【第三十六周】LoRA 微调方法
LoRA
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- LoRA的原理
- LoRA在Transformer中的应用
- 补充
- 其他细节
- 实验与分析
- LoRA的使用
- 论文实验结果分析
- 总结
摘要
本篇博客介绍了LoRA(Low-Rank Adaptation),这是一种面向大规模预训练语言模型的参数高效微调方法,旨在解决全模型微调带来的高计算与存储成本问题。其核心思想是在不修改原始模型权重的前提下,引入一对可训练的低秩矩阵,以近似模拟微调过程中权重的变化,从而以极小的参数量实现模型在下游任务上的快速适配。具体来说,LoRA 针对 Transformer 中的线性层(如注意力机制中的投影矩阵)进行改造,将参数更新表示为两个小矩阵 A A A和 B B B的乘积 Δ W = B A \Delta W = BA ΔW=BA,训练时仅更新这两个矩阵,部署时可与原始权重合并,保持推理效率不变。实验表明,LoRA 能在多种自然语言处理任务中达到接近甚至超过全量微调的性能,同时显著减少所需的可训练参数量。该方法优势在于高效、通用、部署灵活,但在模块选择、模型融合与多任务共享方面仍存在一定限制。
Abstract
This blog introduces LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning method designed for large-scale pre-trained language models. It aims to address the high computational and storage costs associated with full-model fine-tuning. The core idea of LoRA is to approximate weight updates during fine-tuning by introducing a pair of trainable low-rank matrices, without modifying the original model parameters. This enables rapid adaptation to downstream tasks with a minimal number of additional parameters. Specifically, LoRA modifies the linear layers within Transformer architectures—such as the projection matrices in attention mechanisms—by expressing the weight update as the product of two smaller matrices, Δ W = B A \Delta W = BA ΔW=BA. During training, only these matrices are updated, and at deployment time, the update can be merged into the original weights to maintain inference efficiency. Experiments show that LoRA achieves performance comparable to or even better than full fine-tuning across various natural language processing tasks, while significantly reducing the number of trainable parameters. Its advantages include efficiency, generality, and deployment flexibility, though it still faces limitations in terms of module selection, model merging, and multi-task sharing.
文章信息
Title:LoRA: Low-Rank Adaptation of Large Language Models
Author:Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen
Source:https://arxiv.org/abs/2106.09685
引言
在自然语言处理(NLP)领域,“预训练 + 微调”已成为主流范式:研究者先在大规模通用语料上训练语言模型,再针对具体下游任务进行参数更新(微调)。然而,随着模型规模的不断扩大,全模型微调(full fine-tuning)带来了极高的存储和计算成本。例如,对 GPT-3 175B(约 1750 亿参数)进行独立微调,不仅需要为每个任务保存一份同规模的模型检查点,更在部署时产生巨大的显存开销,难以在实际系统中承载与切换多任务需求。
为了解决上述瓶颈,研究者提出了多种参数高效的适配方法,包括仅更新部分参数(如 Bias-only/BitFit)、插入轻量级适配层(Adapters)或对输入进行可微调的提示优化(prefix-tuning、prompt tuning)等。但这些方法存在各自局限:部分方案会引入额外的推理延迟(Adapters),或占用原有序列长度(prefix-tuning),且在模型质量上往往难以完全匹配全模型微调的效果。
本文介绍的LoRA方法在保持原始预训练权重冻结不变的前提下,仅向 Transformer 各层注入一对低秩矩阵来分解并学习微调时的权重增量。LoRA 可以极大地减少需要微调的参数量,同时在推理时可将低秩增量与原权重合并,不引入额外延迟。
方法
传统的全模型微调(full fine-tuning)会对预训练模型的所有权重 W 0 W_0 W0进行梯度更新,导致每个下游任务都需要保存一份与原模型规模相同的参数。
全模型微调主要有以下三个问题:
- 计算成本高,需要微调的参数与预训练好的参数数量一致。
- 存储开销大,每个任务都要保存一份完整模型副本,占用大量硬盘空间。
- 部署不灵活,想切换任务时,需要重新加载整套参数,速度慢且占显存。
LoRA的原理

- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank。
- 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
在标准微调中,会直接更新预训练权重 W W W。但在 LoRA 中,不直接改动原始的 W W W ,公式如下:

LoRA 的关键点在于:不直接学习 Δ W \Delta W ΔW(它的大小和W一样)而是把它拆成两个更小的矩阵 A A A和 B B B的乘积: Δ W = B A \Delta W = BA ΔW=BA其中 A ∈ R r × d A \in \mathbb R^{r\times d} A∈Rr×d, B ∈ R d × r B \in \mathbb R^{d\times r} B∈Rd×r,通常 r 很小(如 4、8、16),远小于 d。
这就叫“低秩分解”,它能大大减少需要学习的参数数量。
例如,如果 W W W 是一个 1024 × 1024 1024\times 1024 1024×1024 的矩阵,有 1,048,576 个参数,而 LoRA 只需要学习两个小矩阵,总参数是 2 × 1024 × r 2\times 1024 \times r 2×1024×r,但 r = 8 r=8 r=8时,只需要 16,384 个参数,相当于只训练原始参数的约 1.6%。
训练时只更新 A A A和 B B B,而模型原始参数 W W W 保持不变,这样就大大减少了存储和计算需求。
另外,LoRA 把 B B B初始化为全零, A A A初始化为小的随机值,是为了让模型一开始行为不变,即 Δ W x = 0 \Delta Wx=0 ΔWx=0。
LoRA的这种使用旁路更新的方法有点类似残差连接的思想,都是保证已学到的不会退化,再学其他的。
LoRA在Transformer中的应用
LoRA 方法可应用于任意密集层,论文中写的主要是Transformer层的自注意力模块,在该模块中,包含查询( W q W_q Wq)、键( W k W_k Wk)、值( W v W_v Wv)和输出投影( W o W_o Wo)。LoRA 的论文主要选择对注意力模块中的查询(Query)和数值(Value)矩阵进行插入,因为这两个部分对模型的表示能力影响很大。其他部分可以保持不变。
补充
为什么矩阵B、A不能同时为0?
这主要是因为如果矩阵 A A A 也用0初始化,那么矩阵 B B B 梯度就始终为0,无法更新参数,导致 Δ W = B A = 0 \Delta W = BA=0 ΔW=BA=0,推导如下:
对于 h = W 0 x + B A x h=W_0x+BAx h=W0x+BAx,设 h ( 2 ) = B A x h^{(2)}=BAx h(2)=BAx,则

因此:

如果矩阵 A A A 也用0初始化,那么上面的梯度就变成了0。所以矩阵 A A A也用0初始化,那么上面的梯度就变成了0。
其他细节
- 缩放因子:由于 Δ W = B A \Delta W = BA ΔW=BA通常比较小,论文中加入了一个缩放因子 α / r \alpha /r α/r,防止它在训练过程中太弱。这个因子可以看作是学习率的调节器。
- 推理时合并参数:在部署模型时,LoRA 可以把 Δ W \Delta W ΔW 直接加到 W W W 里变成一个新的矩阵,然后就不需要再动态计算 B A x BAx BAx 了,这样可以节省运行时计算资源。
实验与分析
LoRA的使用
目前 LORA 已经被 HuggingFace 集成在了 PEFT(Parameter-Efficient Fine-Tuning) 代码库里。
使用也非常简单,比如使用 LORA 微调 BigScience 机器翻译模型:
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
模型微调好之后,加载也非常简单,只需要额外加载 LORA 参数:
model.load_state_dict(torch.load(peft_path), strict=False)
论文实验结果分析
理解任务上:

MNLI、SST-2 、MRPC、CoLA、QNLI、QQP、RTE、STS-B表示各项任务:
- MNLI(Multi-Genre Natural Language Inference):该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含、中立或矛盾)。数据集中包含来自不同文体(新闻、文学等)的句子对。
- SST-2(Stanford Sentiment Treebank):该任务是一个情感分析任务,要求模型判断给定句子的情感是正面还是负面。
- MRPC(Microsoft Research Paraphrase Corpus):该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性。
- CoLA(Corpus of Linguistic Acceptability):该任务是一个语言可接受性任务,要求模型判断给定句子是否符合语法规则和语言习惯。
- QNLI(Question NLI):该任务是一个自然语言推理任务,要求模型根据给定的问题和前提,判断问题是否可以从前提中推导出来。
- QQP(Quora Question Pairs):该任务是一个语义相似度任务,要求模型判断给定问题对是否具有语义相似性。
- RTE(Recognizing Textual Entailment):该任务是一个自然语言推理任务,要求模型根据给定的前提和假设来判断它们之间的关系(蕴含或不蕴含)。
- STS-B(Semantic Textual Similarity Benchmark):该任务是一个语义相似度任务,要求模型判断给定句子对是否具有语义相似性,但是与MRPC不同的是,STS-B中的句子对具有连续的语义相似性等级。
可以看到 LORA 相比其它微调方法,可训练参数最少,但是整体上效果最好。
生成任务上:


在ROBbase 、GPT-2和GPT-3上,LORA 也取得了不错的效果(见上图)。
当增加微调方法的可训练参数量时,其它微调方法都出现了性能下降的现象,只有 LORA 的性能保持了稳定,见下图:
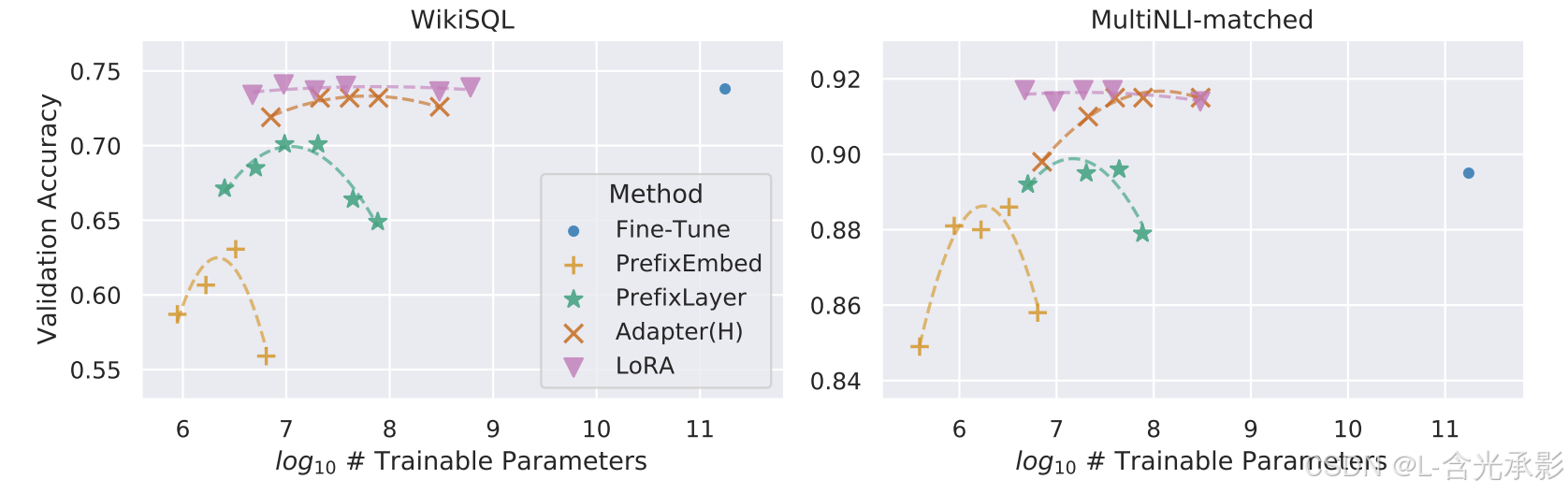
秩的选择:

实验结果显示,对于一般的任务, r r r取1,2,4,8就足够了,而一些领域差距比较大的任务可能需要更大的取值。
同时,增加 r r r 并不能提升微调的效果,这可能是因为参数量增加需要更多的语料。
总结
LoRA(Low-Rank Adaptation)是一种面向大规模预训练语言模型的参数高效微调方法,它通过引入两个低秩矩阵对权重更新进行重参数化,从而在冻结原始模型权重的基础上,仅训练极少量参数以适配下游任务。其核心结构是在特定的线性层(如注意力投影)中加入一个低秩的增量模块,训练时只更新该模块,并通过 Δ W = B A \Delta W = BA ΔW=BA的形式替代对原始权重 W W W的直接微调;推理时,该增量可以被合并进原模型中,不增加计算开销。LoRA 的工作流程包括:选择目标层、插入低秩模块、初始化并训练 A , B A,B A,B,以及部署前合并增量,实现在不影响模型性能的前提下大幅减少计算和存储成本。它的优势在于参数效率高、推理延迟低、适合多任务部署,缺点则包括对任务适配位置敏感、尚未覆盖非线性模块,以及难以在多任务共享权重场景中完全合并模型。未来研究可进一步探索其在 MLP、LayerNorm 等模块中的扩展应用、多任务场景下的动态权重调度机制,以及与提示学习等方法的融合潜力。
相关文章:

【第三十六周】LoRA 微调方法
LoRA 摘要Abstract文章信息引言方法LoRA的原理LoRA在Transformer中的应用补充其他细节 实验与分析LoRA的使用论文实验结果分析 总结 摘要 本篇博客介绍了LoRA(Low-Rank Adaptation),这是一种面向大规模预训练语言模型的参数高效微调方法&…...

fcQCA模糊集定性比较分析法-学习笔记
模糊集定性比较分析(fsQCA,Fuzzy-set Qualitative Comparative Analysis) 是一种结合了定性和定量元素的研究方法,用于分析中小样本数据中的复杂因果关系。 1. 理解基础概念 QCA的核心思想: 基于集合论和布尔代数&a…...

基于WebRTC的实时语音对话系统:从语音识别到AI回复
基于WebRTC的实时语音对话系统:从语音识别到AI回复 在当今数字化时代,实时语音交互已成为人机界面的重要组成部分。本文将深入探讨一个基于WebRTC技术的实时语音对话系统,该系统集成了语音识别(ASR)、大语言模型(LLM)和语音合成(TTS)技术&am…...

Text2SQL:自助式数据报表开发---0517
Text2SQL技术 早期阶段:依赖于人工编写的规则模板来匹配自然语言和SQL语句之间的对应关系 机器学习阶段:采用序列到序列模型等机器学习方法来学习自然语言与SQL之间的关系 LLM阶段:借助LLM强大的语言理解和代码生成能力,利用提示…...
)
关于 Web 漏洞原理与利用:1. SQL 注入(SQLi)
一、原理: 拼接 SQL 语句导致注入 SQL 注入的根本原因是:开发者将用户的输入和 SQL 语句直接拼接在一起,没有任何过滤或校验,最终被数据库“当作语句”执行了。 这就像是我们给数据库写了一封信,结果攻击者在我们的…...

【NLP 75、如何通过API调用智谱大模型】
事事忘记,事事等待,事事自愈 —— 25.5.18 一、调用智谱大模型 zhipuai.model_api.invoke():调用智谱 AI 的大模型(如 ChatGLM)进行文本生成或推理,支持同步请求。 参数列表 参数名类型是否必需默认值说…...
)
【RabbitMQ】 RabbitMQ高级特性(二)
文章目录 一、重试机制1.1、重试配置1.2、配置交换机&队列1.3、发送消息1.4、消费消息1.5、运行程序1.6、 手动确认 二、TTL2.1、设置消息的TTL2.2、设置队列的TTL2.3、两者区别 三 、死信队列6.1 死信的概念3.2 代码示例3.2.1、声明队列和交换机3.2.2、正常队列绑定死信交…...

EMQX开源版安装指南:Linux/Windows全攻略
EMQX开源版安装教程-linux/windows 因最近自己需要使用MQTT,需要搭建一个MQTT服务器,所以想到了很久以前用到的EMQX。但是当时的EMQX使用的是开源版的,在官网可以直接下载。而现在再次打开官网时发现怎么也找不大开源版本了,所以…...

MySQL 数据库备份与还原
作者:IvanCodes 日期:2025年5月18日 专栏:MySQL教程 思维导图 备份 (Backup) 与 冗余 (Redundancy) 的核心区别: 🎯 备份是指创建数据的副本并将其存储在不同位置或介质,主要目的是在发生数据丢失、损坏或逻辑错误时进…...

【数据结构】2-3-4 单链表的建立
数据结构知识点合集 尾插法建立单链表 建立链表时总是将新节点插入到链表的尾部,将新插入的节点作为链表的尾节点 /*尾插法建立链表L*/ LinkList List_TailInsert(LinkList &L) { int x; /*建立头节点*/ L (LNode *)malloc(sizeof(LNode)); /*…...

JVM如何处理多线程内存抢占问题
目录 1、堆内存结构 2、运行时数据 3、内存分配机制 3.1、堆内存结构 3.2、内存分配方式 1、指针碰撞 2、空闲列表 4、jvm内存抢占方案 4.1、TLAB 4.2、CAS 4.3、锁优化 4.4、逃逸分析与栈上分配 5、问题 5.1、内存分配竞争导致性能下降 5.2、伪共享(…...

猫番阅读APP:丰富资源,优质体验,满足你的阅读需求
猫番阅读APP是一款专为书籍爱好者设计的移动阅读应用,致力于提供丰富的阅读体验和多样化的书籍资源。它不仅涵盖了小说、非虚构、杂志等多个领域的电子书,还提供了个性化推荐、书架管理、离线下载等功能,满足不同读者的阅读需求。无论是通勤路…...

Redis 学习笔记 4:优惠券秒杀
Redis 学习笔记 4:优惠券秒杀 本文基于前文的黑马点评项目进行学习。 Redis 生成全局唯一ID 整个全局唯一 ID 的结构如下: 这里的时间戳是当前时间基于某一个基准时间(项目开始前的某个时间点)的时间戳。序列号是依赖 Redis 生…...

C++学习:六个月从基础到就业——C++17:if/switch初始化语句
C学习:六个月从基础到就业——C17:if/switch初始化语句 本文是我C学习之旅系列的第四十六篇技术文章,也是第三阶段"现代C特性"的第八篇,主要介绍C17引入的if和switch语句的初始化表达式特性。查看完整系列目录了解更多内…...

C++跨平台开发经验与解决方案
在当今软件开发领域,跨平台开发已成为一个重要的需求。C作为一种强大的系统级编程语言,在跨平台开发中扮演着重要角色。本文将分享在实际项目中的跨平台开发经验和解决方案。 1. 构建系统选择 CMake的优势 跨平台兼容性好 支持多种编译器和IDE 强大…...
)
RabbitMQ 工作模式(上)
前言 在 RabbitMQ 中,一共有七种工作模式,我们也可以打开官网了解: 本章我们先介绍前三种工作模式 (Simple)简单模式 P:producer 生产者,负责发送消息 C:consumer 消费者&#x…...

为什么需要加密机服务?
前言 大家好,我是老马。 以前我自己在写工具的时候,都是直接自己实现就完事了。 但是在大公司,或者说随着合规监管的要求,自己随手写的加解密之类的,严格说是不合规的。 作为一家技术性公司,特别是金融…...

【Linux】利用多路转接epoll机制、ET模式,基于Reactor设计模式实现
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:多路转接epoll,实现echoserver 至此,Linux与…...

c/c++的findcontours崩溃解决方案
解决 Windows 平台 OpenCV findContours 崩溃:一种更稳定的方法 许多在 Windows 平台上使用 OpenCV 的开发者可能会在使用 findContours 函数时,遇到令人头疼的程序崩溃问题。尽管网络上流传着多种解决方案,但它们并非总能根治此问题。 当时…...

机器学习 Day18 Support Vector Machine ——最优美的机器学习算法
1.问题导入: 2.SVM定义和一些最优化理论 2.1SVM中的定义 2.1.1 定义 SVM 定义:SVM(Support Vector Machine,支持向量机)核心是寻找超平面将样本分成两类且间隔最大 。它功能多样,可用于线性或非线性分类…...

npm与pnpm--为什么推荐pnpm
包管理器中 npm是最经典的,但大家都任意忽略一个更优质的管理器:pnpm 1. 核心区别 特性npmpnpm依赖存储方式扁平化结构(可能重复依赖)硬链接 符号链接(共享依赖,节省空间)安装速度较慢&#…...

ollama调用千问2.5-vl视频图片UI界面小程序分享
1、问题描述: ollama调用千问2.5-vl视频图片内容,通常用命令行工具不方便,于是做了一个python UI界面与大家分享。需要提前安装ollama,并下载千问qwen2.5vl:7b 模型,在ollama官网即可下载。 (8G-6G 显卡可…...

济南国网数字化培训班学习笔记-第三组-1-电力通信传输网认知
电力通信传输网认知 电力通信基本情况 传输介质 传输介质类型(导引与非导引) 导引传输介质,如电缆、光纤; 非导引传输介质,如无线电波; 传输介质的选择影响信号传输质量 信号传输模式(单工…...
:pod sandbox(pause)容器)
Kubernetes控制平面组件:Kubelet详解(六):pod sandbox(pause)容器
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

51单片机,两路倒计时,LCD1602 ,Proteus仿真
初始上电 默认2路都是0分钟的倒计时 8个按键 4个一组 一组控制一路倒计时 4个 按键:加 减 开始或者暂停 复位到0分钟相当于停止 针对第一路倒计时 4个 按键2:加 减 开始或者暂停 复位到0分钟相当于停止 针对第2路倒计时 哪一路到了0后蜂鸣器响 对应LED点亮 main.c 文件实现了…...

MySQL之储存引擎和视图
一、储存引擎 基本介绍: 1、MySQL的表类型由储存引擎(Storage Engines)决定,主要包括MyISAM、innoDB、Memory等。 2、MySQL数据表主要支持六种类型,分别是:CSV、Memory、ARCHIVE、MRG_MYISAN、MYISAM、InnoBDB。 3、这六种又分…...
连接mysql数据库,写入计算结果)
写spark程序数据计算( 数据库的计算,求和,汇总之类的)连接mysql数据库,写入计算结果
1. 添加依赖 在项目的 pom.xml(Maven)中添加以下依赖: xml <!-- Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.3.0…...

一:操作系统之系统调用
系统调用:用户程序与操作系统交互的桥梁 在计算机的世界里,应用程序是我们日常接触最多的部分,比如浏览器、文本编辑器、游戏等等。然而,这些应用程序并不能直接控制硬件资源,比如读写硬盘、创建新进程、发送网络数据…...
)
【ROS2】 核心概念6——通信接口语法(Interfaces)
古月21讲/2.6_通信接口 官方文档:Interfaces — ROS 2 Documentation: Humble documentation 官方接口代码实战:https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/Single-Package-Define-And-Use-Interface.html ROS 2使用简化的描…...

SmartETL函数式组件的设计与应用
SmartETL框架主要采用了面向对象的设计思想,将ETL过程中的处理逻辑抽象为Loader和Processor(对应loader模块和iterator模块),所有流程组件需要继承或实现DataProvider(iter方法)或JsonIterator(…...

Spring Security与SaToken的对比与优缺点分析
Spring Security与SaToken对比分析 一、框架定位 Spring Security 企业级安全解决方案,深度集成Spring生态提供完整的安全控制链(认证、授权、会话管理、攻击防护)适合中大型分布式系统 SaToken 轻量级权限认证框架,专注Token会…...

|从零开始的Pyside2界面编程| 环境搭建以及第一个ui界面
🐑 |从零开始的Pyside2界面编程| 环境搭建以及第一个ui界面🐑 文章目录 🐑 |从零开始的Pyside2界面编程| 环境搭建以及第一个ui界面🐑♈前言♈♈Pyside2环境搭建♈♈做个简单的UI界面♈♒代码实现♒♒QTdesigner设计UI界面♒ ♒总…...

【爬虫】DrissionPage-7
官方文档: https://www.drissionpage.cn/browser_control/get_page_info/ 1. 页面信息 📌 html 描述:返回当前页面的 HTML 文本。注意:不包含 <iframe> 元素的内容。返回类型:str 示例: html_co…...
:统一过程模型(RUP))
系统架构设计(十二):统一过程模型(RUP)
简介 RUP 是由 IBM Rational 公司提出的一种 面向对象的软件工程过程模型,以 UML 为建模语言,是一种 以用例为驱动、以架构为中心、迭代式、增量开发的过程模型。 三大特征 特征说明以用例为驱动(Use Case Driven)需求分析和测…...

深入解析Java事件监听机制与应用
Java事件监听机制详解 一、事件监听模型组成 事件源(Event Source) 产生事件的对象(如按钮、文本框等组件) 事件对象(Event Object) 封装事件信息的对象(如ActionEvent包含事件源信息…...

QT聊天项目DAY11
1. 验证码服务 1.1 用npm安装redis npm install redis 1.2 修改config.json配置文件 1.3 新建redis.js const config_module require(./config) const Redis require("ioredis");// 创建Redis客户端实例 const RedisCli new Redis({host: config_module.redis_…...

Python训练营---Day29
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

Flask-SQLAlchemy_数据库配置
1、基本概念(SQLAlchemy与Flask-SQLAlchemy) SQLAlchemy 是 Python 生态中最具影响力的 ORM(对象关系映射)库,其设计理念强调 “框架无关性”,支持在各类 Python 项目中独立使用,包括 Flask、D…...
-社科数据)
世界银行数字经济指标(1990-2022年)-社科数据
世界银行数字经济指标(1990-2022年)-社科数据https://download.csdn.net/download/paofuluolijiang/90623839 https://download.csdn.net/download/paofuluolijiang/90623839 此数据集涵盖了1990年至2022年间全球各国的数字经济核心指标,数据…...

Redis进阶知识
Redis 1.事务2. 主从复制2.1 如何启动多个Redis服务器2.2 监控主从节点的状态2.3 断开主从复制关系2.4 额外注意2.5拓扑结构2.6 复制过程2.6.1 数据同步 3.哨兵选举原理注意事项 4.集群4.1 数据分片算法4.2 故障检测 5. 缓存5.1 缓存问题 6. 分布式锁 1.事务 Redis的事务只能保…...

NY337NY340美光固态颗粒NC010NC012
NY337NY340美光固态颗粒NC010NC012 在存储技术的浩瀚星空中,美光的NY337、NY340、NC010、NC012等固态颗粒宛如璀璨星辰,闪耀着独特的光芒。它们承载着先进技术与无限潜力,正深刻影响着存储行业的格局与发展。 一、技术架构与核心优势 美光…...

DAY26 函数定义与参数
浙大疏锦行-CSDN博客 知识点回顾: 1.函数的定义 2.变量作用域:局部变量和全局变量 3.函数的参数类型:位置参数、默认参数、不定参数 4.传递参数的手段:关键词参数 5.传递参数的顺序:同时出现三种参数类型时 函数的定义…...

系统安全及应用
目录 一、账号安全控制 1.基本安全措施 (1)系统账号清理 (2)密码安全控制 (3)历史命令,自动注销 2.用户提权和切换命令 2.1 su命令用法 2.2 sudo命令提权 2.3通过是sudo执行特权命令 二、系统引导和登录控制…...
)
微信小程序 地图 使用 射线法 判断目标点是否在多边形内部(可用于判断当前位置是否在某个区域内部)
目录 射线法原理简要逻辑代码 小程序代码调试基础库小程序配置地图数据地图多边形点与多边形关系 射线法 原理 使用射线法来判断,目标点是否在多边形内部 这里简单说下,具体细节可以看这篇文章 平面几何:判断点是否在多边形内(…...

第三十七节:视频处理-视频读取与处理
引言:解码视觉世界的动态密码 在数字化浪潮席卷全球的今天,视频已成为信息传递的主要载体。从短视频平台的爆火到自动驾驶的视觉感知,视频处理技术正在重塑人类与数字世界的交互方式。本指南将深入探讨视频处理的核心技术,通过Python与OpenCV的实战演示,为您揭开动态影像…...

什么是 Flink Pattern
在 Apache Flink 中,Pattern 是 Flink CEP(Complex Event Processing)模块 的核心概念之一。它用于定义你希望从数据流中检测出的 事件序列模式(Event Sequence Pattern)。 🎯 一、什么是 Flink Pattern&am…...

ADB基本操作和命令
1.ADB的含义 adb 命令是 Android 官方提供,调试 Android 系统的工具。 adb 全称为 Android Debug Bridge(Android 调试桥),是 Android SDK 中提供的用于管理 Android 模拟器或真机的工具。 adb 是一种功能强大的命令行工具&#x…...

NSString的三种实现方式
oc里的NSString有三种实现方式,为_ _NSCFConstantString、__NSCFString、NSTaggedPointerString 1._ _NSCFConstantString(字面量字符串) 从字面意思上可以看出,_ _NSCFContantString可以理解为常量字符串,这种类型的字符串在编译期就确定了…...

2025年PMP 学习二十 第13章 项目相关方管理
第13章 项目相关方管理 序号过程过程组过程组1识别相关方启动2规划相关方管理规划3管理相关方参与与执行4监控相关方参与与监控 相关方管理,针对于团队之外的相关方的,核心目标是让对方为了支持项目,以达到项目目标。 文章目录 第13章 项目相…...

学习黑客Kerberos深入浅出:安全王国的门票系统
Kerberos深入浅出:安全王国的门票系统 🎫 作者: 海尔辛 | 发布时间: 2025-05-18 🔑 理解Kerberos:为什么它如此重要? Kerberos是现代网络环境中最广泛使用的身份验证协议之一,尤其在Windows Active Dire…...