RAG-MCP:突破大模型工具调用瓶颈,告别Prompt膨胀

大语言模型(LLM)的浪潮正席卷全球,其强大的自然语言理解、生成和推理能力,为各行各业带来了前所未有的机遇。然而,正如我们在之前的探讨中多次提及,LLM并非万能。它们受限于训练数据的时效性和范围,也无法直接与瞬息万变的外部世界进行实时交互或执行需要特定技能的操作。
为了弥补这些不足,赋予LLM调用外部工具(如搜索引擎、数据库、计算器、各类API服务)的能力,成为了学术界和工业界共同关注的焦点。模型上下文协议(Model Context Protocol, MCP)等标准的出现,为LLM与外部工具的交互提供了一定程度的规范,旨在让LLM能够像人类一样,在需要时“借用”外部工具来完成任务。
然而,当LLM可调用的工具数量从个位数、十位数激增到成百上千,甚至更多时,新的、严峻的挑战便浮出水面。这正是我们今天要深入探讨的核心问题,也是论文《RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation》所致力于解决的痛点。本文将带您详细解读RAG-MCP如何通过引入检索增强生成(RAG)的思想,巧妙化解大模型在规模化工具调用场景下的困境。
一、背景与痛点

1.1 大型语言模型的能力与局限
LLM无疑是强大的。它们能够进行流畅的自然对话,理解复杂的指令,甚至协助我们进行代码编写和复杂推理。但其强大能力的背后,也存在着固有的局限性:
-
知识的静态性:LLM的知识主要来源于其训练数据,这些数据一旦训练完成,就相对固定了。对于训练截止日期之后的新信息、新知识,LLM是无从知晓的。
-
上下文窗口限制:LLM在处理信息时,依赖于一个固定大小的上下文窗口。这意味着它们一次能够“看到”和“记住”的信息量是有限的。
-
缺乏直接行动能力:LLM本身无法直接访问最新的数据库、执行网络搜索或与外部服务进行交互。
1.2 LLM工具扩展趋势:打破壁垒的必然选择

为了克服上述局限,让LLM能够获取实时信息、执行特定领域的计算、与外部系统联动,研究人员和开发者们积极探索外部工具集成技术。通过定义清晰的接口(如API),LLM可以“调用”这些外部工具,从而极大地扩展其能力边界。无论是通过搜索引擎获取最新资讯,通过计算工具进行精确数学运算,还是通过数据库查询结构化数据,工具的引入为LLM打开了通往更广阔应用场景的大门。
1.3 Prompt膨胀问题:难以承受之重

然而,随着LLM可调用工具数量的急剧增加,一个棘手的问题——Prompt膨胀(Prompt Bloat)——日益凸显。
想象一下,为了让LLM知道有哪些工具可用以及如何使用它们,我们需要在Prompt中提供每个工具的描述、功能、参数列表、使用示例等信息。当只有少数几个工具时,这或许还能勉强应付。但当工具数量达到几十、几百甚至更多时,情况就完全不同了:
-
上下文窗口不堪重负:所有工具的描述信息堆积起来,会迅速填满甚至超出LLM的上下文窗口限制。这就像给一个人一本厚厚的工具说明书,却要求他在几秒钟内全部看完并记住。
-
模型选择混乱与效率低下:即使上下文窗口能够容纳,过多的工具信息也会让LLM在选择时感到“困惑”。功能相似的工具、描述冗余的信息,都会增加LLM的决策难度,导致其选择错误工具或花费过长时间进行选择。
-
Token消耗剧增:更长的Prompt意味着更高的API调用成本(对于商业LLM而言)和更长的处理时间。
二、核心研究问题

基于上述背景,我们可以将LLM在规模化工具调用场景下遇到的核心问题归纳为以下两点:
2.1 Prompt膨胀 (Prompt Bloat)
正如前文所述,将所有可用工具的完整定义和使用说明一次性注入到LLM的上下文中,是导致Prompt极度冗长、Token消耗巨大、甚至超出模型最大上下文窗口限制的直接原因。这种“填鸭式”的信息供给方式,使得LLM在工具数量较多时,难以有效地进行信息筛选和聚焦,反而容易被大量无关信息所干扰,导致模型混淆。
2.2 决策过载 (Decision Overhead)
面对一个长长的、可能包含许多功能相似工具的列表,LLM需要做出更复杂的决策:是否需要调用工具?如果需要,应该调用哪个工具?如何正确地填充参数?选择的范围越大,LLM出错的概率就越高。这包括选择了次优的工具、混淆了不同工具的功能,甚至“幻觉”出不存在的API或错误地调用了API。
三、RAG-MCP解决方案

为了应对上述挑战,论文提出了RAG-MCP框架。其核心思想是将广泛应用于问答系统等领域的检索增强生成(Retrieval-Augmented Generation, RAG)范式,创新性地引入到LLM的工具选择过程中。
3.1 传统方法 vs. RAG-MCP方法
为了更清晰地理解RAG-MCP的创新之处,我们不妨将其与传统工具调用方法进行一个直观的对比:
-
传统方法 (Traditional Method):
-
信息注入方式:将所有可用工具的定义和描述信息,在LLM处理用户请求之前,一次性、全量地注入到模型的上下文中。
-
上下文状态:随着工具数量的增加,上下文窗口被迅速填满,充斥着大量可能与当前任务无关的工具信息。
-
模型选择机制:LLM需要自行在庞杂的工具列表中进行搜索、理解和筛选,从中选出合适的工具。
-
性能表现:随着工具库规模的扩大,工具选择的准确率显著下降,Token消耗急剧上升,响应延迟增加。
-
-
RAG-MCP方法 (RAG-MCP Method):
-
信息注入方式:基于用户当前的查询意图,通过一个外部的检索系统,动态地、按需地从一个大规模的工具知识库中检索出少数几个最相关的工具。
-
上下文状态:只将这少数几个经过筛选的高度相关的工具描述注入到模型的上下文中,使得Prompt保持简洁、聚焦。
-
模型选择机制:LLM的决策范围被大幅缩小,只需在少数几个候选工具中进行选择,决策难度和复杂度显著降低。
-
性能表现:即使工具库规模庞大,工具选择的准确率依然能保持在较高水平,Prompt长度和Token消耗得到有效控制。
-

3.2 RAG-MCP的核心思路
RAG-MCP的核心理念是:不再将所有工具的详细信息一次性提供给LLM,而是通过一个外部的、可动态检索的工具知识库,在LLM需要调用工具时,根据当前用户查询的语义,智能地检索出最相关的一小部分候选工具,再将这些精选的工具信息注入到LLM的Prompt中。
这就像我们人类在解决一个复杂问题时,不会把所有可能的工具都摆在面前,而是会先根据问题的性质,从工具箱里挑选出几种最可能用得上的,然后再仔细研究这几种工具的用法,最终做出选择。RAG-MCP正是为LLM模拟了这样一个“按需取用”、“聚焦选择”的智能工具选择过程。
具体来讲,RAG-MCP的解决方案主要包含以下几个关键环节:
-
外部化工具知识库与检索层:将所有MCP工具的详细描述信息(功能、参数、示例等)存储在一个外部的、可高效检索的知识库中(例如向量数据库)。当用户请求到达时,首先由检索层负责理解用户意图,并从该知识库中匹配和召回最相关的工具。
-
智能化工具筛选:检索层不仅仅是简单地返回一批工具,还可能包含进一步的筛选和排序逻辑,以确保提供给LLM的是最优的候选工具集(例如Top-K个最相关的工具)。
-
精简化的上下文与高效执行:只有经过检索和筛选后的、与当前任务高度相关的少数工具描述,才会被注入到主LLM的上下文中。LLM得以在更为清爽、聚焦的上下文中进行后续的任务规划和工具调用执行。
3.3 RAG-MCP的实现步骤

RAG-MCP的解决方案主要包含以下几个关键环节:
-
检索层 (Retrieval):
-
外部工具索引:首先,将所有可用的MCP工具(包括其功能描述、API schema、使用示例等元数据)进行编码(例如,使用文本嵌入模型),构建一个外部的向量化索引库。这个索引库就像一个专门为工具建立的“语义图书馆”。
-
查询编码与检索:当用户发起一个查询时,RAG-MCP首先使用相同的编码模型将用户查询也转换为向量。然后,在这个工具索引库中进行语义相似度搜索,找出与用户查询意图最匹配的Top-k个候选MCP工具。
-
-
工具筛选 (Selection & Validation):
-
Top-k工具选择:从检索结果中选出语义相似度最高的k个工具。
-
(可选) 验证:论文中提到,对于每个检索到的MCP,RAG-MCP可以生成一个few-shot示例查询并测试其响应,以确保基本兼容性,这可以看作是一种“健全性检查”。(论文第6页)
-
-
精简执行 (Invocation):
-
注入精选工具:只有这k个(或经过验证后最优的)被检索出来的工具的描述信息会被传递给LLM。
-
LLM决策与调用:LLM此时面对的是一个大大缩减的、高度相关的工具列表,其决策复杂度和Prompt长度都得到了显著降低。LLM在此基础上进行最终的工具选择和参数填充,并执行调用。
-
通过这种方式,RAG-MCP巧妙地将“工具发现”这一复杂任务从LLM的核心推理过程中剥离出来,交由高效的检索系统处理,从而实现了对LLM的“减负增效”。
四、RAG-MCP框架设计
4.1 框架概览
RAG-MCP将检索增强生成技术与Model Context Protocol标准相结合,通过外部语义索引与动态注入,高效解决大型工具库的选择与调用问题。其核心在于解耦工具发现与生成执行。
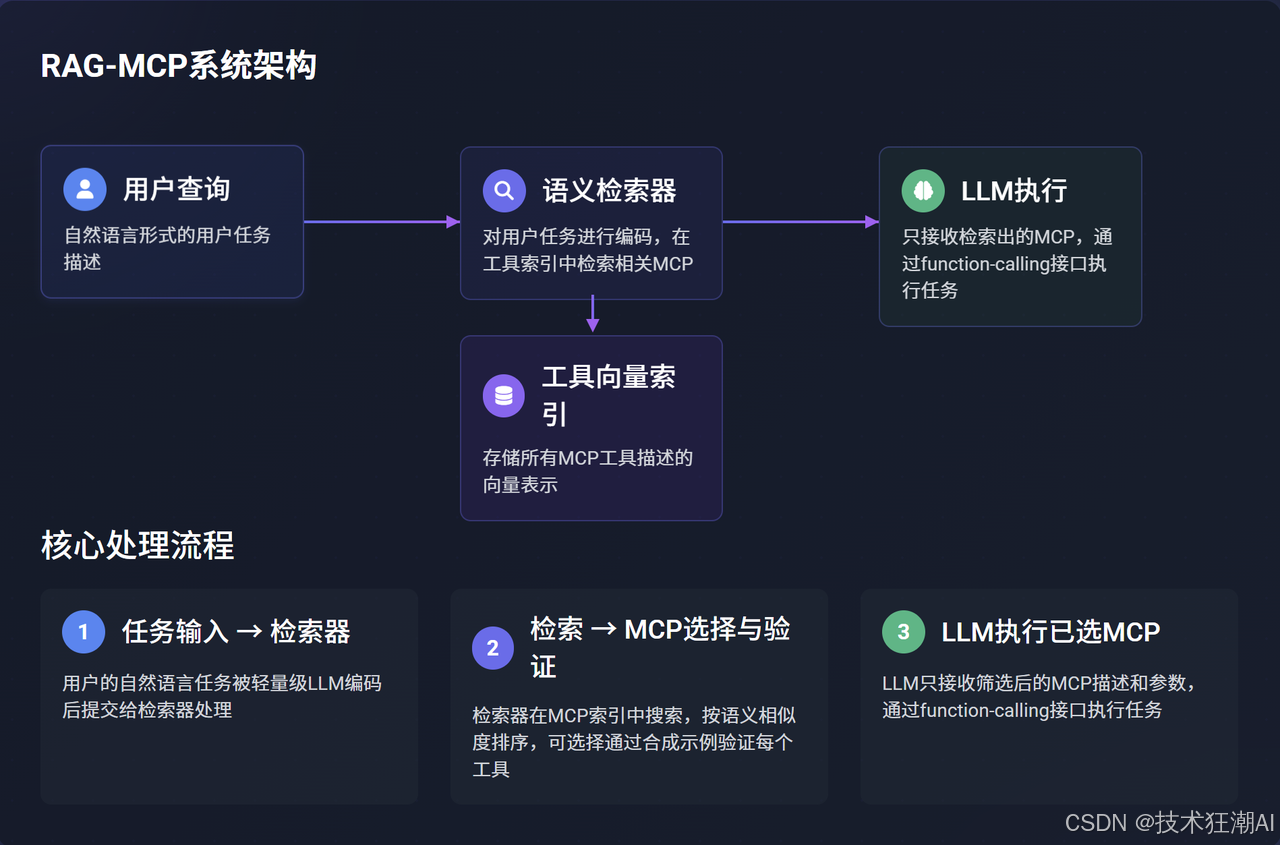
4.2 RAG-MCP系统架构组件
一个典型的RAG-MCP系统主要由以下几个协同工作的核心组件构成:
-
语文检索器 (Retriever):负责对用户的自然语言任务进行编码,并在工具向量索引中检索相关的MCP。论文中提及可以使用轻量级的LLM(如Qwen)作为编码器。(论文第6页)
-
工具向量索引 (Tool Vector Index):存储所有MCP工具描述的向量化表示,支持高效的语义相似度搜索。
-
LLM执行器 (LLM Executor):接收检索器筛选出的MCP工具信息,并基于此进行任务规划和函数调用。
4.3 核心处理流程:三步曲
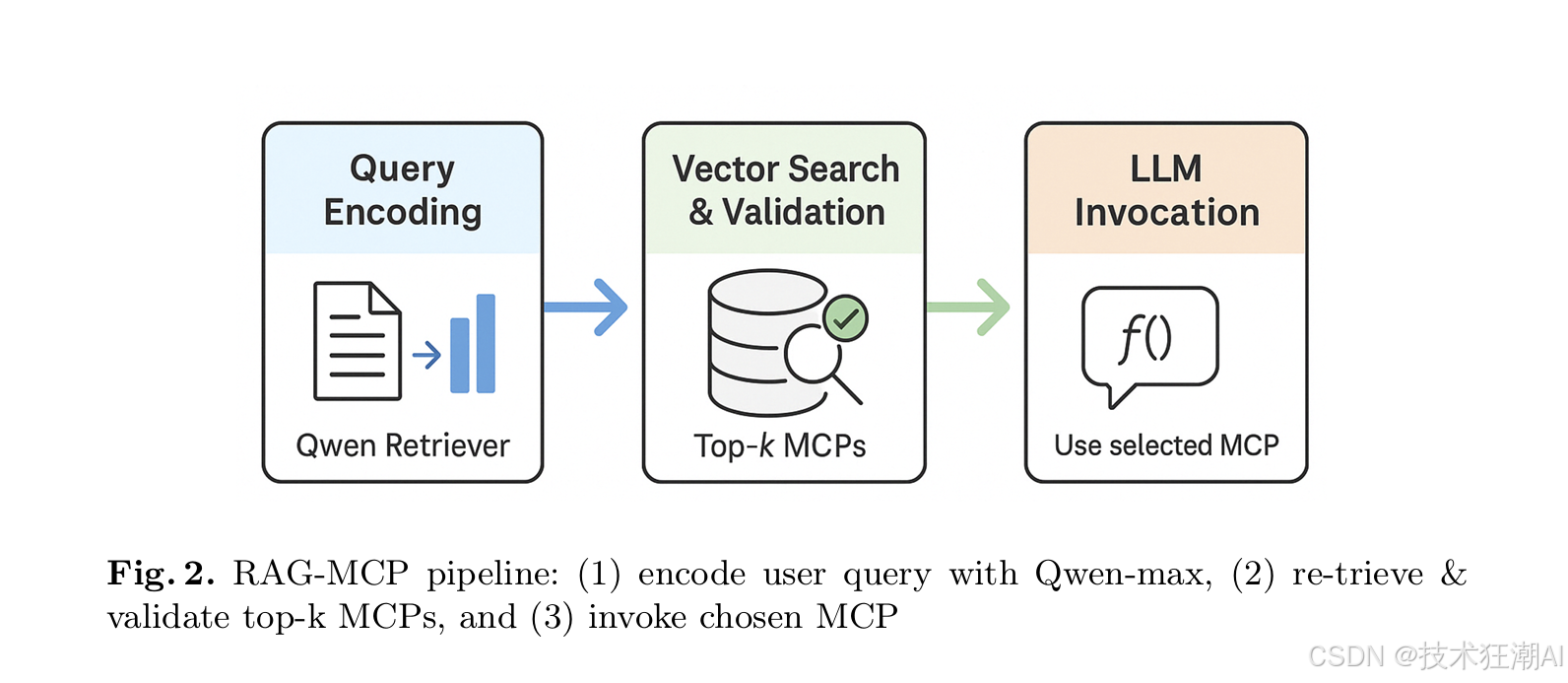
论文中将RAG-MCP的操作总结为三个核心步骤(如图2所示):
步骤一:任务输入与智能编码 (Task Input → Retriever)
-
当用户的自然语言任务请求被输入到RAG-MCP系统后,首先由一个轻量级的LLM(例如Qwen模型,作为检索器的一部分)对该任务描述进行深度的语义分析和编码。
-
这个编码过程旨在将用户的意图转化为一个固定维度的、能够精准捕捉其核心需求的向量表示(Query Embedding)。这个向量将作为后续在工具库中进行检索的“钥匙”。
步骤二:高效检索、MCP选择与可选验证 (Retriever → MCP Selection & Validation)
-
携带用户任务意图的查询向量被提交给检索器。检索器会在预先构建好的、包含所有可用MCP工具描述及其向量表示的“工具向量索引”中执行高效的语义相似度搜索(例如,使用余弦相似度或内积作为度量)。
-
检索器会根据语义相似度得分对所有工具进行排序,并返回得分最高(即与用户任务最相关)的Top-K个候选MCP工具。
-
(可选但推荐的步骤)为了进一步提升选择的准确性,系统还可以对这K个检索到的候选MCP工具进行一个快速的“验证(Validation)”环节。例如,可以为每个候选工具动态生成一些简单的、与用户原始查询相关的“Few-Shot”示例查询,并模拟调用该工具,观察其响应是否符合预期。这个验证过程可以帮助过滤掉那些虽然在文本描述上相似但实际可能不适用的工具。
步骤三:精简上下文、LLM决策与执行已选MCP (LLM Execution with Selected MCP)
-
只有经过上述检索(以及可选的验证)环节后筛选出的、被认为是与当前用户任务最匹配的一个或少数几个MCP工具的详细描述信息(包括其功能Schema、参数定义等),才会被注入到主大型语言模型(Main LLM)的上下文中。
-
此时,主LLM接收到的Prompt是高度精炼和聚焦的,它不再需要面对成百上千的工具选项。LLM基于这个清爽的上下文,可以更轻松、更准确地做出最终的工具选择决策(如果候选工具多于一个),规划具体的执行步骤,并通过标准的函数调用(Function-Calling)接口与选定的MCP工具进行实际的交互,完成用户指定的任务。
4.4 核心组件详解
-
语义检索模块:
-
使用轻量级LLM(如Qwen)进行任务编码。
-
在向量空间中表示和匹配工具描述。
-
返回语义相似度最高的Top-k候选工具。
-
-
MCP验证与执行:
-
对每个检索到的MCP生成few-shot示例进行测试。
-
筛选出最佳工具注入主LLM的Prompt。
-
通过function-calling API执行计划与调用。
-
4.5 设计优势
RAG-MCP框架的核心设计思想在于“解耦工具发现与生成执行”。通过将工具的发现、筛选和初步验证等复杂工作“外包”给一个独立的、高效的检索模块,主LLM得以从繁重的工具管理和选择任务中解脱出来,更专注于其核心的理解、推理和生成能力。这种设计带来了诸多显著优势:
-
高度可扩展性 (Scalability):由于工具信息存储在外部索引中,并且只有相关的工具才会被动态加载到LLM的上下文中,RAG-MCP系统能够轻松扩展至支持包含数百甚至数千个MCP工具的庞大工具生态,而不会像传统方法那样迅速遭遇性能瓶颈。
-
显著降低Prompt膨胀 (Reduced Prompt Bloat):这是RAG-MCP最直接的优势。通过按需检索,极大地减少了注入到LLM上下文中的工具描述信息量,有效避免了Prompt长度超出限制或因信息过载导致模型性能下降的问题。
-
减轻LLM决策疲劳 (Lowered Cognitive Load for LLM):LLM不再需要在海量的工具选项中进行大海捞针式的搜寻和比对,其决策范围被大幅缩小,从而降低了认知负担,提高了决策的准确性和效率,并减少了“幻觉调用”的风险。
-
类比RAG系统:RAG-MCP的设计理念与通用的检索增强生成(RAG)系统有异曲同工之妙。正如RAG系统通过从大型语料库中检索相关段落来辅助LLM回答问题,避免让LLM处理整个语料库一样,RAG-MCP也是通过从大型工具库中检索相关工具来辅助LLM完成任务,避免让LLM被所有工具的描述所淹没。
-
动态适应与灵活性:新的工具可以方便地添加到外部索引中,或对现有工具的描述进行更新,而无需重新训练主LLM,这使得系统能够快速适应工具生态的变化。
通过将工具发现与生成执行解耦,RAG-MCP确保LLM可以扩展到处理数百或数千个MCP,而不会遭受Prompt膨胀或决策疲劳的困扰。这与RAG系统通过仅检索相关段落来避免LLM被整个语料库淹没的原理类似。
五、技术实现细节
5.1 RAG-MCP详细工作流程

整个RAG-MCP的工作流程可以细化为以下几个紧密衔接的步骤,每一步都为最终的高效工具调用贡献力量:
-
步骤一:用户查询的深度语义编码 (Query Encoding)
-
当用户以自然语言形式输入其任务或查询时,RAG-MCP系统首先会调用一个轻量级但语义理解能力强的大型语言模型(例如,PPT中提及的Qwen系列模型或类似的嵌入模型)对该输入进行深度语义编码。
-
此编码过程的目标是将用户的原始文本查询转化为一个固定维度的高维向量表示(我们称之为“查询嵌入”或
query_embedding)。这个向量被设计为能够精准地捕捉和浓缩用户查询的核心意图和语义信息。
-
-
步骤二:基于向量的工具高效检索 (Vector Retrieval)
-
携带着用户查询意图的
query_embedding,系统会进入预先构建好的、存储了所有可用MCP工具描述及其对应向量表示的“工具向量索引库”(vector_db)。 -
在此索引库中,系统会执行高效的语义相似度搜索。这通常涉及到计算
query_embedding与索引库中每一个工具描述向量之间的相似度得分(例如,通过余弦相似度、内积或其他向量空间距离度量)。 -
根据计算出的相似度得分,系统能够快速定位到与用户查询在语义上最为接近(即最可能相关)的一批MCP工具,并按照相似度从高到低进行排序,返回Top-K个候选工具(
tools)。
-
-
步骤三:智能化的工具选择与验证 (Tool Selection & Optional Validation)
-
从检索器返回的Top-K个候选工具列表中,系统需要进一步筛选出最适合当前用户任务的那个(或那几个)MCP工具(
best_tool)。 -
这一步是可选的,但对于提升最终选择的准确性至关重要。RAG-MCP框架支持引入一个“Few-Shot验证”机制。具体而言,可以针对每个检索到的候选MCP工具,基于用户原始查询的上下文,动态地生成一些简单的、小批量的测试样例(Synthetic Test Queries)。然后,模拟使用该候选工具来处理这些测试样例,并评估其返回结果的质量、相关性以及与预期输出的匹配程度。通过这种方式,可以更可靠地判断哪个工具是当前场景下的最优选。
-
-
步骤四:精准上下文注入 (Inject Prompt with Selected Tool(s))
-
一旦通过检索和可选的验证环节确定了最优的MCP工具(
best_tool),系统便会将该工具的Schema(包含其详细的功能描述、输入参数定义、输出格式等)以及必要的参数信息,精准地、有选择性地注入到主大型语言模型(Main LLM)的上下文(Context)中。 -
此时,构建出的Prompt (
prompt) 内容是高度聚焦且信息量适中的,它只包含了用户原始查询 (user_query) 和与该查询最相关的工具信息 (best_tool.schema),避免了大量无关工具描述的干扰。
-
-
步骤五:LLM规划与执行任务 (LLM Planning & Execution)
-
主LLM在接收到这个经过精心构建的、包含用户原始查询及最优工具信息的精简Prompt后,便可以利用其强大的理解、推理和规划能力。
-
LLM会通过其内置的函数调用(Function-Calling)接口,规划具体的执行步骤,并与选定的外部MCP工具进行实际的交互,发送请求、处理响应,最终完成用户指定的任务,并返回结果 (
result)。
-
5.2 检索器技术实现

一个高效且精准的检索器是RAG-MCP系统成功的核心。其技术实现涉及以下几个关键方面:
-
高质量的工具向量表示:
-
每一个MCP工具都需要通过结构化的数据进行详尽的预处理,并最终转化为一个能够准确反映其语义和功能特性的高维度向量表示。这些结构化数据通常应包括:
-
工具名称与核心用途描述:清晰、简洁地阐述工具的主要功能和最典型的适用场景。
-
详细的参数定义与返回值结构:明确定义工具调用时所需的各个输入参数的名称、数据类型、是否必需、取值范围或格式要求,以及工具执行成功或失败后返回结果的数据结构和含义。
-
具体的使用样例与调用场景说明:提供1到多个具体的、具有代表性的调用示例代码或自然语言描述的调用场景,这有助于嵌入模型更好地学习和理解工具的实际用法和上下文。
-
-
例如,一个天气查询API的向量化输入可能包含:
-
tool_embedding = encoder({ "name": "weather_api", "description": "Get current weather conditions and forecast for a specified location.", "parameters": { "location": "string", "days": "integer" }, "examples": ["What's the weather like in Paris tomorrow?", "Get a 3-day forecast for London."]})-
高效的向量索引与存储技术:
-
选择一个能够支持大规模向量数据高效存储和快速相似性搜索的向量索引技术至关重要。业界常用的选项包括基于图的索引(如HNSW)、基于量化的索引(如Product Quantization)或它们的组合。Facebook的FAISS库、Milvus、Pinecone、Qdrant等都是流行的开源或商业向量数据库解决方案。
-
构建的向量索引库需要支持动态更新,以便能够方便地添加新的工具、删除过时的工具或更新现有工具的描述信息及其向量表示,而无需对整个索引库进行重建或重新训练主LLM。
-
在执行检索时,除了基础的语义相似度排序外,还可以结合一些高级策略,如基于工具元数据(例如工具类别、使用频率、用户评分等)的语义过滤(Semantic Filtering)或混合排序(Hybrid Ranking),以进一步提升检索结果的精准度和相关性。
-
例如,典型的操作可能包括:
index.add(tool_id, tool_embedding)用于向索引中添加工具向量,以及results = index.search(query_embedding, top_k=5, filter_conditions={"category": "weather"})用于执行带条件的Top-K检索。
-
5.3 Few-Shot验证技术
当检索器根据语义相似度返回多个候选MCP工具时(即Top-K中的K>1),为了从这些看似都相关的选项中进一步优中选优,提高最终工具选择的准确率和鲁棒性,RAG-MCP框架引入了可选的Few-Shot验证技术。其核心思想是:
-
动态合成验证样例:针对每一个检索到的候选MCP工具,系统可以根据用户原始查询的上下文和意图,自动地、动态地生成一些简单的、小批量的、专门用于测试该工具适用性的“微型”任务样例。这些样例应尽可能地模拟用户可能如何使用该工具。
-
模拟调用与响应质量评估:系统会模拟使用当前的候选工具来执行这些合成的验证样例,并捕获其返回的响应。然后,通过预设的评估标准(例如,检查响应是否包含预期信息、格式是否正确、与用户原始查询的相关性等)来对每个工具在这些验证样例上的表现进行打分。
-
基于综合评分的最终工具筛选:最终的工具选择决策将综合考虑两个方面的因素:一是该工具在初始语义检索阶段获得的相似度得分;二是其在Few-Shot验证环节的表现得分。通过一个加权或其他融合策略,计算出一个综合评分,并选择综合评分最高的那个工具作为最终的“胜出者”。

这种验证机制相当于在正式“上场”前对候选工具进行了一轮“试用”,有助于排除那些看似相关但实际效果不佳的工具。
通过上述这些精心设计的技术实现细节,RAG-MCP框架得以确保在面对日益庞大和复杂的外部工具生态时,依然能够为大型语言模型精准、高效地“导航”,帮助其找到最合适的“左膀右臂”,从而更好地完成用户赋予的各项任务。
六、实验设计与评估方法
6.1 MCP压力测试设计
为了量化评估LLM的工具选择能力如何随着MCP池大小的增加而变化,并分析RAG-MCP的扩展能力,论文设计了MCP压力测试。
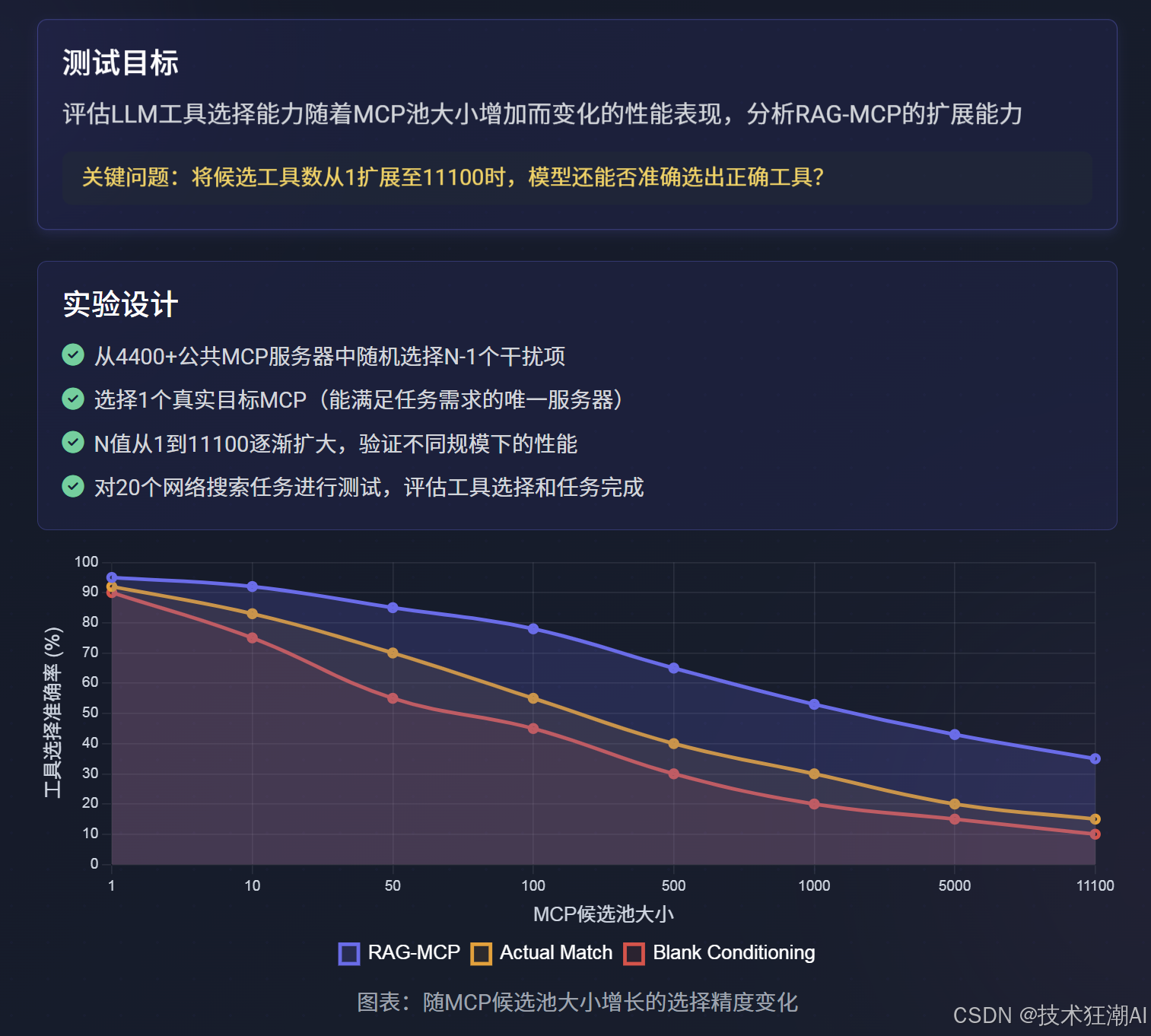
-
关键问题:当候选工具数量从1扩展至11100时,模型还能否准确选出正确的工具?
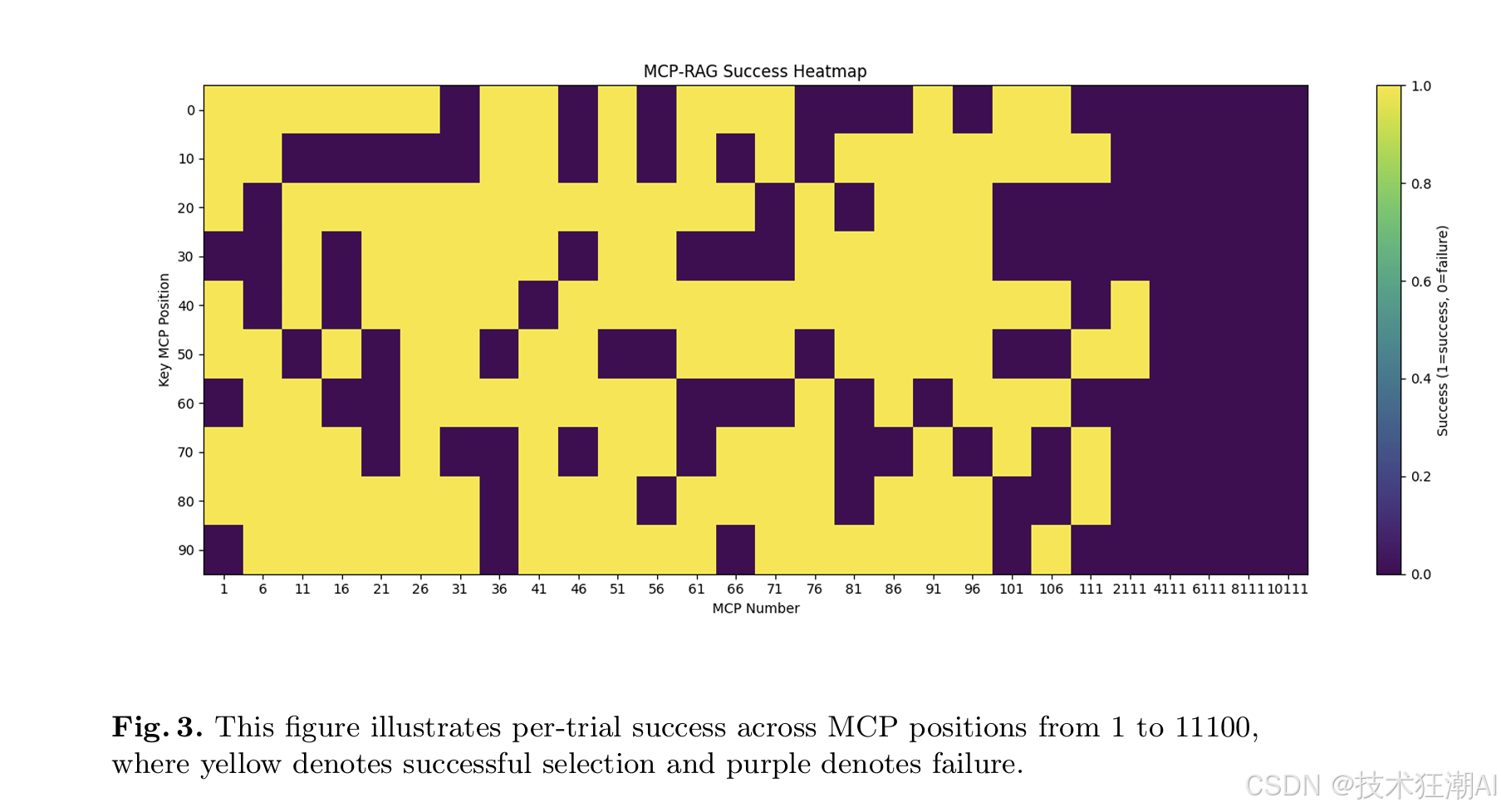
图3展示了MCP压力测试的部分结果,直观地显示了在不同工具数量和目标工具位置下,RAG-MCP的成功率(黄色表示成功,紫色表示失败)。
6.2 MCPBench评估框架
为了确保实验评估的客观性、标准化和可复现性,研究团队采用了领域内公认的MCPBench评估框架,并特别选取了其中的Web搜索任务子集(Web Search Subset)作为固定的、与训练数据无关的留出测试平台(Heldout Testbed)

-
评估设置:
-
每种方法进行20次独立试验。
-
允许模型与MCP服务器进行最多10轮交互以达成最终响应。
-
使用Deepseek-v3作为评估器来判断答案的正确性。
-
使用qwen-max-0125作为基础LLM。
-
-
评估指标:
-
准确率 (%): 模型选择到真实目标MCP的试验比例。
-
平均Prompt Token: 包含注入的MCP元数据在内的Prompt平均Token消耗。
-
平均完成Token: 模型最终输出的生成内容的平均Token长度。
-
-
基础模型:
-
使用qwen-max-0125作为基础LLM。
-
确保实验环境的网络连通性。
-
使用Llama-based验证器自动判断输出正确性。
-
6.3 对比基线方法
为了凸显RAG-MCP的优势,论文将其与以下基线方法进行了对比:

-
Blank Conditioning (BC):将所有N个MCP的描述一次性注入LLM的Prompt,让模型自行选择正确的工具。这是最直接但也最低效的方法。
-
Actual Match (AM):使用简单的关键词匹配对任务描述和MCP元数据进行预筛选,缩小候选范围后,再将筛选后的工具集提供给LLM。这是一种加入了初步过滤的优化方法。
-
RAG-MCP: 即本文提出的方法,使用向量索引检索器语义化地排序所有N个MCP,并仅将排名最高的候选工具的schema注入LLM的Prompt进行执行。
七、实验结果与数据分析

7.1 性能对比分析
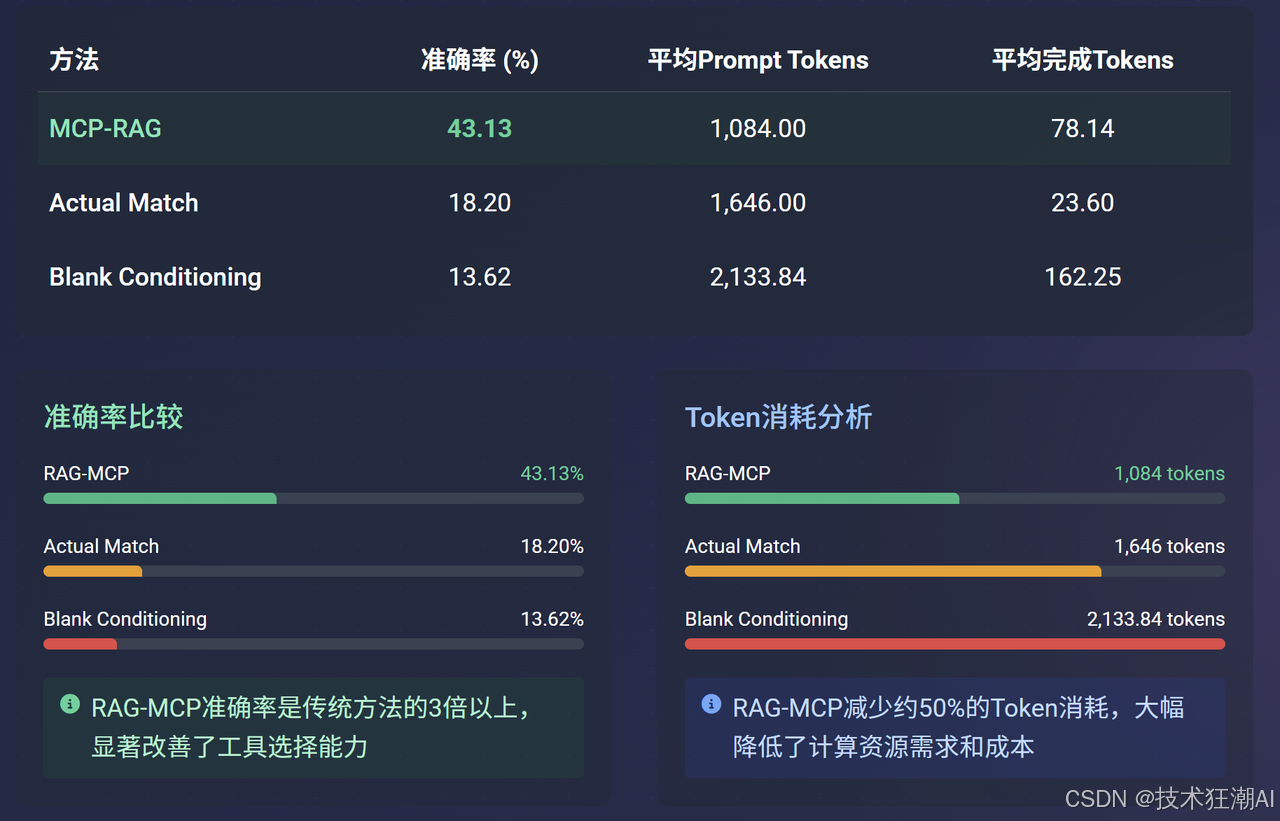
从表格中可以直观地看到:
-
准确率大幅提升:RAG-MCP的工具选择准确率(43.13%)远超Actual Match(18.20%)和Blank Conditioning(13.62%),提升了约3倍。
-
Prompt Token显著减少:RAG-MCP的平均Prompt Token消耗(1084.00)相比Blank Conditioning(2133.84)减少了近一半(约49%),也明显低于Actual Match(1646.00)。
-
完成Token的权衡:虽然RAG-MCP的平均完成Token(78.14)略高于Actual Match(23.60),但这通常与更复杂的推理和更成功的任务完成相关联,是一种值得的“开销”。
7.2 扩展性与容量分析 (基于MCP压力测试结果)
MCP压力测试的结果(如图3所示)揭示了RAG-MCP在不同工具库规模下的性能表现:
-
小规模工具库 (<30个MCP):成功率非常高,通常在90%以上。
-
中等规模工具库 (30-100个MCP):成功率保持稳定,但随着工具描述间语义重叠的增加,可能会出现间歇性的性能波动。
-
大规模工具库 (>100个MCP):虽然检索精度有所下降,但RAG-MCP的整体性能仍然显著优于传统方法。
-
“成功孤岛”现象:即使在非常大的工具库中,对于某些与用户查询高度对齐的特定MCP,系统仍然能够保持较高的检索和选择成功率,显示了其在特定语义领域的鲁棒性。
这些结果证实,RAG-MCP能够有效抑制Prompt膨胀,并在中小型工具池中保持高准确率。尽管在超大规模工具库中检索精度面临挑战,但其整体表现仍远超基线。
八、创新点与应用优势
8.1 核心创新点

-
RAG + MCP融合架构:首创性地将检索增强生成(RAG)机制与模型上下文协议(MCP)的函数调用标准相结合。
-
可扩展的工具检索机制:设计了高效的语义索引机制,使得系统可以在不重新训练LLM的情况下,即时添加新的工具。这赋予了系统极高的灵活性和可扩展性。
-
显著的性能突破:在处理大规模工具库时,RAG-MCP显著提高了工具选择的准确率,同时大幅减少了错误调用和参数“幻觉”的风险。
8.2 技术优势对比

-
传统MCP调用:
-
将全部工具描述注入LLM上下文。
-
随着工具数量增加,Token消耗线性增长。
-
工具选择准确率随规模增大而急剧下降。
-
-
RAG-MCP方法:
-
只注入最相关的工具,降低上下文负担。
-
Token消耗几乎恒定,与总工具数量解耦。
-
语义检索提供更精准的工具选择。
-
8.3 实用价值与优势
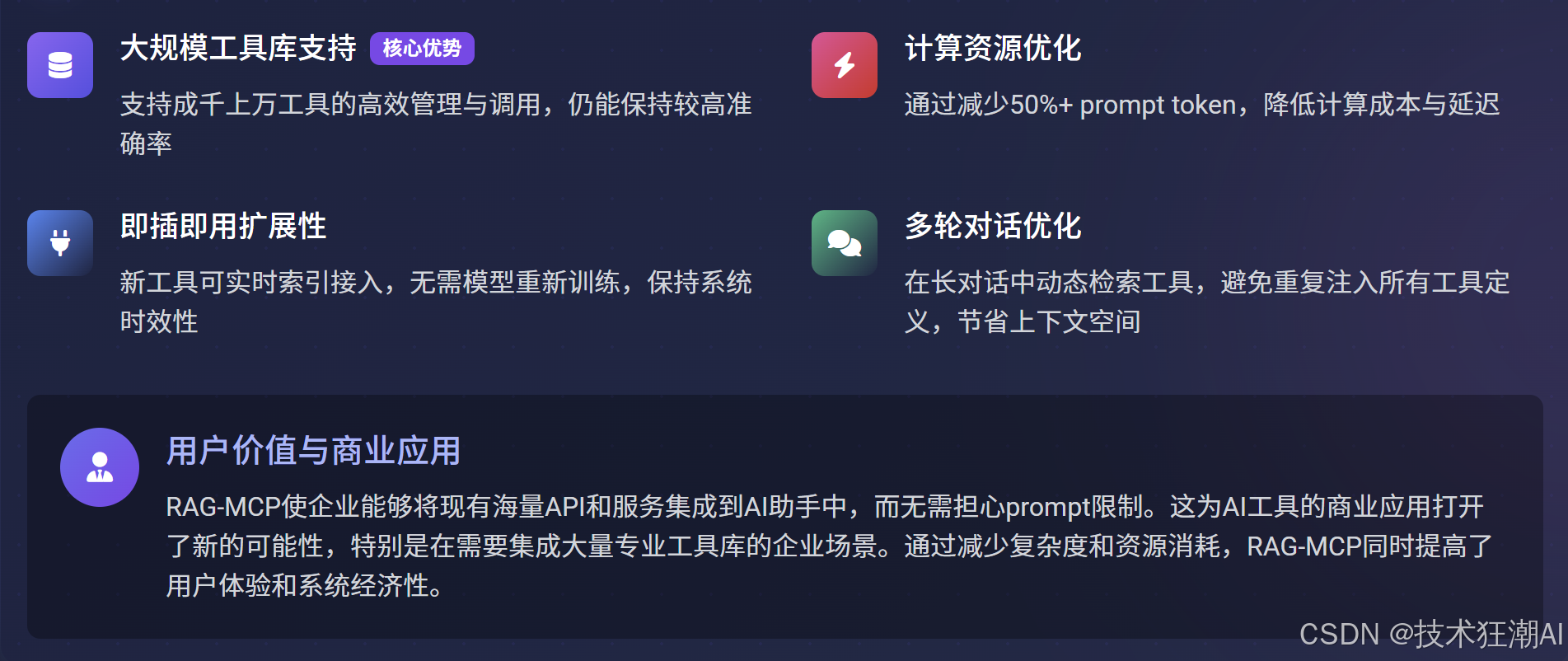
-
支持大规模工具库:即使面对成千上万的工具,RAG-MCP也能保持较高的管理和调用效率与准确性。
-
即插即用的扩展性:新的工具可以实时索引并接入系统,无需对核心LLM进行重新训练,保持了系统的时效性。
-
计算资源优化:通过减少超过50%的Prompt Token,显著降低了计算成本和API调用延迟。
-
优化多轮对话中的工具调用:在持续的多轮对话中,RAG-MCP可以动态检索工具,避免在每一轮都重复注入所有工具的定义,从而节省了宝贵的上下文空间。
-
提升用户价值与商业应用潜力:RAG-MCP使得企业能够将现有的大量API和服务集成到AI助手中,而无需担心Prompt限制。这为AI工具的商业应用开辟了新的可能性,特别是在需要集成大量专业工具库的企业场景中。通过减少复杂度和资源消耗,RAG-MCP同时提高了用户体验和系统经济性。
九、应用场景与未来展望
9.1 实际应用场景
RAG-MCP的框架思想和技术实现,使其在多种需要LLM与大量外部工具交互的场景中具有广阔的应用前景:

-
AI客服系统:企业级客服系统往往需要接入数百种内部工具和API来处理各类用户请求。RAG-MCP可以帮助AI客服精准选择工具,降低运营成本,提升响应速度和问题解决率。
-
开发者助手:整合数千个代码库文档、API参考和代码示例,开发助手可以基于上下文检索最相关的资源,而非一次性加载所有文档,从而为开发者提供更精准、高效的辅助。
-
企业智能体:企业内部的自动化助手需要连接ERP、CRM、HR等多种复杂系统。RAG-MCP可以根据具体任务按需调用合适的系统接口,实现更智能、更高效的企业流程自动化。
9.2 局限性与挑战
尽管RAG-MCP取得了显著进展,但仍存在一些局限性和待解决的挑战:

-
超大规模工具库下的检索精度瓶颈:当工具库规模达到数千甚至上万级别,且工具描述之间语义相似度较高时,检索模块的精度仍可能面临挑战,导致次优工具被选中的风险增加。
-
复杂工具链的处理:当前框架主要关注单个工具的选择。当一个任务需要连续调用多个工具形成复杂工具链时,RAG-MCP在多步骤规划与组合方面的原生支持尚有不足。
9.3 未来研究方向
为了进一步提升RAG-MCP的性能和适用性,未来的研究可以从以下几个方面展开:

-
分层检索架构:针对超大规模工具库,可以发展多层次、层级化的工具检索机制,例如先进行粗粒度的大类检索,再进行细粒度的精确匹配,以适应不同规模的工具库。
-
对话语境感知:增强检索模块对多轮对话历史的理解能力,将上下文信息(如用户之前的提问、偏好等)纳入检索考量,以提高在复杂对话场景下工具匹配的准确性。
-
自我优化与学习:开发系统从用户交互历史中学习的能力,例如,自动调整检索算法的参数、排序权重,甚至动态更新工具的向量表示,以持续提升工具匹配的准确率。
-
多Agent协作:将RAG-MCP的思想扩展到多智能体(Multi-Agent)系统。不同的Agent可以负责管理和调用一部分工具子集,通过协同合作来完成更复杂的任务。
-
安全性与隐私增强:研究如何在工具检索阶段引入安全过滤和权限控制机制,防止未授权的工具被访问或滥用,确保系统的安全性和用户隐私。
十、实施指南与最佳实践
10.1 RAG-MCP实施路线图

-
工具库梳理与标准化:整理并标准化所有需要集成的外部工具的API定义或MCP描述。确保每个工具的描述清晰、结构化,并包含必要的元数据。
-
向量索引构建:选择合适的嵌入模型(Embedding Model),对工具描述进行向量化,并构建高效的向量索引库(如使用FAISS、Milvus、Pinecone等)。
-
检索器调优:优化检索参数(如Top-k值的选择)和语义匹配算法。针对特定领域的工具库,可以考虑微调嵌入模型以提升检索效果。
-
系统集成与测试:将检索模块与主LLM系统集成,并进行全流程的端到端测试,确保各组件协同工作顺畅。
10.2 最佳实践建议

-
优化工具描述:
-
使用结构化、一致的格式来描述工具功能。
-
在描述中包含明确的用例和适用场景。
-
为工具添加相关的关键词标签,以增强语义匹配的鲁棒性。
-
为每个工具提供2-3个典型的使用示例。
-
-
提升检索性能:
-
针对特定的工具领域或任务类型,考虑微调嵌入模型。
-
实验不同的Top-k值(通常建议从3-5开始尝试)。
-
可以探索结合语义检索与关键词匹配的混合策略。
-
定期更新和优化向量索引,以纳入新增或变更的工具。
-
-
考量系统架构:
-
将检索服务与主LLM服务解耦,以确保各自的独立可扩展性。
-
引入缓存机制,减少对高频工具的重复检索开销。
-
可以为高频或关键工具设置更高的检索优先级权重。
-
建立检索结果的监控机制和失败时的回退策略。
-
-
持续评估与优化:
-
跟踪关键指标,如工具选择准确率、误用率等。
-
收集用户交互反馈,用于改进检索算法和工具描述。
-
建立标准化的测试集,定期评估系统性能。
-
定期重新训练或更新工具的向量表示,以适应工具本身的变化和用户使用模式的演变。
-
十一、关键结论与行业影响
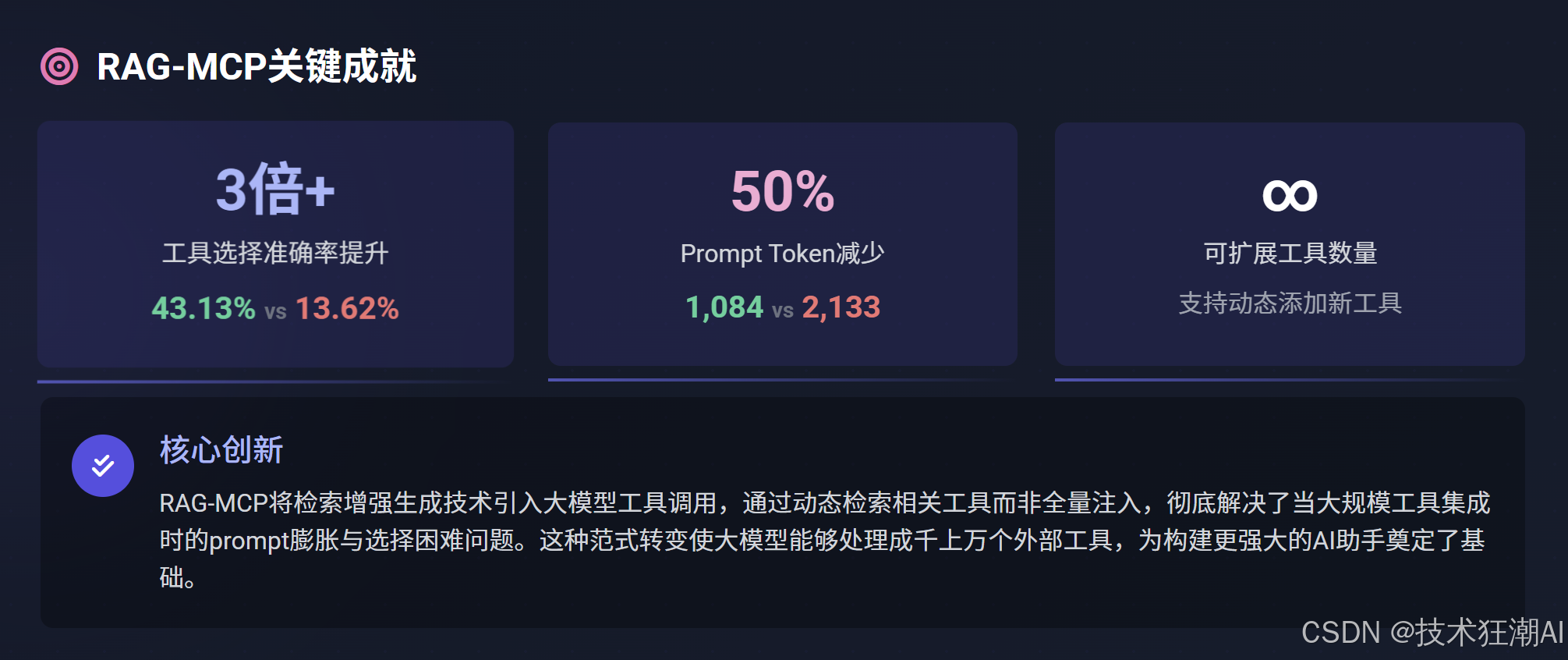
11.1 核心结论与突破

-
性能与效率双提升:RAG-MCP通过动态检索相关工具,成功将Prompt Token数量减少了50%以上,同时使工具选择准确率提升了3倍以上(从基线的13.62%提升至43.13%)。这极大地降低了模型在处理大量工具时的上下文理解负担,使得大规模工具库的应用成为可能。
-
可扩展性的重大突破:通过解耦工具发现与LLM调用,RAG-MCP实现了无需重新训练核心LLM即可动态添加新工具的能力,彻底打破了传统方法在工具数量上的限制。这为LLM接入数千甚至数万种外部工具提供了基础架构。
11.2 突破性意义
RAG-MCP框架代表了LLM工具利用范式的一次重要转变——从过去“一次性注入全部工具信息”的粗放模式,转向了“按需动态检索相关工具”的精细化、智能化模式。这种转变,与RAG技术本身改变知识密集型任务中信息获取方式的理念一脉相承。它不仅有效解决了当前LLM在规模化工具调用中面临的Prompt膨胀和决策过载问题,更为未来构建具备数千种外部能力的、高度可扩展的AI系统铺平了道路。
11.3 行业影响与应用前景

-
赋能AI助手生态扩展:使得AI助手能够无缝连接并使用成千上万的第三方服务和API,而无需担心上下文窗口的限制,从而推动功能更强大、更通用的“超级应用”型AI助手的发展。
-
降低企业AI集成门槛:企业可以将现有的大量内部API和外部服务生态,以较低的成本、更便捷的方式集成到其AI系统中,避免了复杂的技术重构,加速了企业AI自动化转型的进程。
-
革新开发者工具体验:为开发者提供了更高效、更标准的API接入框架,有望催生更繁荣的AI功能市场和新型AI原生服务。
十二、总结与展望
RAG-MCP通过将检索增强生成技术巧妙地引入大模型的工具调用流程,成功地解决了在面对大规模工具集时普遍存在的Prompt膨胀和选择困难问题。它通过动态、按需地向LLM提供最相关的工具信息,而不是一次性加载所有工具,从而在大幅提升工具选择准确率的同时,显著降低了Prompt的长度和LLM的认知负担。

这一创新范式不仅使得LLM能够更有效地利用日益丰富的外部工具和服务,也为构建更强大、更灵活、更具扩展性的AI智能体奠定了坚实的基础。RAG-MCP的出现,标志着我们向着能够自如驾驭海量外部能力的通用人工智能又迈出了坚实的一步。
未来,我们期待看到更多基于RAG-MCP思想的演进和创新,例如更智能的分层检索策略、更强大的多Agent协作机制,以及能够从交互中持续学习和自我优化的自适应工具链等。这些技术的进步,将共同推动LLM工具调用能力的持续飞跃,最终构建出真正可靠、高效的大规模工具增强型AI系统。
对于所有致力于推动大模型应用落地、提升AI系统实用性和智能水平的研究者和开发者而言,RAG-MCP无疑提供了一个极具启发性和实践价值的优秀框架。
论文引用信息: Gan, T., & Sun, Q. (2025). RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation. arXiv preprint arXiv:2505.03275.
相关文章:

RAG-MCP:突破大模型工具调用瓶颈,告别Prompt膨胀
大语言模型(LLM)的浪潮正席卷全球,其强大的自然语言理解、生成和推理能力,为各行各业带来了前所未有的机遇。然而,正如我们在之前的探讨中多次提及,LLM并非万能。它们受限于训练数据的时效性和范围…...

Flask框架入门与实践
Flask框架入门与实践 Flask是一个轻量级的Python Web框架,以其简洁、灵活和易于上手的特点深受开发者喜爱。本文将带您深入了解Flask的核心概念、基本用法以及实际应用。 什么是Flask? Flask是由Armin Ronacher于2010年开发的微型Web框架。与Django等…...

PD 分离推理的加速大招,百度智能云网络基础设施和通信组件的优化实践
为了适应 PD 分离式推理部署架构,百度智能云从物理网络层面的「4us 端到端低时延」HPN 集群建设,到网络流量层面的设备配置和管理,再到通信组件和算子层面的优化,显著提升了上层推理服务的整体性能。 百度智能云在大规模 PD 分离…...

罗杰斯高频板技术解析:低损耗基材如何定义 5G 通信未来
在 5G 通信与尖端电子技术加速融合的时代,高频 PCB 作为信号传输的核心载体,对材料性能与工艺精度提出了极致要求。猎板 PCB 深耕行业多年,始终以罗杰斯(Rogers)板材为核心介质,构建起从材料适配到精密制造…...

QML 动画控制、顺序动画与并行动画
目录 引言相关阅读基础属性说明工程结构示例代码解析示例1:手动控制动画(ControlledAnimation.qml)示例2:顺序动画(SequentialAnimationDemo.qml)示例3:并行动画(ParallelAnimationD…...

【动态导通电阻】GaN HEMT动态导通电阻的精确测量
2023 年 7 月,瑞士洛桑联邦理工学院的 Hongkeng Zhu 和 Elison Matioli 在《IEEE Transactions on Power Electronics》期刊发表了题为《Accurate Measurement of Dynamic ON-Resistance in GaN Transistors at Steady-State》的文章,基于提出的稳态测量方法,研究了氮化镓(…...

2:OpenCV—加载显示图像
加载和显示图像 从文件和显示加载图像 在本节中,我将向您展示如何使用 OpenCV 库函数从文件加载图像并在窗口中显示图像。 首先,打开C IDE并创建一个新项目。然后,必须为 OpenCV 配置新项目。 #include <iostream> #include <ope…...

Qt控件:交互控件
交互控件 1. QAction核心功能API 1.2 实例应用情况应用场景 1. QAction ##1. 1简介与API QAction 是一个核心类,用于表示应用程序中的一个操作(如菜单项、工具栏按钮或快捷键触发的功能)。它将操作的逻辑与 UI 表现分离,使代码更…...

在vue3中使用Cesium的保姆教程
1. 软件下载与安装 1. node安装 Vue.js 的开发依赖于 Node.js 环境,因此我们首先需要安装 Node.js。Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,它允许你在服务器端运行 JavaScript 代码,同时也为前端开发提供了强大的工具支…...

zst-2001 下午题-历年真题 试题一到三
试题一 问题一 1 问题一 2 注意每句话中的“给”… 问题一 3 问题二 1 问题二 2 问题二 3 问题三 1 步骤一.看父图的数据流在子图有没有缺失 步骤二.看加工有没有输入输出 步骤三.阅读理解 问题三 2 实体和存储不能划线 问题三 3 试题二 问题一 1 问题一 2 问题一 3 问题二…...
**和**转换时机(Conversion Time),获取数据的时机详解)
STM32的ADC模块中,**采样时机(Sampling Time)**和**转换时机(Conversion Time),获取数据的时机详解
在STM32的ADC模块中,**采样时机(Sampling Time)和转换时机(Conversion Time)**是ADC工作流程中的两个关键阶段,直接影响采样精度和系统实时性。以下是详细解析: 1. 采样时机(Samplin…...

iOS音视频解封装分析
首先是进行解封装的简单的配置 /// 解封装配置 class KFDemuxerConfig {// 媒体资源var asset: AVAsset?// 解封装类型,指定是音频、视频或两者都需要var demuxerType: KFMediaType .avinit() {} }然后是实现解封装控制器 import Foundation import CoreMedia i…...

探究电阻分压的带负载能力
我们经常使用两个电阻去分压来获得特定的电压,那么我是两个大阻值电阻分压获得的电压驱动能力强,还是小阻值电阻分压得到的电压驱动能力强呢? 一、电压相同时,电流的大小 下面是两个阻值分压得到的仿真图 电路分析: VCC都是5V,探针1和探针2测到的电压都是1.67V; 根据…...

14、Python时间表示:Unix时间戳、毫秒微秒精度与time模块实战
适合人群:零基础自学者 | 编程小白快速入门 阅读时长:约5分钟 文章目录 一、问题:计算机中的时间的表示、Unix时间点?1、例子1:计算机的“生日”:Unix时间点2、答案:(1)U…...

PCL 绘制二次曲面
文章目录 一、简介二、实现代码三、实现效果一、简介 这里基于二次曲面的公式: z = a 0 + a 1 x + a 2 y + a...

消息队列与Kafka基础:从概念到集群部署
目录 一、消息队列 1.什么是消息队列 2.消息队列的特征 3.为什么需要消息队列 二、Kafka基础与入门 1.Kafka基本概念 2.Kafka相关术语 3.Kafka拓扑架构 4.Topic与partition 5.Producer生产机制 6.Consumer消费机制 三、Zookeeper概念介绍 1.zookeeper概述 2.zooke…...

计算机指令分类和具体的表示的方式
1.关于计算机的指令系统 下面的这个就是我们的一个简单的计算机里面涉及到的指令: m就是我们的存储器里面的地址,可以理解为memory这个意思,r可以理解为rom这样的单词的首字母,帮助我们去进行这个相关的指令的记忆,不…...
)
pcie phy-电气层-gen1/2(TX)
S IP物理层讲解 在synopsys IP中对于phy层的内容分离的比较多: cxpl中: u_cx_phy_logical:包含ts序列的解析(smlh); pipe层协议的转换(rmlh,xmlh);pipe转dllp包(rplh&…...

Baklib加速企业AI数据智理转型
Baklib智理AI数据资产 在AI技术深度渗透业务场景的背景下,Baklib通过构建企业级知识中台架构,重塑了数据资产的治理范式。该平台采用智能分类引擎与语义分析模型,将分散在邮件、文档、数据库中的非结构化数据转化为标准化的知识单元…...

深度学习驱动下的目标检测技术:原理、算法与应用创新
一、引言 1.1 研究背景与意义 目标检测作为计算机视觉领域的核心任务之一,旨在识别图像或视频中感兴趣目标的类别,并确定其在图像中的位置,通常以边界框(Bounding Box)的形式表示 。其在现实生活中有着极为广泛且…...

window 显示驱动开发-使用有保证的协定 DMA 缓冲区模型
Windows Vista 的显示驱动程序模型保证呈现设备的 DMA 缓冲区和修补程序位置列表的大小。 修补程序位置列表包含 DMA 缓冲区中命令引用的资源的物理内存地址。 在有保证的协定模式下,用户模式显示驱动程序知道 DMA 缓冲区和修补程序位置列表的确切大小,…...

《指针与整数相加减的深入解析》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、指针与整数相加的原理二、指针与整数相减的原理三、使用场景(一)数组操作(二)内存遍历 四、注意事项&…...

C++_STL_map与set
1. 关联式容器 在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、 forward_list(C11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面 存储的是元素本身。那什么是…...
)
1949-2022年各省农作物播种面积数据(22个指标)
1949-2022年各省农作物播种面积数据(22个指标) 1、时间:1949-2022年 2、来源:各省年鉴、国家统计局、农业部、农业年鉴 3、范围:31省 4、指标:年度标识、省份编码、省份名称、农作物总播种面积、粮食作…...

汽车二自由度系统模型以及电动助力转向系统模型
汽车二自由度系统模型与电动助力转向系统(EPS)的详细建模方案,包含理论推导、MATLAB/Simulink实现代码及参数说明: 一、二自由度汽车模型 1. 模型描述 包含以下两个自由度: 横向运动(侧向加速度…...
—— 存储器管理)
【学习笔记】计算机操作系统(四)—— 存储器管理
第四章 存储器管理 文章目录 第四章 存储器管理4.1 存储器的层次结构4.1.1 多层结构的存储器系统4.1.2 主存储器与寄存器4.1.3 高速缓存和磁盘缓存 4.2 程序的装入和链接4.2.1 程序的装入4.2.2 程序的链接 4.3 连续分配存储管理方式4.3.1 单一连续分配4.3.2 固定分区分配4.3.3 …...

51单片机的lcd12864驱动程序
#include <reg51.h> #include <intrins.h>#define uchar...
数字化转型之库存管理:从进库到出库的数字化运营)
(03)数字化转型之库存管理:从进库到出库的数字化运营
在当今竞争激烈的商业环境中,高效的库存管理已成为企业降低成本、提高运营效率的关键。本文将系统性地介绍库存管理的全流程,包括进库、出库、移库、盘点等核心环节,帮助企业构建科学合理的库存管理体系。 一、进库管理:从计划到执…...

windows编程中加载DLL的两种典型方式的比较
文章目录 DLL定义头文件定义CPP实现DLL的调用代码直接使用通过LoadLibrary调用导入表的依赖LoadLibrary使用DLL库中的类DLL中定义工厂函数调用时的代码补充:为什么LoadLibrary不能直接导出类在windows的编程中,使用DLL是一个非常常见的操作。一般来说,有两种集成DLL的方式:…...

存储器上如何存储1和0
在计算机存储器中,数据最终以**二进制形式(0和1)**存储,这是由硬件特性和电子电路的物理特性决定的。以下是具体存储方式的详细解析: 一、存储的物理基础:半导体电路与电平信号 计算机存储器(…...

【笔记】记一次PyCharm的问题反馈
#工作记录 最近更新至 PyCharm 社区版的最新版本后,我遇到了多个影响使用体验的问题。令人感到不便的是,一些在旧版本中非常便捷的功能,在新版本中却变得操作复杂、不够直观。过去,我一直通过 PyCharm 内置的故障报告与反馈机制反…...

logrotate按文件大小进行日志切割
✅ 编写logrotate文件,进行自定义切割方式 adminip-127-0-0-1:/data/test$ cat /etc/logrotate.d/test /data/test/test.log {size 1024M #文件达到1G就切割rotate 100 #保留100个文件compressdelaycompressmissingoknotifemptycopytruncate #这个情况服务不用…...

基于大模型的脑出血智能诊疗与康复技术方案
目录 一、术前阶段1.1 数据采集与预处理系统伪代码实现流程图1.2 特征提取与选择模块伪代码实现流程图1.3 大模型风险评估系统伪代码实现流程图二、术中阶段2.1 智能手术规划系统伪代码实现流程图2.2 麻醉智能监控系统伪代码实现流程图三、术后阶段3.1 并发症预测系统伪代码片段…...

P21-RNN-心脏病预测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、RNN 循环神经网络(Recurrent Neural Network,简称 RNN)是一类以序列数据为输入,在序列的演进方向进行递归…...

懒汉式单例模式的线程安全实现
懒汉式单例模式的线程安全实现 懒汉式单例模式的核心特点是延迟实例化(在第一次使用时创建对象),但其基础实现存在线程安全问题。以下是不同线程安全实现方式的详细说明和对比: 1. 非线程安全的基础懒汉式 public class UnsafeLazySingleton {private static UnsafeLazyS…...

Java 常用的Arrays函数
文章目录 ArrayssorttoStringbinarySearchequalsfill 数组拷贝copyOfcopyOfRangearraycopy 二维数组定义遍历deepToString空指针异常 Arrays sort int[] array new int[]{1,20,3}; Arrays.sort(array);// 1 3 20toString 帮助数组转为字符串 int[] array new int[]{1,2,3…...

FEKO许可证与版本兼容性问题
随着电磁仿真技术的不断进步,FEKO软件不断更新迭代,为用户提供更强大的功能和更优秀的性能。然而,在升级过程中,FEKO许可证与版本兼容性问题往往成为用户关注的焦点。本文将为您详细解读FEKO许可证与版本兼容性问题,帮…...

HarmonyOs开发之——— ArkWeb 实战指南
HarmonyOs开发之——— ArkWeb 实战指南 谢谢关注!! 前言:上一篇文章主要介绍HarmonyOs开发之———合理使用动画与转场:CSDN 博客链接 一、ArkWeb 组件基础与生命周期管理 1.1 Web 组件核心能力概述 ArkWeb 的Web组件支持加载本地或在线网页,提供完整的生命周期回调体…...

冰箱磁力贴认证标准16CFR1262
在亚马逊平台,冰箱磁力贴这类可能被儿童接触到的产品,有着严格的规范哦。必须得遵守 16 CFR 1262 标准,还得有符合该标准的测试报告和 GCC 证书,不然产品就可能被禁止销售或者面临召回,那可就损失大啦! …...

Java中的锁机制全解析:从synchronized到分布式锁
在多线程编程中,锁是保证线程安全的核心工具。本文将详解Java中常见的锁机制及其实际应用场景,帮助开发者选择最合适的锁方案。 一、内置锁:synchronized 原理 通过JVM内置的监视器锁(Monitor)实现,可修…...

OptiStruct实例:3D实体转子分析
上一节介绍了1D转子的临界转速分析。在1D转子模型中,转子是以集中质量单元的形式建模的。此种建模方法不可避免地会带来一些简化和局部特征的缺失。接下来介绍OptiStruct3D实体转子的建模及临界转速分析实例。 3D实体转子建立详细的转子网格模型,然后将…...

简单记录坐标变换
以三维空间坐标系为例 rTt代表机械手末端相对robot root坐标系的变换关系 rTt dot p_in_tool 可以把tool坐标系下表示的某点转到root坐标系表示 其中rTt表示tool相对于root坐标系的平移和旋转 以二维图像坐标系为例说明 1坐标系定为图片坐标系左上角,横平竖直的…...

自定义快捷键软件:AutoHotkey 高效的快捷键执行脚本软件
AutoHotkey 是一种适用于 Windows 的免费开源脚本语言,它允许用户轻松创建从小型到复杂的脚本,用于各种任务,例如:表单填充、自动点击、宏等。 定义鼠标和键盘的热键,重新映射按键或按钮,并进行类似自动更…...

【Android构建系统】了解Soong构建系统
背景介绍 在Android7.0之前,Android使用GNU Make描述和执行build规则。Android7.0引入了Soong构建系统,弥补Make构建系统在Android层面变慢、容易出错、无法扩展且难以测试等缺点。 Soong利用Kati GNU Make克隆工具和Ninja构建系统组件来加速Android的…...

显性知识的主要特征
有4个主要特征: 客观存在性静态存在性可共享性认知元能性...

STM32F407VET6实战:CRC校验
CRC校验在数据传输快,且量大的时候使用。下面是STM32F407VET6HAL库使用CRC校验的思路。 步骤实现: CubeMX配置 c // 在CubeMX中启用CRC模块 // AHB总线时钟自动启用 HAL库代码 c // 初始化(main函数中) CRC_HandleTypeDef …...

LeetCode 746 使用最小花费爬楼梯
当然可以!LeetCode 746 是一道经典的动态规划入门题,我来用 C 为你详细解释。 题目描述 给定一个整数数组 cost,其中每个元素 cost[i] 表示从第 i 个台阶向上爬需要支付的费用。一旦支付费用,你可以选择向上爬 1 步 或 2 步。 你…...

隧道结构安全在线监测系统解决方案
一、方案背景 隧道是地下隐蔽工程,会受到潜在、无法预知的地质因素影响。随着我国公路交通建设的发展,隧道占新建公路里程的比例越来越大。隧道属于线状工程,有的规模较大,可长达几公里或数十公里,往往穿越许多不同环境…...

牛客网NC22000:数字反转之-三位数
牛客网NC22000:数字反转之-三位数 🔍 题目描述 时间限制:C/C/Rust/Pascal 1秒,其他语言2秒 空间限制:C/C/Rust/Pascal 32M,其他语言64M 📝 输入输出说明 输入描述: 输入一个3位整数n (100 ≤ n ≤ 999)…...

等离子模块【杀菌消毒】
图片来源于网络,与任何公司或实验室无关。 洗衣机中的等离子模块,又叫等离子杀菌模块或等离子发生器,是一种利用等离子体技术进行杀菌消毒、除异味、净化空气的部件。 输出正高压:3.0KV~4.0KV 输出负高压:-3.…...