Bellman - Ford 算法与 SPFA 算法求解最短路径问题 ——从零开始的图论讲解(4)
目录
前言
为什么Dijkstra算法面对负权值图会有误差???
举例说明
什么是Bellman -Ford算法?
BF算法的核心思想
什么是松弛
为什么最多松弛N-1次?
代码实现
举例
初始状态(dist[] 数组)
第 1 轮松弛(遍历所有边)
第 2 轮松弛
第 3 轮松弛
第 4 轮松弛(最后一次)
第 5 轮检测是否还能松弛(负环判断)
完整代码
BF算法的缺陷
SPFA算法
SPFA算法改进的地方
SPFA算法的原理
完整代码
结尾
前言
这是笔者图论系列的第四篇博客了,非常感谢大家的支持,因为本系列的数据很好看,笔者有了更多动力去更新 .
前三篇URL如下:
1.
图的概念,图的存储,图的遍历与图的拓扑排序——从零开始的图论讲解(1)_图论】图的存储与出边的排序-CSDN博客
2.
Dijkstra算法求解最短路径—— 从零开始的图论讲解(2) -CSDN博客
3.
Floyd算法求解最短路径问题——从零开始的图论讲解(3)-CSDN博客
其中第二篇与第三篇笔者已经介绍了两种算法去解决最短路径问题了
Dijkstra 是一种"单源" 最短路径算法,它的利用了贪心的思维,效率相当高,唯一的遗憾是当权值为负时,可能会产生误差
为什么Dijkstra算法面对负权值图会有误差???
因为它的核心是:
每次从未访问的点中,选择一个 当前距离起点最近的点 u,然后从 u 出发去更新其他点的距离(“松弛”操作)。
也就是说,它一旦确定了一个点 u 到起点的最短路径,就永远不会再改变它 —— 因为它“相信”这个距离已经是最短的。
举例说明
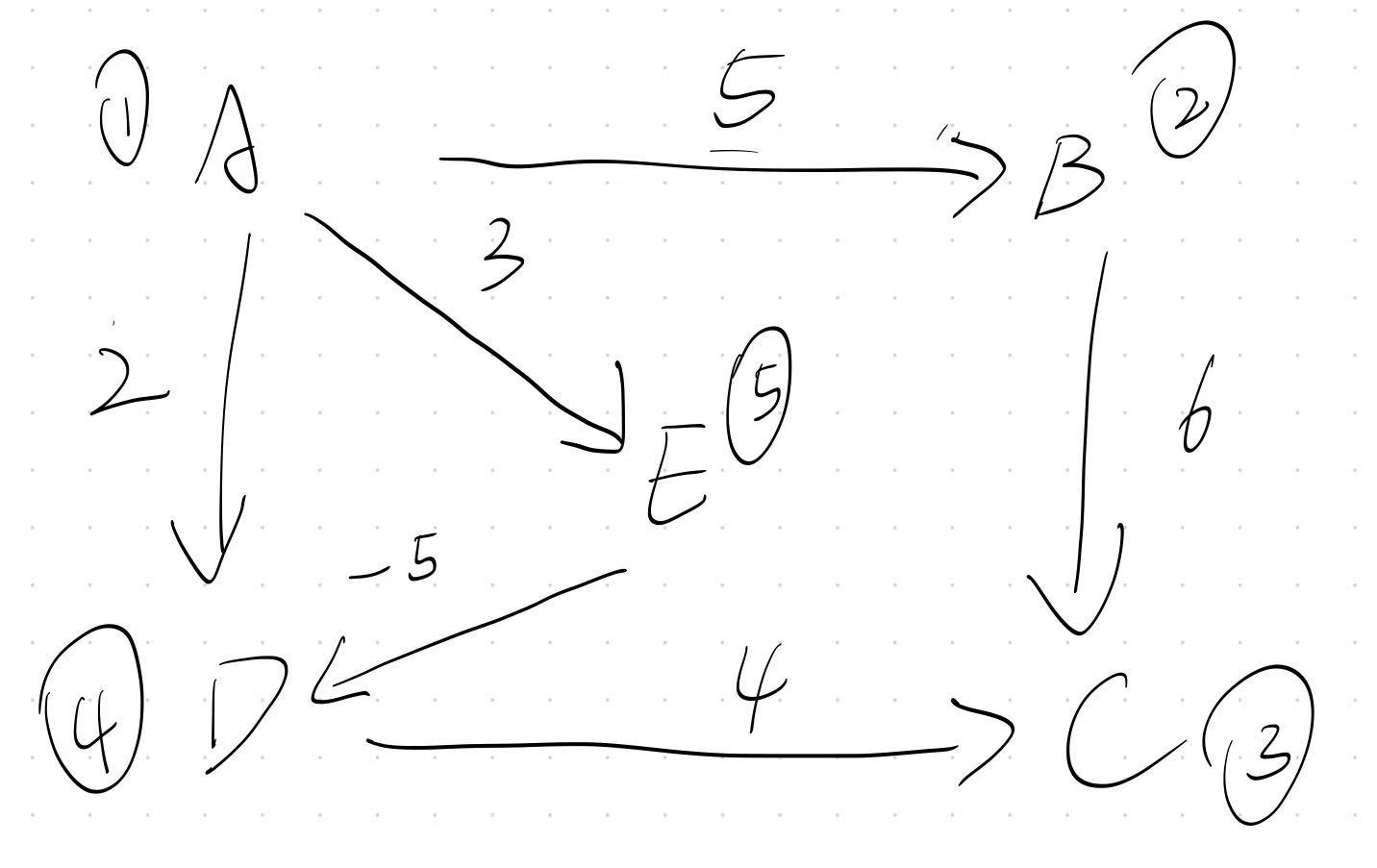
举例来说,请看下面的图:
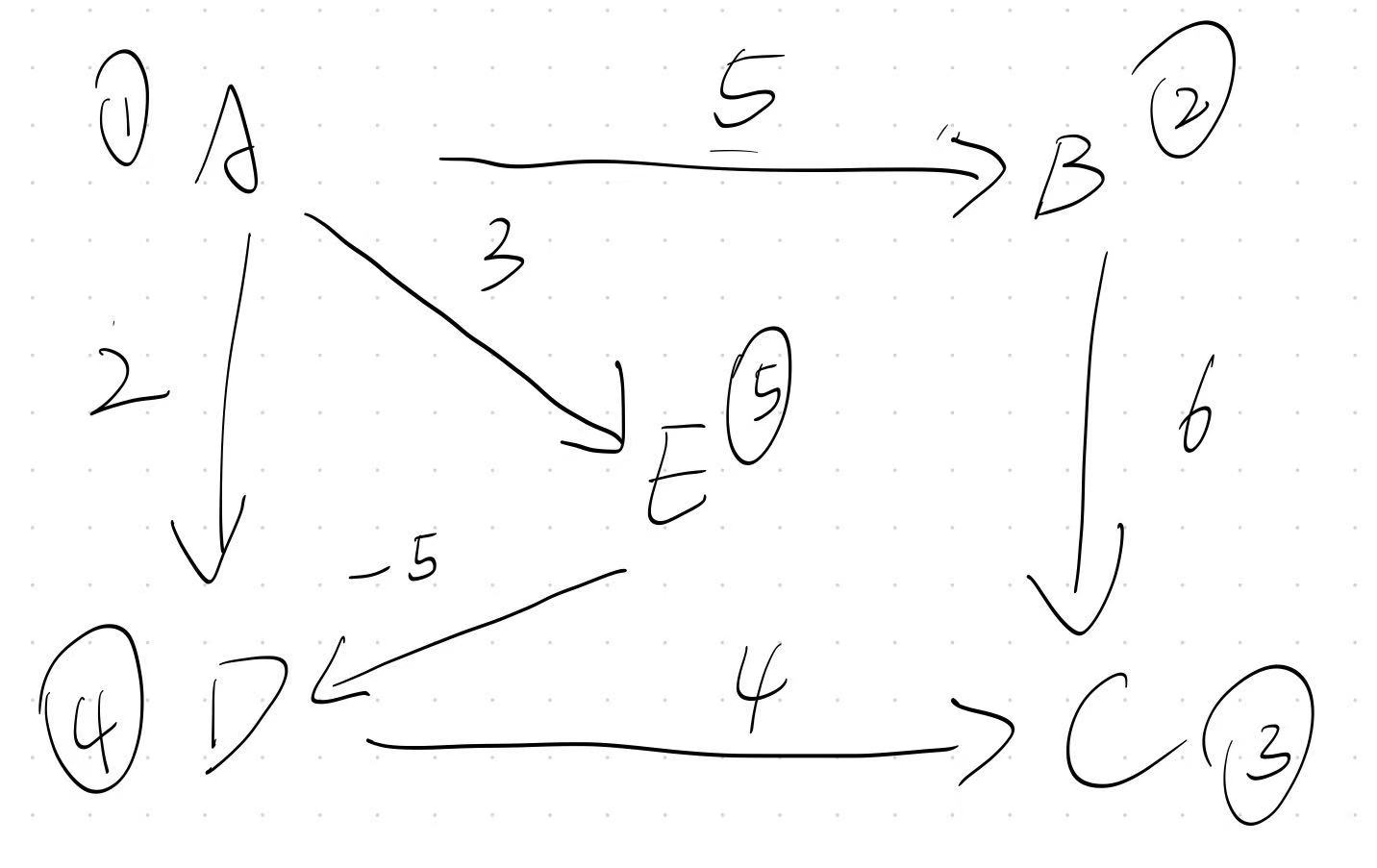
如果以A(1)点为源点,且使用Dijkstra 算法,那么效果如下:
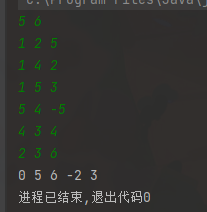
显然,问题出在点 A 到 点 C的距离上,从图上我们就很好的看出来了
如果走 A - E - D - C, A到E的距离将会是2,但是答案中的数字却是6
这是因为,Dijkstra 算法帮我们规划的路径是 A - D - C
为什么Dijkstra 算法会带领我们走一条错误的路, 看似更近了,实则更远了呢?
我们简单过一下 Dijkstra 算法的流程
第一轮:
第一轮中距离 A 点最近的点是 D 点 我们通过 D 点 更新 A 点 到 C 点的距离
此时 dis[3] == 6, vis[4] == true, 也就是说, 在 Dijkstra 算法, A 到 D点的距离已经被定死了,
这个定死指的不是 A 到 D的距离不会变了,事实上你看图也知道是会变的
而是说,在算法的视角里,我们已经得出了 源点 A , 通过走节点D, 达到别的节点的最短距离了
比如上面的点C, 哪怕后面D的距离确确实实变小了 , Dijkstra 算法 也不会给你二次更新的机会
所以哪怕到了后面,我们知道了借节点E到达节点D的距离是-2,是更小的,此时再到点C的距离就变成2了,但是 Dijkstra 算法是不知道的,因为它的标准是 先找距离源点最近的点去更新距离
点E一开始明明离我更远,D是更近的,我怎么后续又可以通过点E去缩短到达D的距离呢?
\0/这不是扯鬼淡吗\0/
所以资料上才会说, Dijkstra 算法没有考虑过负权边的场景
Dijkstra 的算法缺陷和实例举例,我已经在第二篇介绍Floyd 时具体的介绍过了,上述的例子复习一下.
而Floyd 算法 确实可以解决好上述问题,也就是说,即使存在负权值,也可以求出最短路径,而且是任意点到任意点之间的最短距离.
但是Floyd 算法也有缺陷,它利用动态规划的思维保存了所有点到点直接的距离,也因此,它的算法复杂度是O(n^3). 适用于数据量不大的密集图,但是不适用于数据量大且稀疏的图了
正因如此,我们可以学习一下BF算法和他的优化版本 SPFA 算法, 它们和Dijkstra 算法一样,是"单源路径"算法. 但是它们可以解决带负权值图的 最短路径问题.
其中SPFA 算法是对于BF算法的优化 , 但为了让读者们更好入门,笔者先介绍 BF算法,然后再介绍SPFA算法
什么是Bellman -Ford算法?
Bellman-Ford 算法是一个用于求解单源最短路径问题的经典算法,支持图中存在负权边的情况。它的核心优点在于:
相比 Dijkstra 算法,允许边的权值为负;
能够判断图中是否存在 负权环(负环);
时间复杂度为
O(N * M),其中 N 是节点数,M 是边数。
Bellman-Ford 算法适用于以下几种情况:
图中存在负权边;
需要判断是否存在负权环;
点数不大,允许一定的时间复杂度。
BF算法的核心思想
Bellman-Ford 算法的核心思想可以用一句话概括:
“对每条边进行最多 N-1 轮松弛操作,如果第 N 轮仍可松弛,则说明图中存在负环。”
(请注意 N-1 的松弛次数,这个次数不是随便来的,为什么后面会说)
什么是松弛
在图论中,松弛(Relaxation) 是一种操作,用来尝试更新某个点的最短路径估计。
通俗一点来说:
假设现在我们知道从起点到某个点 v 的最短距离是 dist[v],
如果我们找到了一条从 u 到 v 的边(权重为 w),
且 dist[u] + w<dist[v],
那我们就有理由相信“走 u → v 比原来的方案更短”,
那么我们就 更新 dist[v] = dist[u] + w —— 这就是一次“松弛”。
为什么最多松弛N-1次?
那么,为什么说"对每条边进行最多 N-1 轮松弛操作"呢?
我们先思考一个问题:在一个没有环的图中,从节点 1 到节点 N,最多可能经过多少条边?
答案是 N−1 条边。为什么?想象图的结构是一个链表,即 1 → 2 → 3 → ... → N,这种情况下从起点到终点正好需要经过 N−1 条边。
从节点1到节点N,就是把所有节点穿起来的过程,自然是经过N-1条边的
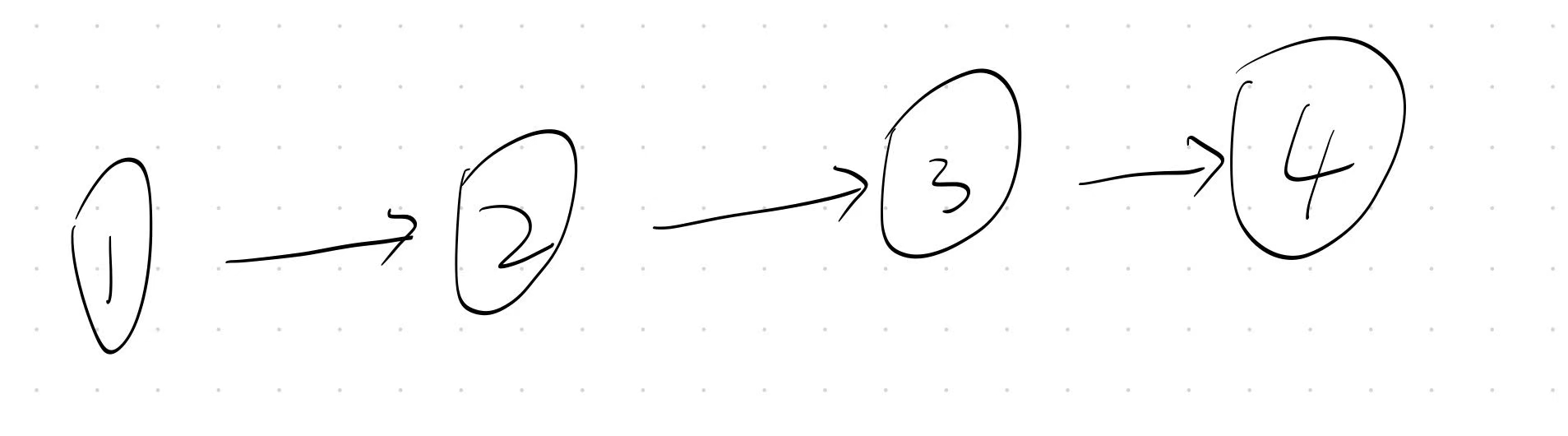
(从节点1到4,需要经过三条边)
但是这个 最多松弛N-1次 有什么关系?
既然任意一条最短路径最多只包含 N−1 条边,那么我们只需要“尝试”最多 N−1 次从起点出发、借助其他节点“中转”,就能将所有最短路径更新到位。如果我可以通过节点A 的道路缩短达到 源点S 的距离,那我何乐而不为呢?
这就是 Bellman-Ford 算法最多执行 N−1 轮松弛操作的原因:每一轮我们都会遍历所有边,尝试进行松弛(即检查是否存在更短的路径),通过反复借道尝试,在 N−1 轮内,所有最短路径一定能够被更新正确。
代码实现
下面是一个标准的 Bellman-Ford 算法 Java 实现。笔者一步一步解释代码中的关键点,帮助读者理解每一处设计背后的原因.
1.图的存储结构:边列表
static class Node {int u, v, w;public Node(int u, int v, int w) {this.u = u;this.v = v;this.w = w;}
}
static List<Node> edges = new ArrayList<>();
Bellman-Ford 算法是“按边松弛”的最短路径算法,因此我们使用**边的列表(edge list)**而非邻接表或邻接矩阵。每条边用一个 Node 对象表示,其中:
u 表示边的起点,
v 表示边的终点,
w 表示这条边的权重。
2. 初始化最短路径数组
static final int INF = Integer.MAX_VALUE / 2;
dist = new int[n + 1];
Arrays.fill(dist, INF);
dist[start] = 0;
定义
dist[i]表示从起点出发到节点 i 的当前最短距离。一开始将所有节点距离初始化为无穷大,表示“不可达”。
起点到自己的距离是 0。
使用 INF == Integer.MAX-VALUE/2 是为了避免后续加法操作时发生溢出。
3.核心逻辑:边的松弛操作
for (int i = 1; i <= n - 1; i++) {for (Node edge : edges) {int u = edge.u, v = edge.v, w = edge.w;if (dist[u] < INF) {dist[v] = Math.min(dist[v], dist[u] + w);}}
}
外层循环进行 N-1 轮松弛操作(N 是点的个数)。
每一轮遍历所有边,尝试“借道”某个点更新路径。
只要
dist[u] + w < dist[v],说明经过 u 再走这条边能得到更短的路径,就更新dist[v]。
举例
我们在开头用了一份带有负权边的图,来体现Dijkstra的缺陷,现在我们依然用它来体现为什么
BF算法可以用来处理带负权值的图
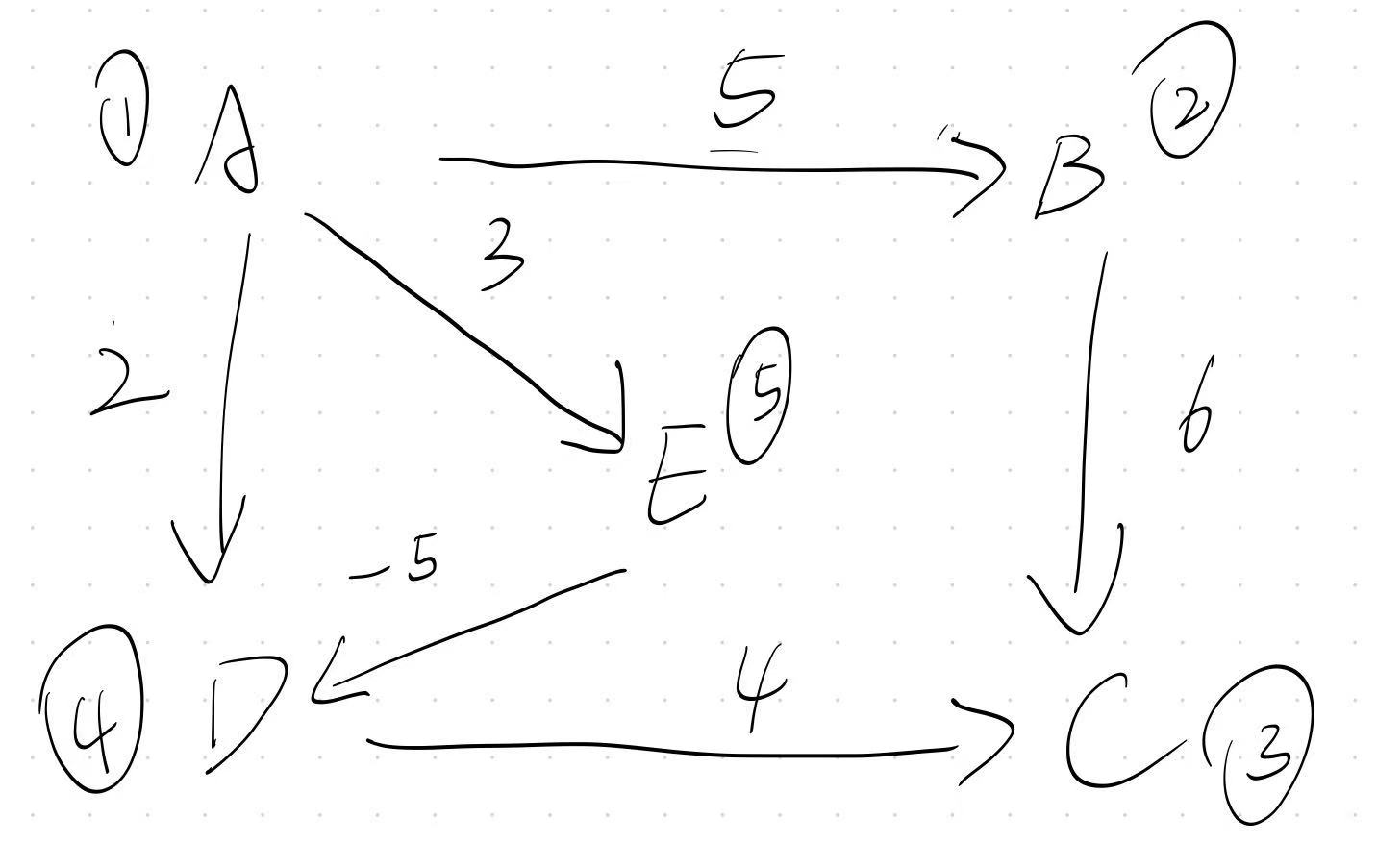
我们接下来模拟一遍算法
图中共有 5 个点、6 条边,编号为 1 到 5,边的定义如下:
1 → 2 权重 5
1 → 4 权重 2
1 → 5 权重 3
2 → 3 权重 6
4 → 3 权重 4
5 → 4 权重 -5
初始状态(dist[] 数组)
dist[1] = 0 // 起点自己到自己为 0
dist[2] = ∞
dist[3] = ∞
dist[4] = ∞
dist[5] = ∞
没有什么特别需要主义的问题
第 1 轮松弛(遍历所有边)
边逐个松弛如下:
-
1 → 2,5 → dist[2] = min(∞, 0+5) = 5
-
1 → 4,2 → dist[4] = min(∞, 0+2) = 2
-
1 → 5,3 → dist[5] = min(∞, 0+3) = 3
-
2 → 3,dist[2] 已更新为 5 → dist[3] = min(∞, 5+6) = 11
-
4 → 3,dist[4] = 2 → dist[3] = min(11, 2+4) = 6
-
5 → 4,dist[5] = 3 → dist[4] = min(2, 3+(-5)) = -2 发生了逆转,这个在Dijkstra算法也有体现
更新后 dist 数组为:
dist[1] = 0
dist[2] = 5
dist[3] = 6
dist[4] = -2
dist[5] = 3
第 2 轮松弛
再次遍历所有边:
-
1 → 2 无更新
-
1 → 4 无更新
-
1 → 5 无更新
-
2 → 3 → dist[3] = min(6, 5+6) = 6 (无变化)
-
4 → 3,dist[4] = -2 → dist[3] = min(6, -2+4) = 2 更新成功
-
5 → 4,dist[5] = 3 → dist[4] = min(-2, 3+(-5)) = -2(无变化)
请大家尤其注意标红的第五步,这是 BF算法能正确得出结果而Dijkstra算法无法得到正确结果的原因
具体来说, Dijkstra算法压根不会有第五步,因为 此时的 节点4(D) 已经被标记为True了
但是我们的BF算法可不管你那么多,它是一种非常暴力的做法,每一轮都要扫一遍,这样你在上一轮松弛中的任何改变都会被继承下来,进而影响下一轮松弛
dist[1] = 0
dist[2] = 5
dist[3] = 2
dist[4] = -2
dist[5] = 3
第 3 轮松弛
再次遍历所有边:
-
1 → 2 无变化
-
1 → 4 无变化
-
1 → 5 无变化
-
2 → 3 → min(2, 5+6) = 2(不更新)
-
4 → 3 → min(2, -2+4) = 2(不更新)
-
5 → 4 → min(-2, 3+(-5)) = -2(不更新)
第 4 轮松弛(最后一次)
全部边遍历后依然无任何更新,说明最短路径已经收敛
dist[1] = 0
dist[2] = 5
dist[3] = 2
dist[4] = -2
dist[5] = 3
第 5 轮检测是否还能松弛(负环判断)
进行一次额外的遍历,发现所有边都无法再更新,说明图中不存在负权环,算法正确结束。
(关于负环问题,后面会单独开博客讲的)
最后的效果如图所示
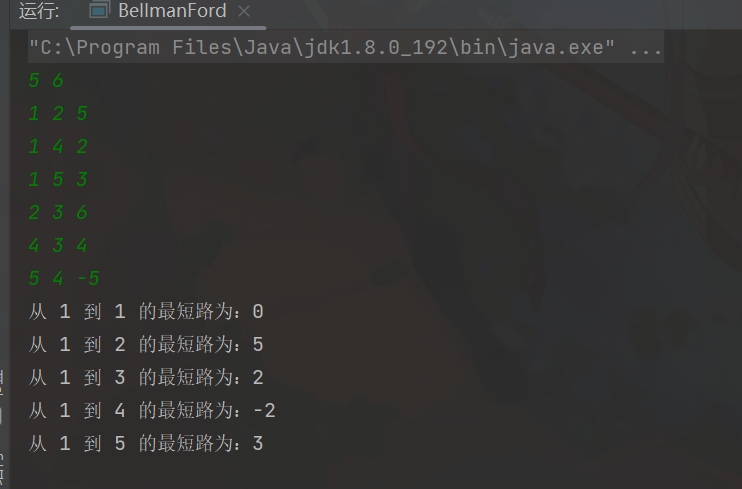
完整代码
import java.util.*;public class BellmanFord {static class Node {int u, v, w;public Node(int u, int v, int w) {this.u = u;this.v = v;this.w = w;}}static final int INF = Integer.MAX_VALUE / 2;static int n, m;static int[] dist;static List<Node> edges = new ArrayList<>();
//Bellman-Ford 是一个“按边遍历”的最短路算法,所以直接维护一个边的列表是最简单、最直接的做法,不需要邻接表!public static boolean bellmanFord(int start) {dist = new int[n + 1];Arrays.fill(dist, INF);dist[start] = 0;// 最多进行 n - 1 次松弛for (int i = 1; i <= n - 1; i++) {for (Node edge : edges) {int u = edge.u, v = edge.v, w = edge.w;if (dist[u] < INF) {dist[v] = Math.min(dist[v], dist[u] + w);}}}// 第 n 次遍历判断是否仍能松弛,判断是否有负环for (Node edge : edges) {int u = edge.u, v = edge.v, w = edge.w;if (dist[u] < INF && dist[u] + w < dist[v]) {return false; // 存在负环}}return true; // 无负环}public static void main(String[] args) {Scanner sc = new Scanner(System.in);n = sc.nextInt();m = sc.nextInt();for (int i = 0; i < m; i++) {int u = sc.nextInt(), v = sc.nextInt(), w = sc.nextInt();edges.add(new Node(u, v, w));}boolean ok = bellmanFord(1);if (!ok) {System.out.println("存在负权环");} else {for (int i = 1; i <= n; i++) {if (dist[i] >= INF / 2) {System.out.println("到达 " + i + " 不可达");} else {System.out.println("从 1 到 " + i + " 的最短路为:" + dist[i]);}}}}
}BF算法的缺陷
虽然笔者提到过了,BF算法可以解决Dijkstra算法的缺陷——即负权边图问题,但这并不代表BF算法没问题,事实上,它的问题也很明显,时间复杂度太高太高了
Bellman-Ford算法的时间复杂度为 O(V×E),其中 V 是图中的顶点数,E 是边数。在稠密图中,这个复杂度可能会非常大,导致算法运行效率很低,尤其是在顶点和边的数量都很庞大的情况下,实际应用中会变得不够实用。相比之下,Dijkstra算法在使用优先队列优化后可以达到 O(ElogV) 的复杂度,明显更高效。
此外,Bellman-Ford算法需要进行最多 V−1 轮的松弛操作,每一轮都遍历所有边。这种“暴力”遍历的方式虽然保证了算法的正确性,但也造成了大量重复计算,浪费了计算资源。
那么有没有改进措施的,当然是有的家人们,这就是SPFA算法
SPFA算法
SPFA的算法和BF别无二致,都是通过不停地松弛边来求得最短距离,但是他改进了如下地方
SPFA算法改进的地方
-
减少无效松弛,避免遍历所有边
-
Bellman-Ford 每次循环都遍历所有边进行松弛操作,重复且浪费,尤其是很多边已经不需要松弛了。
-
SPFA 只对“可能改进最短路径”的顶点对应的边进行松弛,通过维护一个队列,动态入队出队顶点,避免盲目遍历所有边。
-
-
动态维护更新顶点集合
-
SPFA维护一个队列,只有当某个顶点的距离被更新时,才将该顶点加入队列,等待松弛它的邻边。
-
这样只处理“活跃”的顶点,大幅减少冗余计算。
-
-
利用队列结构实现“宽度优先式”的松弛
-
SPFA的队列结构让顶点按松弛顺序逐层推进,类似于BFS的遍历方式,这种方式更快找到最短路径的更新方向。
-
-
入队次数检测负环
-
通过统计每个顶点入队次数,如果超过顶点数(V),说明存在负权回路,能够及时停止并报
-
基于以上改进,SPFA的算法原理就是:
SPFA算法的原理
-
初始时,将源点入队,距离初始化为0,其它点为无穷大。
-
每次从队列头取出一个顶点 u,遍历它的所有邻边 (u,v)
-
如果能通过 u 松弛 v(即 dist[u]+w(u,v)<dist[v]),就更新 dist[v]
-
并且如果 v 不在队列中,则将 v 入队。
-
-
重复上述过程直到队列为空,表示没有可以进一步松弛的边了。
-
若某顶点入队次数超过 V 次,判定存在负权回路。
总结一下就是,SPFA相比BF算法,每次松弛不会访问所有的点,只会访问"距离被访问过"的点,例如上述例子的4(D) 点
完整代码
import java.util.*;public class SPFA {static class Edge {int to, weight;public Edge(int to, int weight) {this.to = to;this.weight = weight;}}static int N, M, S;static List<List<Edge>> graph;static int[] dist;static boolean[] inQueue;static final int INF = Integer.MAX_VALUE / 2;public static void spfa(int start) {Queue<Integer> queue = new LinkedList<>();dist[start] = 0;queue.offer(start);inQueue[start] = true;while (!queue.isEmpty()) {int u = queue.poll();inQueue[u] = false; // 标记出队for (Edge edge : graph.get(u)) {int v = edge.to, w = edge.weight;if (dist[v] > dist[u] + w) {dist[v] = dist[u] + w;if (!inQueue[v]) { // 避免重复入队queue.offer(v);inQueue[v] = true;}}}}}public static void main(String[] args) {Scanner in = new Scanner(System.in);N = in.nextInt();M = in.nextInt();
// S = in.nextInt();graph = new ArrayList<>(N + 1);dist = new int[N + 1];inQueue = new boolean[N + 1];Arrays.fill(dist, INF);for (int i = 0; i <= N; i++) {graph.add(new ArrayList<>());}for (int i = 0; i < M; i++) {int u = in.nextInt();int v = in.nextInt();int w = in.nextInt();graph.get(u).add(new Edge(v, w));}spfa(1);for (int i = 1; i <= N; i++) {System.out.print((dist[i] == INF ? -1 : dist[i]) + " ");}}
}
最后效果如下:
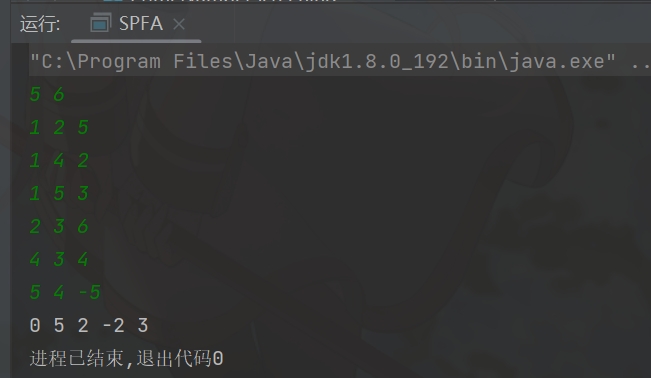
结尾
本篇博客到此结束,博客主要介绍了BF算法和SPFA在解决单元最短路径方面的作用,但是,它们同样可以判断负环,具体是怎么样的,笔者打算再开一篇博客梳理一下.感谢大家阅读到此
相关文章:
)
Bellman - Ford 算法与 SPFA 算法求解最短路径问题 ——从零开始的图论讲解(4)
目录 前言 为什么Dijkstra算法面对负权值图会有误差??? 举例说明 什么是Bellman -Ford算法? BF算法的核心思想 什么是松弛 为什么最多松弛N-1次? 代码实现 举例 初始状态(dist[] 数组) 第 1 轮松弛(遍历所有边) …...

Python训练营打卡 Day27
函数专题2:装饰器 知识点回顾: 装饰器的思想:进一步复用函数的装饰器写法注意内部函数的返回值 昨天我们接触到了函数大部分的功能,然后在你日常ctrl点进某个复杂的项目,发现函数上方有一个xxx,它就是装饰器 装饰器本质…...

初识计算机网络。计算机网络基本概念,分类,性能指标
初识计算机网络。计算机网络基本概念,分类,性能指标 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,祝愿大家期末都能考一个好成绩! 视频链接地址 一、…...

5月16日day27打卡
函数专题2:装饰器 知识点回顾: 装饰器的思想:进一步复用函数的装饰器写法注意内部函数的返回值 作业: 编写一个装饰器 logger,在函数执行前后打印日志信息(如函数名、参数、返回值) logger def …...

【生成式AI文本生成实战】DeepSeek系列应用深度解析
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

【Pandas】pandas DataFrame kurt
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...
)
2025年渗透测试面试题总结-安恒[实习]安全服务工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 安恒[实习]安全服务工程师 1. SQLMap爆出当前库名的参数是什么? 2. Nmap探测系统的参数&am…...
 中配置 MCP(Model Context Protocol))
在 Visual Studio Code (VSCode) 中配置 MCP(Model Context Protocol)
前提条件 安装 VSCode:确保已安装最新版本的 VSCode(建议使用 1.99 或以上版本,支持 MCP)。安装 GitHub Copilot 扩展:MCP 通常与 GitHub Copilot 的代理模式(Agent Mode)结合使用,…...

顶层架构 - 消息集群推送方案
一、推送基础概念简述 在即时通讯(IM)系统中,最基础的一件事就是“如何把消息推送给用户”。为了实现这个过程,我们要先了解两种常见的网络通信方式:HTTP 和 WebSocket。 1. HTTP 是什么? HTTP 就像一次性…...

C++性能测试工具——Vtune等的介绍
一、介绍 我们在前面的相关文章中对C性能的测试和分析工具(见“C性能测试工具gprof和gperftools基础”等)有一个初步的了解和应用,其实类似的相关工具还有不少。为了进一步的让开发者们掌握更多的相关性能测试分析相关的方法,对另…...

车道线检测----CLRKDNet
今天的最后一篇 车道线检测系列结束 CLRKDNet:通过知识蒸馏加速车道检测 摘要:道路车道是智能车辆视觉感知系统的重要组成部分,在安全导航中发挥着关键作用。在车道检测任务中,平衡精度与实时性能至关重要,但现有方法…...

【AI模型部署】
解决python引入huggingface_hub模块下载超时问题 背景问题解决 背景 AMD Ryzen™ AI处理器通过独特的NPUGPU异构架构,为AI工作负载提供强大的并行计算能力。本方案展示了如何将YOLOv8目标检测、RCAN超分辨率重建和Stable Diffusion文生图三类模型分别部署到NPU和GP…...

排序01:多目标模型
用户-笔记的交互 对于每篇笔记,系统记录曝光次数、点击次数、点赞次数、收藏次数、转发次数。 点击率点击次数/曝光次数 点赞率点赞次数/点击次数 收藏率收藏次数/点击次数 转发率转发次数/点击次数 转发是相对较少的,但是非常重要,例如转发…...

电子电器架构 --- Zonal架构正在开创汽车电子设计新时代
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
 源代码?如何解析 Tcc 源代码?)
如何阅读、学习 Tcc (Tiny C Compiler) 源代码?如何解析 Tcc 源代码?
阅读和解析 TCC(Tiny C Compiler) 的源代码需要对编译器的基本工作原理和代码结构有一定的了解。以下是分步骤的指南,帮助你更高效地学习和理解 TCC 的源代码: 1. 前置知识准备 C 语言基础:TCC 是用 C 语言编写的&…...

Java 泛型与类型擦除:为什么解析对象时能保留泛型信息?
引言:泛型的“魔术”与类型擦除的困境 在 Java 中,泛型为开发者提供了类型安全的集合操作,但其背后的**类型擦除(Type Erasure)**机制却常常让人困惑。你是否遇到过这样的场景? List<String> list …...
:复习)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(22):复习
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(22):复习 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)复习(2)復習3、单词(1)日语(2)日语片假名单词4、对话练习5、单词辨析记录6、总结1、前言 (1)情况说明 自己在今年,在日本留学中,目前在语言学校,…...

Java基础学习
Java 基础大纲 1. Java 概述 Java 语言特点(跨平台、面向对象、自动内存管理) JVM、JRE、JDK 的作用与区别 开发环境搭建(安装 JDK、配置环境变量、IDE 使用) 2. 基础语法(已经学习) 变量与数据类型&a…...

MGX:多智能体管理开发流程
MGX的多智能体团队如何通过专家混合系统采用全新方法,彻底改变开发流程,与当前的单一智能体工具截然不同。 Lovable和Cursor在自动化我们的特定开发流程方面取得了巨大飞跃,但问题是它们仅解决软件开发的单一领域。 这就是MGX(MetaGPT X)的用武之地,它是一种正在重新定…...
)
2025第三届盘古石杯初赛(计算机部分)
前言 比赛的时候时间不对,打一会干一会,导致比赛时候思路都跟不上,赛后简单复现一下,希望大家批批一下 计算机取证 1、分析贾韦码计算机检材,计算机系统Build版本为?【标准格式:19000】 183…...

XML介绍及常用c及c++库
一.xml概述 1.什么是XML? XML(eXtensible Markup Language)是一种标记语言,1998 年 2 月:XML 1.0 发布,用于存储和传输结构化数据。与HTML专注于数据显示不同,XML专注于数据本身及其结构。 它…...
)
动态规划-63.不同路径II-力扣(LeetCode)
一、题目解析 与62.不同路径不同的一点是现在网格中有了障碍物,其他的并没有什么不同 二、算法解析 1.状态表示 dp[i][j]表示:到[i,j]位置时,不同的路径数 2.状态转移方程 由于多了障碍物,所以我们要判断是否遇到障碍物 3.初…...

海盗王3.0的数据库3合1并库处理方案
原版的海盗王数据库有3个accountserver,gamedb,tradedb,对应到是账号数据库,游戏数据库,商城数据库。 一直都有个想法,如何把这3个库合并到一起,这样可以实现一些功能。 涉及到sqlserver的数据库…...

Vue百日学习计划Day16-18天详细计划-Gemini版
重要提示: 番茄时钟: 每个番茄钟为25分钟学习,之后休息5分钟。每完成4个番茄钟,进行一次15-30分钟的长休息。动手实践: DOM 操作和事件处理的理解高度依赖于实际编码。请务必在浏览器中创建 HTML 页面,并配…...

【C++】15.并发支持库
本篇内容参考自cplusplus 1. thread 1.1 thread thread库底层是对各个系统的线程库(Linux下的pthread库和Windows下Thread库)进行封装。C11thread库的第一个特点是可以跨平台,第二个特点是Linux和Windows下提供的线程库都是面向过程的&…...

Linux系统编程——exec族函数
我们来完整、系统、通俗地讲解 Linux 系统编程中非常重要的一类函数:exec 族函数(也叫 exec family)。 一、什么是 exec? exec 系列函数的作用是: 用一个新的程序,替换当前进程的内容。 也就是说…...

职教实训室中的写实数字人:技术与应用方案
在当今快速发展的数字化时代,职业教育的重要性日益凸显。面对传统教学模式中个性化不足、互动性差等挑战,深声科技基于2D写实交互数字人的解决方案为职教实训室带来了全新的变革。本文将详细介绍该技术方案的核心原理、产品特色及其在职业培训中的实际应…...

Nginx模块配置与请求处理详解
Nginx 作为模块化设计的 Web 服务器,其核心功能通过不同模块协同完成。以下是各模块的详细配置案例及数据流转解析: 一、核心模块配置案例 1. Handler 模块(内容生成) 功能:直接生成响应内容(如静态文件、重定向等) # 示例1:静态文件处理(ngx_http_static_module)…...

54. 螺旋矩阵
题目链接: a54. 螺旋矩阵 题目描述: 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 题目分析: 改题目需要判断是否溢出边界,与59不同,59可以判断是否为0…...

virtualbox虚拟机中的ubuntu 20.04.6安装新的linux内核5.4.293 | 并增加一个系统调用 | 证书问题如何解决
参考文章:linux添加系统调用【简单易懂】【含32位系统】【含64位系统】_64位 32位 系统调用-CSDN博客 安装新内核 1. 在火狐下载你需要的版本的linux内核压缩包 这里我因为在windows上面下载过,配置过共享文件夹,所以直接复制粘贴通过共享文…...

代码随想录算法训练营第三十八天打卡
今天是动态规划的第三天,昨天的不同路径与整数分解的几道题目大家理解得如何?如果有疑问大家还是多去想想dp数组究竟是什么含义,还有我的状态转移是否正确,初始化是否正确,这一点很重要,今天的题目依旧是跑…...

【论信息系统项目的整合管理】
论信息系统项目的整合管理 某省机场管理集团航空货运站原有物流生产信息系统无法满足机场货运站生产信息与航空公司、对方航站、进出口航空货物按海关监管要求电子报关等行业信息实时共享发展需要,生产信息需多次重复录入问题已成为业务发展最大瓶颈,急需…...

小学数学题批量生成及检查工具
软件介绍 今天给大家介绍一款近期发现的小工具,它非常实用。 软件特点与出题功能 这款软件体积小巧,不足两兆,具备强大的功能,能够轻松实现批量出题。使用时,只需打开软件,输入最大数和最小数,…...

Python线性回归:从理论到实践的完整指南
Python线性回归:从理论到实践的完整指南 线性回归是数据科学和机器学习中最基础且最重要的算法之一。本文将深入探讨如何使用Python实现线性回归,从理论基础到实际应用,帮助读者全面理解这一重要的统计学和机器学习方法。 什么是线性回归&a…...

python 爬虫框架介绍
文章目录 前言一、Requests BeautifulSoup(基础组合)二、Scrapy(高级框架)三、PySpider(可视化爬虫)四、Selenium(浏览器自动化)五、Playwright(新一代浏览器自动化&…...

强化学习算法实战:一个例子搞懂sarsa、dqn、ddqn、qac、a2c及其区别
简介 在学习强化学习算法:sarsa、dqn、ddqn、qac、a2c、trpo、ppo时,由于有大量数学公式的推导,觉得十分晦涩,且听过就忘记了。 但是当把算法应用于实战时,代码的实现要比数学推导直观很多。 接下来通过不同的算法实现…...
)
文章记单词 | 第86篇(六级)
一,单词释义 pretty /ˈprɪti/- adj. 漂亮的;相当的 /adv. 相当地labour /ˈleɪbə(r)/- n. 劳动;劳工;分娩 /v. 劳动;努力(英式英语, labor)imaginary /ɪˈmdʒɪnəri/- adj. …...

firewall防火墙
一.Firewalld 防火墙概述 1.firewalld 简介 firewalld 的作用是为包过滤机制提供匹配规则(或称为策略),通过各种不同的规则告诉netfilter 对来自指定源、前往指定目的或具有某些协议特征的数据包采取何种处理方式为了更加方便地组织和管理防火墙,firewa11d 提供了…...

TII-2024《AGP-Net: Adaptive Graph Prior Network for Image Denoising》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...
)
Pageassist安装(ollama+deepseek-r1)
page-assist网站:https://github.com/n4ze3m/page-assist 首先电脑配置node.js,管理员打开命令窗口输入下面命令下载bun npm install -g buncd 到你想要安装page-assist的地方(推荐桌面) 输入下列命令 git clone https://gith…...

Java—— 方法引用 : :
方法引用是什么 把已经存在的方法拿过来用,当做函数式接口中抽象方法的方法体 方法引用符 :: 方法引用的条件 1.需要有函数式接口 2.被引用方法必须已经存在 3.被引用方法的形参和返回值需要跟抽象方法保持一致 4.被引用方法的功能要满足当前…...

Linux基础开发工具大全
目录 软件包管理器 1>软件包 2>软件生态 3>yum操作 a.查看软件包 b.安装软件 c.卸载软件 4>知识点 vim编辑器 1>基本概念 2>基本操作 3>正常模式命令集 a.模式切换 b.移动光标 c.删除 d.复制 e.替换 f.撤销 g.更改 4>底行模式命令…...

C语言实现INI配置文件读取和写入
一.INI文件介绍 INI配置文件是一种简单的文本文件,用于存储配置信息,通常由一个或多个节(section)组成,每个节包含多个键值对(Key-Value)格式。INI文件易于阅读和编辑,广泛应用于多…...

volatile关键字详解
volatile关键字详解 1. 定义与核心作用 volatile 是Java中的关键字,用于修饰变量,主要解决多线程环境下的内存可见性和指令重排序问题。其核心作用: 保证可见性:确保所有线程读取到变量的最新值。禁止指令重排序:防止…...

二叉树子树判断:从递归到迭代的全方位解析
一、题目解析 题目描述 给定两棵二叉树root和subRoot,判断root中是否存在一棵子树,其结构和节点值与subRoot完全相同。 示例说明 示例1: root [3,4,5,1,2],subRoot [4,1,2] 返回true,因为root的左子树与subRoot完…...
)
【PhysUnits】4.1 类型级比特位实现解释(boolean.rs)
一、源码 该代码实现了一个类型级(type-level)的布尔系统,允许在编译时进行布尔运算。 //! 类型级比特位实现 //! //! 这些是基础的比特位类型,作为本库中其他数值类型的构建基础 //! //! 已实现的**类型运算符**: //! //! - 来自 core::op…...
python开发经验)
(7)python开发经验
文章目录 1 找不到资源文件2 使用subprocess执行时有黑色弹窗3 找不到exec4 pyside6-project lupdate的bug5 找不到pyd模块6 pyd模块编码错误7 运行显示Qt platform plugin "windows" in "8 tr()包含的字符串无法被翻译 更多精彩内容👉内容导航 &…...

【Manim】使用manim画一个高斯分布的动画
1 Manim例子一 最近接触到manim,觉得挺有趣的,来玩一玩把。如下是一个使用manim画的高斯分布的动画。 from manim import * import numpy as npclass GaussianDistribution(Scene):def construct(self):# 创建坐标系axes Axes(x_range[-4, 4, 1],y_ra…...
)
Day11-苍穹外卖(数据统计篇)
前言: 今天写day11的内容,主要讲了四个统计接口的制作。看起来内容较多,其实代码逻辑都是相似的,这里我们过一遍。 今日所学: Apache ECharts营业额统计用户统计订单统计销量排行统计 1. Apache ECharts 1.1 介绍 A…...

论文阅读:Self-Collaboration Code Generation via ChatGPT
地址:Self-Collaboration Code Generation via ChatGPT 摘要 尽管大型语言模型(LLMs)在代码生成能力方面表现出色,但在处理复杂任务时仍存在挑战。在现实软件开发中,人类通常通过团队协作来应对复杂任务,…...