深入浅出拆分学习,图神经网络拆分学习,混合联邦学习
深入浅出解析拆分学习(Split Learning)、图神经网络拆分学习(Split Learning for Graph Neural Networks)以及混合联邦学习(Hybrid Federated Learning),这三者都体现了在分布式数据环境下进行机器学习协作的思想,但各有侧重和适用场景。理解它们的区别和联系,有助于在实际应用中选择或设计更合适的解决方案。
拆分学习 (Split Learning, SL)
核心思想:按层分割模型,协同进行训练,客户端计算量小。
我们有一个深度神经网络模型,它由很多层堆叠而成。在传统的训练方式中,整个模型要么在数据所在的设备上训练,要么数据被发送到拥有完整模型的服务器上训练。拆分学习提供了一种新的协作方式。
工作机制:
-
模型拆分: 深度学习模型被“切分”成多个部分。最常见的场景是切分成两部分:
- 客户端模型 (Client-side model): 模型的前几层被部署在数据持有方(例如,用户的手机、医院的本地服务器)。
- 服务器端模型 (Server-side model): 模型的剩余部分(通常是更深的、计算量更大的层)部署在一个或多个服务器上。
-
训练流程(以客户端-服务器模式为例):
- 客户端前向传播:
- 客户端使用其本地数据输入到它的那部分模型(客户端模型)中,进行前向传播,计算得到一个中间结果,这个中间结果通常被称为“激活值 (activations)”或“切片数据 (cut data / smashed data)”。
- 客户端将这个激活值发送给服务器。注意:原始数据不离开客户端。
- 服务器端前向传播和损失计算:
- 服务器接收到来自客户端的激活值,将其作为输入送入服务器端的模型部分,继续进行前向传播,直到得到最终的预测结果。
- 服务器使用标签(通常也由客户端提供,或者服务器自身拥有,取决于具体场景和数据划分)计算损失。
- 服务器端反向传播:
- 服务器根据损失进行反向传播,计算服务器端模型参数的梯度,并一直反向传播到其输入层,即接收客户端激活值的那一层。
- 服务器计算出关于客户端激活值的梯度 (gradients of activations)。
- 梯度传回与客户端反向传播:
- 服务器将激活值的梯度发送回给对应的客户端。
- 客户端接收到这个梯度后,用它来对其本地的客户端模型进行反向传播,计算并更新客户端模型的参数。
- 迭代: 重复以上步骤,直到模型收敛。
- 客户端前向传播:
图解拆分学习 (简化版):
注:虚线表示模型更新动作,实线表示正向/反向传播流程。
“w.r.t” 是英文短语 “with respect to” 的缩写,中文意思是:“关于”/“相对于”/“针对”某个变量或对象。在深度学习中常用于描述梯度的对象,例如:
-
“Gradient w.r.t Activations”
→ 意思是“相对于中间激活值的梯度” -
“Gradient w.r.t Model Parameters”
→ 表示“关于模型参数的梯度”
“Gradient w.r.t X” 就是 “损失函数对 X 的梯度”
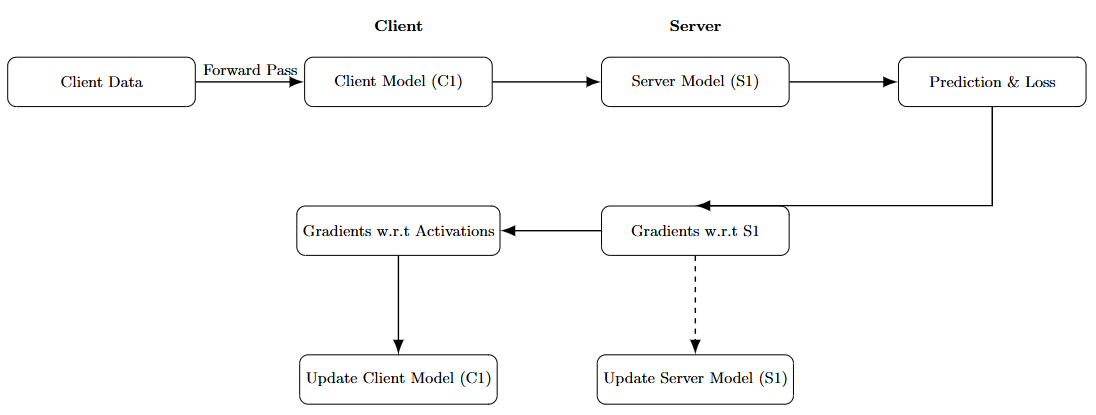
Client Data → Client Model (C1):客户端使用本地数据执行模型前几层的前向传播,生成中间激活值(activations),这些不会包含原始数据。
Client Model → Server Model → Loss:中间激活被传送至服务器,服务器继续执行模型剩余部分并生成预测,进而基于标签计算损失(Loss)。
Loss → Gradients w.r.t S1:服务器开始执行反向传播,计算 Server 端参数(S1)的梯度。
Gradients w.r.t S1 → Gradients w.r.t Activations:在反向传播时,S1 的输出梯度会反向传回客户端,用于继续传播并更新 C1。
Update Client Model (C1):客户端使用接收到的梯度继续反向传播并更新本地模型 C1 的参数,数据始终未离开本地。
Update Server Model (S1):服务器使用梯度更新自己持有的模型参数 S1。
配置方式:
- 标准拆分学习 (Vanilla Split Learning / No Peek): 如上所述,客户端处理一部分,服务器处理另一部分,标签在服务器端。
- U型拆分学习 (U-shaped Split Learning): 在某些配置中,标签可能仍在客户端,服务器完成其中间部分的计算后,会将结果再传回客户端,由客户端完成最后几层和损失计算。这可以进一步增强隐私性,因为服务器甚至看不到最终的预测和标签。
- 多客户端参与:
- 顺序执行: 多个客户端轮流与服务器进行上述训练流程。
- 并行执行(需要协调): 如果服务器端模型设计得当(例如,可以并行处理来自不同客户端的激活值),或者有多个服务器端模型实例。
优点:
- 隐私保护: 原始数据保留在客户端本地,不直接共享,只传输中间的激活值和梯度。这通常比直接传输原始数据更安全,尽管激活值仍可能泄露一些信息(后续有研究关注如何保护激活值)。
- 降低客户端计算负担: 客户端只需要计算模型的前几层,这对于计算资源有限的设备(如物联网设备、移动电话)非常友好。大部分计算密集型任务由服务器承担。
- 减少通信开销(相对于某些联邦学习): 传输的是激活值和其梯度,其维度可能远小于原始数据或完整的模型参数(尤其是在联邦学习中需要频繁传输整个模型或其更新的场景)。
- 模型异构性: 服务器端模型可以非常庞大和复杂,而客户端模型可以保持简单。
缺点:
- 顺序依赖性: 在标准的客户端-服务器拆分学习中,服务器必须等待客户端完成其前向传播,客户端也必须等待服务器完成其前向和反向传播并传回梯度。这在高延迟网络或大量客户端轮流参与时,效率较低。
- 隐私泄露风险依然存在: 尽管原始数据不共享,但中间的激活值和梯度仍可能被恶意服务器或客户端用于推断原始数据。需要额外的隐私增强技术(如差分隐私、同态加密)来进一步加固。
- 资源利用不均衡: 客户端可能大部分时间处于空闲等待状态。
- 标签的可用性: 损失计算需要标签。如果标签也在客户端,并且不希望发送给服务器,就需要采用U型拆分或其他更复杂的配置。
应用场景:
- 医疗健康: 医院(客户端)可以在本地处理患者数据的前几层模型,将激活值发送给拥有强大计算能力和复杂模型的远程服务器进行进一步分析,而无需共享原始病历。
- 金融服务: 银行可以在本地设备上运行部分欺诈检测模型,将中间结果发送给中央服务器。
- 物联网 (IoT): 资源受限的IoT设备可以执行轻量级的特征提取,将结果上传进行更复杂的分析。
- 边缘计算: 将部分计算卸载到边缘节点。
图神经网络拆分学习 (Split Learning for Graph Neural Networks / SplitGNN)
核心思想:将拆分学习的思想应用于图神经网络 (GNN) 的训练,以在保护图数据隐私的同时,利用多方数据或减轻客户端计算负担。
图神经网络在处理图结构数据(如社交网络、分子结构、知识图谱)方面表现出色。然而,图数据往往包含敏感信息(节点特征、连接关系)。直接共享图数据进行GNN训练存在隐私风险。
面临的挑战:
- 图结构的复杂性: GNN的计算依赖于节点的特征以及节点间的连接关系(邻接矩阵或边列表)。如何拆分模型并有效地处理图的局部结构和消息传递是关键。
- 数据划分:
- 节点级拆分?边级拆分?子图拆分? 如何将图数据分布在不同参与方,并进行有效的协同GNN训练。
- 跨参与方的边: 如果图的边连接了不同参与方持有的节点,如何处理这些跨域边的消息传递是个难题。
- 隐私保护: 除了节点特征,图的拓扑结构本身也可能泄露隐私。
SplitGNN 的可能实现方式 (概念性):
目前对 “SplitGNN” 的研究不如标准拆分学习或联邦图神经网络成熟和标准化,但其核心思想是将GNN的计算过程在客户端和服务器之间进行切分。以下是一些可能的思路:
-
基于标准拆分学习的扩展:
- 客户端负责局部特征提取和聚合:
- 客户端拥有其本地的节点子图(或整个图的一部分节点及其一阶邻居)。
- GNN模型的前几层(例如,几轮消息传递层)在客户端上运行。客户端计算其节点经过几轮聚合后的嵌入表示(激活值)。
- 这些节点嵌入(激活值)被发送到服务器。
- 服务器负责更深层次的聚合或特定任务:
- 服务器接收来自一个或多个客户端的节点嵌入。
- 服务器端的GNN模型可以对这些嵌入进行进一步的聚合(如果客户端只发送了部分子图的嵌入,服务器可能需要处理节点间的连接关系以进行全局聚合),或者直接将这些嵌入用于下游任务(如节点分类、链接预测的最后几层)。
- 损失计算和梯度反向传播过程与标准拆分学习类似,服务器将关于客户端发送的嵌入的梯度传回。
- 客户端负责局部特征提取和聚合:
-
针对图结构特点的拆分:
- 服务器存储全局图结构,客户端拥有节点特征: 客户端只发送其节点特征经过初始转换后的结果,服务器利用全局图结构信息进行GNN的聚合操作。这种方式更接近某些类型的纵向联邦图神经网络。
- 场景一:一个大图分布在多个客户端(类似横向划分但有图结构)
- 每个客户端持有一部分节点及其相关的特征和边。
- 客户端模型可以包含GNN层,处理本地子图,并将边界节点(连接到其他客户端子图的节点)的嵌入或“割边”信息(cut-edge representations)发送到服务器。
- 服务器负责整合这些来自不同子图的信息,可能通过一个更高层次的GNN或特定机制来聚合,并协调训练。
- 场景二:多个独立的图,但任务相关(更像标准的HFL应用于GNN)
- 每个客户端有一个独立的图数据。
- 大家训练一个相同结构的GNN模型。客户端在本地图上训练GNN,然后将GNN模型参数(或其更新)发送给服务器进行聚合(这是联邦图神经网络的思路,但也可以结合拆分学习,比如客户端只训练GNN的浅层部分,服务器聚合后再分发)。
与联邦图神经网络 (Federated Graph Neural Networks, FGNN) 的关系:
- FGNN 更侧重于模型参数的聚合: 类似于横向联邦学习,多个客户端各自拥有图数据(可以是独立的图,也可以是同一个大图的子图),在本地训练完整的(或部分的)GNN模型,然后服务器聚合这些模型的参数。数据不离开本地。
- SplitGNN 更侧重于模型计算过程的拆分: 将单个GNN模型的计算任务链式地分布在客户端和服务器之间。
- 两者可以结合:例如,在一个联邦学习的框架下,每个客户端内部的GNN训练过程可能也采用了拆分学习的模式(例如,客户端的GNN一部分在边缘设备,一部分在本地更强的计算节点)。
优点(理论上):
- 继承拆分学习的优点:保护节点特征隐私(原始特征不直接发送),减轻客户端计算负担。
- 可能处理大规模图:将计算分散,使得处理单机难以容纳的巨大图成为可能。
挑战和待研究点:
- 有效处理图拓扑: 如何在拆分后仍能有效利用图的连接信息进行消息传递和表征学习。
- 割边 (cut-edges) 的处理: 当图被切分时,连接不同部分的边的信息如何有效地传递和利用。
- 隐私与效用的权衡: 发送的节点嵌入(激活值)仍可能泄露关于节点及其邻域的信息。如何设计既保护隐私又保证模型性能的嵌入和梯度是关键。
- 通信开销: 节点嵌入的维度和数量可能仍然很大。
- 标准化和框架: 相对于标准拆分学习,SplitGNN 的研究和成熟框架还较少。
应用场景(潜在):
- 分布式社交网络分析: 用户数据和连接在本地,只发送匿名化的嵌入。
- 跨机构的药物发现或分子属性预测: 每个机构有自己的分子图数据。
- 智能交通系统中的路网分析: 不同区域的交通传感器数据构成图。
混合联邦学习 (Hybrid Federated Learning)
核心思想:结合不同联邦学习范式或将联邦学习与其他技术(如拆分学习、中心化训练、差分隐私等)相融合,以适应更复杂的数据分布、隐私需求和系统约束。
标准的联邦学习(横向HFL、纵向VFL)有其特定的数据划分假设。但在现实世界中,数据分布往往更加复杂,单一的联邦学习范式可能无法满足所有需求。混合联邦学习因此而生。
常见的混合模式:
-
横向与纵向的混合 (Hybrid FL combining HFL and VFL):
- 场景: 设想一个多机构协作的场景,其中某些机构之间的数据是横向划分的(特征相同,样本不同),而另一些机构之间或与某个中心方的数据是纵向划分的(样本部分重叠,特征不同)。
- 方法: 可能需要一个分阶段或分层次的联邦学习流程。例如,先在一组横向参与方之间进行横向联邦学习得到一个初步模型或特征表示,然后这个结果再作为一部分特征参与到与其他方的纵向联邦学习中。
- 例子: 几家地方银行(横向)先联合训练一个本地客户行为模型,然后这个模型的输出(或部分参数)与一个拥有不同特征维度(如信用评分)的中央征信机构进行纵向联邦学习,以服务于这些银行共同的客户子集。
-
联邦学习与拆分学习的混合 (FL + SL):
- 场景: 在一个联邦学习的设置中,每个参与的客户端可能计算能力非常有限,无法在本地完整地训练一个复杂的模型(即使是HFL中的本地模型)。
- 方法:
- 客户端内部使用拆分学习: 每个联邦学习的客户端将其本地模型训练过程进一步拆分,一部分在极度资源受限的设备(如传感器)上运行,计算激活值,然后发送给本地一个稍强的边缘服务器或网关完成该客户端的“本地训练”和梯度计算,之后再参与联邦学习的参数聚合。
- 服务器端采用拆分学习: 在联邦学习中,服务器通常只负责聚合。但如果聚合后的模型需要进一步处理或与一个服务器独有的模型部分结合,那么服务器端的行为也可能涉及到拆分学习的后半部分。
- 例子: 一群物联网设备(联邦学习的客户端)收集数据,每个设备只运行模型的第一层(拆分学习的客户端部分),将激活值发送给一个边缘服务器。边缘服务器完成剩余的本地模型训练(拆分学习的服务器部分),并将模型更新发送给中央联邦学习服务器进行聚合。
-
联邦学习与中心化训练的混合:
- 场景: 部分数据由于隐私性要求不高或已获得同意,可以集中存储和训练;而另一部分高度敏感的数据则必须保留在本地进行联邦学习。
- 方法:
- 模型融合: 用中心化数据训练一个模型,用联邦学习方式在分布式数据上训练另一个模型(或微调中心化模型),然后将两个模型进行集成(例如,模型平均、知识蒸馏、集成学习)。
- 迁移学习: 在中心化数据上预训练一个强大的基础模型,然后通过联邦学习的方式在分布式数据上对这个模型进行微调。
- 例子: 一个大型科技公司在其公开数据集上训练了一个通用的图像识别模型(中心化训练),然后与多个企业客户合作,通过联邦学习的方式在客户各自的私有、特定领域图像数据上对这个模型进行个性化微调,以适应特定需求,同时不泄露客户数据。
-
联邦学习与隐私增强技术的深度融合:
- 虽然联邦学习本身提供了基础的隐私保护(数据不原始共享),但模型更新或梯度仍可能泄露信息。混合联邦学习也指将差分隐私 (DP)、同态加密 (HE)、安全多方计算 (MPC) 等技术更紧密地集成到联邦学习的各个环节(本地训练、梯度上传、服务器聚合)。
- 例子: 在横向联邦学习中,客户端在上传本地模型更新前,先对梯度添加满足差分隐私的噪声;或者服务器使用同态加密来聚合加密后的模型更新,解密后得到聚合结果,全程不接触明文梯度。
-
分层联邦学习 (Hierarchical Federated Learning):
- 场景: 参与联邦学习的客户端具有层级结构,例如,边缘设备 -> 边缘服务器 -> 云服务器。
- 方法: 模型聚合在不同层级上进行。边缘设备先进行一轮局部聚合到边缘服务器,边缘服务器再将聚合结果上传到云服务器进行全局聚合。这可以减少直接与云服务器通信的客户端数量,提高通信效率和可扩展性。
- 这本身可以看作一种特殊的联邦学习组织形式,但当不同层级的聚合策略或参与的数据特征不同时,也体现了混合的思想。
优点:
- 灵活性和适应性更强: 能够处理更复杂和异构的数据分布及系统环境。
- 潜在的性能提升: 通过结合不同方法的优势,可能在模型精度、训练效率或隐私保护级别上获得更好的效果。
- 更广泛的应用场景: 打破了单一联邦学习范式的局限,使其能应用于更多现实问题。
挑战:
- 系统设计复杂度高: 设计和实现混合联邦学习系统需要仔细考虑不同组件的交互、数据流、同步机制和安全保障。
- 理论分析困难: 混合模式下的收敛性、隐私保证、公平性等理论分析比单一模式更具挑战。
- 标准化和互操作性: 不同混合方案的组件可能难以标准化和互通。
应用场景:
- 智慧城市: 不同部门(交通、能源、公共安全)的数据特征和隐私级别各不相同,可能需要混合联邦学习来进行城市级的智能决策。
- 大规模工业物联网: 海量设备(可能采用拆分学习减轻负担)的数据通过边缘节点(进行局部联邦聚合)最终汇总到云端。
- 多方参与的复杂金融建模: 结合了不同机构的数据孤岛(横向、纵向并存)和隐私需求。
总结:
- 拆分学习 是一种通过按层切分模型进行协作训练的技术,主要优势在于降低客户端计算负担和保护原始数据。
- 图神经网络拆分学习 是将拆分学习应用于GNN训练的探索,旨在隐私保护地处理图数据,但面临图结构复杂性和割边处理等挑战。
- 混合联邦学习 则是为了应对现实世界中复杂多变的数据和系统环境,将不同联邦学习范式或联邦学习与其他技术(如拆分学习、中心化训练、强隐私技术)相融合的灵活框架。
代码案例
- 伪代码: 这不是可以直接运行的完整代码,而是为了阐释核心逻辑。案例旨在阐明这三种学习范式背后的核心机制和数据流。现实中你需要考虑更多的工程细节、安全性和效率优化。
- 简化处理: 实际系统会涉及更复杂的通信、加密、同步、错误处理等。这里我们主要关注数据和模型的交互流程与核心概念。
- PyTorch 风格: 代码会采用 PyTorch 的常用模式,如
torch.nn.Module,torch.optim等。
1. 拆分学习 (Split Learning - SL) 伪代码
场景: 一个客户端和一个服务器协作训练一个深度学习模型。模型被切分为两部分。
import torch
import torch.nn as nn
import torch.optim as optim# --- 定义模型结构 ---
# 假设模型是一个简单的三层网络: Linear1 -> ReLU -> Linear2 -> ReLU -> Linear3
# 客户端拥有 Linear1 -> ReLU
# 服务器拥有 Linear2 -> ReLU -> Linear3class ClientModelPart(nn.Module):def __init__(self, input_dim, hidden_dim_client):super(ClientModelPart, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim_client)self.relu1 = nn.ReLU()print(f"客户端模型部分: Linear({input_dim}, {hidden_dim_client}) -> ReLU")def forward(self, x):x = self.fc1(x)x = self.relu1(x)return xclass ServerModelPart(nn.Module):def __init__(self, hidden_dim_client, hidden_dim_server, output_dim):super(ServerModelPart, self).__init__()self.fc2 = nn.Linear(hidden_dim_client, hidden_dim_server)self.relu2 = nn.ReLU()self.fc3 = nn.Linear(hidden_dim_server, output_dim)print(f"服务器模型部分: Linear({hidden_dim_client}, {hidden_dim_server}) -> ReLU -> Linear({hidden_dim_server}, {output_dim})")def forward(self, x):x = self.fc2(x)x = self.relu2(x)x = self.fc3(x)return x# --- 模拟客户端 ---
class SplitLearningClient:def __init__(self, input_dim, client_hidden_dim, learning_rate):self.model_part = ClientModelPart(input_dim, client_hidden_dim)self.optimizer = optim.Adam(self.model_part.parameters(), lr=learning_rate)self.activations_from_client = None # 保存前向传播的输出,用于反向传播def forward_pass(self, data_batch):self.model_part.train()self.optimizer.zero_grad()self.activations_from_client = self.model_part(data_batch)# 将 self.activations_from_client.detach().requires_grad_(True) 发送给服务器# .detach() 是为了防止服务器的梯度直接传到客户端的原始计算图,# .requires_grad_(True) 是因为服务器需要计算关于这些激活值的梯度return self.activations_from_client.detach().requires_grad_(True)def backward_pass(self, gradients_on_activations):# 客户端接收到服务器传回的关于其激活值的梯度self.activations_from_client.backward(gradients_on_activations)self.optimizer.step()print("客户端:模型部分已更新。")# --- 模拟服务器 ---
class SplitLearningServer:def __init__(self, client_hidden_dim, server_hidden_dim, output_dim, learning_rate):self.model_part = ServerModelPart(client_hidden_dim, server_hidden_dim, output_dim)self.optimizer = optim.Adam(self.model_part.parameters(), lr=learning_rate)self.criterion = nn.MSELoss() # 假设是回归任务self.received_activations_for_grad = None # 保存用于计算梯度的激活值副本def process_batch(self, activations_from_client, labels_batch):self.model_part.train()self.optimizer.zero_grad()# 保存激活值副本,用于计算回传给客户端的梯度self.received_activations_for_grad = activations_from_client# 服务器端前向传播predictions = self.model_part(activations_from_client)# 计算损失loss = self.criterion(predictions, labels_batch)print(f"服务器:损失值为 {loss.item()}")# 服务器端反向传播 (计算服务器模型参数的梯度)loss.backward()self.optimizer.step()# 获取回传给客户端的梯度 (关于客户端激活值的梯度)gradients_for_client = self.received_activations_for_grad.grad.clone()print("服务器:模型部分已更新,准备将激活值的梯度传回客户端。")return gradients_for_client# --- 拆分学习伪代码执行流程 ---
if __name__ == "__main__":# 0. 定义参数INPUT_DIM = 10CLIENT_HIDDEN_DIM = 20SERVER_HIDDEN_DIM = 15OUTPUT_DIM = 1LEARNING_RATE = 0.01NUM_BATCHES = 50 # 模拟训练的批次数BATCH_SIZE = 32# 1. 初始化客户端和服务器client = SplitLearningClient(INPUT_DIM, CLIENT_HIDDEN_DIM, LEARNING_RATE)server = SplitLearningServer(CLIENT_HIDDEN_DIM, SERVER_HIDDEN_DIM, OUTPUT_DIM, LEARNING_RATE)# 2. 模拟训练迭代for batch_idx in range(NUM_BATCHES):print(f"\n--- 训练批次 {batch_idx + 1}/{NUM_BATCHES} ---")# 2.1 准备数据 (客户端拥有数据和标签,但只将数据用于其模型部分)# 实际中,标签通常在服务器端使用或由客户端安全提供给服务器local_data = torch.randn(BATCH_SIZE, INPUT_DIM)local_labels = torch.randn(BATCH_SIZE, OUTPUT_DIM) # 假设服务器能拿到标签# 2.2 客户端前向传播,并将激活值发送给服务器activations_to_server = client.forward_pass(local_data)print("客户端:已计算激活值并发送给服务器。")# 2.3 服务器处理激活值,计算损失,反向传播,并获取给客户端的梯度# (激活值 activations_to_server 从客户端 "发送" 到服务器)# (标签 local_labels 也 "提供" 给服务器)gradients_for_client_activations = server.process_batch(activations_to_server, local_labels)# (梯度 gradients_for_client_activations 从服务器 "发送" 回客户端)# 2.4 客户端接收梯度并完成其反向传播client.backward_pass(gradients_for_client_activations)print("\n--- 拆分学习训练完成 (模拟) ---")
2. 图神经网络拆分学习 (SplitGNN) 伪代码
场景: 客户端拥有一张图(节点特征和边结构),GNN模型被拆分。客户端执行GNN的前几层,将得到的节点嵌入(激活值)发送给服务器,服务器完成后续处理和预测。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch_geometric.nn import GCNConv # 需要安装 PyTorch Geometric# --- 定义GNN模型部分 ---
# 假设客户端执行一层GCN,服务器在客户端输出的嵌入基础上再执行一层GCN和分类层class ClientGNNPart(nn.Module):def __init__(self, in_channels, client_out_channels):super(ClientGNNPart, self).__init__()self.conv1 = GCNConv(in_channels, client_out_channels)print(f"客户端GNN模型部分: GCNConv({in_channels}, {client_out_channels})")def forward(self, x, edge_index):x = self.conv1(x, edge_index)x = F.relu(x)# x = F.dropout(x, training=self.training) # 可选return xclass ServerGNNPart(nn.Module):def __init__(self, client_out_channels, server_hidden_channels, num_classes):super(ServerGNNPart, self).__init__()# 假设服务器可能也有一层GCN(如果它也接收边信息并进行图操作)# 为简化,这里假设服务器直接在收到的嵌入上做分类,或者只做非图操作# 如果服务器也做GCN,它需要 client_out_channels 作为输入,还需要 edge_indexself.fc_server = nn.Linear(client_out_channels, num_classes) # 直接用作分类器print(f"服务器模型部分 (简化): Linear({client_out_channels}, {num_classes})")# 如果服务器有GCN层:# self.conv2_server = GCNConv(client_out_channels, server_hidden_channels)# self.classifier_server = nn.Linear(server_hidden_channels, num_classes)def forward(self, x_from_client): #, edge_index_on_server=None):# 简化版:服务器直接对客户端传来的节点嵌入进行分类x = self.fc_server(x_from_client)return F.log_softmax(x, dim=1) # 假设是节点分类# 如果服务器有GCN层:# x = self.conv2_server(x_from_client, edge_index_on_server)# x = F.relu(x)# x = self.classifier_server(x)# return F.log_softmax(x, dim=1)# --- 模拟客户端 ---
class SplitGNNClient:def __init__(self, in_channels, client_out_channels, learning_rate):self.model_part = ClientGNNPart(in_channels, client_out_channels)self.optimizer = optim.Adam(self.model_part.parameters(), lr=learning_rate)self.node_embeddings_from_client = None # 保存客户端GNN的输出# 模拟客户端的图数据# 通常是一张图,这里简化为单个图的节点特征和边索引self.num_nodes = 100self.node_features = torch.randn(self.num_nodes, in_channels) # (N, F_in)# 稀疏的边索引 (2, num_edges),随机生成一些边用于演示self.edge_index = torch.randint(0, self.num_nodes, (2, self.num_nodes * 2)) # 示意def forward_pass(self):self.model_part.train()self.optimizer.zero_grad()self.node_embeddings_from_client = self.model_part(self.node_features, self.edge_index)# 将 self.node_embeddings_from_client.detach().requires_grad_(True) 和可能的 edge_index 发送给服务器return self.node_embeddings_from_client.detach().requires_grad_(True) #, self.edge_index (如果服务器需要)def backward_pass(self, gradients_on_embeddings):self.node_embeddings_from_client.backward(gradients_on_embeddings)self.optimizer.step()print("客户端 (SplitGNN):模型部分已更新。")# --- 模拟服务器 ---
class SplitGNNServer:def __init__(self, client_out_channels, server_hidden_channels, num_classes, learning_rate):self.model_part = ServerGNNPart(client_out_channels, server_hidden_channels, num_classes)self.optimizer = optim.Adam(self.model_part.parameters(), lr=learning_rate)self.criterion = nn.NLLLoss() # 对应 log_softmaxself.received_embeddings_for_grad = Nonedef process_graph_embeddings(self, node_embeddings_from_client, graph_labels): #, edge_index_from_client=None):self.model_part.train()self.optimizer.zero_grad()self.received_embeddings_for_grad = node_embeddings_from_client# 服务器端前向传播# 如果服务器GNNPart需要edge_index, 则用 edge_index_from_clientpredictions = self.model_part(node_embeddings_from_client) #, edge_index_from_client)# 计算损失 (假设是节点分类任务,需要对所有节点或特定节点计算)# 假设我们有一部分带标签的节点用于训练 (半监督)train_mask = torch.rand(node_embeddings_from_client.size(0)) > 0.7 # 随机选择一些节点训练loss = self.criterion(predictions[train_mask], graph_labels[train_mask])print(f"服务器 (SplitGNN):损失值为 {loss.item()}")loss.backward()self.optimizer.step()gradients_for_client_embeddings = self.received_embeddings_for_grad.grad.clone()print("服务器 (SplitGNN):模型部分已更新,准备将嵌入的梯度传回客户端。")return gradients_for_client_embeddings# --- SplitGNN 伪代码执行流程 ---
if __name__ == "__main__":# 0. 定义参数NODE_FEATURE_DIM = 16CLIENT_GNN_OUT_CHANNELS = 32SERVER_GNN_HIDDEN_CHANNELS = 24 # 如果服务器有GCN层NUM_CLASSES = 7 # 图节点分类的类别数LEARNING_RATE_GNN = 0.005NUM_TRAIN_STEPS_GNN = 30# 1. 初始化客户端和服务器client_gnn = SplitGNNClient(NODE_FEATURE_DIM, CLIENT_GNN_OUT_CHANNELS, LEARNING_RATE_GNN)server_gnn = SplitGNNServer(CLIENT_GNN_OUT_CHANNELS, SERVER_GNN_HIDDEN_CHANNELS, NUM_CLASSES, LEARNING_RATE_GNN)# 模拟标签 (假设服务器端可知或由客户端提供)# 假设是节点分类任务true_node_labels = torch.randint(0, NUM_CLASSES, (client_gnn.num_nodes,))# 2. 模拟训练迭代for step in range(NUM_TRAIN_STEPS_GNN):print(f"\n--- SplitGNN 训练步骤 {step + 1}/{NUM_TRAIN_STEPS_GNN} ---")# 2.1 客户端进行其GNN部分的前向传播node_embeddings_to_server = client_gnn.forward_pass()# edge_index_to_server = client_gnn.edge_index # 如果服务器需要print("客户端 (SplitGNN):已计算节点嵌入并发送给服务器。")# 2.2 服务器处理节点嵌入,计算损失,反向传播,并获取给客户端的梯度gradients_for_client = server_gnn.process_graph_embeddings(node_embeddings_to_server,true_node_labels# edge_index_to_server # 如果服务器需要)# 2.3 客户端接收梯度并完成其反向传播client_gnn.backward_pass(gradients_for_client)print("\n--- 图神经网络拆分学习训练完成 (模拟) ---")
3. 混合联邦学习 (Hybrid Federated Learning) 伪代码
场景: 此处我们模拟一个 分层联邦学习 (Hierarchical Federated Learning) 的场景,作为混合联邦学习的一种。客户端将模型更新发送给边缘服务器,边缘服务器聚合后再将聚合结果发送给中央服务器进行最终聚合。
import torch
import torch.nn as nn
import torch.optim as optim
from typing import List, Dict# --- 定义共享模型结构 (所有节点使用相同结构) ---
class SimpleNet(nn.Module):def __init__(self, input_dim=5, output_dim=2):super(SimpleNet, self).__init__()self.fc = nn.Linear(input_dim, output_dim)def forward(self, x):return self.fc(x)# --- 模拟最底层的客户端节点 ---
class ClientDevice:def __init__(self, client_id: str, learning_rate: float, input_dim: int, output_dim: int):self.client_id = client_idself.model = SimpleNet(input_dim, output_dim)self.optimizer = optim.SGD(self.model.parameters(), lr=learning_rate)self.criterion = nn.CrossEntropyLoss() # 假设分类任务# 模拟本地数据self.local_data = [(torch.randn(1, input_dim), torch.randint(0, output_dim, (1,)).squeeze()) for _ in range(20)] # 20个样本def set_model_weights(self, weights: Dict):self.model.load_state_dict(weights)def local_train(self, epochs: int) -> Dict:self.model.train()for epoch in range(epochs):for data, target in self.local_data:self.optimizer.zero_grad()output = self.model(data)loss = self.criterion(output, target.unsqueeze(0)) # CrossEntropyLoss期望target为 (N)loss.backward()self.optimizer.step()print(f"客户端 {self.client_id}: 本地训练完成。")return self.model.state_dict()# --- 模拟边缘服务器 ---
class EdgeServer:def __init__(self, edge_id: str, input_dim: int, output_dim: int):self.edge_id = edge_idself.edge_model = SimpleNet(input_dim, output_dim) # 边缘服务器也维护一个模型状态self.clients_under_edge: List[ClientDevice] = []print(f"边缘服务器 {edge_id} 已创建。")def add_client(self, client: ClientDevice):self.clients_under_edge.append(client)client.set_model_weights(self.edge_model.state_dict()) # 新加入的客户端同步边缘模型def aggregate_from_clients(self) -> Dict:if not self.clients_under_edge:return self.edge_model.state_dict() # 如果没有客户端,返回当前模型client_weights_list = []client_data_sizes = [] # 用于加权平均 (简化:此处假设数据量相同)for client in self.clients_under_edge:# 1. (可选) 将当前边缘模型分发给客户端 (或客户端在上一轮已获得)# client.set_model_weights(self.edge_model.state_dict())# 2. 客户端本地训练weights = client.local_train(epochs=1) # 假设每个客户端本地训练1轮client_weights_list.append(weights)client_data_sizes.append(len(client.local_data)) # 实际应为参与训练的数据量# 3. 聚合客户端模型 (FedAvg)if not client_weights_list: return self.edge_model.state_dict()aggregated_weights = self.edge_model.state_dict()total_data_size = sum(client_data_sizes) if sum(client_data_sizes) > 0 else 1for key in aggregated_weights.keys():aggregated_weights[key] = torch.zeros_like(aggregated_weights[key])for i, weights in enumerate(client_weights_list):weight_factor = client_data_sizes[i] / total_data_sizefor key in weights.keys():aggregated_weights[key] += weights[key] * weight_factorself.edge_model.load_state_dict(aggregated_weights)print(f"边缘服务器 {self.edge_id}: 已从其客户端聚合模型。")return aggregated_weightsdef set_model_weights_from_central(self, weights: Dict):self.edge_model.load_state_dict(weights)# 将中心服务器更新的模型分发给其下的所有客户端for client in self.clients_under_edge:client.set_model_weights(weights)print(f"边缘服务器 {self.edge_id}: 模型已从中心服务器更新并下发至客户端。")# --- 模拟中央服务器 ---
class CentralCloudServer:def __init__(self, input_dim: int, output_dim: int):self.global_model = SimpleNet(input_dim, output_dim)self.edge_servers_under_cloud: List[EdgeServer] = []print("中央云服务器已创建。")def add_edge_server(self, edge_server: EdgeServer):self.edge_servers_under_cloud.append(edge_server)edge_server.set_model_weights_from_central(self.global_model.state_dict()) # 新加入的边缘同步全局模型def aggregate_from_edges(self) -> Dict:if not self.edge_servers_under_cloud:return self.global_model.state_dict()edge_weights_list = []edge_client_counts = [] # 用于加权平均,基于每个边缘服务器下的客户端总数据量 (简化:用客户端数量)for edge in self.edge_servers_under_cloud:# 1. 边缘服务器先从其客户端聚合weights = edge.aggregate_from_clients()edge_weights_list.append(weights)edge_client_counts.append(sum(len(c.local_data) for c in edge.clients_under_edge))# 2. 聚合边缘服务器的模型 (FedAvg)if not edge_weights_list: return self.global_model.state_dict()aggregated_global_weights = self.global_model.state_dict()total_edge_data_size = sum(edge_client_counts) if sum(edge_client_counts) > 0 else 1for key in aggregated_global_weights.keys():aggregated_global_weights[key] = torch.zeros_like(aggregated_global_weights[key])for i, weights in enumerate(edge_weights_list):weight_factor = edge_client_counts[i] / total_edge_data_sizefor key in weights.keys():aggregated_global_weights[key] += weights[key] * weight_factorself.global_model.load_state_dict(aggregated_global_weights)print("中央云服务器: 已从边缘服务器聚合得到新的全局模型。")return aggregated_global_weightsdef distribute_to_edges(self):global_weights = self.global_model.state_dict()for edge in self.edge_servers_under_cloud:edge.set_model_weights_from_central(global_weights)print("中央云服务器: 已将新全局模型分发至所有边缘服务器。")# --- 混合联邦学习 (分层) 伪代码执行流程 ---
if __name__ == "__main__":# 0. 定义参数INPUT_DIM_H = 5OUTPUT_DIM_H = 2CLIENT_LR = 0.1NUM_GLOBAL_ROUNDS = 5# 1. 初始化中央服务器central_server = CentralCloudServer(INPUT_DIM_H, OUTPUT_DIM_H)# 2. 初始化边缘服务器并添加到中央服务器edge1 = EdgeServer("Edge1", INPUT_DIM_H, OUTPUT_DIM_H)edge2 = EdgeServer("Edge2", INPUT_DIM_H, OUTPUT_DIM_H)central_server.add_edge_server(edge1)central_server.add_edge_server(edge2)# 3. 初始化客户端并添加到对应的边缘服务器client1_edge1 = ClientDevice("C1_E1", CLIENT_LR, INPUT_DIM_H, OUTPUT_DIM_H)client2_edge1 = ClientDevice("C2_E1", CLIENT_LR, INPUT_DIM_H, OUTPUT_DIM_H)edge1.add_client(client1_edge1)edge1.add_client(client2_edge1)client1_edge2 = ClientDevice("C1_E2", CLIENT_LR, INPUT_DIM_H, OUTPUT_DIM_H)client2_edge2 = ClientDevice("C2_E2", CLIENT_LR, INPUT_DIM_H, OUTPUT_DIM_H)client3_edge2 = ClientDevice("C3_E2", CLIENT_LR, INPUT_DIM_H, OUTPUT_DIM_H)edge2.add_client(client1_edge2)edge2.add_client(client2_edge2)edge2.add_client(client3_edge2)# 4. 模拟分层联邦学习的全局轮次for round_num in range(NUM_GLOBAL_ROUNDS):print(f"\n--- 全局混合联邦学习轮次 {round_num + 1}/{NUM_GLOBAL_ROUNDS} ---")# 4.1 中央服务器从边缘服务器聚合 (边缘服务器内部会先从其客户端聚合)central_server.aggregate_from_edges()# 4.2 中央服务器将更新后的全局模型分发给边缘服务器 (边缘服务器再分发给其客户端)central_server.distribute_to_edges()print("\n--- 混合 (分层) 联邦学习训练完成 (模拟) ---")final_global_model_params = central_server.global_model.state_dict()# 这个 final_global_model_params 就是最终训练得到的全局模型参数
相关文章:

深入浅出拆分学习,图神经网络拆分学习,混合联邦学习
深入浅出解析拆分学习(Split Learning)、图神经网络拆分学习(Split Learning for Graph Neural Networks)以及混合联邦学习(Hybrid Federated Learning),这三者都体现了在分布式数据环境下进行机…...

DDD领域驱动介绍
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、(架构篇)清华大学出版社签约作家、Java领域优质创作者、CSDN博客专家、…...

ubuntu22鼠键失灵恢复记录笔记chatgpt解决
ChatGPT 说: 你提到“Ubuntu 22 鼠键失灵”,这个问题可能涉及以下几方面: 🧭 先确认问题 是鼠标问题还是键盘问题,还是触控板? “鼠键”一般理解为“鼠标键”,请确认你是指鼠标左键/右键失灵&a…...
)
在服务器上安装AlphaFold2遇到的问题(1)
犯了错误,轻信deepseek,误将cuDNN8.9.7删掉 [rootlocalhost ~]# cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 8 #define CUDNN_MINOR 9 #define CUDNN_PATCHLEVEL 7 -- #define CUDNN_VERSION (CUDNN_MA…...

ch10 题目参考思路
ch10 - 最小生成树 有线通讯网 知识点:Prim 算法思路: 该题要求对 n 座城市铺设 n - 1 条光缆,并要求所有城市连通,那本质上是一棵树,又要求铺设光缆的费用最低,即要求选取的 n - 1 条光缆的长度最小&…...

Hudi、Iceberg 、 Paimon 数据湖选型对比
Hudi、Iceberg 和 Paimon 是当前数据湖领域的三大主流开源框架,均致力于解决数据湖场景下的增量更新、事务支持、元数据管理、流批统一等核心问题,但设计理念和适用场景存在差异。以下从技术特性、适用场景和选型建议三方面对比分析: 一、核心技术特性对比 维度HudiIceberg…...
:小行星轨迹预测思路)
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路,详细内容见文末名片 第二阶段问题 1 分析 问题起源与相关性:为了更全面地评估近地小行星对地球的潜在威胁,需要对其轨道进行长期预测。三个月内的观测数据为…...

信息安全基础知识
信息系统 信息系统能进行(数据)的采集、传输、存储、加工,使用和维护的计算机应用系统 例如:办公自动化、CRM/ERP、HRM、12306火车订票系统等。 信息安全 信息安全是指保护信息系统中的计算机硬件、软件、数据不因偶然或者恶意…...

UE RPG游戏开发练手 第二十六课 普通攻击1
UE RPG游戏开发练手 第二十六课 普通攻击1 1.定义攻击的InputTag MyGameplayTags.h代码 RPGGAMETEST_API UE_DECLARE_GAMEPLAY_TAG_EXTERN(InputTag_LightAttack_Axe);MyGameplayTag.cpp代码 UE_DEFINE_GAMEPLAY_TAG(InputTag_LightAttack_Axe, "InputTag.LightAttack.Ax…...

SAP ABAP 程序中归档数据读取方式
上一篇文章记录了字段目录,归档信息结构,这篇文章记录如何通过字段目录,归档信息结构,归档对象读取归档数据。未归档数据是从数据库表直接抽取,本样例是通过归档读取方式复写sql。 发布时间:2025.05.16 示…...

每周资讯 | 腾讯Q1财报:国内游戏业务收入同比增长24%;Tripledot 8亿美元收购AppLovin游戏业务
内容速览: 广州“服务贸易和数字贸易22条”助推游戏产业发展Tripledot Studios 8亿美元收购AppLovin游戏业务苹果紧急申请暂停执行AppStore新规4月中国手游出海收入下载榜,点点互动《Kingshot》收入激增 腾讯Q1财报:国内游戏业务收入同比增长…...
)
iOS SwiftUI的具体运用实例(SwiftUI库的运用)
最近接触到一个 SwiftUI的第三方框架,它非常的好用。以下是 具体运用实例,结合其核心功能与开发场景,分多个维度进行详细解析: 一、基础 UI 组件开发 登录界面 SwiftUI 的 VStack、TextField 和 Button 可快速构建用户登录表单。例…...

杰理ac696配置sd卡随机播放
#define FCYCLE_LIST 0 // 列表循环(按顺序播放文件列表) #define FCYCLE_ALL 1 // 全部循环(播放完所有文件后重新开始) #define FCYCLE_ONE 2 // 单曲循环(重复播放当前文件) #define …...

MCP协议的核心机制和交互过程
MCP的核心是JSON-RPC 2.0 MCP使用了 JSON-RPC 2.0 作为client和server端的消息传输。JSON-RPC 2.0是一个用JSON编码的轻量级远程过程调用协议。它的优越性如下: 易读,易调试与编程语言无关,环境无关技术成熟,规范清晰且应用广泛JSON-NPC 2.0定义了request、response、noti…...

论信息系统项目的范围管理
论信息系统项目的范围管理 前言一、规划范围管理,收集需求二、定义范围三、创建工作分解结构四、确认范围五、控制范围 前言 为了应对烟草零售客户数量大幅度增长所带来的问题,切实履行控烟履约的相关要求,同时也为了响应国务院“放管服”政策…...

米勒电容补偿的理解
米勒电容补偿是使运放放大器稳定的重要手法,可以使两级运放的两个极点分离,从而可以得到更好的相位裕度。 Miller 电容补偿的本质是增加一条通路流电流,流电流才是miller效应的本质。给定一个相同的输入,Miller 电容吃掉的电流比…...
)
力扣654题:最大二叉树(递归)
小学生一枚,自学信奥中,没参加培训机构,所以命名不规范、代码不优美是在所难免的,欢迎指正。 标签: 二叉树、递归 语言: C 题目: 给定一个不重复的整数数组 nums 。最大二叉树可以用下面的算…...

Go语言实现生产者-消费者问题的多种方法
Go语言实现生产者-消费者问题的多种方法 生产者-消费者问题是并发编程中的经典问题,涉及多个生产者生成数据,多个消费者消费数据,二者通过缓冲区(队列)进行协调,保证数据的正确传递和同步。本文将从简单到…...
)
深度学习驱动下的目标检测技术:原理、算法与应用创新(二)
三、主流深度学习目标检测算法剖析 3.1 R - CNN 系列算法 3.1.1 R - CNN 算法详解 R - CNN(Region - based Convolutional Neural Networks)是将卷积神经网络(CNN)应用于目标检测领域的开创性算法,其在目标检测发展历…...

提权脚本Powerup命令备忘单
1. 获取与加载 从 GitHub 下载:(New-Object Net.WebClient).DownloadFile("https://raw.githubusercontent.com/PowerShellMafia/PowerSploit/master/Privesc/PowerUp.ps1", "C:\Temp\PowerUp.ps1")本地加载:Import-Module .\Power…...
 在无线接入网络 (RAN) 中的变革性作用)
人工智能 (AI) 在无线接入网络 (RAN) 中的变革性作用
随着电信行业向更智能、更高效的系统迈进,将 AI 集成到 RAN 中已不再是可有可无,而是至关重要。 随着 6G 时代的到来,人工智能 (AI) 有望降低运营成本,并带来更大的盈利机会。AI-RAN 正处于这一变革的前沿,在 RAN 环境…...

从硬件角度理解“Linux下一切皆文件“,详解用户级缓冲区
目录 前言 一、从硬件角度理解"Linux下一切皆文件" 从理解硬件是种“文件”到其他系统资源的抽象 二、缓冲区 1.缓冲区介绍 2.缓冲区的刷新策略 3.用户级缓冲区 这个用户级缓冲区在哪呢? 解释关于fork再加重定向“>”后数据会打印两份的原因 4.内核缓冲…...

Python-感知机以及实现感知机
感知机定义 如果有一个算法,具有1个或者多个入参,但是返回值要么是0,要么是1,那么这个算法就叫做感知机,也就是说,感知机是个算法 感知机有什么用 感知机是用来表示可能性的大小的,我们可以认…...

根据台账批量制作个人表
1. 前期材料准备 1)要有 人员总的信息台账 2)要有 个人明白卡模板 2. 开始操作 1)打开 人员总的信息台账,选择所需要的数据模块; 2)点击插入,选择数据透视表,按流程操作&…...

ohttps开启群晖ssl证书自动更新
开启群晖ssl证书自动更新OHTTPS ohttps是一个免费自动签发ssl证书、管理、部署的项目。 https://ohttps.com 本文举例以ohttps项目自动部署、更新群晖的ssl证书。 部署 签发证书 打开ohttps-证书管理-创建证书-按你实际情况创建证书。创建部署节点 打开Ohttps-部署节点-添加…...

【Elasticsearch】flattened`类型在查询嵌套数组时可能返回不准确结果的情况
好的!为了更清楚地说明flattened类型在查询嵌套数组时可能返回不准确结果的情况,我们可以通过一个具体的例子来展示。这个例子将展示如何在文档中没有完全匹配的嵌套对象时,flattened类型仍然可能返回该文档。 示例文档结构 假设你有以下文…...

【知识点】语义分割任务中有哪些损失函数?
在语义分割任务中,模型需要对图像中的每个像素进行分类。因此,损失函数的设计不仅要关注整体精度,还需要特别注意目标物体的边界区域。以下是一些常用的损失函数及其适用场景,包括数学公式、PyTorch 实现和是否适合处理边界问题。 📌 一、交叉熵损失 Cross-Entropy Loss …...

Node.js 同步加载问题详解:原理、危害与优化策略
文章目录 一、什么是同步加载?二、同步加载的危害场景三、检测同步加载问题四、解决方案与代码优化 一、什么是同步加载? 1.核心概念 在 Node.js 的 CommonJS 模块系统中,require() 是同步操作: // 模块加载会阻塞后续代码执行 …...

linux下tcp/ip网络通信笔记1,
本文章主要为博主在学习网络通信的笔记一个Udp_echo_server,和client的代码实现 1,网络发展,网络协议,意识到网络通信——不同主机的进程间通信, 2,学习如何在应用层调用系统提供的接口进行通信,echo_Udp…...

网络攻防模拟:城市安全 “数字预演”
在当今数字化快速发展的时代,网络安全和城市安全面临着前所未有的挑战。为有效应对这些挑战,利用先进的技术搭建模拟演练平台至关重要。图扑软件的 HT for Web 技术,为网络攻防模拟与城市安全演练提供了全面且高效的解决方案。 三维场景搭建&…...

在 Ubuntu 20.04 中使用 init.d 或者systemd实现开机自动执行脚本
Ubuntu 20 默认使用的是 systemd 系统管理器,但传统的 SysV Init(/etc/init.d/)脚本依然兼容并可用。本文将介绍如何通过 init.d 写脚本来在开机时自动设置某个 GPIO(如 GPIO407)为高电平,适用于嵌入式系统…...
 解题报告 | 珂学家)
2024 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛) 解题报告 | 珂学家
前言 题解 2024 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(国赛)。 国赛比省赛难一些,做得汗流浃背,T_T. RC-u1 大家一起查作弊 分值: 15分 这题真的太有意思,看看描述 在今年的睿抗比赛上,有同学的提交代码如下࿱…...

【生成式AI文本生成实战】从GPT原理到企业级应用开发
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

【目标检测】RT-DETR
DETRs Beat YOLOs on Real-time Object Detection DETR在实时目标检测任务中超越YOLO CVPR 2024 代码地址 论文地址 0.论文摘要 YOLO系列因其在速度与精度间的均衡权衡,已成为实时目标检测领域最受欢迎的框架。然而我们观察到,非极大值抑制…...

数据库行业竞争加剧,MySQL 9.3.0 企业版开始支持个人下载
最新发现,Oracle 官方网站放开了 MySQL 9.3.0 企业版下载链接,个人用户也可以免费下载,不过只能用于学习、开发或者原型测试,不能用于生产环境。 通常我们都是下载 MySQL 社区版,不过 MySQL 企业版可以支持更多高级功能…...
(理论部分))
QMK宏全面实战教程:从入门到精通(附17个实用案例)(理论部分)
🎯 QMK宏全面实战教程:从入门到精通(附17个实用案例) 大家好!作为一名机械键盘DIY爱好者和QMK固件深度玩家,今天我要带大家彻底掌握QMK宏的使用技巧!无论你是刚接触机械键盘的新手,还是想提升定制化水平的老玩家,这篇包含17个实战案例的教程都能满足你的需求! 🔍…...
常用命令整理)
H3C网络设备(交换机、路由器、防火墙)常用命令整理
H3C网络设备(交换机、路由器、防火墙)的常用命令整理。 一、H3C交换机常用命令 1. 基础操作 命令说明system-view进入系统视图quit返回上一级视图save保存配置display current-configuration查看当前配置(类似 show run)display…...
)
从前序与中序遍历序列构造二叉树(中等)
先从前序遍历列表取出第一个元素,这个元素就是根节点,然后从中序遍历中找到这个根节点,节点左侧就是该节点的左子树的节点集合,右侧就是该节点的右侧节点集合,然后递归构建左右子树。 /*** Definition for a binary t…...
 不会立即复制整个请求流的内容到内存)
ASP.NET/IIS New StreamContent(context.Request.InputStream) 不会立即复制整个请求流的内容到内存
StreamContent 的工作原理与内存占用 New StreamContent(context.Request.InputStream) 不会立即复制整个请求流的内容到内存。这个操作只是创建一个包装器,将原始的请求流(context.Request.InputStream)封装在 StreamContent 对象中&#x…...

Java大师成长计划之第24天:Spring生态与微服务架构之分布式配置与API网关
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4-turbo模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在微服务架构中,如何管理…...

Spring Security vs Shiro vs Sa-Token
一句话总结: Spring Security:大公司专业保安队,功能全面但配置复杂Shiro:轻便灵活的安保工具包,上手简单但功能有限Sa-Token:国产智能门禁系统,开箱即用,代码极简 对比表格&#x…...

MongoTemplate 基础使用帮助手册
前言 MongoDB 是一种流行的 NoSQL 数据库,适合存储大量的非结构化数据。MongoTemplate 是 Spring Data MongoDB 中的一个核心组件,它提供了一组丰富的 API 来与 MongoDB 进行交互。它封装了许多常见的数据库操作,使开发者能够轻松执行 CRUD 操…...

CCIE与HCIE哪个考试难度更大?
CCIE(思科认证互联网专家)与HCIE(华为认证ICT专家)的考试难度差异体现在技术体系、实验要求及评分标准。2023年全球数据显示,CCIE通过率约25%,HCIE通过率32%,但通过率不能完全反映实际挑战。 C…...

子查询对多层join优化记录
需求背景 查询某个用户是否具有某个角色 表 CREATE TABLE mdm_platform_role_user (ID bigint NOT NULL AUTO_INCREMENT,ROLE_ID varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,USER_ID varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci …...

容器编排利器-k8s入门指南
Kubernetes(K8s)入门指南:容器编排利器 什么是 Kubernetes? Kubernetes(常简称为K8s)是一个开源的容器编排平台,由 Google 开源并交由云原生计算基金会(CNCF)管理。它可以帮助我们自动化部署、扩展和管理容器化应用程序。 为什么需要 Kubernetes? 在微服务架构盛行的今…...

MyBatis—动态 SQL
MyBatis—动态 SQL 一、动态 SQL 的核心作用 动态 SQL 主要解决以下问题: 灵活性:根据不同的输入参数生成不同的 SQL 语句(如条件查询、批量操作)。 可维护性:减少重复代码,通过标签化逻辑提高 SQL 可读…...

解决“VMware另一个程序已锁定文件的一部分,进程无法访问“
问题描述 打开VMware里的虚拟机时,弹出"另一个程序已锁定文件的一部分,进程无法访问"如图所示: 这是VM虚拟机的保护机制。虚拟机运行时,为防止数据被篡改,会将所运行的文件保护起来。当虚拟机崩溃或者强制…...

如何创建一个不可变类
写在前面 如果对象在构造后无法更改,则该对象是不可变的。不可变对象不会以任何方式暴露其他对象来修改其状态; 对象的字段仅在构造函数内初始化一次,并且永远不会再次更改。 1.不可变类的用法 如今,每个软件应用程序的*“必备”规范都是分…...

outbox架构解说
Outbox 模式是一种用于实现数据一致性的架构模式,特别是在微服务架构中。 它确保在处理事务时,数据的原子性和最终一致性。 Outbox 模式的详细解说: 1. 概念与背景 背景:在微服务架构中,一个操作可能涉及多个服务&…...

PT2020 20触控I2C输出IC
1.产品概述 ● PT2020是一款电容式触摸控制ASIC,支持20通道触摸输入,I2C键值输出。可通过I2C调节灵敏度以及功能设置。算法带有走线自补偿功能,具有高抗干扰、宽工作电压范围的突出优势。适用于小家电,智能门锁等消费类…...