一周学会Pandas2 Python数据处理与分析-Pandas2数据添加修改删除操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

对数据的修改、增加和删除在数据整理过程中时常发生。修改的情况一般是修改错误,还有一种情况是格式转换,如把中文数字修改为阿拉伯数字。修改也会涉及数据的类型修改。 删除一般会通过筛选的方式,筛选完成后将最终的结果重新赋值给变量,达到删除的目的。增加行和列是最为常见的操作,数据分析过程中会计算出新的指标以新列展示。
修改数据值操作
在Pandas中修改数值非常简单,先筛选出需要修改的数值范围,再 为这个范围重新赋值。
下面是示例:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.iloc[0, 0]='老六' # 修改数据
df.loc[df.语文分数 < 60, '语文分数'] = 60 # 指定范围修改数据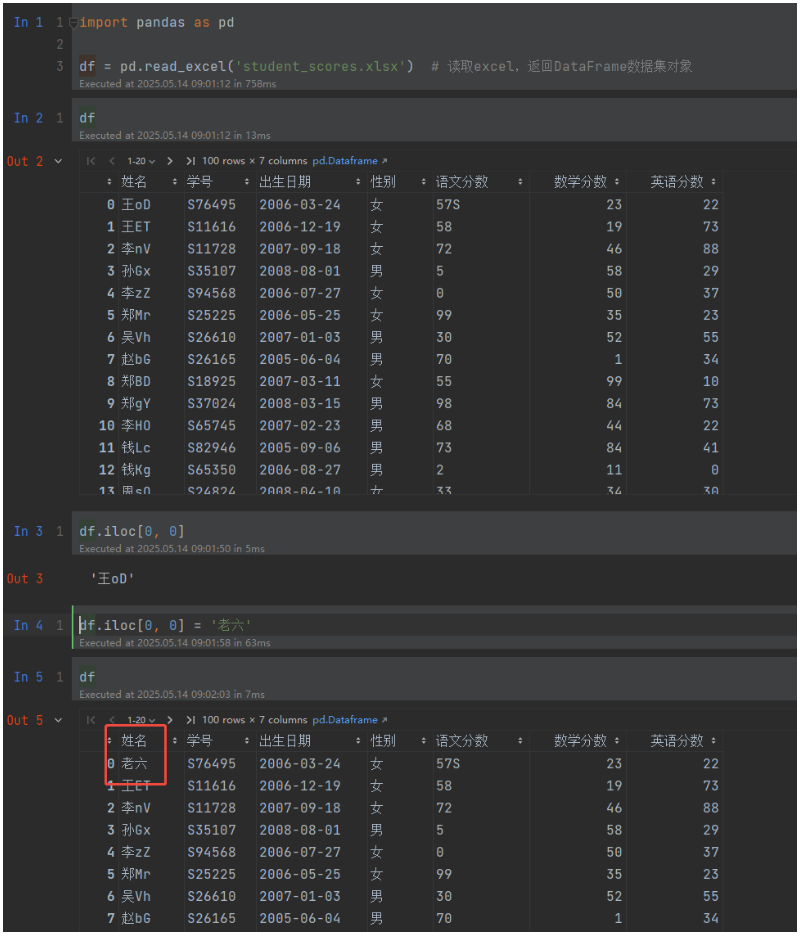
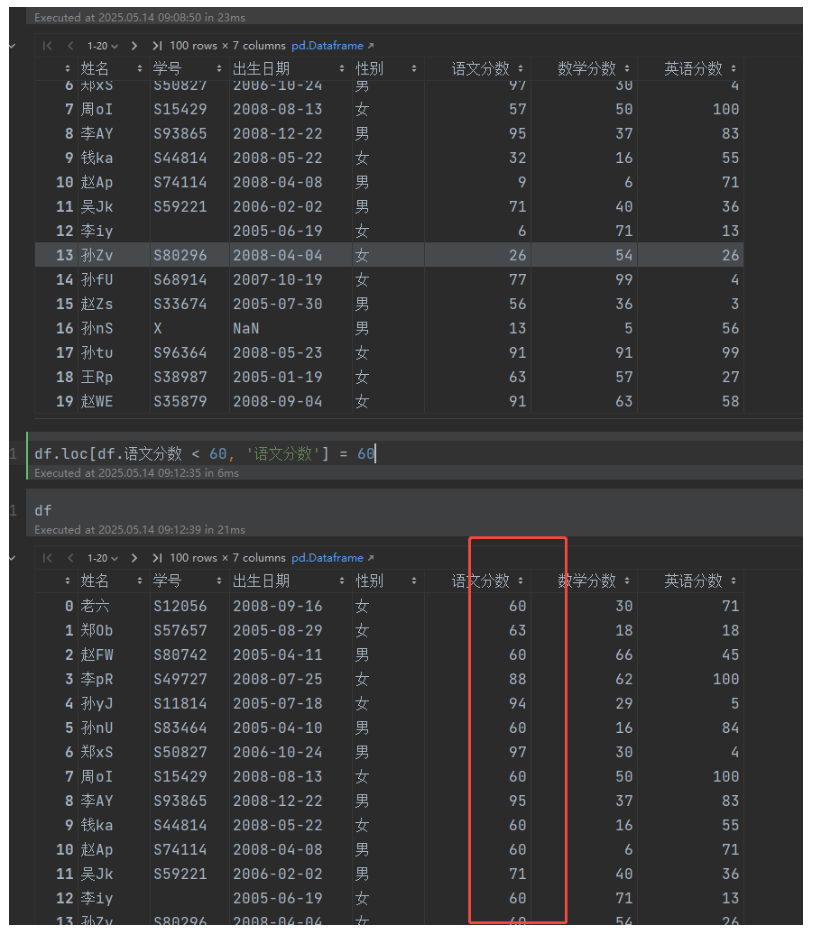
以上操作df变量的内容被修改,这里指定的是一个定值,所有满足条件的数据均被修改为这个定值。还可以传一个同样形状的数据来修改值:
看下示例:
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 22, 28],'Score': [85, 95, 75, 88]
}
df = pd.DataFrame(data)
v = [100, 100, 100, 100]
df.Score = v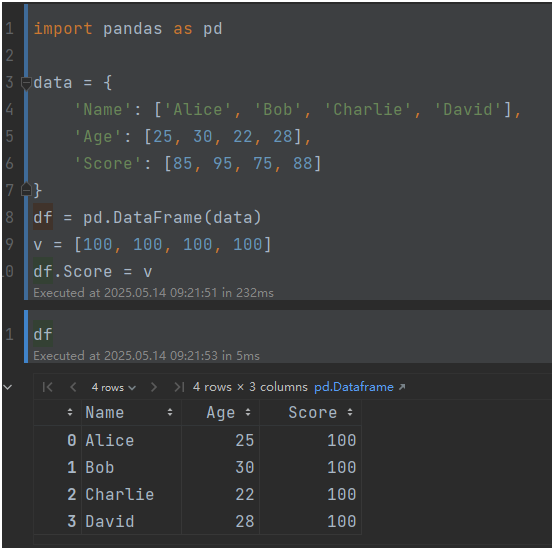
替换数据replace()操作
pandas的replace()方法是用于替换DataFrame或Series中的值的灵活工具。以下是其使用方法的详细介绍:
1,方法定义
replace() 方法的语法如下:
DataFrame.replace(to_replace=None, # 要替换的值(支持多种格式)value=None, # 替换后的值inplace=False, # 是否原地修改limit=None, # 最大替换次数regex=False, # 是否启用正则表达式method=None # 填充方法(已弃用)
)2,核心参数详解
to_replace(必选)
-
功能:指定需要被替换的内容。
-
支持类型:
-
标量:单个值(如
0)。 -
列表:多个值(如
[0, 1])。 -
字典:
-
{old_val: new_val}:全局替换(所有列)。 -
{column: {old_val: new_val}}:按列指定替换规则。
-
-
正则表达式:需设置
regex=True。
-
value(可选)
-
功能:替换后的新值,默认
None。 -
规则:
-
若
to_replace是标量或列表,value可以是单个值或与to_replace等长的列表。 -
若
to_replace是字典,value通常被忽略(直接在字典中定义新旧值)。
-
regex(布尔值,默认 False)
-
功能:是否将
to_replace视为正则表达式模式。 -
示例:
# 将包含数字的字符串替换为 'X' df.replace(to_replace=r'\d+', value='X', regex=True)
inplace(布尔值,默认 False)
-
功能:若为
True,直接修改原对象,不返回新对象;否则返回替换后的副本。
limit(整数,默认 None)
-
功能:限制连续替换的最大次数(适用于相邻重复值的替换场景)。
3,使用场景与示例
简单值替换:
import pandas as pd
import numpy as np# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})# 将 0 替换为 -1(全局)
df.replace(0, -1)# 将 0 和 1 替换为 -1 和 -2
df.replace([0, 1], [-1, -2])# 按列替换:A列的1替换为100,C列的0替换为-1
df.replace({'A': {1: 100}, 'C': {0: -1}})正则表达式替换:
import pandas as pd# 将字符串中的数字替换为 'X'
df = pd.DataFrame({'Text': ['A1', 'B2', 'C3']})
df.replace(to_replace=r'\d', value='X', regex=True)
# 输出:
# Text
# 0 AX
# 1 BX
# 2 CX缺失值处理:
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 将 NaN 替换为 0
df.replace(np.nan, 0)多值嵌套字典替换:
import pandas as pd
import numpy as np# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 多层字典结构:不同列使用不同规则
df.replace({'A': {1: 100, 2: 200}, # A列:1→100,2→200'B': {'a': 'Alpha'} # B列:a→Alpha
})混合类型替换:
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4],'B': ['a', 'b', 'c', 'd'],'C': [0, 1, np.nan, 1]
})
# 同时替换数值和字符串
df.replace({0: 'Zero', # 全局将0替换为'Zero''a': 'Alpha' # 全局将'a'替换为'Alpha'
})空值填充fillna()操作
pandas 的 fillna() 方法是处理缺失值(NaN或None)的核心工具,用于填充或替换数据中的空值。以下是其定义、参数详解及常见使用场景的完整指南:
1,方法定义
DataFrame.fillna(value=None, # 填充值(标量、字典、Series或DataFrame)method=None, # 填充方法:'ffill'(向前填充)、'bfill'(向后填充)axis=None, # 填充方向:0(沿行,默认),1(沿列)inplace=False, # 是否原地修改limit=None, # 最大连续填充次数downcast=None # 自动向下转换数据类型(可选)
)2,核心参数详解
value
-
功能:指定填充缺失值的具体内容。
-
支持类型:
-
标量:如
0、"missing"。 -
字典:按列指定填充值(键为列名)。
-
Series/DataFrame:对齐索引后填充(需形状匹配)。
-
method
-
功能:选择填充策略,与
value互斥(不能同时使用)。-
'ffill'/'pad':用前一个非空值填充。 -
'bfill' / 'backfill':用后一个非空值填充。
-
axis
-
功能:控制填充方向:
-
axis=0或axis='index':按行填充(默认)。 -
axis=1或axis='columns':按列填充。
-
limit
-
功能:限制连续填充的最大次数(如
limit=2表示最多填充连续2个NaN)。
inplace
-
功能:若为
True,直接修改原对象,否则返回新对象。
3,使用场景
用固定值填充
import pandas as pd
import numpy as np
# 示例数据
df = pd.DataFrame({'A': [1, np.nan, 3, np.nan],'B': ['x', np.nan, 'y', np.nan],'C': [np.nan, 5, np.nan, 7]
})
# 所有NaN填充为0
df.fillna(0)
# 按列指定填充值(A列填0,B列填'missing')
df.fillna({'A': 0, 'B': 'missing'})向前/向后填充
# 向前填充(用前一个非空值)
df.fillna(method='ffill')# 向后填充(用后一个非空值)
df.fillna(method='bfill')限制填充次数
# 最多连续填充2个NaN
df.fillna(value='Q', limit=2)增加列操作
增加列是数据处理中最常见的操作,Pandas可以像定义一个变量一 样定义DataFrame中新的列,新定义的列是实时生效的。与数据修改的逻辑一样,新列可以是一个定值,所有行都为此值,也可以是一个同等长度的序列数据,各行有不同的值。接下来我们增加总成绩total列:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df['总分'] = df.语文分数 + df.数学分数 + df.英语分数我们也可以用insert()方法在指定位置插入列。
方法定义:
DataFrame.insert(loc, # 插入位置的索引(从0开始)column, # 新列的名称value, # 新列的数据(标量、数组、Series等)allow_duplicates=False # 是否允许列名重复(默认不允许)
)核心参数说明:
-
loc:插入位置的整数索引(如
0表示第一列前)。 -
column:新列的名称(字符串)。
-
value:新列的数据,可以是标量、列表、NumPy 数组、Series 等。
-
allow_duplicates:若为
True,允许插入与现有列同名的列(默认False会触发错误)。
我们在第5列插入总分字段
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.insert(4, '总分', df.语文分数 + df.数学分数 + df.英语分数) # 在第5列插入总分字段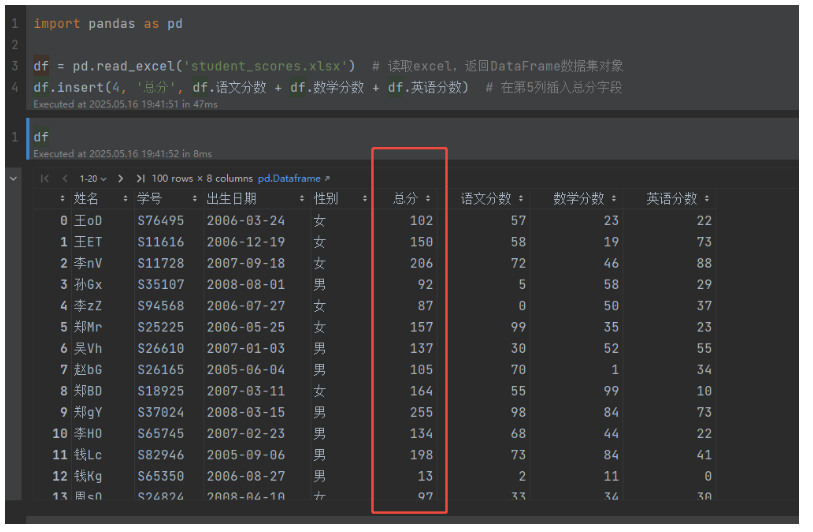
还有一个assign()方法,pandas 的 assign() 方法是 链式操作(Method Chaining) 中的核心工具,用于动态添加新列或覆盖现有列,不修改原 DataFrame,而是返回一个新的 DataFrame。它特别适合在数据处理流程中优雅地添加多列或进行复杂计算。以下是其详细使用指南:
方法定义:
DataFrame.assign(**kwargs) -> DataFrame参数:kwargs 是以列名为键的键值对,值可以是:
-
标量、列表、数组、Series。
-
一个函数(如
lambda),参数为当前 DataFrame。
返回值:返回包含新列的新 DataFrame,原 DataFrame 不变。
特点:支持动态列名、链式调用,适合函数式编程。
我们动态添加一个总分列:
import pandas as pd
df = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df_new = df.assign(总分=df.语文分数 + df.数学分数 + df.英语分数)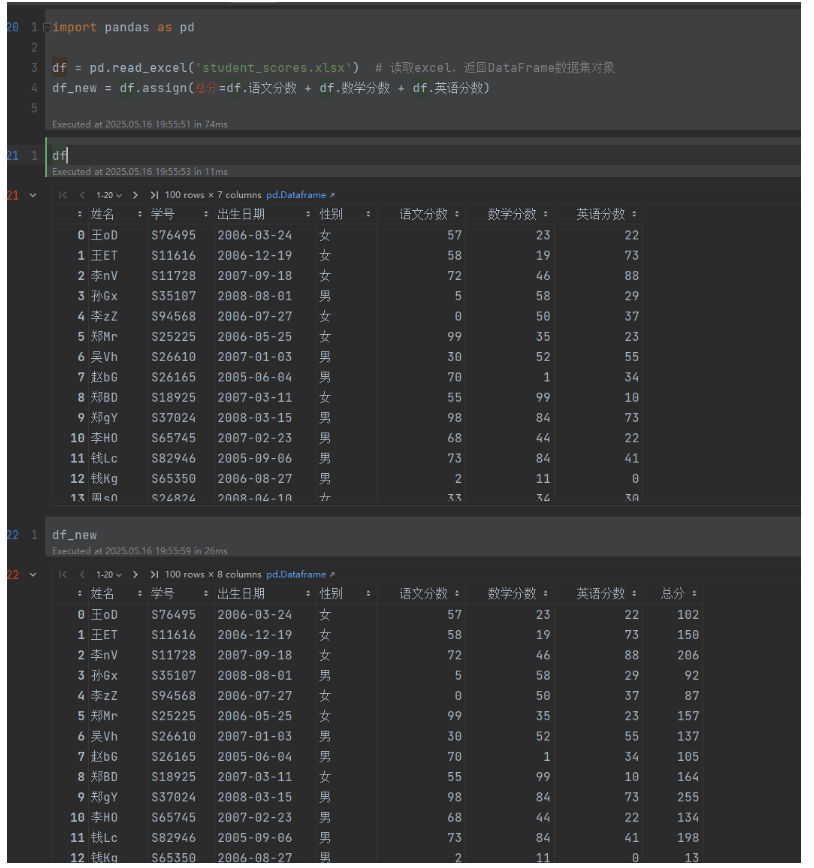
最后再介绍一个eval()方法,可以以字符串的形式传入表达式,增加列数据。我们还是以增加总分示例来学习下:
import pandas as pddf = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.eval('总分=语文分数 + 数学分数 + 英语分数')eval()方法定义:
DataFrame.eval(expr, # 表达式字符串(必填)inplace=False, # 是否原地修改(默认为False)**kwargs # 其他参数(如engine, target等)
)核心参数:
expr: 要执行的表达式字符串(例如 "A + B")。
inplace: 若为 True,直接修改原 DataFrame;若为 False,返回新对象(默认)。
engine: 计算引擎('numexpr' 或 'python'),默认自动选择。
target: 指定计算结果存储的列名或位置(可选)。
增加行操作
可以使用loc[]指定索引给出所有列的值来增加一行数据。
import pandas as pd
df = pd.read_excel('student_scores.xlsx') # 读取excel,返回DataFrame数据集对象
df.loc[100] = ['老六', 'S1111', '1999-11-11', '男', 10, 10, 10]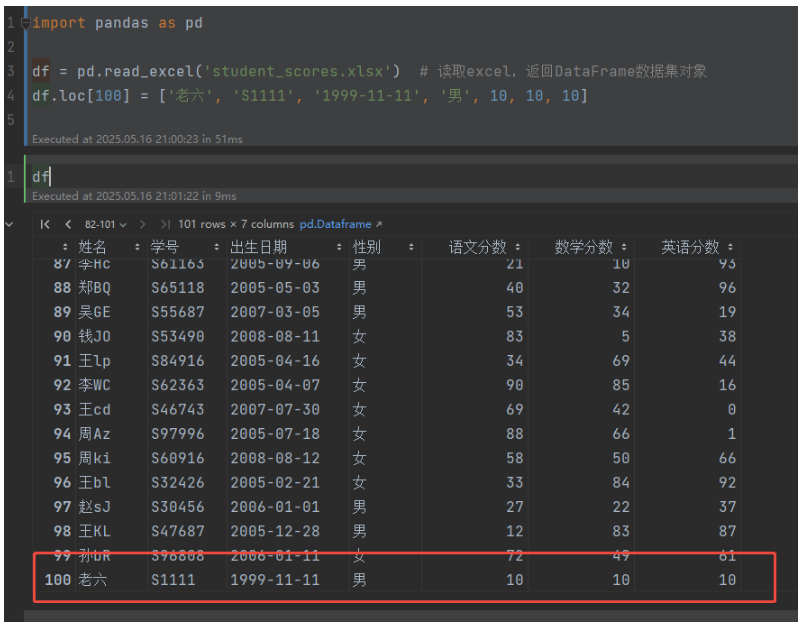
还可以指定列,无数据的列值为NaN
df.loc[101] = {'姓名': '老七', '学号': 'S11122', '性别': '男'}自动增加索引
df.loc[len(df)] = {'姓名': '老八', '学号': 'S11123', '性别': '女'}
追加合并concat()操作
pandas 的 concat() 方法是用于 沿指定轴(行或列)合并多个 DataFrame 或 Series 的核心工具,支持灵活的数据拼接逻辑。
方法定义:
pd.concat(objs, # 要合并的对象列表(如[df1, df2])axis=0, # 合并方向:0(行方向,默认)或1(列方向)join='outer', # 合并方式:'outer'(并集)或 'inner'(交集)ignore_index=False, # 是否忽略原索引(默认保留)keys=None, # 创建分层索引(标识来源)names=None, # 分层索引的名称verify_integrity=False, # 检查索引是否重复sort=False # 是否对列名排序(默认不排序)
) -> DataFrame/Series纵向堆叠(行合并)示例:
import pandas as pd# 示例数据
df1 = pd.DataFrame({'A': [1, 2], 'B': ['x', 'y']})
df2 = pd.DataFrame({'A': [3, 4], 'B': ['z', 'w']})# 沿行方向合并(默认axis=0)
result = pd.concat([df1, df2], ignore_index=True)
print(result)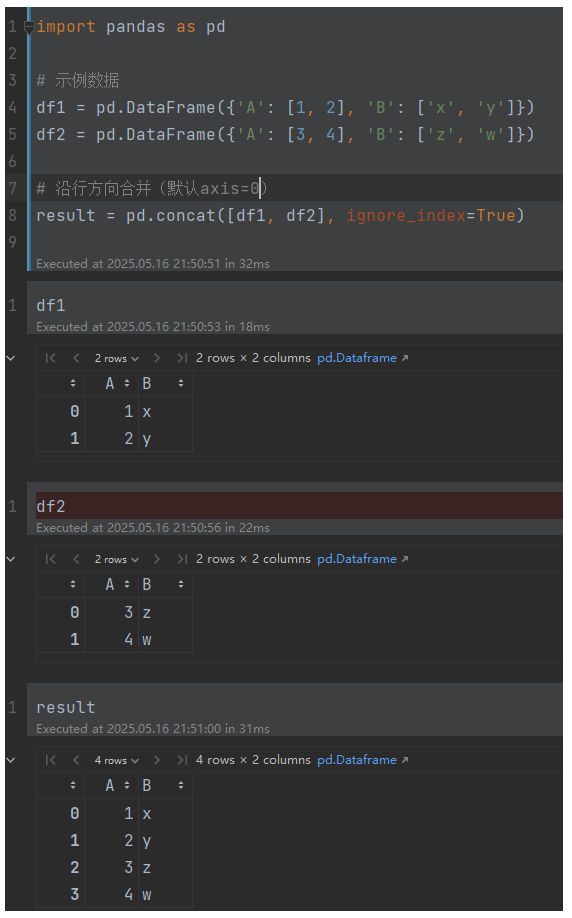
横向拼接(列合并)示例:
df3 = pd.DataFrame({'C': [10, 20], 'D': [True, False]})# 沿列方向合并(axis=1)
result = pd.concat([df1, df3], axis=1)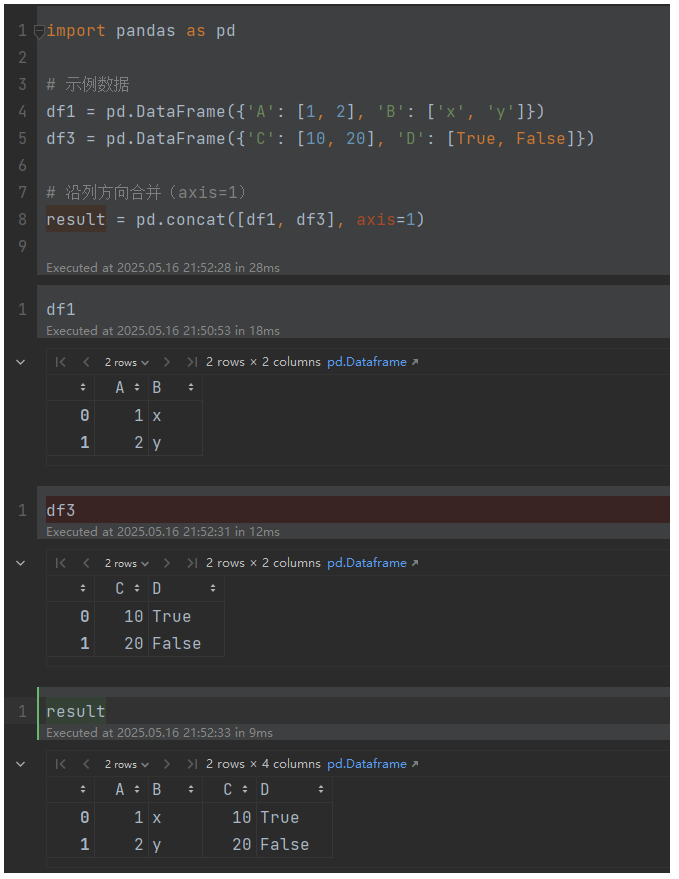
行列删除drop()和pop()操作
pandas 的 pop() 方法用于从 DataFrame 或 Series 中删除指定的列或元素,并返回被删除的数据。该方法直接修改原对象(原地操作),适合需要移除数据并立即使用该数据的场景。以下是详细的使用指南:
方法定义:
# DataFrame 的 pop 方法
DataFrame.pop(item: str) -> Series# Series 的 pop 方法
Series.pop(item: Hashable) -> Any参数说明:
-
item:要删除的列名(DataFrame)或索引标签(Series)。
-
返回值:被删除的列(Series)或元素(标量)。
删除列示例:
import pandas as pd# 创建示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['x', 'y', 'z'],'C': [10, 20, 30]
})# 删除并返回列 'B'
popped_column = df.pop('B')print("删除后的 DataFrame:")
print(df)
print("\n被删除的列:")
print(popped_column)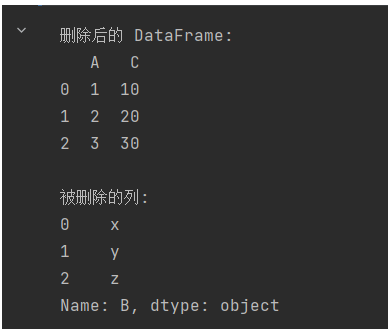
pop()方法只能删除列。我们在学习下drop()方法,行列都能删除。
pandas 的 drop() 方法是用于从 DataFrame 或 Series 中删除指定行或列的核心工具。它支持通过标签或索引位置删除数据,并提供了灵活的参数控制。
方法定义:
DataFrame.drop(labels=None, # 要删除的行/列标签(单个或列表)axis=0, # 删除方向:0(行,默认)或 1(列)index=None, # 直接指定行标签(替代 axis=0)columns=None, # 直接指定列标签(替代 axis=1)level=None, # 多级索引的层级(针对分层索引)inplace=False, # 是否原地修改(默认返回新对象)errors='raise' # 错误处理:'raise'(报错)或 'ignore'
) -> DataFrame | None删除列示例:
import pandas as pd# 创建示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['x', 'y', 'z'],'C': [10, 20, 30]
})# 删除单列(两种等价写法)
df_dropped = df.drop(columns='B') # 写法1:columns参数
df_dropped = df.drop(labels='B', axis=1) # 写法2:labels + axis=1# 删除多列
df_dropped = df.drop(columns=['B', 'C'])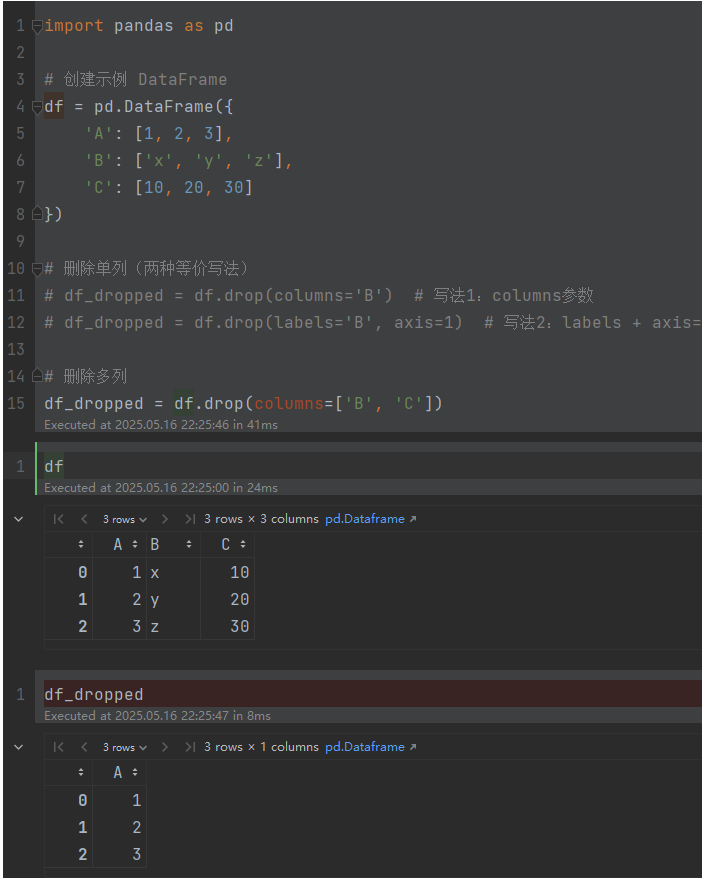
删除行示例:
# 删除单行(按行标签)
df_dropped = df.drop(index=0) # 删除索引为0的行
df_dropped = df.drop(labels=0, axis=0) # 等价写法# 删除多行(按标签或位置)
df_dropped = df.drop(index=[0, 2]) # 删除索引为0和2的行
df_dropped = df.drop([0, 2], axis=0) # 等价写法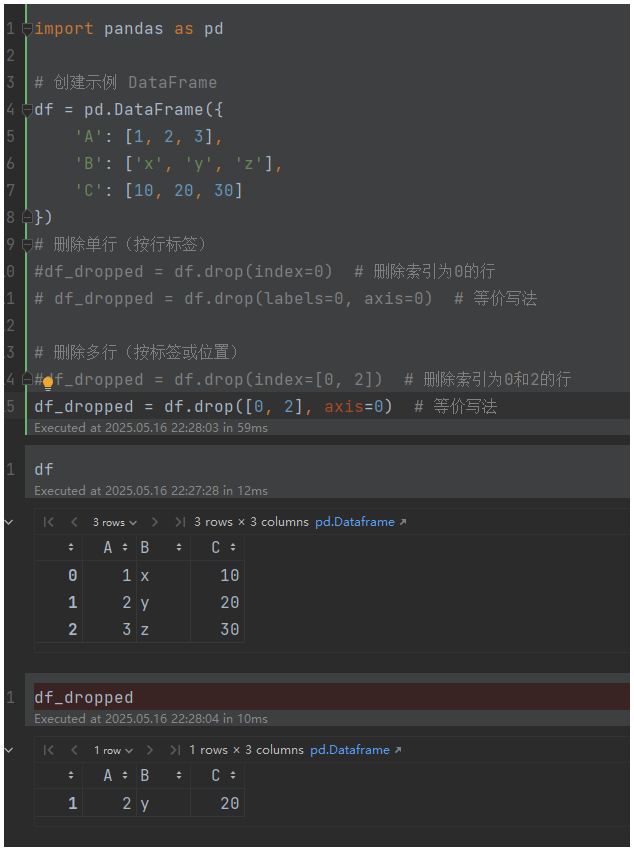
pop()和drop()方法对比
| 方法 | 操作对象 | 返回值 | 修改原对象 | 常用场景 |
|---|---|---|---|---|
pop() | 列或元素 | 被删除的数据 | 是 | 需要立即使用被删除的数据 |
drop() | 行或列 | 新对象(默认) | 否(需inplace=True) | 保留原数据,生成新对象 |
删除空值dropna()操作
dropna方法是pandas中处理缺失值的重要工具,用于删除包含缺失值(NaN或None)的行或列。它在数据清洗阶段非常有用,能帮助我们快速移除不完整的数据记录。以下是dropna方法的详细使用说明:
方法定义:
DataFrame.dropna(axis=0, # 操作方向:0或'index'(删除行),1或'columns'(删除列)how='any', # 删除条件:'any'(存在缺失即删),'all'(全为缺失才删)thresh=None, # 非缺失值的最小数量(阈值)subset=None, # 指定检查的列(行)子集inplace=False # 是否直接修改原数据(默认返回新对象)
)参数解析
-
axis:默认为0,即删除包含缺失值的行。设为1或'columns'时删除列。
-
how:默认'any',只要有一个缺失值就删除。设为'all'时,只有整行(或列)全为缺失值才删除。
-
thresh:设置保留非缺失值的最小数量。例如,thresh=2表示某行至少要有2个非缺失值才保留。
-
subset:指定要检查缺失的列(当axis=0时)或行(当axis=1时)。其他位置的缺失值不影响删除操作。
-
inplace:设为True时直接修改原数据,返回None;否则返回新对象。
示例数据:
import pandas as pd
import numpy as npdata = {'A': [1, np.nan, 3, 4],'B': [np.nan, 2, np.nan, 5],'C': [7, 8, 9, 10]
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)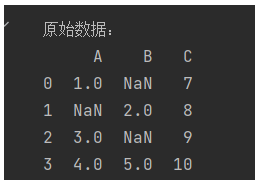
1,默认删除包含缺失值的行
# 删除所有含有NaN的行
df_cleaned = df.dropna()
print("删除含有NaN的行:")
print(df_cleaned)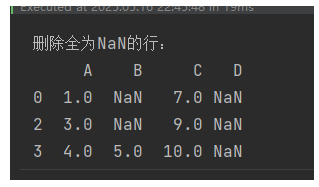
2,删除全为缺失值的行
# 添加一行全为NaN的数据
df.loc[4] = [np.nan, np.nan, np.nan]# 删除全为NaN的行
df_cleaned = df.dropna(how='all')
print("删除全为NaN的行:")
print(df_cleaned)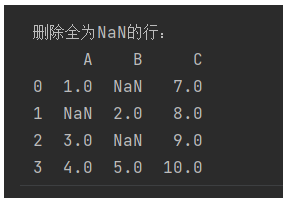
3,按阈值保留数据(thresh参数)
# 保留至少有2个非NaN值的行
df_cleaned = df.dropna(thresh=2)
print("保留至少2个非NaN值的行:")
print(df_cleaned)4,仅检查指定列的缺失值(subset参数)
# 只在列A和B中检查缺失值,列C的NaN不影响结果
df_cleaned = df.dropna(subset=['A', 'B'])
print("仅检查A和B列的缺失值:")
print(df_cleaned)相关文章:

一周学会Pandas2 Python数据处理与分析-Pandas2数据添加修改删除操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 对数据的修改、增加和删除在数据整理过程中时常发生。修改的情况一般是修改错误,还有一种情况是格式转换…...

荷兰国旗问题 之 指针划分区间问题
文章目录 首先介绍一下什么是荷兰国旗问题?问题描述为:给定一个由红色、白色和蓝色三种颜色组成的无序数组,将数组元素按颜色排序,使得所有红色元素在前,白色元素居中,蓝色元素在后。这里的 “颜色” 通常用…...

冒泡排序-java
public class BubbleSort{ public static void bubbleSort(int[] arr) { int n arr.length; boolean swapped; // 外层循环控制遍历的轮数 for (int i 0; i < n - 1; i) { swapped false; for (int j 0; …...

进阶-数据结构部分:2、常用排序算法
飞书文档https://x509p6c8to.feishu.cn/wiki/FfpIwIPtviMMb4kAn3Sc40ABnUh 常用排序算法 这几种算法都是常见的排序算法,它们的优劣和适用场景如下: 冒泡排序(Bubble Sort):简单易懂,时间复杂度较高&…...

人工智能-自然语言与语音产品实现
一、语义相似度 (一)、文本向量化 1、文本向量化(Text Vectorization) 是自然语言处理(NLP)中的核心预处理步骤,旨在将人类语言的文本转换为计算机可处理的数值向量(数学表达&…...

阿里巴巴开源移动端多模态LLM工具——MNN
MNN 是一个高效且轻量级的深度学习框架。它支持深度学习模型的推理和训练,并在设备端的推理和训练方面具有行业领先的性能。目前,MNN 已集成到阿里巴巴集团的 30 多个应用中,如淘宝、天猫、优酷、钉钉、闲鱼等,覆盖了直播、短视频…...

SpringBootAdmin:全方位监控与管理SpringBoot应用
监控的意义 1. 监控服务状态是否宕机 2. 监控服务运行指标 (内存,虚拟机,线程,请求等) 3. 监控日志 4. 管理服务 (服务下线) 可视化监控平台 Spring Boot Admin, 开源社区项目, 用于管理和监控SpringBoot应用程序. 客户端注册到服务端, 通过HTTP请求方式, 服务端定期从客…...

SAP HCM 0008数据存储逻辑
0008信息类型:0008信息类型是存储员工基本薪酬的地方,因为很多企业都会都薪酬带宽,都会按岗定薪,所以在上线前为体现工资体系的标准化,都会在配置对应的薪酬关系,HCM叫间接评估,今天我们就分析下…...
】Config配置中心-ConfigServer端与Git通信(含源代码)(十三))
【springcloud学习(dalston.sr1)】Config配置中心-ConfigServer端与Git通信(含源代码)(十三)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) springcloud学习(dalston.sr1)系统文章汇总如下: 【springcloud学习(dalston…...

2020CCPC河南省赛题解
A. 班委竞选 签到题,模拟。 #include <bits/stdc.h> #define x first #define y second #define int long long //#define double long doubleusing namespace std; typedef unsigned long long ULL ; typedef pair<int,int> PII ; typedef pair<d…...

C语言输入函数对比解析
目录 C语言输入函数全家福(和它们的秘密)fgetsgetsscanfgetcharfscanf函数对比表灵魂总结 哈哈,看来你正在和C语言的输入函数们玩“大家来找茬”!放心,我会用最接地气的方式给你讲明白,保证比看《甄嬛传》还…...

python四则运算计算器
python四则运算计算器 是谁说,python不好写计算器的,我亲自写个无ui的计算器功能,证明这是谣言 step1:C:\Users\wangrusheng\Downloads\num.txt 15 - 4 * 3 10 / 2(5 3) * 2 6 / 31/2 * 8 3/4 * 4 - 0.52.5 * (4 1.6) - 9 / 3-6 12 * (…...

BUUCTF——Nmap
BUUCTF——Nmap 进入靶场 类似于一个nmap的网站 尝试一下功能 没什么用 看看数据包 既然跟IP相关 伪造一个XXF看看 拼接了一下没什么用 果然没这么简单 尝试一下命令注入 构造payload 127.0.0.1 | ls 应该有过滤 加了个\ 直接构造个php木马上传试试 127.0.0.1 | <?…...

【Changer解码头详解及融入neck层数据的实验设计】
Changer解码头详解 ChangerEx中的 Changer 解码头(定义在 [changer.py](file://opencd\models\decode_heads\changer.py))是基于双时相输入的,用于遥感变化检测任务。下面我将详细解释: 🎯 一、解码头输入数据来源 输…...

深度学习推理引擎---OpenVINO
OpenVINO(Open Visual Inference & Neural Network Optimization Toolkit)是英特尔开发的开源工具套件,旨在优化和加速深度学习模型在英特尔硬件(CPU、GPU、VPU、FPGA等)上的推理性能,同时支持从训练到…...
 方法)
JavaScript splice() 方法
1. JavaScript splice() 方法 1.1. 定义和用法 splice() 方法用于添加或删除数组中的元素。 注意:这种方法会改变原始数组。 返回值:如果删除一个元素,则返回一个元素的数组。 如果未删除任何元素,则返回空数组。 1.2. …...

数据库故障排查指南:解决常见问题,保障数据安全与稳定
数据库故障排查指南:解决常见问题,保障数据安全与稳定 📖 前言 数据库作为现代应用的核心组件,其稳定性直接影响业务连续性。本文总结六大常见数据库故障场景,提供快速排查思路与解决方案,助你化身"…...

gem5-gpu教程 第十章 关于topology 的Mesh network
问题一、L1和L2缓存之间的VI_hammer_fusion中指定了互连延迟,如何更改这些数字吗? 我已经实现了一个网格拓扑来连接cpu内核和GPU SM,并对VI_hammer*和网格文件进行了所有必要的更改。我的问题是: 1. There is interconnect latency specified in VI_hammer_fusion betwee…...

【C/C++】C++返回值优化:RVO与NRVO全解析
文章目录 C返回值优化:RVO与NRVO全解析1 简介2 RVO vs NRVO3 触发条件4 底层机制5 应用场景6 验证与限制7 性能影响8 补充说明9 总结 C返回值优化:RVO与NRVO全解析 返回值优化(Return Value Optimization, RVO)是编译器通过消除临…...

使用 Kaniko来构建镜像
使用 Kaniko来构建镜像 Kaniko 是一种专注于容器镜像构建的开源工具,其核心设计理念与 Docker 存在显著差异。以下从功能定位、技术实现和适用场景三方面进行对比分析: 一、Kaniko 的核心特性 无需 Docker 守护进程 Kaniko 直接在容器或 Kubernetes 集…...

2025.05.17淘天机考笔试真题第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 奇偶平衡树分割问题 问题描述 K小姐是一位园林设计师,她设计了一个由多个花坛组成的树形公园。每个花坛中种植了不同数量的花…...

history模式:让URL更美观
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

算法:分治法
实验内容 在一个2kⅹ2k个方格组成的棋盘中,若恰有一个方格与其他方格不同,则称该方格为特殊方格,且称该棋盘为一特殊棋盘。 显然,特殊方格出现的位置有4k 种情况,即k>0,有4k 种不同的特殊棋盘 棋盘覆盖:…...

豆粕ETF投资逻辑整理归纳-20250511
目录 一、什么是豆粕 基本概念 豆粕上游生产国 豆粕下游消耗方 二、豆粕ETF 概念 策略 展期操作 超额收益 行情波动 豆粕资产的低相关性 三、展期收益 Contango升水结构和Backwardation贴水结构 豆粕的贴水逻辑 还有哪些品种拥有长期的展期收益 四、其他相关信…...

使用 Python 连接 Oracle 23ai 数据库完整指南
方法一:使用 oracledb 官方驱动(推荐) Oracle 官方维护的 oracledb 驱动(原 cx_Oracle)是最新推荐方案,支持 Thin/Thick 两种模式。 1. 环境准备 pip install oracledb2. 完整示例代码 import oracledb import getpass from typing import Unionclass Oracle23aiConn…...

构建集成差异化灵巧手和先进机器人控制技术的自动化系统
介绍程序 1.流程分析 通过流程分析审查应用机器人自动化的可行性。 2.系统设计 选择合适的机器人(机械臂、夹持器、视觉系统等),并通过详细的任务分析设计最佳系统。 3.内部测试 建立内部测试平台并解决任何问题。 4.现场测试 现场设…...

题单:汉诺塔问题
题目描述 如下图所示,设有 nn 个大小不等的中空圆盘,按照从小到大的顺序叠套在立柱 A 上,另有两根立柱 B 和 C 。 现在要求把全部圆盘从 A 柱(称为源柱)移到 C 柱(称为目标柱),移动…...

Unable to get end effector tips from jmg
这个错误信息表明在使用MoveIt2时,moveit_visual_tools无法从关节模型组(Joint Model Group,简称JMG)中获取末端执行器(End Effector,简称EE)的尖端信息。这通常是因为配置文件中缺少相关信息&a…...

flutter flutter run 运行项目卡在Running Gradle task ‘assembleDebug‘...
flutter run --verbose在运行flutter run 可以看到是卡在哪一步 最重要的就是自己查看日志,具体哪一步有问题flutter run --verbose使用这个,运行了项目会将错误信息放在控制台 可能原因 静态资源问题如果:图片、字体文件等没有在pubspec.yam…...

STM32烧录程序正常,但是运行异常
一、硬件配置问题 BOOT引脚设置错误 STM32的启动模式由BOOT0和BOOT1引脚决定。若设置为从RAM启动(BOOT01,BOOT10),程序在掉电后无法保存,导致复位后无法正常运行。应确保BOOT00(从Flash启动)15。…...

TTS:F5-TTS 带有 ConvNeXt V2 的扩散变换器
1,项目简介 F5-TTS 于英文生成领域表现卓越,发音标准程度在本次评测软件中独占鳌头。再者,官方预设的多角色生成模式独具匠心,能够配置多个角色,一次性为多角色、多情绪生成对话式语音,别出心裁。 最低配置…...

ecmascript 第6版特性 ECMA-262 ES6
https://blog.csdn.net/zlpzlpzyd/article/details/146125018 在之前写的文章基础上,ES6在export和import的基础外,还有如下特性 特性说明let/const块级作用域变量声明>箭头函数Promise异步编程...

2024 山东省ccpc省赛
目录 I(签到) 题目简述: 思路: 代码: A(二分答案) 题目简述: 思路: 代码: K(构造) 题目: 思路: 代…...

角点特征:从传统算法到深度学习算法演进
1 概述 图像特征是用来描述和分析图像内容的关键属性,通常包括颜色、纹理和形状等信息。颜色特征能够反映图像中不同颜色的分布,常通过 RGB 值或色彩直方图表示。纹理特征则关注图像表面的结构和细节,例如通过灰度共生矩阵或局部二值模式&…...

免费代理IP服务有哪些隐患?如何安全使用?
代理IP已经成为互联网众多用户日常在线活动中不可或缺的一部分。无论是为了保护个人隐私、突破地理限制,还是用于数据抓取、广告投放等商业用途,代理IP都扮演着关键角色。然而,市场上存在大量的免费代理IP服务,尽管它们看起来颇具…...

深入了解 VPC 端点类型 – 网关与接口
什么是VPC 端点 VPC 端点(VPC Endpoint)是 Amazon Web Services (AWS) 提供的一种服务,允许用户在 Virtual Private Cloud (VPC) 内部安全地访问 AWS 服务,而无需通过公共互联网。VPC 端点通过私有连接将 VPC 与 AWS 服务直接连接…...

Android屏幕采集编码打包推送RTMP技术详解:从开发到优化与应用
在现代移动应用中,屏幕采集已成为一个广泛使用的功能,尤其是在实时直播、视频会议、远程教育、游戏录制等场景中,屏幕采集技术的需求不断增长。Android 平台为开发者提供了 MediaProjection API,这使得屏幕录制和采集变得更加简单…...
)
信息系统项目管理师高级-软考高项案例分析备考指南(2023年案例分析)
个人笔记整理---仅供参考 计算题 案例分析里的计算题就是进度、挣值分析、预测技术。主要考査的知识点有:找关键路径、求总工期、自由时差、总时差、进度压缩资源平滑、挣值计算、预测计算。计算题是一定要拿下的,做计算题要保持头脑清晰,认真读题把PV、…...

全栈项目搭建指南:Nuxt.js + Node.js + MongoDB
全栈项目搭建指南:Nuxt.js Node.js MongoDB 一、项目概述 我们将构建一个完整的全栈应用,包含: 前端:Nuxt.js (SSR渲染)后端:Node.js (Express/Koa框架)数据库:MongoDB后台管理系统:集成在同…...

Linux:基础IO
一:理解文件 1-1 狭义理解 文件存储在磁盘中,由于磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的;磁盘也是外设,因此磁盘上对文件的所有操作本质是对外设的输入和输出 1-2 广义理解 Linux下一切皆文件&am…...

MySQL 索引优化以及慢查询优化
在数据库性能优化中,索引优化和慢查询优化是两个关键环节。合理使用索引可以显著提高查询效率,而识别和优化慢查询则能提升整体数据库性能。本文将详细介绍MySQL索引优化和慢查询优化的方法和最佳实践。 一、MySQL 索引优化 1.1 索引的基本概念 索引是…...

Leaflet使用SVG创建动态Legend
接前一篇文章,前一篇文章我们使用 SVG 创建了带有动态文字的图标,今天再看看怎样在地图上根据动态图标生成相关的legend,当然这里也还是使用了 SVG 来生成相关颜色的 legend。 看下面的代码,生成了一个 svg 节点,其中…...

使用 Vue Tour 封装一个统一的页面引导组件
项目开发过程中需要实现用户引导功能,经过调研发现一个好用的 Vue 插件 vue-tour,今天就来分享一下我是如何基于 vue-tour 封装一个统一的引导组件,方便后续在多个页面复用的。 📦 第一步:安装 vue-tour 插件 首先安装…...

OpenResty 深度解析:构建高性能 Web 服务的终极方案
引言 openresty是什么?在我个人对它的理解来看相当于嵌入了lua的nginx; 我们在nginx中嵌入lua是为了不需要再重新编译,我们只需要重新修改lua脚本,随后重启即可; 一.lua指令序列 我们分别从初始化阶段,重写/访问阶段,内容阶段,日志…...

赋能企业级移动应用 CFCA FIDO+提升安全与体验
移动办公与移动金融为企业有效提升业务丰富性、执行便捷性。与此同时,“安全”始终是移动办公与移动金融都绕不开的话题。随着信息安全技术的发展,企业级移动应用中安全与便捷不再是两难的抉择。 中金金融认证中心(CFCA)作为经国…...

Redis 数据类型与操作完全指南
Redis 是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。与传统的关系型数据库不同,Redis 提供了丰富的数据类型和灵活的操作方式,这使得它能够高效地解决各种不同场景下的数据存储和处理问题。本文将全面介绍 R…...

ArrayList-集合使用
自动扩容,集合的长度可以变化,而数组长度不变,集合更加灵活。 集合只能存引用数据类型,不能直接存基本数据类型,除非包装 ArrayList会拿[]展示数据...

深入解析Spring Boot与Redis集成:高效缓存实践
深入解析Spring Boot与Redis集成:高效缓存实践 引言 在现代Web应用开发中,缓存技术是提升系统性能的重要手段之一。Redis作为一种高性能的键值存储数据库,广泛应用于缓存、会话管理和消息队列等场景。本文将详细介绍如何在Spring Boot项目中…...

8天Python从入门到精通【itheima】-11~13
目录 11节-PyCharm的安装和基础使用: 1.第三方IDE(集成开发工具) 2.PyCharm的所属——jetbrains公司 3.进入jetbrains的官网,搜索下载【官网自带中文,太友好了,爱你(づ ̄3&#x…...

day33-网络编程
1. 网络编程入门 1.1 网络编程概述 计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统…...