Python----神经网络(基于DNN的风电功率预测)
一、基于DNN的风电功率预测
1.1、背景
在全球能源转型的浪潮中,风力发电因其清洁和可再生的特性而日益重要。然而,风力发电功率的波动性给电网的稳定运行和能源调度带来了挑战。准确预测风力发电机的功率输出,对于优化能源管理、提高电网可靠性以及促进风能的高效利用至关重要。传统的预测方法在应对风力发电固有的复杂性和非线性时存在局限,因此,利用深度学习等先进人工智能技术,从历史运行数据中学习并预测风功率,已成为一个重要的研究方向。
1.2、目标
旨在探索如何利用风机运行的历史数据,特别是风速、发电机转速和叶片角度等关键参数,构建一个深度学习模型来预测风力发电机的功率输出。通过对数据进行预处理、选择合适的模型架构、进行有效的训练和验证,并在独立的测试集上评估模型的预测性能,最终实现对风力发电机功率的准确预测,并可视化展示预测结果。
1.3、数据展示
二、数据准备与预处理
class PowerData(Dataset):def __init__(self,path,input_len):super().__init__()# 从CSV文件读取数据self.data=pd.read_csv(path)# 定义输入序列的长度self.input_len=input_len# 将功率值限制在0到1500之间,处理异常值self.data['功率(kW)']=np.minimum(self.data['功率(kW)'],1500)# 初始化MinMaxScaler,用于将功率值归一化到[-1, 1]的范围self.scaler=MinMaxScaler(feature_range=(-1,1))# 对功率数据进行归一化处理并存储self.data['power_nomalized']=self.scaler.fit_transform(self.data['功率(kW)'].values.reshape(-1,1))# 返回数据集的长度,即可以生成多少个输入-输出对def __len__(self):return len(self.data)-self.input_len# 根据给定的索引返回一个样本def __getitem__(self, idx):# 定义输入序列的起始和结束索引start_idx=idxend_idx=idx+self.input_len# 获取输入特征序列feature=self.data['power_nomalized'].values[start_idx:end_idx]# 获取对应的目标值(下一个时间点的功率值)target=self.data['power_nomalized'].values[end_idx:end_idx+1]# 将特征和目标转换为PyTorch张量并返回return torch.tensor(feature,dtype=torch.float32),torch.tensor(target,dtype=torch.float32)# 创建PowerData数据集实例,指定数据文件路径和输入序列长度
power_dataset=PowerData('./A01.csv',input_len=6)Scaler之前:(tensor([327.0000, 327.0000, 252.6000, 211.2000, 211.2000, 159.0000]), tensor([184.2000]))
Scaler之后:(tensor([-0.5640, -0.5640, -0.6632, -0.7184, -0.7184, -0.7880]), tensor([-0.7544]))# 定义训练集、验证集和测试集的比例
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 计算各个数据集的大小
train_size = int(train_ratio * len(power_dataset))
val_size = int(val_ratio * len(power_dataset))
test_size = len(power_dataset) - train_size - val_size # 确保测试集大小正确# 创建训练集、验证集和测试集的Subset
train_dataset=Subset(power_dataset,list(range(len(power_dataset)))[:train_size])
val_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size:train_size+val_size])
test_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size+val_size:])# 创建训练集、验证集和测试集的数据加载器
train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=64,shuffle=False)
test_dataloader=DataLoader(test_dataset,batch_size=1,shuffle=False)三、模型构建
class DNN(nn.Module):def __init__(self,input_len=6,hidden_size=128,output_size=1):super().__init__()# 定义第一个线性层self.liner1=nn.Linear(input_len,hidden_size)# 定义第二个线性层(输出层)self.liner2=nn.Linear(hidden_size,output_size)# 定义模型的前向传播过程def forward(self,x):# 通过第一个线性层并应用ReLU激活函数x=F.relu(self.liner1(x))# 通过第二个线性层得到最终的预测值x=self.liner2(x)return x# 创建DNN模型实例
model=DNN()四、模型训练与验证
# 定义损失函数为均方误差
cri=nn.MSELoss()
# 定义优化器为Adam,并设置学习率和权重衰减
optim=torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-5)# 开始训练模型
for epoch in range(1,21):# 设置模型为训练模式model.train()# 初始化每个epoch的总损失total_loss=0# 遍历训练数据加载器for batch_feature,batch_target in train_dataloader:# 使用模型进行预测y_pred=model(batch_feature)# 计算损失loss=cri(y_pred.squeeze(1),batch_target.view(-1))# 清空之前的梯度optim.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optim.step()# 累加批次损失total_loss+=loss# 计算平均训练损失train_loss=total_loss/len(train_dataloader)# 设置模型为评估模式model.eval()# 初始化验证集的总损失total_loss=0# 在不计算梯度的上下文中进行验证with torch.no_grad():# 遍历验证数据加载器for batch_feature,batch_target in val_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 计算损失loss = cri(y_pred.squeeze(1), batch_target.view(-1))# 累加批次损失total_loss += loss# 计算平均验证损失avg_loss = total_loss / len(val_dataloader)# 计算平均验证损失val_loss=total_loss/len(val_dataloader)# 打印每个epoch的训练损失和验证损失print(train_loss.item(),val_loss.item())五、模型评估与结果可视化
# 设置模型为评估模式
model.eval()
# 初始化预测值列表和真实值列表
pred_list=[]
target_list=[]
# 在不计算梯度的上下文中进行测试
with torch.no_grad():# 遍历测试数据加载器for batch_feature, batch_target in test_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 将预测值和真实值添加到列表中pred_list.append(y_pred.squeeze(1).item())target_list.append(batch_target.item())# 将预测值和真实值反归一化到原始范围
pred_list=power_dataset.scaler.inverse_transform(np.array(pred_list).reshape(-1,1))
target_list=power_dataset.scaler.inverse_transform(np.array(target_list).reshape(-1,1))# 绘制最后200个真实值和预测值的对比图
plt.plot(target_list[-200:], label="True values")
plt.plot(pred_list[-200:], label="Predict values")
# 设置x轴标签
plt.xlabel("Time")
# 设置y轴标签
plt.ylabel("Power")
# 显示图例
plt.legend()
# 显示图像
plt.show()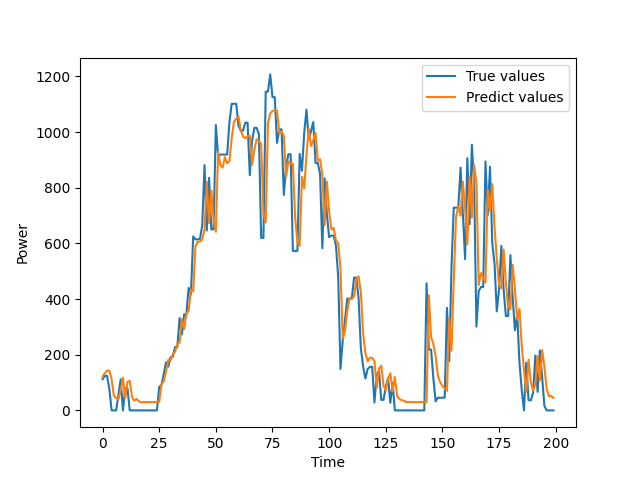
六、完整代码
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader,Subset
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch.nn.functional as F# 定义用于加载电力数据的Dataset类
class PowerData(Dataset):def __init__(self,path,input_len):super().__init__()# 从CSV文件读取数据self.data=pd.read_csv(path)# 定义输入序列的长度self.input_len=input_len# 将功率值限制在0到1500之间,处理异常值self.data['功率(kW)']=np.minimum(self.data['功率(kW)'],1500)# 初始化MinMaxScaler,用于将功率值归一化到[-1, 1]的范围self.scaler=MinMaxScaler(feature_range=(-1,1))# 对功率数据进行归一化处理并存储self.data['power_nomalized']=self.scaler.fit_transform(self.data['功率(kW)'].values.reshape(-1,1))# 返回数据集的长度,即可以生成多少个输入-输出对def __len__(self):return len(self.data)-self.input_len# 根据给定的索引返回一个样本def __getitem__(self, idx):# 定义输入序列的起始和结束索引start_idx=idxend_idx=idx+self.input_len# 获取输入特征序列feature=self.data['power_nomalized'].values[start_idx:end_idx]# 获取对应的目标值(下一个时间点的功率值)target=self.data['power_nomalized'].values[end_idx:end_idx+1]# 将特征和目标转换为PyTorch张量并返回return torch.tensor(feature,dtype=torch.float32),torch.tensor(target,dtype=torch.float32)# 创建PowerData数据集实例,指定数据文件路径和输入序列长度
power_dataset=PowerData('./A01.csv',input_len=6)# 定义训练集、验证集和测试集的比例
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 计算各个数据集的大小
train_size = int(train_ratio * len(power_dataset))
val_size = int(val_ratio * len(power_dataset))
test_size = len(power_dataset) - train_size - val_size # 确保测试集大小正确# 创建训练集、验证集和测试集的Subset
train_dataset=Subset(power_dataset,list(range(len(power_dataset)))[:train_size])
val_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size:train_size+val_size])
test_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size+val_size:])# 创建训练集、验证集和测试集的数据加载器
train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=64,shuffle=False)
test_dataloader=DataLoader(test_dataset,batch_size=1,shuffle=False)# 定义一个简单的深度神经网络模型
class DNN(nn.Module):def __init__(self,input_len=6,hidden_size=128,output_size=1):super().__init__()# 定义第一个线性层self.liner1=nn.Linear(input_len,hidden_size)# 定义第二个线性层(输出层)self.liner2=nn.Linear(hidden_size,output_size)# 定义模型的前向传播过程def forward(self,x):# 通过第一个线性层并应用ReLU激活函数x=F.relu(self.liner1(x))# 通过第二个线性层得到最终的预测值x=self.liner2(x)return x# 创建DNN模型实例
model=DNN()# 定义损失函数为均方误差
cri=nn.MSELoss()
# 定义优化器为Adam,并设置学习率和权重衰减
optim=torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-5)# 开始训练模型
for epoch in range(1,21):# 设置模型为训练模式model.train()# 初始化每个epoch的总损失total_loss=0# 遍历训练数据加载器for batch_feature,batch_target in train_dataloader:# 使用模型进行预测y_pred=model(batch_feature)# 计算损失loss=cri(y_pred.squeeze(1),batch_target.view(-1))# 清空之前的梯度optim.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optim.step()# 累加批次损失total_loss+=loss# 计算平均训练损失train_loss=total_loss/len(train_dataloader)# 设置模型为评估模式model.eval()# 初始化验证集的总损失total_loss=0# 在不计算梯度的上下文中进行验证with torch.no_grad():# 遍历验证数据加载器for batch_feature,batch_target in val_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 计算损失loss = cri(y_pred.squeeze(1), batch_target.view(-1))# 累加批次损失total_loss += loss# 计算平均验证损失avg_loss = total_loss / len(val_dataloader)# 计算平均验证损失val_loss=total_loss/len(val_dataloader)# 打印每个epoch的训练损失和验证损失print(train_loss.item(),val_loss.item())# 设置模型为评估模式
model.eval()
# 初始化预测值列表和真实值列表
pred_list=[]
target_list=[]
# 在不计算梯度的上下文中进行测试
with torch.no_grad():# 遍历测试数据加载器for batch_feature, batch_target in test_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 将预测值和真实值添加到列表中pred_list.append(y_pred.squeeze(1).item())target_list.append(batch_target.item())# 将预测值和真实值反归一化到原始范围
pred_list=power_dataset.scaler.inverse_transform(np.array(pred_list).reshape(-1,1))
target_list=power_dataset.scaler.inverse_transform(np.array(target_list).reshape(-1,1))# 绘制最后200个真实值和预测值的对比图
plt.plot(target_list[-200:], label="True values")
plt.plot(pred_list[-200:], label="Predict values")
# 设置x轴标签
plt.xlabel("Time")
# 设置y轴标签
plt.ylabel("Power")
# 显示图例
plt.legend()
# 显示图像
plt.show()相关文章:
)
Python----神经网络(基于DNN的风电功率预测)
一、基于DNN的风电功率预测 1.1、背景 在全球能源转型的浪潮中,风力发电因其清洁和可再生的特性而日益重要。然而,风力发电功率的波动性给电网的稳定运行和能源调度带来了挑战。准确预测风力发电机的功率输出,对于优化能源管理、提高电网可靠…...

Web前端入门:JavaScript 的应用领域
截至目前,您应该对前端的 HTML CSS 应该有了很清楚的认知,至少实现一个静态网页已经完全不在话下了。 当然,CSS 功能绝不止这些,一些不太常用的 CSS 相关知识,后续将通过案例进行分享。 那么咱们接下来看看 JavaScrip…...
,实现多台电脑共享鼠标和键盘(支持window系统))
实用工具:微软软件PowerToys(完全免费),实现多台电脑共享鼠标和键盘(支持window系统)
实用工具:微软软件 PowerToys 让多台电脑共享鼠标和键盘 在如今的数字化办公与生活场景中,我们常常会面临同时使用多台电脑的情况。例如,办公时可能一台电脑用于处理工作文档,另一台用于运行专业软件或查看资料;家庭环…...
:移情阶段评分体系构建与实战案例解析)
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析 在创业的移情阶段,如何科学评估用户需求的真实性与紧迫性,是决定后续产品方向的关键。今天,我们结合《精益数据分析》中的评分框架,…...

面试题:介绍一下JAVA中的反射机制
什么是反射机制? Java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性。这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的…...

yarn任务筛选spark任务,判断内存/CPU使用超过限制任务
yarn任务筛选spark任务,判断内存/CPU使用超过限制任务 curl -s “http://it-cdh-node01:8088/ws/v1/cluster/apps?statesRUNNING” | jq ‘select(.apps.app[].applicationType “SPARK”) | .apps.app[].id’ | xargs -I {} curl -s “http://it-cdh-node01:808…...
-004)
ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号)-004
ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放_arcgis初学者使用视频-CSDN博客 4大遥感软件!遥感影像解译!ArcGISENVIErdaseCognition_遥感解译软件-CSDN博客 今天介绍一下在ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号&am…...

红黑树解析
目录 一、引言 二、红黑树的概念与性质 2.1 红黑树的概念 2.2 红黑树的性质 三、红黑树的节点定义与结构 3.1 节点定义 四、红黑树的插入操作 4.1 插入步骤 4.2 插入代码实现 五、红黑树的验证 5.1 验证步骤 5.2 验证代码实现 六、红黑树迭代器的实现 6.1 迭代器的…...

在线文档管理系统 spring boot➕vue|源码+数据库+部署教程
📌 一、项目简介 本系统采用Spring Boot Vue ElementUI技术栈,支持管理员和员工两类角色,涵盖文档上传、分类管理、公告发布、员工资料维护、部门岗位管理等核心功能。 系统目标是打造一个简洁高效的内部文档管理平台,便于员工…...

Python3 简易DNS服务器实现
使用Python3开发一个简单的DNS服务器,支持配置资源记录(RR),并能通过dig命令进行查询。 让自己理解DNS原理 实现方案 我们将使用socketserver和dnslib库来构建这个DNS服务器。dnslib库能帮助我们处理DNS协议的复杂细节。 1. 安装依赖 首先确保安装了d…...

雾锁王国开服联机教程-专用服务器
一。阿里云服务器搭建 服务器地址:1分钟畅玩!一键部署联机服务器 《雾锁王国(Enshrouded)》融合了生存、制作以及动作 RPG 战斗,游戏背景设定在了一个基于体素构筑的辽阔大陆。无论是攀登山脉还是跨越沙漠࿰…...

鸿蒙OSUniApp 开发的一键分享功能#三方框架 #Uniapp
使用 UniApp 开发的一键分享功能 在移动应用开发中,分享功能几乎是必不可少的一环。一个好的分享体验不仅能带来更多用户,还能提升产品的曝光度。本文将详细讲解如何在 UniApp 框架下实现一个简单高效的一键分享功能,适配多个平台。 各平台分…...

Hive PredicatePushDown 谓词下推规则的计算逻辑
1. PredicatePushDown 谓词下推 谓词下推的处理顺序是先处理子节点的操作,子节点都处理完,然后处理父节点。 select web_site_sk from (select web_site_sk,web_name from web_site where web_cityPleasant Hill ) t where web_name <> site_…...

2024东北四省ccpc
F题 解题思路 数论 有限小数的条件 p q \frac{p}{q} qp 在 k k k 进制下是有限小数,当且仅当 q q q 的所有质因数都是 p p p 或 k k k 的质因数。 即,若 q q q 的质因数分解为 q ∏ i p i a i q \prod_{i} p_i^{a_i} q∏ipiai&#x…...
)
【C语言】初阶数据结构相关习题(二)
🎆个人主页:夜晚中的人海 今日语录:知识是从刻苦劳动中得来的,任何成就都是刻苦劳动的结果。——宋庆龄 文章目录 🎄一、链表内指定区间翻转🎉二、从链表中删去总和值为零的节点🚀三、链表求和&…...

DeepSeek执行流程加速指南:跨框架转换与编译优化的核心策略全解析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
)
解决 Conda 安装 PyTorch 1.1.0 报错:excluded by strict repo priority(附三种解决方案)
# 💥解决 Conda 安装 PyTorch 1.1.0 报错问题:excluded by strict repo priority在使用旧版本 PyTorch(例如 1.1.0)时,有些开发者会遇到以下 conda 安装报错:LibMambaUnsatisfiableError: package pytorch-…...

面试从微前端拓展到iframe是如何通信的
一、跨域通信 1、父页面发消息给 iframe const iframe document.getElementById(myIframe); iframe.contentWindow.postMessage(form parent, https://iframe-domain.com)// iframe 接收 window.addEventListener(message, (event) > {if (event.origin ! https://paren…...
)
PyTorch循环神经网络(Pytotch)
文章目录 循环神经网络(RNN)简单的循环神经网络长短期记忆网络(LSTM)门控循环单元(GRU) 循环神经网络(RNN) 循环神经网络(RecurrentNeuralNetwork,RNN&#…...

django中用 InforSuite RDS 替代memcache
在 Django 项目中,InforSuite RDS(关系型数据库服务)无法直接替代 Memcached,因为两者的设计目标和功能定位完全不同: 特性MemcachedInforSuite RDS核心用途高性能内存缓存,临时存储键值对数据持久化关系型…...

Git 常用命令详解
Git 常用命令详解(含详细示例) 本文整理了 Git 日常使用中最常用的命令,适合初学者和日常查阅,如有错误,敬请指正,谢谢! ☁️ Git 使用流程入门(从 pull 和 push 开始) …...

AI、机器学习、深度学习:一文厘清三者核心区别与联系
AI、机器学习、深度学习:一文厘清三者核心区别与联系 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 前言 在人工智能技术席卷全球的今天&…...

《数字藏品社交化破局:React Native与Flutter的创新实践指南》
NFT,这种非同质化代币,赋予了数字资产独一无二的身份标识,从数字艺术作品到限量版虚拟物品,每一件NFT数字藏品都承载着独特的价值与意义。当React Native和Flutter这两大跨平台开发框架遇上NFT数字藏品,一场技术与创意…...

工业操作系统核心技术揭秘
摘要 随着工业 4.0 与智能制造的深入推进,工业操作系统作为工业数字化转型的核心支撑,其技术发展备受关注。本文深入剖析工业操作系统的核心技术,包括实时性保障机制、硬件抽象层设计、多任务管理策略等,结合技术原理与实际应用场…...

Python logging模块使用指南
Python 的 logging 模块是一个灵活且强大的日志记录工具,广泛应用于应用程序的调试、运行监控和问题排查。它提供了丰富的功能,包括多级日志记录、多种输出方式、灵活的格式配置等。以下是详细介绍: 一、为什么使用 logging 模块?…...

沃伦森智能无功补偿系统解决电力电容器频繁投切的隐患
在现代电力系统中,无功补偿设备的稳定运行直接影响电网质量。然而,电力电容器的频繁投切问题长期存在,如同电网的“慢性病”,不仅加速设备老化,还可能引发系统性风险。作为电力电子领域的领军企业,沃伦森电…...

【HarmonyOS 5】鸿蒙mPaaS详解
【HarmonyOS 5】鸿蒙mPaaS详解 一、mPaaS是什么? mPaaS 是 Mobile Platform as a Service 的缩写,即移动开发平台。 蚂蚁移动开发平台mPaaS ,融合了支付宝科技能力,可以为移动应用开发、测试、运营及运维提供云到端的一站式解决…...
函数:提取单元素张量值)
PyTorch中.item()函数:提取单元素张量值
PyTorch中,.item()函数是什么 在PyTorch代码中,.item() 主要用于从一个只包含单个元素的张量(Tensor)中提取出对应的Python标量值 ,具体作用和使用场景如下: 作用 获取数值:当通过计算得到一个张量,且该张量仅包含一个元素时,使用 .item() 方法可以方便地将这个元素…...

PyTorch LSTM练习案例:股票成交量趋势预测
文章目录 案例介绍源码地址代码实现导入相关库数据获取和处理搭建LSTM模型训练模型测试模型绘制折线图主函数 绘制结果 案例介绍 本例使用长短期记忆网络模型对上海证券交易所工商银行的股票成交量做一个趋势预测,这样可以更好地掌握股票买卖点,从而提高…...

ARM A64 LDR指令
ARM A64 LDR指令 1 LDR (immediate)1.1 Post-index1.2 Pre-index1.3 Unsigned offset 2 LDR (literal)3 LDR (register)4 其他LDR指令变体4.1 LDRB (immediate)4.1.1 Post-index4.1.2 Pre-index4.1.3 Unsigned offset 4.2 LDRB (register)4.3 LDRH (immediate)4.3.1 Post-index…...

一些问题杂记
1. 在 SSH 会话/bash中仅使用cat命令查看文件后使用umount命令提示挂载点繁忙,lsof命令查看是bash有占用,但是并没有打开文件之类的情况 原因:当前工作目录仍在挂载点内,使用cat查看文件时,可能当前工作目录ÿ…...
创建窗口)
【OpenGL学习】(一)创建窗口
文章目录 【OpenGL】(一)创建窗口 【OpenGL】(一)创建窗口 GLFW OpenGL 本身只是一套图形渲染 API,不提供窗口创建、上下文管理或输入处理的功能。 GLFW 是一个支持创建窗口、处理键盘鼠标输入和管理 OpenGL 上下文的…...

RTSP 播放器技术探究:架构、挑战与落地实践
RTSP 播放器为什么至今无法被淘汰? 在实时视频传输领域,RTSP(Real-Time Streaming Protocol)作为最基础、最常见的协议之一,至今依然被广泛用于监控设备、IP Camera、视频服务器等设备中。然而,要构建一个稳…...

【问题记录】08 MAC电脑,安装HP打印机驱动,提示:此更新需要macOS版本15.0或更低版本
问题描述: MAC电脑,升级了新系统之后(v15.4.1)。 这时,安装惠普(HP)打印机驱动,提示:This update requires macOS version 15.0 or earlier(此更新需要macOS…...

场景新零售:基于开源AI大模型AI智能名片S2B2C商城小程序源码的商业本质回归与创新
摘要:本文聚焦场景新零售,探讨在新生代消费群体推动下传统零售模式的创新升级。通过分析新生代消费群体的特点以及场景新零售的发展趋势,阐述开源AI大模型AI智能名片S2B2C商城小程序源码在场景新零售中的应用优势,包括精准营销、供…...

16.2 VDMA视频转发实验之模拟源
文章目录 1 实验任务2 系统框图3 硬件设计3.1 IP核配置3.2 注意事项3.3 自定义IP核源码 1 实验任务 基于14.1,相较于16.1,使用自定义IP核vid_gen_motion替换Xilinx TPG IP核。 2 系统框图 基于14.1,添加自定义IP核vid_gen_motion作为视频源…...

PADS 9.5安装教程
1.安装包 https://pan.baidu.com/s/1bt6vE3y8VEmlFwJfoV32nA?pwdj2cg 2.PADS 9.5安装教程 PADS 9.5安装教程(Windows11、超详细版)_pads9.5-CSDN博客 3.出现的问题 1.打开无法使用鼠标滚轮 Win10 pads卡死问题解决,输入法的兼容性问…...

趣味编程:钟表
目录 1. 效果展示 2. 源码展示 3. 逻辑概述 3.1 表针绘制函数(DrawHand) 3.2 表盘绘制函数 3.3 主程序逻辑 4. 小结 概述:本篇博客主要介绍简易钟表的绘制。 1. 效果展示 该钟表会随着系统的时间变化而变化,动态的效…...

.NET 通过命令行解密web.config配置
在.NET应用系统中,保护数据库连接字符串的安全性至关重要。.NET 提供了一种通过 DataProtectionConfigurationProvider 加密连接字符串的方法,以防止敏感数据泄露。然而,在内网信息收集阶段,攻击者只需在目标主机上运行aspnet_regiis.exe这个命令行工具即可完成解密,获取数…...

【MySQL】多表连接查询
个人主页:Guiat 归属专栏:MySQL 文章目录 1. 多表连接查询概述1.1 连接查询的作用1.2 MySQL支持的连接类型 2. 内连接 (INNER JOIN)2.1 内连接的特点2.2 内连接语法2.3 内连接实例2.4 多表内连接 3. 左外连接 (LEFT JOIN)3.1 左外连接的特点3.2 左外连接…...

【AI论文】用于评估和改进大型语言模型中指令跟踪的多维约束框架
摘要:接下来的指令评估了大型语言模型(LLMs)生成符合用户定义约束的输出的能力。 然而,现有的基准测试通常依赖于模板化的约束提示,缺乏现实使用的多样性,并限制了细粒度的性能评估。 为了填补这一空白&…...

应用BERT-GCN跨模态情绪分析:贸易缓和与金价波动的AI归因
本文运用AI量化分析框架,结合市场情绪因子、宏观经济指标及技术面信号,对黄金与美元指数的联动关系进行解析,揭示本轮贵金属回调的深层驱动因素。 周三,现货黄金价格单日跌幅达2.1%,盘中触及3167.94美元/盎司关键价位&…...

低成本高效图像生成:GPUGeek和ComfyUI的强强联合
一、时代背景 在如今的数字化时代,图像生成技术正不断发展和演变,尤其是在人工智能领域。无论是游戏开发、虚拟现实,还是设计创意,图像生成已成为许多应用的核心技术之一。然而,随着图像质量需求的提升,生成…...

React 第四十二节 Router 中useLoaderData的用途详解
一、前言 useLoaderData,用于在组件中获取路由预加载的数据。它通常与路由配置中的 loader 函数配合使用,用于在页面渲染前异步获取数据(如 API 请求),并将数据直接注入组件,从而简化数据流管理。 二、us…...

【NLP 74、最强提示词工程 Prompt Engineering 从理论到实战案例】
一定要拼尽全力,才能看起来毫不费劲 —— 25.5.15 一、提示词工程 1.提示词工程介绍 Ⅰ、什么是提示词 所谓的提示词其实就是一个提供给模型的文本片段,用于指导模型生成特定的输出或回答。提示词的目的是为模型提供一个任务的上下文,以便模…...

GPUGeek云平台实战:DeepSeek-R1-70B大语言模型一站式部署
随着人工智能技术的迅猛发展,特别是在自然语言处理领域,大型语言模型如DeepSeek-R1-70B的出现,推动了各行各业的变革。为了应对这些庞大模型的计算需求,云计算平台的普及成为了关键,特别是基于GPU加速的云平台…...

【抽丝剥茧知识讲解】引入mybtis-plus后,mapper实现方式
目录 前言一、传统 Mapper 接口方式二、继承 BaseMapper 的方式三、自定义通用 Mapper 的方式四、使用 MyBatis-Plus 的 ActiveRecord 模式五、使用 MyBatis-Plus 的 IService 接口六、使用建议 前言 mapper文件,作为Mybatis框架中定义SQL语句和映射关系的配置文件&…...

AI浪潮:开启科技新纪元
AI 的多面应用 AI 的影响力早已突破实验室的围墙,在众多领域落地生根,成为推动行业变革的重要力量。 在医疗领域,AI 宛如一位不知疲倦的助手,助力医生提升诊疗效率与准确性。通过对海量医学影像的深度学习,AI 能够快…...

制造业工厂的三大核心系统:ERP+PLM+MES
对于一家制造业工厂来说,要实现数字化转型,哪几个系统最重要?答案是:ERP,PLM和MES这三个核心系统最为重要!本文就为你快速地概览地介绍一下这三个系统 以及 它们之间的关联关系。 ERP:企业资源计划 ERP的全称是Enterprise Resource Planning,即企业资源计划系统。 它…...

驱动-定时-秒-字符设备
文章目录 目的相关资料参考实验驱动程序-timer_dev.c编译文件-Makefile测试程序-timer.c分析 加载驱动-运行测试程序总结 目的 通过定时器timer_list、字符设备、规避竞争关系-原子操作,综合运用 实现一个程序,加深之前知识的理解。 实现字符设备驱动框…...