【Elasticsearch】DSL 篇
Elasticsearch 之 DSL 篇
介绍
-
Elasticsearch 提供了基于 JSON 的 DSL 语句来定义查询条件,其 JavaAPI 就是在组织 DSL 条件。
-
先学习 DSL 的查询语法,然后再基于 DSL 来对照学习 JavaAPI,就会事半功倍
-
json 格式,好理解,和 http 请求最兼容,应用最广
-
官方文档:
- Query DSL | Elasticsearch Guide | Elastic
- Query DSL | 7.12.1
DSL 查询
Elasticsearch 的查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
快速入门
语法:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改- 由于
match_all无条件,所以条件位置不写即可。
GET /{索引库名}/_search
{"query": {"查询类型": {// .. 查询条件}}
}// 示例:无条件查询
GET /user/_search
{"query": {"match_all": {}}
}
执行结果分析:
hits.hits:命中的文档的数组,你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有 10 条。这是因为处于安全考虑,elasticsearch 设置了默认的查询条数。took:花费时间,单位是毫秒hits.total.value:查询总条数(超过 10000 条时最大只显示 10000)hits.total.relation:实际总条数 和 显示总条数 的比较关系,gte代表 大于等于 的关系
{"took" : 880,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : { // 命中的结果"total" : {"value" : 101,"relation" : "eq"},"max_score" : 1.0, // 所有结果中得分最高的文档的相关性算分"hits" : [{"_index" : "user","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : { // 文档中的原始数据,也是json对象"userName" : "zhangsan_0","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"userName" : "zhangsan_1","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"userName" : "zhangsan_2","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"userName" : "zhangsan_3","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"userName" : "zhangsan_4","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "6","_score" : 1.0,"_source" : {"userName" : "zhangsan_5","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "7","_score" : 1.0,"_source" : {"userName" : "zhangsan_6","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "8","_score" : 1.0,"_source" : {"userName" : "zhangsan_7","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "9","_score" : 1.0,"_source" : {"userName" : "zhangsan_8","gender" : 1}},{"_index" : "user","_type" : "_doc","_id" : "10","_score" : 1.0,"_source" : {"userName" : "zhangsan_9","gender" : 1}}]}
}
叶子查询
官方文档:Query DSL | Elasticsearch Guide 7.12 | Elastic
这里列举一些常见的,例如:
- 全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
match:multi_match
- 精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
idstermrange
- 地理坐标查询**:**用于搜索地理位置,搜索方式很多,例如:
geo_bounding_box:按矩形搜索geo_distance:按点和半径搜索
- …略
全文检索查询
官方文档:Full text queries | Elasticsearch Guide 7.12 | Elastic
以全文检索中的 match 为例,语法如下:
- 对搜索条件先分词,得到词条,然后搜索词条
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}
示例:
GET /user/_search
{"query": {"match": {"userName": "zhangsan"}}
}
与 match 类似的还有 multi_match,区别在于可以同时对多个字段搜索,而且多个字段都要满足,语法示例:
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}
示例:
GET /user/_search
{"query": {"multi_match": {"query": "zhangsan","fields": ["user_name", "userName"]}}
}
精确查询
官方文档:Term-level queries | Elasticsearch Guide 7.12 | Elastic
精确查询,英文是 Term-level query,顾名思义,词条级别的查询。
也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。因此推荐查找 keyword、数值、日期、boolean 类型的字段。
例如:
- id
- price
- 城市
- 地名
- 人名
等等,作为一个整体才有含义的字段。
以 term 查询为例,其语法如下:
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}
再来看下 range 查询,语法如下:
GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}
range 是范围查询,对于范围筛选的关键字有:
gte:大于等于gt:大于lte:小于等于lt:小于
复合查询
官方文档:Compound queries | Elasticsearch Guide 7.12 | Elastic
复合查询大致可以分为两类:
- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
function_scoredis_max
算分函数查询
当我们利用 match 查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
- 从 elasticsearch5.1 开始,采用的相关性打分算法是 BM25 算法
- 在 elasticsearch5.1 之前使用 TF-IDF 算法,由于该算法会因词频的增大,二无限增大,BM25 算法相对比较平缓,因此 5.1 之后都采用 BM25 算法
基于这套公式,就可以判断出某个文档与用户搜索的关键字之间的关联度,还是比较准确的。
但是,在实际业务需求中,常常会有竞价排名的功能。不是相关度越高排名越靠前,而是掏的钱多的排名靠前。
要想认为控制相关性算分,就需要利用 elasticsearch 中的 function score 查询了。
基本语法:
function score 查询中包含四部分内容:
- 原始查询条件:query 部分,基于这个条件搜索文档,并且基于 BM25 算法给文档打分,原始算分(query score)
- 过滤条件:filter 部分,符合该条件的文档才会重新算分
- 算分函数:符合 filter 条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score 的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
示例:给 IPhone 这个品牌的手机算分提高十倍,分析如下:
- 过滤条件:品牌必须为 IPhone
- 算分函数:常量 weight,值为 10
- 算分模式:相乘 multiply
对应代码如下:
GET /hotel/_search
{"query": {"function_score": {"query": { .... }, // 原始查询,可以是任意条件"functions": [ // 算分函数{"filter": { // 满足的条件,品牌必须是Iphone"term": {"brand": "Iphone"}},"weight": 10 // 算分权重为10}],"boost_mode": "multipy" // 加权模式:原始分数与函数结果的乘积}}
}
bool 查询
bool 查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。
bool 查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
bool 查询的语法如下:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"should": [{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}],"must_not": [{"range": {"price": {"gte": 2500}}}],"filter": [{"range": {"price": {"lte": 1000}}}]}}
}
出于性能考虑,与搜索关键字无关的查询尽量采用 must_not 或 filter 逻辑运算,避免参与相关性算分。
例如黑马商城的搜索页面:
- 其中输入框的搜索条件肯定要参与相关性算分,可以采用
match。 - 但是价格范围过滤、品牌过滤、分类过滤等尽量采用
filter,不要参与相关性算分。
比如,我们要搜索手机,但品牌必须是华为,价格必须是900~1599,那么可以这样写:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"filter": [{"term": {"brand": { "value": "华为" }}},{"range": {"price": {"gte": 90000, "lt": 159900}}}]}}
}
排序
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/sort-search-results.html
elasticsearch 默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。
不过分词字段无法排序,能参与排序字段类型有:
keyword类型、- 数值类型、
- 地理坐标类型、
- 日期类型等。
语法说明:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}
示例,我们按照商品价格降序排序:
GET /items/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}]
}
分页
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/paginate-search-results.html
elasticsearch 默认情况下只返回 top10 的数据。而如果要查询更多数据就需要修改分页参数了。
基础分页
elasticsearch中通过修改 from、size 参数来控制要返回的分页结果:
from:从第几个文档开始size:总共查询几个文档
类似于 mysql 中的 limit ?, ?
语法如下:
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [{"price": {"order": "desc"}}]
}
深度分页
elasticsearch 的数据一般会采用分片存储,也就是把一个索引中的数据分成 N 份,存储到不同节点上。
- 这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有 100000 条数据,分别存储到 4 个分片,每个分片 25000 条数据。现在每页查询 10 条,查询第 99 页。
那么分页查询的条件如下:
GET /items/_search
{"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}]
}
- 从语句来分析,要查询第 990~1000 名的数据 。
- 从实现思路来分析,肯定是将所有数据排序,找出前 1000 名,截取其中的 990~1000 的部分。
但问题来了,我们如何才能找到所有数据中的前 1000 名呢?
- 要知道每一片的数据都不一样,第 1 片上的第 900~1000,在另 1 个节点上并不一定依然是 900~1000 名。
- 所以我们只能在每一个分片上都找出排名前 1000 的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前 1000 名,此时截取 990~1000 的数据即可。
- 即聚合所有结果,重新排序选取前 1000 个。
内存问题
试想一下,假如我们现在要查询的是第 999 页数据呢,是不是要找第 9990~10000 的数据,
- 那岂不是需要把每个分片中的前 10000 名数据都查询出来,汇总在一起,在内存中排序?
- 如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和 CPU 会产生非常大的压力。
因此 elasticsearch 会禁止 from+ size 超过 10000 的请求。
针对深度分页,elasticsearch 提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档 id 形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
总结
大多数情况下,我们采用普通分页就可以了。
- 查看百度、京东等网站,会发现其分页都有限制。
- 例如百度最多支持 77 页,每页不足 20 条。
- 京东最多 100 页,每页最多 60 条。
因此,一般我们采用限制分页深度的方式即可,无需实现深度分页。
高亮
高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示。
观察页面源码,你会发现两件事情:
- 高亮词条都被加了
<em>标签 <em>标签都添加了红色样式
css 样式肯定是前端实现页面的时候写好的,但是前端编写页面的时候是不知道页面要展示什么数据的,不可能给数据加标签。而服务端实现搜索功能,要是有 elasticsearch 做分词搜索,是知道哪些词条需要高亮的。
因此词条的高亮标签肯定是由服务端提供数据的时候已经加上的。
因此实现高亮的思路就是:
- 用户输入搜索关键字搜索数据
- 服务端根据搜索关键字到 elasticsearch 搜索,并给搜索结果中的关键字词条添加
html标签 - 前端提前给约定好的
html标签添加CSS样式
实现高亮
事实上 elasticsearch 已经提供了给搜索关键字加标签的语法,无需我们自己编码。
基本语法如下:
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match - 参与高亮的字段必须是
text类型的字段 - 默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
总结
查询的DSL是一个大的JSON对象,包含下列属性:
query:查询条件from和size:分页条件sort:排序条件highlight:高亮条件
RestClient 查询
DSL 参数名 和 JavaAPI 命名相似
快速入门
文档搜索的基本步骤是:
- 创建
SearchRequest对象 - 准备
request.source(),也就是DSL。QueryBuilders来构建查询条件- 传入
request.source()的query()方法
- 发送请求,得到结果
- 解析结果(参考JSON结果,从外到内,逐层解析)
代码示例:
@Testvoid testMatchAll() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits(); // 只会返回 10 条数据for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化并打印ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);System.out.println(item);}}
叶子查询
所有的查询条件都是由 QueryBuilders 来构建的,叶子查询也不例外。因此整套代码中变化的部分仅仅是 query 条件构造的方式,其它不动。
例如match查询:
@Test
void testMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
再比如multi_match查询:
@Test
void testMultiMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有range查询:
@Test
void testRange() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有term查询:
@Test
void testTerm() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.termQuery("brand", "华为"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
复合查询
复合查询也是由 QueryBuilders 来构建,
以 bool 查询为例:
@Test
void testBool() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
排序和分页
之前说过,requeset.source() 就是整个请求 JSON 参数,所以排序、分页都是基于这个来设置
代码示例如下:
@Test
void testPageAndSort() throws IOException {int pageNo = 1, pageSize = 5;// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.搜索条件参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
高亮
高亮查询与前面的查询有两点不同:
- 条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造 - 高亮响应结果与搜索的文档结果不在一起,需要单独解析
示例代码如下:
@Testvoid testHighlight() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);// 5.获取高亮结果Map<String, HighlightField> hfs = hit.getHighlightFields();if (CollUtil.isNotEmpty(hfs)) {// 5.1.有高亮结果,获取name的高亮结果HighlightField hf = hfs.get("name");if (hf != null) {// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值String hfName = hf.getFragments()[0].string();item.setName(hfName);}}System.out.println(item);}}
数据聚合
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/search-aggregations.html
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的 sql 要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
- **桶(
Bucket)**聚合:用来对文档做分组 TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组- **度量(
Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等 Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等- **管道(
pipeline)**聚合:其它聚合的结果为基础做进一步运算
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL 实现聚合
Bucket 桶聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category 值一样的放在同一组,属于 Bucket 聚合中的 Term 聚合。
基本语法如下:
GET /items/_search
{"size": 0, "aggs": {"category_agg": {"terms": {"field": "category","size": 20}}}
}
语法说明:
size:设置size为 0,就是每页查 0 条,则结果中就不包含文档,只包含聚合aggs:定义聚合category_agg:聚合名称,自定义,但不能重复terms:聚合的类型,按分类聚合,所以用termfield:参与聚合的字段名称size:希望返回的聚合结果的最大数量
来看下查询的结果:

带条件聚合
真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
例如,我想知道价格高于3000元的手机品牌有哪些,该怎么统计呢?
语法如下:
GET /items/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gte": 300000}}}]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20}}}
}
Metric 度量聚合
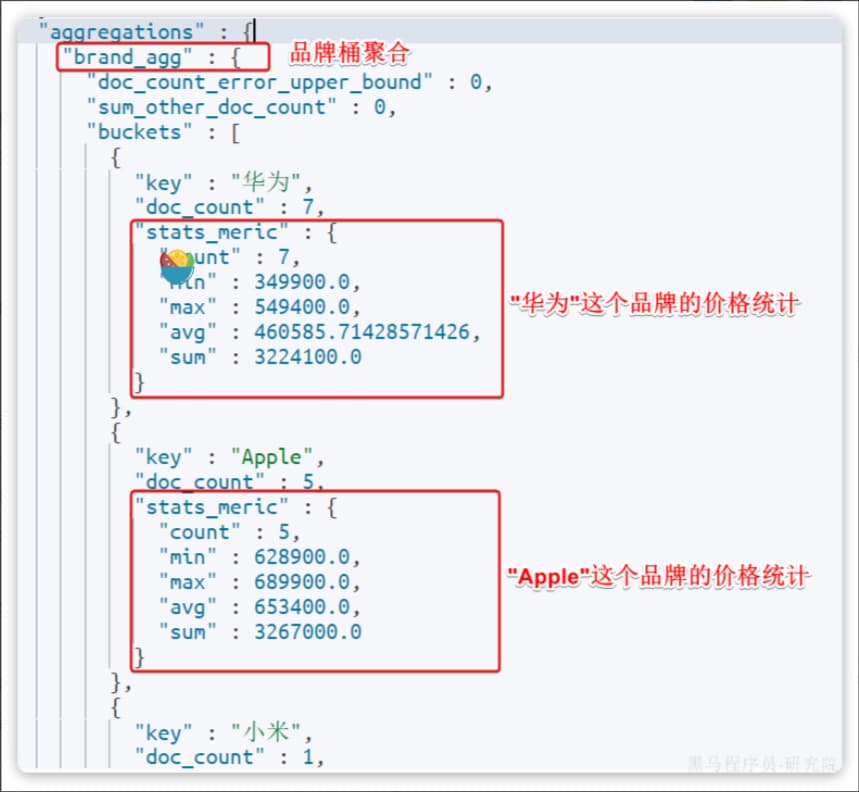
假设现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
这就要用到 Metric 聚合了,例如 stat 聚合,就可以同时获取 min、max、avg 等结果。
语法如下:
GET /items/_search
{"query": {"bool": {"filter": [{"term": {"category": "手机"}},{"range": {"price": {"gte": 300000}}}]}}, "size": 0, "aggs": {"brand_agg": {"terms": {"field": "brand","size": 20},"aggs": {"stats_meric": {"stats": {"field": "price"}}}}}
}
可以看到我们在 brand_agg 聚合的内部,我们新加了一个 aggs 参数。这个聚合就是 brand_agg 的子聚合,会对 brand_agg 形成的每个桶中的文档分别统计。
stats_meric:聚合名称stats:聚合类型,stats 是metric聚合的一种field:聚合字段,这里选择price,统计价格
由于 stats 是对 brand_agg 形成的每个品牌桶内文档分别做统计,因此每个品牌都会统计出自己的价格最小、最大、平均值。
结果如下:
另外,我们还可以让聚合按照每个品牌的价格平均值排序:
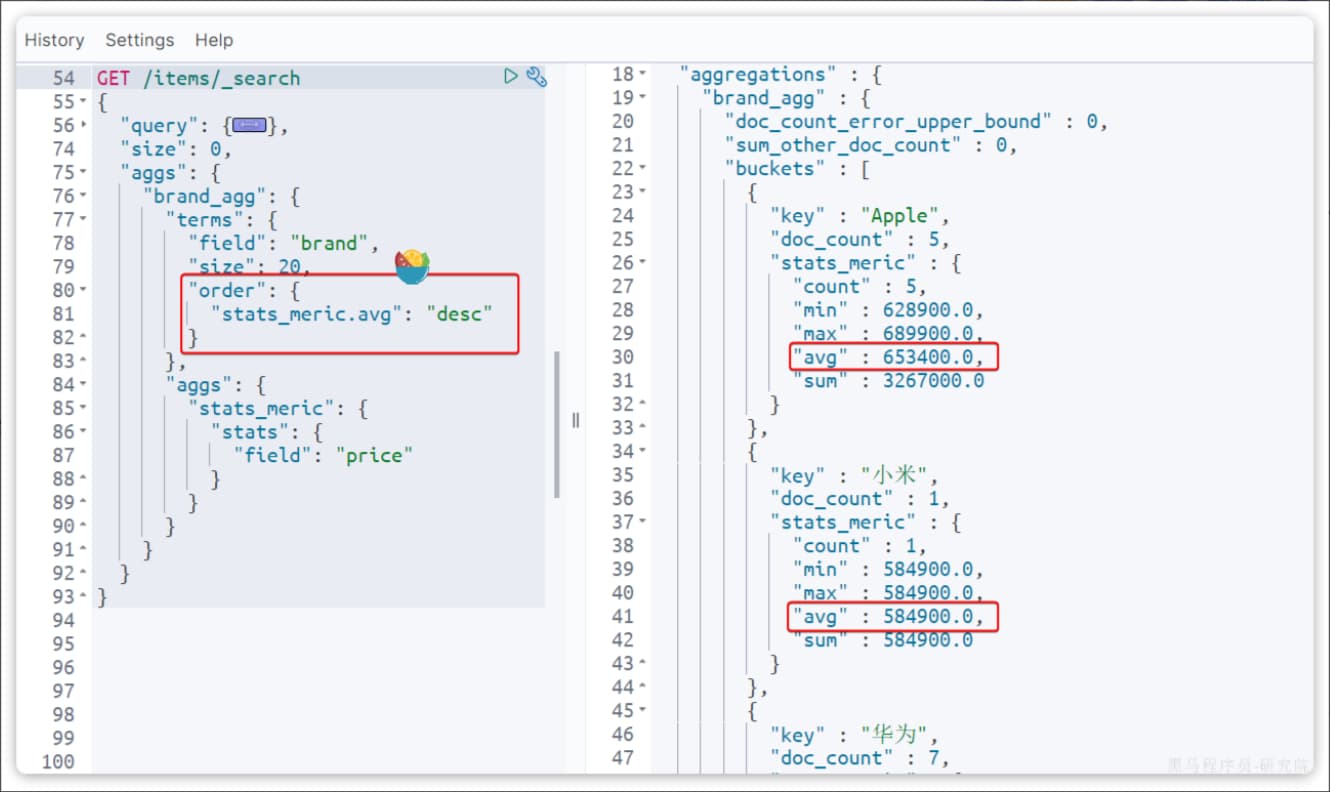
总结
aggs 代表聚合,与 query 同级,此时 query 的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
size:指定聚合结果数量order:指定聚合结果排序方式field:指定聚合字段
RestClient 实现聚合
可以看到在 DSL 中,aggs 聚合条件与 query 条件是同一级别,都属于查询 JSON 参数。
-
因此依然是利用
request.source()方法来设置。 -
不过聚合条件的要利用
AggregationBuilders这个工具类来构造。
@Testvoid testAgg() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.准备请求参数BoolQueryBuilder bool = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("category", "手机")).filter(QueryBuilders.rangeQuery("price").gte(300000));request.source().query(bool).size(0);// 3.聚合参数request.source().aggregation(AggregationBuilders.terms("brand_agg").field("brand").size(5));// 4.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析聚合结果Aggregations aggregations = response.getAggregations();// 5.1.获取品牌聚合Terms brandTerms = aggregations.get("brand_agg");// 5.2.获取聚合中的桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 5.3.遍历桶内数据for (Terms.Bucket bucket : buckets) {// 5.4.获取桶内keyString brand = bucket.getKeyAsString();System.out.print("brand = " + brand);long count = bucket.getDocCount();System.out.println("; count = " + count);}}
竞价排名
官方文档:Compound queries | Java API (deprecated) 7.12 | Elastic
elasticsearch 的默认排序规则是按照相关性打分排序,而这个打分是可以通过 API 来控制的。
- 可参考上文中的《算分函数查询》章节
业务场景:在商品的数据库表中,已经设计了 isAD 字段来标记广告商品,请利用 function_score 查询在原本搜索的结果基础上,让这些 isAD 字段值为 true 的商品排名到最前面。
DSL 语法参考:
POST /items/_search
{"query": {"function_score": {"query": {// 原始查询条件(例如关键词搜索、过滤条件等)"match_all": {} // 示例中匹配所有文档,按需替换为实际查询},"functions": [{"filter": {"term": { "isAD": true } // 仅针对广告商品},"weight": 1000 // 赋予极大权重,确保广告商品分数足够高}],"boost_mode": "sum" // 将权重分与原始分相加}},"sort":[{"_score":{"order":"desc"}}]
}
RestClinet 写法参考:
@Testvoid testBiddingRanking() throws IOException {// 1. 构建基础查询(例如关键词搜索)// QueryBuilder mainQuery = QueryBuilders.matchQuery("name", "手机");MatchAllQueryBuilder mainQuery = QueryBuilders.matchAllQuery();// 2. 构建广告商品的权重函数FilterFunctionBuilder[] functions = new FilterFunctionBuilder[]{new FilterFunctionBuilder(QueryBuilders.termQuery("isAD", true), // 过滤广告商品ScoreFunctionBuilders.weightFactorFunction(1000) // 设置权重为 1000)};// 3. 组合 FunctionScore 查询// FunctionScoreQueryBuilder functionScoreQueryBuilder = new FunctionScoreQueryBuilder(mainQuery, functions);// functionScoreQueryBuilder.boostMode(CombineFunction.SUM);FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(mainQuery, functions).boostMode(CombineFunction.SUM); // 权重分与原始分相加// 4. 构建完整的搜索请求SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(functionScoreQuery);sourceBuilder.sort(SortBuilders.scoreSort().order(SortOrder.DESC)); // 按总分降序// 打印生成的 DSL 查询 JSON(调试用途)System.out.println(JSONUtil.toJsonPrettyStr(sourceBuilder.toString()));// 5. 执行搜索SearchRequest searchRequest = new SearchRequest("items");searchRequest.source(sourceBuilder);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(response);}
学习参考
- day09-Elasticsearch02 - 飞书云文档
相关文章:

【Elasticsearch】DSL 篇
Elasticsearch 之 DSL 篇 介绍 Elasticsearch 提供了基于 JSON 的 DSL 语句来定义查询条件,其 JavaAPI 就是在组织 DSL 条件。 先学习 DSL 的查询语法,然后再基于 DSL 来对照学习 JavaAPI,就会事半功倍 json 格式,好理解&#…...

常见 RPC 协议类别对比
RPC(Remote Procedure Call,远程过程调用)协议是分布式系统中实现跨进程通信的核心机制之一。它允许客户端像调用本地函数一样调用远端服务器上的函数。 根据通信方式、数据编码方式和平台兼容性不同,常见的 RPC 协议分为以下几类…...
)
React系列——nvm、node、npm、yarn(MAC)
nvm,node,npm之间的区别 1、nvm:nodejs版本管理工具。nvm 可以管理很多 node 版本和 npm 版本。 2、nodejs:在项目开发时的所需要的代码库 3、npm:nodejs包管理工具。nvm、nodejs、npm的关系 nvm 管理 nodejs 和 npm…...

LeetCode 热题 100 230. 二叉搜索树中第 K 小的元素
LeetCode 热题 100 | 230. 二叉搜索树中第 K 小的元素 大家好,今天我们来解决一道经典的二叉搜索树问题——二叉搜索树中第 K 小的元素。这道题在 LeetCode 上被标记为中等难度,要求查找二叉搜索树中的第 K 小的元素。 问题描述 给定一个二叉搜索树的根…...

vscode - 笔记
1 IDE就用vscode,安装Remote-SSH插件通过SSH访问树莓派里的文件夹 写在开始:阿尔法Linux开发板学习开始 - 银色的音色 - 博客园 2 VSCode之Linux C/C开发和调试 VSCode之Linux C/C开发和调试 CMake代码编译 json配置_哔哩哔哩_bilibili 3 VS Code 凭…...

使用VSCode编辑Markdown+PlantUml
vscode :https://code.visualstudio.com/ 什么是markdown: Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。 Markdown 编写的文档可以导出 HTML 、Word、图像、PDF、Epub 等多种格式的文档。 在vscode上安装MarkDown相关…...

关于 Golang GC 机制的一些细节:什么是根对象?GC 机制的触发时机?
文章目录 关于 Golang GC 机制的一些细节:什么是根对象?GC 机制的触发时机?简要回顾 Golang GC 三色标记法的工作流程什么是根对象?GC 的触发时机? 关于 Golang GC 机制的一些细节:什么是根对象?…...
是什么?)
内存虚拟盘(RAMDisk)是什么?
内存虚拟盘(RAMDisk)是一种通过软件将计算机的部分物理内存(RAM)模拟为硬盘驱动器的技术,利用内存的高速读写特性显著提升数据访问效率。以下从原理、优势、实现方式及应用场景等方面详细解析: 1. 技术原…...
的工作原理与应用场景)
深入浅出入侵检测系统(IDS)的工作原理与应用场景
网络安全界的“火眼金睛”:入侵检测系统IDS 一、IDS简介:网络安全界的“火眼金睛” 在计算机安全领域,有一个“火眼金睛”的角色,它能在网络世界中识破各种“妖魔鬼怪”的伪装,及时发出警报,保护我们的数…...

AISBench benchmark评测工具实操-精度评测场景-采用命令行指定模型和数据集的方式
一、环境信息 1.1.硬件设备 昇腾Atlas800 I A2:910A 01:00.0 Processing accelerators: Huawei Technologies Co., Ltd. Device d801 (rev 20) 1.2.软件信息 1.2.1模型: DeepSeek-R1-Distill-Qwen-1.5B 1.2.2.物理机系统: NAME="EulerOS" VERSION="2.0 …...

HTTP GET报文解读
考虑当浏览器发送一个HTTP GET报文时,通过Wireshark 俘获到下列ASCII字符串: GET /cs453/index.html HTTP/1.1 Host: gaia.cs.umass.edu User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.2) Gecko/20040804 Netscape/7.2 (ax) Acc…...

南审计院考研分享会 经验总结
汪学长 – 中科大 计科专硕 初试准备 数学先做真题,模拟题刷的越多分越高;408真题最重要,模拟题辅助;英语只做真题;政治9月份开始背 代码能力在低年级培养的重要性和路径 考研不选择机构原因 因为机构里面学习的框…...
)
Android多媒体——媒体解码流程分析(十四)
NuPlayer 的解码模块相对比较简单,统一使用了一个基类 NuPlayerDecoderBase 管理,该类中包含了一个 MediaCodec 的对象,实际解码工作全靠 MediaCodec。 一、解码器创建 解码器创建的入口在 NuPlayer 的 NuPlayer::instantiateDecoder() 函数调用时。NuPlayer 在执行 start(…...

学习threejs,使用Physijs物理引擎,通过控制重力,实现多米诺骨牌效果
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Physijs 物理引擎1.1.1 ☘️…...
)
自由学习记录(60)
Lecture 16 Ray Tracing 4_哔哩哔哩_bilibili 老师说的“高频采样”问题是什么? 现在考虑一个特殊情况: ❗ 一个像素内,图像信号变化很剧烈(高频): 比如: 细网格纹理 马赛克背景 很高频的…...

Gartner《分布式和微服务架构中数据架构》学习心得
一、简介 随着信息技术的不断发展,软件架构也在持续演变以适应不断变化的业务需求。从传统的单体架构向分布式和微服务架构转变,给数据的管理带来了新的挑战和机遇。《Working With Data in Distributed and Microservices Architectures》研究针对在分布式和微服务架构中处…...

谷歌web第三方登录
1.在谷歌控制台创建客户端信息 https://console.cloud.google.com/auth/clients 注:在重定向的url中一定要是https开头的。 创建完成之后主要获取三个信息 clientID、secret、redirctUrl 2.配置pom <dependency><groupId>com.google.auth</group…...

ConfigMap 和 Secret 是否支持热更新
在 Kubernetes 中,ConfigMap 和 Secret 是否支持热更新取决于它们的使用方式和应用程序的行为。以下是详细分析: 1. ConfigMap 的热更新 场景 1:通过 Volume 挂载到 Pod 支持热更新: 如果 Pod 通过 volume 挂载 ConfigMap&#…...

时序数据库IoTDB分布式系统监控基础概述
在分布式系统环境中,系统性能调优与瓶颈定位一直是工程实践与架构设计中的关键挑战。面对诸如系统性能无法提升、查询延迟增加等问题,需要一套有效的监控体系来洞察系统的内部状态与运行情况。 可观测性概念 随着分布式架构的普及,可观测性…...

【乱码】前端js流式输出因为Uint8Array字节不完整导致乱码问题
【乱码】流式输出因为Uint8Array字节不完整导致乱码问题 function push() {reader.read().then(({ done, value }) > {if (done) { 问题代码 var a new Uint8Array([115,44,32,115,101,114,105,102,34,62,230]) var b new Uint8Array([156,136,60,47,115,112,97,110,62…...

PDF Base64格式字符串转换为PDF文件临时文件
需求描述: 在对接电子病历系统与河北CA,进行免密文件签章的时候,两者系统入参不同,前者是pdf文件,base64格式;后者要求File类型的PDF文件。 在业务中间层开发时,则需要接收EMR侧提供的base64格式…...

ClickHouse详解
ClickHouse 是一款开源的列式数据库管理系统(DBMS),由 Yandex 开发,专为联机分析处理(OLAP)设计,具备高性能、低延迟、海量数据处理能力,广泛应用于日志分析、用户行为分析、指标监控…...
`)
Go语言中的函数类型参数:深入理解`func()`
在Go语言中,函数是一等公民,可以作为参数传递、作为返回值,甚至赋值给变量。其中,func()作为一种特殊的函数类型,在Go的并发编程、回调机制和接口设计中扮演着重要角色。本文将全面解析func()的用法、原理和最佳实践。…...

deepseek梳理java高级开发工程师微服务面试题-进阶版
高级Java微服务面试题与深度解析 一、Spring Cloud核心组件深度剖析 1. Eureka服务注册发现机制 题目:详细分析Eureka的AP特性实现原理,包括服务注册、续约、剔除和自我保护机制,并说明与Nacos的CP模式区别。 答案: Eureka A…...

Math工具类全面指南
Math工具类全面指南 前言一、Math 类的基础特性1.1 类的声明与常量1.2 数据类型支持 二、基础算术运算2.1 绝对值运算2.2 取整运算2.2.1 floor():向下取整2.2.2 ceil():向上取整2.2.3 round():四舍五入取整 2.3 最大值与最小值 三、三角函数与…...

为什么 Linux 上默认没有 host.docker.internal
在 Linux 环境中,host.docker.internal 是 Docker 为容器提供的一个特殊 DNS 名称,用于指向宿主机的 IP 地址(类似 macOS/Windows 中的行为)。但这个功能在 Linux 上默认不启用,需要手动配置才能使用。以下是详细解释和…...

HTML 颜色全解析:从命名规则到 RGBA/HSL 值,附透明度设置与场景应用指南
一、HTML 颜色系统详解 HTML 中的颜色可以通过多种方式定义,包括颜色名称、RGB 值、十六进制值、HSL 值等,同时支持透明度调整。以下是详细分类及应用场景: 1. 颜色名称(预定义关键字) HTML 预定义了 140 个标准颜色名…...

HTTP / HTTPS 协议
目录 一、前言: 二、Fiddler 抓包工具: 三、http 协议: 1、http 请求: 1.(1)请求行: 1、(2) 请求头: 1、(3) 请求正文: 2、http 响应: 2、(1) 状态码&#x…...

使用GRPO训练调度事件的语言模型!
参考:https://huggingface.co/blog/anakin87/qwen-scheduler-grpo 现在是2025年,在DeepSeek热潮之后,每个人都想使用GRPO训练自己的推理模型。 作为一名实践者,我也想这样做:仅使用提示和奖励来训练语言模型是一件非常…...

关于 js:9. Node.js 后端相关
一、Node 环境搭建与执行流程 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,它让 JS 不再局限于浏览器内,而是可以在服务器、终端、本地脚本中运行。 核心定位:让我们可以用 JS 写本地程序、脚本、爬虫、加密逻辑、hook 工具、…...
)
More Effective C++:改善编程与设计(上)
More Effective C: 目录 More Effective C: 条款1:仔细区别pointers和 references 条款2:最好使用C转型操作符 条款3:绝对不要以多态方式处理数组 条款4:非必要不要提供default constructor 条款5:对定制的“类型转换函数”保持警觉 …...

SCDN如何有效防护网站免受CC攻击?——安全加速网络的实战解析
在互联网安全威胁日益复杂化的今天,CC(Challenge Collapsar)攻击已成为网站运营者面临的主要挑战之一。这种攻击通过模拟大量合法用户请求,消耗服务器资源,导致正常用户无法访问。而**安全内容分发网络(SCD…...

关于并发编程AQS的学习
目录 1. AQS的核心作用 2. AQS的核心结构 3. 关键方法 4. AQS的应用示例 4.1、ReentrantLock的实现 4.2、CountDownLatch的实现 5. AQS的优势 6. 对比其他同步机制 前言 AQS(AbstractQueuedSynchronizer) 是Java并发编程中一个核心的同步器框架…...
)
16S18S基础知识(1)
相关内容: https://blog.csdn.net/weixin_34315189/article/details/86397125?fromshareblogdetail&sharetypeblogdetail&sharerId86397125&sharereferPC&sharesource2302_80012625&sharefromfrom_link https://metagenome.blog.csdn.net/art…...

Java Spring Boot 控制器中处理用户数据详解
目录 一、获取请求参数1.1 获取查询参数1.2 获取路径参数 二、处理表单提交2.1 处理表单数据 三、处理 JSON 数据3.1 接收 JSON 数据 四、返回 JSON 数据五、处理文件上传5.1 单文件上传5.2 多文件上传 六、总结 在 Spring Boot 应用开发中,控制器(Contr…...

AI产品上市前的“安全通行证“
首席数据官高鹏律师团队 如今AI 产品如雨后春笋般涌现,从智能音箱到自动驾驶汽车,从语音助手到医疗诊断软件,它们正全方位渗透进我们的生活。然而,在 AI 产品迈向市场、走进千家万户之前,有一系列强制性安全认证如同坚…...

sql server 2019 将单用户状态修改为多用户状态
记录两种将单用户状态修改为多用户状态,我曾经成功过的方法,供参考 第一种方法 USE master; GO -- 终止所有活动连接 DECLARE kill_connections NVARCHAR(MAX) ; SELECT kill_connections KILL CAST(session_id AS NVARCHAR(10)) ; FROM sys.dm_ex…...
)
[滑动窗口]越短越合法(可转化成越长越合法)
题目链接 题意 给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于k 的连续子数组的数目。 首先当ans增加时 我们认为r固定 方法一、转化成越长越合法 思路 算出乘积 ≥ k \ge k ≥k的子数组数量 再用所有子数组数量减去上面算出来…...

idea中编写spark程序
### 在 IntelliJ IDEA 中配置和编写 Spark 程序 要在 IntelliJ IDEA 中高效地开发 Spark 程序,需要完成一系列必要的环境配置以及项目搭建工作。以下是详细的说明。 --- #### 1. 安装与配置 IntelliJ IDEA 为了确保 IDE 可以支持 Scala 开发,首先需要…...
)
机器学习入门(一)
机器学习入门(一) 文章目录 机器学习入门(一)一、机器学习分类1.1 监督学习1.2 半监督学习1.3 无监督学习1.4 强化学习 二、scikit-learn工具介绍scikit-learn安装 三、数据集3.1 sklearn玩具数据集介绍3.2 sklearn现实世界数据集…...

力扣每日一题之移动零
题目说明: 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 思路分析:我们可以考虑使用双指针来解答该题。双指针分…...

GaiaEx 盖亚:从合规出发,一家新兴交易平台的全球化路径探索
在加密货币交易平台日益激烈的竞争中,监管趋严、安全要求提升、用户体验优化已成为行业发展的三大核心议题。2025年初正式上线的GaiaEx 盖亚交易所,正是在这一市场背景下,以“合规 产品 生态”的多维路径,逐步建立起自身的发展方…...

车载网关--- 职责边界划分与功能解耦设计
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

EasyRTC嵌入式音视频通信SDK打造带屏IPC全场景实时通信解决方案
一、方案概述 在智能安防与物联网快速发展的背景下,带屏IPC(网络摄像机)不仅承担着视频采集与监控的基础功能,还逐渐向多样化交互与智能化方向演进。EasyRTC作为一款强大的实时通信框架,具备低延迟、高稳定性、跨平…...
:内部高速8Mhz时钟最大时钟可以设置 64 Mhz?如何修改system_stm32f10x.c里面的代码?)
STM32入门笔记(05):内部高速8Mhz时钟最大时钟可以设置 64 Mhz?如何修改system_stm32f10x.c里面的代码?
6.2 Clocks 最大系统时钟频率 当 STM32F103 系列仅使用内部高速振荡器(HSI,8 MHz)作为时钟源,并通过 PLL 放大时,最大可达 64 MHz。([forum.mikroe.com][1], [keil.com][2]) HSI 被内部除以 2(即 4 M…...

iOS 阅后即焚功能的实现
iOS阅后即焚功能实现步骤 一、功能设计要点 消息类型支持:文本、图片、视频、音频等。销毁触发条件: 接收方首次打开消息后启动倒计时。消息存活时间可配置(如5秒、1分钟)。 安全要求: 端到端加密(E2EE&a…...

二叉树前中后序遍历统一迭代法详解:空标记法与栈操作的艺术
二叉树的 前序、中序、后序 遍历是算法中的经典问题。递归实现简单直观,而迭代法则能更好地理解栈的操作逻辑。前文中(中序,前序与后序)所讲过传统的迭代法需要为每种遍历设计不同的入栈顺序,但 统一迭代法 通过引入 空标记节点&a…...

Spark 集群配置、启动与监控指南
Spark 集群的配置和启动需要几个关键步骤。以下是完整的操作流程,包含配置修改、集群启动、任务提交和常见错误排查方法。 1. 修改 Spark 配置文件 首先需要编辑 Spark 配置文件,设置集群参数: bash # 进入 Spark 配置目录 cd $SPARK_HOM…...

综述:拓扑材料的热磁性质
Adv. Funct. Mater. 2025, 2506631 https://doi.org/10.1002/adfm.202506631 近年来,越来越多的拓扑材料表现出优异的热磁(TM)性能,其显著的双极效应和线性能带带来的高载流子迁移率改善了这种性能。 本文综述了TM输运理论、基于…...

lanqiaoOJ 652:一步之遥 ← 扩展欧几里得定理
【题目来源】 https://www.lanqiao.cn/problems/652/learning/ 【题目背景】 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 【题目描述】 从昏迷中醒来,小明发现自己被关在X星球的废矿车里。矿车停在平直的废弃…...