机器学习——逻辑回归
一、逻辑回归概念点
逻辑回归(Logistic Regression)是一种广泛使用的统计分析方法和机器学习算法,主要用于处理二分类问题(即因变量为二元类别,如0和1、是和否等)。尽管名字中有“回归”二字,但它实际上是一种分类算法,而不是回归分析方法
1.1 逻辑回归优缺点
1.优点
- 简单易懂:逻辑回归模型结构简单,易于理解和实现
- 可解释性强:模型参数(权重)具有明确的统计意义,可以解释各个特征对结果的影响
- 计算效率高:逻辑回归算法计算速度快,适合大规模数据集
- 适用于二分类问题:逻辑回归是处理二分类问题的标准方法之一
2.缺点
- 对非线性关系建模能力有限:逻辑回归假设特征与目标变量之间是线性关系,对非线性关系建模能力有限
- 对异常值敏感:逻辑回归对异常值较为敏感,可能会影响模型的准确性
- 需要特征缩放:逻辑回归对特征的尺度敏感,通常需要对特征进行标准化或归一化处理
- 不适合多分类问题:虽然可以通过一对多或一对一的方法扩展到多分类问题,但不如其他算法(如决策树、随机森林等)直接
1.2 逻辑回归原理
逻辑回归的核心是使用 Sigmoid 函数(也称为逻辑函数)将线性回归的输出映射到0和1之间,表示事件发生的概率
Sigmoid 函数的公式为:
其中,z是线性回归的输出,即
逻辑回归的目标是找到一组权重 w ,使得模型对训练数据的预测尽可能准确。这通常通过最大化似然函数来实现,等价于最小化损失函数(如交叉熵损失)
1.3 逻辑回归执行步骤
1.3.1 数据准备
- 收集数据:收集包含特征和目标变量的数据集
- 数据清洗:处理缺失值、异常值等
- 特征选择:选择对目标变量有影响的特征
- 数据分割:将数据集分为训练集和测试集
1.3.2 特征工程
- 特征缩放:对特征进行标准化或归一化处理,以提高模型的收敛速度和准确性
- 特征编码:对分类特征进行编码
1.3.3 模型训练
- 初始化参数:随机初始化模型参数(权重)
- 选择优化算法:如梯度下降法
- 迭代优化:通过迭代优化算法更新模型参数,直到收敛或达到最大迭代次数
1.3.4 模型评估
- 使用测试集评估模型性能,常用的评估指标包括准确率、精确率、召回率、F1分数等
- 交叉验证:使用交叉验证方法评估模型的泛化能力
1.3.5 模型优化
- 参数调优:通过网格搜索或随机搜索等方法调整模型参数。
- 特征选择:使用特征选择方法(如递归特征消除、L1正则化等)选择最佳特征
二、Python代码实现逻辑回归
2.1 数据分析
在给出的数据中,前两列是特征值分别作为X轴和Y轴,第三列是类别标签
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
-1.781871 9.097953 0
-0.566606 5.749003 1
0.931635 1.589505 1
-0.024205 6.151823 1
-0.036453 2.690988 1
-0.196949 0.444165 1
1.014459 5.754399 1
1.985298 3.230619 1
-1.693453 -0.557540 1
-0.576525 11.778922 0
-0.346811 -1.678730 1
-2.124484 2.672471 1
1.217916 9.597015 0
-0.733928 9.098687 0
-3.642001 -1.618087 1
0.315985 3.523953 1
1.416614 9.619232 0
-0.386323 3.989286 1
0.556921 8.294984 1
1.224863 11.587360 0
-1.347803 -2.406051 1
1.196604 4.951851 1
0.275221 9.543647 0
0.470575 9.332488 0
-1.889567 9.542662 0
-1.527893 12.150579 0
-1.185247 11.309318 0
-0.445678 3.297303 1
1.042222 6.105155 1
-0.618787 10.320986 0
1.152083 0.548467 1
0.828534 2.676045 1
-1.237728 10.549033 0
-0.683565 -2.166125 1
0.229456 5.921938 1
-0.959885 11.555336 0
0.492911 10.993324 0
0.184992 8.721488 0
-0.355715 10.325976 0
-0.397822 8.058397 0
0.824839 13.730343 0
1.507278 5.027866 1
0.099671 6.835839 1
-0.344008 10.717485 0
1.785928 7.718645 1
-0.918801 11.560217 0
-0.364009 4.747300 1
-0.841722 4.119083 1
0.490426 1.960539 1
-0.007194 9.075792 0
0.356107 12.447863 0
0.342578 12.281162 0
-0.810823 -1.466018 1
2.530777 6.476801 1
1.296683 11.607559 0
0.475487 12.040035 0
-0.783277 11.009725 0
0.074798 11.023650 0
-1.337472 0.468339 1
-0.102781 13.763651 0
-0.147324 2.874846 1
0.518389 9.887035 0
1.015399 7.571882 0
-1.658086 -0.027255 1
1.319944 2.171228 1
2.056216 5.019981 1
-0.851633 4.375691 1
-1.510047 6.061992 0
-1.076637 -3.181888 1
1.821096 10.283990 0
3.010150 8.401766 1
-1.099458 1.688274 1
-0.834872 -1.733869 1
-0.846637 3.849075 1
1.400102 12.628781 0
1.752842 5.468166 1
0.078557 0.059736 1
0.089392 -0.715300 1
1.825662 12.693808 0
0.197445 9.744638 0
0.126117 0.922311 1
-0.679797 1.220530 1
0.677983 2.556666 1
0.761349 10.693862 0
-2.168791 0.143632 1
1.388610 9.341997 0
0.317029 14.739025 0
2.2 代码展示
2.2.1 导入相关库
import numpy as np
import matplotlib.pyplot as plt2.2.2 数据预处理
path = '文件名.txt'def loaddataset():testset = [[-3.141592, 2.343434], [7.12121, 3.232323], [-1.222222, 3.2323232], [2.794747, -4.67890]]datamat = []labelmat = []fr = open(path)for line in fr.readlines():linearr = line.strip().split()datamat.append([1.0, float(linearr[0]), float(linearr[1])])labelmat.append(int(linearr[2]))return datamat, labelmat, testset代码解析:
1.定义了一个变量 path,对包含数据集的文本文件的路径和文件名进行存储
2.定义函数loaddataset(),将数据集从文件中加载出来
3.定义了一个 testset 的列表,其中包含了测试数据集。每个子列表代表一个测试样本,包含两个
特征值
4.初始化两个空列表,datamat 用于存储训练数据的特征,labelmat 用于存储训练数据的标签
5.打开文件,逐行读取文件中的内容并将数据存储到datamat列表和labelmat列表中
6.返回三个值:datamat(训练数据的特征),labelmat(训练数据的标签),以及 testset(测试数据集)
2.2.3 逻辑回归模型构建
def sigmoid(z):return 1 / (1 + np.exp(-z))# 测试函数并展示图像
def test_sigmoid():nums = np.arange(-10, 10, 0.1)sig_values = sigmoid(nums)fig, ax = plt.subplots(figsize=(12, 8))ax.plot(nums, sig_values, 'g')ax.set_xlabel('Input Value')ax.set_ylabel('Sigmoid Value')ax.set_title('Sigmoid Function')plt.grid(True)plt.show()2.2.4 实现模型的梯度上升函数
# 实现模型的梯度上升函数
def gradascent(datamatin, classlabels, stoptype='bgd'):m, n = np.shape(datamatin) # m为矩阵的行数,n为矩阵的列数weights = np.ones((n, 1)) # 权重矩阵(n,1)的列向量alpha = 0.001 # 学习率(梯度上升的步长)if stoptype == 'bgd':datamatrix = np.asmatrix(datamatin) # 将datamatrix转化为矩阵labelmat = np.asmatrix(classlabels).transpose() # 将labelmat转化为矩阵同时转置maxcycles = 500 # 最大迭代次数for k in range(maxcycles): # 梯度上升循环h = sigmoid(datamatrix * weights) # 使用当前权重和输入数据计算每个数据点的预测概率error = (labelmat - h) # 计算预测概率和真实标签的误差weights = weights + alpha * datamatrix.transpose() * errorreturn weights # datamatrix.transpose()*error为梯度,再利用梯度*学习率来更新权值elif stoptype == 'sgd':weights = np.ones((n, 1)) # 初始化权重for i in range(m):h = sigmoid(np.dot(datamatin[i], weights)) # 使用当前权重和输入数据计算每个数据点的预测概率error = classlabels[i] - h # 计算预测概率和真实标签的误差weights = weights + alpha * error * np.array(datamatin[i]).reshape(n, 1)return weights2.2.5 预测测试集,划分类别
# 预测测试集,划分类别
def classifyVector(testset, weights):count = 0testset = np.array(testset)for sample in testset:count += 1 # 用来记录当前的测试集z = weights[0] * 1 + weights[1] * sample[0] + weights[2] * sample[1]result = sigmoid(z)print(f"第{count}个测试集计算的概率结果为:{result}")if result > 0.5:print(f"第{count}个测试预测类别为1类")else:print(f"第{count}个预测类别为0类")2.2.6 绘制决策边界
# 绘制决策边界
def plotBestFit(weights, dataMat, labelMat):dataArr = np.array(dataMat)n = np.shape(dataArr)[0] # 获取数据总数xcord1 = []; ycord1 = [] # 存放正样本xcord2 = []; ycord2 = [] # 存放负样本for i in range(n): # 依据数据集的标签来对数据进行分类if int(labelMat[i]) == 1: # 数据的标签为1,表示为正样本xcord1.append(dataArr[i, 1]); ycord1.append(dataArr[i, 2])else:xcord2.append(dataArr[i, 1]); ycord2.append(dataArr[i, 2])fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(xcord1, ycord1, s=30, c='b', marker='o') # 绘制正样本ax.scatter(xcord2, ycord2, s=30, c='r', marker='x') # 绘制负样本x = np.arange(-3.0, 3.0, 0.1)y = (-weights[0, 0] - weights[1, 0] * x) / weights[2, 0]ax.plot(x, y)plt.xlabel('X1'); plt.ylabel('X2')plt.legend(["1", "0", "decision boundary"])plt.show()
2.2.7 主函数执行
# 主函数
if __name__ == "__main__":dataMat, labelMat, testset = loaddataset() # 加载数据集test_sigmoid()weights = gradascent(dataMat, labelMat) # 训练模型并获取最优权值print("最优权值:")print(weights)classifyVector(testset, weights) # 预测测试集plotBestFit(weights, dataMat, labelMat) # 绘制决策边界2.3 效果截图
2.3.1 逻辑回归模型展示
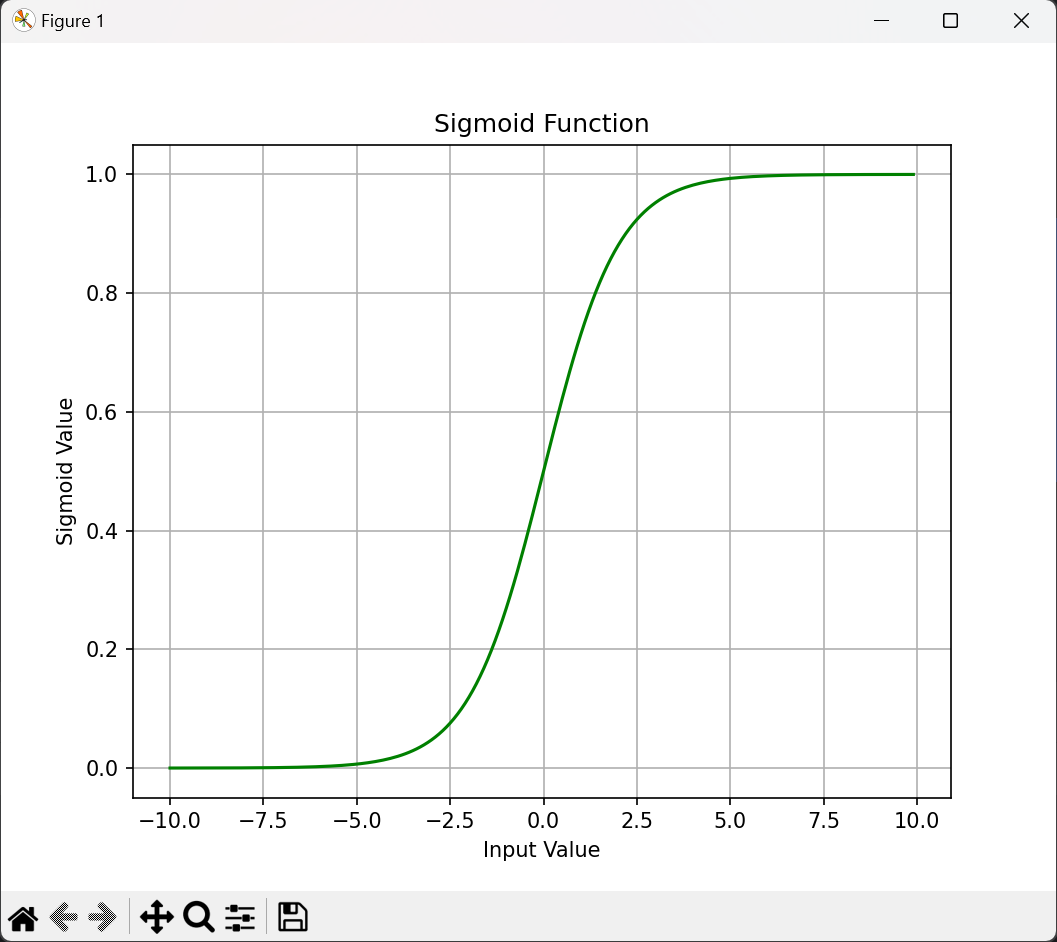
2.3.2 最优权值

2.3.3 测试集预测

2.3.4 绘制决策边界
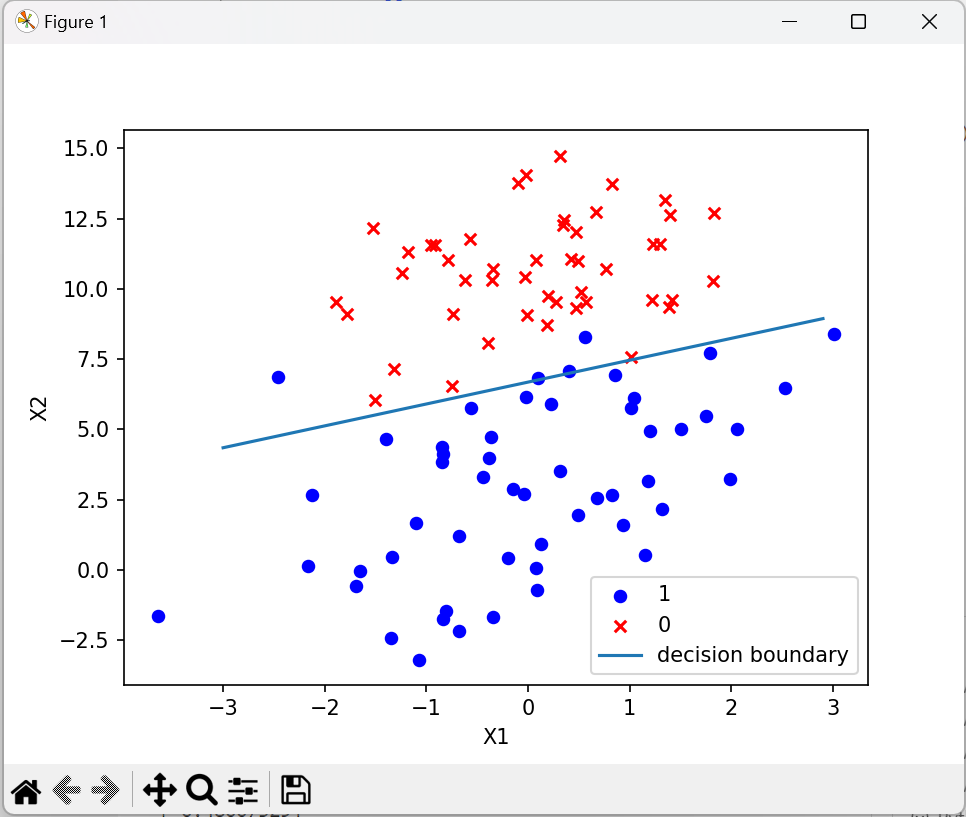
2.4 总结
2.4.1 实验目标
本次实验的目标是通过实现逻辑回归模型,对二分类数据集进行训练和预测,并通过绘制决策边界来直观展示模型的分类效果。实验主要涉及以下内容:
- 数据加载与预处理
- 实现逻辑回归模型的训练(梯度上升法)
- 对测试集进行预测
- 绘制决策边界并评估模型性能
2.4.2 实验方法
本次实验采用 Python 编程语言,使用 NumPy 和 Matplotlib 等库实现逻辑回归模型。实验步骤如下:
1. 数据加载与预处理
- 数据集包含两个特征和一个标签,标签为 0 或 1
- 数据加载时,每行数据被处理为一个特征向量(添加偏置项 1.0)和对应的标签
- 数据集被分为训练集和测试集
2. 模型训练
- 采用梯度上升法(Gradient Ascent)训练逻辑回归模型
- 实现了两种梯度上升方法:批量梯度上升,即使用所有数据点计算梯度,更新权重;随机梯度上升,即每次只使用一个数据点计算梯度,更新权重。
- 学习率设置为 0.001,迭代次数为 500 次(BGD)
3. 预测与评估
- 使用训练好的权重对测试集进行预测
- 预测结果基于 Sigmoid 函数的输出,阈值为 0.5
- 打印每个测试样本的预测概率和预测类别
4. 决策边界绘制
- 根据训练好的权重绘制决策边界
- 决策边界由公式
确定
- 数据点根据标签分为两类,分别用蓝色圆圈(正样本)和红色叉号(负样本)表示
2.4.3 实验分析
1. 模型性能
- 从决策边界图像可以看出,模型能够较好地分隔两类数据,说明训练效果较好
- 测试集的预测结果也表明,模型能够准确地对新样本进行分类
2. 梯度上升法
- 批量梯度上升法(BGD):计算稳定,但计算量较大,适合小数据集
- 随机梯度上升法(SGD):计算速度快,但收敛速度可能较慢,适合大数据集
通过实现逻辑回归模型,加深了对逻辑回归算法的理解,包括 Sigmoid 函数、梯度上升法等核心概念,在实验中, 使用 Python 和 NumPy 实现了数据处理、模型训练和可视化,提升了编程能力
相关文章:

机器学习——逻辑回归
一、逻辑回归概念点 逻辑回归(Logistic Regression)是一种广泛使用的统计分析方法和机器学习算法,主要用于处理二分类问题(即因变量为二元类别,如0和1、是和否等)。尽管名字中有“回归”二字,但…...

服务间的“握手”:OpenFeign声明式调用与客户端负载均衡
现在,假设我们有一个新的order-service,它在创建订单时需要获取用户信息。 如果order-service直接硬编码user-service的IP和端口进行调用,会面临以下问题: 缺乏弹性: 如果user-service实例的IP或端口发生变化(在云环境…...

蓝桥杯11届国B 答疑
题目描述 有 n 位同学同时找老师答疑。每位同学都预先估计了自己答疑的时间。 老师可以安排答疑的顺序,同学们要依次进入老师办公室答疑。 一位同学答疑的过程如下: 首先进入办公室,编号为 i 的同学需要 si 毫秒的时间。然后同学问问题老…...

【单机版OCR】清华TH-OCR v9.0免费版
今天向大家介绍一款非常好用的单机版OCR图文识别软件,它不仅功能多,识别能力强,而且还是免费使用的。OCR软件为什么要使用单机版,懂得都懂,因为如果使用在线识别的OCR软件,用户需要将文档上传互联网服务器的…...

蓝牙耳机什么牌子好?倍思值得冲不?
最近总被问“蓝牙耳机什么牌子好”,作为踩过无数坑的资深耳机党,必须安利刚入手的倍思M2s Pro主动降噪蓝牙耳机!降噪、音质、颜值全都在线,性价比直接拉满。 -52dB降噪,通勤摸鱼神器 第一次开降噪就被惊到!…...

Java卡与SSE技术融合实现企业级安全实时通讯
简介 在数字化转型浪潮中,安全与实时数据传输已成为金融、物联网等高安全性领域的核心需求。本文将深入剖析东信和平的Java卡权限分级控制技术与浪潮云基于SSE的大模型数据推送技术,探索如何将这两项创新技术进行融合,构建企业级安全实时通讯系统。通过从零到一的开发步骤,…...

使用Spring Boot和Spring Security构建安全的RESTful API
使用Spring Boot和Spring Security构建安全的RESTful API 引言 在现代Web开发中,安全性是构建应用程序时不可忽视的重要方面。本文将介绍如何使用Spring Boot和Spring Security框架构建一个安全的RESTful API,并结合JWT(JSON Web Token&…...
)
Win11下轻松搭建wiki.js,Docker.desktop部署指南(mysql+elasticsearch+kibana+wiki.js)
Docker.desktop部署wiki.js指南 前言环境和要求介绍提前准备 1. elasticsearch1.1 部署容器1.2 参数说明1.3 验证容器是否部署成功 2. kibana2.1 部署容器2.2 验证是否部署成功2.3 安装IK分词器 3. MySql3.1 部署容器3.2 增加数据库和wiki.js所需要的账号 4. wiki.js4.1 部署容…...

【JavaWeb】MySQL
1 引言 1.1 为什么学? 在学习SpringBootWeb基础知识(IOC、DI等)时,在web开发中,为了应用程序职责单一,方便维护,一般将web应用程序分为三层,即:Controller、Service、Dao 。 之前的案例中&am…...

数据库实验报告 数据定义操作 3
实验报告(第3次) 实验名称 数据定义操作 实验时间 10月12日1-2节 一、实验内容 1、本次实验是用sql语句创建库和表,语句是固定的,要求熟记这些sql语句。 二、源程序及主…...
)
寻找树的中心(重心)
题目: 思路: “剥洋葱”:每次剥掉一层叶子结点,直到最后剩余不多于2个节点,这些节点就是树的中心(重心)。 解释: 1、根据图论的知识可以知道,一颗树的中心(…...
)
Oracle 高水位线(High Water Mark, HWM)
1. 高水位线(HWM)的定义 基本概念:HWM 是 Oracle 数据库中一个段(如表、索引)中已分配并被格式化(Formatted)的存储空间的最高位置。它标识了该段历史上曾达到的最大数据块使用量。 物理意义&a…...
事务和锁机制)
Redis学习专题(二)事务和锁机制
目录 引言 1、事务三特性 2、事务相关指令 :Multi、Exec、discard 快速入门 注意: 3、事务冲突 解决办法: 1.悲观锁 2.乐观锁 3.watch & unwatch 引言 Redis 的事务是什么? 1、Redis 事务是一个单独的隔离操作:事…...

多平台!像素艺术的最佳选择 , 开源像素画工具
项目简介 如果你喜欢作像素风格的游戏或动画,那么这款Pixelorama或许是你的好帮手。它是一款免费开源的像素画编辑器,功能丰富,操作便捷,支持多平台使用(Windows、macOS、Linux)。无论你是像素新手还是老手…...

使用 Kotlin 和 Jetpack Compose 开发 Wear OS 应用的完整指南
环境配置与项目搭建 1. Gradle 依赖配置 // build.gradle (Module) android {buildFeatures {compose true}composeOptions {kotlinCompilerExtensionVersion "1.5.3"} }dependencies {def wear_compose_version "1.2.0"implementation "androidx.…...

JavaScript【5】DOM模型
1.概述: DOM (Document Object Model):当页面被加载时,浏览器会创建页面的文档对象模型,即dom对象;dom对象会被结构化为对象树,如一个HTML文档会被分为head,body等部分,而每个部分又…...

【诊所电子处方专用软件】佳易王个体诊所门诊电子处方开单管理系统:零售药店电子处方服务系统#操作简单#诊所软件教程#药房划价
一、软件试用版资源文件下载说明 (一)若您想体验软件功能,可通过以下方式获取软件试用版资源文件: 访问头像主页:进入作者头像主页,找到第一篇文章,点击文章最后的卡片按钮,即可了…...

【OpenCV】帧差法、级联分类器、透视变换
一、帧差法(移动目标识别): 好处:开销小,不怎么消耗CPU的算力,对硬件要求不高,但只适合固定摄像头 1、优点 计算效率高,硬件要求 响应速度快,实时性强 直接利用连续帧…...

OpenCV 特征检测全面解析与实战应用
在计算机视觉领域,特征检测是从图像中提取关键信息的核心技术,这些关键特征是图像匹配、目标识别、场景理解等复杂任务的基础。OpenCV 作为计算机视觉领域最受欢迎的开源库之一,提供了丰富且高效的特征检测算法。本文将深入介绍 OpenCV 中多种…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月17日第80弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...

IDEA反斜杠路径不会显示JUnit运行的工作目录配置问题
1. 当在IDEA基准目录下创建junit-reflect-annotation-proxy-app\\src\\data.txt时,如果是Mac电脑,这种\\文件路径时,IDEA里面不会显示,但在Finder下会显示,是直接创建了文件名为junit-reflect-annotation-proxy-app\sr…...

Linux517 rsync同步 rsync借xinetd托管 配置yum源回顾
计划测试下定时服务 同步成功 是否为本地YUM源内容太少?考虑网络YUM源 单词拼错了 计划后面再看下 MX安装 参考 计划回顾配置YUM源 配置本地YUM源配置外网YUM源配置仓库YUM源(不熟) 参考 参考阿里云 配置完毕 本地yum源配置 先备份 再…...

【论文阅读】A Survey on Multimodal Large Language Models
目录 前言一、 背景与核心概念1-1、多模态大语言模型(MLLMs)的定义 二、MLLMs的架构设计2-1、三大核心模块2-2、架构优化趋势 三、训练策略与数据3-1、 三阶段训练流程 四、 评估方法4-1、 闭集评估(Closed-set)4-2、开集评估&…...

大型语言模型中的QKV与多头注意力机制解析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
)
React Flow 节点事件处理实战:鼠标 / 键盘事件全解析(含节点交互代码示例)
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...

AIGC在电商行业的应用:革新零售体验
AIGC在电商行业的应用:革新零售体验 引言 人工智能生成内容(AIGC)正在深刻改变电商行业的格局。从个性化推荐到智能客服,从产品描述生成到虚拟试衣,AIGC技术正在为电商平台带来前所未有的创新和效率提升。本文将深入探…...

【数据结构】线性表--队列
【数据结构】线性表--队列 一.什么是队列二.队列的实现1.队列结构定义:2.队列初始化函数:3.队列销毁函数:4.入队列函数(尾插):5.出队列函数(头删):6.取队头元素ÿ…...
)
CSS- 4.1 浮动(Float)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

Node.js 源码架构详解
Node.js 的源码是一个庞大且复杂的项目,它主要由 C 和 JavaScript 构成。要完全理解每一部分需要大量的时间和精力。我会给你一个高层次的概述,并指出一些关键的目录和组件,帮助你开始探索。 Node.js 的核心架构 Node.js 的核心可以概括为以…...

OpenCV级联分类器
概念 OpenCV 级联分类器是一种基于 Haar 特征、AdaBoost 算法和级联结构的目标检测方法,通过多阶段筛选快速排除非目标区域,实现高效实时检测(如人脸、行人等)。 加载级联分类器 // 加载级联分类器CascadeClassifier cascade;// …...

远程主机状态监控-GPU服务器状态监控-深度学习服务器状态监控
远程主机状态监控-GPU服务器状态监控-深度学习服务器状态监控 ⭐️ 推荐文章: DockerPyCharm远程调试&环境隔离解决方案 1. 整体架构 在本监控系统中,我们采用了Prometheus作为核心监控解决方案,并结合Node Exporter和Grafana构建了一个完整的监控体…...

谈谈未来iOS越狱或巨魔是否会消失
2024年10月的预测,先说结论: 巨魔iOS17.1消失概率为99%。 因为巨魔强依赖的漏洞就是一个签名漏洞,攻击面有限又经过2轮修复,第3次出现漏洞的概率极低。而越狱的话由于系统组件和服务较多,所以出现漏洞概率高攻击面多&…...
OpenGL渲染简单图形)
【OpenGL学习】(二)OpenGL渲染简单图形
文章目录 【OpenGL学习】(二)OpenGL渲染简单图形OpenGL渲染图形流程顶点,图元和片元VAO,VBO ,EBO着色器示例:使用OpenGL渲染三角形 【OpenGL学习】(二)OpenGL渲染简单图形 OpenGL渲…...

学习深度学习是否要先学习机器学习?
有小伙伴问我,最近做毕设要做一个神经网络的课题,想请教一下需不需要把机器学习也都学习一遍? 永远正确的回答是:建议先学机器学习,再学深度学习。 上面那句你从哪都挑不出毛病,毕竟机器学习是深度学习的基…...

六、绘制图片
文章目录 1.创建一个红色图片2.加载bmp图片3.加载png、jpg图片 前面的几个示例,我们已经展示过如果在Linux系统下使用xlib接口向窗口中绘制文本、线、矩形;并设置文本、线条的颜色。并利用xlib提供的接口结合事件处理机制完成了一个自绘按钮控件功能。有…...

【OpenCV】基本数据类型及常见图像模式
是什么?能做什么?解决什么问题?为什么用它? OpenCV:是一个基于开源发行的跨平台计算机视觉库,实现 一、应用场景: 目标识别:人脸、车辆、车牌...自动驾驶医学影像分析视频内容理解与分析&…...

C# WPF .NET Core和.NET5之后引用System.Windows.Forms的解决方案
双击项目名称打开工程文件(.csporj)添加“Microsoft.WindowsDesktop.App.WindowsForms”引用; <Project Sdk"Microsoft.NET.Sdk"><PropertyGroup><OutputType>WinExe</OutputType><TargetFramework&g…...

Mysql 8.0.32 union all 创建视图后中文模糊查询失效
记录问题,最近在使用union all聚合了三张表的数据,创建视图作为查询主表,发现字段值为中文的筛选无法生效.......... sql示例: CREATE OR REPLACE VIEW test_view AS SELECTid,name,location_address AS address,type,"1" AS data_type,COALESCE ( update_time, cr…...

PYTHON训练营DAY28
类 (一)题目1:定义圆(Circle)类 要求: 包含属性:半径 radius。包含方法: calculate_area():计算圆的面积(公式:πr)。calculate_circ…...
:PyTorch 中的 torch.randn 全面指南)
pytorch小记(二十一):PyTorch 中的 torch.randn 全面指南
pytorch小记(二十一):PyTorch 中的 torch.randn 全面指南 PyTorch 中的 torch.randn 全面指南一、接口定义二、参数详解三、常见使用场景四、位置参数 vs. Tuple 传参 —— 数值示例五、必须用关键字传入小结 PyTorch 中的 torch.randn 全面指…...

LeetCode 第 45 题“跳跃游戏 II”
好的,我来帮你解释一下 LeetCode 第 45 题“跳跃游戏 II”,这是一道经典的贪心算法题目。 题目描述: 给你一个非负整数数组 nums,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。你的目标是使用…...

【leetcode】逐层探索:BFS求解最短路的原理与实践
前言 🌟🌟本期讲解关于力扣的几篇题解的详细介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话不…...

副业小程序YUERGS,从开发到变现
文章目录 我为什么写这个小程序网站转小程序有什么坑有什么推广渠道个人开发者如何变现简单介绍YUERGS小程序给独立开发者一点小建议 我为什么写这个小程序 关注我的粉丝应该知道,我在硕士阶段就已经掌握了小程序开发技能,并写了一个名为“约球online”…...

Vue-键盘事件
键盘事件 回车事件 回车输出Input控件输入的内容 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><title>键盘事件</title><!-- 引入Vue --><script type"text/javascript&quo…...

区块链可投会议CCF C--IPCCC 2025 截止6.7 附录用率
Conference:44th IEEE -- International Performance Computing and Communications Conference CCF level:CCF C Categories:计算机网络 Year:2025 Conference time:Nov 21 – 23, 2025 Austin, Texas, USA 录用率…...

Linux `mkdir` 命令深度解析与高阶应用指南
Linux `mkdir` 命令深度解析与高阶应用指南 一、核心功能解析1. 基本作用2. 与类似工具对比二、选项系统详解1. 常用基础选项2. 高级选项组合三、高阶应用场景1. 自动化部署系统2. 安全审计合规3. 容器环境初始化4. 多用户协作体系四、特殊文件处理1. 符号链接处理2. 挂载点管理…...

JVM 调优实战入门:从 GC 日志分析到参数调优
手把手教你理解 GC 日志、识别性能瓶颈并合理配置 JVM 参数! 你是否曾遇到线上系统莫名卡顿、内存暴涨甚至频繁 Full GC? 本篇文章将带你从实际 GC 日志出发,深入剖析 JVM 性能问题,并学会如何通过参数调优提升系统稳定性和吞吐能…...

论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位…...

Kafka 生产者工作流程详解
以下是 Kafka 生产者工作流程的清晰分步解释,结合关键机制与用户数据: 1. 生产者初始化与数据发送 主线程创建生产者对象,调用 send(ProducerRecord) 发送消息。 拦截器(可选):可添加自定义逻辑(…...

leetcode 239. 滑动窗口最大值
暴力解法是一种简单直接的方法,虽然效率较低,但可以帮助你更好地理解问题的逻辑。以下是使用暴力解法解决“滑动窗口最大值”问题的 C 实现。 暴力解法的思路 遍历每个滑动窗口: 使用一个外层循环,从数组的起始位置开始ÿ…...