大语言模型上下文长度:发展历程、局限与技术突破
1. 引言:什么是上下文长度及其重要性
上下文长度(Context Length),也称为上下文窗口(Context Window),指的是大语言模型(LLM)在处理和生成文本时能够有效记忆和利用的信息范围。简单来说,就是模型一次能够“看到”和“记住”的文本序列的最大长度,通常以**词元(token)**的数量来衡量。一个词元可以是一个词、一个子词,甚至一个字符,具体取决于模型的分词策略。
重要性:
-
理解复杂指令和对话: 更长的上下文使得模型能够理解包含多个步骤或依赖先前信息的复杂指令,并在多轮对话中保持连贯性和相关性。
-
处理长文档: 对于文档摘要、问答、信息提取等任务,模型需要能够处理整个文档或大部分内容才能给出准确的结果。例如,分析一份几万词元的法律合同。
-
提升生成质量: 更长的上下文有助于模型捕捉更广泛的语境信息,从而生成更相关、更一致、更有深度的文本。例如,在写故事或报告时,模型可以回顾数千词元前提到的细节。
-
减少信息丢失: 在处理长序列时,如果上下文长度不足,模型可能会丢失早期的重要信息,导致理解偏差或生成内容不连贯。
-
支持更复杂的应用: 许多高级应用,如代码生成与理解(可能涉及数万行代码)、法律文件分析、科学研究等,都依赖于模型处理和理解大规模文本的能力。
因此,扩展上下文长度一直是LLM研究领域的核心目标之一,它直接关系到模型的性能上限和应用场景的广度。
2. 上下文长度的局限性:为什么LLM会受限于上下文长度?
LLM在上下文长度方面受到限制,主要源于以下几个核心技术挑战:
-
计算复杂度 (Computational Complexity):
-
Transformer的自注意力机制 (Self-Attention): 标准的Transformer模型采用自注意力机制,其计算复杂度与上下文长度 N 的平方成正比,即 O(N2⋅d),其中 d 是模型的隐藏层维度。当上下文长度 N 从例如1024词元增加到4096词元(4倍)时,计算量会增加约16倍。这使得在非常长的序列上训练和推理变得非常昂贵和缓慢。
-
-
内存消耗 (Memory Consumption):
-
注意力矩阵: 自注意力机制需要计算并存储一个 N×N 的注意力得分矩阵。这个矩阵的内存消耗同样是 O(N2)。对于一个有32768 (32K) 个词元的上下文,注意力矩阵就需要存储 327682≈109 个值,对内存是巨大的挑战。(大模型在持续推理的过程中,需要缓存一个叫做 KV Cache 的数据快,KV Cache 的大小也与序列长度成正比。以 Llama 2 13B 大模型为例,一个 4K 长的序列大约需要 3G 的显存去缓存 KV Cache,16K 的序列则需要 12G,128K 的序列则需要 100G 显存。)
-

-
激活值存储: 在训练过程中,为了进行反向传播计算梯度,需要存储中间层的激活值。这些激活值的数量也与序列长度 N 成正比,进一步加剧了内存压力。
-
-
位置编码的挑战 (Challenges of Positional Encoding):
-
泛化能力: Transformer模型本身不包含序列顺序信息,需要通过位置编码(Positional Encoding)来注入。传统的绝对位置编码或相对位置编码在训练长度(例如2048词元)之外的序列上泛化能力可能较差。当模型在特定长度的上下文上训练后,直接应用于更长的上下文(例如4096词元)时,位置编码可能无法准确表示超出训练范围的位置信息,导致性能下降。
-
固定与动态: 某些位置编码方法(如正弦位置编码)理论上可以扩展到无限长,但实际效果会受模型学习到的模式限制。可学习的绝对位置编码则直接受限于训练时见过的最大长度。
-
-
长距离依赖问题 (Long-range Dependency Issues):
-
梯度消失/爆炸的缓解: 虽然Transformer通过自注意力机制直接连接任意两个位置的词元,缓解了RNN中的梯度消失/爆炸问题,但在极长的序列中(例如超过数万词元),有效捕捉和利用非常遥远的信息仍然是一个挑战。注意力机制可能会“稀释”或“遗忘”距离过远但仍然相关的信息。
-
信息瓶颈: 即使理论上可以连接,模型是否能有效学习到这些长距离依赖关系,并将其用于后续的预测,也是一个难题。
-
-
训练数据的限制 (Limitations of Training Data):
-
长序列数据的稀缺性: 高质量、多样化的长序列训练数据(例如包含数十万词元的文档)相对短文本数据更为稀缺。模型需要接触足够多的长文本样本才能学会处理长程依赖和利用长上下文。
-
训练成本与效率: 使用长序列进行训练本身就非常耗时耗资源,这限制了研究者和开发者在超长上下文模型上的迭代速度。
-
这些因素共同构成了LLM上下文长度的主要瓶颈。为了突破这些限制,研究者们在注意力机制、模型架构、位置编码和训练策略等多个方面进行了大量的探索和创新。
扩展大模型的上下文长度,一般思路如下:
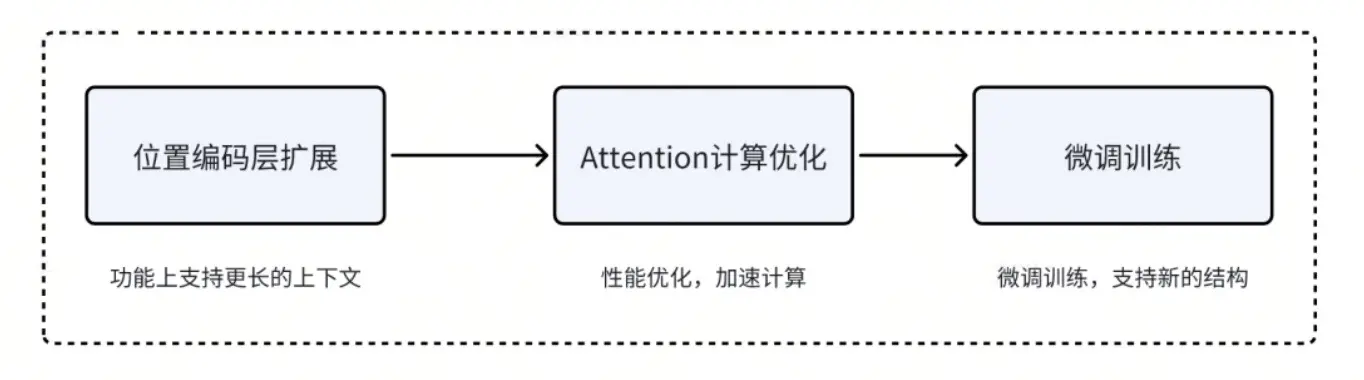
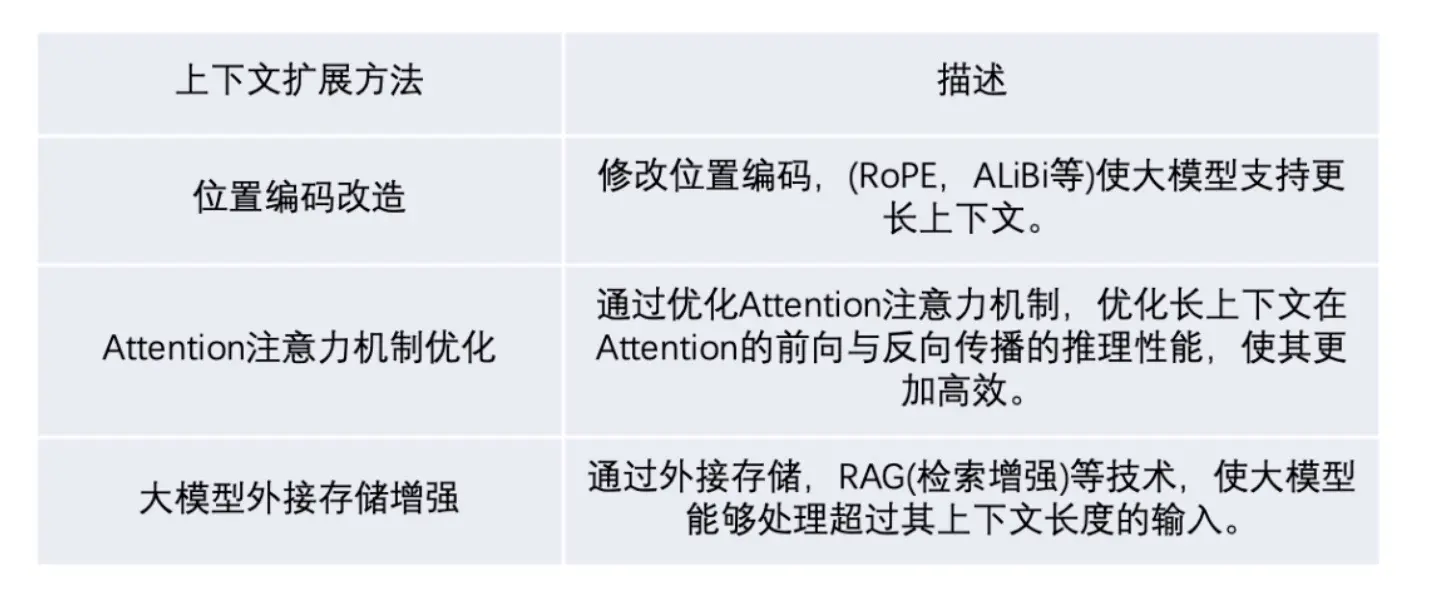
3. 上下文长度的发展历程与技术突破
上下文长度的扩展是LLM发展的一条重要主线,经历了从早期模型的几百个词元到当前动辄数十万甚至上百万词元的过程。
3.1 早期模型 (RNN/LSTM)
-
循环神经网络 (RNN) / 长短期记忆网络 (LSTM) / 门控循环单元 (GRU): 这些模型通过循环结构处理序列信息。
-
Token数范围: 实际有效的上下文长度通常只有几百个词元。
-
技术局限: 它们面临严重的梯度消失/爆炸问题,导致难以捕捉长距离依赖。尽管LSTM和GRU通过门控机制有所缓解,但瓶颈依然存在。
-
3.2 Transformer的出现及其原始Attention
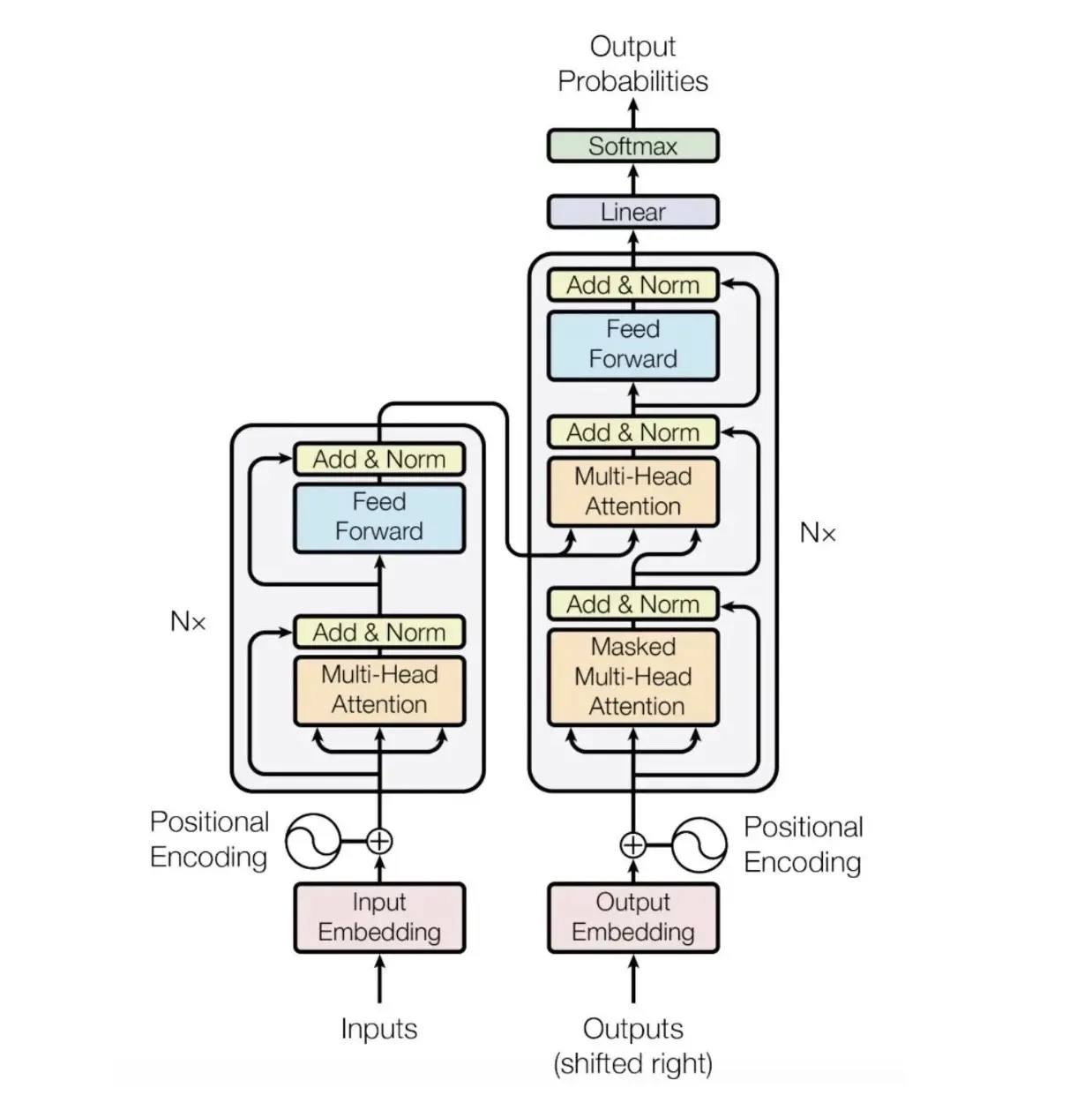
-
Transformer (Vaswani et al., 2017): 引入了自注意力机制 (Self-Attention),允许模型直接计算序列中任意两个词元之间的依赖关系,并行处理整个序列。
-
Token数范围:
-
BERT (Devlin et al., 2018): 通常为 512 词元。
-
GPT-1 (Radford et al., 2018): 512 词元。
-
GPT-2 (Radford et al., 2019): 1024 词元。
-
GPT-3 (Brown et al., 2020): 最初为 2048 词元,后续一些变体支持 4096 词元。
-
-
技术贡献: 极大地改善了长距离依赖的捕捉能力。
-
原始Attention的局限: 其 O(N2) 的计算和内存复杂度成为扩展上下文长度的主要障碍,使得上下文长度难以突破几千词元的规模。
-
3.3 Attention机制的改进
为了克服 O(N2) 的瓶颈,研究者们提出了多种高效的注意力机制变体:
-
稀疏注意力 (Sparse Attention):
-
核心思想: 并非所有词元都需要关注序列中的其他所有词元。
-
代表工作与Token数影响:
-
Longformer (Beltagy et al., 2020): 结合滑动窗口和全局注意力,将复杂度降低到 O(N⋅w)。在其论文中展示了处理高达 4096 词元序列的能力,并为更长序列(如16K甚至32K)提供了理论基础。
-
BigBird (Zaheer et al., 2020): 类似地,通过组合不同类型的稀疏注意力,支持了更长的上下文,例如在实验中达到 4096 词元,并有潜力扩展。
-
-
技术贡献: 这些技术使得模型在不进行近似的情况下,能够处理比标准Transformer更长的序列,通常能将上下文扩展到 4K - 16K 词元的范围。
-
-
线性化注意力 (Linearized Attention):
-
核心思想: 将复杂度降低到线性级别 O(N)。
-
代表工作: Linformer, Performer, Linear Transformer。
-
技术贡献: 理论上允许处理非常长的序列,但有时为了达到线性复杂度可能牺牲一些精度或表达能力。这些方法为探索数十万词元上下文提供了早期思路。
-
-
FlashAttention (Dao et al., 2022) & FlashAttention-2 (Dao, 2023):
-
核心思想: 精确实现标准注意力,但通过I/O感知算法优化内存读写。
-
技术贡献与Token数影响: 这是近年来扩展上下文长度最重要的突破之一。它不是近似注意力,而是通过优化计算过程(分块、重计算)大幅减少了GPU内存带宽瓶颈。
-
这直接推动了主流模型上下文长度的大幅提升:
-
GPT-4 (OpenAI, 2023): 发布时提供 8K 和 32K 词元版本。
-
Claude (Anthropic, 2023): 最初提供 9K,迅速扩展到 100K 词元。
-
Claude 2 & 2.1 (Anthropic, 2023): 上下文长度提升至 200K 词元。
-
GPT-4 Turbo (OpenAI, 2023): 支持高达 128K 词元的上下文。
-
-
FlashAttention使得这些数万到数十万词元级别的精确注意力计算在训练和推理时变得可行且高效。
-
-
3.4 位置编码的改进
-
旋转位置编码 (Rotary Positional Embedding - RoPE) (Su et al., 2021):
-
技术贡献与Token数影响: 具有良好的外推性。例如,LLaMA模型使用RoPE进行预训练,初始上下文长度为 2048 词元。后续通过RoPE的缩放技巧(如NTK-aware scaling, Dynamic NTK)或直接微调,可以将其有效上下文扩展到 4K、8K、16K甚至更长(如Code LLaMA支持高达 100K 词元,LLaMA 2 基础模型支持 4096 词元)。
-
-
ALiBi (Attention with Linear Biases) (Press et al., 2021):
-
技术贡献与Token数影响: 具有出色的外推能力,允许模型在比训练时(例如 2048 词元)更长的序列上(例如 8K 词元或更长)直接推理而无需微调,且性能下降较少。
-
3.5 架构创新
-
Transformer-XL (Dai et al., 2019):
-
Token数影响: 通过片段级循环,有效上下文长度可以远超单个片段的处理长度(例如,片段长度512,但有效上下文可以达到数千)。
-
-
RWKV (Peng et al., 2023):
-
Token数影响: 作为一种结合RNN和Transformer思想的架构,其线性复杂度和常数级推理内存增长,使其在理论上能够处理极长的上下文,已有开源模型支持 数万乃至数十万词元。
-
3.6 其他技术与当前前沿
-
更长的训练序列 (Training with longer sequences):
-
技术贡献与Token数影响: 随着上述高效技术(尤其是FlashAttention和改进的位置编码)的普及,直接使用更长的序列进行预训练和微调成为可能。
-
MPT (MosaicML): 一些MPT模型通过ALiBi等技术支持了 8K 到 65K 的上下文。
-
Gemini 1.5 Pro (Google, 2024): 实现了 100万词元 的标准上下文窗口,并在实验中展示了高达 1000万词元 的处理能力。这是目前公开报道中最长的上下文窗口之一,其背后依赖于注意力机制、架构和训练数据/策略的全面革新。
-
Claude 3 (Anthropic, 2024): 提供高达 200K 词元的上下文窗口,并在“大海捞针”测试中表现出色。
-
-
-
梯度检查点 (Gradient Checkpointing) 和 内存外计算 (Out-of-core computation) 等技术,虽然不直接增加理论上下文长度,但通过优化内存使用,使得在现有硬件上训练和运行具有更长上下文的模型成为现实。
4. 已解决的困难与持续的挑战
4.1 已解决的困难
-
二次方复杂度瓶颈的显著缓解: 通过FlashAttention等技术,精确注意力的实用上下文长度从几千词元(如GPT-3的2K/4K)提升到了数十万词元(如Claude的200K,GPT-4 Turbo的128K),甚至百万级(Gemini 1.5 Pro的1M)。稀疏注意力等方法也为特定场景提供了有效方案。
-
位置编码的外推性增强: RoPE、ALiBi等技术使得模型能够更好地处理超出其原始训练长度的序列。
-
内存管理优化: 使得在有限硬件资源下处理更长序列成为可能。
4.2 持续的挑战
-
计算效率与效果的权衡: 虽然FlashAttention是精确的,但对于百万级甚至更长的上下文,计算成本依然高昂。
-
“大海捞针”问题 (The "Needle in a Haystack" problem): 即使模型能“容纳”100万词元,它是否总能精确找到并利用其中的关键信息?这考验模型在极长上下文中的信息检索和推理能力。虽然像Claude 3和Gemini 1.5 Pro在这方面取得了显著进展,但挑战依然存在,尤其是在信息密度较低或干扰信息较多时。
-
长上下文的有效利用与避免性能退化: 如何确保模型在更长上下文中持续学习和利用信息,而不是仅仅“记住”开头或结尾,或者在中间部分性能下降。
-
评估方法的挑战: 现有的许多基准测试主要针对较短的上下文(几千词元)。如何设计有效的评估方法来衡量模型在数十万乃至百万级词元上下文环境下的真实能力。
-
训练成本和高质量长文本数据: 训练具有超长上下文能力的模型(如百万级)仍然非常昂贵,并且需要大量、多样化的高质量长文本数据。
5. 总结与展望
大语言模型上下文长度的扩展是过去几年中LLM领域最显著的进步之一。从早期RNN的几百词元,到Transformer初期的512-2048词元,再到通过稀疏注意力等技术探索的4K-16K词元,直至以FlashAttention为代表的I/O优化技术带来的32K、128K、200K词元的飞跃,以及当前最前沿的百万级词元上下文(如Gemini 1.5 Pro),我们见证了指数级的增长。
这些技术突破极大地拓展了LLM的应用场景。然而,挑战依然存在。未来,我们可以期待在更高效的注意力机制、更强的长程推理能力、多模态长上下文处理、以及专门优化的硬件等方面取得进一步突破,推动上下文长度的边界持续扩展,并更重要的是,提升模型对这些超长上下文的有效利用率。
相关文章:

大语言模型上下文长度:发展历程、局限与技术突破
1. 引言:什么是上下文长度及其重要性 上下文长度(Context Length),也称为上下文窗口(Context Window),指的是大语言模型(LLM)在处理和生成文本时能够有效记忆和利用的信…...

ControlNet简洁
ControlNet 什么是ControlNet ControlNet是一种用于控制扩散模型生成结果的网络结构。该结构可以将边缘图,结构图等信息注入扩散模型,从而能够对生成结果进行更为精细的控制。 ControlNet是怎么实现的 在模型结构方面,其大致结构如下图所…...

【C】C程序内存分配
文章目录 1. C程序内存布局 1. C程序内存布局 从低地址到高地址依次为: 代码段 存储内容:存放编译后的机器指令特点:代码段是只读的;可共享,多个进程可共享同一份代码 数据段 存储内容 已初始化的全局变量已初始化的静…...

论文学习:《引入TEC - LncMir,通过对RNA序列的深度学习来预测lncRNA - miRNA的相互作用》
长链非编码RNA ( long noncoding RNAs,lncRNAs )是一类长度通常大于200个核糖核苷酸的非编码RNA ,微小RNA ( microRNAs,miRNAs )是一类由22个核糖核苷酸组成的短链非编码RNA。近年来,越来越多的研究表明,lncRNA和miRNA…...

【每日一题丨2025年5.12~5.18】排序相关题
个人主页:Guiat 归属专栏:每日一题 文章目录 1. 【5.12】P1068 [NOIP 2009 普及组] 分数线划定2. 【5.13】P5143 攀爬者3. 【5.14】P12366 [蓝桥杯 2022 省 Python B] 数位排序4. 【5.15】P10901 [蓝桥杯 2024 省 C] 封闭图形个数5.【5.16】P12165 [蓝桥…...

AIDA64 extreme7.5 版本注册激活方法
一、AIDA 7.5 序列号 3BQN1-FUYD6-4GDT1-MDPUY-TLCT7 UVLNY-K3PDB-6IDJ6-CD8LY-NMVZM 4PIID-N3HDB-IWDJI-6DMWY-9EZVU 二、安装激活方法 激活步骤: 1、打开AIDA64软件,点击顶部菜单栏的“帮助”→“输入序列号” 2、将生成的序列号粘贴至输入框&a…...

Python 条件语句详解
条件语句是编程中用于控制程序流程的基本结构,Python 提供了几种条件语句来实现不同的逻辑判断。 1. if 语句 最基本的条件语句形式: if 条件:# 条件为真时执行的代码块示例: age 18 if age > 18:print("你已经成年了")2. …...
)
模型评估与调优(PyTorch)
文章目录 模型评估方法混淆矩阵混淆矩阵中的指标ROC曲线(受试者工作特征)AUCR平方残差均方误差(MSE)均方根误差(RMSE)平均绝对误差(MAE) 模型调优方法交叉验证(CV&#x…...

oppo手机安装APK失败报错:安装包异常
如果你的apk文件在oppo手机安装失败了,像这样: 先说我们当时解决方式: 如果还没上架应用市场的测试包,在上面图一中需要关闭“超级守护”,类似华为的纯净模式。如果开启了还还不行,安装页面的报错太笼统不…...

互联网大厂Java面试场景:从缓存到容器化的技术问答
场景:互联网大厂Java面试之旅 面试官:严肃的技术专家 应聘者:搞笑的水货程序员明哥 第一轮:缓存技术与数据库优化 面试官:明哥,你能谈谈Redis的常见使用场景和一些优化技巧吗? 明哥…...

【android bluetooth 协议分析 01】【HCI 层介绍 6】【WriteLeHostSupport命令介绍】
HCI 指令 HCI_Write_LE_Host_Support 是 Bluetooth Host 向 Controller 发送的一条指令,用于启用或禁用主机对 Bluetooth Low Energy(LE)的支持能力。该指令属于 HCI(Host Controller Interface)命令集合中,…...
)
Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)
文章目录 Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)需求方法1:使用Helm覆盖值方法2: 在Lens中临时修改Deployment配置步骤 1: 创建 Docker Registry Secret步骤 2: 在 Deployment 中引用 Secret参考资料Helm配置之为特定Deployment配置特定Docker仓库(覆…...

项目:在线音乐播放服务器——基于SSM框架和mybatis
介绍项目 项目主要是基于SSM框架和mybatis进行实现 主要的功能: 登陆界面,用户注册,音乐的播放列表,删除指定的歌曲,批量删除指定的歌曲,收藏歌曲,查询歌曲,从收藏列表中删除收藏…...

Linux配置vimplus
配置vimplus CentOS的配置方案很简单,但是Ubuntu的解决方案网上也很多但是有效的很少,尤其是22和24的解决方案,在此我整理了一下我遇到的问题解决方法 CentOS7 一键配置VimForCPP 基本上不会有什么特别难解决的报错 sudo yum install vims…...

Ubuntu22.04开机运行程序
新建启动文件 sudo vim /etc/systemd/system/trojan.service 2. 写入配置文件 [Unit] DescriptionTrojan Proxy Service Afternetwork.target[Service] Typesimple ExecStart/home/cui/Downloads/trojan/trojan -c /home/cui/Downloads/trojan/config.json Restarton-failur…...

高效查询:位图、B+树
1. 位图(BitMap)与布隆过滤器(Bloom Filter) 1.1. 问题背景与解决方案 问题背景 场景:网页爬虫判重 搜索引擎的爬虫会不断地解析网页中的链接并继续爬取。一个网页可能在多个页面中出现,容易重复爬取。…...

HashMap的扩容机制
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75) 每次扩容的时候,都是扩容之前容量的2倍; 扩容之后&#…...

从坏道扫描到错误修复:HD Tune实战指南
一、硬盘检测的必要性 随着计算机使用时间的增加,机械硬盘和固态硬盘都会出现不同程度的性能衰减。定期进行硬盘健康检查可以:及时发现潜在故障;预防数据丢失风险;掌握存储设备实际状态。 二、HD Tune功能解析 性能测试&#x…...

Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II
Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路2. 代码实现 题目链接:3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路 这一题很惭愧,并没有自力搞定,是看了大佬们的解答才有…...
)
算法加训之最短路 上(dijkstra算法)
目录 P4779 【模板】单源最短路径(标准版)(洛谷) 思路 743. 网络延迟时间(力扣) 思路 1514.概率最大路径(力扣) 思路 1631.最小体力消耗路径 思路 1976. 到达目的地的方案数 …...

01 Nginx安装及基本配置
01 Nginx安装 # 官网:https://nginx.org/en/ # 点击下载图1 Nginx下载官网 # https://nginx.org/en/download.html # 全是各个平台的源码包图2 Nginx下载版本 # 找到最下面的stable and mainline(稳定版和主线版)图3 找到最下面的稳定版 # https://nginx.org/en/li…...

ABP vNext 多租户系统实现登录页自定义 Logo 的最佳实践
🚀 ABP vNext 多租户系统实现登录页自定义 Logo 的最佳实践 🧭 版本信息与运行环境 ABP Framework:v8.1.5.NET SDK:8.0数据库:PostgreSQL(支持 SQLServer、MySQL 等)BLOB 存储:本地…...

Docker 网络
目录 前言 1. Docker 网络模式 2. 默认 bridge 网络详解 (1)特点 (2)操作示例 3. host 网络模式 (1)特点 (2)操作示例 4. overlay…...

btc交易所关键需求区 XBIT反弹与上涨潜力分析
在加密货币市场的浪潮中,狗狗币(DOGE)近期的走势吸引了众多投资者的目光。根据XBIT分析,狗狗币刚刚踏入关键需求区,此前虽从高点大幅下跌了10%,但XBIT去中心化交易所平台分析师认为,短期内它有望…...

深度剖析:YOLOv8融入UNetv2 SDI模块的性能提升之旅
文章目录 一、引言二、SDI多层次特征融合模块概述(一)背景和动机(二)模块设计原理 三、SDI模块实现(一)关键代码结构(二)代码解析 四、将SDI模块融入YOLOv8(一࿰…...

图像定制大一统?字节提出DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,有效解决多泛化性冲突。
字节提出了一个统一的图像定制框架DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,不仅在广泛的图像定制场景中取得了高质量的结果,而且在适应多条件场景方面也表现出很强的灵活性。现在已经可以支持消费级 GPU(16G…...

spark数据处理练习题详解【下】
12. (单选题) def main(args: Array[String]): Unit { println(func1("张三",f1)) } def func1(name:String,fp:(________________)): String { fp(name) } def f1(s:String): String { "welcome "s } 选择填空() A.String>S…...
_条件渲染)
Vue基础(11)_条件渲染
原生css想让显示的元素隐藏,方式有以下几点: display: none; opacity: 0; visibility: hidden; 那么vue中是怎样实现元素显示/隐藏的呢? 条件渲染 v-show 写法:v-show"表达式" 判断:表达式转换为布尔值(tr…...

湖北理元理律师事务所:债务优化服务的四维创新实践
在债务问题普遍影响家庭经济稳定的当下,专业法律服务机构的价值不仅在于提供解决方案,更需构建可持续的服务生态。湖北理元理律师事务所通过“法律心理技术教育”四维服务体系,探索出一条兼顾债务化解与生活质量保障的创新路径。 服务模式创…...

ubuntu工控机固定设备usb串口号
ubuntu工控机固定设备usb串口号 1、多个USB设备的ID相同 ubuntu系统中的串口使用权限并没有对所有的用户进行开放,所以在使用代码对串口进行操作时,需要打开用户对串口的使用权限,否则在代码中会出现“串口无法打开的报错”,只有…...

MongoDB的安装及简单使用
MongoDB 是一个开源的文档型 NoSQL 数据库,由 MongoDB Inc. 开发,专为灵活性和可扩展性设计。 特点: 1.文档模型:数据以 BSON(二进制 JSON)格式存储,支持嵌套结构。 2.动态 S…...

卷积神经网络进阶:转置卷积与棋盘效应详解
【内容摘要】 本文深入解析卷积神经网络中的转置卷积(反卷积)技术,重点阐述标准卷积与转置卷积的计算过程、转置卷积的上采样作用,以及其常见问题——棋盘效应的产生原因与解决方法,为图像分割、超分辨率等任务提供理论…...
之信号产生2)
Linux进程信号(三)之信号产生2
文章目录 4. 由软件条件产生信号5. 硬件异常产生信号模拟一下除0错误和野指针异常除0错误野指针错误 总结思考一下 4. 由软件条件产生信号 SIGPIPE是一种由软件条件产生的信号,在“管道”中已经介绍过了。 软件条件不就绪,很明显这个软件条件没有直接报错ÿ…...

【AWS入门】Amazon SageMaker简介
【AWS入门】Amazon SageMaker简介 [AWS Essentials] Brief Introduction to Amazon SageMaker By JacksonML 机器学习(Machine Learning,简称ML) 是当代流行的计算机科学分支技术。通常,人们在本地部署搭建环境,以满足机器学习的要求。 AWS…...

MySQL--day2--基本的select语句
(以下内容全部来自上述课程) SQL概述 结构化查询语句 1. SQL分类 DDL:数据定义(definition)语言:create、drop、alter… DML:数据操作(manipulation)语言ÿ…...

程序代码篇---python获取http界面上按钮或者数据输入
文章目录 前言 前言 本文简单接受了python获取http界面上按钮或者数据输入...

网络安全利器:蜜罐技术详解
蜜罐是网络安全领域中一种主动防御和情报收集的重要工具。本文将深入探讨蜜罐技术的原理、类型、应用场景以及部署注意事项。 1. 什么是蜜罐? 蜜罐(Honeypot)是一种安全资源,其价值在于被探测、攻击或未经授权使用。简单来说,蜜罐就是一个诱饵系统,用来吸引黑客的注意力…...

回溯实战篇3
文章目录 前言排列全排列全排列II 棋盘问题N皇后解数独 其他递增子序列重新安排行程 前言 今天继续带大家进行回溯的实战篇3,去学习如何用回溯的方法去解决排列和棋盘以及其他用回溯方法解决的问题,最重要的就是学会回溯三部曲的构建,一文带…...

Spark 基础自定义分区器
(一)什么是分区 【复习提问:RDD的定义是什么?】 在 Spark 里,弹性分布式数据集(RDD)是核心的数据抽象,它是不可变的、可分区的、里面的元素并行计算的集合。 在 Spark 中…...
/ 曹冲养猪)
【提高+/省选−】洛谷P1495 —— 【模板】中国剩余定理(CRT)/ 曹冲养猪
见:P1495 【模板】中国剩余定理(CRT)/ 曹冲养猪 - 洛谷 题目描述 自从曹冲搞定了大象以后,曹操就开始捉摸让儿子干些事业,于是派他到中原养猪场养猪,可是曹冲满不高兴,于是在工作中马马虎虎&a…...

系统架构设计师考前冲刺笔记-第1章-系统工程与信息系统基础
文章目录 第1章 系统工程与信息系统基础大纲13 DSS5678 BSP910 SCM11 OLAP12 OLAP14 BRP15 集成16 企业门户19 边缘计算 第1章 系统工程与信息系统基础 大纲 1 3 DSS DSS 决策支持系统 Decision Support System 5 6 7 8 BSP 9 10 SCM 注意:生产计划 11 OLAP O…...

Vue环境下数据导出Excel的全面指南
文章目录 1. 前言2. 原生JavaScript实现方案2.1 使用Blob对象和URL.createObjectURL2.2 使用Base64编码实现 3. 常用第三方库方案3.1 使用SheetJS (xlsx)3.2 使用ExcelJS3.3 使用vue-json-excel 4. 服务器端导出方案4.1 前端请求服务器生成Excel4.2 使用Web Worker处理大数据导…...

Linux下 使用 SSH 完成 Git 绑定 GitHub
文章目录 1、检查 SSH2、生成 SSH key3、添加 SSH key4、验证绑定是否成功 1、检查 SSH Git Bash 中输入ssh命令,查看本机是否安装 SSH: 2、生成 SSH key (1)输入 ssh-keygen -t rsa 命令,表示我们指定 RSA 算法生…...

Jsoup库和Apache HttpClient库有什么区别?
Jsoup 和 Apache HttpClient 是两个功能不同的库,它们在 Java 开发中被广泛使用,但用途和功能有明显的区别: Jsoup 用途:Jsoup 是一个用于解析 HTML 文档的库。它提供了非常方便的方法来抓取和解析网页内容,提取和操作…...

安全漏洞频发,如何加强防护措施?
当系统安全漏洞频发时,应从代码安全审查、自动化漏洞扫描、权限控制与访问管理、员工安全意识培训等四个关键维度加强防护。其中,代码安全审查是防止漏洞渗透的第一道防线。企业应将代码安全审查纳入CI/CD流程,实施静态代码分析和依赖包检查机…...

Text models —— BERT,RoBERTa, BERTweet,LLama
BERT 什么是BERT? BERT,全称Bidirectional Encoder Representations from Transformers,BERT是基于Transformer的Encoder(编码器)结构得来的,因此核心与Transformer一致,都是注意力机制。这种…...

CodeBuddy初探
回顾Trae 上一篇博客Trae IDE和VSCode Trae插件初探-CSDN博客,我们进行了TraeIDE和Trae插件初探,给了Trae这样一个任务: 生成一个to do list清单web页面,采用vue实现,可以在页面上进行todolist进行增删改查。 Trae的…...

spark数据处理练习题详解【上】
1. (单选题) scala中属于序列的可变的集合,可以添加,删除元素的是() A.Array B.List C.Tuple D.ListBuffer 答案及解析:D 在Scala中,属于序列的可变集合,可以添加和删除元素的是ÿ…...
)
sparkSQL读入csv文件写入mysql(2)
(二)创建数据库和表 接下来,我们去创建一个新的数据库,数据表,并插入一条数据。 -- 创建数据库 CREATE DATABASE spark; -- 使用数据库 USE spark;-- 创建表 create table person(id int, name char(20), age int);-- …...

产品周围的几面墙
不能把排序,当单选题做。 2025年的杭州咖啡馆,味道最浓的不是咖啡,是聊各种项目和创业的卷味。 在过去几年,聊项目的也不少,那时候带着更加浓烈的自信和松弛感,不过今年略带几分忐忑和试探的口吻。 看到网…...