戳校验时,发现戳值改变就会尝试升级成读锁,而此时写锁还未释放,等待写锁释放后获取读锁
stampedLock的缺点

Semaphore-作用
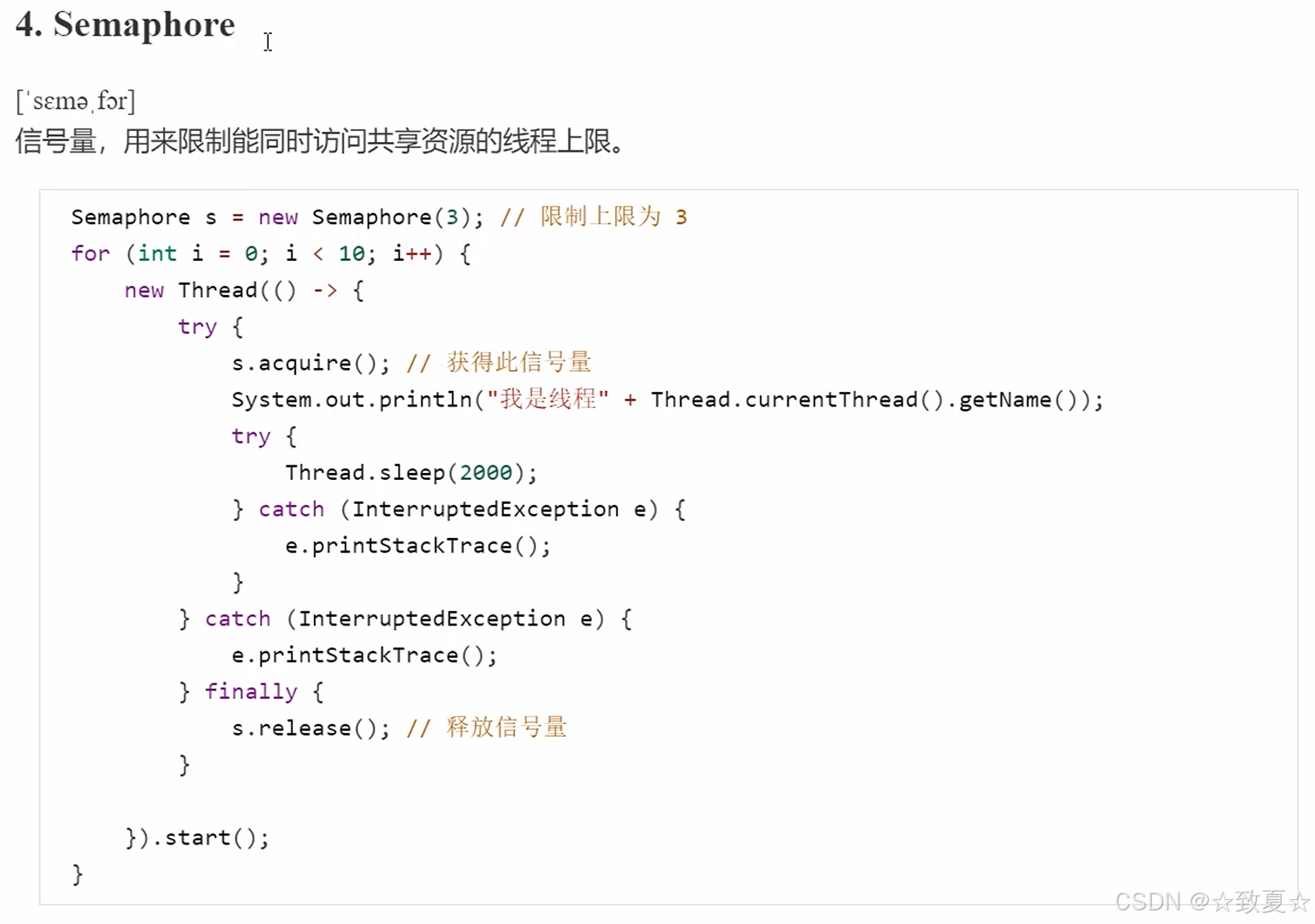
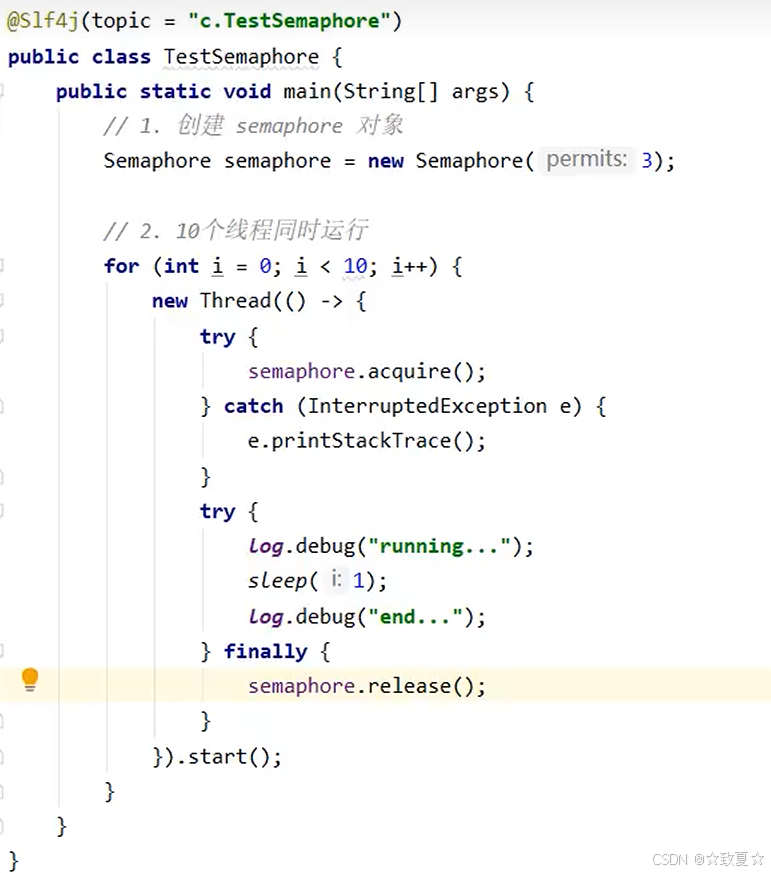
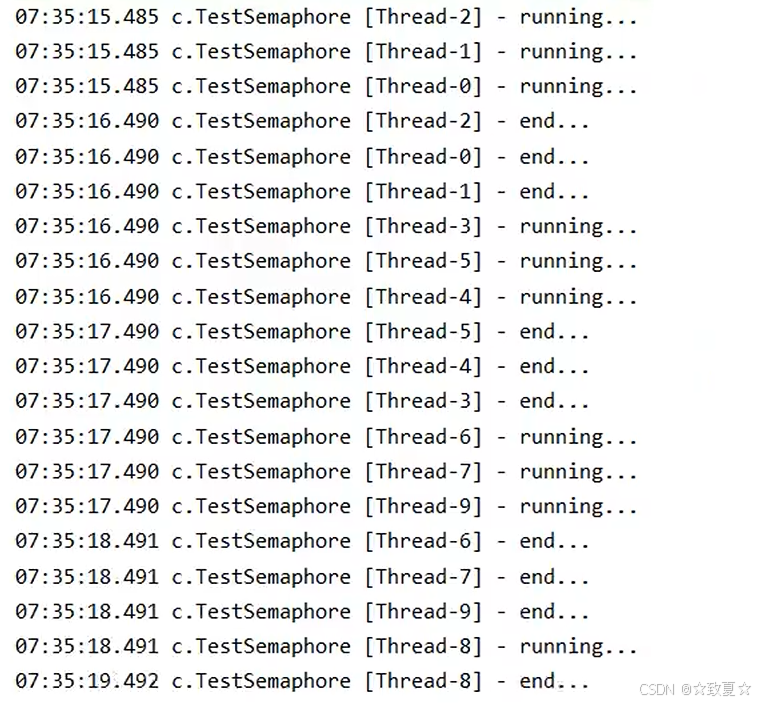
Semaphore-演示
限制了3个线程获取共享资源,10个线程只有三个释放资源后,后续线程才能获取资源。
Semaphore应用

对比之前的wait

对比之前的notify
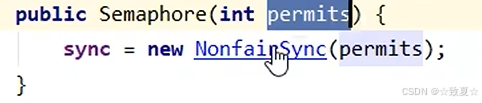
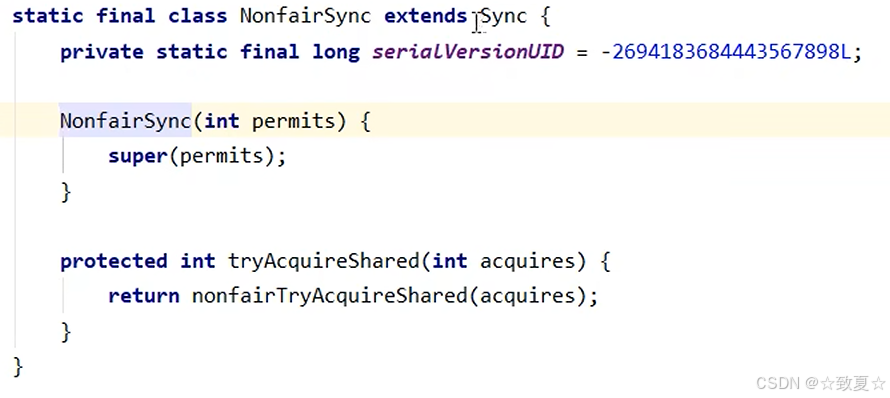
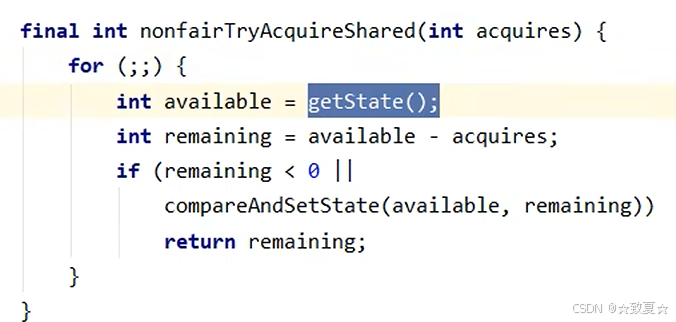
Semaphore原理-acquire
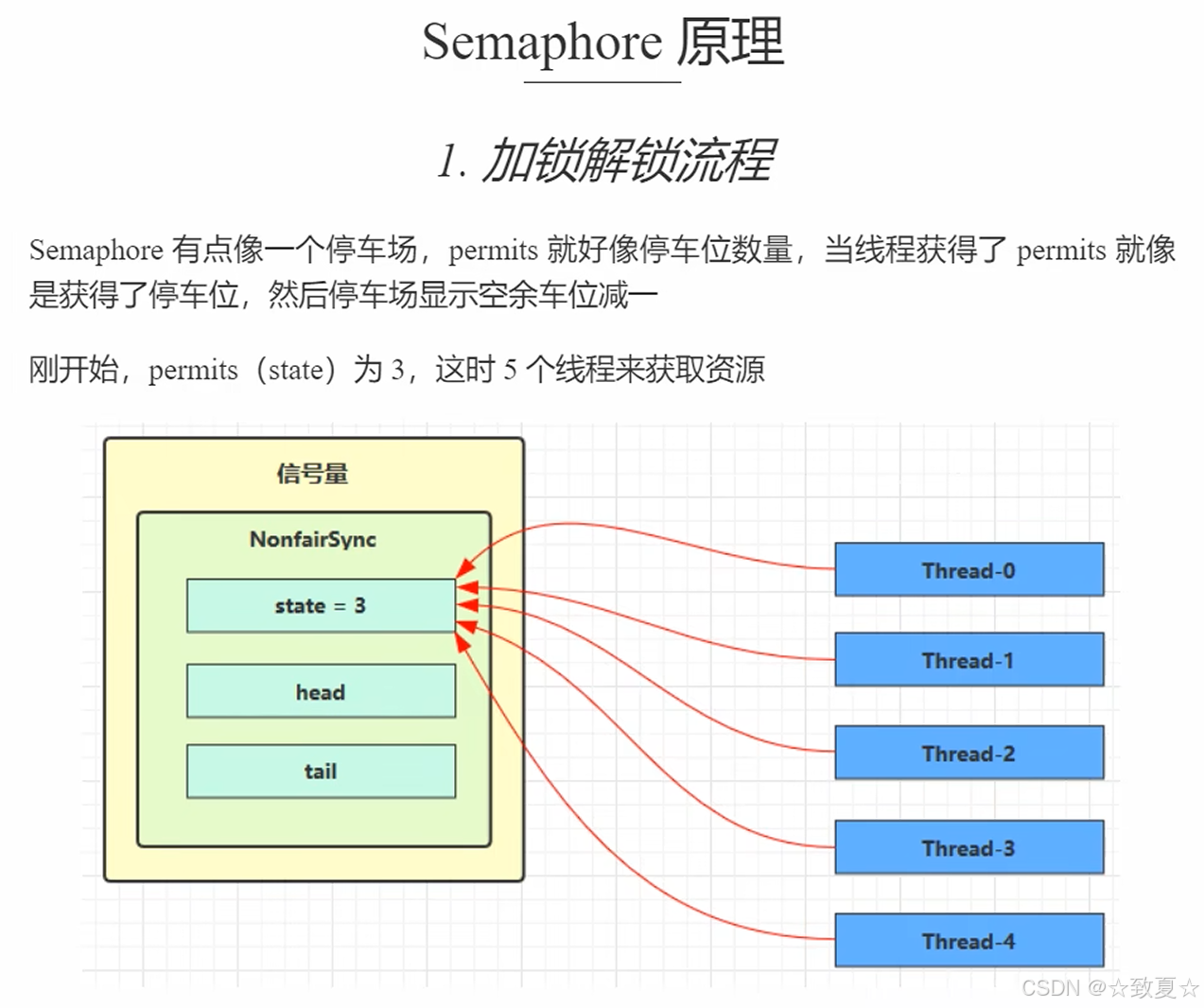
初始化资源数
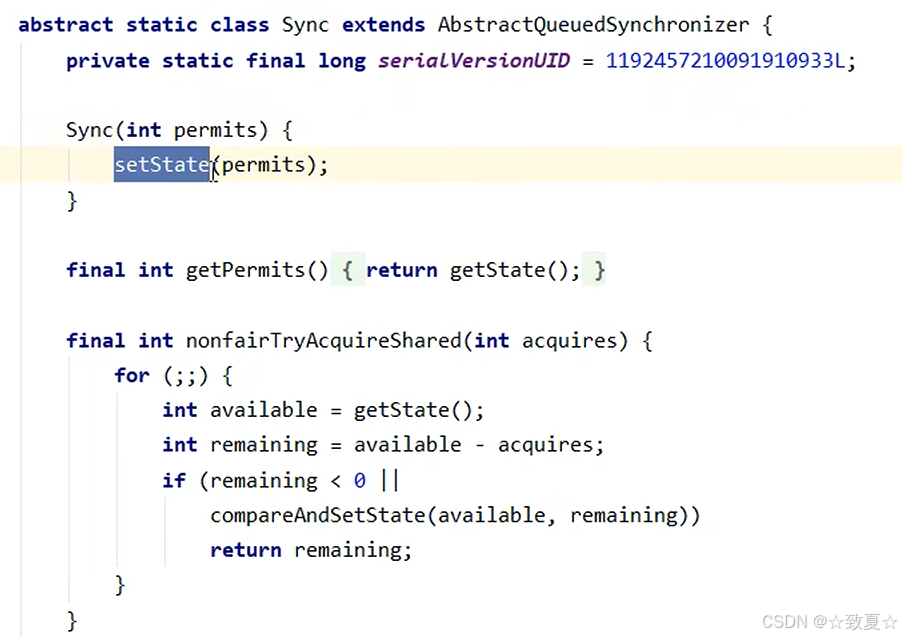
线程发来请求


返回剩余资源数
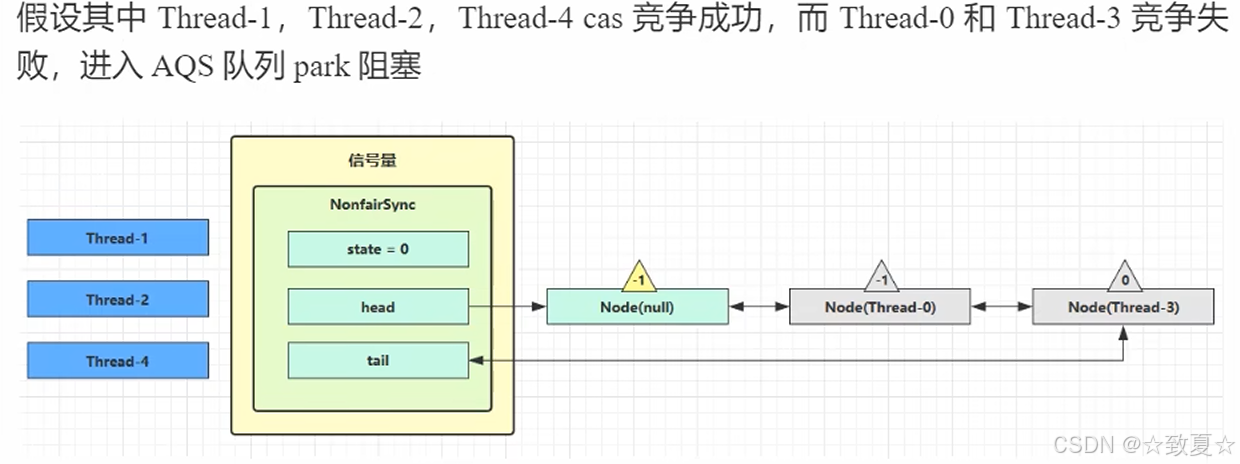
获取资源失败返回负数进入这里
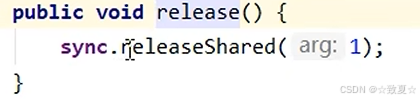
Semaphore原理-release
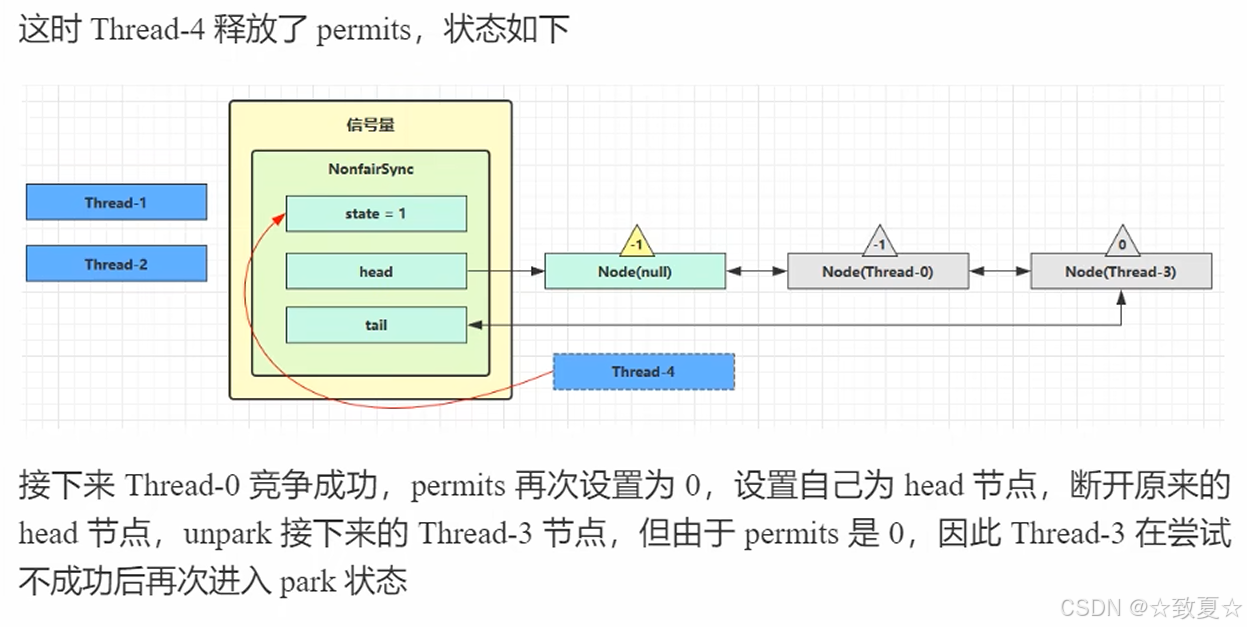
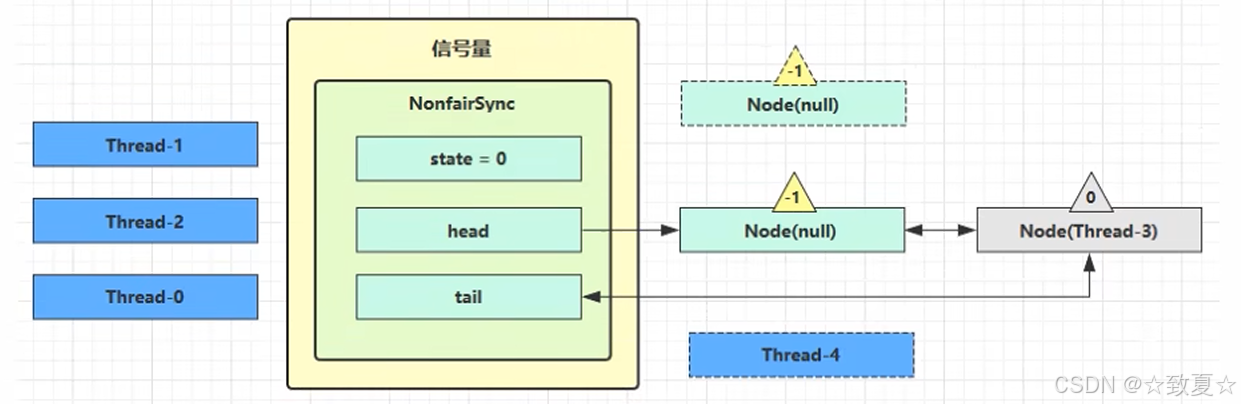
释放锁调用release
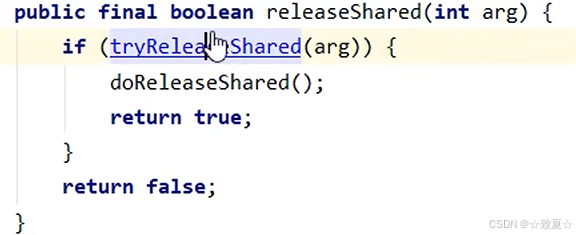

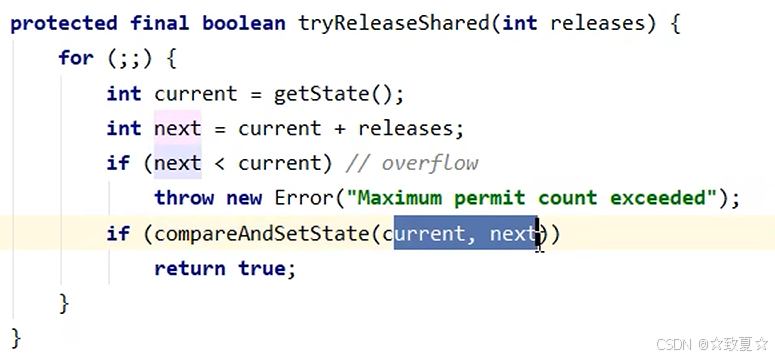
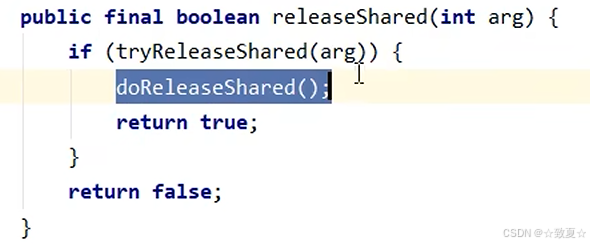

阻塞的线程被唤醒后执行这里
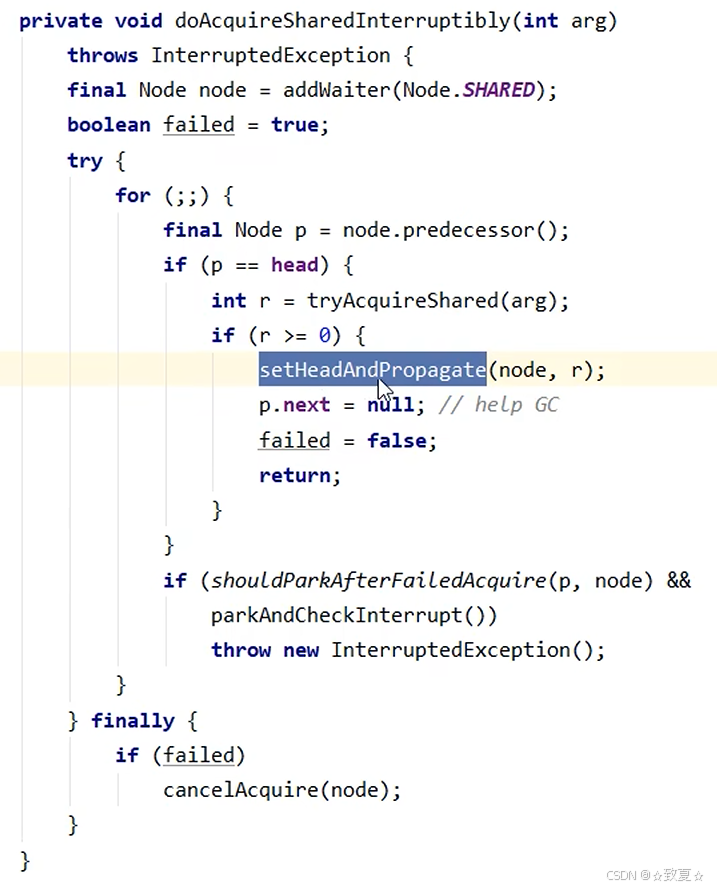
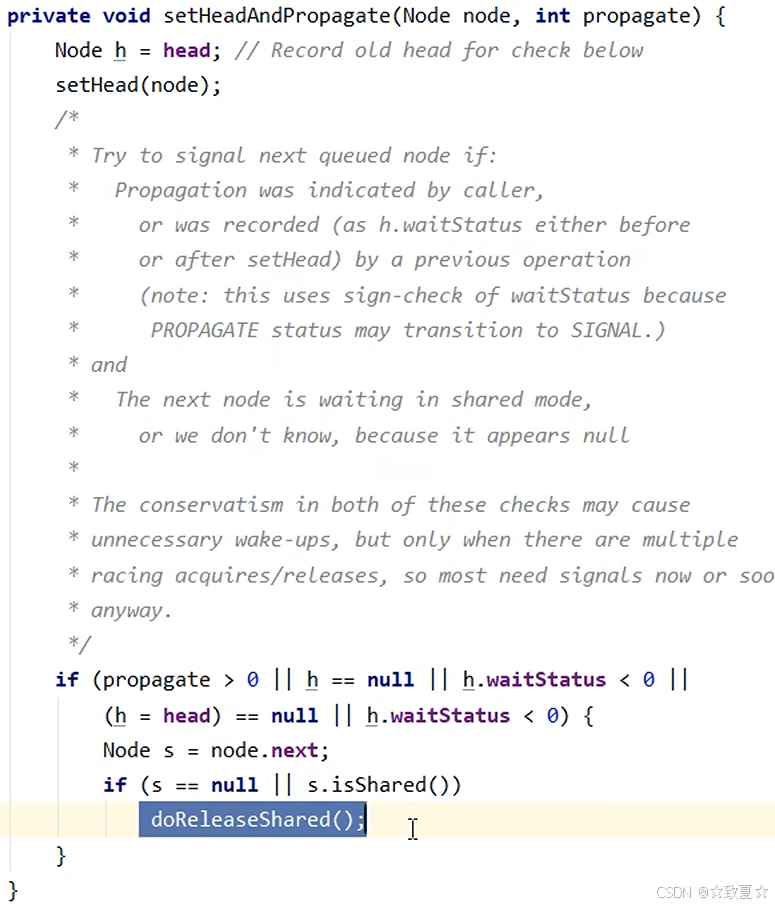

CountdownLatch(倒计时锁)

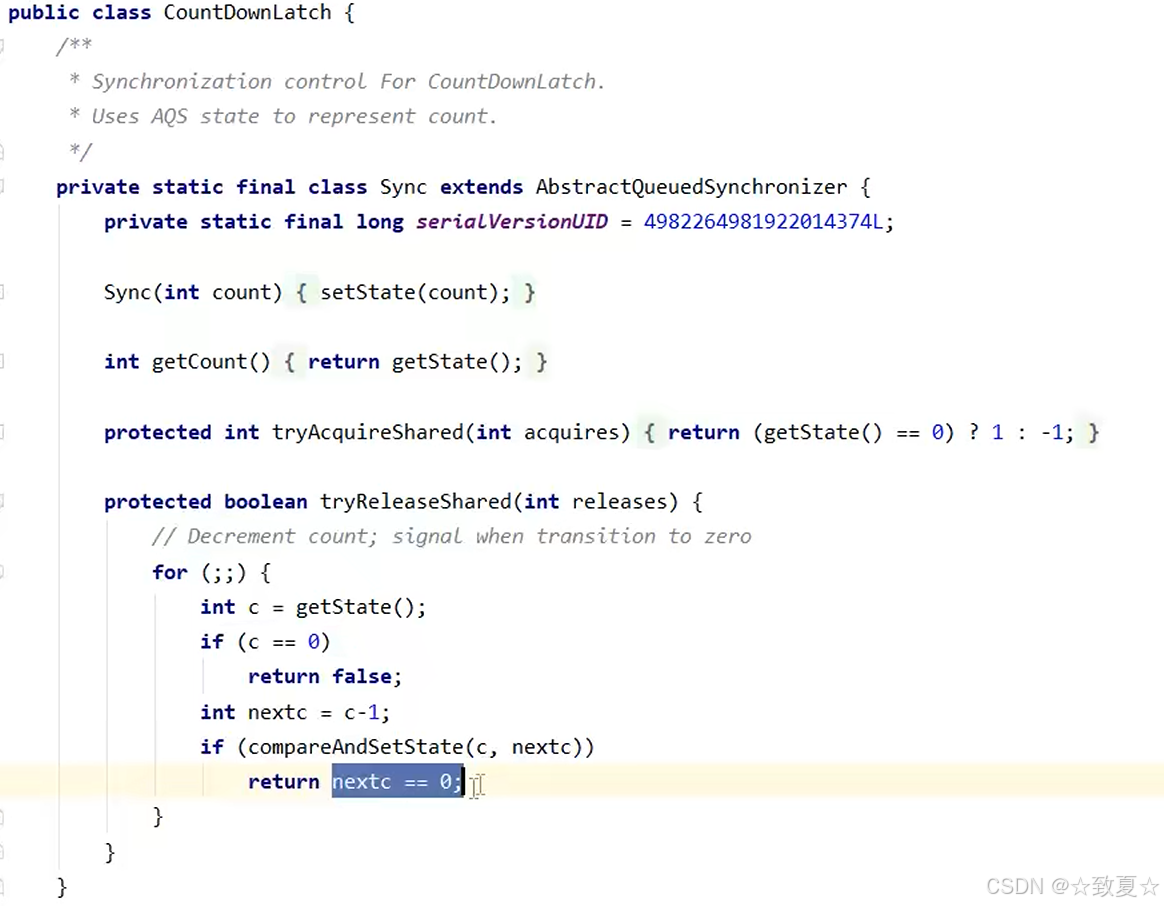
CountDownLatch基本用法
用于主线程等待其他线程执行结束
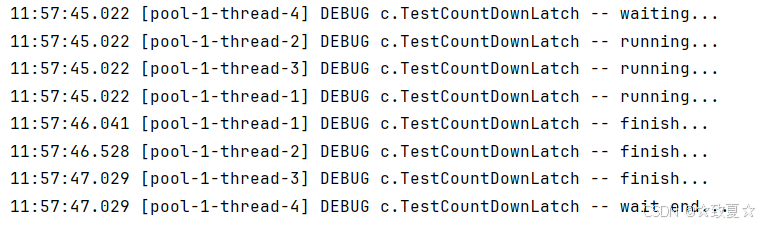
@Slf4j(topic = "c.TestCountDownLatch")
public class TestCountDownLatch {public static void main(String[] args) throws InterruptedException {CountDownLatch latch = new CountDownLatch(3);new Thread(() -> {log.debug("running...");try {sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}latch.countDown();log.debug("finish...");}).start();new Thread(() -> {log.debug("running...");try {sleep(1500);} catch (InterruptedException e) {throw new RuntimeException(e);}latch.countDown();log.debug("finish...");}).start();new Thread(() -> {log.debug("running...");try {sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}latch.countDown();log.debug("finish...");}).start();log.debug("waiting...");latch.await();log.debug("wait end...");}
}CountDownLatch-改进
使用线程池改进
@Slf4j(topic = "c.TestCountDownLatch")
public class TestCountDownLatch {public static void main(String[] args) throws InterruptedException {CountDownLatch latch = new CountDownLatch(3);ExecutorService service = Executors.newFixedThreadPool(4);service.submit(() -> {try {log.debug("running...");sleep(1000);latch.countDown();log.debug("finish...");} catch (InterruptedException e) {throw new RuntimeException(e);}});service.submit(() -> {try {log.debug("running...");sleep(1500);latch.countDown();log.debug("finish...");} catch (InterruptedException e) {throw new RuntimeException(e);}});service.submit(() -> {try {log.debug("running...");sleep(2000);latch.countDown();log.debug("finish...");} catch (InterruptedException e) {throw new RuntimeException(e);}});service.submit(() -> {try {log.debug("waiting...");latch.await();log.debug("wait end...");} catch (InterruptedException e) {throw new RuntimeException(e);}});}
}
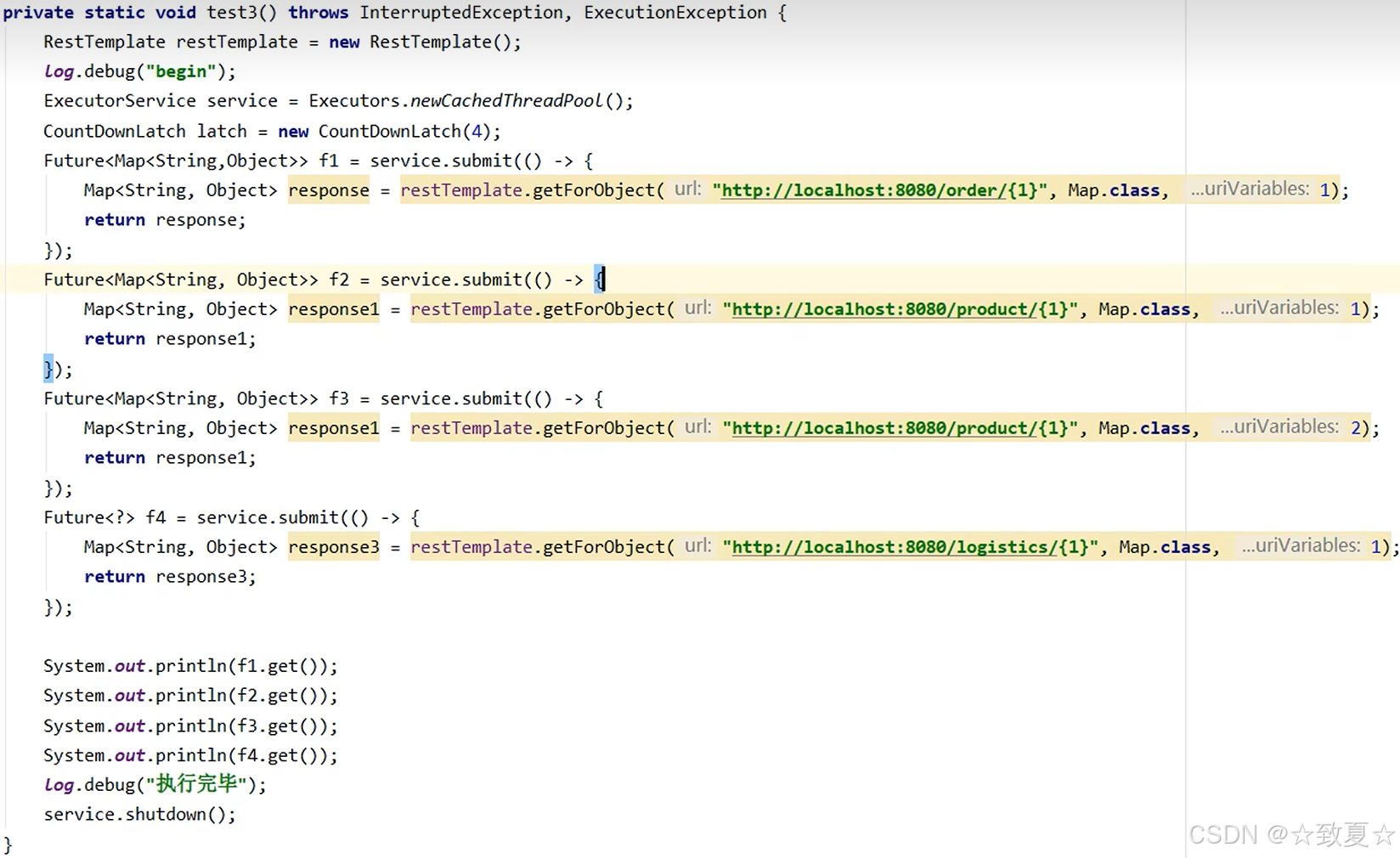
future应用
主线程使用countdownlatch等待多线程执行结束,但是不能获得多线程执行结果,需要优化。
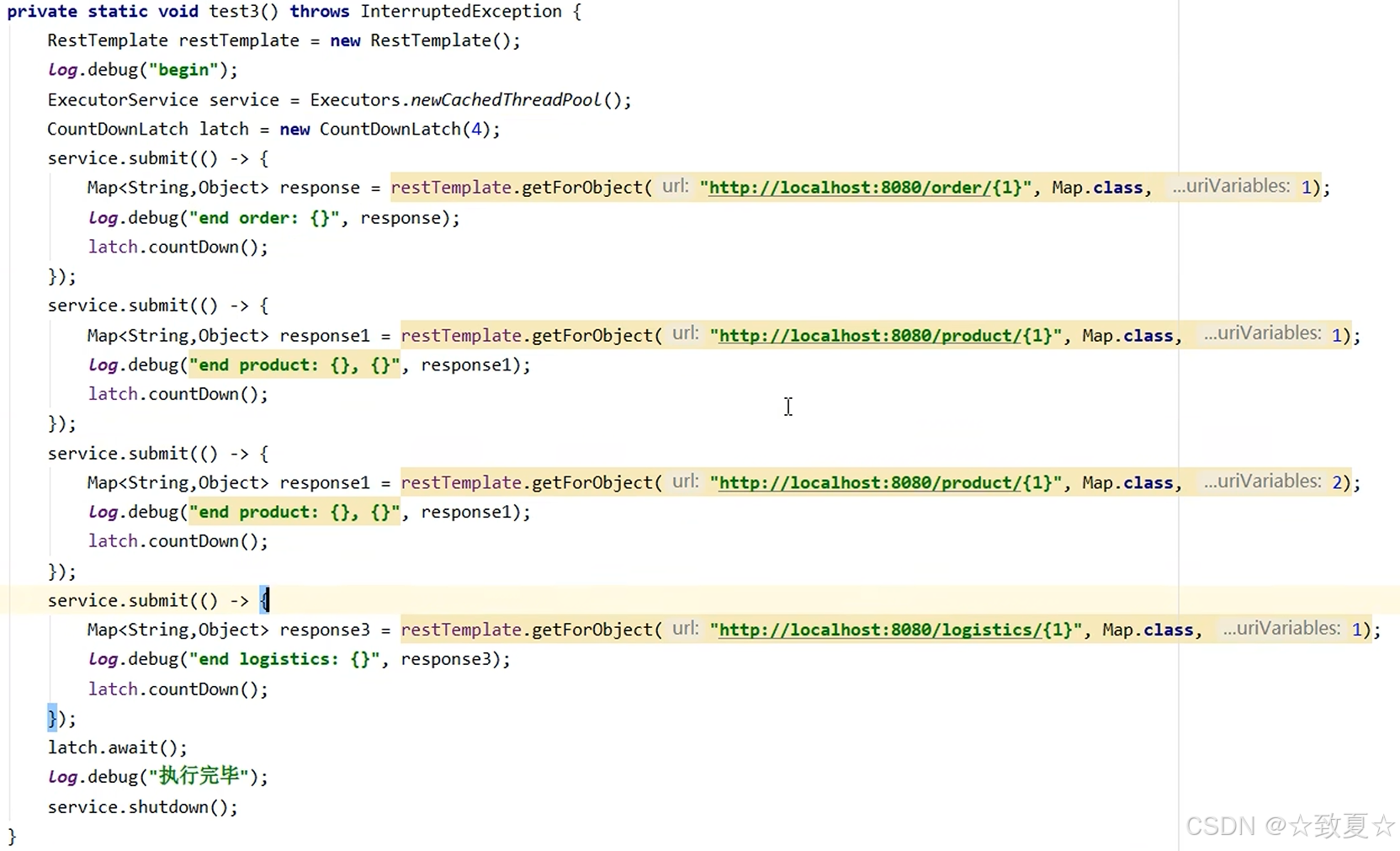
使用future优化代码
CyclicBarrier-问题

CyclicBarrier-使用
线程1执行完等待线程2执行 每await一次,设置的栅栏数都会减1,栅栏数减为0时,等待的线程会继续执行。

CyclicBarrier的栅栏数是可以重用的,当一轮使用完后,再次调用可以重新计数。
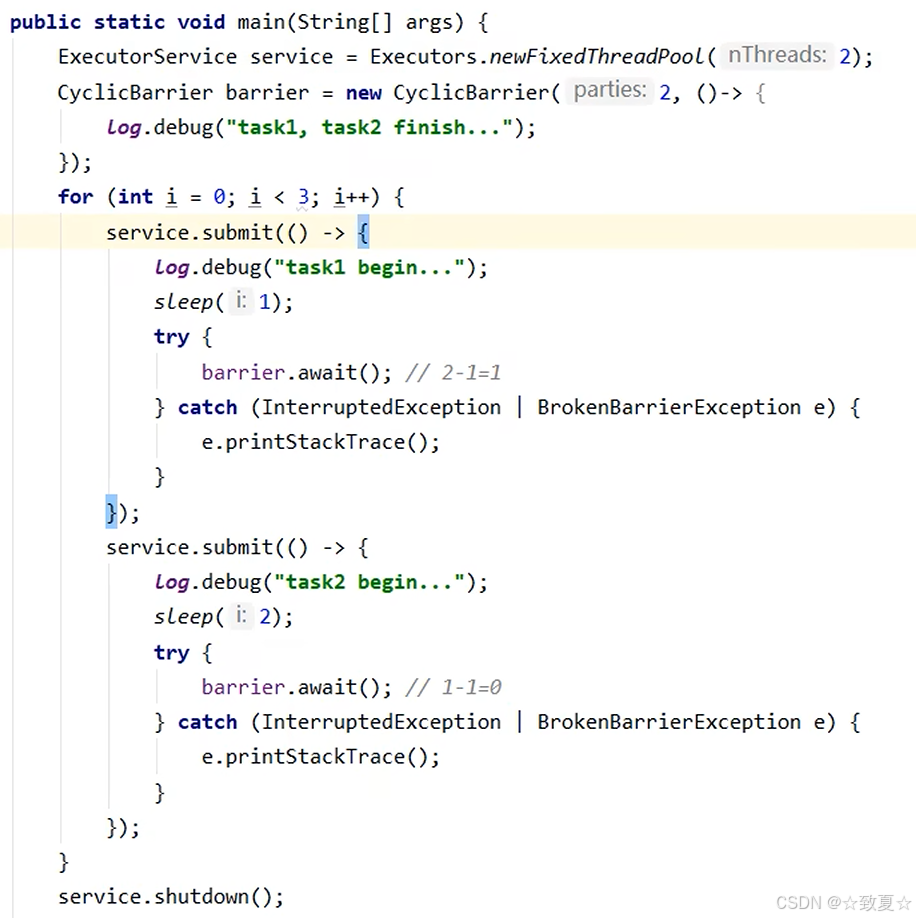
CyclicBarrier-注意
最好保证线程数和栅栏数相同,如图,线程数为3,栅栏数为2,线程1需要1秒,线程2需要2秒,此时会直接开始循环线程3需要1秒,此时最先让栅栏减为0的是线程1和线程3,打印出来的也是线程1和线程3的结果,和预期不符。

线程安全集合类

Hashtable: 使用synchronized保证方法的线程安全导致并发性能很低

Collections装饰的线程安全集合(设计模式-装饰器思想)
将原本不安全的线程集合变成安全的
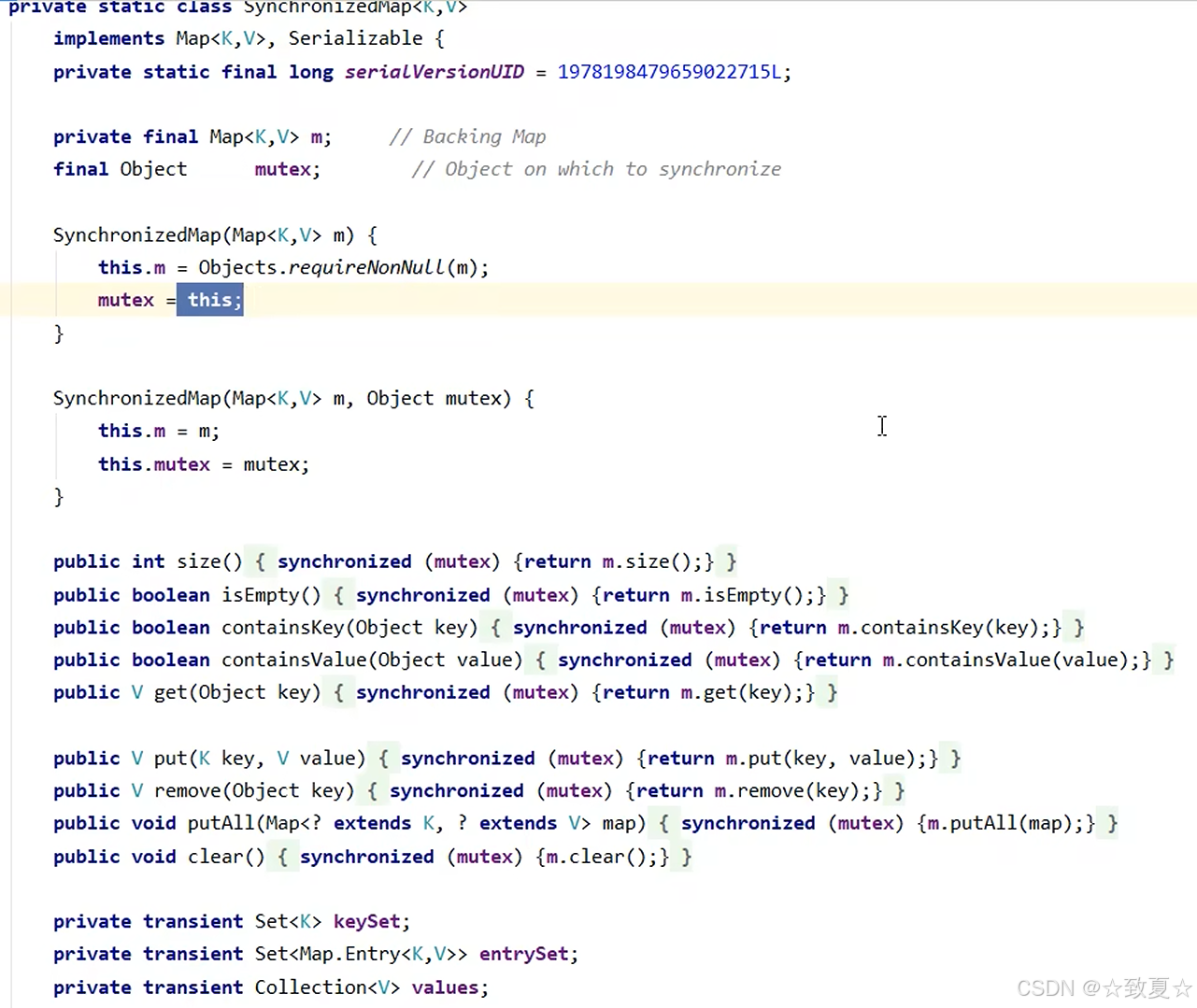
从实现的源码可以看出,本质上是在原来的集合方法上加了synchronized,也没有良好的并发性能


ConcurrentHashMap-错误用法
练习:单词计数
生成测试数据,26个字母,每个字母200个,打乱后存入26的文件中。
@Slf4j(topic = "c.Test35")
public class Test35 {public static void main(String[] args) throws InterruptedException {String test = "abcdefghijklmnopqrstuvwxyz";int length = test.length();List<Character> list = new ArrayList<>();for (int i = 0; i < length; i++) {char c = test.charAt(i);for (int j = 0; j < 200; j++) {list.add(c);}}Collections.shuffle(list);for (int i = 1; i <= 26; i++) {try (PrintWriter out = new PrintWriter(new OutputStreamWriter(new FileOutputStream("testTxt/" + i + ".txt")))) {String collect = list.subList(i * 200 - 200, i * 200).stream().map(String::valueOf).collect(Collectors.joining("\n"));out.print(collect);} catch (FileNotFoundException e) {throw new RuntimeException(e);}}}
}demo代码
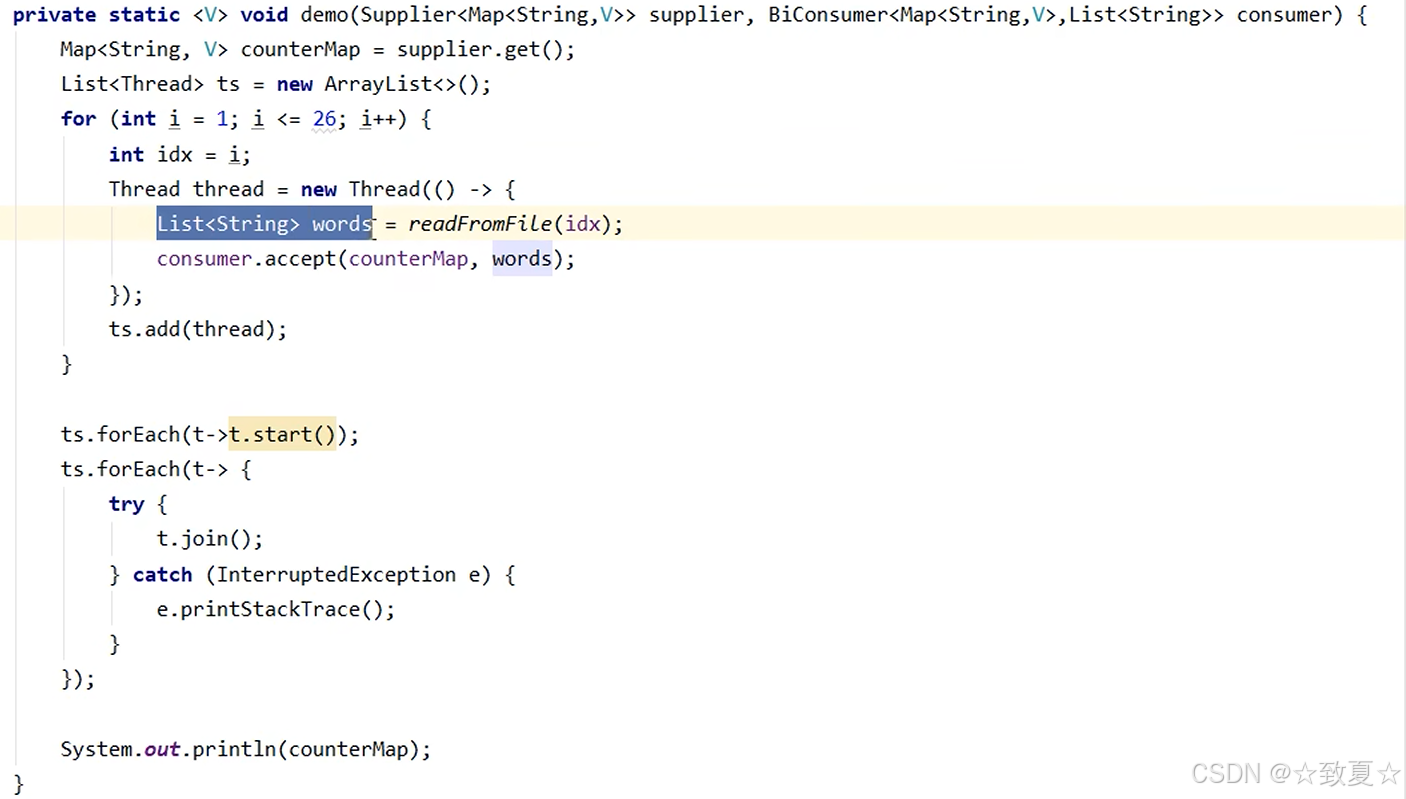
错误测试结果
使用HashMap
从结果看,有线程安全问题,每个字母不是200个,有线程安全问题
![]()
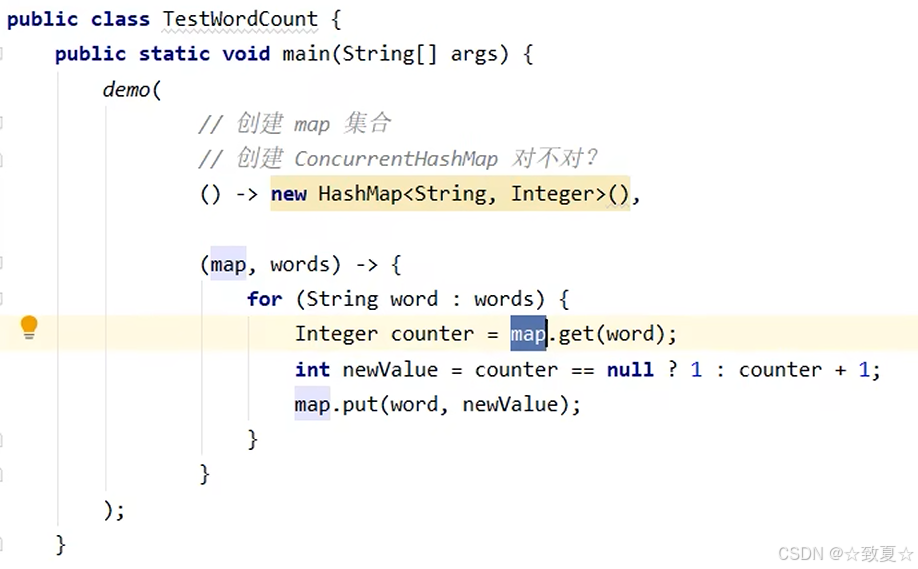
使用ConcurrentHashMap
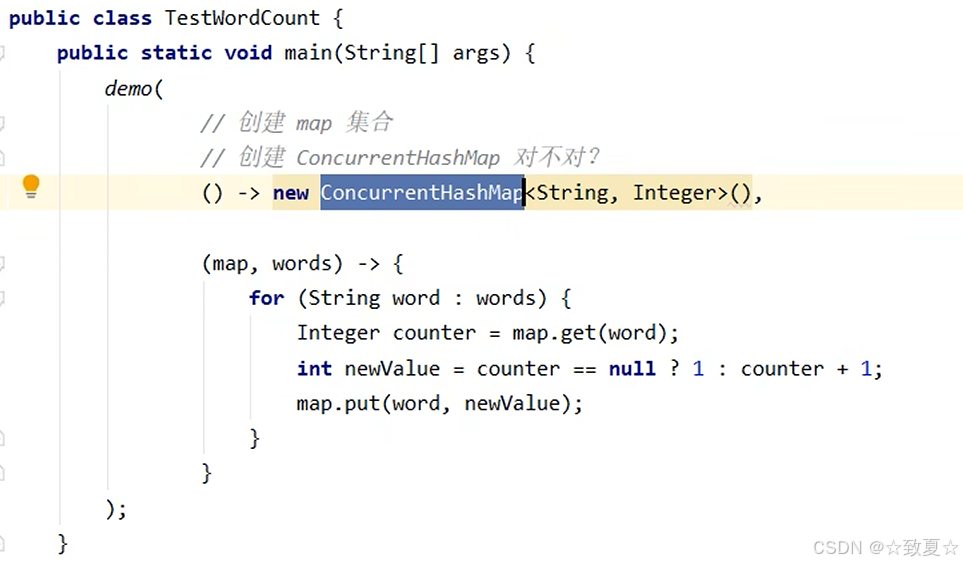
从结果看出也不对,因为有复合操作无法保证原子性
![]()
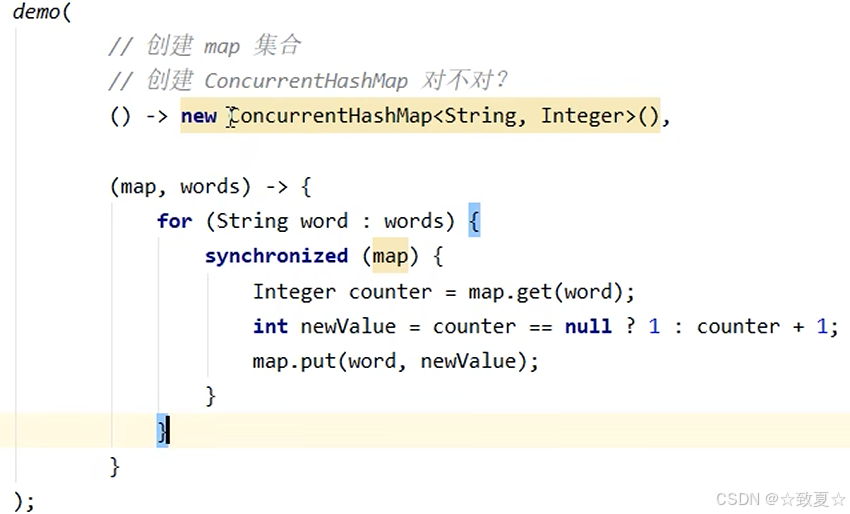
可以通过synchronized解决,但是并发性不高
@Slf4j(topic = "c.Test36")
public class Test36 {public static void main(String[] args) {demo(() -> new HashMap<String, Integer>(),(map, words) -> {for (String word : words) {//map是共享资源,可以用作锁对象synchronized (map) {Integer oldCount = map.get(word);int newCount = oldCount == null ? 1 : oldCount + 1;map.put(word, newCount);}}});}private static <V> void demo(Supplier<Map<String, V>> supplier, BiConsumer<Map<String, V>, List<String>> consumer) {Map<String, V> counterMap = supplier.get();List<Thread> list = new ArrayList<>();for (int i = 0; i < 26; i++) {int idx = i + 1;Thread thread = new Thread(() -> {List<String> words = readFromFile(idx);consumer.accept(counterMap, words);});list.add(thread);}list.forEach(Thread::start);list.forEach(t -> {try {t.join();} catch (InterruptedException e) {e.printStackTrace();}});System.out.println(counterMap);}private static List<String> readFromFile(int i) {List<String> lines = new ArrayList<>();File file = new File("testTxt/" + i + ".txt");if (!file.exists()) {System.err.println("文件不存在: " + file.getAbsolutePath());return lines;}try (BufferedReader br = new BufferedReader(new FileReader(file))) {String line;while ((line = br.readLine()) != null) {lines.add(line);}} catch (IOException e) {e.printStackTrace();}return lines;}
}
ConcurrentHashMap-computeIfAbsent
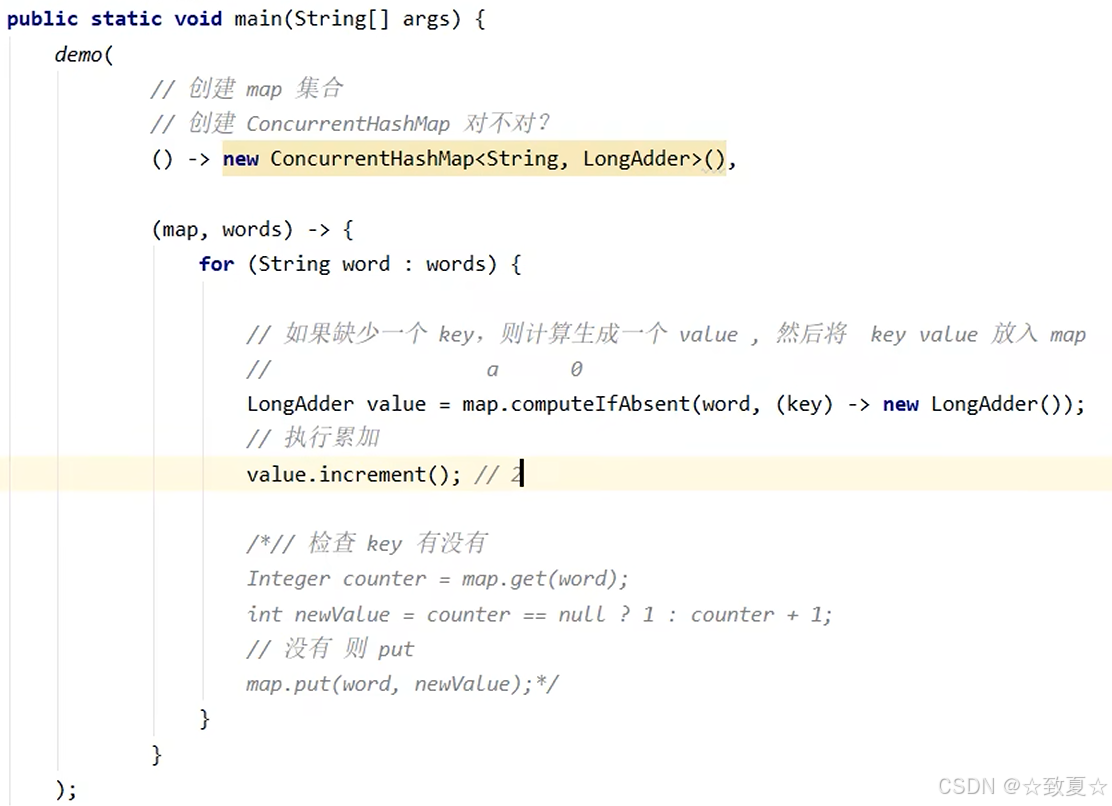
demo(() -> new ConcurrentHashMap<String, LongAdder>(),(map, words) -> {for (String word : words) {LongAdder value = map.computeIfAbsent(word, (key) -> new LongAdder());value.increment();}});ConcurrentHashMap-HashMap并发死链
HashMap回顾
数组+链表的形式
桶下标相同的元素会形成链表
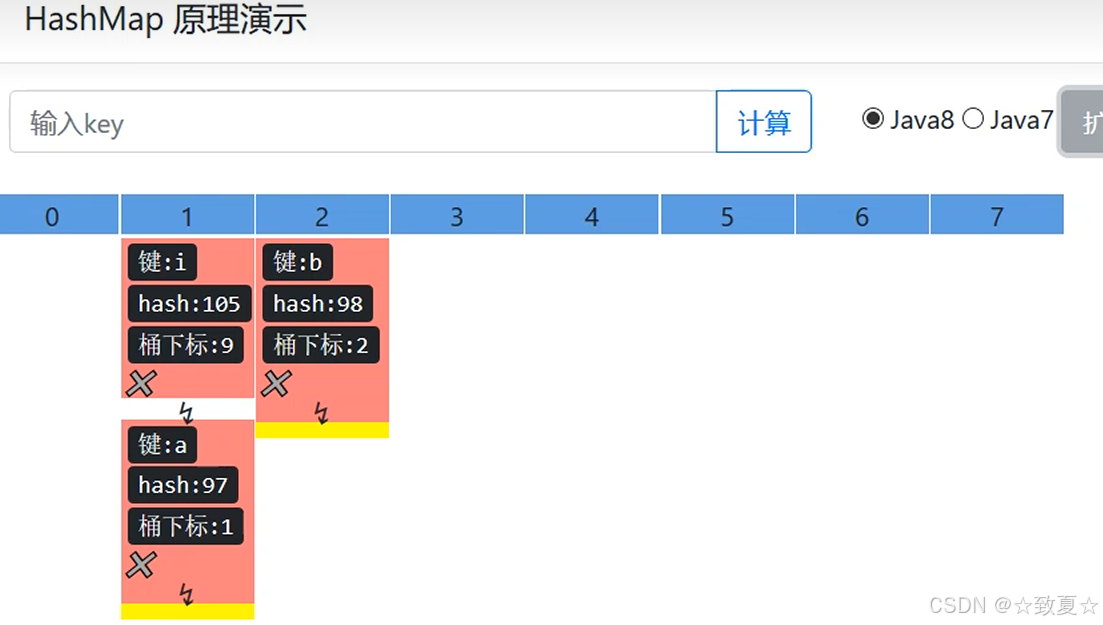
jdk7:后加入链表的元素会放在链表头部
jdk8:后加入链表的元素会放在链表尾部
随着元素越来越多,链表的长度也变长会影响查询速率
当数组长度超过3/4会发生扩容,长度翻倍
 扩容后元素分布更为均匀,链表长度也缩短,查找性能提升
扩容后元素分布更为均匀,链表长度也缩短,查找性能提升
多线程扩容会出现死链问题,问题:程序直接卡死,内存oom
JDK7并发死链

测试环境准备
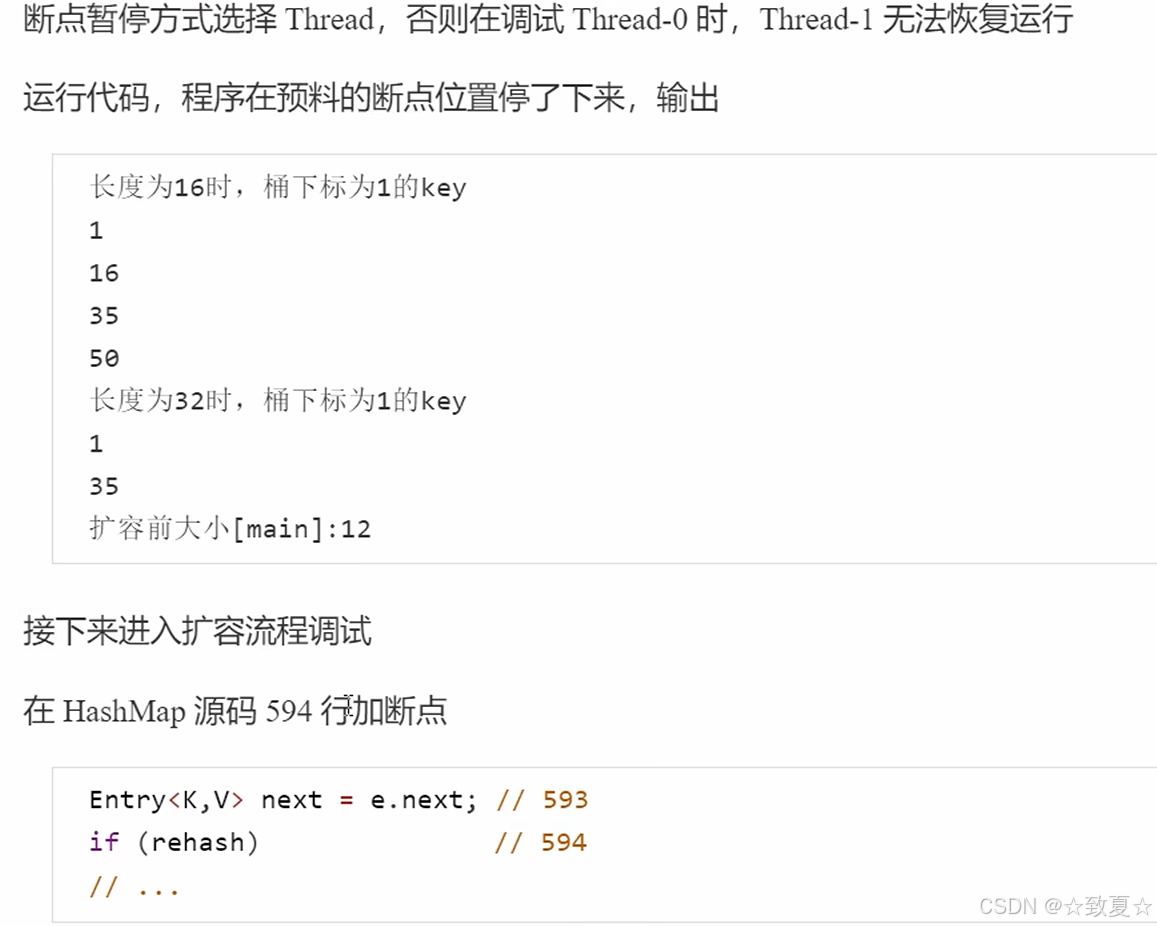
先查看扩容前后模为1的元素链表
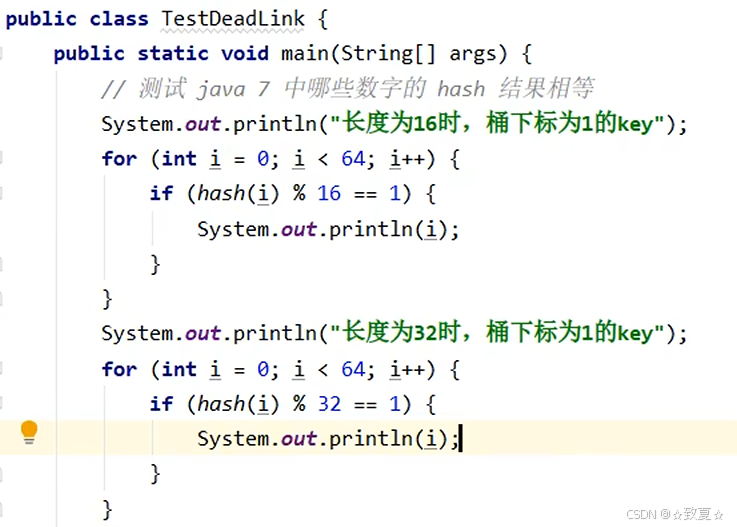
首先向大小为16的Map中添加12个元素达到扩容点
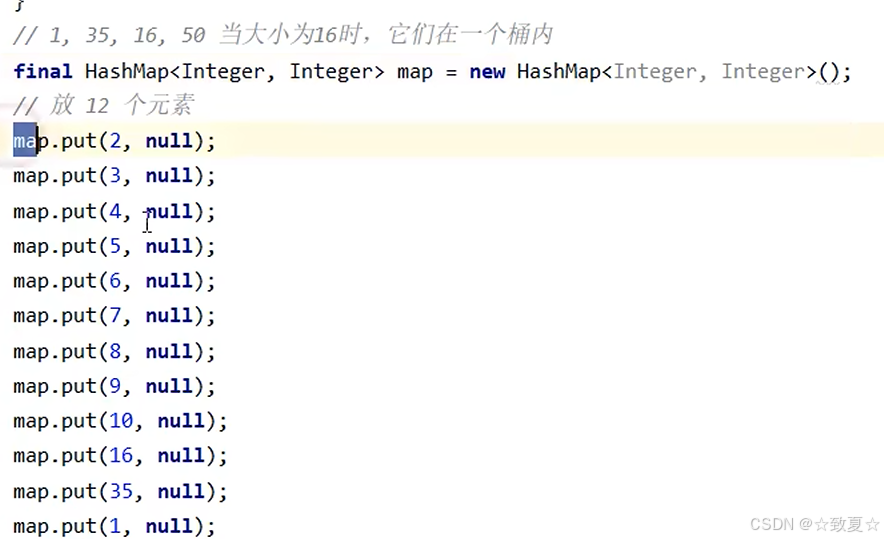
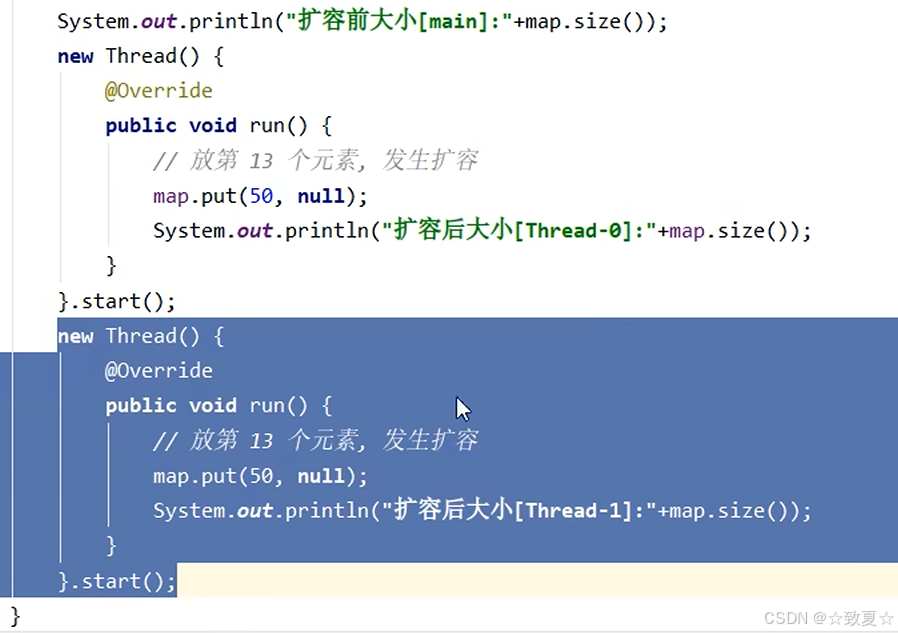
使用多线程向map中添加一个元素同时触发扩容机制

死链复现
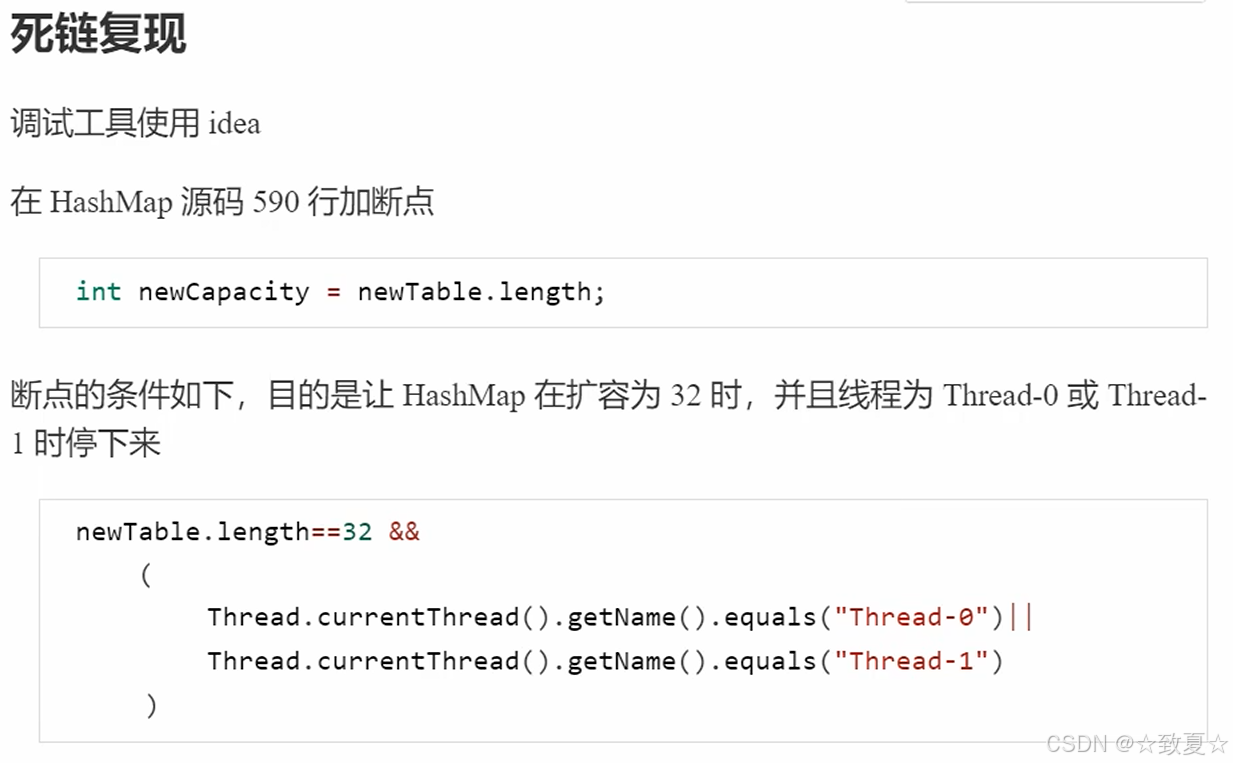
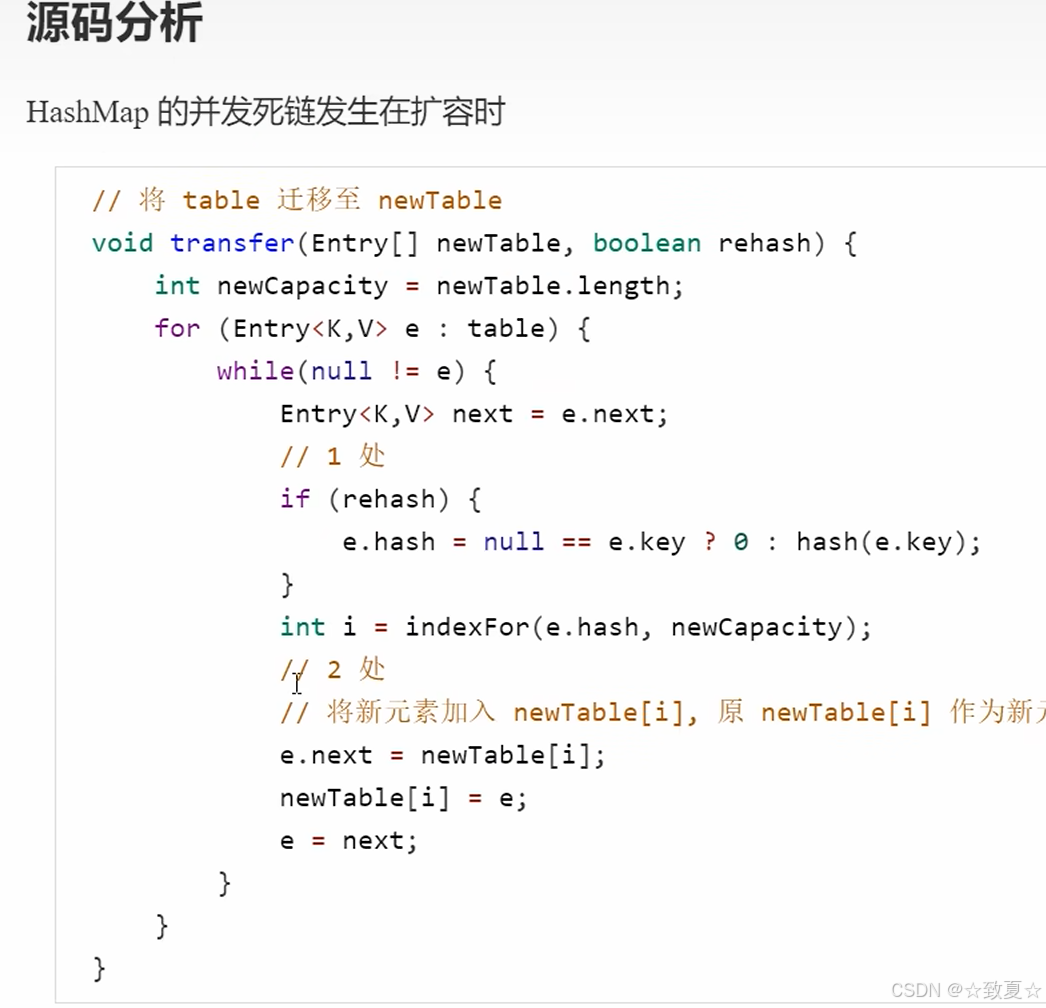
transfer是扩容时调用的方法

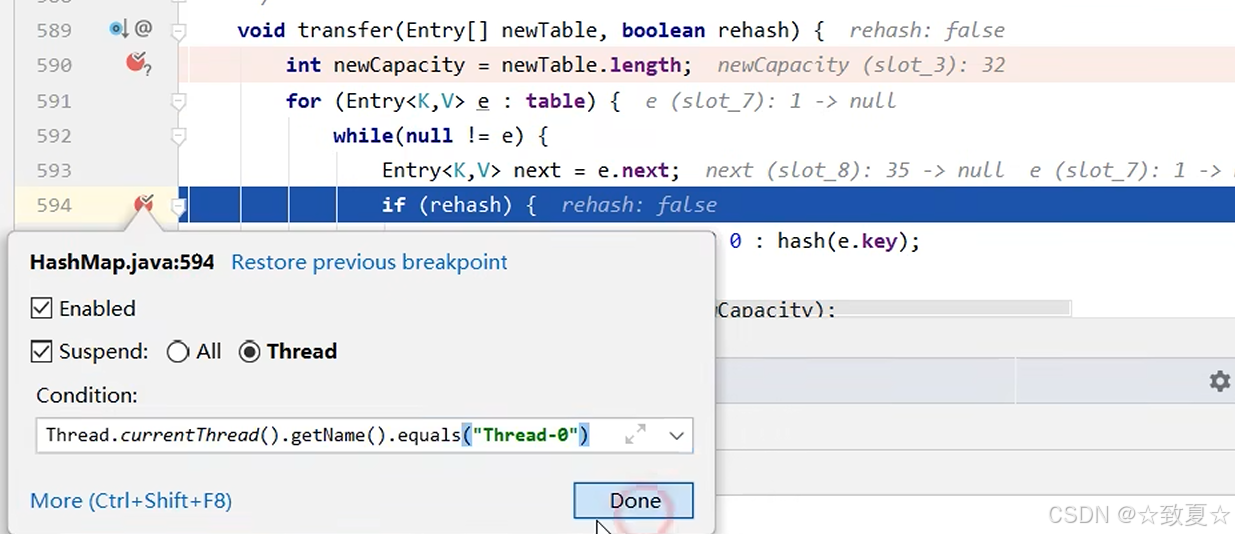
为了避免其他程序对hashmap扩容调试干扰,设置断点停下的条件
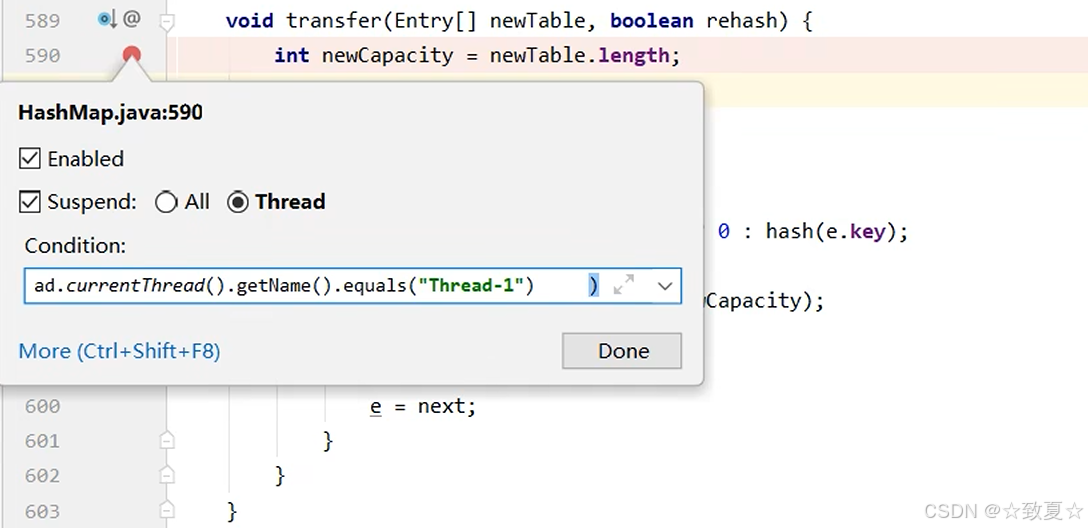
开启debug调试
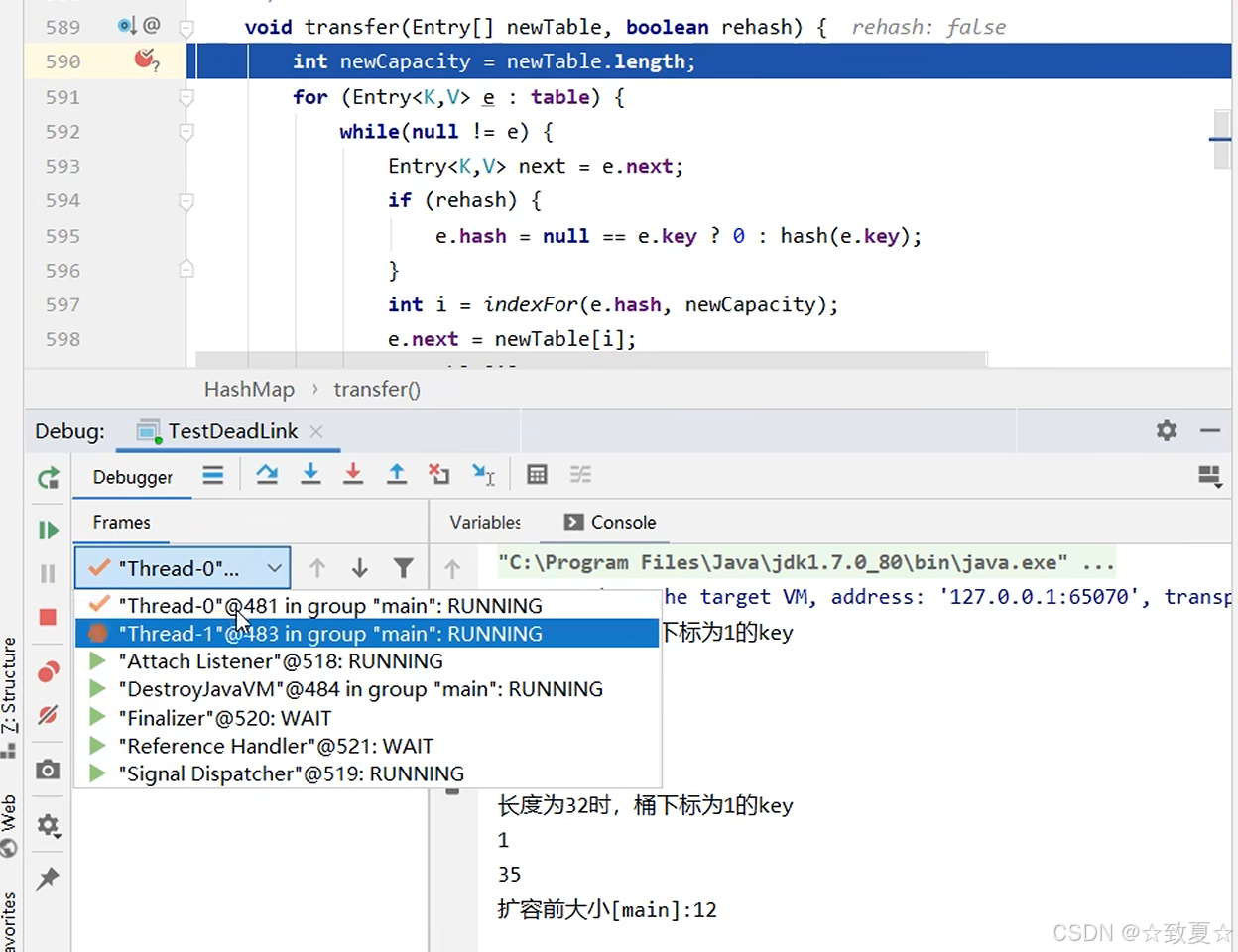
查看hash表的结构
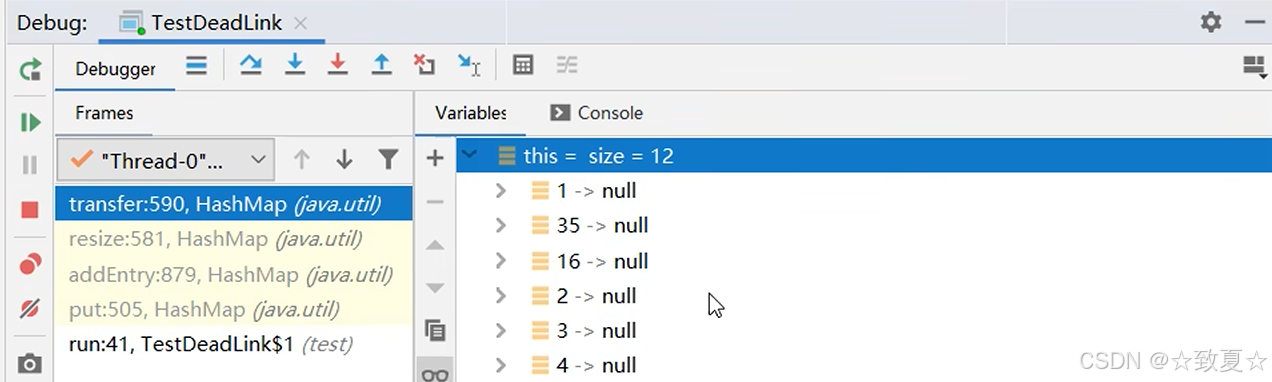
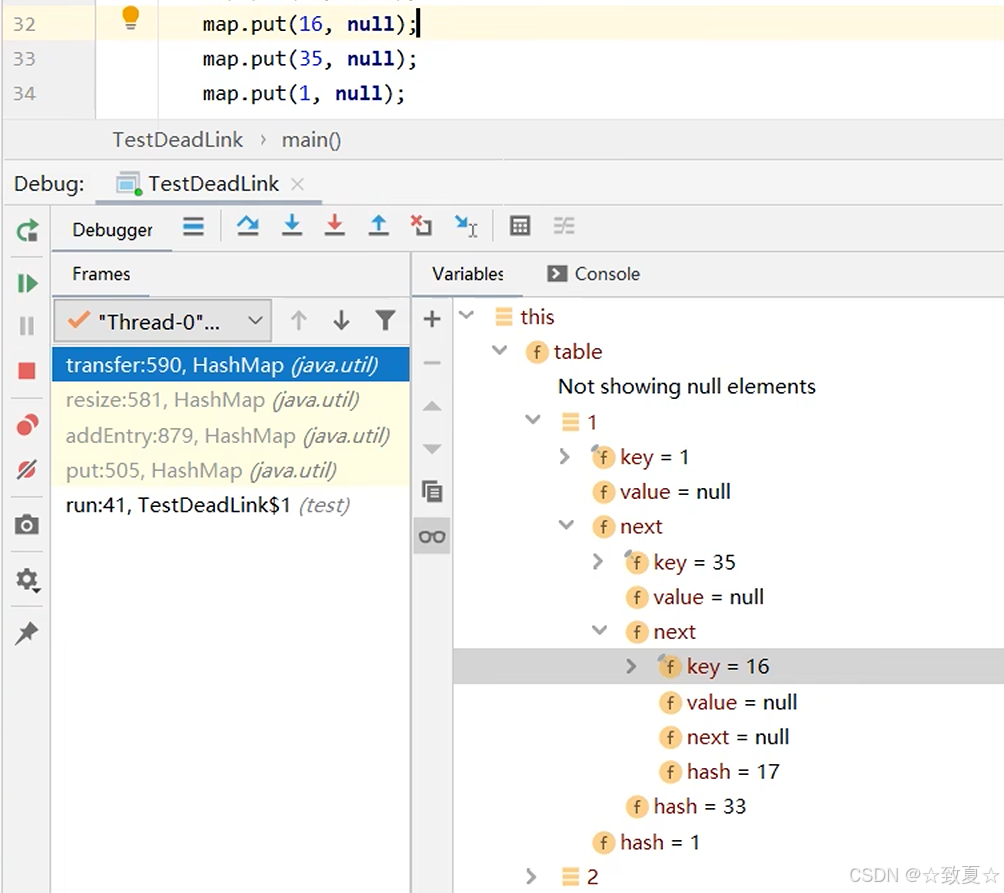

断点处时线程0,切换到线程1,让其扩容先全部运行完成
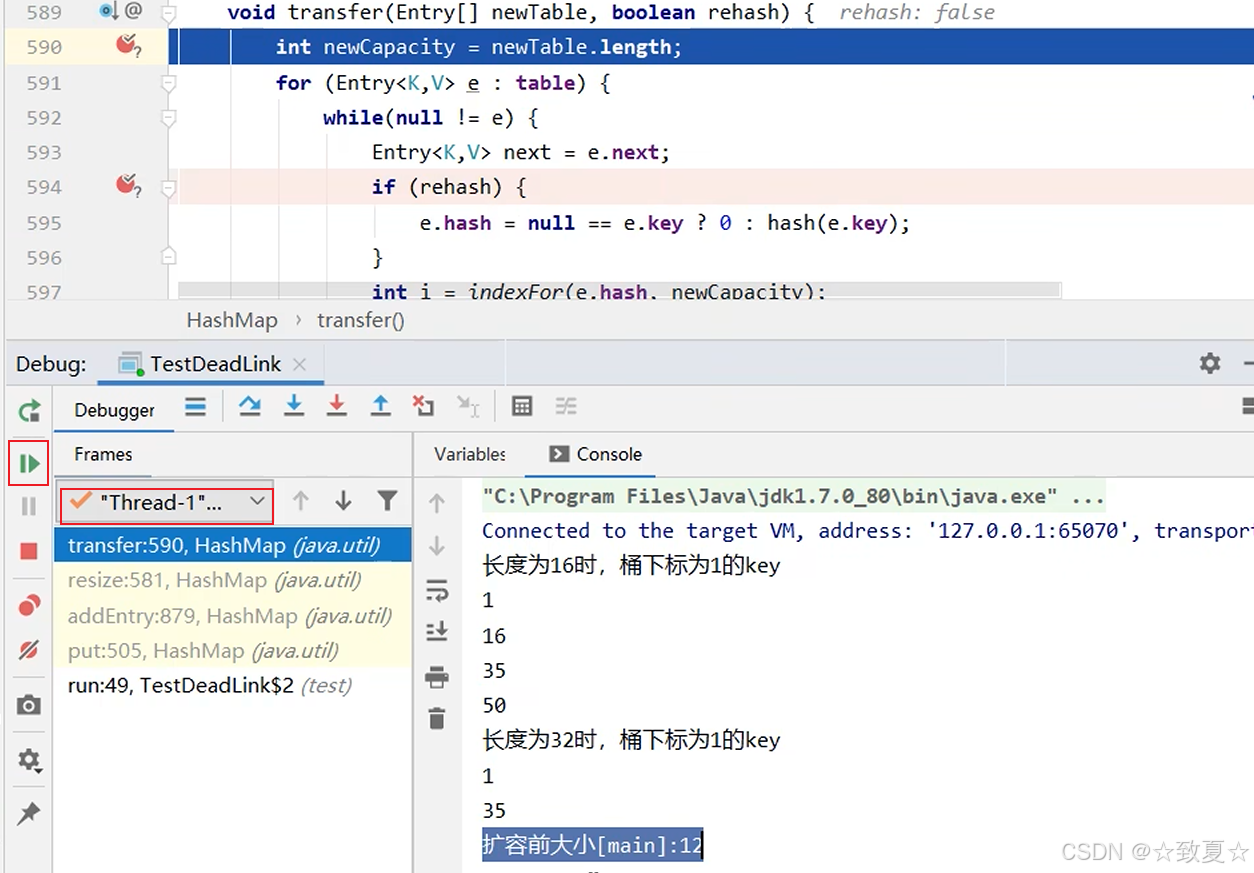
运行完成,线程1扩容完成,线程0还是停留原处
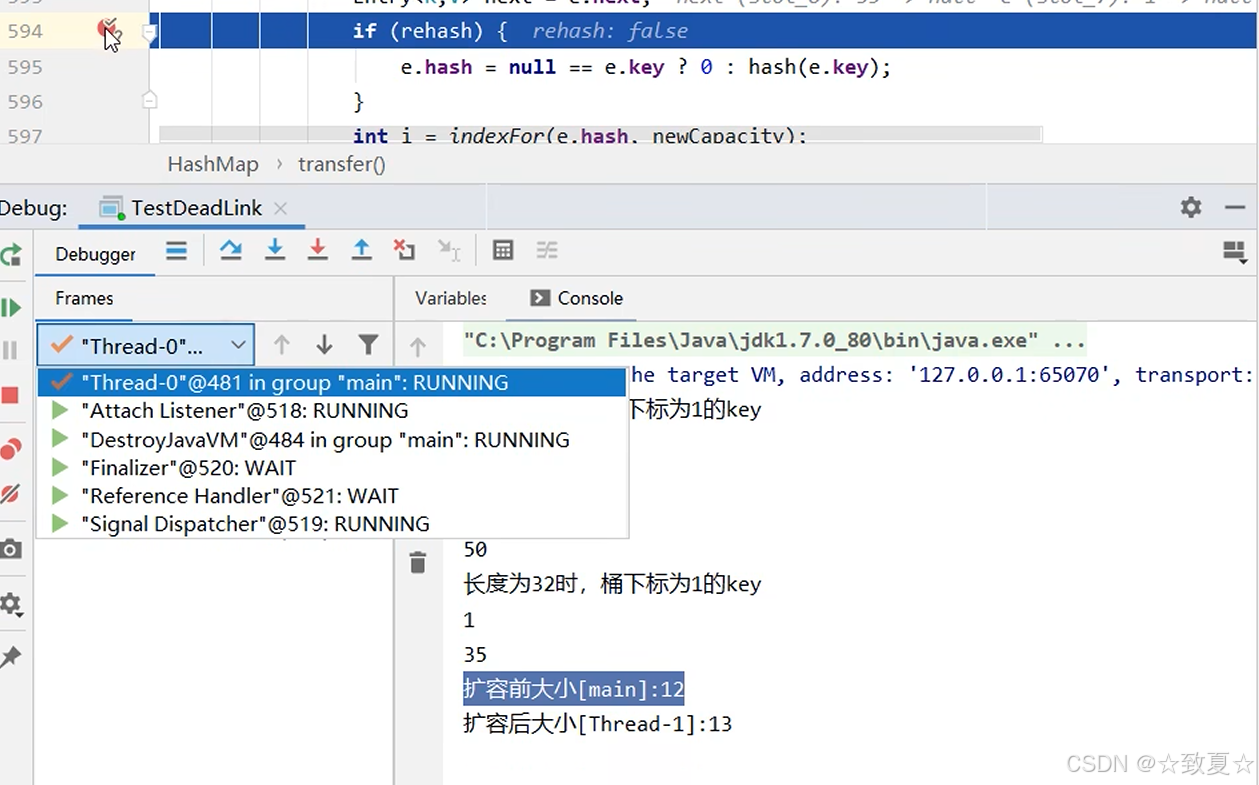
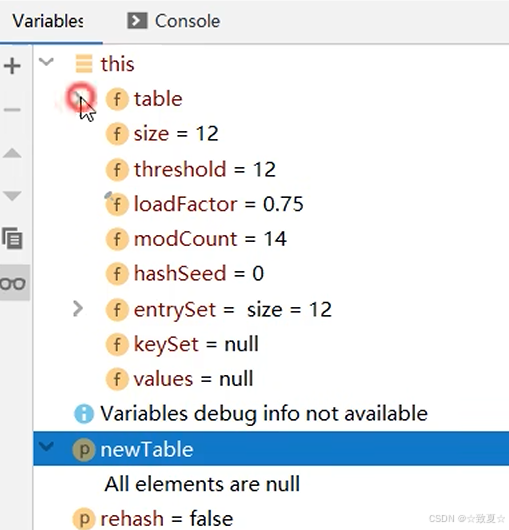
查看hashMap的全部结构,发现容量已经从16->32,newTable也已经没有了,table已经被替换

此时table,35->1->null,中间少了之前没扩容的16
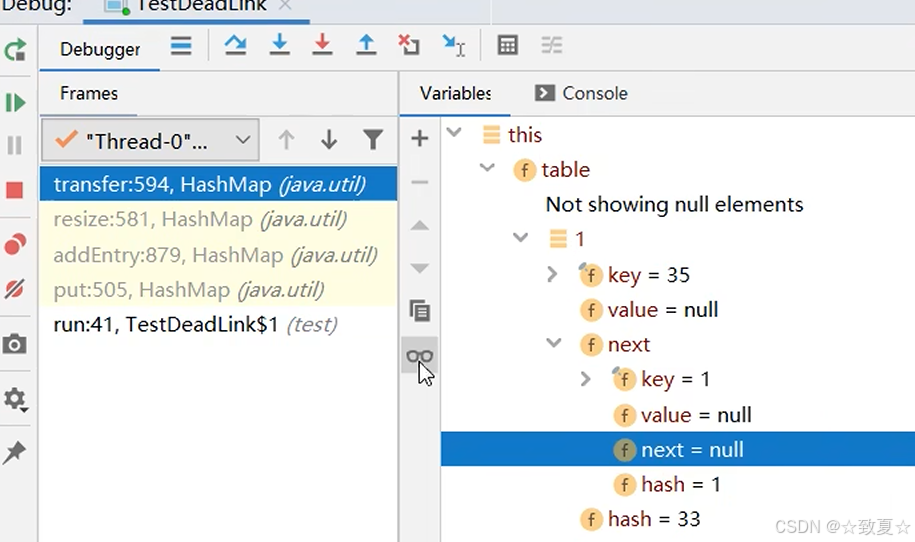

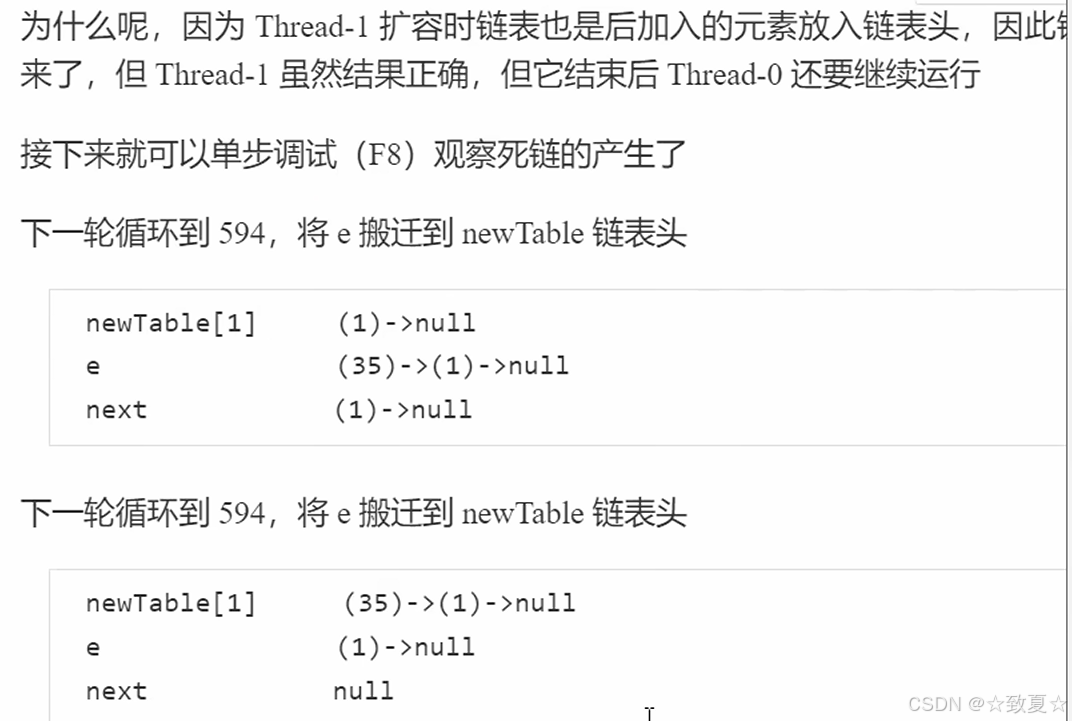


ConcurrentHashMap-重要属性和内部类
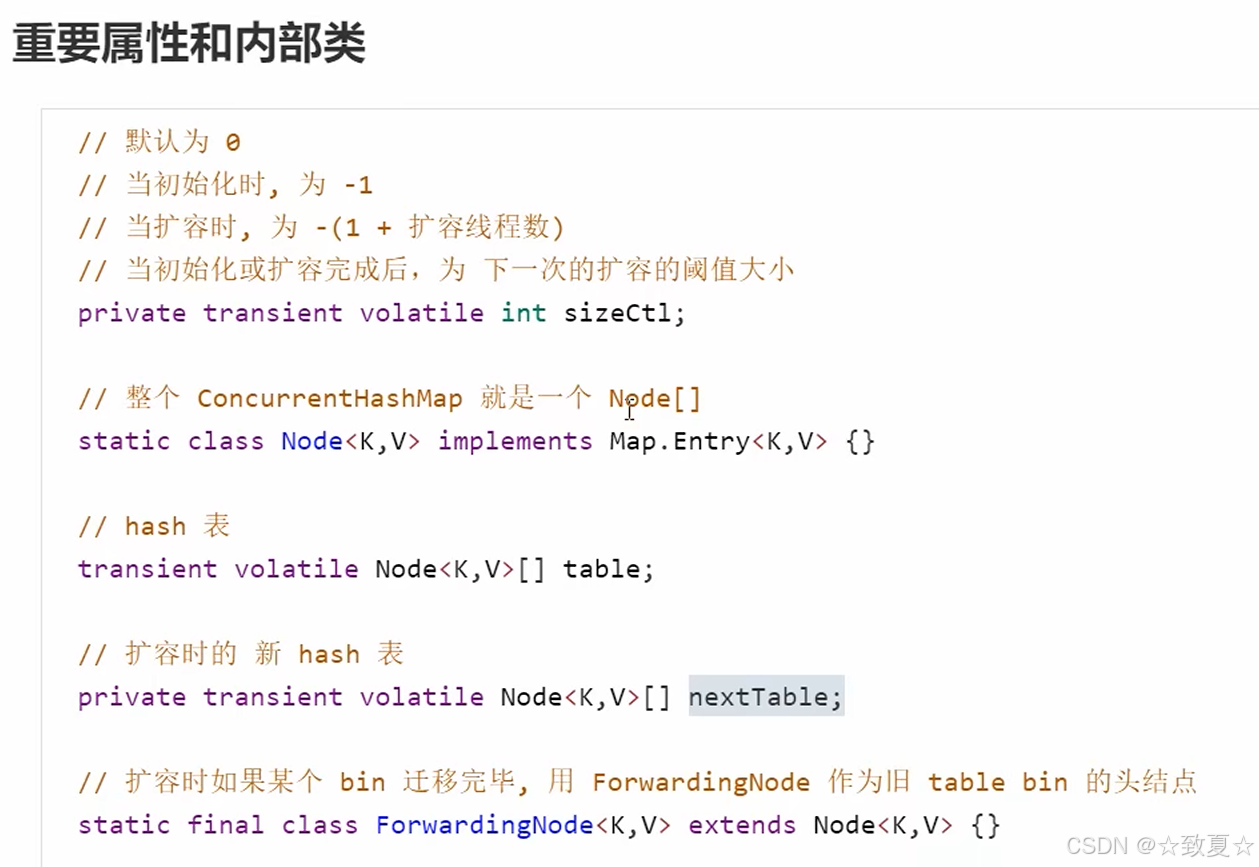


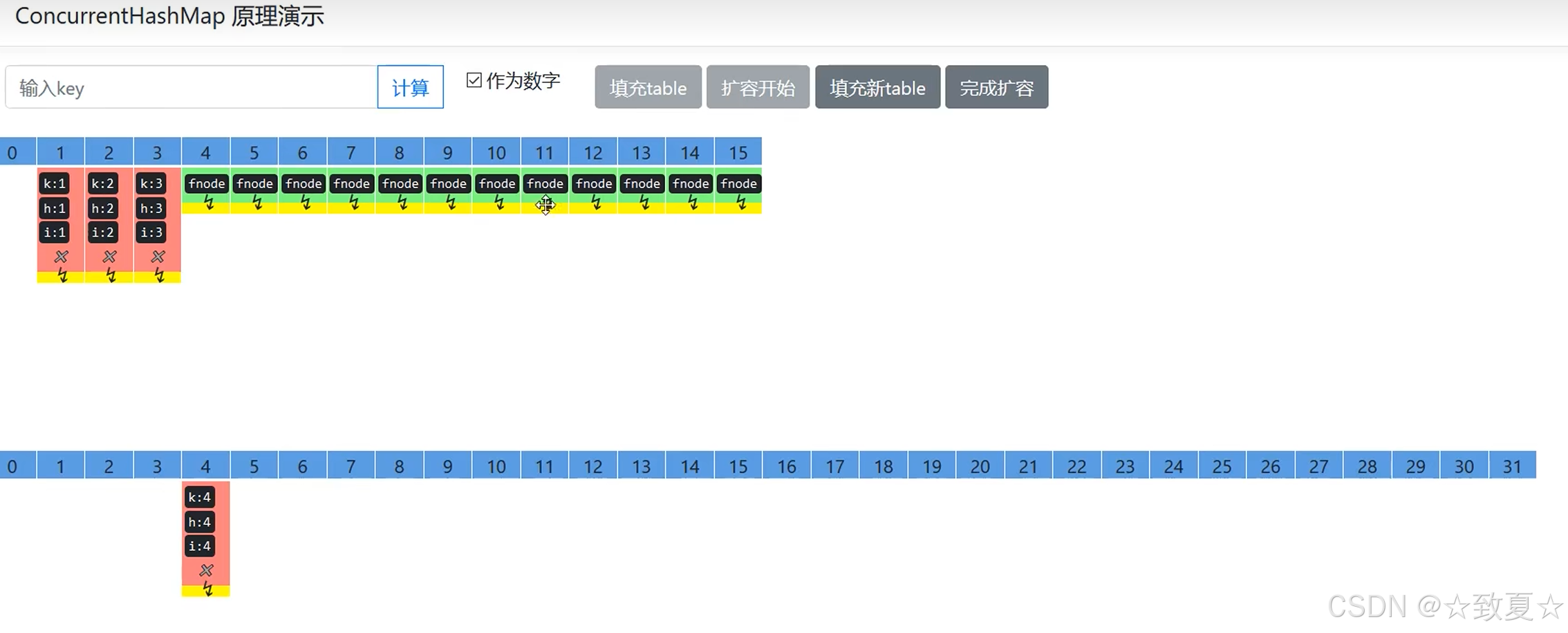
容量使用大小达到3/4会扩容
链表元素从后往前迁移,迁移完的打上fnode标记,其他线程看到标记后去新Map去找元素
当容量大小到达64,链表元素过长(长度 > 6),会进行红黑树优化提升查询效率,发生修改导致长度 < 6时,又会变成链表。
ConcurrentHashMap-构造

构造器三个参数:初识容量大小、负载因子(3/4)、并发度
懒惰初识化,构造器方法只定义了初始化容量大小
无论传的容量大小多少,最终都转为2^n,比如传入8,经过计算得出11,保证2^n,最终为16
后续hash算法必须要hash表大小为2^n
ConcurrentHashMap-get

相关文章:
)
JUC并发编程(下)
五、共享模型之内存 JMM(java内存模型) 主存:所有线程共享的数据(静态成员变量、成员变量) 工作内存:每个线程私有的数据(局部变量) 简化对底层的控制 可见性 问题 线程t通过r…...

Go语言中new与make的深度解析
在 Go 语言中,new 和 make 是两个用于内存分配的内置函数,但它们的作用和使用场景有显著区别。 理解它们的核心在于: new(T): 为类型 T 分配内存,并将其初始化为零值,然后返回一个指向该内存的指针 (*T)。make(T, ar…...

Xilinx 7Series\UltraScale 在线升级FLASH STARTUPE2和STARTUPE3使用
一、FPGA 在线升级 FPGA 在线升级FLASH时,一般是通过逻辑生成SPI接口操作FLASH,当然也可以通过其他SOC经FPGA操作FLASH,那么FPGA就要实现在启动后对FLASH的控制。 对于7Series FPGA,只有CCLK是专用引脚,SPI接口均为普…...

redisson-spring-boot-starter 版本选择
以下是更详细的 Spring Boot 与 redisson-spring-boot-starter 版本对应关系,按照 Spring Boot 主版本和子版本细分: 1. Spring Boot 3.x 系列 3.2.x 推荐 Redisson 版本:3.23.1(最新稳定版,兼容 Redis 7.x…...

QML定时器Timer和线程任务WorkerScript
定时器 Timer 属性 interval: 事件间隔毫秒repeat: 多次执行,默认只执行一次running: 定时器启动triggeredOnStart: 定时器启动时立刻触发一次事件 信号 triggered(): 定时时间到,触发此信号 方法 restart(): 重启定时器start(): 启动定时器stop(): 停止…...

Jsoup解析商品信息具体怎么写?
使用 Jsoup 解析商品信息是一个常见的任务,尤其是在爬取电商网站的商品详情时。以下是一个详细的步骤和代码示例,展示如何使用 Jsoup 解析商品信息。 一、准备工作 确保你的项目中已经添加了 Jsoup 依赖。如果你使用的是 Maven,可以在 pom.…...

jenkins数据备份
jenkins数据备份一般情况下分为两种, 1.使用crontab进行备份.这种备份方式是技术人员手动填写的备份的时候将workspace目录排除. 2.使用jenkins插件备份. 下载备份插件 ThinBackup,这里已经下载完成,如果没下载的情况下点击 安装好之后重启jenkins(直接点击插件安装位置的闲…...

IP核警告,Bus Interface ‘AD_clk‘: ASSOCIATED_BUSIF bus parameter is missing.
创建IP核生成输出的clk信号无法在GUI(customization GUI)显示clk信号,并且出现如下2个warning: [IP_Flow 19-3153] Bus Interface AD_clk: ASSOCIATED_BUSIF bus parameter is missing. [IP_Flow 19-4751] Bus Interface AD_clk:…...

Nginx配置同一端口不同域名或同一IP不同端口
以下是如何在Nginx中配置同一端口不同域名,以及同一IP不同端口的详细说明: 一、同一端口不同域名(基于名称的虚拟主机) 场景: 通过80端口,让 example.com 和 test.com 指向不同的网站目录(如 /…...

一键启动多个 Chrome 实例并自动清理的 Bash 脚本分享!
目录 一、📦 脚本功能概览 二、📜 脚本代码一览 三、🔍 脚本功能说明 (一)✅ 支持批量启动多个 Chrome 实例 (二)✅ 每个实例使用独立用户数据目录 (三)✅ 启动后自…...

LLaMA-Adapter
一、技术背景与问题 1.1 传统方法的数学局限 二、LLaMA-Adapter 核心技术细节 2.1 Learnable Adaption Prompts 的设计哲学 这种零初始化注意力机制的目的是在训练初期稳定梯度,避免由于随机初始化的适配提示带来的不稳定因素。通过门控因子gl的自适应调整,在训…...

鸿蒙电脑系统和统信UOS都是自主可控的系统吗
鸿蒙电脑系统(HarmonyOS)和统信UOS(Unity Operating System)均被定位为自主可控的操作系统,但两者的技术背景、研发路径和生态成熟度存在差异,需结合具体定义和实际情况分析: 1. 鸿蒙系统&#…...
)
【Unity 如何使用 Mixamo下载免费模型/动画资源】Mixamo 结合在 Unity 中的实现(Animtor动画系统,完整配置以及效果展示)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Mixamo介绍1、网址2、Mixamo功能介绍Mixamo 的核心功能Mixamo 适用场景二、Mixamo下载免费模型三、Mixamo下载免费动画四、导入Unity1.人物模型配置2.动画配置五、场景配置和效果测试1.人物…...

linux文件重命名命令
Linux文件重命名指南 方法一:mv命令(单文件操作) mv 原文件名 新文件名基础用法示例: mv old_file.txt new_name.txt保留扩展名技巧: mv document-v1.doc document-v2.doc方法二:rename命令(…...

JavaScript-DOM-02
自定义属性: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title>…...

跨部门项目管理优化:告别邮件依赖
1. 工具整合 1.1 协作平台集中化 1.1.1 一体化协作工具优势 使用Microsoft Teams、Slack等一体化协作工具替代邮件,集成即时消息、文件共享、任务分配和视频会议功能,减少工具切换成本,提高沟通效率。 1.1.2 具体应用案例 在Teams中创建项目频道,关联任务看板(Planner)…...

ADB常用语句
目录 基本语句 pm 包管理操作 查看文件夹内容 查看文件内容 删除文件 dumpsys查看系统服务状态 logcat保存日志 日志级别 基本语句 查看是否安装成功 adb version查看是否连接成功 adb devices断开连接 adb disconnect进入安卓系统 adb shell 退出安卓系统 exit…...

阿里发布扩散模型Wan VACE,全面支持生图、生视频、图像编辑,适配低显存~
项目背景详述 推出与目的 Wan2.1-VACE 于 2025 年 5 月 14 日发布,作为一个综合模型,旨在统一视频生成和编辑任务。其目标是解决视频处理中的关键挑战,即在时间和空间维度上保持一致性。该模型支持多种任务,包括参考到视频生成&a…...

谷歌开源轻量级多模态文本生成模型:gemma-3n-E4B-it-litert-preview
一、Gemma 3n模型概述 1.1 模型简介 Gemma 3n是Google DeepMind开发的一系列轻量级、最先进的开源模型。这些模型基于与Gemini模型相同的研究和技术构建,适合多种内容理解任务,如问答、摘要和推理等。 1.2 模型特点 Gemma 3n模型专为在资源受限设备上…...

【Linux】了解 消息队列 system V信号量 IPC原理
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、了解消息队列 ✨消息队列函数 🍔ftok() --- 系统调用设置key 🍔 msgget() 🍔msgctl() 🍔msgsnd() ✨消息队列的管理指令 二、了…...

Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡
Git Clone 原理详解:为什么它比本地文件复制更快? -优雅草卓伊凡 今天有朋友问我:“为什么 git clone 下载文件这么快?而我在本地复制粘贴文件时,速度却慢得多?” 这个问题很有意思,因为它涉及…...

高级认知型Agent
目标: 构建一个具备自主规划、多步推理、工具使用、自我反思和环境交互能力的智能代理,使其能够高效、可靠地完成复杂任务。 核心理念: Agent的智能涌现于一个精密的认知循环: 感知 (Perceive) -> 理解与规划 (Think/Plan - 想) -> 信息获取 (Search/Act - 查) -&g…...
详解)
网络爬虫(Web Crawler)详解
网络爬虫(Web Crawler)详解 1. 基本概念与核心目标 定义: 网络爬虫是一种自动化的程序,通过HTTP协议访问网页,提取并存储数据(如文本、链接、图片),并根据策略递归访问新链接。核心目标: 数据采集:抓取特定网站或全网公开数据。索引构建:为搜索引擎提供页面内容(如…...

SQL 数值计算全解析:ABS、CEIL、FLOOR与ROUND函数深度精讲
一、问题拆解:数值计算需求分析 1.1 业务需求转换 题目:在numbers表中计算每个数值的绝对值、向上取整、向下取整和四舍五入值。 关键分析点: 需要对同一字段进行四种不同的数学运算每种运算对应一个特定的SQL数学函数需保持原始数据完整…...

智能导览系统多语言解说与AI问答功能:从deepseek到景区知识图谱的构建
本文面向 文旅行业技术决策者、GIS 开发者、AI 算法工程师,旨在解决不够智能化导致游客体验不足的核心痛点,提供从技术选型到落地部署的全链路解决方案。 如需获取智慧景区导览系统解决方案请前往文章最下方获取,如有项目合作及技术交流欢迎私…...

10.18 LangChain ToolMessage实战:多轮交互与状态管理全解析
使用 ToolMessage 管理工具调用输出 关键词:LangChain ToolMessage, 工具调用管理, 多轮交互控制, 状态持久化, 输出解析 1. ToolMessage 的定位与价值 在 LangChain v0.3 的 Agent 工作流中,ToolMessage 是专门用于管理工具调用输出的消息类型,主要解决以下核心问题: #m…...
)
linux基础操作11------(运行级别)
一.前言 这个是linux最后一章节内容,主要还是介绍一下,这个就和安全有关系了,内容还是很多的,但是呢,大家还是做个了解就好了。 二.权限掩码 运行级别 0 关机 运行级别 1 单用户 ,这个类似于windows安全…...

Python Ray 扩展指南
Python Ray 扩展指南 Ray 是一个开源的分布式计算框架,专为扩展 Python 应用程序而设计,尤其在人工智能和机器学习领域表现出色。它提供了简单的 API,使开发者能够轻松编写并行和分布式代码,而无需关注底层复杂性。以下是关于 Py…...

笑林广记读书笔记三
《锯箭杆》 一人往观武场,飞箭误中其臂。请外科医治疗,医遂用小锯截其外露箭杆,即索谢礼。 问:“内截箭头如何?” 医曰:“此是内科的事,你去找他们。” 白话翻译: 有…...

npm、pnpm、yarn 各自优劣深度剖析
在前端开发领域,包管理工具是开发者的得力助手,它们负责处理项目中的依赖安装、更新与管理。npm、pnpm、yarn 是目前最主流的三款包管理工具,它们在功能上有诸多相似之处,但在实际使用中又各有优劣。本文将结合包管理工具常见问题…...

Ulisses Braga-Neto《模式识别和机器学习基础》
模式识别和机器学习基础 [专著] Fundamentals of pattern recognition and machine learning / (美)乌利塞斯布拉加-内托(Ulisses Braga-Neto)著 ; 潘巍[等]译 推荐这本书,作者有自己的见解,而且提供代码。问题是难度高,对于初学…...

python查询elasticsearch 获取指定字段的值的list
from elasticsearch import Elasticsearch from datetime import datetime, timedelta# 1.connect to Elasticsearch------------------------------------------------------------------------------------------------------ # prod连接到 Elasticsearch es_of_prod Elasti…...

百度Q1财报:总营收325亿元超预期 智能云同比增速达42%
发布 | 大力财经 5月21日晚,百度发布2025年第一季度财报,显示一季度总营收达325亿元,百度核心营收255亿元,同比增长7%,均超市场预期。一季度,百度核心净利润同比增48%至76.3亿元,智能云持续强劲…...

BurpSuite Montoya API 详解
文章目录 前言1. API 结构1.1 概述1.2 API文件源码解析 2. BurpExtension 接口3. MontoyaApi接口4. package burp.api.montoya.proxy4.1 Proxy 接口4.2 ProxyRequestHandler接口4.3 Demo 5. BurpSuite burpSuite()6. Extension extension()7. Http http()参考 前言 我们已经学…...

oracle使用SPM控制执行计划
一 SPM介绍 Oracle在11G中推出了SPM(SQL Plan management),SPM是一种主动的稳定执行计划的手段,能够保证只有被验证过的执行计划才会被启用,当由于种种原因(比如统计信息的变更)而导致目标SQL产生了新的执…...

YCKC【二分查找专题】题解
数的范围题解点击跳转题目链接:数的范围 比较经典的二分查找例题,不做过多赘述。注意看二分的对象以及最终想求什么:想求尽可能大 ,那么就是最大值类型的二分;想求尽可能小,就是最小值类型的二分。注意二分…...

【Java高阶面经:微服务篇】8.高可用全链路治理:第三方接口不稳定的全场景解决方案
一、第三方接口治理的核心挑战与架构设计 1.1 不稳定接口的典型特征 维度表现影响范围响应时间P99超过2秒,波动幅度大(如100ms~5s)导致前端超时,用户体验恶化错误率随机返回5xx/429,日均故障3次以上核心业务流程中断,交易失败率上升协议不一致多版本API共存,字段定义不…...

关于FPGA 和 ASIC设计选择方向的讨论
FPGA 和 IC 设计怎么选?哪个发展更好? 一句话总结: 如果你学历极高,追求高薪资、愿意投入长期学习,目标是进入大型芯片公司,建议走 IC(ASIC)设计;如果你更看重灵活性、创…...

项目中常用的docker指令
1. docker ps 查看当前正在运行的容器。 docker ps -a 这将列出所有容器,包括停止运行的。 2. docker exec 在已经运行的容器中执行命令的工具 启动一个交互式 Bash 会话 docker exec -it my-container bash介绍 docker exec 命令 docker exec 是 Docker 提供的…...

以加减法计算器为例,了解C++命名作用域与函数调用
************* C topic: 命名作用域与函数调用 ************* The concept is fully introducted in the last artical. Please refer to 抽象:C命名作用域与函数调用-CSDN博客 And lets make a calculator to review the basic structure in c. 1、全局函数 A…...

MySQL EXPLAIN 使用详解与执行计划分析优化
MySQL EXPLAIN 使用详解与执行计划分析优化 一、什么是 EXPLAIN? EXPLAIN 是 MySQL 提供的 SQL 语句分析工具,可以显示 SQL 语句在执行时的执行计划,包括表的访问顺序、使用的索引、连接类型、扫描行数等。通过分析 EXPLAIN 的输出结果&…...

Arthas:Java诊断利器实战指南
在Java应用开发和运维中,线上问题排查往往是一场与时间的赛跑。传统的日志分析、重启大法或JVM工具(如jstack、jmap)虽然有效,但存在操作复杂、无法实时追踪等问题。Arthas作为阿里巴巴开源的Java诊断工具,凭借无需重启…...

一文读懂迁移学习:从理论到实践
在机器学习和深度学习的快速发展历程中,数据和计算资源成为了制约模型训练的关键因素。当我们面对新的任务时,重新训练一个从头开始的模型往往耗时耗力,而且在数据量不足的情况下,模型的性能也难以达到理想状态。这时,…...

ElasticSearch安装
ElasticSearch 脑图知识图谱地址:ProcessOn Mindmap|思维导图 简介 ES是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建,专为处理海量数据设计,支持实时搜索、分析和可视化。 排行第一的搜索引擎 官网地址࿱…...
)
c#中添加visionpro控件(联合编程)
vs添加vp控件 创建窗体应用 右键选择项 点击确定 加载CogAcqfifoTool工具拍照 设置参数保存.vpp 保存为QuickBuild或者job, ToolBlock 加载保存的acq工具 实例化相机工具类 //引入命名空间 using Cognex.VisionPro; //实例化一个相机工具类 CogAcqFifoTool cogAcqFifoTool n…...

MySQL主键与外键详解:数据关系的基石与守护者
引言 在数据库设计中,主键(Primary Key)和外键(Foreign Key)是构建数据关系模型的核心工具。它们不仅保障了数据的唯一性和完整性,还实现了跨表数据关联的逻辑闭环。本文将通过实例解析这两大关键概念&…...

Go语言打造:超高性能分布式唯一ID生成工具
一、简介 这是一个超高性能唯一ID生成工具,支持docker一键部署,提供API接入功能支持高性能生成Snowflake ID、Sonyflake ID、UUID v1、UUID v4、XID、KSUID以及自定义ID的服务可以用来生成订单编号、学号、高标准唯一标识、有序ID等等开源地址参考&#…...

列表计量单位显示
列表计量单位显示 E:\javaDev\tender-project-vben5\apps\web-antd\src\views\tender\material\data.ts import type { FormSchemaGetter } from #/adapter/form; import type { VxeGridProps } from #/adapter/vxe-table;import { getDictOptions } from #/utils/dict; impor…...

RAG系统的现实困境与突破:数据泥潭到知识自由
一、当前RAG系统的核心痛点 1. 数据处理的阿喀琉斯之踵 知识形态的暴力归一化:将PDF、视频、数据库等异构数据强行转化为统一文本,导致: 纸质文献中的数学公式OCR错误率高达37%(ICDAR2023数据)流程图/思维导图等非连续…...

项目执行中缺乏问题记录和总结,如何改进?
要有效改进项目执行中的问题记录与总结机制,应采取建立标准化问题记录流程、引入专业管理工具、定期开展问题复盘、设立知识库系统、强化团队总结意识等措施。其中,建立标准化问题记录流程是核心。没有统一流程,问题易被忽视、重复发生&#…...