继续预训练 LLM ——数据筛选的思路
GPT生成数据微调qwen-2.5多模态模型实战项目
作者:柠檬养乐多
原文地址:https://zhuanlan.zhihu.com/p/30645776656
qwen2.5-vl是阿里通义实验室推出的qwen系列最新多模态大模型,在许多指标上已经超过或接近了gpt-4o。更为方便的是,qwen团队提供了2.5B、7B等多个尺寸的较小模型,即使是较小的2.5B也在OCR、VQA任务上有一定效果。在实操中,我们常常需要部署类似的开源小模型,但是其效果很难达到闭源模型效果。本项目采用最简单的蒸馏思想,采用gpt和给定prompt、给定图片数据集直接生成微调所用的数据集,然后用ms-swift框架进行微调。

项目目前使用Lora微调。Lora原理可参见:知乎|深入浅出 Lora。
Github代码仓(star一下呀):
gpt_distill_2qwen
地址:https://github.com/QQsugar2000/gpt_distill_2qwen
环境需求
-
显卡:由于qwen-vl有2.5b模型,lora下训练所占显存甚至少于10G,所以有张差不多的卡就可以用了;当然,实测一些任务起码要7b模型才能做到差不多的效果
-
安装modelscope的swift微调框架,python版本最好是3.10,配置好cuda、cudnn等
-
可以使用命令:
pip install ms-swift -U
pip install qwen-vl-utils==0.0.8
数据准备
整体思路是用给定的prompt和图片生成问题,然后使用GPT API生成答案,拿这个答案去微调qwen。注意,这种方法并不保证生成的数据质量,因为GPT API生成的数据可能并不准确。
-
在 script/config/prompt.py中配置Prompt:系统Prompt (system_prompt,选填):用于配置大模型生成数据时使用的系统Prompt,例如:“你是一个XX助手”。用户Prompt:直接发送给大模型的Prompt,默认只需配置此项。示例prompt是对UI图片的功能理解。
-
配置图片数据集:clone代码仓后cd到对应目录,将图片放入data/image目录,之后运行
python process_all_image.py \--image_folder data/image \--output_json data/responses.json \--max_retries 3
本项目已经尽量简化微调所需要的数据和文件结构,如果你有一些开源图片数据集,把里面的图片拿出来放进相应目录即可。
如果需要自定义数据集,你也可以参考responses.json中的结构或者看官方文档:自定义数据集 - swift 3.3.0.dev0 文档。如下,每条messages是一次和模型的对话数据,其中包括system(这条没有也可以,是选填的),user、assistant,user的content字段就是你的prompt,assistant的则是微调数据的回复。
process_all_image.py的作用就是批量对gpt api发送请求,将发回的回复整理成这样的数据。
{"messages": [{"role": "system","content": "你是一个智能助手,请根据用户输入的组件功能语义,生成对应的组件描述。"},{"role": "user","content": "帮我分析这个组件传递的功能,例如展示数据、描述数据变化趋势等"},{"role": "assistant","content": "{\n \"组件名\": \"费用概况组件\",\n \"功能\": [\n {\n \"描述\": \"展示用户账户的财务状况\",\n \"细节\": [\n \"显示可用额度和现余额,以帮助用户了解账户中的资金情况\",\n \"分项显示可开票金额和代金券的信息\"\n ]\n },\n {\n \"描述\": \"提供与财务相关的快捷操作入口\",\n \"细节\": [\n \"提供充值、提现、汇款认领等操作入口,方便用户快速处理资金流动\",\n \"提供开票相关操作以便用户管理发票事务\"\n ]\n },\n {\n \"描述\": \"通过模块化布局增强信息的清晰度\",\n \"细节\": [\n \"采用分块设计使不同财务信息区分开来,提升信息的可读性\",\n \"各部分信息详尽且精炼,便于用户快速了解不同财务状态\"\n ]\n }\n ]\n}"}]
}
转换函数:
def generate_responses(image_folder_path, output_json_path, max_retries=2):"""处理指定文件夹中的所有图片,生成响应并保存到指定的 JSON 文件。:param image_folder_path: 图片文件夹路径:param output_json_path: 输出 JSON 文件路径:param max_retries: 最大重试次数"""# 读取文件夹中的所有图片image_files = [f for f in os.listdir(image_folder_path) if f.endswith('.png')]# 存储生成的所有响应responses = []# 遍历图片文件并生成响应for image_file in image_files:image_path = os.path.join(image_folder_path, image_file)# 尝试调用 image_to_response 并捕获异常retries = 0success = Falsewhile retries <= max_retries:try:# 生成图片响应temp = image_to_response(image_path) #这里就是用gpt生成回复的函数# 组装消息条目message_entry = {"messages": [{"role": "system","content": system_prompt # system_prompt 是系统指令},{"role": "user","content": prompt # prompt 是用户传入的大模型指令},{"role": "assistant","content": temp # 这里是返回的response}]}# 将当前条目添加到响应列表responses.append(message_entry)success = Truebreak # 如果成功,跳出重试循环except Exception as e:# 捕获异常并增加重试次数retries += 1print(f"处理 {image_file} 时出现错误: {e}. 正在进行第 {retries} 次重试...")if retries <= max_retries:time.sleep(2) # 延迟 2 秒后再试else:print(f"处理 {image_file} 失败,已达到最大重试次数。")# 如果达到最大重试次数,保存已处理的部分数据并中断with open(output_json_path, 'w', encoding='utf-8') as f:json.dump(responses, f, ensure_ascii=False, indent=4)print(f"生成的响应已保存到断点文件 '{output_json_path}',处理已中断。")exit(1)# 如果所有图片处理成功,则将响应保存到 JSON 文件if success:with open(output_json_path, 'w', encoding='utf-8') as f:json.dump(responses, f, ensure_ascii=False, indent=4)print(f"生成的响应已保存到 {output_json_path}")
微调模型
微调命令
python train.py \--model_id_or_path Qwen/Qwen2.5-VL-7B-Instruct \--dataset data/sft_data.json \--output_dir checkpoints \--num_train_epochs 10 \--split_dataset_ratio 0.05
必填的是model_id_or_path和dataset,一个是模型类型,一个是数据集路径,其他参数可自行修改。
重要参数说明:(其他参数见github readme)
--cuda_devices:CUDA设备ID,默认值为 0。用于指定要使用的CUDA设备。
--model_id_or_path:模型的路径或ID,必填项。指定你要使用的模型路径或ID。
--output_dir:输出目录,默认值为 checkpoint。模型训练过程中的输出将保存在此目录。
--dataset:数据集路径,必填项。指定训练使用的数据集路径。
--data_seed:数据划分的随机种子,默认值为 42。用于控制数据集划分时的随机性。
--max_length:最大token长度,默认值为 2048。指定模型输入的最大token长度。
--split_dataset_ratio:验证集的划分比例,默认值为 0.01。用于划分训练集与验证集的比例。
--num_proc:数据加载时的进程数,默认值为 4。指定数据加载时使用的并行进程数。
--lora_rank:LoRA的秩,默认值为 8。指定LoRA的秩。
--lora_alpha:LoRA的alpha值,默认值为 32。指定LoRA的alpha值。 训练相关配置
--learning_rate:训练时的学习率,默认值为 1e-4。指定优化器的学习率。
--per_device_train_batch_size:每个设备的训练批量大小,默认值为 1。设置每个设备的训练批量大小。
--per_device_eval_batch_size:每个设备的评估批量大小,默认值为 1。设置每个设备的评估批量大小。
--gradient_accumulation_steps:梯度累积的步数,默认值为 16。指定梯度累积的步数。
--num_train_epochs:训练的总周期数,默认值为 5。设置训练的总周期数。
调参经验:
用大模型蒸馏小模型,生成的数据量、prompt和输入数据的质量根据具体任务做决定。
例如,如果你只是希望生成的数据格式能够更加统一,达到gpt的水准,可能几十条数据即可,这种情况下训10-30个epoch,loss就降得很好了;如果你的数据量达到了千条,这样可能在一个业务场景下能够训出来一个输出格式相对适配的小模型,最好精心设计不同的prompt,按照上面的生成数据方法多生成几个json,然后合并再拿来训练,这种情况需要训50-100个epoch;如果需要适配一个业务场景甚至模型能够学到gpt的一些内化知识,需要大几千甚至上万条数据。
训练速度:在单卡3090上训练2.5b模型,100条数据,30个epoch,10分钟即可跑完;7b模型,500条数据,50个epoch,需要2个小时完成
推理测试
训好模型存好checkpoint之后,即可使用推理脚本测试效果。
推理之前,你可能需要修改推理使用的prompt,在script/config/infer_request.py中配置,之后运行inference.py即可。
python run_infer.py \ --model_path Qwen/Qwen2.5-VL-7B-Instruct \ --checkpoint_path checkpoints \ --cuda_device 0
输入参数说明
-
--model_path:模型的路径或ID,必填项。指定你要使用的模型路径或ID。
-
--checkpoint_path:训练后的checkpoints保存目录,必填项。
-
--cuda_device:使用的GPU设备,默认值为 0。指定使用的GPU设备。
效果演示
这里放了一些我做的UI VQA任务的效果。该任务旨在提取UI图片的结构化功能,并作为json数据返回,这个能力能够用在UI图片的检索里面。
任务的prompt范例:
帮我分析这个图片里组件传递的功能语义,功能语义描述了这个组件的抽象功能,例如展示数据、描述数据变化趋势等,请用json方式返回格式化的数据。例如,环形图通过环形的比例来比较不同类别的数据份额,直观地展示各部分占整体的比例关系,帮助用户快速感知不同类别的相对大小;环形的设计使中心区域可用于显示汇总数值,增强信息的整体理解;颜色的区分进一步加强对数据特征及其状态的认知,提高图表的可读性,示例如下:
{"组件名": "环形图组件","功能": [{"描述": "展示数据的整体结构和各部分的占比","细节": ["通过环形的比例来比较不同类别的数据份额","帮助用户快速感知不同类别的相对大小"]},{"描述": "在中心区域突出显示汇总或关键数值","细节": ["环形图中心可放置总量或其他关键信息","增强用户对整体数值的认知和理解"]},{"描述": "通过颜色区分不同数据类别或状态","细节": ["使用不同颜色来表示不同类别或状态","提高图表可读性并便于快速对比"]}]
}
基本思路是写清楚自己的需求,然后给出例子。这也是VQA任务常见的prompt方法,注意,一定要结构清晰有条理,然后例子要定义清楚,如果没有例子,模型的返回有极大的随机性,基本上不能作为json去读取。
例如,我们对这样一个UI图片做类似的任务:
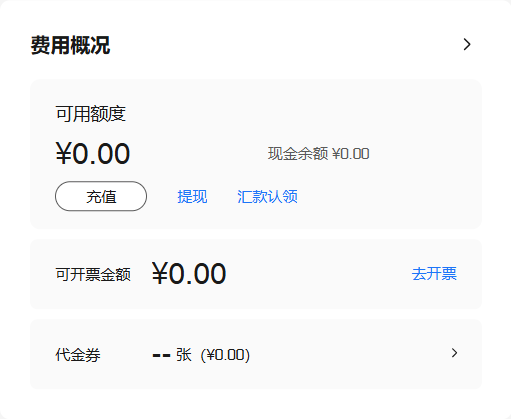
采用GPT4o模型,加上上面的prompt,回复是:
{"组件名": "费用概况组件","功能": [{....这里省略一些不重要的部分},{"描述": "提供提现和汇款认领功能","细节": ["提现按钮允许用户将可用余额转出","汇款认领链接帮助用户确认和领取已到账的款项"]},{"描述": "展示可开票金额,便于财务管理","细节": ["可开票金额部分显示用户当前可以申请发票的金额","提供去开票链接,引导用户进行开票操作"]}]
}
如果没有微调的qwen2.5-3b返回是这样:
"组件名": "费用概况组件","功能": [{....},{"描述": "提供充值和提现选项","细节": ["包含一个'充值'按钮用于增加可用额度","包含一个'提现'按钮用于减少可用额度"]},{"描述": "显示可开票金额","细节": ["显示可开票金额为0元","方便用户了解当前是否可以开具发票"]},....
}
微调后的返回:
{"组件名": "费用概况组件","功能": [{......},{"描述": "提供充值和提现选项","细节": ["包含一个'充值'链接用于增加可用额度","提供一个'提现'链接以便用户将资金转出""提供‘汇款认领’操作链接"]},{"描述": "展示可开票金额","细节": ["显示当前可开票金额为0元","提供一个'去开票'链接以开始开具发票"]}.....]
可以看到,微调后的模型返回更全面,而且很明显学习到了“链接”这件事。当然,你会发现没有微调的模型返回很多时候也差不多,这里我就不多加推测了。
结合之前做微调和prompt工程的一些经验,总结下来大概是这样:
如果需要学习一些固定的返回格式,或者控制模型输出的多样性,可以用少量数据训练,甚至几十张都可以;如果需要学习场景下的一些内化知识,例如上面的,模型应当能够认出来“链接”这种东西,可能需要1k-几k不等的数据以覆盖不同情况;当然,调节epoch和学习率啥的也很重要,不然很容易过拟合失去通用能力。

相关文章:

继续预训练 LLM ——数据筛选的思路
GPT生成数据微调qwen-2.5多模态模型实战项目 作者:柠檬养乐多 原文地址:https://zhuanlan.zhihu.com/p/30645776656 qwen2.5-vl是阿里通义实验室推出的qwen系列最新多模态大模型,在许多指标上已经超过或接近了gpt-4o。更为方便的是࿰…...
的 SELECT 查询执行机制)
深入解析 PostgreSQL 外部数据封装器(FDW)的 SELECT 查询执行机制
引言 PostgreSQL 中的外部数据封装器(Foreign Data Wrapper, FDW)是一种扩展,允许您像访问 PostgreSQL 数据库中的表一样,访问和操作存储在外部数据源中的数据。FDW 使 PostgreSQL 能够与多种数据存储系统(包括关系型…...

数据库系统概论|第六章:关系数据理论—课程笔记2
前言 前文我们介绍了规划化的基本概念,同时引入了关于规范化的相关定义与基本概念,低一级范式的关系模式,通过模式分解,可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化。本文将围绕范式展开讨论&…...

package-lock.json能否直接删除?
package-lock.json能否直接删除? package-lock.json 生成工具:由 npm 自动生成。 触发条件:当运行 npm install 时,如果不存在 package-lock.json,npm 会创建它;如果已存在,npm 会根据它精确安…...

Ubuntu磁盘空间分析:du命令及常用组合
1、du命令的作用 du(Disk Usage)是 Ubuntu 系统中用于查看目录或文件磁盘使用情况的命令,主要用于分析磁盘空间占用。 2、语法 du [选项] [目录/文件路径]常用选项 2.1、-h 以 KB、MB、GB 等人性化可读格式(Human-readable&am…...

《数据库原理》部分习题解析1
《数据库原理》部分习题解析1 1. 名词解释 (1)关系(2)属性(3)域(4)元组(5)码(6)分量(7)关系模式 ࿰…...
)
汇川Easy系列PLC数据值改变功能块(随动增益改变判断)
PLC值改变事件 值改变触发功能块 PLC值改变事件 值改变触发功能块(SCL ST完整源代码)-CSDN博客文章浏览阅读1.1k次。本文介绍了在PLC中处理值改变事件的方法,包括值改变触发功能块的实现,详细讲解了FB接口定义、ST代码,并提供了在博途平台上的实现。此外,还分享了如何利用…...

数据清洗的艺术:如何为AI模型准备高质量数据集?
数据清洗的艺术:如何为AI模型准备高质量数据集? 引言 在人工智能和机器学习领域,我们常常听到"垃圾进,垃圾出"(Garbage in, garbage out)这句格言。无论你的模型架构多么精妙,算法多么先进,如果…...

怎么查看当前vue项目,要求的node.js版本
怎么查看当前vue项目,要求的node.js版本 找到 package.json package-lock.json 搜索 node...

游戏引擎学习第278天:将实体存储移入世界区块
总结并为今天的内容做好铺垫 今天的内容是关于开发一个完整的实体系统,目标是让这个系统更加实际和有效。之前讨论了如何通过一个模拟区域来处理无限大的世界。最初,使用浮动点数而不是双精度浮点数来避免潜在的精度问题,因为一些平台&#…...
)
计算机组成与体系结构:缓存设计概述(Cache Design Overview)
目录 Block Placement(块放置) Block Identification(块识别) Block Replacement(块替换) Write Strategy(写策略) 总结: 高速缓存设计包括四个基础核心概念…...
,向进程发送发送信号)
在Linux中如何使用Kill(),向进程发送发送信号
kill()函数 #include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); 函数参数和返回值含义如下: pid:参数 pid 为正数的情况下,用于指定接收此信号的进程 pid;除此之外,参数 pid 也可设置为 0 或-1 以及小于-1 等不同值,稍后给说明。 …...

ElasticSearch重启之后shard未分配问题的解决
以下是Elasticsearch重启后分片未分配问题的完整解决方案,结合典型故障场景与最新实践: 一、快速诊断定位 检查集群状态 GET /_cluster/health?pretty # status为red/yellow时需关注unassigned_shards字段值 2.查看未分配分片详情 …...
)
基于 Spring Boot 瑞吉外卖系统开发(十四)
基于 Spring Boot 瑞吉外卖系统开发(十四) 查询订单 在管理端的首页,单击左侧菜单栏中的“订单明细”,会在右侧打开订单明细页面。 请求路径:/order/page 请求方法:GET 参数:page pageSize …...

【软件测试】第二章·软件测试的基本概念
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏:🏀软件测试与软件项目管理_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 …...

部署安装gitlab-ce-17.9.7-ce.0.el8.x86_64.rpm
目录 编辑 实验环境 所需软件 实验开始 安装部署gitlab171.配置清华源仓库(版本高的系统无需做)vim /etc/yum.repos.d/gitlab-ce.repo 2.提前下载包dnf localinstall gitlab-ce-17.9.7-ce.0.el8.x86_64.rpm --rocklinux 3.修改配…...

2025五一杭州西湖三天游
2025五一杭州西湖三天游 文章目录 2025五一杭州西湖三天游一、前言二、杭州游玩记录三、杭州三日游小结四、杭州美食街1、河坊街2、胜利河美食街3、高银街4、中山南路美食街5、武林夜市6、啦喜街美食广场7、大兜路美食街 五、豆包推荐的杭州三日游攻略三天主要行程**第一天&…...
)
实验五:以太网UDP全协议栈的实现(通过远程实验系统)
文章目录 FPGA以太网:从ARP到UDP的完整协议栈一、引言二、核心模块详解1. ARP协议处理模块1.1 `arp_cache`:ARP缓存模块1.2 `arp_tx`:ARP请求与应答发送模块1.3 `arp_rx`:ARP接收与解析模块2. MAC层处理模块2.1 `mac_layer`:MAC层顶层模块2.2 `mac_tx_mode`:MAC发送模式选…...
)
现代计算机图形学Games101入门笔记(八)
三角形三点已经知道在uv的位置了,那三角形内部的点,怎么算。 先看A 任一点 面积比求 根据三点坐标属性差值出内部点的位置。 纹理太小了,映射处理方式,取邻近的Nearest感觉一格格的,取周围4个权重Bilinear,取4*4Bicubi…...

C语言学习之文件操作
经过前面的学习,我们已经基本掌握了如何去写一个C语言的代码了。但是在实际的项目中,我们不可能不需要文件去操作。因为如果没有文件,我们写的程序是存储在电脑的内存中的。如果程序推出,内存回收数据就随之丢失了。如果我们要对数…...

《AI大模型应知应会100篇》第63篇:AutoGPT 与 BabyAGI:自主代理框架探索
第63篇:AutoGPT 与 BabyAGI:自主代理框架探索 摘要 随着大语言模型(LLM)技术的不断演进,自主代理(Autonomous Agent) 正在成为 AI 应用的新范式。它不仅能够理解用户意图,还能自主规…...

使用大模型预测急性结石性疾病技术方案
目录 1. 数据预处理与特征工程伪代码 - 数据清洗与特征处理数据预处理流程图2. 大模型构建与训练伪代码 - 模型训练模型训练流程图3. 术前预测系统伪代码 - 术前风险评估术前预测流程图4. 术中实时调整系统伪代码 - 术中风险预警术中调整流程图5. 术后护理系统伪代码 - 并发症预…...

基于运动补偿的前景检测算法
这段代码实现了基于运动补偿的前景检测算法。 主要功能包括: 运动补偿模块:使用基于网格的 KLT 特征跟踪算法计算两帧之间的运动,然后通过单应性变换实现帧间运动补偿。前景检测模块:结合两帧运动补偿结果,通过帧间差…...

鸿蒙OSUniApp开发富文本编辑器组件#三方框架 #Uniapp
使用UniApp开发富文本编辑器组件 富文本编辑在各类应用中非常常见,无论是内容创作平台还是社交软件,都需要提供良好的富文本编辑体验。本文记录了我使用UniApp开发一个跨平台富文本编辑器组件的过程,希望对有类似需求的开发者有所启发。 背景…...

W5500使用SocketTool工具测试
W5500使用SocketTool工具测试 1、按“WINR” 2、输入“IPCONFIG”,得到计算机的IP地址,子网掩码和网关 3、设置W5500设备网络参数如下: 本地网关:192.168.1.1 本地子网掩码: 255.255.255.0 本地物理地址:0C 2…...
与关系抽取)
《Python星球日记》 第71天:命名实体识别(NER)与关系抽取
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、命名实体识别(NER)基础1. 什么是命名实体识别&#…...

双向长短期记忆网络-BiLSTM
5月14日复盘 二、BiLSTM 1. 概述 双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种扩展自长短期记忆网络(LSTM)的结构,旨在解决传统 LSTM 模型只能考虑到过去信息的问题。BiLST…...
【针对GPT分区】)
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...
)
如何在终端/命令行中把PDF的每一页转换成图片(PNG)
今天被对象安排了一个任务: 之前自己其实也有这个需要,但是吧,我懒:量少拖拽,量大就放弃。但这次躲不过去了,所以研究了一下有什么工具可以做到这个需求。 本文记录我这次发现的使用 XpdfReader 的方法。…...

【0415】Postgres内核 释放指定 memory context 中所有内存 ④
1. frees all memory (memory context) Postgres内核中由函数 AllocSetReset() 完成该功能。即 “释放给定set中分配的所有内存。” 它应当将所有已分配的chunks标记为已释放,但不一定需要归还set所拥有的全部资源。我们的实际实现是,除了“保留”块(“keeper” block)(…...

2025年Flutter初级工程师技能要求
在2025年,随着移动应用市场的持续增长和跨平台开发需求的不断增加,Flutter已经成为许多公司构建高性能、跨平台应用的首选框架。对于初入职场的Flutter初级工程师来说,掌握以下技能要求是必不可少的。这些技能不仅能够帮助你在工作中快速上手…...

AWS技术助力企业满足GDPR合规要求
GDPR(通用数据保护条例)作为欧盟严格的数据保护法规,给许多企业带来了合规挑战。本文将探讨如何利用AWS(亚马逊云服务)的相关技术来满足GDPR的核心要求,帮助企业实现数据保护合规。 一、GDPR核心要求概览 GDPR的主要目标是保护欧盟公民的个人数据和隐私权。其核心要求包括: 数…...

MVCC:数据库并发控制的利器
在并发环境下,数据库需要处理多个事务同时访问和修改数据的情况。为了保证数据的一致性和隔离性,数据库需要采用一些并发控制机制。MVCC (Multi-Version Concurrency Control,多版本并发控制) 就是一种常用的并发控制技术,它通过维…...
:SKRL Wrapper)
第二章、Isaaclab强化学习包装器(3):SKRL Wrapper
0 前言 官方文档:https://isaac-sim.github.io/IsaacLab/main/source/api/lab_rl/isaaclab_rl.html#module-isaaclab_rl.skrl https://skrl.readthedocs.io/en/latest/intro/getting_started.html 在本节中,您将学习如何使用 skrl 库的各种组件来创建强…...

AI数字人实现原理
随着人工智能与数字技术的快速发展,AI数字人(Digital Human)作为新一代人机交互媒介,正在多个行业中快速落地。无论是在虚拟主播、在线客服、教育培训,还是在数字代言、元宇宙中,AI数字人都扮演着越来越重要…...

RBTree的模拟实现
1:红黑树的概念 红⿊树是⼀棵⼆叉搜索树,他的每个结点增加⼀个存储位来表⽰结点的颜⾊,可以是红⾊或者⿊⾊。通过对任何⼀条从根到叶⼦的路径上各个结点的颜⾊进⾏约束,红⿊树确保没有⼀条路径会⽐其他路径⻓出2倍,因…...

ssh connect to remote gitlab without authority
ssh connect to remote gitlab without authority 1 this command can produce a ssh key for authority ssh-keygen -t ed25519 -C "your_emailexample.com"2 this command can get the comment about the key cat ~/.ssh/id_ed25519.pubcopy all content !!!...

gitlab提交测试分支的命令和流程
写在前面 先npm run lint:eslint 先走一遍代码校验然后再提交先把检验跑了再add commit push那些注意一下这个问题:git commit规范不对导致报错subject may not be empty[subject-empty]type may not be empty[type-empty]. 配置lint检查后, 使用commitlint之后报…...

序列化和反序列化hadoop实现
### Hadoop 中序列化与反序列化的实现机制 Hadoop 提供了自己的轻量级序列化接口 Writable,用于高效地在网络中传输数据或将其存储到磁盘。以下是关于其核心概念和实现方式的详细介绍: --- #### 1. **Hadoop 序列化的核心原理** Hadoop 的序列化是一…...

[操作系统] 策略模式进行日志模块设计
文章目录 [toc]一、什么是设计模式?二、日志系统的基本构成三、策略模式在日志系统中的落地实现✦ 1. 策略基类 LogStrategy✦ 2. 具体策略类▸ 控制台输出:ConsoleLogStrategy▸ 文件输出:FileLogStrategy 四、日志等级枚举与转换函数五、日…...

LeetCode 每日一题 3341. 到达最后一个房间的最少时间 I + II
3341. 到达最后一个房间的最少时间 I II 有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一个大小为 n x m 的二维数组 moveTime ,其中 moveTime[i][j] 表示在这个时刻 以后 你才可以 开始 往这个房间 移动 。你在时刻 t 0 时从…...

《Python星球日记》 第68天:BERT 与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、BERT模型基础1. 什么是BERT?2. BERT 的结构3.预训练和微调对比二、BERT 的预训练任务1. 掩码语言模型 (MLM)2. 下一句预测 (NSP)三、微调 …...

Angular 知识框架
一、Angular 基础 1. Angular 简介 Angular 是什么? 基于 TypeScript 的前端框架(Google 维护)。 适用于构建单页应用(SPA)。 核心特性 组件化架构 双向数据绑定 依赖注入(DI) 模块化设计…...

python三方库sqlalchemy
SQLAlchemy 是 Python 中最强大、最受欢迎的 ORM(对象关系映射)库,它允许你使用 Python 对象来操作数据库,而不需要直接编写 SQL 语句。同时,它也提供了对底层 SQL 的完全控制能力,适用于从简单脚本到大型企…...

【SSL部署与优化】如何为网站启用HTTPS:从Let‘s Encrypt免费证书到Nginx配置
网站启用HTTPS 的完整实战指南,涵盖从 Let’s Encrypt 免费证书申请到 Nginx 配置的详细步骤,包括重定向、HSTS 设置及常见问题排查: 一、准备工作 1. 确保域名解析正确 • 在 DNS 管理后台,将域名(如 example.com&…...
:gRPC 与 CRI gRPC实现)
Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

电商平台自动化
为什么要进行独立站自动化 纯人工测试人力成本高,相对效率低 回归测试在通用模块重复进行人工测试,测试效率低 前期调研备选自动化框架(工具): Katalon Applitools Testim 阿里云EMAS Playwright Appium Cypress 相关…...

【kafka】kafka概念,使用技巧go示例
1. Kafka基础概念 1.1 什么是Kafka? Kafka是一个分布式流处理平台,用于构建实时数据管道和流式应用。核心特点: 高吞吐量:每秒可处理百万级消息持久化存储:消息按Topic分区存储在磁盘分布式架构:支持水平…...

计算机系统结构——Cache性能分析
一、实验目的 加深对Cache的基本概念、基本组织结构以及基本工作原理的理解。掌握Cache容量、相联度、块大小对Cache性能的影响。掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处。理解LRU与随机法的基本思想以及它们对Cache性能的影响。 二、实验平台 实…...
)
Spring Web MVC————入门(2)
1,请求 我们接下来继续讲请求的部分,上期将过很多了,我们来给请求收个尾。 还记得Cookie和Seesion吗,我们在HTTP讲请求和响应报文的时候讲过,现在再给大家讲一遍,我们HTTP是无状态的协议,这次的…...