数据结构与算法分析实验14 实现基本排序算法
实现基本排序算法
- 1. 常用的排序算法简介
- 2. 上机要求
- 3. 上机环境
- 4.程序清单(写明运行结果及结果分析)
- 4.1 程序清单
- 4.1.1 头文件 sort.h 内容如下:
- 4.1.2 实现文件 sort.cpp 内容如下:
- 4.1.3 源文件 main.cpp 内容如下:
- 4.2 实现展效果示
- 5.上机体会
1. 常用的排序算法简介
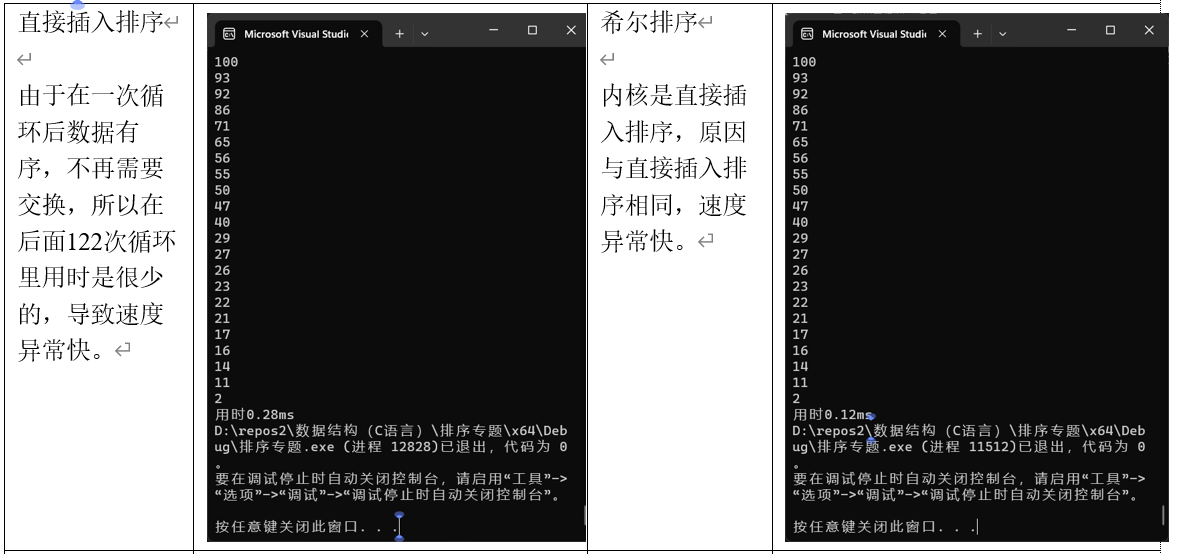
- 冒泡排序
冒泡排序是一种简单的排序算法,通过重复地遍历要排序的列表,比较相邻的元素并交换它们的位置,直到没有需要交换的元素为止。冒泡排序的时间复杂度为 O(n²),适用于小规模数据。 - 选择排序
选择排序通过每次从未排序的部分中选择最小(或最大)的元素,将其放到已排序部分的末尾。选择排序的时间复杂度为 O(n²),适用于小规模数据。 - 插入排序
插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序的时间复杂度为 O(n²),适用于小规模或部分有序的数据。 - 快速排序
快速排序是一种分治算法,通过选择一个“基准”元素,将数组分为两部分,一部分小于基准,另一部分大于基准,然后递归地对这两部分进行排序。快速排序的平均时间复杂度为 O(n log n),适用于大规模数据。 - 归并排序
归并排序也是一种分治算法,通过将数组分成两半,分别对它们进行排序,然后将排序后的两半合并。归并排序的时间复杂度为 O(n log n),适用于大规模数据。 - 堆排序
堆排序利用堆这种数据结构进行排序,通过构建最大堆或最小堆,将堆顶元素与末尾元素交换,然后调整堆,重复此过程直到排序完成。堆排序的时间复杂度为 O(n log n),适用于大规模数据。
………………
2. 上机要求
编写一个程序,实现排序的相关运算,并完成如下功能:
(1)直接插入排序
(2)希尔排序
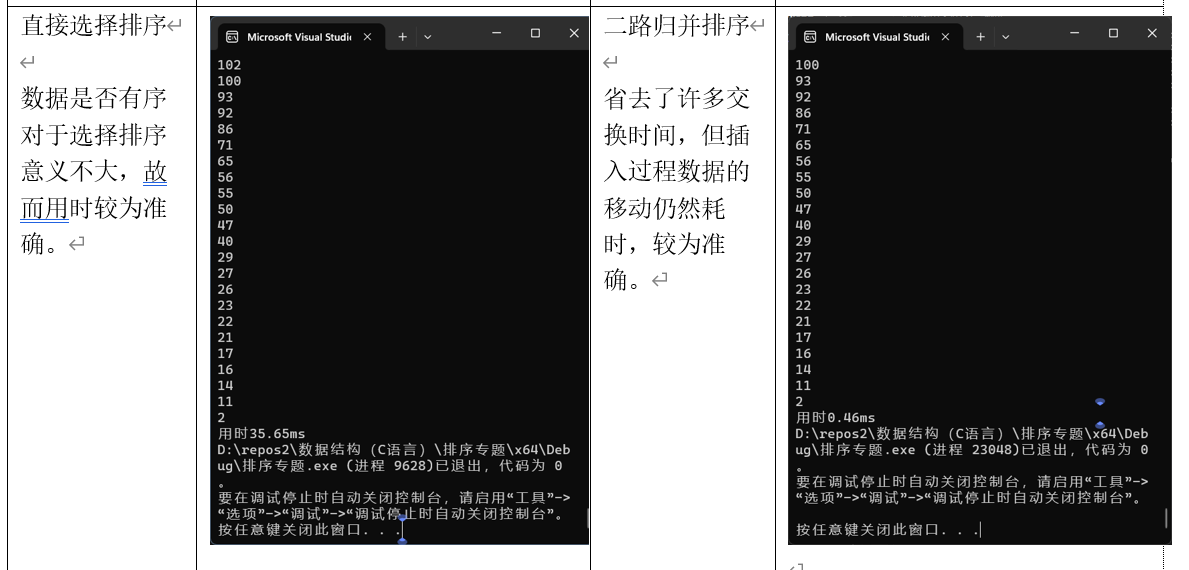
(3)直接选择排序
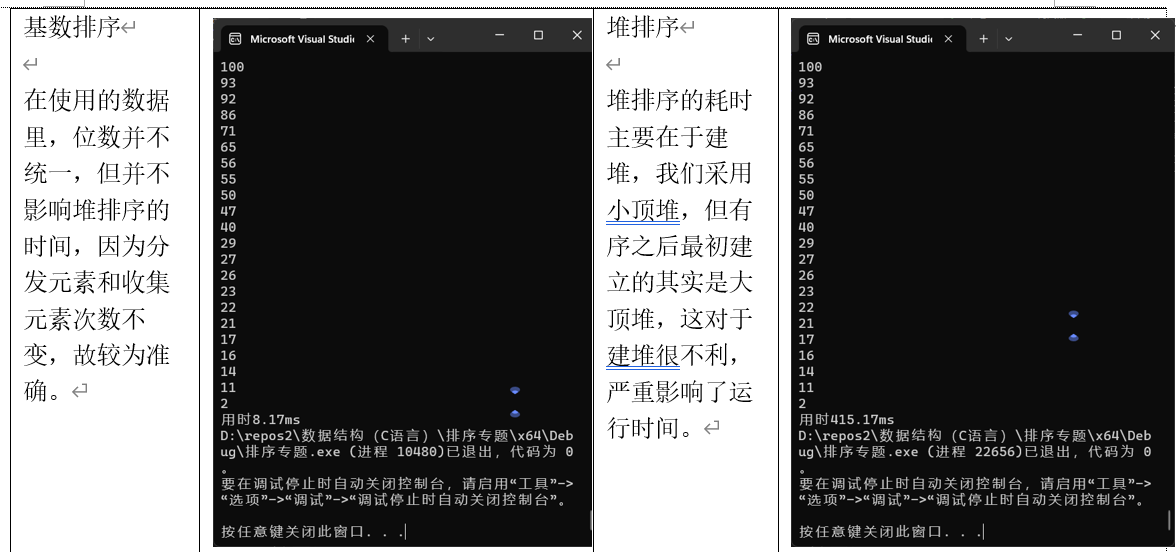
(4)堆排序
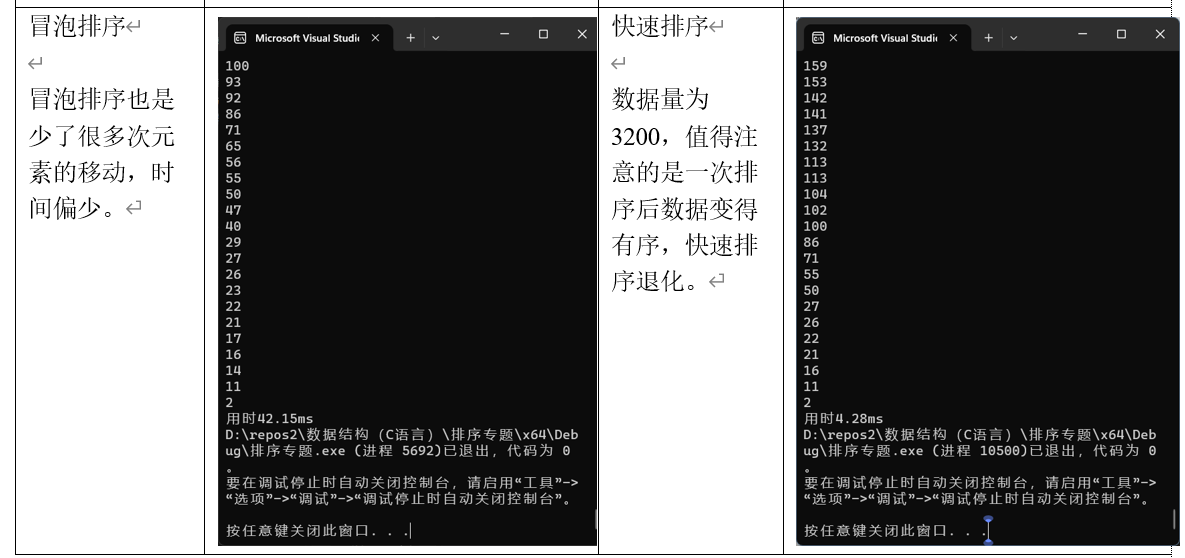
(5)冒泡排序
(6)快速排序
(7)二路归并排序
(8)基数排序
3. 上机环境
visual studio 2022
Windows11 家庭版 64位操作系统
4.程序清单(写明运行结果及结果分析)
4.1 程序清单
4.1.1 头文件 sort.h 内容如下:
#pragma once
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
#include<iostream>
//采用从大到小的顺序typedef int Data;//交换两个元素(值交换)
void swap(Data* a, Data* b);//直接插入排序
void Sort_insert(Data* arr,int len);//希尔排序
void Sort_shell(Data* arr,int len,int* way,int size);
void Sort_jump(Data* arr, int len, int jump); //shell sort 内置函数//直接选择排序,每次确定两个元素
void Sort_choose(Data* arr, int len);//堆排序
void Sort_heap(Data* arr, int len);
void min_down(Data* arr, int index); //一次遍历 arr 数组 将最小元素放在index中
int Lcd(int index); //index 节点“左子树”
int Rcd(int index); //index 节点“右子树”
int Pat(int index); //index 节点“双亲”//冒泡排序
void Sort_bubble(Data* arr, int len);//快速排序
void Sort_quick(Data* arr, int low,int high);//利用二路归并排序的想法将一个数组排序
void Sort_merge(Data* arr,Data* tmp, int low, int high);
void Merge(Data* arr, Data* tmp, int start, int mid, int end); //Sort_merge内置函数//基数排序,需要用链表结构以提升时间,节约空间
void Sort_bucket(Data* arr, int len,int exp);
void distribute_collect(Data* arr, int len,int exp); //发到筒里去,收回去typedef struct Node {Data data;struct Node* next;
}node, * pnode;void push(node* aim, Data data);
Data pop(node* aim);
4.1.2 实现文件 sort.cpp 内容如下:
#include"sort.h"
#include<math.h>void swap(Data* a, Data* b) {Data c = *a;*a = *b;*b = c;
}void Sort_insert(Data* arr, int len){for (int i = 1; i < len; i++) {int tmp = arr[i];for (int j = i-1; j >=0; j--) {if (arr[j] < tmp) arr[j + 1] = arr[j]; else { arr[j+1] = tmp; break; }if (j == 0)arr[j] = tmp;}}
}
希尔排序实现:
希尔排序(Shell Sort)是一种基于插入排序的算法,通过将数组分成多个子序列进行排序,逐步减少子序列的长度,最终完成整个数组的排序。以下是希尔排序的实现步骤:
- 选择增量序列
希尔排序的核心是选择一个增量序列(gap sequence),用于将数组分成多个子序列。常见的增量序列有希尔原始序列(n/2, n/4, …, 1)或更高效的序列如Hibbard序列、Sedgewick序列等。
void Sort_shell(Data* arr, int len, int* way, int size){for (int i = 0; i < size; i++) {Sort_jump(arr, len, way[i]); }
}
//arr 就是选择的序列
- 分组插入排序
根据选定的增量序列,将数组分成若干子序列,对每个子序列进行插入排序。随着增量逐渐减小,子序列的长度逐渐增加,最终当增量为1时,整个数组被当作一个子序列进行插入排序。
void Sort_jump(Data* arr, int len, int jump){for (int i = 1; i < len; i++) {int tmp = arr[i];for (int j = i - jump; j >= 0; j-=jump) {if (arr[j] < tmp) arr[j + jump] = arr[j];else { arr[j + jump] = tmp; break; }if (j <jump)arr[j] = tmp;}}
}
选择排序
void Sort_choose(Data* arr, int len){int maxflag = 0;int minflag = 0;for (int i = 0; i < len; i++) {maxflag = i;minflag = len - 1 - i;for (int j = i; j <= len - 1 - i; j++) {if (arr[maxflag] < arr[j])maxflag = j;if (arr[minflag] > arr[j])minflag = j;}swap(&arr[i], &arr[maxflag]);if (i == minflag) minflag = maxflag; swap(&arr[len - 1 - i], &arr[minflag]);}
}
堆排序
堆排序通过构建一个最大堆或最小堆,将堆顶元素(最大或最小)与堆的最后一个元素交换,然后调整剩余元素使其重新满足堆的性质,重复这一过程直到所有元素有序。
- Sort_heap 函数:这是堆排序的主函数,负责对整个数组进行排序。它从数组的最后一个元素开始,逐个调用 min_down 函数来调整堆。
void Sort_heap(Data* arr, int len){for (int i = len - 1; i >= 0; i--) {min_down(arr, i);}
}
- min_down 函数:该函数用于调整堆,确保从指定索引开始的子树满足最小堆的性质。它通过比较父节点和子节点的值,并在必要时交换它们的位置。
void min_down(Data* arr, int index) {if (Pat(index) >= 0) {int pos = Pat(index);while (pos>=-1) {if (arr[Lcd(pos)] < arr[pos]&&Lcd(pos)<=index) swap(&arr[Lcd(pos)], &arr[pos]);if (arr[Rcd(pos)] < arr[pos]&&Rcd(pos)<=index) swap(&arr[Rcd(pos)], &arr[pos]);pos--;}swap(&arr[index], &arr[0]);}
}
- Lcd 和 Rcd 函数:这两个函数分别用于计算给定索引的左子节点和右子节点的索引。
int Lcd(int index){return 2 * index + 1;
}int Rcd(int index){return 2 * index + 2;
}
- Pat 函数:该函数用于计算给定索引的父节点索引。
int Pat(int index){return (index - 1) / 2;
}
冒泡排序
void Sort_bubble(Data* arr, int len){for (int i = 0; i < len; i++) {for (int j = i + 1; j < len; j++) {if (arr[i] < arr[j])swap(&arr[i], &arr[j]);}}
}
快速排序
快速排序是一种高效的排序算法,采用分治法策略。其基本思想是通过选择一个“标杆”元素(通常称为“pivot”),将数组分为两部分:一部分小于标杆,另一部分大于标杆。然后递归地对这两部分进行排序。
void Sort_quick(Data* arr, int low, int high){int flag = low; //标杆元素下标if (low == high) return;for (int i = flag + 1; i <= high; i++) {if (arr[flag] >= arr[i])continue;if (arr[flag] < arr[i]) {swap(&arr[flag + 1], &arr[i]);swap(&arr[flag], &arr[flag + 1]);flag++;}}if (flag > low) Sort_quick(arr, low, flag - 1);if (flag < high) Sort_quick(arr, flag + 1, high);
}
归并排序
Sort_merge 函数是归并排序的递归部分。它将数组 arr 从 start 到 end 的部分分成两个子数组,分别对这两个子数组进行排序,然后调用 Merge 函数将两个有序的子数组合并。
Merge 函数负责将两个有序的子数组合并成一个有序的数组。它使用两个指针 i 和 j 分别指向两个子数组的起始位置,比较两个指针所指向的元素,将较小的元素放入临时数组 tmp 中。最后,将临时数组中的内容复制回原数组 arr。
void Sort_merge(Data* arr, Data* tmp, int start, int end){int mid;if (start < end) {mid = (start + end) / 2;Sort_merge(arr, tmp, start, mid);Sort_merge(arr, tmp, mid+1, end);Merge(arr, tmp, start, mid, end);}
}void Merge(Data* arr, Data* tmp,int start, int mid, int end){int move = start; int i = start; int j = mid + 1;while (i!=mid+1 && j!= end+1) {if (arr[i] > arr[j]) {tmp[move++] = arr[i++];}else {tmp[move++] = arr[j++];}}while (i != mid + 1) { tmp[move++] = arr[i++]; }while (j != end + 1) { tmp[move++] = arr[j++]; }for (i = start; i <= end; i++) {arr[i] = tmp[i];}
}
桶排序
桶排序(Bucket Sort)是一种分布式排序算法,它将元素分配到有限数量的桶中,然后对每个桶中的元素进行排序,最后将桶中的元素按顺序合并。以下是对代码的详细解析和优化建议。
Sort_bucket函数通过循环调用 distribute_collect 函数,对数组进行多次排序。exp 参数表示排序的轮数,通常与数据的位数相关。
void Sort_bucket(Data* arr, int len, int exp){for (int i = 1; i <= exp; i++) {//printf("exp=%d: \n", i);distribute_collect(arr, len, i);}
}void distribute_collect(Data* arr, int len,int exp){pnode bucket = (pnode)malloc(10 * sizeof(node));for (int i = 0; i < 10; i++) {bucket[i].next = NULL;}int lab = 0;for (int i = len-1; i >=0; i--) { //对到每个元素 从大到小排序就要从小到大塞进去 反之反之lab = arr[i];for (int j = 0; j < exp - 1; j++) lab /= 10;lab %= 10; //找到桶的下标push(&bucket[lab], arr[i]); //塞到桶里去//printf("push %d to lab %d\n", arr[i],lab);}//收回来int index = 0;for (int i = 9; i >= 0; i--) {while (bucket[i].next != NULL) {arr[index++] = pop(&bucket[i]);}}
}void push(node* aim, Data data){node* fresh = (node*)malloc(sizeof(node));fresh->next = NULL;fresh->data = data;fresh->next = aim->next;aim->next = fresh;
}Data pop(node* aim){pnode tmp = aim->next;Data ret = aim->next->data;aim->next = tmp->next;free(tmp);return ret;
}
4.1.3 源文件 main.cpp 内容如下:
#include"sort.h"
//#define size 10000
#define size 3200
#define filename "testdata.txt"
#define tm 123
//注意,在进行快速排序的时候,由于递归深度限制,对于给出的数据量有一个限制
//对于我自己生成的数据,Sort_quick极端情况为3218个数据。
//在实际操作中,Sort_quick数据量应控制在3200以下以确保运行稳定。
//在多次重复排序过程中,由于在后续重复中数据已经排好顺序,快速排序尚且不占优势。
int main() {FILE* fp;fopen_s(&fp, filename, "r");Data* arr = new Data[size];for (int i = 0; i < size; i++) {if (fp)fscanf_s(fp, "%6d", &arr[i]);}clock_t start = clock();Data* ret = NULL;for (int i = 0; i < tm; i++) {//Sort_insert(arr, size);//int way[7] = { 203,101,47,23,7,3,1 };//Sort_shell(arr, size, way, 7);//Sort_choose(arr, size);//Sort_quick(arr, 0, size-1);//Data* tmp = new Data[size];//Sort_merge(arr, tmp, 0, size - 1);//Sort_bucket(arr, size, 5);//Sort_heap(arr, size);}clock_t end = clock();double during = difftime(end, start) / tm;for (int i = 0; i < size; i++) {printf_s("%d\n", arr[i]);}printf_s("用时%.2fms", during);return 0;
}
4.2 实现展效果示
取消注释对应的代码段,将size 定义成10000(快速排序除外),对排序时间进行考察,给出一些现象产生的原因。
5.上机体会
我的收获主要包括:在上理论课之前,我对于排序算法的理解尚且不到位,就写了一些相关的排序算法,然而在很多地方都忽视了优化问题,直到理论课上完,才重新审视了代码的不足,实现了可读性的增强和基本原理的改进。同样的,对于堆排序时间为什么这么长也是在理论课之后才找到了答案,这也提醒我,不同的排序算法在不同的情况下具有不同的性能。通过实验,可以比较不同算法在处理相同数据集时的执行时间和效率,从而了解它们的相对性能,通过对关键参数的选取,例如枢轴量,增量数组,也更体会到好的算法应当由良好的数学分析而得到。数据结构也会对对算法性能产生影响:排序算法通常需要使用一些数据结构来辅助操作,如数组、链表等。不同的数据结构对算法的性能也会有影响。
相关文章:

数据结构与算法分析实验14 实现基本排序算法
实现基本排序算法 1. 常用的排序算法简介2. 上机要求3. 上机环境4.程序清单(写明运行结果及结果分析)4.1 程序清单4.1.1 头文件 sort.h 内容如下:4.1.2 实现文件 sort.cpp 内容如下:4.1.3 源文件 main.cpp 内容如下: 4.2 实现展效果示 5.上机…...

uni-app 中使用 mumu模拟器 进行调试和运行详细教程
一、下载mumu模拟器 二、复制安装路径暴保留 在文件夹中打开 三、配置全局adb命令 adb为Android Debug Bridge,就是起到调试桥的作用 打开shell文件夹、里面有一个adb.exe 将当前文件夹地址复制一下,即‘D:\Program Files\Netease\MuMu Player 12\sh…...
)
Visual Studio Code 改成中文模式(汉化)
1、打开工具软件(双击打开) 2、软件左边图标点开 3、在搜索框,搜索 chinese 出现的第一个 就是简体中文 4、点击第一个简体中文,右边会出来基本信息 点击 install 就可以安装了(记得联网)。 5、安装完右…...

破解 PCB 制造四大痛点:MOM 系统构建智能工厂新范式
在全球电子信息产业加速向智能化、高端化转型的背景下,PCB(印制电路板)作为 "电子产品之母",既是支撑 5G 通信、新能源汽车、人工智能等战略新兴产业发展的核心基础部件,也面临着 "多品种小批量快速切换…...

【基于深度学习的非线性光纤单像素超高速成像】
基于深度学习的非线性光纤单像素超高速成像是一种结合深度学习技术和单像素成像方法的前沿技术,旨在实现高速、高分辨率的成像。以下是一些关键点和方法: 深度学习在单像素成像中的应用 深度学习技术可以通过训练神经网络来优化单像素成像的重建过程。…...

Backend - Oracle SQL
目录 一、CRUD 增删改查(基础) (一)查询 (二)插入 (三)更新 (四)清空 二、常用 SQL 1. exists 搭配 select 1 2. FROM DUAL 3. INSTR()函数 4. 提取…...

WebSocket心跳机制
通常,心跳机制包括: 定期发送消息(如ping)到服务器以保持连接活跃检测服务器的相应(pong)如果一段时间没有收到相应,可能需要重新连接 ::: warning 在连接关闭或者发生错误时,清除心跳定时器,避免内存泄漏 ::: 在实现…...
)
计算机视觉与深度学习 | PSO-MVMD粒子群算法优化多元变分模态分解(Matlab完整代码和数据)
以下是一个基于PSO优化多元变分模态分解(MVMD)的Matlab示例代码框架,包含模拟数据生成和分解结果可视化。用户可根据实际需求调整参数。 %% 主程序:PSO优化MVMD参数 clc; clear; close all;% 生成模拟多变量信号 fs = 1000; % 采样频率 t = 0:1/fs:...

Fast Video Cutter Joiner v6.8.2 视频剪切合并器汉化版
想要快速拆解冗长视频,或是将零散片段拼接成完整作品?Fast Video Cutter Joiner 正是你需要的宝藏视频编辑软件!它以强大功能为核心,将复杂的视频处理变得简单直观。 精准的切割与合并功能,让你能随心所欲地裁剪视频…...
)
【漫话机器学习系列】269.K-Means聚类算法(K-Means Clustering)
一、K-Means 聚类算法简介 K-Means 是一种基于距离的无监督机器学习算法,属于聚类算法(Clustering Algorithm)。它的目标是将数据集划分为 K 个不重叠的子集(簇),使得每个子集中的数据点尽可能相似&#x…...
主要用到的模块库介绍)
【北邮通信系统建模与仿真simulink笔记】(1)主要用到的模块库介绍
【声明】 本博客仅用于记录博主学习内容、分享笔记经验,不得用作其他非学术、非正规用途,不得商用。本声明对本博客永久生效,若违反声明所导致的一切后果,本博客均不负责。 目录 1、信号源模块库(Sources)…...

【信息系统项目管理师】第11章:项目成本管理 - 32个经典题目及详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...
:Sql构建)
Java转Go日记(四十四):Sql构建
1.1.1. 执行原生SQL db.Exec("DROP TABLE users;")db.Exec("UPDATE orders SET shipped_at? WHERE id IN (?)", time.Now, []int64{11,22,33})// Scantype Result struct {Name stringAge int}var result Resultdb.Raw("SELECT name, age FROM use…...

数组day2
209长度最小的子数组 class Solution { public:int minSubArrayLen(int s, vector<int>& nums) {int result INT32_MAX;int sum 0; // 滑动窗口数值之和int i 0; // 滑动窗口起始位置int subLength 0; // 滑动窗口的长度for (int j 0; j < nums.size(); j) …...

《Effective Python》第三章 循环和迭代器——永远不要在迭代容器的同时修改它们
引言 本文基于《Effective Python: 125 Specific Ways to Write Better Python, 3rd Edition》第3章“循环和迭代器”中的 Item 22:“Never Modify Containers While Iterating over Them; Use Copies or Caches Instead(永远不要在迭代容器的同时修改它…...

SQLite基础及优化
SQLite 什么是SQLite SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它&#…...

数据库与存储安全
2.1 SQL注入攻防实战(手工注入、自动化工具) 攻击原理与分类 联合查询注入:通过UNION SELECT窃取数据。 UNION SELECT 1,username,password FROM users-- 布尔盲注:利用页面响应差异逐位提取数据。 AND (SELECT SUBSTRING(password,1,1) FROM users WHERE id=1)=a-- 时间…...

vue3/vue2大屏适配
vue3-scale-box 和 vue2-scale-box 可以帮助你在不同 Vue 版本中实现大屏自适应缩放。vue3-scale-box - npmvue3 scale box. Latest version: 0.1.9, last published: 2 years ago. Start using vue3-scale-box in your project by running npm i vue3-scale-box. There is 1 o…...

【数据结构 -- AVL树】用golang实现AVL树
目录 引言定义旋转方式LL型RR型LR型RL型 实现结构获取结点高度平衡因子更新高度左旋右旋插入结点中序遍历 引言 AVL树,基于二叉搜索树通过平衡得到 前面我们知道,通过🔗二叉搜索树可以便捷快速地查找到数据,但是当序列有序时&am…...

matlab慕课学习3.5
于20250520 3.5 用while 语句实现循环结构 3.5.1while语句 多用于循环次数不确定的情况,循环次数确定的时候用for更为方便。 3.5.2break语句和continue语句 break用来跳出循环体,结束整个循环。 continue用来结束本次循环,接着执行下一次…...

【jmeter】base64加密
base64加密 执行的脚本: import java.io.*; import sun.misc.BASE64Encoder; String strvars.get("param") #设置了一个user paramBASE64Encoder encodernew BASE64Encoder() log.info("--------start----------") String resultencoder.encod…...

优化Hadoop性能:如何修改Block块大小
在处理大数据时,Hadoop的性能和资源管理是至关重要的。Hadoop的分布式文件系统(HDFS)将数据切割成多个块(Block),并将这些块分布在集群中的不同节点上。在默认情况下,HDFS的块大小可能并不适合所…...

jmeter转义unicode变成中文
打开jmeter,添加后置处理器到接口请求后,在添加完成后将代码复制进入 (注意:最后执行后需要到“察看结果树”里看,需要自行添加对应的监听器) 按如下添加代码进入上图位置: //如下复制于链接&…...

ALSA 插件是什么? PortAudio 断言失败是什么意思?
下面用更简单的语言和图文形式帮你理解: 1. ALSA 插件是什么?为什么重要? 想象你电脑里的音频系统就像一个厨房,ALSA 是厨房里的厨师,负责做出声音(做菜)和收集声音(收菜࿰…...

计算机科技笔记: 容错计算机设计05 n模冗余系统 双模冗余系统 Duplex Systems
接收测试 测试 (HA服务器的方法) HA系统 一、基本HA结构 当前常用的HA(High Availability)系统结构大体如下: 双机结构:两台主机(可称为主机A和主机B) 两种运行模式: A…...
Translational Psychiatry | 注意缺陷多动障碍儿童延迟厌恶的行为与神经功能特征茗创科技茗创科技
摘要 尽管已有大量研究致力于解析注意缺陷多动障碍(ADHD)中的认知异质性,但对其动机变化(尤其是延迟厌恶)的探索仍相对有限。本研究旨在通过识别ADHD儿童的同质性延迟厌恶特征来理解其动机缺陷,采用体验式延迟贴现任务对43名ADHD儿童和47名对照参与者(经…...

MYSQL备份恢复知识:第四章:备份锁
为了获得备份数据的一致性,需要在数据库中加锁,保证在备份期间没有数据变化。早期版本的MySQL仅支持表级锁,在加锁期间不允许访问数据库,这对生产环境是极大的挑战。因此,在后续版本中引入了实例级锁,使得备…...

寻找最优美做题曲线
题目描述 一个有趣的评测功能,就是系统自动绘制出用户的“做题曲线”。所谓做题曲线就是一条曲线,或者说是折线,是这样定义的:假设某用户在第 bi 天 AC 了 ci 道题,并且 bi 严格递增,那么该用户的做…...

DeepSeek-V3 vs GPT-4:技术对比与性能评测
DeepSeek-V3 vs GPT-4:技术对比与性能评测 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 DeepSeek-V3 vs GPT-4:技术对比与性能评测摘要引言技术架构对比1. 模型结构:稠密模型 …...

【Fifty Project - D29】
今日完成记录 TimePlan完成情况7:30 - 9:00大论文修改以及小论文修改√9:00 - 9:30整理近期购置物品项√9:30 - 10:00约了个画稿做个毕业冰箱贴!√10:00 - 11:30Leetcod…...

创建一个使用 GPT-4o 和 SERP 数据的 RAG 聊天机器人
亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者https://www.bright.cn/?promogithub15?utm_sourceorganic-social-cn&utm_campaigncsdn 本指南将解释如何使用 Python、GPT-4…...

安装PostgresSQL
目录 安装postgressql所需的依赖环境 编译安装 解压源码包 切换目录 --prefix指定安装目录 编译以及安装 配置环境创建用户 创建数据存储目录 更改数据存储目录的归属用户 配置环境变量 登录数据库 Dnf安装 安装postgresql 初始化数据库 登录数据库 postgresql…...

PL/SQL 安装配置与使用
目录 一、安装与配置 (一)下载PLSQL Developer (二)下载并配置免安装Oracle客户端 1. 下载Instantclient_11_2 2. 配置环境 (1)配置电脑的环境变量 (2)配置PLSQL Developer的…...
)
Oracle RAC ADG备库版本降级方案(19.20 → 19.7)
Oracle RAC ADG备库版本降级方案(19.20 → 19.7) 一、前期准备 1.1环境验证 主库版本:19.7 备库版本:19.20 检查兼容性:确认Oracle 19.20补丁是否支持回滚至19.7 1.2备份与快照 对备库数据库进行全量备份&#…...

SpringBoot-4-Spring Boot项目配置文件和日志配置
文章目录 1 项目全局配置文件1.1 配置示例1.2 配置文件加载顺序2 通过配置文件注入配置项2.1 使用@Value注解注入属性2.2 使用@ConfigurationProperties注入2.3 配置注入的注意事项2.4 配置文件中引用已定义值3 Spring Boot的日志配置3.1 引入日志依赖器3.2 自定义日志格式3.3 …...

mac上安装 Rust 开发环境
1.你可以按照提示在终端中执行以下命令(安全、官方支持): curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh然后按提示继续安装即可。 注意:安装过程中建议选择默认配置(按 1 即可)。 如果遇…...

微软押注“代理式AI网络”:一场重塑软件开发与工作方式的技术革命
在 2025 年 Build 开发者大会上,微软正式发布了其面向“开放代理式网络(Open Agentic Web)”的宏大战略,推出超过 50 项 AI 相关技术更新,涵盖 GitHub、Azure、Windows 和 Microsoft 365 全线产品。这一系列更新的核心…...

鸿蒙HarmonyOS多设备流转:分布式的智能协同技术介绍
随着物联网和智能设备的普及,多设备间的无缝协作变得越来越重要。鸿蒙(HarmonyOS)作为华为推出的新一代操作系统,其分布式技术为实现多设备流转提供了强大的支持。本文将详细介绍鸿蒙多设备流转的技术原理、实现方式和应用场景。 …...
:从移情到黏性——创业阶段的关键跨越与数据驱动策略)
精益数据分析(71/126):从移情到黏性——创业阶段的关键跨越与数据驱动策略
精益数据分析(71/126):从移情到黏性——创业阶段的关键跨越与数据驱动策略 在创业的旅程中,从需求验证的“移情阶段”过渡到产品黏性构建的“黏性阶段”,是决定创业成败的关键转折。今天,我们结合《精益数…...

21. 自动化测试框架开发之Excel配置文件的测试用例改造
21. 自动化测试框架开发之Excel配置文件的测试用例改造 一、测试框架核心架构 1.1 组件依赖关系 # 核心库依赖 import unittest # 单元测试框架 import paramunittest # 参数化测试扩展 from chap3.po import * # 页面对象模型 from file_reader import E…...

学习vue3:监听器
目录 一,关于监听的概述 二,手动监听器(watch函数) watch()函数语法 监听基本数据类型 监听对象,对象属性 三,自动监听器(watchEffect函数) watchEffect()函数语法…...

十大排序算法--快速排序
目录 原理 第一步 第二步 代码 递归实现快速排序 原理 分治法核心步骤 选择基准值(Pivot) 从数组中选一个元素作为基准值(如最右侧元素、中间元素或随机元素)。 分区(Partition) 将数组分为两部分…...

基于Docker搭建Harbor私有镜像仓库
Harbor 是 VMware 开源的企业级 Docker 容器镜像仓库,支持镜像存储、访问控制、镜像复制、安全扫描、审计日志等功能,适合企业级私有化部署。 1.前置环境说明 Harbor的部署依赖于Docker和Docker Compose环境。鉴于Docker已在系统中完成安装,…...

CentOS 7上搭建高可用BIND9集群指南
在 CentOS 7 上搭建一个高可用的 BIND9 集群通常涉及以下几种关键技术和策略的组合:主从复制 (Master-Slave Replication)、负载均衡 (Load Balancing) 以及可能的浮动 IP (Floating IP) 或 Anycast。 我们将主要关注主从复制和负载均衡的实现,这是构成高…...

使用SQLite Studio导出/导入SQL修复损坏的数据库
使用SQLite Studio导出/导入SQL修复损坏的数据库 使用Zotero时遇到了数据库损坏,在软件中寸步难行,遂尝试修复数据库。 一、SQLite Studio简介 SQLite Studio是一款专为SQLite数据库设计的免费开源工具,支持Windows/macOS/Linux。相较于其…...

Liquid Wire 柔性应变传感器:金属凝胶导体 | 仿生肌肉长度监测 | 高精度动作控制
柔性应变传感器通过模拟生物系统反馈机制,为软体机器人提供高精度动作控制能力。研究显示,基于液态导电金属的柔性传感纤维可精准测量仿生手指触觉力(约 1600 kPa)和关节角度变化(约 60),实现特…...

Java IO流操作
Java IO流操作是处理文件和数据流的基础。通过FileInputStream和FileOutputStream,可以读写二进制文件;通过FileReader和FileWriter,可以处理文本文件。BufferedReader提高字符读取效率,InputStreamReader实现字节流到字符流的转换…...
:受身形(3))
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(25):受身形(3)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(25):受身形(3) 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)受身形(1)两要素时,使用【に】(2)三要素时,使用【を】或其他(3)(4)(5) によって(6)から VS で(2)復習(ふくしゅう):3、单词(…...

BPMN.js编辑器设计器与属性面板数据交互
以下是基于提供的Vue组件代码生成的类图,结合BPMN设计器特性与Vue组件封装规范绘制: #mermaid-svg-B6PK7fjqLLTHqh8B {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-B6PK7fjqLLTHqh8B .error…...

os agent智能体软件 - 第三弹 - 纯语音交互
前两期期我们发布了产品的初级形态,那时候还只能是“软件开发者”在本地配置使用,或者运行起来有个大黑框,使用起来美观度太差。 到今天大概20天,我们的第3版已经出来了,不仅做成了电脑端的exe软件(任何人…...