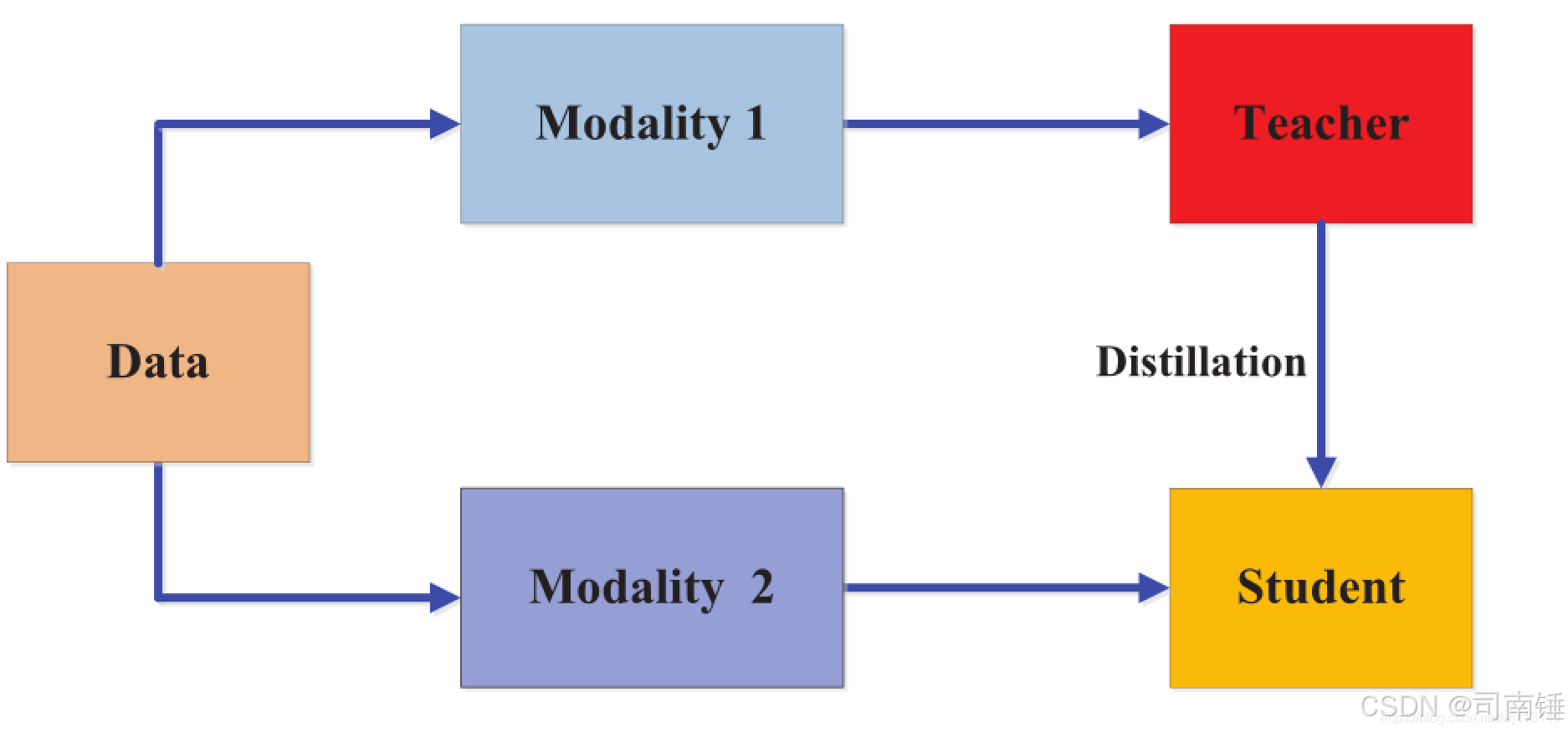
TensorFlow/Keras实现知识蒸馏案例
- 创建一个“教师”模型(一个稍微复杂点的网络)。
- 创建一个“学生”模型(一个更简单的网络)。
- 使用“软标签”(教师模型的输出概率)和“硬标签”(真实标签)来训练学生模型。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np# 0. 准备一些简单的数据 (例如 MNIST)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()# 数据预处理
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)# 将标签转换为独热编码
y_train_cat = keras.utils.to_categorical(y_train, num_classes=10)
y_test_cat = keras.utils.to_categorical(y_test, num_classes=10)# 1. 定义教师模型
teacher_model = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),layers.MaxPooling2D(pool_size=(2, 2)),layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),layers.MaxPooling2D(pool_size=(2, 2)),layers.Flatten(),layers.Dense(128, activation="relu"),layers.Dense(10, name="teacher_logits"), # 输出 logitslayers.Activation("softmax") # 输出概率,用于评估],name="teacher",
)
teacher_model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]
)
print("--- 训练教师模型 ---")
teacher_model.fit(x_train, y_train_cat, epochs=5, batch_size=128, validation_split=0.1, verbose=2)
loss, acc = teacher_model.evaluate(x_test, y_test_cat, verbose=0)
print(f"教师模型在测试集上的准确率: {acc:.4f}")# 2. 定义学生模型 (更小更简单)
student_model = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Flatten(),layers.Dense(32, activation="relu"),layers.Dense(10, name="student_logits"), # 输出 logitslayers.Activation("softmax") # 输出概率,用于评估],name="student",
)# 3. 定义蒸馏损失函数
class Distiller(keras.Model):def __init__(self, student, teacher):super().__init__()self.teacher = teacherself.student = studentself.student_loss_fn = keras.losses.CategoricalCrossentropy(from_logits=False) # 学生模型使用真实标签的损失self.distillation_loss_fn = keras.losses.KLDivergence() # KL散度作为蒸馏损失self.alpha = 0.1 # 蒸馏损失的权重self.temperature = 3 # 蒸馏温度,用于平滑教师模型的输出def compile(self,optimizer,metrics,student_loss_fn,distillation_loss_fn,alpha,temperature,):super().compile(optimizer=optimizer, metrics=metrics)self.student_loss_fn = student_loss_fnself.distillation_loss_fn = distillation_loss_fnself.alpha = alphaself.temperature = temperaturedef train_step(self, data):x, y = data # y 是真实标签 (硬标签)# 获取教师模型的软标签# 注意:我们通常使用教师模型的 logits (softmax之前的输出) 并应用温度# 但为了简化,这里直接使用教师模型的softmax输出,并在损失函数中处理温度# 更严谨的做法是在教师模型输出logits后,除以temperature再进行softmaxteacher_predictions_raw = self.teacher(x, training=False) # 教师模型不参与训练with tf.GradientTape() as tape:# 学生模型对输入的预测student_predictions_raw = self.student(x, training=True)# 计算学生损失 (使用硬标签)student_loss = self.student_loss_fn(y, student_predictions_raw)# 计算蒸馏损失 (使用教师的软标签)# 软化教师和学生的概率分布# 使用教师模型的 logits (如果可用) 并除以 temperature 会更好# 这里为了简化,我们假设 teacher_predictions_raw 是概率,学生也是# 实际上 KLDivergence 期望 y_true 和 y_pred 都是概率分布# KLDivergence(softmax(teacher_logits/T), softmax(student_logits/T))# 这里我们简化为直接使用softmax输出,并在KLDivergence内部处理# 注意:KLDivergence的输入应该是概率分布。# 实际应用中,更常见的做法是先获取教师的logits,然后进行如下操作:# teacher_logits = self.teacher.get_layer('teacher_logits').output# soft_teacher_targets = tf.nn.softmax(teacher_logits / self.temperature)# soft_student_predictions = tf.nn.softmax(self.student.get_layer('student_logits').output / self.temperature)# dist_loss = self.distillation_loss_fn(soft_teacher_targets, soft_student_predictions) * (self.temperature ** 2)# 为了代码的简洁性,我们这里直接使用Keras内置的KLDivergence,它期望概率输入# 我们不显式地在这里应用temperature到softmax,而是理解为蒸馏目标本身就比较“软”# 实际上,更标准的蒸馏损失是 KL(softmax(teacher_logits/T) || softmax(student_logits/T))# Keras 的 KLDivergence(y_true, y_pred) 计算的是 sum(y_true * log(y_true / y_pred))# 当y_true是教师的软标签时,它已经是概率了。distillation_loss = self.distillation_loss_fn(tf.nn.softmax(teacher_predictions_raw / self.temperature), # 软化教师的预测tf.nn.softmax(student_predictions_raw / self.temperature) # 软化学生的预测)# KLDivergence 期望 y_true 和 y_pred 都是概率。# 如果教师输出的是logits,正确的软化方式是:# soft_teacher_labels = tf.nn.softmax(teacher_logits / self.temperature)# soft_student_probs = tf.nn.softmax(student_logits / self.temperature)# dist_loss = self.distillation_loss_fn(soft_teacher_labels, soft_student_probs)# Hinton论文中的蒸馏损失通常乘以 T^2# 但这里KLDivergence的实现可能有所不同,我们先简化# loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss # Hinton论文是这样# 或者,更常见的是:loss = (1 - self.alpha) * student_loss + self.alpha * (self.temperature**2) * distillation_loss# 计算梯度trainable_vars = self.student.trainable_variablesgradients = tape.gradient(loss, trainable_vars)# 更新学生模型的权重self.optimizer.apply_gradients(zip(gradients, trainable_vars))# 更新指标self.compiled_metrics.update_state(y, student_predictions_raw)results = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss, "distillation_loss": distillation_loss})return resultsdef test_step(self, data):x, y = datay_prediction = self.student(x, training=False)student_loss = self.student_loss_fn(y, y_prediction)self.compiled_metrics.update_state(y, y_prediction)results = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss})return results# 4. 初始化和编译蒸馏器
distiller = Distiller(student=student_model, teacher=teacher_model)
distiller.compile(optimizer=keras.optimizers.Adam(),metrics=["accuracy"],student_loss_fn=keras.losses.CategoricalCrossentropy(from_logits=False),distillation_loss_fn=keras.losses.KLDivergence(),alpha=0.2, # 蒸馏损失的权重 (原始学生损失权重为 1-alpha)temperature=5.0, # 蒸馏温度
)# 5. 训练学生模型 (通过蒸馏器)
print("\n--- 训练学生模型 (蒸馏) ---")
distiller.fit(x_train, y_train_cat, epochs=10, batch_size=256, validation_split=0.1, verbose=2)# 评估蒸馏后的学生模型
loss, acc = student_model.evaluate(x_test, y_test_cat, verbose=0)
print(f"蒸馏后的学生模型在测试集上的准确率: {acc:.4f}")# (可选) 单独训练一个没有蒸馏的学生模型作为对比
print("\n--- 训练学生模型 (无蒸馏) ---")
student_model_scratch = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Flatten(),layers.Dense(32, activation="relu"),layers.Dense(10, activation="softmax"),],name="student_scratch",
)
student_model_scratch.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]
)
student_model_scratch.fit(x_train, y_train_cat, epochs=10, batch_size=256, validation_split=0.1, verbose=2)
loss_scratch, acc_scratch = student_model_scratch.evaluate(x_test, y_test_cat, verbose=0)
print(f"从零开始训练的学生模型在测试集上的准确率: {acc_scratch:.4f}")代码解释:
- 数据准备: 使用了经典的 MNIST 数据集。
- 教师模型 (
teacher_model): 一个包含两个卷积层和一个全连接层的简单卷积神经网络。它首先在数据集上进行正常的训练。 - 学生模型 (
student_model): 一个非常简单的模型,只有一个全连接层。我们的目标是让这个小模型通过蒸馏学习到教师模型的部分能力。 Distiller类:__init__: 初始化时接收教师模型和学生模型。compile: 配置优化器、指标,以及两个关键的损失函数:student_loss_fn(学生模型直接与真实标签计算损失) 和distillation_loss_fn(学生模型与教师模型的软标签计算损失)。alpha用于平衡这两种损失,temperature用于平滑教师模型的输出概率,使其更“软”,包含更多类别间的信息。train_step: 这是自定义训练的核心。- 首先,获取教师模型对当前批次数据的预测 (
teacher_predictions_raw)。教师模型设置为training=False,因为我们不希望在蒸馏过程中更新教师模型的权重。 - 然后,在
tf.GradientTape上下文中,获取学生模型的预测 (student_predictions_raw)。 - 学生损失 (
student_loss): 学生模型的预测与真实标签 (y) 之间的交叉熵损失。 - 蒸馏损失 (
distillation_loss):- 我们使用
tf.nn.softmax(predictions / self.temperature)来软化教师和学生的预测。温度T越大,概率分布越平滑,类别之间的差异信息越能被学生模型学习到。 - 然后使用
KLDivergence计算软化的学生预测与软化的教师预测之间的KL散度。KL散度衡量两个概率分布之间的差异。 - Hinton 等人的原始论文中,蒸馏损失项通常还会乘以
temperature**2来保持梯度的大小与不使用温度时的梯度大小相当。
- 我们使用
- 总损失 (
loss): 学生损失和蒸馏损失的加权和。alpha控制蒸馏损失的贡献程度。常见的组合是(1 - alpha) * student_loss + alpha * scaled_distillation_loss。 - 最后,计算梯度并更新学生模型的权重。
- 首先,获取教师模型对当前批次数据的预测 (
test_step: 在评估阶段,我们只关心学生模型在真实标签上的表现。
- 训练和评估:
- 创建
Distiller实例。 - 编译
Distiller,传入必要的参数。 - 调用
distiller.fit()来训练学生模型。 - 最后,评估蒸馏后的学生模型的性能。
- 创建
- 对比: (可选) 我们还训练了一个同样结构但没有经过蒸馏的学生模型 (
student_model_scratch),以便对比蒸馏带来的效果。通常情况下,蒸馏后的学生模型性能会优于从零开始训练的同结构小模型,尤其是在复杂任务或小模型容量有限时。
关键概念:
- 软标签 (Soft Labels): 教师模型输出的概率分布(经过温度平滑)。与硬标签(one-hot 编码的真实类别)相比,软标签包含了更多关于类别之间相似性的信息。例如,教师模型可能认为一张图片是数字 “7” 的概率是 0.7,是数字 “1” 的概率是 0.2,是其他数字的概率很小。这种信息对学生模型很有价值。
- 温度 (Temperature, T): 一个超参数,用于在计算 softmax 时平滑概率分布。较高的温度会产生更软的概率分布(熵更高),使非目标类别的概率也相对提高,从而让学生模型学习到更多类别间的细微差别。
- KL 散度 (Kullback-Leibler Divergence): 用于衡量两个概率分布之间差异的指标。在蒸馏中,我们希望最小化学生模型的软输出与教师模型的软输出之间的KL散度。
- 损失函数组合: 总损失函数通常是学生模型在真实标签上的标准损失(如交叉熵)和蒸馏损失(如KL散度)的加权和。
相关文章:

TensorFlow/Keras实现知识蒸馏案例
创建一个“教师”模型(一个稍微复杂点的网络)。创建一个“学生”模型(一个更简单的网络)。使用“软标签”(教师模型的输出概率)和“硬标签”(真实标签)来训练学生模型。 import tens…...

能源数字化转型关键引擎:Profinet转Modbus TCP网关驱动设备协同升级
在工业自动化的世界中,ModbusTCP和Profinet是两个非常重要的通讯协议。ModbusTCP以其开放性和易用性,被广泛应用于各种工业设备中;而Profinet则以其高效性和实时性,成为了众多高端设备的首选。然而,由于这两种协议的差…...
+LangChain框架+MCP+RAG+传统算法的旅游行程规划系统)
大模型的实践应用43-基于Qwen3(32B)+LangChain框架+MCP+RAG+传统算法的旅游行程规划系统
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用43-基于Qwen3(32B)+LangChain框架+MCP+RAG+传统算法的旅游行程规划系统。本报告将阐述基于大模型Qwen3(32B)、LangChain框架、MCP协议、RAG技术以及传统算法构建的智能旅游行程规划系统。该系统通过整合多种技术优势,实…...

【Unity】用事件广播的方式实现游戏暂停,简单且实用!
1.前言 在做Unity项目的时候,要考虑到“游戏暂停”的功能,最直接的办法是修改游戏的Time.TimeScale 0f。但是这种方式的影响也比较大,因为它会导致游戏中很多程序无法正常运行。 于是我就有了一个想法,在游戏中想要暂停的对象&…...
)
二维数组以及C99中的变长数组(如何在VS2022中使用苹果的clang编译器)
一、二维数组的创建 1.1 二维数组的概念 在上一篇文章中所写的称为一维数组,数组的元素都是内置类型的,如果我们把一维数组作为数组的元素,这时候就是二维数组,二维数组作为数组元素的数组被称为三维数组,二维数组以…...

影楼精修-肤色统一算法解析
注意:本文样例图片为了避免侵权,均使用AIGC生成; 本文介绍影楼精修中肤色统一算法的实现方案,并以像素蛋糕为例,进行分析说明。 肤色统一就是将人像照片中皮肤区域的颜色进行统一,看起来颜色均匀一致&…...

mac的Cli为什么输入python3才有用python --version显示无效,pyenv入门笔记,如何查看mac自带的标准库模块
根据你的终端输出,可以得出以下结论: 1. 你的 Mac 当前只有一个 Python 版本 系统默认的 Python 3 位于 /usr/bin/python3(这是 macOS 自带的 Python)通过 which python3 确认当前使用的就是系统自带的 Pythonbrew list python …...

城市内涝监测预警系统守护城市安全
一、系统背景 城市内涝是指由于强降水或连续性降水超过城市排水能力,导致城市内产生积水灾害的现象。随着气候变化和城市化进程的加快,城市内涝现象愈发频繁和严重。传统的城市排水系统已难以满足当前的城市排水需求,特别是在暴雨等极端天气条…...
)
ThinkPad X250电池换电池芯(理论技术储备)
参考:笔记本电池换电芯的经验与心得分享 - 经典ThinkPad专区 - 专门网 换电池芯,需要克服以下问题: 1 拆电池。由于是超声波焊接,拆解比较费力,如果暴力撬,有可能导致电池壳变形... 2 替换电池芯的时候如…...
)
2025第三届盘古初赛(计算机部分)
前言 比赛的时候时间不对,打一会干一会,导致比赛时候思路都跟不上,赛后简单复现一下,希望大家批批一下 计算机取证 1、分析贾韦码计算机检材,计算机系统Build版本为?【标准格式:19000】 183…...

qtc++ qdebug日志生成
本文介绍了将qdebug注册到日志系统,这样qdebug打印的信息将记录在日志文本文件,方便观看程序运行中的历史信息,但是需要注意的是,注册后qdebug的信息将不会打印在qtcreator的输出中,所以作者建议,在开发的时…...
)
Tomcat 配置 HTTPS 访问全攻略(CentOS 环境)
Tomcat 配置 HTTPS 访问全攻略(CentOS 环境) 一、环境说明 操作系统:CentOS Tomcat 版本:Apache Tomcat/9.0.105 服务器 IP:192.168.1.35 目标:将 Tomcat 默认的 HTTP 访问升级为 HTTPS,提…...

20250516使用TF卡将NanoPi NEO core开发板出厂的Ubuntu core22.04.3系统降级到Ubuntu core16.04.2
20250516使用TF卡将NanoPi NEO core开发板出厂的Ubuntu core22.04.3系统降级到Ubuntu core16.04.2 2025/5/16 10:58 缘起:NanoPi NEO core核心板出厂预制的OS操作系统为Ubuntu core22.04.3系统。 【虽然是友善之臂提供的最新的系统,但是缺少很多用用程序…...

针对大事务问题对业务存储过程改造
针对大事务问题对业务存储过程改造 一、问题描述 1. 问题现象 业务调用存储过程没有成功,发现存在大事务,单独拿出来执行发现问题。 greatsql> INSERT INTOywdb1.t1(TIMEKEY,zbbh,zcbl,zcblms,zjzh,zjzhms,cbzh,ljzjzh,xmbh,xmmc,sfgj,dd,ddsm,cb…...

如何解决Move to iOS 不起作用的问题?
iPhone 16系列已经上市有一段时间了。你已经把旧的 Android 手机换成了 iPhone 16 了吗?然而,当您兴奋地准备传输数据时,您发现 Move to iOS 无法正常工作。这确实令人沮丧。但不用担心,因为我们找到了 9 个有效的解决方案&#x…...
)
npm cross-env工具包介绍(跨平台环境变量设置工具)
文章目录 cross-env:跨平台环境变量设置工具什么是cross-env?为什么需要cross-env?平台差异带来的问题 cross-env的工作原理核心功能技术实现 安装与基本使用安装步骤基本使用方法运行效果 高级使用技巧设置多个环境变量环境变量传递与链式命…...

分布式锁: Redis和ZooKeeper两种分布式锁对比
在分布式系统中,分布式锁是协调多节点共享资源访问的核心机制。Redis 和 ZooKeeper 是两种常用的分布式锁实现方案,但两者的设计理念、适用场景和优缺点存在显著差异。本文将从 一致性模型、性能、可靠性、实现原理 等维度进行对比,并提供技术…...

笔试强训:Day5
一、笨小猴(哈希数学) 笨小猴_牛客题霸_牛客网 #include <iostream> #include <cmath> using namespace std; string s; bool isprime(int x){//试除法if(x2) return true;if(x<2||x%20) return false;int nsqrt(x);for(int i3;i<n;i…...

Flask框架搭建
1、安装Flask 打开终端运行以下命令: pip install Flask 2、创建项目目录 在Windows上: venv\Scripts\activate 执行 3、创建 app.py 文件 可以在windows终端上创建app.py文件 (1)终端中创建 使用echo命令 echo "fr…...
)
【Kubernetes】单Master集群部署(第二篇)
目录 前言 一、实验环境 二、操作系统初始化配置 三、部署 docker引擎 四、部署 etcd 集群 4.1 准备签发证书环境 4.2 准备cfssl证书生成工具 4.3 生成Etcd证书 4.4 启动etcd服务 4.5 检查群集状态 五、部署 Master 组件 5.1 准备软件包 5.2 创建用于生成CA证书、…...
:前端框架性能优化深度解析)
JavaScript性能优化实战(10):前端框架性能优化深度解析
引言 React、Vue、Angular等框架虽然提供了强大的抽象和开发效率,但不恰当的使用方式会导致严重的性能问题,针对这些问题,本文将深入探讨前端框架性能优化的核心技术和最佳实践。 React性能优化核心技术 React通过虚拟DOM和高效的渲染机制提供了出色的性能,但当应用规模…...

vue3中预览Excel文件
1.前言 有时候项目中需要预览Excel文件,特别是对于.xls格式的Excel文件许多插件都不支持,经过尝试,最终有三种方案可以实现.xlsx和.xls格式的Excel文件的预览,各有优缺点 2.luckyexcel插件 2.1说明 该插件优点在于能保留源文件…...

VsCode和AI的前端使用体验:分别使用了Copilot、通义灵码、iflyCode和Trae
1、前言 大杂烩~每次开发一行代码,各个AI争先恐后抢着提供帮助 备注:四款插件都需要先去官网注册账号,安装好之后有个账号验证。 2、插件详解 2.1、AI分析的答案 GitHub Copilot 定位:老牌 AI 代码补全工具,深度集成…...
【问题排查】easyexcel日志打印Empty row!
问题原因 日志打印I/O 操作开销(如 Log4j 的 FileAppender)会阻塞业务线程,直到日志写入完成,导致接口响应变慢 问题描述 在线上环境,客户反馈导入一个不到1MB的excel文件,耗时将近5分钟。 问题排…...
数据库)
若依框架SpringBoot从Mysql替换集成人大金仓(KingBase)数据库
一、安装人大金仓数据库 1、下载 前往人大金仓数据库下载自己想要的版本(建议下载Mysql兼容版)人大金仓官网,点击服务与支持,点击安装包下载 点击软件版本,选择数据库 选择合适的版本,点击下载࿰…...

Graph Representation Learning【图最短路径优化/Node2vec/Deepwalk】
文章目录 Q1:网络性质:1.数据读取与邻接表构建:2.基本特征和连通性: 算法思路:1. 广度优先搜索(BFS)标记前驱:2. 回溯生成所有最短路径: 实验结果:复杂度分析: Q2&#x…...

ZYNQ Overlay硬件库使用指南:用Python玩转FPGA加速
在传统的FPGA开发中,硬件设计需要掌握Verilog/VHDL等硬件描述语言,这对软件开发者而言门槛较高。Xilinx的PYNQ框架通过Overlay硬件库彻底改变了这一现状——开发者只需调用Python API即可控制FPGA的硬件模块,实现硬件加速与灵活配置。本文将深入探讨ZYNQ Overlay的核心概念、…...

Git基础使用方法与命令总结
Git 是一个分布式版本控制系统,用于跟踪代码或文件的修改历史。以下是 Git 的基础使用方法和常用命令,适合快速上手: 1. 安装与配置 安装 Git 下载地址:https://git-scm.com/downloads(支持 Windows/macOS/Linux&…...

rust语言,与c,go语言一样也是编译成二进制文件吗?
是的,Rust 和 C、Go 一样,默认情况下会将代码编译成二进制可执行文件(如 ELF、PE、Mach-O 等格式),但它们的编译过程和运行时特性有所不同: 1. Rust(类似 C,直接编译为机器码&#x…...

从银行排队到零钱支付:用“钱包经济学”重构Java缓存认知
"当你的系统还在频繁访问数据库银行时,聪明的开发者早已学会用钱包零钱策略实现毫秒级响应——本文将用理财思维拆解缓存设计精髓,教你如何让代码学会小额快付的架构艺术。" 【缓存】作为程序员必须理解的概念之一,让我们用 「钱…...

Json rpc 2.0比起传统Json在通信中的优势
JSON-RPC 2.0 相较于直接使用传统 JSON 进行通信,在协议规范性、开发效率、通信性能等方面具有显著优势。以下是核心差异点及技术价值分析: 一、结构化通信协议,降低开发成本 传统 JSON 通信需要开发者自定义数据结构和处理逻辑,…...

无缝部署您的应用程序:将 Jenkins Pipelines 与 ArgoCD 集成
在 DevOps 领域,自动化是主要目标之一。这包括自动化软件部署方式。与其依赖某人在部署软件的机器上进行 rsync/FTP/编写软件,不如使用 CI/CD 的概念。 CI,即持续集成,是通过代码提交创建工件的步骤。这可以是 Docker 镜像&#…...
 2-5-1 GB/T 25070—2019 附录B (资料性附录)第三级系统安全保护环境设计示例)
网络安全-等级保护(等保) 2-5-1 GB/T 25070—2019 附录B (资料性附录)第三级系统安全保护环境设计示例
################################################################################ 文档标记说明: 淡蓝色:时间顺序标记。 橙色:为网络安全标准要点。 引用斜体:为非本文件内容,个人注解说明。 加粗标记:…...

精准掌控张力动态,重构卷对卷工艺设计
一、MapleSim Web Handling Library仿真和虚拟调试解决方案 在柔性材料加工领域,卷对卷(Roll-to-Roll)工艺的效率与质量直接决定了产品竞争力。如何在高动态生产场景中实现张力稳定、减少断裂风险、优化加工速度,是行业长期面临的…...

怎么使用python进行PostgreSQL 数据库连接?
使用Python连接PostgreSQL数据库 在Python中连接PostgreSQL数据库,最常用的库是psycopg2。以下是详细的使用指南: 安装psycopg2 首先需要安装psycopg2库: pip install psycopg2 # 或者使用二进制版本(安装更快) pi…...

SQL Server权限设置的几种方法
SQL Server 的权限设置是数据库安全管理的核心,正确配置权限可以有效防止数据泄露、误操作和恶意篡改。下面详细介绍 SQL Server 权限设置的方法,涵盖从登录名创建到用户授权的完整流程。 一、权限设置的基本概念 SQL Server 的权限体系主要包括以下几…...
 - Neo4j安装教程(Windows))
Neo4j(一) - Neo4j安装教程(Windows)
文章目录 前言一、JDK与Neo4j版本对应关系二、JDK11安装及配置1. JDK11下载2. 解压3. 配置环境变量3.1 打开系统属性设置3.2 新建系统环境变量3.3 编辑 PATH 环境变量3.4 验证环境变量是否配置成功 三、Neo4j安装(Windows)1. 下载并解压Neo4j安装包1.1 下…...

idea启用lombok
有lombok的项目在用idea打开的时候会提示启用lombok,但是。。。不小心就落下了...

uniapp婚纱预约小程序
uniapp婚纱预约小程序,这套设计bug很多,是一个半成品,一个客户让我修改,很多问题,页面显示不了,评论不能用,注册不能用,缺少表,最后稍微改一下,但是也有小问题…...

基于OpenCV的SIFT特征匹配指纹识别
文章目录 引言一、概述二、关键代码解析1. SIFT特征提取与匹配2. 指纹身份识别3. 姓名映射 三、使用示例四、技术分析五、完整代码六、总结 引言 指纹识别是生物特征识别技术中最常用的方法之一。本文将介绍如何使用Python和OpenCV实现一个简单的指纹识别系统,该系…...

Vue3 加快页面加载速度 使用CDN外部库的加载 提升页面打开速度 服务器分发
介绍 CDN(内容分发网络)通过全球分布的边缘节点,让用户从最近的服务器获取资源,减少网络延迟,显著提升JS、CSS等静态文件的加载速度。公共库(如Vue、React、Axios)托管在CDN上,减少…...

C++23:ranges::iota、ranges::shift_left和ranges::shift_right详解
文章目录 引言ranges::iota定义与功能使用场景代码示例 ranges::shift_left定义与功能使用场景代码示例 ranges::shift_right定义与功能使用场景代码示例 总结 引言 C23作为C编程语言的一个重要版本,为开发者带来了许多新的特性和改进。其中,ranges::io…...

Spring 框架中适配器模式的五大典型应用场景
Spring 框架中适配器模式的应用场景 在 Spring 框架中,适配器模式(Adapter Pattern)被广泛应用于将不同组件的接口转化为统一接口,从而实现组件间的无缝协作。以下是几个典型的应用场景: 1. HandlerAdapter - MVC 请…...
ScrollList滚动数据列表)
【Unity】 HTFramework框架(六十五)ScrollList滚动数据列表
更新日期:2025年5月16日。 Github 仓库:https://github.com/SaiTingHu/HTFramework Gitee 仓库:https://gitee.com/SaiTingHu/HTFramework 索引 一、ScrollList滚动数据列表二、使用ScrollList1.快捷创建ScrollList2.ScrollList的属性3.自定义…...

Android SwitchButton 使用详解:一个实际项目的完美实践
Android SwitchButton 使用详解:一个实际项目的完美实践 引言 在最近开发的 Android 项目中,我遇到了一个需要自定义样式开关控件的需求。经过多方比较,最终选择了功能强大且高度可定制的 SwitchButton 控件。本文将基于实际项目中的使用案…...

【C++ 基础数论】质数判断
质数判断 质数:对于所有大于 1 的自然数而言,如果该数除 1 和自身以外没有其它因数 / 约数,则该数被称为为质数,质数也叫素数。 如何判定一个数是否为质数呢? 一个简单的方法是 试除法 : 对于一个数 n&…...
)
【数据结构】手撕AVL树(万字详解)
目录 AVL树的概念为啥要有AVL树?概念 AVL树节点的定义AVL树的插入AVL树的旋转左单旋右单旋左右双旋右左双旋 AVL树的查找AVL树的验证end AVL树的概念 为啥要有AVL树? 在上一章节的二叉搜索树中,我们在插入节点的操作中。有可能一直往一边插…...

Chrome代理IP配置教程常见方式附问题解答
在网络隐私保护和跨境业务场景中,为浏览器配置代理IP已成为刚需。无论是访问地域限制内容、保障数据安全,还是管理多账号业务,掌握Chrome代理配置技巧都至关重要。本文详解三种主流代理设置方式,助你快速实现精准流量管控。 方式一…...

SpringBoot + Shiro + JWT 实现认证与授权完整方案实现
SpringBoot Shiro JWT 实现认证与授权完整方案 下面博主将详细介绍如何使用 SpringBoot 整合 Shiro 和 JWT 实现安全的认证授权系统,包含核心代码实现和最佳实践。 一、技术栈组成 技术组件- 作用版本要求SpringBoot基础框架2.7.xApache Shiro认证和授权核心1.…...

深入解析VPN技术原理:安全网络的护航者
在当今信息化迅速发展的时代,虚拟私人网络(VPN)技术成为了我们在互联网时代保护隐私和数据安全的重要工具。VPN通过为用户与网络之间建立一条加密的安全通道,确保了通讯的私密性与完整性。本文将深入解析VPN的技术原理、工作机制以…...