《Python星球日记》 第71天:命名实体识别(NER)与关系抽取
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、命名实体识别(NER)基础
- 1. 什么是命名实体识别?
- 2. 常见的实体类型
- 3. NER的技术实现
- (1) 基于规则的方法
- (2) 统计机器学习方法
- (3) 深度学习方法
- (4) 预训练语言模型
- 4. NER的标注方式
- 二、深入理解命名实体识别
- 1. NER的应用场景
- 2. NER评估指标
- 3. 领域适应与迁移学习
- 三、关系抽取基础
- 1. 什么是关系抽取?
- 2. 关系类型与表示
- 3. 关系抽取的技术方法
- (1) 基于规则的方法
- (2) 基于监督学习的方法
- (3) 基于远程监督的方法
- (4) 基于预训练语言模型的方法
- 四、NER与关系抽取实战
- 1. 使用spaCy进行NER实践
- 2. 使用Hugging Face进行BERT-NER微调
- 3. 构建端到端信息抽取系统
- 五、命名实体识别与关系抽取的实际应用
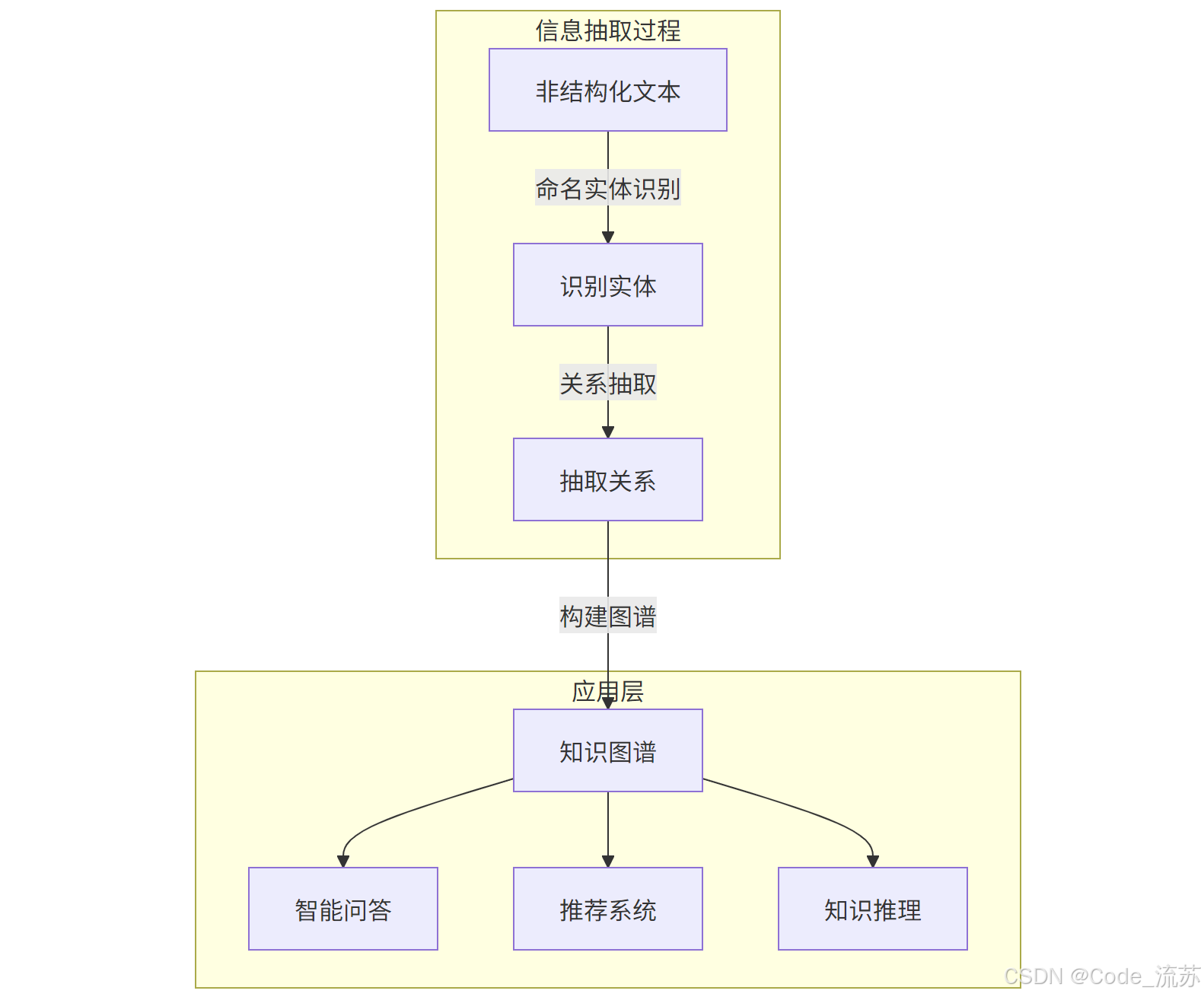
- 1. 知识图谱构建
- 2. 企业智能应用
- 3. 学术研究与医疗应用
- 六、总结与展望
- 未来发展趋势
- 练习与思考
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第70天:Seq2Seq 与Transformer Decoder
欢迎回到Python星球🪐日记!今天是我们旅程的第71天。
在自然语言处理(NLP)领域,理解文本中的实体及其关系是构建智能系统的基础。今天,我们将探索命名实体识别和关系抽取这两项核心技术,它们共同构成了信息抽取的重要环节,为知识图谱、智能问答和文本分析等应用提供关键支持。
一、命名实体识别(NER)基础
1. 什么是命名实体识别?
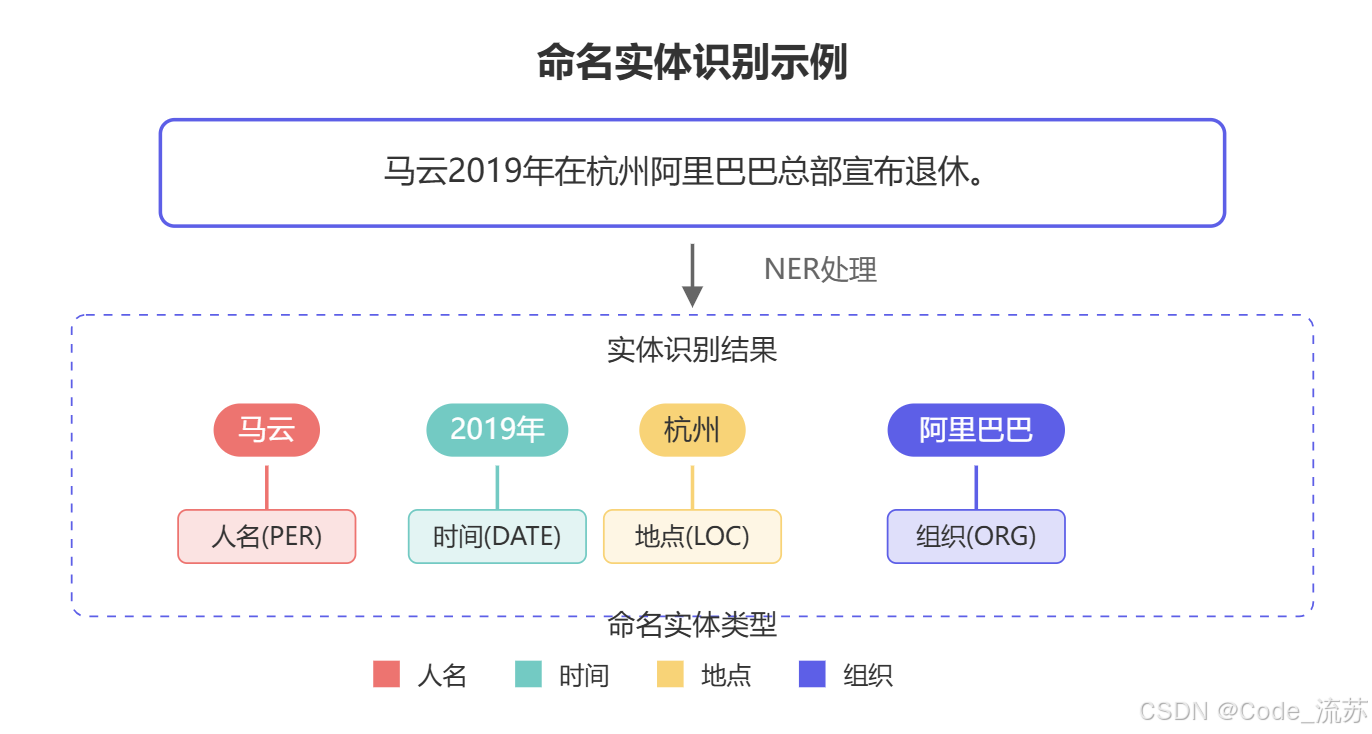
命名实体识别(Named Entity Recognition,简称NER)是指从非结构化文本中识别并提取特定类型的实体(如人名、地名、组织名等)的过程。它是信息抽取和知识图谱构建的第一步,为文本理解奠定基础。
举个例子,在句子"马克·扎克伯格于2004年在哈佛大学创立了Facebook"中,NER系统会识别出:
- “马克·扎克伯格” → 人名(PERSON)
- “2004年” → 时间(DATE)
- “哈佛大学” → 组织名(ORGANIZATION)
- “Facebook” → 组织名(ORGANIZATION)
2. 常见的实体类型
命名实体通常分为以下几种类型:
| 实体类型 | 描述 | 示例 |
|---|---|---|
| PERSON | 人名 | 马云、李彦宏、比尔·盖茨 |
| LOCATION | 地理位置 | 北京、黄河、埃菲尔铁塔 |
| ORGANIZATION | 组织机构名 | 腾讯、清华大学、联合国 |
| DATE | 日期时间 | 2023年、5月1日、下午三点 |
| MONEY | 货币金额 | 100元、$50、5000万美元 |
| PERCENT | 百分比 | 50%、三分之一 |
| EVENT | 事件 | 世界杯、奥运会 |
| PRODUCT | 产品 | iPhone、Tesla Model 3 |
注意:不同的NER系统可能会定义不同的实体类型集合,根据具体应用场景进行调整。
3. NER的技术实现
NER技术经历了从规则到深度学习的演进历程:
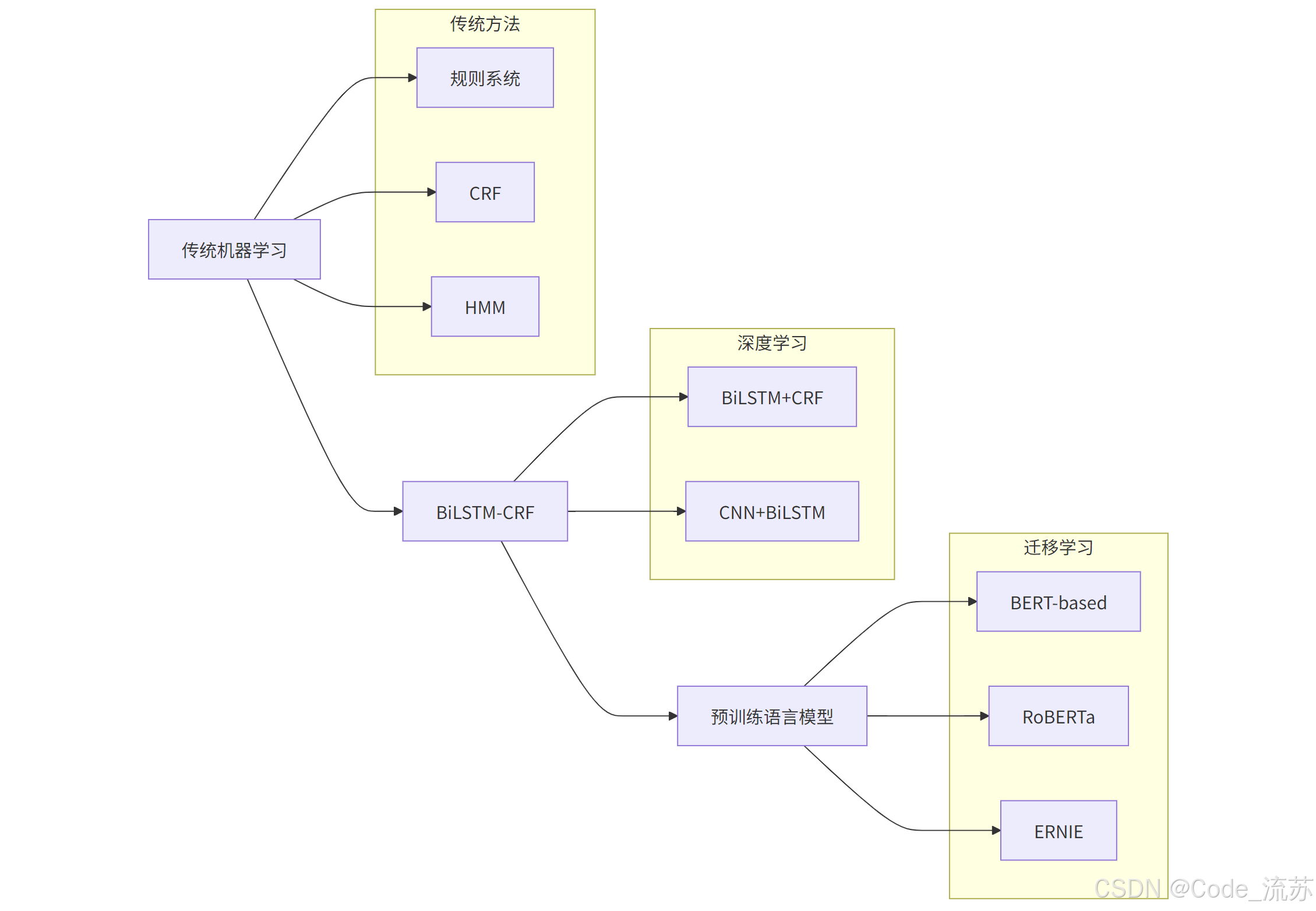
(1) 基于规则的方法
最早的NER系统主要依靠人工编写的规则和匹配模式。虽然在特定领域可以达到不错的效果,但缺乏泛化能力,维护成本高。
(2) 统计机器学习方法
随后出现了基于条件随机场(CRF)、隐马尔可夫模型(HMM)等统计模型的方法,将NER视为序列标注问题,通过手工特征工程提升性能。
(3) 深度学习方法
BiLSTM-CRF模型结合了双向LSTM捕获上下文信息的能力和CRF建模标签依赖关系的优势,成为NER任务的经典架构。
# BiLSTM-CRF模型的简化PyTorch实现
class BiLSTM_CRF(nn.Module):def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):super(BiLSTM_CRF, self).__init__()self.embedding_dim = embedding_dimself.hidden_dim = hidden_dimself.vocab_size = vocab_sizeself.tag_to_ix = tag_to_ixself.tagset_size = len(tag_to_ix)# 词嵌入层self.word_embeds = nn.Embedding(vocab_size, embedding_dim)# 双向LSTMself.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,num_layers=1, bidirectional=True)# 映射到标签空间self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)# CRF层的转移矩阵self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
(4) 预训练语言模型
BERT等预训练语言模型的出现极大提升了NER性能,它们能够捕获丰富的上下文语义信息,为下游任务提供强大的特征表示。
# 使用BERT进行NER的简化示例
from transformers import BertForTokenClassification, BertTokenizertokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForTokenClassification.from_pretrained('bert-base-chinese', num_labels=len(tag_list))# 输入处理
tokens = tokenizer.tokenize(text)
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)# 预测
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=2)
4. NER的标注方式
NER任务常用的标注方式有:
- BIO标注:B-开始,I-内部,O-外部
- BIOES标注:B-开始,I-内部,O-外部,E-结束,S-单个实体
例如,对于句子"张三在北京大学学习":
张/B-PER 三/I-PER 在/O 北/B-ORG 京/I-ORG 大/I-ORG 学/I-ORG 学/O 习/O


二、深入理解命名实体识别
1. NER的应用场景
命名实体识别作为信息抽取的基础环节,在众多应用场景中扮演着关键角色:
- 搜索引擎优化:识别查询中的实体,提供更精准的搜索结果
- 智能问答系统:理解问题中的关键实体,检索相关信息
- 知识图谱构建:自动从文本中提取实体,作为知识图谱的节点
- 舆情分析:识别文本中提及的人物、组织、地点等,进行情感分析
- 医疗信息处理:从医疗文献中提取疾病、药品、症状等专业术语
- 法律文档处理:识别法律文书中的当事人、案由、日期等关键信息
2. NER评估指标
评估NER系统性能通常使用以下指标:
- 精确率(Precision):正确识别的实体数量 / 系统识别出的所有实体数量
- 召回率(Recall):正确识别的实体数量 / 文本中实际存在的所有实体数量
- F1值:精确率和召回率的调和平均,计算公式为 2 * (Precision * Recall) / (Precision + Recall)
对于NER任务,评估时需要完全匹配实体的边界和类型才算正确识别。
3. 领域适应与迁移学习
通用NER系统在特定领域(如医疗、法律、金融等)可能表现不佳,需要进行领域适应:
- 数据增强:使用领域内数据扩充训练集
- 迁移学习:利用预训练模型,在领域数据上进行微调
- 半监督学习:结合少量标注数据和大量未标注数据
三、关系抽取基础
1. 什么是关系抽取?
关系抽取(Relation Extraction)是指从文本中识别并提取实体之间语义关系的过程。它是NER的延伸,共同构成结构化知识的关键环节。
2. 关系类型与表示
关系抽取的第一步是定义关系类型集合。常见的关系类型包括:
| 关系类型 | 描述 | 示例 |
|---|---|---|
| 从属关系 | 表示归属、隶属等 | (腾讯, 创始人, 马化腾) |
| 空间关系 | 表示地理位置相关性 | (故宫, 位于, 北京) |
| 时间关系 | 表示时间相关性 | (奥运会, 举办于, 2022年) |
| 社会关系 | 表示人际关系 | (马云, 创立, 阿里巴巴) |
| 因果关系 | 表示原因和结果 | (吸烟, 导致, 肺癌) |
关系通常表示为三元组形式:(头实体, 关系, 尾实体),如 (北京, 是, 中国首都)。
3. 关系抽取的技术方法
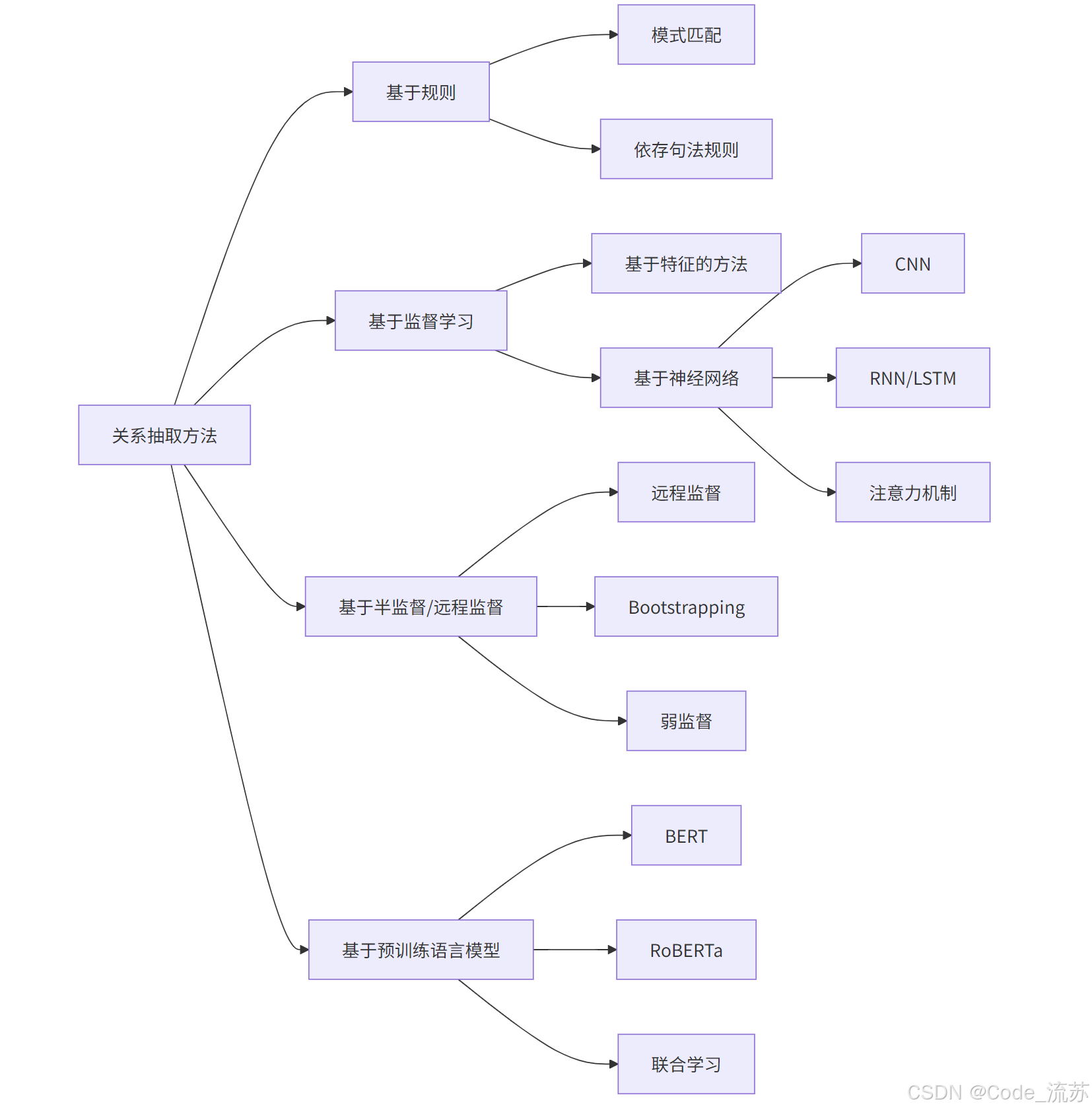
(1) 基于规则的方法
早期关系抽取主要基于人工定义的规则和模式匹配,通过词法和句法分析来提取关系。
# 基于依存句法分析的简单关系抽取示例
import spacynlp = spacy.load("zh_core_web_sm")
text = "马云创立了阿里巴巴公司。"
doc = nlp(text)# 基于依存关系的简单规则
for token in doc:if token.dep_ == "ROOT" and token.pos_ == "VERB": # 谓语动词subject = Noneobject = Nonefor child in token.children:if child.dep_ == "nsubj": # 主语subject = child.textif child.dep_ == "dobj": # 宾语object = child.textif subject and object:print(f"关系三元组: ({subject}, {token.text}, {object})")
(2) 基于监督学习的方法
监督学习方法将关系抽取视为分类任务,给定一对实体和包含它们的句子,预测它们之间的关系类型。
早期使用手工特征(词法、句法、位置信息等),后来发展为基于神经网络的方法:
# 使用BERT进行关系分类的示例
from transformers import BertForSequenceClassification, BertTokenizer
import torchtokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=len(relation_types))# 输入处理:为实体对添加特殊标记
def process_text(text, head_entity, tail_entity):# 用特殊标记标注实体位置marked_text = text.replace(head_entity, f"[E1]{head_entity}[/E1]")marked_text = marked_text.replace(tail_entity, f"[E2]{tail_entity}[/E2]")return marked_text# 训练和预测
inputs = tokenizer(marked_text, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predicted_relation = torch.argmax(outputs.logits, dim=1).item()
(3) 基于远程监督的方法
**远程监督(Distant Supervision)**是解决关系抽取标注数据不足问题的重要方法。其核心思想是:如果两个实体在知识库中存在某种关系,则包含这两个实体的句子很可能表达了这种关系。
# 远程监督示例:利用知识库自动标注训练数据
def generate_training_data(corpus, knowledge_base):training_data = []for sentence in corpus:entities = extract_entities(sentence) # 假设有NER系统# 找出句子中所有可能的实体对for head_entity in entities:for tail_entity in entities:if head_entity != tail_entity:# 在知识库中查找关系relation = knowledge_base.query_relation(head_entity, tail_entity)if relation:# 生成训练样本training_data.append({'sentence': sentence,'head': head_entity,'tail': tail_entity,'relation': relation})return training_data
(4) 基于预训练语言模型的方法
BERT等预训练模型极大提升了关系抽取性能,通过微调和联合学习可以进一步优化效果。
# 使用BERT进行端到端关系抽取(实体识别 + 关系分类)
class JointNERAndRE(nn.Module):def __init__(self, num_entity_types, num_relation_types):super(JointNERAndRE, self).__init__()self.bert = BertModel.from_pretrained('bert-base-chinese')# NER分类器self.ner_classifier = nn.Linear(self.bert.config.hidden_size, num_entity_types)# 关系分类器self.re_classifier = nn.Linear(self.bert.config.hidden_size * 2, num_relation_types)def forward(self, input_ids, attention_mask, token_type_ids):# BERT编码outputs = self.bert(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)sequence_output = outputs.last_hidden_state # 用于NERpooled_output = outputs.pooler_output # 用于RE# NER预测ner_logits = self.ner_classifier(sequence_output)# 关系预测(简化版)re_logits = self.re_classifier(pooled_output)return ner_logits, re_logits
四、NER与关系抽取实战
1. 使用spaCy进行NER实践
spaCy是一个强大的NLP库,提供了高效的命名实体识别功能:
import spacy
from spacy import displacy# 加载中文模型
nlp = spacy.load("zh_core_web_sm")# 处理文本
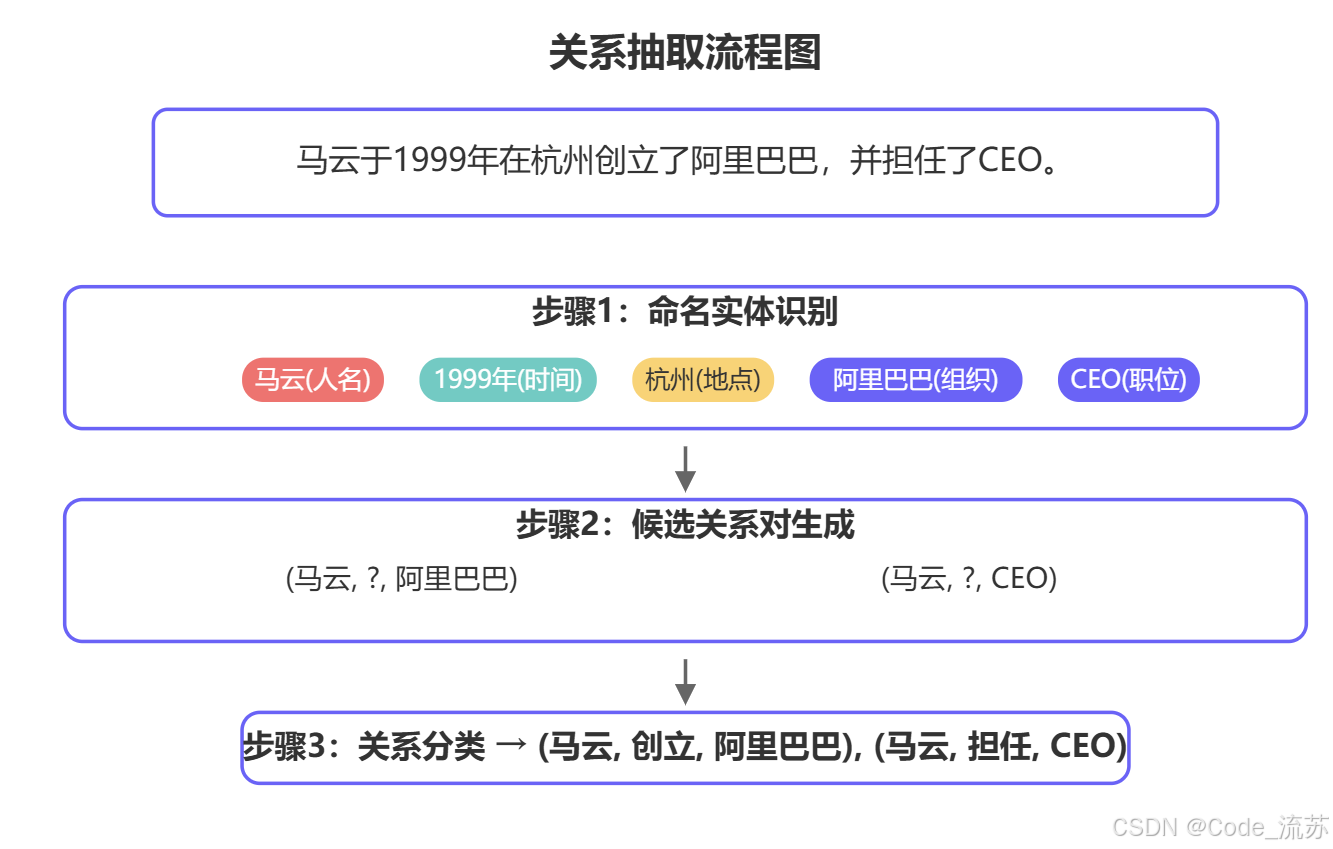
text = "马云于1999年在杭州创立了阿里巴巴,并担任CEO直到2019年。"
doc = nlp(text)# 提取命名实体
for ent in doc.ents:print(f"实体: {ent.text}, 类型: {ent.label_}")# 可视化
displacy.render(doc, style="ent", jupyter=True)# 定义自定义实体类型
custom_labels = {"人物": "PERSON","组织": "ORG","地点": "LOC","时间": "DATE"
}# 训练自定义NER模型
from spacy.training.example import Example# 准备训练数据
train_data = [("马云于1999年在杭州创立了阿里巴巴。", {"entities": [(0, 2, "PERSON"), (3, 8, "DATE"), (9, 11, "LOC"), (14, 18, "ORG")]}),# 更多训练数据...
]# 创建空模型
nlp = spacy.blank("zh")
ner = nlp.add_pipe("ner")# 添加实体标签
for _, annotations in train_data:for ent in annotations.get("entities"):ner.add_label(ent[2])# 训练模型
optimizer = nlp.begin_training()
for i in range(100):losses = {}examples = []for text, annots in train_data:examples.append(Example.from_dict(nlp.make_doc(text), annots))nlp.update(examples, drop=0.5, losses=losses)print(f"Loss: {losses}")
2. 使用Hugging Face进行BERT-NER微调
Hugging Face Transformers库提供了丰富的预训练模型和工具,便于进行NER模型的微调:
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import Trainer, TrainingArguments
from datasets import load_dataset# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForTokenClassification.from_pretrained("bert-base-chinese", num_labels=len(id2label), id2label=id2label, label2id=label2id
)# 数据处理函数
def tokenize_and_align_labels(examples):tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)labels = []for i, label in enumerate(examples["tags"]):word_ids = tokenized_inputs.word_ids(batch_index=i)label_ids = []for word_id in word_ids:if word_id is None:label_ids.append(-100)else:label_ids.append(label[word_id])labels.append(label_ids)tokenized_inputs["labels"] = labelsreturn tokenized_inputs# 加载数据集
dataset = load_dataset("conll2003") # 示例数据集,实际应使用中文NER数据集
tokenized_dataset = dataset.map(tokenize_and_align_labels, batched=True)# 训练参数
training_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=3,weight_decay=0.01,
)# 训练
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["validation"],tokenizer=tokenizer,
)trainer.train()# 保存模型
model.save_pretrained("./ner-model")
tokenizer.save_pretrained("./ner-model")
3. 构建端到端信息抽取系统
结合NER和关系抽取,构建完整的信息抽取系统:
import spacy
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch# 1. 命名实体识别
nlp = spacy.load("zh_core_web_sm") # 或自定义训练的模型# 2. 关系分类
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
relation_model = AutoModelForSequenceClassification.from_pretrained("./relation-model")# 关系标签
relation_labels = {0: "无关系", 1: "创始人", 2: "位于", 3: "工作于", 4: "生产于"}# 端到端信息抽取
def extract_information(text):# 识别实体doc = nlp(text)entities = [(ent.text, ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]# 提取所有可能的实体对entity_pairs = []relations = []for i, (head, head_type, h_start, h_end) in enumerate(entities):for j, (tail, tail_type, t_start, t_end) in enumerate(entities):if i != j: # 不考虑同一实体# 为关系分类准备输入marked_text = text[:h_start] + "[E1]" + head + "[/E1]" + text[h_end:t_start] + "[E2]" + tail + "[/E2]" + text[t_end:]inputs = tokenizer(marked_text, return_tensors="pt", padding=True, truncation=True)# 预测关系with torch.no_grad():outputs = relation_model(**inputs)predicted_class = torch.argmax(outputs.logits, dim=1).item()relation = relation_labels[predicted_class]if relation != "无关系":relations.append((head, relation, tail))return entities, relations# 演示
text = "马云于1999年在杭州创立了阿里巴巴,后来阿里巴巴总部设在杭州。"
entities, relations = extract_information(text)print("实体:")
for entity in entities:print(f"- {entity[0]} ({entity[1]})")print("\n关系:")
for relation in relations:print(f"- ({relation[0]}, {relation[1]}, {relation[2]})")
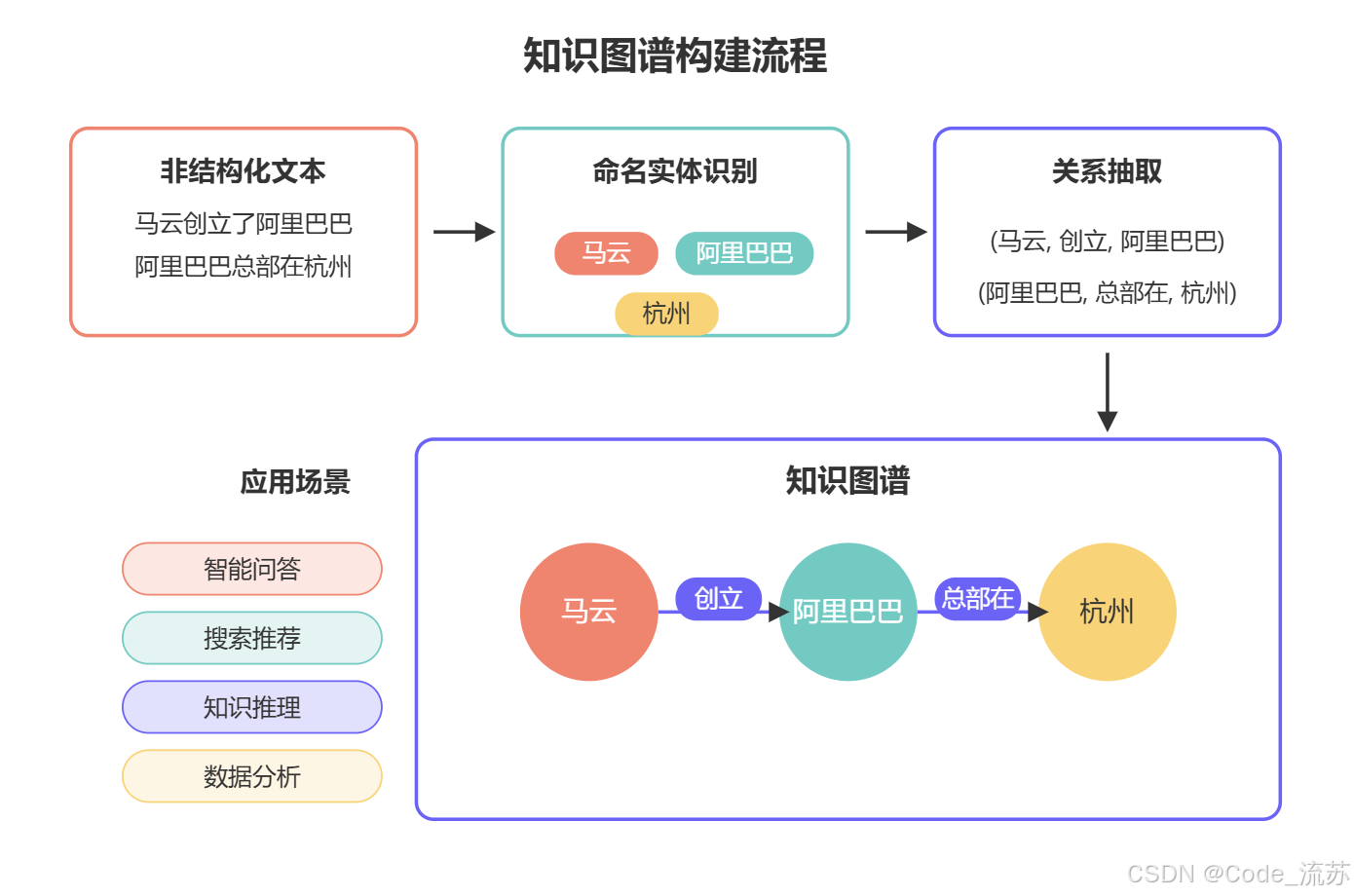
五、命名实体识别与关系抽取的实际应用
1. 知识图谱构建
命名实体识别和关系抽取是构建知识图谱的两大基石。一个完整的知识图谱构建流程包括:
- 使用NER从大规模文本中识别实体,作为图谱中的节点
- 通过关系抽取确定实体间的连接,作为图谱中的边
- 实体链接与消歧,将识别出的实体链接到知识库中的规范实体
- 图谱存储与查询,通常使用图数据库(如Neo4j)进行存储和检索
# 简单的知识图谱构建示例
from py2neo import Graph, Node, Relationship# 连接图数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))# 清空数据库
graph.delete_all()# 处理文本
text = "马云于1999年在杭州创立了阿里巴巴,后来阿里巴巴总部设在杭州。马化腾创办了腾讯,总部位于深圳。"
entities, relations = extract_information(text) # 前面定义的函数# 创建实体节点
nodes = {}
for entity, entity_type, _, _ in entities:if entity not in nodes:node = Node(entity_type, name=entity)nodes[entity] = nodegraph.create(node)# 创建关系
for head, relation_type, tail in relations:if head in nodes and tail in nodes:relationship = Relationship(nodes[head], relation_type, nodes[tail])graph.create(relationship)print("知识图谱构建完成!")
2. 企业智能应用
在企业应用中,NER和关系抽取可以用于:
- 智能客服:自动识别用户问题中的关键实体和意图,提供精准回复
- 合同审核:提取合同中的关键主体、日期、条款等信息,辅助法务审核
- 商业智能:从行业报告中提取公司、产品、指标等信息,进行市场分析
- 风险监控:从新闻、社交媒体中提取实体关系,预警潜在风险
# 智能客服场景下的实体和意图提取示例
def analyze_customer_query(query):# 1. NER识别实体doc = nlp(query)entities = {ent.label_: ent.text for ent in doc.ents}# 2. 意图分类(简化示例)intents = {"查询订单": ["订单", "查询", "物流", "发货"],"退换货": ["退货", "换货", "退款", "质量"],"产品咨询": ["功能", "价格", "规格", "如何使用"]}query_intent = Nonemax_score = 0for intent, keywords in intents.items():score = sum(1 for word in keywords if word in query)if score > max_score:max_score = scorequery_intent = intent# 3. 构建结构化查询result = {"intent": query_intent,"entities": entities}return result# 测试
query = "我昨天买的iPhone 13什么时候能发货?订单号是2023051001"
analysis = analyze_customer_query(query)
print(f"意图: {analysis['intent']}")
print(f"实体: {analysis['entities']}")
3. 学术研究与医疗应用
在学术研究和医疗领域,NER和关系抽取有着特殊的应用价值:
- 文献挖掘:从大量学术论文中提取研究主题、方法、结果等关键信息
- 医疗记录分析:从病历中提取症状、疾病、药物及其关系,辅助临床决策
- 药物相互作用分析:识别论文中描述的药物间相互作用,指导用药安全
# 医疗领域的实体和关系抽取示例
def analyze_medical_text(text):# 加载医疗领域专用模型(这里为示例,实际需要训练)medical_nlp = spacy.load("./medical_ner_model")# 识别医疗实体doc = medical_nlp(text)entities = []for ent in doc.ents:entities.append({"text": ent.text,"type": ent.label_,"start": ent.start_char,"end": ent.end_char})# 识别医疗关系(简化示例)relations = []disease_entities = [e for e in entities if e["type"] == "DISEASE"]symptom_entities = [e for e in entities if e["type"] == "SYMPTOM"]drug_entities = [e for e in entities if e["type"] == "DRUG"]# 疾病-症状关系for disease in disease_entities:for symptom in symptom_entities:# 简单的基于距离的关系推断(实际系统需更复杂算法)if abs(disease["start"] - symptom["end"]) < 50 or abs(symptom["start"] - disease["end"]) < 50:relations.append({"head": disease["text"],"type": "has_symptom","tail": symptom["text"]})# 疾病-药物治疗关系for disease in disease_entities:for drug in drug_entities:if abs(disease["start"] - drug["end"]) < 50 or abs(drug["start"] - disease["end"]) < 50:relations.append({"head": drug["text"],"type": "treats","tail": disease["text"]})return {"entities": entities,"relations": relations}# 测试
medical_text = "患者表现为持续性头痛和发热,考虑为流感,建议服用布洛芬缓解症状,同时使用奥司他韦抗病毒治疗。"
result = analyze_medical_text(medical_text)
print("医疗实体:", [e["text"] + "(" + e["type"] + ")" for e in result["entities"]])
print("医疗关系:", [(r["head"], r["type"], r["tail"]) for r in result["relations"]])
六、总结与展望
命名实体识别(NER)和关系抽取是信息抽取中的关键技术,为结构化知识的自动构建铺平了道路。通过本文的学习,我们掌握了:
- NER的基本原理与主流技术路线,从规则到深度学习
- 关系抽取的核心方法,包括监督学习和远程监督等方式
- 实战应用,使用spaCy和Hugging Face等工具进行模型训练和应用开发
- 行业应用案例,如何将这些技术应用到知识图谱、企业智能和医疗研究中
未来发展趋势
- 多模态信息抽取:结合图像、视频等多模态数据进行实体和关系识别
- 低资源场景优化:针对专业领域或小语种等数据稀缺场景的优化方法
- 知识图谱与大语言模型融合:将结构化知识与生成式模型结合,提升推理能力
- 可解释性研究:提高NER和关系抽取模型决策的可解释性和可信度
命名实体识别和关系抽取技术正逐步走向成熟,未来将与大语言模型、多模态技术深度融合,在各行各业发挥更加重要的作用。作为NLP的基础技术,它们值得每位AI从业者深入学习和掌握。
练习与思考
- 尝试使用spaCy训练一个针对特定领域(如医疗、法律或金融)的NER模型
- 探索远程监督方法构建关系抽取数据集的实际效果
- 结合BERT等预训练模型,实现端到端的信息抽取系统
- 思考:如何评估和优化NER和关系抽取模型在实际应用中的表现?
通过系统学习和实践,你已经具备了实现基础信息抽取系统的能力。下一步,可以尝试将这些技术与大语言模型结合,探索更加智能的文本理解与生成应用。
Happy coding!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:
与关系抽取)
《Python星球日记》 第71天:命名实体识别(NER)与关系抽取
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、命名实体识别(NER)基础1. 什么是命名实体识别&#…...

双向长短期记忆网络-BiLSTM
5月14日复盘 二、BiLSTM 1. 概述 双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种扩展自长短期记忆网络(LSTM)的结构,旨在解决传统 LSTM 模型只能考虑到过去信息的问题。BiLST…...
【针对GPT分区】)
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...
)
如何在终端/命令行中把PDF的每一页转换成图片(PNG)
今天被对象安排了一个任务: 之前自己其实也有这个需要,但是吧,我懒:量少拖拽,量大就放弃。但这次躲不过去了,所以研究了一下有什么工具可以做到这个需求。 本文记录我这次发现的使用 XpdfReader 的方法。…...

【0415】Postgres内核 释放指定 memory context 中所有内存 ④
1. frees all memory (memory context) Postgres内核中由函数 AllocSetReset() 完成该功能。即 “释放给定set中分配的所有内存。” 它应当将所有已分配的chunks标记为已释放,但不一定需要归还set所拥有的全部资源。我们的实际实现是,除了“保留”块(“keeper” block)(…...

2025年Flutter初级工程师技能要求
在2025年,随着移动应用市场的持续增长和跨平台开发需求的不断增加,Flutter已经成为许多公司构建高性能、跨平台应用的首选框架。对于初入职场的Flutter初级工程师来说,掌握以下技能要求是必不可少的。这些技能不仅能够帮助你在工作中快速上手…...

AWS技术助力企业满足GDPR合规要求
GDPR(通用数据保护条例)作为欧盟严格的数据保护法规,给许多企业带来了合规挑战。本文将探讨如何利用AWS(亚马逊云服务)的相关技术来满足GDPR的核心要求,帮助企业实现数据保护合规。 一、GDPR核心要求概览 GDPR的主要目标是保护欧盟公民的个人数据和隐私权。其核心要求包括: 数…...

MVCC:数据库并发控制的利器
在并发环境下,数据库需要处理多个事务同时访问和修改数据的情况。为了保证数据的一致性和隔离性,数据库需要采用一些并发控制机制。MVCC (Multi-Version Concurrency Control,多版本并发控制) 就是一种常用的并发控制技术,它通过维…...
:SKRL Wrapper)
第二章、Isaaclab强化学习包装器(3):SKRL Wrapper
0 前言 官方文档:https://isaac-sim.github.io/IsaacLab/main/source/api/lab_rl/isaaclab_rl.html#module-isaaclab_rl.skrl https://skrl.readthedocs.io/en/latest/intro/getting_started.html 在本节中,您将学习如何使用 skrl 库的各种组件来创建强…...

AI数字人实现原理
随着人工智能与数字技术的快速发展,AI数字人(Digital Human)作为新一代人机交互媒介,正在多个行业中快速落地。无论是在虚拟主播、在线客服、教育培训,还是在数字代言、元宇宙中,AI数字人都扮演着越来越重要…...

RBTree的模拟实现
1:红黑树的概念 红⿊树是⼀棵⼆叉搜索树,他的每个结点增加⼀个存储位来表⽰结点的颜⾊,可以是红⾊或者⿊⾊。通过对任何⼀条从根到叶⼦的路径上各个结点的颜⾊进⾏约束,红⿊树确保没有⼀条路径会⽐其他路径⻓出2倍,因…...

ssh connect to remote gitlab without authority
ssh connect to remote gitlab without authority 1 this command can produce a ssh key for authority ssh-keygen -t ed25519 -C "your_emailexample.com"2 this command can get the comment about the key cat ~/.ssh/id_ed25519.pubcopy all content !!!...

gitlab提交测试分支的命令和流程
写在前面 先npm run lint:eslint 先走一遍代码校验然后再提交先把检验跑了再add commit push那些注意一下这个问题:git commit规范不对导致报错subject may not be empty[subject-empty]type may not be empty[type-empty]. 配置lint检查后, 使用commitlint之后报…...

序列化和反序列化hadoop实现
### Hadoop 中序列化与反序列化的实现机制 Hadoop 提供了自己的轻量级序列化接口 Writable,用于高效地在网络中传输数据或将其存储到磁盘。以下是关于其核心概念和实现方式的详细介绍: --- #### 1. **Hadoop 序列化的核心原理** Hadoop 的序列化是一…...

[操作系统] 策略模式进行日志模块设计
文章目录 [toc]一、什么是设计模式?二、日志系统的基本构成三、策略模式在日志系统中的落地实现✦ 1. 策略基类 LogStrategy✦ 2. 具体策略类▸ 控制台输出:ConsoleLogStrategy▸ 文件输出:FileLogStrategy 四、日志等级枚举与转换函数五、日…...

LeetCode 每日一题 3341. 到达最后一个房间的最少时间 I + II
3341. 到达最后一个房间的最少时间 I II 有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一个大小为 n x m 的二维数组 moveTime ,其中 moveTime[i][j] 表示在这个时刻 以后 你才可以 开始 往这个房间 移动 。你在时刻 t 0 时从…...

《Python星球日记》 第68天:BERT 与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、BERT模型基础1. 什么是BERT?2. BERT 的结构3.预训练和微调对比二、BERT 的预训练任务1. 掩码语言模型 (MLM)2. 下一句预测 (NSP)三、微调 …...

Angular 知识框架
一、Angular 基础 1. Angular 简介 Angular 是什么? 基于 TypeScript 的前端框架(Google 维护)。 适用于构建单页应用(SPA)。 核心特性 组件化架构 双向数据绑定 依赖注入(DI) 模块化设计…...

python三方库sqlalchemy
SQLAlchemy 是 Python 中最强大、最受欢迎的 ORM(对象关系映射)库,它允许你使用 Python 对象来操作数据库,而不需要直接编写 SQL 语句。同时,它也提供了对底层 SQL 的完全控制能力,适用于从简单脚本到大型企…...

【SSL部署与优化】如何为网站启用HTTPS:从Let‘s Encrypt免费证书到Nginx配置
网站启用HTTPS 的完整实战指南,涵盖从 Let’s Encrypt 免费证书申请到 Nginx 配置的详细步骤,包括重定向、HSTS 设置及常见问题排查: 一、准备工作 1. 确保域名解析正确 • 在 DNS 管理后台,将域名(如 example.com&…...
:gRPC 与 CRI gRPC实现)
Kubernetes控制平面组件:Kubelet详解(四):gRPC 与 CRI gRPC实现
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

电商平台自动化
为什么要进行独立站自动化 纯人工测试人力成本高,相对效率低 回归测试在通用模块重复进行人工测试,测试效率低 前期调研备选自动化框架(工具): Katalon Applitools Testim 阿里云EMAS Playwright Appium Cypress 相关…...

【kafka】kafka概念,使用技巧go示例
1. Kafka基础概念 1.1 什么是Kafka? Kafka是一个分布式流处理平台,用于构建实时数据管道和流式应用。核心特点: 高吞吐量:每秒可处理百万级消息持久化存储:消息按Topic分区存储在磁盘分布式架构:支持水平…...

计算机系统结构——Cache性能分析
一、实验目的 加深对Cache的基本概念、基本组织结构以及基本工作原理的理解。掌握Cache容量、相联度、块大小对Cache性能的影响。掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处。理解LRU与随机法的基本思想以及它们对Cache性能的影响。 二、实验平台 实…...
)
Spring Web MVC————入门(2)
1,请求 我们接下来继续讲请求的部分,上期将过很多了,我们来给请求收个尾。 还记得Cookie和Seesion吗,我们在HTTP讲请求和响应报文的时候讲过,现在再给大家讲一遍,我们HTTP是无状态的协议,这次的…...

Adobe DC 2025安装教程
一.软件下载 点此下载 二.软件安装...

W1电力线载波通信技术
CK_Label_W1 产品型号:CK_Label_W1 尺寸:37*65*33.7mm 按键:1 指示灯:1 RGB灯(红/绿/蓝/黄/紫/白/青) 外观颜色:白色 合规认证:CE, RoHS 工作温度:0-50℃ 提示功能:蜂鸣器声音…...

现代 Web 自动化测试框架对比:Playwright 与 Selenium 的深度剖析
现代 Web 自动化测试框架对比:Playwright 与 Selenium 的深度剖析 摘要:本文对 Playwright 与 Selenium 在开发适配性、使用难度、场景适用性及性能表现等方面进行了全面深入的对比分析。通过详细的技术实现细节阐述与实测数据支撑,为开发者…...

第二章:CSS秘典 · 色彩与布局的力量
剧情承接:色彩失衡的荒原 林昊穿过 HTML 大门,眼前却是一片 灰白扭曲的荒原。所有页面元素如同幽灵般漂浮,没有色彩、没有结构,错乱无章。 “这是失控的样式荒原。” 零号导师的声音再次响起, “HTML 给了你骨架&…...

ubuntu studio 系统详解
Ubuntu Studio 系统详解:面向多媒体创作的专业 Linux 发行版 一、定位与目标用户 Ubuntu Studio 是 Ubuntu 的官方衍生版本(Flavor),专为 音频、视频、图形设计、音乐制作、影视后期 等多媒体创作场景设计。目标用户包括&#x…...

在 Ubuntu 20.04.6 LTS 中将 SCons 从 3.1.2 升级到 4.9.1
在 Ubuntu 20.04.6 LTS 中将 SCons 从 3.1.2 升级到 4.9.1,可以通过以下步骤完成: 方法 1:使用 pip 安装(推荐) 步骤 1:卸载旧版本 SCons # 如果通过 apt 安装的旧版本,先卸载 sudo apt remov…...

边缘计算网关工业物联网应用:空压机远程运维监控管理
边缘计算网关在空压机远程运维监控管理中的工业物联网应用,主要体现在数据采集与处理、设备监控、故障诊断与预警、远程控制等方面,以下是具体介绍: 数据采集与处理 多源数据采集:边缘计算网关能连接空压机的各类传感器…...

【大模型面试每日一题】Day 18:大模型中KV Cache的作用是什么?如何通过Window Attention优化其内存占用?
【大模型面试每日一题】Day 18:大模型中KV Cache的作用是什么?如何通过Window Attention优化其内存占用? 📌 题目重现 🌟🌟 面试官:大模型中KV Cache的作用是什么?如何通过Window Attention优…...

Spring的 @Validate注解详细分析
在 Spring Boot 中,参数校验是保证数据合法性的重要手段。除了前面提到的NotNull、Size等基础注解外,JSR-303(Bean Validation 1.0)、JSR-349(Bean Validation 1.1)和 JSR-380(Bean Validation …...
)
现代计算机图形学Games101入门笔记(三)
三维变换 具体形式缩放,平移 特殊点旋转。这里涉及到坐标系,先统一定义右手坐标系,根据叉乘和右手螺旋判定方向。这里还能法线Ry Sina 正负与其他两个旋转不一样。这里可以用右手螺旋,x叉乘z,发现大拇指朝下࿰…...

AI时代的弯道超车之第八章:具体分享几个AI实际操作方法和案例
在这个AI重塑世界的时代,你还在原地观望吗?是时候弯道超车,抢占先机了! 李尚龙倾力打造——《AI时代的弯道超车:用人工智能逆袭人生》专栏,带你系统掌握AI知识,从入门到实战,全方位提升认知与竞争力! 内容亮点: AI基础 + 核心技术讲解 职场赋能 + 创业路径揭秘 打破…...

企业网络新选择:软件定义架构下的MPLS
随着现代企业园区网络和运营商级基础设施的不断发展,多协议标签交换 (MPLS) 已成为一项基础技术,这要归功于其高效的数据包转发、高级流量工程功能以及对多租户环境的强大支持。 什么是MPLS? MPLS(多协议…...

SparkSQL操作Mysql
(一)准备mysql环境 我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。 以下是具体步骤: 使用finalshell连接hadoop001.查看是否已安装MySQL。命令是: rpm -qa|grep…...

【论文阅读】UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening
ECCV2024 https://github.com/Megum1/UNIT 我们的主要贡献总结如下: 我们引入了UNIT(“AUtomated Neural DIstribution Tightening”),这是一种创新的后门缓解方法,它为每个神经元近似独特的分布边界,用于…...
 IDA逆向编辑Android so文件)
Android逆向学习(十) IDA逆向编辑Android so文件
Android逆向学习(十) IDA逆向编辑Android so文件 一、 写在前面 这是吾爱破解论坛正己大大的第10个教程 native code在我之前的博客中讲到过,所以这里就不讲了 简单来说,native code就是在android中使用c或c语言进行开发 这样…...

OpenCV + PyAutoGUI + Tkinter + FastAPI + Requests 实现的远程控制软件设计方案
以下是基于 OpenCV PyAutoGUI Tkinter FastAPI Requests 实现的远程控制软件设计方案。该方案分为 被控端(服务端) 和 控制端(客户端),支持屏幕实时查看、键盘映射和鼠标操作。 1. 系统架构 ------------------- …...
(会二次修改))
C++.神经网络与深度学习(赶工版)(会二次修改)
神经网络与深度学习 1. 神经网络基础1.1 神经元模型与激活函数1.2 神经网络结构与前向传播2.1 损失函数与优化算法均方误差损失函数交叉熵损失函数梯度下降优化算法 2.2 反向传播与梯度计算神经元的反向传播 3.1 神经元类设计与实现神经元类代码实现代码思路 3.2 神经网络类构建…...

砷化镓太阳能电池:开启多元领域能源新篇
砷化镓太阳能电池作为一种高性能的光伏产品,具有诸多独特优势。其中,锗衬底砷化镓太阳能电池表现尤为突出,它具备高转化效率、耐辐照和高电压等特性。在空间供电电源领域,这些优势使其成为人造卫星、太空站、太空探测器和登陆探测…...

[Linux] vim及gcc工具
目录 一、vim 1.vim的模式 2.vim的命令集 (1):命令模式 (2):底行模式 3.vim配置 二、gcc 1.gcc格式及选项 2.工作布置 三、自动化构建工具makefile 1.基本使用方法 2.配置文件解析 3.拓展 在linux操作系统的常用工具中,常用vim来进行程序的编写;…...

java加强 -stream流
Stream流是jdk8开始新增的一套api,可以用于操作集合或数组的内容。 Stream流大量的结合了Lambda的语法风格来编程,功能强大,性能高效,代码简洁,可读性好。 体验Stream流 把集合中所有以三开头并且三个字的元素存储到…...

RHCE认证通过率
红帽RHCE考试总体通过率38%(2023年数据),细分数据显示自学者通过率18%,参加官方培训者47%,企业团体考生53%。通过率差异由备考资源和考试策略决定。 RHCE考试重点考Ansible自动化运维,需在3.5小时内完成12…...

OpenEvidence AI临床决策支持工具平台研究报告
平台概述 OpenEvidence是一个专为医疗专业人士设计的临床决策支持工具,旨在通过整合各类临床计算器和先进的人工智能技术,提高医生的诊疗决策效率和准确性。作为一款综合性医疗平台,OpenEvidence将复杂的医学计算流程简化,同时提供个性化的临床建议,使医生能够更快、更准…...

gd32e230c8t6 keil6工程模板
下载固件gd32e230c8t6固件官方下载(需登录) 或 蓝奏云 新建一个文件夹,把固件压缩包里的里的Firmware和Template拖进去 keil新建gd32e230c8工程 必须勾选CMSIS-CORE 新建一个文件夹,双击任意改名 点击manage project it…...

正向代理与反向代理区别及应用
正向代理和反向代理是两种常见的代理服务器类型,它们在网络架构中扮演不同角色,核心区别在于代理对象和使用场景。 1. 正向代理(Forward Proxy) 定义:正向代理是客户端(如浏览器)主动配置的代理…...

自然语言处理入门级项目——文本分类
文章目录 前言1.数据预处理1.1数据集介绍1.2数据集抽取1.3划分数据集1.4数据清洗1.5数据保存 2.样本的向量化表征2.1词汇表2.2向量化2.3自定义数据集2.4备注 结语 前言 本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还…...