【综述】视频目标分割VOS
目录
- 1、Associating Objects with Transformers for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)结论
- 2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 3、Recurrent Dynamic Embedding for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 双分支传播
- 门控传播模块(GPM)
- 3)实验结果
- 4)关键结论
- 6、Tracking Anything with Decoupled Video Segmentation
- 背景知识
- 研究方法
- 双向传播
- 时序传播模块
- 实验结果
- 关键结论
- 7、Putting the Object Back into Video Object Segmentation
- 1)背景知识与研究动机
- 2)研究方法
- 3)实验
- 关键数值结果
- 4)结论
1、Associating Objects with Transformers for Video Object Segmentation
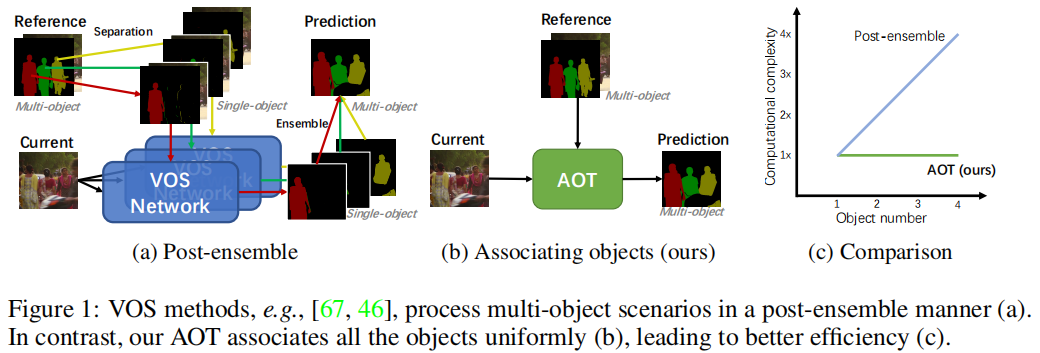
这篇文章提出了一种名为“Associating Objects with Transformers (AOT)”的新方法,用于解决半监督视频目标分割(VOS)任务中的多目标场景问题。AOT通过将多个目标统一嵌入到同一个高维嵌入空间中,实现了多目标的匹配和解码,显著提高了效率,并在多个基准测试中取得了优异的性能。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,其目标是根据视频序列中第一帧提供的目标掩码,跟踪并分割整个视频中的目标。半监督VOS是其中的主要任务类型。尽管已有方法取得了显著进展,但它们大多针对单个目标进行解码,导致在多目标场景下需要独立匹配每个目标,并将单目标预测组合成多目标分割,这种后处理方式效率低下,尤其是在计算资源有限的情况下。
2)研究方法
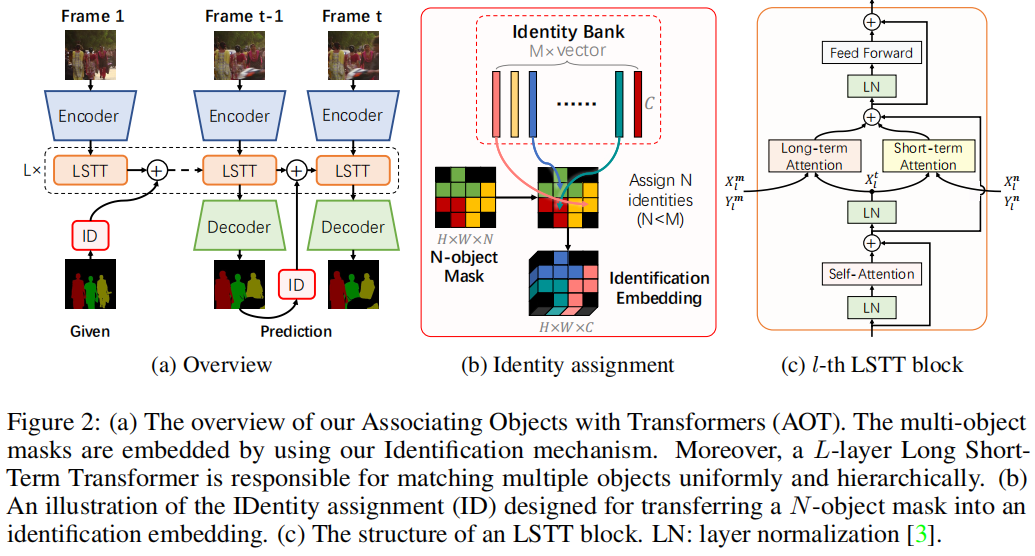
AOT的核心在于提出了一个识别机制,将多个目标嵌入到同一个特征空间中,从而可以同时处理多个目标的匹配和分割解码,效率与处理单个目标相当。具体来说,AOT包含以下几个关键部分:
-
识别机制:通过为每个目标分配一个唯一的身份标识,并将这些目标嵌入到同一个特征空间中,网络可以学习目标之间的关联。这种机制允许直接从聚合的特征中解码多目标分割。
-
长短期变换器(LSTT):为了充分建模多目标关联,设计了LSTT模块,用于构建层次化的匹配和传播。LSTT模块结合了长期注意力(匹配第一帧的嵌入)和短期注意力(匹配附近几帧的嵌入),以更有效地关联多个目标。
-
网络架构:AOT使用轻量级的MobileNet-V2作为骨干网络,并设计了不同复杂度的变体,包括AOT-Tiny、AOT-Small、AOT-Base和AOT-Large,以满足不同的效率和性能需求。
3)实验结果
实验部分,作者在YouTube-VOS、DAVIS 2017和DAVIS 2016这三个流行的基准数据集上验证了AOT的性能。结果显示:
- YouTube-VOS:AOT在验证集2018和2019的分割性能(J&F指标)上均优于所有现有方法,例如AOT-L达到了83.8%和83.7%,而之前的最佳方法CFBI+为82.8%和81.8%。同时,AOT在多目标运行时效率上也显著优于其他方法,例如AOT-T在保持实时性能(41.0 FPS)的同时,性能优于CFBI+。
- DAVIS 2017:AOT在验证集和测试集上均取得了最佳性能,例如R50-AOT-L在验证集上达到了84.9%,在测试集上达到了79.6%,并且保持了较高的运行效率(18.0 FPS)。
- DAVIS 2016:尽管AOT主要针对多目标VOS,但在单目标场景下也取得了新的最佳性能,例如R50-AOT-L达到了91.1%,并且运行效率是现有方法的两倍。
此外,文章还提供了与其他最新实时方法(如SAT和GC)的比较,AOT在保持实时性能的同时,显著优于这些方法。
4)结论
AOT通过其创新的识别机制和LSTT模块,在多目标视频目标分割任务中实现了效率和性能的双重提升。该方法不仅在多个基准测试中取得了优异的性能,还保持了较高的运行效率,使其在实际应用中具有很大的潜力。此外,AOT的架构设计允许通过调整LSTT模块的数量来灵活平衡性能和速度,为未来的研究和应用提供了更多的可能性。
2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
这篇文章提出了一种名为“Space-Time Correspondence Network (STCN)”的新型视频目标分割(VOS)方法,旨在通过改进时空对应关系建模来提高效率和性能。STCN通过直接在帧之间建立对应关系,避免了为每个目标重新编码掩码特征,从而实现了一个高效且鲁棒的框架。该方法在DAVIS和YouTubeVOS数据集上取得了新的最高性能,并且运行速度超过20 FPS,显著优于现有方法。
1)背景知识
视频目标分割(VOS)任务的目标是在视频序列中标记和分割目标实例。本文关注半监督设置,即第一帧的分割掩码已知,算法需要推断剩余帧的分割掩码。与视频目标跟踪不同,VOS需要详细的目标掩码,而不仅仅是简单的边界框。一个高性能的算法应该能够在部分或完全遮挡、外观变化和目标变形的情况下,将目标从背景或其他干扰因素中区分出来。
2)研究方法
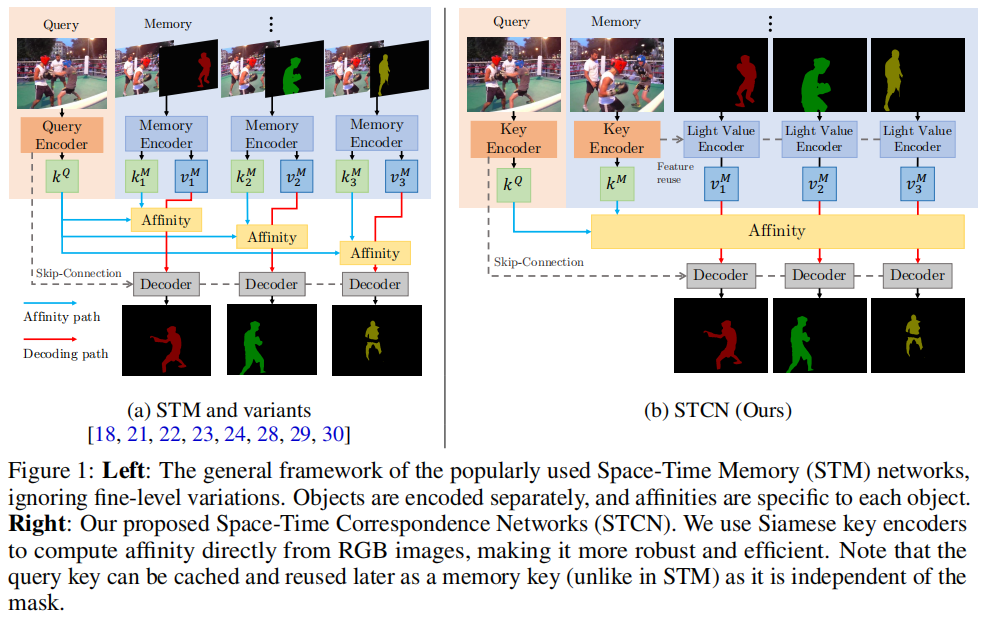

STCN的核心思想是直接在帧之间建立对应关系,而不是为视频中的每个目标构建特定的内存库和亲和力。这种方法不仅更高效,而且更鲁棒,因为模型被迫学习所有目标之间的关系,而不仅仅是标记的目标。STCN通过以下关键步骤实现:
-
特征提取:STCN使用ResNet50作为键编码器(仅输入图像)和ResNet18作为值编码器(输入图像和掩码)。键特征(和结果亲和力)可以独立于掩码提取,每个帧只计算一次,并且在内存和查询之间是对称的。这种设计允许在不引入掩码作为干扰的情况下,在视频帧之间建立对应关系。
-
记忆读取和解码:给定T个记忆帧和一个查询帧,STCN计算记忆键和查询键之间的亲和力矩阵,并使用softmax归一化。然后,通过加权和的方式从记忆特征中聚合查询帧的特征,这些特征随后被传递到解码器以生成掩码。
-
记忆管理:STCN在记忆管理上进行了优化,避免了使用临时记忆帧,因为这会导致记忆键与查询帧过于相似,从而导致漂移。这种修改减少了对值编码器的调用次数,显著提高了速度。
-
亲和力计算:STCN提出了使用负平方欧几里得距离代替点积来计算亲和力。这种改变确保了每个记忆节点都有机会显著贡献(给定正确的查询),从而提高了性能、鲁棒性和内存使用效率。
3)实验结果
STCN在DAVIS 2017和YouTubeVOS 2018验证集上进行了广泛的实验,并与其他方法进行了比较。结果显示:
- DAVIS 2017:STCN在验证集上取得了85.4%的J&F分数,超过了之前最好的方法MiVOS(83.3%)和STM(81.8%),并且运行速度为20.2 FPS,显著快于STM(10.2 FPS)。
- YouTubeVOS 2018:STCN在验证集上取得了83.0%的G分数,超过了之前的最高成绩82.7%,并且在多目标场景下运行速度超过20 FPS。
此外,STCN在DAVIS 2016和YouTubeVOS 2019验证集上也取得了优异的成绩,并在DAVIS交互式赛道上展示了其性能。
4)关键结论
STCN通过直接帧到帧的对应关系和改进的亲和力计算方法,提供了一种简单、高效且强大的视频目标分割解决方案。它不仅在性能上超越了现有的最先进方法,而且在运行速度上也具有显著优势。STCN的提出为未来视频目标分割的研究提供了一个新的高效基线。
尽管STCN在多个基准测试中取得了优异的性能,但它在处理具有相似外观且相隔较远的目标时可能会出现错误分割的情况。这是因为STCN目前没有考虑时间一致性线索,例如光流或局部匹配。作者认为,STCN的框架足够简单,可以很容易地扩展以包含时间一致性考虑,从而实现进一步的改进。
3、Recurrent Dynamic Embedding for Video Object Segmentation
这篇文章提出了一种名为“Recurrent Dynamic Embedding (RDE)”的新型视频目标分割(VOS)方法,旨在解决基于时空记忆(STM)的VOS网络在处理长视频时面临的内存需求不断增加和噪声积累的问题。RDE通过引入循环动态嵌入和时空聚合模块(SAM),构建了一个固定大小的记忆库,并通过无偏指导损失和自校正策略来提高模型的鲁棒性和准确性。该方法在多个基准数据集上取得了优异的性能,并在合成长视频中展示了其有效性。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,特别是在半监督设置中,给定第一帧的实例标注,算法需要分割出其他帧中的实例。现有的基于STM的VOS网络通过不断增加记忆库的大小来提高性能,但这种方法存在两个主要问题:一是硬件难以承受不断增加的内存需求;二是存储大量信息会引入噪声,不利于从记忆库中读取最重要的信息。
2)研究方法

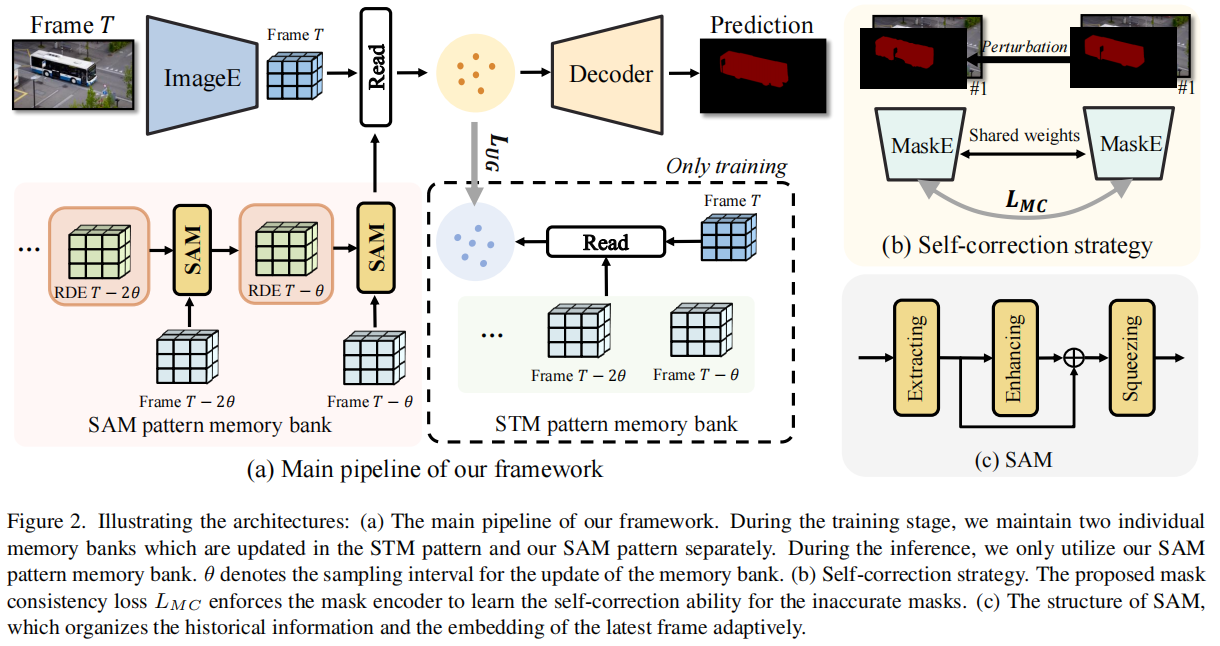
为了解决上述问题,文章提出了RDE方法,其核心是构建一个固定大小的记忆库。具体来说,RDE通过以下三个关键部分实现:
-
循环动态嵌入(RDE):RDE通过SAM生成和更新,利用历史信息的线索和最新帧的嵌入来提供更丰富的表示。RDE的更新过程包括三个部分:提取、增强和压缩。提取部分负责组织历史RDE和最新帧嵌入之间的时空关系;增强部分通过空洞空间金字塔池化(ASPP)强化这种关系;压缩部分则通过卷积操作压缩增强后的特征。
-
时空聚合模块(SAM):SAM负责生成和更新RDE,通过组织历史信息和最新帧的嵌入来适应性地更新记忆库。SAM包括提取、增强和压缩三个部分,分别负责组织时空关系、强化关系和压缩信息。
-
无偏指导损失(Unbiased Guidance Loss):为了避免SAM在长视频中由于循环使用而导致的误差累积,文章提出了一种无偏指导损失。这种损失通过比较SAM模式记忆库和STM模式记忆库的分布来控制SAM的更新过程,使其在训练阶段更加稳定。
-
自校正策略(Self-correction Strategy):考虑到记忆库中掩码的质量会影响查询帧的分割性能,文章设计了一种自校正策略,通过模拟不同质量的掩码并约束这些掩码的嵌入与真实掩码的嵌入接近,从而在训练阶段学习自校正能力。
3)实验结果
文章在DAVIS 2017、DAVIS 2016和YouTube-VOS 2019等多个基准数据集上进行了广泛的实验。实验结果表明,RDE方法在性能和速度上都取得了最佳的权衡:
- DAVIS 2017验证集:RDE方法达到了86.1%的J&F分数,比STCN高出0.7%,并且速度更快(27 FPS对比20.2 FPS)。
- DAVIS 2017测试集:RDE方法在测试集上也表现出色,J&F分数为78.9%。
- DAVIS 2016验证集:RDE方法达到了91.6%的J&F分数,速度为35 FPS,比STCN快40%。
- YouTube-VOS 2019验证集:尽管RDE方法没有超过STCN,但它仍然超过了其他最先进的方法,无论是否使用BL30K数据集进行训练。
此外,文章还通过合成长视频实验验证了RDE方法在处理长视频时的有效性。实验结果表明,随着合成长视频长度的增加,RDE方法的性能和速度几乎不受影响,而STCN的性能和速度明显下降。
4)关键结论
文章提出的RDE方法通过构建固定大小的记忆库,有效地解决了STM方法在处理长视频时面临的内存需求和噪声积累问题。通过SAM模块和无偏指导损失,RDE方法在训练阶段更加稳定,并且能够自适应地更新记忆库。自校正策略进一步提高了模型对记忆库中掩码质量的鲁棒性。实验结果表明,RDE方法在多个基准数据集上都取得了优异的性能,并且在处理长视频时表现出色。
4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
这篇文章介绍了一种名为 XMem 的新型视频目标分割(VOS)架构,专门针对长视频设计,灵感来源于 Atkinson-Shiffrin 记忆模型。XMem 通过引入多种独立但深度连接的特征记忆库,解决了传统 VOS 方法在处理长视频时面临的内存需求和性能衰减问题。该方法在长视频数据集上大幅超越了现有技术,并在短视频数据集上与现有技术持平。
1)背景知识

视频目标分割(VOS)任务的目标是在给定视频中标记和分割出特定的目标对象。在半监督设置中,用户提供了第一帧的标注,算法需要尽可能准确地分割出其他帧中的目标对象,同时尽量实现实时在线处理,并在处理长视频时保持较小的内存占用。现有的 VOS 方法大多使用单一类型的特征记忆库来存储目标对象的深度网络表示,但对于超过一分钟的长视频,单一记忆库模型会将内存消耗和准确性紧密联系在一起,限制了模型的扩展性。
2)研究方法

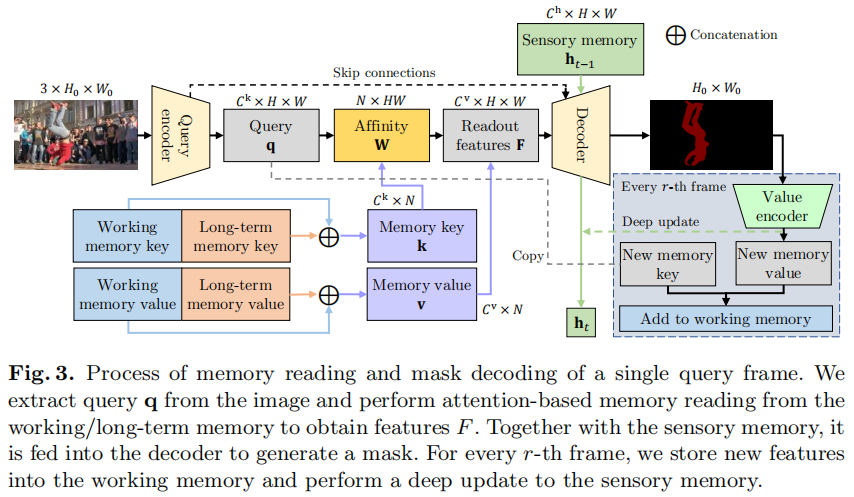
XMem 的核心在于模仿 Atkinson-Shiffrin 记忆模型,引入了三种特征记忆库:
- 感觉记忆(Sensory Memory):快速更新,提供时间平滑性,但不适合长期预测,因为存在表示漂移问题。
- 工作记忆(Working Memory):从历史帧的子集中聚合而来,不随时间漂移,用于短期预测。
- 长期记忆(Long-term Memory):紧凑且持久,通过记忆强化算法将工作记忆中的元素整合到长期记忆中,避免内存爆炸并最小化长期预测的性能衰减。
XMem 的关键创新点包括:
- 记忆强化算法(Memory Potentiation Algorithm):通过聚合更丰富的信息到长期记忆的原型中,防止由于子采样导致的混叠现象。
- 记忆阅读机制(Memory Reading Mechanism):结合工作记忆和长期记忆,通过注意力机制提取查询帧所需的特征。
- 自适应更新策略(Adaptive Update Strategy):根据视频内容动态调整记忆库的更新频率,确保在不同场景下都能保持高效的性能。
3)实验结果
XMem 在多个基准数据集上进行了广泛的实验,包括长视频数据集和短视频数据集。实验结果表明,XMem 在长视频数据集上大幅超越了现有技术,同时在短视频数据集上与现有技术持平。具体结果如下:
- 长视频数据集(Long-time Video Dataset):XMem 在长视频数据集上取得了显著的性能提升,例如在 3× 变体上,XMem 的 J&F 分数为 90.0%,而其他方法如 STCN 的分数为 84.6%,性能衰减仅为 0.2%,而 STCN 的衰减为 -2.7%。
- 短视频数据集(DAVIS 和 YouTube-VOS):XMem 在 DAVIS 2017 验证集上达到了 86.2% 的 J&F 分数,在 YouTube-VOS 2018 验证集上达到了 85.7% 的 G 分数,与现有技术持平,同时在处理长视频时保持了较低的内存占用。
4)关键结论
XMem 通过引入多种特征记忆库和记忆强化算法,有效地解决了传统 VOS 方法在处理长视频时面临的内存需求和性能衰减问题。XMem 不仅在长视频数据集上取得了显著的性能提升,还在短视频数据集上与现有技术持平,展示了其在不同场景下的广泛适用性。此外,XMem 的内存占用低,适合在资源受限的设备上运行,例如移动设备。
尽管 XMem 在处理长视频时表现出色,但在目标对象移动过快或存在严重运动模糊的情况下,即使是更新速度最快的感官记忆也无法跟上目标对象的变化,导致分割失败。作者认为,使用具有更大感受野的感官记忆可以解决这一问题。
5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
这篇文章提出了一种名为 Decoupling Features in Hierarchical Propagation (DeAOT) 的新型视频目标分割(VOS)方法,旨在解决现有基于层次传播的VOS方法(如AOT)在传播过程中因增加目标特定信息而导致目标无关视觉信息丢失的问题。DeAOT通过解耦目标无关和目标特定的特征传播,并引入高效的门控传播模块(Gated Propagation Module, GPM),显著提高了VOS的性能和效率。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,目标是在给定视频中标记和分割出特定的目标对象。半监督VOS要求算法在给定某些帧的标注掩码后,能够将这些掩码信息传播到整个视频序列中。近年来,基于注意力机制的VOS方法取得了显著进展,其中AOT通过引入基于Transformer的层次传播机制,实现了从过去帧到当前帧的信息传播,并将当前帧的特征从目标无关(object-agnostic)转换为目标特定(object-specific)。
2)研究方法
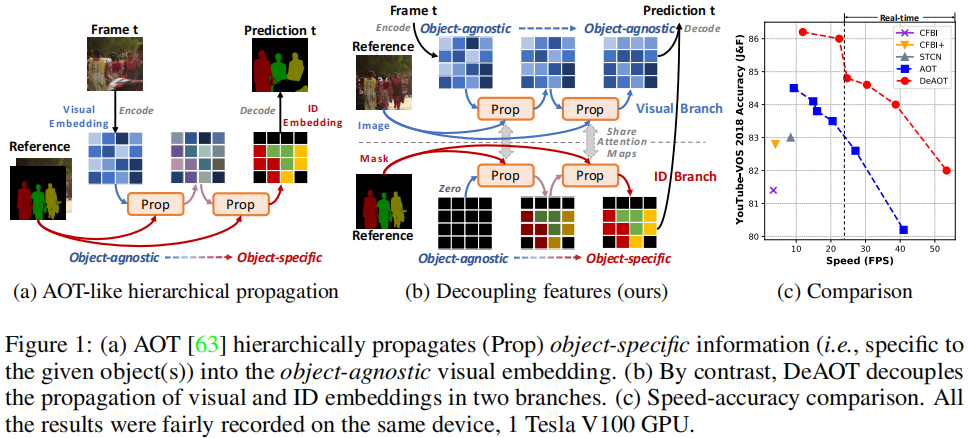
DeAOT的核心思想是将目标无关和目标特定的特征传播解耦到两个独立的分支中,即视觉分支(Visual Branch)和ID分支(ID Branch)。视觉分支负责匹配对象、收集过去的视觉信息并细化对象特征;ID分支则利用视觉分支计算的注意力图(attention maps)将ID嵌入从过去帧传播到当前帧。这种双分支结构避免了在深层传播层中丢失目标无关的视觉信息,从而有助于学习更鲁棒的视觉嵌入。
双分支传播
- 视觉分支:通过计算注意力图在视觉嵌入上进行对象匹配,并传播过去的视觉信息。
- ID分支:利用视觉分支的注意力图将ID嵌入从过去帧传播到当前帧。
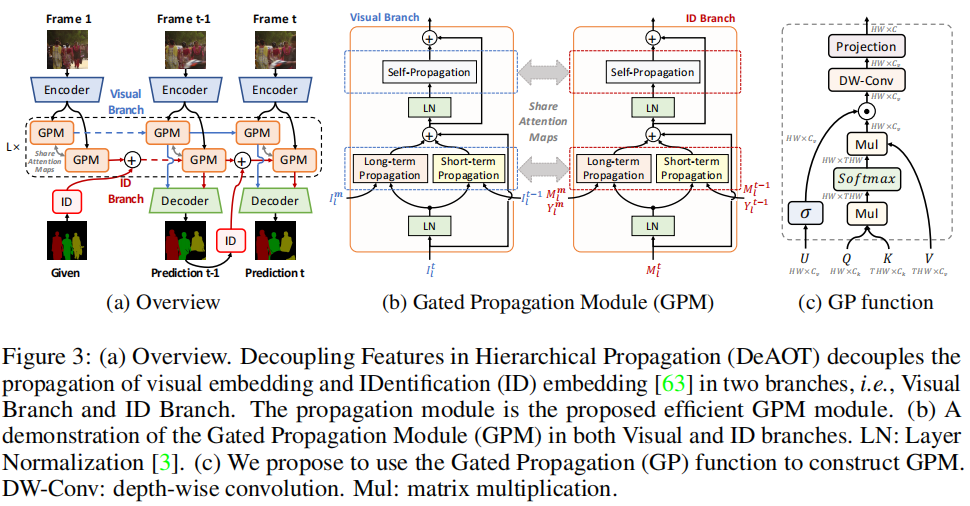
门控传播模块(GPM)
为了提高效率,DeAOT提出了一种基于单头注意力的GPM模块,用于构建层次传播。GPM包括长时传播、短时传播和自传播三种类型的传播过程,每种传播过程都使用了门控传播函数(GP function)。
3)实验结果
DeAOT在多个基准数据集上进行了广泛的实验,包括YouTube-VOS、DAVIS 2017、DAVIS 2016和VOT 2020。实验结果表明,DeAOT在准确性和运行速度上均优于现有的AOT方法。
- YouTube-VOS:DeAOT在2018和2019年的验证集上分别达到了86.0%和85.9%的J&F分数,运行速度为22.4fps,显著优于AOT的84.1%和14.9fps。
- DAVIS 2017:DeAOT在验证集和测试集上分别达到了85.2%和80.7%的J&F分数,运行速度为27fps,优于AOT的83.8%和18.7fps。
- DAVIS 2016:DeAOT达到了92.3%的J&F分数,运行速度为27fps,优于AOT的91.1%和18.0fps。
- VOT 2020:DeAOT在EAO分数上达到了0.622,显著优于现有的跟踪方法。
4)关键结论
DeAOT通过解耦目标无关和目标特定的特征传播,避免了在深层传播层中丢失视觉信息,从而提高了VOS的性能。此外,DeAOT提出的GPM模块在保持高效的同时,进一步提升了性能。DeAOT在多个基准数据集上取得了新的最高性能,并在运行速度上优于现有方法。
尽管DeAOT在多个基准数据集上取得了优异的性能,但在处理具有严重遮挡的多个高度相似目标时,DeAOT仍然可能失败。这表明在复杂场景下,进一步改进特征传播和目标匹配机制仍然是一个挑战。
6、Tracking Anything with Decoupled Video Segmentation
这篇文章提出了一种名为 DEVA(Decoupled Video Segmentation Approach)的新型视频分割方法,旨在通过解耦图像级分割和时序传播来实现对任意目标的跟踪和分割。DEVA通过结合任务特定的图像级分割模型和通用的时序传播模型,有效减少了对大规模视频训练数据的依赖,并在多个视频分割任务中取得了优异的性能。
背景知识
视频分割是计算机视觉中的一个基础任务,对于视频理解至关重要。传统的端到端视频分割方法需要在标注好的视频数据集上进行训练,这在大规模词汇表或开放世界设置中变得不切实际,因为标注成本高昂且难以扩展。DEVA通过解耦图像级分割和时序传播,利用更便宜的图像级模型和通用的时序传播模型,减少了对大规模视频训练数据的需求。

研究方法
DEVA的核心思想是将视频分割任务分解为两个独立但相互协作的模块:图像级分割模块和时序传播模块。图像级分割模块负责提供特定任务的分割假设,而时序传播模块则负责在视频序列中传播这些分割假设,生成连贯的分割结果。
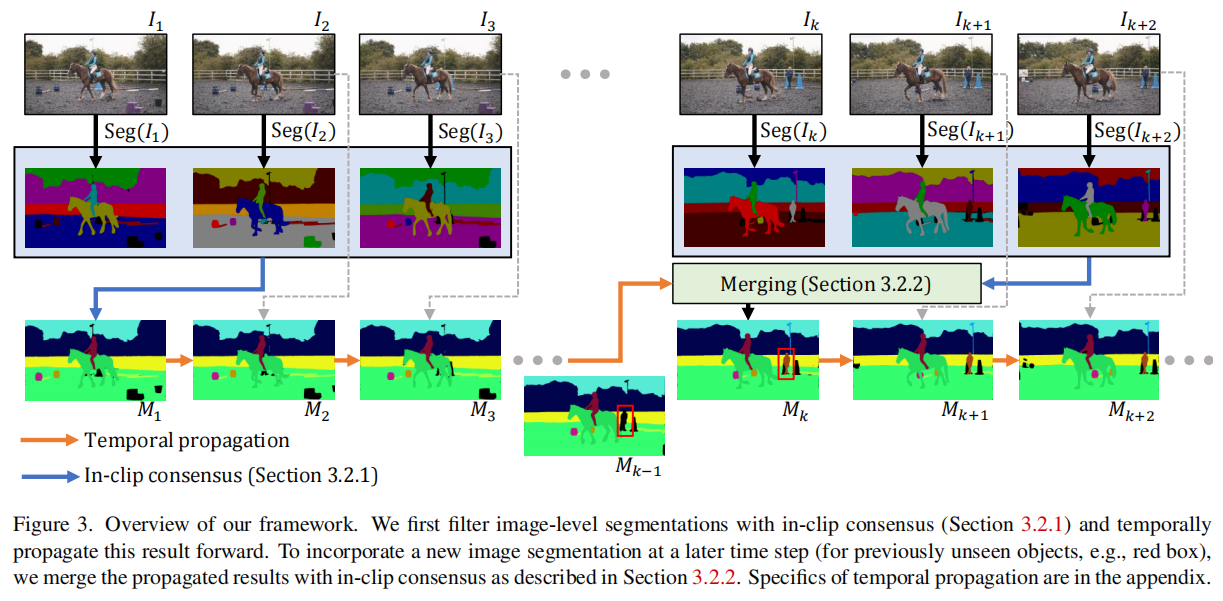

双向传播
DEVA提出了一种双向传播算法,用于在(半)在线设置中融合不同帧的分割假设。具体来说,DEVA通过以下步骤实现:
- In-clip Consensus(剪辑内共识):通过查看未来几帧的分割结果,DEVA在当前帧上达成共识,从而减少单帧分割的噪声。
- Temporal Propagation(时序传播):将经过剪辑内共识处理后的分割结果传播到后续帧。
- Merging Propagation and Consensus(传播和共识的融合):将传播得到的分割结果与新的图像分割结果合并,以处理新出现的对象。
时序传播模块
DEVA的时序传播模块基于XMem模型,该模型通过维护一个内部特征记忆来实现高效的视频对象分割。DEVA对XMem进行了几项改进,包括增加感知记忆的通道数、使用加法而不是连接来融合记忆读出结果,以及引入辅助损失来监督感知记忆。
实验结果
DEVA在多个基准数据集上进行了广泛的实验,包括大规模视频全景分割(VIPSeg)、开放世界视频分割(BURST)、引用视频分割(Ref-YouTubeVOS 和 Ref-DAVIS)以及无监督视频对象分割(DAVIS-16 和 DAVIS-17)。实验结果表明,DEVA在这些任务中均取得了优异的性能。
- 大规模视频全景分割(VIPSeg):DEVA在VIPSeg验证集上取得了42.1%的VPQ分数,显著优于现有的端到端方法。
- 开放世界视频分割(BURST):DEVA在BURST数据集上取得了69.9%的OWTA分数,优于现有的跟踪方法。
- 引用视频分割:DEVA在Ref-YouTubeVOS和Ref-DAVIS数据集上分别取得了66.0%和66.3%的J&F分数,优于现有的方法。
- 无监督视频对象分割:DEVA在DAVIS-16和DAVIS-17数据集上分别取得了88.9%和73.4%的J&F分数,表现出色。
关键结论
DEVA通过解耦图像级分割和时序传播,有效地减少了对大规模视频训练数据的依赖,并在多个视频分割任务中取得了优异的性能。这种方法特别适合于大规模词汇表或开放世界设置,其中视频数据和标注成本高昂且难以获取。DEVA的双向传播算法和改进的时序传播模块是其实现高性能的关键。
尽管DEVA在多个任务中表现出色,但它也有一些限制。首先,由于时序传播模块是任务无关的,它无法自行检测新对象,这可能导致新对象的检测延迟。其次,在数据充足的情况下,端到端方法仍然优于DEVA,但DEVA在大规模词汇表或开放世界设置中更具潜力。
7、Putting the Object Back into Video Object Segmentation
这篇文章介绍了一种名为Cutie的视频目标分割(Video Object Segmentation, VOS)网络,它通过对象级别的记忆读取来提高在复杂场景下的分割性能。Cutie的核心创新在于其对象级别的记忆读取机制,通过对象查询和对象变换器(object transformer)实现,能够有效地将对象从记忆中重新引入到查询帧中,从而在具有挑战性的数据集上取得了显著的性能提升。
1)背景知识与研究动机
视频目标分割(VOS)任务要求在给定第一帧注释的情况下,跟踪并分割视频中的目标对象。近年来,基于记忆的VOS方法通过从过去的分割帧中计算记忆表示,并在新查询帧中读取这些记忆来实现分割。然而,这些方法主要依赖于像素级别的匹配,容易受到干扰,尤其是在存在干扰物的情况下,导致性能下降。为了解决这一问题,Cutie提出了一种对象级别的记忆读取方法,通过对象查询和对象变换器来整合像素特征,从而在复杂场景下实现更鲁棒的分割性能。

2)研究方法
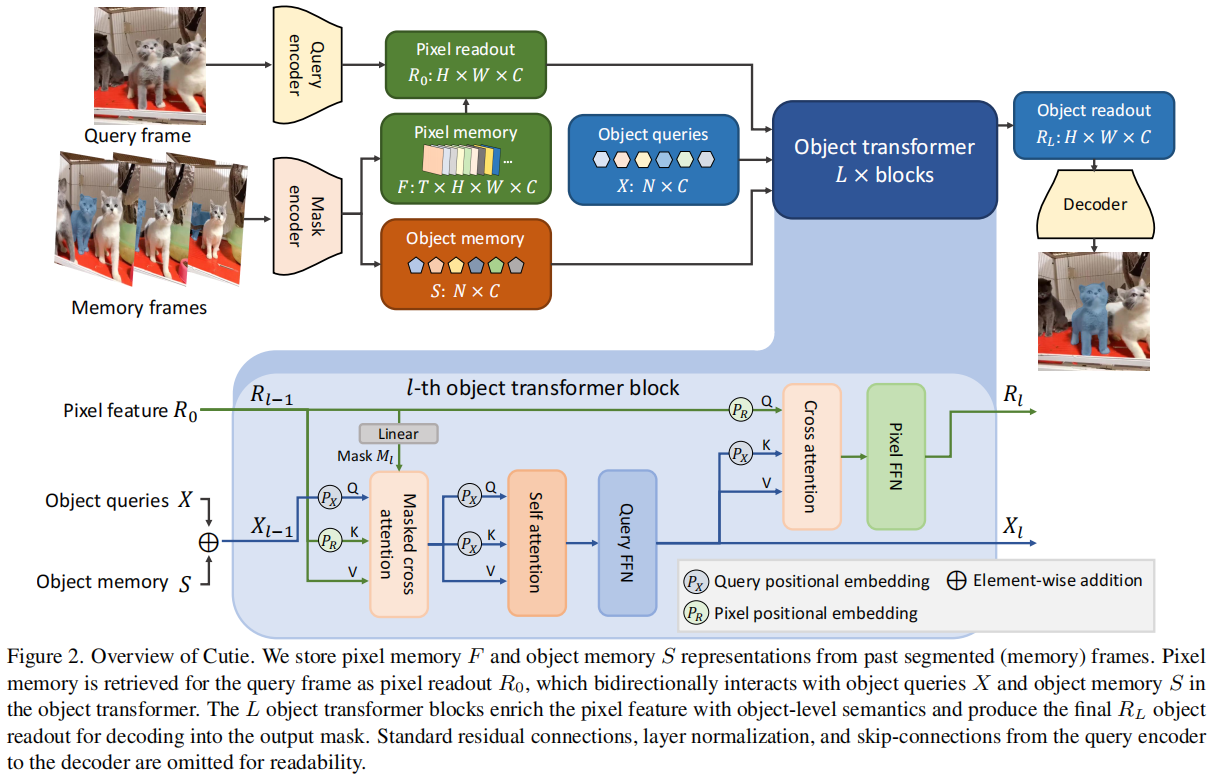
Cutie的核心是对象级别的记忆读取机制,它通过以下三个主要部分实现:
- 对象变换器(Object Transformer):Cutie使用一组对象查询(object queries)与从像素记忆中读取的特征进行交互。这些对象查询作为目标对象的高级摘要,而高分辨率特征图则用于精确分割。对象变换器通过迭代的方式将对象查询与像素特征结合起来,从而在保持全局对象信息的同时,也保留了高分辨率的像素特征。
- 前景-背景掩码注意力(Foreground-Background Masked Attention):为了清晰地分离前景和背景的语义,Cutie扩展了掩码注意力机制,使得部分对象查询只关注前景,而其余的则只关注背景。这种分离有助于在存在干扰物的情况下保持分割的准确性。
- 紧凑对象记忆(Compact Object Memory):Cutie引入了一个紧凑的对象记忆来总结目标对象的特征,这些特征在查询时被检索为目标特定的对象级表示,从而增强了对象查询的表示能力。
3)实验
实验部分评估了Cutie在多个标准基准测试上的性能,包括DAVIS 2017、YouTubeVOS和具有挑战性的MOSE数据集。结果显示,Cutie在MOSE数据集上相较于XMem和DeAOT等方法有显著的性能提升,同时在DAVIS和YouTubeVOS数据集上也保持了竞争力,无论是在准确性还是效率上。
关键数值结果
- 在MOSE数据集上,Cutie相比于XMem提升了8.7 J&F,同时保持了类似的运行时间。
- 在DAVIS-2017和YouTubeVOS数据集上,Cutie-base模型的J&F分数分别为67.9和87.7,表现出色。
- 在长视频评估中,Cutie在BURST数据集上的表现也优于其他方法,例如Cutie-base在长视频上的HOTA分数为61.8%,优于XMem的57.9%。
4)结论
Cutie通过其对象级别的记忆读取机制,在复杂场景下的视频目标分割任务中取得了显著的性能提升。它有效地整合了自顶向下的对象级信息和自底向上的像素级特征,使得在存在干扰物和遮挡的情况下也能保持鲁棒的分割性能。此外,Cutie的设计允许它在实时应用中保持高效率。
尽管Cutie在许多情况下表现出色,但在高度相似的对象靠近或相互遮挡时,它可能会失败。这种情况下,像素记忆和对象记忆可能无法提供足够的区分特征供对象变换器操作。
相关文章:

【综述】视频目标分割VOS
目录 1、Associating Objects with Transformers for Video Object Segmentation1)背景知识2)研究方法3)实验结果4)结论 2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentat…...

基于线性回归的数据预测
1. 自主选择一个公开回归任务数据集(如房价预测、医疗数据、空气质量预测等,可Kaggle)。 2. 数据预处理:完成标准化(Normalization)、特征选择或缺失值处理等步骤。 3. 使用线性回归模型进行建模。采用80…...

第5天-python饼图绘制
一、基础饼图绘制(Matplotlib) 1. 环境准备 python 复制 下载 pip install matplotlib numpy 2. 基础饼图代码 python 复制 下载 import matplotlib.pyplot as plt# 数据准备 labels = [1, 2, 3, 4] sizes = [30, 25, 15, 30] # 各部分占比(总和建议100) colors…...

c++学习方向选择说明
文章目录 前言一、什么样的人适合用c找编程相关工作二、c可以投递什么岗位三、应届生c怎么学才可以找到好工作那这样的话,校招生搞c应该怎么学才能凸显自己的优势呢?那有人就问了,那我应该学啥啊? 四、零基础学习c路线 前言 做了…...

采集需要登录网站的教程
有些网站需要用户登录才能显示相关信息,如果要采集这类网站,有以下几个方法: 1. 写发布模块来抓包获取post的数据; 2. 有些采集器内置浏览器获取这些信息,但是经常获取的不准确,可靠性太低; 3. …...

在hadoop中实现序列化与反序列化
在 Hadoop 分布式计算环境中,序列化与反序列化是数据处理的核心机制之一。由于 Hadoop 需要在集群节点间高效传输数据并进行分布式计算,其序列化框架不仅要支持对象的序列化与反序列化,还要满足高效、紧凑、可扩展等特殊需求。本文将深入探讨…...

数据结构*排序
排序的一些相关概念 稳定性 假设在待排序序列中,存在两个元素A和B,A和B的值相同。在排序后,A和B的相对位置没有变化,就说这排序是稳定的。反之不稳定。 内部排序与外部排序 内部排序:数据完全存储在内存中…...

新浪《经济新闻》丨珈和科技联合蒲江政府打造“数字茶园+智能工厂+文旅综合体“创新模式
5月14日,新浪网《经济新闻》频道专题报道珈和科技在第十四届四川国际茶业博览会上的精彩亮相,并深度聚焦我司以数字技术赋能川茶产业高质量发展创新技术路径,及在成都市“茶业建圈强链”主题推介会上,珈和科技与蒲江县人民政府就智…...

【Linux】第二十三章 控制启动过程
1. 请简要说明 RHEL9的启动过程。 (1)计算机通电。系统固件 (UEFI 或 BIOS) 开机自检 (POST),并初始化部分硬件,然后,固件会寻找启动设备(如硬盘、USB、网络等),并将控制权交给引导…...

深信服golang面经
for range 中赋值的变量,这个变量指向的是真实的地址吗,还是临时变量 不是真实地址,是临时变量 package mainimport "fmt"func main() {slice : []int{4, 2, 3}for _, v : range slice {fmt.Println(v, &v) // 这里的 v 是临…...

基于 Netty + SpringBoot + Vue 的高并发实时聊天系统设计与实现
一、系统架构设计 1.1 整体架构图 ------------------ WebSocket (wss) ------------------ Netty TCP ------------------ | Vue前端 | <-------------------------> | SpringBoot网关 | <------------------> | Netty服务集…...

根据当前日期计算并选取上一个月和上一个季度的日期范围,用于日期控件的快捷选取功能
代码如下: <el-date-picker v-model"value" type"monthrange" align"right" unlink-panels range-separator"至"start-placeholder"开始月份" end-placeholder"结束月份" :picker-options"pic…...

Spring Boot 使用 jasypt配置明文密码加密
引入依赖 <dependency><groupId>com.github.ulisesbocchio</groupId><artifactId>jasypt-spring-boot-starter</artifactId><version>3.0.4</version> </dependency>添加配置 jasypt:encryptor:password: pssw0rd&Hubt2ec…...

ubuntu下docker安装mongodb-支持单副本集
1.mogodb支持事务的前提 1) MongoDB 版本:确保 MongoDB 版本大于或等于 4.0,因为事务支持是在 4.0 版本中引入的。 2) 副本集配置:MongoDB 必须以副本集(Replica Set)模式运行,即使是单节点副本集&#x…...

科技赋能,开启现代健康养生新潮流
在科技与生活深度融合的当下,健康养生也迎来了全新的打开方式。无需传统医学的介入,借助现代科学与智能设备,我们能以更高效、精准的方式守护健康。 饮食管理步入精准化时代。利用手机上的营养计算 APP,录入每日饮食࿰…...

《安徽日报》聚焦珈和科技AI创新:智慧虫情测报护航夏粮提质丰产
5月7日,《安徽日报》焦点新闻版块以《高科技助力田管,确保夏粮丰收——为4300多万亩小麦守好防线》为题,深度报道了农业科技在夏粮生产中的关键作用。其中,珈和科技自主研发的AI虫情测报一体机作为绿色防控、农业智慧化的标杆被重…...

企业级 Go 多版本环境部署指南-Ubuntu CentOS Rocky全兼容实践20250520
🛠️ 企业级 Go 多版本环境部署指南-Ubuntu / CentOS / Rocky 全兼容实践 兼顾 多版本管理、安全合规、最小权限原则与 CI/CD 可复现性,本指南以 Go 官方 toolchain 为主,结合 asdf 实现跨语言统一管理,并剔除已过时的 GVM。支持 …...

MCP 协议传输机制大变身:抛弃 SSE,投入 Streamable HTTP 的怀抱
在技术的江湖里,变革的浪潮总是一波接着一波。最近,模型上下文协议(MCP)的传输机制就搞出了大动静,决定和传统的服务器发送事件(SSE)说拜拜,转身拥抱 Streamable HTTP,这…...

Windows 上配置 Docker,Docker 的基本原理和用途,以及如何在 Docker 中运行程序
Windows 系统上的 Docker 安装与使用指南 1. Windows 上配置 Docker 检查系统要求:使用 64 位 Windows 10/11,BIOS 已启用硬件虚拟化(VT-x/AMD-V)。Windows 版本最好更新到 2004 及以上(内部版本19041)&am…...

CBCharacteristic:是「特征」还是「数据通道」?
目录 名词困惑:两种中文译法的由来官方定义 & 开发者视角乐高类比:文件夹与文件智能手表实例:Characteristic 长什么样?iOS 代码实战:读 / 写 / 订阅小结 & Best Practice 1. 名词困惑:为什么有两…...

【JavaEE】多线程
线程 在Java中,鼓励多线程编程。进程可以满足并发编程,但是效率不高(创建、销毁、调度时间都比较长,这些都消耗在申请资源上了),而线程就不一样。 线程也叫“轻量级进程”,创建、销毁、调度都更…...

docker- Harbor 配置 HTTPS 协议的私有镜像仓库
Harbor通过配置 HTTPS 协议,可以确保镜像传输的安全性,防止数据被窃取或篡改。本文将详细介绍如何基于 Harbor 配置 HTTPS 协议的私有镜像仓库。 1.生成自建ca证书 [rootdocker01 ~]# mkdir -p /liux/softwares/harbor/certs/custom/{ca,server,client…...
----留言板)
[SpringBoot]Spring MVC(5.0)----留言板
Spring留言板实现 预期结果 可以发布并显示点击提交后,显示并清除输入框并且再次刷新后,不会清除下面的缓存 约定前后端交互接口 Ⅰ 发布留言 url : /message/publish . param(参数) : from,to,say . return : true / false . Ⅱ 查询留言 url : /messag…...

Jules 从私有预览阶段推向全球公测
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

vLLM框架高效原因分析
vLLM框架在模型推理中以高效出名,主要基于以下核心原理和技术优化,这些设计使其在处理大语言模型时显著提升性能: 一、PagedAttention:动态显存管理技术 vLLM的核心创新在于PagedAttention,灵感源自操作系统的虚拟内存…...

【Git】常用命令大全
以下是 Git 的常用命令大全,分为几个常见类别,便于理解和使用: 1. 初始化与克隆 初始化本地仓库:git init克隆远程仓库到本地:git clone <repository_url> 2. 添加与提交 添加指定文件到暂存区:git…...

pycharm无需科学上网工具下载插件的解决方案
以下是两种无需科学上网即可下载 PyCharm 插件的解决思路: 方法 1:设置 PyCharm 代理 打开 PyCharm选择菜单:File → Settings → Appearance & Behavior → System Settings → HTTP Proxy在代理设置中进行如下配置: 代理地…...

学习threejs,使用Physijs物理引擎,使用DOFConstraint自由度约束,模拟小车移动
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Physijs 物理引擎1.1.1 ☘️…...

仓颉开发语言入门教程:常见UI组件介绍和一些问题踩坑
幽蓝君发现一个问题,仓颉开发语言距离发布马上一年了,一些知名App已经使用仓颉开发了许多功能,但是网络上关于仓颉开发语言的教程少之又少,系统性的教程更是没有,仓颉官网的文档也远远不如ArkTS详尽。 现阶段对于想学…...

[Git] 初识 Git 与安装入门
告别文件噩梦:初识 Git 与安装入门 嘿,朋友!不知道你是不是也遇到过这样的情况:你在写一份重要的文档、报告,或者更常见的,一段代码时,为了安全起见,怕改错了回不去,或者…...

海康威视摄像头C#开发指南:从SDK对接到安全增强与高并发优化
一、海康威视SDK核心对接流程 1. 开发环境准备 官方SDK获取:从海康开放平台下载最新版SDK(如HCNetSDK.dll、PlayCtrl.dll)。依赖项安装:确保C运行库(如vcredist_x86.exe)与S…...

大语言模型 14 - Manus 超强智能体 开源版本 OpenManus 上手指南
写在前面 Manus 是由中国初创公司 Monica.im 于 2025 年 3 月推出的全球首款通用型 AI 智能体(AI Agent),旨在实现“知行合一”,即不仅具备强大的语言理解和推理能力,还能自主执行复杂任务,直接交付完整成…...
[全网首发,保姆级教程,建议收藏])
使用 LibreOffice 实现各种文档格式转换(支持任何开发语言调用 和 Linux + Windows 环境)[全网首发,保姆级教程,建议收藏]
以下能帮助你可以使用任何开发语言,在任何平台都能使用 LibreOffice 实现 Word、Excel、PPT 等文档的自动转换,目前展示在 ASP.NET Core 中为 PDF的实战案例,其他的文档格式转换逻辑同理。 📦 1. 安装 LibreOffice 🐧…...
一主两从高可用集群)
CentOS Stream 9 中部署 MySQL 8.0 MGR(MySQL Group Replication)一主两从高可用集群
🐇明明跟你说过:个人主页 🏅个人专栏:《MySQL技术精粹》🏅 🔖行路有良友,便是天堂🔖 目录 一、前言 1、MySQL 8.0 中的高可用方案 2、适用场景 二、环境准备 1、系统环境说明…...

软考中级软件设计师——计算机网络篇
一、计算机网络体系结构 1.OSI七层模型 1. 物理层(Physical Layer) 功能:传输原始比特流(0和1),定义物理介质(如电缆、光纤)的电气、机械特性。 关键设备:中继器&#…...

RK3568 OH5.1 源码编译及问题
安装编译器和二进制工具 在源码根目录下执行prebuilts脚本,安装编译器及二进制工具。 bash build/prebuilts_download.sh在源码根目录执行如下指令安装hb编译工具: python3 -m pip install --user build/hb使用build.sh脚本编译源码 进入源码根目录&…...

【razor】回环结构导致的控制信令错位:例如发送端收到 SR的问题
一、razor的echo程序 根据对 yuanrongxi/razor 仓库的代码和 echo 测试程序相关实现的分析,下面详细解读 echo 程序中 RTCP sender report(SR)、receiver report(RR)回显的问题及项目的解决方式。 1. 问题背景 在 RTP/RTCP 体系下,SR(Sender Report)由发送端周期性发…...
、双指针(移动零、盛最多水的容器、三数之和、接雨水))
leetcode hot100:三、解题思路大全:哈希(两数之和、字母异位词分组、最长连续序列)、双指针(移动零、盛最多水的容器、三数之和、接雨水)
哈希 两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返…...

MySQL 8.0 OCP 1Z0-908 161-170题
Q161.Examine this command, which executes successfully: cluster.addInstance ( ‘:’,{recoveryMethod: ‘clone’ 1}) Which three statements are true? (Choose three.) A)The account used to perform this recovery needs the BACKUP_ ADMIN privilege. B)A target i…...

onlyoffice 源码 调试说明 -ARM和x86双模式安装支持
很多用户在调试onlyoffice源码最大的问题是如何搭建环境,这个难度很高,下面提供一键安装的方式,让普通用户也能快速调试源码。 OnlyOffice Document Server 基于源码运行的容器调试模式,凭借 Docker 容器化技术的核心优势,为开发者提供了跨平台、高兼容性…...

workflow:高效的流式工作架构
引言 workflow是sougou的一款开源框架 主要是以请求回应的模式解决各自网络/IO任务而发明的 一.workflow的任务流 1.workflow都封装了哪些任务流 以请求回应的模式来解释 ① 网络层 服务端 在服务端的request 相当于发送了一个获取客户端请求的请求,response相当…...

音视频之H.265/HEVC速率控制
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 5、音视频之H.265/HEVC量化 6、音视频之H.265/HEVC环路后处理 7、音视频之H.265/HEVC熵编…...

jsmpeg+java+ffmpeg 调用摄像头RTSP流播放
原理就是这样,明白吧。本次用springboot netty起这个2个服务,执行拉代码执行即可 <!-- netty --><dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.68.Final</ver…...

深度剖析ZooKeeper
1. ZooKeeper架构总览 ZooKeeper 是一个分布式协调服务,广泛用于分布式系统中的配置管理、命名服务、分布式锁和领导选举等场景。以下是对 ZooKeeper 架构、通信机制、容错处理、数据一致性与可靠性等方面的详细剖析。 一、ZooKeeper 主从集群 ZooKeeper 采用 主从…...

Zookeeper 集群安装与脚本化管理详解
安装之前:先关闭所有服务器的防火墙!!!!!!!!!!!! systemctl stop firewalld 关闭防火墙 systemctl disable firewalld 开机不启动防火…...

第10天-Python操作MySQL数据库全攻略:从基础连接到高级应用
一、环境准备 1. 安装MySQL驱动 bash 复制 下载 # 官方推荐驱动 pip install mysql-connector-python# 或使用PyMySQL(兼容性更好) pip install pymysql 2. 创建测试数据库 sql 复制 下载 CREATE DATABASE python_db; USE python_db;CREATE TABLE users (id INT AU…...

Spring Cloud Gateway深度解析:原理、架构与生产实践
文章目录 前言一、概述二、核心架构设计及设计原理2.1 分层架构模型网络层(I/O模型)核心处理层 2.2 核心组件协作流程路由定位阶段过滤器执行阶段 2.3 响应式编程模型实现Reactor上下文传递背压处理机制 2.4 动态路由设计原理2.5 异常处理体系2.6 关键路…...

Trae 04.22版本深度解析:Agent能力升级与MCP市场对复杂任务执行的革新
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:Trae - AI 原生 IDE 目录 引言 一、Trae 04.22版本概览 二、统一对话体验的深度整合 2.1 Chat与Builder面板合并 2.2 统一对话的优势 三、上下文能力的显著增强 3.1 W…...

股指期货模型,简单易懂的套利策略
在股指期货投资领域,有不少实用的模型和策略,今天咱们就用大白话来唠唠其中几个重要的概念。 一、跨期套利:合约间的“差价游戏” 跨期套利简单来说,就是投资者以赚取期货合约之间的价差为目的,在同一个期货品种的不…...

MySQL 故障排查与生产环境优化
目录 1. MySQL单实例故障排查 2. MySQL 主从故障排查 3. MySQL 优化 3.1 硬件方面 3.2 MySQL 配置文件 3.3 SQL 方面 1. MySQL单实例故障排查 (1) 故障现象1 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /data/mysql…...