spark数据处理练习题详解【下】
12. (单选题)
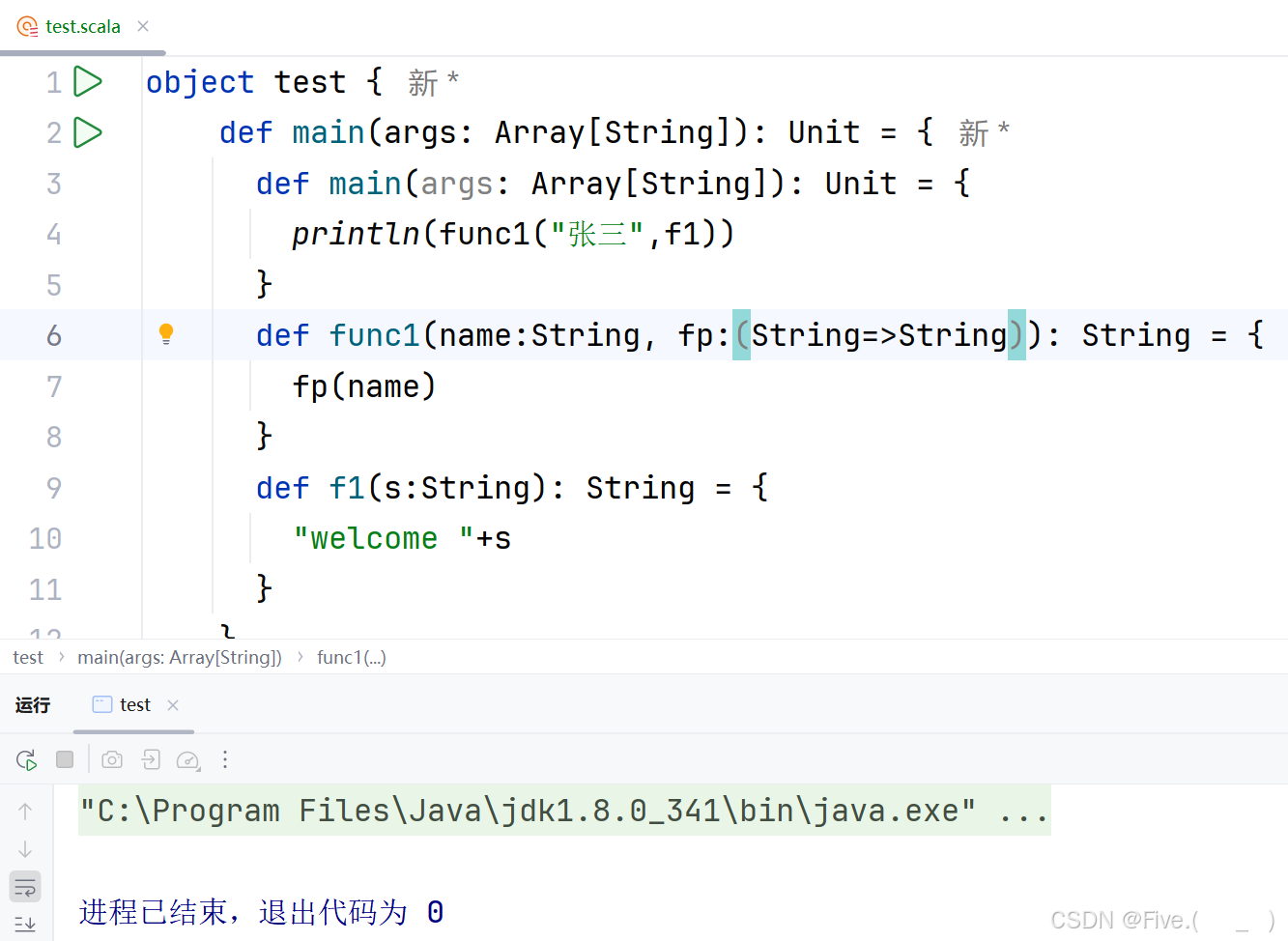
def main(args: Array[String]): Unit = {
println(func1("张三",f1))
}
def func1(name:String,fp:(________________)): String ={
fp(name)
}
def f1(s:String): String ={
"welcome "+s
}
选择填空()
A.String=>String
B.String=>Unit
C.String=>Int
D.Unit=>String
答案及解析:A
解释:
要确定fp参数的类型,需要分析几个关键点:
-
函数签名:
func1接受两个参数:一个字符串name和一个需要确定类型的函数fpfunc1返回类型为String
-
函数使用:
func1内部调用了fp(name)并返回其结果- 这意味着
fp接受一个String类型参数(即name) fp的返回值必须是String类型(因为func1返回String)
-
传入参数分析:
- 在
main函数中,传入的是f1函数 f1的定义为def f1(s:String): String,它接受一个String参数并返回String
- 在
由此可见,fp的类型应该是一个接受String参数并返回String的函数,即String=>String。
13. (单选题)
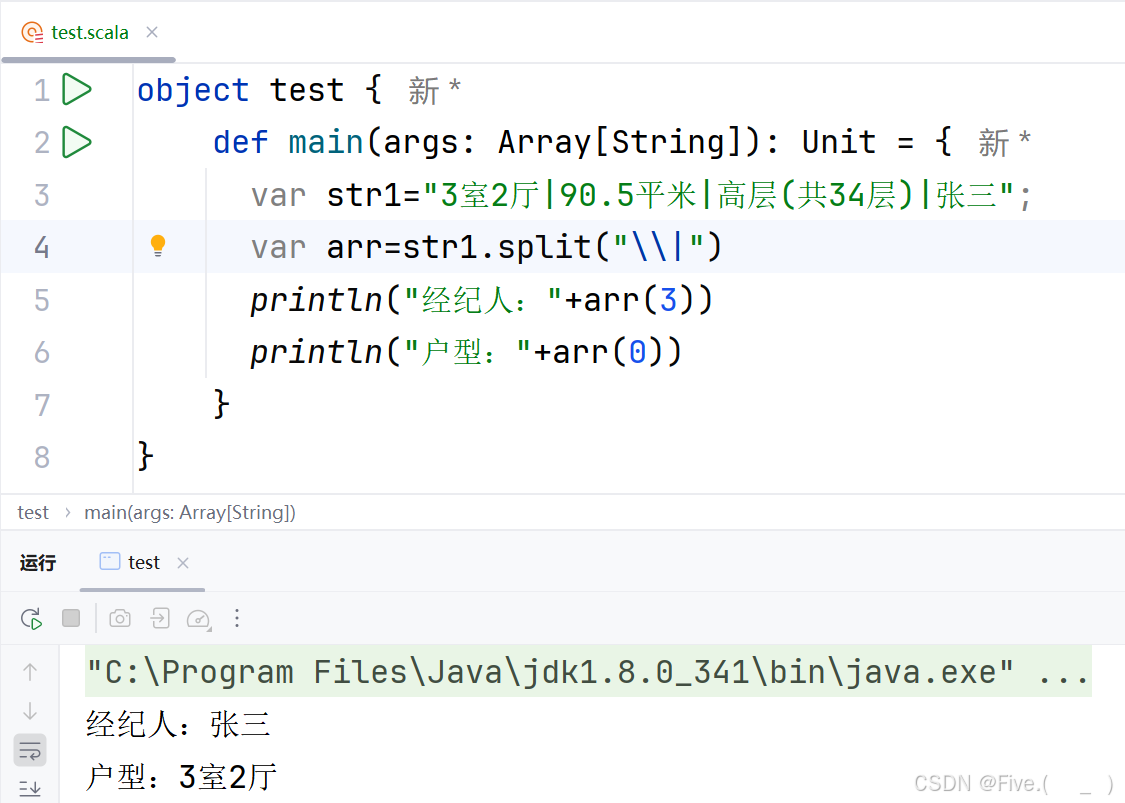
var str1="3室2厅|90.5平米|高层(共34层)|张三";
var arr=str1.split("_________")
println("经纪人:"+arr(______))
println("户型:"+arr(______))
A.,
B.|
C.\|
D.\\|
答案及解析:D
解释:
-
为什么需要双反斜线转义:
- 在Scala中,
split方法接受一个正则表达式作为参数 - 在正则表达式中,
|是一个特殊字符,表示"或"操作符 - 要将其视为普通字符,需要转义,在正则表达式中使用
\| - 但在Scala字符串中,
\本身也是转义字符,所以需要再次转义,变成\\|
- 在Scala中,
-
分割后的数组:
- 使用
\\|作为分隔符分割字符串后,得到的数组包含:- arr(0) = "3室2厅"
- arr(1) = "90.5平米"
- arr(2) = "高层(共34层)"
- arr(3) = "张三"
- 使用
-
索引填空:
- "经纪人"对应的是"张三",位于索引
3 - "户型"对应的是"3室2厅",位于索引
0
- "经纪人"对应的是"张三",位于索引
var str1="3室2厅|90.5平米|高层(共34层)|张三"; var arr=str1.split("\\|") println("经纪人:"+arr(3)) println("户型:"+arr(0))其他选项不正确:
- A:逗号不是原字符串中使用的分隔符
- B:直接使用
|会被解释为正则表达式的OR操作符 - C:
\|在Scala字符串中实际会变成|(错误的转义)
14. (单选题)
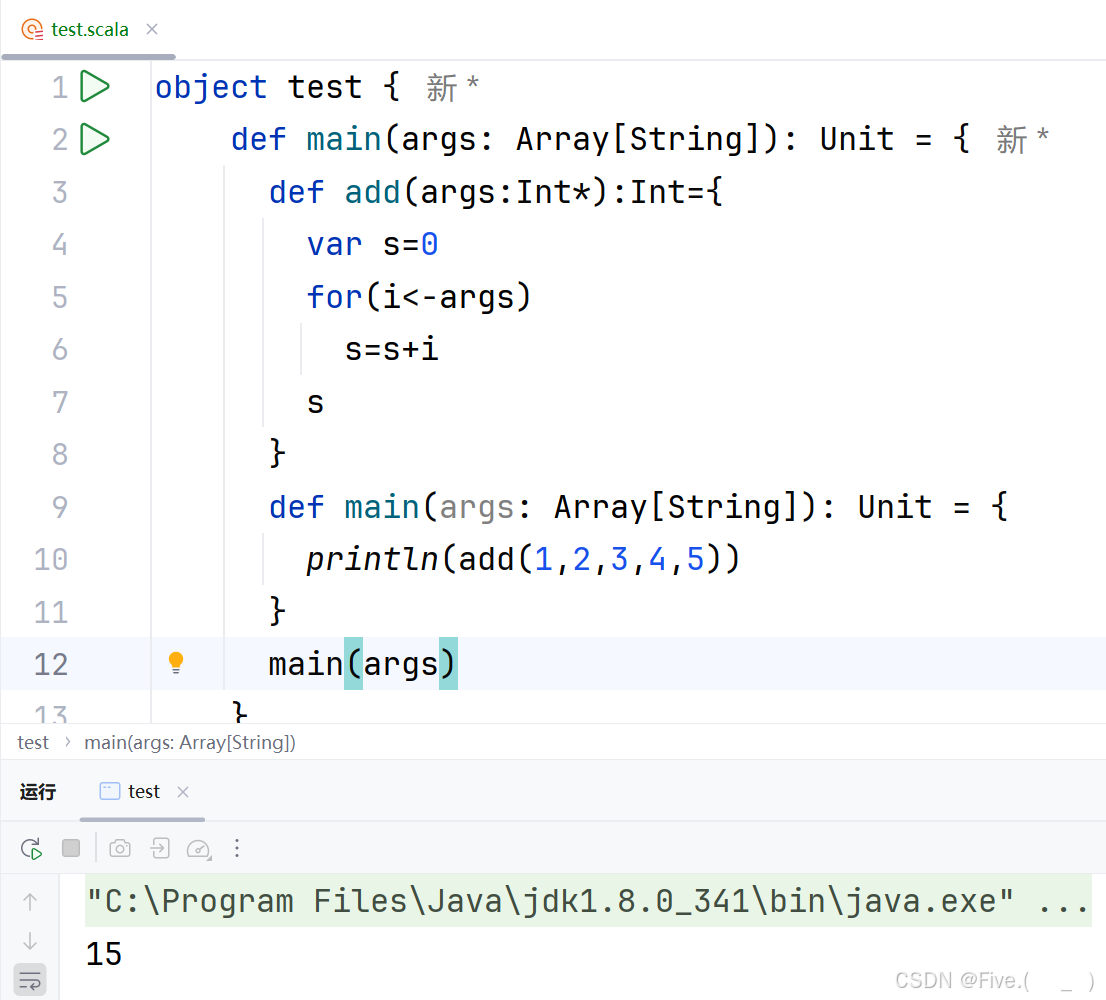
def add(args:_________):Int={
var s=0
for(i<-args)
s=s+i
s
}
def main(args: Array[String]): Unit = {
println(add(1,2,3,4,5))
}
A.List[Int]
B.Array[Int]
C.Int*
D.Array[Int*]
答案及解析:C
解释:
-
函数调用分析:
- 在
main函数中,add函数被调用时传入了多个单独的整数参数:add(1,2,3,4,5) - 这表明
add函数应该接受可变数量的参数(varargs)
- 在
-
函数内部实现:
add函数内部使用for(i<-args)来遍历所有参数- 将每个参数累加到变量
s中 - 这表明参数应该是整数类型(Int)
-
Scala可变参数语法:
- 在Scala中,接受可变数量参数的语法是:
参数类型* - 对于整数类型的可变参数,正确的声明是
Int*
- 在Scala中,接受可变数量参数的语法是:
-
选项分析:
- A.
List[Int]- 这要求以List对象形式传参,不是多个独立参数 - B.
Array[Int]- 这要求以Array对象形式传参,不是多个独立参数 - C.
Int*- 这是Scala中声明可变数量整数参数的正确语法 - D.
Array[Int*]- 这不是有效的Scala语法
- A.
15. (单选题)
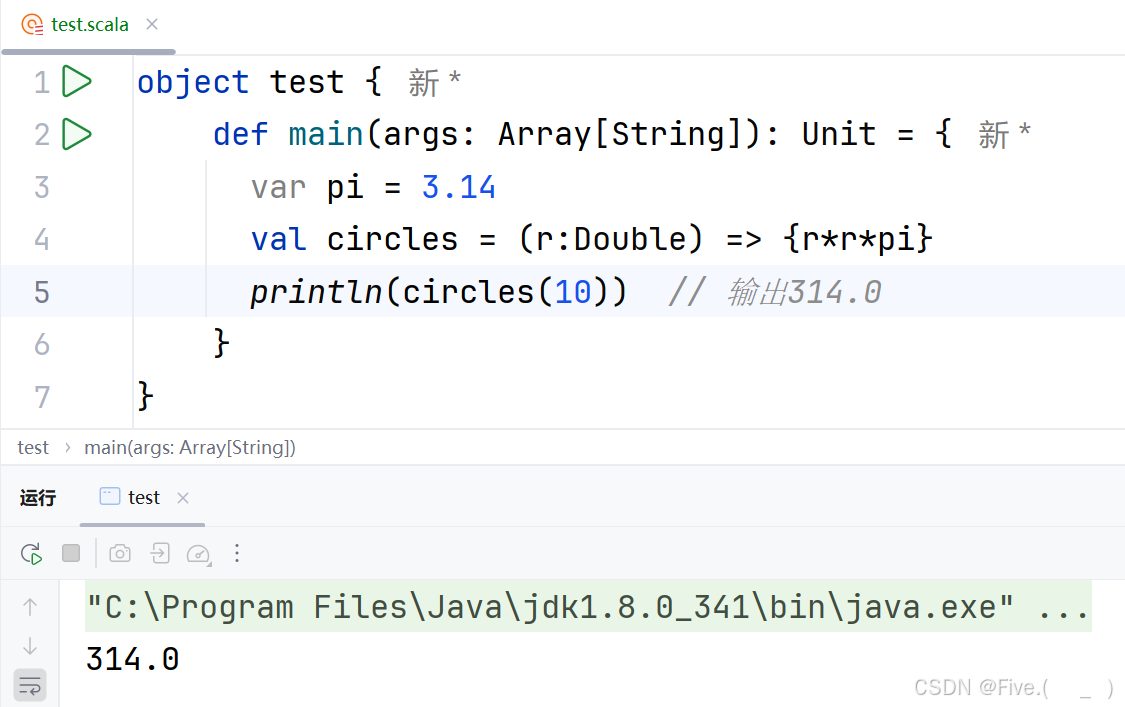
var pi=3.14
val circles=__________{r*r*pi}
println(circles(10))
//实现求圆面积的闭包
A.(r:Double)=>
B.(r:Double)->
C.(r:Double)<-
D.(r:Double)=
答案及解析:A
解释:
-
问题要求:
- 实现一个求圆面积的闭包
- 闭包需要捕获外部变量
pi - 通过
circles(10)调用计算半径为10的圆的面积
-
Scala闭包语法:
- 在Scala中,闭包(匿名函数)使用
参数列表 => 函数体的语法 - 参数类型需要明确声明,这里参数
r应该是Double类型 - 闭包可以访问其外部作用域中定义的变量(如这里的
pi)
- 在Scala中,闭包(匿名函数)使用
-
选项分析:
- A.
(r:Double)=>- Scala中定义匿名函数的正确语法 - B.
(r:Double)->- 这不是Scala的语法(在某些其他语言如Kotlin中使用) - C.
(r:Double)<-- 这不是定义函数的语法(<-在Scala中用于for循环和模式匹配) - D.
(r:Double)=- 这是命名函数定义的一部分语法,不是匿名函数语法
- A.
16. (单选题)
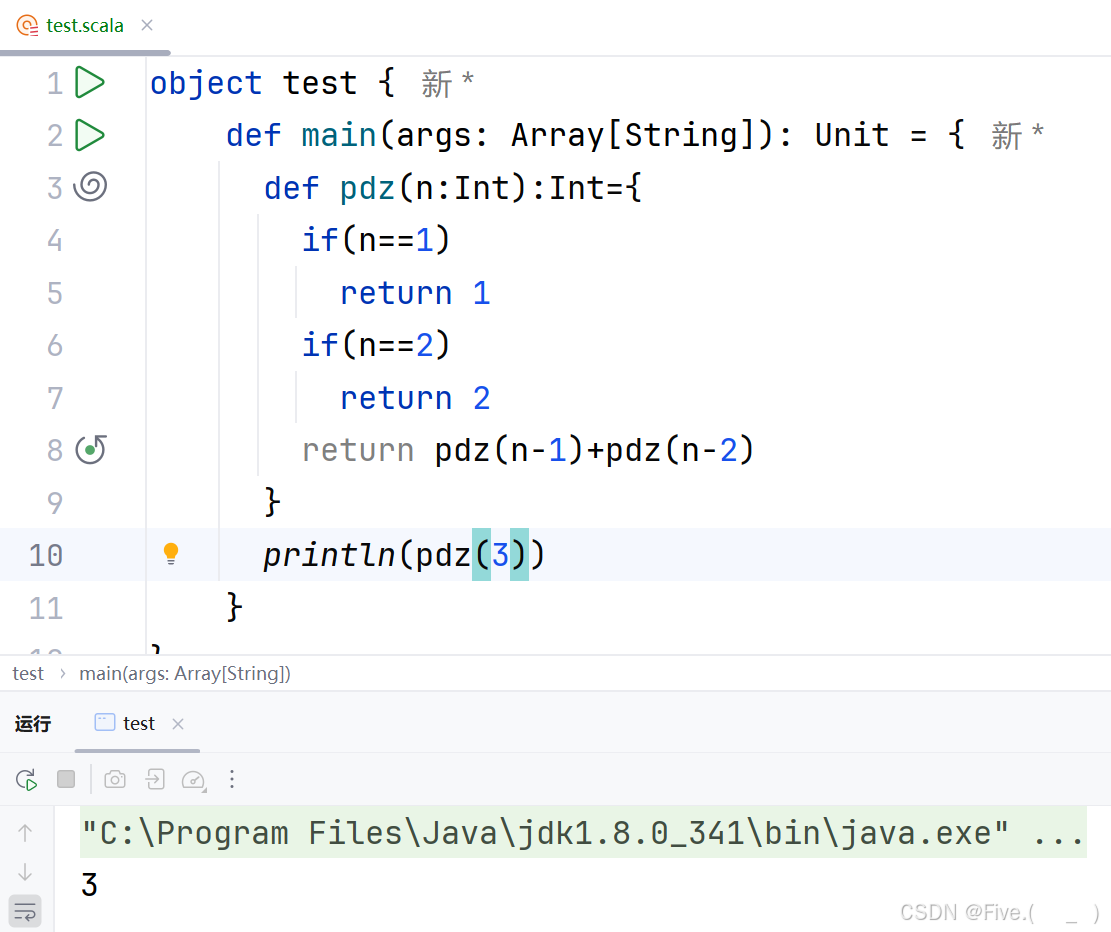
//有长为N,宽为2的小路,需要铺上地砖,地砖长为2,宽为1,那么有多少种铺法,补充完整代码
def pdz(n:Int):Int={
if(n==1)
return 1
if(n==2)
return 2
return ______________
}
A.2n-1
B.n
C.pdz(n-1)+pdz(n-2)
D.pdz(n-1)+n
答案及解析:C
解释:
-
问题分析:
- 我们有一条长为N、宽为2的小路
- 地砖尺寸为2×1(长为2,宽为1)
- 需要计算总共有多少种不同的铺设方法
-
基本情况:
- 当n=1时(小路长1宽2),只能竖着放一块地砖,只有1种铺法
- 当n=2时(小路长2宽2),有2种铺法:
- 两块地砖竖着放
- 两块地砖横着放(一上一下)
-
递推关系:
- 考虑铺设n长度小路时的最后一步可能情况:
- 在已铺好n-1长度的基础上,最后放一块竖着的地砖 → pdz(n-1)种方式
- 在已铺好n-2长度的基础上,最后放两块横着的地砖 → pdz(n-2)种方式
- 这两种情况互斥且覆盖所有可能性,所以总铺法为两者之和
- 考虑铺设n长度小路时的最后一步可能情况:
-
递推公式:
- pdz(n) = pdz(n-1) + pdz(n-2)
- 这是一个斐波那契数列变种,初始值为pdz(1)=1, pdz(2)=2
17. (单选题)
Hadoop框架的缺陷有()
1.表达能力有限,MR编程框架的限制
2.过多的磁盘操作,缺乏对分布式内存的支持
3.无法高效低支持迭代式计算
4.海量的数据存储
A.1,2
B.1,2,3
C.2,3
D.1,2,3,4
答案及解析:B
Hadoop框架的缺陷主要包括以下几点:
-
表达能力有限,MR编程框架的限制:MapReduce编程模型较为底层,复杂逻辑需拆分为多个作业,灵活性不足。
-
过多的磁盘操作,缺乏对分布式内存的支持:MapReduce的中间结果频繁读写磁盘,导致性能瓶颈,而内存计算能力不足。
-
无法高效支持迭代式计算:迭代计算(如机器学习)需多次读写数据,MapReduce的磁盘依赖导致效率低下。
选项4(海量的数据存储)是Hadoop的优势而非缺陷,HDFS专为大规模数据存储设计。
18. (单选题)
与hadoop相比,Spark主要有以下哪些优点()
1. 提供多种数据集操作类型而不仅限于MapReduce
2. 数据集中式计算而更加高效
3. 提供了内存计算,带来了更高的迭代运算效率
4. 基于DAG的任务调度执行机制
A.1,2,3,4
B.1,2
C.3,4
D.1,3,4
答案及解析:D
选项分析:
1. 提供多种数据集操作类型而不仅限于MapReduce ✓
- Spark提供了丰富的高级API操作,包括map、filter、reduce、join、groupBy等
- Hadoop主要基于MapReduce编程模型,操作类型较为有限
- Spark的RDD、DataFrame和Dataset API提供了更灵活的数据操作方式
2. 数据集中式计算而更加高效 ✗
- 这一说法不正确
- Spark和Hadoop都是分布式计算框架,而非集中式
- 两者都在集群上分布式处理数据,Spark的效率优势来自其处理模型和内存利用
3. 提供了内存计算,带来了更高的迭代运算效率 ✓
- 这是Spark最显著的优势之一
- Spark可以将中间数据存储在内存中,避免了Hadoop频繁的磁盘I/O操作
- 对于机器学习等需要多次迭代的算法,Spark性能提升显著
- 内存计算使Spark在某些场景下比Hadoop快10-100倍
4. 基于DAG的任务调度执行机制 ✓
- Spark使用有向无环图(DAG)进行任务调度和执行
- DAG引擎可以优化整个工作流程,减少中间结果的物化
- 相比Hadoop的MapReduce模型更加灵活和高效
- 支持更复杂的数据处理流程和任务依赖关系
19. (单选题)
//1~100中有多少个2
var count:Int=0
for(n<-1 to 100){
__________
}
println(count)
A. if(n%10==2)
count++
if(n/10==2)
count=++
B. if(n%10==2 || n/10==2)
count=count+1
C. if(n%10==2 && n/10==2)
count=count+1
D. if(n%10==2)
count=count+1
if(n/10==2)
count=count+1
答案及解析:D
解释:
-
问题理解:
- 需要计算1~100中数字2出现的总次数
- 数字2可能出现在个位或十位
-
选项分析:
A.
if(n%10==2) count++ if(n/10==2) count=++- 语法错误:Scala中没有
++运算符 count=++是错误语法
B.
if(n%10==2 || n/10==2) count=count+1- 逻辑错误:只检查数字中是否存在2,而不是计算2的个数
- 对于22这样的数字,只会计数一次,但实际有两个2
C.
if(n%10==2 && n/10==2) count=count+1- 逻辑错误:只有当个位和十位都是2时才计数
- 只会对22一个数字计数,忽略了12, 20, 21等数字中的2
D.
if(n%10==2) count=count+1 if(n/10==2) count=count+1- 正确:分别检查个位和十位
- 对于22,会计数两次(个位一次,十位一次)
- 可以正确统计所有出现的数字2
- 语法错误:Scala中没有
-
验证:
- 1~100中,个位是2的数有:2, 12, 22, 32, ..., 92 (共10个)
- 1~100中,十位是2的数有:20, 21, 22, ..., 29 (共10个)
- 因此总共有20个2

20. (单选题)
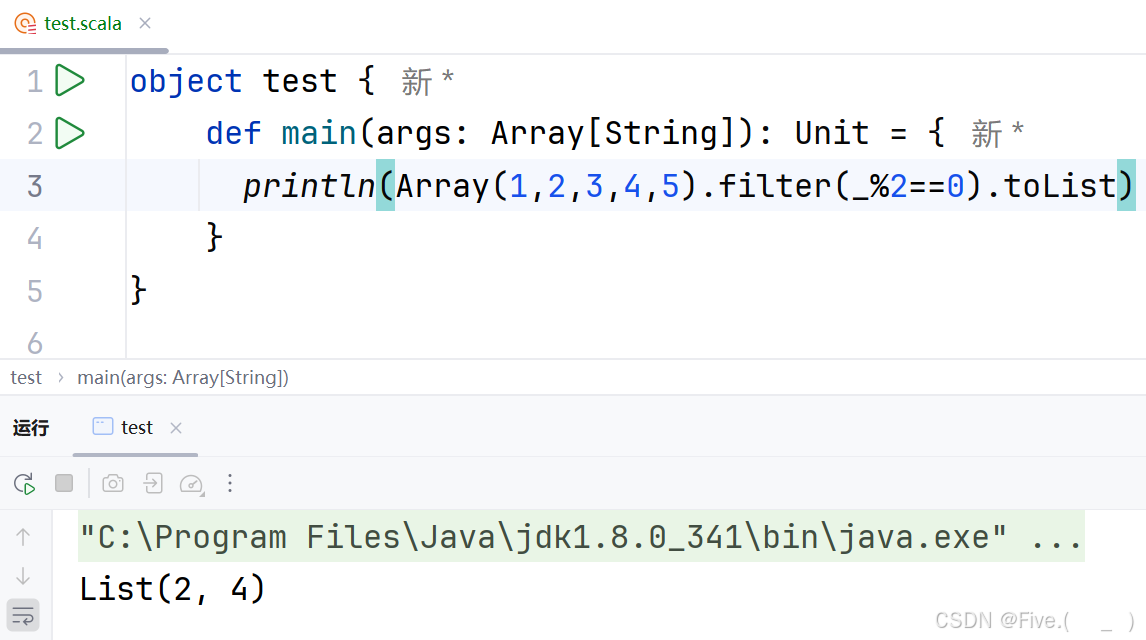
println(Array(1,2,3,4,5).filter(_%2==0).toList)
输出结果是()
A.2
4
B.List(2, 4)
C.List(1, 3,5)
D.1
3
5
答案及解析:B
解释:
-
代码执行步骤:
- 首先创建了一个包含元素1,2,3,4,5的数组:
Array(1,2,3,4,5) - 然后使用
filter(_%2==0)方法过滤出数组中所有偶数元素_%2==0是匿名函数简写,等同于x => x%2==0,表示取模2等于0的元素- 这个条件只有2和4满足
- 最后调用
toList将过滤后的数组转换为List类型 - 最终结果为
List(2, 4)被打印出来
- 首先创建了一个包含元素1,2,3,4,5的数组:
-
选项分析:
- A选项错误:显示的是独立的数字而不是List
- B选项正确:完整输出为
List(2, 4) - C选项错误:这是过滤出奇数的结果,而题目是过滤偶数
- D选项错误:不仅内容错误,格式也不是Scala输出List的格式
21. (单选题)
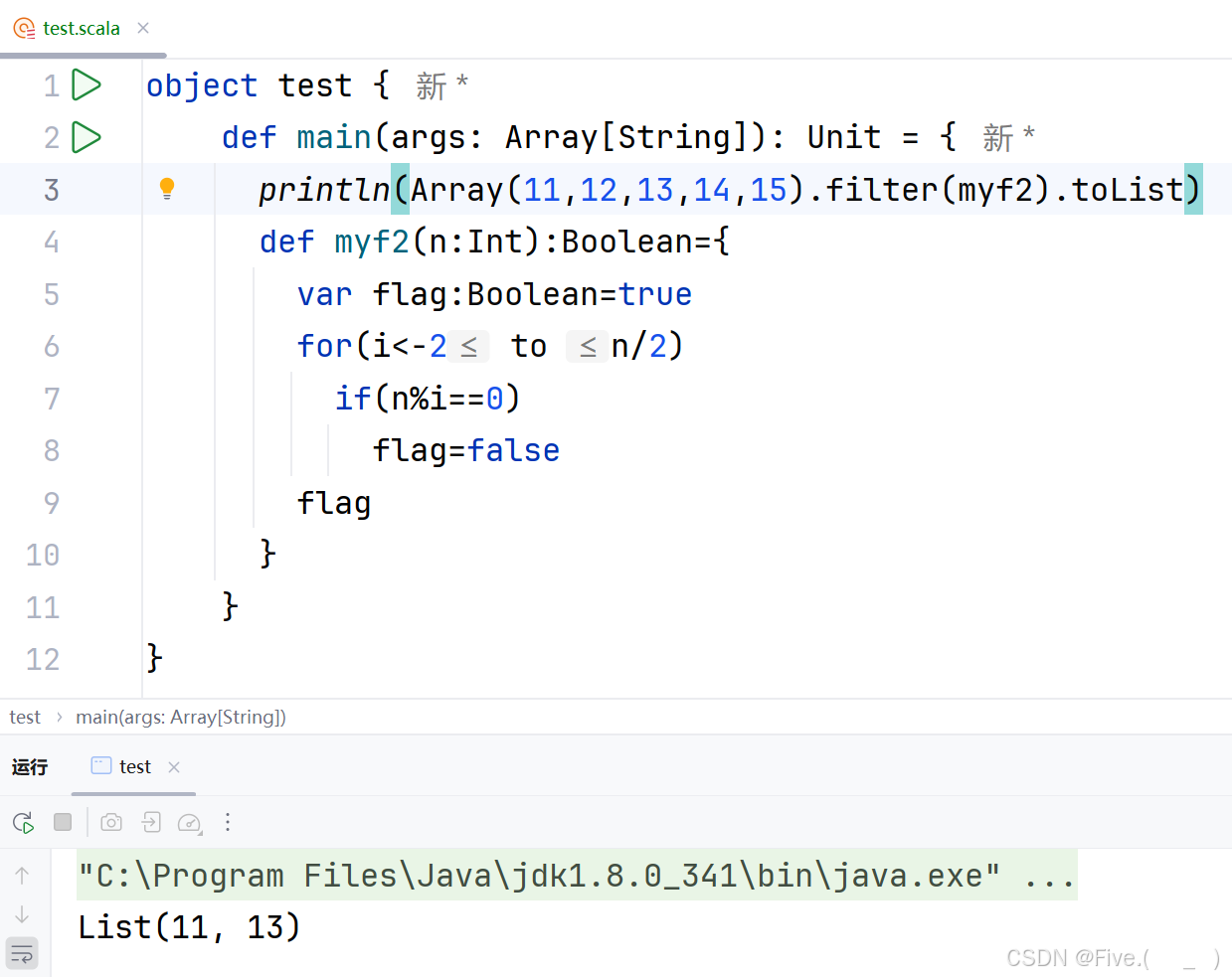
println(Array(11,12,13,14,15).filter(myf2).toList)
def myf2(n:Int):Boolean={
var flag:Boolean=true
for(i<-2 to n/2)
if(n%i==0)
flag=false
flag
}
输出结果是()
A.List(11, 13)
B.List(11, 13,15)
C.11
13
D.11
13
15
答案及解析:A
解释:
-
myf2函数分析:
- 这是一个判断素数(质数)的函数
- 初始化flag为true
- 遍历从2到n/2的所有整数
- 如果n能被任何一个i整除,将flag设为false
- 最终返回flag值
- 如果n是质数,函数返回true;如果n不是质数,返回false
-
数组元素分析:
- 11:从2到5没有能整除它的数,是质数,myf2(11)返回true
- 12:能被2、3、4、6整除,不是质数,myf2(12)返回false
- 13:从2到6没有能整除它的数,是质数,myf2(13)返回true
- 14:能被2、7整除,不是质数,myf2(14)返回false
- 15:能被3、5整除,不是质数,myf2(15)返回false
-
过滤结果:
- filter方法保留所有myf2函数返回true的元素
- 只有11和13会被保留
- 转换为List后,结果为List(11, 13)
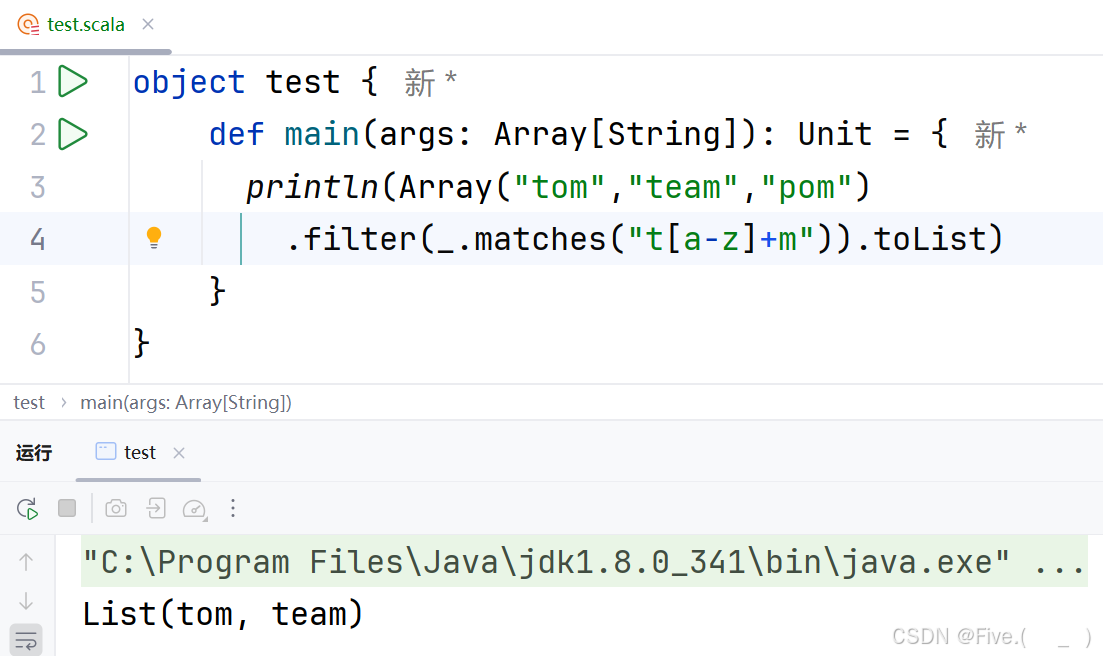
22. (单选题)
println(Array("tom","team","pom")
.filter(_.matches("____________")).toList)
输出结果为(List(tom,team))请填空
A.t[a-z]+m
B.t[a-z]m
C.[a-z]+
D.t[a-z]{2}
答案及解析:A
解释:
-
问题分析:
- 需要找到一个正则表达式,能匹配"tom"和"team",但不匹配"pom"
- 观察发现,"tom"和"team"都以't'开头,以'm'结尾,中间有若干小写字母
- "pom"与其他两个字符串的区别在于它不是以't'开头
-
选项分析:
A.
t[a-z]+m- 含义:以't'开头,然后是一个或多个小写字母,以'm'结尾
- 匹配"tom":✓ (t+o+m)
- 匹配"team":✓ (t+ea+m)
- 匹配"pom":✗ (不以't'开头)
B.
t[a-z]m- 含义:以't'开头,然后是一个小写字母,以'm'结尾
- 匹配"tom":✓ (t+o+m)
- 匹配"team":✗ (中间有两个字母"ea",而正则只允许一个)
- 匹配"pom":✗ (不以't'开头)
C.
[a-z]+- 含义:一个或多个小写字母
- 匹配"tom":✓
- 匹配"team":✓
- 匹配"pom":✓ (会匹配所有三个字符串)
D.
t[a-z]{2}- 含义:以't'开头,后跟两个小写字母
- 匹配"tom":✗ (应为t+om,但正则只匹配t+o)
- 匹配"team":✗ (应为t+eam,但正则只匹配t+ea)
- 匹配"pom":✗ (不以't'开头)
23. (单选题)
println(List("c","java","c","python").map((_,1)))
输出结果为()
A.List((c,1), (java,1), (c,1), (python,1))
B.(c,1), (java,1), (c,1), (python,1)
C.Map((c->1), (java->1), (c->1), (python->1))
D.List((c,2), (java,1), (c,1))
答案及解析:A
解释:
-
代码执行步骤:
- 首先创建了一个字符串列表:
List("c","java","c","python") - 然后使用
map函数对列表中的每个元素进行转换 (_,1)是一个匿名函数简写,等同于x => (x,1)- 这个函数将每个元素转换为一个二元组(元素本身,1)
- 对列表中的每个元素应用这个转换,得到一个新的元组列表
- 首先创建了一个字符串列表:
-
选项分析:
- A选项正确:完整输出为
List((c,1), (java,1), (c,1), (python,1)),每个元素都变成了一个二元组 - B选项错误:没有包含List外层容器
- C选项错误:结果不是Map类型,且箭头表示法不对
- D选项错误:这个结果像是进行了元素计数和合并,但代码只是简单映射,并没有聚合操作
- A选项正确:完整输出为
在函数式编程中,map操作是一个常用的高阶函数,它会对集合中的每个元素应用给定函数,并返回一个包含结果的新集合。在这个例子中,转换后的结果保持了原始列表的结构和元素顺序,只是每个元素变成了一个二元组。
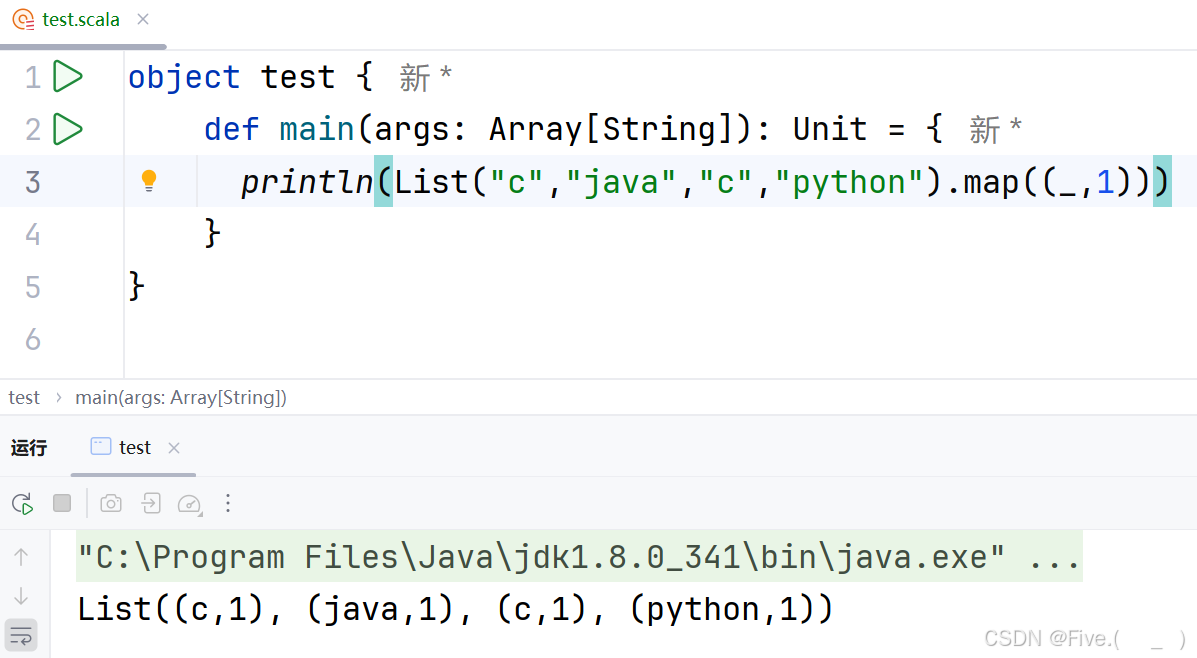
24. (单选题)
println(List("c","java","c","python").map(myf))
def myf(s:String):Map[String,Int]={
Map(s->s.length)
}
输出结果是( )
A.Map(c -> 1), Map(java -> 4), Map(c -> 1), Map(python -> 6)
B.List(Map(c -> 1), Map(java -> 1), Map(c -> 1), Map(python -> 1))
C.List(Map(c -> 1), Map(java -> 4), Map(c -> 1), Map(python -> 6))
D.Tuple4(Map(c -> 1), Map(java -> 4), Map(c -> 1), Map(python -> 6))
答案及解析:C
解释:
-
myf函数分析:
- 该函数接收一个字符串参数
s - 返回一个Map,其中键是字符串
s本身,值是字符串的长度s.length - 例如:对于输入"java",返回
Map("java" -> 4)
- 该函数接收一个字符串参数
-
map操作分析:
- 对列表
List("c","java","c","python")中的每个元素应用myf函数 - 每个元素都会被转换为一个包含单个键值对的Map
- "c" → Map("c" -> 1) // 长度为1
- "java" → Map("java" -> 4) // 长度为4
- "c" → Map("c" -> 1) // 长度为1
- "python" → Map("python" -> 6) // 长度为6
- 对列表
-
结果分析:
- map操作的结果是一个新的List,其中包含了所有转换后的Map
- 最终输出为
List(Map(c -> 1), Map(java -> 4), Map(c -> 1), Map(python -> 6))
-
选项分析:
- 选项A错误:缺少外层List结构
- 选项B错误:值不正确,所有值都是1
- 选项C正确:完整正确展示了map操作的结果
- 选项D错误:结果是List类型,而不是Tuple4类型
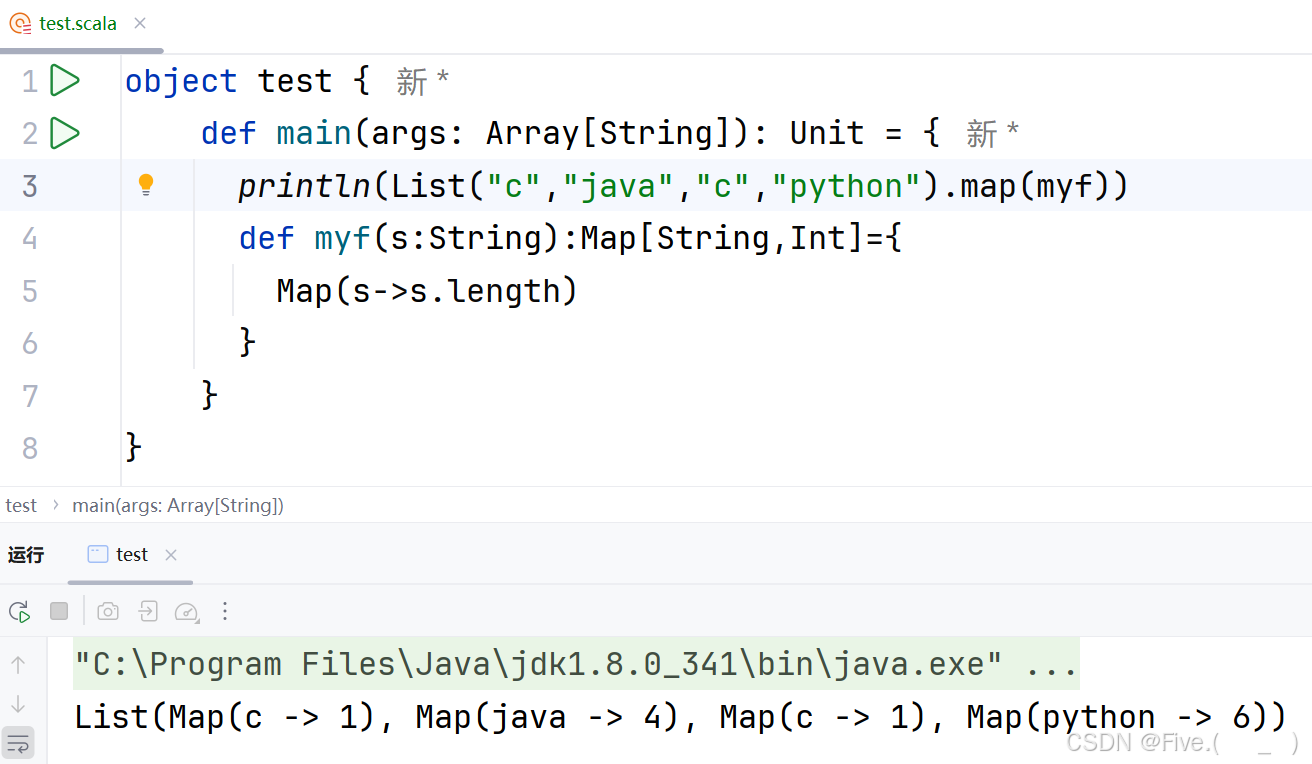
25. (单选题)
println(Array(1,2,3,4,5).filter(myf).toList)
输出结果为List(2,4),请填空
def myf(n:Int):_______={
_________
}
A.Boolean
n%2==0
B.Boolean
n>2
C.Int
n>4
D.Int
n>2
答案及解析:A
解释:
-
问题分析:
- 给定数组
Array(1,2,3,4,5) - 经过
filter(myf)过滤后得到List(2,4) - 这表示函数
myf对于2和4返回true,对于1、3和5返回false - 观察发现,
2和4是数组中的偶数,说明myf函数很可能是在判断一个数是否为偶数
- 给定数组
-
函数定义要求:
- Scala中的
filter方法需要接收一个返回Boolean类型的函数 - 判断偶数的方法是检查一个数除以2的余数是否为0:
n % 2 == 0
- Scala中的
-
完整的函数定义应为:
def myf(n:Int):Boolean={ n%2==0 } -
选项分析:
- A选项:返回类型为
Boolean,函数体为n%2==0,正好能过滤出偶数 - B选项:返回类型正确,但
n>2会过滤出3,4,5,不符合要求 - C选项:返回类型
Int错误(filter需要布尔返回值),且条件也不符合 - D选项:返回类型
Int错误,条件也不符合要求
- A选项:返回类型为
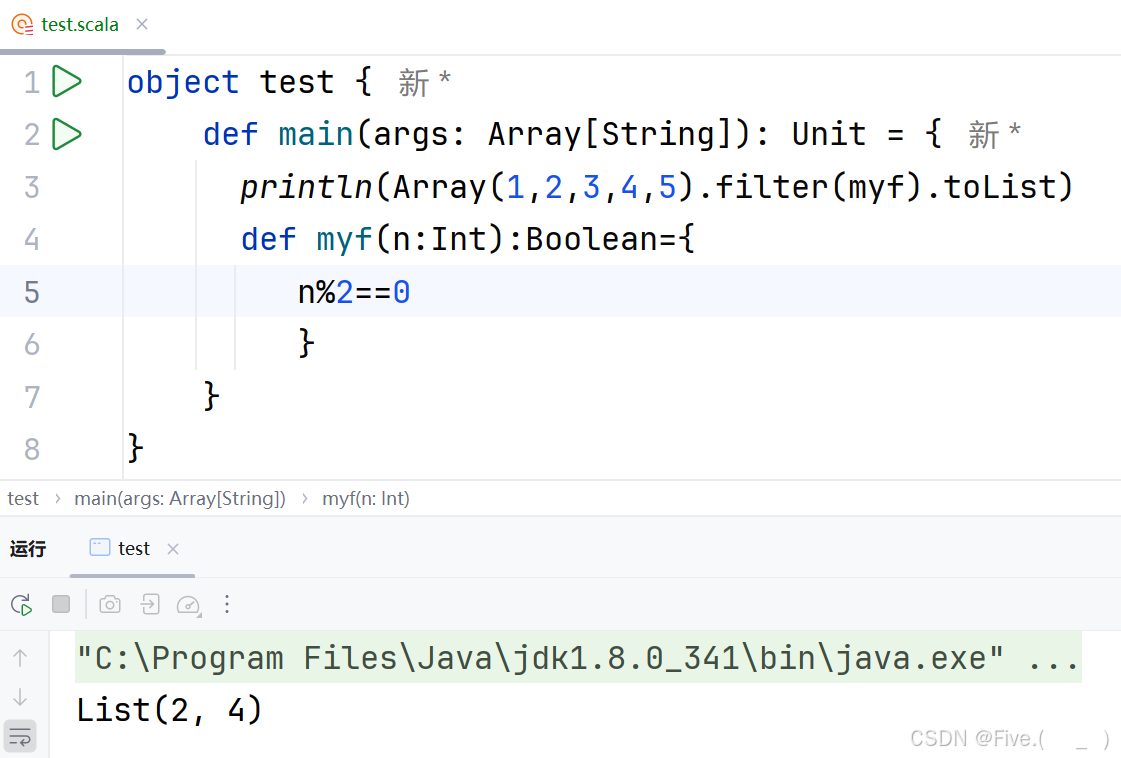
26. (单选题)
println(Array("tom","jerry").filter(__________).toList)
输出结果为List("jerry")
下列错误的是
A._.length>3
B._.startsWith("j")
C._>"j"
D._.endsWith("y")
答案及解析:C
解释:
要使过滤后只剩下"jerry",我们需要一个条件,该条件对"jerry"返回true,对"tom"返回false。让我们分析每个选项:
-
选项A:
_.length>3- "tom"的长度为3,不满足条件(3 > 3为false)
- "jerry"的长度为5,满足条件(5 > 3为true)
- 过滤结果:
List("jerry"),符合要求 ✓
-
选项B:
_.startsWith("j")- "tom"不是以"j"开头,不满足条件
- "jerry"以"j"开头,满足条件
- 过滤结果:
List("jerry"),符合要求 ✓
-
选项C:
_>"j"- 这是字符串的字典序比较
- "tom"字典序大于"j"(t在j之后),满足条件
- "jerry"字典序大于"j",满足条件
- 过滤结果:
List("tom", "jerry"),不符合只保留"jerry"的要求 ✗
-
选项D:
_.endsWith("y")- "tom"不是以"y"结尾,不满足条件
- "jerry"以"y"结尾,满足条件
- 过滤结果:
List("jerry"),符合要求 ✓
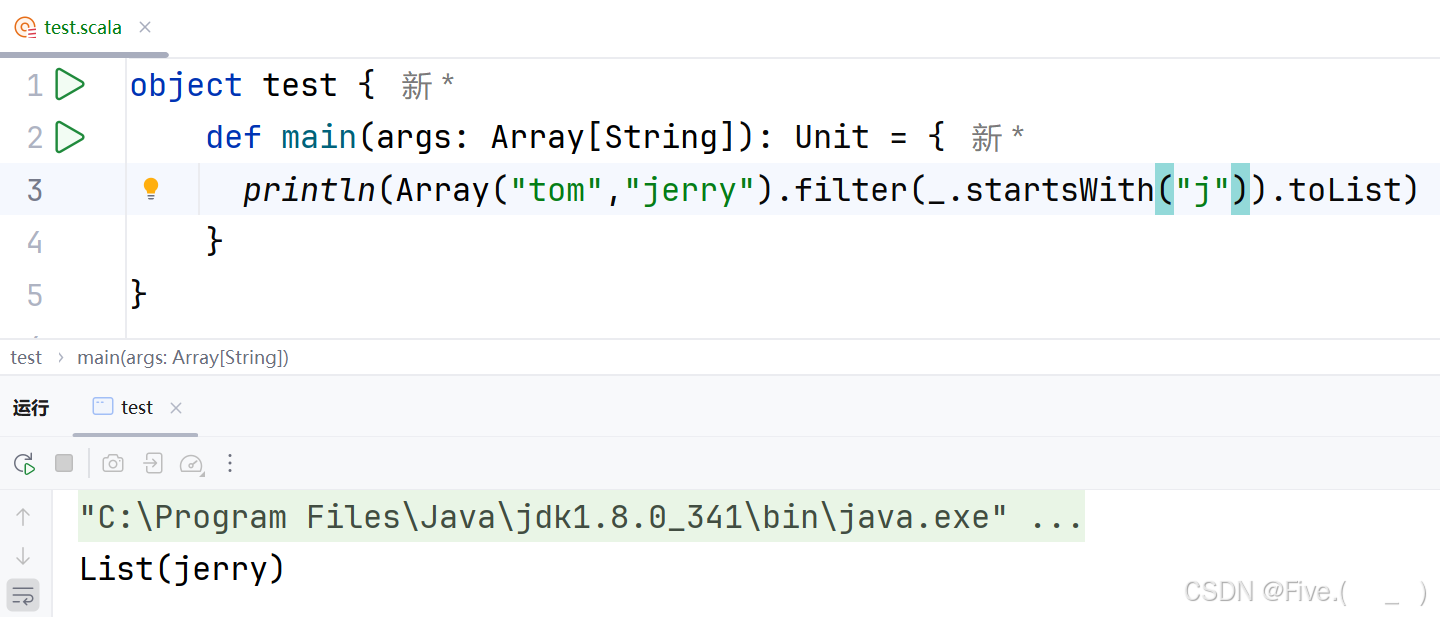
27. (单选题)
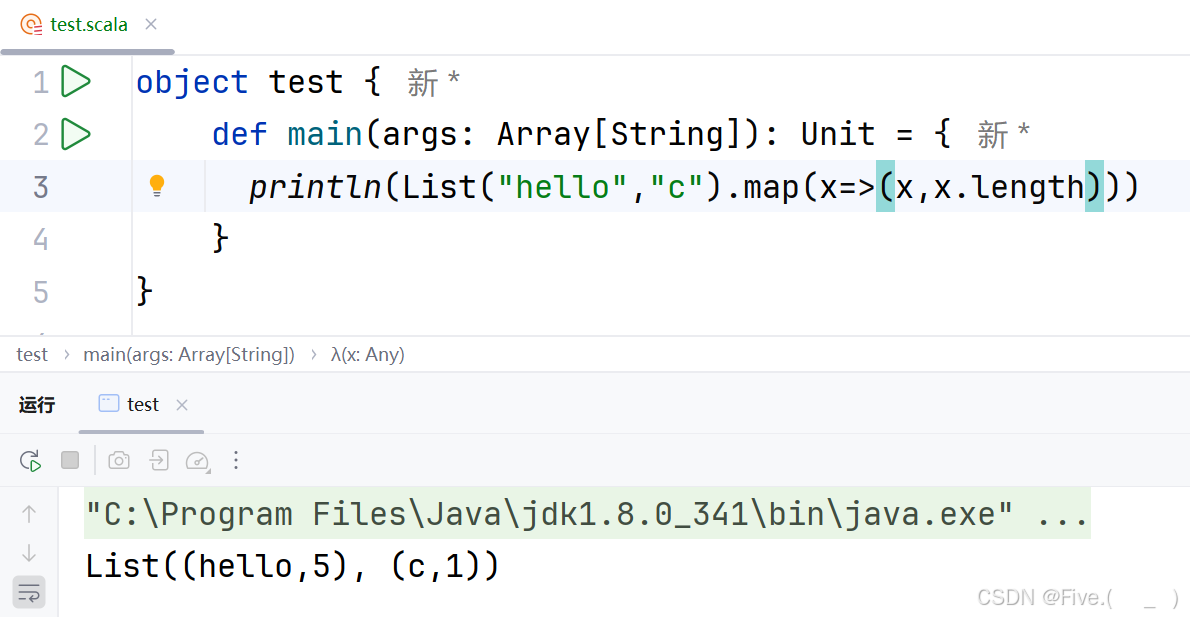
println(List("hello","c").map(x=>__________))
输出结果是List((hello,5),(c,1))
A.x,x.toInt
B.(x,x.length)
C.(_,1)
D.(_,5)
答案及解析:B
解释:
-
输出结果分析:
- 输出中的每个元素都是一个二元组
- 第一个元素是原始字符串:"hello"和"c"
- 第二个元素分别是5和1,这正好是对应字符串的长度
- 这表明映射函数将每个字符串转换为(字符串本身,字符串长度)的形式
-
选项分析:
-
A选项
x,x.toInt:- 这是语法错误,不会生成二元组
- 字符串无法直接转换为整数,
x.toInt会产生错误
-
B选项
(x,x.length):- 创建包含原字符串和其长度的二元组
- "hello" → ("hello", 5)
- "c" → ("c", 1)
- 完全符合预期输出
-
C选项
(_,1):- 创建二元组,第一个元素是原字符串,第二个元素固定为1
- 输出将是
List((hello,1),(c,1)),不符合预期
-
D选项
(_,5):- 创建二元组,第一个元素是原字符串,第二个元素固定为5
- 输出将是
List((hello,5),(c,5)),不符合预期
-
28. (单选题)
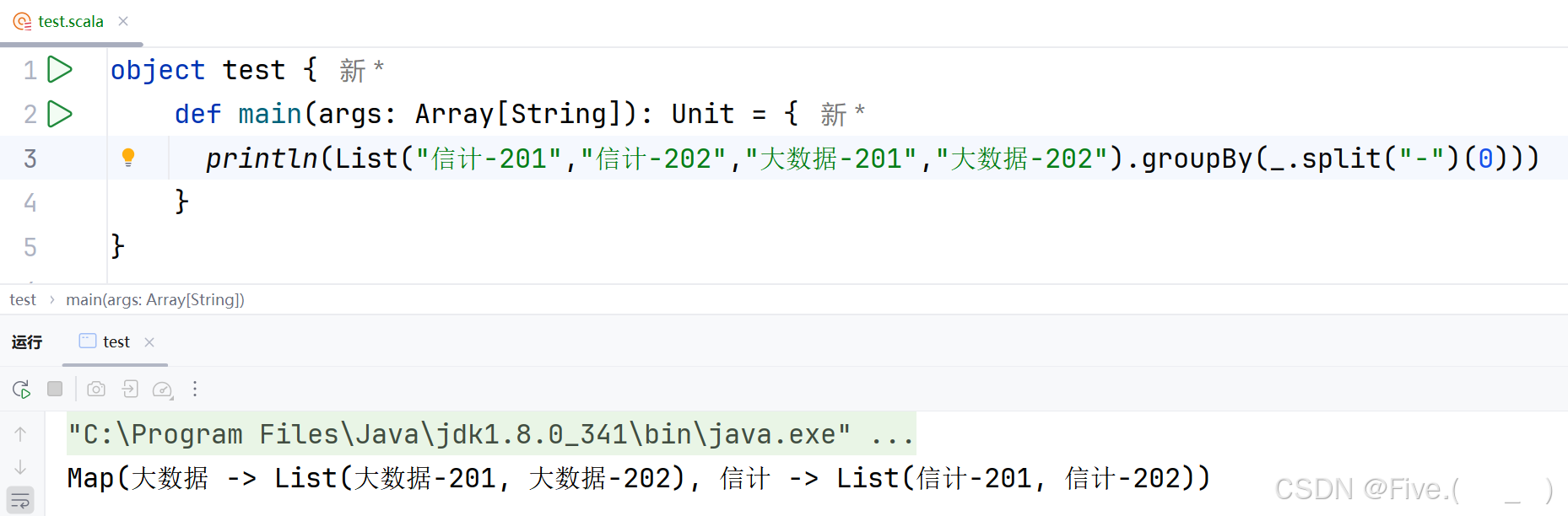
println(List("信计-201","信计-202","大数据-201","大数据-202")
.groupBy(_.split("-")(0)))
输出结果是
A.Map(大数据 -> List(大数据-201, 大数据-202), 信计 -> List(信计-201, 信计-202))
B.Map(大数据-20 -> List(大数据-201, 大数据-202), 信计-20 -> List(信计-201, 信计-202))
C.Map(大数据- -> List(大数据-201, 大数据-202), 信计- -> List(信计-201, 信计-202))
D.Map(大数据 -> List(201, 202), 信计 -> List(201, 202))
答案及解析:A
解释:
-
groupBy方法:
groupBy方法根据指定的函数对集合元素进行分组- 结果是一个Map,其中键是分组依据,值是原始元素的List
-
分组函数分析:
_.split("-")(0)表示将每个字符串按"-"分割,并取第一部分- 对于"信计-201",分割后得到["信计", "201"],取第一部分为"信计"
- 对于"信计-202",同样得到"信计"
- 对于"大数据-201"和"大数据-202",都得到"大数据"
-
分组结果:
- "信计"对应的分组包含原始列表中以"信计"开头的元素:["信计-201", "信计-202"]
- "大数据"对应的分组包含原始列表中以"大数据"开头的元素:["大数据-201", "大数据-202"]
- 最终形成
Map("大数据" -> List("大数据-201", "大数据-202"), "信计" -> List("信计-201", "信计-202"))
-
选项分析:
- 选项A正确反映了以上分组结果
- 选项B错误,键不是"大数据-20"和"信计-20"
- 选项C错误,键不包含连字符"-"
- 选项D错误,值列表包含的是完整原始元素,不是只有后半部分
29. (单选题)
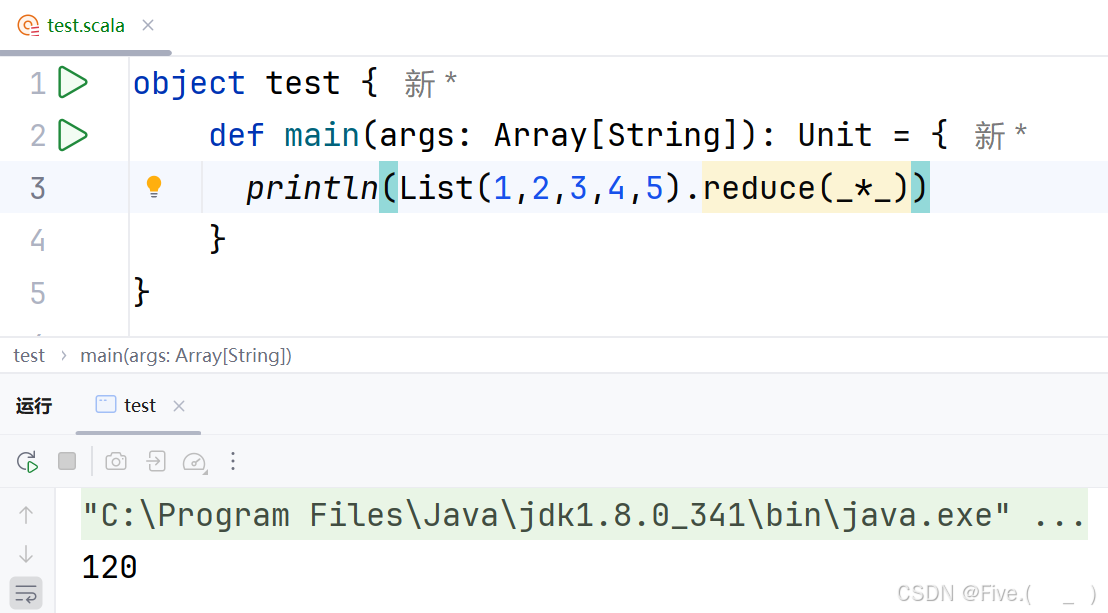
println(List(1,2,3,4,5).reduce(_*_))
输出结果是
A.120
B.15
C.1 3 6 10 15
D.1 2 6 24 120
答案及解析:A
解释:
-
reduce方法:
reduce方法接收一个二元操作函数,将此操作依次应用于集合中的元素- 它从集合的第一个元素开始,然后将结果与下一个元素进行操作,以此类推
- 表达式
_*_是(a, b) => a * b的简写,表示将两个数相乘
-
执行过程:
- 初始值:列表的第一个元素 1
- 第一步:1 * 2 = 2
- 第二步:2 * 3 = 6
- 第三步:6 * 4 = 24
- 第四步:24 * 5 = 120
- 最终结果:120
-
选项分析:
- 选项A:120 - 正确,这是所有元素相乘的结果
- 选项B:15 - 错误,这是所有元素相加的结果(1+2+3+4+5),而不是相乘
- 选项C:1 3 6 10 15 - 错误,这似乎是展示累加操作的中间结果
- 选项D:1 2 6 24 120 - 错误,这是展示了计算过程中的每一步结果,而不是最终输出
30. (单选题)
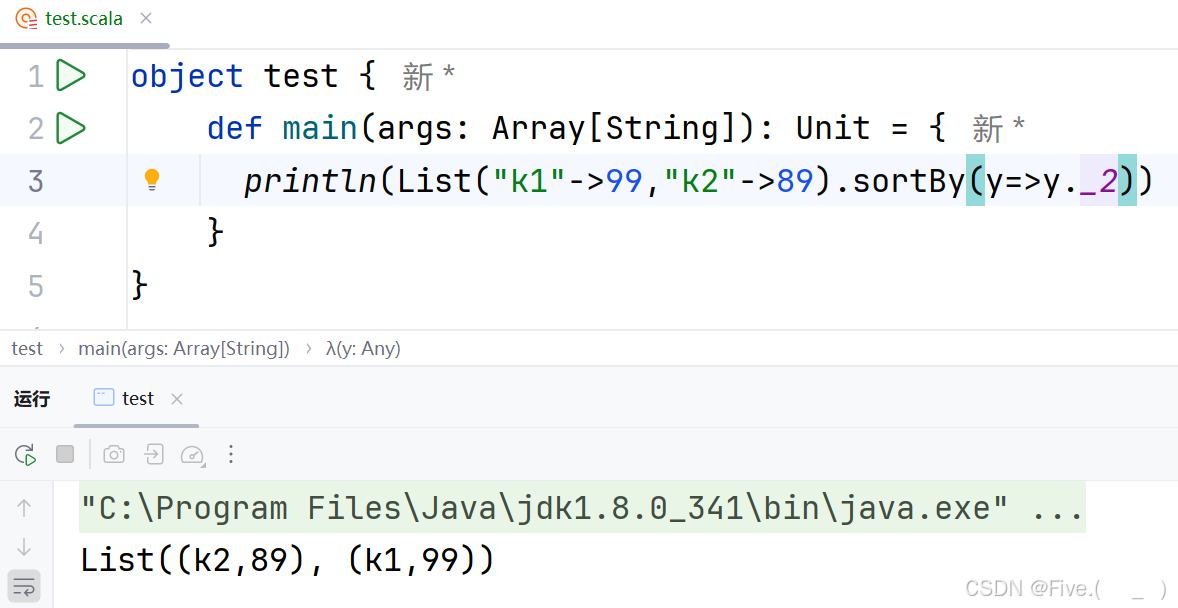
println(List("k1"->99,"k2"->89).sortBy(_______))
输出结果为List((k2,89), (k1,99)),请填空
A._._1
B._2
C.x=>x._1
D.y=>y._2
答案及解析:D
解释:
-
问题分析:
- 输入是一个包含两个键值对的列表:
("k1",99)和("k2",89) - 输出显示元素已按照数值(89和99)从小到大排序
- 这表明排序依据是元组的第二个元素(即
._2)
- 输入是一个包含两个键值对的列表:
-
sortBy方法:
sortBy接收一个函数参数,该函数指定如何从元素中提取排序关键字- 默认按照提取的关键字升序排列
-
选项分析:
-
A选项
_._1:- 按元组的第一个元素(即字符串"k1"和"k2")排序
- 结果将是
List((k1,99), (k2,89)),不符合预期输出
-
B选项
_2:- 语法错误,不是有效的Scala表达式
- sortBy需要一个函数,而
_2不是一个有效的函数表达式
-
C选项
x=>x._1:- 按元组的第一个元素排序的完整写法
- 结果同A选项,不符合预期输出
-
D选项
y=>y._2:- 按元组的第二个元素排序的完整写法
- 将按89和99排序,结果为
List((k2,89), (k1,99)) - 完全符合预期输出
-
二. 多选题
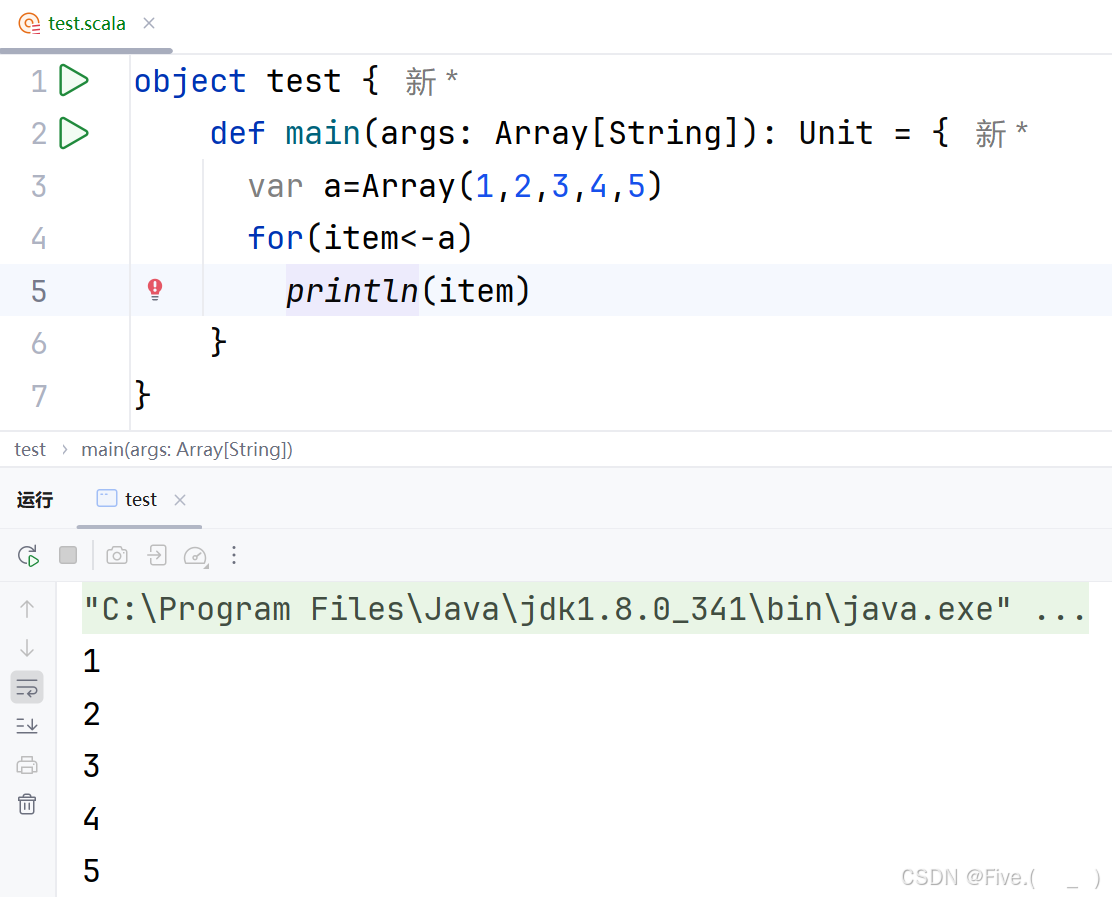
31. (多选题) 打印数组中每个元素
A. for(i<-0 to a.length-1)
println(a(i))
B.for(item->a)
println(item)
C.for(item<-a)
println(item)
D.for(item=>a)
println(item)
答案及解析:A、C
选项分析:
A. for(i<-0 to a.length-1) println(a(i))
✓ 正确
- 使用索引遍历方式
0 to a.length-1创建从0到数组末尾索引的范围a(i)通过索引访问数组元素- 这是标准的索引遍历写法,语法正确
B. for(item->a) println(item)
✗ 错误
- 使用了错误的操作符
->而不是<- - 在Scala的for循环中,应使用
<-表示元素来自集合 ->通常用于创建键值对,而非遍历操作
C. for(item<-a) println(item)
✓ 正确
- 使用了
<-操作符,这是Scala中for表达式的正确语法 - 直接遍历数组a中的每个元素
- 这是Scala中最常用的简洁遍历写法
D. for(item=>a) println(item)
✗ 错误
- 使用了
=>操作符,这在for循环语法中是错误的 =>通常用于定义函数或匿名函数,不能用于遍历集合
相关文章:

spark数据处理练习题详解【下】
12. (单选题) def main(args: Array[String]): Unit { println(func1("张三",f1)) } def func1(name:String,fp:(________________)): String { fp(name) } def f1(s:String): String { "welcome "s } 选择填空() A.String>S…...
_条件渲染)
Vue基础(11)_条件渲染
原生css想让显示的元素隐藏,方式有以下几点: display: none; opacity: 0; visibility: hidden; 那么vue中是怎样实现元素显示/隐藏的呢? 条件渲染 v-show 写法:v-show"表达式" 判断:表达式转换为布尔值(tr…...

湖北理元理律师事务所:债务优化服务的四维创新实践
在债务问题普遍影响家庭经济稳定的当下,专业法律服务机构的价值不仅在于提供解决方案,更需构建可持续的服务生态。湖北理元理律师事务所通过“法律心理技术教育”四维服务体系,探索出一条兼顾债务化解与生活质量保障的创新路径。 服务模式创…...

ubuntu工控机固定设备usb串口号
ubuntu工控机固定设备usb串口号 1、多个USB设备的ID相同 ubuntu系统中的串口使用权限并没有对所有的用户进行开放,所以在使用代码对串口进行操作时,需要打开用户对串口的使用权限,否则在代码中会出现“串口无法打开的报错”,只有…...

MongoDB的安装及简单使用
MongoDB 是一个开源的文档型 NoSQL 数据库,由 MongoDB Inc. 开发,专为灵活性和可扩展性设计。 特点: 1.文档模型:数据以 BSON(二进制 JSON)格式存储,支持嵌套结构。 2.动态 S…...

卷积神经网络进阶:转置卷积与棋盘效应详解
【内容摘要】 本文深入解析卷积神经网络中的转置卷积(反卷积)技术,重点阐述标准卷积与转置卷积的计算过程、转置卷积的上采样作用,以及其常见问题——棋盘效应的产生原因与解决方法,为图像分割、超分辨率等任务提供理论…...
之信号产生2)
Linux进程信号(三)之信号产生2
文章目录 4. 由软件条件产生信号5. 硬件异常产生信号模拟一下除0错误和野指针异常除0错误野指针错误 总结思考一下 4. 由软件条件产生信号 SIGPIPE是一种由软件条件产生的信号,在“管道”中已经介绍过了。 软件条件不就绪,很明显这个软件条件没有直接报错ÿ…...

【AWS入门】Amazon SageMaker简介
【AWS入门】Amazon SageMaker简介 [AWS Essentials] Brief Introduction to Amazon SageMaker By JacksonML 机器学习(Machine Learning,简称ML) 是当代流行的计算机科学分支技术。通常,人们在本地部署搭建环境,以满足机器学习的要求。 AWS…...

MySQL--day2--基本的select语句
(以下内容全部来自上述课程) SQL概述 结构化查询语句 1. SQL分类 DDL:数据定义(definition)语言:create、drop、alter… DML:数据操作(manipulation)语言ÿ…...

程序代码篇---python获取http界面上按钮或者数据输入
文章目录 前言 前言 本文简单接受了python获取http界面上按钮或者数据输入...

网络安全利器:蜜罐技术详解
蜜罐是网络安全领域中一种主动防御和情报收集的重要工具。本文将深入探讨蜜罐技术的原理、类型、应用场景以及部署注意事项。 1. 什么是蜜罐? 蜜罐(Honeypot)是一种安全资源,其价值在于被探测、攻击或未经授权使用。简单来说,蜜罐就是一个诱饵系统,用来吸引黑客的注意力…...

回溯实战篇3
文章目录 前言排列全排列全排列II 棋盘问题N皇后解数独 其他递增子序列重新安排行程 前言 今天继续带大家进行回溯的实战篇3,去学习如何用回溯的方法去解决排列和棋盘以及其他用回溯方法解决的问题,最重要的就是学会回溯三部曲的构建,一文带…...

Spark 基础自定义分区器
(一)什么是分区 【复习提问:RDD的定义是什么?】 在 Spark 里,弹性分布式数据集(RDD)是核心的数据抽象,它是不可变的、可分区的、里面的元素并行计算的集合。 在 Spark 中…...
/ 曹冲养猪)
【提高+/省选−】洛谷P1495 —— 【模板】中国剩余定理(CRT)/ 曹冲养猪
见:P1495 【模板】中国剩余定理(CRT)/ 曹冲养猪 - 洛谷 题目描述 自从曹冲搞定了大象以后,曹操就开始捉摸让儿子干些事业,于是派他到中原养猪场养猪,可是曹冲满不高兴,于是在工作中马马虎虎&a…...

系统架构设计师考前冲刺笔记-第1章-系统工程与信息系统基础
文章目录 第1章 系统工程与信息系统基础大纲13 DSS5678 BSP910 SCM11 OLAP12 OLAP14 BRP15 集成16 企业门户19 边缘计算 第1章 系统工程与信息系统基础 大纲 1 3 DSS DSS 决策支持系统 Decision Support System 5 6 7 8 BSP 9 10 SCM 注意:生产计划 11 OLAP O…...

Vue环境下数据导出Excel的全面指南
文章目录 1. 前言2. 原生JavaScript实现方案2.1 使用Blob对象和URL.createObjectURL2.2 使用Base64编码实现 3. 常用第三方库方案3.1 使用SheetJS (xlsx)3.2 使用ExcelJS3.3 使用vue-json-excel 4. 服务器端导出方案4.1 前端请求服务器生成Excel4.2 使用Web Worker处理大数据导…...

Linux下 使用 SSH 完成 Git 绑定 GitHub
文章目录 1、检查 SSH2、生成 SSH key3、添加 SSH key4、验证绑定是否成功 1、检查 SSH Git Bash 中输入ssh命令,查看本机是否安装 SSH: 2、生成 SSH key (1)输入 ssh-keygen -t rsa 命令,表示我们指定 RSA 算法生…...

Jsoup库和Apache HttpClient库有什么区别?
Jsoup 和 Apache HttpClient 是两个功能不同的库,它们在 Java 开发中被广泛使用,但用途和功能有明显的区别: Jsoup 用途:Jsoup 是一个用于解析 HTML 文档的库。它提供了非常方便的方法来抓取和解析网页内容,提取和操作…...

安全漏洞频发,如何加强防护措施?
当系统安全漏洞频发时,应从代码安全审查、自动化漏洞扫描、权限控制与访问管理、员工安全意识培训等四个关键维度加强防护。其中,代码安全审查是防止漏洞渗透的第一道防线。企业应将代码安全审查纳入CI/CD流程,实施静态代码分析和依赖包检查机…...

Text models —— BERT,RoBERTa, BERTweet,LLama
BERT 什么是BERT? BERT,全称Bidirectional Encoder Representations from Transformers,BERT是基于Transformer的Encoder(编码器)结构得来的,因此核心与Transformer一致,都是注意力机制。这种…...

CodeBuddy初探
回顾Trae 上一篇博客Trae IDE和VSCode Trae插件初探-CSDN博客,我们进行了TraeIDE和Trae插件初探,给了Trae这样一个任务: 生成一个to do list清单web页面,采用vue实现,可以在页面上进行todolist进行增删改查。 Trae的…...

spark数据处理练习题详解【上】
1. (单选题) scala中属于序列的可变的集合,可以添加,删除元素的是() A.Array B.List C.Tuple D.ListBuffer 答案及解析:D 在Scala中,属于序列的可变集合,可以添加和删除元素的是ÿ…...
)
sparkSQL读入csv文件写入mysql(2)
(二)创建数据库和表 接下来,我们去创建一个新的数据库,数据表,并插入一条数据。 -- 创建数据库 CREATE DATABASE spark; -- 使用数据库 USE spark;-- 创建表 create table person(id int, name char(20), age int);-- …...

产品周围的几面墙
不能把排序,当单选题做。 2025年的杭州咖啡馆,味道最浓的不是咖啡,是聊各种项目和创业的卷味。 在过去几年,聊项目的也不少,那时候带着更加浓烈的自信和松弛感,不过今年略带几分忐忑和试探的口吻。 看到网…...
)
【锂电池剩余寿命预测】LSTM长短期记忆神经网络锂电池剩余寿命预测(Pytorch完整源码和数据)
目录 效果一览程序获取程序内容代码分享效果一览 程序获取 获取方式一:文章顶部资源处直接下载:...

螺旋矩阵--LeetCode
题目 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2: 输入:matrix [[…...

湖北理元理律师事务所:债务管理的社会价值探索
债务问题从来不是孤立的经济事件,其背后牵涉家庭稳定、社会信用体系乃至区域经济发展。湖北理元理律师事务所通过五年服务数据发现:科学债务规划可使单个家庭挽回约23%的可支配收入,间接降低离婚率、心理健康问题发生率等社会成本。 债务优化…...
与大语言模型(LLM))
知识图谱(KG)与大语言模型(LLM)
知识图谱(KG)以其结构化的知识表示和推理能力,为大语言模型(LLM)的“幻觉”、知识更新滞后和可解释性不足等问题提供了有力的解决方案。反过来,LLM的强大文本理解和生成能力也为KG的构建、补全、查询和应用…...

LLM大语言模型系列1-token
一,什么是token 1,什么是token: 参考:https://en.wikipedia.org/wiki/Token https://en.wikipedia.org/wiki/Lexical_analysis#Token 我们有很多描述token的解释,建议是汇总在一起进行综合理解: 1️⃣To…...

数据清洗-案例
四)实现代码 在之前的项目的基础之上,重写去写一个包,并创建两个类:WebLogMapper和WebLogDriver类。 (1)编写WebLogMapper类 package com.root.mapreduce.weblog; import java.io.IOException; import…...

项目的部署发布和访问的流程
首先打包项目: npm run build 打包后的文件会生成在dist文件夹中,将dist文件夹需要放到服务器里面,意味着服务有dist静态资源(index.html,css/,js/,img/) 用户在浏览器输入域名&am…...

人工智能、机器学习、深度学习定义与联系
人工智能、机器学习、深度学习定义与联系目录 一、人工智能(Artificial Intelligence, AI)1、定义2、特征:3、关键阶段的概述:1. 萌芽期(1940s–1950s):理论奠基2. 形成期(1950s–19…...
集成到应用架构》学习心得)
Gartner《如何将生成式人工智能(GenAI)集成到应用架构》学习心得
针对软件架构师、技术专业人士如何更好的把 GenAI 如何融入解决方案,提升用户体验、生产力并带来差异化成果的趋势,Gartner发布了《Integrating GenAI Into Your Application Architecture》研究报告。 报告首先介绍了 GenAI 的发展背景,指出其已成为主流趋势,大型语言模型…...

vscode中Debug c++
在vscode中Debug ros c程序 1 在Debug模式下编译 如果用命令行catkin_make,在输入catkin_make时加上一个参数: catkin_make -DCMAKE_BUILD_TYPEDebug 或者直接修改CMakelist.txt,添加以下代码: SET(CMAKE_BUILD_TYPE "D…...
--特殊工具与技术-完结篇)
c++从入门到精通(六)--特殊工具与技术-完结篇
特殊工具与技术-完结篇 控制内存分配 重载new和delete: 如果应用程序希望控制内存分配的过程,则它们需要定义自己的operator new函数和operator delete函数。当自定义了全局的operator new函数和operator delete函数后,我们就担负起了控…...

原型链的详细解释及使用场景
一、原型链的概念 原型链是JavaScript实现继承和属性共享的核心机制。每个对象都有一个内部属性[[Prototype]](可通过proto访问),指向其原型对象。当访问对象的属性时,若对象自身不存在该属性,则会沿着原型链向上查找…...

OpenCL C C++核心对象与属性对比
基础对象对应关系 OpenCL C 对象OpenCL C 对应类型创建函数示例cl::Platformcl_platform_idclGetPlatformIDs(1, &platform, NULL)cl::Devicecl_device_idclGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL)cl::Contextcl_contextclCreateContext(NULL,…...

Azure 机器学习初学者指南
Azure 机器学习初学者指南 在我们的初学者指南中探索Azure机器学习,了解如何设置、部署模型以及在Azure生态系统中使用AutoML & ML Studio。Azure 机器学习 (Azure ML) 是一项全面的云服务,专为机器学习项目生命周期而设计&am…...

一文读懂----Docker 常用命令
Docker 是一个强大的容器化平台,广泛用于开发、测试和生产环境。通过 Docker 命令行工具(CLI),我们可以轻松管理容器、镜像、网络和卷等资源。本文将详细介绍 Docker 的常用命令,带你熟练掌握 Docker 的核心操作命令。…...

React 19 中的useRef得到了进一步加强。
文章目录 前言一 useRef 的核心原理1.1 为什么需要 useRef?1.2 基本语法 二、React 19 中 useRef 的常见用法2.1 访问 DOM 元素2.2 保存跨渲染的数据 三、React 19 中的改进ref 作为一个属性案例演示(触发子组件焦点事件) 注意 总结 前言 在 React 的世界里&#x…...
”)
报错System.BadImageFormatException:“试图加载格式不正确的程序。 (异常来自 HRESULT:0x8007000B)”
this.hWindowControl_Player new HalconDotNet.HWindowControl();报错System.BadImageFormatException:“试图加载格式不正确的程序。 (异常来自 HRESULT:0x8007000B)” System.BadImageFormatException 错误通常是由于平台架构不匹配导致的。它意味着你正在尝试在一个平台上加…...

【图像处理基石】OpenCV中都有哪些图像增强的工具?
OpenCV 图像增强工具系统性介绍 OpenCV 提供了丰富的图像增强工具,主要分为以下几类: 亮度与对比度调整 线性变换(亮度/对比度调整)直方图均衡化自适应直方图均衡化(CLAHE) 滤波与平滑 高斯滤波中值滤波双…...
的介绍)
Nordic 的RTC(Real-time counter)的介绍
目录 概述 1 RTC(Real-time counter)介绍 1.1 框架结构 1.2 时钟源 1.3 分辨率与溢出和precaler 2 寄存器功能介绍 2.1 计数寄存器 2.2 事件控制功能 2.3 比较功能 2.4 读取COUNTER寄存器 概述 本文主要介绍Nordic 的RTC(Real-time…...

【数据结构】2-2-2 顺序表的插入删除查找
数据结构知识点合集 知识点 顺序表的插入 ListInsert(&L,i,e):插入操作。在表L中的第i个位置上插入指定元素e。 /*在顺序表L的第i个位置插入元素e*/ bool ListInsert(SqList &L,int i,int e) {/*判断i的范围是否有效*/if(i<0||i>L.length)return fals…...
动态API)
【免杀】C2免杀技术(五)动态API
一、什么是动态API 在C2免杀领域中,“动态API” 主要指的是绕过静态检测的一种技术手段,其本质是运行时动态解析和调用Windows API函数,而不是在程序编译阶段就明确引用这些API。这种方式可以有效躲避静态分析工具和杀软的签名识别。 为什么…...

77.数据大小端赋值的差异与联系
上述赋值a定义为大端模式 a[7] a[6] a[5] a[4] a[3] a[2] a[1] a[0] 上述赋值b定义为小端模式 a[0] a[1] a[2] a[3] a[4] a[5] a[6] a[7] 因为5的二进制数…...

GO语言语法---switch语句
文章目录 基本语法1. 特点1.1 不需要break1.2 表达式可以是任何类型1.3 省略比较表达式1.4 多值匹配1.5 类型switch1.6 case穿透1.7 switch后直接声明变量1.7.1 基本语法1.7.2 带比较表达式1.7.3 不带比较表达式1.7.4 结合类型判断 1.8 switch后的表达式必须与case语句中的表达…...

PH热榜 | 2025-05-16
1. Tolt 标语:专为SaaS初创公司打造的一体化联盟营销软件 介绍:Tolt帮助SaaS初创公司启动和发展联盟计划。它提供自动化的支付、欺诈保护、与多种平台的无缝集成(包括Stripe、Paddle和Chargebee),还有一个品牌化的联…...

Java正则表达式:从基础到高级应用全解析
Java正则表达式应用与知识点详解 一、正则表达式基础概念 正则表达式(Regular Expression)是通过特定语法规则描述字符串模式的工具,常用于: 数据格式验证文本搜索与替换字符串分割模式匹配提取 Java通过java.util.regex包提供支持,核心类…...

iOS 初识RunLoop
iOS 初识RunLoop 文章目录 iOS 初识RunLoopRunLoop的概念RunLoop的功能RunLoop和线程的关系RunLoop的结构ModeObserverTimer 和 source小结 RunLoop的核心RunLoop的流程RunLoop的应用AutoreleasePool响应触控事件刷新界面常驻线程网络请求NSTimer 和 CADisplayLinkNSTimerGCDTi…...