从c++到python
从c++到python
- 前言
- print格式化
- print按原始格式输出
- input
- 变量、常量和数据类型
- 整型和type()
- 浮点型
- 复数
- 字符串类型
- 数据类型转换
- 变量地址
- 注释
- 关键字
- 容器
- 列表list
- 下标索引
- 常用功能
- 元组tuple
- 字符串str
- 字符串的成员函数:
- 字符串初始化为几个固定字符
- 字符和int型数据之间的运算
- 集合set
- 字典dict
- 五大容器的通用操作
- py的运算符
- 算术运算符
- 比较运算符
- 赋值运算符
- 位运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 运算符优先级
- py的分支结构
- 单分支
- 二分支
- 多分支
- 嵌套分支
- py的循环结构
- while循环
- for循环
- 循环嵌套
- 函数
- 自定义函数
- 全局变量和局部变量
- 内置函数
- 递归
- 包和模块
- 模块的调用
- 其他模块有语句
- 模块同名功能覆盖
- 导入指定元素
- 模拟c++的多维数组
- 类和对象
- 简单使用
- 构造方法和其他内置方法
- 封装
- 继承
- 多态
- 注解类型
- 变量的类型注解
- 函数和方法的类型注解
- Union类型
前言
简单整理的笔记,自己忘记了python的语法的时候查资料用。默认阅读笔记的都是懂c语言和c++的。
python解释器版本:Python 3.10.7
IDE:pycharm和vscode居多,偶尔使用jupyter notebook。
查资料用的网站:Python 语言参考手册 — Python 3.10.17 文档
print用于向终端输出信息,print函数格式:
print(*object,sep='',end='\n')
*object表示1个或者多个对象,多个对象用,分隔开。
sep用来设置输出对象之间的分隔符。可以没有,默认为空。
end用来设置输出以什么东西结尾,默认是换行符。
示例:
a=456 # 给定一个变量,保存值456print(a) # 输出变量print(123,'ab',45,'dog') # 输出多个对象print(123,45,67,89,sep=':',end='#') # 输出对个对象,以:分割,以#结尾print格式化
print按照制定格式输出:
print("格式字符串"%变量)
例如:
a=486
print("%d"%456)#输出常量print("%d"%a)#输出变量print("%.3f"%3.14149)
b=3.14149print("%d %d"%(a,b))#输出多个#常用格式和c语言差不多print("%c"%66)
格式对照表,不用记,用的时候查一下即可。
| 格式符 | 功 能 |
|---|---|
| f/F | 十进制浮点数格式,%m.nf 表示格式化为 m 长度的浮点数,小数点后保留 n 位小数 |
| d | 带符号的十进制整数格式 |
| s | 字符串格式 |
| o | 不带符号的八进制格式 |
| u | 不带符号的十进制格式 |
| x/X | 不带符号的十六进制格式 |
| C | 单字符格式,可以接收整数或者单个字符的字符串 |
| e/E | 科学记数法表示的浮点格式 |
示例1:
# print("格式字符串"%变量)
a = 123
print("%.2f" % a)
b = 233.3
print("%.4f\n%.3f" % (a, b)) # 不可实现连续输出
print(end='\n') # 直接输出print()即可输出:
123.00
123.0000
233.300示例2:
a = 123# 输出7位保留2位小数的a,不足的位补0
print("%07.2f" % a)# 这个不够的补空格,两个f是一样的
print("%7.2f" % a)
print("%7.2F" % a)
print()输出:
0123.00123.00123.00示例3:
c = 6.6
print("%f" % c)
# 忽略小数部分输出
print("%d" % c)输出:
6.600000
6
示例4:
print("%s" % "abc")a = 233
c = 455
print("%s"% (c + a))b = 13
print("%d" % b)
print("%o" % b)
print("%x" % b)
print("%e" % b)
print("%.2e" % b)示例5:
print("%s" % "abc")a = 233
c = 455
# 将运算结果按字符串输出
print("%s"% (c + a))b = 13# 十进制
print("%d" % b)# 八进制
print("%o" % b)# 十六进制
print("%x" % b) # 输出的十六进制字符小写
print("%X" % b) # 输出的十六进制字符大写# 科学计数法
print("%e" % b) # 输出e表示指数
print("%E" % b) # 输出E表示指数输出:
abc
688
13
15
d
D
1.300000e+01
1.300000e+01
1.300000E+01
print按原始格式输出
print将对象无视格式直接输出:
print(f"无关字符串{object}无关字符串")
例如:
a = 300
print(f"The value of a is {a}.")输出:
The value of a is 300.
input
input格式:
变量 = input('提示信息')
示例:input函数输入给变量a并打印
a = input('可填可不填')
print(a)
a = input()
print(a)示例2:强制转换
a=int(input('请输入第1个整数:'))
b=int(input('请输入第2个整数:'))
c=a+b
print(c)a=input('请输入第1个整数:')
b=input('请输入第2个整数:')
c=a+b
print(c)
pycharm的快捷键
# pycharm的快捷键: # ctrl+alt+s # ctrl+d # shift+alt+上/下 # ctrl+shift+f10 # shift+f6 # ctrl+a/c/v/f
变量、常量和数据类型
py支持多变量赋不同值。
# 格式:
# 变量1, 变量2, ..., 变量n = 值1, 值2, ..., 值n
school,Class,assister,iq='某某学院','3','某导员',6
print(school,Class,assister,iq,sep=',')
print()变量无数据类型。定义时给什么,变量的数据类型就是什么。
python无常量,只有程序员的个人约束。
根据数据类型在内存单元中存储的形式不同,分数值类型和复杂的组合类型。
其中数值类型又可以分为整型(int)、浮点型(float)、复数类型(complex)和布尔类型(bool)。组合类型可以分为字符串型、列表、元组、字典、集合等。
这里只介绍数值类型。
整型和type()
a=0B1001
# 给a赋值二进制数1001
print(a,type(a),"%d"%a,sep=',',end='\n')a=0o234
# a赋值八进制数
print(a,type(a),sep=',',end='\n')# 变量的类型取决于存储的数据
a='Bjarne'
print(a,type(a),end='\n')b=-165
# b赋值十进制数
print(b,type(b),end='\n')b=14
# b赋值十进制数
print(b,type(b),end='\n')# c赋值十六进制数
c=0xfff
print(c,type(c),end='\n')输出:
9,<class 'int'>,9
156,<class 'int'>
Bjarne <class 'str'>
-165 <class 'int'>
14 <class 'int'>
4095 <class 'int'>type()的功能是输出对象的类型。
浮点型
a=6.6
print(a,type(a),"%d"%a,sep=',',end='\n\n')输出:
6.6,<class 'float'>,6复数
数学上的带实部和虚部的复数类型。
f=3+4j
g=1+2j
print(f,type(f),end='\n')
print(f+g,type(f+g),sep=',',end='\n')
print(6.6+f,type(6.6+f),end='\n')# bool类型, py中是特殊的整数
print(type(True),end='\n')
print(1+True,end='\n')
print(2+True,end='\n')
print(1*False,end='\n')输出:
(3+4j) <class 'complex'>
(4+6j),<class 'complex'>
(9.6+4j) <class 'complex'>
<class 'bool'>
2
3
0字符串类型
py无字符数据类型,从input中获取的数据是字符串,需要二次强转。
a='asdfg' # 单撇表示字符串
print(a)b="asdfg" # 双撇
print(b)c='''asdfg''' # 三撇
print(c)d="""asdfg""" # 六撇
print(d)# 嵌套
# ''可包含""
b='"dfs" algorithm'
print(b)# ""也可包含''
c="'bfs' algorithm"
print(c)# '''可包含''和""
g='''as"df"g'hj'kl'''
print(g)# 用\来续行
d="'Dynamic " \"progra" \"mming'"
print(d)# 通过str()来强制转换
e=str(996)
print(e,type(e))输出:
asdfg
asdfg
asdfg
asdfg
"dfs" algorithm
'bfs' algorithm
as"df"g'hj'kl
'Dynamic programming'
996 <class 'str'>数据类型转换
数值的默认转换方向为布尔 → \rightarrow →整数 → \rightarrow → 浮点数 → \rightarrow → 复数。
# 浮点型
a=2
b=2.3
print(a+b,type(a+b),sep=',')# 复数型,仅仅是实部或虚部变浮点型
c=2+4j
print(b+c,type(b+c),sep=',')# 默认一般的/是浮点型,和c++不同
d=4
print(a/d,type(a/d),sep=',')# Bool型
print(a-True,type(a-True),sep=',')
print(a-False,type(a-False),sep=',')输出:
4.3,<class 'float'>
(4.3+4j),<class 'complex'>
0.5,<class 'float'>
1,<class 'int'>
2,<class 'int'>
也可强制转换:
# 数据类型强制转换
a=233
print(bin(a), #二进制oct(a), #八进制hex(a), #十六进制int(6.6),float(a),bool(a),complex(a),str(a),sep='\n');
# 数据转换免不了精度损失,类似int('str')这种会出现异常输出:
0b11101001
0o351
0xe9
6
233.0
True
(233+0j)
233变量地址
变量也有地址的概念,但感觉没啥用。
通过id(object)查看object的地址。
# 相同内容的字符串会共享地址
i="qwerty"
j="qwerty"
print(id(i),id(j),sep="\n")输出结果之一:
2848676147568
2848676147568注释
py的注释在上文也有应用。
行注释:
# 被注释的内容
块注释和字符串:
"""
被注释的内容
"""
例如:
# 注释1
a = 3 # 注释2,python的格式标准里,注释离语句至少2个空格"""
注释3,也可以表示字符串
"""
print(a)关键字
关键字是 python 中具有特定用途或者被赋予特殊意义的单词,python 中不允许使用关键字作为标识符。
通过这个代码打开关键字
import keyword#导入模块print(keyword.kwlist)#以链表的格式打印关键字help('keywords')#以表格的形式打印关键字# print(help('for'))#查看for的声明,并打印到控制台
容器
即组合类型,可以分为字符串型(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)等。
列表list
列表类似于c++的STL的工具vector,但又比vector多了一些功能。
列表定义:
# 字面量
[元素1,元素2,元素3,元素4,...]# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,...]# 定义空列表
变量名称 = []
变量名称 = list()
- 列表内的每一个数据,称之为元素。
- 列表以
[]作为标识。 - 列表内每一个元素之间用逗号隔开 。
a = []
b = list()
print(type(a), type(b), sep='\n')# py的列表允许元素不同类型,包括容器
a = [1, 1, 4, 5, 1, 4, "0721"]
print(type(a), a, sep='\n')输出:
<class 'list'>
<class 'list'>
<class 'list'>
[1, 1, 4, 5, 1, 4, '0721']下标索引
列表可以使用下标索引,也可以使用负数反向索引。
# py的列表允许元素不同类型,包括自身
a = [1, 1, 4, 5, 1, 4, [0, 7, 2, 1]]
print(a[0], a[1], a[2], a[3], a[4], a[5], a[6], sep=' ')
print(a[-1], a[-2], a[-3], a[-4], a[-5], a[-6], a[-7], sep=' ')# # 越界访问,报错IndexError: list index out of range
# print(a[-8])
# print(a[7])# 支持通过下标修改
a[6] = "r18"
print(a[0], a[1], a[2], a[3], a[4], a[5], a[6], sep=' ')输出:
1 1 4 5 1 4 [0, 7, 2, 1]
[0, 7, 2, 1] 4 1 5 4 1 1
1 1 4 5 1 4 r18常用功能
py的列表类比成c++的类,内部有成员变量、成员函数(py叫做方法)。
| 函数 | 描述 |
|---|---|
list(x) | 使用 x 这个容器创建列表 x 转换为列表 |
list.append(x) | 在列表 list 的尾部添加 1 个元素 x |
list.insert(index,x) | 在列表的索引 index 位置插入元素 x,之前的元素依次向后移动一个位置 |
list.extend(x) | 将列表 x 中的元素全部插入列表 list 的尾部 |
del list[index] | 删除列表 list 或者删除列表 list 中 index 位置的元素 |
list.remove(x) | 删除列表中的元素 x |
list.pop(index) | 删除列表中 index 位置的元素,当 index 省略时默认删除尾部的 1 个元素 |
list.clear() | 删除列表 list 中的所有元素,留下空列表 |
list.sort(key,reverse) | 对列表中的元素进行排序(原地排序),key用于指定排序规则,也可以指定索引。reverse为True则数组为降序,False为升序。两个都可以省略 |
sorted(list) | 按升序排列列表元素,返回新列表,原 list 不变 |
list.reverse() | 逆置列表(原地翻转) |
list.index(x) | 返回列表中 x 元素的下标位置(即 index 值) |
list.count(x) | 返回元素 x 在列表 list 中出现的次数 |
len(x) | 返回容器x的长度 |
部分功能的使用:
# list(x)
a = list("3.0")
print(a, type(a), sep=' ')print("-------------------------------------------")# list.append(x)
a.append(3.14)
print(a)
# 容器会当成一个整体插入
a.append("2.718")print("-------------------------------------------")# list.insert(index, x)
a.insert(1, 114514)
# 中间插入容器则是当成一个整体
a.insert(1, "0721")
print(a)print("-------------------------------------------")# list.extend(x)
# 尾插容器会拆分
a.extend("nene")
print(a)print("-------------------------------------------")# del list[index]
del a[2]
print(a)print("-------------------------------------------")# clear
a.clear()
print(a)print("-------------------------------------------")from functools import cmp_to_key
# 展开包(暂时理解为文件夹)中的模块cmp_to_key(原文本是cmp_to_key.py)
def cmd(a, b):return a - b # 前后比较,大于0则交换
# sort
a = [7, 5, 8, 6, 3, 2, 1, 4]
print(a)
# a.sort() # 默认升序
# a.sort(reverse=True) # 降序
# py的sort需要使用cmp_to_key将用户自定义的比较函数转换
a.sort(key=cmp_to_key(cmd))
print(a)print("-------------------------------------------")# sorted
a = [8, 7, 6, 5, 4, 3, 2, 1]
print(a)
b = sorted(a)
print(a, b, sep='\n')print("-------------------------------------------")# a.reverse()
# 元素有序后再翻转
a.reverse()
print(a)print("-------------------------------------------")# a.index(x)
a = [8, 7, 6, 5, 4, 3, 2, 1]
print(a)
print(a.index(3))print("-------------------------------------------")# len(a)
a = [8, 7, 6, 5, 4, 3, 2, 1]
print(len(a))输出:
['3', '.', '0'] <class 'list'>
-------------------------------------------
['3', '.', '0', 3.14]
-------------------------------------------
['3', '0721', 114514, '.', '0', 3.14, '2.718']
-------------------------------------------
['3', '0721', 114514, '.', '0', 3.14, '2.718', 'n', 'e', 'n', 'e']
-------------------------------------------
['3', '0721', '.', '0', 3.14, '2.718', 'n', 'e', 'n', 'e']
-------------------------------------------
[]
-------------------------------------------
[7, 5, 8, 6, 3, 2, 1, 4]
[1, 2, 3, 4, 5, 6, 7, 8]
-------------------------------------------
[8, 7, 6, 5, 4, 3, 2, 1]
[8, 7, 6, 5, 4, 3, 2, 1]
[1, 2, 3, 4, 5, 6, 7, 8]
-------------------------------------------
[1, 2, 3, 4, 5, 6, 7, 8]
-------------------------------------------
[8, 7, 6, 5, 4, 3, 2, 1]
5
-------------------------------------------
8元组tuple
# 定义元组字面量
(元素, 元素, ..., 元素)# 定义元组变量
变量名称 = (元素, 元素, ..., 元素)# 定义1个元素的元组,逗号不可省略
变量名称 = (元素, )# 定义空元组
变量名称 = () # 方式1
变量名称 = tuple() # 方式2
元组支持下标索引,但内容一旦确定便不可修改。
元组的方法只有index、count。类外函数支持len。
字符串str
name = '字符串内容'
name = "字符串内容"
name = '''字符串内容'''
name = """字符串内容"""
字符串支持下标索引,和元组一样无法修改,只能重新赋值。
字符串的成员函数:
| 操作 | 说明 |
|---|---|
| 字符串[下标] | 根据下标索引取出特定位置字符 |
| 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 字符串.replace(字符串1, 字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔 不会修改原字符串,而是得到一个新的列表 |
| 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符或指定字符串 |
| 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| len(字符串) | 统计字符串的字符个数 |
a = 'sakura'
b = "syaoran"
c = '''fai'''
d = """kurogane"""
print(a, b, c, d, sep='\n')print("-------------------------------------------")print(a[2], b[2], c[2], d[2], sep=' ')
print(a[-2], b[-2], c[-2], d[-2], sep=' ')print("-------------------------------------------")print(b.index("aor"))print("-------------------------------------------")new_b = b.replace("syao", "tsubasa")
print(b, new_b, sep='\n')print("-------------------------------------------")# 和c++的string一样,通过+=进行字符串拼接
a += ' ' + b
a += ' ' + c
a += ' ' + d
a += ' ' + "mokona"
print(a)
e = a.split(' ')
print(e)print("-------------------------------------------")a = ' ' + a + ' \n '
print(a)
# 默认去除开头结尾的空格、换行符
new_a = a.strip()
print(a)
print(new_a)print("-------------------------------------------")a = "feiwang" + ' ' + 'feiwang' + new_a + 'feiwang'
print(a)
aa = a.strip("feiwang")
print(a, aa, sep='\n')print("-------------------------------------------")print(a.count('a'))
print(len(a))输出:
sakura
syaoran
fai
kurogane
-------------------------------------------
k a i r
r a a n
-------------------------------------------
2
-------------------------------------------
syaoran
tsubasaran
-------------------------------------------
sakura syaoran fai kurogane mokona
['sakura', 'syaoran', 'fai', 'kurogane', 'mokona']
-------------------------------------------sakura syaoran fai kurogane mokona sakura syaoran fai kurogane mokonasakura syaoran fai kurogane mokona
-------------------------------------------
feiwang feiwangsakura syaoran fai kurogane mokonafeiwang
feiwang feiwangsakura syaoran fai kurogane mokonafeiwangfeiwangsakura syaoran fai kurogane moko
-------------------------------------------
10
56
字符串初始化为几个固定字符
可以通过字符*字符数得到。
st = 'c' * 8
print(st)输出:
cccccccc
字符和int型数据之间的运算
在c++会发生隐式类型转换,那是因为c++允许单个字符的存在。
但py哪怕是通过下标得到1个字符,它也还是字符串。所以实现字符和int之间通过ASCII码作为桥梁进行计算,需要用到两个函数:chr和ord。
chr将整型数据转换成单个字符的字符串,其中会发生截短操作。
ord返回单个字符的字符串中,字符的ASCII码值。
使用示例:
st = "sakura"
print(ord(st[1]), type(ord(st[1])))
print(chr(81), type(chr(81)))输出:
97 <class 'int'>
Q <class 'str'>集合set
# 定义集合字面量
{元素,元素,……,元素}# 定义集合变量
变量名称 = {元素,元素,……,元素}# 定义空集合
变量名称 = set()和列表、元组、字符串等定义基本相同,但用的载体不同:
- 列表使用:
[] - 元组使用:
() - 字符串使用:
'...'、"..."、'''...'''、"""...""" - 集合使用:
{}
集合无序,看上去升序,不支持下标索引访问,但允许修改。
集合支持的功能:
| 函数 | 描述 |
|---|---|
set1.add(x) | 将元素 x 添加到集合 set1 中,如果 x 已经存在于 set1 中,则不添加 |
set1.copy() | 复制集合 set1,返回新集合 |
set1.pop() | 随机返回集合中的任意一个元素,同时将该元素删除;如果集合为空,则抛 KeyError 异常 |
set1.remove(x) | 删除集合中指定的 x 元素;如果 x 元素不存在,则抛 KeyError 异常 |
set1.discard(x) | 删除集合中指定的 x 元素;如果 x 元素不存在,则不报错 |
set1.clear() | 删除集合中所有的元素 |
set1.isdisjoint(T) | 判断集合 set1 和集合 T 是否无交集(无相同元素),无交集则返回 True,否则返回 False |
set1.difference(set2) | 得到一个新集合,内含两个集合的差集(set1有而set2没有的元素) 返回新集合,原集合不变 |
set1.difference_update(set2) | 在set1中删除set2中存在的元素直接修改set1,无返回值 |
set1.union(set2) | 得到一个新集合,内含两个集合的全部元素(并集)返回新集合,原集合不变 |
len(set1) | 得到一个整数,记录set1的元素数量返回整数 |
使用示例:
# 集合默认升序,并且保证元素唯一
a = {1, 1, 4, 5, 1, 4, 0, 7, 2, 1}
print(a)print("-------------------------------------------")# 集合不支持下标访问,但可以转换成容器再访问
b = list(a)
print(b[3])print("-------------------------------------------")# a.add(x)
a.add(2) # 2加不进去
a.add(8) # 8可以加进去
print(a)print("-------------------------------------------")# a.copy(x)
b = a.copy()
print(a)
print(b)print("-------------------------------------------")# a.pop() 说是随机,但使用下来是删除开头
b = a.pop()
print(a, b, sep=' ')
b = a.pop()
print(a, b, sep=' ')
b = a.pop()
print(a, b, sep=' ')
b = a.pop()
print(a, b, sep=' ')print("-------------------------------------------")# a.remove(x)
a = {1, 1, 4, 5, 1, 4, 0, 7, 2, 1}
a.remove(4)
print(a)print("-------------------------------------------")# a.remove(x)
a = {1, 1, 4, 5, 1, 4, 0, 7, 2, 1}
a.discard(4)
a.discard(9) # 没有9就无视,也不报错
print(a)print("-------------------------------------------")# a.isdisjoint(x)
a = {1, 2, 3}
b = {4, 5, 6}
print(a.isdisjoint(b)) # 无交集返回True
b = {1, 5, 6}
print(a.isdisjoint(b)) # 有交集返回Falseprint("-------------------------------------------")# a.defferent(x)
print(a, b, sep='\n')
c = a.difference(b)
print(c)
c = b.difference(a)
print(c)print("-------------------------------------------")# a.defferent_update(x)
print(a, b, sep='\n')
a.difference_update(b)
print(a)
print(b)print("-------------------------------------------")# a.union(x)
a = {1, 2, 3}
b = {1, 5, 6}
print(a, b, sep='\n')
c = a.union(b)
print(a)
print(b)
print(c)
print(len(c))字典dict
字典感觉上就是c++的容器map,都是用于保存键值对的容器。
# 定义字典字面量
{key: value, key: value, ……, key: value}# 定义字典变量
my_dict = {key: value, key: value, ……, key: value}# 定义空字典
my_dict = {} # 空字典定义方式1
my_dict = dict() # 空字典定义方式2
- 列表使用:
[] - 元组使用:
() - 字符串使用:
'...'、"..."、'''...'''、"""...""" - 集合使用:
{} - 字典使用:
{},但仅键位不可重复。
字典的键位和集合一样,不支持下标索引访问,但允许通过键位找到映射的值。
字典的常用功能:
| 方法 | 描述 |
|---|---|
d.keys() | 返回字典中所有的"键" |
d.values() | 返回字典中所有的"值" |
d.items() | 返回字典中所有的键-值对元素 |
d.setdefault(k, default) | 返回字典中k对应的值,如果不存在,则创建键为k,值为default的新元素 |
d.copy() | 字典的复制,返回新字典 |
d.get(k, default) | 获取键k对应的值,如果不存在则返回默认值 |
d.fromkeys(k, v) | 以k为"键",v为"值"创建字典 |
d.update(d2) | 将字典d2中的元素更新到字典d中 |
d.pop(k) | 返回键k对应的值并删除该键-值对 |
d.popitem() | 随机删除并返回一个键-值对 |
d.clear() | 清空字典所有元素 |
简单使用
a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
print(a)
print(a["1"], type(a), sep=' ')print("-------------------------------------------")# 定义重复Key的字典
b = {"0401": "小狼", "0401": "四月一日君寻", "0401": "sakura"}
print(b)print("-------------------------------------------")# 定义嵌套字典
# 从嵌套字典中获取数据
b = {"0401": {"11": "sakura", "233": "小狼", "00": "四月一日君寻"}, "0229": "abaaba"}
print(b["0401"]["11"])print("-------------------------------------------")# a.keys()
# a.values()
b = a.keys()
c = a.values()
print(f"type(b)={type(b)}, type(c)={type(c)}")
print(b, c, sep='\n')print("-------------------------------------------")a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
# a.items() 返回新类型字典道具的对象,这是一个视图对象,不可直接访问
b = a.items()
print(f"type(b)={type(b)}")
print(a, b, sep='\n')
c = list(b)
print(c)
print(c[1][1])print("-------------------------------------------")a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
# a.setdefault(k, d) 和[]功能重复
a.setdefault(3, "shiro mokona")
a["4"] = "kuro mokona"
print(a)print("-------------------------------------------")a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
# a.get(k, d) 和[]功能重复
print(a.get("1"), a["1"], sep=' ')print("-------------------------------------------")# a.fromkeys(k, v) # 感觉这个函数过于抽象,几乎用不上它
c = dict().fromkeys("9", "库洛缺德") # 效仿生成c++的匿名对象来调用成员函数
print(c)print("-------------------------------------------")a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
# a.update(k)
c.update(a)
print(c)print("-------------------------------------------")# a.pop(k)
keyc = c.pop("9")
print(c)
print(keyc)print("-------------------------------------------")c = {'9': '库洛缺德', '1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane'}
# a.popitem(k) 感觉上,像是从后往前删
keyc = c.popitem()
print(c)
print(keyc)
keyc = c.popitem()
print(c)
print(keyc)
keyc = c.popitem()
print(c)
print(keyc)
c.clear()
print(c)输出:
{'1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane'}
sakura <class 'dict'>
-------------------------------------------
{'0401': 'sakura'}
-------------------------------------------
sakura
-------------------------------------------
type(b)=<class 'dict_keys'>, type(c)=<class 'dict_values'>
dict_keys(['1', '2', '6', 5])
dict_values(['sakura', 'syaoran', 'fai', 'kurogane'])
-------------------------------------------
type(b)=<class 'dict_items'>
{'1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane'}
dict_items([('1', 'sakura'), ('2', 'syaoran'), ('6', 'fai'), (5, 'kurogane')])
[('1', 'sakura'), ('2', 'syaoran'), ('6', 'fai'), (5, 'kurogane')]
syaoran
-------------------------------------------
{'1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane', 3: 'shiro mokona', '4': 'kuro mokona'}
-------------------------------------------
sakura sakura
-------------------------------------------
{'9': '库洛缺德'}
-------------------------------------------
{'9': '库洛缺德', '1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane'}
-------------------------------------------
{'1': 'sakura', '2': 'syaoran', '6': 'fai', 5: 'kurogane'}
库洛缺德
-------------------------------------------
{'9': '库洛缺德', '1': 'sakura', '2': 'syaoran', '6': 'fai'}
(5, 'kurogane')
{'9': '库洛缺德', '1': 'sakura', '2': 'syaoran'}
('6', 'fai')
{'9': '库洛缺德', '1': 'sakura'}
('2', 'syaoran')
{}五大容器的通用操作
- 支持容器之间强制转换。格式:
容器(其他容器)。但键值对转换成其他容器只能得到键值,可用其他方法。
a = {"1":"sakura", "2":"syaoran", "6":"fai", 5:"kurogane"}
b = list(a) # 只能得到键
print(b)b = (2, 7, 1, 8, 2, 8, "Euler")
c = list(b)
print(c)- 都可通过
sorted排序。 - 支持
len。除字典,其余都支持用max(容器)和min(容器)取最大、最小值。
| 特性 | 列表 | 元组 | 字符串 | 集合 | 字典 |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key: 除字典外任意类型 Value: 任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以Key检索Value的数据记录场景 |
py的运算符
照搬c语言的理解即可。
算术运算符
算术运算符用来对数字进行数学运算。
| 运算符 | 说 明 | 实 例 |
|---|---|---|
| + | 加,两个对象做加法运算,求和 | a + b |
| - | 减,两个对象做减法运算,求差 | a - b |
| * | 乘,两个对象做乘法运算,求积 | a * b |
| / | 除,两个对象做除法运算,求商 | a / b |
| // | 整除,返回商的整数部分(向下取整) | a // b |
| % | 求余,返回除法运算的余数 | a % b |
| ** | 幂,次方(乘方),返回x的y次幂 | a ** b |
比较运算符
比较运算符用来比较两个对象的关系(不全是大小)。
| 运算符 | 说 明 | 实 例 |
|---|---|---|
| == | 等于,比较两个对象是否相等 | x == y |
| != | 不等于,比较两个对象是否不相等 | x != y |
| > | 大于,返回x是否大于y | x > y |
| < | 小于,返回x是否小于y | x < y |
| >= | 大于或等于,返回x是否大于或等于y | x >= y |
| <= | 小于或等于,返回x是否小于或等于y | x <= y |
赋值运算符
用于给变量赋值的运算符。
| 运算符 | 说 明 | 实 例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b将a + b的运算结果赋值给c |
| += | 加法赋值运算符 | c += a等效于c = c + a |
| -= | 减法赋值运算符 | c -= a等效于c = c - a |
| *= | 乘法赋值运算符 | c *= a等效于c = c * a |
| /= | 除法赋值运算符 | c /= a等效于c = c / a |
| %= | 取模赋值运算符 | c %= a等效于c = c % a |
| **= | 幂赋值运算符 | c **= a等效于c = c ** a |
| //= | 整除赋值运算符 | c //= a等效于c = c // a |
位运算符
| 运算符 | 说 明 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个二进制位,如果都为1,则该位的结果为1,否则为0 | a&b |
| | | 按位或运算符:参与运算的两个二进制位,如果有一个为1,结果位就为1 | a|b |
| ^ | 按位异或运算符:参与运算的两个二进制位,相同时,结果为0,相异时,结果为1 | a^b |
| ~ | 按位取反运算符:对运算数的每个二进制位取反,即把1变为0,把0变为1。类似于 -x - 1 | ~a |
| << | 按位左移运算符:运算数的各个二进制位全部左移若干位,由<<右边的数字指定移动的位数,高位丢弃,低位补0 | a<<b |
| >> | 按位右移运算符:运算数的各个二进制位全部右移若干位,由>>右边的数字指定移动的位数,低位丢弃,高位补0 | a>>b |
逻辑运算符
这个和c语言的&&、||、!不太一样。
| 运算符 | 说明 | 实例 |
|---|---|---|
| and | 逻辑与运算,等价于数学中的"且" | x and y |
| or | 逻辑或运算,等价于数学中的"或" | x or y |
| not | 逻辑非运算,等价于数学中的"非" | not x |
成员运算符
| 运算符 | 说明 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值,则返回 True,否则返回 False | x in y |
| not in | 如果在指定的序列中没有找到值,则返回 True,否则返回 False | x not in y |
身份运算符
| 运算符 | 说明 | 实例 |
|---|---|---|
| is | 用于判断两个标识符是否是引用自同一个对象 | x is y |
| is not | 用于判断两个标识符是否是引用自不同对象 | x is not y |
运算符优先级
py的运算符也有优先级,但个人倾向于要么查表,要么用()给符合表达式调整优先级。
| 运算符 | 说明 | 结合性 |
|---|---|---|
| ** | 指数运算符的优先级最高 | 右 |
| ~ + - | 按位取反运算符,正数/负数运算符 | 右 |
| * / % // | 乘、除、取模和整除 | 左 |
| + - | 加法、减法运算符 | 左 |
| >> << | 按位右移,按位左移运算符 | 左 |
| & | 按位与运算符 | 右 |
| ^ | 按位异或运算符 | 左 |
| | | 按位或运算符 | 左 |
| <= < >= != == | 比较运算符 | 左 |
| is is not | 身份运算符 | 左 |
| in not in | 成员运算符 | 左 |
| not | 逻辑非运算符 | 右 |
| and | 逻辑与运算符 | 左 |
| or | 逻辑或运算符 | 左 |
| = %= /= //= -= += *= **= | 赋值运算符 | 右 |
py的分支结构
py虽然也是顺序结构,但个人感觉更像是c++语句,但是塞各种语句、(lambda)函数定义、类定义、头文件展开在一个main函数中的写法。
而且py相比c++的用{}区分代码块,它用的是4个空格或1个Tab键来区分代码块。
单分支
if 能判断bool值的表达式:其他语句1其他语句2# py靠空格区分代码块,其他语句前有4个空格即1个Tab间,表示这些语句属于if
其他语句3
其他语句3不属于if代码块,可以正常执行。
a = 3
if a == 4:print("666")print("999")输出:999。
二分支
if 能判断bool值的表达式:其他语句1其他语句2
else:其他语句3其他语句4其他语句5
其他语句5不属于if代码块,可以正常执行。
a = 3
if a == 4:print("666")
else:print("why")print("999")输出:
why
999多分支
if 能判断bool值的表达式:其他语句1其他语句2
elif 能判断bool值的表达式2:其他语句3其他语句4
else:其他语句5其他语句6其他语句7其他语句7不属于if代码块,可以正常执行。
a = 3
if a == 4:print("666")
elif a == 3:print("az")
else:print("why")print("999")输出:
az
999更多分支靠elif关键字拓展,else一般放最后一个。
嵌套分支
if 能判断bool值的表达式:if 能判断bool值的表达式2:其他语句1其他语句2
elif 能判断bool值的表达式3:其他语句3其他语句4
else:其他语句5其他语句6其他语句7其他语句7不属于if代码块,可以正常执行。
a = 3
if a == 4:print("666")
elif a == 3:if (a + 4) % 2 == 0:print("az")else:print("nnnnn")
else:print("why")print("999")输出:
nnnnn
999py的循环结构
py的循环嵌套只有while和for,循环控制依旧是continue和break。
while循环
while 能判断真假的表达式:其他语句其他语句2使用:
a = 1
while a < 5:print(a*9, end=' ')a += 1输出:
9 18 27 36
while有造成死循环的风险,使用需谨慎。
for循环
range(1,10)表示i从1枚举到9。i可换成别名。
for i in range(1,10):其他语句其他语句2
使用:
for i in range(1, 5):print(i * i, end=' ')输出:
1 4 9 16
其他容器即之前学的字符串、列表、元素、字典和集合。字典只能获取键位。
for i in 其他容器:其他语句其他语句2
使用:
a = ["sakura", "syaoran", "fai", "kurogane", "mokona", 7]
for i in a:print(i, end=' ')a = {"sakura":1, "syaoran":2, "fai":6, "kurogane":8, "mokona":3, 7:4}
for i in a:print(i, end=' ') # 字典只能通过for循环获取键位print(a[i])输出:
sakura syaoran fai kurogane mokona 7 sakura 1
syaoran 2
fai 6
kurogane 8
mokona 3
7 4
循环嵌套
py的循环支持嵌套。
例如,九九乘法表:
for i in range(1, 10):for j in range(1, i + 1):print(f"{j}*{i}={i*j}", end=' ')print()for i in range(1, 10):j = 1while j < i +1:print(f"{j}*{i}={i*j}", end=' ')j += 1print()函数
和c++的函数,除了格式不同,不用定义返回值,形参类型可不指定外,其他全都相同。
自定义函数
返回值不写的话,函数会返回None表示空。
def 函数名(参数列表):其他语句return 返回值;使用样例:
def add(x, y):z = x + yreturn zprint(add(12, 34))参数列表可以有缺省值,但缺省值不能放在参数中间或开头。
def add(x, y = 4):z = x + yreturn zprint(add(12))输出:
16
*参数名表示可变参数,它可以当成一个元组使用。
def f(*args):print(args)f(1, 2, 3, 4, 5)输出:
(1, 2, 3, 4, 5)
全局变量和局部变量
全局变量想在函数内部修改,需要加关键字global。
a = 4; b = 5def f():a = 66global bb = 66print(type(f())) # py的函数即使不指定,有返回值,默认为None
print(a, b)输出:
<class 'NoneType'>
4 66内置函数
即python将一部分函数作为python语言的一部分。
对比c语言,几乎所有的库函数都要展开头文件,不评价哪一个更好。
本人是肯定记不住这么多的,用到了再查。链接:内置函数 — Python 3.10.17 文档
A
abs() # 返回一个数的绝对值。 参数可以是整数、浮点数或任何实现了 __abs__() 的对象。如果参数是一个复数,则返回它的模。
aiter()
all()
any()
anext()
ascii()B
bin() # 将整数转变为以“0b”前缀的二进制字符串
bool() #
breakpoint()
bytearray()
bytes()C
callable()
chr() # 将整型数据转换为在ASCII表映射的字符
classmethod()
compile()
complex()D
delattr()
dict() # 字典
dir()
divmod()E
enumerate()
eval()
exec()F
filter()
float() # 返回从数字或字符串 x 生成的浮点数
format()
frozenset()G
getattr()
globals()H
hasattr()
hash()
help()
hex() # 将整数转换为以“0x”为前缀的小写十六进制字符串I
id() # 返回对象的“标识值”,在c语言中,这个标识符相当于地址
input() # 从输入中读取一行,将其转换为字符串(除了末尾的换行符)并返回,读到EOF则触发EOFerror
int()
isinstance()
issubclass()
iter()
L
len() # 返回对象的长度
list() # 列表
locals()M
map() # 因为是初学,不知道官方文档的描述,只知道这个在算法竞赛中用于将一整行由空格分隔的数据转换成列表
max() # 返回可迭代对象中最大的元素
memoryview()
min() # 返回可迭代对象中最小的元素N
next()O
object()
oct() # 将一个整数转变为一个前缀为“0o”的八进制字符串
open() # 打开文件,并返回对应的file object,文件无法打开则触发错误
ord() # 将单个字符转换成整型的ASCII码值P
pow() # pow(x,y):计算x^y。pow(x,y,p):计算x^y mod p,相当于c的快速幂算法
print() # 将*object打印输出到file指定的文本流(默认终端)
property()R
range() # 生成不可变的序列类型,常用于配合for循环
repr()
reversed()
round()S
set() # 集合
setattr()
slice()
sorted() # python自带的比较靠谱的排序函数,相当于c++STL的sort
staticmethod()
str() # 字符串
sum() # 对容器对象进行求和
super()T
tuple() # 元组对象
type() # 返回对象的类型(字符串)V
vars()Z
zip()_
__import__()
部分函数的使用例如map:
# map
n, m = map(int, input().split()) # 类似c++的 cin>>n>>m; 但数据过多时会报错
print(n, m)# 获取一行只包含整数和空格的数据并转换成列表,只有1个数据也可以
a = list(map(int,input().split()))
print(a)# 获取一行包含字符串和空格的数据并转换成列表
a = list(map(str,input().split()))
print(a)range函数:
a = list(range(10))
print(a)a = list(range(1, 10))
print(a)a = list(range(10, -1, -1))
print(a)
递归
函数调用自己。
例如斐波那契数列:
def fib(n):if(n < 2):return nreturn fib(n - 1) + fib(n - 2)# pycharm的规范是,语句和函数定义建议空两行
print(fib(7))包和模块
py的导入包和模块的行为,其实就是c++展开头文件的行为。
包是内部含有文件__init__.py的文件夹,模块是各种 .py 文本文件。
模块在声明和定义上做的并没有c++的模块化编程做的好,但也有其他方法达到同样的效果。
模块的调用
格式:
[from 模块名] import [模块|类|变量|函数|*] [as 别名]
[]表示里面的内容可有可无。
常用的组合:
import 模块名
import 包名.模块名
from 模块名 import 类、变量、方法等
from 模块名 import * # 展开当前包下能展开的所有模块
import 模块名 as 别名
from 模块名 import 功能名 as 别名
例如,导入this模块,就有作者对pychon程序员说的话。
import this输出:
The Zen of Python, by Tim PetersBeautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
翻译:
优美优于丑陋,
明瞭优于隐晦;
简单优于复杂,
复杂优于凌乱,
扁平优于嵌套,
稀疏优于稠密,
可读性很重要!
即使实用比纯粹更优,
特例亦不可违背原则。
错误绝不能悄悄忽略,
除非它明确需要如此。
面对不确定性,
拒绝妄加猜测。
任何问题应有一种,
且最好只有一种,
显而易见的解决方法。
尽管这方法一开始并非如此直观,
除非你是荷兰人。
做优于不做,
然而不假思索还不如不做。
很难解释的,必然是坏方法。
很好解释的,可能是好方法。
命名空间是个绝妙的主意,
我们应好好利用它。
其他模块有语句
在上文已经演示过this模块会输出一首诗,这首诗某种意义上也是作者设计的,不属于模块职能的行为。
例如这里运行testpy.py:
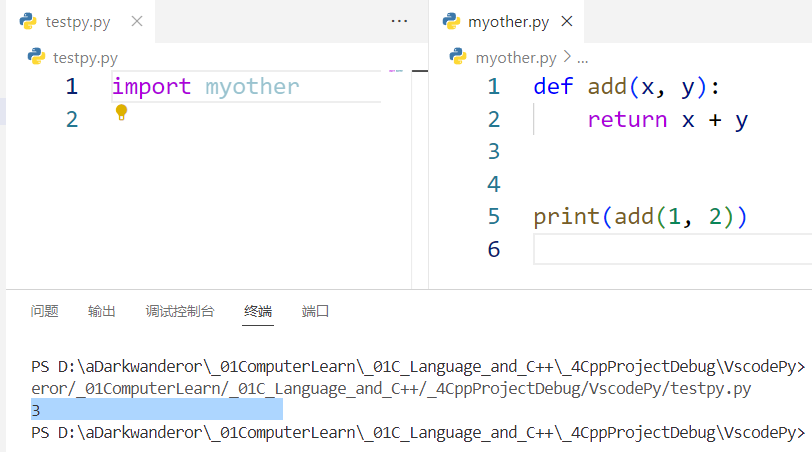
解决方法:在待开发模块加这句判断:
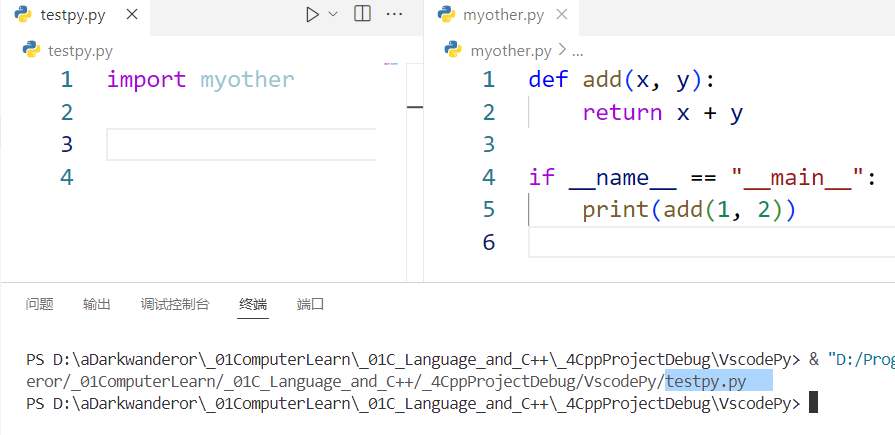
if __name__ == '__main__':# 测试用的语句
这个判断的作用是限制模块内的语句,使得语句只有在当前文件被运行时才能被调用。
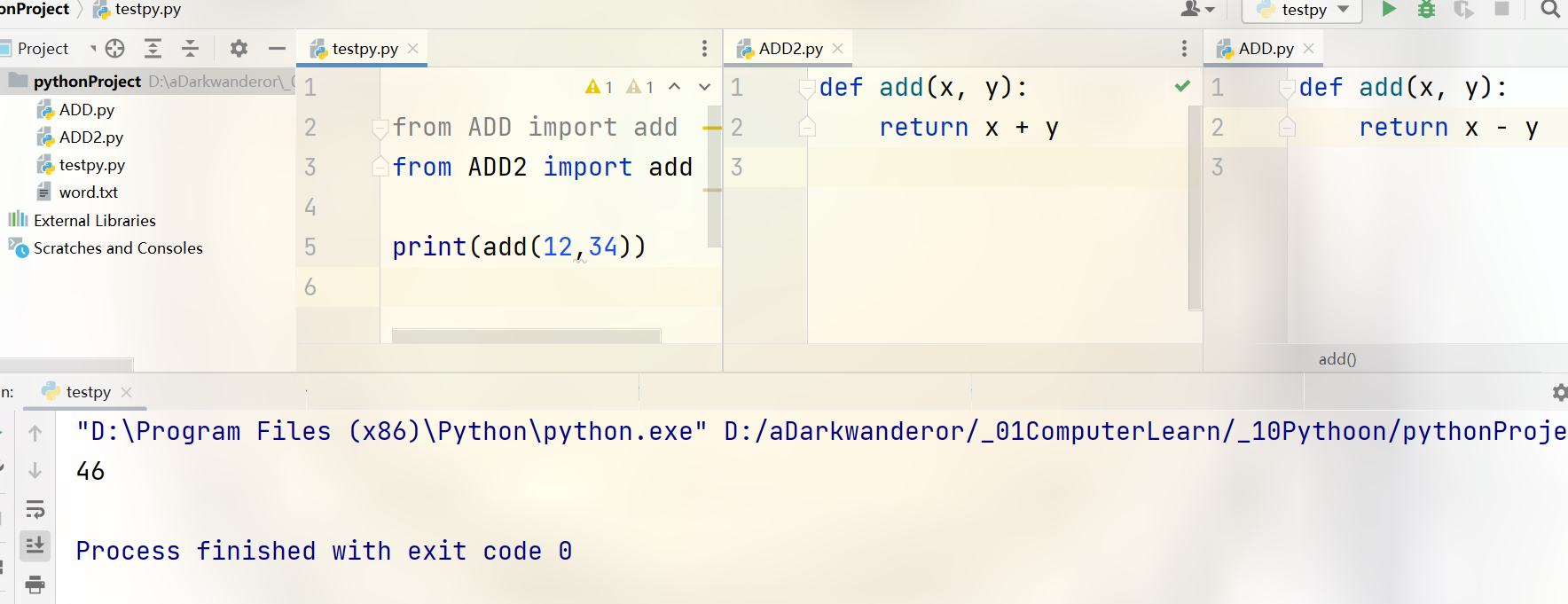
模块同名功能覆盖
当调用了不同的包内的同名模块时,以最后一次调用的模块为准。
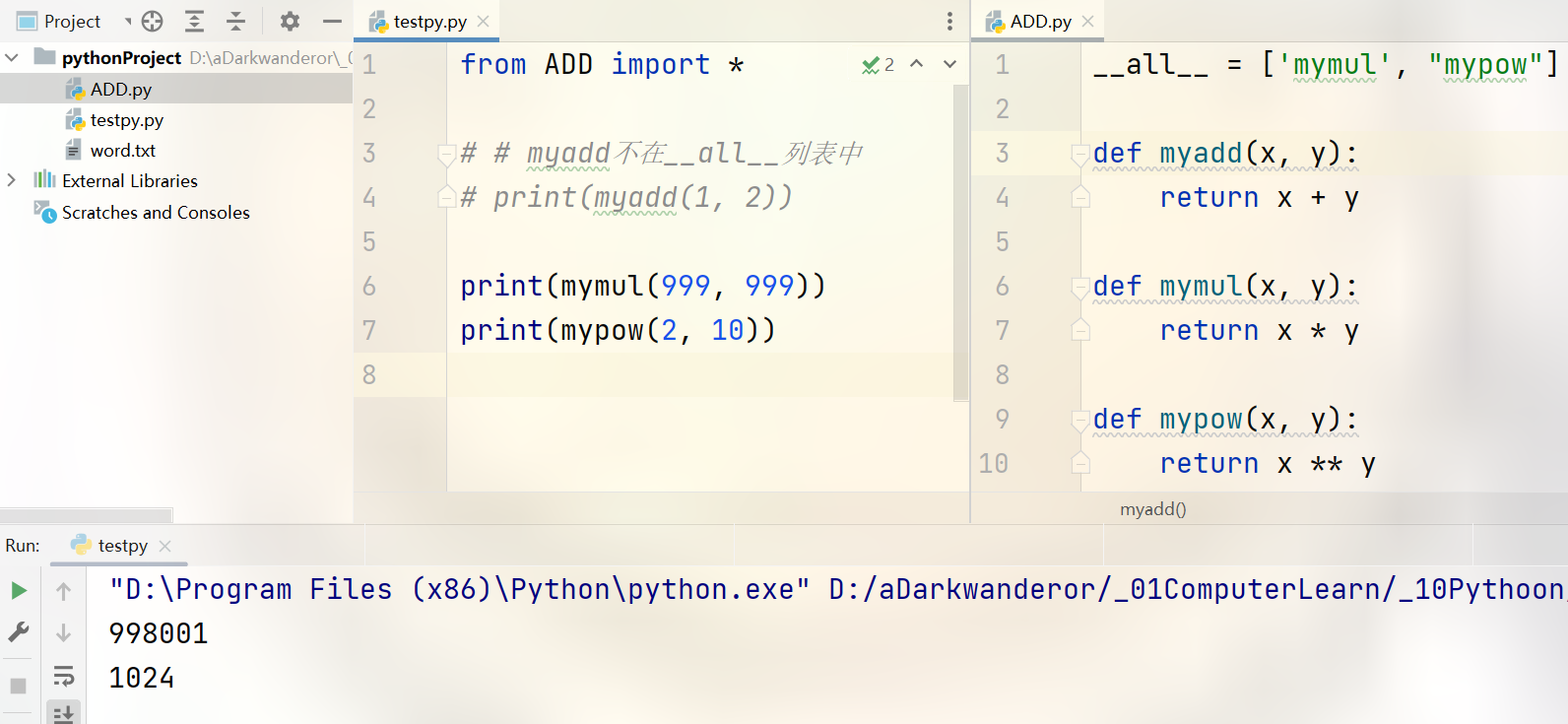
导入指定元素
可以通过指定列表__all__来控制from 模块名 import *能打开的模块。
例如,ADD.py:
__all__ = ['mymul', "mypow"]def myadd(x, y):return x + ydef mymul(x, y):return x * ydef mypow(x, y):return x ** ytestpy.py
from ADD import *# # myadd不在__all__列表中
# print(myadd(1, 2))print(mymul(999, 999))
print(mypow(2, 10))结果:
模拟c++的多维数组
- 用
list模拟。
例如,创建一个二维数组a[n][n]和三维数组a[n][n][n]。
n = 3
a = [[0 for i in range(n)] for i in range(n)] #二维数组
for i in range(n):for j in range(n):a[i][j]=i*n+jprint(a[i][j], end=' ')print()a = [[[0]*n for i in range(n)]for i in range(n)] # 三维数组
for i in range(n):for j in range(n):for k in range(n):a[i][j][k] = i*(n**2)+j*n+kprint(a[i][j][k], end=' ')print()print()这种方法无外界依赖,但终究是使用py的容器去模拟,性能差。
- 使用
NumPy库,科学计算推荐,但算法竞赛可能不允许调用第三方库。
import numpy as npn = 3
a = np.zeros((n, n), dtype=int) # 二维数组
for i in range(n):for j in range(n):a[i][j] = i*n+jprint(a[i][j], end=' ')print()print()
a = np.zeros((n, n, n), dtype=int) # 三维数组
for i in range(n):for j in range(n):for k in range(n):a[i][j][k] = i*(n*n)+j*n+kprint(a[i][j][k], end=' ')print()print()- 使用
array模块模拟。但不接受py自带的容器。
from array import arrayn = 3
a = array('i', [0]*(n*n))for i in range(n):for j in range(n):a[i*n+j] = i*n+jprint(a[i*n+j], end=' ')print()
print()
a = array('i', [0]*(n*n*n))for i in range(n):for j in range(n):for k in range(n):a[i*n*n+j*n+k] = i*n*n+j*n+kprint(a[i*n*n+j*n+k], end=' ')print()print()其中类型码:
| 类型码 | C 类型 | Python 类型 | 描述 |
|---|---|---|---|
'b' | signed char | int | 有符号字节(-128 到 127) |
'B' | unsigned char | int | 无符号字节(0 到 255) |
'h' | signed short | int | 有符号短整型 |
'H' | unsigned short | int | 无符号短整型 |
'i' | signed int | int | 有符号整型 |
'I' | unsigned int | int | 无符号整型 |
'l' | signed long | int | 有符号长整型 |
'L' | unsigned long | int | 无符号长整型 |
'q' | signed long long | int | 有符号长长整型(Python 3.3+) |
'Q' | unsigned long long | int | 无符号长长整型(Python 3.3+) |
'f' | float | float | 单精度浮点数 |
'd' | double | float | 双精度浮点数 |
类和对象
py的类只有class,可以定义成员变量和成员函数,默认成员公开。成员函数一般叫做方法。
class 类名:成员变量 = 值def 方法名(self, 参数列表):各种语句return 值
简单使用
class A:x = 3y = "asdfg"def f(self):print("f(self)")return None # 不指定也可a = A() # 调用默认构造函数
print(a.x, a.y, sep='\n')
print(a.f())输出:
3
asdfg
f(self)
Noneself相当于c++的this指针,py需要将它写出来,c++是它默认存在但不显示。
构造方法和其他内置方法
参考:3. 数据模型 — Python 3.10.17 文档
就是c++的构造函数,但名字统一命名为__init__。
c++支持函数重载,但py不支持函数重载,多少函数只会被最下方的那个替代。
class A:__a = None__b = Nonedef __init__(self, a): # py和c++不同,别想了self.__a = aself.__b = Nonedef __init__(self, a = 0, b = 0):self.__a = aself.__b = bdef get_a(self):return self.__adef get_b(self):return self.__ba = A()
print(a.get_a())
print(a.get_b())b = A(4)
print(b.get_a())
print(b.get_b())c = A(4, 2)
print(c.get_a())
print(c.get_b())d = A(None, 2)
print(d.get_a())
print(d.get_b())即使py不支持函数重载,但py也有办法达到和c++的运算符重载一样的效果。
例如__lt__和__le__方法能使类的对象使用小于符号和大于符号,__eq__方法能使类的对象使用等于符号。
封装
封装即限制别人对类的成员进行访问,需要将成员设置成私有。
想成员私有,需要成员名以2个_开头,_即下划线。
class A:x = 3__y = "asdfg"def __f(self):print("f(self)")return None # 不指定也可def get_f(self):self.__f()return 1def get_y(self):return self.__ya = A() # 调用默认构造函数
print(a.x)
# print(a.__f()) # 私有成员不可访问
print(a.get_f()) # 私有成员需要通过公有方法间接访问
print(a.get_y()) # 私有成员需要通过公有方法间接访问输出:
3
f(self)
1
asdfg继承
和c++一样,py支持多继承。
格式:
class 类名(父类名1, 父类名2, ...):# ...
和c++不同,py内部采用独特的优化方式,使得py不会出现c++的菱形继承的问题。
class A:a = Noneclass B(A):b = Noneclass C(A):c = Noneclass D(B, C):d = Nonea = D()
print(a.a)
print(a.b)
print(a.c)
print(a.d)多态
和c++一样,py支持多态。
class A:def f(self):print("class A")class B(A):def f(self):print("class B")class C(A):def f(self):print("class C")def test(x: A):x.f()a = A()
test(a)
b = B()
test(b)
test(C())注解类型
和c++不同,py的变量、函数的形参、返回值都是在给数据的时候才能确定类型,这可能给程序员造成带来困惑。
因此需要对这些类型进行类型注解。py在3.5版本引入。
变量的类型注解
格式:
变量名: 类型
容器的类型注解格式:
变量名:容器[数据类型1, 属于类型2, ...]
例如:
a: int = 6
b: float = 3.14
c: complex = 2+0.71j
d: str = "sakura"
e: list[int] = [1, 2, 3]
f: tuple[int, str, bool] = (1, "2", False)print(a, b, c, d, sep=' ')
print(e, f, sep='\n')在vscode和pycharm,将鼠标悬停在对象上会显示推荐的类型。
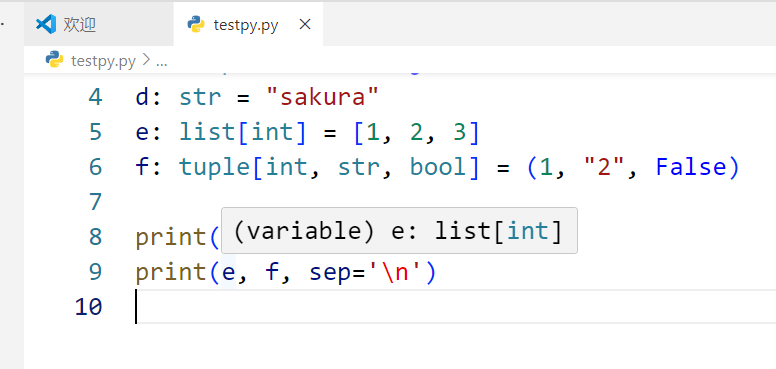
当然注解类型只是给予程序员建议,真正上传什么还是取决于程序员。
函数和方法的类型注解
格式:
def 函数方法名(形参名: 类型, 形参名: 类型, ...) -> 返回值类型:其他语句
例如:
def add(a: float, b: float) ->float:return float(a + b)print(add(314, 271))class A:def add(self, a: float, b: float) ->float:return float(a + b)print(A().add(3.14, 2.71))Union类型
使用Union类型可以定义联合类型注解。但需要提前导入模块Union。
from typing import Union
a: list[Union[int, str]] = [1, 2, "345"] # 使用Union类型需要先导入模块Union
b: dict[str, Union[str, int]] = {"0412":"蓝桥杯省赛", "0608":"icpc邀请赛", "0721":6}print(a)
print(b)相关文章:

从c++到python
从c到python 前言printprint格式化print按原始格式输出 input变量、常量和数据类型整型和type()浮点型复数字符串类型数据类型转换变量地址 注释关键字容器列表list下标索引常用功能 元组tuple字符串str字符串的成员函数:字符串初始化为几个固定字符字符和int型数据…...

仿腾讯会议——房间界面用户设置
1、房间界面设置 2、 添加新设计师界面类 3、设置用户设置 4、添加新类&&设置房间标题 5、设置控件 6、修改用户展示头文件 7、 设置用户名 8、客户端添加用户展示 9、测试数据 10、成功截图...

Vue+Go 自定义打字素材的打字网站
Typing_Key_Board 这是一个基于Vue 3和Go语言的自定义素材打字练习网站,灵感来源于常用字打字练习,解决了大多数网站无法自定义打字素材的问题。在 Typing_Key_Board (简称TKB)中,用户可以自定义打字素材进行练习,在复习代码的同…...

生产级编排AI工作流套件:Flyte全面使用指南 — Data input/output
生产级编排AI工作流套件:Flyte全面使用指南 — Data input/output Flyte 是一个开源编排器,用于构建生产级数据和机器学习流水线。它以 Kubernetes 作为底层平台,注重可扩展性和可重复性。借助 Flyte,用户团队可以使用 Python SDK…...
)
JUC入门(二)
5、8锁现象:就是关于锁的八个问题 谁来充当锁?要锁的是什么东西?这个锁有什么用? 其实锁的作用就是:哪个线程先拿到锁,谁就有先执行同步方法的权力 那么谁能充当锁?任何对象都可以充当锁 要…...
)
深入浅出:CPU寻址方式完全指南(从理论到实践)
引言:为什么需要寻址方式? 当我们写下一行高级语言代码(比如 int sum a b;),计算机底层是如何找到变量 a 和 b 的? 寻址方式(Addressing Modes) 就是 CPU 定位操作数的策略&#…...
)
PyQt5基本窗口控件(对话框类控件)
对话框类控件 QDialog 为了更好地实现人机交互,比如Windows及Linux等系统均会提供一系列的标 准对话框来完成特定场景下的功能,如选择字号大小、字体颜色等。在PyQt5中定 义了一系列的标准对话框类,让使用者能够方便和快捷地通过各个类完成…...

【PostgreSQL系列】PostgreSQL 复制参数详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

给easyui的textbox绑定回车事件
项目有一个textbox输入框,需要绑定一个回车搜索事件。 一开始想着,直接使用js的on或者jquery的keydown方法直接绑定,但是事件不生效。 $("#propName").textbox({width: 200,prompt: "请输入物品名称进行搜索" }).keydo…...

量子计算 | 量子密码学的挑战和机遇
量子计算在密码学中的应用现主要体现在对现有加密算法的威胁上。最著名的例子是Shor算法,该算法能够在多项式时间内分解大整数,从而威胁到基于大数分解的加密算法,如RSA加密。此外,量子计算还可以加速某些类型的密码分析ÿ…...

什么是着色器 Shader
本人就是图形学结课了,对 OpenGL着色器还有很多疑问嘿嘿 文章目录 为什么要有着色器vshaderfshader 本文围绕 vshader 和 fshader 代码示例讲解。 (着色器代码取自本人简单OpenGL项目 https://github.com/DBWGLX/-OpenGL-3D-Lighting-and-Shadow-Modeli…...

STM32H562----------启动时钟分析
1、H562启动过程分析 1.1、启动模式 复位方式有三种:上电复位、硬件复位和软件复位。当产生复位后,离开复位状态后 CM33 内核做的第一件事就是 读取堆栈指针 MSP 的初始值及程序计数器指针 PC 的初始值: 1、从地址 0x0000 0000 处读取出堆栈指针 MSP 的初始值,该值即栈…...

MIT 6.S081 2020 Lab4 traps 个人全流程
零、写在前面 做之前可以看看Chapter 4:Traps and systems calls,了解XV6 下的陷入机制 https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf 这个实验旨在探索系统调用如何实现了trap,会先做一个有关栈的练习,然后…...

基于YOLOv8-OBB的旋转目标检测:从数据制作到自动标注完整指南
一、引言 目标检测作为计算机视觉中的核心任务,广泛应用于安防监控、自动驾驶、工业质检等场景。传统的目标检测方法多使用水平边界框(HBB)进行目标定位。然而在一些特殊应用场景(如遥感图像、文本检测、PCB检测等)中…...

【自然语言处理与大模型】向量数据库:Chroma使用指南
Chroma是一款功能强大的开源 AI 应用数据库,专为高效数据存储与检索而设计。它不仅支持 Embedding 和 Metadata 的存储,还集成了多项核心功能,包括向量搜索、全文搜索、Document 存储、Metadata 过滤以及多模态检索。此外,Chroma …...

一文掌握工业相机选型计算
目录 一、基本概念 1.1 物方和像方 1.2 工作距离和视场 1.3 放大倍率 1.4 相机芯片尺寸 二、公式计算 三、实例应用 一、基本概念 1.1 物方和像方 在光学领域,物方(Object Space)是与像方(Image Space)相对的…...

【周输入】510周阅读推荐-3
前文 【周输入】510周阅读推荐-1-CSDN博客 【周输入】510周阅读推荐-2-CSDN博客 本次推荐 目录 前文 本次推荐 算法技术 模型产品 算法技术 vLLM和DeepSpeed部署模型的优缺点_vllm deepspeed-CSDN博客 优点缺点总结vLLM 适用于推理 优化内存管理 高效并行化 功能单…...
——xgboost)
机器学习(11)——xgboost
文章目录 1. 算法背景和动机1.1. 提升算法(Boosting)1.2. XGBoost的改进动机2. 算法基础 3. 核心创新3.4 稀疏感知算法 4. 系统优化4.1 列块(Column Block)4.2 缓存感知访问4.3 外存计算 5. 算法细节5.1 树生长策略5.2 特征重要性评估5.3 自定义目标函数…...

大语言模型上下文长度:发展历程、局限与技术突破
1. 引言:什么是上下文长度及其重要性 上下文长度(Context Length),也称为上下文窗口(Context Window),指的是大语言模型(LLM)在处理和生成文本时能够有效记忆和利用的信…...

ControlNet简洁
ControlNet 什么是ControlNet ControlNet是一种用于控制扩散模型生成结果的网络结构。该结构可以将边缘图,结构图等信息注入扩散模型,从而能够对生成结果进行更为精细的控制。 ControlNet是怎么实现的 在模型结构方面,其大致结构如下图所…...

【C】C程序内存分配
文章目录 1. C程序内存布局 1. C程序内存布局 从低地址到高地址依次为: 代码段 存储内容:存放编译后的机器指令特点:代码段是只读的;可共享,多个进程可共享同一份代码 数据段 存储内容 已初始化的全局变量已初始化的静…...

论文学习:《引入TEC - LncMir,通过对RNA序列的深度学习来预测lncRNA - miRNA的相互作用》
长链非编码RNA ( long noncoding RNAs,lncRNAs )是一类长度通常大于200个核糖核苷酸的非编码RNA ,微小RNA ( microRNAs,miRNAs )是一类由22个核糖核苷酸组成的短链非编码RNA。近年来,越来越多的研究表明,lncRNA和miRNA…...

【每日一题丨2025年5.12~5.18】排序相关题
个人主页:Guiat 归属专栏:每日一题 文章目录 1. 【5.12】P1068 [NOIP 2009 普及组] 分数线划定2. 【5.13】P5143 攀爬者3. 【5.14】P12366 [蓝桥杯 2022 省 Python B] 数位排序4. 【5.15】P10901 [蓝桥杯 2024 省 C] 封闭图形个数5.【5.16】P12165 [蓝桥…...

AIDA64 extreme7.5 版本注册激活方法
一、AIDA 7.5 序列号 3BQN1-FUYD6-4GDT1-MDPUY-TLCT7 UVLNY-K3PDB-6IDJ6-CD8LY-NMVZM 4PIID-N3HDB-IWDJI-6DMWY-9EZVU 二、安装激活方法 激活步骤: 1、打开AIDA64软件,点击顶部菜单栏的“帮助”→“输入序列号” 2、将生成的序列号粘贴至输入框&a…...

Python 条件语句详解
条件语句是编程中用于控制程序流程的基本结构,Python 提供了几种条件语句来实现不同的逻辑判断。 1. if 语句 最基本的条件语句形式: if 条件:# 条件为真时执行的代码块示例: age 18 if age > 18:print("你已经成年了")2. …...
)
模型评估与调优(PyTorch)
文章目录 模型评估方法混淆矩阵混淆矩阵中的指标ROC曲线(受试者工作特征)AUCR平方残差均方误差(MSE)均方根误差(RMSE)平均绝对误差(MAE) 模型调优方法交叉验证(CV&#x…...

oppo手机安装APK失败报错:安装包异常
如果你的apk文件在oppo手机安装失败了,像这样: 先说我们当时解决方式: 如果还没上架应用市场的测试包,在上面图一中需要关闭“超级守护”,类似华为的纯净模式。如果开启了还还不行,安装页面的报错太笼统不…...

互联网大厂Java面试场景:从缓存到容器化的技术问答
场景:互联网大厂Java面试之旅 面试官:严肃的技术专家 应聘者:搞笑的水货程序员明哥 第一轮:缓存技术与数据库优化 面试官:明哥,你能谈谈Redis的常见使用场景和一些优化技巧吗? 明哥…...

【android bluetooth 协议分析 01】【HCI 层介绍 6】【WriteLeHostSupport命令介绍】
HCI 指令 HCI_Write_LE_Host_Support 是 Bluetooth Host 向 Controller 发送的一条指令,用于启用或禁用主机对 Bluetooth Low Energy(LE)的支持能力。该指令属于 HCI(Host Controller Interface)命令集合中,…...
)
Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)
文章目录 Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)需求方法1:使用Helm覆盖值方法2: 在Lens中临时修改Deployment配置步骤 1: 创建 Docker Registry Secret步骤 2: 在 Deployment 中引用 Secret参考资料Helm配置之为特定Deployment配置特定Docker仓库(覆…...

项目:在线音乐播放服务器——基于SSM框架和mybatis
介绍项目 项目主要是基于SSM框架和mybatis进行实现 主要的功能: 登陆界面,用户注册,音乐的播放列表,删除指定的歌曲,批量删除指定的歌曲,收藏歌曲,查询歌曲,从收藏列表中删除收藏…...

Linux配置vimplus
配置vimplus CentOS的配置方案很简单,但是Ubuntu的解决方案网上也很多但是有效的很少,尤其是22和24的解决方案,在此我整理了一下我遇到的问题解决方法 CentOS7 一键配置VimForCPP 基本上不会有什么特别难解决的报错 sudo yum install vims…...

Ubuntu22.04开机运行程序
新建启动文件 sudo vim /etc/systemd/system/trojan.service 2. 写入配置文件 [Unit] DescriptionTrojan Proxy Service Afternetwork.target[Service] Typesimple ExecStart/home/cui/Downloads/trojan/trojan -c /home/cui/Downloads/trojan/config.json Restarton-failur…...

高效查询:位图、B+树
1. 位图(BitMap)与布隆过滤器(Bloom Filter) 1.1. 问题背景与解决方案 问题背景 场景:网页爬虫判重 搜索引擎的爬虫会不断地解析网页中的链接并继续爬取。一个网页可能在多个页面中出现,容易重复爬取。…...

HashMap的扩容机制
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75) 每次扩容的时候,都是扩容之前容量的2倍; 扩容之后&#…...

从坏道扫描到错误修复:HD Tune实战指南
一、硬盘检测的必要性 随着计算机使用时间的增加,机械硬盘和固态硬盘都会出现不同程度的性能衰减。定期进行硬盘健康检查可以:及时发现潜在故障;预防数据丢失风险;掌握存储设备实际状态。 二、HD Tune功能解析 性能测试&#x…...

Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II
Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路2. 代码实现 题目链接:3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路 这一题很惭愧,并没有自力搞定,是看了大佬们的解答才有…...
)
算法加训之最短路 上(dijkstra算法)
目录 P4779 【模板】单源最短路径(标准版)(洛谷) 思路 743. 网络延迟时间(力扣) 思路 1514.概率最大路径(力扣) 思路 1631.最小体力消耗路径 思路 1976. 到达目的地的方案数 …...

01 Nginx安装及基本配置
01 Nginx安装 # 官网:https://nginx.org/en/ # 点击下载图1 Nginx下载官网 # https://nginx.org/en/download.html # 全是各个平台的源码包图2 Nginx下载版本 # 找到最下面的stable and mainline(稳定版和主线版)图3 找到最下面的稳定版 # https://nginx.org/en/li…...

ABP vNext 多租户系统实现登录页自定义 Logo 的最佳实践
🚀 ABP vNext 多租户系统实现登录页自定义 Logo 的最佳实践 🧭 版本信息与运行环境 ABP Framework:v8.1.5.NET SDK:8.0数据库:PostgreSQL(支持 SQLServer、MySQL 等)BLOB 存储:本地…...

Docker 网络
目录 前言 1. Docker 网络模式 2. 默认 bridge 网络详解 (1)特点 (2)操作示例 3. host 网络模式 (1)特点 (2)操作示例 4. overlay…...

btc交易所关键需求区 XBIT反弹与上涨潜力分析
在加密货币市场的浪潮中,狗狗币(DOGE)近期的走势吸引了众多投资者的目光。根据XBIT分析,狗狗币刚刚踏入关键需求区,此前虽从高点大幅下跌了10%,但XBIT去中心化交易所平台分析师认为,短期内它有望…...

深度剖析:YOLOv8融入UNetv2 SDI模块的性能提升之旅
文章目录 一、引言二、SDI多层次特征融合模块概述(一)背景和动机(二)模块设计原理 三、SDI模块实现(一)关键代码结构(二)代码解析 四、将SDI模块融入YOLOv8(一࿰…...

图像定制大一统?字节提出DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,有效解决多泛化性冲突。
字节提出了一个统一的图像定制框架DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,不仅在广泛的图像定制场景中取得了高质量的结果,而且在适应多条件场景方面也表现出很强的灵活性。现在已经可以支持消费级 GPU(16G…...

spark数据处理练习题详解【下】
12. (单选题) def main(args: Array[String]): Unit { println(func1("张三",f1)) } def func1(name:String,fp:(________________)): String { fp(name) } def f1(s:String): String { "welcome "s } 选择填空() A.String>S…...
_条件渲染)
Vue基础(11)_条件渲染
原生css想让显示的元素隐藏,方式有以下几点: display: none; opacity: 0; visibility: hidden; 那么vue中是怎样实现元素显示/隐藏的呢? 条件渲染 v-show 写法:v-show"表达式" 判断:表达式转换为布尔值(tr…...

湖北理元理律师事务所:债务优化服务的四维创新实践
在债务问题普遍影响家庭经济稳定的当下,专业法律服务机构的价值不仅在于提供解决方案,更需构建可持续的服务生态。湖北理元理律师事务所通过“法律心理技术教育”四维服务体系,探索出一条兼顾债务化解与生活质量保障的创新路径。 服务模式创…...

ubuntu工控机固定设备usb串口号
ubuntu工控机固定设备usb串口号 1、多个USB设备的ID相同 ubuntu系统中的串口使用权限并没有对所有的用户进行开放,所以在使用代码对串口进行操作时,需要打开用户对串口的使用权限,否则在代码中会出现“串口无法打开的报错”,只有…...

MongoDB的安装及简单使用
MongoDB 是一个开源的文档型 NoSQL 数据库,由 MongoDB Inc. 开发,专为灵活性和可扩展性设计。 特点: 1.文档模型:数据以 BSON(二进制 JSON)格式存储,支持嵌套结构。 2.动态 S…...

卷积神经网络进阶:转置卷积与棋盘效应详解
【内容摘要】 本文深入解析卷积神经网络中的转置卷积(反卷积)技术,重点阐述标准卷积与转置卷积的计算过程、转置卷积的上采样作用,以及其常见问题——棋盘效应的产生原因与解决方法,为图像分割、超分辨率等任务提供理论…...