《从零开始入门递归算法:搜索与回溯的核心思想 + 剑指Offer+leetcode高频面试题实战(含可视化图解)》
一.递归
1.汉诺塔
题目链接:面试题 08.06. 汉诺塔问题 - 力扣(LeetCode)

题目解析:将A柱子上的盘子借助B柱子全部移动到C柱子上。
算法原理:递归
当A柱子上的盘子只有1个时,我们可以直接将A上的盘子直接移动到C上。
当A上有2个盘子时,先将1个盘子直接移动到B上(重复n=1时的做法),接着在将A上的盘子移动到C上,最后再将B上的盘子直接移动到C盘上。
当A上有3个盘子时,我们可以先将上面的2个盘子移动到B上(重复n=2时的做法),接着将A上的盘子移动到C上,最终将B上的2个盘子移动到C上(重复n=2时的做法)
最终,我们发现我们将一个大问题划分成一个子问题来解决,子问题也被划分成子问题来解决,这时候我们就可以用递归了。
温馨提示:以后看这里的时候,不用纠结递归里面的细节是怎么样的,要宏观来看待递归,坚信move(A,C,B,n-1)这个递归一定能将A上n-1个盘子全部移动到B上,move(B,A,C,n-1)这个递归一定能将B上的n-1个盘子全部移动到C上。
代码实现:
class Solution {public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {int n=A.size();move(A,B,C,n);}public void move(List<Integer> A, List<Integer> B, List<Integer> C,int n){if(n==1){C.add(A.remove(A.size()-1));return;}move(A,C,B,n-1);//将A上n-1个柱子借助C移动到B上C.add(A.remove(A.size()-1));//将A上最大的盘子移动到Cmove(B,A,C,n-1);//将剩下的n-1个盘子移动到C}
}不讲武德写法:
class Solution {public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {for(int x: A) C.add(x);}
}2.合并两个有序链表
题目链接:21. 合并两个有序链表 - 力扣(LeetCode)
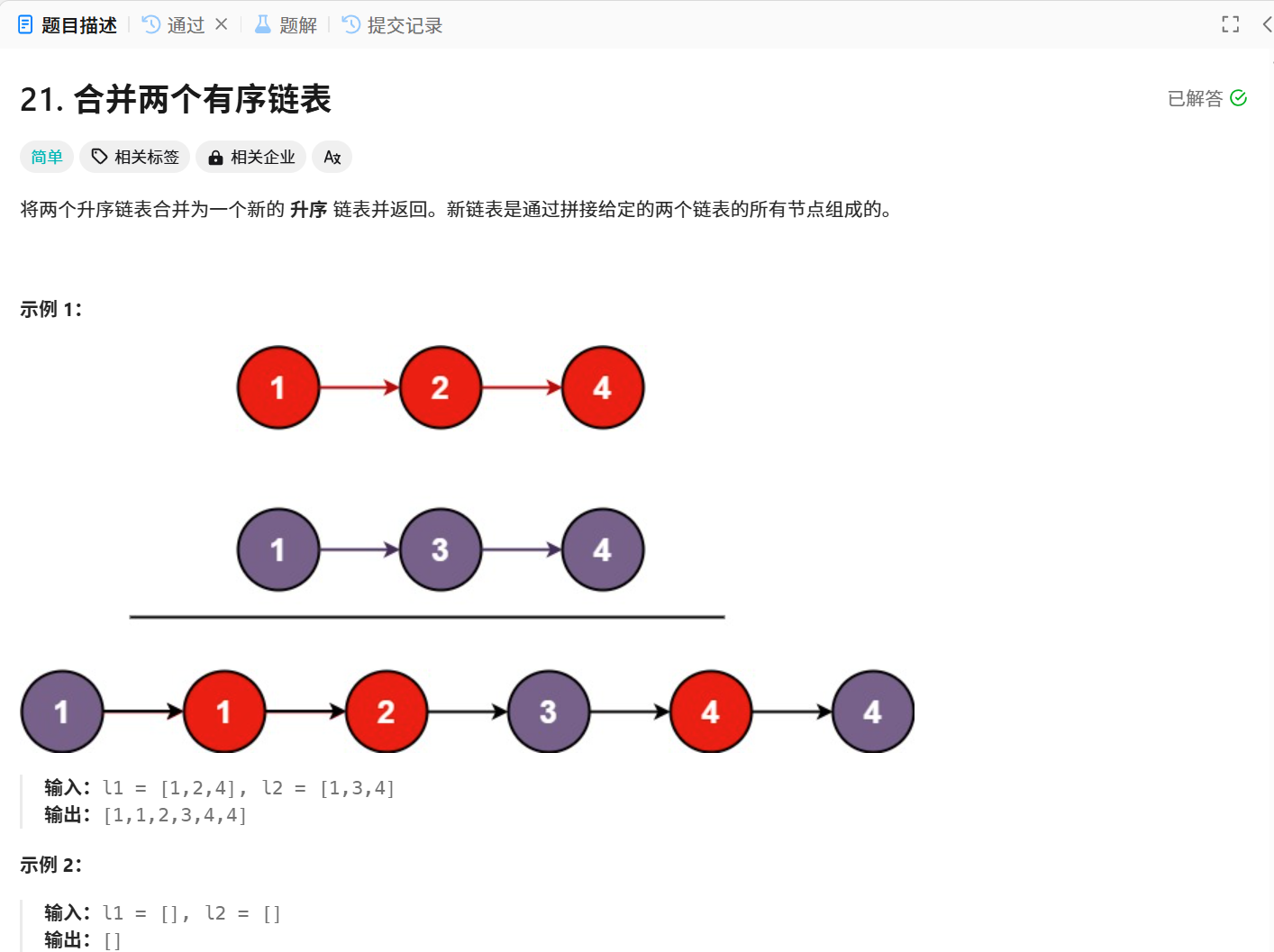
题目描述:将两个有序链表合并为一个有序链表,并返回合并有序链表的头结点。
算法原理:递归算法
首先,我们找出重复的子问题,这涉及到递归函数头的设计,这道题的重复子问题就是合并两个有序链表,也就是给我们两条链表的头结点,帮我们合并两条链表,并返回合并链表的头结点。
接着,只关心一个子问题里面做什么事情,这涉及到函数体的设计,子问题的操作是先比较两条链表头结点的大小,让小的头结点作为返回值,然后再继续合并剩下的链表,如下图
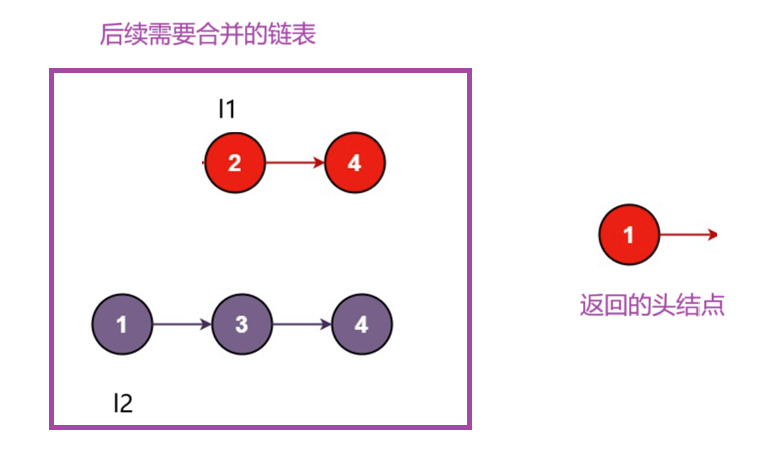
假设红色1节点是我们返回的头结点,那么接下来的操作就是让合并左边剩下的节点 。
最后,我们要找出递归的出口,当某一个链表为空时,我们只需要返回另一个链表的头指针就行了。
代码实现:
这里在提醒一下,以后看这篇博客时,不要去细想递归的具体操作是什么,我们要坚信l1.next=dfs(l1.next,l2)或者l2.next=dfs(l2.next,l)能帮我们完成合并链表的操作,要用宏观的角度来看待递归
class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {return dfs(list1,list2);}public ListNode dfs(ListNode l1,ListNode l2){if(l1==null){return l2;}if(l2==null){return l1;}if(l1.val<=l2.val){l1.next=dfs(l1.next,l2);//合并剩下的链表节点return l1;//返回头结点}else{l2.next=dfs(l2.next,l1);//合并剩下的链表节点return l2;//返回头结点}}
}3.反转链表
题目链接:206. 反转链表 - 力扣(LeetCode)
题目解析:将一个链表进行翻转,并返回翻转后链表的头结点。
解法:递归
第一种递归的视角:从宏观角度看问题
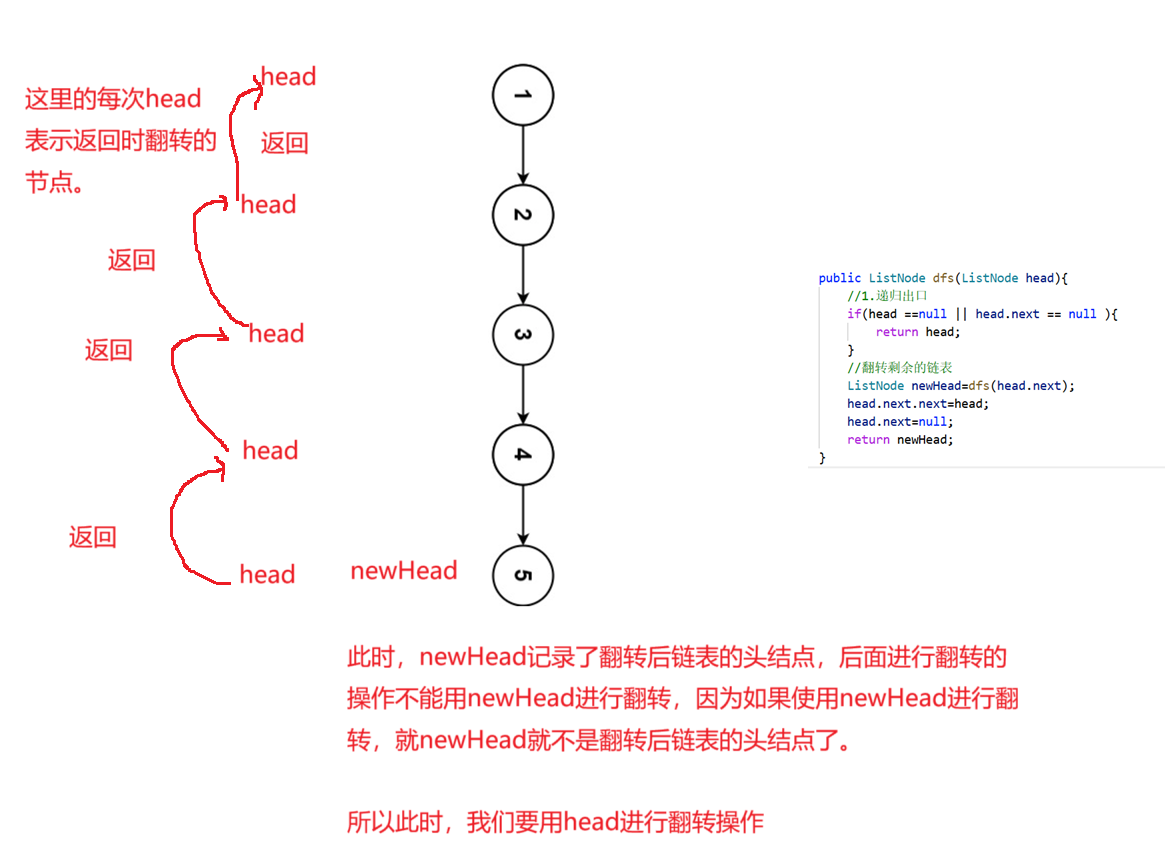
在翻转链表时,如果我们先让head.next.next=head和head.next=null,但是后面继续进行翻转时,就会丢失第3个节点的信息,所以递归时不能从前往后翻转,但是,可以从前往后进行翻转,而递归就是一种从后往前进行翻转的。
此时,先让除了头结点之外的链表进行翻转,并获取到后面链表的头结点,最后在将翻转链表的头结点和head拼接起来就行了。

小细节:翻转时的head.next是为了统一操作,因为递归时,所有递归的函数的操作必须是一样的,head.next=null是为了考虑最后头结点翻转时,此时原来的头结点就是尾节点了,此时就需要将head.next=null.
代码实现:
class Solution {public ListNode reverseList(ListNode head) {return dfs(head);}public ListNode dfs(ListNode head){//1.递归出口if(head ==null || head.next == null ){return head;}//翻转剩余的链表并获取后面翻转链表的头结点ListNode newHead=dfs(head.next);head.next.next=head;head.next=null;return newHead;}
}第二种视角:我们可以将链表看做一棵树
此时,如果我们将链表看做一棵树的话,解决此道题我们就只需要做一遍后续遍历即可,我们先遍历到叶子节点,如果遍历到叶子节点,就返回,并进行翻转。
下面这个有我的理解,后面复习一定要看下面这个图
4.两辆交换链表中的节点
题目链接:24. 两两交换链表中的节点 - 力扣(LeetCode)
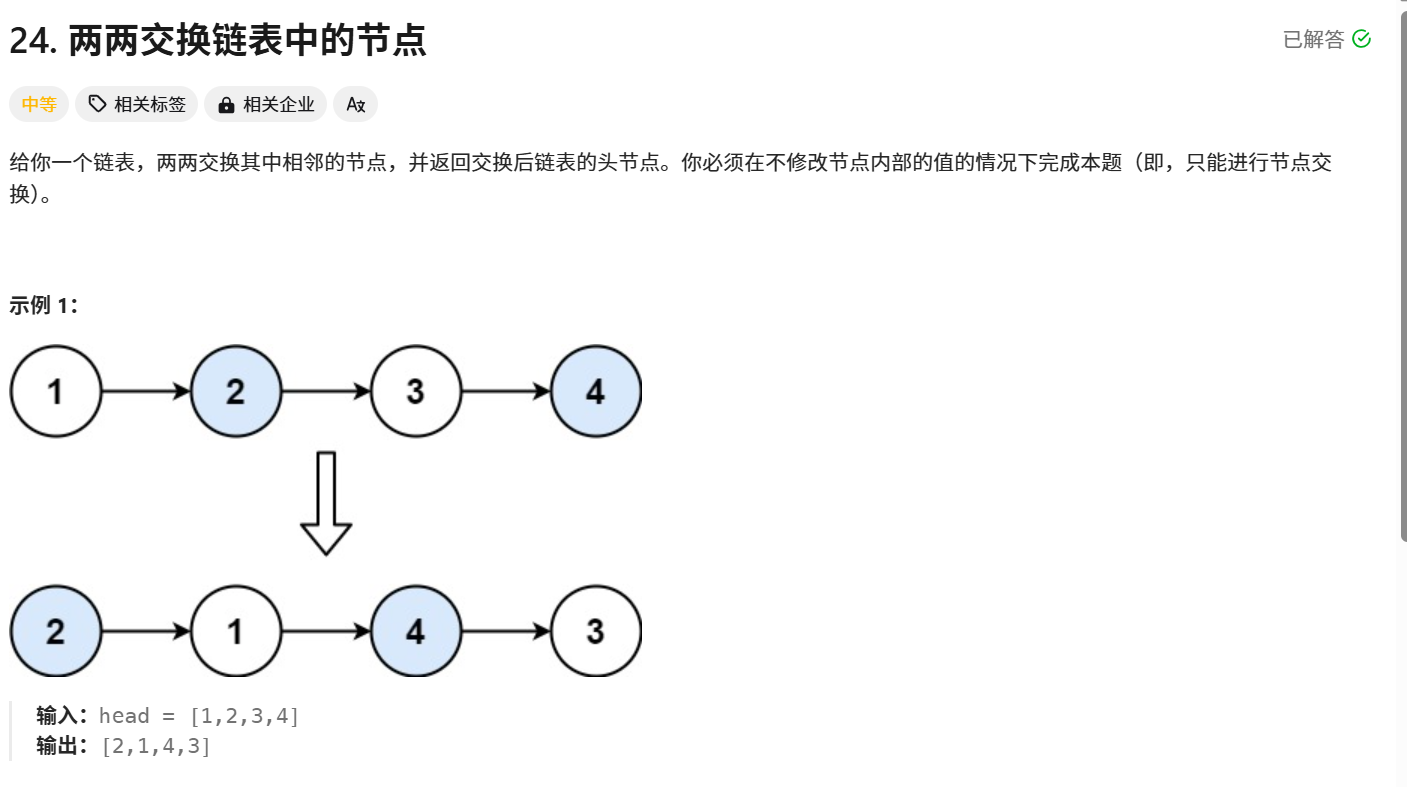
题目解析:将链表中相邻的节点依次交换,只能交换节点的位置(就是修改节点的next的指向),不能通过修改节点中的值实现交换相邻节点。
算法原理:递归
先让后面的链表实现交换的操作,返回一个tmp头结点,然后再将前面两个节点进行交换,最后进行拼接就行了。
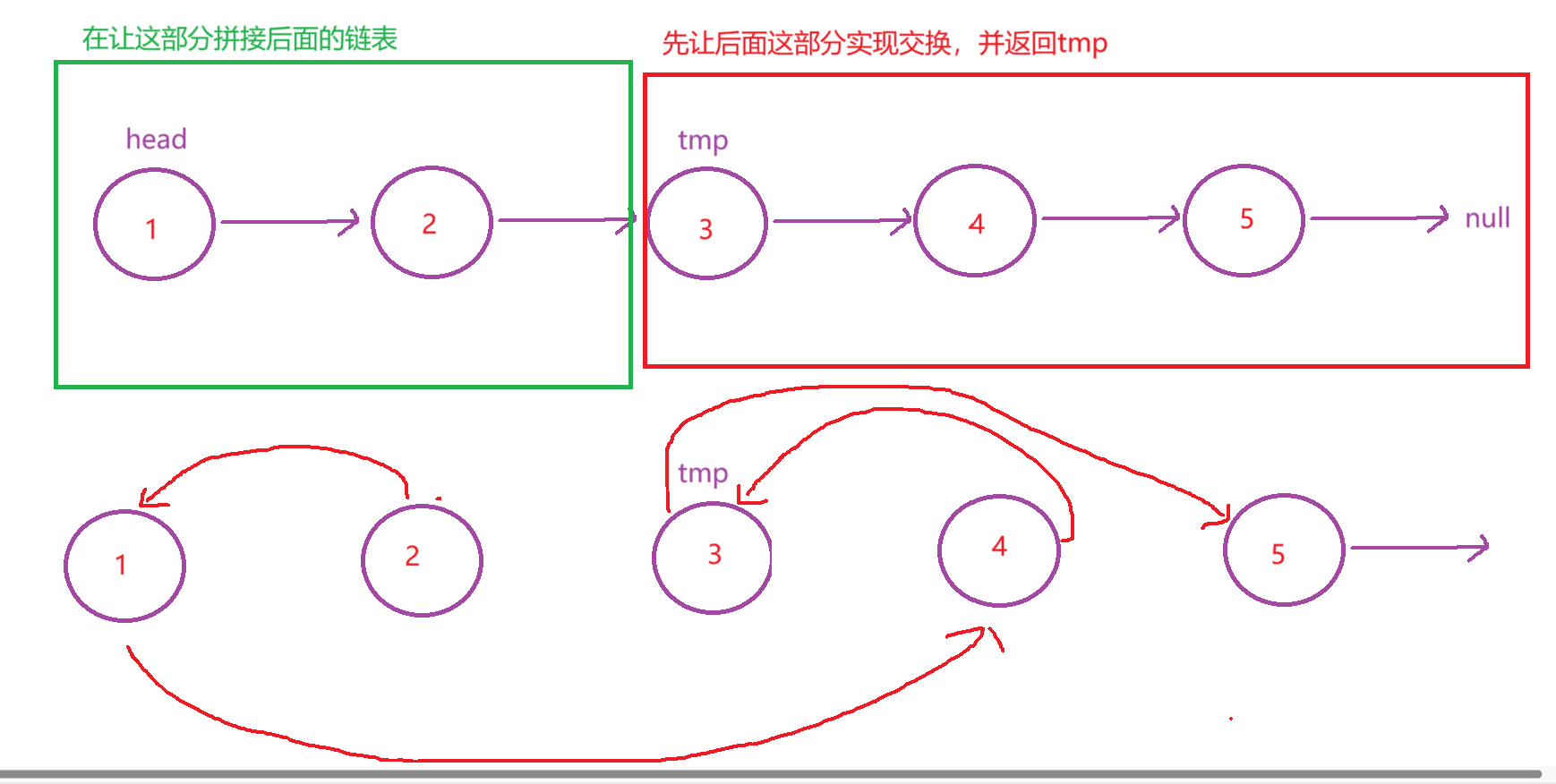
代码实现
class Solution {public ListNode swapPairs(ListNode head) {return dfs(head);}public ListNode dfs(ListNode head){if(head==null || head.next==null){return head;}ListNode tmp=dfs(head.next.next);ListNode newHead=head.next;//记录返回的头结点head.next.next=head;head.next=tmp;return newHead;}
}5.快速幂
题目链接:50. Pow(x, n) - 力扣(LeetCode)
 题目分析:求x的n次方。
题目分析:求x的n次方。
解法一:暴力循环
直接将x乘n次,并返回最终结果,要处理n是负数的情况,会超时
代码实现:
class Solution {public double myPow(double x, int n) {double ret = 1.0;if (n < 0) {n = -n;for (int i = 0; i < n; i++) {ret *= x;}return 1.0 / ret;}for (int i = 0; i < n; i++) {ret *= x;}return ret;}
}解法二:递归
上面那种解法为什么会超时呢?因为当n=2^31次方时,上面的解法就会循环2^31次,此时就会超时,所以,要避免循环2^31次循环的出现。
此时,没必要一次一次的进行x*x的操作,当我们知道要求x^n次方,我们先找出x^n的一半,也就是x^(n/2),通过x^(n/2)求x^n,如下图

此时,要考虑n为奇数,n/2除不尽的情况,当n为奇数时,只需要在乘上一个x就行了。

通过上面的分析,每次求x的n次幂,都是相同的操作,都是根据x的(n/2)次方去求x的n次方,所以,每求x的n次幂就可以看做一个相同的子操问题。
每个子问题就是求x的n次方,我们用tmp来保存每次递归求x的n次方的结果,当n==0时,直接返回1即可
代码实现:
class Solution {public double myPow(double x, int n) {if(n<0){n=n-2*n;return 1.0/dfs(x,n);}return dfs(x,n);}public double dfs(double x,int n){if(n==0){return 1;}double tmp = dfs(x,n/2);return n%2==0?tmp*tmp:tmp*tmp*x;}
}递归代码解析:dfs函数是用来递归求x的n次幂的,我们不要去细想里面的细节是如何实现的,只要我们dfs函数里面的求x的n次方实现逻辑是正确的,我们坚信dfs能求出x的n次幂即可。
二.二叉树的深度搜索
1.计算布尔二叉树的值
题目链接:2331. 计算布尔二叉树的值 - 力扣(LeetCode)
题目解析:根据题意,该题中的二叉树是完整二叉树,完整二叉树就是每个非叶子节点一定会有左子节点和右子节点,如果该非叶子节点没有左子节点,那么也不会有右子节点,如果该非叶子结点没有右子节点,那么也不会有左子节点。在该题中,完整二叉树的叶子节点的value有0(对应false)或1(对应true)这两个值,非叶子节点的value有 || 或者 && 这两个值,此时,让我们计算并返回该二叉树的布尔值。
算法原理:递归
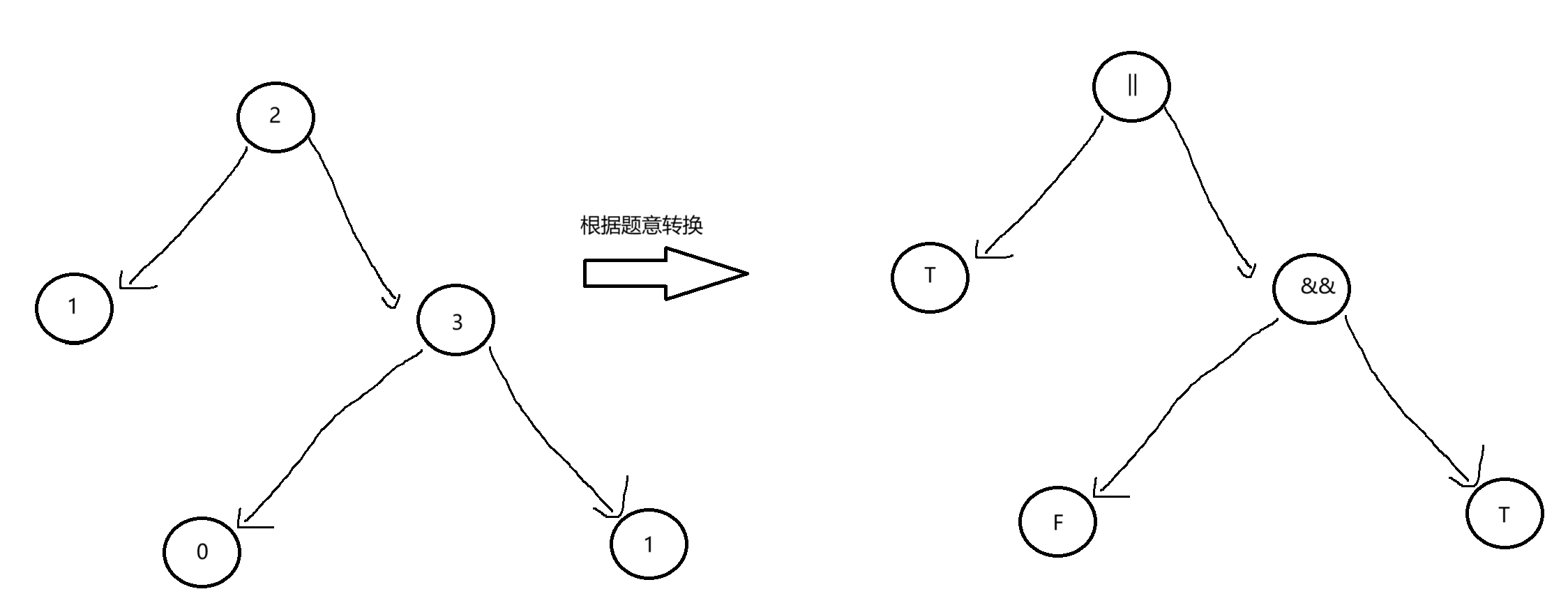
此时,为了求出整根树的布尔值,我们首先要求出左右子数的布尔值,当我们遇到叶子节点时,直接返回叶子节点的值即可,得到左右子数的布尔值之后,我们就直接返回左右子数的布尔值和根节点进行计算的结果即可。
其实也可以换一个角度来看,其实就是对完整二叉树进行一遍后续遍历,在后续遍历的过程中,计算并返回并保存左右子数的布尔值,最后在根据左右子树的布尔值和根节点的值进行计算并返回即可。
代码实现
class Solution {public boolean evaluateTree(TreeNode root) {return dfs(root);}public boolean dfs(TreeNode root){//遇到叶子节点if(root.left == null && root.right == null){if(root.val == 0) return false;else return true;}//计算左子树的布尔值boolean left = false;if(root.left != null){left = dfs(root.left);}//计算右子树的布尔值boolean right = false;if(root.right != null){right = dfs(root.right);}if(root.val == 2){return left || right;}else {return left && right;}}
}2.求根节点到叶子节点的数字之和

题目链接:129. 求根节点到叶节点数字之和 - 力扣(LeetCode)
题目解析;计算从根节点到叶子节点的所有数字之和,如下图
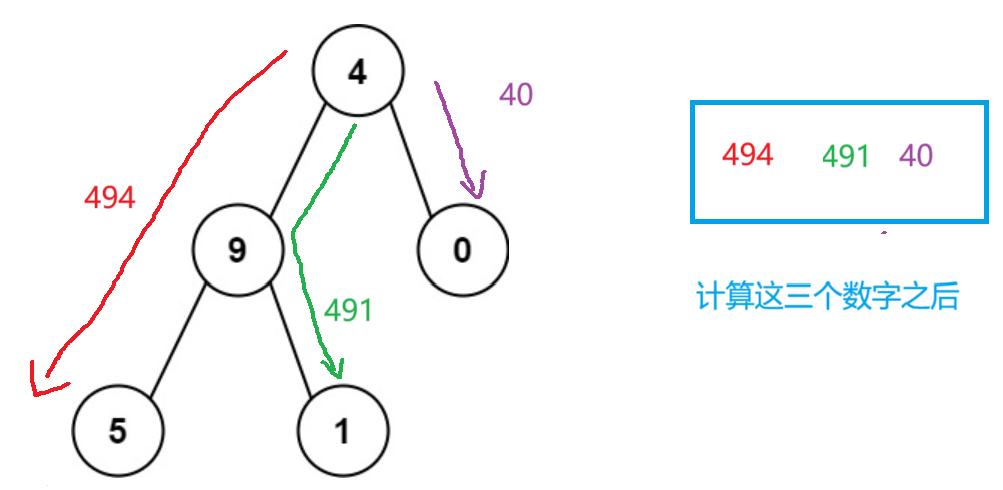
算法原理:递归
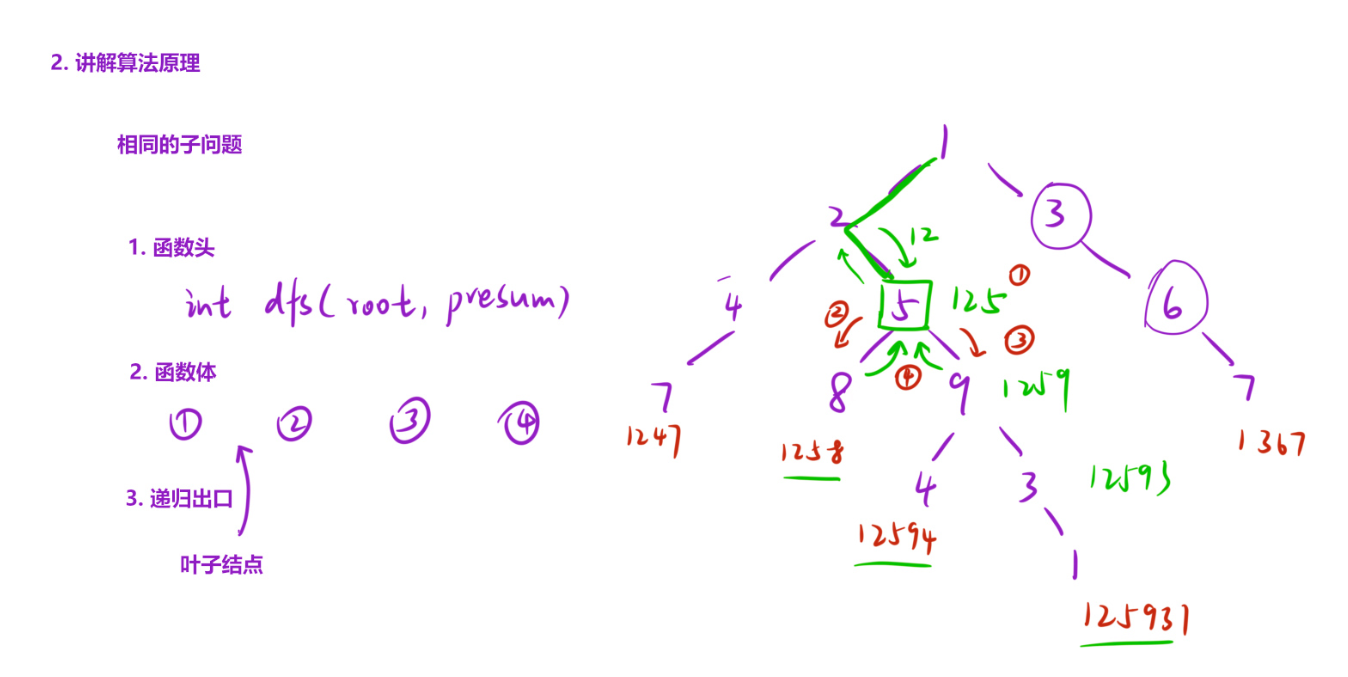
如上图中的二叉树,假如我们现在递归到了5这个节点,要是想求出1258,12594,12593这三个数字,我们就需要得到前面的125,125怎么来的呢?是递归到5的时候,这时候我们进行一个求前驱的操作,此时得到前驱12,然后进行12*10+5就得到了125,然后再求1258,12594,12593这3个数的时候,以125作为前驱去进行相同的计算,就可以得到这三个数了,当计算出这三个数的同时,直接返回对应的数字即可。
递归的出口,当遇到叶子节点直接返回即可,注意此时递归的结束是要在求前驱的操作之后。
总结函数体的操作,先求前驱,接着判断递归条件,如递归不结束,继续去递归左子树和右子树,最后返回ret即可。
代码实现:
class Solution {public int sumNumbers(TreeNode root) {return dfs(root,0);}public int dfs(TreeNode root,int presum){//1.求前驱presum = presum*10+root.val;//2.递归出口if(root.left == null && root.right == null) return presum;//3.递归左右子数int ret = 0;if(root.left != null) ret += dfs(root.left,presum);if(root.right != null) ret +=dfs(root.right,presum);return ret;}
}3.二叉树剪枝
题目链接:814. 二叉树剪枝 - 力扣(LeetCode)

题目解析:遍历二叉树,将只含数值0的子数全部去掉,返回剪枝后的二叉树。
算法原理:递归
递归函数头的设计:由于要将只含数值0的子数全部去掉,由于在删除子数的时候,此时我们要去收集左子树和右子树的信息,所以在此题中,递归的函数是要有一个返回值的,且要通过后序遍历来遍历这棵树,
在后续遍历中,我们可以先去处理左子树,再去处理右子树,分别记录左子树和右子树的情况,在处理完左子树和右子树之后,还要根据当前根节点的值去判断要不要删除该子数,如果当前根节点的值为0,我们直接返回null即可,如果根节点的值为1,直接返回该根节点即可。
递归的出口:当root==null时,返回一个null即可。
代码实现:
class Solution {public TreeNode pruneTree(TreeNode root) {return dfs(root);}public TreeNode dfs(TreeNode root){if(root==null){return null;}//处理左子树root.left = dfs(root.left);//处理右子树root.right = dfs(root.right);//判断if(root.val == 0&&root.left==null&&root.right==null){return null;}return root;}
} 
4.验证二叉搜索树
题目链接:98. 验证二叉搜索树 - 力扣(LeetCode)
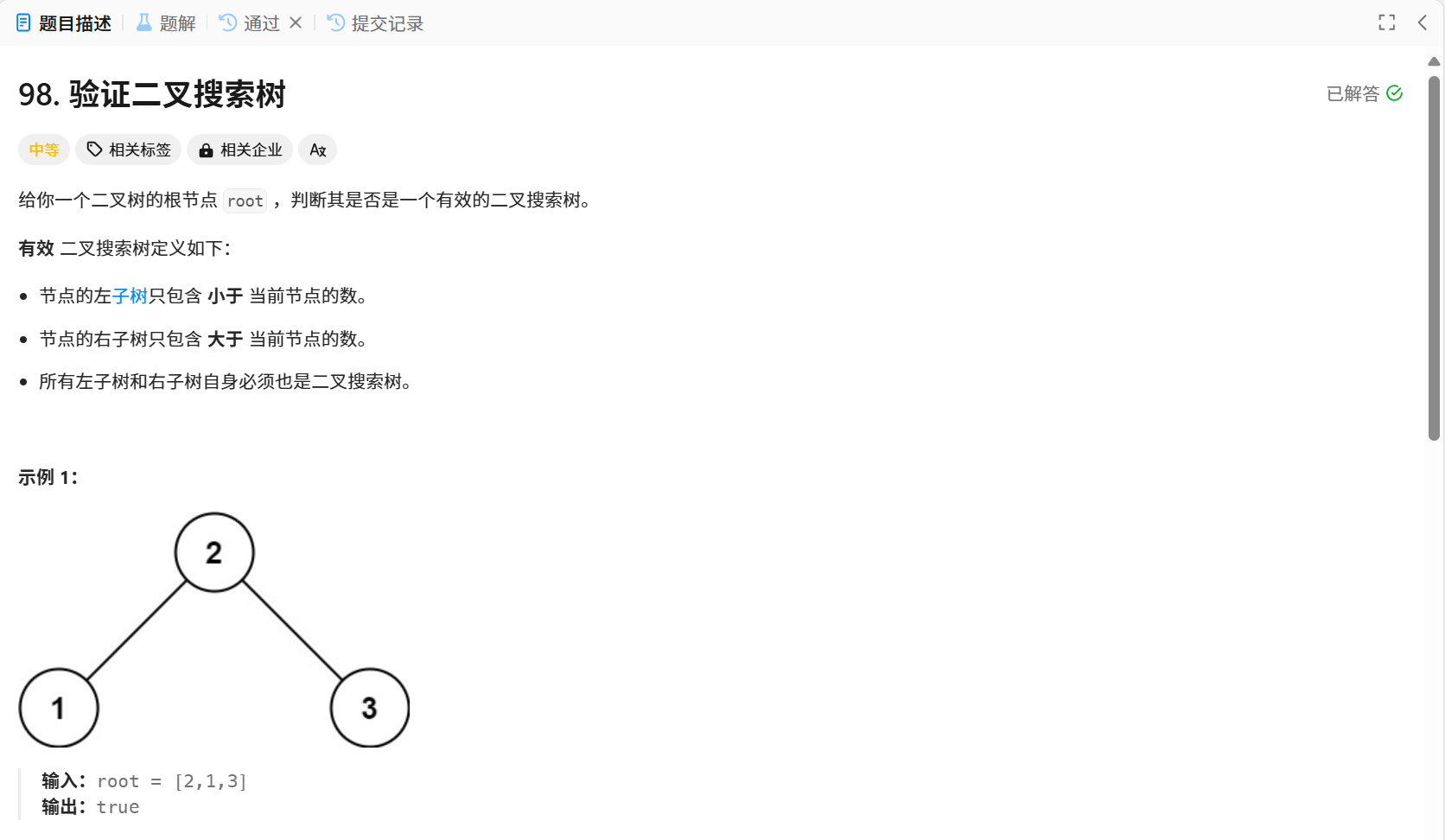
题目解析:验证该二叉树是不是二叉搜索树,如果是,则返回true,如果不是,则返回false。
算法原理:递归
由于搜索二叉树的左子树中的所有节点中的值都是小于根节点的值,右子树中的所有节点的值都是大于根节点的值。此时就可以根据二叉搜索树的中序遍历是一个升序的排列, 因此可以定义一个全局变量prev,一开始prev的值为无穷小,全局变量prev是用来记录中序遍历时的前驱。
为什么要将prev设为全局变量呢?
将prev设为全局变量,我们就不用在递归时传入这个参数,写递归代码时比计较方便。
此时,就可以在中序遍历中,如果前驱的值和当前递归到的节点的值构成递增序列,就可以让prev=root.val,为下一次递归使用。
算法流程:
递归出口:如果当前节点为null,则该子数也是二叉搜索树,直接返回true。
递归逻辑:由于是中序遍历,我们先判断当前节点的左子树是不是二叉搜索树(用left变量来记录),然后再去判断当前节点是否与左子树构成二叉搜索树(用cur来记录),最后在判断当前节点的右子树是不是二叉搜索树(用right类记录)。
代码实现:
class Solution {//前驱long prev=Long.MIN_VALUE;public boolean isValidBST(TreeNode root) {return dfs(root);}public boolean dfs(TreeNode root){//递归出口if(root == null){return true;}//判断左子树是不是二叉搜索树boolean left = dfs(root.left);//判断当前节点是不是二叉搜索树boolean cur = false;if(root.val>prev) cur = true;prev = root.val;//判断右子树是不是二叉搜索树boolean right = dfs(root.right);return left && cur && right;}
}小优化:剪枝
如果我们在中序遍历时,发现左子树不是二叉搜索树 或者 当前节点不与左子树构成二叉搜索树时,这时就没必要再去遍历右子树,直接返回false即可。
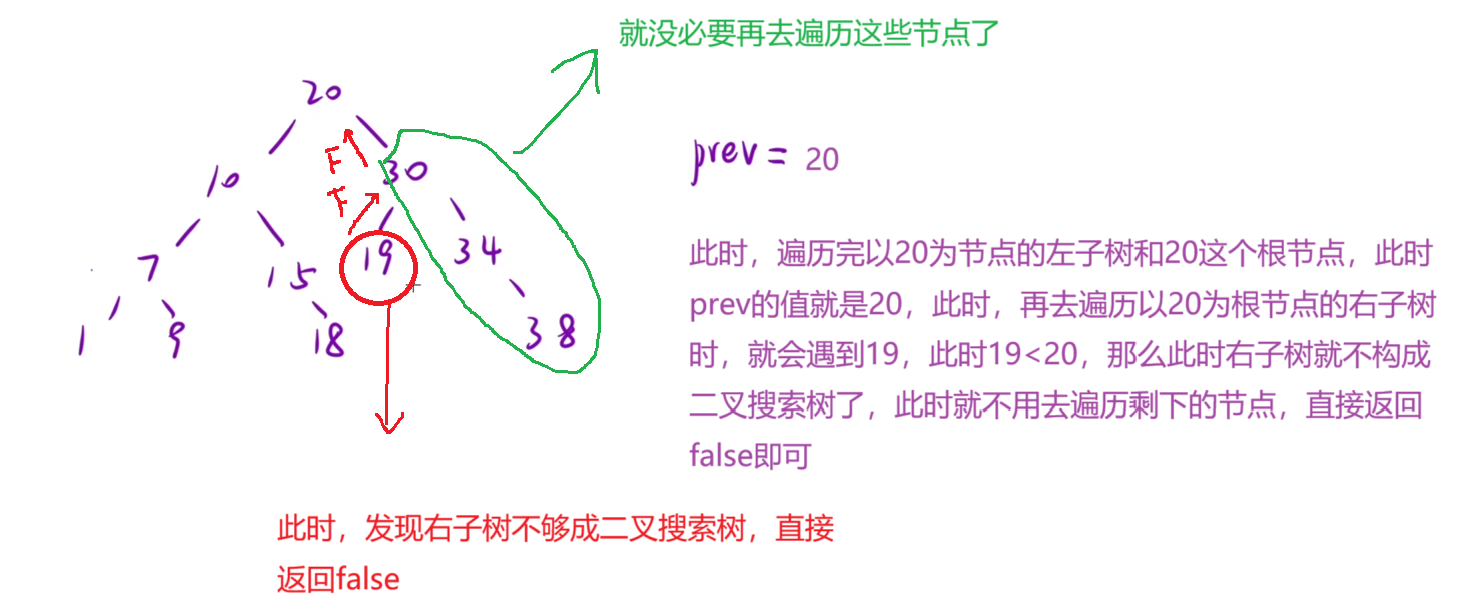
代码实现:
其实就是在原来的代码上加上几个判断即可。
class Solution {long prev=Long.MIN_VALUE;public boolean isValidBST(TreeNode root) {return dfs(root);}public boolean dfs(TreeNode root){//递归出口if(root == null){return true;}//判断左子树是不是二叉搜索树boolean left = dfs(root.left);//剪枝if(left == false) return false;//判断当前节点是不是二叉搜索树boolean cur = false;if(root.val>prev) cur = true;//剪枝if(cur == false) return false;prev = root.val;//判断右子树是不是二叉搜索树boolean right = dfs(root.right);return left && cur && right;}
}5.二叉搜索树中第k小的元素
题目链接:230. 二叉搜索树中第 K 小的元素 - 力扣(LeetCode)

题目解析:找出并返回二叉搜索树中的第k小的元素。
算法原理:深度搜索
在此道题中还是可以使用二叉搜索树的中序遍历是一个升序的序列,此时,我们就可以定义两个全局变量count和ret,count是用来计数的,ret是用来保存最终结果的。
中序遍历时, 当我们遍历到一个节点时,先让count--,知道count==0时,遍历的节点的值就是题目要求寻找的值,直接让ret==root.val。
剪枝优化
当递归时发现count已经递减为0了,就没必要继续遍历剩下的节点了,直接返回即可。
class Solution {int count;int ret;public int kthSmallest(TreeNode root, int k) {count = k;dfs(root);return ret;}public void dfs(TreeNode root){//递归出口和剪枝优化if(root==null || count==0) return;dfs(root.left);count--;if(count==0) ret = root.val;//剪枝优化if(count==0) return;dfs(root.right);}
}一个小收货
当我们将count和ret设计为全局变量,此时,我们设计递归的函数时,就不用考虑设计递归函数的返回值和其他多余的传参等,这样写递归函数的时候就很方便。
6.二叉树的所有路径
题目链接:257. 二叉树的所有路径 - 力扣(LeetCode)
题目解析:找出并返回每一条从根节点到叶子节点的路径。
讲解算法原理:在这道题中,我们主要分析全局变量,回溯(恢复现场)和剪枝这三点。
我一开始的做法,我首先创建了2个全局变量,一个ret(返回结果)和一个path(用来记录从根节点到也叶子节点的路径),但是这样会有一个问题,就是当我们遍历完一个左子树时,会去遍历右子树,遍历右子树时,由于path会带着左子树的叶子节点,这样会导致遍历右子树的路径不正确。如下图
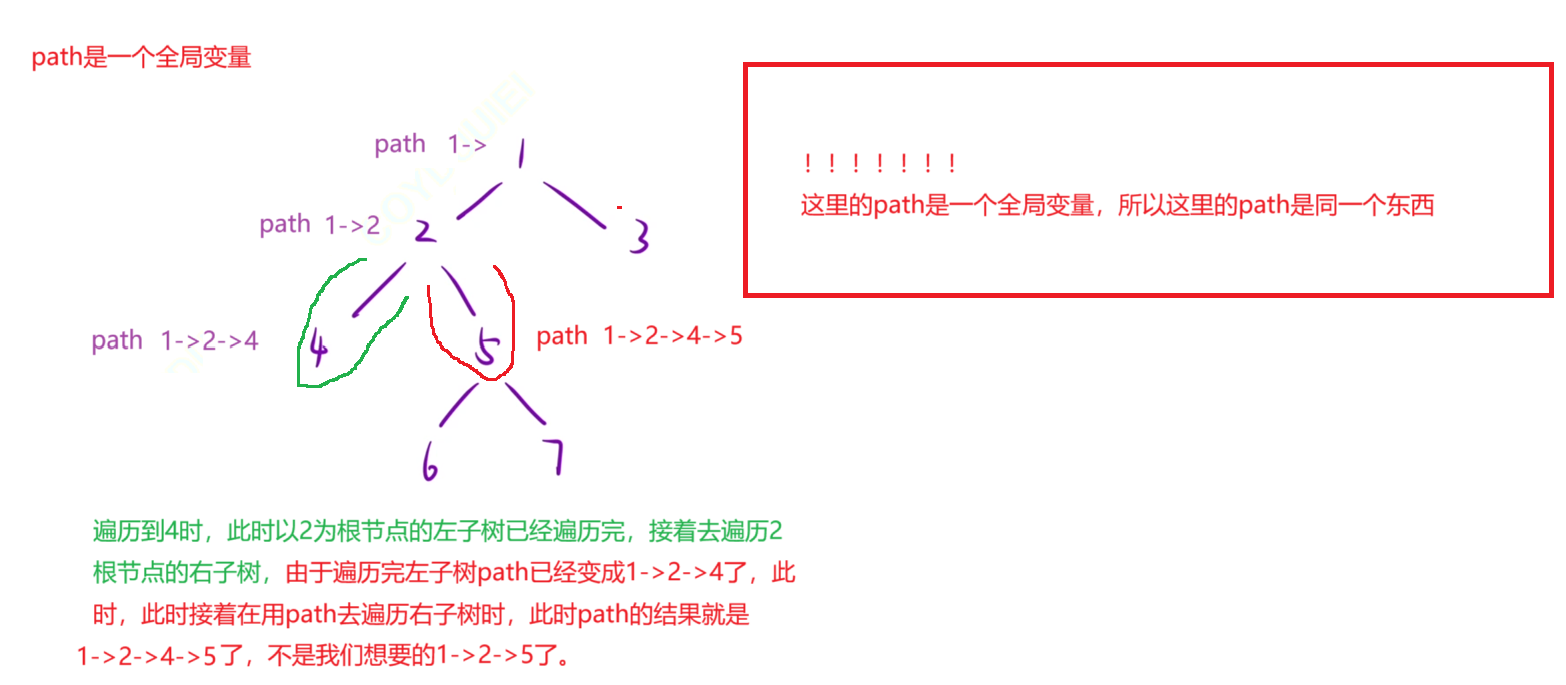
所以我们在回溯的过程中,要进行恢复现场,也就是在回溯去遍历右子树时,要将path恢复成1->2->,此时在去遍历右子树。所以在这道题中,将path设置为全局变量并不好用。
但是,我们可以将path设置为函数的参数去进行递归,此时,我们可能会写出以下代码
class Solution {List<String> ret = new ArrayList();public List<String> binaryTreePaths(TreeNode root) {dfs(root,new StringBuffer(""));return ret;}public void dfs(TreeNode root,StringBuffer path){//StringBuffer path = new StringBuffer(_path);path.append(root.val);if(root.left == null && root.right == null){ret.add(path.toString());}path.append("->");if(root.left != null) dfs(root.left,path);if(root.right != null) dfs(root.right,path);}
}但是,这个代码是有bug的,运行如下图,我们发现并没有起到恢复现场的作用,因为此时,我们将path作为参数时,每次递归也是直接对path进行append,此时path就无法记录上一层path的情况,所以此时,可以另外设计一个变量,让新设计的变量去进行每一次递归的append操作,这样我们就没有直接对每一层的path进行append,此时,递归的每一层都会有一个path来记录每一层的路径(每一层的path不是同一个东西),这样在回溯时,path就起到一个恢复现场的作用。
正确代码实现:
//剪枝优化版本
class Solution {List<String> ret = new ArrayList();public List<String> binaryTreePaths(TreeNode root) {dfs(root,new StringBuffer(""));return ret;}public void dfs(TreeNode root,StringBuffer _path){StringBuffer path = new StringBuffer(_path);path.append(root.val);if(root.left == null && root.right == null){ret.add(path.toString());}path.append("->");if(root.left != null) dfs(root.left,path);if(root.right != null) dfs(root.right,path);}
}//未剪枝优化版本
class Solution {List<String> ret = new ArrayList();public List<String> binaryTreePaths(TreeNode root) {dfs(root,new StringBuffer(""));return ret;}public void dfs(TreeNode root,StringBuffer _path){if(root == null) return;StringBuffer path = new StringBuffer(_path);path.append(root.val);if(root.left == null && root.right == null){ret.add(path.toString());}path.append("->");dfs(root.left,path);dfs(root.right,path);}
}//我写的版本
class Solution {List<String> ret = new ArrayList();public List<String> binaryTreePaths(TreeNode root) {dfs(root,"");return ret;}public void dfs(TreeNode root,String path){if(root == null) return;StringBuilder sb = new StringBuilder();if(root.left == null && root.right == null){sb.append(path+root.val+"");path=sb.toString();ret.add(path);}sb.append(path+root.val+"->");path=sb.toString();dfs(root.left,path);dfs(root.right,path);}
}我写的版本中,sb变量起到进行append的1作用
此时,我们通过_path去记录上一层路径的情况,让新设计的path去进行每一次遍历的append,如下图

三.穷距vs暴搜vs深搜vs回溯vs剪枝
1.全排列
题目链接:46. 全排列 - 力扣(LeetCode)
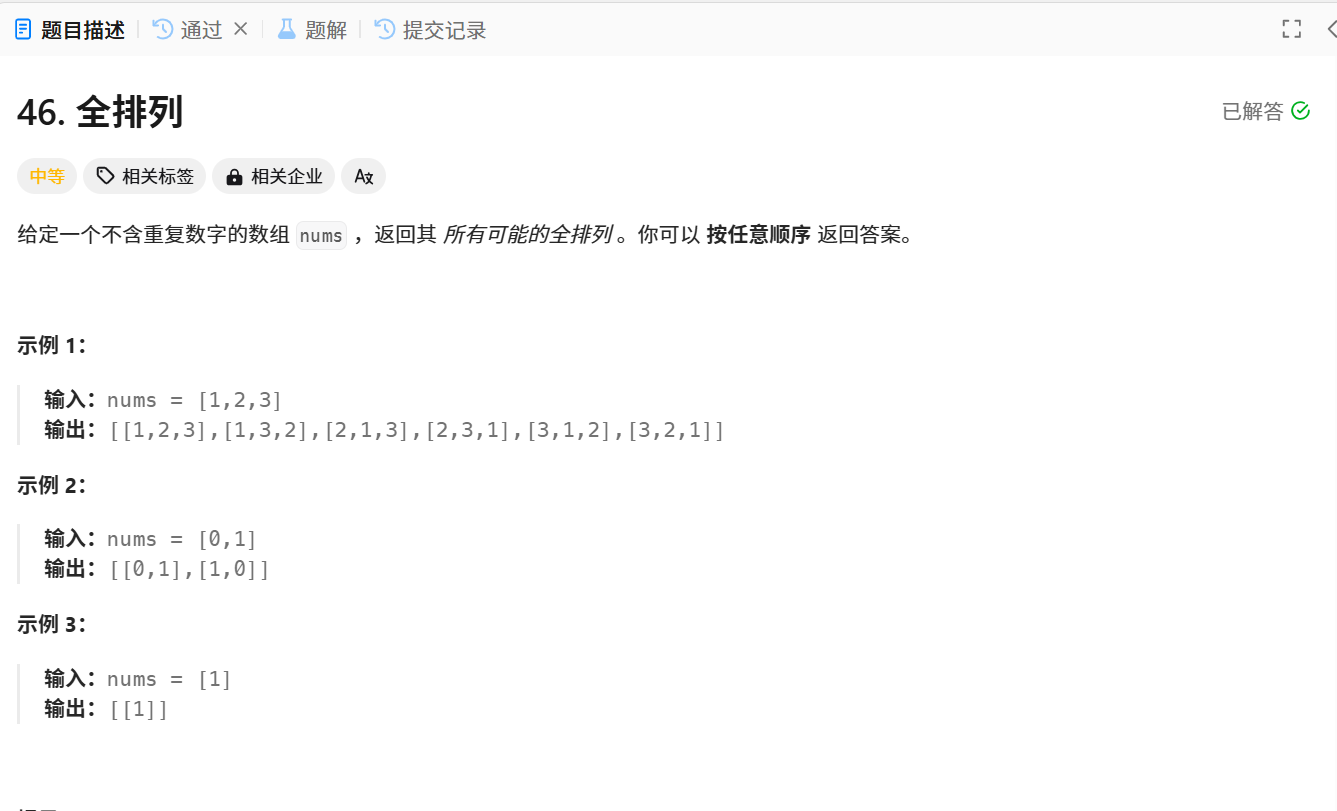
题目解析:找出并nums数组中所有的全排列组合
算法原理: 递归(涉及回溯)
涉及到一些复杂的递归问题,第一步我们可以画出决策树,越详细越好。
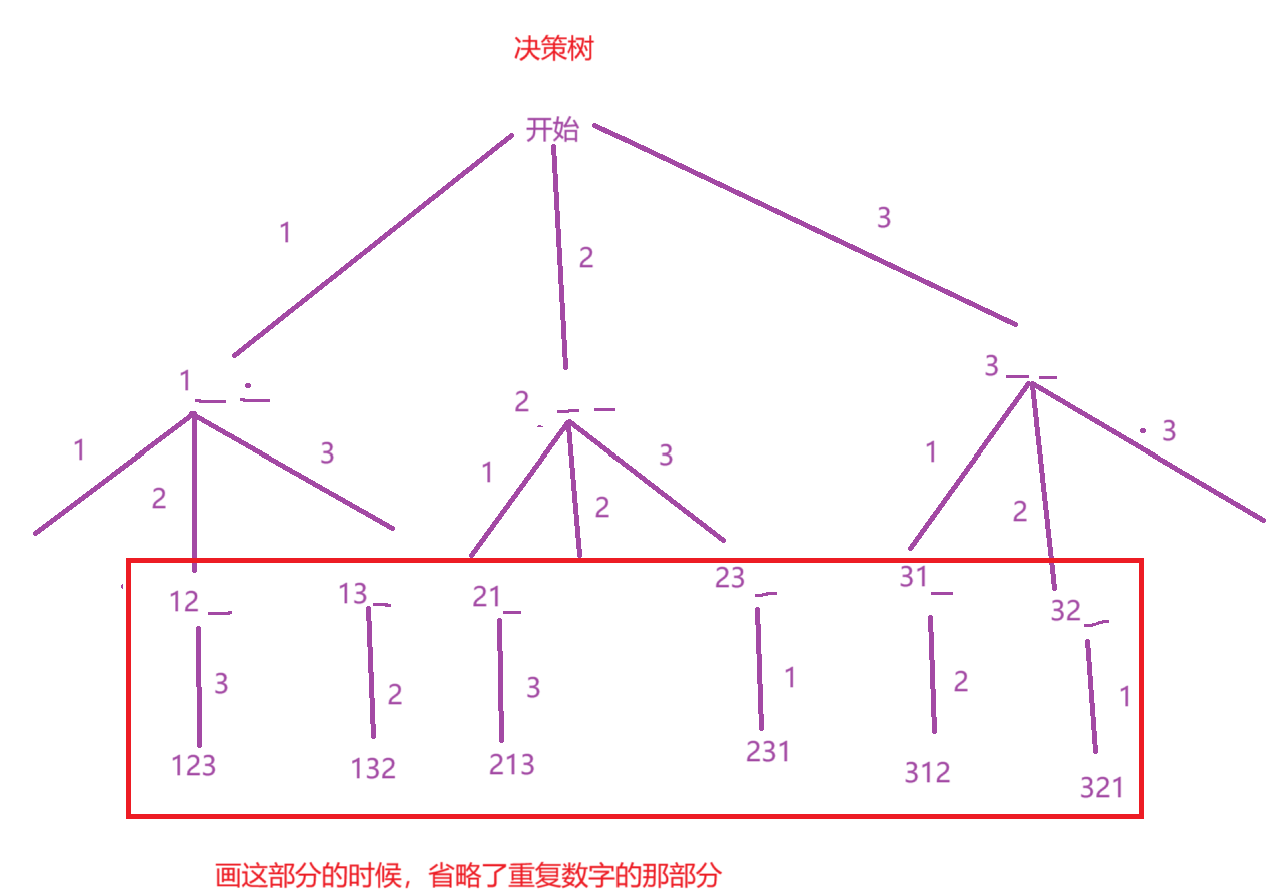
接着来设计代码,当我们画出策略树,我们就看看如何使用这个策略树。
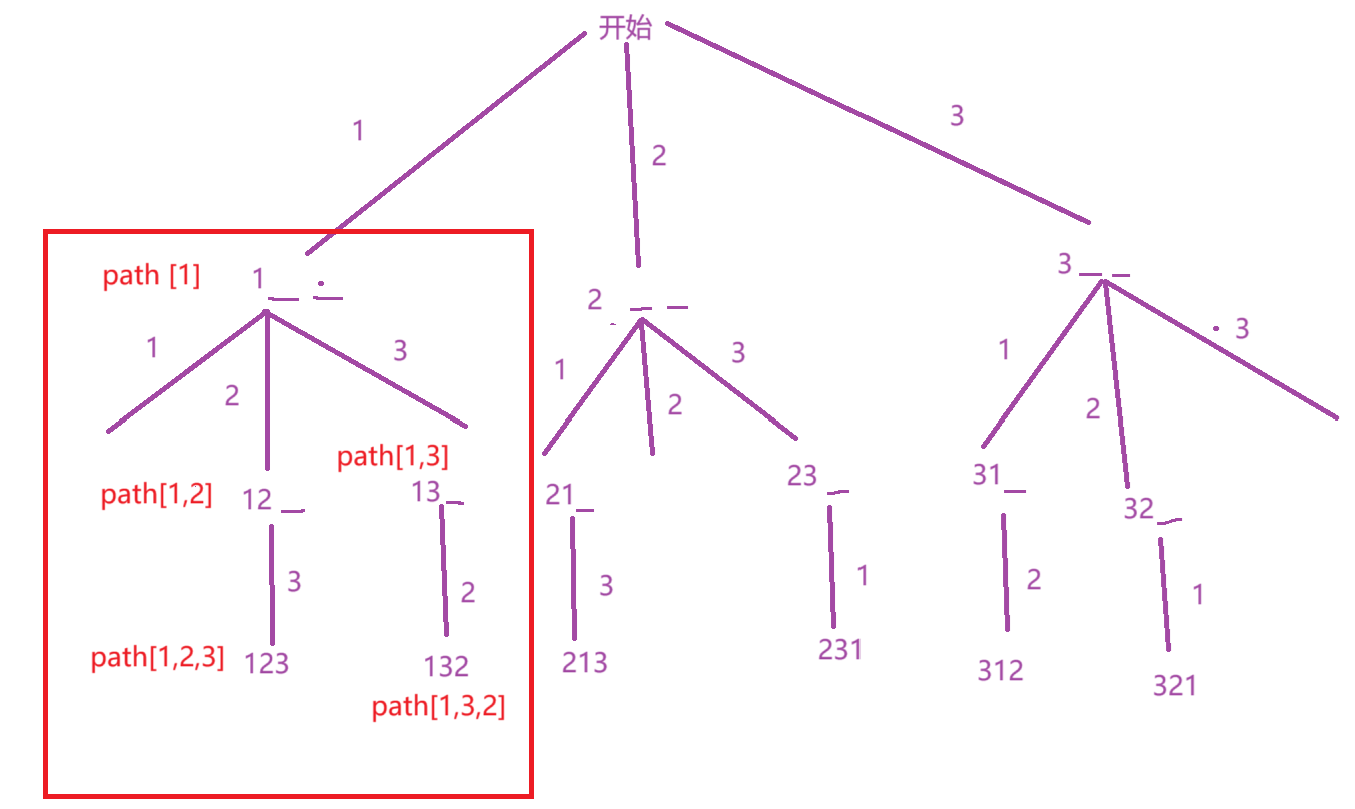
首先,我们要定义一个全局变量ret去记录找到的所有的全排列组合,由于要在遍历策略树时保存排列情况,所以还要设计一个path去记录递归时的排列变化情况,如下面画红框部分,用记录递归到每一层的排列变化情况。
此时,还有一个问题,遇到了重复数字怎么办?
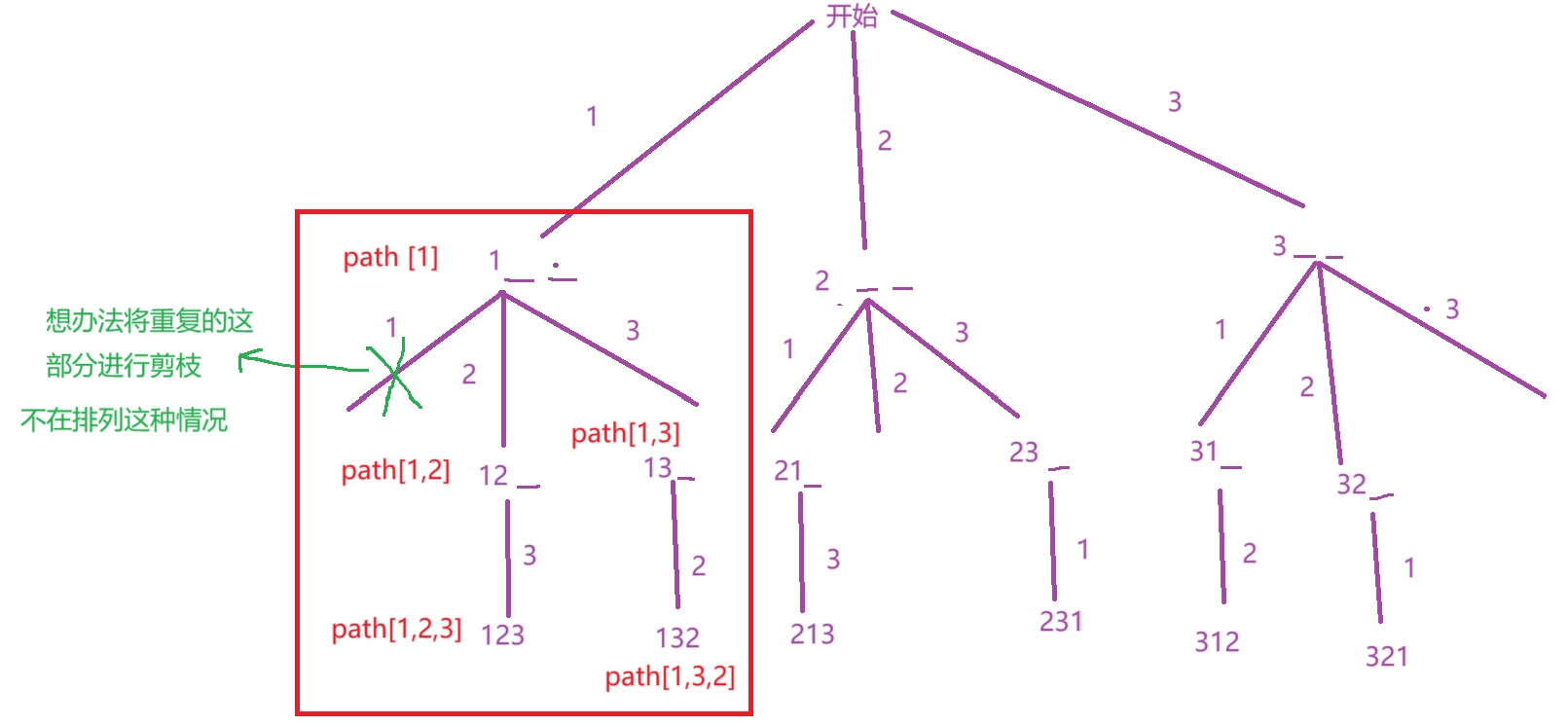
此时,还要设计一个全局变量checked去记录已经进行排列的数字, 当一个数字已经进行排列,我们就将其对应的check[i]置为false。
所以,此时,要去判断一下该数字是否已经在排列组合中了,不在排列组合中,才将该数字插入到path。
细节问题:
1.回溯
回溯时,要将path的最后一个元素给干掉,还要修改其对应的check数组的值。
2.递归出口
当遇到叶子节点(path的长度等于nums的长度)时,说明此时已经出现一种全排列组合,直接往ret中add即可。
代码实现
class Solution {List<List<Integer>> ret;List<Integer> path;boolean[] check;public List<List<Integer>> permute(int[] nums) {ret = new ArrayList<>();path = new ArrayList<>();check = new boolean[nums.length];dfs(nums);return ret;}public void dfs(int[] nums){//递归出口if(path.size() == nums.length){ret.add(new ArrayList<>(path));return;}for(int i=0;i<nums.length;i++){if(check[i]==false){path.add(nums[i]);check[i]=true;dfs(nums);//回溯->恢复现场path.remove(path.size()-1);check[i]=false;}}}
}2.子集
题目链接:78. 子集 - 力扣(LeetCode)
题目解析:找出并返回nums数组中的所有子集。
算法原理:递归
找子集可以理解为我们选或者不选nums数组中的一个数来组成一个集合,此时,就可以设计决策树,如下图,
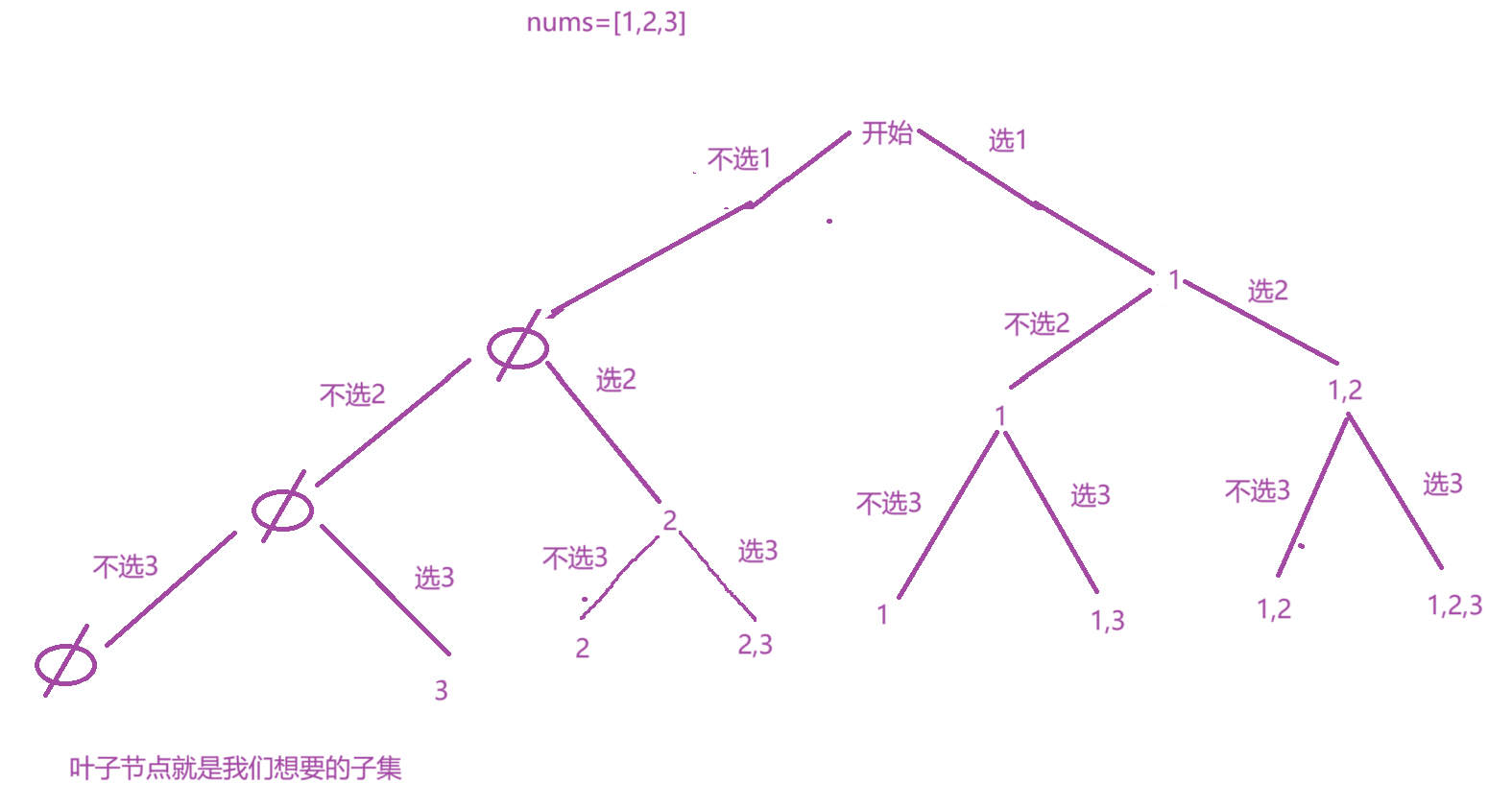
此时,按照选或者不选nums中一个数字组成子集的思路,发现画出来的叶子节点就是我们想要找的子集
此时,我们就可以设计代码了,去设计全局变量,设计dfs和处理一些细节问题(剪枝,回溯,递归出口)
在这道题中,要设计两个全局变量,分别设计一个path变量去记录遍历决策树时子集的组成情况和设计一个ret去存储nums中可以组成的子集。
dfs函数的设计
函数头的设计:由于我们要知道每一层递归时要选择或者不要选择的数组,所以此时在设计函数头时还要传一个下标index。
函数体的设计:根据上面的分析,遍历到策略树的每一层时,会有2中情况。第一种情况:如果我们选择这个数字,我们就要将这个数字尾插到path中(path.add(nums[index])), 尾插完这个数字后,还要递归到下一层。第二种情况:如果我们不选择这个数字,直接递归到下一层即可,不过,此时要进行回溯,因为path是随时在改变的,所以每次返回时,我们都要将path还原成原来的样子,否则就会出现下图篮框的情况。
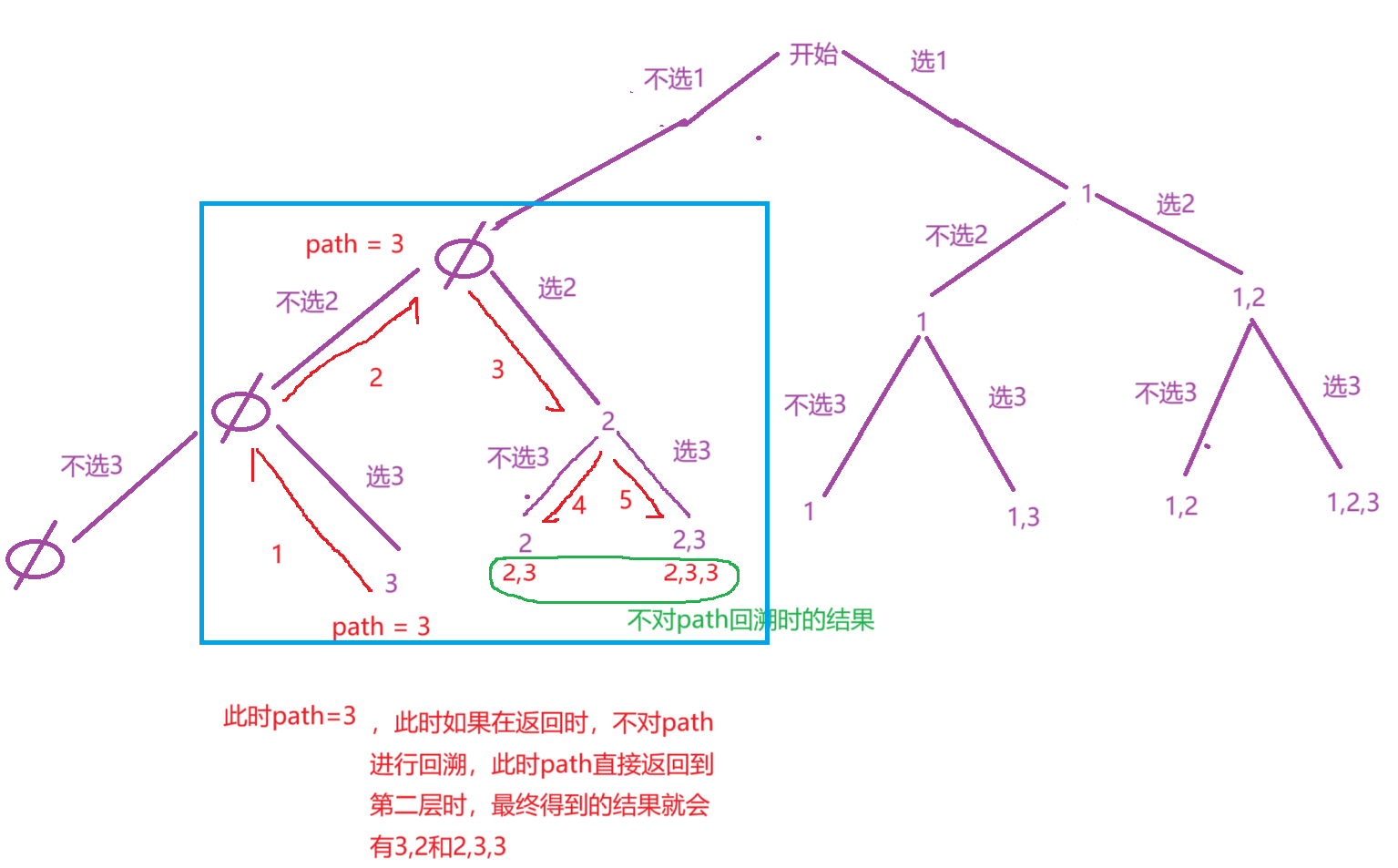
递归出口的设计,当遇到叶子节点时,直接返回,并且向ret中添加结果。
代码实现:
class Solution {List<List<Integer>> ret;List<Integer> path;public List<List<Integer>> subsets(int[] nums) {ret = new ArrayList<>();path = new ArrayList<>();dfs(nums,0);return ret;}public void dfs(int[] nums,int index){//递归出口if(index == nums.length){ret.add(new ArrayList<>(path));return;}//选path.add(nums[index]);dfs(nums,index+1);path.remove(path.size()-1);//不选dfs(nums,index+1);}
}写代码时一个非常细节的细节,就是往ret中添加结果中是ret.add(new ArrayList<>(path))而不是直接ret.add(path),因为path存储的是引用(也就是此时ret存储的path都是同一个东西,ret里面的path都是同一个引用,会同时指向同一个值,也就是到最后,ret中存储的path的值都是相同的),如果我们直接存储path,后面我们会修改path,也会影响ret里面的path指向的值,如下图

所以,在ret.add时,存储的是path的副本,也就是ret.add(new ArrayList<>(path))这种写法。
解法二:按照子集中数字的个数来找
上面那种解法是按照选或者不选这个数字的思路来寻找nums数组中所有子集,此时我们也可以按照子集中数字的个数的思路去寻找nums数组中子集的个数,按照此思路画出决策树
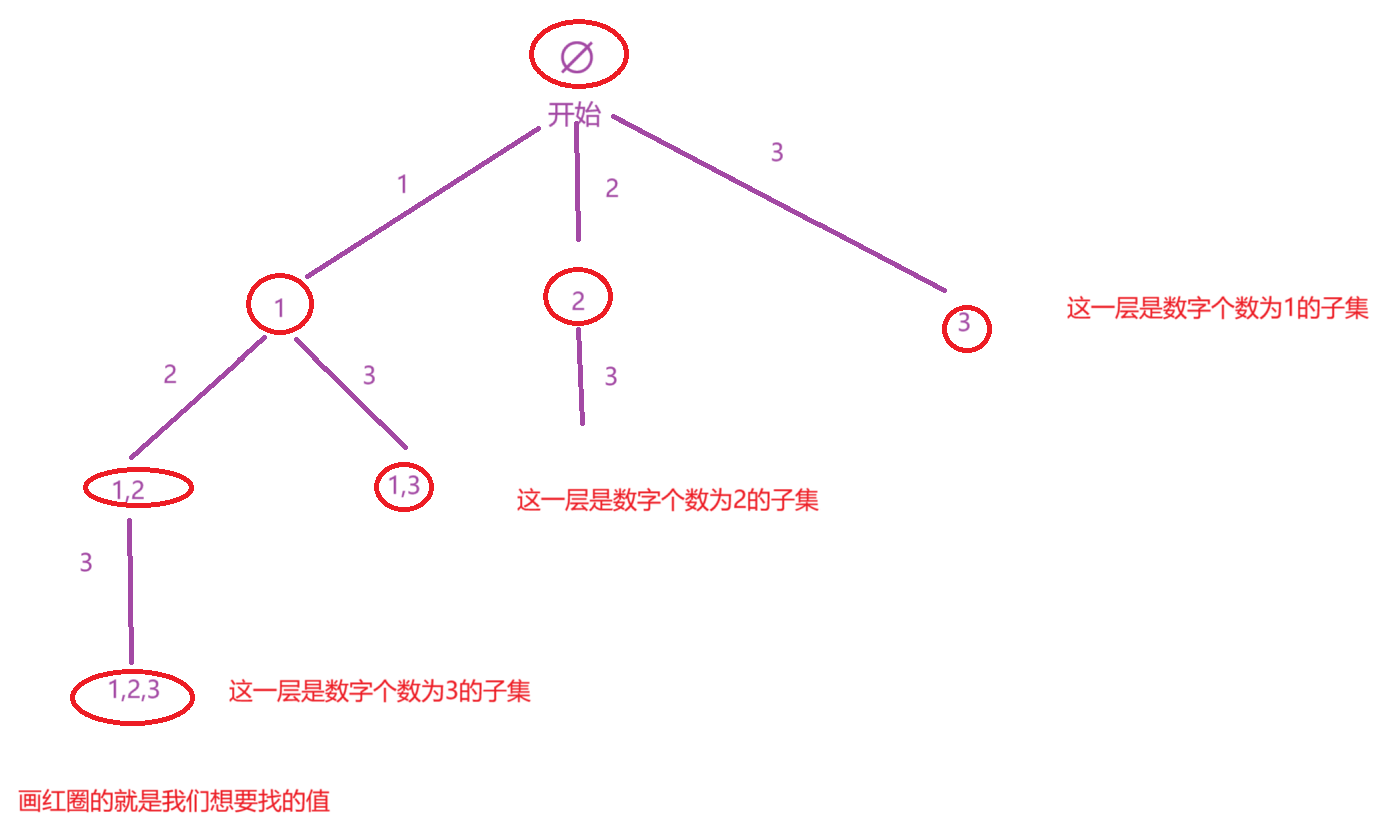
此时按照策略树去设计函数,分别设计一个path变量去记录遍历决策树时子集的组成情况和设计一个ret去存储nums中可以组成的子集。
函数头的设计,此时依旧传一个index变量,index变量表示该层递归是从哪一层开始的。
函数体的设计,在这个思路中,我们是一进入递归就要ret中添加结果,往ret中添加完结果后,就直接去递归到下一层,返回时在进行一个回溯就行了。
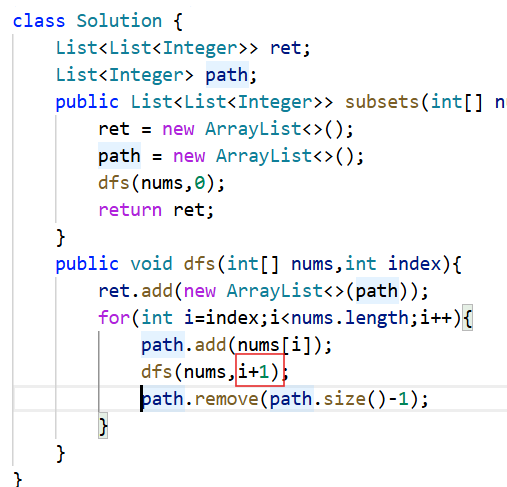
class Solution {List<List<Integer>> ret;List<Integer> path;public List<List<Integer>> subsets(int[] nums) {ret = new ArrayList<>();path = new ArrayList<>();dfs(nums,0);return ret;}public void dfs(int[] nums,int index){ret.add(new ArrayList<>(path));for(int i=index;i<nums.length;i++){path.add(nums[i]);dfs(nums,i+1);path.remove(path.size()-1);//回溯}}
}写代码时一个非常细节的细节
就是当我们dfs时是dfs(nums,i+1)这种写法,不能写成dfs(nums,i++),因为i++是直接对递归到这层的i的值进行了修改 ,后面返回到这一层时还要用到这一层的i,由于在递归时修改了原来i的值,所以后面再去使用i时,结果就会出错。
相关文章:
》)
《从零开始入门递归算法:搜索与回溯的核心思想 + 剑指Offer+leetcode高频面试题实战(含可视化图解)》
一.递归 1.汉诺塔 题目链接:面试题 08.06. 汉诺塔问题 - 力扣(LeetCode) 题目解析:将A柱子上的盘子借助B柱子全部移动到C柱子上。 算法原理:递归 当A柱子上的盘子只有1个时,我们可以直接将A上的盘子直…...

船舶制造业数字化转型:驶向智能海洋新航道
在全球海洋经济蓬勃发展的当下,船舶制造业作为海洋产业的重要支柱,正面临着前所未有的机遇与挑战。船舶制造周期长、技术复杂,从设计图纸到最终交付,涉及成千上万的零部件和复杂的工艺流程,传统制造模式已难以满足市场…...

SpringBoot 自动装配流程
Spring Boot 的自动装配(Auto Configuration)是其最核心的特性之一,它让你能“开箱即用”,极大简化了配置。下面是 Spring Boot 自动装配的整体流程(从启动到生效) 的详细解析: ✅ 一、整体流程…...
)
Vue 3 实现后端 Excel 文件流导出功能(Blob 下载详解)
💡 本文以告警信息导出为例,介绍 Vue 3 中如何通过 Axios 调用后端接口并处理文件流,实现 Excel 自动下载功能。 📑 目录 一、前言 二、后端接口说明 三、前端实现思路 四、导出功能完整代码 五、常见问题处理 六、效果展示 …...

基于IBM BAW的Case Management进行项目管理示例
说明:使用IBM BAW的难点是如何充分利用其现有功能根据实际业务需要进行设计,本文是示例教程,因CASE Manager使用非常简单,这里重点是说明如何基于CASE Manager进行项目管理,重点在方案设计思路上,其中涉及的…...

《Python星球日记》 第78天:CV 基础与图像处理
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、计算机视觉(CV)简介1. 什么是计算机视觉?2. 计算机视觉的应用场景3. 图像的基本属性a》像素(Pixel)b》通道(Channel)c》分辨率(Res…...

Google DeepMind 推出AlphaEvolve
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Flink 1.13.2 日志配置优化:保留最近 7 天日志文件
Flink 1.13.2 日志配置优化:保留最近 7 天日志文件 在使用 Apache Flink 1.13.2 进行流处理任务时,合理的日志配置对于作业的监控、调试和故障排查至关重要。本文将介绍如何通过修改log4j.properties文件,将 Flink 的默认日志配置升级为保留最近 7 天的日志文件配置,并解决…...
)
【优化算法】协方差矩阵自适应进化策略(Covariance Matrix Adaptation Evolution Strategy,CMA-ES)
CMA-ES(Covariance Matrix Adaptation Evolution Strategy)算法是一种无导数、基于多元正态分布的迭代优化方法,通过自适应地调整搜索分布的均值、协方差矩阵和步长,能够高效地解决非线性、非凸的连续优化问题。 算法以最大似然和…...

基于Leaflet和天地图的免费运动场所WebGIS可视化-以长沙市为例
目录 前言 一、免费运动场所数据整理 1、本地宝数据简介 2、Java后台数据解析 二、Leaflet前端地图展示 1、基础数据准备 2、具体位置及属性标记 三、成果展示 1、空间位置分布 2、东风路立交桥运动公园 3、芙蓉区花侯路浏阳河大桥下方 4、梅岭国际小区 5、湖南大学…...

399. 除法求值
https://leetcode.cn/problems/evaluate-division/description/?envTypestudy-plan-v2&envIdtop-interview-150思路:读完题后我们可以发现这题的考察已经很明确了就是考我们矩阵,我们将矩阵构建出来后,这题就变成可达性分析题了。 所以解…...
)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示(实操部分)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示 📢 前言: 作为一名键盘爱好者,近期研究了QMK固件的OLED显示屏配置,发现网上的教程要么太过复杂,要么过于简单无法实际操作。因此决定写下这篇教程,从零基础出发,带大家一步步实现键盘OLED屏幕的配置与个性化显示…...

深度解析 Meta 开源 MR 项目《North Star》:从交互到渲染的沉浸式体验设计
🌌 一、项目概览:什么是 North Star? North Star 是由 Meta 官方推出并开源 的一款面向 Meta Quest 平台 的混合现实(MR)视觉演示项目。它不仅上线了 Horizon Store,更以完整的技术栈与高质量内容向开发者展示了如何在 VR/MR 设备上实现“视觉上限”和“交互潜力”的结…...

使用VS Code通过SSH编译Linux上的C++程序
引言 在软件开发领域,跨平台开发是一项常见需求。特别是对于C开发者来说,有时需要在Windows环境下编写代码,但却需要在Linux环境中编译和运行。这种情况在系统编程、嵌入式开发或高性能计算领域尤为常见。 Visual Studio Code (VS Code) 提…...

Datawhale 5月llm-universe 第2次笔记
第二章 使用 LLM API 开发应用 名词解释 Temperature 参数/场景低 Temperature(0 ~ 0.3)高 Temperature(0.7 ~ 1.0)输出特点保守、稳定、可预测创造性强、多样化、不可预测语言模型行为更少的随机性,倾向于选择高概…...

【Vue】CSS3实现关键帧动画
关键帧动画 两个重点keyframesanimation子属性 实现案例效果展示: 两个重点 keyframes 和 animation 作用:通过定义关键帧(keyframes)和动画(animation)规则,实现复杂的关键帧动画。 keyframes 定义动画的关键帧序列…...

Spring 模拟转账开发实战
一、转账业务场景分析 转账是金融类应用的核心场景之一,涉及付款方扣减金额和收款方增加金额两个关键操作。在开发中需解决以下问题: 业务层与数据层解耦:通过分层架构(Service 层调用 Dao 层)实现逻辑分离。数据库事…...

Baklib内容中台赋能资源管理升级
内容中台驱动管理升级 在数字化转型进程中,企业级内容管理工具的效能直接影响资源协同效率。以全渠道资源整合为核心的内容中台,通过集中化处理文档、FAQ及社区论坛等非结构化数据,有效解决信息孤岛问题。例如,某金融集团通过部署…...
——排序)
数据结构(九)——排序
一、排序的基本概念 1.排序:重新排列表中的元素,使表中的元素满足按关键字有序 2.稳定性:Ri和Rj相对位置保持不变 3.内部排序:指在排序期间元素全部存在内存中的排序(比较和移动),如插入排序…...
)
MinerU安装(pdf转markdown、json)
在Windows上安装MinerU,参考以下几个文章,可以成功安装,并使用GPU解析。 整体安装教程: MinerU本地化部署教程——一款AI知识库建站的必备工具 其中安装conda的教程: 一步步教你在 Windows 上轻松安装 Anaconda以及使…...

Spring框架核心技术深度解析:JDBC模板、模拟转账与事务管理
一、JDBC模板技术:简化数据库操作 在传统JDBC开发中,繁琐的资源管理和重复代码一直是开发者的痛点。Spring框架提供的 JDBC模板(JdbcTemplate) 彻底改变了这一现状,它通过封装底层JDBC操作,让开发者仅需关注SQL逻辑&a…...

LCD电视LED背光全解析:直下式 vs 侧光式、全局调光 vs 局部调光与HDR体验
Abstract: This article explores the various types of LED backlighting used in televisions and monitors. It categorizes backlight systems based on structural design—direct-lit and edge-lit—as well as by dimming technology—global dimming and local dimmin…...

ET EntityRef EntityWeakRef 类分析
EntityRef EntityWeakRef 相同点 也是这两个的作用:这两个都是用来表示一个实体引用。一般来说使用一个对象,直接持有对象就可以,但是如果对象来自于对象池,这个时候直接持有对象不合适,对象可能已经被对象池回收&…...
)
Python----神经网络(基于DNN的风电功率预测)
一、基于DNN的风电功率预测 1.1、背景 在全球能源转型的浪潮中,风力发电因其清洁和可再生的特性而日益重要。然而,风力发电功率的波动性给电网的稳定运行和能源调度带来了挑战。准确预测风力发电机的功率输出,对于优化能源管理、提高电网可靠…...

Web前端入门:JavaScript 的应用领域
截至目前,您应该对前端的 HTML CSS 应该有了很清楚的认知,至少实现一个静态网页已经完全不在话下了。 当然,CSS 功能绝不止这些,一些不太常用的 CSS 相关知识,后续将通过案例进行分享。 那么咱们接下来看看 JavaScrip…...
,实现多台电脑共享鼠标和键盘(支持window系统))
实用工具:微软软件PowerToys(完全免费),实现多台电脑共享鼠标和键盘(支持window系统)
实用工具:微软软件 PowerToys 让多台电脑共享鼠标和键盘 在如今的数字化办公与生活场景中,我们常常会面临同时使用多台电脑的情况。例如,办公时可能一台电脑用于处理工作文档,另一台用于运行专业软件或查看资料;家庭环…...
:移情阶段评分体系构建与实战案例解析)
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析 在创业的移情阶段,如何科学评估用户需求的真实性与紧迫性,是决定后续产品方向的关键。今天,我们结合《精益数据分析》中的评分框架,…...

面试题:介绍一下JAVA中的反射机制
什么是反射机制? Java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性。这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的…...

yarn任务筛选spark任务,判断内存/CPU使用超过限制任务
yarn任务筛选spark任务,判断内存/CPU使用超过限制任务 curl -s “http://it-cdh-node01:8088/ws/v1/cluster/apps?statesRUNNING” | jq ‘select(.apps.app[].applicationType “SPARK”) | .apps.app[].id’ | xargs -I {} curl -s “http://it-cdh-node01:808…...
-004)
ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号)-004
ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放_arcgis初学者使用视频-CSDN博客 4大遥感软件!遥感影像解译!ArcGISENVIErdaseCognition_遥感解译软件-CSDN博客 今天介绍一下在ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号&am…...

红黑树解析
目录 一、引言 二、红黑树的概念与性质 2.1 红黑树的概念 2.2 红黑树的性质 三、红黑树的节点定义与结构 3.1 节点定义 四、红黑树的插入操作 4.1 插入步骤 4.2 插入代码实现 五、红黑树的验证 5.1 验证步骤 5.2 验证代码实现 六、红黑树迭代器的实现 6.1 迭代器的…...

在线文档管理系统 spring boot➕vue|源码+数据库+部署教程
📌 一、项目简介 本系统采用Spring Boot Vue ElementUI技术栈,支持管理员和员工两类角色,涵盖文档上传、分类管理、公告发布、员工资料维护、部门岗位管理等核心功能。 系统目标是打造一个简洁高效的内部文档管理平台,便于员工…...

Python3 简易DNS服务器实现
使用Python3开发一个简单的DNS服务器,支持配置资源记录(RR),并能通过dig命令进行查询。 让自己理解DNS原理 实现方案 我们将使用socketserver和dnslib库来构建这个DNS服务器。dnslib库能帮助我们处理DNS协议的复杂细节。 1. 安装依赖 首先确保安装了d…...

雾锁王国开服联机教程-专用服务器
一。阿里云服务器搭建 服务器地址:1分钟畅玩!一键部署联机服务器 《雾锁王国(Enshrouded)》融合了生存、制作以及动作 RPG 战斗,游戏背景设定在了一个基于体素构筑的辽阔大陆。无论是攀登山脉还是跨越沙漠࿰…...

鸿蒙OSUniApp 开发的一键分享功能#三方框架 #Uniapp
使用 UniApp 开发的一键分享功能 在移动应用开发中,分享功能几乎是必不可少的一环。一个好的分享体验不仅能带来更多用户,还能提升产品的曝光度。本文将详细讲解如何在 UniApp 框架下实现一个简单高效的一键分享功能,适配多个平台。 各平台分…...

Hive PredicatePushDown 谓词下推规则的计算逻辑
1. PredicatePushDown 谓词下推 谓词下推的处理顺序是先处理子节点的操作,子节点都处理完,然后处理父节点。 select web_site_sk from (select web_site_sk,web_name from web_site where web_cityPleasant Hill ) t where web_name <> site_…...

2024东北四省ccpc
F题 解题思路 数论 有限小数的条件 p q \frac{p}{q} qp 在 k k k 进制下是有限小数,当且仅当 q q q 的所有质因数都是 p p p 或 k k k 的质因数。 即,若 q q q 的质因数分解为 q ∏ i p i a i q \prod_{i} p_i^{a_i} q∏ipiai&#x…...
)
【C语言】初阶数据结构相关习题(二)
🎆个人主页:夜晚中的人海 今日语录:知识是从刻苦劳动中得来的,任何成就都是刻苦劳动的结果。——宋庆龄 文章目录 🎄一、链表内指定区间翻转🎉二、从链表中删去总和值为零的节点🚀三、链表求和&…...

DeepSeek执行流程加速指南:跨框架转换与编译优化的核心策略全解析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
)
解决 Conda 安装 PyTorch 1.1.0 报错:excluded by strict repo priority(附三种解决方案)
# 💥解决 Conda 安装 PyTorch 1.1.0 报错问题:excluded by strict repo priority在使用旧版本 PyTorch(例如 1.1.0)时,有些开发者会遇到以下 conda 安装报错:LibMambaUnsatisfiableError: package pytorch-…...

面试从微前端拓展到iframe是如何通信的
一、跨域通信 1、父页面发消息给 iframe const iframe document.getElementById(myIframe); iframe.contentWindow.postMessage(form parent, https://iframe-domain.com)// iframe 接收 window.addEventListener(message, (event) > {if (event.origin ! https://paren…...
)
PyTorch循环神经网络(Pytotch)
文章目录 循环神经网络(RNN)简单的循环神经网络长短期记忆网络(LSTM)门控循环单元(GRU) 循环神经网络(RNN) 循环神经网络(RecurrentNeuralNetwork,RNN&#…...

django中用 InforSuite RDS 替代memcache
在 Django 项目中,InforSuite RDS(关系型数据库服务)无法直接替代 Memcached,因为两者的设计目标和功能定位完全不同: 特性MemcachedInforSuite RDS核心用途高性能内存缓存,临时存储键值对数据持久化关系型…...

Git 常用命令详解
Git 常用命令详解(含详细示例) 本文整理了 Git 日常使用中最常用的命令,适合初学者和日常查阅,如有错误,敬请指正,谢谢! ☁️ Git 使用流程入门(从 pull 和 push 开始) …...

AI、机器学习、深度学习:一文厘清三者核心区别与联系
AI、机器学习、深度学习:一文厘清三者核心区别与联系 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 前言 在人工智能技术席卷全球的今天&…...

《数字藏品社交化破局:React Native与Flutter的创新实践指南》
NFT,这种非同质化代币,赋予了数字资产独一无二的身份标识,从数字艺术作品到限量版虚拟物品,每一件NFT数字藏品都承载着独特的价值与意义。当React Native和Flutter这两大跨平台开发框架遇上NFT数字藏品,一场技术与创意…...

工业操作系统核心技术揭秘
摘要 随着工业 4.0 与智能制造的深入推进,工业操作系统作为工业数字化转型的核心支撑,其技术发展备受关注。本文深入剖析工业操作系统的核心技术,包括实时性保障机制、硬件抽象层设计、多任务管理策略等,结合技术原理与实际应用场…...

Python logging模块使用指南
Python 的 logging 模块是一个灵活且强大的日志记录工具,广泛应用于应用程序的调试、运行监控和问题排查。它提供了丰富的功能,包括多级日志记录、多种输出方式、灵活的格式配置等。以下是详细介绍: 一、为什么使用 logging 模块?…...

沃伦森智能无功补偿系统解决电力电容器频繁投切的隐患
在现代电力系统中,无功补偿设备的稳定运行直接影响电网质量。然而,电力电容器的频繁投切问题长期存在,如同电网的“慢性病”,不仅加速设备老化,还可能引发系统性风险。作为电力电子领域的领军企业,沃伦森电…...

【HarmonyOS 5】鸿蒙mPaaS详解
【HarmonyOS 5】鸿蒙mPaaS详解 一、mPaaS是什么? mPaaS 是 Mobile Platform as a Service 的缩写,即移动开发平台。 蚂蚁移动开发平台mPaaS ,融合了支付宝科技能力,可以为移动应用开发、测试、运营及运维提供云到端的一站式解决…...