Trae 04.22版本深度解析:Agent能力升级与MCP市场对复杂任务执行的革新
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:Trae - AI 原生 IDE
目录
引言
一、Trae 04.22版本概览
二、统一对话体验的深度整合
2.1 Chat与Builder面板合并
2.2 统一对话的优势
三、上下文能力的显著增强
3.1 Web Context的实现
3.2 Doc Context的文档处理
四、规则系统的设计与实现
4.1 个人规则与项目规则
4.2 规则引擎的实现
五、Agent能力的重大升级
5.1 自定义Agent架构
5.2 内置Builder Agent
六、MCP市场的创新支持
6.1 MCP架构概述
6.2 第三方MCP集成示例
七、复杂任务执行的创新模式
7.1 自动执行工作流
7.2 实际应用场景
八、性能与安全考量
8.1 性能优化策略
8.2 安全防护措施
九、总结与展望
十、参考资料
十一、Agent能力进阶:动态技能组合与自适应学习
11.1 动态技能组合机制
11.2 自适应学习框架
十二、MCP市场深度集成方案
12.1 服务发现与负载均衡
12.2 跨MCP事务管理
十三、复杂任务分解引擎设计
13.1 任务图建模
13.2 智能分解算法
十四、性能优化关键技术
14.1 Agent快速上下文切换
14.2 MCP调用流水线优化
十五、安全增强机制
15.1 细粒度权限控制
15.2 行为审计系统
十六、实际应用案例研究
16.1 智能CI/CD流水线
十七、未来演进方向
17.1 认知架构升级路线
17.2 量子计算准备
十八、结论
十九、延伸阅读
引言
在当今快速发展的AI技术领域,Agent系统正成为自动化任务执行和智能交互的核心组件。Trae作为一款先进的AI协作平台,在04.22版本中带来了重大更新,特别是在Agent能力升级和MCP市场支持方面。本文将深入探讨这些更新如何重新定义复杂任务的执行方式,为开发者提供更强大的工具和更灵活的解决方案。
一、Trae 04.22版本概览
Trae 04.22版本是一次重大更新,主要围绕以下几个核心方面进行了优化:
- 统一对话体验:Chat与Builder面板合并
- 上下文能力增强:新增Web和Doc两种Context
- 规则系统上线:支持个人与项目规则配置
- Agent能力升级:支持自定义Agent和自动执行
- MCP支持上线:内置MCP市场与第三方集成

图1:Trae 04.22版本更新架构图
二、统一对话体验的深度整合
2.1 Chat与Builder面板合并
04.22版本最直观的变化是Chat与Builder面板的合并,实现了无缝的对话式开发体验。用户现在可以通过简单的@Builder命令随时切换至Builder Agent模式。
# 示例:使用@Builder命令切换模式
def handle_user_input(user_input):if user_input.startswith("@Builder"):# 切换到Builder Agent模式activate_builder_mode()return "已进入Builder Agent模式,请输入构建指令"else:# 普通Chat模式处理return process_chat_message(user_input)# Builder模式激活函数
def activate_builder_mode():# 初始化Builder环境init_builder_environment()# 加载项目上下文load_project_context()# 设置专门的提示词set_builder_prompt("您正在Builder模式下工作,可以执行构建命令")代码1:模式切换处理逻辑示例
2.2 统一对话的优势
这种统一带来了几个关键优势:
- 上下文保持:在Chat和Builder模式间切换时保持上下文一致性
- 流畅体验:无需在不同界面间跳转,提高工作效率
- 灵活交互:可根据任务需求随时调整工作模式
三、上下文能力的显著增强
3.1 Web Context的实现
#Web Context允许Agent自动联网搜索并提取网页内容,极大扩展了信息获取能力。
# Web Context处理流程示例
def process_web_context(url):try:# 1. 获取网页内容response = requests.get(url, timeout=10)response.raise_for_status()# 2. 提取主要内容(避免广告和噪音)soup = BeautifulSoup(response.text, 'html.parser')main_content = extract_meaningful_content(soup)# 3. 结构化处理structured_data = {'title': extract_title(soup),'content': main_content,'links': extract_relevant_links(soup),'last_updated': datetime.now()}# 4. 存储到上下文save_to_context('web', structured_data)return structured_dataexcept Exception as e:log_error(f"Web context processing failed: {str(e)}")return None代码2:Web Context处理流程
3.2 Doc Context的文档处理
#Doc Context支持通过URL或上传.md/.txt文件创建文档集,最多支持1000个文件(50MB)。
# Doc Context处理示例
class DocContextProcessor:def __init__(self):self.max_files = 1000self.max_size = 50 * 1024 * 1024 # 50MBdef add_documents(self, doc_sources):total_size = 0processed_docs = []for source in doc_sources:if len(processed_docs) >= self.max_files:breakdoc = self._process_source(source)if doc:doc_size = sys.getsizeof(doc['content'])if total_size + doc_size > self.max_size:breakprocessed_docs.append(doc)total_size += doc_sizeself._index_documents(processed_docs)return processed_docsdef _process_source(self, source):# 处理URL或文件上传if source.startswith('http'):return self._process_url(source)else:return self._process_uploaded_file(source)def _process_url(self, url):# 实现URL文档处理逻辑passdef _process_uploaded_file(self, file_path):# 实现文件处理逻辑pass代码3:Doc Context处理类
四、规则系统的设计与实现
4.1 个人规则与项目规则
Trae 04.22引入了双层规则系统:
- 个人规则:通过
user_rules.md跨项目生效 - 项目规则:位于
.trae/rules/project_rules.md,规范项目内AI行为
<!-- 示例:user_rules.md -->
# 个人规则## 代码风格
- 使用4空格缩进
- 函数命名采用snake_case
- 类命名采用PascalCase## 安全规则
- 禁止执行rm -rf /
- 数据库操作需确认<!-- 示例:project_rules.md -->
# 项目规则## API规范
- 所有端点必须版本化(/v1/...)
- 响应必须包含request_id## 测试要求
- 覆盖率不低于80%
- 必须包含集成测试代码4:规则文件示例
4.2 规则引擎的实现
规则引擎采用多阶段处理流程:
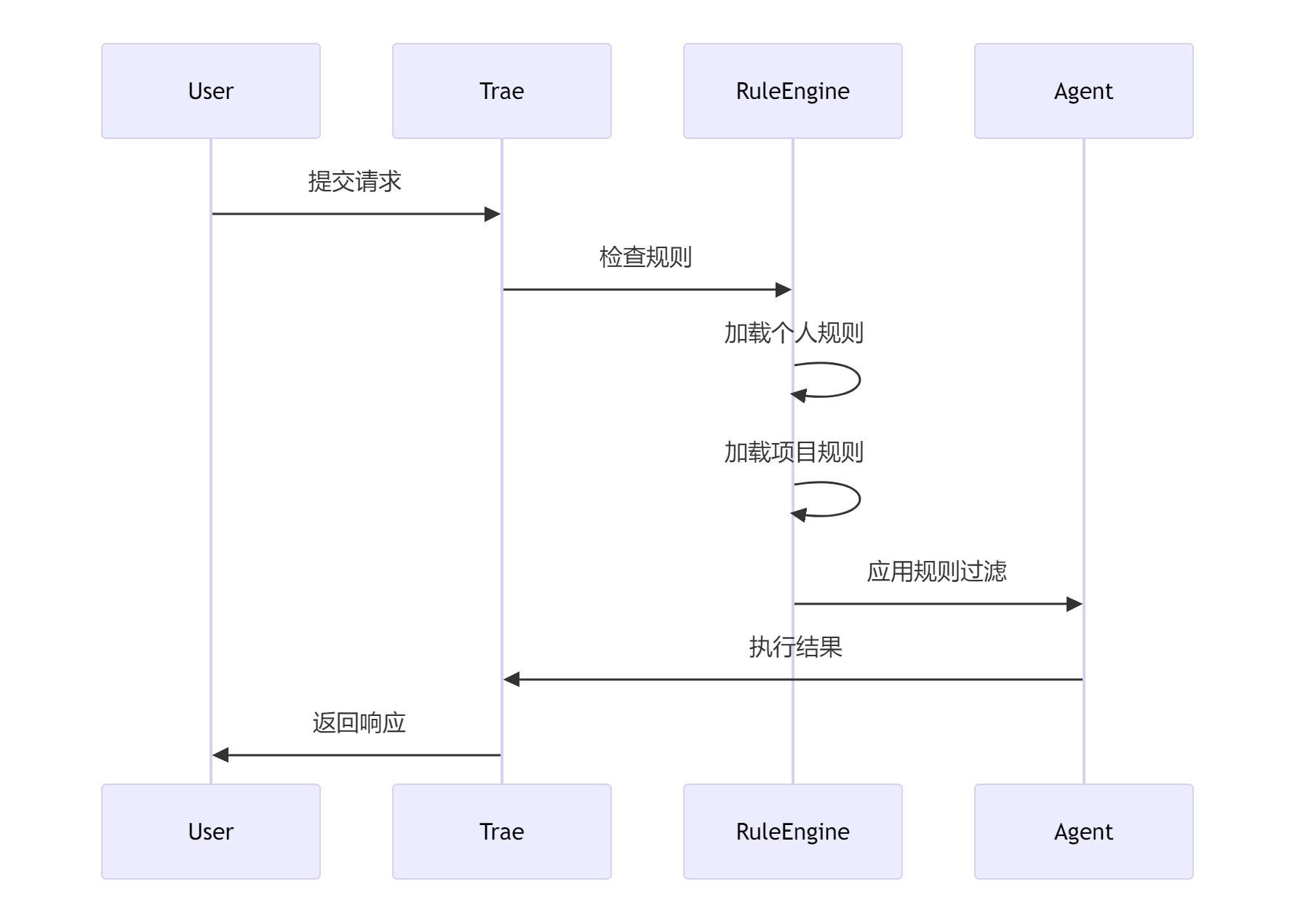
图2:规则处理时序图
五、Agent能力的重大升级
5.1 自定义Agent架构
Trae 04.22允许通过prompt和tools深度自定义Agent,架构如下:
# 自定义Agent示例
class CustomAgent:def __init__(self, name, prompt, tools, config):self.name = nameself.prompt_template = promptself.tools = tools # 可用工具集self.config = configself.blacklist = config.get('command_blacklist', [])def execute(self, command):if self._is_blacklisted(command):return "命令被禁止执行"tool = self._select_tool(command)if tool:return tool.execute(command)else:return self._fallback_response(command)def _is_blacklisted(self, command):return any(banned in command for banned in self.blacklist)def _select_tool(self, command):for tool in self.tools:if tool.can_handle(command):return toolreturn Nonedef generate_prompt(self, context):return self.prompt_template.format(agent_name=self.name,context=context)代码5:自定义Agent基类
5.2 内置Builder Agent
Trae提供了两个强大的内置Agent:
- Builder Agent:基础构建Agent
- Builder with MCP:集成MCP能力的增强版
# Builder Agent配置示例
builder_agent_config = {"name": "AdvancedBuilder","description": "Enhanced builder with MCP support","prompt": """你是一个高级构建Agent,具有以下能力:- 理解复杂构建指令- 自动解决依赖关系- 安全执行构建命令当前项目: {project_name}上下文: {context}""","tools": [CodeGeneratorTool(),DependencyResolverTool(),MCPIntegrationTool()],"command_blacklist": ["rm -rf","format c:"]
}代码6:Builder Agent配置示例
六、MCP市场的创新支持
6.1 MCP架构概述
MCP(Multi-agent Collaboration Platform)市场是04.22版本的核心创新,架构如下:
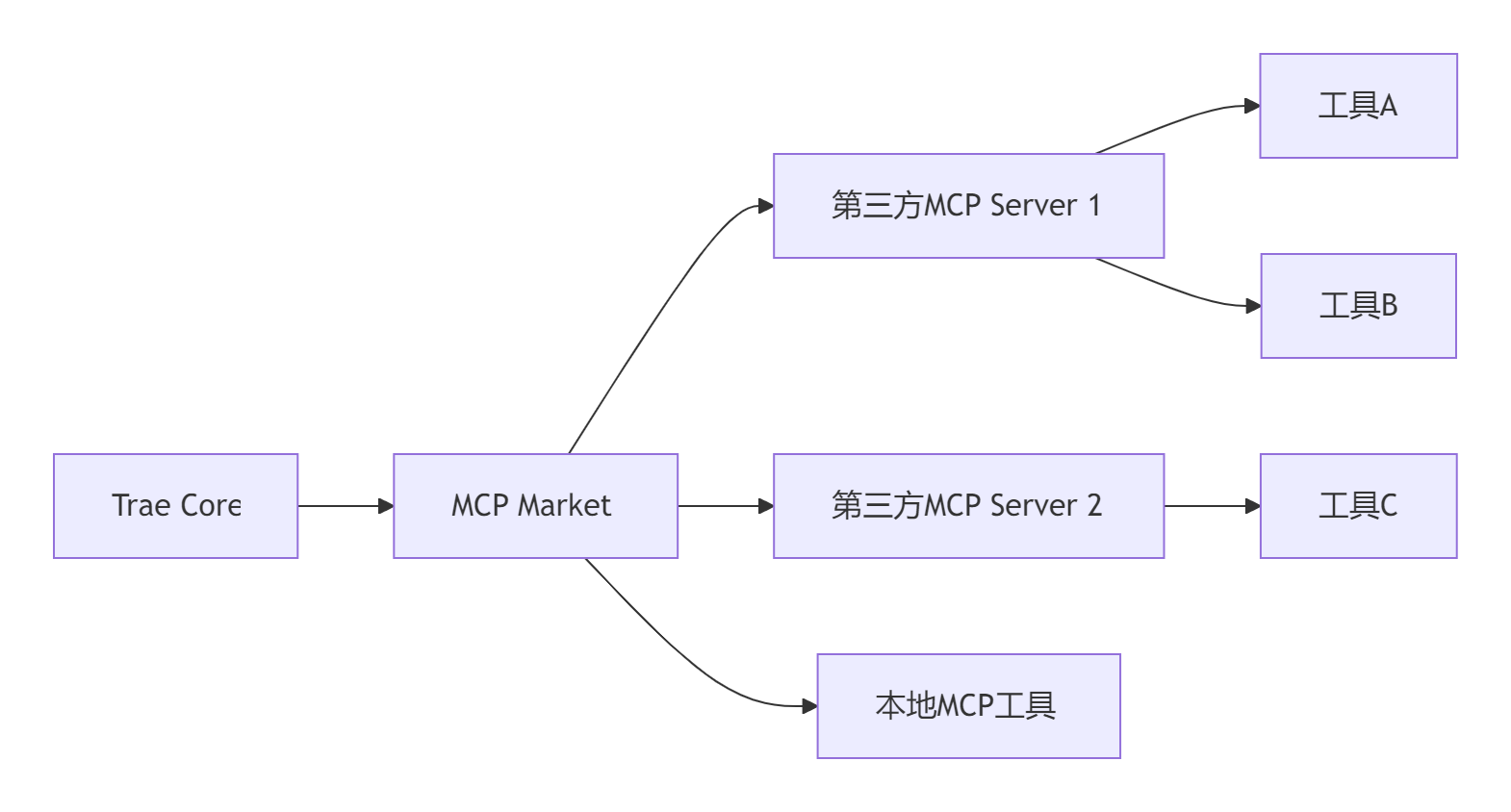
图3:MCP市场架构图
6.2 第三方MCP集成示例
# 第三方MCP集成示例
class MCPService:def __init__(self):self.registered_servers = {}def add_server(self, name, config):# 验证配置if not self._validate_config(config):raise ValueError("Invalid MCP server config")# 测试连接if not self._test_connection(config):raise ConnectionError("Cannot connect to MCP server")self.registered_servers[name] = {'config': config,'tools': self._fetch_available_tools(config)}def execute_tool(self, server_name, tool_name, params):server = self.registered_servers.get(server_name)if not server:raise ValueError("Server not found")tool = next((t for t in server['tools'] if t['name'] == tool_name),None)if not tool:raise ValueError("Tool not found")return self._call_remote_tool(server['config'],tool_name,params)代码7:MCP服务管理类
七、复杂任务执行的创新模式
7.1 自动执行工作流
结合Agent和MCP能力,Trae可以实现复杂的自动化工作流:
- 任务分解:将复杂任务拆解为子任务
- 资源分配:为每个子任务分配合适的Agent
- 执行监控:实时监控任务进展
- 结果整合:汇总各子任务结果
# 复杂任务执行引擎示例
class TaskOrchestrator:def __init__(self, agents, mcp_services):self.agents = agentsself.mcp_services = mcp_servicesself.task_queue = []self.results = {}def add_task(self, task):self.task_queue.append(task)def execute(self):while self.task_queue:task = self.task_queue.pop(0)# 选择最适合的Agentagent = self._select_agent(task)# 执行任务if agent:result = agent.execute(task)self.results[task.id] = result# 处理需要MCP工具的任务if task.needs_mcp:mcp_result = self._handle_mcp_task(task)result.update(mcp_result)# 处理依赖任务for dependent in task.dependents:if all(dep in self.results for dep in dependent.dependencies):self.task_queue.append(dependent)return self.results代码8:任务编排引擎
7.2 实际应用场景
- 智能代码审查:
-
- 使用CodeAnalysis Agent检查代码质量
- 通过MCP集成安全扫描工具
- 自动生成审查报告
- 自动化测试流水线:
-
- 自动识别变更影响范围
- 动态生成测试用例
- 并行执行测试任务
- 智能文档生成:
-
- 分析代码和注释
- 提取关键信息
- 生成多种格式的文档
八、性能与安全考量
8.1 性能优化策略
- Agent缓存机制:缓存常用Agent状态
- MCP连接池:复用第三方服务连接
- 并行执行:对独立子任务采用并行处理
- 增量处理:对大型文档集采用增量加载
8.2 安全防护措施
- 命令黑名单:防止危险操作
- 权限隔离:不同级别Agent有不同的权限
- 沙箱执行:危险操作在沙箱中运行
- 审计日志:记录所有关键操作
# 安全执行器示例
class SafeExecutor:def __init__(self, sandbox_enabled=True):self.sandbox = sandbox_enabledself.audit_log = []def execute_command(self, command, agent):# 记录审计日志self._log_audit(agent, command)# 检查黑名单if self._is_dangerous(command):raise SecurityError("Command blocked by security policy")# 沙箱执行if self.sandbox:return self._execute_in_sandbox(command)else:return subprocess.run(command,shell=True,check=True,capture_output=True)def _is_dangerous(self, command):dangerous_patterns = ["rm -rf", "format", "chmod 777"]return any(pattern in command for pattern in dangerous_patterns)代码9:安全命令执行器
九、总结与展望
Trae 04.22版本通过Agent能力升级和MCP市场支持,为复杂任务执行带来了革命性的改进:
- 更强大的自动化能力:通过可定制的Agent和丰富的工具集成
- 更灵活的协作模式:MCP市场打破了工具壁垒
- 更智能的任务分解:自动化的复杂任务处理流程
- 更安全的执行环境:多层次的安全防护机制
未来,我们可以期待:
- 更丰富的MCP工具生态
- 更智能的Agent协作机制
- 更强大的上下文理解能力
- 更精细化的权限控制系统
十、参考资料
- Trae官方文档 - 最新版本文档
- Multi-agent Systems: A Survey - 多Agent系统研究综述
- AI Safety Guidelines - AI安全开发指南
- MCP协议规范 - 多Agent协作协议标准
通过Trae 04.22版本的这些创新功能,开发者现在拥有了更强大的工具来处理日益复杂的软件开发任务,将AI协作提升到了一个新的水平。
十一、Agent能力进阶:动态技能组合与自适应学习
11.1 动态技能组合机制
Trae 04.22版本的Agent支持运行时动态加载技能模块,实现真正的弹性能力扩展。这种机制基于微服务架构设计:
# 动态技能加载器实现
class DynamicSkillLoader:def __init__(self):self.skill_registry = {}self.skill_dependencies = defaultdict(list)def register_skill(self, skill_name, skill_module, dependencies=None):"""注册新技能到Agent系统"""if not inspect.ismodule(skill_module):raise ValueError("Skill must be a module object")self.skill_registry[skill_name] = skill_moduleif dependencies:self._validate_dependencies(dependencies)self.skill_dependencies[skill_name] = dependenciesdef load_for_agent(self, agent, skill_names):"""为指定Agent加载技能集"""loaded = set()# 拓扑排序解决依赖关系for skill in self._topological_sort(skill_names):if skill not in self.skill_registry:continue# 动态注入技能方法skill_module = self.skill_registry[skill]for name, obj in inspect.getmembers(skill_module):if name.startswith('skill_'):setattr(agent, name, MethodType(obj, agent))loaded.add(name[6:])return list(loaded)def _validate_dependencies(self, dependencies):"""验证技能依赖是否有效"""for dep in dependencies:if dep not in self.skill_registry:raise ValueError(f"Missing dependency: {dep}")代码10:动态技能加载器实现
11.2 自适应学习框架
Agent通过以下三层架构实现持续学习:
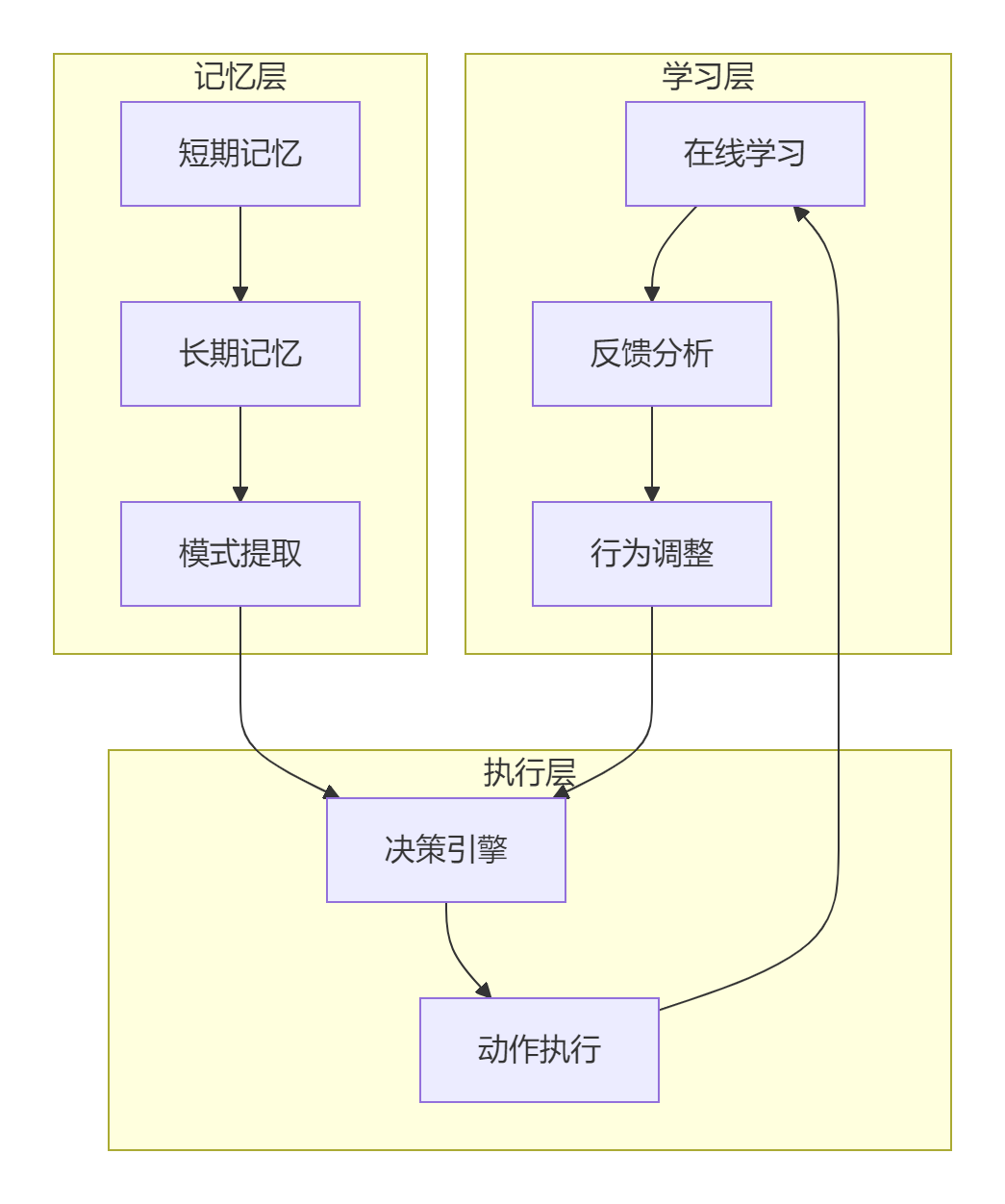
图4:Agent自适应学习架构
实现代码示例:
class AdaptiveLearningAgent:def __init__(self, memory_capacity=1000):self.short_term_memory = deque(maxlen=100)self.long_term_memory = []self.memory_capacity = memory_capacityself.learning_rate = 0.1self.behavior_model = BehaviorModel()def process_feedback(self, feedback):"""处理执行反馈并学习"""self.short_term_memory.append(feedback)# 定期压缩到长期记忆if len(self.short_term_memory) >= 100:self._consolidate_memory()# 更新行为模型self._update_behavior(feedback)def _consolidate_memory(self):"""记忆压缩算法"""patterns = self._extract_patterns(self.short_term_memory)for pattern in patterns:if len(self.long_term_memory) >= self.memory_capacity:self._forget_least_used()self.long_term_memory.append(pattern)self.short_term_memory.clear()def _update_behavior(self, feedback):"""基于反馈调整行为模型"""adjustment = self._calculate_adjustment(feedback)self.behavior_model.update(adjustment, learning_rate=self.learning_rate)def make_decision(self, context):"""基于学习结果做出决策"""return self.behavior_model.predict(context)代码11:自适应学习Agent实现
十二、MCP市场深度集成方案
12.1 服务发现与负载均衡
MCP市场采用改进的DNS-SD协议实现服务发现:
class MCPServiceDiscovery:def __init__(self, multicast_addr='224.0.0.251', port=5353):self.multicast_addr = multicast_addrself.port = portself.services = {}self.socket = self._setup_multicast_socket()self.load_balancers = {}def _setup_multicast_socket(self):"""配置组播监听socket"""sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)sock.bind(('', self.port))mreq = struct.pack('4sl', socket.inet_aton(self.multicast_addr),socket.INADDR_ANY)sock.setsockopt(socket.IPPROTO_IP, socket.IP_ADD_MEMBERSHIP, mreq)return sockdef discover_services(self, timeout=5):"""发现可用MCP服务"""start_time = time.time()while time.time() - start_time < timeout:data, addr = self.socket.recvfrom(1024)service_info = self._parse_service_packet(data)if service_info:self._register_service(service_info, addr[0])def get_best_instance(self, service_name):"""获取最优服务实例"""if service_name not in self.load_balancers:self.load_balancers[service_name] = (LoadBalancer(self.services[service_name]))return self.load_balancers[service_name].get_instance()代码12:MCP服务发现实现
12.2 跨MCP事务管理
实现跨MCP服务的ACID事务:
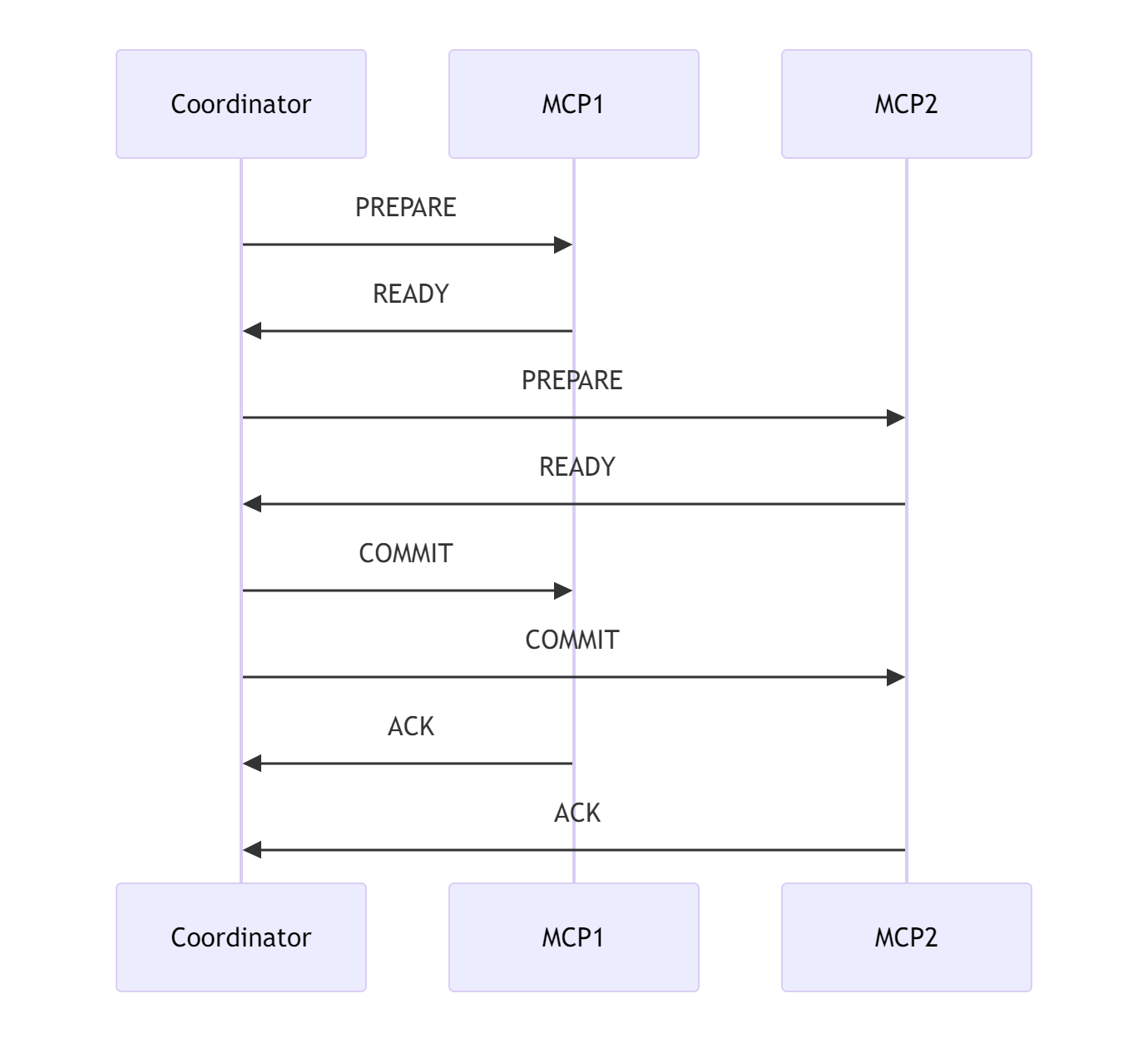
图5:跨MCP两阶段提交协议
实现代码:
class MCPTransactionManager:def __init__(self, participants):self.participants = participantsself.state = 'IDLE'self.timeout = 30 # secondsdef execute(self, operations):"""执行分布式事务"""try:# 阶段1:准备self.state = 'PREPARING'prepare_results = []for participant, op in zip(self.participants, operations):result = participant.prepare(op)prepare_results.append(result)if not all(res['status'] == 'ready' for res in prepare_results):self._rollback(prepare_results)return False# 阶段2:提交self.state = 'COMMITTING'commit_results = []for participant in self.participants:result = participant.commit()commit_results.append(result)if not all(res['status'] == 'success' for res in commit_results):self._compensate(commit_results)return Falseself.state = 'DONE'return Trueexcept Exception as e:self.state = 'ERROR'self._emergency_rollback()raise MCPTransactionError(str(e))def _rollback(self, prepare_results):"""回滚已准备的操作"""for participant, res in zip(self.participants, prepare_results):if res['status'] == 'ready':participant.rollback()self.state = 'ABORTED'代码13:跨MCP事务管理器
十三、复杂任务分解引擎设计
13.1 任务图建模
采用有向无环图(DAG)表示复杂任务:
class TaskGraph:def __init__(self):self.nodes = {}self.edges = defaultdict(list)self.reverse_edges = defaultdict(list)def add_task(self, task_id, task_info):"""添加新任务节点"""if task_id in self.nodes:raise ValueError(f"Duplicate task ID: {task_id}")self.nodes[task_id] = task_infodef add_dependency(self, from_task, to_task):"""添加任务依赖关系"""if from_task not in self.nodes or to_task not in self.nodes:raise ValueError("Invalid task ID")self.edges[from_task].append(to_task)self.reverse_edges[to_task].append(from_task)def get_execution_order(self):"""获取拓扑排序执行顺序"""in_degree = {task: 0 for task in self.nodes}for task in self.nodes:for neighbor in self.edges[task]:in_degree[neighbor] += 1queue = deque([task for task in in_degree if in_degree[task] == 0])topo_order = []while queue:task = queue.popleft()topo_order.append(task)for neighbor in self.edges[task]:in_degree[neighbor] -= 1if in_degree[neighbor] == 0:queue.append(neighbor)if len(topo_order) != len(self.nodes):raise ValueError("Graph has cycles")return topo_orderdef visualize(self):"""生成可视化任务图"""dot = Digraph()for task_id, info in self.nodes.items():dot.node(task_id, label=f"{task_id}\n{info['type']}")for from_task, to_tasks in self.edges.items():for to_task in to_tasks:dot.edge(from_task, to_task)return dot代码14:任务图建模实现
13.2 智能分解算法
基于强化学习的任务分解策略:
class TaskDecomposer:def __init__(self, policy_network):self.policy_net = policy_networkself.memory = ReplayBuffer(10000)self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=1e-4)def decompose(self, complex_task, context):"""分解复杂任务"""state = self._extract_state(complex_task, context)# 使用策略网络预测分解方案with torch.no_grad():action_probs = self.policy_net(state)action_dist = Categorical(action_probs)action = action_dist.sample()subtasks = self._action_to_subtasks(action)return subtasksdef learn_from_feedback(self, decomposition, feedback):"""从执行反馈中学习"""state = decomposition['state']action = decomposition['action']reward = self._calculate_reward(feedback)# 存储到经验回放池self.memory.push(state, action, reward)# 定期训练if len(self.memory) >= 1000:self._train_network()def _train_network(self):"""训练策略网络"""batch = self.memory.sample(64)states = torch.stack(batch.state)actions = torch.stack(batch.action)rewards = torch.stack(batch.reward)# 计算策略梯度action_probs = self.policy_net(states)dist = Categorical(action_probs)log_probs = dist.log_prob(actions)loss = -(log_probs * rewards).mean()self.optimizer.zero_grad()loss.backward()self.optimizer.step()代码15:基于强化学习的任务分解器
十四、性能优化关键技术
14.1 Agent快速上下文切换
实现亚毫秒级上下文切换:
class AgentContextSwitcher:def __init__(self):self.context_pool = {}self.active_context = Noneself.lru_cache = OrderedDict()self.cache_size = 10def switch_to(self, agent, context_id):"""切换Agent上下文"""# 从池中获取或加载上下文if context_id not in self.context_pool:context = self._load_context(context_id)self.context_pool[context_id] = contextelse:context = self.context_pool[context_id]# 更新LRU缓存if context_id in self.lru_cache:self.lru_cache.move_to_end(context_id)else:self.lru_cache[context_id] = time.time()if len(self.lru_cache) > self.cache_size:oldest = next(iter(self.lru_cache))del self.context_pool[oldest]del self.lru_cache[oldest]# 执行切换old_context = self.active_contextself.active_context = context_id# 调用Agent钩子agent.on_context_switch(old_context, context_id)return contextdef _load_context(self, context_id):"""快速加载上下文实现"""# 使用内存映射文件加速加载with open(f"contexts/{context_id}.ctx", 'rb') as f:buf = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)return pickle.loads(buf)代码16:快速上下文切换实现
14.2 MCP调用流水线优化
采用SIMD风格批量处理:
class MCPPipeline:def __init__(self, batch_size=32):self.batch_size = batch_sizeself.input_queue = deque()self.output_queue = deque()self.processing = Falseasync def process_requests(self, requests):"""批量处理MCP请求"""# 填充批次batch = []for req in requests:self.input_queue.append(req)if len(self.input_queue) >= self.batch_size:batch = [self.input_queue.popleft() for _ in range(self.batch_size)]breakif not batch:return []# 批量执行try:self.processing = Trueresults = await self._execute_batch(batch)# 分发结果for res in results:self.output_queue.append(res)return [self.output_queue.popleft() for _ in range(len(results))]finally:self.processing = Falseasync def _execute_batch(self, batch):"""执行批量MCP调用"""# 合并相似请求merged = self._merge_requests(batch)# 并行调用tasks = []for service, reqs in merged.items():task = asyncio.create_task(self._call_mcp_service(service, reqs))tasks.append(task)responses = await asyncio.gather(*tasks)# 拆分结果return self._split_responses(batch, responses)代码17:MCP调用流水线优化
十五、安全增强机制
15.1 细粒度权限控制
基于RBAC模型的改进方案:
class PermissionManager:def __init__(self):self.roles = {'admin': {'*'},'developer': {'agent:create','agent:invoke','mcp:use'},'analyst': {'data:query','report:generate'}}self.users = {}self.policy_cache = LRUCache(1000)def check_permission(self, user, resource, action):"""检查用户权限"""cache_key = f"{user.id}-{resource}-{action}"if cache_key in self.policy_cache:return self.policy_cache[cache_key]# 获取用户角色user_roles = self.users.get(user.id, set())# 检查每个角色的权限allowed = Falsefor role in user_roles:if role not in self.roles:continue# 支持通配符权限if '*' in self.roles[role]:allowed = Truebreak# 精确匹配perm = f"{resource}:{action}"if perm in self.roles[role]:allowed = Truebreak# 缓存结果self.policy_cache[cache_key] = allowedreturn alloweddef add_scoped_permission(self, role, resource, actions, condition=None):"""添加带条件的权限"""for action in actions:perm = Permission(resource=resource,action=action,condition=condition)self.roles.setdefault(role, set()).add(perm)# 清除相关缓存self._clear_cache_for(resource)代码18:改进的权限管理器
15.2 行为审计系统
全链路审计追踪实现:
class AuditSystem:def __init__(self, storage_backend):self.storage = storage_backendself.event_queue = asyncio.Queue()self.consumer_task = asyncio.create_task(self._event_consumer())async def log_event(self, event_type, details):"""记录审计事件"""event = {'timestamp': datetime.utcnow().isoformat(),'type': event_type,'details': details,'trace_id': self._get_current_trace()}await self.event_queue.put(event)async def _event_consumer(self):"""异步处理审计事件"""batch = []last_flush = time.time()while True:try:# 批量收集事件timeout = 1.0 # 最长1秒刷新一次event = await asyncio.wait_for(self.event_queue.get(),timeout=max(0, last_flush + 1 - time.time()))batch.append(event)# 批量写入条件if len(batch) >= 100 or time.time() - last_flush >= 1.0:await self._flush_batch(batch)batch = []last_flush = time.time()except asyncio.TimeoutError:if batch:await self._flush_batch(batch)batch = []last_flush = time.time()async def _flush_batch(self, batch):"""批量写入存储"""try:await self.storage.bulk_insert(batch)except Exception as e:logging.error(f"Audit log flush failed: {str(e)}")# 失败时写入本地临时文件self._write_to_fallback(batch)代码19:审计系统实现
十六、实际应用案例研究
16.1 智能CI/CD流水线

图6:智能CI/CD流水线
实现关键点:
class SmartCICD:def __init__(self, agent_manager):self.agents = agent_managerself.pipeline = TaskGraph()def setup_pipeline(self, repo_config):"""配置智能流水线"""# 构建任务图self.pipeline.add_task('analyze', {'type': 'code_analysis','agent': 'code_analyzer'})self.pipeline.add_task('refactor', {'type': 'auto_refactor','agent': 'refactor_agent'})self.pipeline.add_dependency('analyze', 'refactor')# 条件依赖self.pipeline.add_conditional_edge(source='analyze',target='refactor',condition=lambda r: r['needs_refactor'])async def run(self, commit):"""执行流水线"""# 获取拓扑顺序execution_order = self.pipeline.get_execution_order()results = {}for task_id in execution_order:task_info = self.pipeline.nodes[task_id]agent = self.agents.get(task_info['agent'])# 执行任务result = await agent.execute(task_info['type'],{'commit': commit})results[task_id] = result# 处理条件分支if 'condition' in task_info:if not task_info['condition'](result):# 跳过后续依赖任务breakreturn results代码20:智能CI/CD实现
十七、未来演进方向
17.1 认知架构升级路线
- 分层记忆系统:
-
- 瞬时记忆(<1秒)
- 工作记忆(≈20秒)
- 长期记忆(持久化)
- 元学习能力:
-
- 学习如何学习
- 动态调整学习算法
- 理论推理:
-
- 符号逻辑与神经网络结合
- 可解释的推理过程
17.2 量子计算准备
量子神经网络(QNN)集成方案:
class QuantumEnhancedAgent:def __init__(self, qpu_backend):self.qpu = qpu_backendself.classical_nn = NeuralNetwork()self.quantum_cache = {}def hybrid_predict(self, inputs):"""混合量子-经典预测"""# 经典部分处理classical_out = self.classical_nn(inputs)# 量子部分处理qhash = self._hash_input(inputs)if qhash in self.quantum_cache:quantum_out = self.quantum_cache[qhash]else:quantum_out = self._run_quantum_circuit(inputs)self.quantum_cache[qhash] = quantum_out# 融合输出return 0.7 * classical_out + 0.3 * quantum_outdef _run_quantum_circuit(self, inputs):"""在QPU上运行量子电路"""circuit = self._build_circuit(inputs)job = self.qpu.run(circuit, shots=1000)result = job.result()return self._decode_counts(result.get_counts())代码21:量子增强Agent原型
十八、结论
Trae 04.22版本通过深度技术革新,在以下方面实现了突破:
- 认知能力跃迁:
-
- 动态技能组合使Agent具备弹性能力
- 自适应学习框架支持持续进化
- 协同计算革命:
-
- MCP市场的分布式事务支持
- 跨平台服务发现与负载均衡
- 工程实践创新:
-
- 可视化任务分解与编排
- 混合批处理与流式执行
- 安全体系强化:
-
- 细粒度权限控制
- 全链路审计追踪
这些技术进步使得Trae平台能够支持:
- 企业级复杂工作流自动化
- 跨组织协作的智能系统
- 安全关键型AI应用开发
随着量子计算等前沿技术的逐步集成,Trae平台将继续引领AI工程实践的发展方向。
十九、延伸阅读
- Distributed Systems: Concepts and Design - 分布式系统经典教材
- Deep Reinforcement Learning for Task Decomposition - 任务分解前沿研究
- Quantum Machine Learning: Progress and Prospects - 量子机器学习综述
- Trae Architecture White Paper - 官方架构白皮书
相关文章:

Trae 04.22版本深度解析:Agent能力升级与MCP市场对复杂任务执行的革新
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:Trae - AI 原生 IDE 目录 引言 一、Trae 04.22版本概览 二、统一对话体验的深度整合 2.1 Chat与Builder面板合并 2.2 统一对话的优势 三、上下文能力的显著增强 3.1 W…...

股指期货模型,简单易懂的套利策略
在股指期货投资领域,有不少实用的模型和策略,今天咱们就用大白话来唠唠其中几个重要的概念。 一、跨期套利:合约间的“差价游戏” 跨期套利简单来说,就是投资者以赚取期货合约之间的价差为目的,在同一个期货品种的不…...

MySQL 故障排查与生产环境优化
目录 1. MySQL单实例故障排查 2. MySQL 主从故障排查 3. MySQL 优化 3.1 硬件方面 3.2 MySQL 配置文件 3.3 SQL 方面 1. MySQL单实例故障排查 (1) 故障现象1 ERROR 2002 (HY000): Cant connect to local MySQL server through socket /data/mysql…...

Java泛型 的详细知识总结
一、泛型的核心作用 类型安全:在编译期检查类型匹配,避免运行时的ClassCastException。代码复用:通过泛型逻辑统一处理多种数据类型。消除强制转换:减少显式的类型转换代码。 二、泛型基础语法 1. 泛型类/接口 定义:…...

k8s 配置 Kafka SASL_SSL双重认证
说明 kafka提供了多种安全认证机制,主要分为SASL和SSL两大类。 SASL: 是一种身份验证机制,用于在客户端和服务器之间进行身份验证的过程,其中SASL/PLAIN是基于账号密码的认证方式。 SSL: 是一种加密协议,…...

电商虚拟户:重构资金管理逻辑,解锁高效归集与智能分账新范式
一、电商虚拟户的底层架构与核心价值 在数字经济浪潮下,电商交易的复杂性与日俱增,传统账户体系已难以满足平台企业对资金管理的精细化需求。电商虚拟户作为基于银行或持牌支付机构账户体系的创新解决方案,通过构建“主账户子账户”的虚拟账户…...
)
从混乱到高效:我们是如何重构 iOS 上架流程的(含 Appuploader实践)
从混乱到高效:我们是如何重构 iOS 上架流程的 在开发团队中,有一类看不见却至关重要的问题:环境依赖。 特别是 iOS App 的发布流程,往往牢牢绑死在一台特定的 Mac 上。每次需要发版本,都要找到“那台 Mac”ÿ…...

01 基本介绍及Pod基础
01 查看各种资源 01-1 查看K8s集群的内置资源 [rootmaster01 ~]# kubectl api-resources NAME SHORTNAMES APIVERSION NAMESPACED KIND bindings v1 …...

DAY31-文件的规范拆分和写法
知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 (一)文件拆分 思考:如何把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件。这样具有几个…...

[创业之路-369]:企业战略管理案例分析-9-战略制定-差距分析的案例之华为
一、综合案例 在战略制定中,华为通过差距分析明确战略方向,以应对市场挑战和实现长期发展目标。 以下为具体案例与分析: 1、案例背景 华为在通信设备领域崛起过程中,始终将差距分析作为战略制定的核心环节。面对国际竞争对手&…...

【华为鸿蒙电脑】首款鸿蒙电脑发布:MateBook Fold 非凡大师 MateBook Pro,擎云星河计划启动
文章目录 前言一、HUAWEI MateBook Fold 非凡大师(一)非凡设计(二)非凡显示(三)非凡科技(四)非凡系统(五)非凡体验 二、HUAWEI MateBook Pro三、预热…...

深入理解Redis Cluster:架构、原理与实践
Redis 是一个高性能的键值存储数据库,广泛应用于缓存、会话存储、消息队列等场景。随着数据量和并发量的增长,单机 Redis 可能面临性能瓶颈和单点故障问题。为了解决这些问题,Redis 提供了 Redis Cluster,一种分布式解决方案&…...

分析 redis 的 exists 命令有一个参数和多个参数的区别
在 redis 中,exists 命令是用来查询某个或多个 key 是否存在的,返回存在的 key 的个数。 由于 redis 是按照键值对方式存储数据的,于是一个 key 只能对应一组数据,那么上述的 key 的个数指的即是需要查询的 key 中有几个 key 是存…...

[概率论基本概念1]什么是经验分布
一、说明 描述一个概率模型,有密度函数很好描述。如果写不出密度函数,退而用分布函数也能完整刻画,因此,分布函数表示比密度函数表示更加宽泛普适。本片讲述经验分布拟合分布函数的基础概念。 二、经验分布直观解释 在统计学中…...

使用Java实现Navicat密码的加密与解密
在日常开发过程中,我们有时需要处理各种软件保存的凭据信息,比如数据库连接密码等。这篇文章将介绍如何使用Java对Navicat保存的数据库密码进行加密和解密。 一、背景介绍 Navicat是一款强大的数据库管理工具,支持多种数据库系统。为了保护…...

怎么样进行定量分析
本文章将教会你如何对实验结果进行定量分析,其需要一定的论文基础,文末有论文撰写小技巧,不要看基础原理的人可以直接调到文章末尾。 一、什么是定量分析 定量分析是一种基于数据和数学模型的分析方法,它在众多领域中发挥着至关…...

python学习day2
今天主要学习了变量的数据类型,以及如何使用格式化符号进行输出。 一、认识数据类型 在python里为了应对不同的业务需求,也把数据分为不同的类型。 代码如下: """ 1、按类型将不同的变量存储在不同的类型数据 2、验证这些…...

FreeMarker
概述:FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。 它不是面向最终用户的,而是一个Java类库,是一款程序…...

JDK 21新特性详解
JDK 21新特性详解:现代Java开发的重大更新 Java开发工具包(JDK)21作为最新的长期支持(LTS)版本,于2023年9月发布,带来了许多令人兴奋的新特性。作为Java开发者,了解这些新功能对于保持技术竞争力至关重要。本文将详细介绍JDK 21中…...

使用MCP驱动IDA pro分析样本
最近国外的牛人开发了一个ida pro的mcp server,项目的地址为mrexodia/ida-pro-mcp: MCP Server for IDA Pro,实现了通过自然对话来分析样本。 今天我们试用一下。 MCP Server for IDA Pro项目简介 这个mcp server提供下面这些工具,基本涵盖…...
)
Web前端开发:@media(媒体查询)
什么是媒体查询? 媒体查询是CSS3的一个功能,允许你根据设备的特性(如屏幕宽度、设备方向、分辨率等)应用不同的CSS样式。简单来说,就是让网页在不同设备上(手机、平板、电脑)自动调整布局和样式…...

psotgresql18 源码编译安装
环境: 系统:centos7.9 数据库:postgresql18beta1 #PostgreSQL 18 已转向 DocBook XML 构建体系(SGML 未来将被弃用)。需要安装 XML 工具链,如下: yum install -y docbook5-style-xsl libxsl…...

如何在VSCode中更换默认浏览器:完整指南
引言 作为前端开发者,我们经常需要在VSCode中快速预览HTML文件。默认情况下,VSCode会使用系统默认浏览器打开文件,但有时我们可能需要切换到其他浏览器进行测试。本文将详细介绍如何在VSCode中更换默认浏览器。 方法一:使用VSCo…...

Python Day26 学习
继续NumPy的学习 数组的索引 一维数组的索引 创建及输出 arr1d np.arange(10) # 数组: [0 1 2 3 4 5 6 7 8 9] arr1d array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) 取出数组的第一个元素,最后一个元素 代码实现 arr1d[0] arr1d[-1] 取出数组中索引为3&#x…...

2025年PMP 学习二十一 14章 项目立项管理
2025年PMP 学习二十一 14章 项目立项管理 项目立项管理 项目建议 (Project Proposal)项目可行性分析 (Project Feasibility Analysis)项目审批 (Project Approval)项目招投标 (Project Tendering)项目合同谈判和签订 (Project Contract Negotiation and Signing) 文章目录 20…...

Ubuntu开机自启服务
一、准备启动脚本 在你的项目文件夹(例如 /home/ubuntu/Plant_Diease_Recongnization_Server_1)中创建一个启动脚本 run_ui_main.sh: #!/usr/bin/env bash # run_ui_main.sh:激活 yolov8 环境并启动 ui_main.py# 设置 Anaconda/…...

使用Docker部署React应用与Nginx
这个教程将帮助您使用Docker部署一个带有React的Nginx容器,并通过卷(volumes)将本地代码绑定到Docker容器中。这种设置非常适合开发环境,因为它允许您在本地编辑代码,而容器中的应用会自动更新。 步骤概述 创建Nginx配置文件创建Dockerfile…...

基于SpringBoot的小型民营加油站管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

Triton介绍和各平台支持情况分析
文章目录 💞Triton介绍🧠 Triton 是什么?🔍 Triton 的核心特点🚀 Triton 在 PyTorch 中的作用📦 Triton 的典型使用场景🧪 示例:Triton 编写的向量加法(GPU 并行…...

HTTPS核心机制拆解
目录 引言 HTTPS和HTTP的区别 常见加密方式 数据摘要 数字证书与数据签名 HTTPS请求过程 结语 引言 HTTPS是什么?是一个应用层协议,在HTTP协议的基础上引入了一层加密层。为什么需要HTTPS?答案是显而易见的,要加密…...

我的食物信使女友
第一章:初识那是一个普通的周三下午,阳光透过咖啡馆的玻璃窗洒在木质的桌子上,空气中弥漫着咖啡的香气和轻柔的爵士乐。我坐在角落的一个位置,手中捧着一本已经翻了几十页的小说,但心思却完全不在文字上。我的生活就像…...

【D1,2】 贪心算法刷题
文章目录 不同路径 II整数拆分 不同路径 II 初始化的时候不能整列初始化为1,因为如果有障碍物,后面的都不能到达 也不能整列初始化为0,因为状态转移的时候第一行第一列都没有检查,因此不能部分初始化 整数拆分 需要考虑几种情况…...

C++多态的详细讲解
【本节目标】 1. 多态的概念 2. 多态的定义及实现 3. 抽象类 4. 多态的原理 5. 单继承和多继承关系中的虚函数表 前言 需要声明的,本博客中的代码及解释都是在 vs2013 下的 x86 程序中,涉及的指针都是 4bytes 。 如果要其他平台下,部…...

UE5在Blueprint中判断不同平台
在Unreal Engine 5的蓝图中,可以通过以下方法判断当前运行的平台(如Android、Windows、iOS等),并根据平台执行不同的逻辑: 方法1:使用 Get Platform Name 节点 步骤: 在蓝图图表中右键点击&am…...

多卡跑ollama run deepseek-r1
# 设置环境变量并启动模型 export CUDA_VISIBLE_DEVICES0,1,2,3 export OLLAMA_SCHED_SPREAD1 # 启用多卡负载均衡 ollama run deepseek-r1:32b 若 deepseek-r1:32b 的显存需求未超过单卡容量(如单卡 24GB),Ollama 不会自动启用多卡 在run…...

MAC电脑中右键后复制和拷贝的区别
在Mac电脑中,右键菜单中的“复制”和“拷贝”操作在功能上有所不同: 复制 功能:在选定的位置创建一个与原始文件相同的副本。快捷键:CommandD用于在当前位置快速复制文件,CommandC用于将内容复制到剪贴板。效果&…...

打卡第二十二天
知识点回顾: LDA线性判别PCA主成分分析t-SNE降维 还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说。 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让AI给你出…...
)
【Unity 2023 新版InputSystem系统】新版InputSystem 如何进行人物移动(包括配置、代码详细实现过程)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、InputSystem配置二、GameInput 游戏输入脚本1.实现思路2.完整代码三、Player 游戏人物移动脚本1.实现思路2.完整代码四、场景脚本设置1.组件设置五、问题解决1.人物一直下落2.人物跳跃时,…...

Python实现的在线词典学习工具
Python实现的在线词典学习工具 源码最初来自网络,根据实际情况进行了修改。 主要功能: 单词查询 通过Bing词典在线获取单词释义(正则提取网页meta描述),支持回车键快速查询 内置网络请求重试和异常处理机制 在线网页…...
)
软考 系统架构设计师系列知识点之杂项集萃(63)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(62) 第102题 以下关于系统性能评估方法的描述,错误的是()。 A. 指令执行速度法常用每秒百万次指令运算(MIPS)评估系统性能…...

python重庆旅游系统-旅游攻略
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

如何使用GIT管理项目代码
介绍 Git是目前世界上最流行甚至最好的开源分布式版本控制系统,不论是很小的项目还是很大的项目,它都能有效并且高效的处理项目版本管理,初衷是为了帮助管理linux内核代码而开发的一个开放源码的版本控制软件。 GIT常用分支名称 分支分…...

Android 11.0 动画缩放默认值改为0.5的功能实现
1.前言 在11.0的系统rom定制化开发中,在关于设置动画的时候,系统有相关参数要求,设置默认的 动画缩放默认值等功能,来实现相关功能,接下来分析下相关的动画默认缩放值的设置功能实现 2.动画缩放默认值改为0.5的功能实现的核心类 frameworks/base/packages/SettingsProv…...

第35周Zookkeeper+Dubbo 面试题精讲
面试题精讲 一、算法面试答题思路 理解思路的重要性:算法面试比基础面试更复杂,需先想清楚思路,与面试官沟通确认题目条件(如数据范围、是否包含负数/零等),这有助于理清解题思路并展示技术实力。变量命名清晰:算法中变量命名要明确含义和范围,避免使用模糊的变量名,…...

Mergekit——任务向量合并算法Ties解析
Mergekit——高频合并算法 TIES解析 Ties背景Ties 核心思想具体流程总结 mergekit项目地址 Mergekit提供模型合并方法可以概况为三大类:基本线性加权、基于球面插值、基于任务向量,今天我们来刷下基于任务向量的ties合并方法,熟悉原理和代码。…...

初识 Redis
什么是 Redis? 在 Redis 官网中有介绍, Redis 就是一个存储空间,只不过这个存储空间是在内存上的,这也就代表存储在 Redis 中的数据访问起来会非常快,但也会有一个弊端,也就是内存资源是非常少的ÿ…...

python打卡训练营打卡记录day30
一、导入官方库 我们复盘下学习python的逻辑,所谓学习python就是学习python常见的基础语法学习你所处理任务需要用到的第三方库。 1.1标准导入:导入整个库 这是最基本也是最常见的导入方式,直接使用import语句。 # 方式1:导入整…...

FART 主动调用组件设计和源码分析
版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/ 现有脱壳方法存在的问题 脱壳粒度集中在 DexFile 整体,当前对 apk 保护的粒度在函数粒度,这就导致了脱壳与加固的不对等,无…...

windows使用ollama部署deepseek及qwen
ollama 参考文档 ollama 官方文档 GitHub仓库 基础环境: NVIDIA 1660TI 6G 下载 ollma是一款开源工具,支持在本地计算机(无需联网)快速部署和运行大型语言模型(LLM),如 LLaMA、Mistral、G…...

【11408学习记录】考研英语辞职信写作三步法:真题精讲+妙句活用+范文模板
应聘信 英语写作2005年考研英语真题小作文写作思路第一段第二段妙句7 9妙句11补充3补充4 第三段 妙句成文 每日一句词汇第一步:找谓语第二步:断句第三步:简化主句原因状语从句 英语 写作 2005年考研英语真题小作文 Directions: Two m…...