大语言模型 09 - 从0开始训练GPT 0.25B参数量 补充知识之数据集 Pretrain SFT RLHF
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

数据介绍
Tokenizer
分词器将单词从自然语言通过“词典”映射到0, 1, 36这样的数字,可以理解为数字就代表了单词在“词典”中的页码。 可以选择自己构造词表训练一个“词典”,代码可见./scripts/train_tokenizer.py(仅供学习参考,若非必要无需再自行训练,MiniMind已自带tokenizer)。
或者选择比较出名的开源大模型分词器, 正如同直接用新华/牛津词典的优点是token编码压缩率很好,缺点是页数太多,动辄数十万个词汇短语; 自己训练的分词器,优点是词表长度和内容随意控制,缺点是压缩率很低(例如"hello"也许会被拆分为"h e l l o" 五个独立的token),且生僻词难以覆盖。
“词典”的选择固然很重要,LLM的输出本质上是SoftMax到词典N个词的多分类问题,然后通过“词典”解码到自然语言。 因为MiniMind体积需要严格控制,为了避免模型头重脚轻(词嵌入embedding层参数在LLM占比太高),所以词表长度短短益善。
下面是常见的词表长度如下:
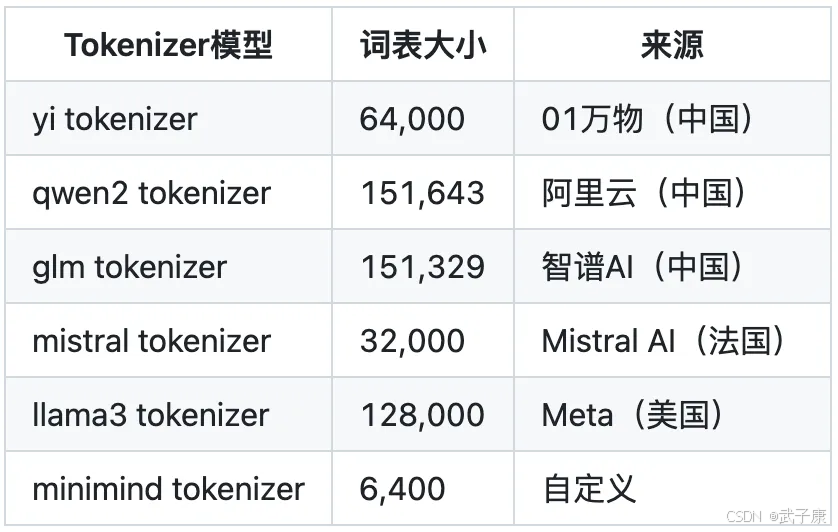
来自项目作者:
一些自言自语
尽管minimind_tokenizer长度很小,编解码效率弱于qwen2、glm等中文友好型分词器。
但minimind模型选择了自己训练的minimind_tokenizer作为分词器,以保持整体参数轻量,避免编码层和计算层占比失衡,头重脚轻,因为minimind的词表大小只有6400。
且minimind在实际测试中没有出现过生僻词汇解码失败的情况,效果良好。
由于自定义词表压缩长度到6400,使得LLM总参数量最低只有25.8M。
训练数据tokenizer_train.jsonl均来自于匠数大模型数据集,这部分数据相对次要,如需训练可以自由选择。
Pretrain数据
经历了MiniMind-V1的低质量预训练数据,导致模型胡言乱语的教训,2025-02-05 之后决定不再采用大规模无监督的数据集做预训练。 进而尝试把匠数大模型数据集的中文部分提取出来, 清洗出字符<512长度的大约1.6GB的语料直接拼接成预训练数据 pretrain_hq.jsonl,hq即为high quality(当然也还不算high,提升数据质量无止尽)。
文件pretrain_hq.jsonl 数据格式为:
{"text": "如何才能摆脱拖延症? 治愈拖延症并不容易,但以下建议可能有所帮助..."}
SFT数据
匠数大模型SFT数据集 “是一个完整、格式统一、安全的大模型训练和研究资源。 从网络上的公开数据源收集并整理了大量开源数据集,对其进行了格式统一,数据清洗, 包含10M条数据的中文数据集和包含2M条数据的英文数据集。” 以上是官方介绍,下载文件后的数据总量大约在4B tokens,肯定是适合作为中文大语言模型的SFT数据的。 但是官方提供的数据格式很乱,全部用来sft代价太大。 我将把官方数据集进行了二次清洗,把含有符号污染和噪声的条目去除;另外依然只保留了总长度<512 的内容,此阶段希望通过大量对话补充预训练阶段欠缺的知识。 导出文件为sft_512.jsonl(~7.5GB)。
Magpie-SFT数据集 收集了1M条来自Qwen2/2.5的高质量对话,我将这部分数据进一步清洗,把总长度<2048的部分导出为sft_2048.jsonl(9GB)。 长度<1024的部分导出为sft_1024.jsonl(~5.5GB),用大模型对话数据直接进行sft就属于“黑盒蒸馏”的范畴。
进一步清洗前两步sft的数据(只保留中文字符占比高的内容),筛选长度<512的对话,得到sft_mini_512.jsonl(~1.2GB)。
所有sft文件 sft_X.jsonl 数据格式均为
{"conversations": [{"role": "user", "content": "你好"},{"role": "assistant", "content": "你好!"},{"role": "user", "content": "再见"},{"role": "assistant", "content": "再见!"}]
}
RLHF数据
来自Magpie-DPO数据集 大约200k条偏好数据(均是英文)生成自Llama3.1-70B/8B,可以用于训练奖励模型,优化模型回复质量,使其更加符合人类偏好。 这里将数据总长度<3000的内容重组为dpo.jsonl(~0.9GB),包含chosen和rejected两个字段,chosen 为偏好的回复,rejected为拒绝的回复。
文件 dpo.jsonl 数据格式为:
{"chosen": [{"content": "Q", "role": "user"}, {"content": "good answer", "role": "assistant"}], "rejected": [{"content": "Q", "role": "user"}, {"content": "bad answer", "role": "assistant"}]
}
Reason数据集
不得不说2025年2月谁能火的过DeepSeek… 也激发了我对RL引导的推理模型的浓厚兴趣,目前已经用Qwen2.5复现了R1-Zero。 如果有时间+效果work(但99%基模能力不足)我会在之后更新MiniMind基于RL训练的推理模型而不是蒸馏模型。 时间有限,最快的低成本方案依然是直接蒸馏(黑盒方式)。 耐不住R1太火,短短几天就已经存在一些R1的蒸馏数据集R1-Llama-70B、R1-Distill-SFT、 Alpaca-Distill-R1、 deepseek_r1_zh等等,纯中文的数据可能比较少。 最终整合它们,导出文件为r1_mix_1024.jsonl,数据格式和sft_X.jsonl一致。
更多数据集
目前已经有HqWu-HITCS/Awesome-Chinese-LLM 在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,并持续更新这方面的最新进展。全面且专业,Respect!
数据集下载
MiniMind训练数据集 (ModelScope | HuggingFace)
无需全部clone,可单独下载所需的文件
将下载的数据集文件放到./dataset/目录下(✨为推荐的必须项)
./dataset/
├── dpo.jsonl (909MB)
├── lora_identity.jsonl (22.8KB)
├── lora_medical.jsonl (34MB)
├── pretrain_hq.jsonl (1.6GB, ✨)
├── r1_mix_1024.jsonl (340MB)
├── sft_1024.jsonl (5.6GB)
├── sft_2048.jsonl (9GB)
├── sft_512.jsonl (7.5GB)
├── sft_mini_512.jsonl (1.2GB, ✨)
└── tokenizer_train.jsonl (1GB)
各数据集简介:
● dpo.jsonl --RLHF阶段数据集
● lora_identity.jsonl --自我认知数据集(例如:你是谁?我是minimind…),推荐用于lora训练(亦可用于全参SFT,勿被名字局限)
● lora_medical.jsonl --医疗问答数据集,推荐用于lora训练(亦可用于全参SFT,勿被名字局限)
● pretrain_hq.jsonl✨ --预训练数据集,整合自jiangshu科技
● r1_mix_1024.jsonl --DeepSeek-R1-1.5B蒸馏数据,每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)
● sft_1024.jsonl --整合自Qwen2.5蒸馏数据(是sft_2048的子集),每条数据字符最大长度为1024(因此训练时设置max_seq_len=1024)
● sft_2048.jsonl --整合自Qwen2.5蒸馏数据,每条数据字符最大长度为2048(因此训练时设置max_seq_len=2048)
● sft_512.jsonl --整合自匠数科技SFT数据,每条数据字符最大长度为512(因此训练时设置max_seq_len=512)
● sft_mini_512.jsonl✨ --极简整合自匠数科技SFT数据+Qwen2.5蒸馏数据(用于快速训练Zero模型),每条数据字符最大长度为512(因此训练时设置max_seq_len=512)
● tokenizer_train.jsonl --均来自于匠数大模型数据集,这部分数据相对次要,(不推荐自己重复训练tokenizer,理由如上)如需自己训练tokenizer可以自由选择数据集。
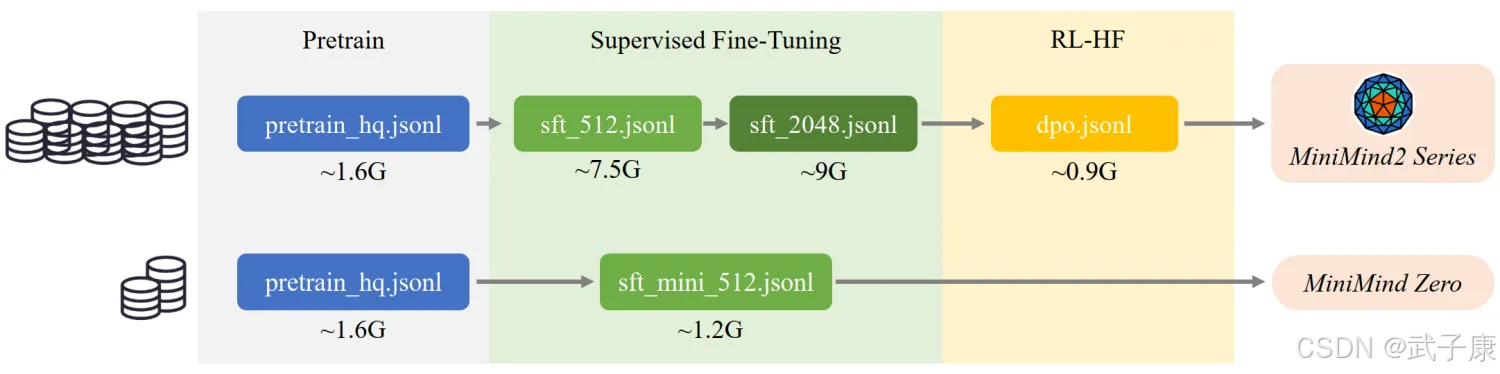
整体结构如下:
相关文章:

大语言模型 09 - 从0开始训练GPT 0.25B参数量 补充知识之数据集 Pretrain SFT RLHF
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

文本分类任务Qwen3-0.6B与Bert:实验见解
文本分类任务Qwen3-0.6B与Bert:实验见解 前言 最近在知乎上刷到一个很有意思的提问Qwen3-0.6B这种小模型有什么实际意义和用途。查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)、也有人提出小模型只是为了开…...

Mysql、Oracle、Sql Server、达梦之间sql的差异
1:分页查询 Sql Server: <bind name"startRow" value"(page - 1) * limit 1"/> <bind name"endRow" value"page * limit"/> SELECT *FROM (SELECT ROW_NUMBER() OVER (<if test"sortZd!…...

STM32外设AD-DMA+定时读取模板
STM32外设AD-DMA定时读取模板 一,方法引入二,CubeMX配置三,变量声明四,代码实现 (单通道) 一,方法引入 轮询法虽然简单,但 CPU 一直在忙着等待,效率太低。为了让 CPU 能在 ADC 转换的同时处理其…...

SQL里where条件的顺序影响索引使用吗?
大家好,我是锋哥。今天分享关于【SQL里where条件的顺序影响索引使用吗?】面试题。希望对大家有帮助; SQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 SQL 查询中,W…...

Java 接口中实现异步处理的方法
在Java中,接口本身不能直接实现逻辑(接口中的方法默认是抽象的,JDK 8+允许通过default方法提供非抽象实现,但通常不用于复杂的异步处理)。异步处理的逻辑需要在实现接口的类中通过多线程、异步框架或回调机制来实现。以下是几种常见的在接口实现类中实现异步处理<...

数值分析证明题
文章目录 第一题第二题第三题第四题第五题第六题第七题第八题第九题 第一题 例 给出 cos x \cos x cosx, x ∈ [ 0 ∘ , 9 0 ∘ ] x\in[0^{\circ},90^{\circ}] x∈[0∘,90∘]的函数表,步长 h 1 ′ ( 1 60 ) ∘ h 1 (\frac{1}{60})^{\circ} h1′…...

深入理解二叉树:遍历、存储与算法实现
在之前的博客系列中,我们系统地探讨了多种线性表数据结构,包括顺序表、栈和队列等经典结构,并通过代码实现了它们的核心功能。从今天开始,我们将开启一个全新的数据结构篇章——树结构。与之前讨论的线性结构不同,树形…...

Python web 开发 Flask HTTP 服务
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编写,特别适合构建简单的 Web 应用和 RESTful API。Flask 的设计理念是提供尽可能少的约定和配置,从而让开发者能够灵活地构建自己的 Web 应用。 https://andi.cn/page/622189.html...

【AI】用Dify实现一个模拟面试的功能
前言 Dify,一个将LLM转换为实际工作流的工具,以及火了一段时间了,但直到最近才开始研究它的使用(主要前段时间在忙着自己的独立开发项目),我发现它的功能基本上满足了我对大语言模型,从仅对话转…...
)
研华服务器ASMB-825主板无法识别PCIE-USB卡(笔记本)
系统下无法识别到USB卡,排除硬件问题,系统问题。 最后在BIOS中更改此PCIE端口参数为X4X4X4X4,设置完成后可正常使用USB卡。 底部有问题详细解析。 针对研华主板ASMB-825安装绿联PCIE-USB卡无法识别的问题,结合BIOS设置调整的解决过…...

Redisson 四大核心机制实现原理详解
一、可重入锁(Reentrant Lock) 可重入锁是什么? 通俗定义 可重入锁类似于一把“智能锁”,它能识别当前的锁持有者是否是当前线程: 如果是,则允许线程重复获取锁(重入),并…...
)
云计算与大数据进阶 | 26、解锁云架构核心:深度解析可扩展数据库的5大策略与挑战(上)
在云应用/服务的 5 层架构里,数据库服务层稳坐第 4 把交椅,堪称其中的 “硬核担当”。它的复杂程度常常让人望而生畏,不少人都将它视为整个架构中的 “终极挑战”。 不过,也有人觉得可扩展存储系统才是最难啃的 “硬骨头”&#…...

Android从单体架构迁移到模块化架构。你会如何设计模块划分策略?如何处理模块间的通信和依赖关系
从单体架构迁移到模块化架构。可能有些小伙伴已经深陷单体架构的泥潭,代码耦合得跟一团麻线似的,改个小功能都能牵一发而动全身;也可能有些团队在协作时,经常因为代码冲突或者职责不清搞得焦头烂额。相信我,这些问题我…...

基于MATLAB的人脸识别,实现PCA降维,用PCA特征进行SVM训练
基于MATLAB的人脸识别完整流程,包含PCA降维和SVM分类的实现。我们以经典的ORL人脸数据库为例,演示从数据加载到结果评估的全过程。 1. 数据准备与预处理 1.1 下载数据集 下载ORL人脸数据库(40人10张,共400张图像)…...

AI 赋能 Copula 建模:大语言模型驱动的相关性分析革新
技术点目录 R及Python语言及相关性研究初步二元Copula理论与实践(一)二元Copula理论与实践(二)【R语言为主】Copula函数的统计检验与选择【R语言为主】高维数据与Vine Copula 【R语言】正则Vine Copula(一)…...

机器学习与人工智能:NLP分词与文本相似度分析
DIY AI & ML NLP — Tokenization & Text Similarity by Jacob Ingle in Data Science Collective 本文所使用的数据是在 Creative Commons license 下提供的。尽管我们已尽力确保信息的准确性和完整性,但我们不对数据的完整性或可靠性做任何保证。数据的使…...

特斯拉虚拟电厂:能源互联网时代的分布式革命
在双碳目标与能源转型的双重驱动下,特斯拉虚拟电厂(Virtual Power Plant, VPP)通过数字孪生技术与能源系统的深度融合,重构了传统电力系统的运行范式。本文从系统架构、工程实践、技术挑战三个维度,深度解析这一颠覆性…...
在医学编程中的初步分析与探索)
系统提示学习(System Prompt Learning)在医学编程中的初步分析与探索
一、SPL 的核心定义 系统提示学习(SPL)是一种通过策略性设计输入提示(Prompts),引导大型语言模型(LLMs)生成特定领域行为与输出的方法。其核心在于不修改模型参数,而是通过上下文工程(Context Engineering)动态控制模型响应,使其适配复杂任务需求。 与微调(Fine-…...
)
使用DDR4控制器实现多通道数据读写(十二)
一、章节概括 这一节使用interconnect RTL ip核将DDR4与四个读写通道级联,在测试工程中,将四个通道同时写入/读出地址与数据,并使用modelsim仿真器仿真,四个通道同时发送写请求或读请求后,经过interconnect后ÿ…...

PCIe数据采集系统详解
PCIe数据采集系统详解 在上篇文章中,废了老大劲儿我们写出了PCIe数据采集系统;其中各个模块各司其职,相互配合。完成了从数据采集到高速存储到DDR3的全过程。今天我们呢就来详细讲解他们之间的关系?以及各个模块的关键点ÿ…...

小白级通信小号、虚拟小号查询技术讲解
手机号构成与归属地原理 手机号码由国家代码、运营商代码和用户号码等部分组成。全球手机号段由国际电信联盟(ITU)统一规划,各国通信管理机构负责分配具体号段。在我国,通过解析手机号码前几位,就能确定其所属运营商及…...

【爬虫】DrissionPage-4
官网文档:https://www.drissionpage.cn/browser_control/browser_options 一、核心对象与初始化 1. 类定义 作用:管理Chromium内核浏览器的启动配置,仅在浏览器启动时生效。导入方式:from DrissionPage import ChromiumOptions…...

数据通信原理 光纤通信 期末速成
一、图表题 1. 双极性不归零、单极性不归零、曼彻斯特码、抑制载频2ASK,2PSK、2DPSK信号的波形 双极性不归零 和 单极性不归零:不归零意思是 0 低 1 高 非归零编码(NRZ):用不同电平表示二进制数字,常以…...

Java微服务架构实战:Spring Boot与Spring Cloud的完美结合
Java微服务架构实战:Spring Boot与Spring Cloud的完美结合 引言 随着云计算和分布式系统的快速发展,微服务架构已成为现代软件开发的主流模式。Java作为一门成熟的编程语言,凭借其强大的生态系统和丰富的框架支持,成为构建微服务…...

React底层架构深度解析:从虚拟DOM到Fiber的演进之路
一、虚拟DOM:性能优化的基石 1.1 核心工作原理 React通过JSX语法将组件转换为轻量级JavaScript对象(即虚拟DOM),而非直接操作真实DOM。这一过程由React.createElement()实现,其结构包含元素类型、属性和子节点等信息&a…...

今日行情明日机会——20250516
上证缩量收阴线,小盘股表现相对更好,上涨的个股大于下跌的,日线已到前期压力位附近,注意风险。 深证缩量收假阳线,临近日线周期上涨末端,注意风险。 2025年5月16日涨停股行业方向分析 机器人概念&#x…...

小结:网页性能优化
网页性能优化是提升用户体验、减少加载时间和提高资源利用率的关键。以下是针对网页生命周期和事件处理的性能优化技巧,结合代码示例,重点覆盖加载、渲染、事件处理和资源管理等方面。 1. 优化加载阶段 减少关键资源请求: 合并CSS/JS文件&a…...

2025年PMP 学习十五 第10章 项目资源管理
2025年PMP 学习十五 第10章 项目资源管理 序号过程过程组1规划沟通管理规划2管理沟通执行3监控沟通监控 项目沟通管理包括为确保项目的信 息及时且恰当地规划、收集、生成、发布、存储、检索、管理、控制、监 警和最终处理所需的过程; 项目经理绝大多数时间都用于与…...

速通RocketMQ配置
配置RocketMQ又出问题了,赶紧记录一波 这个是我的RocketMQ配置文件 通过网盘分享的文件: 链接: https://pan.baidu.com/s/1UUYeDvKZFNsKPFXTcalu3A?pwd8888 提取码: 8888 –来自百度网盘超级会员v9的分享 里面有这三个东西 里面还有一些broker和names…...

宇宙中是否存在量子现象?
一、宇宙中的量子现象 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 好的,请提供具体的搜索词或意图,以便进行检索和生成简洁的回答。 量子涨落与宇宙结构 早期宇宙的量子涨落(微观尺度的不确定性…...

背包问题详解
一、问题引入:什么是背包问题? 背包问题是经典的动态规划问题,描述如下: 有一个容量为 m 的背包 有 n 个物品,每个物品有体积 v 和价值 w 目标:选择物品装入背包,使总价值最大且总体积不超过…...

oracle linux 95 升级openssh 10 和openssl 3.5 过程记录
1. 安装操作系统,注意如果可以选择,选择安装开发工具,主要是后续需要编译安装,需要gcc 编译工具。 2. 安装操作系统后,检查zlib 、zlib-dev是否安装,如果没有,可以使用安装镜像做本地源安装&a…...

Tomcat发布websocket
一、tomcal的lib放入文件 tomcat-websocket.jar websocket-api.jar 二、代码示例 package com.test.ws;import com.test.core.json.Jmode;import javax.websocket.*; import javax.websocket.server.ServerEndpoint; import java.util.concurrent.CopyOnWriteArraySet; imp…...

[思维模式-41]:在确定性与不确定性的交响中:人类参与系统的韧性密码。
前言: “任何信息系统,无论怎么复杂,哪怕是几万人同时开发的系统,如无线通信网络,通过标准、设计、算法、完毕的测试、过程的管控等,都是可预测和确定性的。 一个系统,一旦叠加了人的元素和因素…...

维智定位 Android 定位 SDK
概述 维智 Android 定位 SDK是为 Android 移动端应用提供的一套简单易用的定位服务接口,为广大开发者提供融合定位服务。通过使用维智定位SDK,开发者可以轻松为应用程序实现极速、智能、精准、高效的定位功能。 重要:为了进一步加强对最终用…...

Vue3:脚手架
工程环境配置 1.安装nodejs 这里我已经安装过了,只需要打开链接Node.js — Run JavaScript Everywhere直接下载nodejs,安装直接一直下一步下一步 安装完成之后我们来使用电脑的命令行窗口检查一下版本 查看npm源 这里npm源的地址是淘宝的源࿰…...

Android native崩溃问题分析
最近在做NDK项目的时候,出现了启动应用就崩溃了,崩溃日志如下: 10:41:04.743 A Build fingerprint: samsung/g0qzcx/g0q:13/TP1A.220624.014/S9060ZCU4CWH1:user/release-keys 10:41:04.743 A Revision: 12 10:41:04.743 A ABI: arm64…...

Playwright vs Selenium:2025 年 Web 自动化终极对比指南
1. 引言 Web 自动化领域正在迅速发展,在 2025 年,Playwright 与 Selenium 之间的选择已成为开发团队面临的重要决策。Selenium 作为行业标准已有十多年,而 Playwright 作为现代替代方案,以卓越的性能和现代化特性迅速崛起。 本指…...
线性表-链表-单链表)
数据结构(3)线性表-链表-单链表
我们学习过顺序表时,一旦对头部或中间的数据进行处理,由于物理结构的连续性,为了不覆盖,都得移,就导致时间复杂度为O(n),还有一个潜在的问题就是扩容,假如我们扩容前是10…...

Python 中的 typing.ClassVar 详解
一、ClassVar 的定义和基本用途 ClassVar 是 typing 模块中提供的一种特殊类型,用于在类型注解中标记类变量(静态变量)。根据官方文档,使用 ClassVar[…] 注释的属性表示该属性只在类层面使用,不应在实例上赋值 例如&…...

主流数据库运维故障排查卡片式速查表与视觉图谱
主流数据库运维故障排查卡片式速查表与视觉图谱 本文件将主文档内容转化为模块化卡片结构,并补充数据库结构图、排查路径图、锁机制对比等视觉图谱,以便在演示、教学或现场排障中快速引用。 📌 故障卡片速查:连接失败 数据库检查…...
)
Unity:延迟执行函数:Invoke()
目录 Unity 中的 Invoke() 方法详解 什么是 Invoke()? 基本使用方法 使用要点 延伸功能 ❗️Invoke 的局限与注意事项 在Unity中,延迟执行函数是游戏逻辑中常见的需求,比如: 延迟切换场景 延迟播放音效或动画 给玩家时间…...

医学影像系统性能优化与调试技术:深度剖析与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
)
【HTML5学习笔记1】html标签(上)
web标准(重点) w3c 构成:结构、表现、行为,结构样式行为相分离 结构:网页元素整理分类 html 表现:外观css 行为:交互 javascript html标签 1.html语法规范 1) 所有标签都在…...

SearchIndexablesProvider
实现的 provider 根据索引添加文档可知,该 provider 需要继承自 frameworks/base/core/java/android/provider/SearchIndexablesProvider.java 类,并且添加权限 android.permission.READ_SEARCH_INDEXABLES。过滤 Settings 代码,可以轻易找到…...

《k-means 散点图可视化》实验报告
一,实验目的 本次实验旨在通过Python编程实现k - means算法的散点图可视化。学习者将编写代码,深入理解聚类分析基本原理与k - means算法实现流程,掌握数据聚类及可视化方法,以直观展示聚类结果。 二,实验原理 k-mea…...

数学复习笔记 12
前言 现在做一下例题和练习题。矩阵的秩和线性相关。另外还要复盘前面高数的部分的内容。奥,之前矩阵的例题和练习题,也没有做完,行列式的例题和练习题也没有做完。累加起来了。以后还是得学一个知识点就做一个部分的内容,日拱一…...

Web-CSS入门
WEB前端,三部分:HTML部分、CSS部分、Javascript部分。 1.HTML部分:主要负责网页的结构层 2.CSS部分:主要负责网页的样式层 3.JS部分:主要负责网页的行为层 **基本概念** 层叠样式表,Cascading Style Sh…...

Qt/C++编写音视频实时通话程序/画中画/设备热插拔/支持本地摄像头和桌面
一、前言 近期有客户提需求,需要在嵌入式板子上和电脑之间音视频通话,要求用Qt开发,可以用第三方的编解码组件,能少用就尽量少用,以便后期移植起来方便。如果换成5年前的知识储备,估计会采用纯网络通信收发…...