【Boost搜索引擎】构建Boost站内搜索引擎实践
目录
1. 搜索引擎的相关宏观原理
2. 正排索引 vs 倒排索引 - 搜索引擎具体原理
3. 编写数据去标签与数据清洗的模块 Parser
去标签
编写parser
用boost枚举文件名
解析html
提取title
编辑 去标签
构建URL
将解析内容写入文件中
4. 编写建立索引的模块 Index
建立正排的基本代码
建立倒排的基本代码
5. 编写索引模块 Searcher
安装jsoncpp
获取摘要
代码
去重后的代码
测试
编写http_server 模块
基本使用测试
简单编写日志
编写前端模块
成品
搜索展示
项目源码:https://gitee.com/uyeonashi/boost
1. 搜索引擎的相关宏观原理
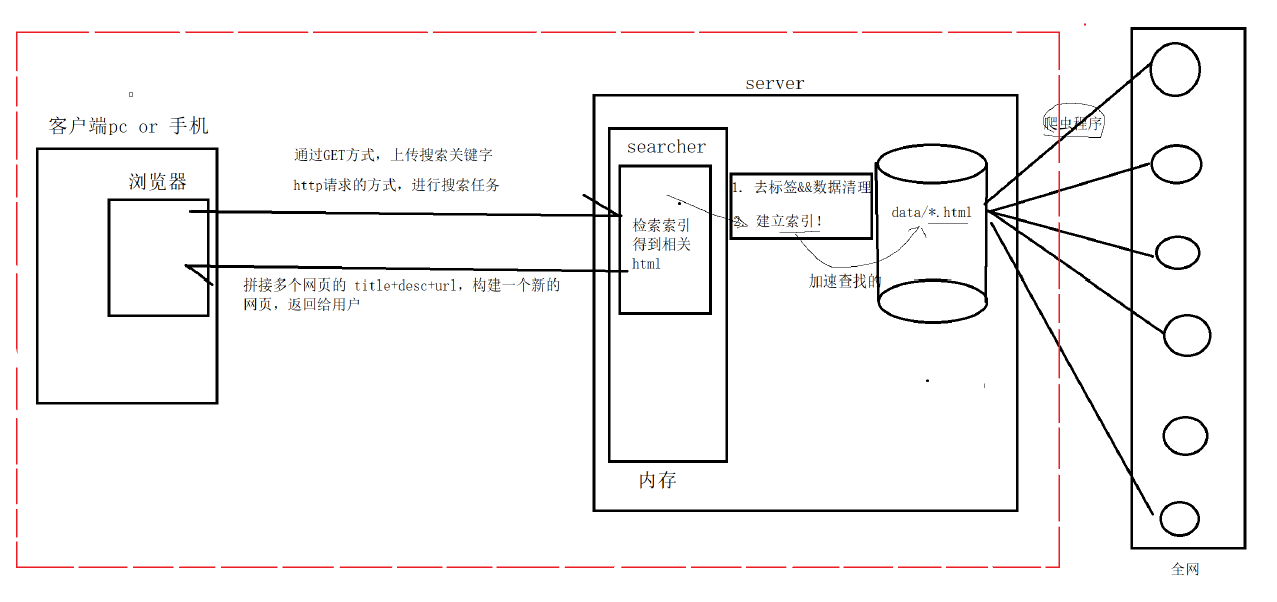
搜索引擎技术栈和项目环境
• 技术栈: C/C++ C++11, STL, 准标准库Boost,Jsoncpp,cppjieba,cpp-httplib ,
• 项目环境: Ubuntu22.04,vim/gcc(g++)/Makefile , vs code
2. 正排索引 vs 倒排索引 - 搜索引擎具体原理
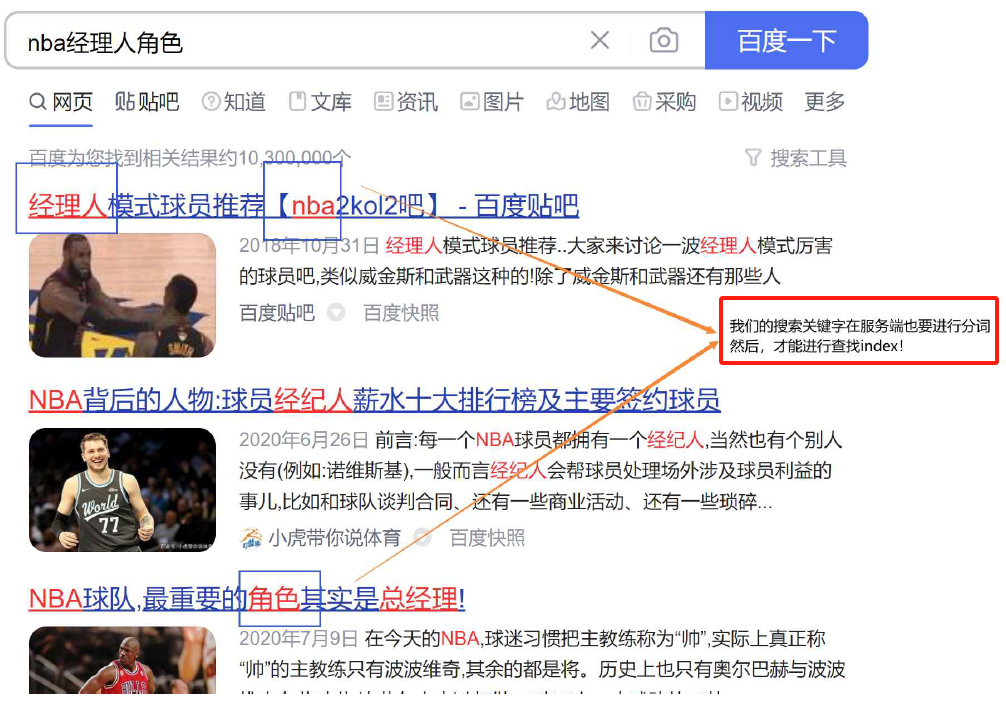
• 文档1: 雷军买了四斤小米
• 文档2: 雷军发布了小米手机
| 文档ID | 文档内容 |
| 1 | 雷军买了四斤小米 |
| 2 | 雷军发布了小米手机 |
目标文档进行分词(目的:方便建立倒排索引和查找):
• 文档1[雷军买了四斤小米 ]: 雷军/买/四斤/小米/四斤小米
• 文档2[雷军发布了小米手机]:雷军/发布/小米/小米手机
停止词:了,的,吗,a,the,一般我们在分词的时候可以不考虑
倒排索引:根据文档内容,分词,整理不重复的各个关键字,对应联系到文档ID的方案
| 关键字(具有唯一性) | 文档id,weight权重 |
| 雷军 | 文档1, 文档2 |
| 买 | 文档1 |
| 四斤 | 文档1 |
| 小米 | 文档1, 文档2 |
| 四斤小米 | 文档1 |
| 小米手机 | 文档2 |
模拟一次查找的过程:
用户输入:小米 -> 倒排索引中查找 -> 提取出文档ID(1,2) -> 根据正排索引 -> 找到文档的内容 -> title+conent(desc)+url 文档结果进行摘要 -> 构建响应结果
3. 编写数据去标签与数据清洗的模块 Parser
boost 官网:https://www.boost.org/
下载一个最新版的即可
//目前只需要boost_1_88_0/doc/html目录下的html文件,用它来进行建立索引

![]()
现在搜索源就在data中了,我们拼接一下即可
去标签
touch parser.cc
//原始数据 -> 去标签之后的数据 (随便截取一段举个例子)
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html> <!--这是一个标签-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Chapter 30. Boost.Process</title>
<link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css">
<meta name="generator" content="DocBook XSL Stylesheets V1.79.1">
<link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook
Documentation Subset">
<link rel="up" href="libraries.html" title="Part I. The Boost C++ Libraries
(BoostBook Subset)">
<link rel="prev" href="poly_collection/acknowledgments.html"
title="Acknowledgments">
<link rel="next" href="boost_process/concepts.html" title="Concepts">
</head>
<body bgcolor="white" text="black" link="#0000FF" vlink="#840084"
alink="#0000FF">
<table cellpadding="2" width="100%"><tr>
<td valign="top"><img alt="Boost C++ Libraries" width="277" height="86"
src="../../boost.png"></td>
<td align="center"><a href="../../index.html">Home</a></td>
<td align="center"><a href="../../libs/libraries.htm">Libraries</a></td>
<td align="center"><a href="http://www.boost.org/users/people.html">People</a>
</td>
<td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td>
<td align="center"><a href="../../more/index.htm">More</a></td>
</tr></table>
.........
// <> : html的标签,这个标签对我们进行搜索是没有价值的,需要去掉这些标签,一般标签都是成对出现的!yang@hcss-ecs-5a79:~/boost$ cd data
yang@hcss-ecs-5a79:~/boost/data$ mkdir raw_html
yang@hcss-ecs-5a79:~/boost/data$ ll
drwxrwxr-x 56 yang yang 12288 Apr 24 21:27 input/ //这里放的是原始的html文档
drwxrwxr-x 2 yang yang 4096 Apr 24 21:37 raw_html/ //这是放的是去标签之后的干净文档yang@hcss-ecs-5a79:~/boost/data$ ls -Rl | grep -E '*.html' | wc -l
8637目标:把每个文档都去标签,然后写入到同一个文件中!每个文档内容不需要任何\n!文档和文档之间用 \3 区分
version1:
类似:XXXXXXXXXXXXXXXXX\3YYYYYYYYYYYYYYYYYYYYY\3ZZZZZZZZZZZZZZZZZZZZZZZZZ\3采用下面的方案:
version2: 写入文件中,一定要考虑下一次在读取的时候,也要方便操作!
类似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3url编写parser
先将代码结构罗列出来
#include <iostream>
#include <string>
#include <vector>//是一个目录,下面放的就是所以的html网页
const std::string src_path = "data/intput/";
const std::string output = "data/raw_html/raw.txt";typedef struct DocInfo
{std::string title; //文档的标题std::string content; //文档的内容std::string url; //该文档在官网中的url
}DocInfo_t;bool EnumFile(const std::string &stc_path,std::vector<std::string> *file_lists);
bool ParseHtml(const std::vector<std::string> &file_lists,std::vector<DocInfo_t> *result);
bool SaveHtml(const std::vector<DocInfo_t> &result,const std::string &output);int main()
{std::vector<std::string> files_list;//第一步:递归式的吧每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件进行读取if(!EnumFile(src_path,&files_list)){std::cerr << "enum file name error!" << std::endl;return 1;}//第二步:按照files_list读取每个文件的内容,并进行解析std::vector<DocInfo_t> result;if(!ParseHtml(files_list,&result)){std::cout << "parse html error" << std::endl;return 2;}//第三步:把解析完毕的各个文件内容,写入到output,按照/3最为文档的分割符if(!SaveHtml(result,output)){std::cerr << "save html error" << std::endl;return 3;}
}boost 开发库的安装
因为这里我们需要用到boost库中的功能
sudo apt-get install libboost-all-dev用boost枚举文件名
//枚举文件名
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{namespace fs = boost::filesystem;fs::path root_path(src_path);//判断路径是否存在,不存在,就没有必要再往后走了if(!fs::exists(root_path)){std::cerr << src_path << " not exists" << std::endl;return false;}//定义一个空的迭代器,用来进行判断递归结束fs::recursive_directory_iterator end;for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){//判断文件是否是普通文件,html都是普通文件if(!fs::is_regular_file(*iter))continue;if(iter->path().extension() != ".html")//判断文件路径名的后缀是否符合要求continue;std::cout << "debug: " << iter->path().string() << std::endl;//当前的路径一定是一个合法的,以.html结束的普通网页文件files_list->push_back(iter->path().string()); //将所有带路径的html保存在files_list,方便后续进行文本分析}return true;
}解析html
先把结构列出
//枚举文件名
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{namespace fs = boost::filesystem;fs::path root_path(src_path);//判断路径是否存在,不存在,就没有必要再往后走了if(!fs::exists(root_path)){std::cerr << src_path << " not exists" << std::endl;return false;}//定义一个空的迭代器,用来进行判断递归结束fs::recursive_directory_iterator end;for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){//判断文件是否是普通文件,html都是普通文件if(!fs::is_regular_file(*iter))continue;if(iter->path().extension() != ".html")//判断文件路径名的后缀是否符合要求continue;std::cout << "debug: " << iter->path().string() << std::endl;//当前的路径一定是一个合法的,以.html结束的普通网页文件files_list->push_back(iter->path().string()); //将所有带路径的html保存在files_list,方便后续进行文本分析}return true;
}提取title
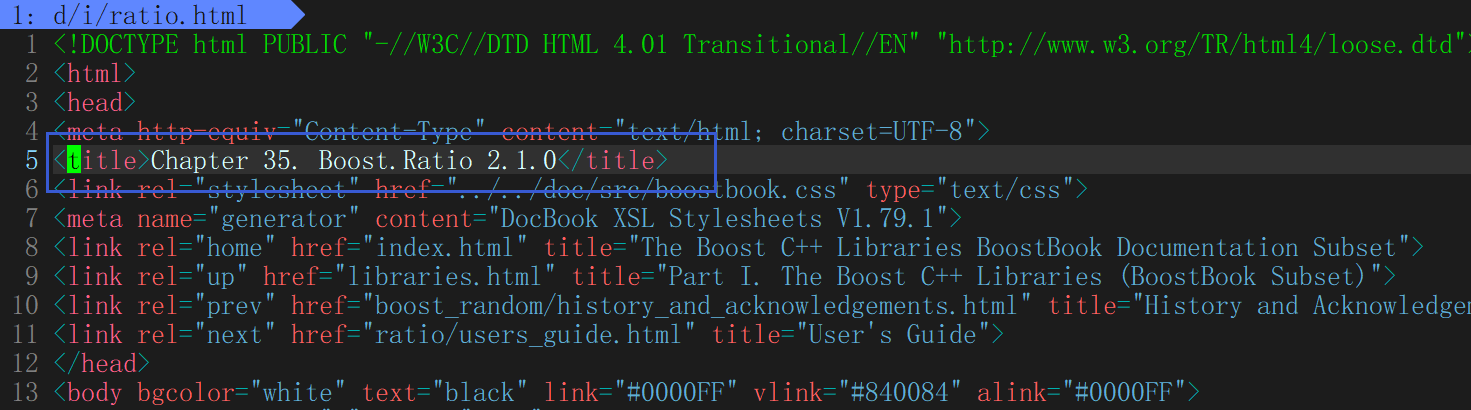
用string 找 < >, 找到title的起始位置,前闭后开,找到的是中间的位置
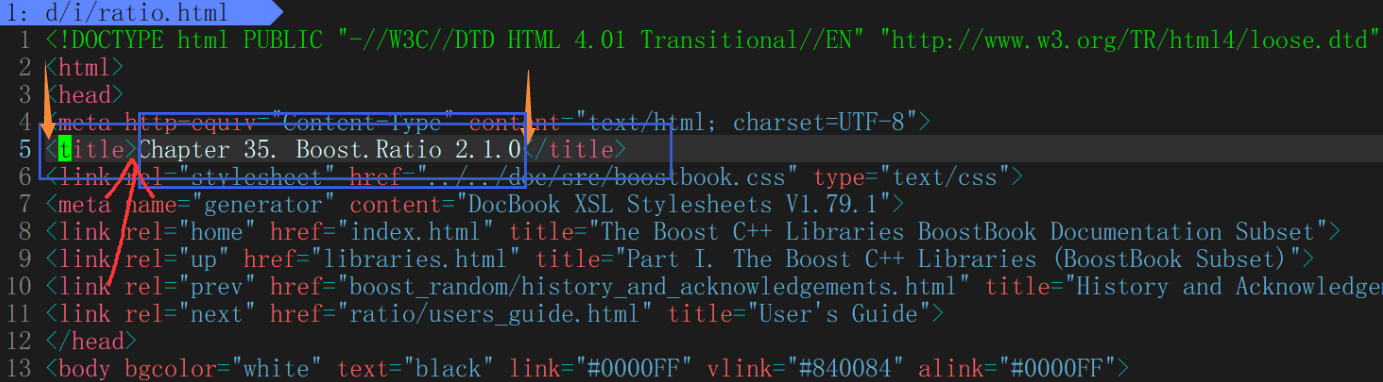 去标签
去标签
提取content,本质是进行去标签,只保留有效字段
在进行遍历的时候,只要碰到了 > ,就意味着,当前的标签被处理完毕.;只要碰到了< 意味着新的标签开始了
构建URL
boost库的官方文档,和我们下载下来的文档,是有路径的对应关系的
官网URL样例:
https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html我们下载下来的url样例:boost_1_78_0/doc/html/accumulators.html我们拷贝到我们项目中的样例:data/input/accumulators.html //我们把下载下来的boost库doc/html/* copy data/input/url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
url_tail = [data/input](删除) /accumulators.html -> url_tail = /accumulators.htmlurl = url_head + url_tail ; 相当于形成了一个官网链接static bool ParseUrl(const std::string &file_path,std::string *url)
{std::string url_head = "https://www.boost.org/doc/libs/1_88_0/doc/html";std::string url_tail = file_path.substr(src_path.size());*url = url_head + url_tail;return true;
}将解析内容写入文件中
//见代码
采用下面的方案:
version2: 写入文件中,一定要考虑下一次在读取的时候,也要方便操作!
类似:title\3content\3url \n title\3content\3url \n title\3content\3url \n ...
方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3urlbool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP '\3'//按照二进制方式写入std::ofstream out(output,std::ios::out | std::ios::binary);if(!out.is_open()){std::cerr << "open " << output << std::endl;return false;}//就可以进行文件内容的携入了for(auto &item : results){std::string out_string;out_string = item.title;out_string += SEP;out_string += item.content;out_string += SEP;out_string += item.url;out_string += '\n';out.write(out_string.c_str(),out_string.size());}out.close();return true;
}4. 编写建立索引的模块 Index
先把基本结构搭建出
#pragma once
#include <iostream>
#include<vector>
#include<string>
#include<unordered_map>namespace ns_index
{struct DocInfo{std::string title; //标题std::string content; //文档去标签后的内容std::string url;uint64_t doc_id; //文档的ID};struct InvertedElem{uint64_t doc_id;std::string word;int weight;};//倒排拉链typedef std::vector<InvertedElem> InvertedList;class Index{public:Index(){}~Index(){}public:DocInfo *GetForwardIndex(uint64_t doc_id){return nullptr;}//根据关键字string,获得倒排拉链InvertedList * GetForwardIndex(const std::string &word){return nullptr;}//根据去标签,格式化之后的文档,构建正排和倒排索引//data/raw_html/raw.txtbool BuildIndex(const std::string &input) //parse处理完的数据交给我{}private://正排索引的数据结构用数组,数组下标天然石文档的IDstd::vector<DocInfo> forward_index; //正排索引//倒排索引一定是一个关键字和一组InvertedElem对应(关键字和倒排拉链的映射关系)std::unordered_map<std::string,InvertedList> inverted_index;};
}建立正排的基本代码
DocInfo *BuildForwardIndex(const std::string &line)
{//1. 解析line,字符串切分//line -> 3 string, title, content, urlstd::vector<std::string> results;const std::string sep = "\3"; //行内分隔符ns_util::StringUtil::CutString(line, &results, sep);//ns_util::StringUtil::CutString(line, &results, sep);if(results.size() != 3)return nullptr;//2. 字符串进行填充到DocIinfoDocInfo doc;doc.title = results[0]; //titledoc.content = results[1]; //contentdoc.url = results[2]; ///url//先进行保存id,在插入,对应的id就是当前doc在vector中的下标!doc.doc_id = forward_index.size();//3. 插入到正排索引的vectorforward_index.push_back(std::move(doc)); //doc,html文件内容return &forward_index.back();
}建立倒排的基本代码
//原理:
struct InvertedElem
{uint64_t doc_id;std::string word;int weight;
};//倒排拉链
typedef std::vector<InvertedElem> InvertedList;
//倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系]
std::unordered_map<std::string, InvertedList> inverted_index;//我们拿到的文档内容
struct DocInfo
{std::string title; //文档的标题std::string content; //文档对应的去标签之后的内容std::string url; //官网文档urluint64_t doc_id; //文档的ID,暂时先不做过多理解
};
//文档:
title : 吃葡萄
content: 吃葡萄不吐葡萄皮
url: http://XXXX
doc_id: 123根据文档内容,形成一个或者多个InvertedElem(倒排拉链)
因为当前我们是一个一个文档进行处理的,一个文档会包含多个”词“, 都应当对应到当前的doc_id1. 需要对 title && content都要先分词 --使用jieba分词
title: 吃/葡萄/吃葡萄(title_word)
content:吃/葡萄/不吐/葡萄皮(content_word)词和文档的相关性(词频:在标题中出现的词,可以认为相关性更高一些,在内容中出现相关性低一些
2. 词频统计
struct word_cnt
{title_cnt;content_cnt;
}
unordered_map<std::string, word_cnt> word_cnt;
for &word : title_word
{word_cnt[word].title_cnt++; //吃(1)/葡萄(1)/吃葡萄(1)
}
for &word : content_word
{word_cnt[word].content_cnt++; //吃(1)/葡萄(1)/不吐(1)/葡萄皮(1)
}知道了在文档中,标题和内容每个词出现的次数
3. 自定义相关性
for &word : word_cnt
{
//具体一个词和123文档的对应关系,当有多个不同的词,指向同一个文档的时候,此时该优先显示谁??相关性!struct InvertedElem elem;elem.doc_id = 123;elem.word = word.first;elem.weight = 10*word.second.title_cnt + word.second.content_cnt ; //相关性inverted_index[word.first].push_back(elem);
}//jieba的使用--cppjieba
获取链接:https://gitcode.com/gh_mirrors/cp/cppjieba
如何使用:源代码都写进头文件include/cppjieba/*.hpp里,include即可使用
如何使用:注意细节,我们需要自己执行: cp -rf deps/limonp include/cppjieba/
也就是说要将limonp移到cppjieba目录下,不然会报错
//使用 demo.cpp
#include "inc/cppjieba/Jieba.hpp"
#include <iostream>
#include <string>
#include <vector>
using namespace std;const char* const DICT_PATH = "./dict/jieba.dict.utf8";
const char* const HMM_PATH = "./dict/hmm_model.utf8";
const char* const USER_DICT_PATH = "./dict/user.dict.utf8";
const char* const IDF_PATH = "./dict/idf.utf8";
const char* const STOP_WORD_PATH = "./dict/stop_words.utf8";int main(int argc, char** argv)
{cppjieba::Jieba jieba(DICT_PATH,HMM_PATH,USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH);vector<string> words;string s;s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造";cout << s << endl;cout << "[demo] CutForSearch" << endl;jieba.CutForSearch(s, words);cout << limonp::Join(words.begin(), words.end(), "/") << endl;return EXIT_SUCCESS;
} bool BuildForwardIndex(const DocInfo &doc){//DoInfo(title,content,url,doc_id)//word->倒排拉链struct word_cnt{int title_cnt;int content_cnt;word_cnt():title_cnt(0),content_cnt(0){}};std::unordered_map<std::string,word_cnt> word_map; //用来暂存词频的映射表//对标题进行分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutString(doc.title,&title_words);//对标题词频进行统计for(auto &s : title_words){word_map[s].title_cnt++;//如果存在就获取,不存在就新建}//对文档内容进行分词std::vector<std::string> content_words;ns_util::JiebaUtil::CutString(doc.content,&content_words);//对内容进行词频统计std::unordered_map<std::string,word_cnt> concent_map;for(auto &c : content_words){word_map[c].content_cnt++;}#define X 10#define Y 1for(auto &word_pair : word_map){InvertedElem item;item.doc_id = doc.doc_id;item.word = word_pair.first;item.weight = X*word_pair.second.title_cnt + Y*word_pair.second.content_cnt;InvertedList &inverted_list = inverted_index[word_pair.first];inverted_list.push_back(item);}return true;}5. 编写索引模块 Searcher
先把基本代码结构搭建出来
namespace ns_seracher
{class Searcher{public:Searcher() {} ~Searcher() {}public:void InitSercher(const std::string &input){//1. 获取或者创建Index对象//2. 根据index对象建立索引}void Search(const std::string &queue, std::string *ison String){//1. [分词]:对我们的query进行按照searcher的要求进行分词//2. [触发]:就是根据分词的各个“词”,进行index查找//3. [合并]:汇总查找结果,按照相关性(weight)降序排序//4. [构建]: 根据查找出来的结果,构建json串 -- jsoncpp}private:ns_index::Index *index; //索引};
}
搜索:雷军小米 -> 雷军、小米->查倒排->两个倒排拉链(文档1,文档2,文档1、文档2)
安装jsoncpp
sudo apt-get install libjsoncpp-dev具体实现代码
https://gitee.com/uyeonashi/boost
获取摘要
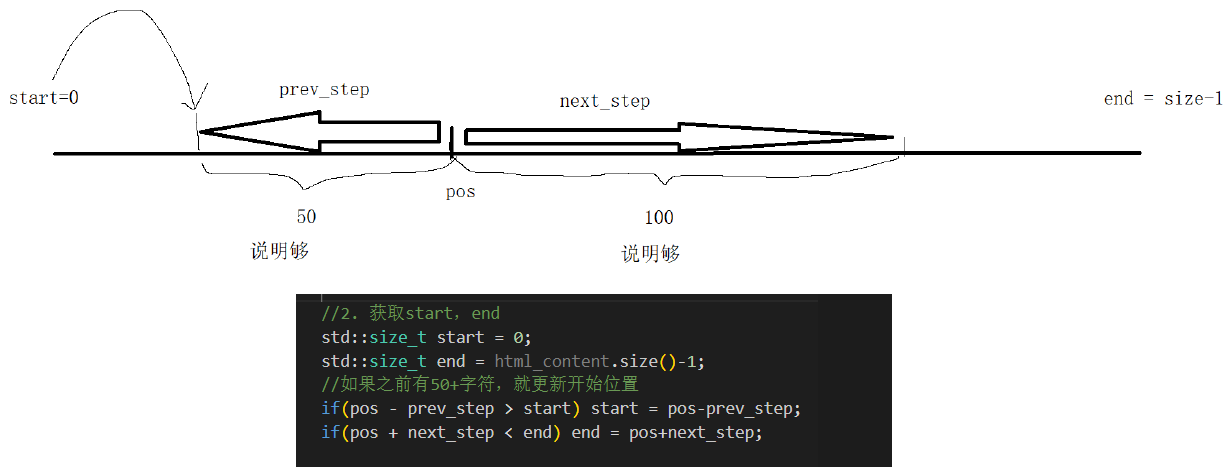
注意定义start和end双指针的时候,要注意size_t类型与int类型的符号比较,很容易出错!
- 由于size_t是无符号类型,如果使用不当(比如使用负数做运算),可能会导致意想不到的结果。例如,将负数赋值给size_t会导致它变成一个很大的正数。
代码
std::string GetDesc(const std::string &html_content, const std::string &word)
{// 找到word在html_content中的首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以的)// 截取出这部分内容const int prev_step = 50;const int next_step = 100;// 1. 找到首次出现// 不能使用find查找,可能因为大小写不匹配而报错auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){ return (std::tolower(x) == std::tolower(y)); });if (iter == html_content.end()){return "None1";}int pos = std::distance(html_content.begin(), iter);// 2. 获取start,end , std::size_t 无符号整数int start = 0;int end = html_content.size() - 1;// 如果之前有50+字符,就更新开始位置if (pos > start + prev_step)start = pos - prev_step;if (pos < end - next_step)end = pos + next_step;// 3. 截取子串,returnif (start >= end)return "None2";std::string desc = html_content.substr(start, end - start);desc += "...";return desc;
}比如我们在搜索“你是一个好人”时,jieba会将该语句分解为你/一个/好人/一个好人,在建立图的时候,可能会指向同一个文档,导致我们在搜索的时候会出现重复的结果。
所以我们要做去重操作,如何判断相同呢?直接看文档id即可。并且要将权值修改,我们应该将搜索到的相同内容进行权值的累加,作为该文档的真正权值!
去重后的代码
#pragma once#include "index.hpp"
#include "util.hpp"
#include "log.hpp"
#include <algorithm>
#include <unordered_map>
#include <jsoncpp/json/json.h>namespace ns_searcher
{struct InvertedElemPrint{uint64_t doc_id;int weight;std::vector<std::string> words;InvertedElemPrint() : doc_id(0), weight(0) {}};class Searcher{private:ns_index::Index *index; // 供系统进行查找的索引public:Searcher() {}~Searcher() {}public:void InitSearcher(const std::string &input){// 1. 获取或者创建index对象index = ns_index::Index::GetInstance();std::cout << "获取index单例成功..." << std::endl;// LOG(NORMAL, "获取index单例成功...");// 2. 根据index对象建立索引index->BuildIndex(input);std::cout << "建立正排和倒排索引成功..." << std::endl;// LOG(NORMAL, "建立正排和倒排索引成功...");}// query: 搜索关键字// json_string: 返回给用户浏览器的搜索结果void Search(const std::string &query, std::string *json_string){// 1.[分词]:对我们的query进行按照searcher的要求进行分词std::vector<std::string> words;ns_util::JiebaUtil::CutString(query, &words);// 2.[触发]:就是根据分词的各个"词",进行index查找,建立index是忽略大小写,所以搜索,关键字也需要// ns_index::InvertedList inverted_list_all; //内部InvertedElemstd::vector<InvertedElemPrint> inverted_list_all;std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;for (std::string word : words){boost::to_lower(word);ns_index::InvertedList *inverted_list = index->GetInvertedList(word);if (nullptr == inverted_list){continue;}// 不完美的地方: 你/是/一个/好人 100// inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());for (const auto &elem : *inverted_list){auto &item = tokens_map[elem.doc_id]; //[]:如果存在直接获取,如果不存在新建// item一定是doc_id相同的print节点item.doc_id = elem.doc_id;item.weight += elem.weight;item.words.push_back(elem.word);}}for (const auto &item : tokens_map){inverted_list_all.push_back(std::move(item.second));}// 3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序// std::s ort(inverted_list_all.begin(), inverted_list_all.end(),\// [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){// return e1.weight > e2.weight;// });std::sort(inverted_list_all.begin(), inverted_list_all.end(),[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){return e1.weight > e2.weight;});// 4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp --通过jsoncpp完成序列化&&反序列化Json::Value root;for (auto &item : inverted_list_all){ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc){continue;}Json::Value elem;elem["title"] = doc->title;elem["desc"] = GetDesc(doc->content, item.words[0]); // content是文档的去标签的结果,但是不是我们想要的,我们要的是一部分 TODOelem["url"] = doc->url;// for deubg, for deleteelem["id"] = (int)item.doc_id;elem["weight"] = item.weight; // int->stringroot.append(elem);}Json::StyledWriter writer;// Json::FastWriter writer;*json_string = writer.write(root);}std::string GetDesc(const std::string &html_content, const std::string &word){// 找到word在html_content中的首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以的)// 截取出这部分内容const int prev_step = 50;const int next_step = 100;// 1. 找到首次出现// 不能使用find查找,可能因为大小写不匹配而报错auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){ return (std::tolower(x) == std::tolower(y)); });if (iter == html_content.end()){return "None1";}int pos = std::distance(html_content.begin(), iter);// 2. 获取start,end , std::size_t 无符号整数int start = 0;int end = html_content.size() - 1;// 如果之前有50+字符,就更新开始位置if (pos > start + prev_step)start = pos - prev_step;if (pos < end - next_step)end = pos + next_step;// 3. 截取子串,returnif (start >= end)return "None2";std::string desc = html_content.substr(start, end - start);desc += "...";return desc;}};
}测试
每写一个模块,最好都要测试一下不然最后bug成群
测试代码
#include "seracher.hpp"
#include <cstdio>
#include <cstring>
#include <iostream>
#include <string>const std::string input = "data/raw_html/raw.txt";int main()
{ns_seracher::Searcher *search = new ns_seracher::Searcher();search->InitSercher(input);std::string query;std::string json_string;char buffer[1024];while (true){std::cout << "Plase Enter Your Search Query# ";fgets(buffer,sizeof(buffer)-1,stdin);buffer[strlen(buffer)-1] = 0;query = buffer;search->Search(query,&json_string);std::cout << json_string << std::endl;}return 0;
}编译然后运行,查看
编写http_server 模块
我们这里不用自己去搭建轮子,直接用网上的cpp-httplib库即可搭建网络通信。
所以我们只要会使用基本的接口即可
cpp-httplib库:https://gitee.com/royzou/cpp-httplib
注意:cpp-httplib在使用的时候需要使用较新版本的gcc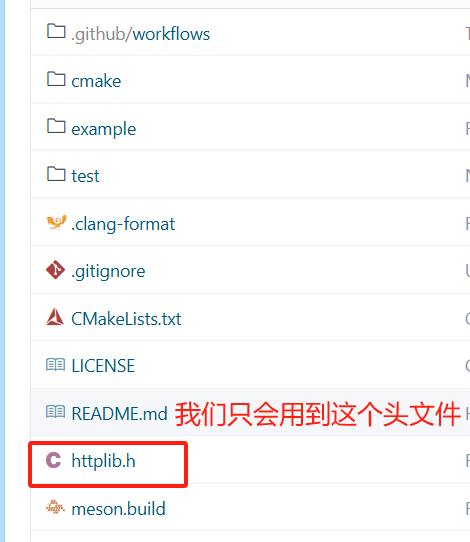
基本使用测试
#include"httplib.h"int main()
{httplib::Server svr;svr.Get("/hi", [](const httplib::Request &req, httplib::Response &rsp){rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}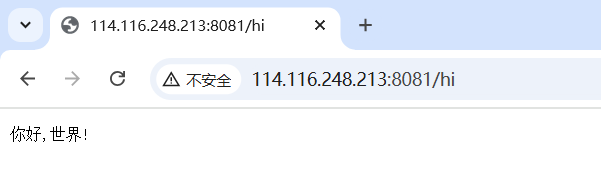
编写一个简单的前端做测试
#include"httplib.h"const std::string root_path = "./wwwroot";int main()
{httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/hi", [](const httplib::Request &req, httplib::Response &rsp){rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}<!DOCTYPE html><html>
<head><meta charset="UTF-8"><title>for test</title>
</head>
<body><h1>你好,世界</h1><p>这是一个测试网页</p>
</body>
</html>
#include"httplib.h"
#include "seracher.hpp"const std::string input = "data/raw_html/raw.txt";
const std::string root_path = "./wwwroot";int main()
{ns_seracher::Searcher search;search.InitSercher(input);httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){if(!req.has_param("word")){rsp.set_content("要有搜索关键词!","text/plain: charset=utf-8");return;}std::string word = req.get_param_value("word");std::cout << "用户在搜索:" << word << std::endl;std::string json_string;search.Search(word,&json_string);rsp.set_content(json_string,"application/json"); // rsp.set_content("你好,世界!", "text/plain; charset=utf-8");});svr.listen("0.0.0.0",8081);return 0;
}简单编写日志
#pragma once#include <iostream>
#include <string>
#include <ctime>#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)void log(std::string level, std::string message, std::string file, int line)
{std::cout << "[" << level << "]" << "[" << time(nullptr) << "]" << "[" << message << "]" << "[" << file << " : " << line << "]" << std::endl;
}
编写前端模块
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><script src="http://code.jquery.com/jquery-2.1.1.min.js"></script><title>boost 搜索引擎</title><style>/* 去掉网页中的所有的默认内外边距,html的盒子模型 */* {/* 设置外边距 */margin: 0;/* 设置内边距 */padding: 0;}/* 将我们的body内的内容100%和html的呈现吻合 */html,body {height: 100%;}/* 类选择器.container */.container {/* 设置div的宽度 */width: 800px;/* 通过设置外边距达到居中对齐的目的 */margin: 0px auto;/* 设置外边距的上边距,保持元素和网页的上部距离 */margin-top: 15px;}/* 复合选择器,选中container 下的 search */.container .search {/* 宽度与父标签保持一致 */width: 100%;/* 高度设置为52px */height: 52px;}/* 先选中input标签, 直接设置标签的属性,先要选中, input:标签选择器*//* input在进行高度设置的时候,没有考虑边框的问题 */.container .search input {/* 设置left浮动 */float: left;width: 600px;height: 50px;/* 设置边框属性:边框的宽度,样式,颜色 */border: 1px solid black;/* 去掉input输入框的有边框 */border-right: none;/* 设置内边距,默认文字不要和左侧边框紧挨着 */padding-left: 10px;/* 设置input内部的字体的颜色和样式 */color: #000be2;font-size: 14px;}/* 先选中button标签, 直接设置标签的属性,先要选中, button:标签选择器*/.container .search button {/* 设置left浮动 */float: left;width: 150px;height: 52px;/* 设置button的背景颜色,#4e6ef2 */background-color: #4e6ef2;/* 设置button中的字体颜色 */color: #FFF;/* 设置字体的大小 */font-size: 19px;font-family: Georgia, 'Times New Roman', Times, serif;}.container .result {width: 100%;}.container .result .item {margin-top: 15px;}.container .result .item a {/* 设置为块级元素,单独站一行 */display: block;/* a标签的下划线去掉 */text-decoration: none;/* 设置a标签中的文字的字体大小 */font-size: 20px;/* 设置字体的颜色 */color: #4e6ef2;}.container .result .item a:hover {text-decoration: underline;}.container .result .item p {margin-top: 5px;font-size: 16px;font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;}.container .result .item i {/* 设置为块级元素,单独站一行 */display: block;/* 取消斜体风格 */font-style: normal;color: rgba(103, 6, 193, 0.838);}</style>
</head><body><div class="container"><div class="search"><input type="text" value="请输入搜索关键字"><button onclick="Search()">搜索一下</button></div><div class="result"><!-- 动态生成网页内容 --></div></div><script>function Search() {// 是浏览器的一个弹出框// alert("hello js!");// 1. 提取数据, $可以理解成就是JQuery的别称let query = $(".container .search input").val();console.log("query = " + query); //console是浏览器的对话框,可以用来进行查看js数据//2. 发起http请求,ajax: 属于一个和后端进行数据交互的函数,JQuery中的$.ajax({type: "GET",url: "/s?word=" + query,success: function (data) {console.log(data);BuildHtml(data);}});}function BuildHtml(data) {// 获取html中的result标签let result_lable = $(".container .result");// 清空历史搜索结果result_lable.empty();for (let elem of data) {// console.log(elem.title);// console.log(elem.url);let a_lable = $("<a>", {text: elem.title,href: elem.url,// 跳转到新的页面target: "_blank"});let p_lable = $("<p>", {text: elem.desc});let i_lable = $("<i>", {text: elem.url});let div_lable = $("<div>", {class: "item"});a_lable.appendTo(div_lable);p_lable.appendTo(div_lable);i_lable.appendTo(div_lable);div_lable.appendTo(result_lable);}}</script>
</body></html>成品
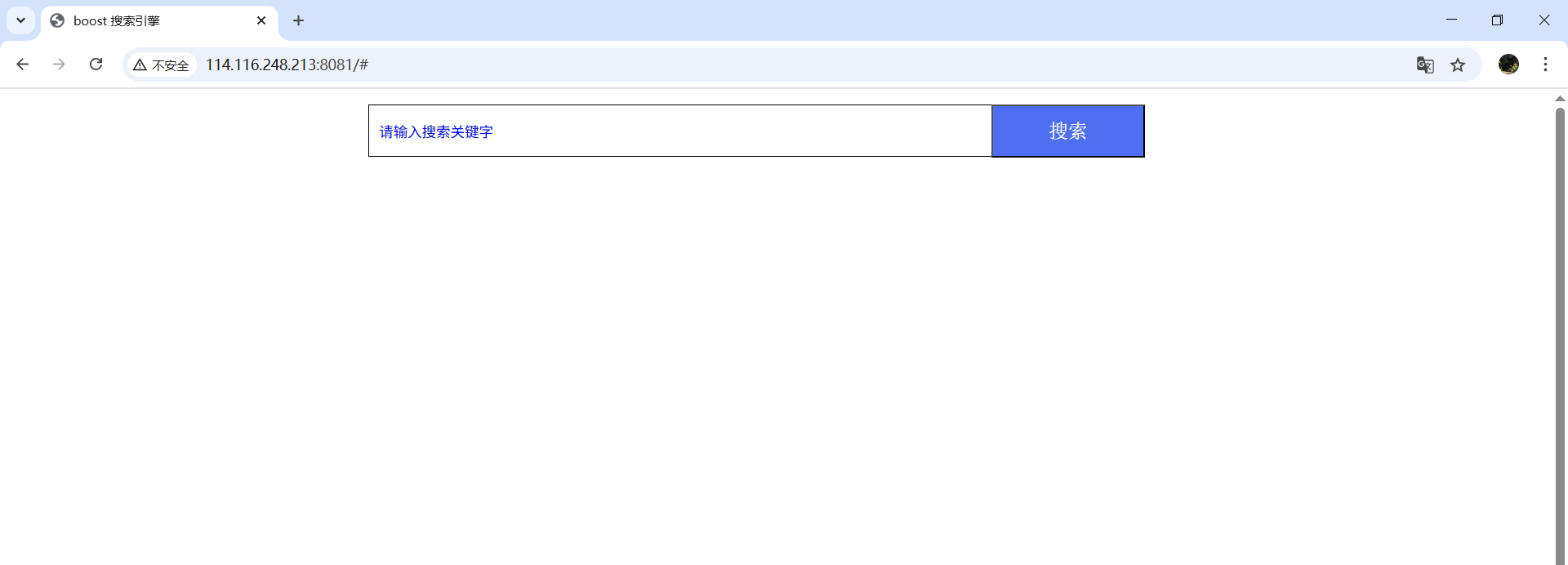
搜索展示
OK,还是很不错的,本篇完!

相关文章:

【Boost搜索引擎】构建Boost站内搜索引擎实践
目录 1. 搜索引擎的相关宏观原理 2. 正排索引 vs 倒排索引 - 搜索引擎具体原理 3. 编写数据去标签与数据清洗的模块 Parser 去标签 编写parser 用boost枚举文件名 解析html 提取title 编辑 去标签 构建URL 将解析内容写入文件中 4. 编写建立索引的模块 Index 建…...

记参加一次数学建模
题目请到全国大学生数学建模竞赛下载查看。 注:过程更新了很多文件,所有这里贴上的有些内容不是最新的(而是草稿)。 注:我们队伍并没有获奖,文章内容仅供一乐。 从这次比赛,给出以下赛前建议 …...

【gRPC】HTTP/2协议,HTTP/1.x中线头阻塞问题由来,及HTTP/2中的解决方案,RPC、Protobuf、HTTP/2 的关系及核心知识点汇总
HTTP/2协议特点 gRPC基于HTTP/2协议,原因: 多路复用:允许在同一个TCP连接上并行传输多个请求和响应,即多个gRPC调用可以通过同一个连接同时进行,避免了HTTP/1.x中常见的线头阻塞问题,减少了连接建立和关闭…...

mac中加载C++动态库文件
前言 需要再mac系统下运行C开发的程序,通过摸索,初步实现了一版,大致记录下 1. 前提准备 安装OpenCV 使用Homebrew安装OpenCV: brew install opencv确认安装路径: brew --prefix opencv默认路径为/opt/homebrew/…...

Apollo Client 1.6.0 + @RefreshScope + @Value 刷新问题解析
问题描述 在使用 Apollo Client 1.6.0 结合 Spring Cloud 的 RefreshScope 和 Value 注解时,遇到以下问题: 项目启动时第一次属性注入成功后续配置变更时,Value 属性会刷新,但总是刷新为第一次的旧值,而不是最新的配…...

大语言模型 09 - 从0开始训练GPT 0.25B参数量 补充知识之数据集 Pretrain SFT RLHF
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

文本分类任务Qwen3-0.6B与Bert:实验见解
文本分类任务Qwen3-0.6B与Bert:实验见解 前言 最近在知乎上刷到一个很有意思的提问Qwen3-0.6B这种小模型有什么实际意义和用途。查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)、也有人提出小模型只是为了开…...

Mysql、Oracle、Sql Server、达梦之间sql的差异
1:分页查询 Sql Server: <bind name"startRow" value"(page - 1) * limit 1"/> <bind name"endRow" value"page * limit"/> SELECT *FROM (SELECT ROW_NUMBER() OVER (<if test"sortZd!…...

STM32外设AD-DMA+定时读取模板
STM32外设AD-DMA定时读取模板 一,方法引入二,CubeMX配置三,变量声明四,代码实现 (单通道) 一,方法引入 轮询法虽然简单,但 CPU 一直在忙着等待,效率太低。为了让 CPU 能在 ADC 转换的同时处理其…...

SQL里where条件的顺序影响索引使用吗?
大家好,我是锋哥。今天分享关于【SQL里where条件的顺序影响索引使用吗?】面试题。希望对大家有帮助; SQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 SQL 查询中,W…...

Java 接口中实现异步处理的方法
在Java中,接口本身不能直接实现逻辑(接口中的方法默认是抽象的,JDK 8+允许通过default方法提供非抽象实现,但通常不用于复杂的异步处理)。异步处理的逻辑需要在实现接口的类中通过多线程、异步框架或回调机制来实现。以下是几种常见的在接口实现类中实现异步处理<...

数值分析证明题
文章目录 第一题第二题第三题第四题第五题第六题第七题第八题第九题 第一题 例 给出 cos x \cos x cosx, x ∈ [ 0 ∘ , 9 0 ∘ ] x\in[0^{\circ},90^{\circ}] x∈[0∘,90∘]的函数表,步长 h 1 ′ ( 1 60 ) ∘ h 1 (\frac{1}{60})^{\circ} h1′…...

深入理解二叉树:遍历、存储与算法实现
在之前的博客系列中,我们系统地探讨了多种线性表数据结构,包括顺序表、栈和队列等经典结构,并通过代码实现了它们的核心功能。从今天开始,我们将开启一个全新的数据结构篇章——树结构。与之前讨论的线性结构不同,树形…...

Python web 开发 Flask HTTP 服务
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编写,特别适合构建简单的 Web 应用和 RESTful API。Flask 的设计理念是提供尽可能少的约定和配置,从而让开发者能够灵活地构建自己的 Web 应用。 https://andi.cn/page/622189.html...

【AI】用Dify实现一个模拟面试的功能
前言 Dify,一个将LLM转换为实际工作流的工具,以及火了一段时间了,但直到最近才开始研究它的使用(主要前段时间在忙着自己的独立开发项目),我发现它的功能基本上满足了我对大语言模型,从仅对话转…...
)
研华服务器ASMB-825主板无法识别PCIE-USB卡(笔记本)
系统下无法识别到USB卡,排除硬件问题,系统问题。 最后在BIOS中更改此PCIE端口参数为X4X4X4X4,设置完成后可正常使用USB卡。 底部有问题详细解析。 针对研华主板ASMB-825安装绿联PCIE-USB卡无法识别的问题,结合BIOS设置调整的解决过…...

Redisson 四大核心机制实现原理详解
一、可重入锁(Reentrant Lock) 可重入锁是什么? 通俗定义 可重入锁类似于一把“智能锁”,它能识别当前的锁持有者是否是当前线程: 如果是,则允许线程重复获取锁(重入),并…...
)
云计算与大数据进阶 | 26、解锁云架构核心:深度解析可扩展数据库的5大策略与挑战(上)
在云应用/服务的 5 层架构里,数据库服务层稳坐第 4 把交椅,堪称其中的 “硬核担当”。它的复杂程度常常让人望而生畏,不少人都将它视为整个架构中的 “终极挑战”。 不过,也有人觉得可扩展存储系统才是最难啃的 “硬骨头”&#…...

Android从单体架构迁移到模块化架构。你会如何设计模块划分策略?如何处理模块间的通信和依赖关系
从单体架构迁移到模块化架构。可能有些小伙伴已经深陷单体架构的泥潭,代码耦合得跟一团麻线似的,改个小功能都能牵一发而动全身;也可能有些团队在协作时,经常因为代码冲突或者职责不清搞得焦头烂额。相信我,这些问题我…...

基于MATLAB的人脸识别,实现PCA降维,用PCA特征进行SVM训练
基于MATLAB的人脸识别完整流程,包含PCA降维和SVM分类的实现。我们以经典的ORL人脸数据库为例,演示从数据加载到结果评估的全过程。 1. 数据准备与预处理 1.1 下载数据集 下载ORL人脸数据库(40人10张,共400张图像)…...

AI 赋能 Copula 建模:大语言模型驱动的相关性分析革新
技术点目录 R及Python语言及相关性研究初步二元Copula理论与实践(一)二元Copula理论与实践(二)【R语言为主】Copula函数的统计检验与选择【R语言为主】高维数据与Vine Copula 【R语言】正则Vine Copula(一)…...

机器学习与人工智能:NLP分词与文本相似度分析
DIY AI & ML NLP — Tokenization & Text Similarity by Jacob Ingle in Data Science Collective 本文所使用的数据是在 Creative Commons license 下提供的。尽管我们已尽力确保信息的准确性和完整性,但我们不对数据的完整性或可靠性做任何保证。数据的使…...

特斯拉虚拟电厂:能源互联网时代的分布式革命
在双碳目标与能源转型的双重驱动下,特斯拉虚拟电厂(Virtual Power Plant, VPP)通过数字孪生技术与能源系统的深度融合,重构了传统电力系统的运行范式。本文从系统架构、工程实践、技术挑战三个维度,深度解析这一颠覆性…...
在医学编程中的初步分析与探索)
系统提示学习(System Prompt Learning)在医学编程中的初步分析与探索
一、SPL 的核心定义 系统提示学习(SPL)是一种通过策略性设计输入提示(Prompts),引导大型语言模型(LLMs)生成特定领域行为与输出的方法。其核心在于不修改模型参数,而是通过上下文工程(Context Engineering)动态控制模型响应,使其适配复杂任务需求。 与微调(Fine-…...
)
使用DDR4控制器实现多通道数据读写(十二)
一、章节概括 这一节使用interconnect RTL ip核将DDR4与四个读写通道级联,在测试工程中,将四个通道同时写入/读出地址与数据,并使用modelsim仿真器仿真,四个通道同时发送写请求或读请求后,经过interconnect后ÿ…...

PCIe数据采集系统详解
PCIe数据采集系统详解 在上篇文章中,废了老大劲儿我们写出了PCIe数据采集系统;其中各个模块各司其职,相互配合。完成了从数据采集到高速存储到DDR3的全过程。今天我们呢就来详细讲解他们之间的关系?以及各个模块的关键点ÿ…...

小白级通信小号、虚拟小号查询技术讲解
手机号构成与归属地原理 手机号码由国家代码、运营商代码和用户号码等部分组成。全球手机号段由国际电信联盟(ITU)统一规划,各国通信管理机构负责分配具体号段。在我国,通过解析手机号码前几位,就能确定其所属运营商及…...

【爬虫】DrissionPage-4
官网文档:https://www.drissionpage.cn/browser_control/browser_options 一、核心对象与初始化 1. 类定义 作用:管理Chromium内核浏览器的启动配置,仅在浏览器启动时生效。导入方式:from DrissionPage import ChromiumOptions…...

数据通信原理 光纤通信 期末速成
一、图表题 1. 双极性不归零、单极性不归零、曼彻斯特码、抑制载频2ASK,2PSK、2DPSK信号的波形 双极性不归零 和 单极性不归零:不归零意思是 0 低 1 高 非归零编码(NRZ):用不同电平表示二进制数字,常以…...

Java微服务架构实战:Spring Boot与Spring Cloud的完美结合
Java微服务架构实战:Spring Boot与Spring Cloud的完美结合 引言 随着云计算和分布式系统的快速发展,微服务架构已成为现代软件开发的主流模式。Java作为一门成熟的编程语言,凭借其强大的生态系统和丰富的框架支持,成为构建微服务…...

React底层架构深度解析:从虚拟DOM到Fiber的演进之路
一、虚拟DOM:性能优化的基石 1.1 核心工作原理 React通过JSX语法将组件转换为轻量级JavaScript对象(即虚拟DOM),而非直接操作真实DOM。这一过程由React.createElement()实现,其结构包含元素类型、属性和子节点等信息&a…...

今日行情明日机会——20250516
上证缩量收阴线,小盘股表现相对更好,上涨的个股大于下跌的,日线已到前期压力位附近,注意风险。 深证缩量收假阳线,临近日线周期上涨末端,注意风险。 2025年5月16日涨停股行业方向分析 机器人概念&#x…...

小结:网页性能优化
网页性能优化是提升用户体验、减少加载时间和提高资源利用率的关键。以下是针对网页生命周期和事件处理的性能优化技巧,结合代码示例,重点覆盖加载、渲染、事件处理和资源管理等方面。 1. 优化加载阶段 减少关键资源请求: 合并CSS/JS文件&a…...

2025年PMP 学习十五 第10章 项目资源管理
2025年PMP 学习十五 第10章 项目资源管理 序号过程过程组1规划沟通管理规划2管理沟通执行3监控沟通监控 项目沟通管理包括为确保项目的信 息及时且恰当地规划、收集、生成、发布、存储、检索、管理、控制、监 警和最终处理所需的过程; 项目经理绝大多数时间都用于与…...

速通RocketMQ配置
配置RocketMQ又出问题了,赶紧记录一波 这个是我的RocketMQ配置文件 通过网盘分享的文件: 链接: https://pan.baidu.com/s/1UUYeDvKZFNsKPFXTcalu3A?pwd8888 提取码: 8888 –来自百度网盘超级会员v9的分享 里面有这三个东西 里面还有一些broker和names…...

宇宙中是否存在量子现象?
一、宇宙中的量子现象 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 量子涨落与宇宙结构 早期宇宙的量子涨落(微观尺度的不确定性…...

背包问题详解
一、问题引入:什么是背包问题? 背包问题是经典的动态规划问题,描述如下: 有一个容量为 m 的背包 有 n 个物品,每个物品有体积 v 和价值 w 目标:选择物品装入背包,使总价值最大且总体积不超过…...

oracle linux 95 升级openssh 10 和openssl 3.5 过程记录
1. 安装操作系统,注意如果可以选择,选择安装开发工具,主要是后续需要编译安装,需要gcc 编译工具。 2. 安装操作系统后,检查zlib 、zlib-dev是否安装,如果没有,可以使用安装镜像做本地源安装&a…...

Tomcat发布websocket
一、tomcal的lib放入文件 tomcat-websocket.jar websocket-api.jar 二、代码示例 package com.test.ws;import com.test.core.json.Jmode;import javax.websocket.*; import javax.websocket.server.ServerEndpoint; import java.util.concurrent.CopyOnWriteArraySet; imp…...

[思维模式-41]:在确定性与不确定性的交响中:人类参与系统的韧性密码。
前言: “任何信息系统,无论怎么复杂,哪怕是几万人同时开发的系统,如无线通信网络,通过标准、设计、算法、完毕的测试、过程的管控等,都是可预测和确定性的。 一个系统,一旦叠加了人的元素和因素…...

维智定位 Android 定位 SDK
概述 维智 Android 定位 SDK是为 Android 移动端应用提供的一套简单易用的定位服务接口,为广大开发者提供融合定位服务。通过使用维智定位SDK,开发者可以轻松为应用程序实现极速、智能、精准、高效的定位功能。 重要:为了进一步加强对最终用…...

Vue3:脚手架
工程环境配置 1.安装nodejs 这里我已经安装过了,只需要打开链接Node.js — Run JavaScript Everywhere直接下载nodejs,安装直接一直下一步下一步 安装完成之后我们来使用电脑的命令行窗口检查一下版本 查看npm源 这里npm源的地址是淘宝的源࿰…...

Android native崩溃问题分析
最近在做NDK项目的时候,出现了启动应用就崩溃了,崩溃日志如下: 10:41:04.743 A Build fingerprint: samsung/g0qzcx/g0q:13/TP1A.220624.014/S9060ZCU4CWH1:user/release-keys 10:41:04.743 A Revision: 12 10:41:04.743 A ABI: arm64…...

Playwright vs Selenium:2025 年 Web 自动化终极对比指南
1. 引言 Web 自动化领域正在迅速发展,在 2025 年,Playwright 与 Selenium 之间的选择已成为开发团队面临的重要决策。Selenium 作为行业标准已有十多年,而 Playwright 作为现代替代方案,以卓越的性能和现代化特性迅速崛起。 本指…...
线性表-链表-单链表)
数据结构(3)线性表-链表-单链表
我们学习过顺序表时,一旦对头部或中间的数据进行处理,由于物理结构的连续性,为了不覆盖,都得移,就导致时间复杂度为O(n),还有一个潜在的问题就是扩容,假如我们扩容前是10…...

Python 中的 typing.ClassVar 详解
一、ClassVar 的定义和基本用途 ClassVar 是 typing 模块中提供的一种特殊类型,用于在类型注解中标记类变量(静态变量)。根据官方文档,使用 ClassVar[…] 注释的属性表示该属性只在类层面使用,不应在实例上赋值 例如&…...

主流数据库运维故障排查卡片式速查表与视觉图谱
主流数据库运维故障排查卡片式速查表与视觉图谱 本文件将主文档内容转化为模块化卡片结构,并补充数据库结构图、排查路径图、锁机制对比等视觉图谱,以便在演示、教学或现场排障中快速引用。 📌 故障卡片速查:连接失败 数据库检查…...
)
Unity:延迟执行函数:Invoke()
目录 Unity 中的 Invoke() 方法详解 什么是 Invoke()? 基本使用方法 使用要点 延伸功能 ❗️Invoke 的局限与注意事项 在Unity中,延迟执行函数是游戏逻辑中常见的需求,比如: 延迟切换场景 延迟播放音效或动画 给玩家时间…...

医学影像系统性能优化与调试技术:深度剖析与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
)
【HTML5学习笔记1】html标签(上)
web标准(重点) w3c 构成:结构、表现、行为,结构样式行为相分离 结构:网页元素整理分类 html 表现:外观css 行为:交互 javascript html标签 1.html语法规范 1) 所有标签都在…...