创建一个使用 GPT-4o 和 SERP 数据的 RAG 聊天机器人
 亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者
亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者![]() https://www.bright.cn/?promo=github15?utm_source=organic-social-cn&utm_campaign=csdn
https://www.bright.cn/?promo=github15?utm_source=organic-social-cn&utm_campaign=csdn
本指南将解释如何使用 Python、GPT-4o 以及 Bright Data 的 SERP API 来构建一个能够生成更精确且富含上下文信息的 AI 回答的 RAG 聊天机器人。
- 简介
- 什么是 RAG?
- 为什么要使用 SERP 数据来为 AI 模型提供信息
- 在 Python 中使用 GPT 模型和 SERP 数据进行 RAG:分步教程
- 步骤 1:初始化 Python 项目
- 步骤 2:安装所需的库
- 步骤 3:准备项目
- 步骤 4:配置 SERP API
- 步骤 5:实现 SERP 数据抓取逻辑
- 步骤 6:从 SERP URL 中提取文本
- 步骤 7:生成 RAG Prompt
- 步骤 8:执行 GPT 请求
- 步骤 9:创建应用程序的 UI
- 步骤 10:整合所有部分
- 步骤 11:测试应用程序
- 结论
什么是 RAG?
RAG,全称 Retrieval-Augmented Generation,是一种将信息检索与文本生成相结合的 AI 方法。在 RAG 工作流程中,应用程序首先会从外部来源(如文档、网页或数据库)检索相关数据。然后,它将这些数据传递给 AI 模型,以便生成更具上下文相关性的回复。
RAG 能够增强像 GPT 这样的大型语言模型(LLM)的功能,使其可以访问并引用超出其原始训练数据范围的最新信息。在需要精确且具有上下文特定信息的场景中,RAG 方法至关重要,因为它能够提高 AI 生成回复的质量和准确性。
为什么要使用 SERP 数据来为 AI 模型提供信息
GPT-4o 的知识截止日期是 2023 年 10 月,这意味着它无法访问该时间之后发生的事件或信息。然而,得益于 GPT-4o 模型能够通过 Bing 搜索集成实时获取互联网数据,它可以提供更实时、更详细且更具上下文意义的回复。
在 Python 中使用 GPT 模型和 SERP 数据进行 RAG:分步教程
本教程将指导你如何使用 OpenAI 的 GPT 模型来构建一个 RAG 聊天机器人。基本思路是:先从 Google 上与搜索词相关的优质页面中获取文本,并将其作为 GPT 请求的上下文。
最大的难点在于如何获取 SERP 数据。大多数搜索引擎都具备高级的反爬虫措施,用以阻止机器人对其页面的自动访问。关于详细说明,请参考我们关于 如何在 Python 中抓取 Google 的指南。
为了简化抓取流程,我们将使用 Bright Data 的 SERP API。
通过此 SERP 抓取器,你可以使用简单的 HTTP 请求,从 Google、DuckDuckGo、Bing、Yandex、Baidu 以及其他搜索引擎中轻松获取 SERP。
之后,我们将使用无头浏览器 (headless browser)从返回的所有 URL 中提取文本数据,并将其作为 GPT 模型在 RAG 工作流中的上下文。如果你希望直接使用 AI 实时获取网络数据,可以参考我们关于 使用 ChatGPT 进行网页抓取 的文章。
本指南的所有代码都已上传到一个 GitHub 仓库中:
git clone https://github.com/Tonel/rag_gpt_serp_scraping
按照 README.md 文件中的指示来安装项目依赖并启动该项目。
请注意,本指南展示的方法可以轻松适配到其他搜索引擎或 LLM。
注意:
本教程适用于 Unix 和 macOS 环境。如果你使用 Windows,可以通过 Windows Subsystem for Linux (WSL) 进行类似操作。
步骤 #1:初始化 Python 项目
确保你的机器上安装了 Python 3。如果没有,请从 Python 官网 下载并安装。
创建项目文件夹并在终端中切换到该文件夹:
mkdir rag_gpt_serp_scrapingcd rag_gpt_serp_scraping
rag_gpt_serp_scraping 文件夹将包含你的 Python RAG 项目。
然后,用你喜欢的 Python IDE(如 PyCharm Community Edition 或 安装了 Python 插件的 Visual Studio Code)打开该文件夹。
在 rag_gpt_serp_scraping 目录下,新建一个空的 app.py 文件,用来存放你的抓取和 RAG 逻辑。
接下来,在项目目录下初始化一个 Python 虚拟环境:
python3 -m venv env
使用以下命令激活虚拟环境:
source ./env/bin/activate
步骤 #2:安装所需的库
本 Python RAG 项目将使用以下依赖:
- python-dotenv: 用于安全地管理敏感凭据(例如 Bright Data 凭据和 OpenAI API 密钥)。
- requests: 用于向 Bright Data 的 SERP API 发起 HTTP 请求。
- langchain-community: 用于从 Google SERP 返回的页面中获取文本,并进行清洗,从而为 RAG 生成相关内容。
- openai: 用于与 GPT 模型交互,从输入和 RAG 上下文中生成自然语言回复。
- streamlit: 用于创建一个简单的 UI,以便用户可以输入 Google 搜索关键词和 AI prompt 并动态查看结果。
安装所有依赖:
pip install python-dotenv requests langchain-community openai streamlit
我们将使用 AsyncChromiumLoader(来自 langchain-community),它需要以下依赖:
pip install --upgrade --quiet playwright beautifulsoup4 html2text
Playwright 还需要安装浏览器才能正常工作:
playwright install
步骤 #3:准备项目
在 app.py 中添加以下导入:
from dotenv import load_dotenvimport osimport requestsfrom langchain_community.document_loaders import AsyncChromiumLoaderfrom langchain_community.document_transformers import BeautifulSoupTransformerfrom openai import OpenAIimport streamlit as st
然后,在项目文件夹中新建一个 .env 文件,用于存放所有凭据信息。现在你的项目结构大致如下图所示:
在 app.py 中使用以下函数来告诉 python-dotenv 从 .env 文件中加载环境变量:
load_dotenv()
之后,你就可以使用下面的语句从 .env 或系统中读取环境变量:
os.environ.get("<ENV_NAME>")
步骤 #4:配置 SERP API
我们将使用 Bright Data 的 SERP API 来获取搜索引擎结果页信息,并在 Python RAG 工作流中使用这些信息。具体来说,我们会从 SERP API 返回的页面 URL 中提取文本。
要配置 SERP API,请参考 官方文档。或者,按照下述说明进行操作。
如果你还没有创建账号,请先在 Bright Data 注册。登录后,进入账号控制台:
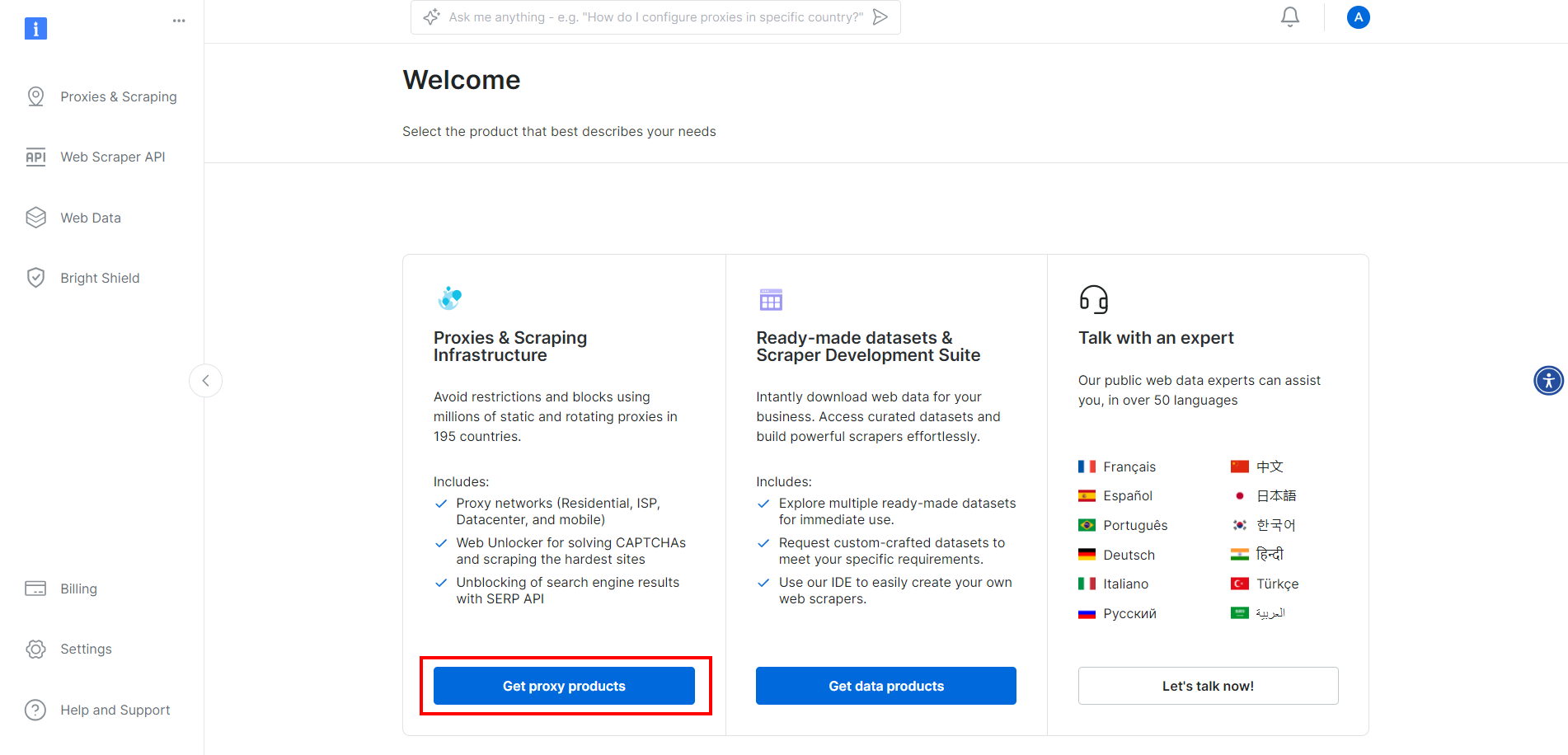
点击 “Get proxy products” 按钮。
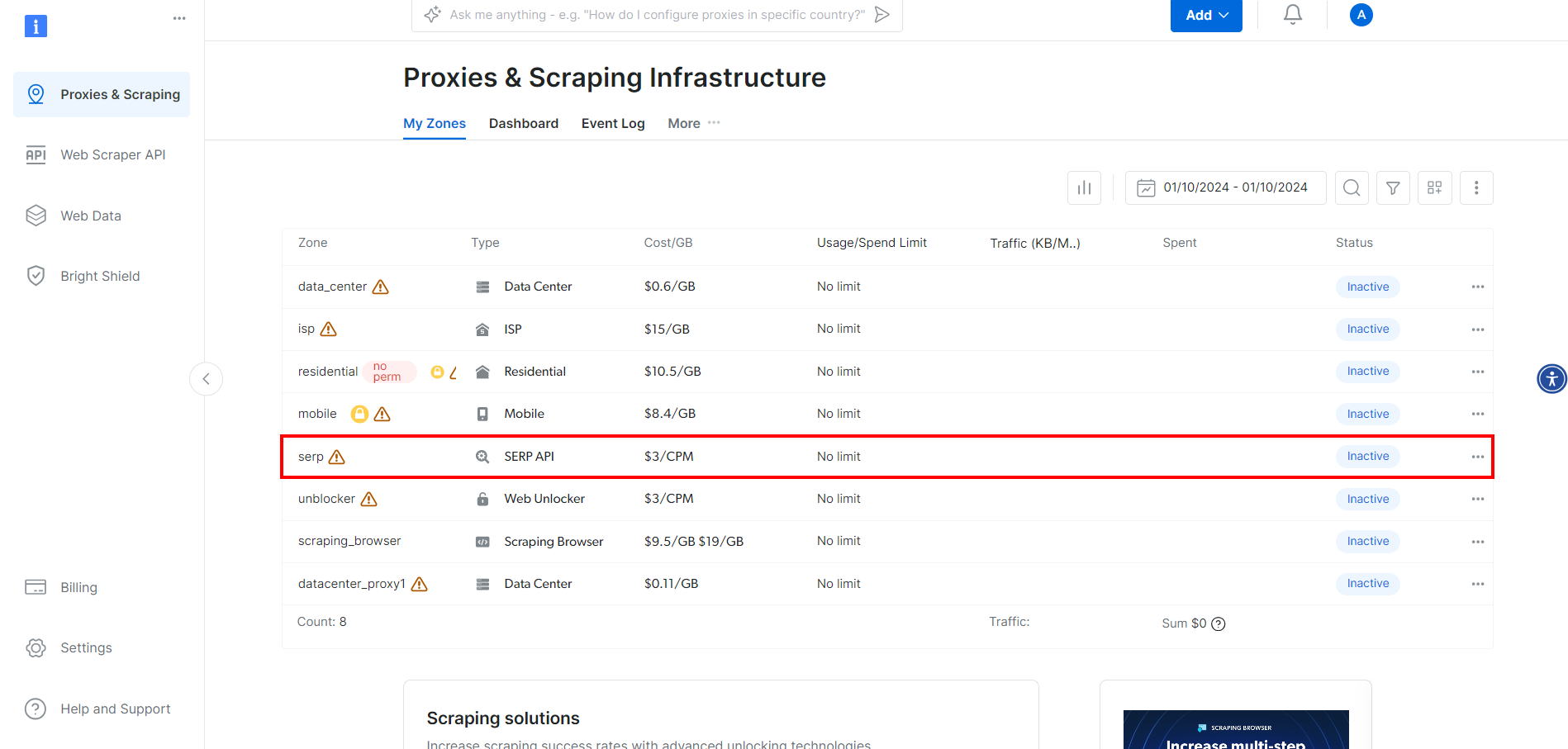
随后会跳转到下图所示页面,点击 “SERP API” 对应一行:
在 SERP API 产品页中,切换 “Activate zone” 开关来启用该产品:
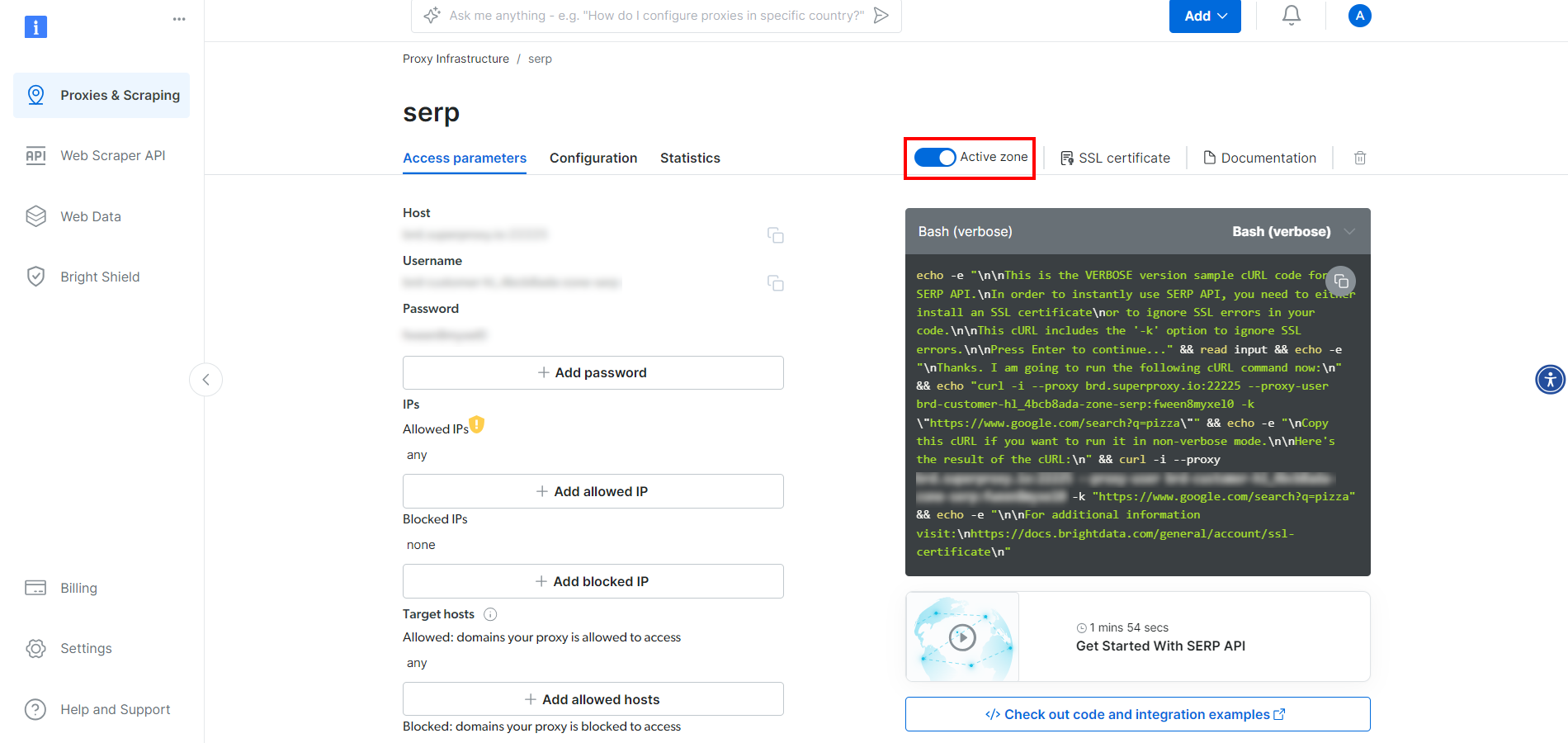
然后在 “Access parameters” 区域复制 SERP API 的 host、port、username 和 password,将它们添加到 .env 文件中:
BRIGHT_DATA_SERP_API_HOST="<YOUR_HOST>"BRIGHT_DATA_SERP_API_PORT=<YOUR_PORT>BRIGHT_DATA_SERP_API_USERNAME="<YOUR_USERNAME>"BRIGHT_DATA_SERP_API_PASSWORD="<YOUR_PASSWORD>"
将 <YOUR_XXXX> 占位符替换成 Bright Data 在 SERP API 页面上给出的实际值。
注意,此处 “Access parameters” 中的 host 格式类似于:
brd.superproxy.io:33335
需要将其拆分为:
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"BRIGHT_DATA_SERP_API_PORT=33335
步骤 #5:实现 SERP 数据抓取逻辑
在 app.py 中添加以下函数,用于获取 Google SERP 第一页的前 number_of_urls 个结果链接:
def get_google_serp_urls(query, number_of_urls=5):# 使用 Bright Data 的 SERP API 发起请求# 并获取自动解析后的 JSON 数据host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")proxy_url = f"http://{username}:{password}@{host}:{port}"proxies = {"http": proxy_url, "https": proxy_url}url = f"https://www.google.com/search?q={query}&brd_json=1"response = requests.get(url, proxies=proxies, verify=False)# 获取解析后的 JSON 响应response_data = response.json()# 从响应中提取前 number_of_urls 个 Google SERP URLgoogle_serp_urls = []if "organic" in response_data:for item in response_data["organic"]:if "link" in item:google_serp_urls.append(item["link"])return google_serp_urls[:number_of_urls]
以上代码会向 SERP API 发起一个 HTTP GET 请求,其中包含搜索词 query 参数。通过设置 brd_json=1,SERP API 会将搜索结果自动解析为 JSON 格式,类似如下结构:
{"general": {"search_engine": "google","results_cnt": 1980000000,"search_time": 0.57,"language": "en","mobile": false,"basic_view": false,"search_type": "text","page_title": "pizza - Google Search","code_version": "1.90","timestamp": "2023-06-30T08:58:41.786Z"},"input": {"original_url": "https://www.google.com/search?q=pizza&brd_json=1","user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, like Gecko) Version/13.0.3 Safari/608.2.11","request_id": "hl_1a1be908_i00lwqqxt1"},"organic": [{"link": "https://www.pizzahut.com/","display_link": "https://www.pizzahut.com","title": "Pizza Hut | Delivery & Carryout - No One OutPizzas The Hut!","image": "omitted for brevity...","image_alt": "pizza from www.pizzahut.com","image_base64": "omitted for brevity...","rank": 1,"global_rank": 1},{"link": "https://www.dominos.com/en/","display_link": "https://www.dominos.com › ...","title": "Domino's: Pizza Delivery & Carryout, Pasta, Chicken & More","description": "Order pizza, pasta, sandwiches & more online for carryout or delivery from Domino's. View menu, find locations, track orders. Sign up for Domino's email ...","image": "omitted for brevity...","image_alt": "pizza from www.dominos.com","image_base64": "omitted for brevity...","rank": 2,"global_rank": 3}// 省略...],// 省略...
}
最后几行分析 JSON 数据并从中选取前 number_of_urls 个 SERP 结果链接并返回列表。
步骤 #6:从 SERP URL 中提取文本
定义一个函数,用于从获取的 SERP URL 中提取文本:
# 注意:有些网站包含动态内容或反爬虫机制,可能导致文本无法提取。
# 如遇到此类问题,可考虑使用其它工具,比如 Selenium。
def extract_text_from_urls(urls, number_of_words=600): # 指示一个无头 Chrome 实例访问给定的 URLs# 并使用指定的 user-agentloader = AsyncChromiumLoader(urls,user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",)html_documents = loader.load()# 使用 BeautifulSoupTransformer 处理抓取到的 HTML 文档,从中提取文本bs_transformer = BeautifulSoupTransformer()docs_transformed = bs_transformer.transform_documents(html_documents,tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],unwanted_tags=["a"],remove_comments=True,)# 确保每个 HTML 文档仅保留 number_of_words 个单词extracted_text_list = []for doc_transformed in docs_transformed:# 将文本切分成单词,仅取前 number_of_words 个words = doc_transformed.page_content.split()[:number_of_words]extracted_text = " ".join(words)# 略过内容为空的文本if len(extracted_text) != 0:extracted_text_list.append(extracted_text)return extracted_text_list
该函数将会:
- 使用无头 Chrome 浏览器实例访问传入的 URLs。
- 利用 BeautifulSoupTransformer 处理每个页面的 HTML,以从特定标签(如
<p>、<h1>、<strong>等)中提取文本,跳过不需要的标签(如<a>)及注释。 - 对每个页面的文本只保留指定的单词数(
number_of_words)。 - 返回一个含有每个 URL 所提取文本的列表。
对于某些特殊场景,你可能需要调整要提取的 HTML 标签列表,或者增加/减少需要保留的单词数。例如,假设我们对如下页面 Transformers One 影评 应用此函数:
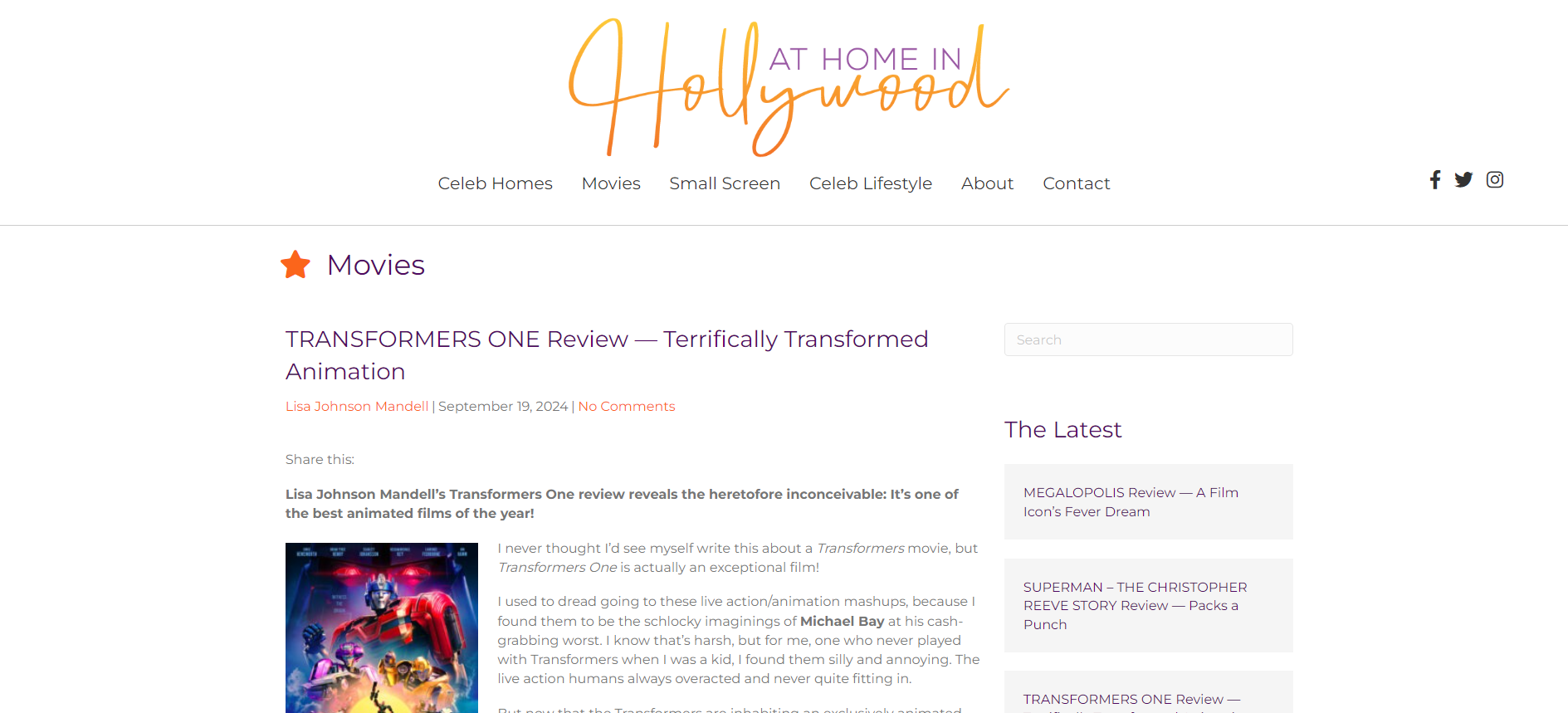
执行 extract_text_from_urls() 后得到的文本列表示例:
["Lisa Johnson Mandell’s Transformers One review reveals the heretofore inconceivable: It’s one of the best animated films of the year! I never thought I’d see myself write this about a Transformers movie, but Transformers One is actually an exceptional film! ..."]
extract_text_from_urls() 返回的文本列表将用于为 OpenAI 模型提供 RAG 上下文。
步骤 #7:生成 RAG Prompt
定义一个函数,用于将 AI 请求(prompt)与文本上下文拼接成最后用于 RAG 的 prompt:
def get_openai_prompt(request, text_context=[]):# 默认 promptprompt = request# 如果有传入上下文,则将上下文与 prompt 拼接if len(text_context) != 0:context_string = "\n\n--------\n\n".join(text_context)prompt = f"Answer the request using only the context below.\n\nContext:\n{context_string}\n\nRequest: {request}"return prompt
如果指定了 RAG 上下文,上面这个函数返回的 Prompt 大致如下格式:
Answer the request using only the context below.Context:Bla bla bla...--------Bla bla bla...--------Bla bla bla...Request: <YOUR_REQUEST>
步骤 #8:执行 GPT 请求
首先,在 app.py 顶部初始化 OpenAI 客户端:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
其中 OPENAI_API_KEY 存储于环境变量,可直接定义在系统环境变量或 .env 文件中:
OPENAI_API_KEY="<YOUR_API_KEY>"
将其中的 <YOUR_API_KEY> 替换为你的 OpenAI API key 值。如果需要创建或查找该密钥,请参考 官方指南。
然后,编写一个函数通过 OpenAI 官方客户端向 gpt-4o-mini 模型发送请求:
def interrogate_openai(prompt, max_tokens=800):# 使用给定 prompt 向 OpenAI 模型发送请求response = openai_client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": prompt}],max_tokens=max_tokens,)return response.choices[0].message.content
注意:
你也可以使用 OpenAI API 提供的其他任意 GPT 模型。
如果在调用时传入的 prompt 包含 get_openai_prompt() 拼接的文本上下文,那么 interrogate_openai() 就能按我们的需求执行检索增强式生成(RAG)。
步骤 #9:创建应用程序的 UI
使用 Streamlit 来定义一个简单的 Form UI,让用户能够输入:
- 用于 SERP API 的搜索关键词
- 想要发送给 GPT-4o mini 的 AI prompt
示例如下:
with st.form("prompt_form"):# 初始化输出结果result = ""final_prompt = ""# 让用户输入他们的 Google 搜索词google_search_query = st.text_area("Google Search:", None)# 让用户输入他们的 AI promptrequest = st.text_area("AI Prompt:", None)# 提交按钮submitted = st.form_submit_button("Send")# 如果表单被提交if submitted:# 从给定搜索词中获取 Google SERP URLsgoogle_serp_urls = get_google_serp_urls(google_search_query)# 从相应 HTML 页面中提取文本extracted_text_list = extract_text_from_urls(google_serp_urls)# 使用提取到的文本作为上下文生成 AI promptfinal_prompt = get_openai_prompt(request, extracted_text_list)# 调用 OpenAI 模型进行询问result = interrogate_openai(final_prompt)# 展示生成后的完整 Promptfinal_prompt_expander = st.expander("AI Final Prompt:")final_prompt_expander.write(final_prompt)# 输出来自 OpenAI 模型的回复st.write(result)
至此,我们的 Python RAG 脚本就完成了。
步骤 #10:整合所有部分
你的 app.py 文件整体应如下所示:
from dotenv import load_dotenvimport osimport requestsfrom langchain_community.document_loaders import AsyncChromiumLoaderfrom langchain_community.document_transformers import BeautifulSoupTransformerfrom openai import OpenAIimport streamlit as st# 加载 .env 文件中的环境变量
load_dotenv()# 使用你的 API 密钥初始化 OpenAI 客户端
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))def get_google_serp_urls(query, number_of_urls=5):# 使用 Bright Data 的 SERP API 发起请求# 并获取自动解析后的 JSON 数据host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")proxy_url = f"http://{username}:{password}@{host}:{port}"proxies = {"http": proxy_url, "https": proxy_url}url = f"https://www.google.com/search?q={query}&brd_json=1"response = requests.get(url, proxies=proxies, verify=False)# 获取解析后的 JSON 响应response_data = response.json()# 从响应中提取前 number_of_urls 个 Google SERP URLgoogle_serp_urls = []if "organic" in response_data:for item in response_data["organic"]:if "link" in item:google_serp_urls.append(item["link"])return google_serp_urls[:number_of_urls]def extract_text_from_urls(urls, number_of_words=600):# 指示一个无头 Chrome 实例访问给定的 URLs# 并使用指定的 user-agentloader = AsyncChromiumLoader(urls,user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",)html_documents = loader.load()# 使用 BeautifulSoupTransformer 处理抓取到的 HTML 文档,从中提取文本bs_transformer = BeautifulSoupTransformer()docs_transformed = bs_transformer.transform_documents(html_documents,tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],unwanted_tags=["a"],remove_comments=True,)# 确保每个 HTML 文档仅保留 number_of_words 个单词extracted_text_list = []for doc_transformed in docs_transformed:words = doc_transformed.page_content.split()[:number_of_words]extracted_text = " ".join(words)if len(extracted_text) != 0:extracted_text_list.append(extracted_text)return extracted_text_listdef get_openai_prompt(request, text_context=[]):# 默认 promptprompt = request# 如果有传入上下文,则将上下文与 prompt 拼接if len(text_context) != 0:context_string = "\n\n--------\n\n".join(text_context)prompt = f"Answer the request using only the context below.\n\nContext:\n{context_string}\n\nRequest: {request}"return promptdef interrogate_openai(prompt, max_tokens=800):# 使用给定 prompt 向 OpenAI 模型发送请求response = openai_client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "user", "content": prompt}],max_tokens=max_tokens,)return response.choices[0].message.content# 创建 Streamlit 表单,供用户输入
with st.form("prompt_form"):# 初始化输出结果result = ""final_prompt = ""# 让用户输入 Google 搜索词google_search_query = st.text_area("Google Search:", None)# 让用户输入 AI Promptrequest = st.text_area("AI Prompt:", None)# 提交按钮submitted = st.form_submit_button("Send")if submitted:# 获取搜索词对应的 Google SERP URL 列表google_serp_urls = get_google_serp_urls(google_search_query)# 从对应的 HTML 页面中提取文本extracted_text_list = extract_text_from_urls(google_serp_urls)# 使用提取到的文本作为上下文生成最终的 Promptfinal_prompt = get_openai_prompt(request, extracted_text_list)# 调用 OpenAI 模型获取结果result = interrogate_openai(final_prompt)# 展示生成后的完整 Promptfinal_prompt_expander = st.expander("AI Final Prompt")final_prompt_expander.write(final_prompt)# 输出来自 OpenAI 的结果st.write(result)
步骤 #11:测试应用程序
使用以下命令运行你的 Python RAG 应用:
# 注意:Streamlit 在轻量级应用场景非常方便,但如果要用于生产环境,
# 可以考虑使用 Flask 或 FastAPI 等更适合生产部署的框架。
streamlit run app.py
在终端里,你应该会看到类似如下输出:
You can now view your Streamlit app in your browser.Local URL: http://localhost:8501
Network URL: http://172.27.134.248:8501
根据提示,在浏览器中打开 http://localhost:8501。你会看到如下界面:
可以尝试输入如下一条搜索:
Transformers One review
以及如下 AI prompt:
Write a review for the movie Transformers One
点击 “Send”,等待应用处理请求。数秒后,你就能看到类似下图的结果:
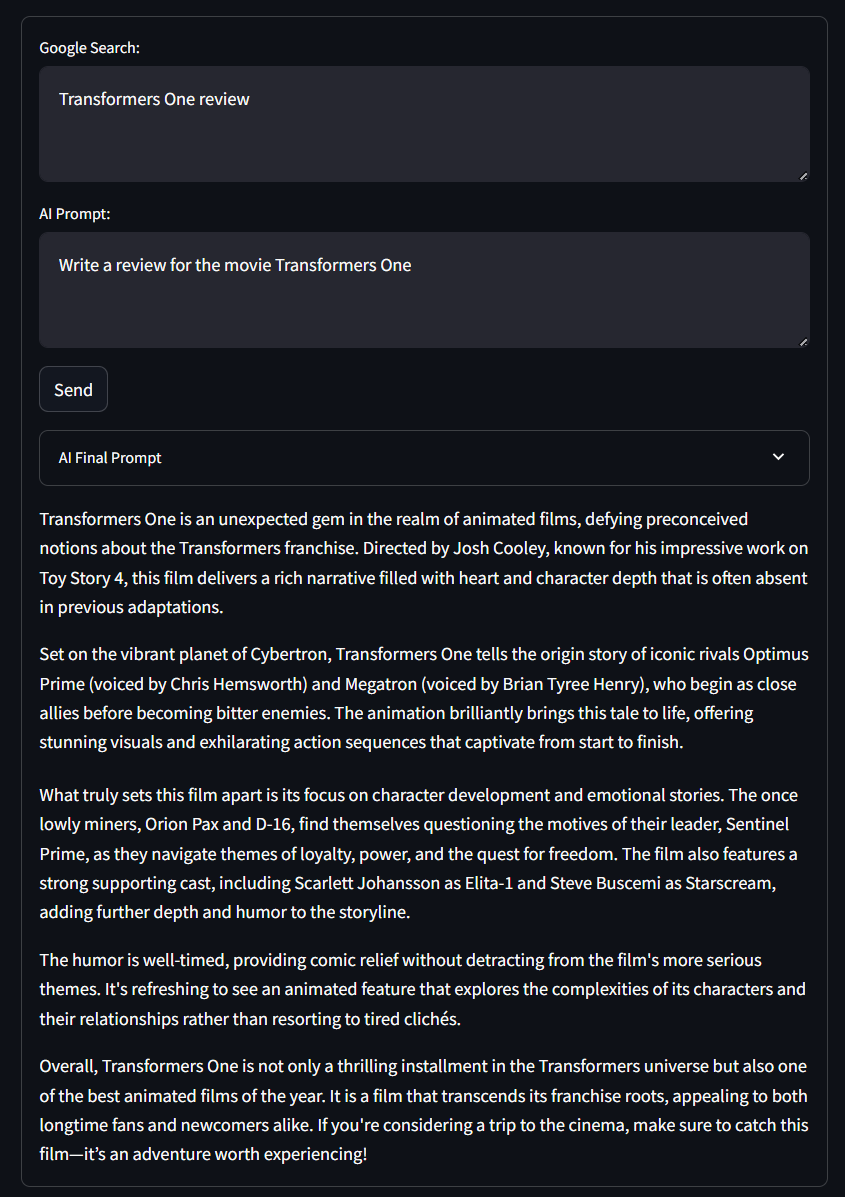
若展开 “AI Final Prompt” 下拉框,你会看到应用为 RAG 生成的完整 Prompt。
结论
在使用 Python 来构建 RAG 聊天机器人时,主要挑战在于如何抓取像 Google 这样的搜索引擎:
- 它们会频繁修改 SERP 页面的结构。
- 它们拥有十分复杂的反爬虫机制。
- 并发大规模获取 SERP 数据成本高且实现困难。
Bright Data 的 SERP API 可以帮助你轻松地从各大搜索引擎获取实时 SERP 数据,同时也支持 RAG 以及许多其他应用场景。现在就开始你的免费试用吧!
相关文章:

创建一个使用 GPT-4o 和 SERP 数据的 RAG 聊天机器人
亮数据-网络IP代理及全网数据一站式服务商屡获殊荣的代理网络、强大的数据挖掘工具和现成可用的数据集。亮数据:网络数据平台领航者https://www.bright.cn/?promogithub15?utm_sourceorganic-social-cn&utm_campaigncsdn 本指南将解释如何使用 Python、GPT-4…...

安装PostgresSQL
目录 安装postgressql所需的依赖环境 编译安装 解压源码包 切换目录 --prefix指定安装目录 编译以及安装 配置环境创建用户 创建数据存储目录 更改数据存储目录的归属用户 配置环境变量 登录数据库 Dnf安装 安装postgresql 初始化数据库 登录数据库 postgresql…...

PL/SQL 安装配置与使用
目录 一、安装与配置 (一)下载PLSQL Developer (二)下载并配置免安装Oracle客户端 1. 下载Instantclient_11_2 2. 配置环境 (1)配置电脑的环境变量 (2)配置PLSQL Developer的…...
)
Oracle RAC ADG备库版本降级方案(19.20 → 19.7)
Oracle RAC ADG备库版本降级方案(19.20 → 19.7) 一、前期准备 1.1环境验证 主库版本:19.7 备库版本:19.20 检查兼容性:确认Oracle 19.20补丁是否支持回滚至19.7 1.2备份与快照 对备库数据库进行全量备份&#…...

SpringBoot-4-Spring Boot项目配置文件和日志配置
文章目录 1 项目全局配置文件1.1 配置示例1.2 配置文件加载顺序2 通过配置文件注入配置项2.1 使用@Value注解注入属性2.2 使用@ConfigurationProperties注入2.3 配置注入的注意事项2.4 配置文件中引用已定义值3 Spring Boot的日志配置3.1 引入日志依赖器3.2 自定义日志格式3.3 …...

mac上安装 Rust 开发环境
1.你可以按照提示在终端中执行以下命令(安全、官方支持): curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh然后按提示继续安装即可。 注意:安装过程中建议选择默认配置(按 1 即可)。 如果遇…...

微软押注“代理式AI网络”:一场重塑软件开发与工作方式的技术革命
在 2025 年 Build 开发者大会上,微软正式发布了其面向“开放代理式网络(Open Agentic Web)”的宏大战略,推出超过 50 项 AI 相关技术更新,涵盖 GitHub、Azure、Windows 和 Microsoft 365 全线产品。这一系列更新的核心…...

鸿蒙HarmonyOS多设备流转:分布式的智能协同技术介绍
随着物联网和智能设备的普及,多设备间的无缝协作变得越来越重要。鸿蒙(HarmonyOS)作为华为推出的新一代操作系统,其分布式技术为实现多设备流转提供了强大的支持。本文将详细介绍鸿蒙多设备流转的技术原理、实现方式和应用场景。 …...
:从移情到黏性——创业阶段的关键跨越与数据驱动策略)
精益数据分析(71/126):从移情到黏性——创业阶段的关键跨越与数据驱动策略
精益数据分析(71/126):从移情到黏性——创业阶段的关键跨越与数据驱动策略 在创业的旅程中,从需求验证的“移情阶段”过渡到产品黏性构建的“黏性阶段”,是决定创业成败的关键转折。今天,我们结合《精益数…...

21. 自动化测试框架开发之Excel配置文件的测试用例改造
21. 自动化测试框架开发之Excel配置文件的测试用例改造 一、测试框架核心架构 1.1 组件依赖关系 # 核心库依赖 import unittest # 单元测试框架 import paramunittest # 参数化测试扩展 from chap3.po import * # 页面对象模型 from file_reader import E…...

学习vue3:监听器
目录 一,关于监听的概述 二,手动监听器(watch函数) watch()函数语法 监听基本数据类型 监听对象,对象属性 三,自动监听器(watchEffect函数) watchEffect()函数语法…...

十大排序算法--快速排序
目录 原理 第一步 第二步 代码 递归实现快速排序 原理 分治法核心步骤 选择基准值(Pivot) 从数组中选一个元素作为基准值(如最右侧元素、中间元素或随机元素)。 分区(Partition) 将数组分为两部分…...

基于Docker搭建Harbor私有镜像仓库
Harbor 是 VMware 开源的企业级 Docker 容器镜像仓库,支持镜像存储、访问控制、镜像复制、安全扫描、审计日志等功能,适合企业级私有化部署。 1.前置环境说明 Harbor的部署依赖于Docker和Docker Compose环境。鉴于Docker已在系统中完成安装,…...

CentOS 7上搭建高可用BIND9集群指南
在 CentOS 7 上搭建一个高可用的 BIND9 集群通常涉及以下几种关键技术和策略的组合:主从复制 (Master-Slave Replication)、负载均衡 (Load Balancing) 以及可能的浮动 IP (Floating IP) 或 Anycast。 我们将主要关注主从复制和负载均衡的实现,这是构成高…...

使用SQLite Studio导出/导入SQL修复损坏的数据库
使用SQLite Studio导出/导入SQL修复损坏的数据库 使用Zotero时遇到了数据库损坏,在软件中寸步难行,遂尝试修复数据库。 一、SQLite Studio简介 SQLite Studio是一款专为SQLite数据库设计的免费开源工具,支持Windows/macOS/Linux。相较于其…...

Liquid Wire 柔性应变传感器:金属凝胶导体 | 仿生肌肉长度监测 | 高精度动作控制
柔性应变传感器通过模拟生物系统反馈机制,为软体机器人提供高精度动作控制能力。研究显示,基于液态导电金属的柔性传感纤维可精准测量仿生手指触觉力(约 1600 kPa)和关节角度变化(约 60),实现特…...

Java IO流操作
Java IO流操作是处理文件和数据流的基础。通过FileInputStream和FileOutputStream,可以读写二进制文件;通过FileReader和FileWriter,可以处理文本文件。BufferedReader提高字符读取效率,InputStreamReader实现字节流到字符流的转换…...
:受身形(3))
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(25):受身形(3)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(25):受身形(3) 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)受身形(1)两要素时,使用【に】(2)三要素时,使用【を】或其他(3)(4)(5) によって(6)から VS で(2)復習(ふくしゅう):3、单词(…...

BPMN.js编辑器设计器与属性面板数据交互
以下是基于提供的Vue组件代码生成的类图,结合BPMN设计器特性与Vue组件封装规范绘制: #mermaid-svg-B6PK7fjqLLTHqh8B {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-B6PK7fjqLLTHqh8B .error…...

os agent智能体软件 - 第三弹 - 纯语音交互
前两期期我们发布了产品的初级形态,那时候还只能是“软件开发者”在本地配置使用,或者运行起来有个大黑框,使用起来美观度太差。 到今天大概20天,我们的第3版已经出来了,不仅做成了电脑端的exe软件(任何人…...
)
PCB设计教程【入门篇】——电路分析基础-基本元件(二极管三极管场效应管)
前言 本教程基于B站Expert电子实验室的PCB设计教学的整理,为个人学习记录,旨在帮助PCB设计新手入门。所有内容仅作学习交流使用,无任何商业目的。若涉及侵权,请随时联系,将会立即处理、 目录 前言 1.二极管 1.发光…...

python打卡训练营打卡记录day31
知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 作业:尝试针对之前的心脏病项目ipynb,将他按照今天的示例项目整理成规范的形式,思考下哪些部分可以未来复用。 心脏病项目目录 目录结构:heart/ ├── conf…...

Python列表推导式和生成器表达式详解
Python列表推导式和生成器表达式详解 引言 Python以其简洁优雅的语法而闻名,其中列表推导式(List Comprehensions)和生成器表达式(Generator Expressions)就是这种优雅性的典型代表。本文将深入浅出地介绍这两种强大的…...

Redis 命令大全
Redis 是一个开源的内存数据结构存储系统,支持多种数据结构。以下是 Redis 的常用命令分类总结: 一、Key(键)相关命令 命令描述示例DEL key删除键DEL nameEXISTS key检查键是否存在EXISTS nameEXPIRE key seconds设置键的过期时间(秒)EXPIRE name 60TTL key查看键剩余过期…...

Wan2.1 图生视频 支持批量生成
Wan2.1 图生视频 支持批量生成 flyfish 综合效果 实现基于 Wan2.1 模型的配置化批量生成功能,支持从prompt.json读取多个 “图像 - 文本提示” 组合(每个任务可关联多图像),通过config.json集中管理模型路径、分辨率、帧数、引…...

Git 删除大文件教程
🧹 Git 删除大文件完整教程 🧩 适用场景 不小心将大文件(如视频、压缩包、模型文件等)提交到了 Git 仓库想彻底从仓库和提交历史中删除这个文件希望远程仓库体积减小(如 GitHub 上传失败) 🛠️…...

题海拾贝:P2285 [HNOI2004] 打鼹鼠
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 1、题目 P2285 [HNOI2004] 打…...

第40天-Python开发音乐播放器完整指南
一、技术选型与工具准备 核心库: Pyqt5:Python标准GUI库,构建用户界面 os / sys:文件系统操作 开发环境: bash 复制 下载 pip install pyqt5 二、功能设计 功能模块描述播放控制播放/暂停/停止/上一曲/下一曲播放列表管理添加/删除/保存/加载歌曲音频可视化进度条显示与拖…...

【优秀三方库研读】在 quill 开源库中为什么封装 safe_fwrite,而不是直接使用系统 fwrite
在 Quill 日志库中,safe_fwrite 函数的封装是为了解决直接使用系统 fwrite 时可能存在的 可靠性 和 错误处理 问题,同时兼顾性能优化。以下从多个维度详细分析其设计动机和实现原理: 一、代码功能解析 QUILL_ATTRIBUTE_HOT static void safe_fwrite(void const* ptr, size_…...
学习(六)插件打包在UE5.3.2下Value cannot be null的错误)
UE(虚幻)学习(六)插件打包在UE5.3.2下Value cannot be null的错误
自己写的插件打包出现了Unhandled exception: System.ArgumentNullException: Value cannot be null.的错误,发现只有UE5.3会报出。 D:\UE_5.3\Engine\Build\BatchFiles>Runuat.bat BuildPlugin -PluginF:\UEProjects\DQSDK5_3\Plugins\DQSDK\DQSDK.uplugin -Pa…...

JDBC在Java项目开发中的核心作用与实战应用
一、JDBC概述及其在项目开发中的重要性 JDBC(Java Database Connectivity)是Java语言中用来规范客户端程序如何访问数据库的应用程序接口(API),它为Java开发者提供了与各种关系型数据库进行交互的统一方式。 JDBC的核心价值: 提供与数据库无关的标准接…...

为 Jenkins添加 Windows Slave远程执行 python项目脚本
测试环境 JAVA JDK 1.7.0_13 (jdk-7u13-windows-i586.exe) Jenkins Win11 64 python项目环境 实践操作 1、新建与配置结点 【系统管理】-> 【管理结点】-> 【新建结点】, 如上,输入结点名称,勾选 【Dumb Slave】,点击【OK】 说明&am…...

深入解析Spring Boot与Redis的缓存集成实践
深入解析Spring Boot与Redis的缓存集成实践 引言 在现代Web应用中,缓存技术是提升系统性能的重要手段之一。Redis作为一种高性能的内存数据库,广泛应用于缓存场景。本文将详细介绍如何在Spring Boot项目中集成Redis,并探讨其在实际开发中的…...

硬件工程师笔记——三极管Multisim电路仿真实验汇总
目录 1 三极管基础 更多电子器件基础知识汇总链接 1.1 工作原理 NPN型三极管的工作原理 PNP型三极管的工作原理 1.2 三极管的特性曲线 输入特性曲线 理想和现实输出特性 三极管的主要参数包括: 2 三极管伏安特性 2.1 伏安特性仿真 Multisim使用说明链接…...

基于 ABP vNext + CQRS + MediatR 构建高可用与高性能微服务系统:从架构设计到落地实战
🧠 基于 ABP vNext CQRS MediatR 构建高可用与高性能微服务系统:从架构设计到落地实战 目录 🧠 基于 ABP vNext CQRS MediatR 构建高可用与高性能微服务系统:从架构设计到落地实战🧰 模块结构概览📦 各…...

java云原生实战之graalvm 环境安装
windows环境安装 在Windows环境下安装GraalVM并启用原生镜像功能时,需要Visual Studio的组件支持。具体要点如下: 核心依赖: 需要安装Visual Studio 2022或更新版本,并确保勾选以下组件: "使用C的桌面开发"…...

Python 包管理工具uv依赖分组概念解析
在 Python 包管理工具 uv 中,依赖分组(如 dev、prod)是一种将项目的不同依赖按用途分类管理的机制。通过分组,开发者可以清晰地分离生产环境(运行项目所需的核心依赖)和开发环境(仅在开发阶段使…...

C语言-9.指针
9.1指针 9.1-1取地址运算:&运算符取得变量的地址 运算符& scanf(“%d”,&i);里的&获取变量的地址,它们操作数必须是变量int i;printf(“%x”,&i);地址的大小是否与int相同取决于编译器int i;printf(“%p”,&i); &不能取的地址不能对没有地址的…...

GitHub 自动认证教程
## 简介 在使用 GitHub 时,为了避免每次提交代码都需要输入用户名和密码,我们可以使用 SSH 密钥进行自动认证。本教程将详细介绍如何设置 SSH 密钥并配置 GitHub 自动认证。 ## 步骤一:检查现有 SSH 密钥 首先,检查您的电脑是否…...
、labelme格式标签转换)
labelme的安装与使用(以关键点检测为例)、labelme格式标签转换
注:labelme 和 labelImg 是两款不同的数据标注工具。labelme 的 Github 官方地址: https://github.com/wkentaro/labelmehttps://github.com/wkentaro/labelme 参考笔记: Labelme标注工具安装及使用_labelme安装及使用教程-CSDN博客 学习视…...

【Git】远程操作
Git 是一个分布式版本控制系统 可以简单理解为,每个人的电脑上都是一个完整的版本库,这样在工作时,就不需要联网 了,因为版本库就在自己的电脑上。 因此, 多个人协作的方式,譬如说甲在自己的电脑上改了文件…...

密码学实验
密码学实验二 一、实验目的(本次实验所涉及并要求掌握的知识点) 掌握RSA算法的基本原理并根据给出的RSA算法简单的实现代码源程序,以及能够使用RSA对文件进行加密。掌握素性测试的基本原理,并且会使用Python进行简单的素性测试以及初步理解…...

nettrace工具介绍
简介 仓库地址: https://github.com/OpenCloudOS/nettrace 背景: 在云原生场景中,linux系统中的网络部署变得越来越复杂,一个tcp连接,从客户端到服务器,中间可能要经过复杂的NAT、GRE、IPVS等过程&#x…...

Jenkins+Docker+Harbor快速部署Spring Boot项目详解
JenkinsDockerHarbor快速部署Spring Boot项目详解 Jenkins、Docker和Harbor是现代DevOps流程中的核心工具,结合使用可以实现自动化构建、测试和部署。下面我将详细介绍如何搭建这个集成环境。 一、各工具的核心作用 Jenkins 自动化CI/CD工具,负责拉取代…...

Windows 安装Anaconda
一、下载Anaconda 1.阿里云镜像: https://developer.aliyun.com/mirror/ 2.中科大镜像: https://mirrors.ustc.edu.cn/ 二、配置环境变量 Windows: 1.右键“此电脑” → “属性” → “高级系统设置” → “环境变量”25;…...

《微机原理与接口技术》第 8 章 常用接口芯片
8.1 可编程定时/计数器8253/8254 8.1.1 8253的外部引脚及内部结构 8.1.2 8253的工作方式 8.1.3 8253的方式控制字和读/写操作 8.1.4 8253的初始化编程及应用 8.1.5 可编程定时/计数器8254 …… 8.2 可编程并行接口8255 8.2.1 并行通信的概念 (1)…...

upload-labs靶场通关详解:第12-13关
目录 第12关:get00截断 一、分析源代码 二、解题思路 三、解题步骤 第13关:post00截断 一、分析源代码 二、解题思路 三、解题步骤 第12关:get00截断 一、分析源代码 $is_upload false; $msg null; if(isset($_POST[submit])){$ex…...
)
YOLO模型初次训练体验(+实测)
1.训练目的 做一个简单的示例,本次训练的目的希望模型能够识别桌面的两个图标。(主要是方便准备数据) 2.数据准备 安装一个截图软件,在桌面不同分辨率,不同背景的情况下,随机调整两个图标的位置并截图保存。 原始图片: 先为截图批量重命名: 使用重命名工具,设置命…...

OSA实战笔记二
本文是我在实际项目开发中,总结和归纳的笔记,主要记录了OSA常用的参数释义。 OSA的Params 1、Scroll Sensivity 对⿏标滚轮(或类似)输⼊的敏感度,与通过滚动条拖动或滚动⽆关。 2、Scroll Sensivity On X Axis 对…...

OSI 网络七层模型中的物理层、数据链路层、网络层
一、OSI 七层模型 物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 1. 物理层(Physical Layer) 功能:传输原始的比特流(0和1),通过物理介质(如电缆、光纤、无线电波)…...