机器学习-人与机器生数据的区分模型测试 - 模型选择与微调
内容继续机器学习-人与机器生数据的区分模型测试
整体模型的准确率
X_train_scaled = pd.DataFrame(X_train_scaled,columns =X_train.columns )
X_test_scaled = pd.DataFrame(X_test_scaled,columns =X_test.columns)from ngboost.distns import Bernoulli
# 模型训练和评估
models = {'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),'XGBoost': XGBClassifier(n_estimators=100, random_state=42), # 假设使用XGBoost模型,'Logistic Regression': LogisticRegression(random_state=42), # 假设使用逻辑回归模型,'K-Nearest Neighbors': KNeighborsClassifier(), # 假设使用KNN模型,'Decision Tree': DecisionTreeClassifier(random_state=42), # 假设使用决策树模型,'LightGBM': LGBMClassifier(n_estimators=100, random_state=42), # 假设使用LightGBM模型,'CatBoost': CatBoostClassifier(n_estimators=100, random_state=42), # 假设使用CatBoost模型,#'NGBoost': NGBClassifier(Dist=Bernoulli,n_estimators=100, random_state=42) # 假设使用NGBoost模型,
}# 训练模型并评估
for name, model in models.items():model.fit(X_train_scaled, y_train) # 训练模型y_pred = model.predict(X_test_scaled) # 预测测试集accuracy = accuracy_score(y_test, y_pred) # 计算准确率print(f"{name} Accuracy: {accuracy}") # 打印准确率# 绘制混淆矩阵cm = confusion_matrix(y_test, y_pred) # 计算混淆矩阵sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') # 绘制混淆矩阵plt.xlabel('Predicted') # 设置x轴标签plt.ylabel('True') # 设置y轴标签plt.title('Confusion Matrix') # 设置标题plt.show() # 显示混淆矩阵代码输出准确率与混淆矩阵,最后模型选择 随机森林,xgboost,lightgbm catboost四个模型。结果不一一展示。

输出准确率
def plot_param_impact(model_class, param_name, param_values):"""绘制不同参数值对模型训练集和测试集准确率的影响曲线。:param model_class: 模型类,例如 RandomForestClassifier、LogisticRegression 等:param param_name: 要调整的参数名称,字符串类型:param param_values: 要测试的参数值列表"""# 用于存储不同参数值下训练集的准确率train_acc = []# 用于存储不同参数值下测试集的准确率test_acc = []for value in param_values:# 创建模型实例,使用 ** 解包字典的方式传递当前参数值,并固定 random_state 以保证结果可复现model = model_class(**{param_name: value}, random_state=42)# 使用训练集数据对模型进行训练model.fit(X_train_scaled, y_train)# 计算模型在训练集上的准确率,并添加到 train_acc 列表中train_acc.append(model.score(X_train_scaled, y_train))# 计算模型在测试集上的准确率,并添加到 test_acc 列表中test_acc.append(model.score(X_test_scaled, y_test))# 创建一个新的图形,设置图形大小为 8x5 英寸plt.figure(figsize=(8, 5))# 绘制训练集准确率曲线,蓝色圆点连线plt.plot(param_values, train_acc, 'bo-', label='Training Accuracy')# 绘制测试集准确率曲线,红色方块虚线plt.plot(param_values, test_acc, 'rs--', label='Testing Accuracy')# 设置 x 轴标签为要调整的参数名称plt.xlabel(param_name)# 设置 y 轴标签为准确率plt.ylabel('Accuracy')# 设置图形标题,显示参数名称和模型类名plt.title(f'Impact of {param_name} on {model_class.__name__} Performance')# 显示图例plt.legend()# 显示网格线plt.grid(True)# 显示绘制好的图形plt.show()catboost 这里需要单独处理
def catboost_plot_param_impact(model_class, param_name, param_values):"""绘制不同参数值对 CatBoost 模型训练集和测试集准确率的影响曲线。:param model_class: 模型类,通常为 CatBoostClassifier:param param_name: 要调整的参数名称,字符串类型:param param_values: 要测试的参数值列表"""# 用于存储不同参数值下训练集的准确率train_acc = []# 用于存储不同参数值下测试集的准确率test_acc = []for value in param_values:# 创建 CatBoost 模型实例,使用 ** 解包字典的方式传递当前参数值# grow_policy='Lossguide':设置树的生长策略为损失引导# random_state=42:固定随机种子以保证结果可复现# eval_metric='Accuracy':使用准确率作为评估指标# verbose=False:不输出训练过程信息model = model_class(**{param_name: value}, grow_policy='Lossguide', random_state=42,eval_metric='Accuracy',\verbose=False)# 使用训练集数据对模型进行训练model.fit(X_train_scaled, y_train)# 计算模型在训练集上的准确率,并添加到 train_acc 列表中train_acc.append(model.score(X_train_scaled, y_train))# 计算模型在测试集上的准确率,并添加到 test_acc 列表中test_acc.append(model.score(X_test_scaled, y_test))# 创建一个新的图形,设置图形大小为 8x5 英寸plt.figure(figsize=(8, 5))# 绘制训练集准确率曲线,蓝色圆点连线plt.plot(param_values, train_acc, 'bo-', label='Training Accuracy')# 绘制测试集准确率曲线,红色方块虚线plt.plot(param_values, test_acc, 'rs--', label='Testing Accuracy')# 设置 x 轴标签为要调整的参数名称plt.xlabel(param_name)# 设置 y 轴标签为准确率plt.ylabel('Accuracy')# 设置图形标题,显示参数名称和模型类名plt.title(f'Impact of {param_name} on {model_class.__name__} Performance')# 显示图例plt.legend()# 显示网格线plt.grid(True)# 显示绘制好的图形plt.show()
模型的评估与比对
#随机模型调参
def model_tuning_pipeline(model_class,default_params=None,param_grid=None,search_cv=GridSearchCV,search_cv_args=None,X_train=X_train_scaled,y_train=y_train,X_test=X_test_scaled,y_test=y_test,random_state=42,title_suffix=""
):"""通用模型调参流水线(训练默认模型+超参数搜索+结果对比)参数:model_class: 模型类 (RandomForestClassifier/XGBClassifier等)default_params: 默认参数字典param_grid: 调参参数空间search_cv: 搜索器类 (GridSearchCV/RandomizedSearchCV)search_cv_args: 搜索器参数字典X_train: 训练特征数据(默认使用缩放后的数据)y_train: 训练标签数据X_test: 测试特征数据(默认使用缩放后的数据)y_test: 测试标签数据random_state: 随机种子title_suffix: 图表标题后缀返回:包含所有结果的字典"""# 参数初始化default_params = default_params or {}search_cv_args = search_cv_args or {}# 合并随机种子参数merged_params = {**default_params, "random_state": random_state}# ========== 默认模型训练 ==========default_model = model_class(**merged_params)default_model.fit(X_train_scaled, y_train)default_train_acc = default_model.score(X_train_scaled, y_train)default_test_acc = model.score(X_test_scaled, y_test)# ========== 参数搜索优化 ==========# 配置搜索器参数param_key = "param_grid" if search_cv == GridSearchCV else "param_distributions"search_args = {"estimator": model_class(**merged_params),param_key: param_grid,**search_cv_args}# 执行参数搜索search = search_cv(**search_args)search.fit(X_train_scaled, y_train)# ========== 最佳模型评估 ==========best_model = search.best_estimator_tuned_train_acc = best_model.score(X_train_scaled, y_train)tuned_test_acc = best_model.score(X_test_scaled, y_test)# ========== 可视化对比 ==========plt.figure(figsize=(10, 6))labels = ['Default (Train)', 'Default (Test)', 'Tuned (Train)', 'Tuned (Test)']values = [default_train_acc, default_test_acc, tuned_train_acc, tuned_test_acc]colors = ['#1f77b4', '#ff7f0e', '#1f77b4', '#ff7f0e'] # 保持颜色一致性bars = plt.bar(labels, values, color=colors, alpha=0.7)plt.ylabel("Accuracy", fontsize=12)plt.title(f"Model Performance Comparison: {title_suffix}", fontsize=14)plt.ylim(min(values)-0.05, max(values)+0.05)# 添加数值标签for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height,f"{height:.4f}", ha="center", va="bottom")plt.grid(axis="y", linestyle="--", alpha=0.7)plt.tight_layout()plt.show()# 输出最佳参数print("="*50)print(f"Best parameters for {model_class.__name__}:")print(json.dumps(search.best_params_, indent=2))return {"default_model": default_model,"best_model": best_model,"performance": {"default_train": default_train_acc,"default_test": default_test_acc,"tuned_train": tuned_train_acc,"tuned_test": tuned_test_acc},"best_params": search.best_params_}添加模型验证的范围
随机森林
from sklearn.model_selection import RandomizedSearchCV
num_classes = len(np.unique(y_train))# 随机森林调参
# 调用 model_tuning_pipeline 函数对随机森林模型进行超参数调优
rf_result = model_tuning_pipeline(# 指定要调参的模型类为随机森林分类器model_class=RandomForestClassifier,# 设置随机森林模型的默认参数,这里设置了树的数量为 100default_params={"n_estimators": 100},# 定义要搜索的超参数空间,包含树的数量、最大深度、最小样本分割数和最大特征数param_grid={"n_estimators": [100, 200], # 尝试不同的树的数量"max_depth": [None, 10, 20], # 尝试不同的最大深度,None 表示不限制深度"min_samples_split": [2, 5], # 尝试不同的最小样本分割数"max_features": ["sqrt", "log2"] # 尝试不同的最大特征数选择方法},# 指定使用网格搜索进行超参数搜索search_cv=GridSearchCV,# 设置网格搜索的参数,cv 表示交叉验证的折数,n_jobs=-1 表示使用所有可用的 CPU 核心search_cv_args={"cv": 5, "n_jobs": -1},# 设置图表标题的后缀,用于标识当前调参的模型title_suffix="Random Forest"
)
xgboost
xgb_result = model_tuning_pipeline(# 指定要调优的模型类为 XGBClassifier,即 XGBoost 分类器model_class=XGBClassifier,# 设置 XGBoost 模型的默认参数default_params={# 多分类任务使用 softmax 作为目标函数"objective": "multi:softmax",# 分类的类别数量,由 num_classes 变量指定"num_class": num_classes},# 定义要搜索的超参数空间param_grid={# 尝试不同的树的数量"n_estimators": [50, 100, 150, 200],# 尝试不同的树的最大深度"max_depth": [3, 4, 5, 6],# 尝试不同的学习率"learning_rate": [0.001, 0.01, 0.1]},# 指定使用随机搜索(RandomizedSearchCV)进行超参数搜索search_cv=RandomizedSearchCV,# 设置随机搜索的参数search_cv_args={"n_iter": 20, "cv": 3},# 设置图表标题的后缀,用于标识当前调优的模型title_suffix="XGBoost"
)
lightgbm
# 调用 model_tuning_pipeline 函数对 LightGBM 模型进行超参数调优
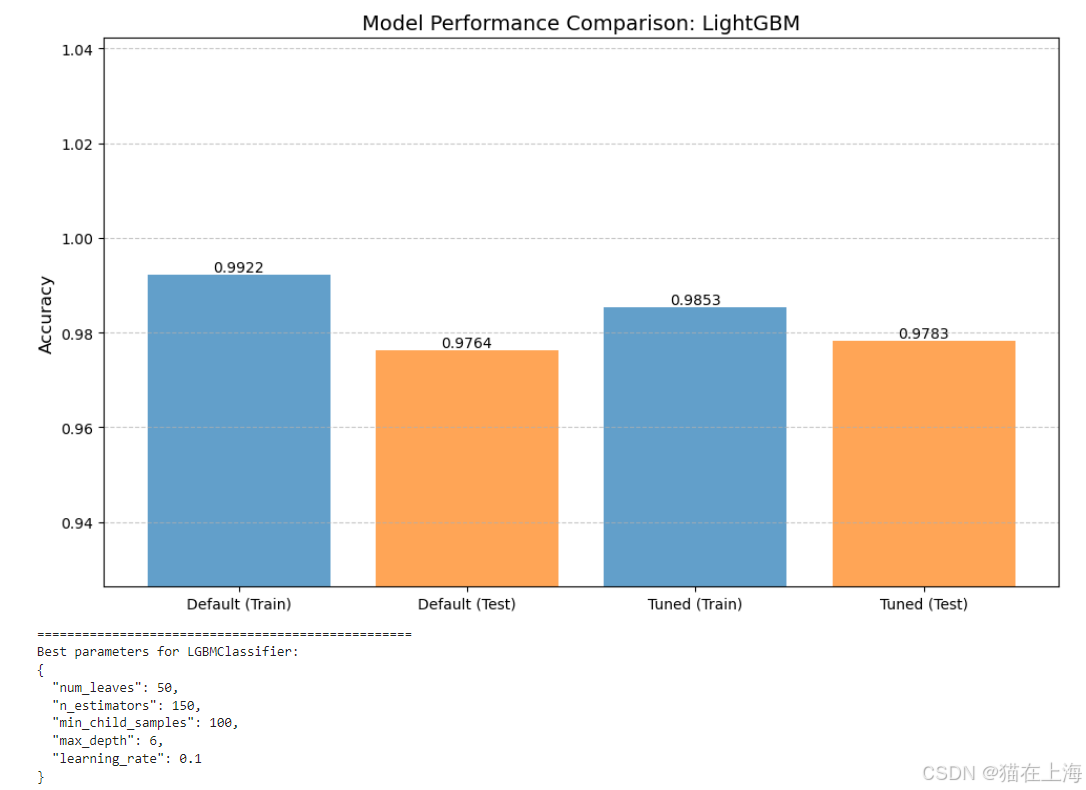
lgb_result = model_tuning_pipeline(# 指定要调优的模型类为 LGBMClassifier,即 LightGBM 分类器model_class=LGBMClassifier,# 设置 LightGBM 模型的默认参数default_params={# 多分类任务使用 multiclass 作为目标函数"objective": "multiclass",# 分类的类别数量,由 num_classes 变量指定"num_class": num_classes,# 设置日志输出级别为 -1,即不输出日志信息"verbose": -1},# 定义要搜索的超参数空间param_grid={# 尝试不同的树的数量"n_estimators": [50, 100, 150, 200],# 尝试不同的树的最大深度"max_depth": [3, 4, 5, 6],# 尝试不同的学习率"learning_rate": [0.001, 0.01, 0.1],# 尝试不同的叶子节点数量"num_leaves": [31, 50, 100],# 尝试不同的叶子节点最小样本数"min_child_samples": [20, 50, 100]},# 指定使用随机搜索(RandomizedSearchCV)进行超参数搜索search_cv=RandomizedSearchCV,# 设置随机搜索的参数search_cv_args={"n_iter": 20, "cv": 3},# 设置图表标题的后缀,用于标识当前调优的模型title_suffix="LightGBM"
)
catboost
# CATBoost调参
cat_result = model_tuning_pipeline(model_class=CatBoostClassifier,default_params={'silent':True, 'random_state':42},param_grid={'iterations': [100, 200, 300], # 树的数量'depth': [4, 6, 8], # 树深度'learning_rate': [0.01, 0.1, 0.2], # 学习率'l2_leaf_reg': [1, 3, 5], # L2正则化系数'border_count': [32, 64, 128], # 特征分箱数(适用于数值特征)'bagging_temperature': [0, 0.5, 1.0] # 贝叶斯自助采样强度},search_cv=RandomizedSearchCV,search_cv_args={"n_iter": 20, "cv": 3},title_suffix="CATBoost"
)
手动调参
# 随机森林
plot_param_impact(RandomForestClassifier, 'n_estimators', [10, 50, 100, 200, 300])
plot_param_impact(RandomForestClassifier, 'max_depth', [None, 5, 10, 20, 30])
plot_param_impact(RandomForestClassifier, 'min_samples_split', [2, 5, 10, 20])
plot_param_impact(RandomForestClassifier, 'max_features', ['sqrt', 'log2'])# XGBoost
plot_param_impact(XGBClassifier, 'n_estimators', [50, 100, 150, 200,250,300])
plot_param_impact(XGBClassifier, 'max_depth', [3, 4, 5, 6,7])
plot_param_impact(XGBClassifier, 'learning_rate', [0.1, 0.01, 0.001])
plot_param_impact(XGBClassifier, 'lambda', [0.1, 1, 5, 10])
plot_param_impact(XGBClassifier, 'alpha', [0.01, 0.01, 0.05, 1])# lightgbm
plot_param_impact(LGBMClassifier,'num_leaves', [5, 50, 100, 200,300]) # 控制模型复杂度
plot_param_impact(LGBMClassifier,'max_depth', [3, 5, 7, 10,12])
plot_param_impact(LGBMClassifier,'learning_rate', [0.01, 0.1, 0.2, 0.3]) # 学习率影响
plot_param_impact(LGBMClassifier,'lambda_l1', [0, 0.01, 0.05, 0.1, 0.5]) # 正则
plot_param_impact(LGBMClassifier,'lambda_l2', [0, 0.1, 0.5, 1, 2]) # 正则
#$bagging_freq,bagging_fraction feature_fraction lambda_l2# catboost
#catboost_plot_param_impact(CatBoostClassifier,'num_leaves', [15, 31, 63, 127]) # 控制模型复杂度
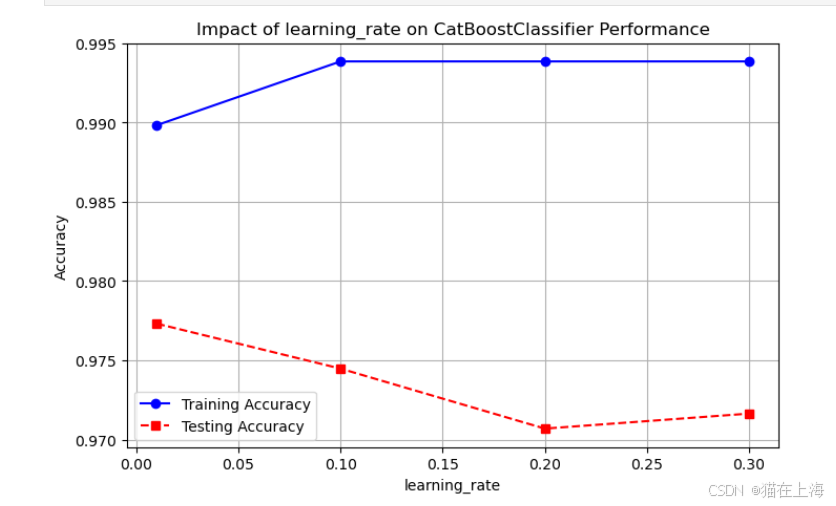
catboost_plot_param_impact(CatBoostClassifier,'learning_rate', [0.01, 0.1, 0.2, 0.3]) # 学习率影响
catboost_plot_param_impact(CatBoostClassifier,'max_depth', [3, 5, 7, 10])
catboost_plot_param_impact(CatBoostClassifier,'n_estimators', [50, 100, 150, 200,300,500]) 随机调参的结果如下。数量很多不一一截图。
手动调参:
最后综合比对模型的参数效果。
相关文章:

机器学习-人与机器生数据的区分模型测试 - 模型选择与微调
内容继续机器学习-人与机器生数据的区分模型测试 整体模型的准确率 X_train_scaled pd.DataFrame(X_train_scaled,columns X_train.columns ) X_test_scaled pd.DataFrame(X_test_scaled,columns X_test.columns)from ngboost.distns import Bernoulli # 模型训练和评估 m…...
)
学习黑客Active Directory 入门指南(四)
Active Directory 入门指南(四):组策略的威力与操作主机角色 📜👑 大家好!欢迎来到 “Active Directory 入门指南” 系列的第四篇。在前几篇中,我们已经构建了对AD逻辑结构、物理组件、关键服务…...

十一、STM32入门学习之FREERTOS移植
目录 一、FreeRTOS1、源码下载:2、解压源码 二、移植步骤一:在需要移植的项目中新建myFreeRTOS的文件夹,用于存放FREERTOS的相关源码步骤二:keil中包含相关文件夹和文件引用路径步骤三:修改FreeRTOSConfig.h文件的相关…...

Spring ioc和Aop
IOC 在传统Java当中,我们的对象都需要new关键字来生成,这在面对很多对象的情况产生了不必要的麻烦,因为我不需要在一个项目中一直做重复的事情,那怎么办把,自然而然的一些好的框架就诞生了,避免我们去做这…...

动态内存管理2+柔性数组
一、动态内存经典笔试题分析 分析错误并改正 题目1 void GetMemory(char *p) {p (char *)malloc(100); } void Test(void) {char *str NULL;GetMemory(str);strcpy(str, "hello world");printf(str); } int main() {Test();return 0; }错误的原因: …...

USB传输速率 和 RS-232/RS-485串口协议速率 的倍数关系
一、技术背景 RS-232:传统串口标准,典型速率 115.2 kbps(最高约 1 Mbps)。RS-485:工业串口标准,典型速率 10 Mbps(理论最高可达 50 Mbps)。USB:不同版本差异巨大&#x…...

多线程代码案例-4 线程池
1、引入 池是一个非常重要的概念,我们有常量池,数据库连接池,线程池,进程池,内存池…… 池的作用: 1、提前把要用的对象准备好 2、用完的对象也不立即释放,先留着以备下次使用,提…...

JSON Schema 高效校验 JSON 数据格式
在数据交换和API开发中,JSON 已成为最流行的数据格式之一。但你是否遇到过这些困扰? 接收的JSON字段缺失关键数据?数值类型意外变成了字符串?嵌套结构不符合预期? JSON Schema 正是解决这些问题的利器。本文将带你全…...

机器学习09-正规方程
机器学习笔记:正规方程(Normal Equation) 概述 正规方程是线性回归中求解参数的一种解析方法。它基于最小化损失函数(如最小二乘法)来直接计算出参数的最优值。在机器学习中,这种方法尤其适用于特征数量不…...

Java大师成长计划之第26天:Spring生态与微服务架构之消息驱动的微服务
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4-turbo模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在现代微服务架构中,服务…...
)
Linux 文件(1)
1. 文件 1.1 文件是什么 一个文件,是由其文件属性与文件内容构成的。文件属性又称为一个文件的元数据,因此如果一个文件,内容为空,这个文件依然要占据磁盘空间。 1.2 文件在哪里 一个文件,如果没有被打开ÿ…...

程序代码篇---python向http界面发送数据
文章目录 前言 前言 本文简单接受了python向http界面发送数据...

【iOS】探索消息流程
探索消息流程 Runtime介绍OC三大核心动态特性动态类型动态绑定动态语言 方法的本质代码转换objc_msgSendSELIMPMethod 父类方法在子类中的实现 消息查找流程开始查找快速查找流程慢速查找流程二分查找方法列表父类缓存查找 动态方法解析动态方法决议实例方法类方法优化 消息转发…...

院校机试刷题第六天:1134矩阵翻转、1052学生成绩管理、1409对称矩阵
一、1134矩阵翻转 1.题目描述 2.解题思路 很简单的模拟题,甚至只是上下翻转,遍历输出的时候先把最下面那一行输出即可。 3.代码 #include <iostream> #include <vector> using namespace std;int main() {int n;cin >> n;vector&l…...

DeepSeek在简历筛选系统中的深度应用
一、多模态解析引擎的技术突破 1.1 复杂格式的精准解析 针对简历格式多样性挑战,DeepSeek采用三级解析架构: 格式标准化层:基于Transformer的DocParser模型支持200+种文档格式转换视觉特征提取:使用改进的YOLOv8进行证书印章识别(mAP@0.5达93.7%)语义重构模块:通过注意…...

c++多线程debug
debug demo 命令行查看 ps -eLf|grep cam_det //查看当前运行的轻量级进程 ps -aux | grep 执行文件 //查看当前运行的进程 ps -aL | grep 执行文件 //查看当前运行的轻量级进程 pstree -p 主线程ID //查看主线程和新线程的关系 查看线程栈结构 pstack 线程ID 步骤&…...

【回溯 剪支 状态压缩】# P10419 [蓝桥杯 2023 国 A] 01 游戏|普及+
本文涉及知识点 C回溯 位运算、状态压缩、枚举子集汇总 P10419 [蓝桥杯 2023 国 A] 01 游戏 题目描述 小蓝最近玩上了 01 01 01 游戏,这是一款带有二进制思想的棋子游戏,具体来说游戏在一个大小为 N N N\times N NN 的棋盘上进行,棋盘…...

CUDA 纹理入门
一、什么是CUDA纹理 CUDA纹理是NVIDIA GPU提供的一种特殊内存访问机制,它允许高效地访问和过滤结构化数据。纹理内存最初是为图形渲染设计的,但在通用计算(GPGPU)中也很有用。 二、纹理内存的优势 缓存优化:纹理内存有专用的缓存,适合空间局部性好的访问模式 硬件过滤:支…...

大模型微调步骤整理
在对深度学习模型进行微调时,我通常会遵循以下几个通用步骤。 第一步是选择一个合适的预训练模型。PyTorch 的 torchvision.models 模块提供了很多经典的预训练模型,比如 ResNet、VGG、EfficientNet 等。我们可以直接使用它们作为模型的基础结构。例如,加载一个预训练的 Re…...

【GPT入门】第39课 OPENAI官方API调用方法
【GPT入门】第39课 OPENAI官方API调用方法 1. OPENAI 免费API2. openai调用最简单的API3.apiKey提取到环境变量 1. OPENAI 免费API 需要科学上网,可以调用 gpt-4o-mini 的 api, 使用其它旧的GPT,反而可能需要收费,例如 gpt-3.5-turbo 2. op…...

【DeepSeek论文精读】11. 洞察 DeepSeek-V3:扩展挑战和对 AI 架构硬件的思考
欢迎关注[【AIGC论文精读】](https://blog.csdn.net/youcans/category_12321605.html)原创作品 【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1 【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术 【DeepSeek论文精读】11. 洞察 DeepSeek-V3ÿ…...

MySQL事务的一些奇奇怪怪知识
Gorm事务有error却不返回会发生什么 Gorm包是大家比较高频使用。正常的用法是,如果有失败返回error,整体rollback,如果不返回error则commit。下面是Transaction的源码: // Transaction start a transaction as a block, return …...

C语言内存函数与数据在内存中的存储
一、c语言内存函数 1、memcpy函数是一个标准库函数,用于内存复制。功能上是用来将一块内存中的内容复制到另一块内存中。用户需要提供目标地址、源地址以及要复制的字节数。例如结构体之间的复制。 memcpy函数的原型是:void* memcpy(void* …...

Power BI Desktop运算符和新建列
1.运算符 运算符 含义 加 - 减 * 乘 / 除 ^ 幂 运算符 含义 等于 > 大于 < 小于 > 大于等于 < 小于等于 <> 不等于 运算符 含义 && 与 || 或 not 非 & 字符串连接 in 包含 not in 不包含 2.新建列 …...

windows 安装gdal实现png转tif,以及栅格拼接
windows 安装gdal实现png转tif,以及栅格拼接 一、安装gdal 网上有很多安装gdal的方法,此处通过osgeo4w安装gdal 1.下载osgeo4w 下载地址 https://trac.osgeo.org/osgeo4w/ 2、安装osgeo4w exe文件安装,前面部分很简单,就不再…...

【嵙大o】C++作业合集
参考: C swap(交换)函数 指针/引用/C自带-CSDN博客 Problem IDTitleCPP指针CPP引用1107 Problem A编写函数:Swap (I) (Append Code)1158 Problem B整型数据的输出格式1163 Problem C时间:24小时制转12小时制1205…...

论信息系统项目的采购管理
论信息系统项目的采购管理 背景一、规划采购管理二、实施采购三、控制采购结语 背景 某市为对扶贫对象实施精确识别、精确帮扶、精确管理,决定由民政部门牵头,建设家庭经济状况分析及市、县(区)、镇(街)三级…...

创建型:单例模式
目录 1、核心思想 2、实现方式 2.1 饿汉式 2.2 懒汉式 2.3 枚举(Enum) 3、关键注意事项 3.1 线程安全 3.2 反射攻击 3.3 序列化与反序列化 3.4 克隆保护 4、适用场景 1、核心思想 目的:确保一个类仅有一个实例 功能:…...
-如何正确地汇报)
职场方法论总结(4)-如何正确地汇报
一、明确汇报目标 区分类型:是项目进展汇报?数据总结?问题解决方案?还是资源申请?明确目标才能聚焦内容。听众需求: 所有人都希望你用最简短的语言把事情讲清楚,节省时间领导关注结果、风险和资…...

STM32SPI实战-Flash模板
STM32SPI实战-Flash模板 一,常用指令集(部分)二,组件库GD25QXX API 函数解析1,前提条件2,初始化与识别1, void spi_flash_init(void)2, uint32_t spi_flash_read_id(void) 3,擦除操作1, void spi_flash_sector_erase(uint32_t sec…...
 咖啡售卖官网实例)
CSS- 4.4 固定定位(fixed) 咖啡售卖官网实例
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

【Retinanet】训练自己的数据集
目录 1.下载源码2.配置环境3.数据集准备4.训练自己的数据5.成功训练! 1.下载源码 Retinanet代码:代码 下载到你的目录中,进行打开。 2.配置环境 这里就是cudapytorch,没有配置过的可以参考博客: 深度学习环境的搭建…...

微软将于 8 月 11 日关闭 Bing Search API 服务
微软宣布将于 2025 年 8 月 11 日正式关闭 Bing Search API 服务。届时,所有使用 Bing Search API 的实例将完全停用,同时不再接受新用户注册。 此次停用决定主要影响 Bing Search F1 及 S1 到 S9 资源的用户,以及 Custom Search F0 与 S1 到…...
、dir() 与 AI 工具的结合应用)
探索 Python 的利器:help()、dir() 与 AI 工具的结合应用
引言 在编程世界中,Python 以其简洁的语法、强大的功能和丰富的库生态系统成为众多开发者的首选语言。无论是初学者还是资深工程师,在学习新模块、调试代码或探索未知功能时,常常需要有效的工具来帮助理解和解决问题。Python 提供了内置的 help() 和 dir() 函数,让开发者能…...

MySQL查询优化器底层原理解析:从逻辑优化到物理优化
MySQL查询优化器底层原理解析:从逻辑优化到物理优化 引言 在数据库系统中,SQL语句的执行效率直接影响着整个应用的性能表现。一条普通的SQL执行前会经历五个关键阶段:SQL输入、语法分析、语义检查、SQL优化、SQL执行。其中,SQL优…...

UI架构的历史与基础入门
本笔记的目的是通过一系列连贯的例子来探讨“事物-模型-视图-编辑器”这一隐喻。 这些例子都来自我的规划系统(planning system),用于解释上述四个概念。所有例子都已实现,但并未在本文描述的清晰类结构中实现。 这些隐喻对应于《…...
MMA(KeyCloak身份服务器/OutBox Pattern))
(三)MMA(KeyCloak身份服务器/OutBox Pattern)
文章目录 项目地址一、KeyCloak二、OutBox Pattern2.1 配置Common模块的OutBox1. OutboxMessage2. 数据库配置OutboxMessageConfiguration3. 创建Save前的EF拦截器4. 创建Quartz后台任务5. 配置后台任务6. 注册服务2.2 创建OutBox的消费者项目地址 教程作者:教程地址:代码仓库…...

【通用智能体】Playwright:跨浏览器自动化工具
Playwright:跨浏览器自动化工具 一、Playwright 是什么?二、应用场景及案例场景 1:端到端(E2E)测试场景 2:UI 自动化(表单批量提交)场景 3:页面截图与 PDF 生成场景 4&am…...
)
单片机设计_停车场车位管理系统(AT89C52、LCD1602)
想要更多项目私wo!!! 一、电路设计 此电路由AT89C52单片机和LCD1602液晶显示模块等器件组成。 二、运行结果 三、部分代码 #include <reg52.h> //调用单片机头文件 #define uchar unsigned char //无符号字符型 宏定义 变量范围0~255 #define uint unsigned…...

【android bluetooth 协议分析 01】【HCI 层介绍 5】【SetEventMask命令介绍】
1. HCI_Set_Event_Mask 命令作用 项目内容命令名HCI_Set_Event_MaskOCF0x0001作用主机通过设置 Event Mask 告诉控制器:我只对某些事件感兴趣,屏蔽其他事件,以减少中断。事件来源事件是 HCI 与主机之间通信的反馈机制,控制器通过…...

python打卡day29
类的装饰器 知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 回顾一下,函数的装饰器是 :接收一个函数,返回一个修改后的函数。类也有修饰器,类装饰器本质上确…...

【数据结构】树状数组
树状数组 假设一个数可以 x x x可以被二进制分解成 x 2 i 1 2 i 2 . . . 2 i m x 2^{i_1} 2^{i_2} ... 2^{i_m} x2i12i2...2im,不妨设 i 1 > i 2 > . . . > i m i_1 > i_2 > ... > i_m i1>i2>...>im,进…...

Java虚拟机 - JVM与Java体系结构
Java虚拟机 JVM与Java体系结构为什么要学习JVMJava与JVM简介Java 语言的核心特性JVM:Java 生态的基石JVM的架构模型基于栈的指令集架构(Stack-Based)基于寄存器的指令集架构(Register-Based)JVM生命周期 总结 JVM与Jav…...

翻译:20250518
翻译题 文章目录 翻译题一带一路中国结 一带一路 The “One Belt and One Road” Initiative aims to achieve win-win and shared development. China remains unchanged in its commitment to foster partnerships. China pursues an independent foreign policy of peace, …...

SparkSQL基本操作
以下是 Spark SQL 的基本操作总结,涵盖数据读取、转换、查询、写入等核心功能: 一、初始化 SparkSession scala import org.apache.spark.sql.SparkSession val spark SparkSession.builder() .appName("Spark SQL Demo") .master("…...

Ansible模块——文件内容修改
修改文件单行内容 ansible.builtin.lineinfile 可以按行修改文件内容,一次修改一行,支持正则表达式。 选项名 类型 默认值 描述 attributesstrnull 设置目标文件的 Linux 文件系统属性(attribute bits),作用类似于…...

基于单片机路灯自动控制仪仿真设计
标题:基于单片机路灯自动控制仪仿真设计 内容:1.摘要 本设计旨在解决传统路灯控制方式效率低、能耗大的问题,开展了基于单片机的路灯自动控制仪仿真设计。采用单片机作为核心控制单元,结合光照传感器、时钟模块等硬件,运用相关软件进行编程和…...
)
Spring Web MVC————入门(3)
今天我们来一个大练习,我们要实现一个登录界面,登录进去了先获取到登录人信息,可以选择计算器和留言板两个功能,另外我们是学后端的,对于前端我们会些基础的就行了,知道ajax怎么用,知道怎么关联…...

拓展运算符与数组解构赋值的区别
拓展运算符与数组解构赋值是ES6中用于处理数组的两种不同的特性,它们有以下区别: 概念与作用 • 拓展运算符:主要用于将数组展开成一系列独立的元素,或者将多个数组合并为一个数组,以及在函数调用时将数组作为可变参…...

【Linux】第二十章 管理基本存储
目录 1. 对 Linux 磁盘进行分区时有哪两种方案?分别加以详细说明。 2. 简单说下创建MBR磁盘分区涉及哪几个步骤? 3. 创建GPT分区与创建MBR分区有什么不同? 4. 在创建分区时就会在分区上创建文件系统吗? 5. 如何持久挂载文件系…...