角点特征:从传统算法到深度学习算法演进
1 概述
图像特征是用来描述和分析图像内容的关键属性,通常包括颜色、纹理和形状等信息。颜色特征能够反映图像中不同颜色的分布,常通过 RGB 值或色彩直方图表示。纹理特征则关注图像表面的结构和细节,例如通过灰度共生矩阵或局部二值模式(LBP)等方法提取。形状特征则主要借助边缘检测和轮廓提取技术,帮助识别物体的几何形状。不同类型的特征适用于不同的计算机视觉任务,如物体识别、场景分析和图像检索等。
角点特征是一种重要的图像特征,通常用于识别图像中的显著点。角点通常是图像中变化显著的区域,如物体的边缘和交点。常见的角点检测算法包括 Harris 角点检测、Shi-Tomasi 角点检测和 FAST 算法等。Harris 算法通过计算图像梯度的变化来判断角点,而 Shi-Tomasi 方法是其改进,提供更好的特征点选择。FAST 算法则因其高效率而广泛应用于实时系统。角点特征的稳定性和重复性使其在图像匹配和运动跟踪中非常有效。
角点特征在多个领域具有广泛的应用。例如,在计算机视觉中的物体识别任务中,角点可以作为关键点进行匹配,帮助系统识别和分类物体。在视频监控中,通过追踪角点特征,可以实现对移动物体的实时监控。此外,角点特征还在三维重建中起到重要作用,通过匹配不同视角下的角点,可以恢复场景的三维结构。随着深度学习的兴起,结合传统角点检测与深度学习特征提取的方法逐渐成为研究热点,进一步提升了图像分析的精度和效率。
2 传统角点检测算法
2.1 Moravec角点
2.1.1 原理
Moravec是最早的角点检测算法之一,是一种基于灰度方差的角点检测方法,算法的主要思想是计算像素点在局部范围内八个方向上的灰度变化情况,如果该点沿各个方向灰度变化都较大则认为该点是角点。基本步骤为:
-
滑动窗口
选择一个滑动窗口(通常为3x3或5x5),该窗口在当前点的8个方向(垂直,水平,45度角,135度角)。计算图像上每个点每个方向的灰度变化值,一个方向的计算方式为:
V ( x , y ) = min ( ∑ i = − k / 2 1 ∑ j = − k / 2 1 ( I ( x + i , y + j ) − I ( x + i + d x , y + j + d y ) ) 2 ) V(x, y) = \min \left( \sum_{i=-k/2}^{1} \sum_{j=-k/2}^{1} (I(x+i, y+j) - I(x+i+dx, y+j+dy))^2 \right) V(x,y)=min i=−k/2∑1j=−k/2∑1(I(x+i,y+j)−I(x+i+dx,y+j+dy))2
其中 k k k为滑动窗口的半径, d x dx dx和 d y dy dy表示当前点的偏移量。
然后选取8个方向中最小的值作为该点的响应值:
R ( x , y ) = min { V 1 , V 2 , . . . , V 8 ) } R(x, y) = \min \left\{ V_1,V_2,...,V_8) \right\} R(x,y)=min{V1,V2,...,V8)} -
筛选角点
首先,根据设定的阈值 T T T,筛选出所有响应值大于 T T T的点,这些点被认为是候选角点,然后对这些候选点进行进一步的处理,如非极大值抑制和亚像素精确化。得到最终的角点。
2.1.2 实践代码
import cv2
import numpy as np
import matplotlib.pyplot as plt
import requests
from PIL import Image
from io import BytesIOdef moravec_corner_detection(image, window_size=3, threshold=100):rows, cols = image.shapeoffset = window_size // 2corner_response = np.zeros(image.shape, dtype=np.float32)for y in range(offset, rows - offset):for x in range(offset, cols - offset):min_ssd = float('inf')for shift_x, shift_y in [(1, 0), (0, 1), (1, 1), (1, -1)]:ssd = 0.0for dy in range(-offset, offset + 1):for dx in range(-offset, offset + 1):if (0 <= y + dy < rows) and (0 <= x + dx < cols) and \(0 <= y + dy + shift_y < rows) and (0 <= x + dx + shift_x < cols):diff = image[y + dy, x + dx] - image[y + dy + shift_y, x + dx + shift_x]ssd += diff ** 2min_ssd = min(min_ssd, ssd)corner_response[y, x] = min_ssdcorner_response[corner_response < threshold] = 0corners = np.argwhere(corner_response > 0)corners = [(x, y) for y, x in corners]return cornersimage = Image.open("imgs/source.jpg").convert("L")
image = np.array(image)corners = moravec_corner_detection(image, window_size=3, threshold=500)image_with_corners = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)for corner in corners:cv2.circle(image_with_corners, corner, 2, (0, 0, 255), 1)image_rgb = cv2.cvtColor(image, cv2.COLOR_GRAY2RGB)
image_with_corners_rgb = cv2.cvtColor(image_with_corners, cv2.COLOR_BGR2RGB)cv2.imshow('Moravec Corners', image_with_corners_rgb)
cv2.imwrite('imgs/moravec_result.jpg', image_with_corners)

2.1.3 总结
-
提取的角点:
- 影响角点数量主要有两个:筛选CRF的阈值和非极大值抑制时的局部窗口大小。
- 阈值越大,提取的待选角点越少。
- 同参数下,非极大值抑制窗口越大,提取的角点个数越少、越稀疏。
- 影响角点数量主要有两个:筛选CRF的阈值和非极大值抑制时的局部窗口大小。
-
与算法效率相关的因素:
- 滑动窗口大小以及非极大值抑制的步长大小。
- 滑动窗口越大,计算量也越大。
- 步长越小,需要计算的次数也越多。
- 滑动窗口大小以及非极大值抑制的步长大小。
-
影响算法效果相关的因素:滑动窗口偏移距离,越小越能反映灰度细节的变化。
-
Moravec算子的局限性:
- 只在8个方向进行灰度计算,未考虑全部方向上的变化,容易误判或漏判信息。
- 在计算CRF时,对窗口内的所有像素权重相同,容易对噪声敏感。
- 可以考虑通过加权求和的方式来改善。
-
边缘响应敏感性:
- 由于选取8个方向上的灰度方差最小值作为CRF,容易将边缘非角点当作角点。
- 当边缘与某一方向重合时,算出的方差可能非常小,从而错误地赋值给CRF。
Moravec算子虽然简单、快速,但准确性欠缺。作为第一个广泛应用的角点检测算法,Moravec算子开启了角点检测的新概念,为后续许多角点算子奠定了基础。
2.1 Harris 角点检测
2.1.1 原理
Harris 角点检测器是由 Chris Harris 和 Mike Stephens 于 1988 年在Moravec 角点检测器的改进基础上进行改进。与之前的角点检测器相比,Harris 角点检测器直接参考方向计算角点得分的微分,而不是每 45 度角移动一个面片,能够能更准确地区分边缘和角点。
Harris是对Moravec的改进,将原有的8个方向的灰度变化量计算改为了一个矩阵的特征值,从而提高了计算效率。对图像 I I I在窗口 W W W上计算灰度响应:
f ( Δ x , Δ y ) = ∑ ( x k , y k ) ∈ W ( I ( x k , y k ) − I ( x k + Δ x , y k + Δ y ) ) 2 {\displaystyle f(\Delta x,\Delta y)={\underset {(x_{k},y_{k})\in W}{\sum }}\left(I(x_{k},y_{k})-I(x_{k}+\Delta x,y_{k}+\Delta y)\right)^{2}} f(Δx,Δy)=(xk,yk)∈W∑(I(xk,yk)−I(xk+Δx,yk+Δy))2
I ( x + Δ x , y + Δ y ) {\displaystyle I(x+\Delta x,y+\Delta y)} I(x+Δx,y+Δy)可以用泰勒展开式来近似得到:
I ( x + Δ x , y + Δ y ) ≈ I ( x , y ) + I x ( x , y ) Δ x + I y ( x , y ) Δ y f ( Δ x , Δ y ) ≈ ∑ ( x , y ) ∈ W ( I x ( x , y ) Δ x + I y ( x , y ) Δ y ) 2 \begin{aligned} {\displaystyle I(x+\Delta x,y+\Delta y) \approx I(x,y)+I_{x}(x,y)\Delta x+I_{y}(x,y)\Delta y} \\ {\displaystyle f(\Delta x,\Delta y)\approx {\underset {(x,y)\in W}{\sum }}\left(I_{x}(x,y)\Delta x+I_{y}(x,y)\Delta y\right)^{2}} \end{aligned} I(x+Δx,y+Δy)≈I(x,y)+Ix(x,y)Δx+Iy(x,y)Δyf(Δx,Δy)≈(x,y)∈W∑(Ix(x,y)Δx+Iy(x,y)Δy)2
写成矩阵形式为:
f ( Δ x , Δ y ) ≈ ( Δ x Δ y ) M ( Δ x Δ y ) M = ∑ ( x , y ) ∈ W [ I x 2 I x I y I x I y I y 2 ] = [ ∑ ( x , y ) ∈ W I x 2 ∑ ( x , y ) ∈ W I x I y ∑ ( x , y ) ∈ W I x I y ∑ ( x , y ) ∈ W I x I y ] \begin{aligned} {\displaystyle f(\Delta x,\Delta y)\approx {\begin{pmatrix}\Delta x&\Delta y\end{pmatrix}}M{\begin{pmatrix}\Delta x\\\Delta y\end{pmatrix}}}\\ {\displaystyle M={\underset {(x,y)\in W}{\sum }}{\begin{bmatrix}I_{x}^{2}&I_{x}I_{y}\\I_{x}I_{y}&I_{y}^{2}\end{bmatrix}}={\begin{bmatrix}{\underset {(x,y)\in W}{\sum }}I_{x}^{2}&{\underset {(x,y)\in W}{\sum }}I_{x}I_{y}\\{\underset {(x,y)\in W}{\sum }}I_{x}I_{y}&{\underset {(x,y)\in W}{\sum }}I_{x}I_{y}\end{bmatrix}}} \end{aligned} f(Δx,Δy)≈(ΔxΔy)M(ΔxΔy)M=(x,y)∈W∑[Ix2IxIyIxIyIy2]= (x,y)∈W∑Ix2(x,y)∈W∑IxIy(x,y)∈W∑IxIy(x,y)∈W∑IxIy
M M M是一个二阶实对称矩阵,若不考虑高斯滤波函数,M可以写成椭圆的表达式。设 α , β α,β α,β是 M M M的特征值,当两特征值都大时, M M M所表示的椭圆长轴和短轴都很长,则对应像素点可以判断为角点;当两特征值一大一小时,即 α > > β α>>β α>>β时, M M M所表示的椭圆长轴很长且短轴很短,则可以将对应像素点判断为边缘点;当两特征值都较小时, M M M所表示的椭圆两轴都较短,则对应像素点可以判断为平平坦区域。
由于直接求解矩阵的特征值会增大算法计算的复杂度,降低运算速度,所以便使用 M M M的迹 t r ( M ) tr(M) tr(M)和M的行列式 d e t ( M ) det(M) det(M)来表示角点响应函数,最终的响应函数为:
R = λ 1 λ 2 − k ( λ 1 + λ 2 ) 2 = det ( M ) − k tr ( M ) 2 {\displaystyle R=\lambda _{1}\lambda _{2}-k(\lambda _{1}+\lambda _{2})^{2}=\det(M)-k\operatorname {tr} (M)^{2}} R=λ1λ2−k(λ1+λ2)2=det(M)−ktr(M)2
其中, k k k是一个经验常数,通常取值为 0.04 − 0.06 0.04-0.06 0.04−0.06。
Harris算法的具体步骤如下:
- 计算图像像素点在x方向和y方向上的梯度 I x I_x Ix和 I y I_y Iy,以及二者的乘积和各自的平方,构建结构张量M。
- 使用高斯滤波函数对图像进行噪声过滤,得到新的的 M M M
- 计算原图像上所有像素的角点响应值,即 R R R值。
- 局部非极大值抑制,将一定窗口范围内的极力大 R R R值对应的像素点判断为候选角点。
- 设定阈值,选取符合条件的最终角点。
2.1.2 实践代码
import cv2
import numpy as np# 读取图像
img = cv2.imread("imgs/source.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# Harris角点检测
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)# 结果膨胀,以便于标记角点
dst = cv2.dilate(dst, None)# 设置阈值
img[dst > 0.01 * dst.max()] = [0, 0, 255]# 显示结果
cv2.imshow("Harris Corners", img)
cv2.imwrite("imgs/harris_corners_res.jpg", img)

2.1.3 总结
2.3 FAST 角点检测
2.3.1 原理
FAST算法计算性能比较好但是不具备尺度不变性,旋转不变性以及检测到的特征点没有旋转方向。oFAST正是针对这些缺点改进FAST而来。
FAST:Features from Accelerated Segment Test
FAST:Features from Accelerated Segment Test (FAST)

FAST在进行特征点提取是根据当前点邻域内的点的差值作为特征点的筛选标准,它假定如果一个点与周围邻域内足够多的点的差值够大则认为是一个特征点:
- 选择像素 p p p,该像素的像素值为 I p I_{p} Ip,确定一个筛选的阈值 T T T(测试集参考值20%);
- 计算以像素 p p p为圆心3为半径确定16个像素点的灰度值和圆心 p p p的灰度值 I p I_{p} Ip的差值,如果存在连续 n n n个点(算法的第一个版本的n取值为12)满足 I x − I p > ∣ t ∣ I_x-I_p>|t| Ix−Ip>∣t∣( I x I_x Ix表示以 p p p为圆心的点的灰度值, t t t为根据 T T T计算出的偏移量),则认为点 p p p可以作为一个候选点,否则剔除;
- 对于16个点都计算差值时间复杂度过高,因此FAST采用即特征点过滤的方式:先判断圆上1,5,9,13号4个点中如果至少3个点满足特征点初选的要求在进行逐个计算,否则终止计算;
- 遍历图像中每一个像素,重复上述操作,直到遍历结束;
上面的筛选方式是FAST初版的筛选方式,但是该方式有一些基本的缺陷:
- 邻域内点数量 n n n过小,容易导致筛选的点过多,降低计算效率;
- 筛选的点完全取决于图像中点的分布情况;
- 筛选出的点部分点集中在一起。
问题1,2可以通过机器学习的方式来解决,问题3通过飞机大致抑制解决。
机器学习的解决方式是针对应用场景训练一个决策树,利用该决策树进行筛选:
Machine learning for high-speed corner detection
- 确定训练集;
- 对于训练集中每一张图像运行FAST算法筛选出图像中的特征点构成集合 P P P;
- 对于筛选出的每一个特征点,将其邻域内的16个像素存储为一个一维向量;
- 对于每一个一维的邻域向量中的像素值 I p → x , x ∈ 1 , . . . , 16 I_{p\rightarrow x},x\in{1,...,16} Ip→x,x∈1,...,16将其通过下面的规则映射到3中状态 darker than I p I_p Ip, brighter then I p I_p Ip或者和 I p I_p Ip相似;
S p → x { d , I p → x ≤ I p − t ( d a r k e r ) s , I p − t < I p → x < I p + t ( s i m i l a r ) b , I p + t ≤ I p → x ( b r i g h t e r ) \begin{equation} S_{p\rightarrow x}\left\{ \begin{array}{ll} d,I_{p\rightarrow x}&\le I_p - t\quad(darker)\\ s,I_p-t&\lt I_{p\rightarrow x}\lt I_p+t\quad(similar)\\ b,I_p+t&\le I_{p\rightarrow x}\quad (brighter) \end{array}\right. \end{equation} Sp→x⎩ ⎨ ⎧d,Ip→xs,Ip−tb,Ip+t≤Ip−t(darker)<Ip→x<Ip+t(similar)≤Ip→x(brighter) - 对于给定的 x x x可以将集合 P P P分为三类 P d , P s , P b P_d,P_s,P_b Pd,Ps,Pb,即 P b = { p ∈ P : S p → x = b } P_b=\{p\in P:S_{p\rightarrow x=b}\} Pb={p∈P:Sp→x=b};
- 定义一个布尔变量 K p K_p Kp,表示如果 p p p为角点则真,否则为假(由于有训练集所以GT我们都是已知的);
- 使用ID3决策树分类器以 K p K_p Kp查询每个子集,以训练出正确特征点的分类器;
- 决策树使用熵最小化来逼近,类似交叉熵。
H ( P ) = ( c + c ‾ ) l o g 2 ( c + c ‾ ) − c l o g 2 c − c ‾ l o g 2 c ‾ c = ∣ { p ∣ K p i s t r u e } ∣ (角点数量) c ‾ = ∣ { p ∣ K p i s f a l s e } ∣ (非角点的数量) \begin{equation} \begin{aligned} H(P)&=(c+\overline{c})log_2(c+\overline{c})-clog_2c-\overline{c}log_2\overline{c}\\ c&=|\{p|K_p\quad is\quad true\}|(角点数量)\\ \overline{c}&=|\{p|K_p\quad is\quad false\}|(非角点的数量) \end{aligned} \end{equation} H(P)cc=(c+c)log2(c+c)−clog2c−clog2c=∣{p∣Kpistrue}∣(角点数量)=∣{p∣Kpisfalse}∣(非角点的数量)
- 决策树使用熵最小化来逼近,类似交叉熵。
- 递归应用熵最小化来处理所有的集合,直到熵值为0终止计算,得到的决策树就可以用来进行特征点筛选。
ID3 Descision Tree
问题3可以用非极大值抑制来解决:
- 针对每个点计算打分函数 V V V,打分函数的输出是通过周围16个像素的差分和
- 去除 v v v值较低的点即可。
V = m a x { ∑ ( I s − I p ) , i f ( I s − I p ) > t ∑ ( I p − I s ) , i f ( I p − I s ) > t \begin{equation} V=max\left\{ \begin{array}{ll} \sum(I_s-I_p),if\quad(I_s-I_p)\gt t\\ \sum(I_p-I_s),if\quad(I_p-I_s)\gt t \end{array}\right. \end{equation} V=max{∑(Is−Ip),if(Is−Ip)>t∑(Ip−Is),if(Ip−Is)>t
oFAST
oFAST采用的是FAST-9,邻域半径为9。
oFAST使用多尺度金字塔解决FAST不具备尺度不变性的问题,使用矩来确定特征点的方向,来解决其不具备旋转不变形的问题。
多尺度金字塔就是将给定的图像以一个给定的尺度进行缩放,来生成多层不同尺度的图像 I 1 , I 2 , . . . , I n I_1,I_2,...,I_n I1,I2,...,In。这些图像每张图像的尺寸不同但是相邻两层图像间的宽高比例相同。然后针对多个尺度的图像应用FAST算法筛选特征点。
oFAST使用强度质心(intensity centroid,强度质心假设角的强度偏离其中心,并且该向量可用于估算方向)来确定特征点的方向,即计算特征点以 r r r为半径范围内的质心,特征点坐标到质心形成一个向量作为特征点的方向。矩的定义
m p q = ∑ x , y ∈ r x p y q I ( x , y ) m_{pq}=\sum_{x,y\in r}x^p y^q I(x,y) mpq=x,y∈r∑xpyqI(x,y)
矩的质心为(这里计算是限定的 r r r的邻域内):
C = ( m 10 m 00 , m 01 m 00 ) C=(\frac{m_{10}}{m_{00}},\frac{m_{01}}{m_{00}}) C=(m00m10,m00m01)
特征点的方向为:
θ = a t a n 2 ( m 01 , m 10 ) \theta=atan2(m_{01},m_{10}) θ=atan2(m01,m10)
oFast会使用Harris角点检测对筛选出的特征点进行角点度量,然后根据度量值将特征点排序,最后取出top-N得到目标特征点。
2.3.2 实践代码
import cv2# 读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)# 创建FAST检测器
fast = cv2.FastFeatureDetector_create()# 检测角点
keypoints = fast.detect(image, None)# 绘制角点
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None, (255, 0, 0))# 显示结果
cv2.imshow('FAST Keypoints', image_with_keypoints)
cv2.waitKey(0)
cv2.destroyAllWindows()

3.4 SIFT 角点检测
3.4.1 原理
1999 年,Lowe 提出了尺度不变特征转换(Scale Invariant Features Transform,
SIFT)算法,随后,在 2004 年,Lowe 又在此基础上对 SIFT 算法进行了完善。其检
测部分的算法大致可以分为以下几步:
- 尺度空间极值检测
- 关键点定位
- 方向分配
- 特征描述
尺度空间极值检测
为了使检测到的特征点具备尺度不变性,使能够在不同尺度检测到尽可能完整的特征点或关键点,则需要借助尺度空间理论来描述图像的多尺度特征。尺度空间理论的基本思想是:在图像处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获取多尺度下的空间表示序列,对这些空间序列提取某些特征描述子,抽象成特征向量,实现图像在不同尺度或不同分辨率的特征提取。
尺度空间在实际应用中可以通过图像的高斯金字塔实现。高斯金字塔的生成过程如下:
- 对原始图像应用高斯滤波。高斯滤波器的标准差(σ)决定了模糊的程度。
- 对模糊后的图像进行下采样(通常是每隔一个像素取一个像素),生成较小的图像。这一步骤通常是将图像的宽度和高度都减半。
- 重复高斯模糊和下采样的过程,直到达到所需的金字塔层数。每一层都是前一层模糊和下采样的结果。
通过对不同尺度的高斯图像进行相减,构造差分高斯图像 D o g Dog Dog
D o G ( x , y , σ ) = G ( x , y , k σ ) − G ( x , y , σ ) DoG(x,y,σ)=G(x,y,kσ)−G(x,y,σ) DoG(x,y,σ)=G(x,y,kσ)−G(x,y,σ)
其中, G ( x , y , k σ ) G(x,y,kσ) G(x,y,kσ)是高斯函数, k k k是一个尺度因子。
一旦得到DoG后,可找出DoG中的极大、极小值作为关键点。为了决定关键点,DoG中的每个像素会跟以自己为中心周围的八个像素,以及在同一组DoG中相邻尺度倍率相同位置的九个像素,一共二十六个点作比较,若此像素为这二十六个像素中的最大、最小值,则此称此像素为关键点。
关键点定位
当我们检测到极值点之后,会发现一个问题,高斯差分金字塔是离散的(因为尺度空间和像素点都是离散的),所以找到的极值点不太准确的,很大可能在真正极值点附近。所以需要对极值点进行精确定位。可
以采用连续的曲线来拟合尺度空间的 D o G DoG DoG函数。将尺度空间函数 D ( x , y , δ ) D(x,y,\delta) D(x,y,δ)在 ( x , y , δ ) (x,y,\delta) (x,y,δ)处泰勒展开为:
D ( x ) = D + ∂ D T ∂ x x + 1 2 x T ∂ 2 D ∂ x 2 x {\displaystyle D({\textbf {x}})=D+{\frac {\partial D^{T}}{\partial {\textbf {x}}}}{\textbf {x}}+{\frac {1}{2}}{\textbf {x}}^{T}{\frac {\partial ^{2}D}{\partial {\textbf {x}}^{2}}}{\textbf {x}}} D(x)=D+∂x∂DTx+21xT∂x2∂2Dx
令式中的导数等于零得到点偏移量:
X ′ = − ( ∂ 2 D ∂ x 2 ) − 1 ∂ D ∂ x {\displaystyle {\boldsymbol {X^{'} }}=-\left({\frac {\partial ^{2}D}{\partial {\boldsymbol {x}}^{2}}}\right)^{-1}{\frac {\partial D}{\partial {\boldsymbol {x}}}}} X′=−(∂x2∂2D)−1∂x∂D
当它在任一维度上 (即 x 或 y 或 σ )的偏移量大于 0.5 时,意味着插值中心已经偏移到它的邻近点上,所以必须改变当前关键点的位置。同时在新的位置上反复插值直到收敛,也有可能超出所设定的迭代次数或者超出图像边界的范围,此时这样的点应该删除。精确关键点处的函数值为:
D ( X ′ ) = D ( X ) + 1 2 X ′ ∂ D ∂ x X ′ {\displaystyle D({\boldsymbol {X^{'} }})=D({\boldsymbol {X}})+\frac{1}{2}{\boldsymbol {X^{'} }}{\frac {\partial D}{\partial {\boldsymbol {x}}}}{\boldsymbol {X^{'} }}} D(X′)=D(X)+21X′∂x∂DX′
当精确关键点处的函数值小于某一阈值时,说明此点为关键点,否则删除。
消除边缘响应
DoG函数对于侦测边缘上的点相当敏感,即使其找出位于边缘的关键点易受噪声干扰也会被侦测为关键点。 因此为了增加关键点的可靠性,需要消除有高度边缘响应但其位置不佳不符合需求的关键点。为了找出边缘上的点,可分别计算关键点的主曲率,对于在边上的关键点而言,因为穿过边缘方向的主曲率会远大于沿着边缘方向上的主曲率,因此其主曲率比值远大于位于角落的比值。为了算出关键点的主曲率,可解其二次海森矩阵矩阵的特征值:
H = [ D x x D x y D x y D y y ] {\displaystyle {\textbf {H}}={\begin{bmatrix}D_{xx}&D_{xy}\\D_{xy}&D_{yy}\end{bmatrix}}} H=[DxxDxyDxyDyy]
其特征值的比例与特征点主曲率的比例相同,因此假设解出的特征值为 α {\displaystyle \alpha } α, β {\displaystyle \beta } β,其中 α > β {\displaystyle \alpha >\beta } α>β。在上述矩阵中:
Tr ( H ) = D x x + D y y = α + β Det ( H ) = D x x D y y − D x y 2 = α β \begin{aligned} {\displaystyle \operatorname {Tr} ({\textbf {H}})=D_{xx}+D_{yy}=\alpha +\beta }\\ {\displaystyle \operatorname {Det} ({\textbf {H}})=D_{xx}D_{yy}-D_{xy}^{2}=\alpha \beta } \end{aligned} Tr(H)=Dxx+Dyy=α+βDet(H)=DxxDyy−Dxy2=αβ
得到:
R = Tr ( H ) 2 / Det ( H ) = ( r + 1 ) 2 / r {\displaystyle {\text{R}}=\operatorname {Tr} ({\textbf {H}})^{2}/\operatorname {Det} ({\textbf {H}})=(r+1)^{2}/r} R=Tr(H)2/Det(H)=(r+1)2/r
其中 r = α / β {\displaystyle r=\alpha /\beta } r=α/β。由此可知当R越大, α {\displaystyle \alpha } α、 β {\displaystyle \beta } β的比例越大,此时设定一阈值 r th {\displaystyle r_{\text{th}}} rth,若R大于 ( r th + 1 ) 2 / r th {\displaystyle (r_{\text{th}}+1)^{2}/r_{\text{th}}} (rth+1)2/rth表示此关键点位置不合需求因此可以去除。
方向分配
在方位定向中,关键点以相邻像素的梯度方向分布作为指定方向参数,使关键点描述子能以根据此方向来表示并具备旋转不变性。经高斯模糊处理后的影像 $ L(x,y,\sigma) $,在 $\sigma $ 尺寸下的梯度量 $ m(x,y) $ 与方向 $ \theta(x,y) $ 可由相邻之像素值计算:
m ( x , y ) = ( L ( x + 1 , y ) − L ( x − 1 , y ) ) 2 + ( L ( x , y + 1 ) − L ( x , y − 1 ) ) 2 m(x,y) = \sqrt{(L(x+1,y) - L(x-1,y))^2 + (L(x,y+1) - L(x,y-1))^2} m(x,y)=(L(x+1,y)−L(x−1,y))2+(L(x,y+1)−L(x,y−1))2
θ ( x , y ) = arctan ( L ( x , y − 1 ) − L ( x , y + 1 ) L ( x − 1 , y ) − L ( x + 1 , y ) ) \theta(x,y) = \arctan\left(\frac{L(x,y-1) - L(x,y+1)}{L(x-1,y) - L(x+1,y)}\right) θ(x,y)=arctan(L(x−1,y)−L(x+1,y)L(x,y−1)−L(x,y+1))
计算每个关键点与其相邻像素之梯度的量值与方向后,为其建立一个以10度为单位36条的直方图。每个相邻像素依据其量值大小与方向加入关键点的直方图中,最后直方图中最大值的方向即为此关键点的方向。若最大值与局部极大值的差在20%以内,则此判断此关键点含有多个方向,因此将会再额外建立一个位置、尺寸相同方向不同的关键点。
针对最后算出的方向还有许多优化步骤,为了符合人体的视觉感官,在加入梯度量值到直方图时会乘以距离权重(高斯函数),以减低离关键点较远的影响程度。为了增加角度的分辨率,不同角度在加入值方图时也需考量线性的权重,依照其角度偏移各区间平均值的量,照比例分配于两个区间内。最后可将值方图以差补的方式求得某个特定的角度值,而非一固定的区间。
特征描述
找到关键点的位置、尺寸并赋予关键点方向后,将可确保其移动、缩放、旋转的不变性。此外还需要为关键点建立一个描述子向量,使其在不同光线与视角下皆能保持其不变性,并且能够轻易与其他关键点作区分。为了使描述子在不同光线下保有不变性,需将描述子正规化为一128维的单位向量。
构建步骤为:首先每个 4 ∗ 4 4*4 4∗4的子区域内建立一个八方向的直方图,且在关键点周围 16 ∗ 16 16*16 16∗16的区域中——共 4 ∗ 4 4*4 4∗4个子区域,计算每个像素的梯度量值大小与方向后加入此子区域的直方图中,共可产生一个128维的描述——16个子区域*8个方向。此外为了减少非线性亮度的影响,把大于0.2的向量值设为0.2,最后将正规化后的向量乘上256,且以8位元无号数储存,可有效减少储存空间。
3.4.2 实践代码
import cv2
import numpy as np# 读取图像
img = cv2.imread("imgs/source.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 创建SIFT对象
sift = cv2.SIFT_create()# 检测关键点和计算描述符
keypoints, descriptors = sift.detectAndCompute(gray, None)# 绘制关键点
img_keypoints = cv2.drawKeypoints(img, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)# 显示结果
cv2.imshow("SIFT Keypoints", img_keypoints)
cv2.imwrite("imgs/sift_keypoints_res.jpg", img_keypoints)

3.5 SURF 角点检测
3.5.1 原理
SURF(Speeded-Up Robust Features)最初由Herbert Bay、Tinne Tuytelaars 和 Luc Van Gool发表,旨在提高SIFT的计算速度,同时保持特征的稳定性和不变性。SURF算法与SIFT算法基于相同的原理和步骤,但每个步骤的细节有所不同。该算法主要包含三个部分:兴趣点检测、局部邻域描述。
兴趣点检测
SURF使用方形滤波器作为高斯平滑的近似值(SIFT方法使用级联滤波器来检测尺度不变的特征点,其中高斯差(DoG)是在重新缩放的图像上逐步计算的)。对图像进行滤波时,如果使用积分图像,则正方形的速度要快得多:
S ( x , y ) = ∑ i = 0 x ∑ j = 0 y I ( i , j ) S(x,y) = \sum_{i=0}^{x}\sum_{j=0}^{y} I(i,j) S(x,y)=i=0∑xj=0∑yI(i,j)
SURF使用基于Hessian矩阵的blob检测器来查找感兴趣的点。Hessian矩阵的行列式被用来衡量点周围的局部变化,并选择行列式最大的点。与Mikolajczyk和Schmid提出的Hessian-Laplacian检测器不同,SURF也使用Hessian矩阵的行列式来选择尺度,Lindeberg也采用了这种方法。给定一个点 p = ( x , y ) p=(x,y) p=(x,y)在图像中,Hessian矩阵 H ( p , σ ) H(p,\sigma) H(p,σ)在点 p p p和尺度 σ \sigma σ下为:
H ( p , σ ) = ( L x x ( p , σ ) L x y ( p , σ ) L x y ( p , σ ) L y y ( p , σ ) ) H(p,\sigma) = \begin{pmatrix} L_{xx}(p,\sigma) & L_{xy}(p,\sigma) \\ L_{xy}(p,\sigma) & L_{yy}(p,\sigma) \end{pmatrix} H(p,σ)=(Lxx(p,σ)Lxy(p,σ)Lxy(p,σ)Lyy(p,σ))
其中, L x x ( p , σ ) L_{xx}(p,\sigma) Lxx(p,σ)等是高斯二阶导数与图像 I ( x , y ) I(x,y) I(x,y)的卷积。大小为9×9的盒式滤波器是 σ = 1.2 \sigma=1.2 σ=1.2的高斯近似值,代表斑点响应图的最低级别(最高空间分辨率)。
尺度空间表示和兴趣点定位
兴趣点可以在不同的尺度上找到,部分原因是寻找对应关系通常需要比较在不同尺度下看到的图像。在其他特征检测算法中,尺度空间通常实现为图像金字塔。图像用高斯滤波器反复平滑,然后进行下采样以获得金字塔的下一层。因此,需要计算具有不同掩模尺寸的几层或几级:
σ approx = 当前滤波器尺寸 × ( 基本滤波器比例 基本滤波器尺寸 ) \sigma_{\text{approx}} = \text{当前滤波器尺寸} \times \left( \frac{\text{基本滤波器比例}}{\text{基本滤波器尺寸}} \right) σapprox=当前滤波器尺寸×(基本滤波器尺寸基本滤波器比例)
尺度空间被划分为若干个八度,其中一个八度指的是覆盖一倍尺度的一系列响应图。在SURF中,尺度空间的最低层由9×9滤波器的输出获得。
因此,与以前的方法不同,SURF中的尺度空间是通过应用不同大小的盒式过滤器实现的。因此,通过增加过滤器尺寸而不是迭代地减小图像尺寸来分析尺度空间。上述9×9过滤器的输出被视为尺度 s = 1.2 s=1.2 s=1.2处的初始尺度层(对应于 σ = 1.2 \sigma=1.2 σ=1.2的高斯导数)。接下来的层是通过使用逐渐变大的掩模对图像进行滤波获得的,同时考虑到积分图像的离散性质和特定的过滤器结构。这会产生大小为9×9、15×15、21×21、27×27等的过滤器。在3×3×3邻域中应用非最大值抑制来定位图像中和尺度上的兴趣点。然后使用Brown等人提出的方法在尺度和图像空间中插值Hessian矩阵行列式的最大值。在这种情况下,尺度空间插值尤为重要,因为每个八度音阶的第一层之间的尺度差异相对较大。
描述符
描述符的目标是提供对图像特征的唯一且鲁棒的描述,例如,通过描述兴趣点邻域内像素的强度分布。因此,大多数描述符都是以局部方式计算的,对于之前识别的每个兴趣点,都会得到一个描述。
描述符的维度直接影响其计算复杂度和点匹配的鲁棒性/准确率。较短的描述符可能对外观变化具有更强的鲁棒性,但可能无法提供足够的区分度,从而导致过多的误报。
第一步是根据兴趣点周围圆形区域的信息确定一个可重现的方向。然后,我们构建一个与所选方向对齐的方形区域,并从中提取SURF描述符。
方向任务
为了实现旋转不变性,需要找到感兴趣点的方向。Haar小波在半径为6s计算兴趣点周围的s是检测到兴趣点的比例。获得的响应由以兴趣点为中心的高斯函数加权,然后绘制为二维空间中的点,横坐标为水平响应,纵坐标为垂直响应。通过计算大小为 π / 3 \pi/3 π/3的滑动方向窗口内所有响应的总和来估计主要方向。将窗口内的水平和垂直响应相加。然后,两个相加的响应产生一个局部方向向量。最长的此类向量总体上定义了兴趣点的方向。滑动窗口的大小是一个必须仔细选择的参数,以在稳健性和角度分辨率之间实现所需的平衡。基于Haar小波响应总和的描述符:
- 为了描述该点周围的区域,提取一个方形区域,该方形区域以兴趣点为中心,并沿着上面选择的方向。该窗口的大小为20s。
- 将感兴趣区域分割成更小的4x4正方形子区域,并针对每个子区域,以5x5等距采样点提取Haar小波响应。这些响应采用高斯加权(以提高对变形、噪声和平移的鲁棒性)。
3.5.2 实践代码
import cv2# 读取图像
img = cv2.imread("imgs/source.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 创建SURF对象
# 注意:如果使用OpenCV 4.4.0及更高版本,您可能需要通过`cv2.xfeatures2d.SURF_create()`来创建SURF对象
surf = cv2.xfeatures2d.SURF_create(hessianThreshold=400)# 检测关键点和计算描述符
keypoints, descriptors = surf.detectAndCompute(gray, None)# 绘制关键点
img_keypoints = cv2.drawKeypoints(img, keypoints, None, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)# 显示结果
cv2.imshow("SURF Keypoints", img_keypoints)
cv2.imwrite("imgs/surf_keypoints_res.jpg", img_keypoints)

3.6 ORB 角点检测
- 参考之前的文章:ORB算法实现原理源码分析
4 深度学习角点检测算法
深度学习网络已经百花齐放,这里只选择一种简单描述下:
4.1 SuperPoint
SuperPoint 是一种创新的特征点检测与描述框架,它引入了多项新技术,以提高特征点检测的准确性和效率。首先,SuperPoint 采用了全卷积网络架构,这使得模型能够在处理完整图像时,直接输出像素级的兴趣点热图和描述符。这种方法与传统基于图块的算法不同,后者需要将图像分割为小块进行处理,导致计算效率低下和信息丢失。全卷积设计使得 SuperPoint 能够在一次前向传播中同时获取兴趣点位置和描述符,从而显著提高了处理速度。
同时,SuperPoint 引入了单应性适应(Homographic Adaptation)技术。这一多尺度、多单应性的策略旨在提升兴趣点检测的重复性,并实现合成数据与真实数据之间的有效迁移。通过在多个视角和尺度下对图像进行训练,SuperPoint 能够适应不同场景中的变化,增强了模型的鲁棒性。这种适应能力使得 SuperPoint 能够在不同的图像域中保持一致的性能,尤其是在处理真实世界图像时,相比于其他传统方法如 SIFT 和 ORB,表现更加稳定。
最后,SuperPoint 的训练过程采用了自监督学习的方式,通过合成数据生成器生成标注数据。这一策略避免了手动标注的繁琐,提高了训练效率。在训练过程中,模型优化损失函数,以逐步提高对关键点的检测能力和描述符的区分度。这种无监督学习方法使得 SuperPoint 能够在大规模数据集上进行训练,同时确保了其在特征检测任务中的高效性和准确性。因此,SuperPoint 在多个计算机视觉任务中,如图像匹配和三维重建,展现出显著的优势。
SuperPoint 网络的结构主要由 Encoder 和 Decoder 两部分组成,分别用于特征提取和描述符生成。下面详细描述这两个部分的结构和功能。Encoder采用VGG-Style结构进行特征提取,Decoder拆分为两个输出,分别用于生成兴趣点的热图和对应的描述符。
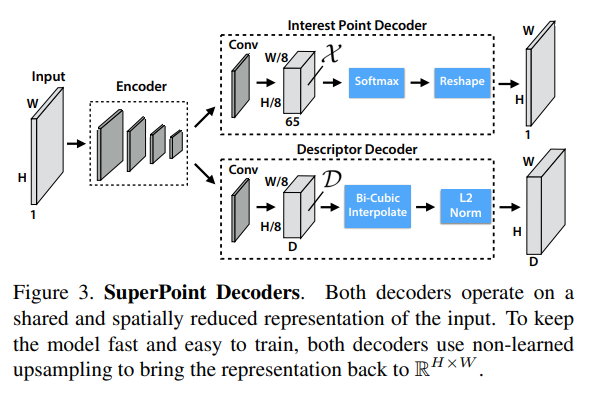
SuperPoint 网络的最终损失是两个中间损失的总和:一个用于兴趣点检测器 ( L_p ),另一个用于描述符 ( L_d )。我们使用成对的合成扭曲图像,这些图像具有(a)伪真实的兴趣点位置和(b)由随机生成的单应性矩阵 ( H ) 关联的真实对应关系。这使得我们能够同时优化两个损失。
最终损失函数为:
L ( X , X ′ , D , D ′ ; Y , Y ′ ; S ) = L p ( X , Y ) + L p ( X ′ , Y ′ ) + λ L d ( D , D ′ , S ) . L(X, X', D, D'; Y, Y'; S) = L_p(X, Y) + L_p(X', Y') + \lambda L_d(D, D', S). L(X,X′,D,D′;Y,Y′;S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S).
** 兴趣点检测损失**
兴趣点检测损失函数 ( L_p ) 是在单元格 ( x_{hw} \in X ) 上进行的全卷积交叉熵损失。对应的真实兴趣点标签集合为 ( Y ),单个条目为 ( y_{hw} )。损失计算公式为:
L p ( X , Y ) = 1 H c W c ∑ h = 1 H c ∑ w = 1 W c l p ( x h w ; y h w ) , L_p(X, Y) = \frac{1}{H_c W_c} \sum_{h=1}^{H_c} \sum_{w=1}^{W_c} l_p(x_{hw}; y_{hw}), Lp(X,Y)=HcWc1h=1∑Hcw=1∑Wclp(xhw;yhw),
其中:
l p ( x h w ; y ) = − log ( exp ( x h w y ) ∑ k = 1 65 exp ( x h w k ) ) . l_p(x_{hw}; y) = -\log\left(\frac{\exp(x_{hw}^y)}{\sum_{k=1}^{65} \exp(x_{hw}^k)}\right). lp(xhw;y)=−log(∑k=165exp(xhwk)exp(xhwy)).
描述符损失
描述符损失应用于第一幅图像的所有描述符单元 ( d_{hw} \in D ) 和第二幅图像的描述符单元 ( d’_{h’w’} \in D’ )。通过单应性引起的对应关系可以表示为:
s h w h ′ w ′ = { 1 , 如果 ∣ ∣ H p h w − p h ′ w ′ ∣ ∣ ≤ 8 0 , 否则 s_{hwh'w'} = \begin{cases} 1, & \text{如果 } ||H p_{hw} - p_{h'w'}|| \leq 8 \\ 0, & \text{否则} \end{cases} shwh′w′={1,0,如果 ∣∣Hphw−ph′w′∣∣≤8否则
这里 ( p_{hw} ) 表示单元格中心像素的位置,( H p_{hw} ) 表示通过单应性矩阵 ( H ) 转换后的坐标。描述符损失定义为:
L d ( D , D ′ , S ) = 1 ( H c W c ) 2 ∑ h = 1 H c ∑ w = 1 W c ∑ h ′ = 1 H c ∑ w ′ = 1 W c l d ( d h w , d h ′ w ′ ′ ; s h w h ′ w ′ ) . L_d(D, D', S) = \frac{1}{(H_c W_c)^2} \sum_{h=1}^{H_c} \sum_{w=1}^{W_c} \sum_{h'=1}^{H_c} \sum_{w'=1}^{W_c} l_d(d_{hw}, d'_{h'w'}; s_{hwh'w'}). Ld(D,D′,S)=(HcWc)21h=1∑Hcw=1∑Wch′=1∑Hcw′=1∑Wcld(dhw,dh′w′′;shwh′w′).
其中描述符损失 ( l_d(d, d’; s) ) 使用了一个 hinge 损失,定义为:
l d ( d , d ′ ; s ) = λ d ⋅ s ⋅ max ( 0 , m p − d T d ′ ) + ( 1 − s ) ⋅ max ( 0 , d T d ′ − m n ) . l_d(d, d'; s) = \lambda_d \cdot s \cdot \max(0, m_p - d^T d') + (1 - s) \cdot \max(0, d^T d' - m_n). ld(d,d′;s)=λd⋅s⋅max(0,mp−dTd′)+(1−s)⋅max(0,dTd′−mn).
代码参考:Github-SuperPointPretrainedNetwork

5 总结
| 特征点检测算法 | 特点 | 优势 | 劣势 |
|---|---|---|---|
| M偶然AV而出 | 经典的角点检测算法,以局部灰度变化为基础。 | 计算简单,实时性强。 | 对噪声敏感,检测重复性差。 |
| Harris | 基于图像灰度的二阶导数,检测角点。 | 对角点的检测效果好,鲁棒性强。 | 对尺度变化不敏感,计算较复杂。 |
| FAST | 采用像素强度比较的快速角点检测方法。 | 检测速度快,适合实时应用。 | 对噪声敏感,可能漏检角点。 |
| SIFT | 通过尺度空间极值检测特征点,生成描述符。 | 对旋转、尺度变化和光照变化具有鲁棒性。 | 计算复杂,速度较慢,专利限制。 |
| SURF | 使用Hessian矩阵进行特征点检测和描述。 | 速度快于SIFT,对光照变化鲁棒。 | 仍然较复杂,专利问题。 |
| ORB | 结合FAST和BRIEF,快速且高效的特征点检测与描述。 | 速度快,免费且无专利限制,旋转不变性。 | 对尺度变化不够鲁棒,描述符维度较低。 |
| SuperPoint | 全卷积网络,结合兴趣点检测和描述符生成。 | 端到端训练、实时性强,适应性好。 | 训练需要大量合成数据,模型较复杂。 |
6 参考文献
- FAST
- 图像特征之FAST角点检测
- Faster and better: a machine learning approach to corner detection
- 手写计算机视觉算法:Moravec角点检测算子
- Harris corner detector
- 尺度不变特征转换
- SIFT 特征
- 图像特征之SURF特征匹配
- 加速鲁棒特征
- 加速鲁棒特征( SURF )
- SURF特征提取算法
- SuperPoint: Self-Supervised Interest Point Detection and Description
相关文章:

角点特征:从传统算法到深度学习算法演进
1 概述 图像特征是用来描述和分析图像内容的关键属性,通常包括颜色、纹理和形状等信息。颜色特征能够反映图像中不同颜色的分布,常通过 RGB 值或色彩直方图表示。纹理特征则关注图像表面的结构和细节,例如通过灰度共生矩阵或局部二值模式&…...

免费代理IP服务有哪些隐患?如何安全使用?
代理IP已经成为互联网众多用户日常在线活动中不可或缺的一部分。无论是为了保护个人隐私、突破地理限制,还是用于数据抓取、广告投放等商业用途,代理IP都扮演着关键角色。然而,市场上存在大量的免费代理IP服务,尽管它们看起来颇具…...

深入了解 VPC 端点类型 – 网关与接口
什么是VPC 端点 VPC 端点(VPC Endpoint)是 Amazon Web Services (AWS) 提供的一种服务,允许用户在 Virtual Private Cloud (VPC) 内部安全地访问 AWS 服务,而无需通过公共互联网。VPC 端点通过私有连接将 VPC 与 AWS 服务直接连接…...

Android屏幕采集编码打包推送RTMP技术详解:从开发到优化与应用
在现代移动应用中,屏幕采集已成为一个广泛使用的功能,尤其是在实时直播、视频会议、远程教育、游戏录制等场景中,屏幕采集技术的需求不断增长。Android 平台为开发者提供了 MediaProjection API,这使得屏幕录制和采集变得更加简单…...
)
信息系统项目管理师高级-软考高项案例分析备考指南(2023年案例分析)
个人笔记整理---仅供参考 计算题 案例分析里的计算题就是进度、挣值分析、预测技术。主要考査的知识点有:找关键路径、求总工期、自由时差、总时差、进度压缩资源平滑、挣值计算、预测计算。计算题是一定要拿下的,做计算题要保持头脑清晰,认真读题把PV、…...

全栈项目搭建指南:Nuxt.js + Node.js + MongoDB
全栈项目搭建指南:Nuxt.js Node.js MongoDB 一、项目概述 我们将构建一个完整的全栈应用,包含: 前端:Nuxt.js (SSR渲染)后端:Node.js (Express/Koa框架)数据库:MongoDB后台管理系统:集成在同…...

Linux:基础IO
一:理解文件 1-1 狭义理解 文件存储在磁盘中,由于磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的;磁盘也是外设,因此磁盘上对文件的所有操作本质是对外设的输入和输出 1-2 广义理解 Linux下一切皆文件&am…...

MySQL 索引优化以及慢查询优化
在数据库性能优化中,索引优化和慢查询优化是两个关键环节。合理使用索引可以显著提高查询效率,而识别和优化慢查询则能提升整体数据库性能。本文将详细介绍MySQL索引优化和慢查询优化的方法和最佳实践。 一、MySQL 索引优化 1.1 索引的基本概念 索引是…...

Leaflet使用SVG创建动态Legend
接前一篇文章,前一篇文章我们使用 SVG 创建了带有动态文字的图标,今天再看看怎样在地图上根据动态图标生成相关的legend,当然这里也还是使用了 SVG 来生成相关颜色的 legend。 看下面的代码,生成了一个 svg 节点,其中…...

使用 Vue Tour 封装一个统一的页面引导组件
项目开发过程中需要实现用户引导功能,经过调研发现一个好用的 Vue 插件 vue-tour,今天就来分享一下我是如何基于 vue-tour 封装一个统一的引导组件,方便后续在多个页面复用的。 📦 第一步:安装 vue-tour 插件 首先安装…...

OpenResty 深度解析:构建高性能 Web 服务的终极方案
引言 openresty是什么?在我个人对它的理解来看相当于嵌入了lua的nginx; 我们在nginx中嵌入lua是为了不需要再重新编译,我们只需要重新修改lua脚本,随后重启即可; 一.lua指令序列 我们分别从初始化阶段,重写/访问阶段,内容阶段,日志…...

赋能企业级移动应用 CFCA FIDO+提升安全与体验
移动办公与移动金融为企业有效提升业务丰富性、执行便捷性。与此同时,“安全”始终是移动办公与移动金融都绕不开的话题。随着信息安全技术的发展,企业级移动应用中安全与便捷不再是两难的抉择。 中金金融认证中心(CFCA)作为经国…...

Redis 数据类型与操作完全指南
Redis 是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。与传统的关系型数据库不同,Redis 提供了丰富的数据类型和灵活的操作方式,这使得它能够高效地解决各种不同场景下的数据存储和处理问题。本文将全面介绍 R…...

ArrayList-集合使用
自动扩容,集合的长度可以变化,而数组长度不变,集合更加灵活。 集合只能存引用数据类型,不能直接存基本数据类型,除非包装 ArrayList会拿[]展示数据...

深入解析Spring Boot与Redis集成:高效缓存实践
深入解析Spring Boot与Redis集成:高效缓存实践 引言 在现代Web应用开发中,缓存技术是提升系统性能的重要手段之一。Redis作为一种高性能的键值存储数据库,广泛应用于缓存、会话管理和消息队列等场景。本文将详细介绍如何在Spring Boot项目中…...

8天Python从入门到精通【itheima】-11~13
目录 11节-PyCharm的安装和基础使用: 1.第三方IDE(集成开发工具) 2.PyCharm的所属——jetbrains公司 3.进入jetbrains的官网,搜索下载【官网自带中文,太友好了,爱你(づ ̄3&#x…...

day33-网络编程
1. 网络编程入门 1.1 网络编程概述 计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统…...

CMake基础及操作笔记
CMake 基础与操作:从入门到精通 前言 CMake 是一个功能强大、跨平台的构建工具,广泛用于 C 项目管理。它通过简洁的配置文件(CMakeLists.txt)描述编译过程,生成适用于不同平台的构建脚本(如 Makefile 或 …...

使用lvm进行磁盘分区
使用lvm进行磁盘分区 目的: 使用/dev/vdb创建一个5g的逻辑卷挂载到/mnt/lvmtest 前提: /dev/vdb是一块干净的空磁盘,数据会被清空!!! 1. 创建物理卷(PV): pvcreate /dev/sdb2. 验证…...

Java的线程通信机制是怎样的呢?
核心观点:线程通信本质是状态同步与数据传递的协同控制 (类比测试团队协作:如同测试用例执行需要同步进度,测试数据需要跨线程传递) 一、基础通信机制(附测试验证方法) 1. 共享内存(最常用但最危险) // 测试典型场景:多线程统计测试用例通过率 public class Share…...

线性回归策略
一种基于ATR(平均真实范围)、线性回归和布林带的交易策略。以下是对该策略的全面总结和分析: 交易逻辑思路 1. 过滤条件: - 集合竞价过滤:在每个交易日的开盘阶段,过滤掉集合竞价产生的异常数据。 - 价格异常过滤:排除当天开盘价与最高价或最低价相同的情况,这…...

Sparse4D运行笔记
Sparse4D有三个版本,其中V1和V2版本的官方文档中环境依赖写得比较模糊且依赖库有版本冲突。 1. Sparse4D V1 创建环境 conda create sparse4dv1 python3.8 激活环境 conda activate sparse4dv1 安装torch, torchvision, torchaudio pip install torch1.13.0c…...

Bitmap、Roaring Bitmap、HyperLogLog对比介绍
一、Bitmap(位图)概述 Bitmap 是一种用位(bit)来表示集合元素是否存在的数据结构。每个位代表一个元素的状态(0或1),非常节省空间且支持快速集合操作。 常见Bitmap类型: 普通Bitmap 最简单的位数组,适合元素范围固定且不稀疏的场景。例如,元素范围是0~1000,用1001…...

Rust 数据结构:HashMap
Rust 数据结构:HashMap Rust 数据结构:HashMap创建一个新的哈希映射HashMap::new()将元组变成哈希表 访问哈希映射中的值哈希映射和所有权更新哈希映射重写一个值仅当键不存在时才添加键和值基于旧值更新值 散列函数 Rust 数据结构:HashMap …...

Spring6学习及复习笔记
1、快速入门认识 通过编写xml配置文件来创建对象,读取bean标签的id值和class值来创建。 之后再通过对象调用相关的方法(这里实际上用到的是反射机制) 对象会存放到Map集合中 大致反射思路如下:(这里只是模拟&#x…...

开源语音-文本基础模型和全双工语音对话框架 Moshi 介绍
介绍 一、项目背景 Moshi是一种语音-文本基础模型和全双工语音对话框架。它使用了Mimi这一业界领先的流式神经音频编解码器。Mimi能够以完全流式处理的方式(80毫秒的延迟,即帧大小),将24千赫兹的音频信号压缩为12.5赫兹的表示形式…...
:MATLAB数学建模)
MATLAB学习笔记(六):MATLAB数学建模
MATLAB 是数学建模的强大工具,其丰富的函数库和可视化能力可以高效解决各类数学建模问题。以下是 MATLAB 数学建模的完整指南,涵盖建模流程、常用方法、代码示例及实际应用。 一、数学建模的基本流程 问题分析 • 明确目标(预测、优化、分类等…...

博客打卡-求解流水线调度
题目如下: 有n个作业(编号为1~n)要在由两台机器M1和M2组成的流水线上完成加工。每个作业加工的顺序都是先在M1上加工,然后在M2上加工。M1和M2加工作业i所需的时间分别为ai和bi(1≤i≤n)。 流水…...
:用户会话管理/文件类型拓展/诸多优化更新)
【Ragflow】22.RagflowPlus(v0.3.0):用户会话管理/文件类型拓展/诸多优化更新
概述 在历经三周的阶段性开发后,RagflowPlus顺利完成既定计划,正式发布v0.3.0版本。 开源地址:https://github.com/zstar1003/ragflow-plus 新功能 1. 用户会话管理 在后台管理系统中,新增用户会话管理菜单。在此菜单中&…...

深度学习中ONNX格式的模型文件
一、模型部署的核心步骤 模型部署的完整流程通常分为以下阶段,用 “跨国旅行” 类比: 步骤类比解释技术细节1. 训练模型学会一门语言(如中文)用 PyTorch/TensorFlow 训练模型2. 导出为 ONNX翻译成国际通用语言(如英语…...

【机器人】复现 WMNav 具身导航 | 将VLM集成到世界模型中
WMNav 是由VLM视觉语言模型驱动的,基于世界模型的对象目标导航框架。 设计一种预测环境状态的记忆策略,采用在线好奇心价值图来量化存储,目标在世界模型预测的各种场景中出现的可能性。 本文分享WMNav复现和模型推理的过程~ 下…...

C++中析构函数不设为virtual导致内存泄漏示例
一、问题示例 #include <iostream> using namespace std;class Base { public:Base() { cout << "Base constructor\n"; }~Base() { cout << "Base destructor\n"; } // 不是 virtual };class Derived : public Base { public:Derived(…...

UDP--DDR--SFP,FPGA实现之模块梳理及AXI读写DDR读写上板测试
模块梳理介绍 在之前的几篇文章中,笔者详细介绍了整个项目的框架结构以及部分关键模块的实现细节。这些模块包括UDP协议栈、UDP指令监测、数据跨时钟域处理、DDR读写控制、内存读取控制以及DDR AXI控制器等。这些模块共同构成了项目的基础架构,每个模块…...

Slidev集成Chart.js:专业数据可视化演示文稿优化指南
引言:为何选择在Slidev中集成Chart.js? 在现代演示文稿中,高效的数据可视化对于清晰传达复杂信息至关重要。Slidev是一款灵活的开源演示文稿工具,基于Web技术构建,但在高级数据可视化方面存在一定局限。本文旨在提供一…...
学习方法论:构建思维模型)
动态规划(3)学习方法论:构建思维模型
引言 动态规划是算法领域中一个强大而优雅的解题方法,但对于许多学习者来说,它也是最难以掌握的算法范式之一。与贪心算法或分治法等直观的算法相比,动态规划往往需要更抽象的思维和更系统的学习方法。在前两篇文章中,我们介绍了动态规划的基础概念、原理以及问题建模与状…...

NDS3211HV单路H.264/HEVC/HD视频编码器
1产品概述 NDS3211HV单路高清编码器是一款功能强大的音/视频编码设备,支持2组立体声,同时还支持CC(CVBS)字幕。支持多种音频编码方式。该设备配备了多种音/视频输入接口:HD-SDI数字视频输入、HDMI高清输入(支持CC)、A…...

GO语言语法---if语句
文章目录 1. 基本语法1.1 单分支1.2 双分支1.3 多分支 2. Go特有的if语句特性2.1 条件前可以包含初始化语句2.2 条件表达式不需要括号2.3 必须使用大括号2.4 判断语句所在行数控制 Go语言的if语句用于条件判断,与其他C风格语言类似,但有一些独特的语法特…...
Cell Ranger)
单细胞转录组(4)Cell Ranger
使用 Cell Ranger 分析单细胞数据 1. 数据转换 BCL2FASTQ 在进行单细胞数据分析之前,需要将 Illumina 测序仪生成的 BCL 格式数据转换为 FASTQ 格式。这一步通常使用 bcl2fastq 软件完成。 1.1 安装 bcl2fastq bcl2fastq 是 Illumina 提供的软件,用于…...

Python爬虫-爬取百度指数之人群兴趣分布数据,进行数据分析
前言 本文是该专栏的第56篇,后面会持续分享python爬虫干货知识,记得关注。 在本专栏之前的文章《Python爬虫-爬取百度指数之需求图谱近一年数据》中,笔者有详细介绍过爬取需求图谱的数据教程。 而本文,笔者将再以百度指数为例子,基于Python爬虫获取指定关键词的人群“兴…...

使用Python和Selenium打造一个全网页截图工具
无论是归档网站、测试页面设计,还是为报告记录网页内容,一个可靠的截图工具都能大大提升效率。本文将介绍如何使用Python、Selenium和wxPython构建一个用户友好的网页截图工具。该工具能在浏览器中显示网页,自动平滑滚动到底部以触发懒加载内…...

自动化脚本开发:Python调用云手机API实现TikTok批量内容发布
在2025年的技术生态下,通过Python实现TikTok批量内容发布的自动化脚本开发需结合云手机API调用、TikTok开放接口及智能调度算法。以下是基于最新技术实践的系统化开发方案: 一、云手机环境配置与API对接 云手机平台选择与API接入 推荐使用比特云手机或丁…...

React Hooks 必须在组件最顶层调用的原因解析
文章目录 前言一、Hooks 的基本概念二、Hooks 的调用规则三、为什么 Hooks 必须在最顶层调用?1. 维护 Hooks 的调用顺序2. 闭包与状态关联3. 实现细节:Hook 的链表结构 四、违反规则的后果五、如何正确使用 Hooks六、示例:正确与错误的用法对…...

西门子 Teamcenter13 Eclipse RCP 开发 1.2 工具栏 开关按钮
西门子 Teamcenter13 Eclipse RCP 开发 1.2 工具栏 开关按钮 1 配置文件2 插件控制3 命令框架 位置locationURI备注菜单栏menu:org.eclipse.ui.main.menu添加到传统菜单工具栏toolbar:org.eclipse.ui.main.toolbar添加到工具栏 style 值含义显示效果push普通按钮(默…...

5.27本日总结
一、英语 复习list2list29 二、数学 学习14讲部分内容 三、408 学习计组1.2内容 四、总结 高数和计网明天结束当前章节,计网内容学完之后主要学习计组和操作系统 五、明日计划 英语:复习lsit3list28,完成07年第二篇阅读 数学&#…...

【持续更新中】架构面试知识学习总结
1.分库分表出现冗余数据: ☆分库分表方法:水平和垂直(业务场景,数据关联性。逻辑要调查清楚) 垂直:将一个表(库)按照列的业务相关性进行拆分,把经常一起使用的列放在一张表(库)&…...

文字溢出省略号显示
一、 单行文字溢出、省略号显示 二、 多行文字溢出,省略号显示 有较大的兼容性问题,适用于Webkit为内核的浏览器软件,或者移动端的(大部分也是webkit) 此效果建议后端人员开发 三、图片底侧空白缝隙的修复技巧&#…...

力扣-283-移动零
1.题目描述 2.题目链接 283. 移动零 - 力扣(LeetCode) 3.题目代码 class Solution {public void moveZeroes(int[] nums) {int dest-1;int cur0;while(cur<nums.length){if(nums[cur]0){cur;}else if(nums[cur]!0){swap(nums,cur,dest1);cur;dest…...

【001】RenPy打包安卓apk 流程源码级别分析
1. 入口在下图 2. SDK版本及代码入口 (renpy-8.3.7-sdk) 由于SDK一直在升级,本文采用 标题中的版本进行分析,整体逻辑变化不太大。 实际执行逻辑是调用的rapt 2.1 点击按钮实际执行逻辑 def AndroidIfState(state, needed, acti…...

机器学习-人与机器生数据的区分模型测试-数据处理 - 续
这里继续 机器学习-人与机器生数据的区分模型测试-数据处理1的内容 查看数据 中1的情况 #查看数据1的分布情况 one_ratio_list [] for col in data.columns:if col city or col target or col city2: # 跳过第一列continueelse:one_ratio data[col].mean() # 计算1值占…...
)
计算机视觉与深度学习 | Python实现EMD-VMD-LSTM时间序列预测(完整源码和数据)
EMD-VMD-LSTM 一、完整代码实现二、代码结构解析三、关键参数说明四、性能优化建议五、工业部署方案以下是用Python实现EMD-VMD-LSTM时间序列预测的完整代码,结合经验模态分解(EMD)、变分模态分解(VMD)与LSTM深度学习模型,适用于复杂非平稳信号的预测任务。代码包含数据生…...