学习以任务为中心的潜动作,随地采取行动
25年5月来自香港大学、OpenDriveLab 和智元机器人的论文“Learning to Act Anywhere with Task-centric Latent Actions”。
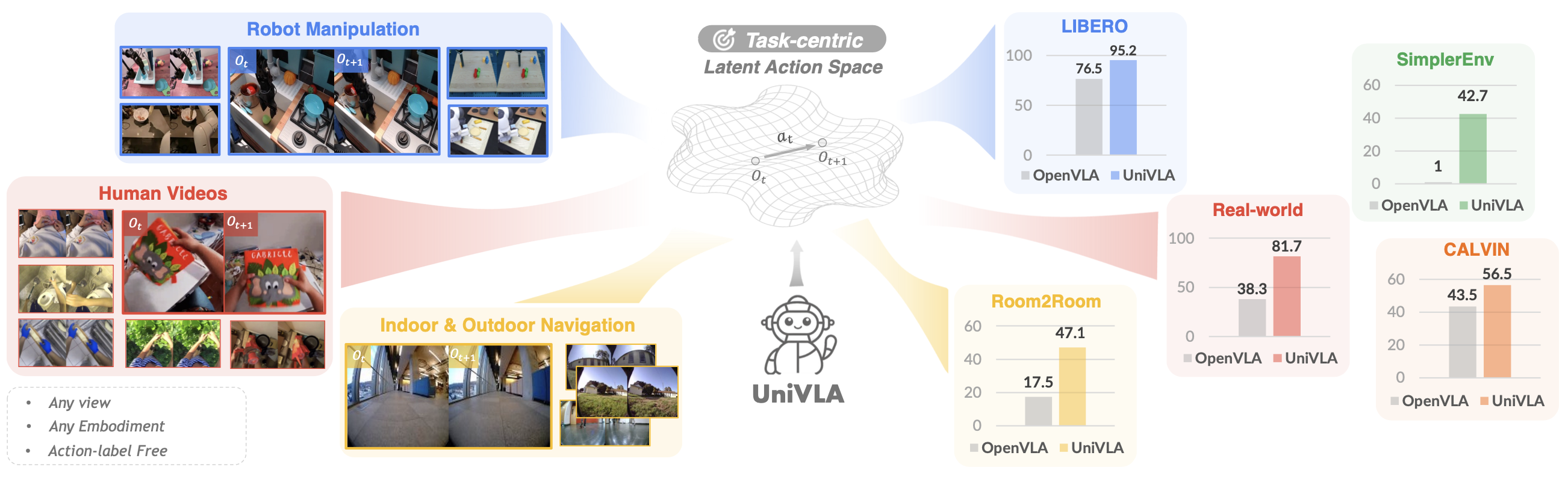
通用机器人应该在各种环境中高效运行。然而,大多数现有方法严重依赖于扩展动作标注数据来增强其能力。因此,它们通常局限于单一的物理规范,难以学习跨不同具身和环境的可迁移知识。为了突破这些限制,UniVLA,是一个用于学习跨具身视觉-语言-动作 (VLA) 策略的全新框架。关键创新在于利用潜动作模型从视频中获取以任务为中心的动作表征,这样能够利用涵盖广泛具身和视角的海量数据。为了减轻与任务无关动态变化的影响,结合语言指令,并在 DINO 特征空间内建立一个潜动作模型。该通用策略基于互联网规模的视频学习,可以通过高效的潜动作解码部署到各种机器人上。在多个操作和导航基准测试以及实际机器人部署中均获得最佳结果。 UniVLA 的性能远超 OpenVLA,其预训练计算量和下游数据量分别不到 OpenVLA 的二十分之一和十分之一。随着异构数据(甚至包括真人视频)被纳入训练流程,性能持续提升。这些结果凸显 UniVLA 在促进可扩展且高效的机器人策略学习方面的潜力。
得益于大规模机器人数据集 [78, 63, 38, 18] 的出现,基于视觉-语言-动作模型 (VLA) 的机器人策略近期取得了令人鼓舞的进展 [9, 28, 39]。然而,这些策略通常依赖于真实动作标签进行监督,这限制了它们在利用来自不同环境互联网规模数据方面的可扩展性。此外,不同具身(例如,Franka、WidowX,甚至人手)和任务(例如,操作和导航)之间动作和观察空间的异质性,对有效的知识迁移构成了重大挑战。这引出了一个关键问题:能否学习一种统一的动作表征,使通用策略能够有效地进行规划,从而释放互联网规模视频的潜力,并促进跨不同具身和环境的知识迁移?
视觉-语言-动作模型。在预训练视觉基础模型、大语言模型 (LLM) 和视觉-语言模型 (VLM) 的成功基础上,VLA 已被引入用于处理多模态输入(视觉观察和语言指令),并生成用于完成具身任务的机器人动作。RT-1 [10] 和 Octo [28] 采用基于 Transformer 的策略,该策略整合各种数据,包括跨各种任务、目标、环境和具身的机器人轨迹。相比之下,一些先前的研究 [9, 39, 46] 利用预训练的 VLM,通过利用来自大规模视觉-语言数据集的世界知识来生成机器人动作。例如,RT-2 [9] 和 OpenVLA [39] 将动作视为语言模型词汇表中的 tokens,而 RoboFlamingo [46] 引入一个额外的策略头用于动作预测。在这些通用策略的基础上,RoboDual [12] 提出一种协同双系统,融合通用策略和专家策略的优势。其他研究则结合目标图像 [8] 或视频 [24, 82, 13] 预测任务,以语言指令为条件生成有效、可执行的规划,并利用这些视觉线索指导策略生成动作。然而,这些方法严重依赖于带有真实动作标签的交互式数据,这显著限制 VLA 的可扩展性。
跨具身学习。由于不同机器人系统的摄像机视角、本体感受输入、关节配置、动作空间和控制频率存在差异,训练通用机器人策略极具挑战性。早期方法 [86] 侧重于在导航和操作之间手动方式对齐动作空间,但操作时仅限于腕部摄像机。近期基于 Transformer 的方法 [28, 23] 通过适应不同的观测和动作解决这些挑战,其中 CrossFormer [23] 可在四个不同的动作空间中进行协同训练,而无需对观测空间施加限制或要求显式对齐动作空间。流表征(用于捕捉图像或点云中查询点的未来轨迹)已被广泛应用于跨具身学习 [81, 88, 26, 83]。ATM [81] 从人类演示中学习流生成,而 Im2Flow2Act [83] 则无需域内数据,即可从人类视频中预测物体流。同时,以目标为中心的表征 [32, 7] 提供了一种替代方法,SPOT [32] 可以在 SE(3) 中预测目标轨迹,从而将具身动作与感官输入分离。现有方法需要大量、多样化的数据集来涵盖所有可能的状态转换模式,并且需要明确的注释,导致数据利用率低下。
潜动作学习。一些先前的研究侧重于学习变分自编码器 [64, 76] 来构建新的动作空间,强调紧凑的潜表征以促进行为生成和任务自适应,例如 VQ-BeT [44] 和 Quest [59]。这些方法也被强化学习采用以加速收敛 [2]。最近的研究 [79, 74] 探索将矢量量化作为动作空间适配器,以便更好地将动作集成到大语言模型中。然而,这些方法的一个关键限制是它们依赖于真实动作标签,这限制它们的可扩展性。为了利用更广泛的视频数据,Genie [11] 通过因果潜动作模型提取潜动作,并以下一帧预测为条件。同样,LAPO [70] 和 DynaMo [20] 直接从视觉数据中学习潜动作,绕过在域内操作任务中使用显式动作标签的方法。LAPA [87] 和 IGOR [15] 引入无监督的预训练方法来教授 VLA 离散潜动作,旨在从人类视频中迁移知识。然而,这些方法对原始像素中的所有视觉变化进行编码,捕获了与任务无关的动态,例如相机抖动、其他智体的移动或新目标的出现,这最终会降低策略性能。
为了应对这些挑战,UniVLA,是一个通用策略学习框架,能够跨各种具身和环境进行可扩展且高效的规划。就像大语言模型 (LLM) 学习跨语言共享知识 [22, 17] 一样,目标是构建一个统一的动作空间,以促进跨视频数据的知识迁移,包括各种机器人演示和以自我为中心的人类视频。通才策略包含三个关键阶段:1)以任务为中心的潜动作学习,以无监督的方式从大量跨具身视频中提取与任务相关的动作表征。这是通过使用 VQ-VAE [76] 从成对帧的逆动态中离散化潜动作来实现的。2)下一个潜动作预测,使用离散化的潜动作 tokens 训练自回归视觉语言模型,赋予其与具身无关的规划能力。3)潜解码,将潜规划解码为物理行为,并专门化预训练的通才策略,以便有效地部署到未见过的任务中。
如图所示:
虽然最近的研究 [87, 15] 已经探索从网络规模视频中学习潜动作的可行性,但它们存在一个关键的局限性:它们基于重建的简单目标函数通常会捕捉与任务无关的动态,例如非自智体的移动或不可预测的摄像机移动。这些嘈杂的表征会引入与任务无关的干扰,从而阻碍策略预训练。为了解决这个问题,利用预训练的 DINOv2 特征 [62] 从像素中提取块级表征,提供空间和以目标为中心的先验知识,从而更好地捕获与任务相关的信息。通过使用现成的语言指令作为条件,进一步将动作分解为两个互补的动作表征,其中一个明确地表示以任务为中心的动作。
本文开发三个步骤来实现 UniVLA:1)(第三部分 A)利用基于语言的目标规范,以无监督的方式从大量视频数据集中提取逆动态,从而生成一组以任务为中心的离散潜动作,这些动作可泛化至不同的具体实现和领域;2)(第三部分 B)在此基础上,训练一个基于自回归 Transformer 的视觉-语言-动作模型,该模型以视觉观察和任务指令作为输入,在统一的潜空间中预测潜动作token;3)(第三部分 C)为了高效地适应各种机器人控制系统,引入专门的策略头,将潜动作解码为可执行的控制信号。
以任务为中心的潜动作学习
第一步通过生成伪动作标签(即潜动作 tokens)奠定了该框架的基础,这些标签是后续阶段训练泛化策略的基础。
潜动作量化。如图展示潜动作模型的两阶段训练流程和整体架构。从一对连续的视频帧开始,记为 {o_t,o_t+k},两个帧之间间隔为 k。为了确保不同数据集的时间间隔统一为大约 1 秒,帧间隔根据每个数据集特定的记录频率进行标定。为了从视频中得出潜动作,潜动作模型围绕基于逆动力学模型 (IDM) 的编码器 I(a_t|o_t,o_t+k) 和基于前向动力学模型 (FDM) 的解码器 F(o_t+k|o_t,a_t) 构建。编码器根据连续的观察推断潜动作,解码器经过训练,可以根据指定的潜动作预测未来的观察结果。遵循 Villegas [77] 的研究,将编码器实现为具有随意时间掩码的时空transformer [84]。一组可学习的动作 tokens a_q(具有预定义的维度 d)按顺序连接到视频特征以提取动态特征。
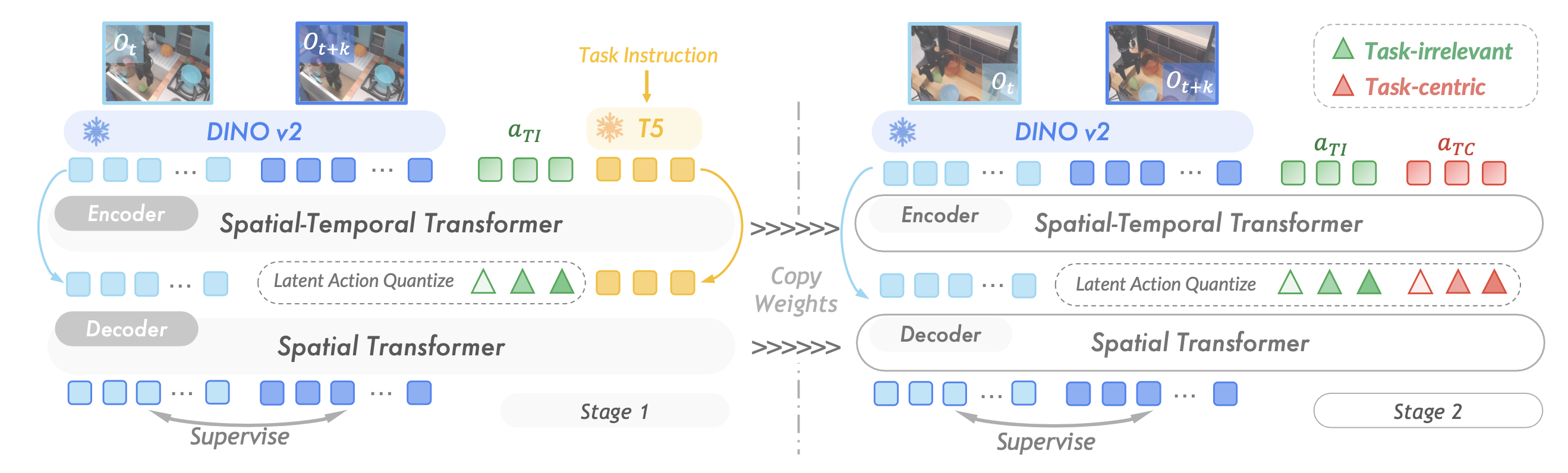
为了进一步压缩信息并使其与基于自回归 transformer 策略的学习目标 [66] 保持一致,对动作 tokens 应用潜量化。量化的动作 tokens a_z 使用 VQ-VAE [76] 目标进行优化,其码本词汇量为 |C|。解码器实现为空间 transformer,经过优化,仅使用量化的动作 tokens 即可预测未来帧。不将历史帧输入解码器,以防止模型过度依赖上下文信息或仅仅记忆数据集。
虽然最近的研究 [11, 27, 87] 使用原始像素进行预测,但像素空间预测会迫使模型关注嘈杂的、与任务无关的细节(例如,纹理、光照)[30]。这一问题在网络规模和众包视频数据集 [29] 中尤为突出,因为不受控制的捕获条件会引入进一步的变化。受联合嵌入预测架构 (JEPA) [4, 5, 96] 的启发,本文提出使用 DINOv2 [62] 空间块特征作为语义丰富的表征。它们以目标为中心和空间感知的特性使它们不仅适合用作输入,也适合用作潜动作模型的预测目标。自监督目标是最小化嵌入重构误差:||Oˆ_t+k − O_t+k||^2。用 {O_t, O_t+k} 来表示成对视频帧 {o_t, o_t+k} 的 DINOv2 特征。因此,紧凑的潜动作必须对观测值之间的变换进行编码,以最小化预测误差。
潜动作解耦。如前所述,在网络规模视频中,机器人的动作通常会与不相关的环境变化纠缠在一起。为了减轻与任务无关的动态特征带来的不利影响,将现成的语言指令融入到潜动作模型的第一训练阶段(如上图左)。语言输入使用预训练的 T5 文本编码器 [67] 进行编码,并作为编码器和解码器上下文中的条件信号。
向解码器发送任务指令提供了关于底层动作的高级语义指导。因此,量化的潜动作经过优化,仅编码环境变化和视觉细节[89],由于码本容量有限,省略与任务相关的高级信息[1]。此阶段建立一组潜动作,其中包含与任务无关的信息,例如新目标的出现、外智体的移动或摄像机引起的运动伪影。这些动态特征虽然对于将模型应用于视觉环境至关重要,但与任务的具体目标无关。
接下来,将在第 1 阶段训练的潜动作模型任务无关码本和参数重新用于下一阶段(如图右所示),其目标是学习一组新的以任务为中心的潜动作 aˆ_TC,并在此基础上训练策略。
基于已获取的与任务无关的表征,冻结相应的码本,使模型能够专注于细化和特化新的潜动作集合。这种特化有助于精确建模与任务相关的动态,例如目标(object)操控或目标(goal)导向的运动轨迹。隐性动作表征的显式解耦增强了泛化策略在不同环境和任务中的泛化能力。与简单的隐性动作学习方法(例如 LAPA [87])相比,仅基于以任务为中心的表征进行训练可以实现更快的收敛速度,同时实现稳健的性能,这表明这些隐性动作对于后续的策略学习更具参考价值。
泛化策略的预训练
基于上一步训练的潜动作模型,继续在给定 o_t+k 的情况下,用隐动作 a_z tokens 任意视频帧 o_t。然后,使用这些标签来开发泛化策略。为了与 Kim [39] 的研究保持一致,提出一种基于隐性动作的通才策略,建立在 Prismatic-7B [37] 视觉语言模型 (VLM) 之上。该架构集成源自 SigLip [90] 和 DINOv2 [62] 的融合视觉编码器、用于将视觉嵌入与语言模态对齐的投影层,以及 LLaMA-2 大语言模型 (LLM) [75]。与之前基于 LLM 的通才策略(即 RT-2 [9] 和 OpenVLA [39])不同,这些策略通过将 LLaMA token化器词汇表中不常用的词映射到 [-1, 1] 内均匀分布的动作区间来直接在低级动作空间中进行规划,而本文用 |C| 个特殊 tokens 扩展了词汇表,具体为 {ACT_1, ACT_2, ACT_3, …, ACT_C}。潜动作会根据其在动作码本中的索引投影到此词汇表中。这种方法保留了 VLM 的原始模型架构和训练目标,充分利用其预训练知识,并将其迁移到机器人控制任务中。具体来说,策略模型 π_φ 接收观测值 o_t、任务指令 l 以及潜动作 token 前缀 a_z,<i,并进行优化,以最小化下一个潜动作负对数概率之和。
此外,经验证据表明,压缩动作空间(例如,当 |C| = 16 时,动作空间从 OpenVLA [39] 中的 2567 减少到 16^4)可显著加速模型收敛。该方法仅需 960 个 A100 小时的预训练就取得具有竞争力的结果,与 OpenVLA 预训练所需的 21,500 个 A100 小时相比,大幅减少。
通过在统一的潜动作空间内训练策略,该模型充分利用从跨领域数据集中获得的可迁移知识。与 Yang [86] 的论文不同,该论文需要通过视觉上相似的自我中心运动(例如操作任务中的腕部摄像头运动和自我中心导航)手动调整动作空间,而该方法则省去了这一步骤。因此,UniVLA 扩展可用数据集的范围并提升整体性能,证明利用以任务为中心的潜动作表征进行可扩展策略学习的有效性。
部署后训练
潜动作解码。在下游自适应过程中,预训练的通用策略通过预测下游自适应过程中的下一个潜动作来保持其与具身无关的特性。为了弥合潜动作与可执行行为之间的差距,采用额外的动作解码器(如图所示)。具体来说,视觉嵌入序列首先通过多头注意池 [43] 聚合为单个 tokens,然后该 tokens 作为查询从潜动作嵌入中提取信息。
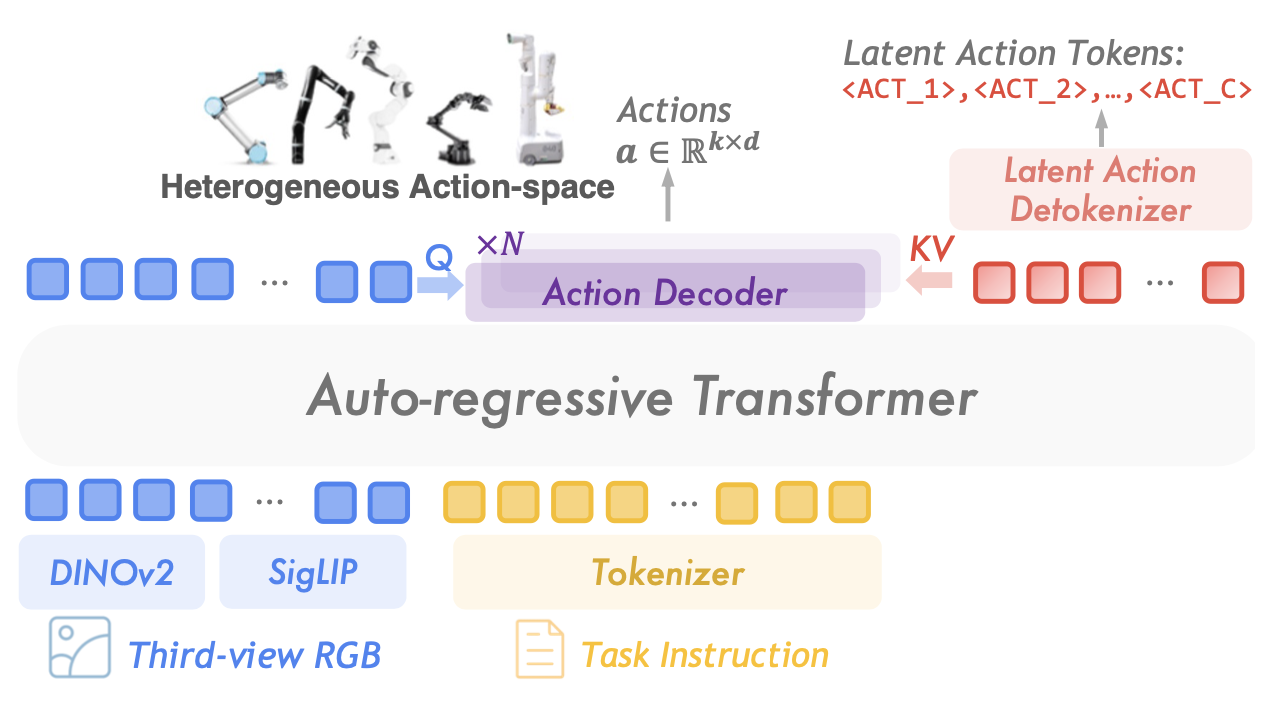
鉴于潜动作旨在表示大约一秒间隔内发生的动作,它们可以自然地解码为动作块 [93]。块大小可根据具身轻松定制,以实现更流畅、更精确的控制。
在实践中,利用 LoRA [33] 进行参数高效的微调,以实现高效的自适应。加上仅包含 12.6M 个参数的动作头,可训练参数总数约为 123M。整个模型采用端到端训练,优化下一个潜动作预测损失以及真实动作与预测低级动作之间的 L1 损失。
从历史输出中学习。历史观察已被证明在增强机器人控制的序贯决策过程中发挥着关键作用 [60, 42, 45]。然而,直接为大型视觉-语言-动作模型提供多个历史观测数据会导致显著的推理延迟,并导致视觉 token 中的信息冗余 [94, 45]。得到大语言模型 (LLM) 中成熟的思维链 (CoT) 推理范式 [80](可生成中间推理步骤来解决复杂任务)启发,本文提出利用历史潜动作输出来促进机器人控制中的决策制定。与 LLM 逐步解决问题类似,在部署过程中的每个时间步将过去的动作融入到输入提示中。这为机器人策略建立一个反馈回路,使策略能够从自身的决策中学习并适应动态环境。
为了将这种方法付诸实践,用潜动作模型来注释从历史帧中提取的动作。然后,这些带注释的动作被映射到 LLaMA tokens 词汇表中,并附加到任务指令中。在训练后阶段,历史动作输入被集成为输入,使模型具备上下文学习(ICL)能力。在推理时,除初始步骤外,每个时间步都会合并一个历史潜动作(编码为 N = 4 个 token)。实证结果表明,这种简单的设计能够提升模型性能,尤其是在长周期任务中。
实验1
基于操作数据、导航数据和人体视频数据(这三者分别是 Open X-Embodiment (OpenX) 数据集 [63]、GNM 数据集 [72] 和人体视频 (Ego4D [29]) 的子集)对完整潜动作模型进行预训练。LIBERO 基准 [48] 包含四个任务套件,专门用于促进机器人操作的终身学习研究。实验专注于在目标任务套件中进行监督微调,评估通过行为克隆训练的各种策略在成功任务演示上的表现。如图所示,实验设置包含以下任务套件,每个任务套件包含 10 个任务,每个任务包含 50 个人类遥控演示:

- LIBERO-Spatial 要求策略推断空间关系以准确放置碗,评估模型推理几何结构的能力;
- LIBERO-Object 保持相同的场景布局,但引入了目标类型的变化,以此评估策略在不同目标实例间的泛化能力;
- LIBERO-Goal 保持一致的目标和布局,同时分配不同的任务目标(goal),以此挑战策略展现面向目标的行为和适应性;
- LIBERO-Long 专注于涉及多个子目标的长期操作任务,结合异构目标、布局和任务序列来评估模型在复杂、多步骤规划中的能力。
选择的基线模型包括以下五个代表性模型,其中 OpenVLA 和 LAPA 与本文方法更为接近:
• LAPA [87] 引入一个无监督框架,用于从未标记的人类视频中学习潜动作。
• Octo [28] 是一种基于 Transformer 的策略,在多样化的机器人数据集上进行训练,它采用统一的动作表示来处理异构的动作空间。
• MDT [68] 利用扩散模型生成由多模态目标决定的灵活动作序列。
• OpenVLA [39] 是一种视觉-语言-动作模型,它利用包括 OpenX 在内的多样化数据集进行大规模预训练,以实现通用的机器人策略。
• MaIL [35] 通过整合选择性状态空间模型来增强模仿学习,从而提高策略学习的效率和可扩展性。
实验 2
另外,本实验在 VLN-CE 基准 [41] 上评估 UniVLA,以评估其在导航任务中的表现。这些基准提供一组语言引导的导航任务和连续环境,用于在重建的照片级真实感室内场景中执行低级动作。具体来说,专注于 VLN-CE 中的 Room2Room (R2R) [3] 任务,这是视觉和语言导航 (VLN) 领域最受认可的基准之一。所有方法均基于 R2R 训练集的 10,819 个样本进行训练,并基于 R2R val-unseen 集的 1,839 个样本进行评估。使用 oracle 成功率来评估导航性能。在 VLN-CE 中,如果智体到达目标 3 米以内,则认为该回合成功。
为了确保与 UniVLA 进行公平比较,评估仅基于 RGB 的方法,这些方法无需深度或里程计数据,可直接预测 VLN-CE 环境中的低级动作。选定的基准如下:
• Seq2Seq [40] 是一种循环的序列到序列策略,可根据 RGB 观测值预测动作。
• CMA [40] 采用跨模态注意机制,将指令与 RGB 观测值相结合,进行动作预测。
• LLaVA-Nav 是 LLaVA [49] 的改进版本,与 NaVid [91] 提出的数据进行协同微调,并使用“从观测到历史”的技术对历史记录进行编码。
• OpenVLA [39] 是一个视觉-语言-动作模型。引入一些特殊的 tokens 来 token 化导航动作,并在 R2R 训练样本上对模型进行微调。
• NaVid [91] 是一个基于视频的大型视觉-语言模型,它对所有历史 RGB 观测值进行编码。
实验 3
所有真实世界实验均采用 AgileX Robotics 的 Piper 机械臂进行,该机械臂具有 7 自由度动作空间和第三视角 Orbecc DABAI RGB-D 相机,仅使用 RGB 图像作为输入。为了评估策略,设计一套涵盖策略能力各个维度的综合任务,包括:
- 空间感知:拿起螺丝刀放入柜子并关上柜门(“存放螺丝刀”)。
- 工具使用和非抓握操作:拿起扫帚,将砧板上的物品扫入簸箕(“清洁砧板”)。
- 可变形目标操作:将毛巾对折两次(“折叠毛巾两次”)。
- 语义理解:先将中等大小的塔堆叠在大塔之上,然后将小塔堆叠在中等大小的塔之上。(“堆叠汉诺塔”)
对于每个任务,收集 20 到 80 条轨迹,并根据任务复杂度进行缩放,以微调模型。为了全面评估泛化能力,设计了涵盖多个未见过场景的实验,包括光照变化、视觉干扰和目标泛化(如图所示)。鉴于单凭成功率不足以反映策略性能或区分其能力,引入一个分阶式评分系统。对于四个任务中的每一个,分配最高 3 分,以反映任务执行过程中不同阶段的完成情况。

选择扩散策略 [16] 以及通用策略 OpenVLA [39] 和 LAPA [87] 作为基准。扩散策略以单任务方式训练,而通用模型则在所有任务上同时进行指令输入训练。为了公平起见,使用 Prismatic-7B VLM [37] 和动作解码器头复现LAPA,并将其架构与该方法保持一致。这种设置能够分离并强调以任务为中心潜动作空间的贡献。
相关文章:

学习以任务为中心的潜动作,随地采取行动
25年5月来自香港大学、OpenDriveLab 和智元机器人的论文“Learning to Act Anywhere with Task-centric Latent Actions”。 通用机器人应该在各种环境中高效运行。然而,大多数现有方法严重依赖于扩展动作标注数据来增强其能力。因此,它们通常局限于单一…...

《数据结构初阶》【二叉树 精选9道OJ练习】
【二叉树 精选9道OJ练习】目录 前言:二叉树的OJ练习[144. 二叉树的前序遍历](https://leetcode.cn/problems/binary-tree-preorder-traversal/)题目介绍方法一:[104. 二叉树的最大深度](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)题目…...

协议不兼容?Profinet转Modbus TCP网关让恒压供水系统通信0障碍
在现代工业自动化领域中,通信协议扮演着至关重要的角色。ModbusTCP和Profinet是两种广泛使用的工业通信协议,它们各自在不同的应用场合中展现出独特的优势。本文将探讨如何通过开疆智能Profinet转Modbus TCP的网关,在恒压供水系统中实现高效的…...

基于大模型预测的脑出血全流程诊疗技术方案
目录 一、系统架构设计技术架构图二、核心算法实现1. 多模态数据融合算法伪代码2. 风险预测模型实现三、关键模块流程图1. 术前风险预测流程图2. 术中决策支持流程图3. 并发症预测防控流程图四、系统集成方案1. 数据接口规范五、性能优化策略1. 推理加速方案2. 分布式训练架构六…...

掌握 LangChain 文档处理核心:Document Loaders 与 Text Splitters 全解析
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是LangChain 2、LangChain 在智能应用中的作用 …...

Oracle — 总结
Oracle 公司及产品概述 公司背景 Oracle(甲骨文)是全球领先的数据库软件和服务提供商,成立于1977年,核心产品包括: Oracle Database:关系型数据库管理系统(RDBMS)。Java:…...

【Vue 3全栈实战】从响应式原理到企业级架构设计
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

升级kafka4.0.0,无ZK版本
设备规划: 172.20.192.47 kafka-0 172.20.192.48 kafka-1 172.20.192.49 kafka-2 单机块7TB Nvme磁盘一共9块 # 格式化成GPT分区 sudo parted /dev/nvme0n1 --script mklabel gpt sudo parted /dev/nvme1n1 --script mklabel gpt sudo parted /dev/nvme2n1 --s…...
等差矩阵))
GESP2025年3月认证C++二级( 第三部分编程题(1)等差矩阵)
参考程序: #include <bits/stdc.h> using namespace std;int n, m; // 声明矩阵的行数 n 和列数 mint main() {// 输入两个正整数 n 和 mscanf("%d%d", &n, &m);// 遍历每一行for (int i 1; i < n; i)// 遍历每一列for (int j 1; j &…...

Linux系统启动相关:vmlinux、vmlinuz、zImage,和initrd 、 initramfs,以及SystemV 和 SystemD
目录 一、vmlinux、vmlinuz、zImage、bzImage、uImage 二、initrd 和 initramfs 1、initrd(Initial RAM Disk) 2、initramfs(Initial RAM Filesystem) 3、initrd vs. initramfs 对比 4. 如何查看和生成 initramfs 三、Syste…...

单序列双指针---初阶篇
目录 相向双指针 344. 反转字符串 125. 验证回文串 1750. 删除字符串两端相同字符后的最短长度 2105. 给植物浇水 II 977. 有序数组的平方 658. 找到 K 个最接近的元素 1471. 数组中的 k 个最强值 167. 两数之和 II - 输入有序数组 633. 平方数之和 2824. 统计和小于…...

K8s CoreDNS 核心知识点总结
文章目录 一、章节介绍背景与主旨核心知识点及面试频率 二、知识点详解1. CoreDNS 概述2. 工作原理(高频考点)服务发现流程 3. 配置与插件系统(高频考点)核心配置文件:Corefile常用插件 4. Pod DNS策略(中频…...

Java视频流RTMP/RTSP协议解析与实战代码
在Java中实现视频直播的输入流处理,通常需要结合网络编程、多媒体处理库以及流媒体协议(如RTMP、HLS、RTSP等)。以下是实现视频直播输入流的关键步骤和技术要点: 1. 视频直播输入流的核心组件 网络输入流:通过Socket或…...

卓力达电铸镍网:精密制造与跨领域应用的创新典范
目录 引言 一、电铸镍网的技术原理与核心特性 二、电铸镍网的跨领域应用 三、南通卓力达电铸镍网的核心优势 四、未来技术展望 引言 电铸镍网作为一种兼具高精度与高性能的金属网状材料,通过电化学沉积工艺实现复杂结构的精密成型,已成为航空航天、电…...

label-studio功能常用英文翻译
Projects 项目 Settings 设置 Labeling Interface 标注界面 1、Computer Vision 计算机视觉 Semantic Segmentation with Polygons 多边形语义分割 Semantic Segmentation with Masks 掩码语义分割 Object Detection with Bounding Boxes 边界框目标检测 Keypoint Label…...
)
2025年PMP 学习十六 第11章 项目风险管理 (总章)
2025年PMP 学习十六 第11章 项目风险管理 (总章) 第11章 项目风险管理 序号过程过程组1规划风险管理规划2识别风险规划3实施定性风险分析规划4实施定量风险分析规划5规划风险应对执行6实施风险应对执行7监控风险监控 目标: 提高项目中积极事件的概率和…...
如何调整限制?)
Jenkins 执行器(Executor)如何调整限制?
目录 现象原因解决 现象 Jenkins 构建时,提示如下: 此刻的心情正如上图中的小老头,火冒三丈,但是不要急,因为每一次错误,都是系统中某个环节在说‘我撑不住了’。 原因 其实是上图的提示表示 Jenkins 当…...

Jenkins 安装与配置指南
Jenkins 安装与配置指南(MD 示例) markdown Jenkins 安装与配置指南 ## 一、环境准备 1. **系统要求** - 操作系统:Linux/macOS/Windows - Java 版本:JDK 8 或更高(建议 JDK 11)2. **安装方式** - **L…...

使用unsloth对Qwen3在本地进行微调
Fine-tune Qwen3(100% locally) 使用unsloth进行微调,使用huggingface在本地运行model。 load model from unsloth import FastLanguageModel import torchMODEL = "unsloth/Qwen3-14B" model,tokenizer = FastLanguageModel.from_pretrained(model_name=MODE…...

GpuGeek 实操指南:So-VITS-SVC 语音合成与 Stable Diffusion 文生图双模型搭建,融合即梦 AI 的深度实践
GpuGeek 实操指南:So-VITS-SVC 语音合成与 Stable Diffusion 文生图双模型搭建,融合即梦 AI 的深度实践 前言 本文将详细讲解 So-VITS-SVC 语音合成与 Stable Diffusion 文生图的搭建方法,以及二者与即梦 AI 融合的实践技巧,无论你…...

CSS- 3.1 盒子模型-块级元素、行内元素、行内块级元素和display属性
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...
)
使用exceljs将excel文件转化为html预览最佳实践(完整源码)
前言 在企业应用中,我们时常会遇到需要上传并展示 Excel 文件的需求,以实现文件内容的在线预览。经过一番探索与尝试,笔者最终借助 exceljs 这一库成功实现了该功能。本文将以 Vue 3 为例,演示如何实现该功能,代码示例…...

7. 进程控制-进程替换
目录 1. 进程替换 1.1 单进程版: 1.2 进程替换的原理 1.3 多进程版-验证各种程序替换接口 2. 进程替换的各种接口 2.1 execl 2.2 execlp 2.3 execv 2.4 execvp 2.5 execle 1. 进程替换 上图为程序替换的接口,之后会详细介绍。 1.1 单进程版&am…...

关于计算机系统和数据原子性的联系
目录 1、计算机架构 1.1、处理器架构 1.2、内存寻址能力 1.3、性能差异 1.4、软件兼容性 1.5、指令集 1.6、开发和维护 2.、基本数据类型 3、原子类型 3.1、基本概念 3.2、基本数据类型的原子性 3.3、原子操作的解释 3.4、不保证原子性 3.5、解决方案 4、原子性…...

Armijo rule
非精线搜索步长规则Armijo规则&Goldstein规则&Wolfe规则_armijo rule-CSDN博客 [原创]用“人话”解释不精确线搜索中的Armijo-Goldstein准则及Wolfe-Powell准则 – 编码无悔 / Intent & Focused...

从数据包到可靠性:UDP/TCP协议的工作原理分析
之前我们已经使用udp/tcp的相关接口写了一些简单的客户端与服务端代码。也了解了协议是什么,包括自定义协议和知名协议比如http/https和ssh等。现在我们再回到传输层,对udp和tcp这两传输层巨头协议做更深一步的分析。 一.UDP UDP相关内容很简单…...

Prometheus实战教程:k8s平台-Mysql监控案例
配置文件优化后的 Prometheus 自动发现 MySQL 实例的完整 YAML 文件。该配置包括: MySQL Exporter 部署:使用 ConfigMap 提供 MySQL 连接信息。Prometheus 自动发现:通过 Kubernetes 服务发现自动抓取 MySQL 实例。 1、mysql 配置文件 &…...

执行apt-get update 报错ModuleNotFoundError: No module named ‘apt_pkg‘的解决方案汇总
Ubuntu版本ubuntu18.04 报错内容: //执行apt-get upgrade报错: Traceback :File “/usr/lib/cnf-update-db”, line 8, in <module>from CommandNotFound.db.creator import DbcreatorFile “/usr/lib/python3/dist-packages/CommandNotFound/db…...
篇一:阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试)
QT6 源(101)篇一:阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试
(1) (2) (3)属性学习与测试 : (4) (5) 谢谢...
:Redis + Lua为什么可以实现原子性)
Redis(2):Redis + Lua为什么可以实现原子性
Redis 作为一款高性能的键值对存储数据库,与 Lua 脚本相结合,为实现原子性操作提供了强大的解决方案,本文将深入探讨 Redis Lua 实现原子性的相关知识 原子性概念的厘清 在探讨 Redis Lua 的原子性之前,我们需要明确原子性的概念…...

ios打包ipa获取证书和打包创建经验分享
在云打包或本地打包ios应用,打包成ipa格式的app文件的过程中,私钥证书和profile文件是必须的。 其实打包的过程并不难,因为像hbuilderx这些打包工具,只要你输入的是正确的证书,打包就肯定会成功。因此,证书…...

Python生成器:高效处理大数据的秘密武器
生成器概述 生成器是 Python 中的一种特殊迭代器,通过普通函数的语法实现,但使用 yield 语句返回数据。生成器自动实现了 __iter__() 和 __next__() 方法,因此可以直接用于迭代。生成器的核心特点是延迟计算(lazy evaluation&…...
)
C++11(2)
文章目录 右值引用和移动语义在传参中的提效list容器push_back & insert右值版本的模拟实现类型分类 (了解即可)引用折叠万能引用 完美转发(跟引用折叠有关) 简介:这篇文章是继续介绍C11的一些新语法知识点,也是对…...

unity terrain 在生成草,树,石头等地形障碍的时候,无法触发碰撞导致人物穿过模型
1.terrain地形的草,石头之类要选择模型预制体 2.在人物身上挂碰撞器和刚体,或者单挂一个character controller组件也行 3.在预制体上挂碰撞盒就好了,挂载meshcollider会导致碰撞无效...
——超详细讲解(120000多字详细讲解,涵盖qt大量知识)逐步更新!)
以项目的方式学QT开发C++(二)——超详细讲解(120000多字详细讲解,涵盖qt大量知识)逐步更新!
API 描述 函数原型 参数说明 push_back() 在 list 尾部 添加一个元素 void push_back(const T& value); value :要添 加到尾部的元 素 这个示例演示了如何创建 std::list 容器,并对其进行插入、删除和迭代操作。在实际应用中&am…...

养生:健康生活的极简攻略
在追求高效生活的当下,养生也能化繁为简。通过饮食、运动、睡眠与心态的精准调节,就能轻松为健康续航。 饮食上,遵循 “均衡、节制” 原则。早餐用一杯热豆浆搭配水煮蛋和半个苹果,唤醒肠胃活力;午餐以糙米饭为主食&am…...

C语言-8.数组
8.1数组 8.1.1初试数组 如何写一个程序计算用户输入的数字的平均数? #include<stdio.h> int main() {int digit;//输入要求平均数的数字double sum=0;//记录输入数字的和int count=0;//记录输入数字的个数printf("请输入一组数字,用来求平均数,以-1结束\n&quo…...

代码随想录算法训练营第四十一天
LeetCode题目: 739. 每日温度496. 下一个更大元素 I503. 下一个更大元素 II 其他: 今日总结 往期打卡 739. 每日温度 跳转: 739. 每日温度 学习: 代码随想录公开讲解 问题: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer &…...

c++,windows,多线程编程详细介绍
目录 一、C11 标准库 <thread> 实现多线程编程1. 基本线程创建2. 线程管理3. 线程传参4. 同步机制5. 异步编程 二、Windows API 实现多线程编程1. 基本线程创建2. 线程管理3. 线程传参 三、两种方法的对比 在 Windows 平台上使用 C 进行多线程编程,可以通过 C…...

Python多线程
Python多线程 作为一名Python开发者,你是否遇到过这样的场景:程序需要同时处理多个任务,但单线程执行效率太低?这时候,多线程技术就能派上用场了。本文将带你深入浅出地理解Python多线程,并通过丰富的示例…...

VisionPro斑点寻找工具Blob
斑点寻找工具Blob 斑点概述 斑点分析 探测并且分析图像中的二维形状Blob是先根据用户设定好的灰阶范围对图像进行分割,然后对目标进行查找和分析。斑点报告多种属性: 面积质心周长主轴…….. 应用场景 Blob分析非常适合以下场合的应用: 对…...

【Python】【面试凉经】Fastapi为什么Fast
核心的关键词:ASGI、原生异步、协程、uvloop、异步生态、Pydantic编译时生成校验代码、DI system预计算依赖树 interviewer 00:32:49 FastAPI 它优越于其他一些主流web框架像 django或 flask 的这个点在哪里? 我 00:33:00fastapi 就是说它的 fast 性能高…...

LocalDateTime类型的时间在前端页面不显示或者修改数据时因为LocalDateTime导致无法修改,解决方案
1.数据库中的时间数据,在控制台可以正常返回,在前端无法返回,即显示空白,如下图所示: 2.这种问题一般时由于数据库和我们实体类的名称不一致引起的,我们数据库一般采用_的方式命名,但是在Java中我们一般采用…...

【Linux】gcc从源码编译安装,修改源码,验证修改的源码
前阵子电脑使用的win10,win10过几天就让升级,烦得不行。 然后把操作系统切换到ubuntu24的样子,然后也是让升级,又烦的不行,然后切换到ubuntu server版本,感觉用起来要舒服些了,至少不会天天让升级。 回到标…...

牛客网NC22157:牛牛学数列2
牛客网NC22157:牛牛学数列2 📝 题目描述 🔍 输入输出说明 输入描述: 输入一个整数 N,范围在 0 到 1000 输出描述: 输出一个保留6位小数的浮点数 示例: 输入:2输出:1.500000 …...
)
智能手表集成测试报告(Integration Test Report)
📄 智能手表集成测试报告(Integration Test Report) 项目名称:Aurora Watch S1 测试阶段:系统集成测试 测试周期:2025年xx月xx日 – 2025年xx月xx日 报告编号:AW-S1-ITR-2025-001 版本…...
)
1C:ENTERPRISE 8.3 实用开发者指南-示例和标准技术(Session1-Session3)
1C:ENTERPRISE 8.3(1课-3课) 本博客是全网首个关于1C:Enterprice的中文指南,支持快速吸收使用 1C:Enterprise 8.3 软件开发和调整应用程序的技术 在这篇博客中我会基于实际应用示例,演示各种系统对象的结构、功能和用法。使用内…...

AgenticSeek开源的完全本地的 Manus AI。无需 API,享受一个自主代理,它可以思考、浏览 Web 和编码,只需支付电费。
一、软件介绍 文末提供程序和源码下载 AgenticSeek开源的完全本地的 Manus AI。无需 API,享受一个自主代理,它可以思考、浏览 Web 和编码,只需支付电费。这款支持语音的 AI 助手是 Manus AI 的 100% 本地替代品 ,可自主浏览网页…...

Java类一文分解:JavaBean,工具类,测试类的深度剖析
解锁Java类的神秘面纱:从JavaBean到测试类的深度剖析 前言一、JavaBean 类:数据的守护者(一)JavaBean 类是什么(二)JavaBean 类的特征(三)JavaBean 类的使用场景(四&…...

2025认证杯数学建模第二阶段C题:化工厂生产流程的预测和控制,思路+模型+代码
2025认证杯数学建模第二阶段思路模型代码,详细内容见文末名片 一、探秘化工世界:问题背景大揭秘 在 2025 年 “认证杯”数学中国数学建模网络挑战赛第二阶段 C 题中,我们一头扎进了神秘又复杂的化工厂生产流程预测与控制领域。想象一下&…...