深入理解二叉树:遍历、存储与算法实现
在之前的博客系列中,我们系统地探讨了多种线性表数据结构,包括顺序表、栈和队列等经典结构,并通过代码实现了它们的核心功能。从今天开始,我们将开启一个全新的数据结构篇章——树结构。与之前讨论的线性结构不同,树形结构以其独特的层次性和分支特性,为我们打开了算法世界的新大门。
1.树
1.1树的概念与结构
树是⼀种非线性的数据结构,它是由 n(n>=0) 个有限结点组成⼀个具有层次关系的集合。把它叫做树是因为它看起来像⼀棵倒挂的树,也就是说它是根朝上,而叶朝下的。
• 有⼀个特殊的结点,称为根结点,根结点没有前驱结点。
• 除根结点外,其余结点被分成 M(M>0) 个互不相交的集合 T1、T2、……、Tm ,其中每⼀个集合Ti(1 <= i <= m) ⼜是⼀棵结构与树类似的⼦树。每棵⼦树的根结点有且只有⼀个前驱,可以有 0 个或多个后继。
因此,树是递归定义的。
示例:
树形结构中,子树之间不能有交集,否则就不是树形结构。
• 子树是不相交的(如果存在相交就是图了)
•除了根结点外,每个结点有且仅有⼀个父结点
• ⼀棵N个结点的树有N-1条边
我们来看一些示例,它们都是一些非树型结构:
1.2树相关术语
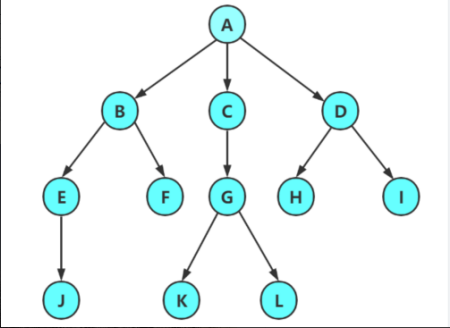
与线性结构的直观简洁不同,树形结构展现出了更为丰富的层次关系和分支特性。为了准确描述和分析这种非线性的数据结构,我们引入了一系列专业术语:根节点、父节点、子节点、叶子节点、度、深度等。这些术语不仅帮助我们精确描述树的组成,也为后续讨论树的遍历和操作奠定了重要基础。下面我们来一一介绍,看下图:
父结点/双亲结点:若一个结点含有子结点,则这个结点称为其子结点的父结点; 如上图:A是B的父结点
子结点/孩子点:⼀个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
结点的度:⼀个结点有几个孩⼦,他的度就是多少;比如A的度为6,F的度为2,K的度为0
树的度:⼀棵树中,最大的结点的度称为树的度; 如上图:树的度为 6
叶子结点/终端结点:度为 0 的结点称为叶结点; 如上图: B、C、H、I… 等结点为叶结点
分支结点/非终端结点:度不为 0 的结点; 如上图: D、E、F、G… 等结点为分支结点
兄弟结点:具有相同父结点的结点互称为兄弟结点(亲兄弟); 如上图: B、C 是兄弟结点
结点的层次:从根开始定义起,根为第 1 层,根的⼦结点为第 2 层,以此类推;
树的高度或深度:树中结点的最大层次; 如上图:树的⾼度为 4
结点的祖先:从根到该结点所经分支上的所有结点;如上图: A 是所有结点的祖先
路径:⼀条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列;比如A到Q的路径为:A-E-J-Q;H到Q的路径H-D-A-E-J-Q
子孙:以某结点为根的子树中任⼀结点都称为该结点的子孙。如上图:所有结点都是A的⼦孙
森林:由 m(m>0) 棵互不相交的树的集合称为森林
理解这些树结构的基本概念不在于死记硬背,而在于培养实际应用能力。我们需要能够具备在树型结构中准确识别各个节点的父子关系,计算节点的度(子节点数量),区分内部节点和叶子节点等等能力,这些实操能力将为后续的代码实现打下坚实的基础。
1.3树的表示
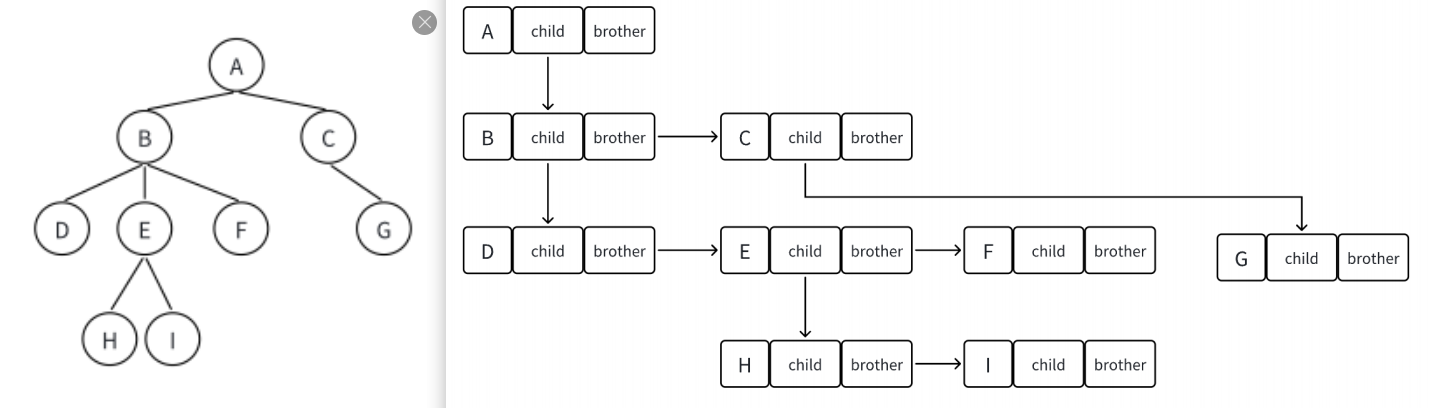
掌握了树结构的基本概念和术语后,我们现在需要解决一个关键问题:如何在程序中有效地表示和存储树形结构?在计算机科学中,树的表示方法多种多样,每种方法都有其适用的场景和优缺点。常见的表示方式包括:双亲表示法(父指针表示法),孩子表示法,孩子兄弟表示法(二叉链表表示法)
我们这里简单介绍一下孩子兄弟表示法:
struct TreeNode
{
struct Node* child; // 左边开始的第⼀个孩⼦结点
struct Node* brother; // 指向其右边的下⼀个兄弟结点
int data; // 结点中的数据域
};
1.4树形结构实际运用场景
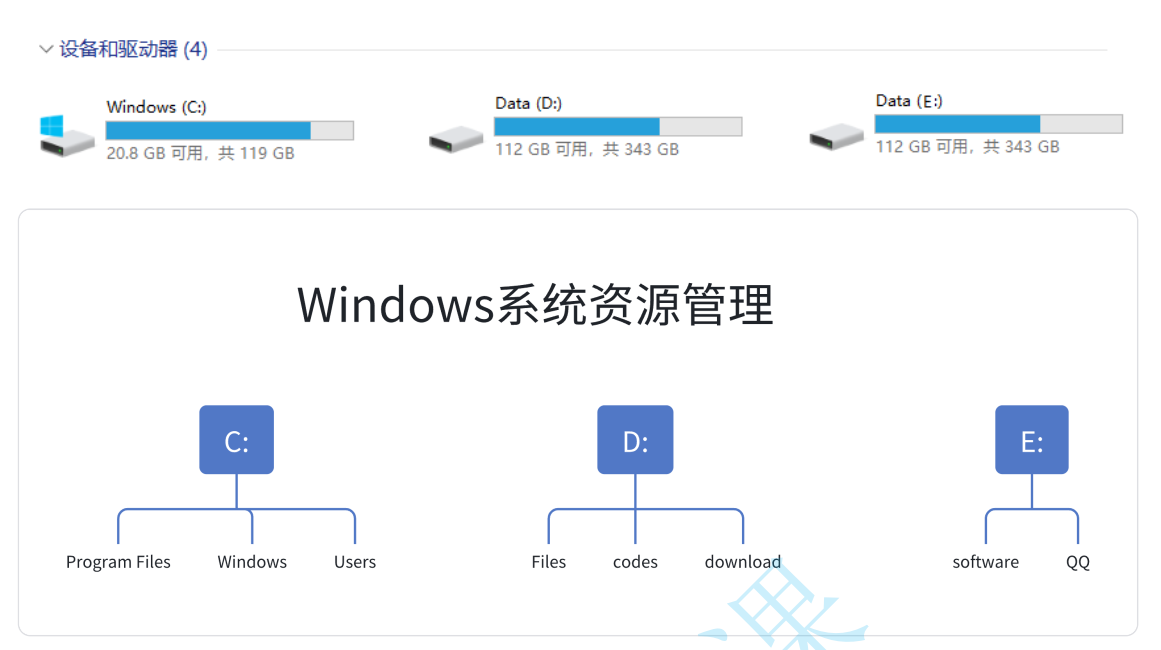
文件系统是计算机存储和管理文件的一种⽅式,它利用树形结构来组织和管理文件和文件夹。在文件系统中,树结构被广泛应用,它通过父结点和子结点之间的关系来表示不同层级的文件和文件夹之间的关联。
2.二叉树
2.1概念与结构
在树形结构中,我们最常用的就是⼆叉树,⼀棵二叉树是结点的⼀个有限集合,该集合由⼀个根结点加上两棵别称为左子树和右子树的⼆叉树组成或者为空。
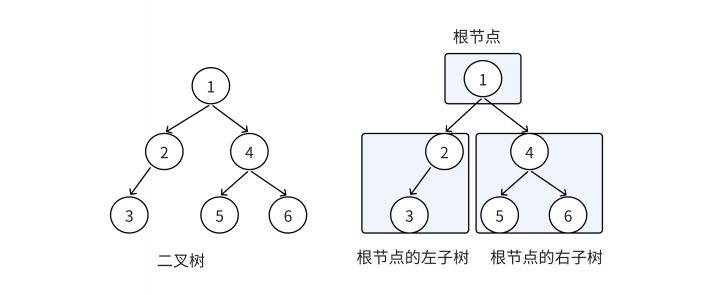
从上图可以看出二叉树具备以下特点:
- 二叉树不存在度大于 2 的结点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
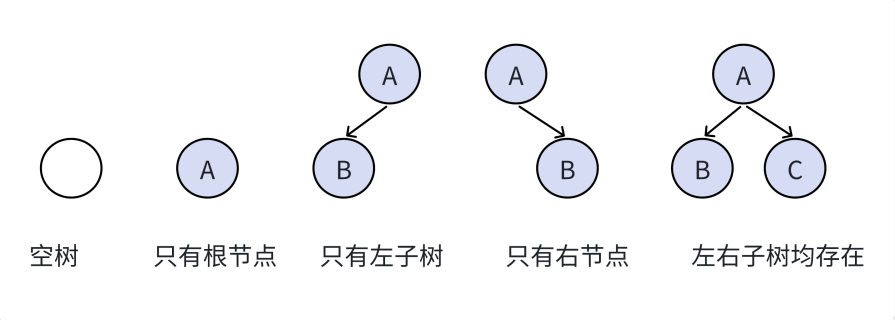
注意:对于任意的二叉树都是由以下几种情况复合而成的:
2.2特殊的二叉树
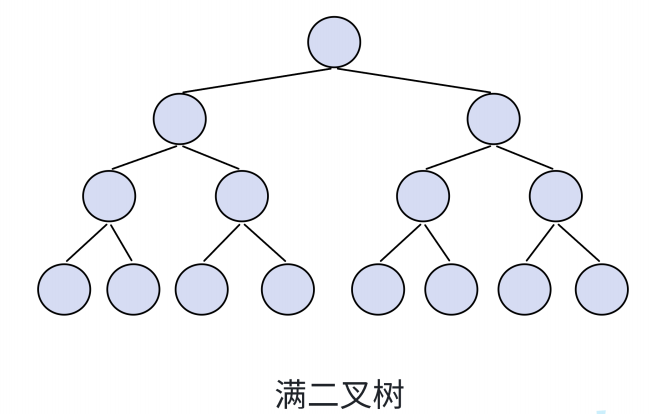
2.2.1满二叉树
⼀个二叉树,如果每⼀个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果⼀个二叉树的层数为 K ,且结点总数是 2k − 1 ,则它就是满二叉树。
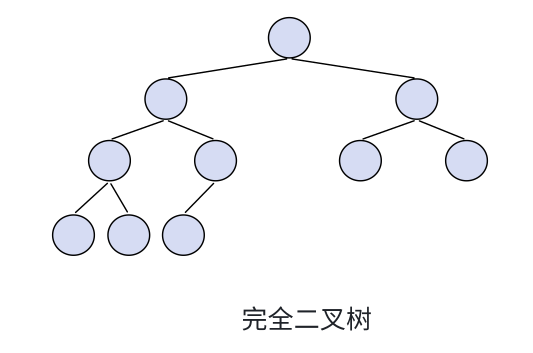
2.2.2完全二叉树!
完全二叉树(Complete Binary Tree)是一种特殊的二叉树,它的定义是基于满二叉树的概念。在完全二叉树中,除了最后一层,其他各层的节点数都达到了最大个数,而最后一层的节点则都连续集中在最左边。这种结构的二叉树,其深度为h时,除了第h层外,其余各层(1~h-1)的节点数都是满的,第h层的节点从左到右连续排列,但不一定是满的。
⼆叉树性质
根据满⼆叉树的特点可知:
1)若规定根结点的层数为 1 ,则⼀棵非空⼆叉树的第i层上最多有 2i−1 个结点
2)若规定根结点的层数为 1 ,则深度为 h 的⼆叉树的最⼤结点数是 2h − 1
3)若规定根结点的层数为 1 ,具有 n 个结点的满⼆叉树的深度 h = log2 (n + 1)( log以2为底, n+1 为对数)
2.3二叉树存储结构
二叉树⼀般使用两种结构存储,⼀种顺序结构,⼀种链式结构。
2.3.1顺序存储
顺序结构存储就是使用数组来存储,⼀般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。
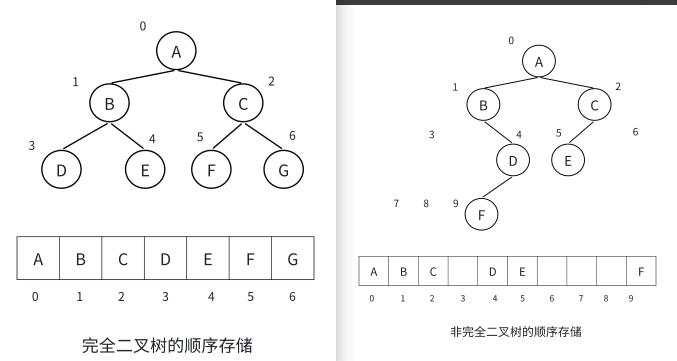
现实中我们通常把堆(⼀种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,⼀个是数据结构,⼀个是操作系统中管理内存的⼀块区域分段。
2.3.2链式存储
二叉树的链式存储结构通过链表形式动态表示结点间的逻辑关系,其核心设计思想如下:
-
结点结构设计
- 每个链式结点由三个域构成:
- 数据域:存储当前结点的元素值
- 左指针域:指向左子结点的内存地址
- 右指针域:指向右子结点的内存地址
- 通过指针的动态链接实现树形拓扑结构,形成"结点-子树"的递归关系
- 每个链式结点由三个域构成:
-
链式类型划分
- 二叉链:
- 仅含左右子结点指针
- 空间效率高,满足基础算法实现需求
- 三叉链:
- 增加父结点指针域
- 便于逆向溯源,应用于红黑树等复杂数据结构
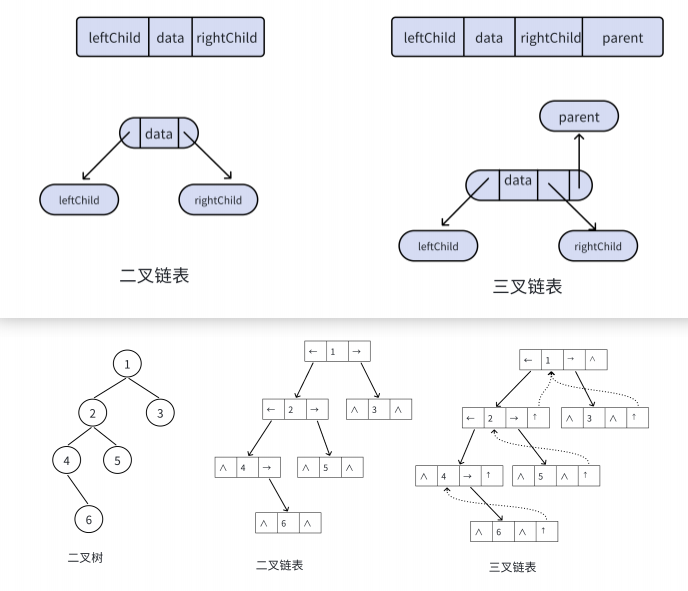
- 二叉链:
3.实现顺序结构二叉树
3.1堆的概念与结构
堆通常采用顺序存储结构(如数组)实现,其在逻辑上表现为一棵完全二叉树,同时满足关键有序性:每个结点的值总保持大于等于(大顶堆)或小于等于(小顶堆)其子节点的值。这种双重要求既继承了完全二叉树的层级结构特性,又通过父子结点间的有序性约束,赋予堆快速获取极值、动态调整高效的核心优势,成为优先队列等场景的理想数据结构载体。
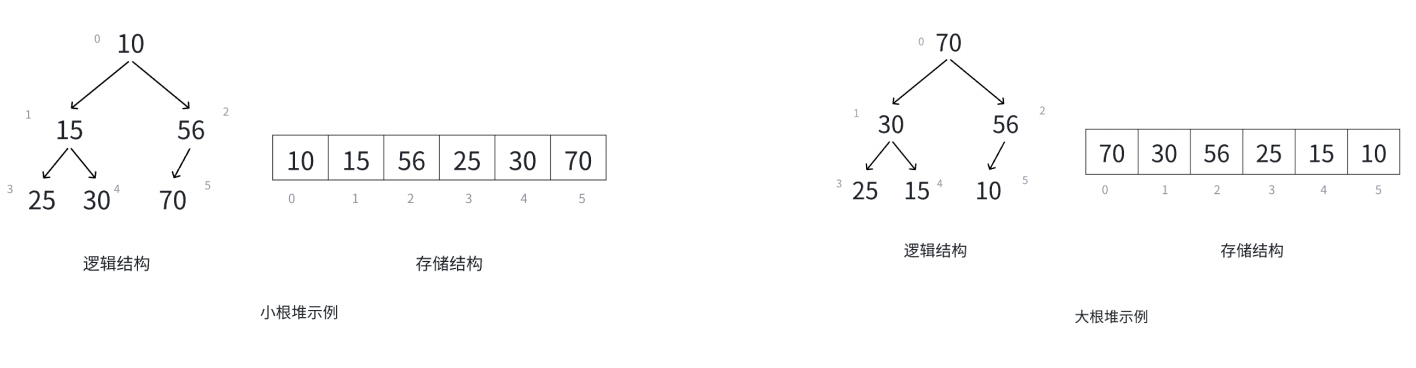
对于具有 n 个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0 开始编号,则对于序号为 i 的结点有:
- 若 i>0 , i 位置结点的双亲序号: (i-1)/2 ; i=0 , i 为根结点编号,无双亲结点
- 若 2i+1<n ,左孩⼦序号: 2i+1 , 2i+1>=n 否则无左孩子
- 若 2i+2<n ,右孩⼦序号: 2i+2 , 2i+2>=n 否则无右孩子
3.2堆的实现及堆排序算法
该代码实现了小根堆(Min-Heap)的所有基本操作,具备插入、删除、调整等核心功能。
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int HPDataType;// 堆结构定义(数组存储)
typedef struct Heap
{HPDataType* arr; // 动态数组指针int size; // 当前元素个数int capacity; // 数组容量
}HP;/* 堆基础操作 */
void HPInit(HP* php) // 初始化空堆
{assert(php);php->arr = NULL;php->capacity = php->size = 0;
}// 元素交换函数
void Swap(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}/* 核心调整算法 */
// 向上调整(插入时使用)时间复杂度O(logN)
void AdjustUp(HPDataType* a, int child)
{assert(a);int parent = (child - 1) / 2; // 计算父节点索引// 小堆:子节点 < 父节点时交换(大堆改为>)while (child > 0) // 循环直到到达根节点{if (a[child] < a[parent]) // 小堆条件判断{Swap(&a[child], &a[parent]);child = parent; // 向上移动指针parent = (child - 1) / 2; // 更新父节点}elsebreak; // 满足堆条件时退出}
}// 插入元素(自动扩容)
void HPPush(HP* php, HPDataType x)
{assert(php);// 容量检查(2倍扩容策略)if (php->capacity == php->size){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* temp = (HPDataType*)realloc(php->arr, newcapacity * sizeof(HPDataType));if (temp == NULL){perror("realloc fail");exit(1);}php->arr = temp;php->capacity = newcapacity;}// 插入尾部并调整php->arr[php->size++] = x;AdjustUp(php->arr, php->size-1); // 从新插入位置开始调整
}// 判断堆是否为空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}// 向下调整(删除堆顶时使用)时间复杂度O(logN)
void AdjustDown(HPDataType* a, int n, int parent)
{assert(a);int child = parent * 2 + 1; // 左孩子索引while (child < n) // 在有效范围内调整{// 选择较小的子节点(小堆特性,大堆则选较大值)if (child + 1 < n && a[child] > a[child + 1])child++;// 小堆条件判断(父节点 > 子节点时交换)if (a[child] < a[parent]) {Swap(&a[child], &a[parent]);parent = child; // 向下移动指针child = parent * 2 + 1; // 更新左孩子索引}elsebreak; // 满足堆条件时退出}
}// 删除堆顶元素
void HPPop(HP* php)
{assert(php);assert(!HPEmpty(php));// 交换首尾元素并删除尾部Swap(&php->arr[0], &php->arr[php->size - 1]);php->size--;// 从根节点开始向下调整AdjustDown(php->arr, php->size, 0);
}/* 辅助功能 */
int HPSize(HP* php) // 获取当前元素数量
{assert(php);return php->size;
}void HPDestroy(HP* php) // 销毁堆释放内存
{assert(php);if (php->arr)free(php->arr);php->arr = NULL;php->capacity = php->size = 0;
}HPDataType HPTop(HP* php) // 获取堆顶元素
{assert(php && php->size > 0);return php->arr[0];
}/* 建堆方法*/
void HPInitArray(HP* php, HPDataType* a, int n)
{for (int i = 0; i < n; i++){HPPush(php, a[i]); // 逐个插入方式建堆}
}
在这里我们着重介绍一下向上调整算法(AdjustUp)和向下调整算法(AdjustDown)这两个核心函数。
3.2.1向上调整算法
向上调整算法用于在插入新元素后,维护堆的有序性。
当向堆的尾部插入一个新元素时,可能破坏堆的父子节点大小关系(如小根堆中父节点应 ≤ 子节点),该算法通过逐层向上比较与交换,确保堆结构恢复有效状态。
示例:
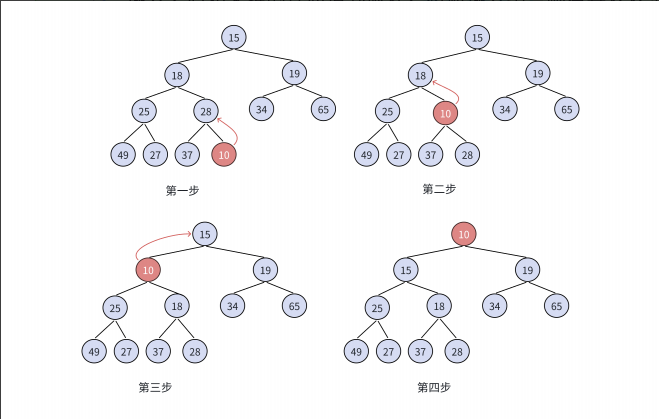
如果我们要用向上调整算法来建立一个堆并将它排序,代码非常简单,如下:
//向上调整算法建堆时间复杂度为: O(n ∗ log2 n)
void HeapSort(int* a, int n)
{// a数组直接建堆 O(N)for (int i = 0; i < n; i++){AdjustUp(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
注意:数据降序需用小堆,升序则用大堆
究其原因是小堆每次调整完将最小值放在数组最后,大堆调整完将最大值放在最后。
3.2.2向下调整算法
删除堆是删除堆顶的数据,将堆顶的数据根最后⼀个数据⼀换,然后删除数组最后⼀个数据,再进行向下调整算法。
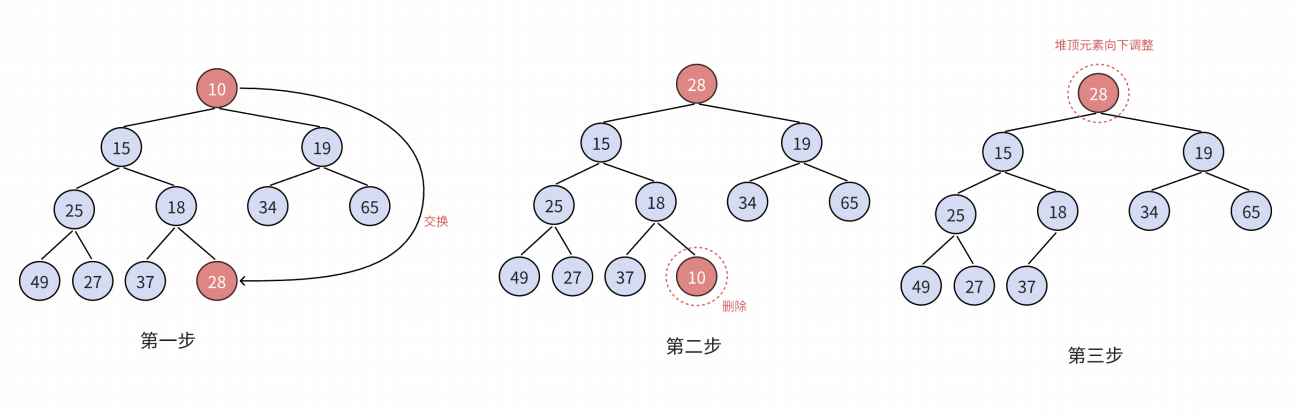
向下调整算法有⼀个前提:左右子树必须是⼀个堆,才能调整。
• 将堆顶元素与堆中最后⼀个元素进行交换
• 删除堆中最后⼀个元素
• 将堆顶元素向下调整到满足堆特性为止
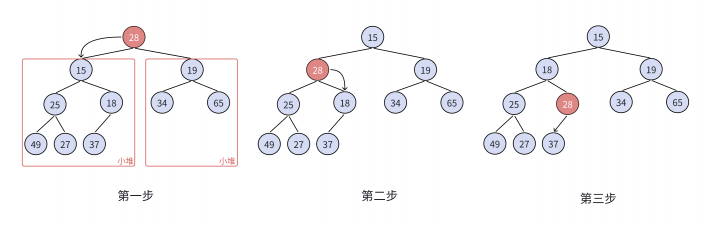
同样的,用向下调整算法来建立一个堆并将它排序,代码也非常简单,如下:
//堆排序整体算法复杂度为O(N*logN)
//向下调整算法建堆时间复杂度为: O(n)
void HeapSort(int* a, int n)
{// a数组直接建堆 O(N)for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
因为向下调整算法建堆的时间复杂度要小于向上调整算法,所以在堆排序实际应用中我们大多采用向下调整算法建堆,并且向上调整算法并不适合后续的排序算法,所以整体来说向下调整算法更加优秀。
3.3.TOK-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,⼀般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了。(数据不能⼀下子全部加载到内存中)。
最佳的方式就是用堆来解决,基本思路如下:
1)用数据集合中前K个元素来建堆,求前k个最大的元素,则建小堆,求前k个最小的元素,则建大堆
2)用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素
代码实现:
void CreateNDate()
{// 造数据int n = 100000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (int i = 0; i < n; ++i){int x = (rand() + i) % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}void TOPk()
{int k = 0;printf("请输入k:");scanf("%d", &k);const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen fail!");exit(1);}int* minHeap = (int*)malloc(k * sizeof(int));if (minHeap == NULL){perror("malloc fail!");exit(2);}//从文件中读取前K个数据for (int i = 0; i < k; i++){fscanf(fout, "%d", &minHeap[i]);}//建堆---小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(minHeap, k, i);}int x = 0;while (fscanf(fout, "%d", &x) == 1){//读取到的数据跟堆顶的数据进行比较//比堆顶值大,交换入堆if (x > minHeap[0]){minHeap[0] = x;AdjustDown(minHeap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", minHeap[i]);}fclose(fout);
}执行过程中
CreateData函数创建一份写有十万个数据的文件,用到了创建随机数的三个函数rand,srand,time,这些知识都在前面的博客内容中有所提到,不了解的读者可以去看看这两篇博客。
猜数字小游戏
文件操作手册
然后我们动态创建一个数组,将文件中前k个数据存入数组中,并建立小堆,然后将文件中其他数据与小堆堆顶进行比较,如果大于堆顶数据,则替换,并重新向下调整,保证堆顶是堆内最小数据,直至遍历完所有数据,最后打印堆内数据为最后结果。
4.实现链式结构二叉树
4.1链式二叉树的基本结构
用链表来表示⼀棵二叉树,即用链式结构表示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 ,其结构如下:
typedef int BTDataType;
// ⼆叉链
typedef struct BinaryTreeNode
{struct BinTreeNode* left; // 指向当前结点左孩⼦struct BinTreeNode* right; // 指向当前结点右孩⼦BTDataType val; // 当前结点值域
}BTNode;
⼆叉树的创建方式比较复杂,为了更好的步入到⼆叉树内容中,我们手动先创建⼀棵链式⼆叉树:
BTNode* CreateNode(BTDataType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}
int main()
{BTNode* node1 = CreateNode(1);BTNode* node2 = CreateNode(2);BTNode* node3 = CreateNode(3);BTNode* node4 = CreateNode(4);BTNode* node5 = CreateNode(5);BTNode* node6 = CreateNode(6);node1->left = node2;node1->right = node3;node2->left = node4;node2->right = node5;node3->left = node6;return 0;
}
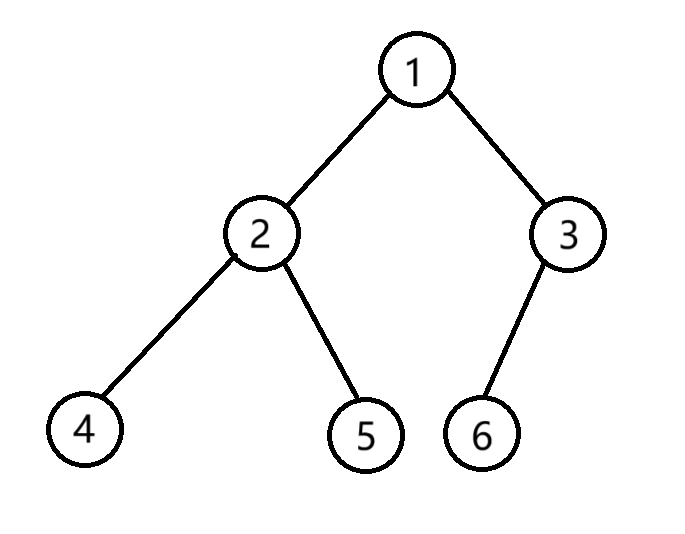
这是上面代码创建的二叉树示意图。
回顾二叉树的概念,二叉树分为空树和非空二叉树,非空二叉树由根结点、根结点的左子树、根结点的右子树组成的。
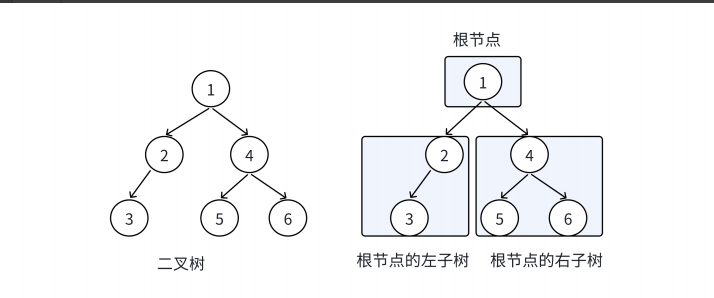
根结点的左子树和右子树分别又是由子树结点、子树结点的左子树、子树结点的右子树组成的,因此二叉树定义是递归式的,后面链式二叉树的许多操作中基本都是借助该概念帮助实现的
4.2二叉树的四种遍历方式
还是上面我们自己创建的二叉树,我们分别用不同的遍历方式来遍历,看看都是怎么个顺序。
首先我们来介绍三种遍历方式,它们是一体的,分别是前序遍历,中序遍历,后序遍历。遍历规则为:
- 前序遍历(亦称先序遍历):访问根结点的操作发生在遍历其左右⼦树之前,访问顺序为:根结点、左子树、右子树
- 中序遍历:访问根结点的操作发生在遍历其左右子树中间,访问顺序为:左子树、根结点、右子树
- 后序遍历:访问根结点的操作发生在遍历其左右子树之后,访问顺序为:左子树、右子树、根结点
//前序遍历
void PreOrder(BTNode* root)
{if (root == NULL){return;}printf("%d ", root->data);PreOrder(root->left);PreOrder(root->right);
}//中序遍历
void InOrder(BTNode* root)
{if (root == NULL){return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}//后序遍历
void PostOrder(BTNode* root)
{if (root == NULL){return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);
}
前序遍历遵循"根节点-左子树-右子树"的顺序访问二叉树。以上文创建二叉树为例,遍历从根节点1开始:首先访问并打印根节点1,接着遍历左子树,访问节点2并打印,继续深入节点2的左子树,访问节点4并打印(节点4没有子节点,该分支遍历结束),返回处理节点2的右子树,访问节点5并打印(节点5没有子节点),最后处理根节点的右子树,访问节点3并打印,继续访问节点3的左子树节点6并打印(节点6没有子节点,且节点3没有右子树),程序结束。
最终前序遍历结果为:1 2 4 5 3 6
中序遍历与后续遍历一样按照自身规则一步一步递归实现,这里不再重复赘述,最后中序遍历结果为:4 2 5 1 6 3,后序遍历结果为:4 5 2 6 3 1,大家可以自己试着遍历。
还有一种遍历方式是层序遍历,我们设二叉树的根结点所在层数为1,从所在二叉树的根结点出发,首先访问第一层的树根结点,然后从左到右访问第二层上的结点,接着是第三层的结点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
实现层序遍历我们需要用到之前学过的一种数据结构:队列。在实现层序遍历代码中用到了之前队列博客里的封装函数,大家可以去这篇博客里看一下:
栈与队列,要注意:typedef struct BinaryTreeNode* QDataType;
void LevelOrder(BTNode* root)
{Queue pq;QueueInit(&pq);if(root)QueuePush(&pq, root);while (!QueueEmpty(&pq)){BTNode* front = QueueFront(&pq);printf("%d ", front->data);QueuePop(&pq);if(front->left)QueuePush(&pq, front->left);if(front->right)QueuePush(&pq, front->right);}QueueDestroy(&pq);
}
实现过程:
初始化队列:首先创建一个先进先出(FIFO)的队列结构,用于临时存储待访问的节点指针。根节点入队:若二叉树非空,将根节点指针存入队列,作为遍历的起始点。
循环处理队列:
取出队首节点:通过队列接口获取当前队首元素(即最早入队的节点)
访问节点数据:输出该节点的数值信息(或其他处理操作)
节点出队:将该节点从队列中移除
子节点入队:若当前节点存在左孩子,将其左孩子指针入队;同理处理右孩子
终止条件:当队列为空时,表明所有节点均已访问完毕,遍历结束。
资源释放:最终销毁队列结构,释放系统资源。
该算法通过队列的先进先出特性,确保节点总是按照层级顺序被处理:首先访问根节点,接着是第二层的左右子节点,然后是第三层的节点,以此类推。
4.3链式二叉树其他函数封装
/* 计算二叉树节点总数 */
int BinaryTreeSize(BTNode* root)
{// 递归终止条件:空树节点数为0if (root == NULL) return 0;// 当前节点(1) + 左子树节点数 + 右子树节点数return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);
}/* 计算二叉树叶子节点数 */
int BinaryTreeLeafSize(BTNode* root)
{// 递归终止条件:空树没有叶子节点if (root == NULL) return 0;// 当前节点是叶子节点的条件:左右子树均为空if (root->left == NULL && root->right == NULL) return 1;// 左子树叶子数 + 右子树叶子数return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}/* 计算第K层节点数 */
int BinaryTreeLevelKSize(BTNode* root, int k)
{// 递归终止条件1:空树if (root == NULL) return 0;// 递归终止条件2:到达目标层级if (k == 1) return 1;// 左子树第k-1层节点数 + 右子树第k-1层节点数return BinaryTreeLevelKSize(root->left, k-1) + BinaryTreeLevelKSize(root->right, k-1);
}/* 计算二叉树深度/高度 */
int BinaryTreeDepth(BTNode* root)
{// 递归终止条件:空树深度为0if (root == NULL) return 0;// 分别计算左右子树深度int leftDepth = BinaryTreeDepth(root->left);int rightDepth = BinaryTreeDepth(root->right);// 取较大值 + 当前层(1)return (leftDepth > rightDepth ? leftDepth : rightDepth) + 1;
}/* 查找值为x的节点 */
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{// 递归终止条件1:空树或找到目标节点if (root == NULL) return NULL;if (root->data == x) return root;// 先在左子树查找BTNode* leftResult = BinaryTreeFind(root->left, x);if (leftResult) return leftResult;// 左子树未找到则在右子树查找BTNode* rightResult = BinaryTreeFind(root->right, x);if (rightResult) return rightResult;// 整棵树未找到返回NULLreturn NULL;
}/* 销毁二叉树(二级指针版) */
void BinaryTreeDestory(BTNode** root)
{// 递归终止条件:空树if (*root == NULL) return;// 后序方式递归释放BinaryTreeDestory(&(*root)->left);BinaryTreeDestory(&(*root)->right);// 释放当前节点并将指针置NULLfree(*root);*root = NULL;
}/* 判断是否完全二叉树 */
bool BinaryTreeComplete(BTNode* root)
{Queue pq;QueueInit(&pq);// 根节点入队开始层序遍历if (root) QueuePush(&pq, root);// 第一阶段:遇到第一个NULL节点时停止while (!QueueEmpty(&pq)){BTNode* front = QueueFront(&pq);QueuePop(&pq);// 遇到空节点则跳出循环if (front == NULL) break;// 无论子节点是否NULL都入队QueuePush(&pq, front->left);QueuePush(&pq, front->right);}// 第二阶段:检查队列剩余节点while (!QueueEmpty(&pq)){BTNode* front = QueueFront(&pq);QueuePop(&pq);// 如果还有非NULL节点,则不是完全二叉树if (front != NULL) {QueueDestroy(&pq);return false;}}QueueDestroy(&pq);return true;
}
关键点与注意点:
-
递归实现:
多数函数(节点计数、深度计算、查找等)采用递归实现,需确保:
-
明确的递归终止条件(如root == NULL)
-
正确的递归分解(如左子树+右子树+当前节点)
注意:递归深度可能导致栈溢出(极端深度的树)
-
-
遍历方式选择:
-
销毁二叉树必须使用后序遍历(先释放子树再释放根)
-
层级相关操作(如K层节点数)适合前序/深度优先
-
完全二叉树判断必须用层序遍历
-
-
完全二叉树检测:
核心逻辑:层序遍历中遇到NULL后,后续不得出现非NULL节点
需注意:
-
所有子节点(包括NULL)都要入队
-
队列中存储的是节点指针,需处理NULL值
-
-
内存管理:
-
销毁函数使用二级指针(BTNode**),确保外部指针置NULL
-
队列操作后必须调用Destroy,避免内存泄漏
-
查找函数返回节点指针,注意不要误修改原树结构
-
这一系列函数完整实现了二叉树的核心操作,涵盖了节点统计、结构分析和内存管理。递归思想贯穿多数实现,需特别注意终止条件和资源释放。
相关文章:

深入理解二叉树:遍历、存储与算法实现
在之前的博客系列中,我们系统地探讨了多种线性表数据结构,包括顺序表、栈和队列等经典结构,并通过代码实现了它们的核心功能。从今天开始,我们将开启一个全新的数据结构篇章——树结构。与之前讨论的线性结构不同,树形…...

Python web 开发 Flask HTTP 服务
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编写,特别适合构建简单的 Web 应用和 RESTful API。Flask 的设计理念是提供尽可能少的约定和配置,从而让开发者能够灵活地构建自己的 Web 应用。 https://andi.cn/page/622189.html...

【AI】用Dify实现一个模拟面试的功能
前言 Dify,一个将LLM转换为实际工作流的工具,以及火了一段时间了,但直到最近才开始研究它的使用(主要前段时间在忙着自己的独立开发项目),我发现它的功能基本上满足了我对大语言模型,从仅对话转…...
)
研华服务器ASMB-825主板无法识别PCIE-USB卡(笔记本)
系统下无法识别到USB卡,排除硬件问题,系统问题。 最后在BIOS中更改此PCIE端口参数为X4X4X4X4,设置完成后可正常使用USB卡。 底部有问题详细解析。 针对研华主板ASMB-825安装绿联PCIE-USB卡无法识别的问题,结合BIOS设置调整的解决过…...

Redisson 四大核心机制实现原理详解
一、可重入锁(Reentrant Lock) 可重入锁是什么? 通俗定义 可重入锁类似于一把“智能锁”,它能识别当前的锁持有者是否是当前线程: 如果是,则允许线程重复获取锁(重入),并…...
)
云计算与大数据进阶 | 26、解锁云架构核心:深度解析可扩展数据库的5大策略与挑战(上)
在云应用/服务的 5 层架构里,数据库服务层稳坐第 4 把交椅,堪称其中的 “硬核担当”。它的复杂程度常常让人望而生畏,不少人都将它视为整个架构中的 “终极挑战”。 不过,也有人觉得可扩展存储系统才是最难啃的 “硬骨头”&#…...

Android从单体架构迁移到模块化架构。你会如何设计模块划分策略?如何处理模块间的通信和依赖关系
从单体架构迁移到模块化架构。可能有些小伙伴已经深陷单体架构的泥潭,代码耦合得跟一团麻线似的,改个小功能都能牵一发而动全身;也可能有些团队在协作时,经常因为代码冲突或者职责不清搞得焦头烂额。相信我,这些问题我…...

基于MATLAB的人脸识别,实现PCA降维,用PCA特征进行SVM训练
基于MATLAB的人脸识别完整流程,包含PCA降维和SVM分类的实现。我们以经典的ORL人脸数据库为例,演示从数据加载到结果评估的全过程。 1. 数据准备与预处理 1.1 下载数据集 下载ORL人脸数据库(40人10张,共400张图像)…...

AI 赋能 Copula 建模:大语言模型驱动的相关性分析革新
技术点目录 R及Python语言及相关性研究初步二元Copula理论与实践(一)二元Copula理论与实践(二)【R语言为主】Copula函数的统计检验与选择【R语言为主】高维数据与Vine Copula 【R语言】正则Vine Copula(一)…...

机器学习与人工智能:NLP分词与文本相似度分析
DIY AI & ML NLP — Tokenization & Text Similarity by Jacob Ingle in Data Science Collective 本文所使用的数据是在 Creative Commons license 下提供的。尽管我们已尽力确保信息的准确性和完整性,但我们不对数据的完整性或可靠性做任何保证。数据的使…...

特斯拉虚拟电厂:能源互联网时代的分布式革命
在双碳目标与能源转型的双重驱动下,特斯拉虚拟电厂(Virtual Power Plant, VPP)通过数字孪生技术与能源系统的深度融合,重构了传统电力系统的运行范式。本文从系统架构、工程实践、技术挑战三个维度,深度解析这一颠覆性…...
在医学编程中的初步分析与探索)
系统提示学习(System Prompt Learning)在医学编程中的初步分析与探索
一、SPL 的核心定义 系统提示学习(SPL)是一种通过策略性设计输入提示(Prompts),引导大型语言模型(LLMs)生成特定领域行为与输出的方法。其核心在于不修改模型参数,而是通过上下文工程(Context Engineering)动态控制模型响应,使其适配复杂任务需求。 与微调(Fine-…...
)
使用DDR4控制器实现多通道数据读写(十二)
一、章节概括 这一节使用interconnect RTL ip核将DDR4与四个读写通道级联,在测试工程中,将四个通道同时写入/读出地址与数据,并使用modelsim仿真器仿真,四个通道同时发送写请求或读请求后,经过interconnect后ÿ…...

PCIe数据采集系统详解
PCIe数据采集系统详解 在上篇文章中,废了老大劲儿我们写出了PCIe数据采集系统;其中各个模块各司其职,相互配合。完成了从数据采集到高速存储到DDR3的全过程。今天我们呢就来详细讲解他们之间的关系?以及各个模块的关键点ÿ…...

小白级通信小号、虚拟小号查询技术讲解
手机号构成与归属地原理 手机号码由国家代码、运营商代码和用户号码等部分组成。全球手机号段由国际电信联盟(ITU)统一规划,各国通信管理机构负责分配具体号段。在我国,通过解析手机号码前几位,就能确定其所属运营商及…...

【爬虫】DrissionPage-4
官网文档:https://www.drissionpage.cn/browser_control/browser_options 一、核心对象与初始化 1. 类定义 作用:管理Chromium内核浏览器的启动配置,仅在浏览器启动时生效。导入方式:from DrissionPage import ChromiumOptions…...

数据通信原理 光纤通信 期末速成
一、图表题 1. 双极性不归零、单极性不归零、曼彻斯特码、抑制载频2ASK,2PSK、2DPSK信号的波形 双极性不归零 和 单极性不归零:不归零意思是 0 低 1 高 非归零编码(NRZ):用不同电平表示二进制数字,常以…...

Java微服务架构实战:Spring Boot与Spring Cloud的完美结合
Java微服务架构实战:Spring Boot与Spring Cloud的完美结合 引言 随着云计算和分布式系统的快速发展,微服务架构已成为现代软件开发的主流模式。Java作为一门成熟的编程语言,凭借其强大的生态系统和丰富的框架支持,成为构建微服务…...

React底层架构深度解析:从虚拟DOM到Fiber的演进之路
一、虚拟DOM:性能优化的基石 1.1 核心工作原理 React通过JSX语法将组件转换为轻量级JavaScript对象(即虚拟DOM),而非直接操作真实DOM。这一过程由React.createElement()实现,其结构包含元素类型、属性和子节点等信息&a…...

今日行情明日机会——20250516
上证缩量收阴线,小盘股表现相对更好,上涨的个股大于下跌的,日线已到前期压力位附近,注意风险。 深证缩量收假阳线,临近日线周期上涨末端,注意风险。 2025年5月16日涨停股行业方向分析 机器人概念&#x…...

小结:网页性能优化
网页性能优化是提升用户体验、减少加载时间和提高资源利用率的关键。以下是针对网页生命周期和事件处理的性能优化技巧,结合代码示例,重点覆盖加载、渲染、事件处理和资源管理等方面。 1. 优化加载阶段 减少关键资源请求: 合并CSS/JS文件&a…...

2025年PMP 学习十五 第10章 项目资源管理
2025年PMP 学习十五 第10章 项目资源管理 序号过程过程组1规划沟通管理规划2管理沟通执行3监控沟通监控 项目沟通管理包括为确保项目的信 息及时且恰当地规划、收集、生成、发布、存储、检索、管理、控制、监 警和最终处理所需的过程; 项目经理绝大多数时间都用于与…...

速通RocketMQ配置
配置RocketMQ又出问题了,赶紧记录一波 这个是我的RocketMQ配置文件 通过网盘分享的文件: 链接: https://pan.baidu.com/s/1UUYeDvKZFNsKPFXTcalu3A?pwd8888 提取码: 8888 –来自百度网盘超级会员v9的分享 里面有这三个东西 里面还有一些broker和names…...

宇宙中是否存在量子现象?
一、宇宙中的量子现象 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 量子涨落与宇宙结构 早期宇宙的量子涨落(微观尺度的不确定性…...

背包问题详解
一、问题引入:什么是背包问题? 背包问题是经典的动态规划问题,描述如下: 有一个容量为 m 的背包 有 n 个物品,每个物品有体积 v 和价值 w 目标:选择物品装入背包,使总价值最大且总体积不超过…...

oracle linux 95 升级openssh 10 和openssl 3.5 过程记录
1. 安装操作系统,注意如果可以选择,选择安装开发工具,主要是后续需要编译安装,需要gcc 编译工具。 2. 安装操作系统后,检查zlib 、zlib-dev是否安装,如果没有,可以使用安装镜像做本地源安装&a…...

Tomcat发布websocket
一、tomcal的lib放入文件 tomcat-websocket.jar websocket-api.jar 二、代码示例 package com.test.ws;import com.test.core.json.Jmode;import javax.websocket.*; import javax.websocket.server.ServerEndpoint; import java.util.concurrent.CopyOnWriteArraySet; imp…...

[思维模式-41]:在确定性与不确定性的交响中:人类参与系统的韧性密码。
前言: “任何信息系统,无论怎么复杂,哪怕是几万人同时开发的系统,如无线通信网络,通过标准、设计、算法、完毕的测试、过程的管控等,都是可预测和确定性的。 一个系统,一旦叠加了人的元素和因素…...

维智定位 Android 定位 SDK
概述 维智 Android 定位 SDK是为 Android 移动端应用提供的一套简单易用的定位服务接口,为广大开发者提供融合定位服务。通过使用维智定位SDK,开发者可以轻松为应用程序实现极速、智能、精准、高效的定位功能。 重要:为了进一步加强对最终用…...

Vue3:脚手架
工程环境配置 1.安装nodejs 这里我已经安装过了,只需要打开链接Node.js — Run JavaScript Everywhere直接下载nodejs,安装直接一直下一步下一步 安装完成之后我们来使用电脑的命令行窗口检查一下版本 查看npm源 这里npm源的地址是淘宝的源࿰…...

Android native崩溃问题分析
最近在做NDK项目的时候,出现了启动应用就崩溃了,崩溃日志如下: 10:41:04.743 A Build fingerprint: samsung/g0qzcx/g0q:13/TP1A.220624.014/S9060ZCU4CWH1:user/release-keys 10:41:04.743 A Revision: 12 10:41:04.743 A ABI: arm64…...

Playwright vs Selenium:2025 年 Web 自动化终极对比指南
1. 引言 Web 自动化领域正在迅速发展,在 2025 年,Playwright 与 Selenium 之间的选择已成为开发团队面临的重要决策。Selenium 作为行业标准已有十多年,而 Playwright 作为现代替代方案,以卓越的性能和现代化特性迅速崛起。 本指…...
线性表-链表-单链表)
数据结构(3)线性表-链表-单链表
我们学习过顺序表时,一旦对头部或中间的数据进行处理,由于物理结构的连续性,为了不覆盖,都得移,就导致时间复杂度为O(n),还有一个潜在的问题就是扩容,假如我们扩容前是10…...

Python 中的 typing.ClassVar 详解
一、ClassVar 的定义和基本用途 ClassVar 是 typing 模块中提供的一种特殊类型,用于在类型注解中标记类变量(静态变量)。根据官方文档,使用 ClassVar[…] 注释的属性表示该属性只在类层面使用,不应在实例上赋值 例如&…...

主流数据库运维故障排查卡片式速查表与视觉图谱
主流数据库运维故障排查卡片式速查表与视觉图谱 本文件将主文档内容转化为模块化卡片结构,并补充数据库结构图、排查路径图、锁机制对比等视觉图谱,以便在演示、教学或现场排障中快速引用。 📌 故障卡片速查:连接失败 数据库检查…...
)
Unity:延迟执行函数:Invoke()
目录 Unity 中的 Invoke() 方法详解 什么是 Invoke()? 基本使用方法 使用要点 延伸功能 ❗️Invoke 的局限与注意事项 在Unity中,延迟执行函数是游戏逻辑中常见的需求,比如: 延迟切换场景 延迟播放音效或动画 给玩家时间…...

医学影像系统性能优化与调试技术:深度剖析与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
)
【HTML5学习笔记1】html标签(上)
web标准(重点) w3c 构成:结构、表现、行为,结构样式行为相分离 结构:网页元素整理分类 html 表现:外观css 行为:交互 javascript html标签 1.html语法规范 1) 所有标签都在…...

SearchIndexablesProvider
实现的 provider 根据索引添加文档可知,该 provider 需要继承自 frameworks/base/core/java/android/provider/SearchIndexablesProvider.java 类,并且添加权限 android.permission.READ_SEARCH_INDEXABLES。过滤 Settings 代码,可以轻易找到…...

《k-means 散点图可视化》实验报告
一,实验目的 本次实验旨在通过Python编程实现k - means算法的散点图可视化。学习者将编写代码,深入理解聚类分析基本原理与k - means算法实现流程,掌握数据聚类及可视化方法,以直观展示聚类结果。 二,实验原理 k-mea…...

数学复习笔记 12
前言 现在做一下例题和练习题。矩阵的秩和线性相关。另外还要复盘前面高数的部分的内容。奥,之前矩阵的例题和练习题,也没有做完,行列式的例题和练习题也没有做完。累加起来了。以后还是得学一个知识点就做一个部分的内容,日拱一…...

Web-CSS入门
WEB前端,三部分:HTML部分、CSS部分、Javascript部分。 1.HTML部分:主要负责网页的结构层 2.CSS部分:主要负责网页的样式层 3.JS部分:主要负责网页的行为层 **基本概念** 层叠样式表,Cascading Style Sh…...

Qt/C++编写音视频实时通话程序/画中画/设备热插拔/支持本地摄像头和桌面
一、前言 近期有客户提需求,需要在嵌入式板子上和电脑之间音视频通话,要求用Qt开发,可以用第三方的编解码组件,能少用就尽量少用,以便后期移植起来方便。如果换成5年前的知识储备,估计会采用纯网络通信收发…...

Ubuntu快速安装Python3.11及多版本管理
之前文章和大家分享过,将会出一篇专栏(从电脑装ubuntu系统,到安装ubuntu的常用基础软件:jdk、python、node、nginx、maven、supervisor、minio、docker、git、mysql、redis、postgresql、mq、ollama等),目前…...

Qt功能区:Ribbon使用
Ribbon使用 1. Ribbon功能区介绍1.1 样式 2. 基本功能区设置2.1 安装动态库(推荐)2.2 在MainWindow中使用Ribbon2.3 在QWidget中使用SARibbonBar2.4 创建Category和Pannel2.5 ContextCategory 上下文标签创建 2.6 ApplicationButton2.7 QuickAccessBar和…...

【学习心得】Jupyter 如何在conda的base环境中其他虚拟环境内核
如果你在conda的base环境运行了jupyter lab打开了一个ipynb文本,此时选择的内核是base虚拟环境的Python内核,如果我想切换成其他conda虚拟环境来运行这个文件该怎么办?下面我们试着还原一下问题,并且解决问题。 【注】 这个问题出…...

在微创手术中使用Kinova轻型机械臂进行多视图图像采集和3D重建
在微创手术中,Kinova轻型机械臂通过其灵活的运动控制和高精度的操作能力,支持多视图图像采集和3D重建。这种技术通过机械臂搭载的光学系统实现精准的多角度扫描,为医疗团队提供清晰且详细的解剖结构模型。其核心在于结合先进的传感器配置与重…...

[Java][Leetcode middle] 238. 除自身以外数组的乘积
第一个想法是: 想求出所有元素乘积,然后除以i对应的元素本书;这个想法是完全错误的: nums[I] 可能有0题目要求了不能用除法 第二个想法是: 其实写之前就知道会超时,但是我什么都做不到啊! 双…...

【leetcode】144. 二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,2,3] 解释: 示例 2: 输入:root [1,2,3,4,5,null,8,null,null,6,7,9] 输出:…...

SpringBoot常用注解详解
文章目录 1. 前言2. 核心注解2.1 SpringBootApplication2.2 Configuration2.3 EnableAutoConfiguration2.4 ComponentScan2.5 Bean2.6 Autowired2.7 Qualifier2.8 Primary2.9 Value2.10 PropertySource2.11 ConfigurationProperties2.12 Profile 3. Web开发相关注解3.1 Control…...